1. Introduction
Computational quantification of neurodevelopmental disorders is one of the most attractive research areas [
1] since it overcomes limitations of human perception and it also allows caregivers to get quick and objective outcomes [
2]. Invasive tools are the most explored method so far to accomplish this challenging task. Unfortunately, they require acceptance and collaborative behaviors during calibration. Moreover, they have no negligible costs and caregivers have to be trained to properly use them. Besides, the gathered data are conditioned by the bias introduced by the presence of the tools. On the one hand, high costs make their pervasive use economically unsustainable for most private and public organizations and, on the other hand, their effectiveness in the assessment of neurodevelopmental disorders is controversial. This is even truer in the case of Autism Spectrum Disorders (ASD) [
3], particularly in the case of treatment of children. Accurate evaluation, using non-invasive tools, is becoming a primary need, also considering the increase of ASD prevalence (1/59) [
4] in the general population. In particular, since it is well known that ASD children show a clear deficit in the quality of facial expression production compared to typically developing ones [
5,
6], some computer vision and machine learning techniques can be successfully implemented to automatically assess emotional skills in a not invasive and accurate way [
7] and, finally, to give an automatic assessment of autism spectrum disorders. Unfortunately, to the best of our knowledge, there are no works exploiting the aforementioned computational technologies to provide a comprehensive study carried out comparing psychologists and automatic outcomes to quantify children’s ability to produce basic emotions. Prior works mainly report qualitative assessment (ASD vs. non-ASD behavioral features) or just rough quantitative assessments (e.g., smiling/not smiling). A pioneering approach towards this challenging research line was the one in [
8]: it introduced an algorithmic pipeline able to analyze facial dynamics using a continuously updated and personalized reference model, differently from the plethora of approaches in the literature that lies on predefined facial models. Unfortunately, that work had two main drawbacks: its outcomes were validated only on ASD children and, besides, it did not exploit the great potential of convolutional neural networks. This leads to an incomplete analysis of its potential in assessing ASD, to a sub-optimal correlation between numerical outcomes and the strength of facial expressions and, last but not least, to collect unreliable outcomes especially in the cases of non-frontal head pose and non-collaborative behaviors of children. To overcome the above limitations, in this paper, the pipeline in [
8] has been improved by advanced computer vision and machine learning modules that rely on deep learning strategies. The updated pipeline, as proved in the experimental section carried out on both ASD and typically developing children, allows the framework to get numerical outcomes more correlated to the actual strength of the expression executions. Besides, it increases the system’s performance in terms of accuracy with respect to manual annotations provided by a team of psychologists. It is worth noting that, even if the pipeline relies on existing strategies, it combines them in a fruitful, and still unexplored, way in order to achieve the pursued application goal. The exploitation of the pipeline brought to a generalization of the knowledge by allowing to perform a deeper computational analysis of how children with ASD manifest their deficit in emotional competence, in particular, by comparing them to typically developing (TD henceforth) children 24-36 months old. Indeed, studies on emotional competence [
9,
10,
11] considered this age range the crucial moment in which children start to develop the ability to name and recognize the facial expression of basic emotions (i.e., happiness, sadness, fear, and anger). Summing up, this paper has two levels of innovation: on the one side, it improves the pipeline in [
8] by introducing deep learning strategies for face detection and facial landmark positioning. On the other side it extends the experimental evidence about the possibility of using the proposed pipeline to computationally analyze facial expressions also for typically developing children (in [
8] only ASD children were involved). From the above, an important additional contribution derives: for the first time the computational outcomes on ASD and TD groups are compared and a discussion about the gathered outcomes is provided from both technological and clinical sides.
The rest of the paper is organized as follows: in
Section 2 related works achieving the automatic assessment of ASD behavioral cues are reported and discussed. In addition, a brief overview of the most recent computer vision techniques addressing facial expressions recognition is given. Then, in
Section 3, the proposed pipeline is described whereas
Section 4 describes method and participants.
Section 5 reports experimental results on both ASD and TD children and it numerically compares gathered outcomes. Subsequently,
Section 6 reports and discusses a performance comparison, on the same set of data, with some leading approaches in the literature.
Section 7 reports instead a discussion about clinical evidence emerged from experimental outcomes and, finally,
Section 8 concludes the paper, giving an explanation of how the proposed framework could be exploited in the clinical treatment to improve emotional competence’s evaluation of ASD children. It gives also a sight of possible future works.
2. Related Work
This section firstly discusses some works dealing with the exploitation of computer vision and machine learning techniques to assess behavioral cues in ASD children. Subsequently, a brief overview of the most recent computer vision techniques addressing facial expressions recognition is given. Concerning the assessment of ASD behavioral cues, computer vision and machine learning techniques have been effectively exploited in the last years to highlight signs that are considered early features of ASD [
12]. Computer vision analysis measured participants’ attention and orienting in response to name calls in [
13] whereas in [
14] the head postural stability was evaluated while the children watched a series of dynamic movies involving different types of stimuli. Both works made use of an algorithm that detects and tracks 49 facial landmarks on the child’s face and estimates head pose angles relative to the camera by computing the optimal rotation parameters between the detected landmarks and a 3D canonical face model. In [
15] a video segmentation approach was exploited to retrieve social interactions that happen in unstructured video collected during social games, such as a “peek-a-boo” or “patty cake,” that consist of repetitions of stylized, turn-taking interactions between a child and a caregiver or peer. More complex behaviors (i.e., sharing Interest, visual tracking and disengagement of attention) were analyzed in [
16] by using a semiautomatic system relying on a dense motion estimator, multi-scale Histograms of Orientated Gradients (HOG) and Support Vector Machine. The authors assumed that, in the first frame, the bounding boxes of the left ear, left eye and nose are available and proposed a way to estimate yaw and pitch motion from images acquired in unstructured environments. Unfortunately, the relevant deficit of ASD children in recognizing and producing facial expressions (that is clinically considered a robust feature to evaluate ASD conditions) has not been deeply investigated by using automatic techniques. This is due to the fact that computational analysis of facial expressions in digital images is an emerging research topic: there are only a few attempts to quantify facial expression production [
17] whereas most of the scientific productions aim at the easier task of evaluating the ability to recognize if either a facial expression is present or not [
18]. Very recently, some pioneering studies introduced advanced approaches to get computational outcomes able to numerically prove only the differences in facial skills of ASD vs. TD children groups [
19,
20,
21,
22]. Other approaches focused instead on detecting early risk markers of ASD. An application of displaying movie stimuli on a mobile device which were expertly designed to capture the toddler’s attention and elicit behaviors relevant to early risk markers of ASD, including orienting to name call, social referencing, smiling while watching the movie stimuli, pointing, and social smiling was, for example, proposed in [
23]. A rough assessment with respect to smiling/ not smiling labels provided by human raters was carried out. Authors in [
24] presented an end-to-end system (based on the multi-task learning approach) for ASD classification using different facial attributes: facial expressions, Action units, arousal, and valence. High-level diagnostic labels (ASD or No-ASD) were used as a reference.
Table 1 sums-up the most relevant prior works in the literature. For each work the involved computer vision tasks are indicated and, in the last column, the validation process put in place is mentioned. In particular, from the last column, it is possible to derive that works in [
19,
20,
21,
22] did not consider any quantitative evaluation but just a qualitative analysis of the outcomes to highlight the differences in affective abilities of ASD vs. TD groups.
The last row in
Table 1 reports the work in [
8] that has been the first attempt to introduce an algorithm pipeline to quantify affective abilities by analyzing facial traits. As already stated in
Section 1, it had a major limitation consisting in the use of the handcrafted features and shallow learning strategies that are operational choices largely overcome by the recent literature on facial analysis. The recognition of facial expression can be achieved with high accuracy by learning robust and discriminative features from the data as proposed in [
25] where deep sparse auto-encoders are established. A deep learning architecture, that includes convolutional and recurrent neural network layers, has been also proposed in [
26] and it has been exploited for the estimation of emotional valence and arousal in-the-wild. An approach that combines automatic features learned by convolutional neural networks (CNN) and handcrafted features computed by the bag-of-visual-words (BOVW) model has been proposed in [
27]. Similarly in [
28], an improved expression recognition network that combines the improved Local Binary Patterns (LBP) features with deep convolution neural network facial features was designed. Facial expressions can be also modeled directly from image intensities using deep neural networks (i.e., without requiring or involving facial landmark detection) as proposed in [
29]. Computational aspects have been addressed in [
30] where a new Convolutional Neural Network (CNN) model, namely MobileNet, is proposed in order to compound accuracy and speed. Finally, even automatic recognition of micro-expressions has been effectively tackled by convolutional neural networks [
31]. However, most of the aforementioned existing facial expression recognition methods work on static images. Unfortunately, their intrinsic nature makes them useless in a context where it is important to evaluate the facial dynamics following external elicitation stimuli or verbal requests to produce facial expressions. On the other hand, it is ineluctable that this kind of evaluation can benefit from the temporal correlations of consecutive frames in a sequence. In literature, there are some works that addressed this challenging problem: some of the simply aggregate outcomes on consecutive frames whereas more effective approaches learned spatio-temporal evolution in producing facial expressions. Although dynamic FER is known to have a higher recognition rate than static FER, it does suffer from a few drawbacks: the extracted dynamic features depend on the facial geometry, the different temporal transient from inexpressive face to emotion apex, the initial facial configuration that can trick the classifier by affecting temporal evolution of facial features. Very outstanding survey papers on this topic can be found in [
32] and [
33]. The above limitations are emphasized when the goal is to recognize and even to quantify facial expression in individuals with limited skills due to cognitive impairments (e.g., affected by ASD) or still under functional development (e.g., toddlers). Under those circumstances, classical FER approaches decrease their accuracy since their models are built on typically developed individuals and their generalization could be not trivial. Finally, it should also be pointed out that also outstanding papers that treat the expression intensity estimation as a regression problem [
34] are not suited for the considered application context since they make use of a common (not personalized) reference model.
