Current Techniques for Diabetes Prediction: Review and Case Study


Abstract
1. Introduction
2. Related Works
2.1. Related Works Using Machine Learning
2.2. Related Works Using Deep Learning
3. Discussion
3.1. Datasets
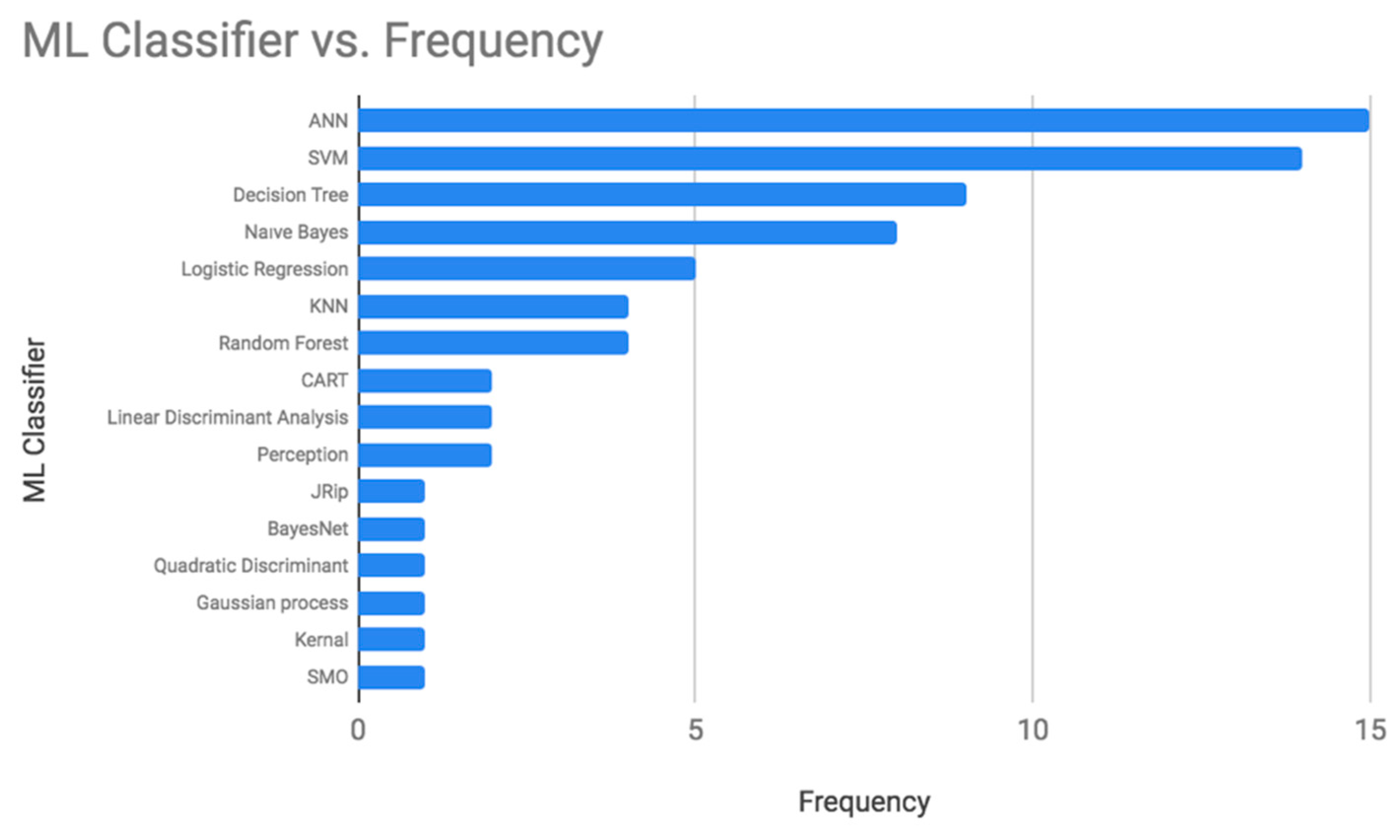
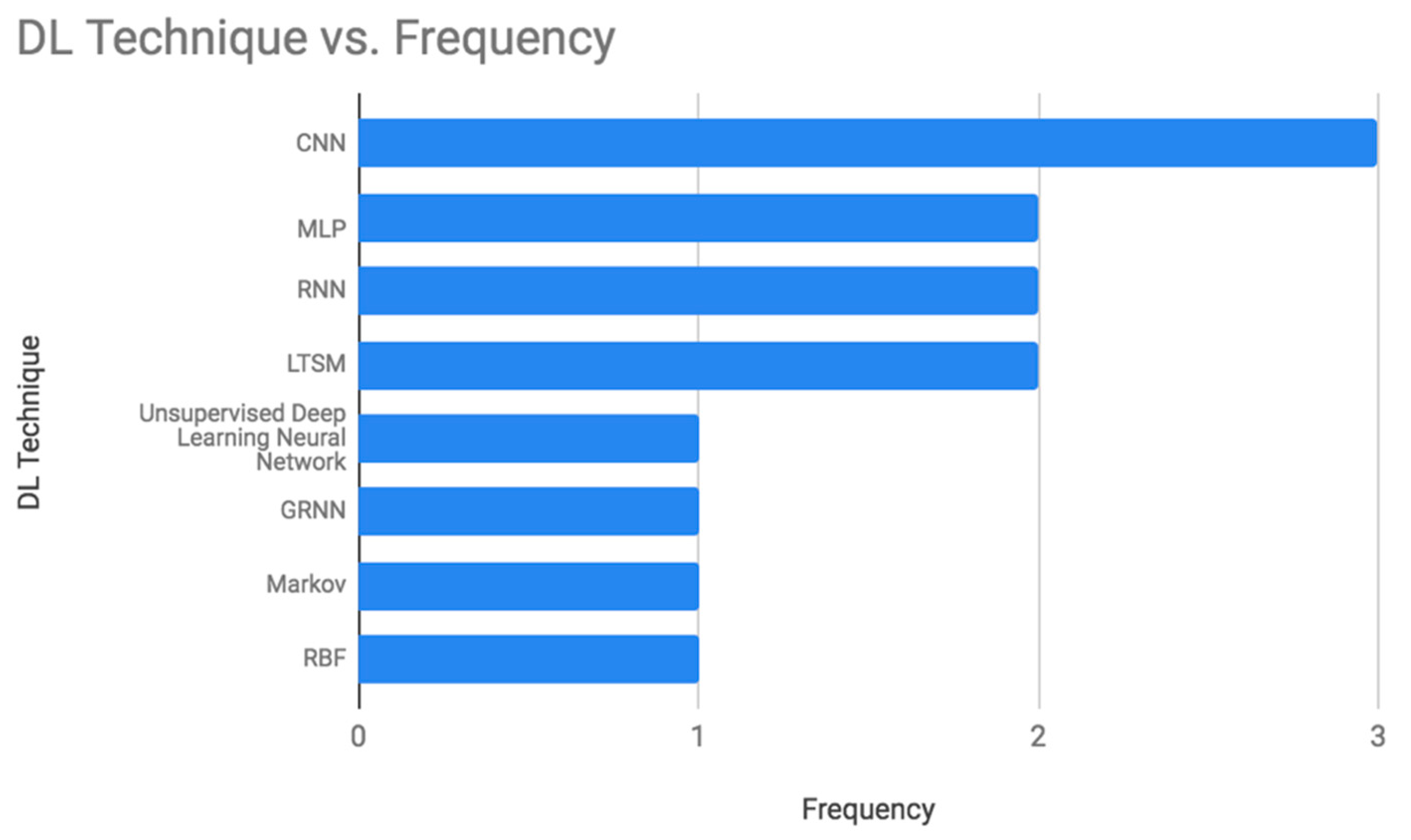
3.2. Diabetes Prediction Based ML/DL Techniques
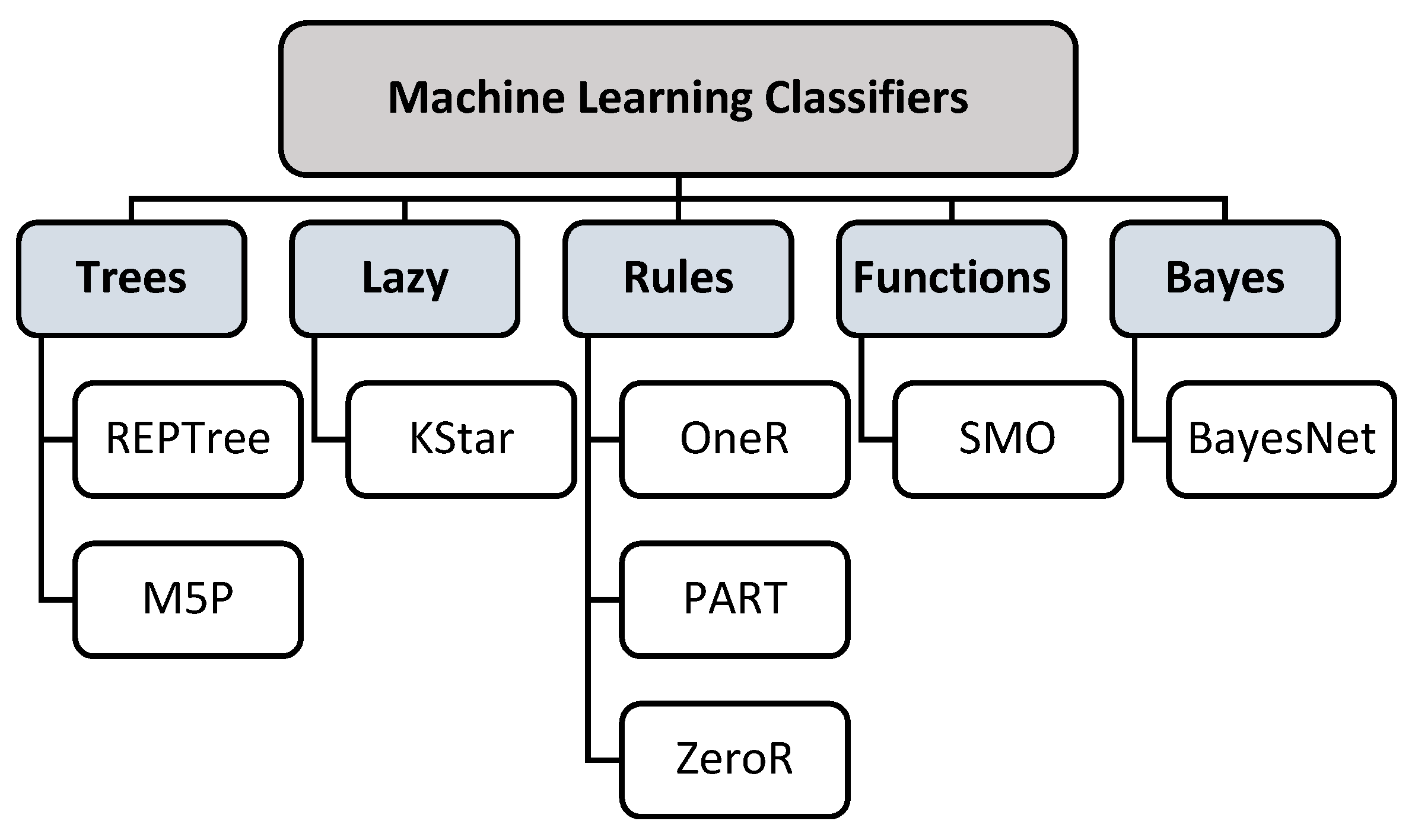
4. Case Study
4.1. Data Collection
4.2. Data Pre-Processing
4.3. Implementation and Results
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Ref | Year | Technique | Result | Dataset |
|---|---|---|---|---|
| [4] | 2015 | J48 | Accuracy: 73.82% | Pima Indians Diabetes Database |
| K-Nearest Neighbors (KNN) | Accuracy: K = 1, 70.18%, K = 3, 72.65%, K = 5, 73.17% | |||
| Random Forest | Accuracy: 71.74% | |||
| [5] | 2015 | J48 | Accuracy: 74.87% | Pima Indians Diabetes Database |
| Naïve Bayes | Accuracy: 76.96% | |||
| [17] | 2017 | Random Forest | Accuracy: 94% | Pima Indians Diabetes Database |
| Decision Tree- (ID3) | Accuracy: 88% | |||
| Naïve Bayes | Accuracy: 91% | |||
| [18] | 2015 | Support Vector Machine (SVM) | Accuracy: 95.52% | Private Dataset (Collected Manually) |
| Naïve Bayes | Accuracy: 94.52% | |||
| [19] | 2018 | Decision Tree | Accuracy: 73.82% | Pima Indians Diabetes Database |
| Support Vector Machine (SVM) | Accuracy: 65.10% | |||
| Naïve Bayes | Accuracy: 76.30% | |||
| [20] | 2017 | J48 | Precision:0.74, Recall: 0.74 F-Measure: 0.74 | Pima Indians Diabetes Database |
| Multilayer Perceptron Neural Network (MLP) | Precision: 0.75, Recall: 0.75, F-Measure: 0.75 | |||
| HoeffdingTree | Precision: 0.76, Recall: 0.76, F-Measure: 0.76 | |||
| JRip | Precision: 0.76, Recall: 0.76, F-Measure: 0.76 | |||
| BayesNet | Precision: 0.74, Recall: 0.74, F-Measure: 0.74 | |||
| Random Forest | Precision: 0.75, Recall: 0.76, F-Measure: 0.76 | |||
| [21] | 2016 | Support Vector Machine (SVM) | Accuracy: 72.93% | Global dataset Combined of All the Available Datasets |
| [22] | 2014 | Multilayer Feed Forward Neural Network - Back-Propagation Algorithm (ANN) | Accuracy: 82% | Pima Indians Diabetes Database |
| [23] | 2016 | Probabilistic Neural Network (PNN) | Training Accuracy: 89.56%, Testing Accuracy: 81.49% | Pima Indians Diabetes Database |
| [24] | 2017 | Two-Class Neural Network | Accuracy: 83.3% | Pima Indians Diabetes Database |
| [25] | 2017 | The Levenberg Marquardt Learning Algorithm | Mean squared error: 0.00025091 | Pima Indians Diabetes Database |
| The Bayesian Regulation Learning Algorithm | Mean squared error: 2.021e-05 | |||
| The Scaled Conjugate Gradient Learning Algorithm | Mean squared error: 8.3583 | |||
| [26] | 2013 | Support Vector Machine (SVM) | Accuracy: 78% | Pima Indians Diabetes Database |
| [27] | 2013 | Logistic Regression (LR), K-Nearest Neighbour (K-NN), and Support Vector Machines (SVM) | Accuracy: LR 79.4%, K-NN 77.6%, SVM 79.4% | Kuwait Health Network (KHN) that integrates data from primary health centers and hospitals in Kuwait. |
| [28] | 2013 | Artificial Neural Networks (ANN), Support Vector Machines (SVM), and Random Forests (RF) | Area Under Curve (AUC): ANN 75.1%, Radial Base Function (RBF)-SVM 97.9%, RF 76.3% | Iran Population Dataset |
| [29] | 2013 | Higher Order Neural Network (HONN) | Mean Square Error: Training: 7.5257e-04, Testing: 1.4219e-05 | Pima Indians Diabetes Database |
