A Text Abstraction Summary Model Based on BERT Word Embedding and Reinforcement Learning


Abstract
:
1. Introduction
- (1)
- In this paper, we applied BERT word embedding to the text summarization task, and improved the performance of the task by taking advantage of the rich semantic features of BERT word embedding.
- (2)
- We train a single unified model, which combines the advantages of universal language model BERT, extraction method, and abstraction method.
- (3)
- Our approach is based on the strategy gradient of reinforcement learning and bridges the abstractive model and the extractive model. We have carried experiments on a large dataset to find that our approach achieves state-of-the-art ROUGE scores.
2. Related Works
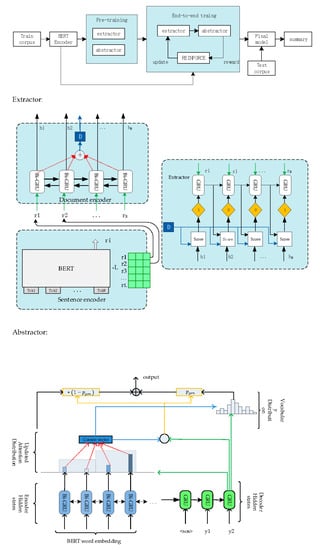
3. Methods
3.1. Problems
3.2. Word Embedding
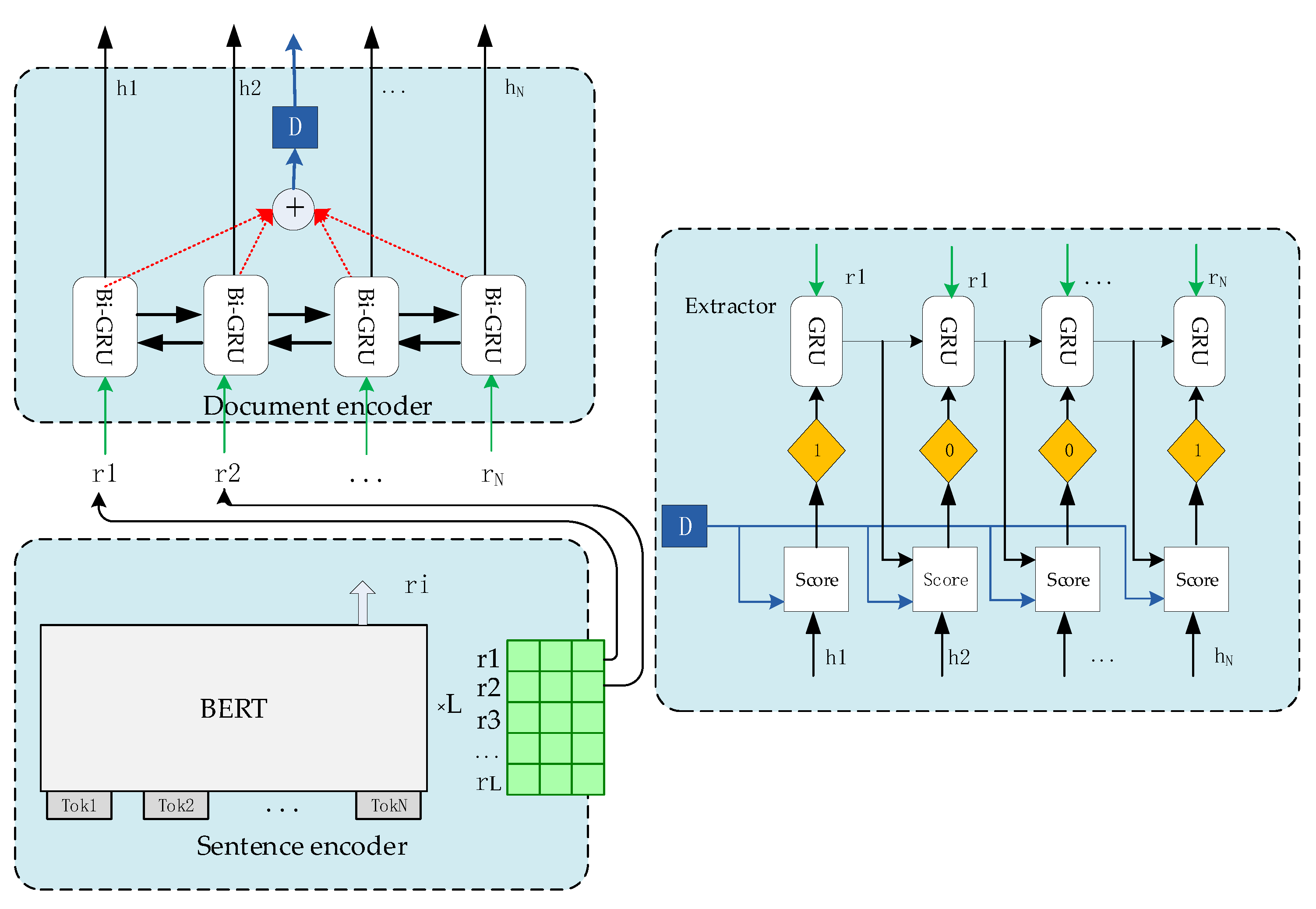
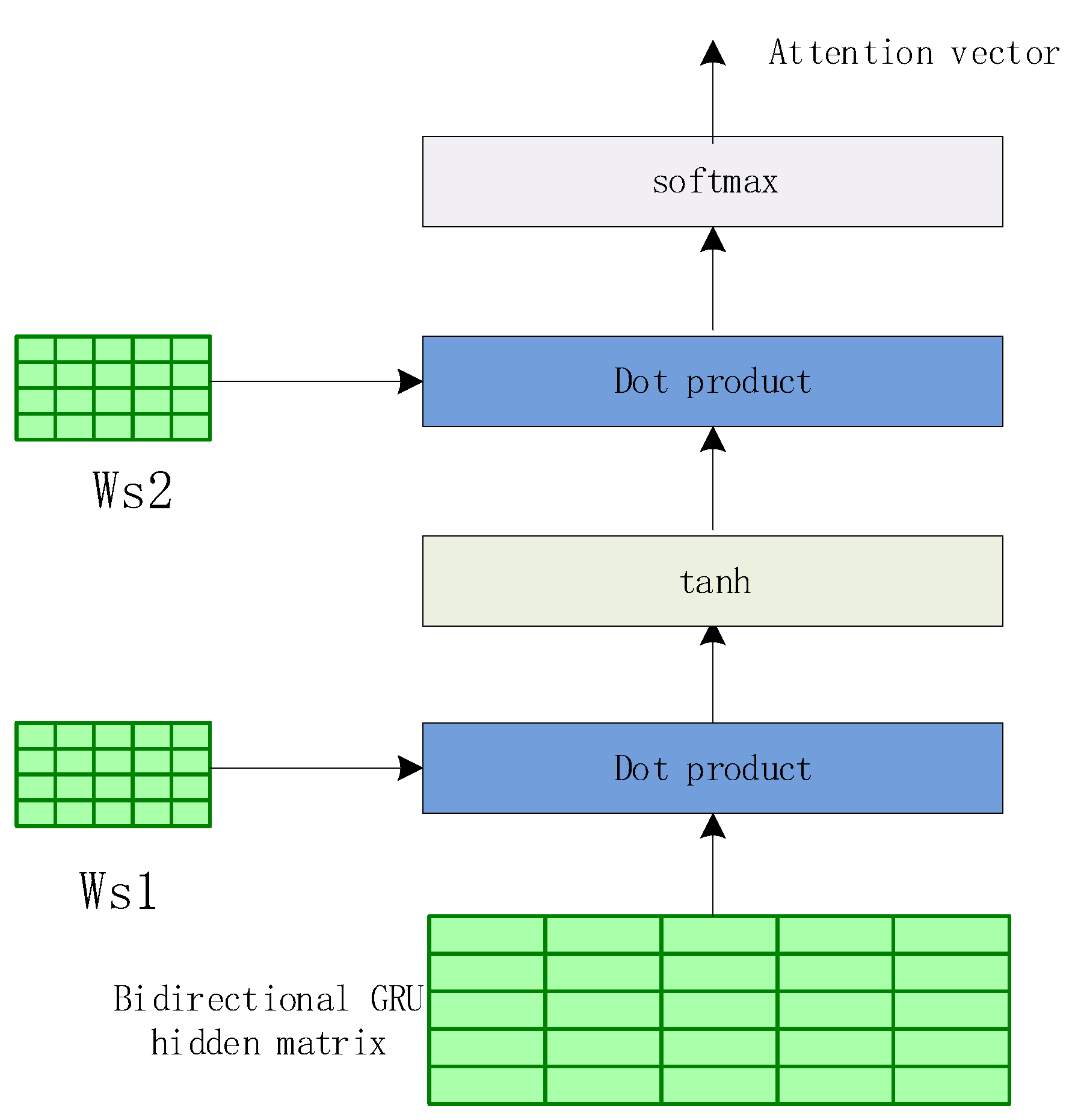