3. The Proposed Framework
The framework mainly consists of four algorithmic modules performing face detection, facial landmark detection and tracking, facial action unit intensity estimation and high-level semantic analysis that provides the computational quantification of the facial expressions. In
Figure 1 the proposed algorithmic pipeline is schematized. It is worth noting that the figure points out, by the horizontal dotted line and the blocks differently colored, that the two modules above the line (face detection and facial landmark detection and tracking) are the ones heavily improved with regards to the former work in [
8]. To be as clear as possible, the heavily changed algorithmic modules with respect to the framework in [
8] are colored in light orange.
The system works on the images acquired by off-the-shelf cameras. In each acquired image human face detection is performed by multiple CNNs (cascaded) integrating, by multi-task learning, both face detection and alignment [
35]. After resizing the input image to different scales, the resulting image pyramid is given as input to a three-stage series of cascaded convolutional neural networks, that have been proved to be a very effective approach to solve the face detection problem under unconstrained conditions [
36]. At first, a fully convolutional network is used to detect candidate facial regions and related bounding boxes. Candidates are then refined by a linear regression model followed by a non-maximal suppression. Resulting regions are fed to another CNN which further rejects a large number of false candidates and newly performs bounding box regression followed by non-maximal suppression. Finally, the same network used at stage 1 but empowered by a larger number of convolutional layers is used to accurately localize faces in the input image. The face detector was trained on WIDER FACE [
37] and CelebA [
38] datasets. Details on employed network architectures can be found in [
35].
Each facial patch, extracted by the aforementioned face detector, is given as input to the facial landmark detection and tracking step. This crucial step is carried out by making use of the Convolutional Experts Constrained Local Model (CECLM) [
39]. CECLM algorithm consists of two main parts: response map computation using Convolutional Experts Network and shape parameter update. The first step is to compute a response map that helps to accurately localize individual landmarks by evaluating the landmark alignment probability at individual pixel locations. During the parameter update, the positions of all landmarks are updated jointly and penalized for misaligned landmarks and irregular shapes using a point distribution model. The following objective function
is used where
is the optimal set of parameters controlling the position of landmarks, with
being the current estimate.
is the alignment probability of landmark
i in location
for input facial image
I computed by Convolutional Experts Network.
R is the regularization enforced by a point distribution model exploiting mean-shift over the landmarks but with regularization imposed through a global prior over their joint motion [
40].
The estimation of Action Unit (AU) intensities is subsequently carried out on the basis of the detected facial landmarks. The AU estimation starts from the initial regression outcomes coming from a Support Vector Regressor [
41] having linear kernels. The regressor was trained on feature vectors built by concatenating geometry (i.e., the CECLM parameters) and appearance features. The CE-CLM parameters consist of the scale factor, the first two rows of a 3D rotation matrix, the 2D translation t and a vector describing the linear variations of non-rigid shape. In addition, geometry is described by the locations of each detected landmark. In particular, the location into the 3D reference model is used starting from the inferred 2D position in the facial region. This led to a 23 + 204 (i.e., 68 × 3) = 227 dimensional vector describing the face geometry [
42]. On the other hand, in order to extract appearance features, the detected face is mapped onto a common reference frame by transforming detected landmarks to a representation of frontal landmarks from a neutral expression (pivoting on a 3d model) in order to get a
pixel image of the face with 45 pixel inter-papillary distance. Histograms of Oriented Gradients (HOG) features [
43] are then extracted only from the facial region (surroundings are discarded) by exploiting blocks of
cells, of
pixels. This leads to
blocks of 31 dimensional histograms that represent the facial appearance features. The resulting vector (having 4464 elements) is subsequently reduced to 1391 elements by projecting it on the most informative data directions through principal component analysis. The complete vector is then made up by the concatenation of geometry and appearance ones features (
elements). Finally, the AU intensities are estimated by Support Vector Regression (SVR) employing linear kernels [
41]. The models used in the proposed approach were trained on DISFA [
44], SEMAINE [
45] and BP4DD-Spontaneous [
46] datasets coontaining video data of people responding to emotion-elicitation tasks.
Estimated AU intensity values are subsequently smoothed in time by an adaptive degree polynomial filter (ADPF)) [
47] and regularized by geometrical constraints raising from probabilistic reasonings.
ADPFs are smoothing filters that, unlike most common Finite Impulse Response (FIR) digital filters, are represented by polynomial equations. The basic idea is to take advantage of a process, known as convolution, to fit successive subsets of adjacent data points with a low-degree polynomial by the method of linear least squares. This kind of filters is typically used to smooth a noisy signal whose frequency range of the signal without noise is large. In the considered application, ADPFs perform better than the standard FIR filters because these tend to attenuate a significant portion of high frequencies of the signal along with noise. It is worth noting that the variation in each AU brings information about facial expression production and then high frequencies have to be preserved during smoothing processes. The particular formulation of ADPFs preserves moments of higher orders much better than other methods. As a consequence, the widths and amplitudes of the peaks for the desired signals tend to be preserved. This is the reason why an ADPF is used in the proposed pipeline, although it is less effective in removing high-level noises in a signal than common finite impulse response filters. Concerning ADPF’s parameters, the number of points used in each subset of model fits is 5 (frame length) and a polynomial of order 3 is exploited to represent each signal portion.
Since the intensities of multiple AUs are not independent of each other their cross-correlation can, therefore, be exploited to mitigate the effects of single random variations (due for example to noise and/or errors in the estimation or involuntary movements of the muscles) and, on the other hand, to emphasize significant patterns instead. To accomplish this fundamental task a Bayesian Network (BN) has been trained using a large number of videos containing annotated facial expressions as suggested in [
48]. In particular, AU dependencies were learned on the well known Cohn-Kanade Dataset (CK+) [
49]. Each node of the BN has been associated with an AU label, whereas the links among nodes and their transition probabilities capture the conditional dependencies among AUs. Conditional dependencies among AUs were exploited to regularize AU intensities by the following rule:
where
with
n the number of considered co-occurrent action units (in this paper
). The outputs of this step are regularized AU intensities, i.e., AU intensities whose values at each time instant have been ’smoothed’ or ’enhanced’ according to the learned parameters of the model there are applied on the values of the intensities of the related AUs.
Facial Expression Analysis is subsequently performed on the basis of the estimated, temporally smoothed and regularized AU intensities. To this purpose, the Ekman model [
50] that attributes the character of basic emotions to happiness, sadness, fear, and anger has been taken as theoretical reference.
To this end, firstly, the actual variation in each
intensity is computed by introducing a short-term statistics on a modeling window
where
is the observation period whose length depends on the expected temporal distance between two consecutive relevant facial expressions. The modeling window
is exploited to build a probabilistic model with multiple Gaussian functions built on the observed configurations of the facial muscles. The probability to observe the value
X of the intensity of
is then computed as:
where
K is the number of distributions (
in this paper),
is an estimate of the weight of the
ith Gaussian in the mixture,
and
are the mean value and covariance matrix of the
ith Gaussian respectively, and
is a Gaussian probability density function.
Given the model, the largest value of
in the observation window
is extracted, its probability to fit the model is computed and its negative log-likelihood
is retained as a measure of the variation of the current values with respect to the expected ones.
