3.1. Document Image Registration
The image registration problem has been intensively studied in remote sensing images, medical images, and camera images and very rarely, research can be found for document image registration. The most popular registration in the context of exposure bracketing is from [
3], where a translational geometric model was employed to account for the geometric disparity between two images. However, we found that the translational model is not suitable for general camera document images.
Figure 4 shows two pseudo color image patches that are composed of two LDR images that are already illustrated in
Figure 1. The green band and blue band come from the corresponding bands in the well-exposed image while the red band is from the corresponding band in the over-exposed image. If there are no geometric disparities between these two images, the foreground (textual part) of the image should overlap. In
Figure 4, we can clearly see that geometric difference exists as the foreground texts do not overlap. On top of it, we can clearly see that the global translational model cannot account for the geometric disparity between these two images. For example,
Figure 4a is the left central image patch and we can see that the geometric difference between the well-exposed image and over-exposed image in this region is around 10 pixels (half the size of the lowercase letter “a”) in the vertical direction. However, in
Figure 4b, the right central image patch, we can see that the geometric difference between the well-exposed image and over-exposed image in this region is around 20 pixels (the size of the lowercase letter “a”) in the vertical direction. This is obvious evidence that the geometric disparity between LDR images cannot be translational and that it must follow a more complicated geometric model.
Among all the geometric models, such as the affine model, translational model, rotation model, and so on, we ended up selecting the planar homograph model [
6] to represent the geometric disparity between LDR images. Under this model, points in two different images can be mapped as:
where points are represented by homogeneous coordinates and so point (
x,
y,
z) is the same as (
x/
z,
y/
z) in the inhomogeneous coordinate. We selected this model because during the bracketing stage, hand-shake is inevitably introduced, leading to different imaging angles for the same document object, and the planar homograph model is suitable for the situation where the imaging object is put on a planar surface and is captured from different view-angles.
When the planar homograph model is selected, we have to estimate this model’s eight parameters. Basically, there are two methods [
7]. The first method is called the area-based method. Using this method to estimate the planar homograph model involves two steps: in the first step, a moving window is defined in the reference image and the image patch within the window is regarded as the template. We used the template to search for a corresponding image patch in the sensed image (an image that was registered). The centers of matched image templates are used as control points (CPs). There are many ways of finding a matching template, and one of the most popular criteria is cross correlation. When multiple CPs are generated, we then use these CPs to estimate the planar homograph model. Area-based methods, however, are not employed due to two reasons: (1) the first reason is that this method is computationally heavy as it performs cross correlation on multiple image patches and (2) the second reason is that image patches under different exposure levels may display extremely different characteristics, which may fail cross the correlation method.
The second method to estimate the planar homograph transformation is called the feature-based method. Two critical steps in feature-based methods are feature extraction and feature matching. We expect that the extracted features will be consistent regardless of exposure levels and among all the feature extraction methods, we selected the Scale-invariant Feature Transform (SIFT) method [
8] because it improves detection stability in situations of illumination changes. In the meantime, it achieves almost real-time performance and the features that are detected are highly distinctive. SIFT does not only define the position of detected points, but also provides a description of the region around the feature point by means of a descriptor, which is then used to match SIFT feature points. Therefore, we have used the SIFT method to find CP pairs.
Figure 5 shows the extracted matched SIFT features for two LDR images.
As we can observe from
Figure 5, some SIFT feature points that cannot find correct corresponding pairs always exist. Therefore, some CP pairs cannot be used for inferring the planar homograph model as they are outliers. In order to remove these outliers, we used the Random Sample Consensus (RANSAC) algorithm combined with spatial constrains to prone the outliers [
9]. The basic idea behind this is that we can estimate the planar homograph model with four randomly selected points. With the estimated model, we can check how close the CP pair is if they are put in the same coordinate system after transformation with formula (1). Then we calculate how many CP pairs are consistent with the estimated projective transform model, which indicates the confidence level of the estimated projective transform model. We performed this procedure multiple times and selected the projective model with the highest confidence level. After that, we re-estimated the projective model once again using the least-square method with all the CPs that fit the selected model.