3.3. Extraction Model
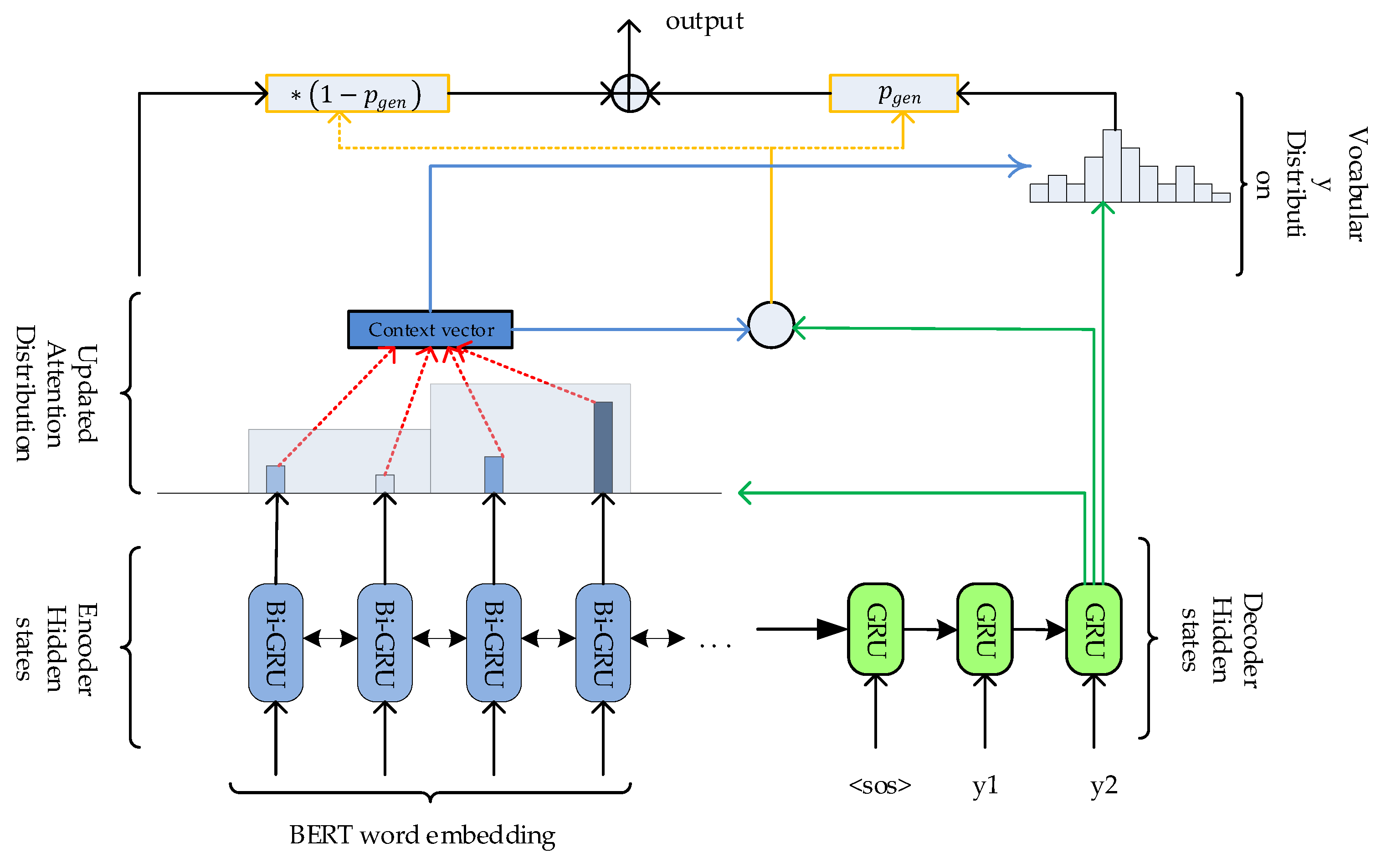
3.4. Abstraction Model
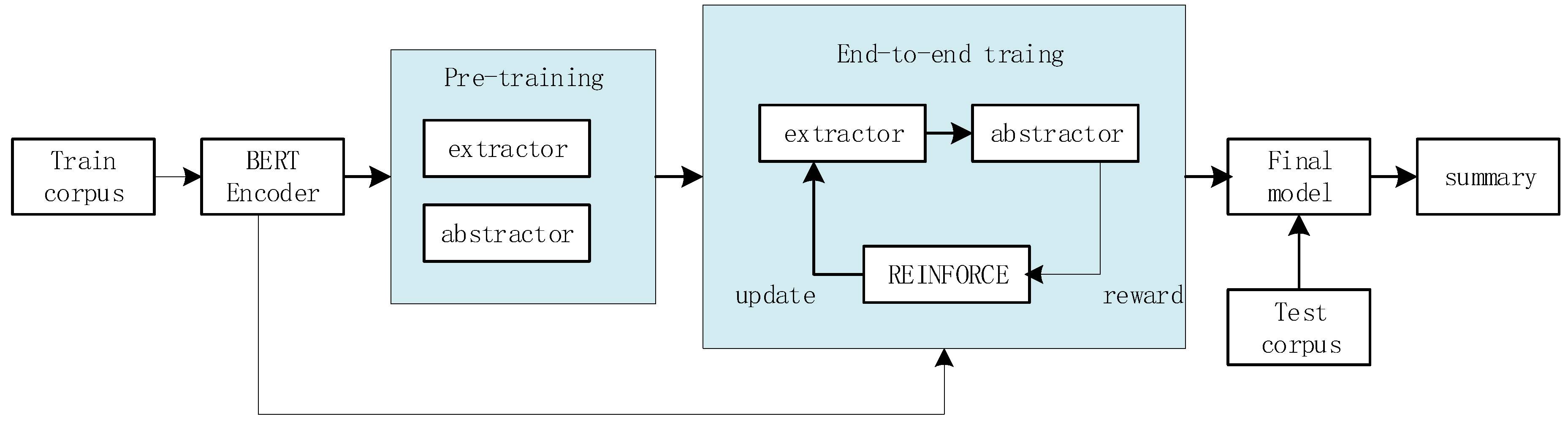
3.5. Training Procedure
3.5.1. Pre-Training
3.5.2. End-to-End Training
3.6. Reinforcement Learning
3.7. Redundancy Issue
4. Experiments
4.1. Datasets
4.2. Detail
4.3. Metrics
4.4. Baselines
- Leading sentences (Lead-3): It directly extracts the first three sentences of the article as a summary. This model as extractive baseline.