The values
are finally exploited to compute the production scores
with
and
that are the outcomes of the proposed algorithm pipeline in each time instant
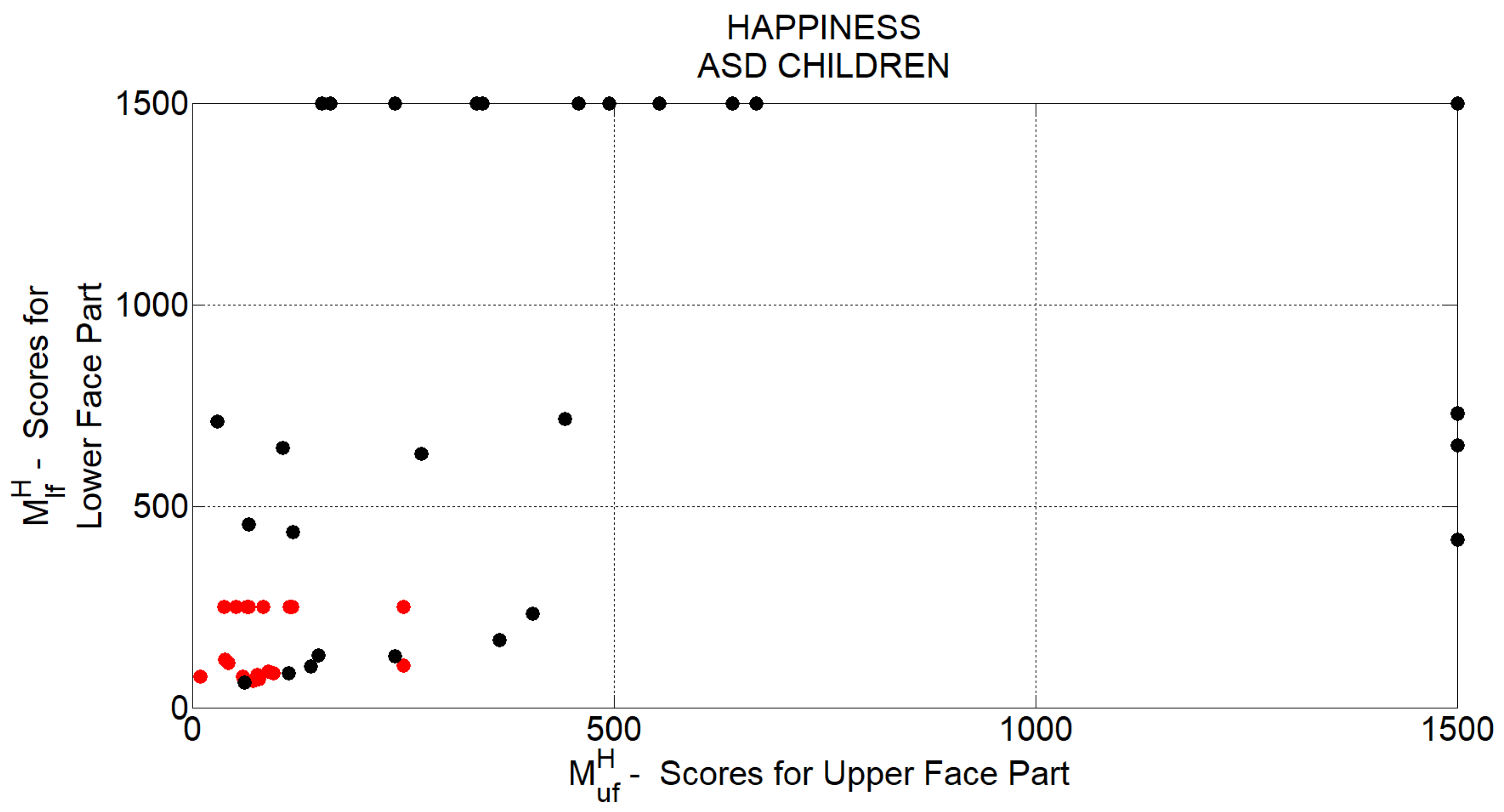
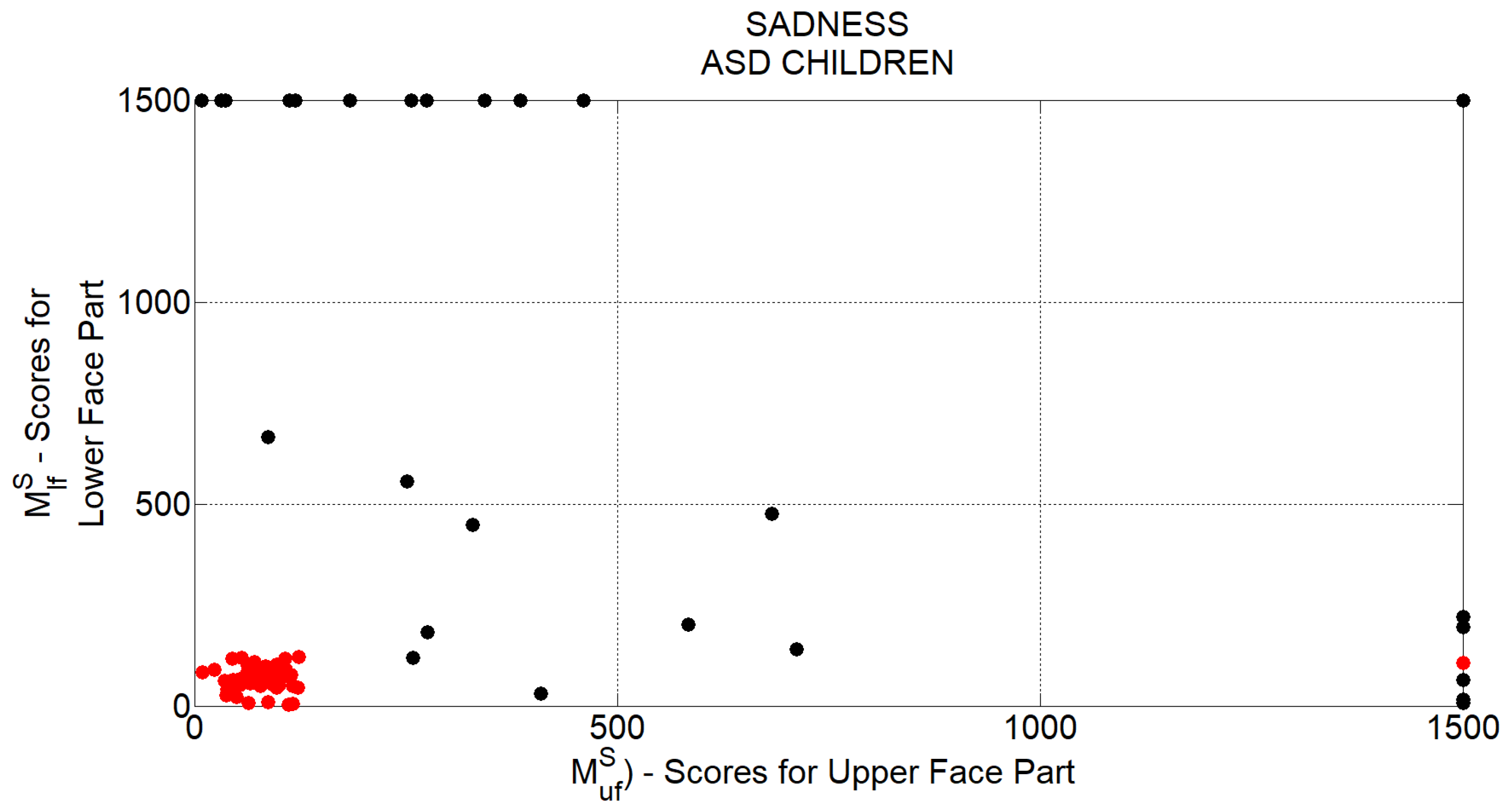
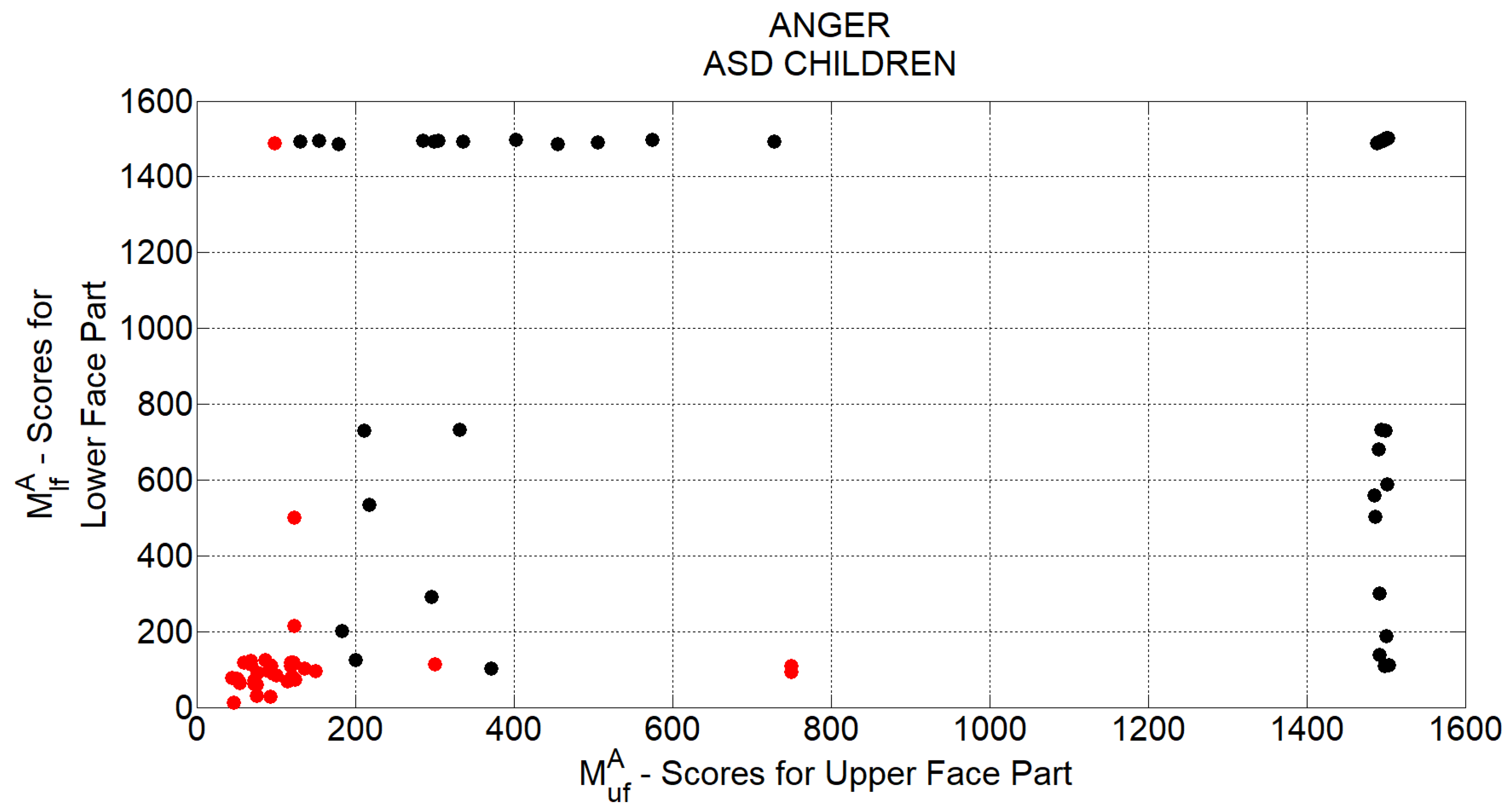
t. For each of the 4 basic facial expressions taken into consideration, at each time instant, a measure of production ability is separately computed for lower and upper facial part (indicated by
and
subscripts respectively) as reported in
Table 2.
