Recommendation Framework Combining User Interests with Fashion Trends in Apparel Online Shopping


Abstract
:1. Introduction
- We construct an item trend graph to sensitively capture the temporal dynamics of item search flow resulting from any external factors.
- We score the user’s preference for item clusters using user-based CF along with methods to overcome the sparsity problem and combine it with the item trend graph.
- We predict the user’s needs with respect to item category and gender based on recent access logs and reflect them in the final recommendation.
2. Related Works
3. Proposed Method
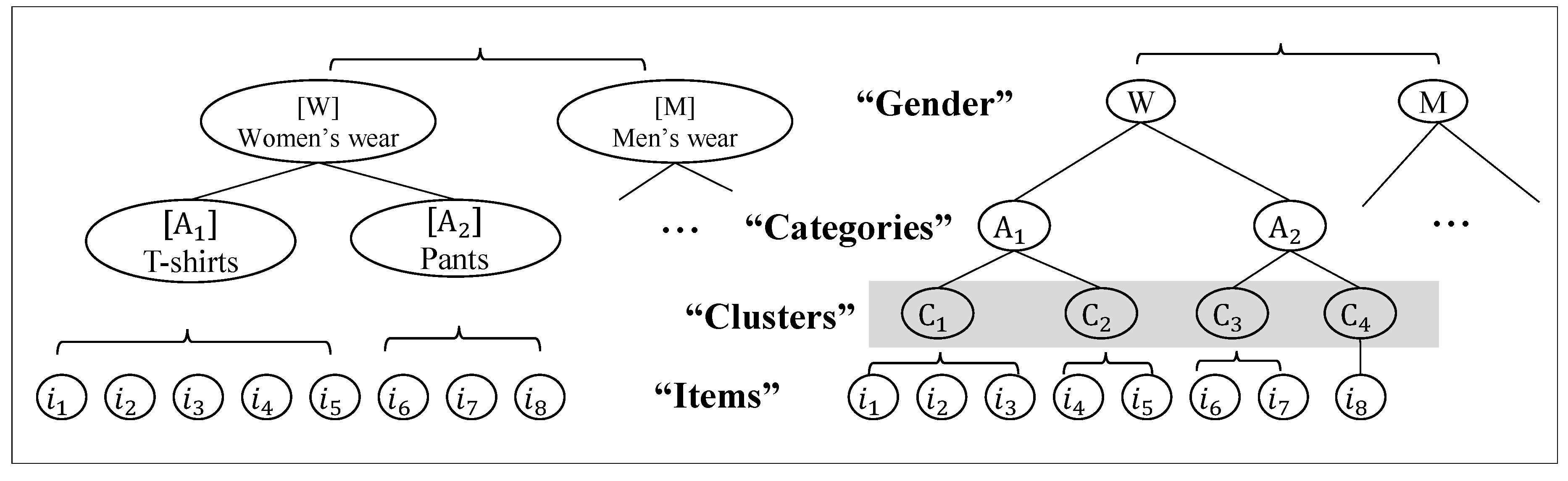
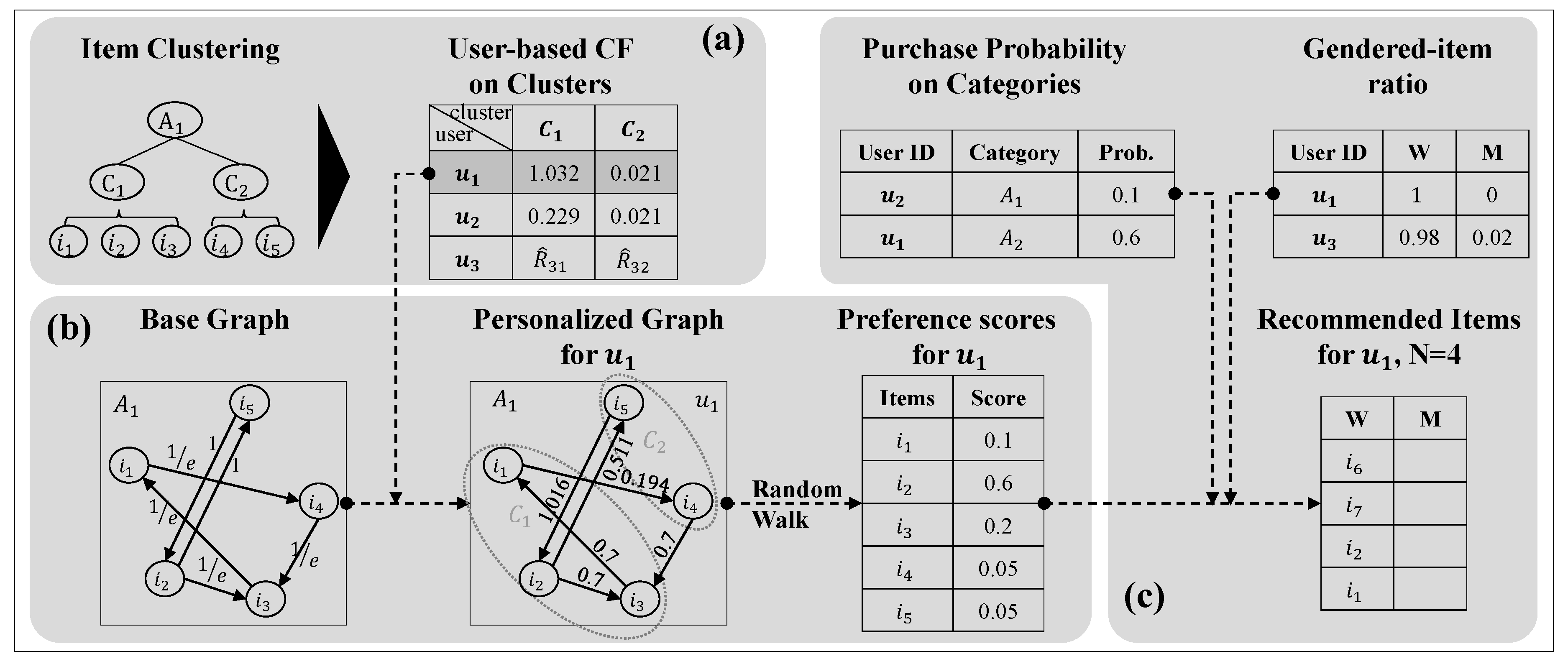
