Air Quality Index and Air Pollutant Concentration Prediction Based on Machine Learning Algorithms



Abstract
1. Introduction
2. Materials and Methods
2.1. Area of Investigation and Datasets
2.2. Pattern Recognition Methods
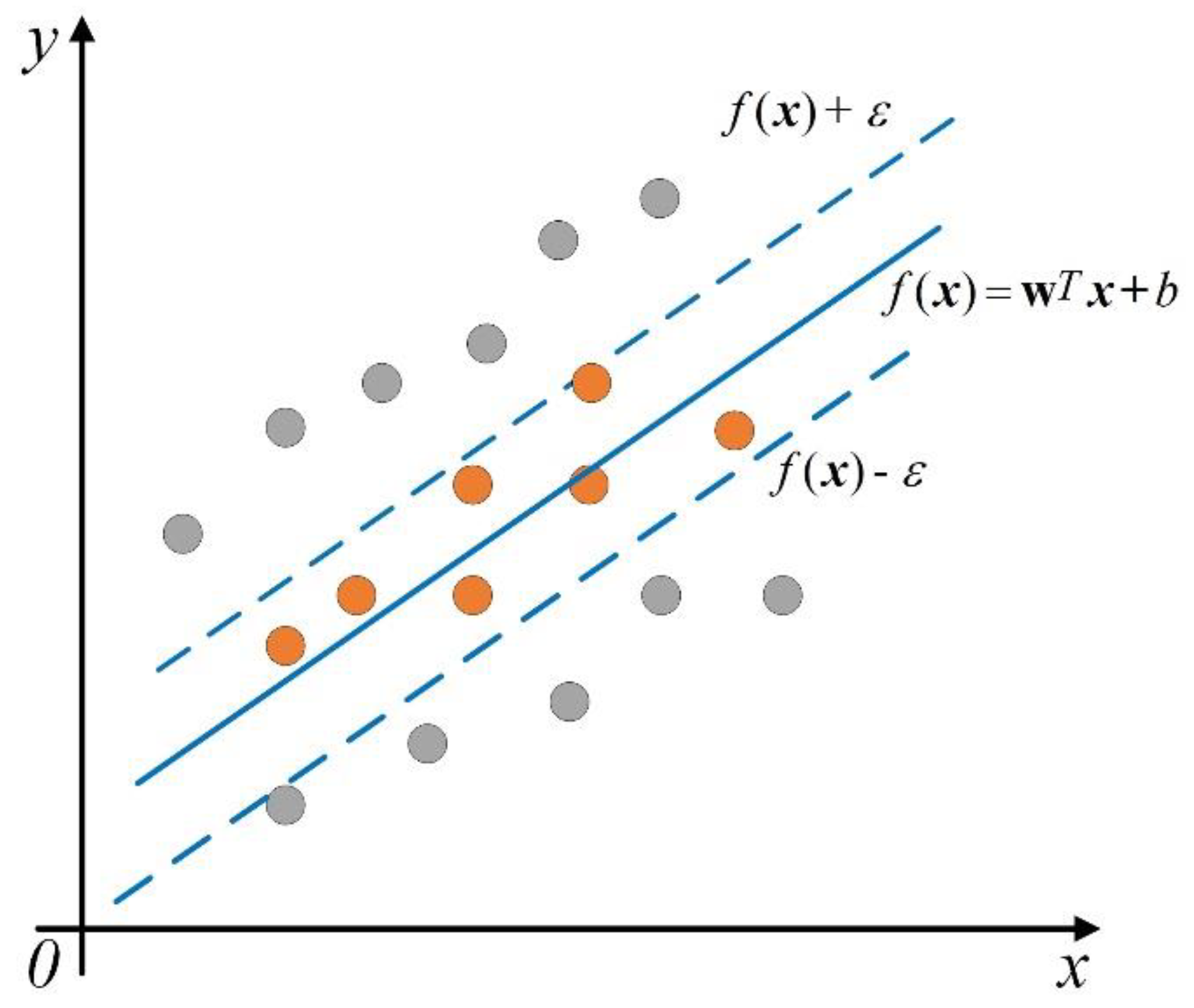
2.2.1. Support Vector Machines (SVMs)
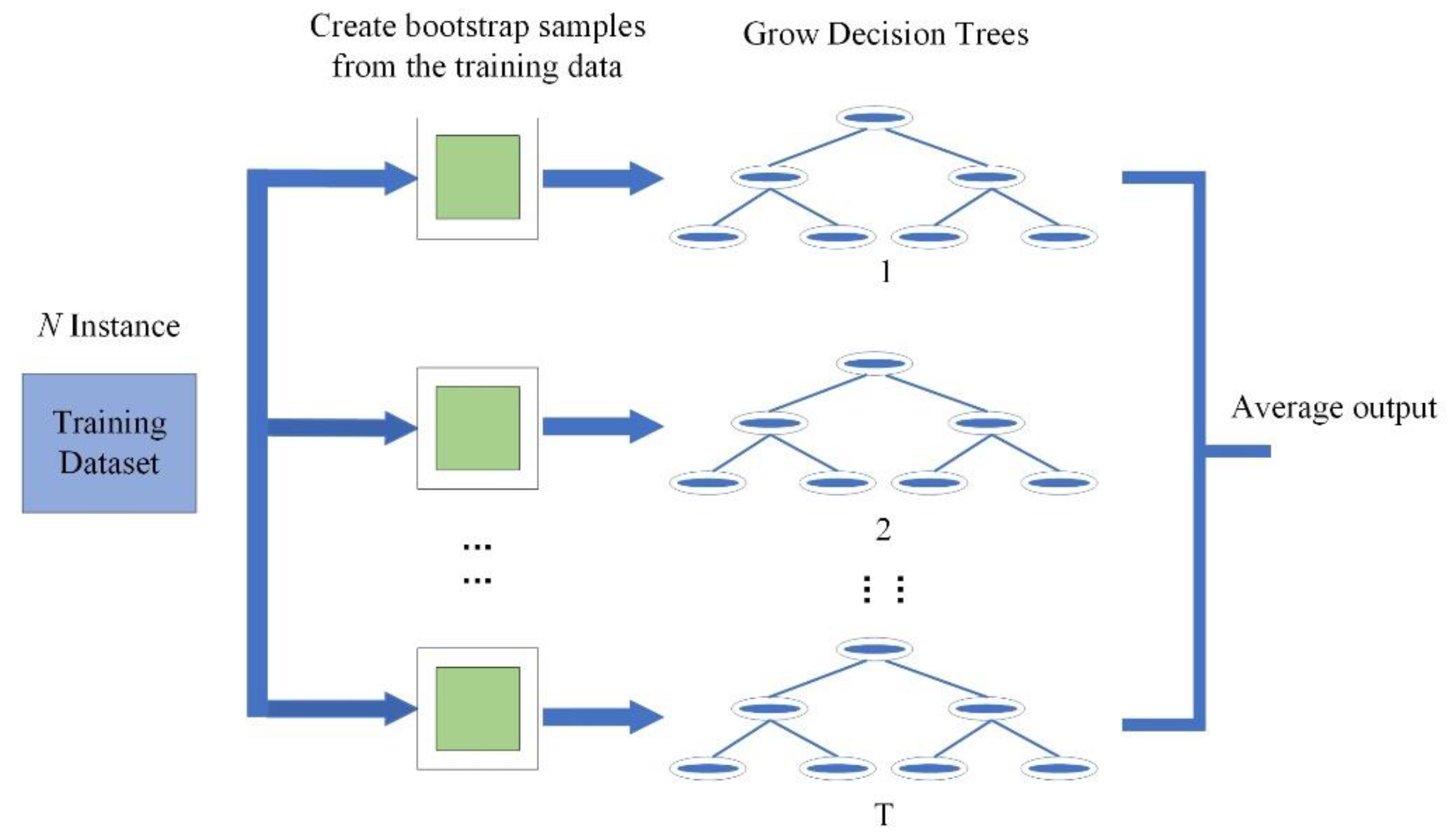
2.2.2. Random Forest (RF)
3. Results and Discussion
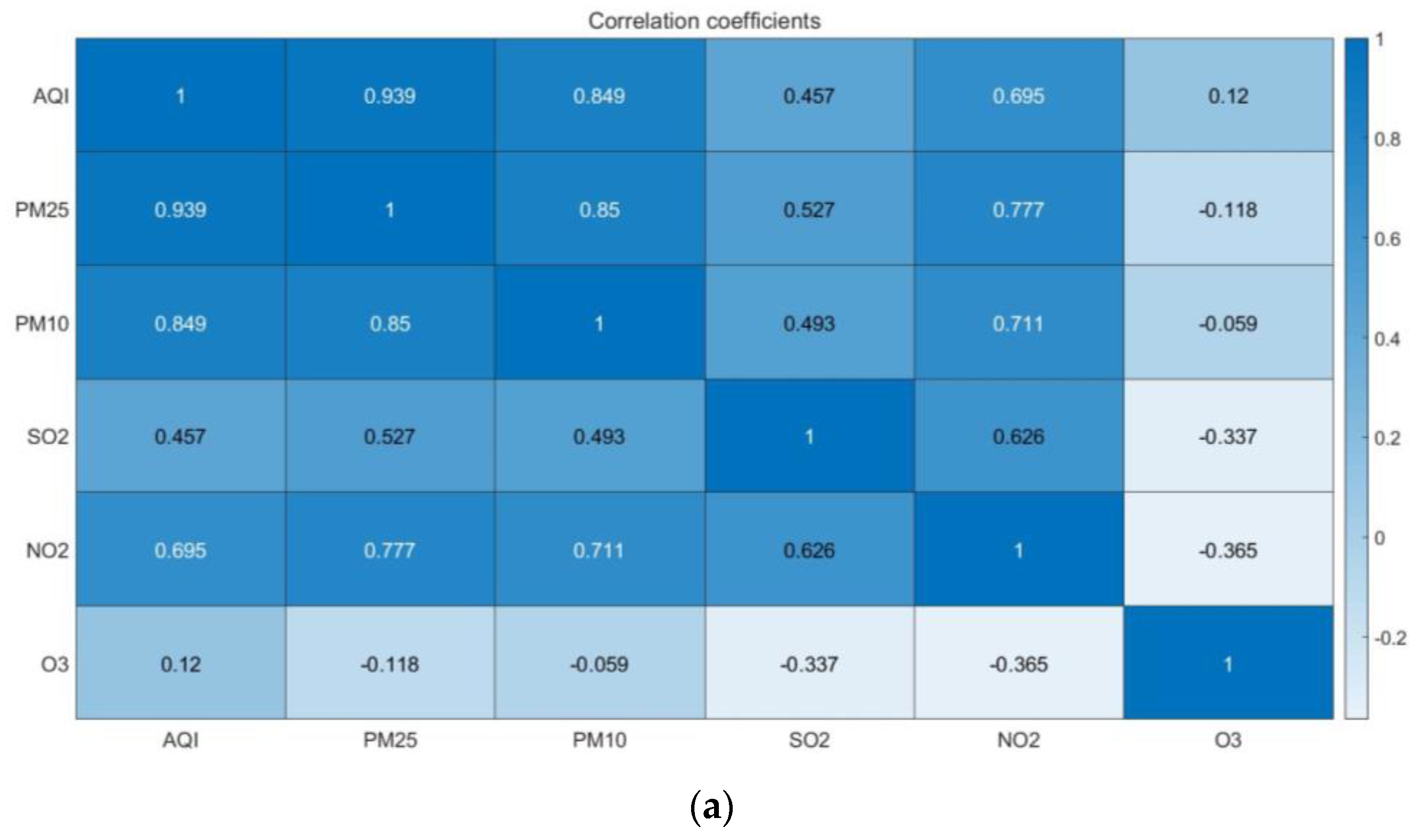
3.1. Air Quality Index Prediction of Beijing
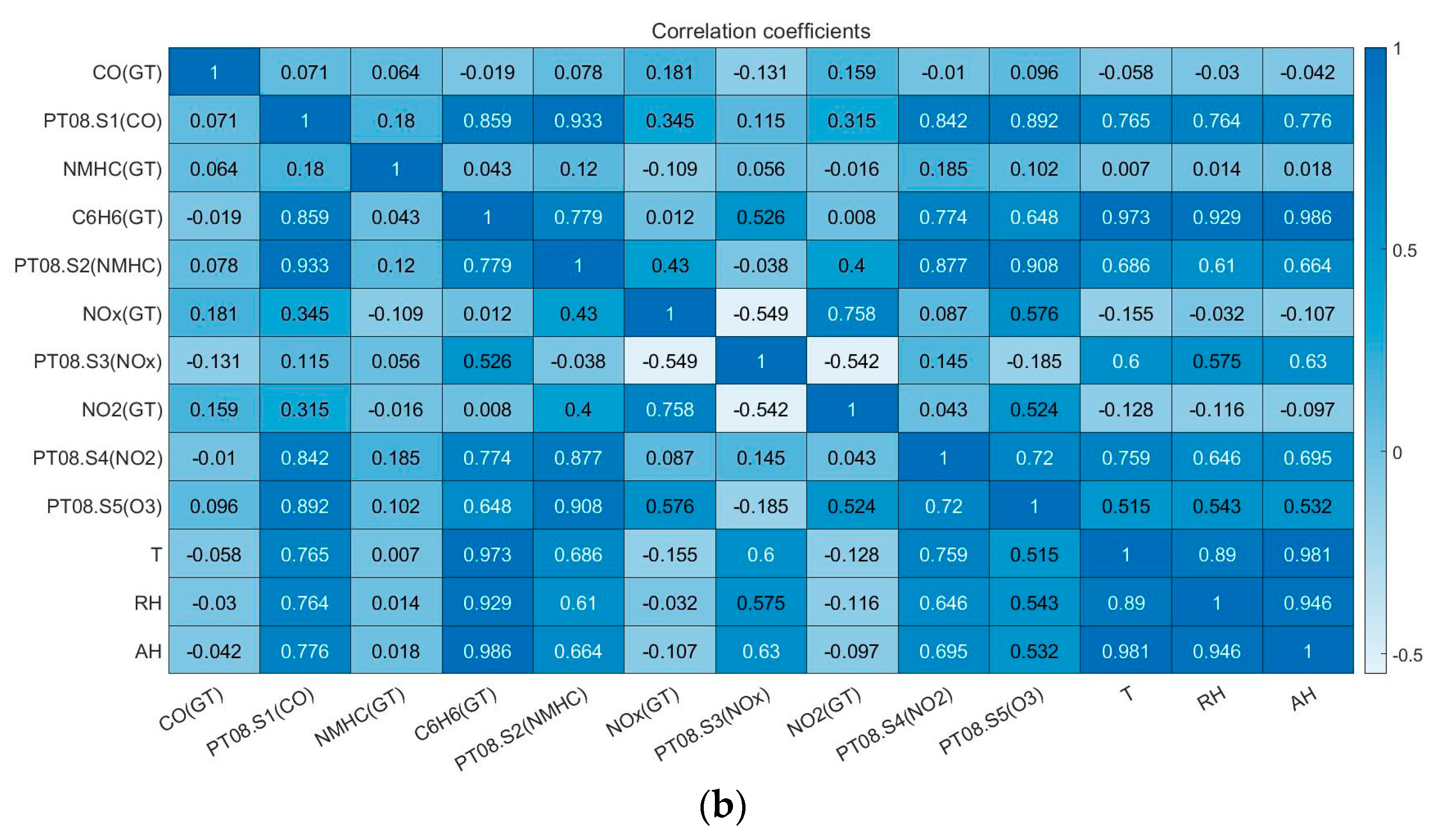
3.2. NOX Prediction in an Italian City
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Vitousek, P.M. Beyond global warming: Ecology and global change. Ecology 1994, 75, 1861–1876. [Google Scholar] [CrossRef]
- Yilmaz, O.; Kara, B.Y.; Yetis, U. Hazardous waste management system design under population and environmental impact considerations. J. Environ. Manag. 2017, 203, 720–731. [Google Scholar] [CrossRef] [PubMed]