| [30] | 2014 | Artificial Neural Network (ANN) and Support Vector Machine (SVM) | Dataset for KNHANES 2010: Accuracy: ANN 69%, SVM 64.9% | Korean National Health and Nutrition Examination Survey (KNHANES) 2010 and 2011 Datasets |
| Dataset for KNHANES 2011: Accuracy: ANN 60.7%, SVM 66.1% | ||||
| [31] | 2014 | Naïve Bayes | Accuracy: 96% | Private Dataset (Collected Manually) |
| Artificial Neural Networks (ANN) | Accuracy: 95% | |||
| K- Nearest Neighbors (KNN) | Accuracy: 91% | |||
| [32] | 2015 | Back Propagation Neural Network and Levenberg–Marquardt Optimizer | Accuracy: 91% | Pima Indians Diabetes Database |
| [33] | 2015 | Classification and Regression Tree (CART) | Accuracy: 75% | Private Dataset (Collected Manually) |
| [34] | 2016 | Logistic Regression (LR), Support Vector Machine (SVM) and Artificial Neural Network (ANN) | Accuracy: LR 75.86%, Radial Base Function (RBF)-SVM 84.09%, NN 80.7% | Private Dataset (Collected Manually) |
| [35] | 2016 | Standalone J48, Adaboost Ensemble using J48, and Bagging Ensemble using J48 | Accuracy Based on Area under Receiver Operating Characteristic (AROC): Bagging Ensemble using J48 0.98% (The accuracies weren’t mentioned explicitly for Standalone J48 and Adaboost Ensemble using J48) | CPCSSN Database |
| [36] | 2016 | Back Propagation Neural Network (ANN) | Accuracy: 81% | Not Mentioned |
| [37] | 2015 | J48 | Sensitivity: 0.89, Specificity: 0.91 | Private Dataset (Collected Manually) |
| Naïve Bayes | Sensitivity: 0.77, Specificity: 0.86 | |||
| Support Vector Machine with Polykernel (SVM) | Sensitivity: 0.81, Specificity: 0.89 | |||
| Support Vector Machine (SVM) with Radial Basis Function Kernel (RBF) | Sensitivity: 0.83, Specificity: 0.83 | |||
| Multilayer Perceptron Neural Network (MLP) | Sensitivity: 0.83, Specificity: 0.89 | |||
| [38] | 2015 | Logistic Regression (LR), Linear Discriminant Analysis (LDA), Naïve Bayes (NB) and Support Vector Machine (SVM) | Accuracy using mRMR method: SVM 75%, LR: 75%, LDA: 75%, NB: 72% | Chinese Gut Microbiota Datasets |
| Accuracy using mRMR method: SVM: 71%, LR: 73%, LDA: 68%, NB: 69% | European Gut Microbiota Datasets | |||
| [39] | 2017 | Kernel Cross Validation 10: Linear Discriminant Analysis | Accuracy: 77.86% | Pima Indians Diabetes Database |
| Kernel Cross Validation 10: Quadratic Discriminant Analysis | Accuracy: 76.56% | |||
| Kernel Cross Validation 10: Naïve Bayes | Accuracy: 77.57% | |||
| Kernel Cross Validation 10: Gaussian Process | Accuracy: 81.97% | |||
| [40] | 2017 | Perception | Accuracy: 0.72 | 3 Datasets: NHANES0506, NHANES0708, and NHANES0910 |
| Ensemble Perception | Accuracy: 0.75 | |||
| [41] | 2017 | Kernel-Based Adaptive Filtering Algorithm | The CGM signals of a random subject are used to assess the prediction accuracy. | Private Dataset |
| Ref | Year | Technique | Result | Dataset |
|---|---|---|---|---|
| [43] | 2016 | Unsupervised Deep Learning Neural Network (Deep Patient) | Area Under the ROC Curve (AUC-ROC): 0.91 | Electronic Health Records |
| [42] | 2017 | Convolutional Neural Network (CNN) | Accuracy: 77.5% | Continuous Glucose Monitoring (CGM) signals. |
| Multilayer Perceptron Neural Network (MLP) | Accuracy: 72.5% | |||
| Logistic Regression | Accuracy: 65.2% | |||
| [7] | 2017 | Recurrent Deep Neural Network (RNN) | Accuracy: Type 1 Diabetes = 78% | Pima Indians Diabetes Dataset |
| Type 2 Diabetes = 81% | ||||
| [44] | 2017 | Deep Neural Network Long Short-Term Memory (LTSM) | Precision: 59.6% | large regional Australian hospital dataset |
| Markov Chain Neural Network | Precision: 34.1% | |||