3.1. System Overview
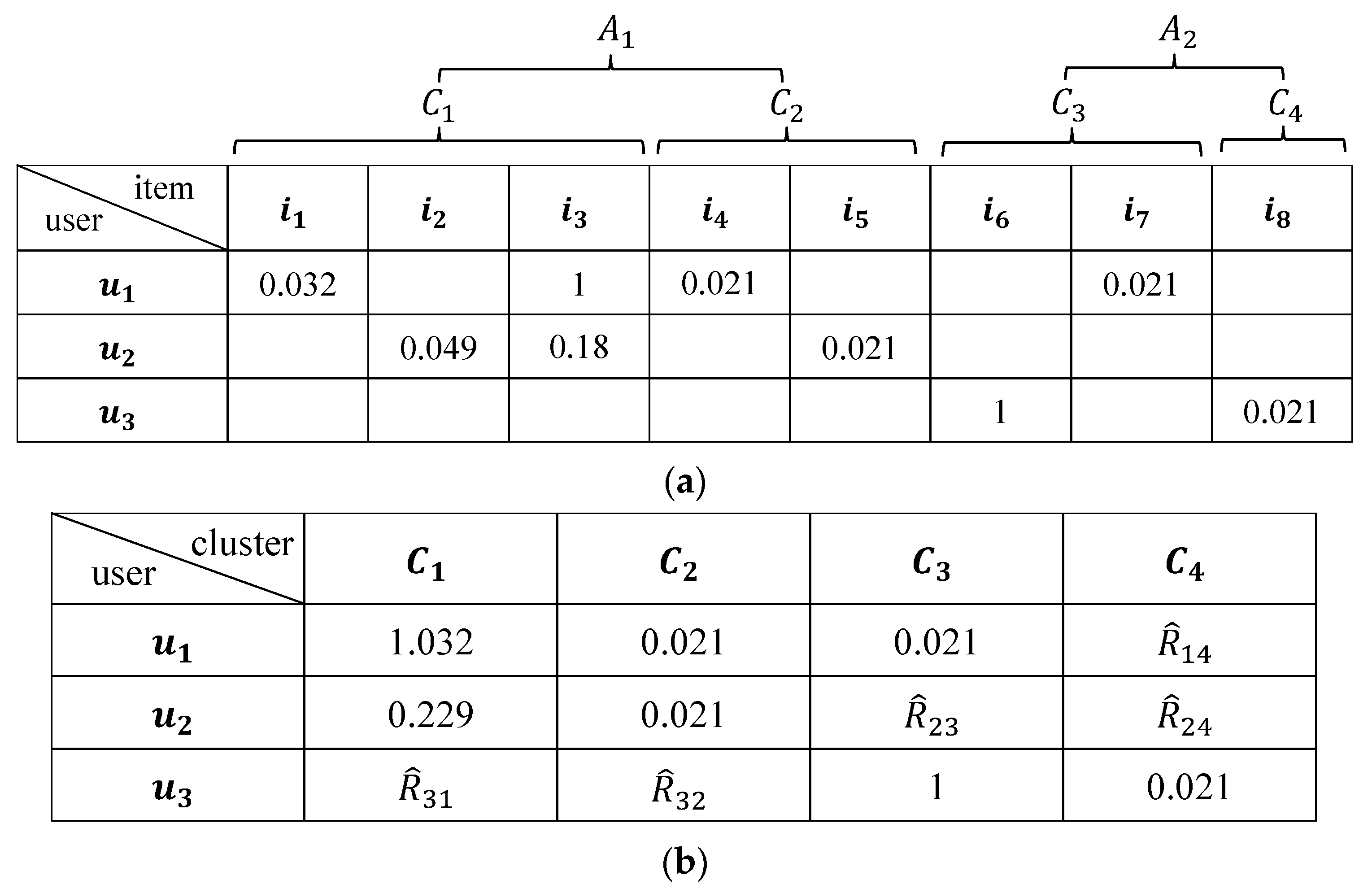
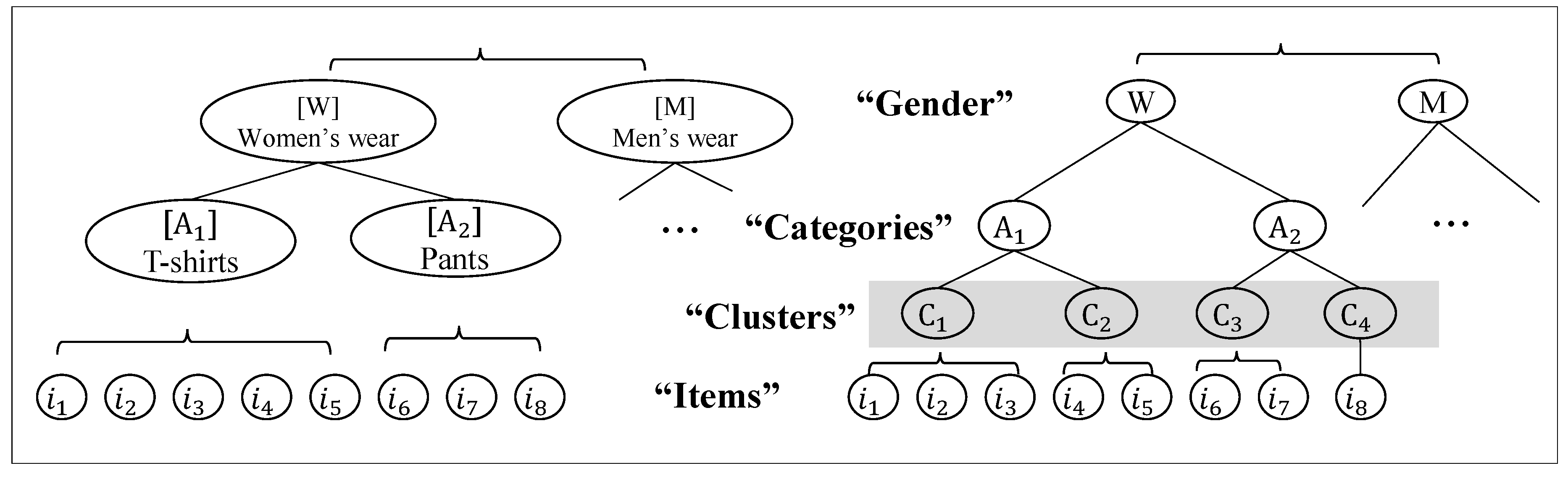
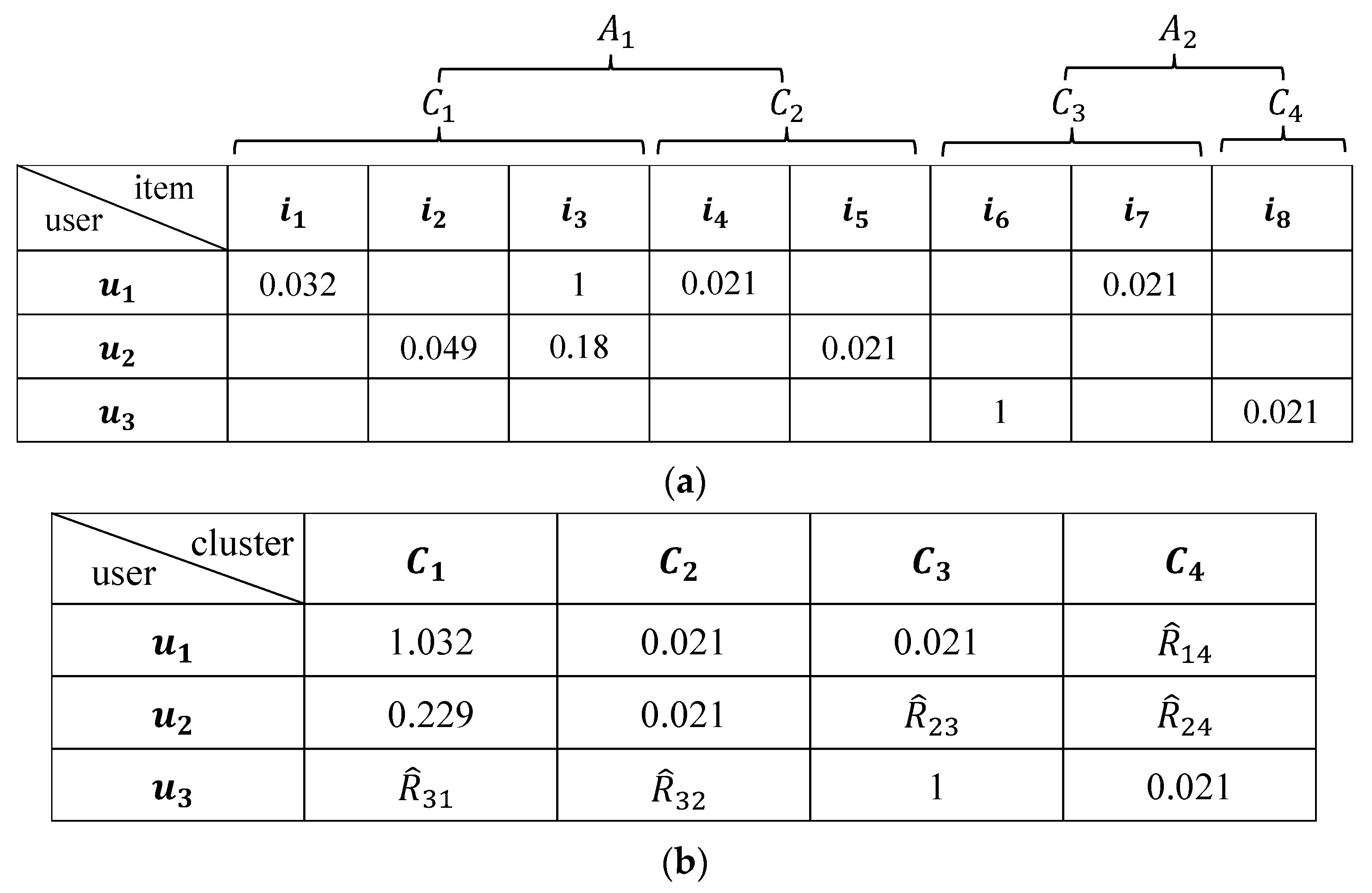
3.2. Rating Item Clusters