- De Vito, S.; Piga, M.; Martinotto, L.; Di Francia, G. CO, NO2 and NOX urban pollution monitoring with on-field calibrated electronic nose by automatic bayesian regularization. Sens. Actuators B 2009, 143, 182–191. [Google Scholar] [CrossRef]
- Northey, S.A.; Mudd, G.M.; Werner, T.T. Unresolved complexity in assessments of mineral resource depletion and availability. Nat. Resour. Res. 2018, 27, 241–255. [Google Scholar] [CrossRef]
- Zhang, Q.; Jiang, X.; Tong, D.; Davis, S.J.; Zhao, H.; Geng, G.; Feng, T.; Zhang, B.; Lu, Z.; Streets, D.G.; et al. Transboundary health impacts of transported global air pollution and international trade. Nature 2017, 543, 705. [Google Scholar] [CrossRef] [PubMed]
- Du, X.A.; Kong, Q.A.; Ge, W.H.; Zhang, S.J.; Fu, L.X. Characterization of personal exposure concentration of fine particles for adults and children exposed to high ambient concentrations in Beijing, China. J. Environ. Sci. China 2010, 22, 1757–1764. [Google Scholar] [CrossRef]
- Annual Average Concentration of Air Pollutants of Beijing, China in 2018 (in Micrograms per Cubic Meter). Available online: https://www.statista.com/statistics/1042215/china-average-concentration-of-air-pollutants-in-beijing/ (accessed on 24 September 2019).
