An Indoor Room Classification System for Social Robots via Integration of CNN and ECOC

Abstract
1. Introduction
2. Related Work
3. Adopted Approaches for Room Classification Problem
3.1. Convolutional Neural Network (CNN) Architectures
3.1.1. Convolutional Layers
3.1.2. ReLu Layers
3.1.3. Pooling Layers
3.1.4. FL Layers
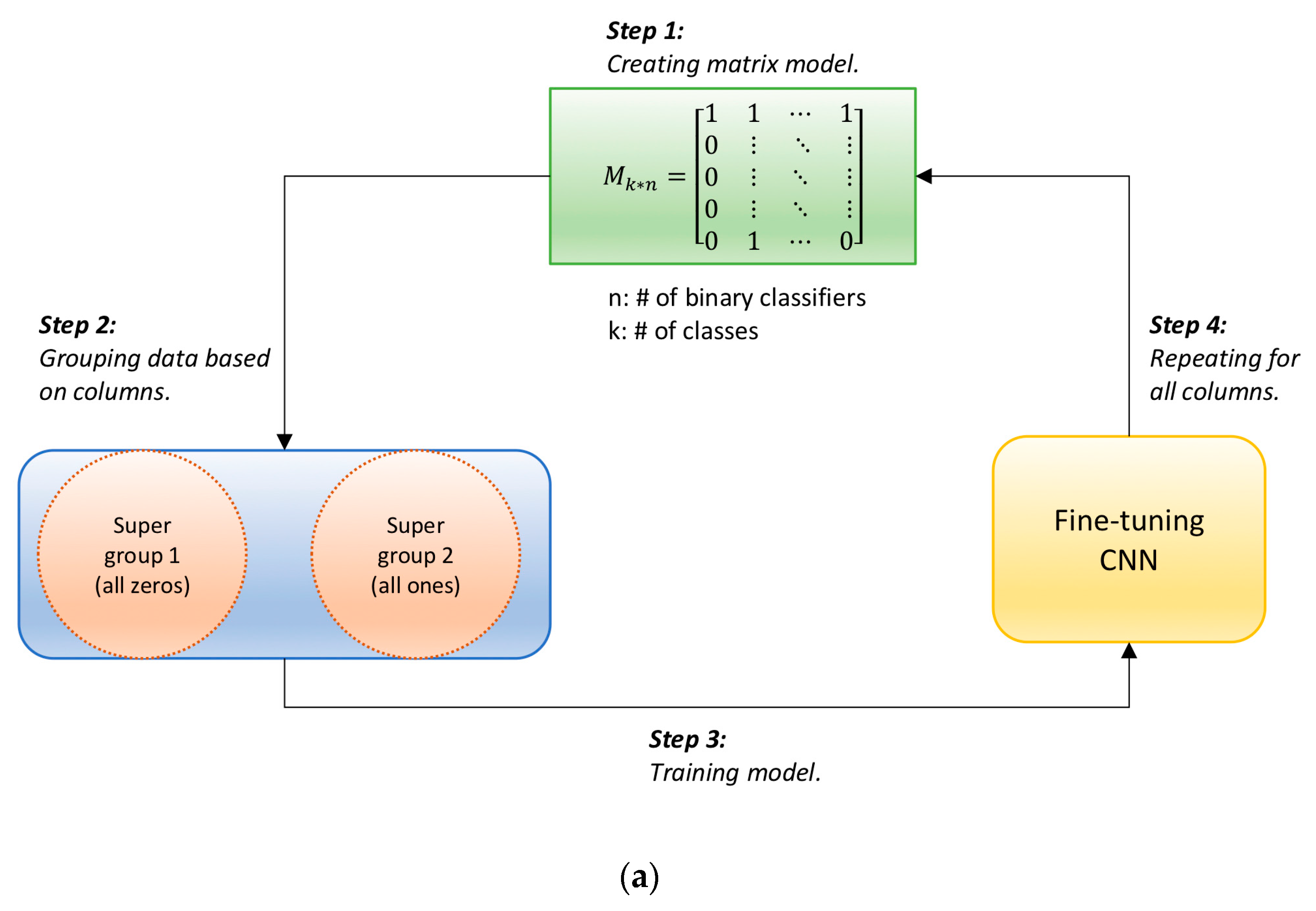
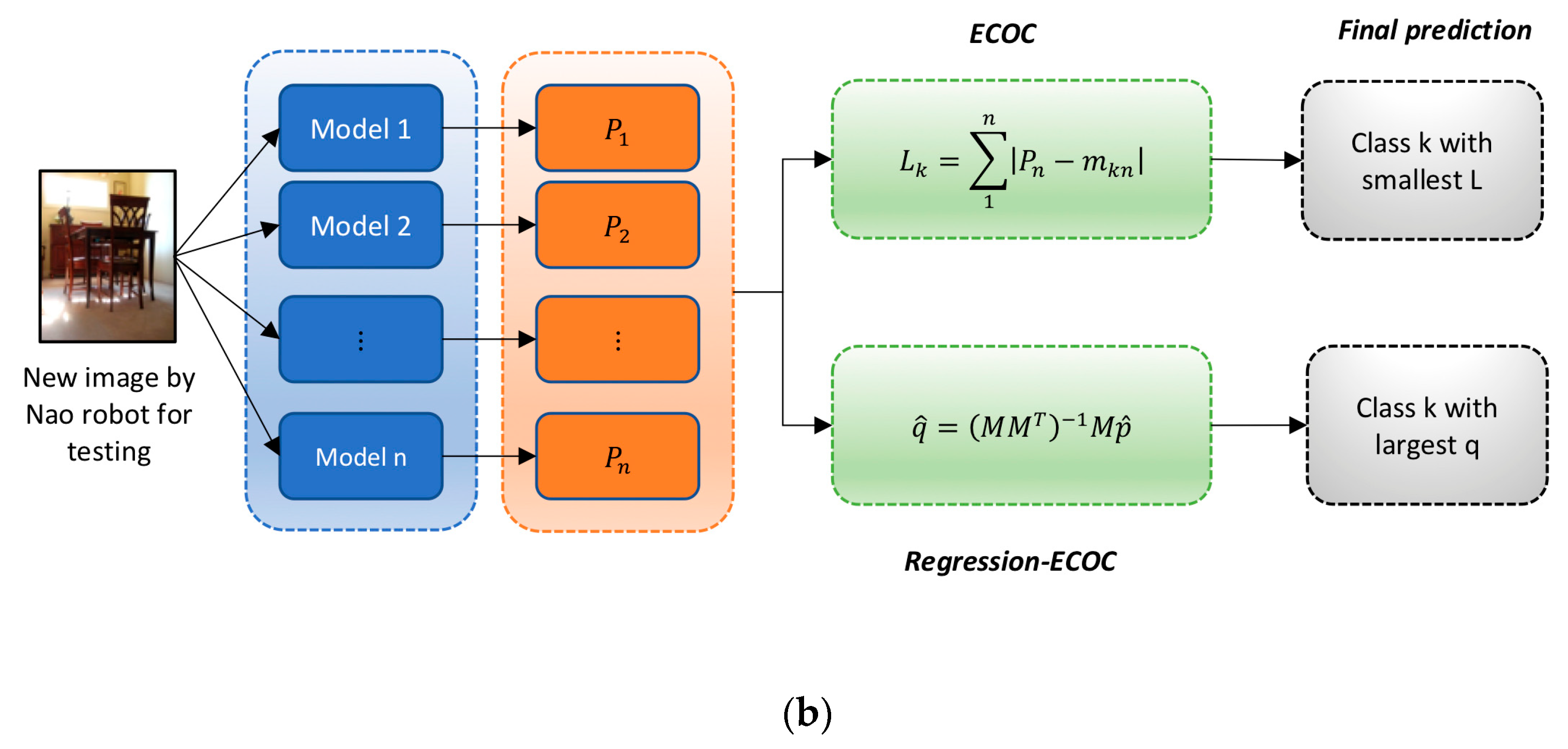
3.2. Error Correcting Output Code (ECOC)
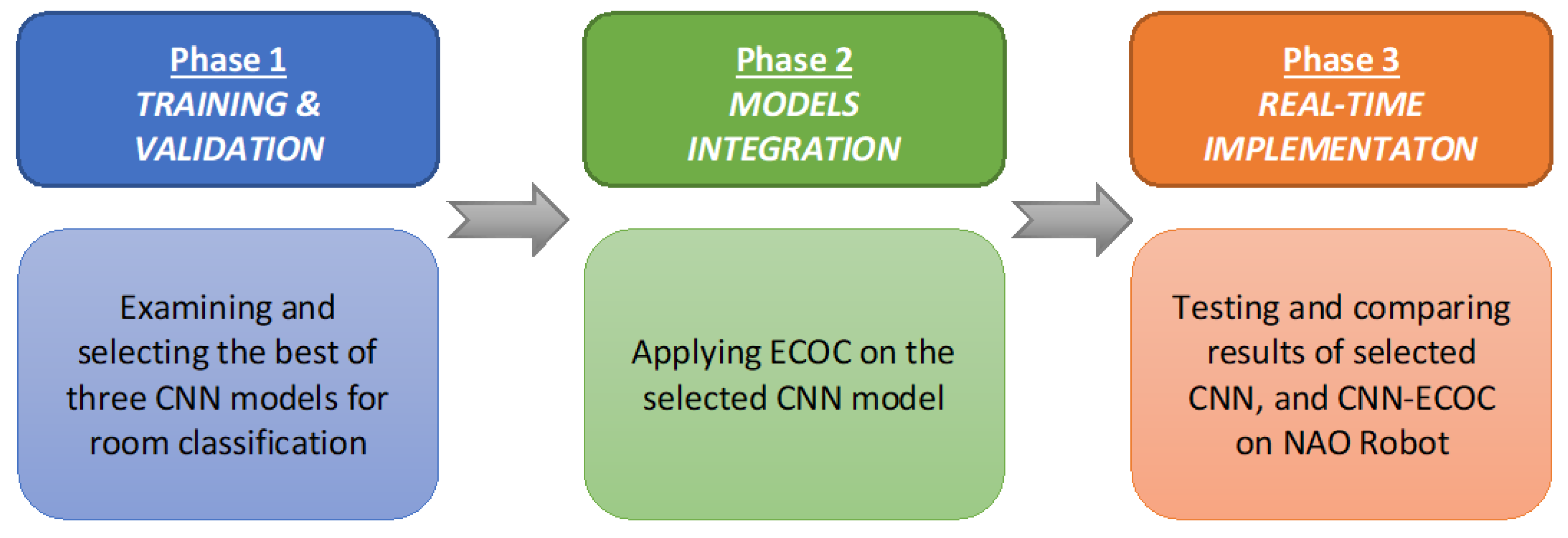
4. Dataset & Simulation Experiments
4.1. Scene Dataset
Cleaning Data
4.2. Multi-Class Room Classification Experiments Using Fine-Tuning Pre-Trained Models
4.3. Binary-Class Room Classification Experiments Using a Matrix Code
4.4. Discussion
5. Real-Time Experiment on NAO Humanoid Robot
5.1. NAO Humanoid Robot
5.2. Practical Implementation Results
5.3. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Campa, R. The Rise of Social Robots: A Review of the Recent Literature. J. Evol. Technol. 2016, 26, 106–113. [Google Scholar]
- Mejia, C. Bibliometric Analysis of Social Robotics Research: Identifying Research Trends and Knowledgebase. Appl. Sci. 2017, 7, 1316. [Google Scholar] [CrossRef]
- Louridas, P.; Ebert, C. Machine Learning. IEEE Softw. 2016, 33, 110–115. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2323. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 1, 1097–1105. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition using Places Database. Adv. Neural Inf. Process. Syst. 2014, 27, 487–495. [Google Scholar]
- Dietterich, T.G.; Bakiri, G. Solving Multiclass Learning Problems via Error-Correcting Output Codes. J. Artif. Intell. Res. 1995, 2, 263–286. [Google Scholar] [CrossRef]
- SoftBank Robotics. Available online: Https://www.ald.softbankrobotics.com/en/press/press-releases/softbank-increases-its-interest (accessed on 29 January 2019).