| Plain Recurrent Deep Neural Network (RNN) | Precision: 58.0 | |||
| [46] | 2018 | Modified Convolution Neural Network (CNN) | Receiver Operating Characteristic (ROC): 0.96 | Breath Dataset Private |
| [8] | 2018 | Convolutional Neural Network (CNN) | Accuracy: 90.9% | Electrocardiograms (ECG) Private |
| Convolutional Neural Network (CNN) combined with Long Short-Term Memory (LSTM) | Accuracy: 95.1% | |||
| [7] | 2018 | Deep Learning Architecture (MLP/General regression neural network (GRNN)/Radial Basis Function (RBF) | Accuracy: 88.41% | Pima Indians Diabetes Dataset |
| Ref | Year | Technique | Result | Dataset |
|---|---|---|---|---|
| [47] | 2013 | Feedforward Neural Network and Bird Mating Optimizer | Training Set: Avg. 23.57. Std. 1.44, Testing Set: Avg. 22.55. Std. 1.89. | Pima Indians Diabetes Dataset |
| [11] | 2013 | Simple KNN | Accuracy: 73.17% | Pima Indians Diabetes Dataset |
| K-means and KNN | Accuracy: 97.0% | |||
| Amalgam and KNN | Accuracy: 97.4% | |||
| [9] | 2016 | Logistic Regression and Feedforward Neural Network | Error Rate: 0.0002. | Association of Diabetic’s City of Urmia Dataset |
| [10] | 2016 | Support Vector Machine (SVM) and Neural Network (NN) | Accuracy: 96.09% | Pima Indians Diabetes Dataset |
| [23] | 2017 | Classification and Regression Trees (CART) is used to generate the fuzzy rules that were used in predicting diabetes | Accuracy for Pima Indian Dataset: 92% | Pima Indian Dataset, Mesothelioma, WDBC, StatLog, Cleveland and Parkinson’s Telemonitoring datasets |
| [48] | 2018 | Sequential Minimal Optimization (SMO), Support Vector Machine (SVM) and Elephant Herding Optimizer | Accuracy for Pima Indian: 78.21% | 17 Medical Dataset Including Pima Indian Diabetes Dataset |
| Dataset | Reference | Number of Samples | Number of Features | Features | Link |
|---|---|---|---|---|---|
| University of California Irvine (UCI) machine learning data repository for diabetes mellitus | [4] | -- | 8 | Number of times pregnant, Plasma glucose concentration (glucose tolerance test), Diastolic blood pressure (mm Hg), Triceps skin fold thickness (mm), Hour serum insulin (mu U/mL), Body mass index (weight in kg/(height in m)^2), Diabetes pedigree function, Age (years) | http://mldata.org/repository/data/viewslug/datasets-uci-diabetes |
| Pima Indians Diabetes Dataset [17] | [17] | 75,664 | 13 | The main used: Plasma glucose concen-tration, Diastolic blood pressure, Triceps skin fold thickness, 2-hour serum insulin, Body mass index (BMI), Diabetes pedigree function, and Age. | https://www.kaggle.com/uciml/pima-indians-diabetes-database |
| [19] | 768 | 8 | |||
| [20] | 768 | 8 | |||
| [21] | 102,538 | 49 | |||
| [22] | 768 | 8 | |||
| [23] | 768 | 8 | |||
| [24] | 392 | 8 | |||
| [25] | 768 | 8 | |||
| [7] | 768 | 8 | |||
| [45] | 768 | 8 | |||
| Electrocardiograms (ECG) | [8] | 142,000 | 8 | The main attributes: glucose concentration in plasma, blood pressure, body mass index, age. | Private |
| Private dataset collected from three different locations in Kosovo | [18] | 402 | 8 | BMI, Pre meal glucose, Post meal glucose, Diastolic blood pressure, Systolic blood pressure, Family history of diabetes, Regular diet, and Physical activities. | Not available |
| Breath Dataset | [46] | 15 | 7 | Type (Healthy, Type 2, Type 1), Gender (Male/Female), Age, BMI, Range of HbA1c, Duration of Diabetes (years), Range of Acetone Values Obtained (ppm). | Not available |
| Advantages | Disadvantages | |
