DGA Domain Name Classification Method Based on Long Short-Term Memory with Attention Mechanism



Abstract
1. Introduction
- We only use the character sequence of the domain name for DGA domain name classification to further prove that the character sequence contains DGA features.
- We combine LSTM with attention mechanisms and apply them to DGA domain name classifications to prove that the weights of characters in DGA domain names are different.
2. Related Work
3. Theoretical Basis
3.1. Recurrent Neural Network (RNN)
3.2. Long Short-Term Memory (LSTM)
3.3. Attention Mechanism
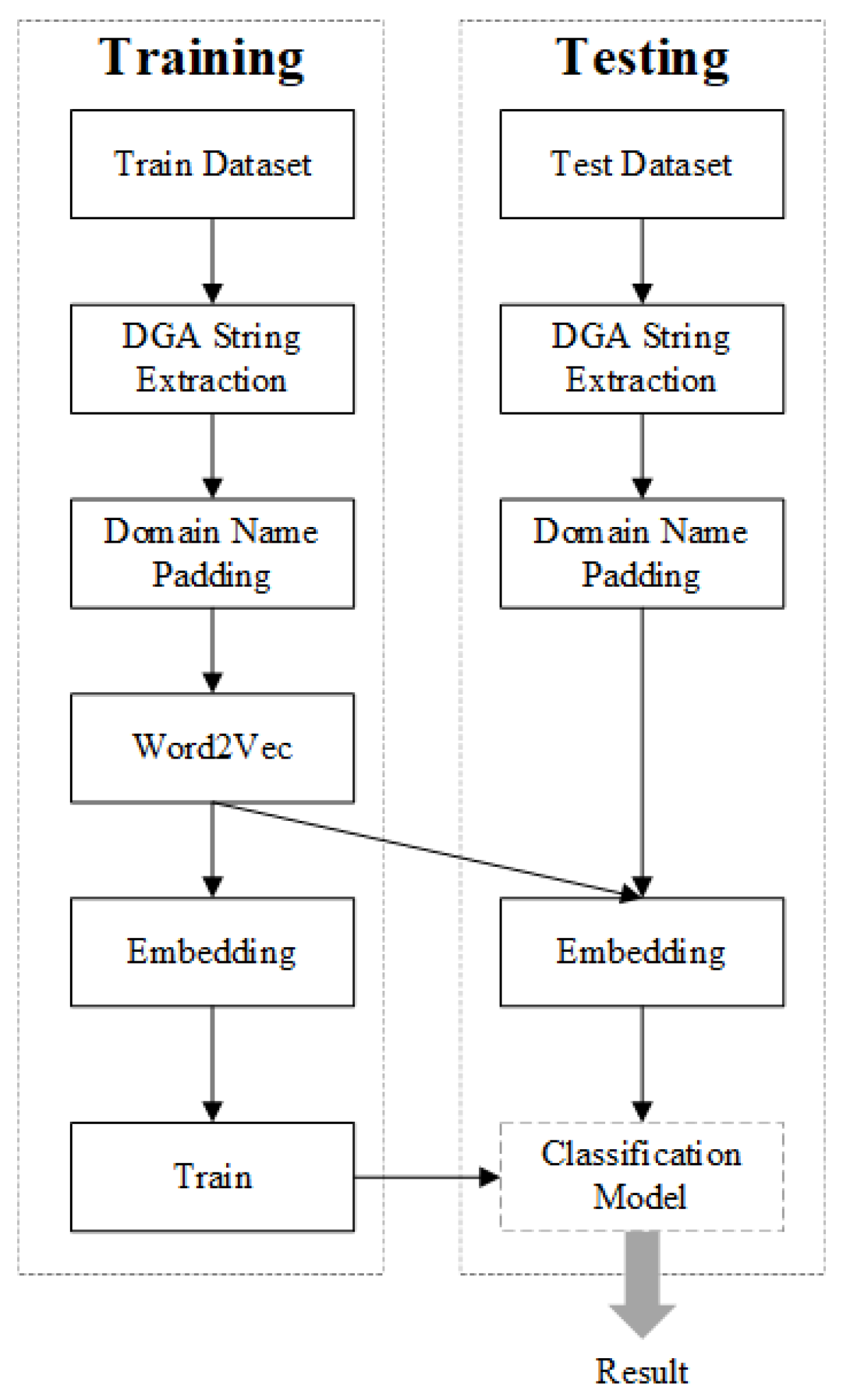
4. Methodology
4.1. Overview
4.2. DGA String Extraction
- If it is a second-level domain name, the second-level domain name part is extracted,
- If it is a third-level domain name, first determine whether the second-level domain name is the domain name of the dynamic domain name service, such as “no-ip.com”, “afraid.org”, “duckdns.com”, “dnsdynamic.org”, “dyndns.net”, “dynu.com”, etc., if so, the third-level domain name part is extracted.
