The segmentation algorithm presented in this paper was designed to robustly label and segment ethnomusicological field recordings into consistent units, such as speech, sung, and instrumental parts. Resulting segmentations should be comparable to manual segmentations researchers make when studying recordings. Field recordings are documents of entire recording sessions and typically contain interviews with performers intertwined with actual performances. As these are live recordings of amateur folk musicians, they usually contain lots of “noise” and interruptions, such as silence when performers momentarily forget parts of songs, false starts and restarts, dancing noises, interruptions by other persons, or cars driving by. Performances may also change character; singing may become reciting, a second voice may join or drop out of a performance, etc.
The described nature of field recordings calls for a robust segmentation algorithm that would not over-segment a recording at each interruption—for example, we are not interested in each boundary separating speech and sung parts, as only some of them are actual segment boundaries. We would also like to distinguish between several different classes of segments and would like to take some prior knowledge of the classes into account. Last, we are not interested in millisecond-exact segment boundaries or exact labeling of each small recording fragment; sometimes placing a boundary between two performances is a very soft decision and accuracy of a few seconds is good enough. Taking these points into account, we propose a three step approach to segmentation:
2.1. Deep Neural Networks for Labelling
Exploration of field recordings from a variety of ethnomusicological archives revealed four major classes of contents that appear in various cultures: Solo singing, choir (more than one singing voice) singing, instrumental performances, and speech. Our goal was, therefore, to classify field recordings into the four classes, and not to limit ourselves to just speech and music.
To train deep learning classifiers, large datasets are needed—the larger the better as recent experiences show. For speech/music segmentation, some datasets, such as the well-known GTZAN speech music collection [
13], are available, but they mostly contain studio-grade samples labelled as speech or music, which is not very suitable for our goal. On the other hand, the recent Audio Set dataset [
12] is an excellent large-scale audio classification dataset, however, its categories and contents are also not ideal for our purpose; for example, there is no solo singing category, examples labeled with singing are mostly accompanied by music, while the musical genres are mostly oriented towards popular music genres (pop, rock, etc.).
2.1.1. Dataset
To train and evaluate deep learning models, we decided to gather and label a dataset that would contain short excerpts from a variety of ethnomusicological (and related) archives that put their collections online in recent years. The sources include: The British Library world & traditional music collection (
https://sounds.bl.uk//World-and-traditional-music), Alan Lomax recordings (
http://research.culturalequity.org/home-audio.jsp), sound archives of the CRNS (French National Centre for Scientific Research) (
http://archives.crem-cnrs.fr/), and a number of recordings from the Slovenian sound archive Ethnomuse and the National Library of Norway, which are not available online, but were made available to us by ethnomusicologists with the respective institutions. These field recordings were augmented by the GTZAN music/speech collection, the Mirex 2015 music/speech detection public dataset, and the MUSAN corpus [