|---|---|---|
| ANN | (1) Extracts the essential attributes from inputs that contain irrelevant data. (2) Deals with vague cases. (3) Has been successfully applied in many fields such as disease prediction. | (1) Too many hidden layers will result in an overfitting problem. (2) The random initialization of the weight does not always lead to the best solution. (3) The structure can be determined only through trial and experience. (4) Works only with numerical data. |
| SVM | (1) Works well with unstructured and semi-structured datasets such as images and text. (2) Can attain accurate and robust results. (3) Is successfully used in medical applications. | (1) Requires long training time when it is used with large datasets. (2) Is hard sometimes to select the right kernel function. (3) The weights of the variables are difficult to interpret in the final model |
| Naive Bayes | (1) Works well with the data that has missing values or unbalancing issues. (2) Works with categorical and continuous values. (3) Requires a small amount of data to set its parameters. | (1) All the features must be independent to each other. (2) The conditional independence might cause a drop in the accuracy. |
| Decision Tree | (1) Easy to understand and implement especially when using a graphical representation. (2) Works well with numerical and categorical data. (3) Does not require much data pre-processing work. | (1) Small change in the data can have a significant effect on the final predictions. (2) Does not perform well with large datasets due to the increase complexity of the tree. |
| CNN | (1) Performs automatic feature extraction. (2) Can show the correlation between the elements for the provided inputs. (3) Requires less time in classification and result in a high accuracy especially in image processing. | (1) The computational cost is high. (2) Can’t perform well without a large amount of training data. |
| MLP | (1) Suitable for classification, regression, and prediction problems. (2) Can be employed to different types of data: image, text, etc. | (1) Inadequate for modern advanced computer vision field. (2) The total number of parameters can be very large. |
| RNN | (1) More accurate in predicting what will be next thanks to remembering capability. (2) Powerful in complex problems. (3) Deals with sequential data inputs instead of fixed-sized vectors. | (1) Vanishing gradients problem. (2) Difficult to calculate the weights and biases which drop the accuracy. |
| LTSM | (1) Encompasses of multiple memory blocks that can overcome the vanishing gradient problem. (2) Used in Natural Language Processing applications. | (1) High computational time required to calculate the memory bandwidth for the processing units which makes it harder to train the data. |
References
- Cho, N.; Shaw, J.; Karuranga, S.; Huang, Y.; Fernandes, J.D.R.; Ohlrogge, A.; Malanda, B. IDF Diabetes Atlas: Global estimates of diabetes prevalence for 2017 and projections for 2045. Diabetes Res. Clin. Pr. 2018, 138, 271–281. [Google Scholar] [CrossRef] [PubMed]
- Sanz, J.A.; Galar, M.; Jurio, A.; Brugos, A.; Pagola, M.; Bustince, H. Medical diagnosis of cardiovascular diseases using an interval-valued fuzzy rule-based classification system. Appl. Soft Comput. 2014, 20, 103–111. [Google Scholar] [CrossRef]
- Varma, K.V.; Rao, A.A.; Lakshmi, T.S.M.; Rao, P.N. A computational intelligence approach for a better diagnosis of diabetic patients. Comput. Electr. Eng. 2014, 40, 1758–1765. [Google Scholar] [CrossRef]