- If the second-level domain name in the third-level domain name is not the domain name of the dynamic domain name service provider, the longest string is extracted.
- Otherwise, extract the longest string.
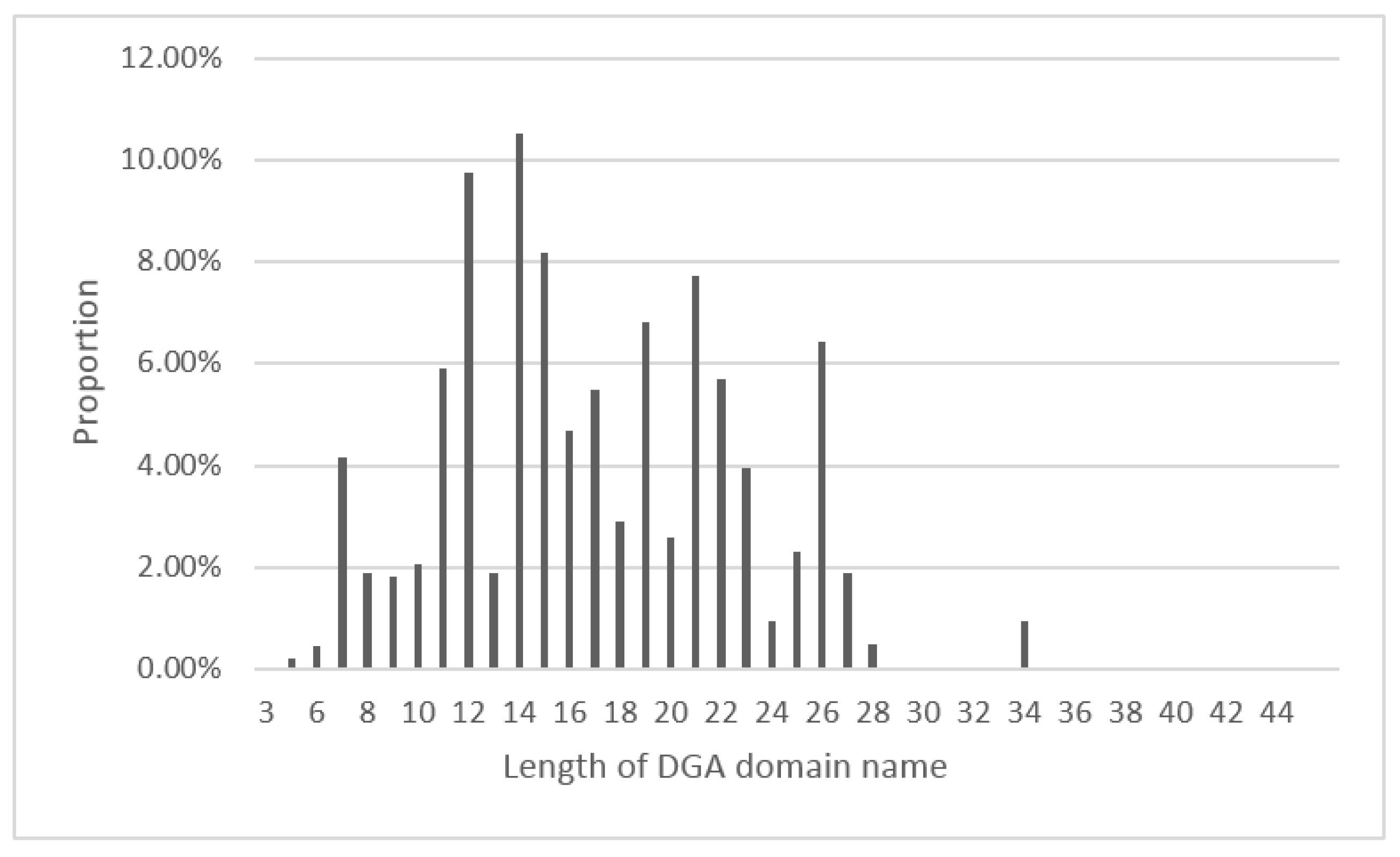
4.3. Domain Name Padding
4.4. Embedding
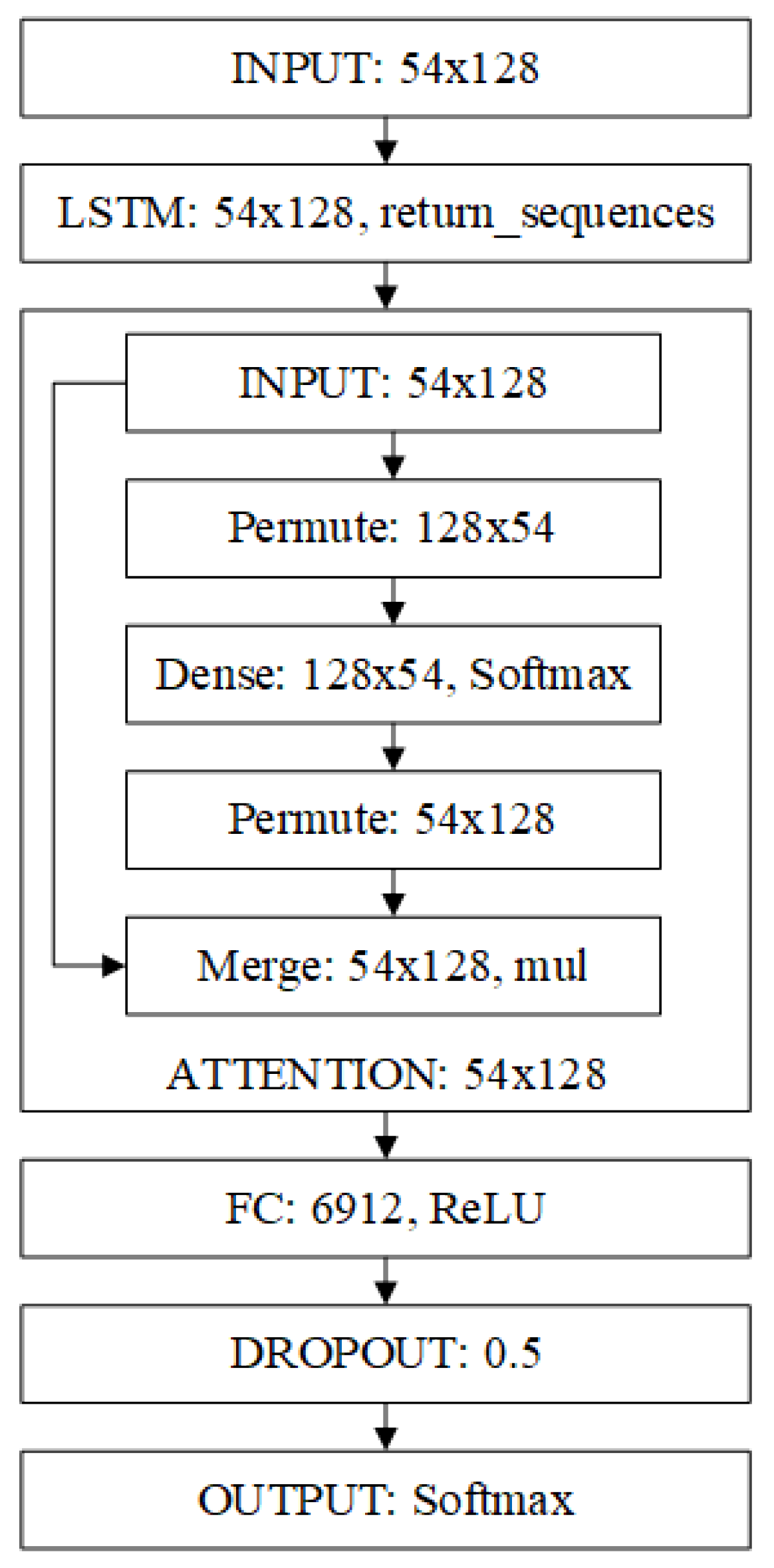
4.5. Deep Learning Network Structure
- INPUT: Input layer, the domain name is converted to a matrix of dimension 54 × 128 after the length is padded and embedding, so the input dimension is 54 × 128.
- LSTM: LSTM layer, sequence output, and output 54 × 128 feature vector.
- ATTENTION: Attention mechanism, according to Section 3.3, and output 54 × 128 feature vector.
- FC: Fully connected layer, which stretches the feature vector output by ATTENTION. Each pixel represents a unit. The output feature is 6912 units using the fully connected layer operation, and the probability of DROPOUT is set to 0.5.
- OUTPUT: Output layer, this layer is fully connected with the FC layer; the output length is the required number of classifications, which represents which classification the extracted features belong to; and the classification function is Softmax.