- Mozos, O.M.; Stachniss, C.; Burgard, W. Supervised learning of places from range data using AdaBoost. In Proceedings of the IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; Volume 2005, pp. 1730–1735. [Google Scholar]
- Rottmann, A.; Mozos, Ó.M.; Stachniss, C.; Burgard, W. Semantic Place Classification of Indoor Environments with Mobile Robots using Boosting. In Proceedings of the 20th National Conference on Artificial Intelligence, Pittsburgh, PA, USA, 9–13 July 2005; Volume 3, pp. 1306–1311. [Google Scholar]
- Mozos, Ó.M.; Triebel, R.; Jensfelt, P.; Rottmann, A.; Burgard, W. Supervised semantic labeling of places using information extracted from sensor data. Rob. Auton. Syst. 2007, 55, 391–402. [Google Scholar] [CrossRef]
- Ayers, B.; Boutell, M. Home interior classification using SIFT keypoint histograms. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007. [Google Scholar]
- Ursic, P.; Kristan, M.; Skocaj, D.; Leonardis, A. Room classification using a hierarchical representation of space. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Algarve, Portugal, 7–12 October 2012; pp. 1371–1378. [Google Scholar]
- Swadzba, A.; Wachsmuth, S. Indoor scene classification using combined 3d and gist features. In Proceedings of the 10th Asian Conference on Computer Vision, Queenstown, New Zealand, 8–12 November 2010; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2011; Volume 6493, pp. 201–215. [Google Scholar]
- Mozos, O.M.; Mizutani, H.; Kurazume, R.; Hasegawa, T. Categorization of indoor places using the Kinect sensor. Sensors (Switzerland) 2012, 12, 6695–6711. [Google Scholar] [CrossRef] [PubMed]
- Zivkovic, Z.; Booij, O.; Kröse, B. From images to rooms. Rob. Auton. Syst. 2007, 55, 411–418. [Google Scholar] [CrossRef]
- Varadarajan, K.M.; Vincze, M. Functional Room Detection and Modeling using Stereo Imagery in Domestic Environments. In Proceedings of the Workshop on Semantic Perception, Mapping and Exploration at IEEE International Conference on Robotics and Automation (ICRA 2011), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Varvadoukas, T.; Giannakidou, E.; Gómez, J.V.; Mavridis, N. Indoor furniture and room recognition for a robot using internet-derived models and object context. In Proceedings of the 10th International Conference on Frontiers of Information Technology (FIT 2012), Islamabad, Pakistan, 17–19 December 2012; pp. 122–128. [Google Scholar]
- Jackel, L.D.L.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; LeCun, B.; Denker, J.; Henderson, D. Handwritten Digit Recognition with a Back-Propagation Network. Adv. Neural Inf. Process. Syst. 1990, 2, 396–404. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the IEEE International Symposium on Circuits and Systems: Nano-Bio Circuit Fabrics and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An Analysis of Deep Neural Network Models for Practical Applications. arxiv, 2016; arXiv:1605.0767. [Google Scholar]
- Quattoni, A.; Torralba, A. Recognizing indoor scenes. In Proceedings of the 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 413–420. [Google Scholar]
- Espinace, P.; Kollar, T.; Soto, A.; Roy, N. Indoor scene recognition through object detection. In Proceedings of the IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 4–8 May 2010; pp. 1406–1413. [Google Scholar]