- Kyrkilis, G.; Chaloulakou, A.; Kassomenos, P.A. Development of an aggregate Air Quality Index for an urban Mediterranean agglomeration: Relation to potential health effects. Environ. Int. 2007, 33, 670–676. [Google Scholar] [CrossRef]
- China Ministry of Environmental Protection. Ambient Air Quality Standards. GB 3095-2012; China Environmental Science Press: Beijing, China, 2012. [Google Scholar]
- Sheng, N.; Tang, U.W. The first official city ranking by air quality in China—A review and analysis. Cities 2016, 51, 139–149. [Google Scholar] [CrossRef]
- Zhu, S.; Lian, X.; Liu, H.; Hu, J.; Wang, Y.; Che, J. Daily air quality index forecasting with hybrid models: A case in China. Environ. Pollut. 2017, 231, 1232–1244. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, S.; Hao, J.; Wang, X.; Wang, S.; Chai, F.; Li, M. Air pollution and control action in Beijing. J. Clean. Prod. 2016, 112, 1519–1527. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Machine Learning Algorithms. Available online: https://www.packtpub.com/big-data-and-business-intelligence/machine-learning-algorithms-second-edition (accessed on 9 September 2019).
- Chen, M.; Mao, S.; Liu, Y. Big data: A survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Cabaneros, S.M.S.; Calautit, J.K.S.; Hughes, B.R. A review of artificial neural network models for ambient air pollution prediction. Environ. Model. Softw. 2019, 119, 285–304. [Google Scholar] [CrossRef]
- Cabaneros, S.M.S.; Calautit, J.K.S.; Hughes, B.R. Hybrid artificial neural network models for effective prediction and mitigation of urban roadside NO2 pollution. Energy Procedia 2017, 142, 3524–3530. [Google Scholar] [CrossRef]
- Lightstone, S.; Moshary, F.; Gross, B. Comparing CMAQ Forecasts with a Neural Network Forecast Model for PM2.5 in New York. Atmosphere 2017, 8, 161. [Google Scholar] [CrossRef]
- Ibarra-Berastegi, G.; Elias, A.; Barona, A.; Saenz, J.; Ezcurra, A.; de Argandoña, J.D. From diagnosis to prognosis for forecasting air pollution using neural networks: Air pollution monitoring in Bilbao. Environ. Model. Softw. 2008, 23, 622–637. [Google Scholar] [CrossRef]
- Pérez, P.; Trier, A.; Reyes, J. Prediction of PM2.5 concentrations several hours in advance using neural networks in Santiago, Chile. Atmos. Environ. 2000, 34, 1189–1196. [Google Scholar] [CrossRef]
- Corani, G. Air quality prediction in Milan: Feed-forward neural networks, pruned neural networks and lazy learning. Ecol. Model. 2005, 185, 513–529. [Google Scholar] [CrossRef]
- Biancofiore, F.; Busilacchio, M.; Verdecchia, M.; Tomassetti, B.; Aruffo, E.; Bianco, S.; Di Tommaso, S.; Colangeli, C.; Rosatelli, G.; Di Carlo, P. Recursive neural network model for analysis and forecast of PM10 and PM2.5. Atmos. Pollut. Res. 2017, 8, 652–659. [Google Scholar] [CrossRef]
- Fuller, G.W.; Carslaw, D.C.; Lodge, H.W. An empirical approach for the prediction of daily mean PM10 concentrations. Atmos. Environ. 2002, 36, 1431–1441. [Google Scholar] [CrossRef]
- Beijing Municipal Environmental Monitoring Center. Available online: www.bjmemc.com.cn (accessed on 9 September 2019).