- Classifier: Based on the characteristics of DGA domains, we use Softmax classifier to judge which type the domain belongs to. The essence of Softmax function is to map a K-dimensional arbitrary real vector to another K-dimensional real vector, where the value of each element in the vector is in the interval, as shown by Formula (11), where is the j element of the vector, and the Softmax value of the element is ,
- Loss function: When the model is trained, the loss is calculated according to the loss function, and then back-propagation (BP) is used to adjust the parameter adjustment. In this paper, the Categorical Cross-Entropy Loss function is used as the loss function of the model.
- Activation function: The formula of the ReLU activation function is as follows. This function can satisfy the sparsity in bionics. It activates the units when the input value is higher than a certain number, and can quickly converge in the stochastic gradient descent algorithm. The gradient of the function is 0 or constant, which can alleviate the problem of gradient disappearance, thereby improving the learning precision and speed of the neural network. Therefore, this paper uses ReLU as the activation function in two convolutional layers and two fully connected layers.
5. Experimental Evaluation
5.1. DGA Data Set
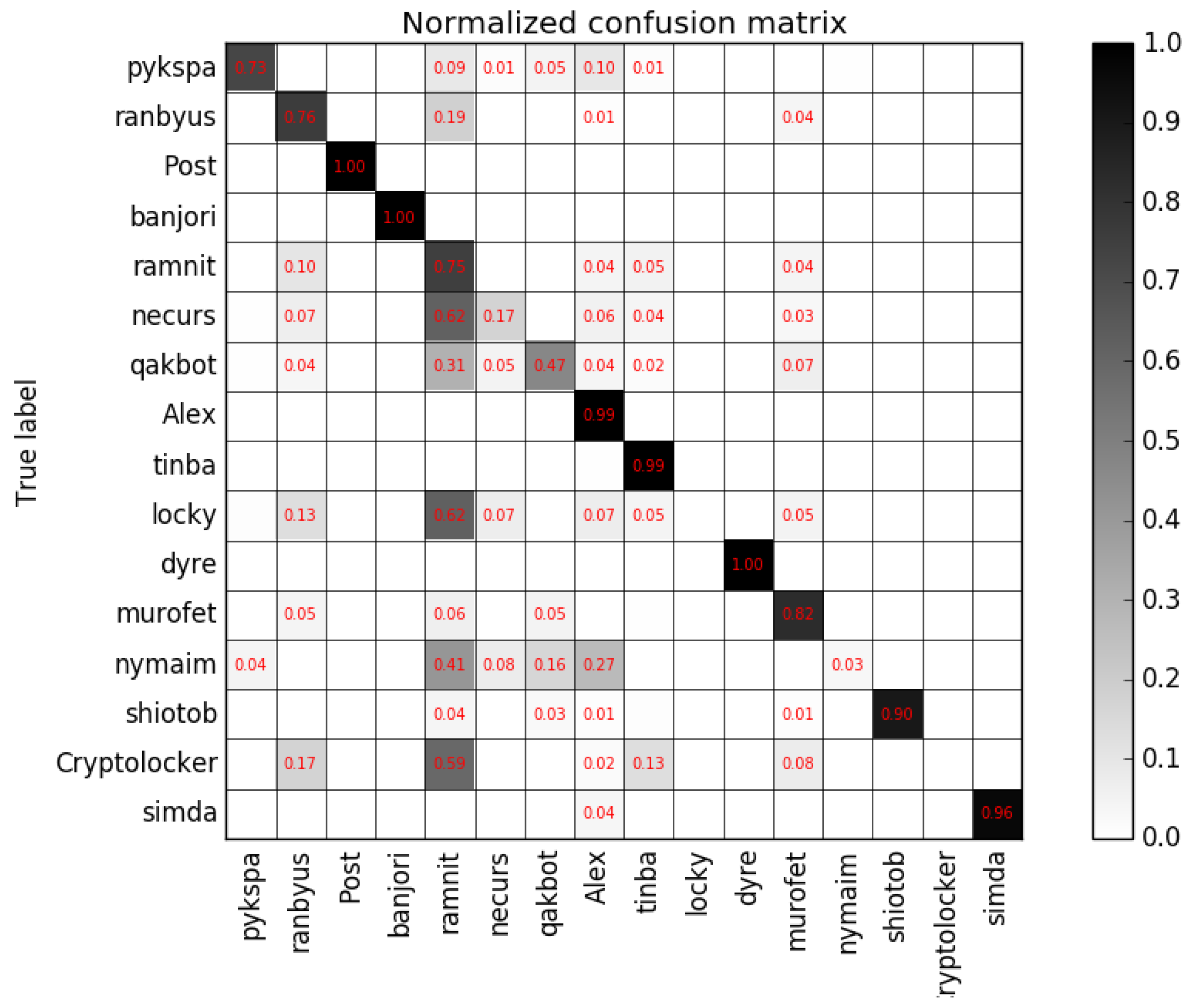
5.2. Experimental Results
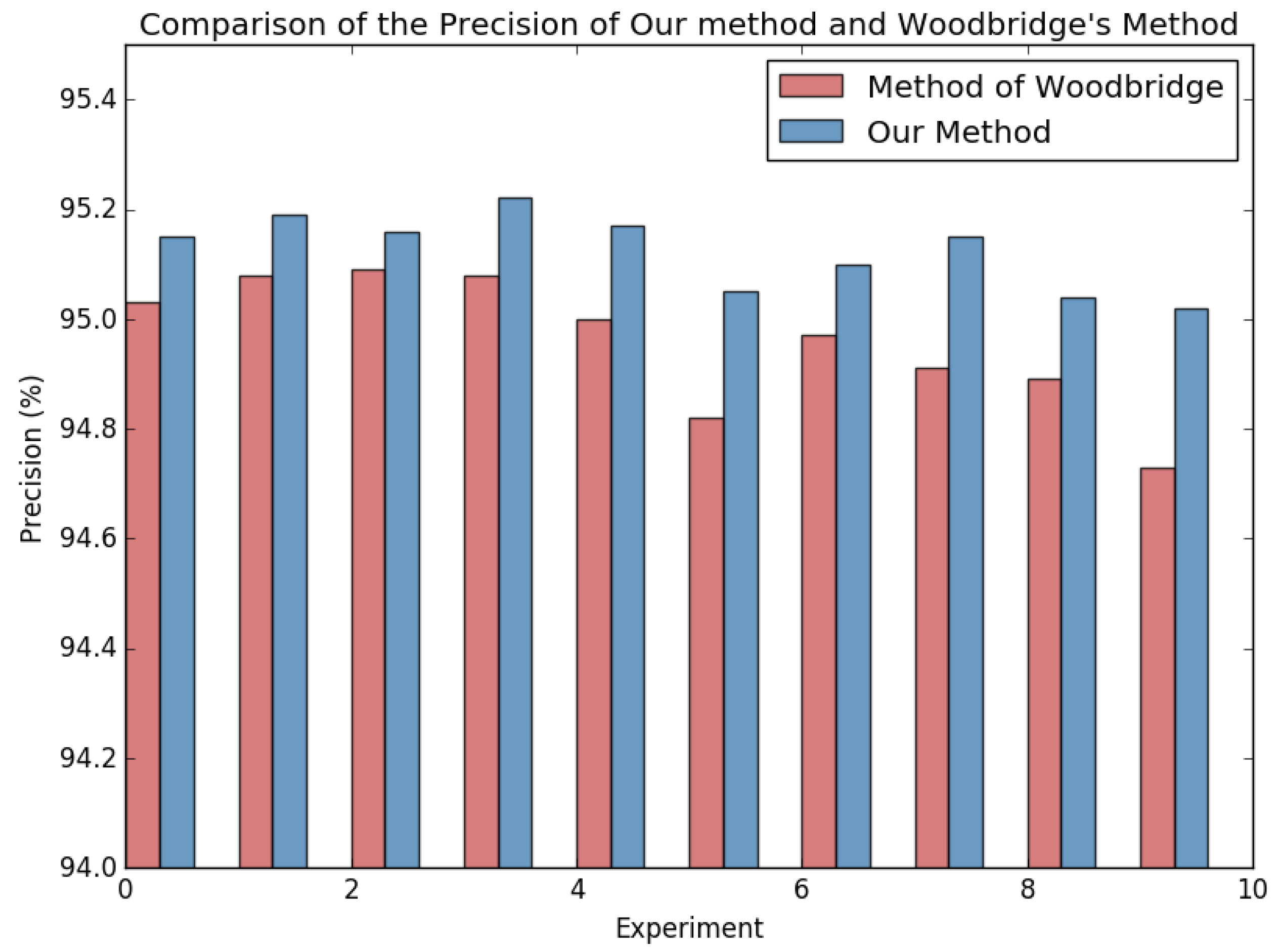
5.3. Work Comparison and Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- McGrath, D.K.; Gupta, M. Behind Phishing: An Examination of Phisher Modi Operandi. In Proceedings of the 1st Usenix Workshop on Large-Scale Exploits and Emergent Threats, San Francisco, CA, USA, 15 April 2008; USENIX Association: Berkeley, CA, USA, 2008; pp. 4:1–4:8. [Google Scholar]
- Ma, J.; Saul, L.K.; Savage, S.; Voelker, G.M. Beyond Blacklists: Learning to Detect Malicious Web Sites from Suspicious URLs. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; ACM: New York, NY, USA, 2009; pp. 1245–1254. [Google Scholar] [CrossRef]