- Ursic, P.; Mandeljc, R.; Leonardis, A.; Kristan, M. Part-based room categorization for household service robots. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 2287–2294. [Google Scholar]
- Liu, M.; Chen, R.; Li, D.; Chen, Y.; Guo, G.; Cao, Z.; Pan, Y. Scene Recognition for Indoor Localization Using a Multi-Sensor Fusion Approach. Sensors 2017, 17, 2847. [Google Scholar] [CrossRef] [PubMed]
- Cruz, E.; Rangel, J.C.; Gomez-Donoso, F.; Bauer, Z.; Cazorla, M.; Garcia-Rodriguez, J. Finding the Place: How to Train and Use Convolutional Neural Networks for a Dynamically Learning Robot. In Proceedings of the International Joint Conference on Neural Networks, Rio de Janeiro, Brazil, 8–13 July 2018. [Google Scholar]
- Martínez-Gómez, J.; García-Varea, I.; Cazorla, M.; Morell, V. ViDRILO: The visual and depth robot indoor localization with objects information dataset. Int. J. Rob. Res. 2015, 34, 1681–1687. [Google Scholar] [CrossRef]
- Deng, H.; Stathopoulos, G.; Suen, C.Y. Error-correcting output coding for the convolutional neural network for optical character recognition. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Barcelona, Spain, 26–29 July 2009. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Shum, K.; Tang, X. Deep Representation Learning with Target Coding. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Abd-Ellah, M.K.; Awad, A.I.; Khalaf, A.A.M.; Hamed, H.F.A. Two-phase multi-model automatic brain tumour diagnosis system from magnetic resonance images using convolutional neural networks. EURASIP J. Image Video Process. 2018, 2018, 97. [Google Scholar] [CrossRef]
- Dorj, U.O.; Lee, K.K.; Choi, J.Y.; Lee, M. The skin cancer classification using deep convolutional neural network. Multimed. Tools Appl. 2018, 77, 9909–9924. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2015; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Rocha, A.; Goldenstein, S.K. Multiclass from binary: Expanding One-versus-all, one-versus-one and ECOC-based approaches. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 289–302. [Google Scholar] [CrossRef]
- Aly, M. Survey on multiclass classification methods. Neural Netw. 2005, 19, 1–9. [Google Scholar]
- James, G.; Hastie, T. The error coding method and PICTs? J. Comput. Graph. Stat. 1998, 7, 377–387. [Google Scholar]
- Chen, C.; Ren, Y.; Jay, K.C. Big Visual Data Analysis Scene Classification and Geometric Labeling; Briefs in Electrical and Computer Engineering; Springer: Singapore, 2016. [Google Scholar]
- Song, S.; Yu, F.; Zeng, A.; Chang, A.X.; Savva, M.; Funkhouser, T. Semantic scene completion from a single depth image. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), San Juan, Puerto Rico, USA, 24–30 June 2017; Volume 2017, pp. 190–198. [Google Scholar]
- Walch, F.; Hazirbas, C.; Leal-Taixe, L.; Sattler, T.; Hilsenbeck, S.; Cremers, D. Image-Based Localization Using LSTMs for Structured Feature Correlation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; Volume 2017, pp. 627–637. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Khosla, A.; Oliva, A.; Torralba, A. Places: A 10 million Image Database for Scene Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017. [Google Scholar] [CrossRef] [PubMed]
- Compute Canada. Available online: https://www.computecanada.ca (accessed on 29 January 2019).