- Refresh: The model proposed by [3], takes the reinforcement learning objective as the extraction baseline and optimizes the rouge evaluation index globally.
- SummaRuNNer: It is proposed by [22] to generate the summary by extracting some key subset of the content for the article, as an extractive baseline.
- HSSAS: It is proposed by [21] to employ the self-attention mechanism to create a good sentence and document embeddings, as an extractive baseline.
- NeuSum: It is proposed by [30] to extract the document summarization by jointly learning to score and select sentences, as an extractive baseline.
- Pointer-generator+coverage: It is proposed by [6] to copy words from the source article and retain the ability to generate new words, as an abstractive baseline.
- Inconsistency loss: The method proposed by [10], which uses sentence-level attention to modulate the word-level attention, introduces inconsistency loss function to penalize the inconsistency between two attentions, as an abstractive baseline.
- DCA: The method proposed by [11], which encodes long text with the deep communication agents and then connects to a single decoder to generate a focused and coherent summary through reinforcement learning, is the best abstract model in 2018 and serve as an abstractive baseline.
- RNN-ext+abs+rl+rerank: It is proposed by [9], which first selects salient sentences and then rewrites them abstractly to generate a concise overall summary, as an abstractive baseline.
5. Result and Analysis
5.1. Result
5.2. Ablation Study
5.3. Generalization
5.4. Redundancy Issue
5.5. Training Speed
5.6. Case Study
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cheng, J.; Lapata, M. Neural summarization by extracting sentences and words. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 484–494. [Google Scholar]