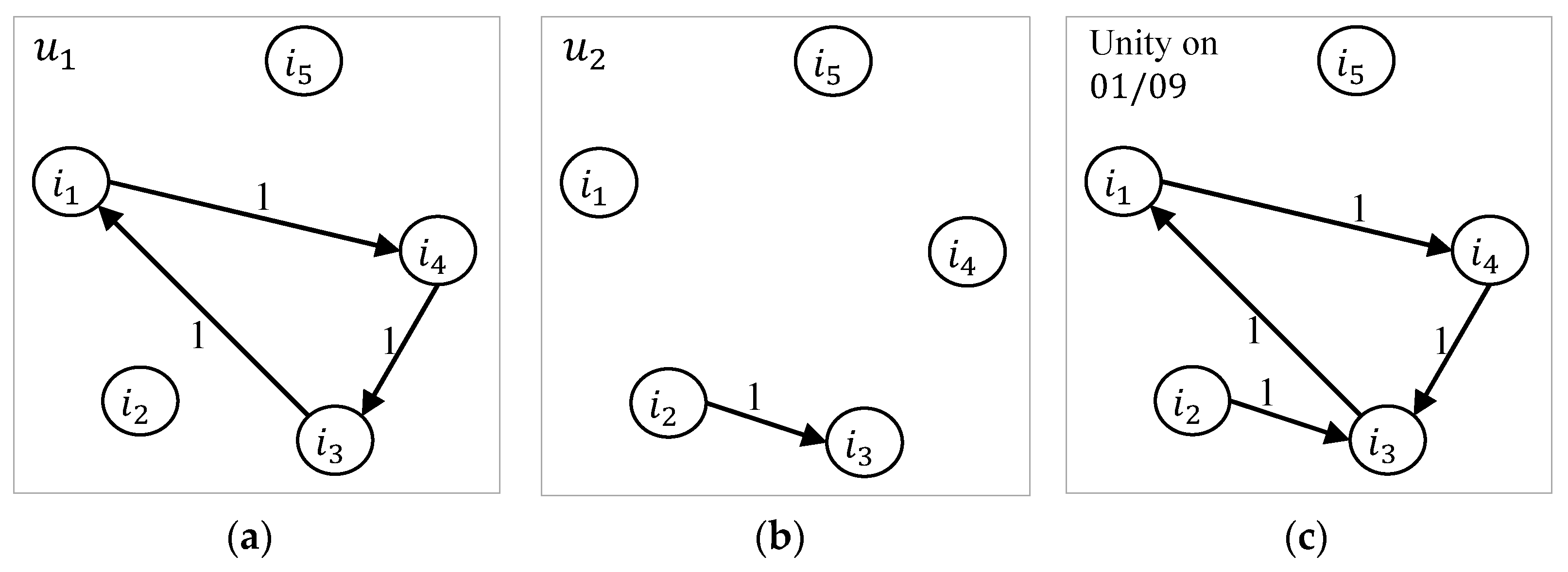
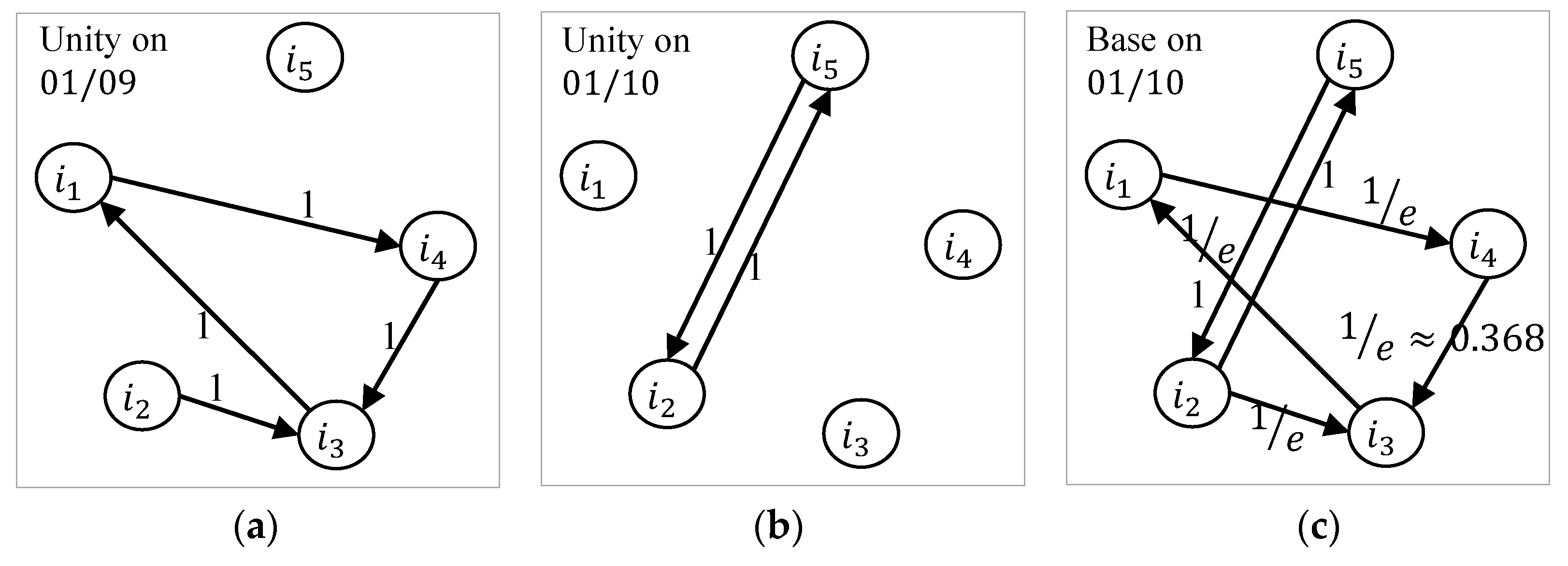
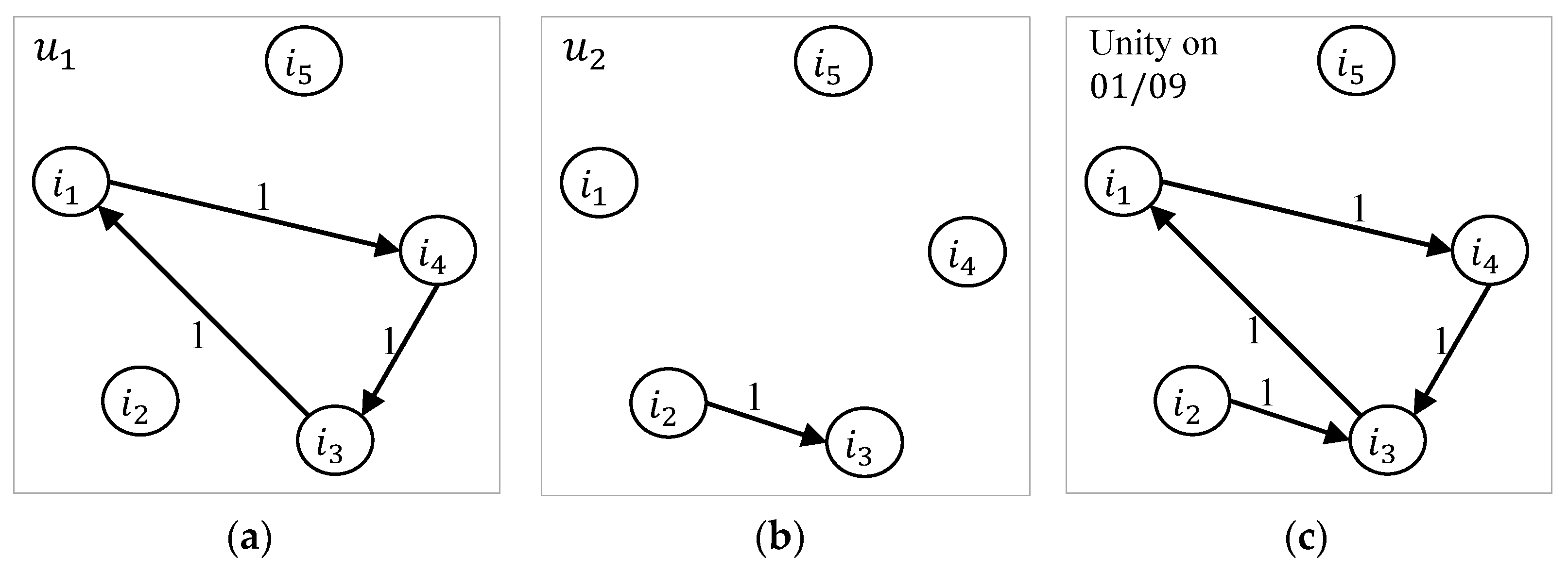
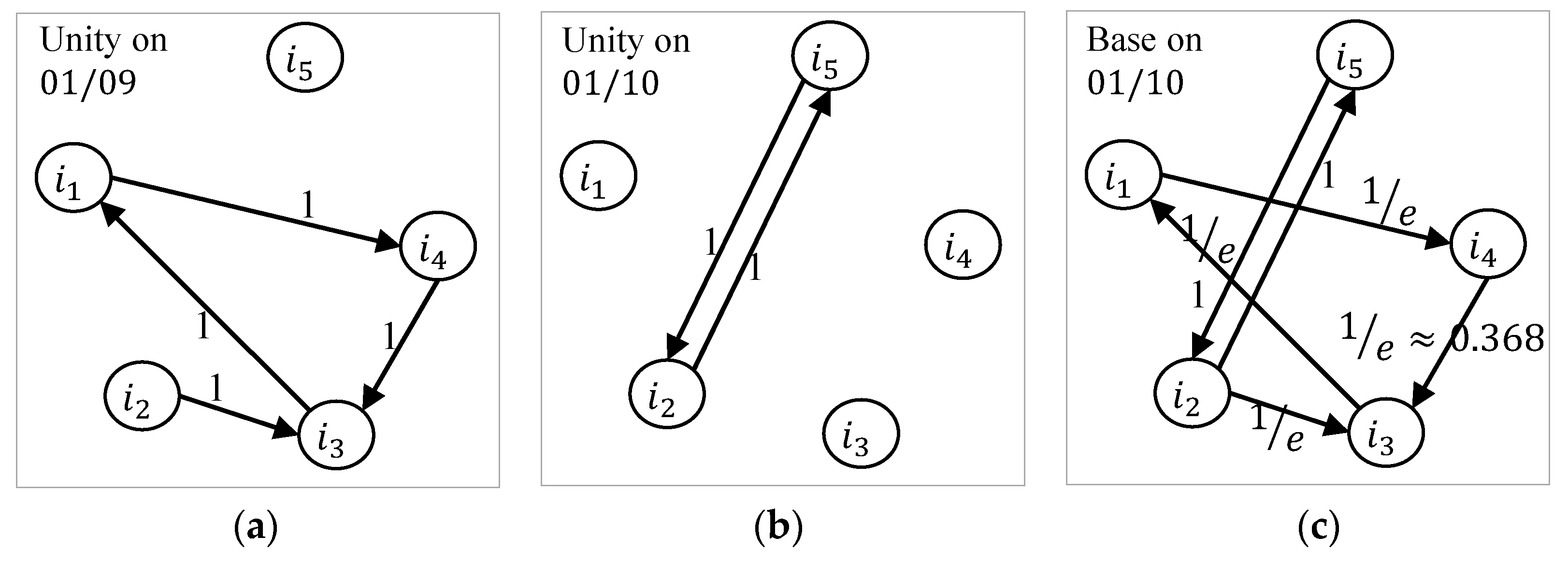