14].
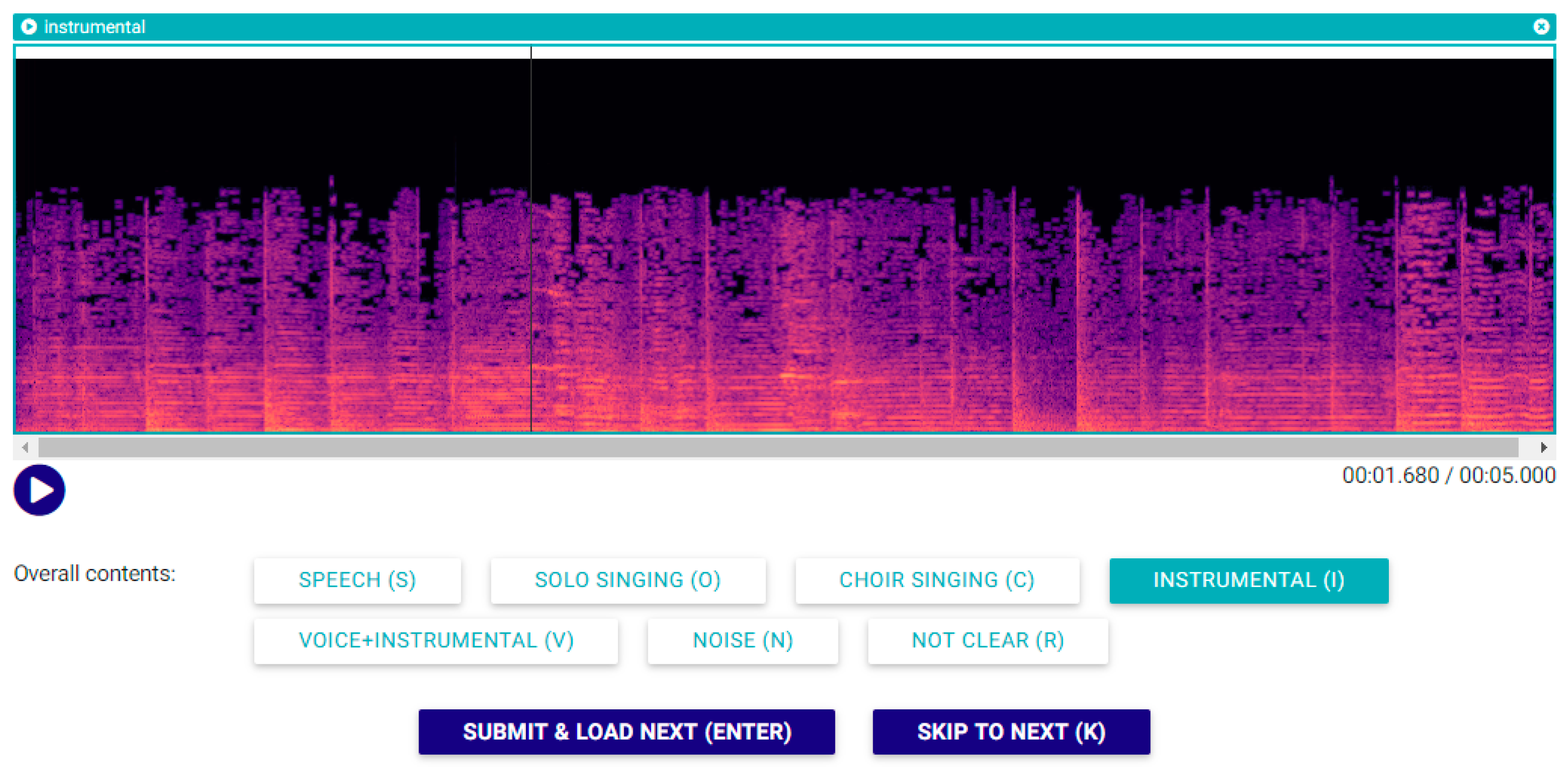
Five second long excerpts were extracted from recordings in these collections. To manually label them into the target classes, we enhanced the web-based audio annotator tool [
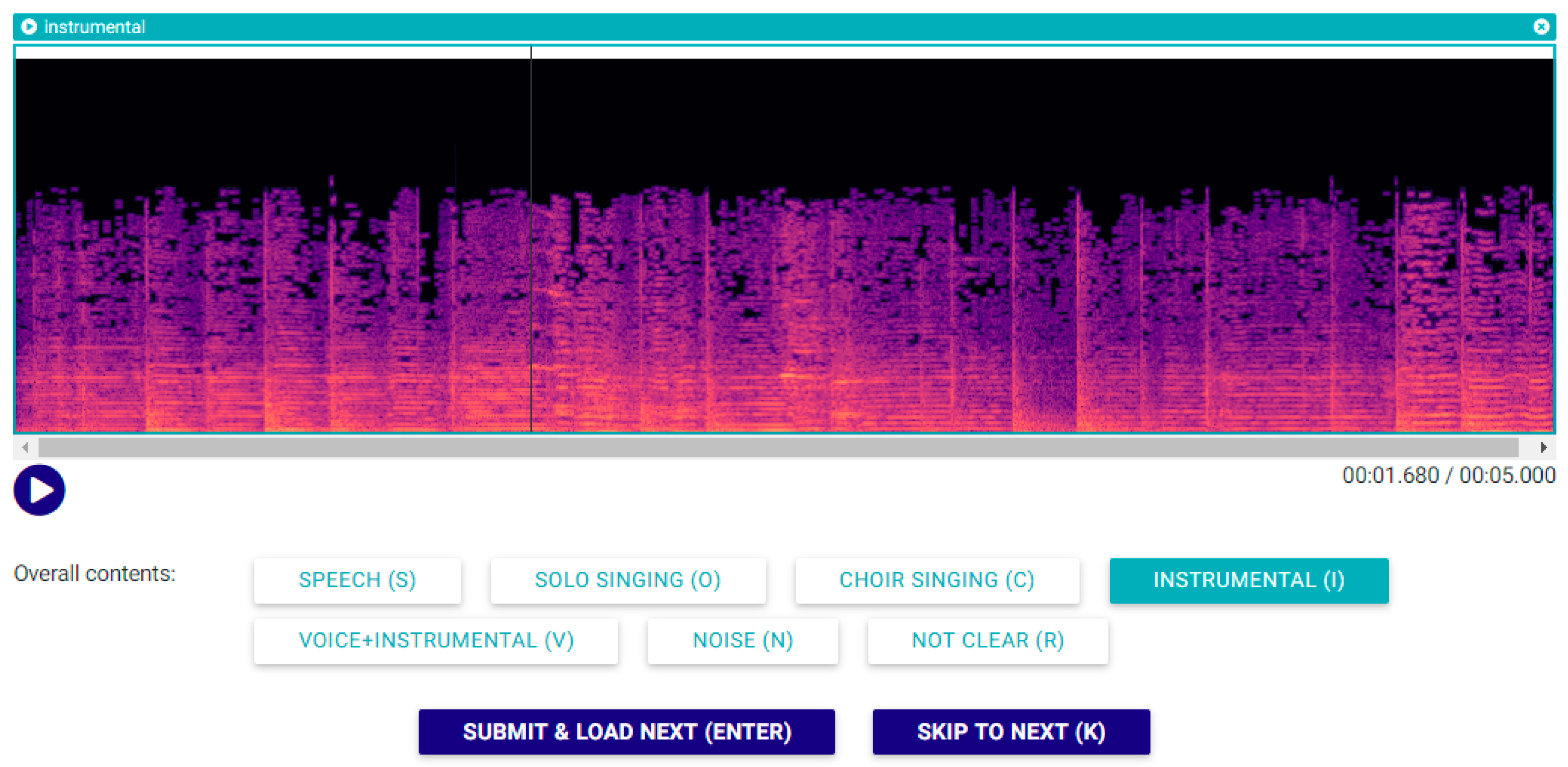
15], so that it can be controlled exclusively by the keyboard. This makes labelling very fast when an excerpt contains just one class (e.g., speech). When an excerpt contains multiple classes, the user can still use the mouse to choose individual regions and label them accordingly. The enhancements enabled fast multi-user annotation of audio excerpts into the four main classes (speech, solo singing, choir singing, and instrumental), which we augmented with three additional classes. The “Not clear” class was introduced for sections containing too many short fragments of different types or for sections where the class is difficult to establish due to performance peculiarities (e.g., when it is difficult to discern between speech and singing). The “Noise” class was introduced for excerpts with no discernable contents, and, finally, the “Voice over instrumental” class to separately annotate this type of recording, which will be useful in our future work. The annotator’s goal was to label each five second clip with the corresponding label(s), where the clips were randomly chosen from the dataset of unlabeled clips for each participating annotator. The user interface of the annotation application, showing the spectrogram of an excerpt with the labelled class, was kept very similar to the original audio annotator and is shown in
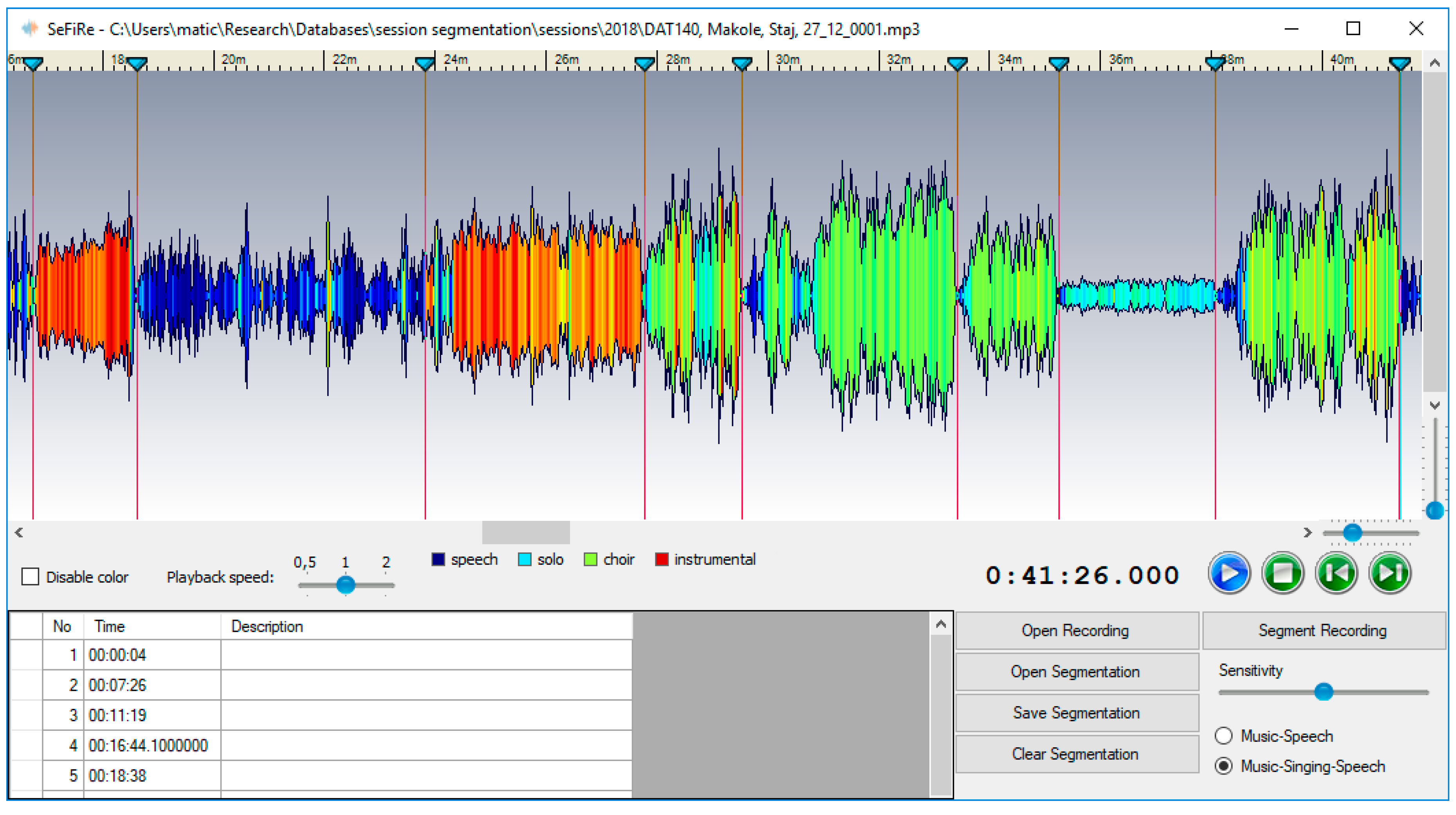
Figure 1.