- Nallapati, R.; Zhou, B.; Santos, C.N.D.; Gulcehre, C.; Xiang, B. Abstractive text summarization using sequence-to-sequence rnns and beyond. In Proceedings of the SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; p. 280. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Ranking sentences for extractive summarization with reinforcement learning. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 2–4 June 2018; pp. 1747–1759. [Google Scholar]
- Yasunaga, M.; Zhang, R.; Meelu, K.; Pareek, A.; Srinivasan, K.; Radev, D. Graph-based neural multi-document summarization. In Proceedings of the 21st Conference on Computational Natural Language Learning, Vancouver, BC, Canada, 3–4 August 2017; pp. 452–462. [Google Scholar]
- Rush, A.M.; Chopra, S.; Weston, J. A neural attention model for abstractive sentence summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1073–1083. [Google Scholar]
- Paulus, R.; Xiong, C.; Socher, R. A deep reinforced model for abstractive summarization. In Proceedings of the Sixth International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Li, P.; Bing, L.; Lam, W. Actor-critic based training framework for abstractive summarization. arXiv 2018, arXiv:1803.11070V2. [Google Scholar]
- Chen, Y.C.; Bansal, M. Fast abstractive summarization with reinforce-selected sentence rewriting. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 675–686. [Google Scholar]
- Hsu, W.T.; Lin, C.K.; Lee, M.Y.; Min, K.; Tang, J.; Sun, M. A unified model for extractive and abstractive summarization using inconsistency loss. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 132–141. [Google Scholar]
- Celikyilmaz, A.; Bosselut, A.; He, X.; Choi, Y. Deep communicating agents for abstractive summarization. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 2–4 June 2018; pp. 1662–1675. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Cho, K.; Van, M.B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O.K. Incorporating copying mechanism in sequence-to-sequence learning. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1631–1640. [Google Scholar]