- Felegyhazi, M.; Kreibich, C.; Paxson, V. On the Potential of Proactive Domain Blacklisting. In Proceedings of the 3rd USENIX Conference on Large-scale Exploits and Emergent Threats: Botnets, Spyware, Worms, and More, San Jose, CA, USA, 17 April 2010; USENIX Association: Berkeley, CA, USA, 2010; p. 6. [Google Scholar]
- Bilge, L.; Kirda, E.; Kruegel, C.; Balduzzi, M. EXPOSURE: Finding Malicious Domains Using Passive DNS Analysis. In Proceedings of the 18th Network and Distributed System Security Symposium, San Diego, CA, USA, 6 February 2011; Internet Society: Reston, VA, USA, 2011; pp. 1–17. [Google Scholar]
- Canali, D.; Cova, M.; Vigna, G.; Kruegel, C. Prophiler: A Fast Filter for the Large-scale Detection of Malicious Web Pages. In Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India, 28 March–1 April 2011; ACM: New York, NY, USA, 2011; pp. 197–206. [Google Scholar] [CrossRef]
- Zhang, J.; Saha, S.; Gu, G.; Lee, S.; Mellia, M. Systematic Mining of Associated Server Herds for Malware Campaign Discovery. In Proceedings of the 2015 IEEE 35th International Conference on Distributed Computing Systems, Columbus, OH, USA, 29 June–2 July 2015; pp. 630–641. [Google Scholar] [CrossRef]
- GReAT. Winnti. More than Just a Game. 2013. Available online: https://securelist.com/analysis/internal-threats-reports/37029/winnti-more-than-just-a-game/ (accessed on 27 June 2019).
- Yadav, S.; Reddy, A.K.K.; Reddy, A.L.N.; Ranjan, S. Detecting Algorithmically Generated Domain-Flux Attacks With DNS Traffic Analysis. IEEE/ACM Trans. Netw. 2012, 20, 1663–1677. [Google Scholar] [CrossRef]
- Antonakakis, M.; Perdisci, R.; Nadji, Y.; Vasiloglou, N.; Abu-Nimeh, S.; Lee, W.; Dagon, D. From Throw-away Traffic to Bots: Detecting the Rise of DGA-based Malware. In Proceedings of the 21st USENIX Conference on Security Symposium, Bellevue, WA, USA, 8–10 August 2012; USENIX Association: Berkeley, CA, USA, 2012; p. 24. [Google Scholar]
- Antonakakis, M.; Perdisci, R.; Dagon, D.; Lee, W.; Feamster, N. Building a Dynamic Reputation System for DNS. In Proceedings of the 19th USENIX Conference on Security, Washington, DC, USA, 11–13 August 2010; USENIX Association: Berkeley, CA, USA, 2010; p. 18. [Google Scholar]