4. Participants and Method
Participants. Twenty-seven children were recruited for this study: 17 were children with ASD recruited at two diagnosis and treatment associations in the South of Italy and 10 were typically developing children recruited at a daycare in a little city of South of Italy. For this research Ethical Committee of the Local Health Service gave its approval and informed consent was obtained from children’s parents. All children’s families were contacted to obtain agreement and they received a cover letter with the project research description and the signed informed consent.
ASD group. This group is equivalent to the one used in [
8]. It included 14 males and 3 females children aged 6–13 years (mean = 8.94;
standard deviation = 2.41) and who received a High Functioning—ASD diagnoses by local health service using Autism Diagnostic Observation Schedule (ADOS) scores [
51]. Their IQ was assessed by Raven’s Colored Progressive Matrices [
52] and the scores were on average level (mean = 105;
standard deviation = 10.98; range = 90–120). Furthermore, all children followed a behavioral intervention program using the Applied Behavioral Analysis (ABA).
TD group. This group included 10 children (6 males) aged 26–35 months of life (Mean = 31.3;
Standard Deviation = 3.1) who were not referred for any developmental disability. Children were voluntarily recruited aged between the second and third year of life since that age range is the crucial moment in which children start developing the ability to name and recognize facial expression (e.g., [
9,
10,
11]) of basic emotions (happiness, sadness, fear, and anger).
Table 3 describes the sample divided by children’s group.
Here it could be useful to make a clarification: the main aim of the paper is to quantify facial expression production while it is not completely developed. For this reason, the experimental setup involved 2–3 years old TD children. Evaluation of TD children of the same age of ASD ones would bring to pointless results since all the scores would tend to the maximum in subjects having the facial expression production skills fully acquired. What really matters in the considered application context is the level of development of competences, not the chronological age of the involved individuals. In light of this, for both groups, the clinical baseline was assessed by the Facial Emotion Recognition (FER) task [
53,
54] which evaluated the child’s ability to recognize each emotion between four visual stimuli. A point is awarded to a child if he recognizes the stimulus. Since there are four visual stimuli (each associate to a basic emotion) and each stimulus is supplied 5 times to each child, the total score ranges from 0 to 20 (i.e., from 0 to 5 for each basic emotion).