- Vinyals, O.; Fortunato, M.; Jaitly, N. Pointer networks. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–10 December 2015. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning Cambridge; MIT Press: Cambridge, MA, USA, 1998; Volume 2. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. Comput. Sci. 2014. [Google Scholar]
- Lin, Z.; Feng, M.; Santos, C.N.D.; Yu, M.; Xiang, B.; Zhou, B. A Structured Self-Attentive Sentence Embedding. arXiv 2017, arXiv:1703.03130. [Google Scholar]
- Li, Z.; Wei, Y.; Zhang, Y.; Yang, Q. Hierarchical attention transfer network for cross-domain sentiment classification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Al-Sabahi, K.; Zuping, Z.; Nadher, M. A hierarchical structured self-attentive model for extractive document summarization (hssas). IEEE Access 2018. [Google Scholar] [CrossRef]
- Nallapati, R.; Zhai, F.; Zhou, B. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3075–3081. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 5998–6008. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144V2. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. Lstm: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2015, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of summaries. In Proceedings of the Workshop on Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; pp. 74–81. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching Machines to Read and Comprehend. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 1693–1701. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. Comput. Sci. 2014. [Google Scholar]
- Zhou, Q.; Yang, N.; Wei, F.; Huang, S.; Zhou, M.; Zhao, T. Neural document summarization by jointly learning to score and select sentences. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 654–663. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | Validation | Test | |
