Abstractive Sentence Compression with Event Attention


Abstract
1. Introduction
2. Related Work
3. Sentence Compression by a Sequence-to-Sequence Model
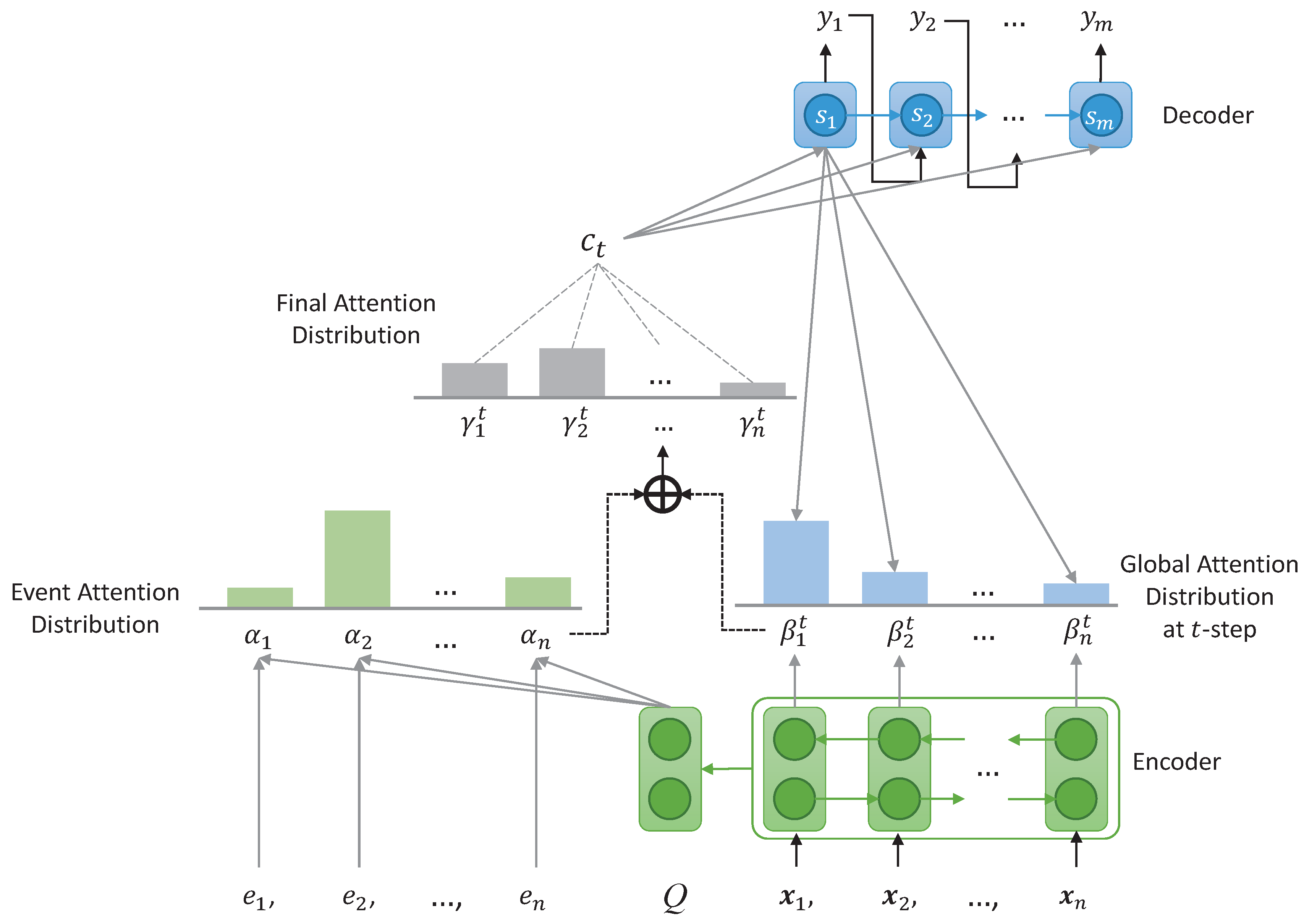
4. Abstractive Sentence Compression with Event Attention
5. Experiments
5.1. Experimental Setting
5.2. Experimental Results
6. Conclusions
Supplementary Materials
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Clarke, C.; Agichtein, E.; Dumais, S.; White, R. The Influence of Caption Features on Clickthrough Patterns in Web Search. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 135–142. [Google Scholar]
- Kanungo, T.; Orr, D. Predicting the Readability of Short Web Summaries. In Proceedings of the 2th ACM International Conference on Web Search and Data Mining, Barcelona, Spain, 9–12 February 2009; pp. 202–211. [Google Scholar]
- Knight, K.; Marcu, D. Summarization beyond sentence extraction: A probabilistic approach to sentence compression. Artif. Intell. 2002, 139, 91–107. [Google Scholar] [CrossRef]
- McDonald, R. Discriminative Sentence Compression with Soft Syntactic Evidence. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 3–7 April 2006; pp. 297–304. [Google Scholar]
- Filippova, K. Multi-Sentence Compression: Finding Shortest Paths in Word Graphs. In Proceedings of the 23th International Conference on Computational Linugustics, Beijing, China, 23–27 August 2010; pp. 322–330. [Google Scholar]
- Filippova, K.; Altun, Y. Overcoming the Lack of Parallel Data in Sentence Compression. In Proceedings of the 2013 Conference on Empirical Method in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1481–1491. [Google Scholar]
- Wang, L.; Jiang, J.; Chieu, H.; Ong, C.; Song, D.; Liao, L. Can Syntax Help? Improving an LSTM-based Sentence Compression Model for New Domains. In Proceedings of the 55th Annual Meetings of the Association for Computational Linguistics, Vancouver, BC, Canada, 30–4 July 2017; pp. 1385–1393. [Google Scholar]