Using the interface, over 7000 excerpts were labelled. Approximately 80% of the excerpts were labelled into one of the four target classes, the distribution of class labels within the target classes was approximately equal (roughly 23% for speech, solo singing, and choir singing, and 33% for instrumentals). This was expected, as we chose the classes to be the ones most often represented in the field recordings. Ten percent of the other excerpts were labeled as vocals and instrumental, approximately 6% as not clear, and 4% as noise. The entire dataset with audio excerpts for internal sources and links to original materials is made publicly available with this paper (the URL is given at the end of the paper).
2.1.2. Network Architecture and Training
The basic architecture of the deep neural network for classification stems from our previous work [
16], where we demonstrated their usability for the task. We chose convolutional deep networks as our main classification tool and focused specifically on residual networks [
17], which demonstrated good performance for a variety of image, as well as audio-based tasks. The main feature of residual networks are their shortcut connections that implement identity mappings and enable convolutional blocks to learn residuals between the underlying mapping of features and the input. We augmented the first layer of the previously presented approach with music-specific feature filters and zero-mean convolutions, which together with data augmentation, improved the overall classification accuracy.
To provide network input, all the audio excerpts were first downsampled to 22,050 Hz, mixed to a single channel, and normalized. The audio was then split into 46 ms frames with a 14.3 ms step size, and 80 bin mel-scale spectra (30–8000 Hz) computed for all frames. We log-scaled the mel values, adding 1e-5 before applying the logarithm and used 2 s long feature blocks (80 × 140) as network inputs.