|---|---|---|---|
| Pairs of data | 287,113 | 13,368 | 11,490 |
| Article length | 749 | 769 | 778 |
| Summary length | 55 | 61 | 58 |
| Model | R-1 | R-2 | R-L | R-AVG |
|---|---|---|---|---|
| Lead-3 [6] | 40.34 | 17.70 | 36.57 | 31.54 |
| Refresh [3] | 40.00 | 18.20 | 36.60 | 31.60 |
| SummaRuNNer [22] | 39.9 | 16.3 | 35.1 | 30.43 |
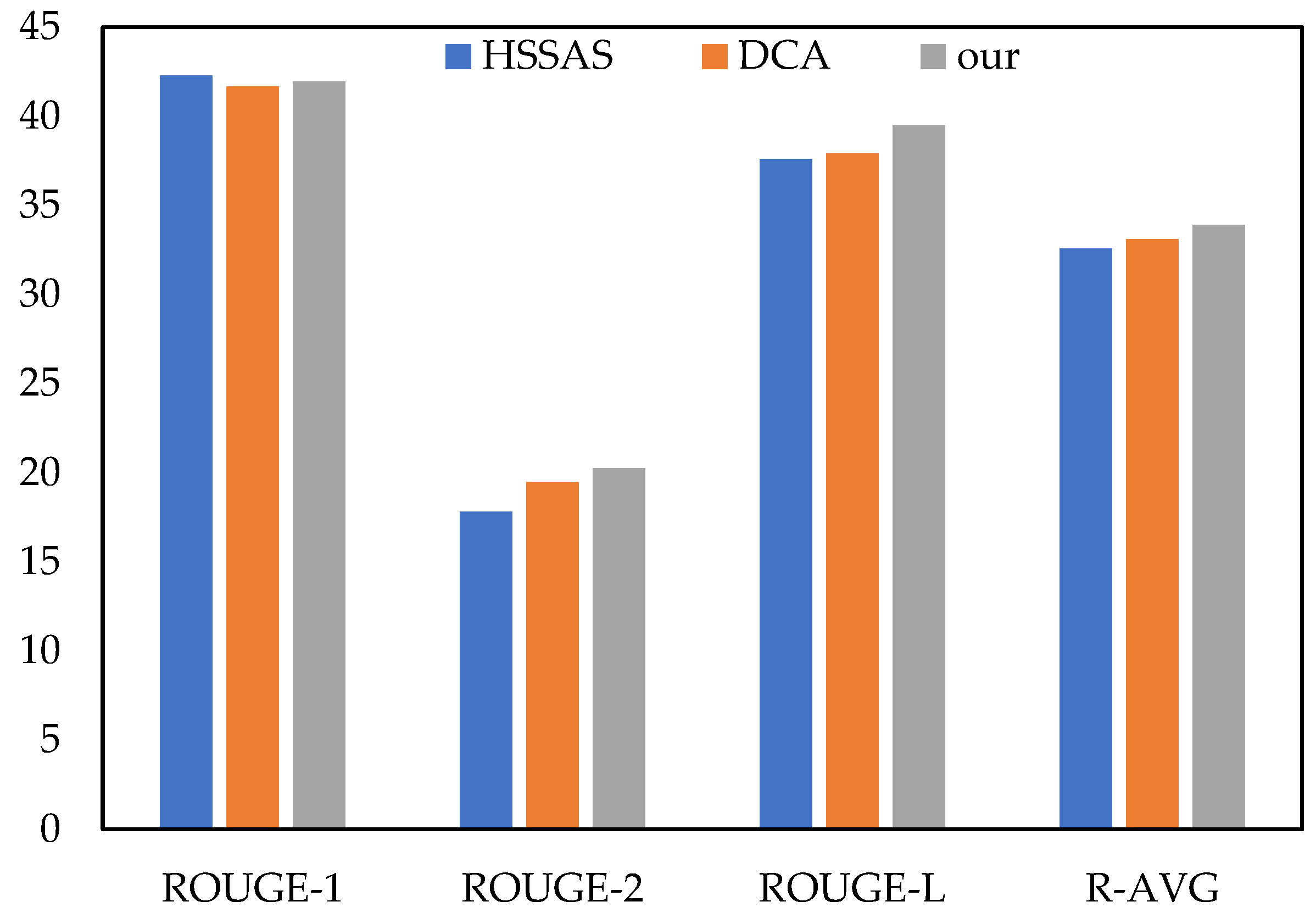
| HSSAS [21] | 42.3 | 17.8 | 37.6 | 32.57 |
| NeuSUM [30] | 41.59 | 19.01 | 37.98 | 32.86 |
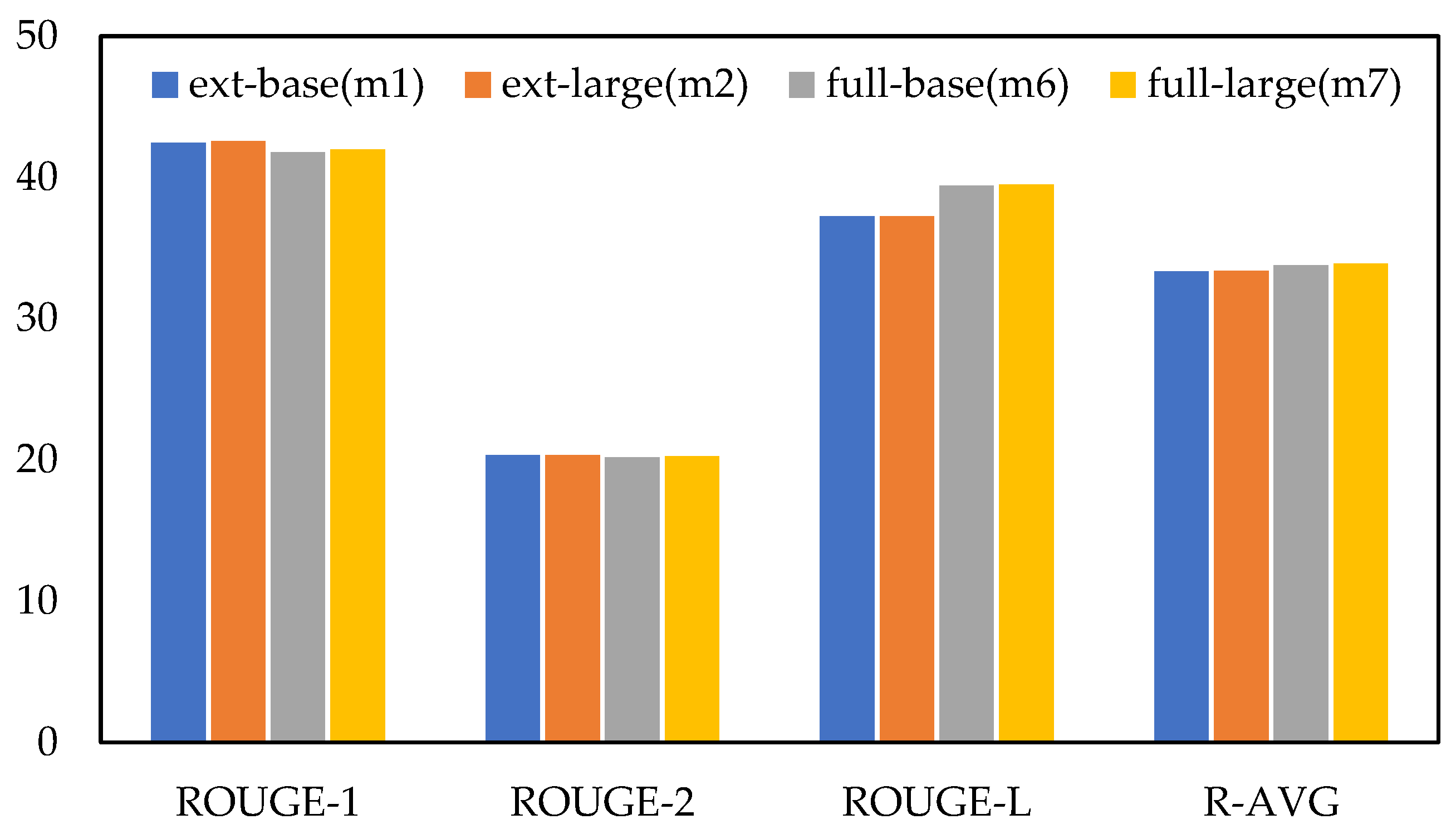
| (m1) BEAR (ext+base) | 42.43 | 20.36 | 37.23 | 33.34 |
| (m2) BEAR (ext +large) | 42.54 | 20.35 | 37.24 | 33.38 |
| Model | R-1 | R-2 | R-L | R-AVG |
|---|---|---|---|---|
| Pointer Generator + Coverage [6] | 39.53 | 17.28 | 36.38 | 31.06 |
| Inconsistency loss [10] | 40.68 | 17.97 | 37.13 | 31.93 |
| DCA [11] | 41.69 | 19.47 | 37.92 | 33.11 |
| Rnn-ext + abs + RL + rerank [9] | 40.88 | 17.80 | 38.54 | 32.41 |
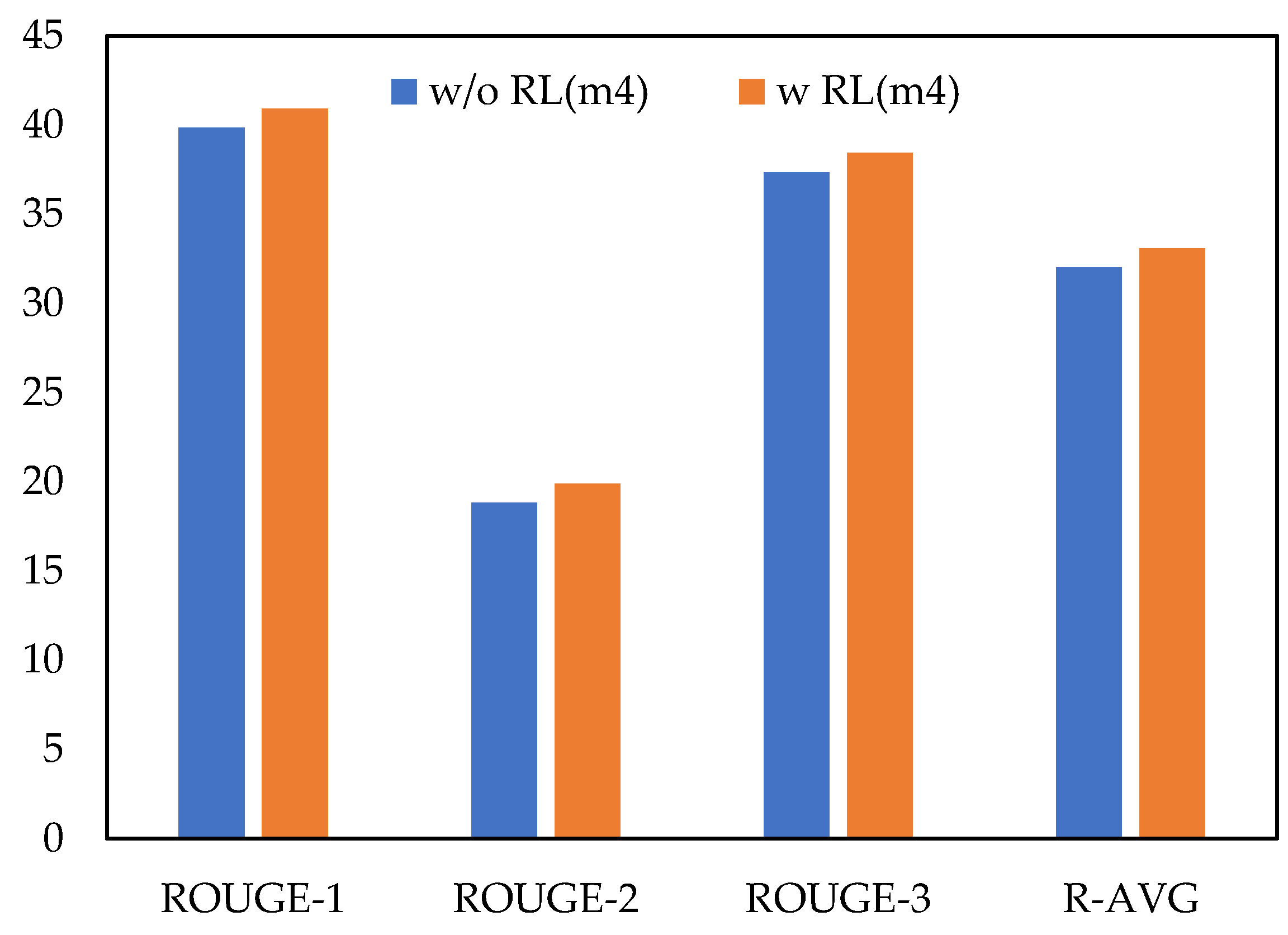
| (m3) BEAR (ext + abs + base) | 39.84 | 18.83 | 37.35 | 32.01 |
| (m4) BEAR (ext + abs + RL + base) | 40.91 | 19.88 | 38.45 | 33.08 |
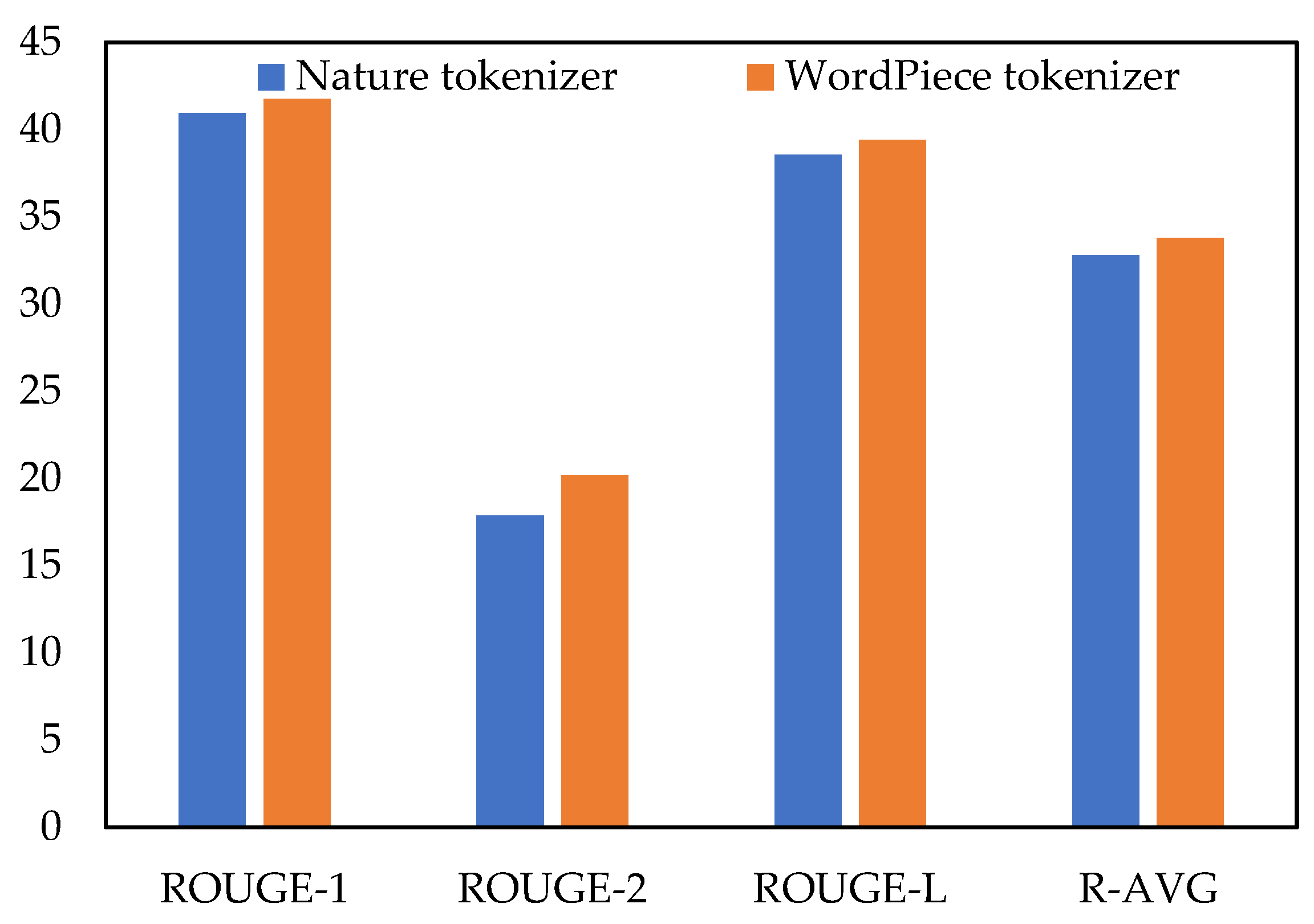
| (m5) BEAR (base + nature) | 40.95 | 17.89 | 38.55 | 32.80 |
| (m6) BEAR (base + WordPiece) | 41.76 | 20.20 | 39.39 | 33.78 |
| (m7) BEAR (large + WordPiece) | 41.95 | 20.26 | 39.49 | 33.9 |
| Models | R-1 | R-2 | R-L | R-AVG |
|---|---|---|---|---|
| Pointer-generator | 37.22 | 15.78 | 33.90 | 28.97 |
| Rnn-ext + abs + RL | 39.46 | 17.34 | 36.72 | 31.17 |
| BEAR (m7) | 40.53 | 19.85 | 38.37 | 32.92 |
| Pre-Traing | Training | Total Training | Test | GPU | |
|---|---|---|---|---|---|
| BEAR | 19 h | 6 h | 22 h | 0.67 h | K80 |
| Rnn-ext + abs + RL | 4.15 h | 15.56 h | 19.71 h | K40 | |
| Pointer-generator | 76 h | K40 |
| Reference: |
|---|