Table 4 and
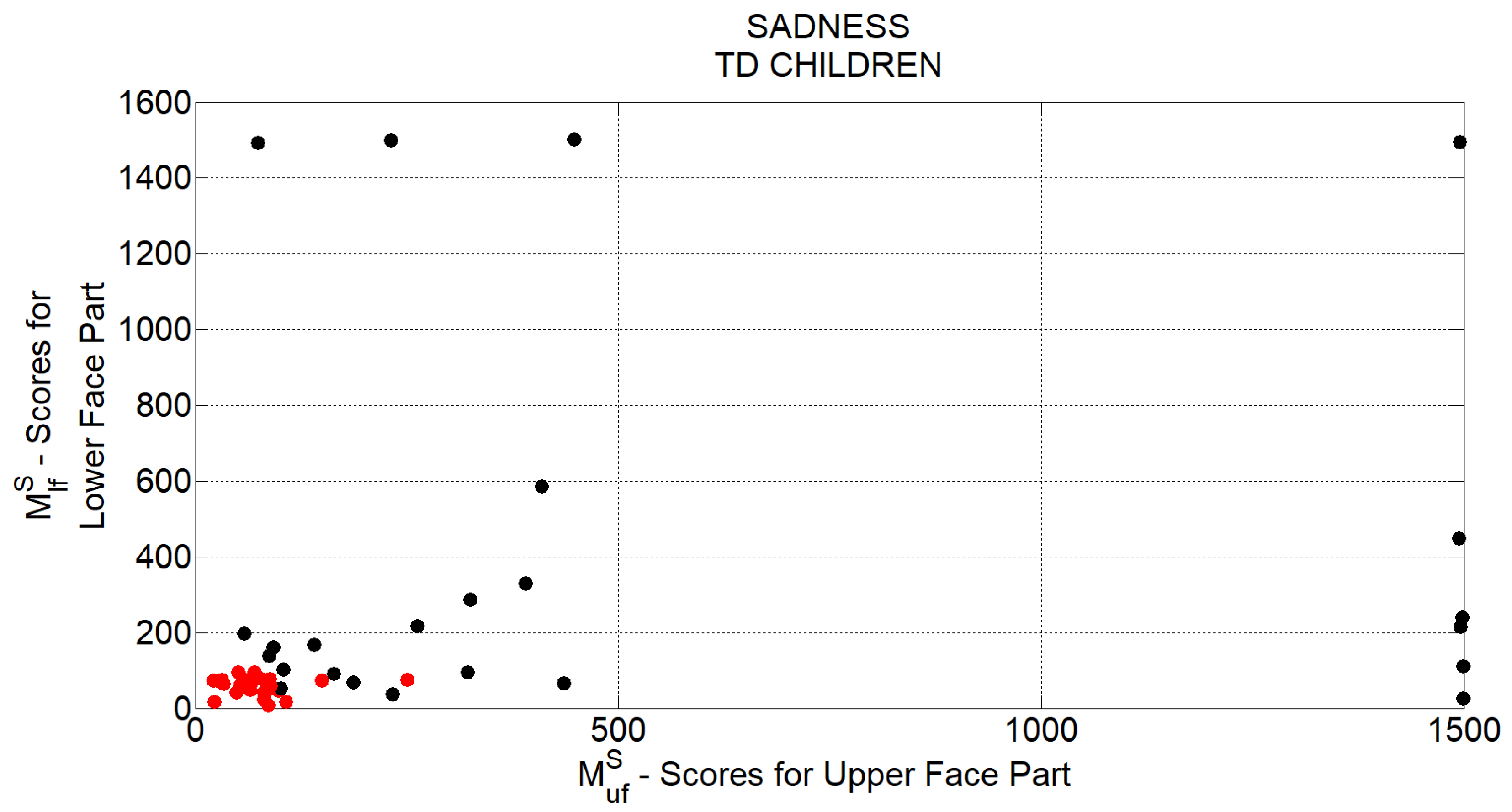
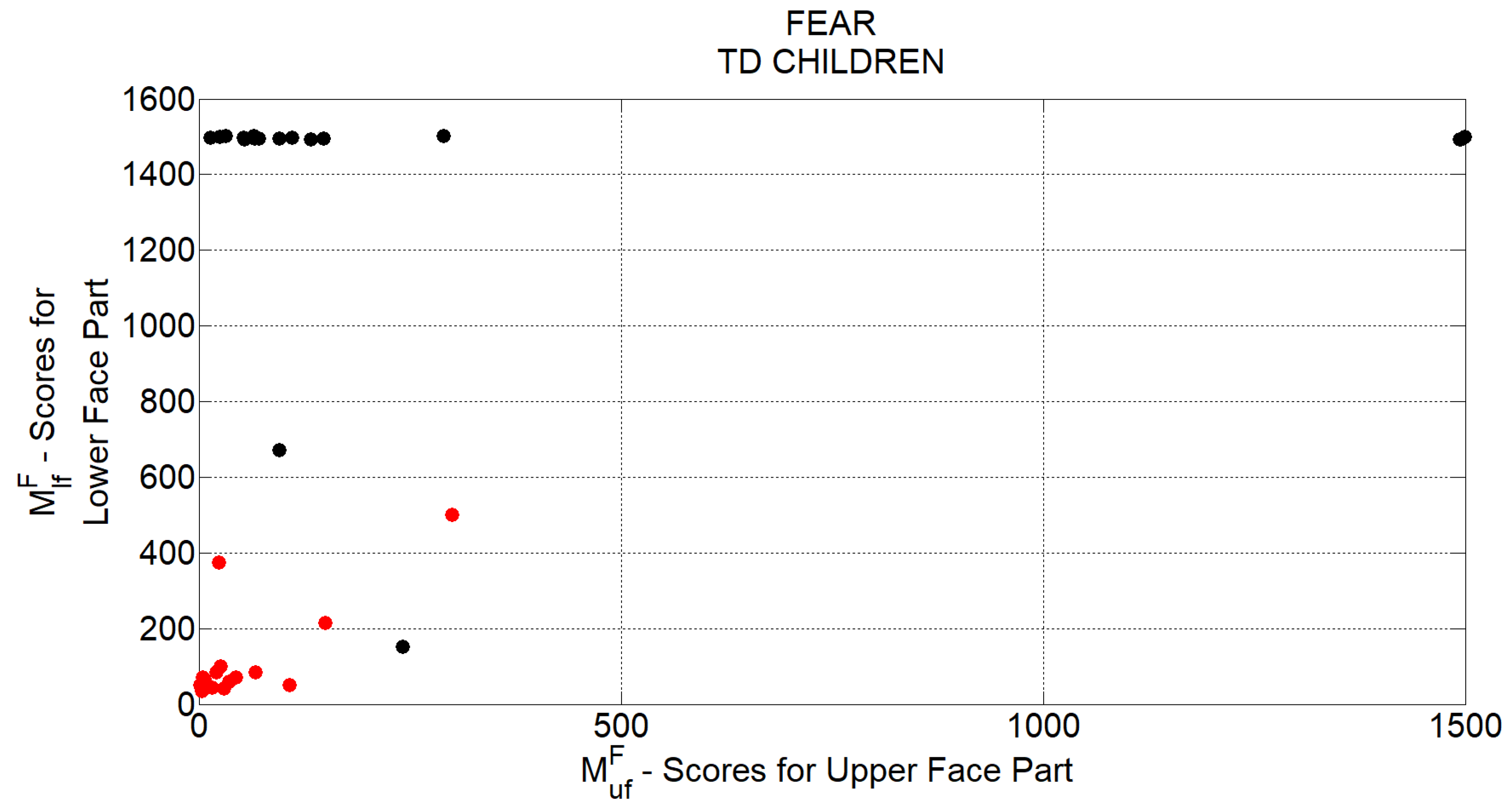
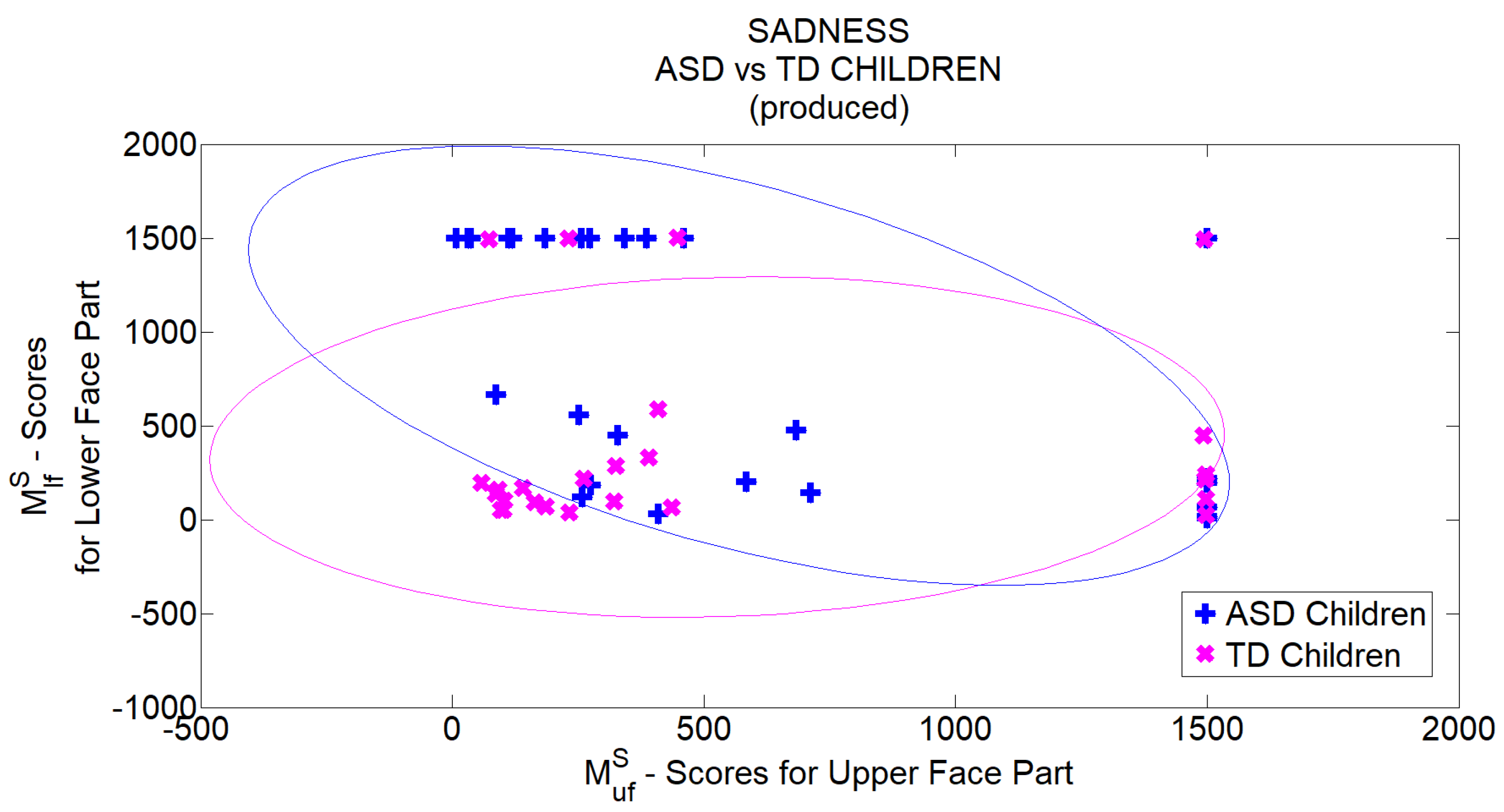
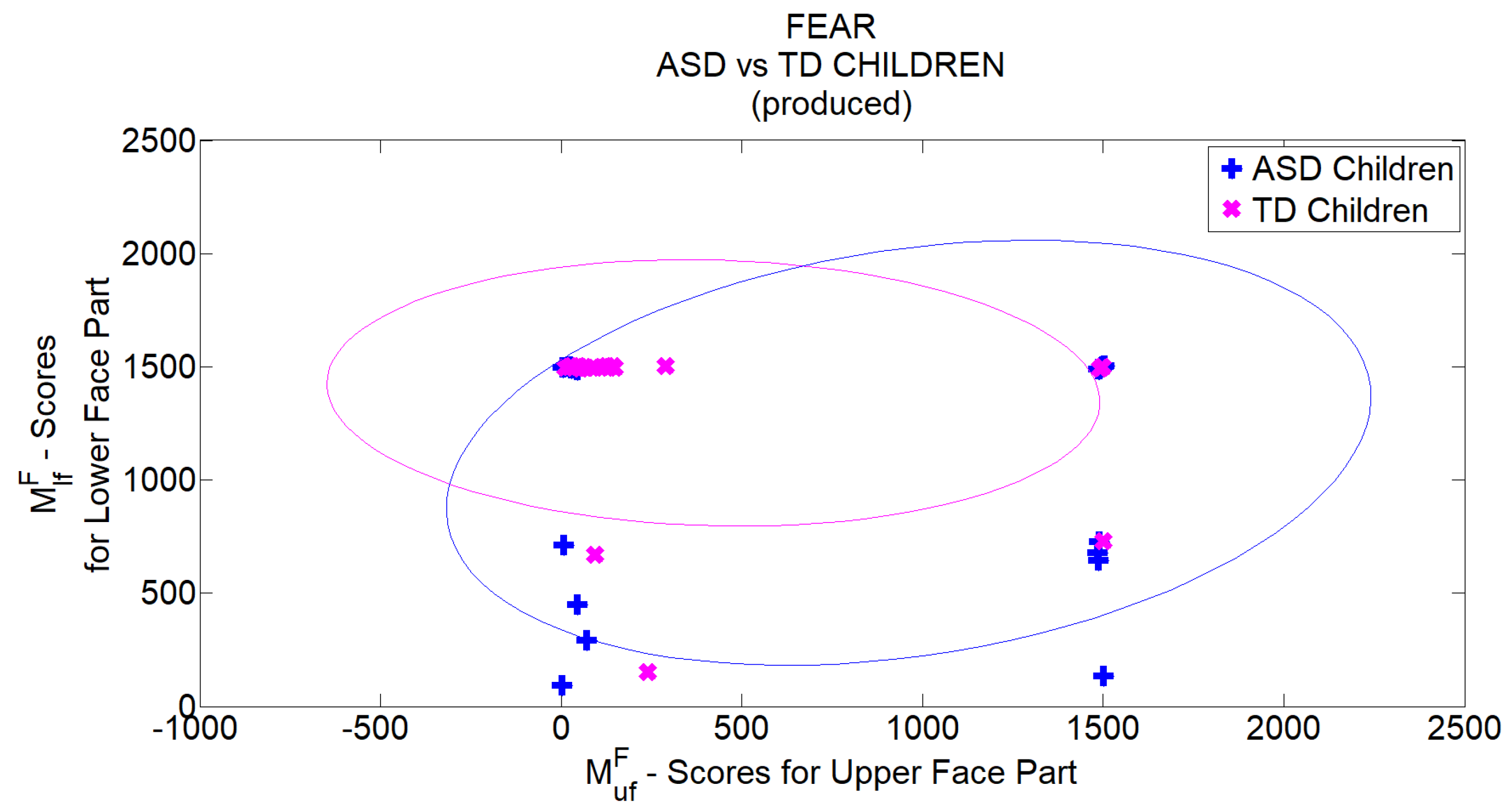
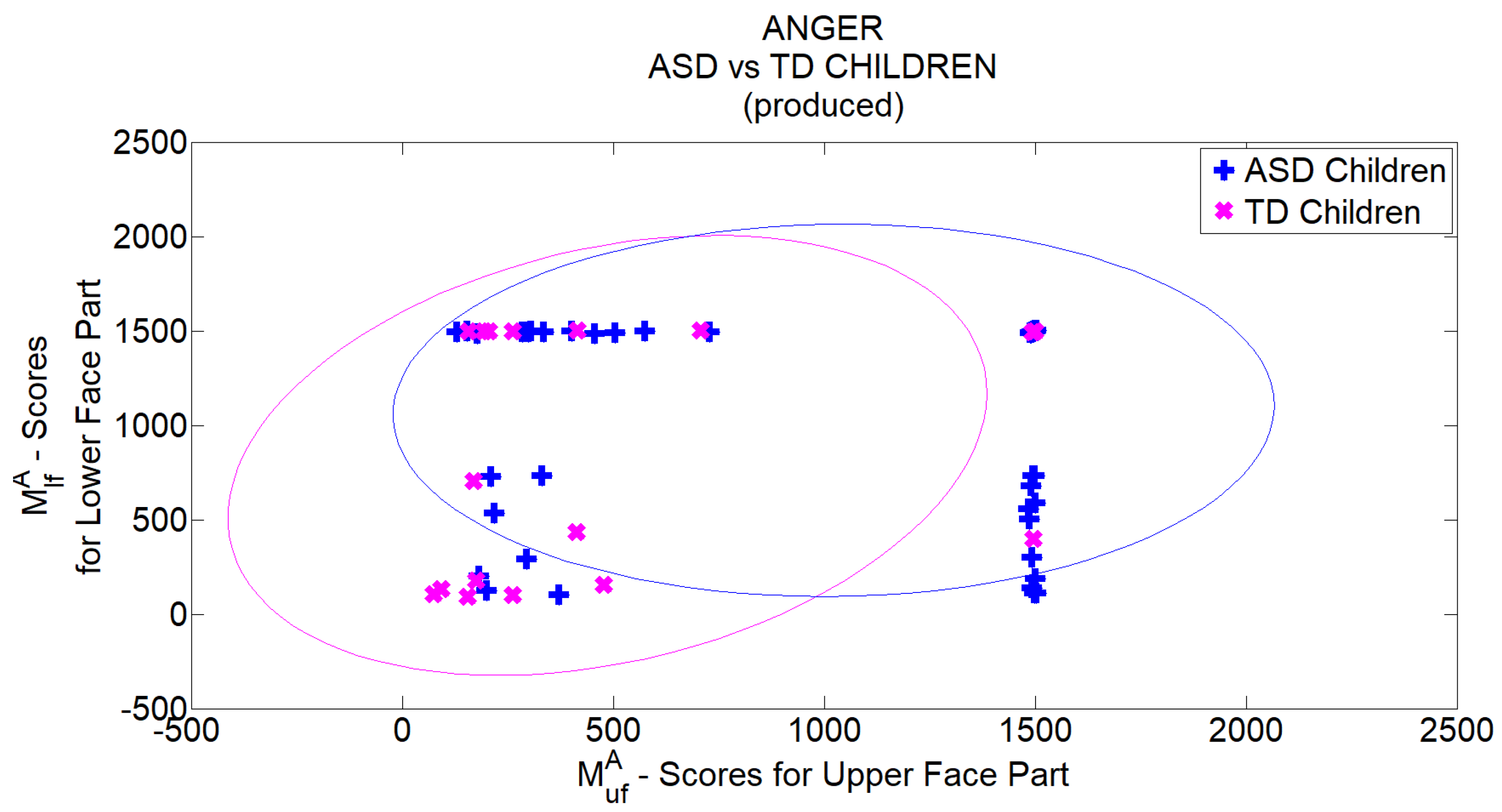
Table 5 show grouped FER scores for TD and ASD children respectively. In each table, the first column indicates the emotion to which the visual stimulus was related to, whereas the second column reports the total number of recognized emotions for the related group. In the second column also the percentage of correct executions of the recognition task with respect to the total number of supplied stimuli is reported. In each table, the last row reports the overall scores. Tables point out that the development of the TD group’s competence was still in progress since the percentage of correct recognition was on average the 62%. On the other hand, ASD children obtained very good performances in basic emotion recognition task (on average correct recognition of 94%). This could be associated with their higher chronological age than children in the TD group. Besides, for both groups, the most recognized emotion was happiness (in particular all ASD children succeeded in recognizing it), whereas negative emotions were less recognized. This is further evidence of the homogeneity between groups related to the competence in facial emotion recognition. According to this homogeneity, it is possible to assert the fairness in comparing the two groups on the subsequent and evolutionary emotion competence, which is the production of basic emotions.
Method. To evaluate children’s ability to produce a specific basic emotion, the
Basic Emotion Production Test [
55] was administered. Each child was tested while seated in front of a therapist who asks him/her to produce one of the basic facial expressions. The requests of the production of facial expressions were provided sequentially to the child as happiness-sadness-fear-anger and the sequence was repeated five times. This way, each child was asked to produce 20 facial expressions and a psychologist assigned 1 point if the emotion was correctly produced and 0 points if the child refused or did not produce the requested emotion. The total score for each child thus ranged from 0 to 20. A video was recorded for each child so that, at the end of the acquisition phase
videos became available for further processing. Videos were acquired from an off-the-shelf camera (image resolution