- De Vito, S.; Massera, E.; Piga, M.; Martinotto, L.; Di Francia, G. On field calibration of an electronic nose for benzene estimation in an urban pollution monitoring scenario. Sens. Actuators B 2008, 129, 750–757. [Google Scholar] [CrossRef]
- De Vito, S.; Fattoruso, G.; Pardo, M.; Tortorella, F.; Di Francia, G. Semi-supervised learning techniques in artificial olfaction: A novel approach to classification problems and drift counteraction. IEEE Sens. J. 2012, 12, 3215–3224. [Google Scholar] [CrossRef]
- Man, C.K.; Gibbins, J.R.; Witkamp, J.G.; Zhang, J. Coal characterisation for NOX prediction in air-staged combustion of pulverised coals. Fuel 2005, 84, 2190–2195. [Google Scholar] [CrossRef]
- Boningari, T.; Smirniotis, P.G. Impact of nitrogen oxides on the environment and human health: Mn-based materials for the NOx abatement. Curr. Opin. Chem. Eng. 2016, 13, 133–141. [Google Scholar] [CrossRef]
- Vapnik, V.; Cortes, C. Support Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support vector regression machines. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997; pp. 155–161. [Google Scholar]
- Leo, B. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Liu, H.; Li, Q.; Yan, B.; Zhang, L.; Gu, Y. Bionic Electronic Nose Based on MOS Sensors Array and Machine Learning Algorithms Used for Wine Properties Detection. Sensors 2019, 19, 45. [Google Scholar] [CrossRef] [PubMed]
- Coefficient of Determination. Available online: https://en.wikipedia.org/wiki/Coefficient_of_determination (accessed on 9 September 2019).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Result of AQI Prediction | Result of NOX Prediction | ||||
|---|---|---|---|---|---|---|
| r | R2 | RMSE | r | R2 | RMSE | |
| SVR | 0.9887 | 0.9766 | 7.666 | 0.8923 | 0.7960 | 94.4918 |
| RFR | 0.9823 | 0.9633 | 9.602 | 0.9180 | 0.8401 | 83.6716 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, H.; Li, Q.; Yu, D.; Gu, Y. Air Quality Index and Air Pollutant Concentration Prediction Based on Machine Learning Algorithms. Appl. Sci. 2019, 9, 4069. https://doi.org/10.3390/app9194069
Liu H, Li Q, Yu D, Gu Y. Air Quality Index and Air Pollutant Concentration Prediction Based on Machine Learning Algorithms. Applied Sciences. 2019; 9(19):4069. https://doi.org/10.3390/app9194069
Chicago/Turabian StyleLiu, Huixiang, Qing Li, Dongbing Yu, and Yu Gu. 2019. "Air Quality Index and Air Pollutant Concentration Prediction Based on Machine Learning Algorithms" Applied Sciences 9, no. 19: 4069. https://doi.org/10.3390/app9194069
APA StyleLiu, H., Li, Q., Yu, D., & Gu, Y. (2019). Air Quality Index and Air Pollutant Concentration Prediction Based on Machine Learning Algorithms. Applied Sciences, 9(19), 4069. https://doi.org/10.3390/app9194069