- Kamigaito, H.; Hayashi, K.; Hirao, T.; Nagata, M. Higher-order Syntactic Attention Network for Long Sentence Compression. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 1716–1726. [Google Scholar]
- Filippova, K.; Alfonseca, E.; Colmenares, C.; Kaiser, L.; Vinyals, O. Sentence Compression by Deletion with LSTMs. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 360–368. [Google Scholar]
- Galanis, D.; Androutsopoulos, I. A New Sentence Compression Dataset and Its Use in an Abstractive Generate-and-Rand Sentence Compressor. In Proceedings of the UCNLG+Eval: Language Generation and Evaluation Workshop, Edinburgh, UK, 31 July 2011; pp. 1–11. [Google Scholar]
- Rush, A.; Chopra, S.; Weston, J. A Neural Attention Model for Sentence Summarization. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 379–389. [Google Scholar]
- Shafieibavani, E.; Ebrahimi, M.; Wong, R.; Chen, F. An Efficient Approach for Multi-Sentence Compression. In Proceedings of the 8th Asian Conference on Machine Learning, Hamilton, New Zealand, 16–18 November 2016; pp. 414–429. [Google Scholar]
- Zhang, X.; Lapata, M. Sentence Simplication with Deep Reinforcement Learning. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Procedding, Copenhagen, Denmark, 7–11 September 2017; pp. 584–594. [Google Scholar]
- Mallinson, J.; Sennrich, R.; Lapata, M. Sentence Compression for Arbitrary Language via Multilingual Pivoting. In Proceedings of the 2018 Conference on Empirical Methods in Natural Lanague Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2453–2464. [Google Scholar]
- Yu, N.; Zhang, J.; Huang, M.; Zhu, Z. An Operation Network for Abstractive Sentence Compression. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1065–1076. [Google Scholar]
- Cho, K.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Method in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Pouget-Abadie, J.; Bahdanau, D.; van Merriënboer, B.; Bengio, Y. Overcoming the Curse of Sentence Length for Neural Machine Translation using Automatic Segmentation. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; pp. 78–85. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, G. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Advances in Neural Information Processing Systems 27. pp. 3104–3112. [Google Scholar]