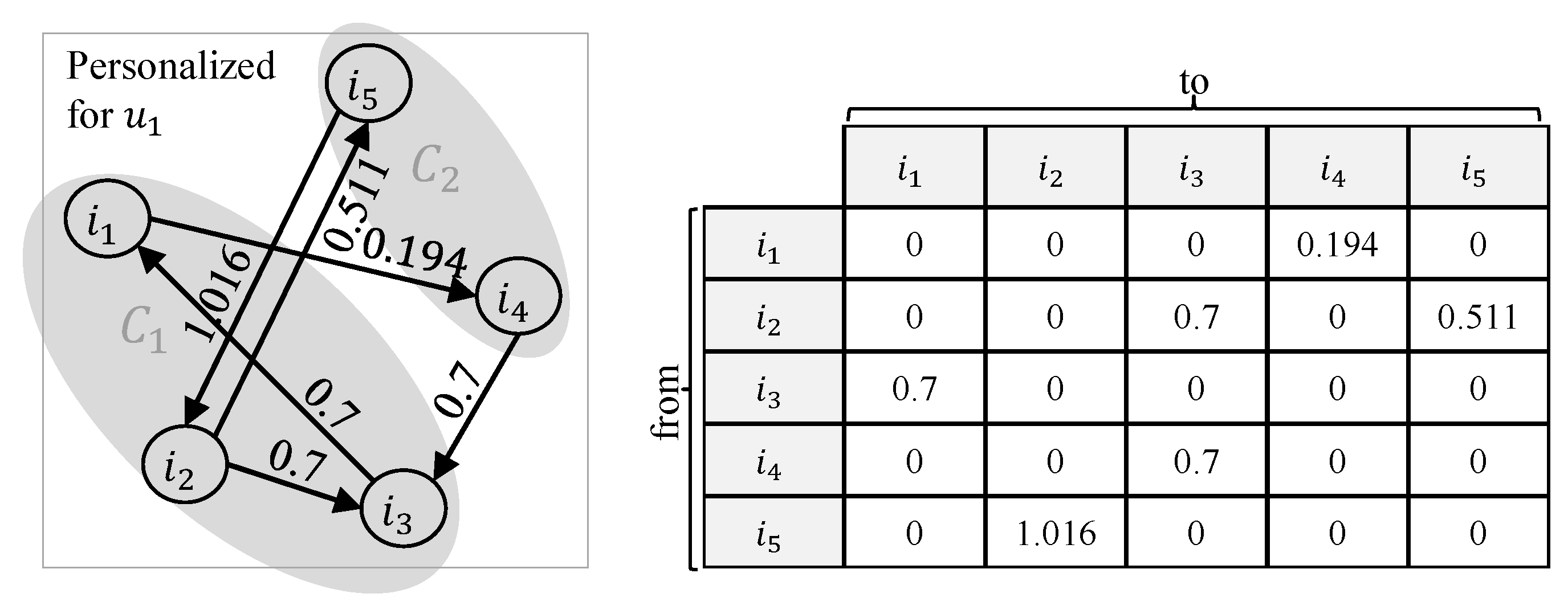
3.3. Personalized Random Walk
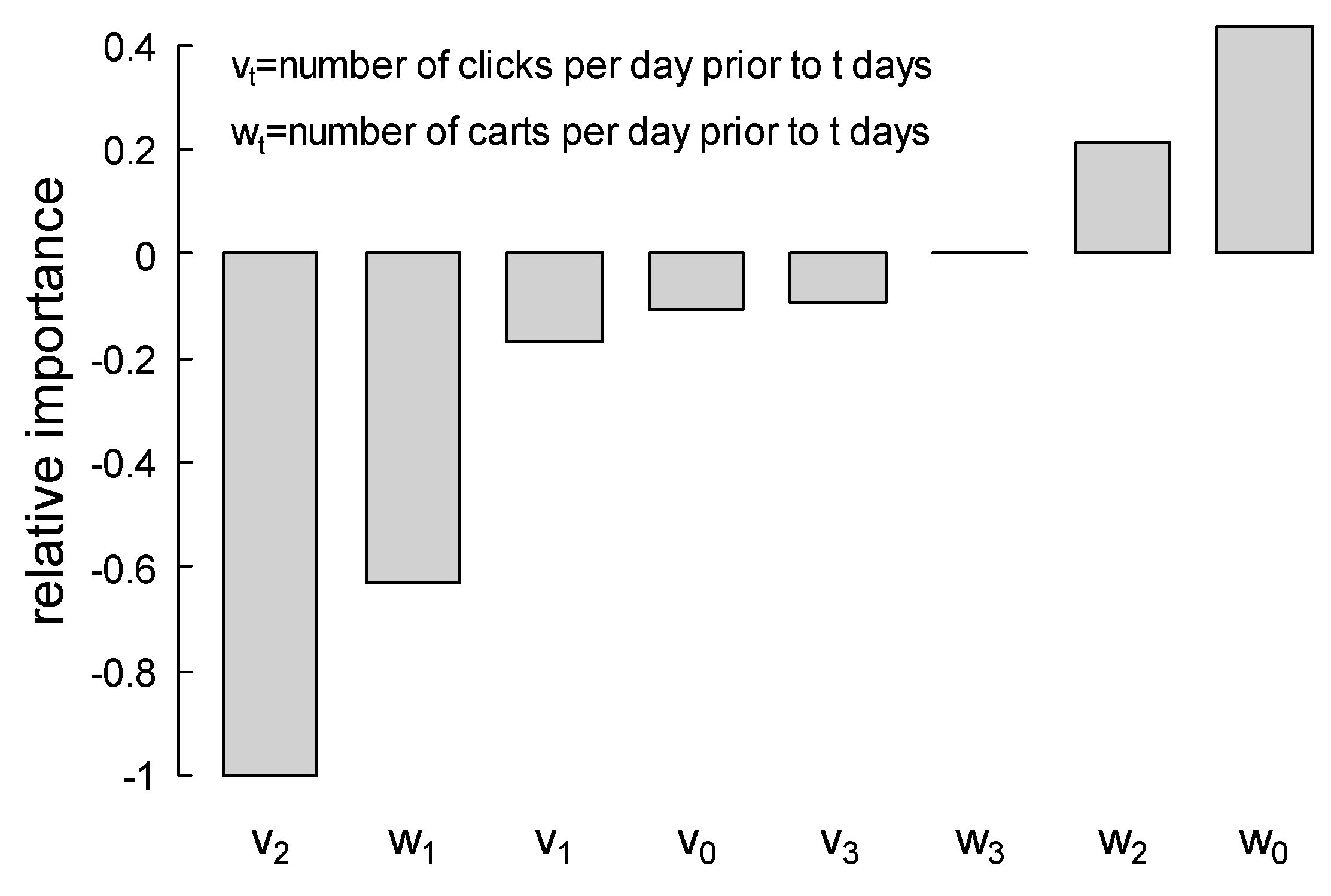
3.4. Reflecting User’s Needs
4. Numerical Experiments