Figure 6 shows the selected CPs that can be used to infer the planar homograph model using the above point pruning procedure. From this figure, we can clearly observe that all the outliers have been removed and each SIFT point in one image can always find its correct counterpart in another image.
After the planar homograph model is estimated, we can perform the registration so that pixels from the same target share the same coordinate in the image stack.
Figure 7 shows the pseudo color image after the registration, where the color configuration is the same as
Figure 4. Overlapping the registered image of different exposure levels shows that a decent registration result has been obtained.
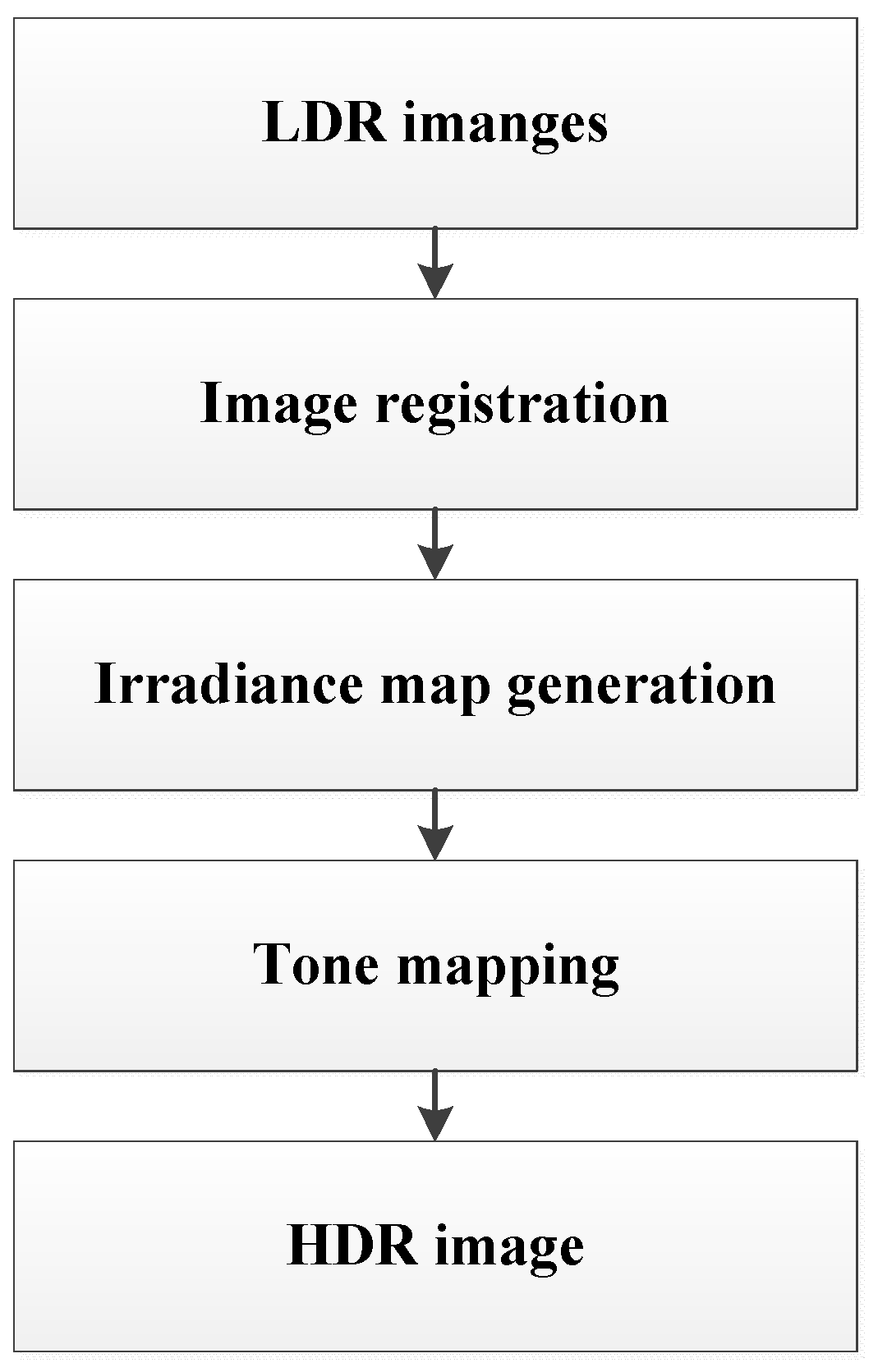
3.2. Tone Mapping Method
The tone mapping method can generate an HDR image by capturing multiple images of the same scene at different exposure levels and merging them to reconstruct the original dynamic range of the captured scene. In order to understand why HDR is possible with multiple images of different exposure times, it is necessary to know the image acquisition pipeline, which is illustrated in
Figure 8.