- Kandhasamy, J.P.; Balamurali, S. Performance Analysis of Classifier Models to Predict Diabetes Mellitus. Procedia Comput. Sci. 2015, 47, 45–51. [Google Scholar] [CrossRef]
- Iyer, A.; Jeyalatha, S.; Sumbaly, R. Diagnosis of Diabetes Using Classification Mining Techniques. Int. J. Data Min. Knowl. Manag. Process. 2015, 5, 1–14. [Google Scholar] [CrossRef]
- Razavian, N.; Blecker, S.; Schmidt, A.M.; Smith-McLallen, A.; Nigam, S.; Sontag, D. Population-Level Prediction of Type 2 Diabetes from Claims Data and Analysis of Risk Factors. Big Data 2015, 3, 277–287. [Google Scholar] [CrossRef]
- Ashiquzzaman, A.; Kawsar Tushar, A.; Rashedul Islam, M.D.; Shon, D.; Kichang, L.M.; Jeong-Ho, P.; Dong-Sun, L.; Jongmyon, K. Reduction of overfitting in diabetes prediction using deep learning neural network. In IT Convergence and Security; Lecture Notes in Electrical Engineering; Springer: Singapore, 2017; Volume 449. [Google Scholar]
- Swapna, G.; Soman, K.P.; Vinayakumar, R. Automated detection of diabetes using CNN and CNN-LSTM network and heart rate signals. Procedia Comput. Sci. 2018, 132, 1253–1262. [Google Scholar]
- Rahimloo, P.; Jafarian, A. Prediction of Diabetes by Using Artificial Neural Network, Logistic Regression Statistical Model and Combination of Them. Bull. Société R. Sci. Liège 2016, 85, 1148–1164. [Google Scholar]
- Gill, N.S.; Mittal, P. A computational hybrid model with two level classification using SVM and neural network for predicting the diabetes disease. J. Theor. Appl. Inf. Technol. 2016, 87, 1–10. [Google Scholar]
- NirmalaDevi, M.; Alias Balamurugan, S.A.; Swathi, U.V. An amalgam KNN to predict diabetes mellitus. In Proceedings of the 2013 IEEE International Conference ON Emerging Trends in Computing, Communication and Nanotechnology (ICECCN), Tirunelveli, India, 25–26 March 2013; pp. 691–695. [Google Scholar]
- Sun, Y.L.; Zhang, D.L. Machine Learning Techniques for Screening and Diagnosis of Diabetes: A Survey. Teh. Vjesn. 2019, 26, 872–880. [Google Scholar]
- Choudhury, A.; Gupta, D. A Survey on Medical Diagnosis of Diabetes Using Machine Learning Techniques. In Recent Developments in Machine Learning and Data Analytics; Springer: Singapore, 2019; pp. 67–68. [Google Scholar]
- Meherwar, F.; Maruf, P. Survey of Machine Learning Algorithms for Disease Diagnostic. J. Intell. Learn. Syst. Appl. 2017, 9, 1–16. [Google Scholar]
- Vijiyarani, S.; Sudha, S. Disease Prediction in Data Mining Technique—A Survey. Int. J. Comput. Appl. Inf. Technol. 2013, 2, 17–21. [Google Scholar]
- Deo, R.C. Machine Learning in Medicine. Circulation 2015, 132, 1920–1930. [Google Scholar] [CrossRef] [PubMed]
- Yuvaraj, N.; SriPreethaa, K.R. Diabetes prediction in healthcare systems using machine learning algorithms on Hadoop cluster. Clust. Comput. 2017, 22, 1–9. [Google Scholar] [CrossRef]
- Tafa, Z.; Pervetica, N.; Karahoda, B. An intelligent system for diabetes prediction. In Proceedings of the 2015 4th Mediterranean Conference on Embedded Computing (MECO), Budva, Montenegro, 14–18 June 2015; pp. 378–382. [Google Scholar]
- Sisodia, D.; Sisodia, D.S. Prediction of Diabetes using Classification Algorithms. Procedia Comput. Sci. 2018, 132, 1578–1585. [Google Scholar] [CrossRef]
- Mercaldo, F.; Nardone, V.; Santone, A. Diabetes Mellitus Affected Patients Classification and Diagnosis through Machine Learning Techniques. Procedia Comput. Sci. 2017, 112, 2519–2528. [Google Scholar] [CrossRef]