- See, A.; Liu, P.; Manning, C. Get To The Point: Summarization with Pointer-Generator Networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1073–1083. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Tranlation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representations, Shanghai, China, 23–26 June 2015. [Google Scholar]
- Toutanova, K.; Brockett, C.; Tran, K.; Amershi, S. A Dataset and Evaluation metrics for Abstractive Compression of Sentences and Short Paragraphs. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 340–350. [Google Scholar]
- Lin, C. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of Text Summarization Branches Out; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 74–81. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Napoles, C.; Durme, B.; Callison-Burch, C. Evaluating sentence compression: Pitfalls and suggested remedies. In Proceedings of the Workshop on Monolingual Text-To-Text, Portland, OR, USA, 24 June 2011; pp. 91–97. [Google Scholar]
- Jing, H. Sentence Reduction for Automatic Text Summarization. In Proceedings of the 6th Conference on Applied Natural Language Processing, Seattle, WA, USA, 29 April–4 May 2000; pp. 310–315. [Google Scholar]
- Clarke, J.; Lapata, M. Global Inference for Sentence Compression: An Integer Linear Programming Approach. J. Artif. Intell. Res. 2008, 31, 399–429. [Google Scholar] [CrossRef]
- Fevry, T.; Phang, J. Unsupervised Sentence Compression using Denoising Auto-Encoders. In Proceedings of the 22th Conference on Computational Natural Language Learning, Hong Kong, China, 3–4 November 2018; pp. 413–422. [Google Scholar]
- Filippova, K.; Strube, M. Dependency Tree Based Sentence Compression. In Proceedings of the 5th International Natural Language Generation Conference, Tilburg, The Netherlands, 5–8 November 2008; pp. 25–32. [Google Scholar]