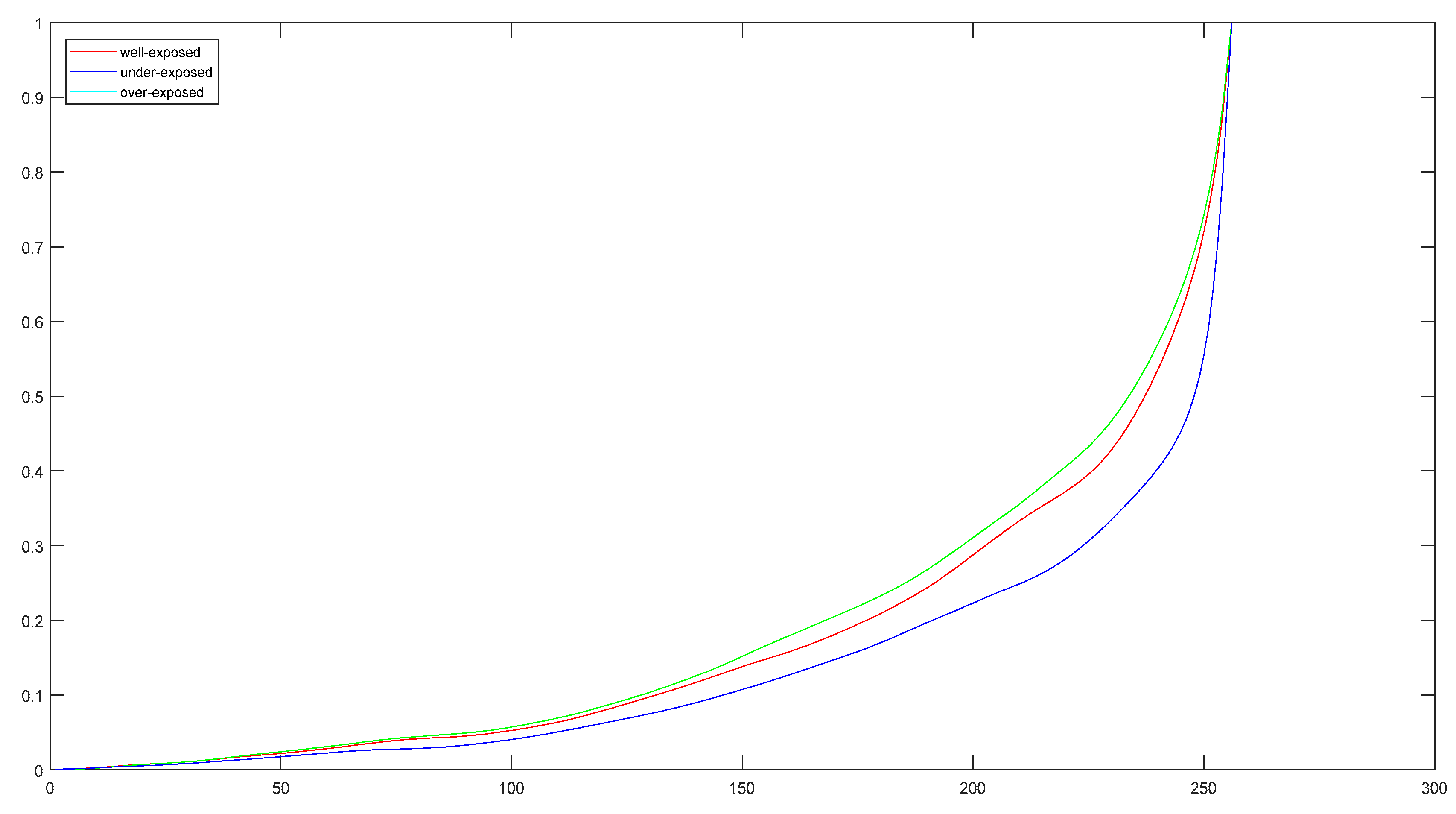
Figure 8 shows how scene radiance becomes pixel values for both film and digital cameras, and we can use an unknown aggregate nonlinear mapping function to transform scene radiance L to digital pixel values Z. The unknown aggregate nonlinear mapping function is called the camera response function (CRF). It attempts to compress as much of the dynamic range of the real world as possible into the limited 8-bit storage. There are many methods that exist in the literature on how to estimate CRF and in this paper, we used the classical CRF estimation method that was proposed by Debevec and Malik [
10]. With this method, estimating CRF is equal to optimizing the following objective function:
where
is the inverse of the CRF,
M is the number of pixels used in the minimization,
and
are, respectively, the maximum and minimum integer values in all LDR images
,
is the number of LDR images, and
is a weighting function defined as:
The implementation of Debevec and Malick’s method relies on the HDR Matlab Toolbox [
3] and with this method, the estimated reverse CRF functions for images captured in
Figure 1 are shown in
Figure 9.
Once the reverse CRF is recovered, it can be used to quickly convert pixel values to relative radiance values based on the following formula:
The unit of radiance is of double-float format in order to keep the high dynamic range of real-world radiance, while most monitors can only display 255 colors. Therefore, in the last two decades, researchers have spent a significant amount of time and effort on compressing the range of HDR images and videos so that data may be visualized more naturally on LDR display.
Tone mapping is the operation that adapts the dynamic range of HDR content to suit the lower dynamic range that is available on a given display. Furthermore, only luminance is usually tone mapped by a tone mapping operator (TMO), while colors are unprocessed.
The TMO processing chain is as follows [
11]:
Step 1: the luminance channel is first extracted from the radiance map and color information compression is avoided.