- Keras Documentation. Available online: https://keras.io (accessed on 29 January 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | # Images out of 11,600 | % of Removed Images |
|---|---|---|
| Bedrooms | 9323 | 19.6% |
| Dining Rooms | 7919 | 31.7% |
| Kitchens | 6611 | 43.0% |
| Living Rooms | 8571 | 26.1% |
| Bathrooms | 8959 | 22.8% |
| CNN Models | Non-Trainable Layers | All Data | Clean Data | ||
|---|---|---|---|---|---|
| Time | Accuracy % | Time | Accuracy % | ||
| VGG16 | 15 | 11:50:40 | 86.03 | 8:16:16 | 89.69 |
| 11 | 11:50:41 | 88.09 | 8:15:38 | 91.49 | |
| 7 | 11:53:42 | 88.9 | 8:18:49 | 93.22 | |
| 0 | 12:13:55 | 87.78 | 8:34:45 | 93.29 | |
| VGG19 | 20 | 13:11:07 | 78.69 | 9:16:00 | 82.50 |
| 17 | 13:14:56 | 86.22 | 9:18:38 | 89.65 | |
| 0 | 13:43:40 | 90.30 | 9:40:52 | 93.61 | |
| Inception V3 | 299 | 10:17:29 | 75.12 | 7:8:33 | 78.83 |
| 249 | 10:17:46 | 79.11 | 7:07:50 | 84.05 | |
| Binary Classifiers | 1 Bath vs. All | 2 | 3 | 4 | 5 | 6 | 7 | 8 Bed vs. All | 9 | 10 | 11 | 12 Dining vs. All | 13 | 14 Kitchen vs. All | 15 Living vs. All | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Accuracy % | 98.50 | 93.62 | 97.38 | 92.01 | 94.84 | 93.95 | 96.06 | 95.73 | 95.59 | 96.10 | 94.94 | 95.89 | 92.76 | 97.95 | 95.31 | 95.37 |
| Model | Bath | Bed | Dining | Kitchen | Living | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| T1 | T2 | T1 | T2 | T1 | T2 | T1 | T2 | T1 | T2 | |
| CNN | 100 | - | 69.2 | 100 | 66.7 | 83.3 | 15.4 | 61.5 | 50 | 75 |
| CNN-ECOC | 100 | - | 69.2 | 100 | 66.7 | 100 | 15.4 | 100 | 41.7 | 91.7 |
| CNN-ECOC-REG | 100 | - | 69.2 | 100 | 66.7 | 100 | 30.8 | 100 | 50 | 100 |
| # Images | # False Images in Top 1 | bath | bed | din | kit | liv | ||
|---|---|---|---|---|---|---|---|---|
| Top-1 with CNN | bath | 12 | 12 | |||||
| bed | 13 | 4 | 9 | |||||
| din | 6 | 2 | 4 | |||||
| kit | 13 | 10 | 2 | 1 | ||||
| liv | 12 | 4 | 2 | 6 | ||||
| Top-2 with CNN | bath | 0 | ||||||
| bed | 4 | 4 | ||||||
| din | 2 | 1 | 1 | |||||
| kit | 11 | 1 | 4 | 6 | ||||
| liv | 6 | 2 | 1 | 3 | ||||
| Top-1 with CNN-ECOC | bath | 12 | 12 | |||||
| bed | 13 | 4 | 9 | |||||
| din | 6 | 2 | 4 | |||||
| kit | 13 | 11 | 2 | |||||
| liv | 12 | 6 | 1 | 5 | ||||
| Top-2 with CNN-ECOC | bath | 0 | ||||||
| bed | 4 | 4 | ||||||
| din | 2 | 1 | 1 | |||||
| kit | 11 | 11 | ||||||
| liv | 7 | 1 | 6 | |||||
| Top-1 with CNN-ECOC-REG | bath | 12 | 12 | |||||
| bed | 13 | 4 | 9 | |||||
| din | 6 | 2 | 4 | |||||
| kit | 13 | 9 | 4 | |||||
| liv | 12 | 4 | 1 | 1 | 6 | |||
| Top-2 with CNN-ECOC-REG | bath | 0 | ||||||
| bed | 4 | 4 | ||||||
| din | 2 | 2 | ||||||
| kit | 9 | 9 | ||||||
| liv | 6 | 6 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Othman, K.M.; Rad, A.B. An Indoor Room Classification System for Social Robots via Integration of CNN and ECOC. Appl. Sci. 2019, 9, 470. https://doi.org/10.3390/app9030470
Othman KM, Rad AB. An Indoor Room Classification System for Social Robots via Integration of CNN and ECOC. Applied Sciences. 2019; 9(3):470. https://doi.org/10.3390/app9030470
Chicago/Turabian StyleOthman, Kamal M., and Ahmad B. Rad. 2019. "An Indoor Room Classification System for Social Robots via Integration of CNN and ECOC" Applied Sciences 9, no. 3: 470. https://doi.org/10.3390/app9030470
APA StyleOthman, K. M., & Rad, A. B. (2019). An Indoor Room Classification System for Social Robots via Integration of CNN and ECOC. Applied Sciences, 9(3), 470. https://doi.org/10.3390/app9030470