- Hasegawa, S.; Kikuchi, Y.; Takamura, H.; Okumura, M. Japanese Sentence Compression with a Large Training Dataset. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30–4 July 2017; pp. 281–286. [Google Scholar]
- Vu, T.; Hu, B.; Munkhdalai, T.; Yu, H. Sentence Simplification with Memory-Augmented Neural Networks. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; pp. 79–85. [Google Scholar]
- Chopra, S.; Auli, M.; Rush, A. Abstractive Sentence Summarization with Attentive Recurrent Neural Networks. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 93–98. [Google Scholar]
- Schuster, M.; Paliwal, K. Bidirectional Recurrent Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Pustejovsky, J.; Castano, J.; Ingria, R.; Sauri, R.; Gaizauskas, R.; Setzer, A.; Katz, G.; Radev, D. TimeML: Robust Specification of Event and Temporal Expression in Text. In Proceedings of the 5th International Workshop on Computational Semantics, Tilburg, The Netherlands, 15–17 January 2003; pp. 28–34. [Google Scholar]
- Chambers, N.; Cassidy, T.; McDowell, B.; Bethard, S. Dense Event Ordering with a Multi-Pass Architecture. Trans. Assoc. Comput. Linguistics 2014, 2, 273–284. [Google Scholar] [CrossRef]
- Chaudhari, S.; Polatkan, G.; Ramanath, R.; Mithal, V. An Attentive Survey of Attention Models. arXiv 2019, arXiv:1904.02874. [Google Scholar]
- Goldberg, Y. Neural Network Methods in Natural Language Processing; Synthesis Lectures on Human Language Technologies; Morgan & Claypool Publishers: San Rafael, CA, USA, 2017; Volume 10, pp. 1–309. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Source sentence | If IBM has miscalculated the demand, it will suffer badly as both the high operating costs and depreciation on the huge capital investment for the East Fishkill factory drag down earnings. |
| Compressed sentences | · If IBM has miscalculated the demand, high operating costs and depreciation will drag down earnings. |
| · Miscalculation will lead IBM to have both high operating costs and capital investment depreciation for the East Fishkill earnings. | |