pixels, 25 fps) and each video was accompanied by information regarding the time instants in which the requests were provided to the child. Each video had a different duration (minimum
min, maximum 6 min) depending on the degree of collaboration of the child and then on time spent to attract his attention at the beginning or even between one request and another. For all children, the requests were anyway provided to the child with a minimum interval of 4 s from each other. Videos were manually annotated by a team of professionals (3 psychologists with advanced knowledge on issues related to ASD). The professionals watched recorded videos and pointed out, for each request, if the child either performed or not the related facial expression.
Table 6 and
Table 7 report the annotations carried out by experts for TD and ASD children respectively. Each row indicates the number of correct (second column) and incorrect (third column) productions of the facial expressions according to the items in the first column.
6. Comparison with Leading Approaches and Technical Discussion
In this section, the outcomes of the performance comparison on the same set of videos with some of the leading approaches in the literature are reported. The comparison concerned three approaches in the literature. The first comparing approach is the one in [
8], that shares with the proposed one the same modules for AU intensity estimation and facial expressions quantification but it uses shallow methods instead of convolutional approaches for face detection and facial landmark positioning. In addition two leading approaches performing FER by deep neural networks to process dynamic image sequences were compared: the first one is based on Recurrent Neural Networks (
https://github.com/saebrahimi/Emotion-Recognition-RNN) [
56] whereas the second one is based cascaded networks (code retrieved from
https://github.com/ebadawy/EmotiW2017) [
57]. The approach in [
56] is a two-step approach that models emotion as the spatio-temporal evolution of image structure. In the first step, CNN is trained to classify static images containing emotions. In the second step, an RNN is trained on the higher layer representation of the CNN inferred from individual frames to predict a single emotion for the entire video. The core module of the system in [
57] is a hybrid network that combines a recurrent neural network (RNN) and 3D convolutional networks (C3D). RNN takes appearance features extracted by a convolutional neural network (CNN) over individual video frames as input and encodes motion later, while C3D models appearance and motion of video simultaneously.