- Negi, A.; Jaiswal, V. A first attempt to develop a diabetes prediction method based on different global datasets. In Proceedings of the 2016 Fourth International Conference on Parallel, Distributed and Grid Computing (PDGC), Waknaghat, India, 22–24 December 2016; pp. 237–241. [Google Scholar]
- Olaniyi, E.O.; Adnan, K. Onset diabetes diagnosis using artificial neural network. Int. J. Sci. Eng. Res. 2014, 5, 754–759. [Google Scholar]
- Soltani, Z.; Jafarian, A. A New Artificial Neural Networks Approach for Diagnosing Diabetes Disease Type II. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 89–94. [Google Scholar] [CrossRef]
- Somnath, R.; Suvojit, M.; Sanket, B.; Riyanka, K.; Priti, G.; Sayantan, M.; Subhas, B. Prediction of Diabetes Type-II Using a Two-Class Neural Network. In Proceedings of the 2017 International Conference on Computational Intelligence, Communications, and Business Analytics, Kolkata, India, 24–25 March 2017; pp. 65–71. [Google Scholar]
- Mamuda, M.; Sathasivam, S. Predicting the survival of diabetes using neural network. In Proceedings of the AIP Conference Proceedings, Bydgoszcz, Poland, 9–11 May 2017; Volume 1870, pp. 40–46. [Google Scholar]
- Kumari, V.A.; Chitra, R. Classification of diabetes disease using support vector machine. Int. J. Adv. Comput. Sci. Appl. 2013, 3, 1797–1801. [Google Scholar]
- Farran, B.; Channanath, A.M.; Behbehani, K.; Thanaraj, T.A. Predictive models to assess risk of type 2 diabetes, hypertension and comorbidity: Machine-learning algorithms and validation using national health data from Kuwait—A cohort study. BMJ Open 2013, 3, 24–57. [Google Scholar] [CrossRef]
- Tapak, L.; Mahjub, H.; Hamidi, O.; Poorolajal, J. Real-Data Comparison of Data Mining Methods in Prediction of Diabetes in Iran. Healthc. Inform. Res. 2013, 19, 177–185. [Google Scholar] [CrossRef] [PubMed]
- Anand, R.; Kirar, V.P.S.; Burse, K. K-fold cross validation and classification accuracy of pima Indian diabetes data set using higher order neural network and PCA. Int. J. Soft Comput. Eng. 2013, 2, 2231–2307. [Google Scholar]
- Choi, S.B.; Kim, W.J.; Yoo, T.K.; Park, J.S.; Chung, J.W.; Lee, Y.H.; Kang, E.S.; Kim, D.W. Screening for Prediabetes Using Machine Learning Models. Comput. Math. Methods Med. 2014, 2014, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Sarwar, A.; Sharma, V. Comparative analysis of machine learning techniques in prognosis of type II diabetes. AI Soc. 2014, 29, 123–129. [Google Scholar] [CrossRef]
- Durairaj, M.; Kalaiselvi, G. Prediction of Diabetes using Back propagation Algorithm. Int. J. Innov. Technol. 2015, 1, 21–25. [Google Scholar]
- Anand, A.; Shakti, D. Prediction of diabetes based on personal lifestyle indicators. In Proceedings of the 2015 1st International Conference on Next Generation Computing Technologies (NGCT), Dehradun, India, 4–5 September 2015; pp. 673–676. [Google Scholar]
- Malik, S.; Khadgawat, R.; Anand, S.; Gupta, S. Non-invasive detection of fasting blood glucose level via electrochemical measurement of saliva. SpringerPlus 2016, 5, 701. [Google Scholar] [CrossRef] [PubMed]
- Perveen, S.; Shahbaz, M.; Guergachi, A.; Keshavjee, K. Performance Analysis of Data Mining Classification Techniques to Predict Diabetes. Procedia Comput. Sci. 2016, 82, 115–121. [Google Scholar] [CrossRef]
- Joshi, S.; Borse, M. Detection and Prediction of Diabetes Mellitus Using Back-Propagation Neural Network. In Proceedings of the 2016 International Conference on Micro-Electronics and Telecommunication Engineering (ICMETE), Uttarpradesh, India, 22–23 September 2016; pp. 110–113. [Google Scholar]