| · If IBM miscalculated demand, it will suffer as high operating costs and depreciation on capital investment for the factory lower earnings. | |
| · IBM will suffer if it miscalculates the demand as the operating costs and depreciation on investment for East Fishkill drag down earnings. | |
| · If IBM has miscalculated the demand, it will suffer badly as both the high operating costs and depreciation on the huge capital. |
| Dataset | MSR | Filippova | Korean |
|---|---|---|---|
| No. of training examples | 21,145 | 8000 | 2493 |
| No. of validation examples | 1908 | 1000 | 312 |
| No. of test examples | 3370 | 1000 | 312 |
| Average length of source sentences | 31.85 | 23.04 | 14.12 |
| Average length of target sentences | 21.97 | 9.34 | 8.11 |
| BLEU | ROUGE-1 | ROUGE-2 | ROUGE-L | CR(%) | |
|---|---|---|---|---|---|
| seq-to-seq | 18.32 | 30.05 | 10.42 | 26.87 | 69.39 (+0.79) |
| seq-to-seq + Event | 18.04 | 45.70 | 25.94 | 41.63 | 59.03 (−9.57) |
| Yu et al. | 26.30 | 36.21 | 17.43 | 33.72 | 65.53 (−3.07) |
| PG | 31.70 | 61.35 | 41.91 | 56.66 | 66.46 (−2.14) |
| PG + Event | 34.41 | 63.25 | 43.58 | 59.69 | 67.97 (−0.63) |
| BLEU | ROUGE-1 | ROUGE-2 | ROUGE-L | CR (%) | |
|---|---|---|---|---|---|
| seq-to-seq | 25.62 | 53.14 | 36.12 | 50.59 | 38.61 (−4.01) |
| seq-to-seq + Event | 28.70 | 56.03 | 39.77 | 53.51 | 38.72 (−3.90) |
| PG | 42.50 | 68.60 | 57.06 | 65.83 | 42.45 (−0.17) |
| PG + Event | 46.28 | 72.54 | 58.97 | 68.94 | 41.70 (−0.92) |
| BLEU | ROUGE-1 | ROUGE-2 | ROUGE-L | CR(%) | |
|---|---|---|---|---|---|
| seq-to-seq | 6.28 | 26.03 | 9.44 | 23.06 | 38.06 (−9.46) |
| seq-to-seq + Event | 12.38 | 36.16 | 18.32 | 33.08 | 56.09 (+8.57) |
| PG | 29.30 | 64.99 | 42.38 | 61.31 | 45.26 (−2.26) |
| PG + Event | 31.52 | 66.09 | 44.62 | 62.72 | 44.95 (−2.57) |
| Sentence 1 | Sentence 2 | Sentence 3 | |
|---|---|---|---|
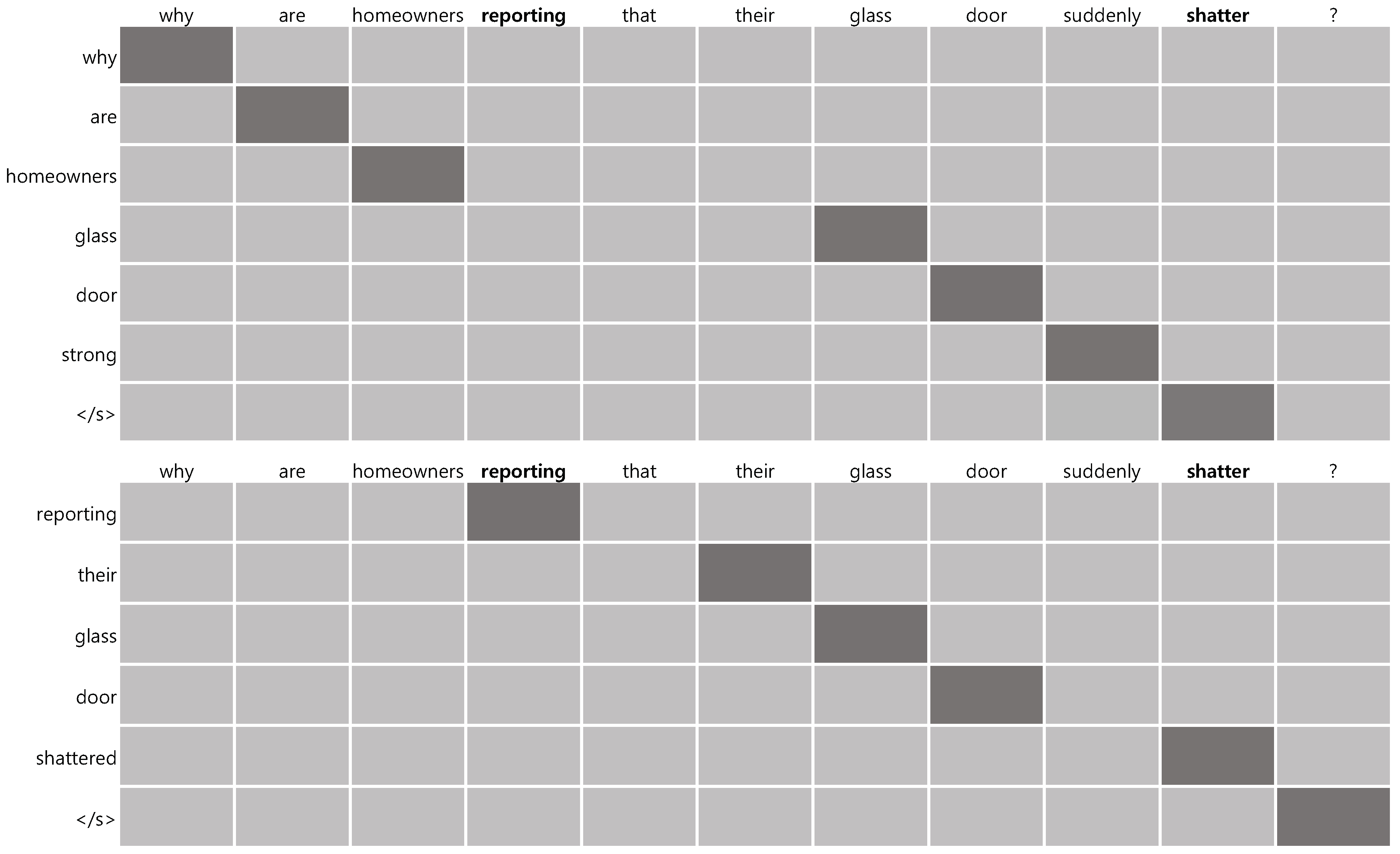
| Source | Anticipated outcomes from the spring | Support is needed both to maintain | why are homeowners |
| survey include: 80% of youth will | and expand these comprehensive | reporting that their glass | |