| “17 americans were exposed to the ebola virus while in sierra leone in march”, |
| “another person was diagnosed with the disease and taken to hospital in maryland”, |
| “national institutes of health says the patient is in fair condition after weeks of treatment.” |
| Model (m4): |
| five americans were monitored for three weeks at an omaha hospital. |
| one of the five had a heart—related issue on saturday and has been discharged but hasn’t left the area, taylor wilson wrote. |
| they were exposed to ebola in sierra leone in march but none developed the virus. |
| the others have already gone home. |
| Model (m7): |
| five americans were monitored for three weeks at an omaha, nebraska. |
| they all had contact with a colleague who was diagnosed with the disease. |
| the last of 17 patients who were being monitored are expected to be released by thursday. |
| more than 10,000 people have died in a west african epidemic of ebola. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Q.; Liu, P.; Zhu, Z.; Yin, H.; Zhang, Q.; Zhang, L. A Text Abstraction Summary Model Based on BERT Word Embedding and Reinforcement Learning. Appl. Sci. 2019, 9, 4701. https://doi.org/10.3390/app9214701
Wang Q, Liu P, Zhu Z, Yin H, Zhang Q, Zhang L. A Text Abstraction Summary Model Based on BERT Word Embedding and Reinforcement Learning. Applied Sciences. 2019; 9(21):4701. https://doi.org/10.3390/app9214701
Chicago/Turabian StyleWang, Qicai, Peiyu Liu, Zhenfang Zhu, Hongxia Yin, Qiuyue Zhang, and Lindong Zhang. 2019. "A Text Abstraction Summary Model Based on BERT Word Embedding and Reinforcement Learning" Applied Sciences 9, no. 21: 4701. https://doi.org/10.3390/app9214701
APA StyleWang, Q., Liu, P., Zhu, Z., Yin, H., Zhang, Q., & Zhang, L. (2019). A Text Abstraction Summary Model Based on BERT Word Embedding and Reinforcement Learning. Applied Sciences, 9(21), 4701. https://doi.org/10.3390/app9214701