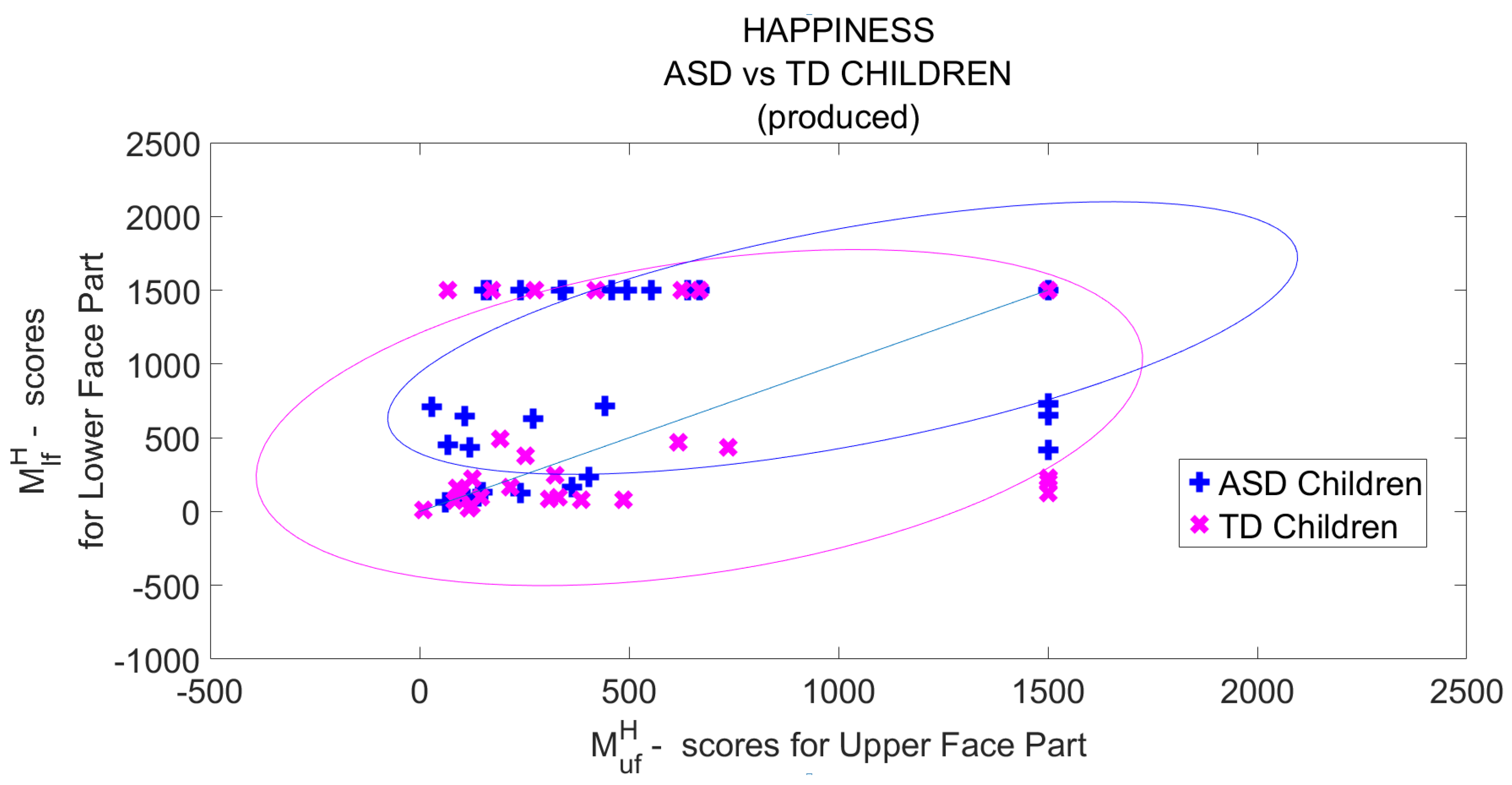
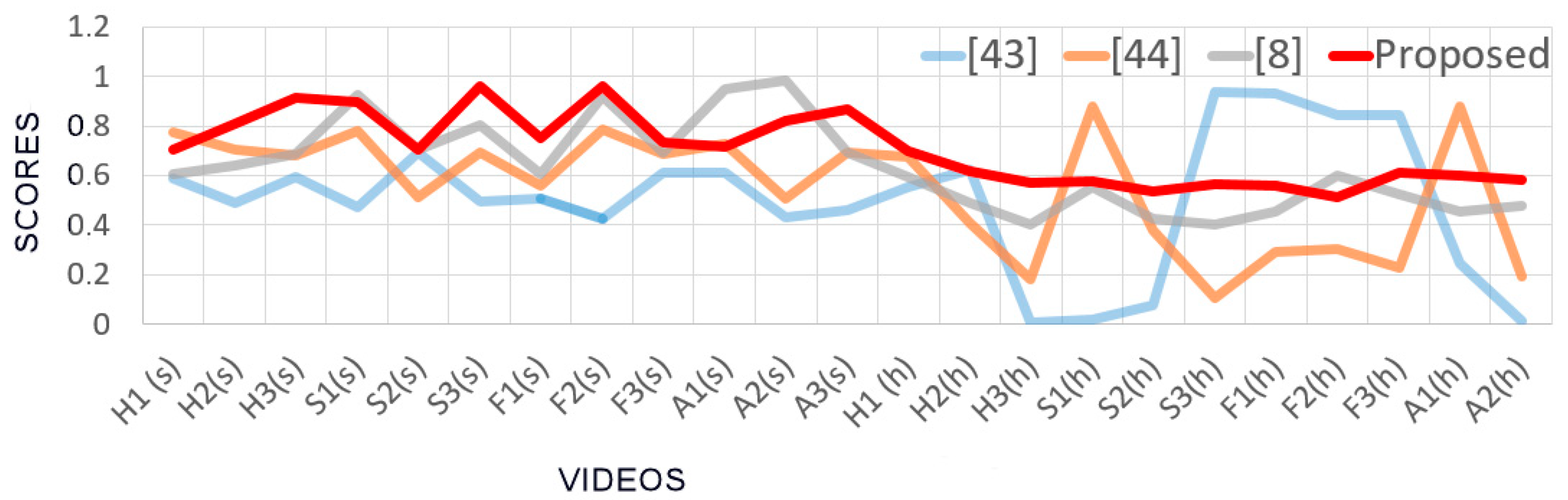
The comparison was accomplished in two steps: the first step was aimed to verify the reliability of the outputs to quantify the ability in producing basic emotions in the considered application context, whereas the second step compares computational outcomes to manual annotations provided by the team of psychologists. In the first step, two subsets of videos concerning ASD children were considered: the first subset consists of 12 videos in which children showed a strong production of required expressions (3 videos for each of the 4 considered basic expressions) whereas the second subset consists of 12 videos in which children reacted with a just hinted production of the required expressions (again 3 for each of the 4 considered basic expressions). In other words, the former videos were selected among those on which the team of psychologists immediately agreed during the annotation process whereas the second subset of videos was built taking sample videos among them in which the team of experts has resorted to an inter-annotator agreement due to the initial disagreement. All the comparing approaches were tested on the selected videos and all the outputs were normalized in [0.0, 1.0] followed by per 4 class re-scaling so that the related scores sum up to 1. In
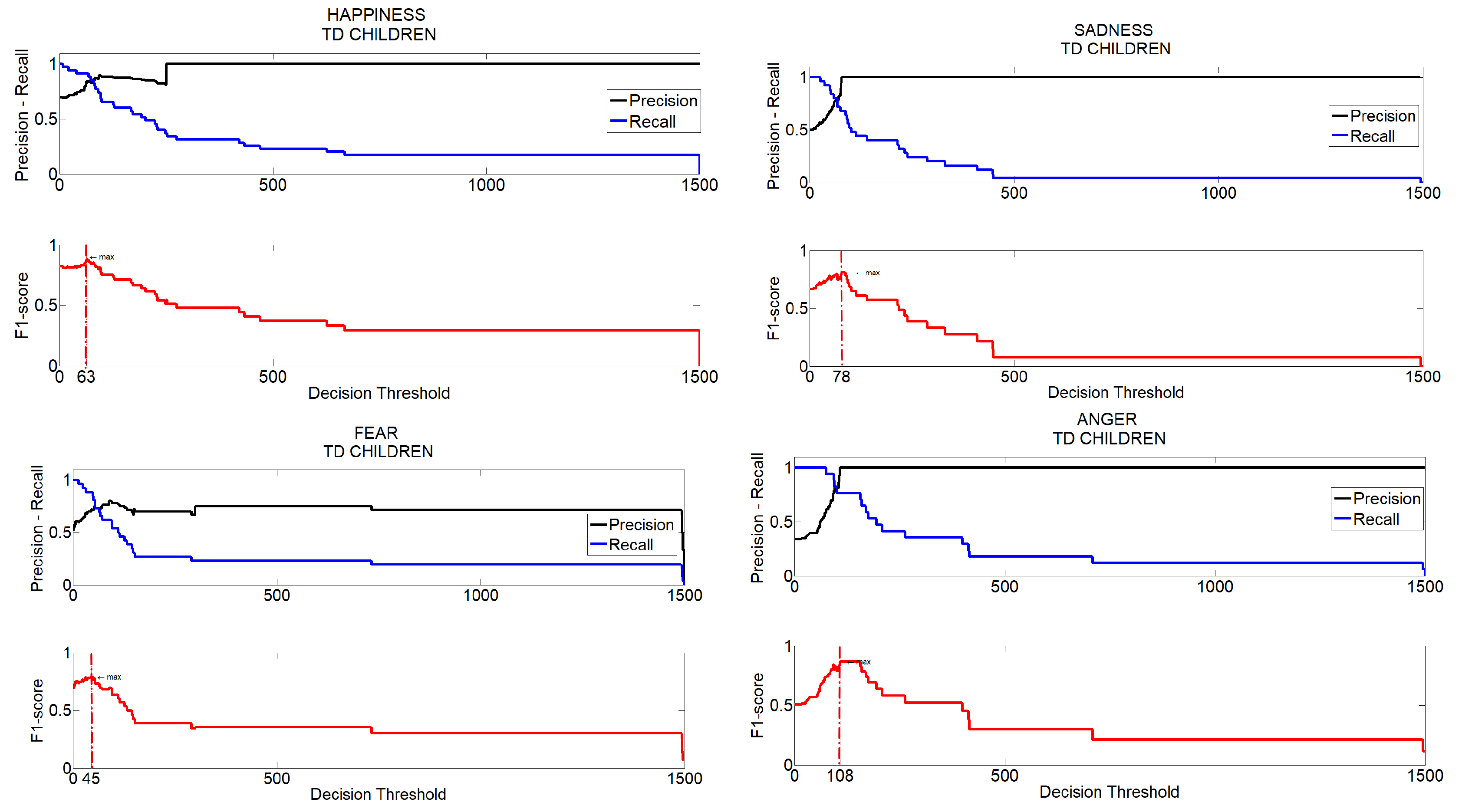
Figure 17 the scores computed by the comparing approaches on the selected videos are reported.
Labels on the
x-axis indicate the performed expression (H,S,F,A), the related cardinal number (from 1 to 3) and, in brackets, the belonging subset (s for strong executions and h for hinted executions). What we would like in this case, at the very least, is that highest scores are associated to strongest executions of facial expressions and lowest scores to just hinted executions but, unfortunately, it is possible to observe that for approaches in [
56] and [
57] this not happened. Sometimes, hinted expressions even drew to scores higher than those obtained for strongly executed expressions. It follows that outcomes of classical approaches (blue and orange lines) are not suitable to quantify the abilities in facial expression production since both approaches showed no significant correlation the strength of the facial expression production and the automatically gathered scores. On the other hand, the approach in [
8] (grey line) showed an appreciable level of correlation and the proposed approach a desirable very high level of correlation.
In the second comparison step, the aforementioned approaches were evaluated in terms of accuracy with respect to manual annotations provided by the team of psychologists (on both ASD and TD videos).
Table 10 reports the accuracy values related to each comparing method in terms of matching between gathered scores and manual annotations.