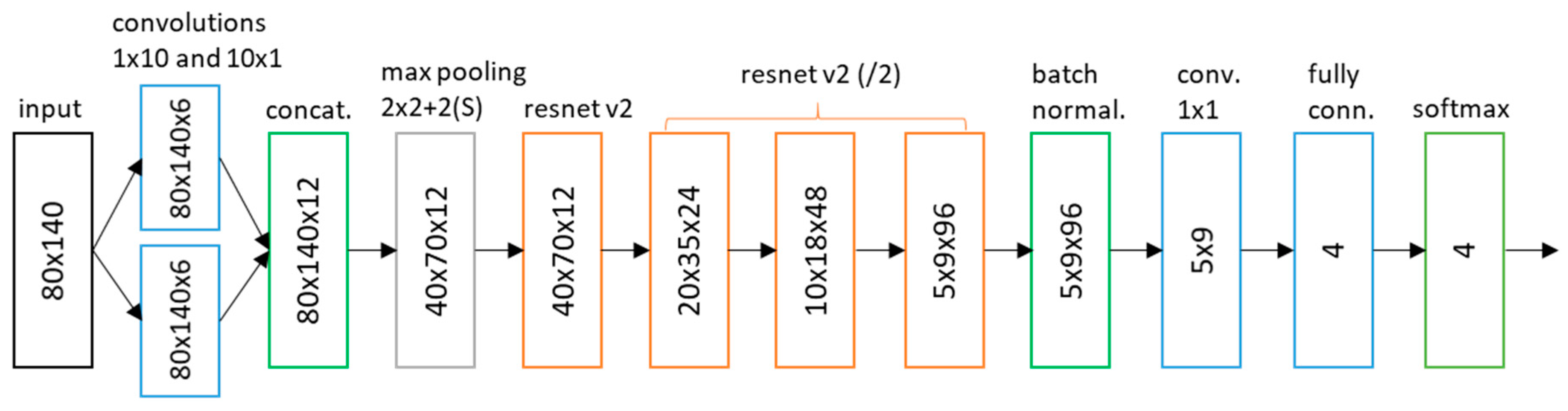
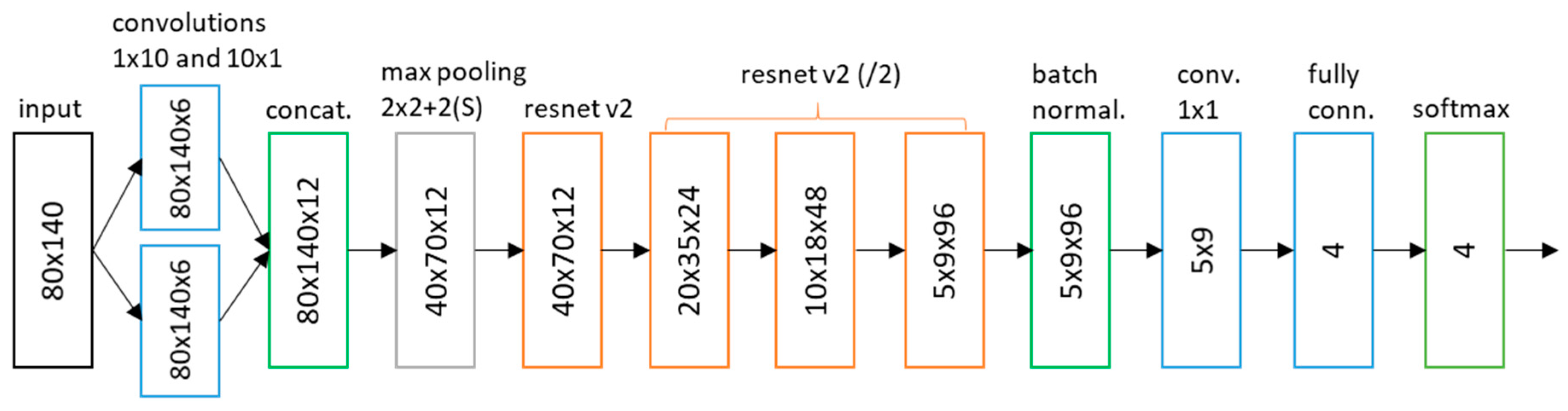
The network architecture is shown in
Figure 2. The input is processed by two sets of music-specific feature filters: frequency filters and temporal filters. Frequency filters model changes in the frequency domain regardless of time—we used 10-by-1 filters, corresponding to the average frequency range of 700 cents. Temporal filters, on the other hand, model temporal dependencies independent of frequency—we used 1-by-10 filters, which thus correlate with approximately 143 ms (10 frames) of audio. This type of filter specialization has been shown to be effective for various audio processing tasks, such as genre classification and emotion prediction [
18,
19]. Although each type of filters ignores one dimension (temporal or frequency), these dependencies are learned on higher network layers.
Additionally, to make the first layer filters more robust to varying recording conditions, we enforced the filters to have a zero mean, thus effectively learning to recognize the differences in the signal and ignoring constant offsets. Zero-mean convolutions were introduced to singing voice detection by Schlüter and Lehner [
20] and were shown to be very robust to signal gain changes.
Output feature maps of the initial layer are subsampled by a 2 × 2 max pooling layer, and followed by four resnet v2 blocks [
17], where the size of the feature maps is halved (in each dimension) and the number of filters doubles between three consecutive blocks. Exponential linear units [
21] are used as activation functions of the resnet layers. The batch normalized output of resnet blocks is gathered by 1 × 1 convolutions into a 2D feature map. The map is processed by a small fully connected layer with four outputs, and the softmax activation function calculates final class probabilities.