- Sowjanya, K.; Singhal, A.; Choudhary, C. MobDBTest: A machine learning based system for predicting diabetes risk using mobile devices. In Proceedings of the 2015 IEEE International Advance Computing Conference (IACC), Bangalore, India, 12–13 June 2015; pp. 397–402. [Google Scholar]
- Cai, L.; Wu, H.; Li, D.; Zhou, K.; Zou, F. Type 2 Diabetes Biomarkers of Human Gut Microbiota Selected via Iterative Sure Independent Screening Method. PLoS ONE 2015, 10, e0140827. [Google Scholar] [CrossRef] [PubMed]
- Maniruzzaman, M.; Kumar, N.; Menhazul Abedin, M.; Shaykhul Islam, M.; Suri, H.S.; El-Baz, A.S.; Suri, J.S. Comparative approaches for classification of diabetes mellitus data: Machine learning paradigm. Comput. Methods Programs Biomed. 2017, 152, 23–34. [Google Scholar] [CrossRef]
- Mirshahvalad, R.; Zanjani, N.A. Diabetes prediction using ensemble perceptron algorithm. In Proceedings of the 2017 9th International Conference on Computational Intelligence and Communication Networks (CICN), Girne, Cyprus, 16–17 September 2017; pp. 190–194. [Google Scholar]
- Sun, X.; Yu, X.; Liu, J.; Wang, H. Glucose prediction for type 1 diabetes using KLMS algorithm. In Proceedings of the 2017 36th Chinese Control Conference (CCC), Liaoning, China, 26–28 July 2017; pp. 1124–1128. [Google Scholar]
- Mohebbi, A.; Aradóttir, T.B.; Johansen, A.R.; Bengtsson, H.; Fraccaro, M.; Mørup, M. A deep learning approach to adherence detection for type 2 diabetics. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju, Korea, 11–15 July 2017; pp. 2896–2899. [Google Scholar]
- Miotto, R.; Li, L.; Kidd, B.A.; Dudley, J.T. Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records. Sci. Rep. 2016, 6, 26094. [Google Scholar] [CrossRef]
- Pham, T.; Tran, T.; Phung, D.; Venkatesh, S. Predicting healthcare trajectories from medical records: A deep learning approach. J. Biomed. Inform. 2017, 69, 218–229. [Google Scholar] [CrossRef] [PubMed]
- Balaji, H.; Iyengar, N.; Caytiles, R.D. Optimal Predictive analytics of Pima Diabetics using Deep Learning. Int. J. Database Theory Appl. 2017, 10, 47–62. [Google Scholar] [CrossRef]
- Lekha, S.; Suchetha, M. Real-Time Non-Invasive Detection and Classification of Diabetes Using Modified Convolution Neural Network. IEEE J. Biomed. Health Inform. 2018, 22, 1630–1636. [Google Scholar] [CrossRef] [PubMed]
- Askarzadeh, A.; Rezazadeh, A. Artificial neural network training using a new efficient optimization algorithm. Appl. Soft Comput. 2013, 13, 1206–1213. [Google Scholar] [CrossRef]
- Rao, N.M.; Kannan, K.; Gao, X.Z.; Roy, D.S. Novel classifiers for intelligent disease diagnosis with multi-objective parameter evolution. Comput. Electr. Eng. 2018, 67, 483–496. [Google Scholar]
- Begg, R.; Kamruzzaman, J.; Sarkar, R. Neural Networks in Healthcare: Potential and Challenges; Idea Group Publishing: Hershey, PA, USA, 2006. [Google Scholar]
- Greeshma, U.; Annalakshmi, S. Artificial Neural Network (Research paper on basics of ANN). Int. J. Sci. Eng. Res. 2015, 110–115. [Google Scholar]
- Zhang, G.; Patuwo, B.E.; Hu, M.Y. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Vidyasagar, M. Learning and Generalisation: With Applications to Neural Networks; Springer Science & Business Media: London, UK, 2013. [Google Scholar]