At a first glance, from the table, It is evident that CNN based approaches, i.e., the ones in [
56,
57], perform worse than approaches based on statistical modeling of non-emotional face configurations like the one proposed in this paper and the one introduced in [
8]. In fact, besides to provide output scores strictly correlated to the ability in producing a required expression (as the previous comparison proved), the statistical modeling of non-emotional face configurations makes the related frameworks able to adapt their internal parameters to the individual behaviors. Through this desirable feature they can then embed stereotyped movements and to highlight even subtle voluntary movements of facial muscles with respect to the inexpressive facial model, continuously updated, that the system uses as a reference baseline. However,
Table 10 shows also that the improved pipeline proposed in this paper is able to better understand actual emotional dynamics of the face by exploiting the capability of introduced convolutional approaches for accurately detect face and to precisely positioning facial landmarks even under severe occlusions and extreme poses. Certainly not all critical situations have been resolved (as reported in
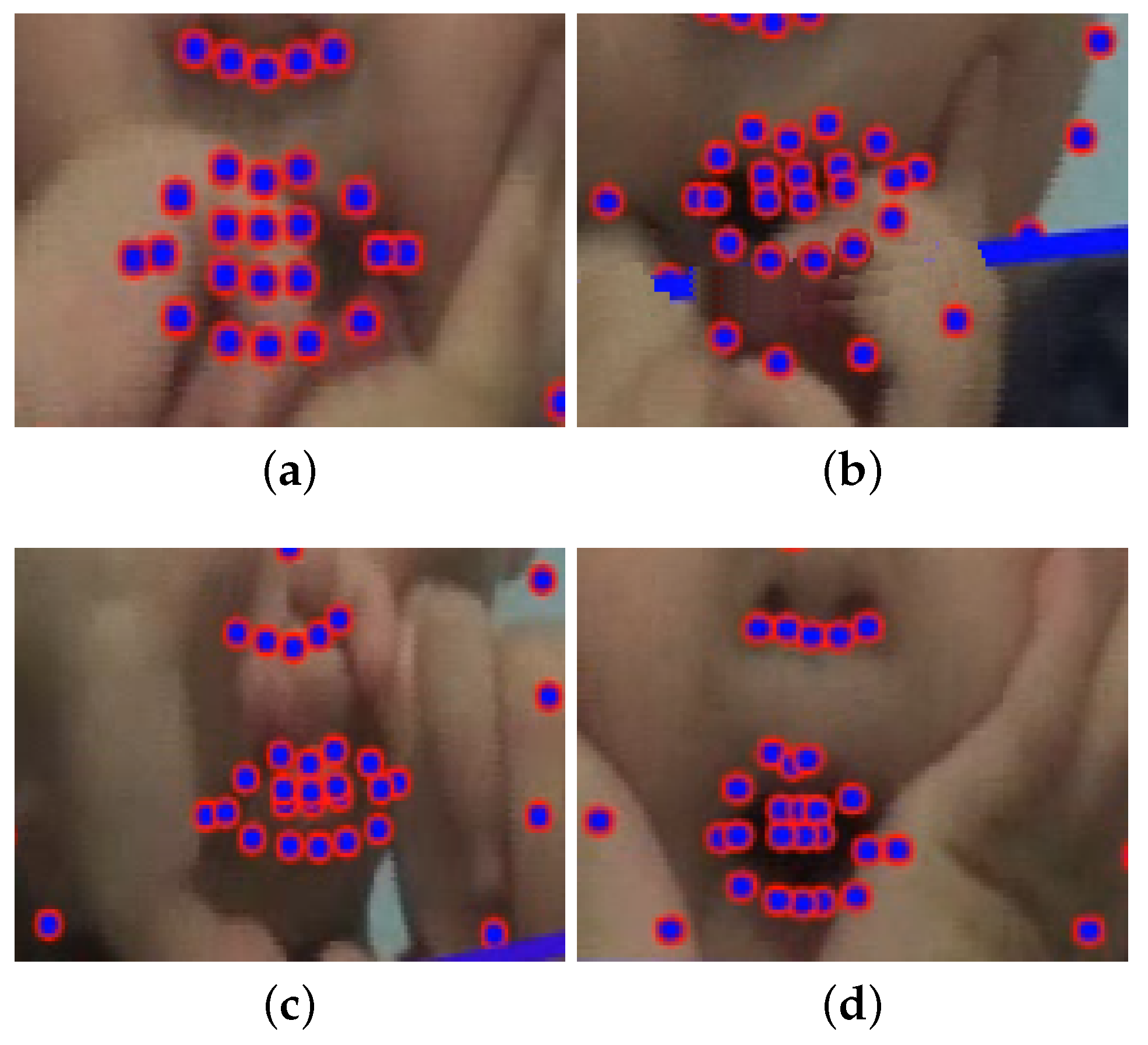
Figure 6), but the comparisons make is possible to state that a step forward has been made towards the alignment between the human annotations and the automatic scores provided by an automatic system.
In light of the encouraging experimental results, it is useful to discuss how each component in the proposed pipeline affects the overall performance. The most practical way to derive some useful considerations about this important issue is to deeply analyze the results of the above experimental comparisons. From the first comparison step, it emerged that the face analysis based on a personalized, continuously updated, model of the non-expressive face is a fundamental step to make possible a convincing quantification of the ability in performing facial expression. Besides, given that detecting the face is not a particularly complex task in this context (very few faces, not a cluttered scene, zoomed images), from the second comparing step, it is possible to derive that a key role is played by the landmark detection and tracking step. This is particularly evident by observing outcomes of the proposed approach with respect to the one in [
8] in which the same strategy was used to perform the subsequent face analysis. Facial landmark detection algorithms can be categorized into three major categories [
58]: holistic methods, Constrained Local Model (CLM) methods, and regression-based methods. Holistic methods require models to represent facial appearance and shape information. CLMs require instead a global shape model but they learn local appearance. Finally, the regression-based methods do not require any information and capture facial shape and appearance information from data. Comparisons made in this paper proved that the use of Convolutional Experts Constrained Local Model introduced a very effective local detector able to model the very complex individual landmark appearance bringing together the advantages of neural architectures and mixtures of experts in an end-to-end framework. This way an individual model of the appearance of each landmark is introduced making it possible to accomplish the landmark detection and tracking tasks in a robust way with respect to occlusions and changes in pose, which are two of the main challenging issues to be addressed in the considered application context.
Besides, experiments proved that Constrained Local Model (CLM) methods can be a more effective solution than regression-based methods, at least for those exploited in [
56] and [
57]. The last technical consideration relates to processing times. The system in the current version processes about 20 frames per second ( images having HD resolution) on a notebook equipped with an Intel i-7 processor, 32 GB of RAM and GPU RTX 2080. In particular, the face detection module takes on average 50 ms, face landmark positioning takes 5 ms and facial expression analysis takes about 40 ms. To speed up the processing, in order to achieve the aforementioned rate of 20 fps, face detection is carried out only every 8 frames (the tracking trick is used in the meanwhile making the hypothesis very likely to have no abrupt changes of position between one frame and another). It follows that the actual bottleneck is the calculation of Gaussian mixtures for the definition of the non-emotional facial model. It follows that, although the software was designed primarily for offline processing of videos acquired during training sessions, the current implementation of the algorithms could also be exploited to process videos in real-time, for example, to provide positive feedback to the individual receiving therapy (as recommended in some efficient strategies in Applied Behavioral Analysis).
8. Conclusions
This paper proposed a novel framework to computationally analyze how both ASD and TD children produce facial expressions. The proposed pipeline was applied to evaluate competence in the production of basic emotions. This competence was evaluated both when it is starting to be acquired in typically developing children and when it is a deficit in ASD children. Numerical outcomes highlighted how the pipeline is accurate (more than existing approaches), quick and objective to evaluate both the strength of facial expressions and how much each facial part is involved in facial expression. The reference baseline consisted of the manual annotations made by a team of psychologists.
It is worth noting how this automatic system could have important implications in the treatment of children who are a deficit in emotional competence (e.g., ASD children) since it is able to identify both facial movements which are not detected by human eyes and their strength. Therefore, it could help professionals to understand (a) if child is starting to produce a specific facial expression, (b) which facial part (upper or lower) is starting to be involved in facial expression and thus enhance it, and finally (c) which facial part is not involved by child in facial expression and thus focus intervention on it. All the above considerations allow concluding that the automatic system could be useful for professionals who treat ASD child to obtain a learning trend of acquisition and production of facial expression of basic emotions.
A limitation of the present study is the sample size. Future works will also deal with the monitoring of the evolution of children’s skills over time to objectively highlight the improvements, for example by comparing the individual ability to produce specific facial expression before and after targeted therapies. Another issue concerns the computation of facial landmarks that, in the proposed approach, were computed without any prior knowledge about the final goal (facial expression recognition) to be accomplished. Several researchers are trying to improve landmark positioning accuracy [
59] using different metrics (root mean squared error on ground truth data, some application objective function, landmark detection rate) and different competitions on this topic are hosted in top computer vision conferences [
60] revealing excellent performance on the reference datasets. However, there is also a research area that is studying how to specify the landmarks (virtual electromyography sensors) to detect and monitor the facial muscles movements depending on the application context. This is a very interesting perspective and the idea of using size variant patches for landmark detection [
61] could help to further improve computational analysis of facial expression production abilities. Learning active landmarks for each AU, i.e., finding the best representative patch size for each landmark in a unified framework is the research line to be pursued. The preliminary experiments have shown that the subtle muscle movements belonging to the upper face require smaller landmark patches while the lower face AUs are detected better in larger patches. How this could impact the outcomes of the proposed pipeline will be investigated in future works.

 ,
, 
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}