The architecture and parameters of the higher layers are derived from our previous work [
16], where we showed the efficiency of ELU and resnet layers for the task.
Altogether the network contains 172,708 trainable parameters, which is relatively small in the deep learning world, where sizes of tens of millions of parameters are usual, we wanted to keep the network small due to the relatively small training set. Also, in our experiments, larger network sizes did not bring a significant increase in accuracy.
The network was trained on a dataset of 7136 audio excerpts with minibatches of 128 examples. For each audio example, the block of input features was drawn from a random location within the five second audio excerpt, so that for each epoch, the feature blocks used to train the network differed in their location within training files. Such time translation diversifies the limited training data available and improves performance, as was also demonstrated elsewhere [
22]. In addition, time stretching and pitch transposition (scaling and shifting of the FFT spectrogram) of up to 30% was used to further augment the training data and reduce overfitting.
Stochastic gradient descent was used for training in 1000 epochs, and the learning rate was set to decay from 0.1 by a factor of 0.96 each 500 steps. The experiments were implemented in Tensorflow, and links to code are provided at the end of the paper. Training was done using the NVIDIA Quadro K5000 GPU and on average took 7 h for one model.
2.2. Segmentation
The goal of segmentation is to split the recording into a set of consistent units, such as speech or singing. Unlike broadcast segmentation, we are not interested in each small change of contents (e.g., just a few spoken sentences), but aim to segment the recording into larger units (entire songs or longer spoken parts). This is also where the presented approach differs the most when compared to other speech-music segmentation approaches (e.g., [
5,
6])—it is designed to segment audio into broader regions and to ignore small local changes.
The presented segmentation algorithm is a modification of our approach first presented in [
1]. To segment a recording, we first find a set of candidate segment boundaries and calculate the likelihood of splitting the recording at each boundary. We consider two criteria for boundary placement: A criterion based on signal energy, such as when performances are separated by regions of silence (or noise, since recordings may be quite noisy), and a criterion based on the change in signal content, such as when speech is followed by singing. The way the two criteria are calculated is the main distinction between the presented approach and [