- Yadav, S.; Reddy, A.K.K.; Reddy, A.N.; Ranjan, S. Detecting Algorithmically Generated Malicious Domain Names. In Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement, Melbourne, Australia, 1–3 November 2010; ACM: New York, NY, USA, 2010; pp. 48–61. [Google Scholar] [CrossRef]
- Krishnan, S.; Taylor, T.; Monrose, F.; McHugh, J. Crossing the threshold: Detecting network malfeasance via sequential hypothesis testing. In Proceedings of the 2013 43rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Budapest, Hungary, 24–27 June 2013; pp. 1–12. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988. [Google Scholar]
- Bilge, L.; Sen, S.; Balzarotti, D.; Kirda, E.; Kruegel, C. Exposure: A Passive DNS Analysis Service to Detect and Report Malicious Domains. ACM Trans. Inf. Syst. Secur. 2014, 16, 14:1–14:28. [Google Scholar] [CrossRef]
- Schiavoni, S.; Maggi, F.; Cavallaro, L.; Zanero, S. Phoenix: DGA-Based Botnet Tracking and Intelligence. In Detection of Intrusions and Malware, and Vulnerability Assessment; Dietrich, S., Ed.; Springer International Publishing: Cham, Switzerland, 2014; pp. 192–211. [Google Scholar]
- Woodbridge, J.; Anderson, H.S.; Ahuja, A.; Grant, D. Predicting Domain Generation Algorithms with Long Short-Term Memory Networks. arXiv 2016, arXiv:1611.00791. [Google Scholar]
- Yu, B.; Gray, D.L.; Pan, J.; Cock, M.D.; Nascimento, A.C.A. Inline DGA Detection with Deep Networks. In Proceedings of the 2017 IEEE International Conference on Data Mining Workshops (ICDMW), New Orleans, LA, USA, 18–21 November 2017; pp. 683–692. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Graves, A.; Wayne, G.; Danihelka, I. Neural Turing Machines. arXiv 2014, arXiv:1410.5401. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv Preprint 2015, arXiv:1508.04025. [Google Scholar]
- Cheng, J.; Li, D.; Lapata, M. Long Short-Term Memory-Networks for Machine Reading. arXiv 2016, arXiv:1601.06733. [Google Scholar]
- Bambenek, J. OSINT Feeds from Bambenek Consulting. 2019. Available online: http://osint.bambenekconsulting.com/feeds/ (accessed on 10 September 2019).