- Maren, A.J.; Harston, C.T.; Pap, R.M. Handbook of Neural Computing Applications; Academic Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Karayiannis, N.; Venetsanopoulos, A.N. Artificial Neural Networks: Learning Algorithms, Performance Evaluation and Applications; Springer Science & Business Media: London, UK, 2013; Volume 209. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hassan, A. Deep Neural Language Model for Text Classification Based on Convolutional and Recurrent Neural Networks. Ph.D. Thesis, University of Bridgeport, Bridgeport, CT, USA, 2018. [Google Scholar]
- Kar, A.K. Bio inspired computing—A review of algorithms and scope of applications. Expert Syst. Appl. 2016, 59, 20–32. [Google Scholar] [CrossRef]
- Naji, H.; Ashour, W. Text Classification for Arabic Words Using Rep-Tree. Int. J. Comput. Sci. Inf. Technol. 2016, 8, 101–108. [Google Scholar] [CrossRef]
- Kumar, S.C.; Chowdary, E.D.; Venkatramaphanikumar, S.; Kishore, K.V.K. M5P model tree in predicting student performance: A case study. In Proceedings of the IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT), Bangalore, India, 20–21 May 2016; pp. 1103–1107. [Google Scholar]
- Sharma, R.; Kumar, S.; Maheshwari, R. Comparative Analysis of Classification Techniques in Data Mining Using Different Datasets. Int. J. Comput. Sci. Mobile Comput. 2015, 44, 125–134. [Google Scholar]
- Fernández-Delgado, M.; Cernadas, E.; Barro, S.; Amorim, D. Do we need hundreds of classifiers to solve real world classification problems. J. Mach. Learn. Res. 2014, 15, 3133–3181. [Google Scholar]
- Platt, J. Fast Training of Support Vector Machines Using Sequential Minimal Optimization. In Advances in Kernel Methods: Support Vector Learning, Advances in Kernel Methods—Support Vector Learning, Advances; MIT Press: Cambridge, MA, USA, 1998; pp. 185–208. ISBN 0-262-19416-3. [Google Scholar]
- Su, J.; Zhang, H. Full Bayesian network classifiers. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 897–904. [Google Scholar]
- Mahmood, D.Y.; Hussein, M.A. Intrusion detection system based on K-star classifier and feature set reduction. IOSR J. Comput. Eng. 2013, 15, 107–112. [Google Scholar]



| Classifiers | Evaluation Metrics | ||||
|---|---|---|---|---|---|
| Accuracy | Precision | Recall | F-Measure | ROC Area | |
| REPTree | 74.48% | 0.67 | 0.53 | 0.59 | 0.76 |
| M5P | Root Mean Squared Error = 0.43 | ||||
| KStar | 68.23% | 0.58 | 0.33 | 0.42 | 0.68 |
| oneR | 70.83% | 0.61 | 0.46 | 0.52 | 0.65 |
| PART | 74.35% | 0.70 | 0.47 | 0.56 | 0.77 |
| ZeroR | Root Mean Squared Error = 0.4771 | ||||
| SMO | 72.14% | 0.78 | 0.28 | 0.41 | 0.62 |
| BayesNet | 73.83% | 0.64 | 0.57 | 0.60 | 0.81 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Larabi-Marie-Sainte, S.; Aburahmah, L.; Almohaini, R.; Saba, T. Current Techniques for Diabetes Prediction: Review and Case Study. Appl. Sci. 2019, 9, 4604. https://doi.org/10.3390/app9214604
Larabi-Marie-Sainte S, Aburahmah L, Almohaini R, Saba T. Current Techniques for Diabetes Prediction: Review and Case Study. Applied Sciences. 2019; 9(21):4604. https://doi.org/10.3390/app9214604
Chicago/Turabian StyleLarabi-Marie-Sainte, Souad, Linah Aburahmah, Rana Almohaini, and Tanzila Saba. 2019. "Current Techniques for Diabetes Prediction: Review and Case Study" Applied Sciences 9, no. 21: 4604. https://doi.org/10.3390/app9214604
APA StyleLarabi-Marie-Sainte, S., Aburahmah, L., Almohaini, R., & Saba, T. (2019). Current Techniques for Diabetes Prediction: Review and Case Study. Applied Sciences, 9(21), 4604. https://doi.org/10.3390/app9214604