1].
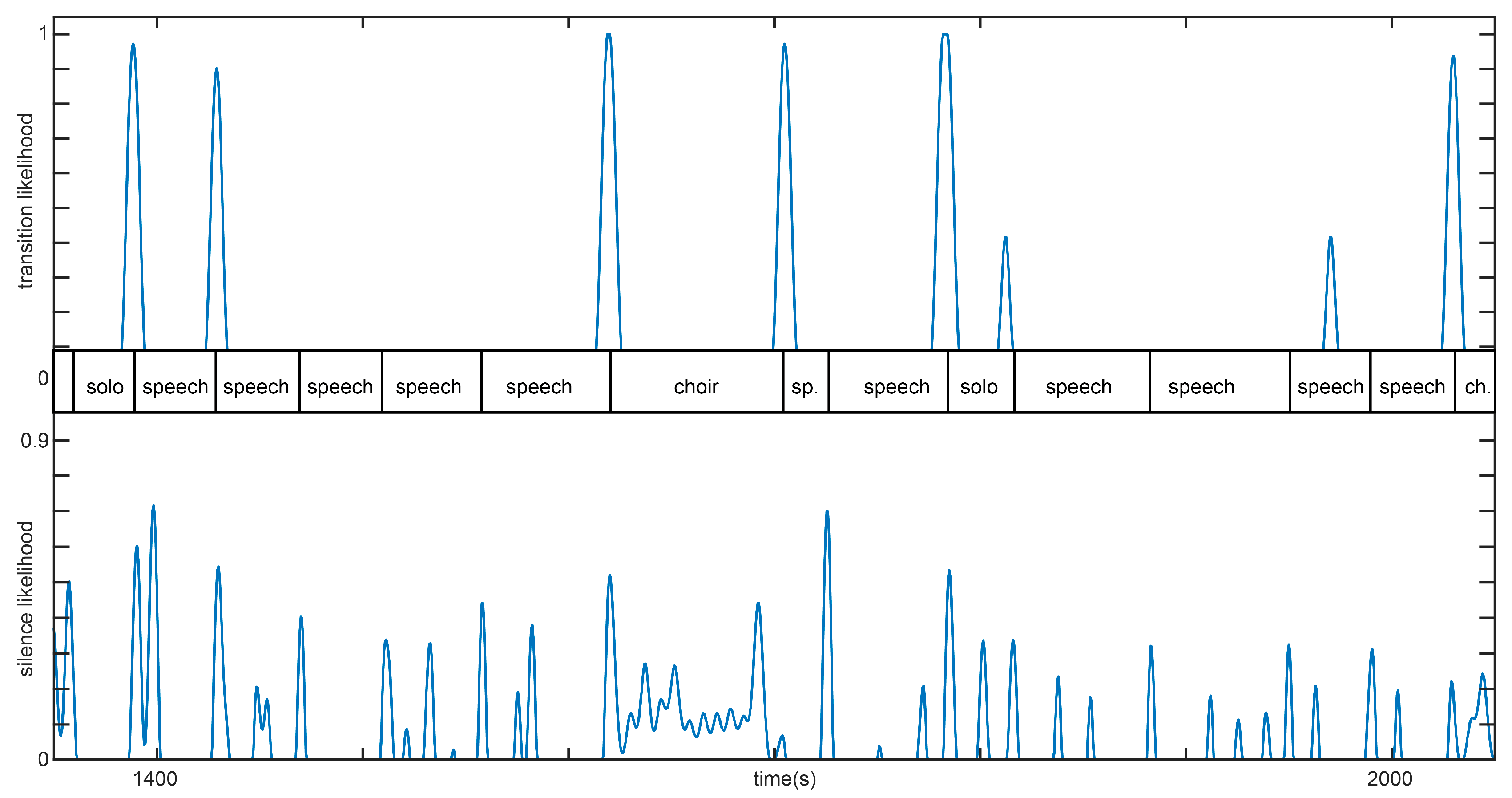
To observe the presence of a signal (vs. silence or noise), we first calculate the RMS energy,
, of the audio signal over 46 ms time frames. The energy is compared to two measures capturing the global and local amplitude thresholds. First, the 1st percentile of the energy within 20 s time windows is calculated and the global noise floor,
, is set to 5 dB over this value and lower bounded to
dB. Such an adaptive estimate is needed, as field recordings are often noisy or recorded with varying dynamics, so an absolute threshold would not be suitable as a global noise floor estimate. The local noise floor,
, captures local dynamics and is set to 15 dB below the energy median filtered with a 6 s time window. Based on both noise floors, the silence indicator function,
, is set to a value of one, when energy at time
t falls below any of the two noise floors, and zero elsewhere. The likelihood of placing a boundary at time
,
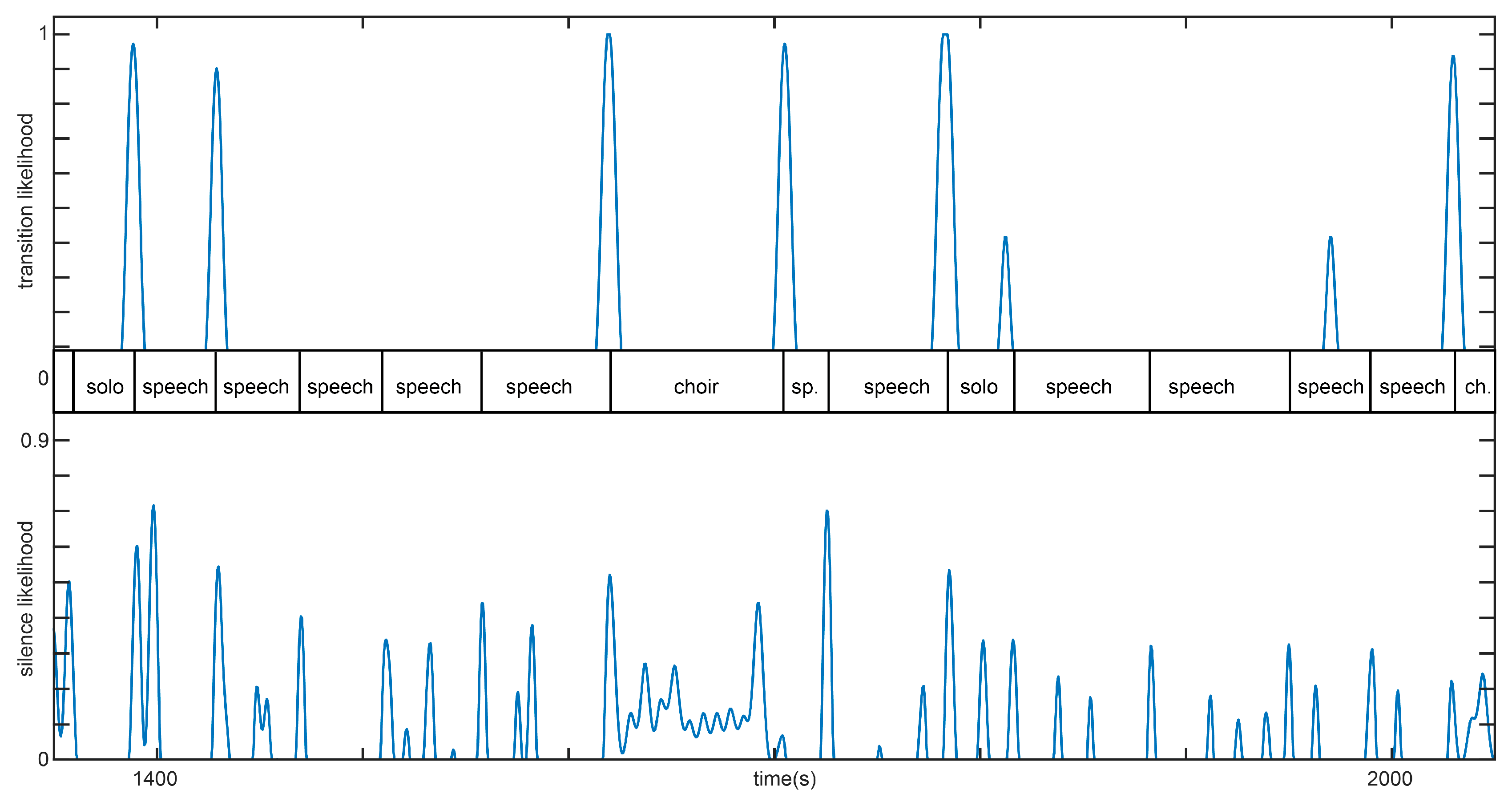
, is calculated by zero-phase filtering the indicator function with a second order low pass filter with 0.1 Hz cutoff. An example is given in
Figure 3.
Transitions between different kinds of signal content (e.g., speech to singing) are detected by calculating the symmetric Kullback-Leibler (KL) divergence,
, between probabilities of target classes (as calculated by the deep classifier) within 10 s windows to the left and right of each time frame. KL divergence will be large when the contents (class probabilities) on both sides will be different, and close to zero, when they will be similar. The transition boundary placement likelihood,
, is obtained similarly to the silence likelihood by thresholding and low-pass filtering the divergence function,
. Both likelihood curves are depicted in
Figure 3, which shows an excerpt of a field recording, where content varies between speech and singing. The transition likelihood indicates segment boundaries due to transitions between different content types well, while the silence likelihood indicates boundaries between individual units separated by silence/noise, as well as short pauses, which often occur during speech segments.