Step 2: the luminance is mapped to (0, 255) with a TMO.
Step 3: the following formula is used to obtain the mapping RGB channels:
where
s is a saturation factor that decreases saturation. Tone mapping often increases saturation and hence,
s is a floating value that is less than 1.
Step 4: Gamma correction is applied and each color channel is clamped in the range (0, 255).
TMOs are mainly composed of two methods:
(1) Global operators. With global operators, the same operator is applied to all pixels of the input image, preserving global contrast. They are non-linear functions based on the luminance and other global variables of the image. Once the optimal function has been estimated according to the particular image, every pixel in the image is mapped in the same way, independent of the value of the surrounding pixels in the image. These techniques are simple and fast, however they can cause a loss of contrast.
(2) Local operator. In this case, the parameters of the non-linear function change in each pixel, according to features extracted from the surrounding parameters. In other words, the effect of the algorithm changes in each pixel according to the local features of the image. These algorithms are more complicated than the global ones, they can show artifacts (e.g., halo effect and ringing), and the output can look unrealistic, however they can (if used correctly) provide the best performance since human vision is mainly sensitive to local contrast.
Among all the TMO operators provided by the HDR Matlab Toolkit, we selected one global TMO method, the ReinhardTMO method [
12], and one local method, the DurandTMO method [
13], for comparison.
Figure 10 shows the ReinhardTMO method result and DurandTMO method result for the datasets that are shown in
Figure 1. Visually, we can see some general improvements compared to the original captured images. However, the improvement may be negligible for some areas in the image. On top of it, we also observe that color distortion exists in the result images, and this becomes more obvious for the DurandTMO method.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}