- Alex. Keyword Research, Competitive Analysis, & Website Ranking | Alexa. 2019. Available online: https://www.alexa.com/ (accessed on 10 September 2019).
- Cohen, R. Banking Trojans: A Reference Guide to the Malware Family Tree. 2019. Available online: https://www.f5.com/labs/articles/education/banking-trojans-a-reference-guide-to-the-malware-family-tree (accessed on 3 September 2019).
- Kessem, L. The Necurs Botnet: A Pandora’s Box of Malicious Spam. 2017. Available online: https://securityintelligence.com/the-necurs-botnet-a-pandoras-box-of-malicious-spam/ (accessed on 3 September 2019).
- Spring, T. Locky Ransomware Roars Back to Life Via Necurs Botnet. 2017. Available online: https://threatpost.com/locky-ransomware-roars-back-to-life-via-necurs-botnet/125156/ (accessed on 3 September 2019).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DGA | Length | Example |
|---|---|---|
| banjori | 10 | pdtmstring |
| corebot | 23 | a0c4e8sr70oluhsf3t1h1va |
| cryptolocker | 8 | rifxkpdx |
| dircrypt | 10 | xzdiobjady |
| kraken | 8 | iuhqhbmq |
| locky | 17 | qqeuxqbetndnsclkm |
| pykspa | 9 | folmecyca |
| qakbot | 20 | gutkdzfamdgsjbhpuoyb |
| ramdo | 8 | kuekesqm |
| ramnit | 9 | byqdmekgd |
| simda | 23 | jewumerydatyvyjolyvofoh |
| DGA | Amount |
|---|---|
| banjori | 439,223 |
| Post | 66,000 |
| tinba | 65,603 |
| ramnit | 47,510 |
| necurs | 32,768 |
| qakbot | 20,000 |
| murofet | 14,260 |
| pykspa | 14,215 |
| ranbyus | 13,960 |
| simda | 13,681 |
| shiotob/urlzone/bebloh | 12,521 |
| dyre | 7998 |
| Cryptolocker | 6000 |
| nymaim | 6000 |
| locky | 5352 |
| Alex | 910,313 |
| Domain Type | Precision | Recall | Score | Support |
|---|---|---|---|---|
| nymaim | 0.3988 | 0.1115 | 0.1743 | 601 |
| ranbyus | 0.4672 | 0.8455 | 0.6018 | 1346 |
| murofet | 0.7641 | 0.7207 | 0.7418 | 1443 |
| pykspa | 0.8972 | 0.7207 | 0.7994 | 1393 |
| locky | 0.0000 | 0.0000 | 0.0000 | 574 |
| shiotob | 0.9751 | 0.9251 | 0.9494 | 1268 |
| banjori | 0.9998 | 1.0000 | 0.9999 | 43,808 |
| necurs | 0.6651 | 0.1722 | 0.2735 | 3241 |
| Cryptolocker | 0.1000 | 0.0018 | 0.0035 | 562 |
| simda | 0.9264 | 0.9669 | 0.9462 | 1418 |
| dyre | 1.0000 | 1.0000 | 1.0000 | 797 |
| Post | 0.9994 | 0.9998 | 0.9996 | 6644 |
| tinba | 0.9259 | 0.9920 | 0.9578 | 6498 |
| qakbot | 0.7862 | 0.5013 | 0.6122 | 1973 |
| ramnit | 0.4688 | 0.7525 | 0.5777 | 4856 |
| Alex | 0.9898 | 0.9956 | 0.9927 | 91,119 |
| avg/total | 0.9505 | 0.9514 | 0.9458 | 167,541 |
| Yadav et al. [8] | Woodbridge et al. [16] | Our Method | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Domain Type | Precision | Recall | Score | Precision | Recall | Score | Precision | Recall | Score | Support |