To segment a recording, we construct a probabilistic model, which integrates the data on segment boundary likelihoods with prior knowledge of typical segment lengths. First, a set of boundary candidates, , is obtained by finding peaks of both curves. Based on the boundary candidates, segmentation is defined as a sequence of segments, , where starts at time 0 and ends at candidate boundary, , starts at candidate boundary, , and ends at , starts at and ends at , and so on.
We treat each candidate boundary,
, as a discrete random variable with two outcomes: Either the candidate boundary represents an actual boundary and splits the recording into two segments, or not. The probability mass function for the variable is defined as the maximum of both likelihood curves:
In our model, the probability of each segment is only dependent on the location of the previous segment, so we can express the joint probability of all segments as:
To calculate the probability of placing a segment boundary at
given
, we consider all candidate boundaries within the segment, as well as its duration. If the segment is to start at time
j and end at
i, values of all candidate boundary variables within the segment must be
false, while the value of the candidate boundary variable at time
i must be
true. Segmentation can be further constrained by previous knowledge of the typical lengths of segments,
, given their class, leading to the following formulation:
Probability, , of the segment duration given its boundaries is dependent on the class of the segment, as calculated by the deep classifier. Probability, , that the segment, , belongs to class c is calculated by averaging all class labels within the segment.
By analyzing durations of segments in our collection of field recordings, we estimated the means and standard deviations for all segment classes
; for example, the duration of speech segments varies a lot and ranges from several seconds to over 10 min, while the average length of choir singing segments is around three minutes and their standard deviation below two minutes. By additionally enforcing minimal segment duration,
, we obtain the following expression for the probability of segment duration:
where
G is the unscaled Gaussian function.
We find the sequence of segments that maximizes the joint probability as given in Equation (2) with dynamic programming, which leads to a simple and efficient solution. After segmentation is calculated, segments can be labeled by finding the class, , that maximizes .





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}