| report increased supervised time in | programs. Please help the | door suddenly shattered? | |
| safe environments. 80% of participants | American Cancer Society | ||
| will report increased conflict | continue its vital work. | ||
| resolution skills. | |||
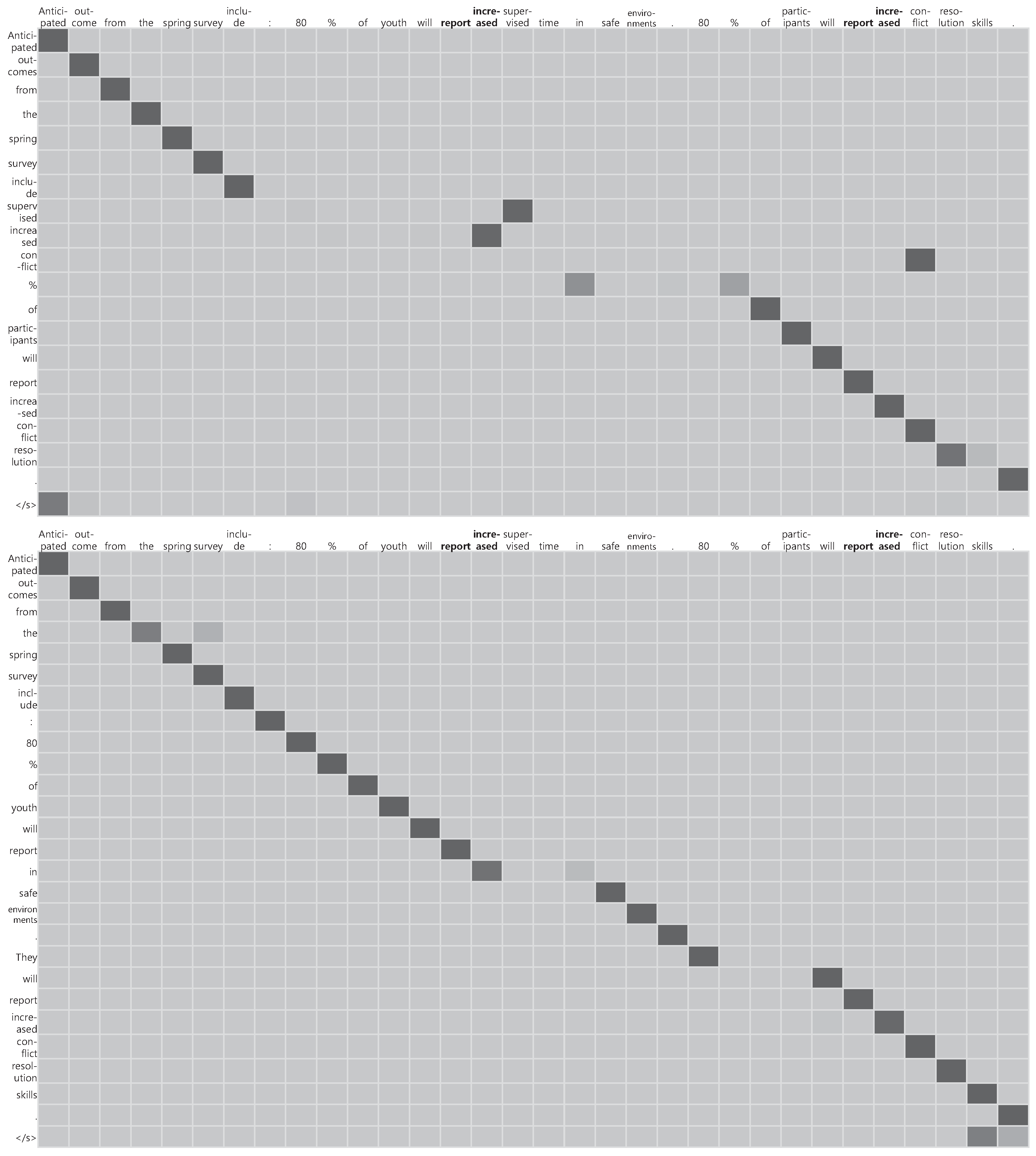
| Target | Expected outcomes from survey: | Maintenance and expansion | reporting their glass |
| 80% of youth will report more time | of our programs needs support. | door suddenly shattered | |
| in safe places. 80% of people will report | Help the American Cancer | ||
| greater conflict resolution skills. | Society continue. | ||
| PG | Anticipated outcomes from | nature much to maintain | why are homeowners |
| the spring survey include supervised | these comprehensive programs. | glass door strong | |
| increased conflict % of participants | The American Cancer Society’s | ||
| will report increased conflict resolution. | vital work. | ||
| PG + Event | Anticipated outcomes from the | Support the American Cancer | reporting their glass |
| spring survey include: 80% of youth | Society continue its vital work | door shattered | |
| will report in safe environments. | and help to maintain. | ||
| They will report increased conflict | |||
| resolution skills. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, S.J.; Jung, I.; Park, S.; Park, S.-B. Abstractive Sentence Compression with Event Attention. Appl. Sci. 2019, 9, 3949. https://doi.org/10.3390/app9193949
Choi SJ, Jung I, Park S, Park S-B. Abstractive Sentence Compression with Event Attention. Applied Sciences. 2019; 9(19):3949. https://doi.org/10.3390/app9193949
Chicago/Turabian StyleChoi, Su Jeong, Ian Jung, Seyoung Park, and Seong-Bae Park. 2019. "Abstractive Sentence Compression with Event Attention" Applied Sciences 9, no. 19: 3949. https://doi.org/10.3390/app9193949
APA StyleChoi, S. J., Jung, I., Park, S., & Park, S.-B. (2019). Abstractive Sentence Compression with Event Attention. Applied Sciences, 9(19), 3949. https://doi.org/10.3390/app9193949