| Alex | 0.9612 | 0.9863 | 0.9736 | 0.9865 | 0.9970 | 0.9917 | 0.9956 | 0.9956 | 0.9927 | 91,119 |
| banjori | 0.9741 | 0.9889 | 0.9814 | 0.9998 | 1.0000 | 0.9999 | 1.0000 | 1.0000 | 0.9999 | 43,808 |
| Cryptolocker | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0018 | 0.0018 | 0.0035 | 562 |
| dyre | 0.9820 | 1.0000 | 0.9909 | 0.9975 | 1.0000 | 0.9987 | 1.0000 | 1.0000 | 1.0000 | 797 |
| locky | 0.0294 | 0.0038 | 0.0067 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 0.0000 | 574 |
| murofet | 0.5139 | 0.4861 | 0.4996 | 0.7441 | 0.7477 | 0.7459 | 0.7207 | 0.7207 | 0.7418 | 1443 |
| necurs | 0.2609 | 0.0253 | 0.0461 | 0.6225 | 0.1725 | 0.2701 | 0.1722 | 0.1722 | 0.2735 | 3241 |
| nymaim | 0.1080 | 0.0409 | 0.0593 | 0.3621 | 0.1048 | 0.1626 | 0.1115 | 0.1115 | 0.1743 | 601 |
| Post | 0.9897 | 0.9913 | 0.9905 | 0.9995 | 1.0000 | 0.9998 | 0.9998 | 0.9998 | 0.9996 | 6644 |
| pykspa | 0.7253 | 0.5690 | 0.6377 | 0.9407 | 0.6827 | 0.7912 | 0.7207 | 0.7207 | 0.7994 | 1393 |
| qakbot | 0.7160 | 0.3483 | 0.4686 | 0.7970 | 0.4774 | 0.5971 | 0.5013 | 0.5013 | 0.6122 | 1973 |
| ramnit | 0.3541 | 0.5580 | 0.4333 | 0.4711 | 0.7360 | 0.5745 | 0.7525 | 0.7525 | 0.5777 | 4856 |
| ranbyus | 0.0000 | 0.0000 | 0.0000 | 0.4599 | 0.8522 | 0.5974 | 0.8455 | 0.8455 | 0.6018 | 1346 |
| shiotob | 0.9349 | 0.6584 | 0.7727 | 0.9873 | 0.9211 | 0.9531 | 0.9251 | 0.9251 | 0.9494 | 1268 |
| simda | 0.8203 | 0.6839 | 0.7459 | 0.9688 | 0.8533 | 0.9074 | 0.9669 | 0.9669 | 0.9462 | 1418 |
| tinba | 0.6709 | 0.8588 | 0.7533 | 0.9264 | 0.9912 | 0.9577 | 0.9920 | 0.9920 | 0.9578 | 6498 |
| avg/total | 0.8960 | 0.9127 | 0.9001 | 0.9482 | 0.9504 | 0.9445 | 0.9505 | 0.9514 | 0.9458 | 167,541 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, Y.; Zhang, B.; Zhang, W.; Sangaiah, A.K.; Wu, H. DGA Domain Name Classification Method Based on Long Short-Term Memory with Attention Mechanism. Appl. Sci. 2019, 9, 4205. https://doi.org/10.3390/app9204205
Qiao Y, Zhang B, Zhang W, Sangaiah AK, Wu H. DGA Domain Name Classification Method Based on Long Short-Term Memory with Attention Mechanism. Applied Sciences. 2019; 9(20):4205. https://doi.org/10.3390/app9204205
Chicago/Turabian StyleQiao, Yanchen, Bin Zhang, Weizhe Zhang, Arun Kumar Sangaiah, and Hualong Wu. 2019. "DGA Domain Name Classification Method Based on Long Short-Term Memory with Attention Mechanism" Applied Sciences 9, no. 20: 4205. https://doi.org/10.3390/app9204205
APA StyleQiao, Y., Zhang, B., Zhang, W., Sangaiah, A. K., & Wu, H. (2019). DGA Domain Name Classification Method Based on Long Short-Term Memory with Attention Mechanism. Applied Sciences, 9(20), 4205. https://doi.org/10.3390/app9204205