4.1. Real World Dataset
4.2. Performance Measurement
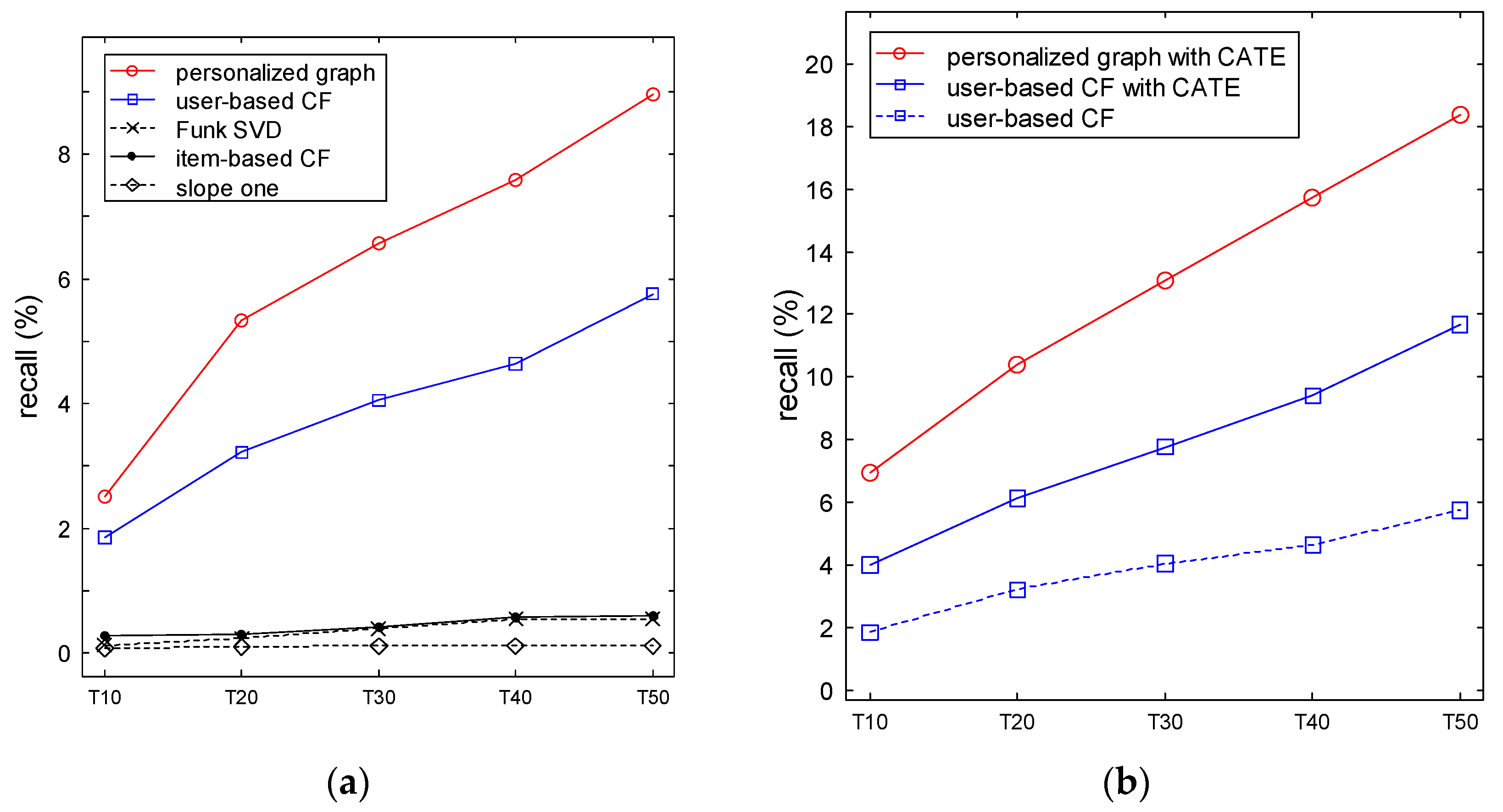
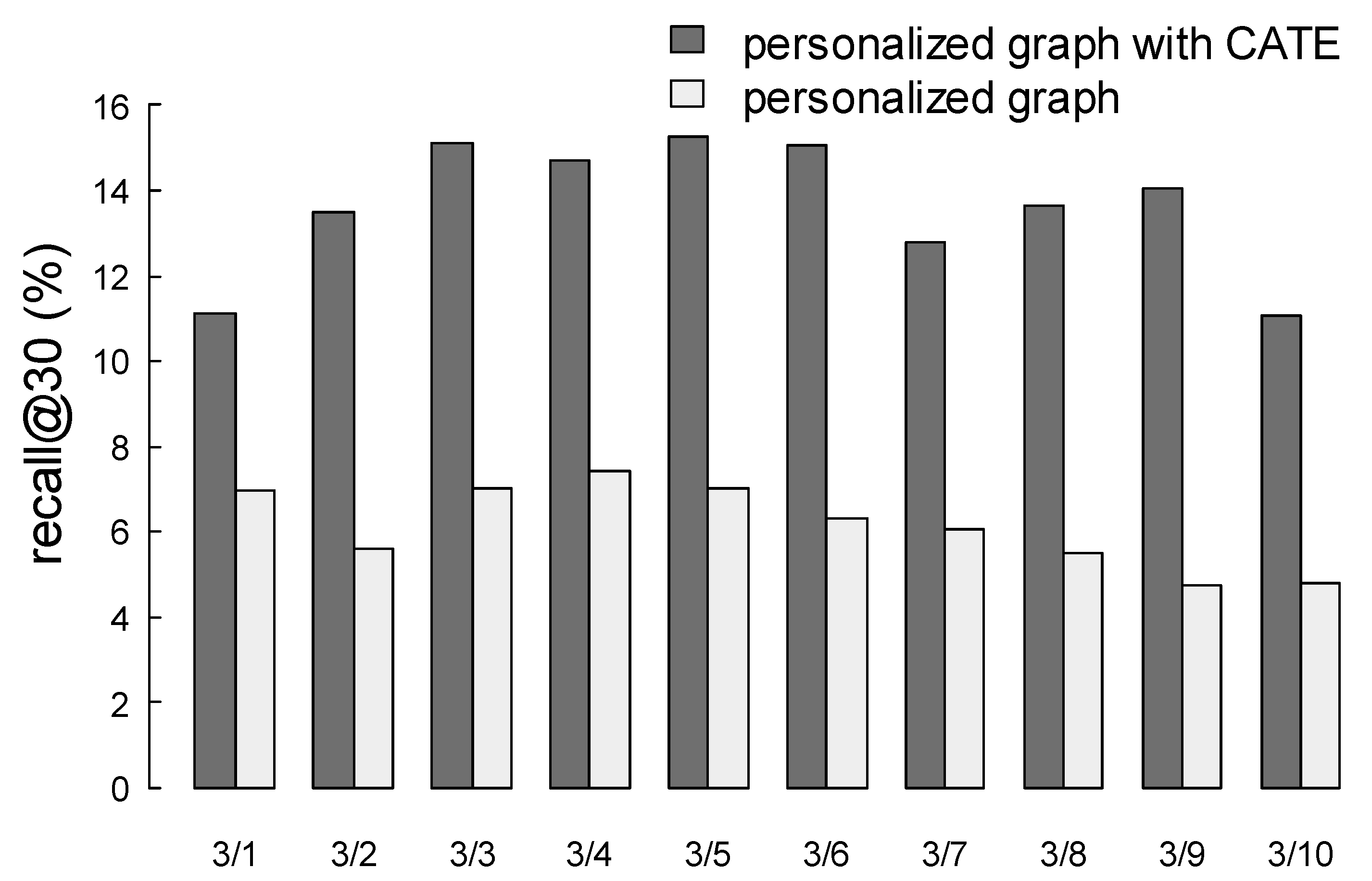
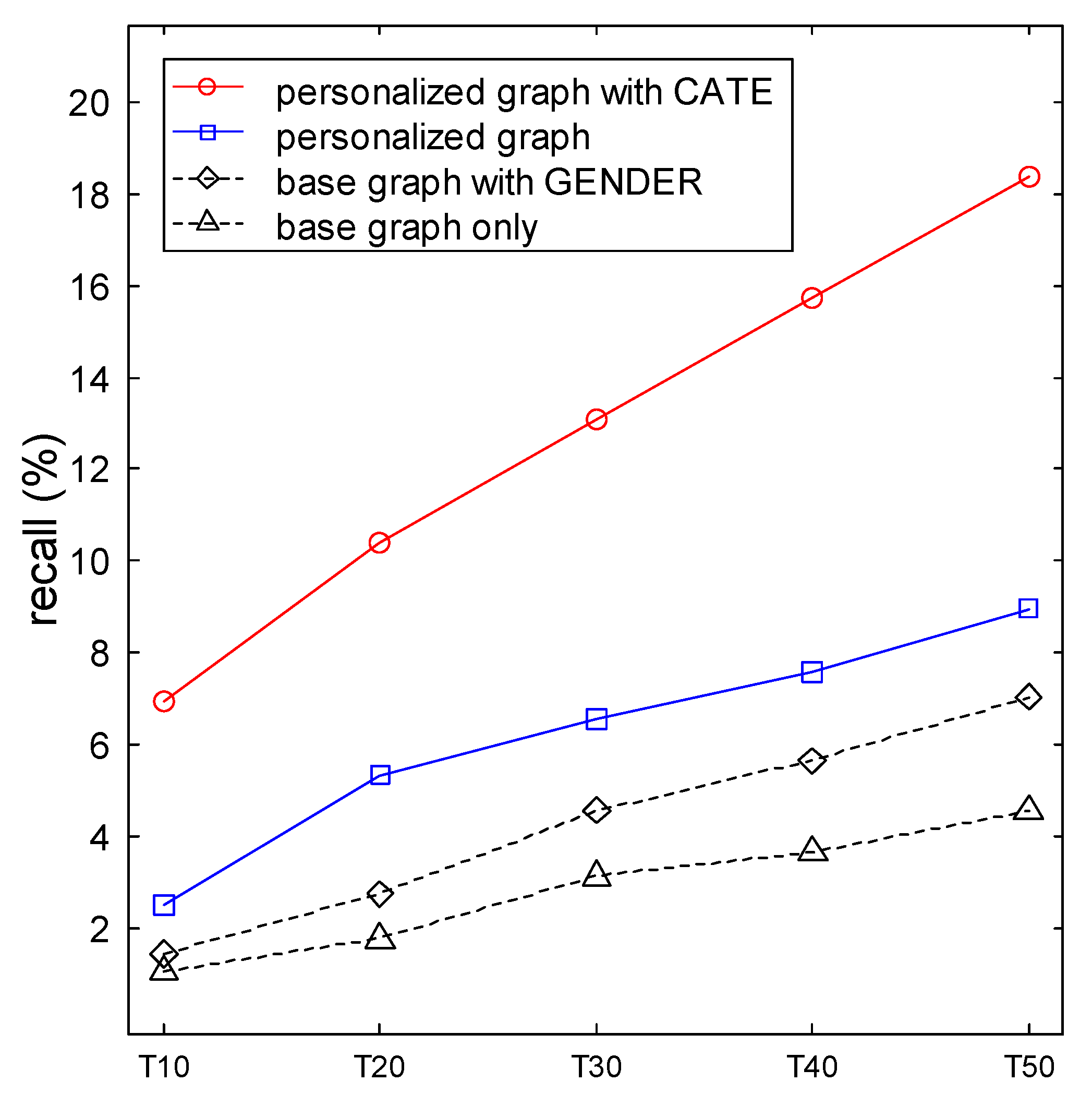
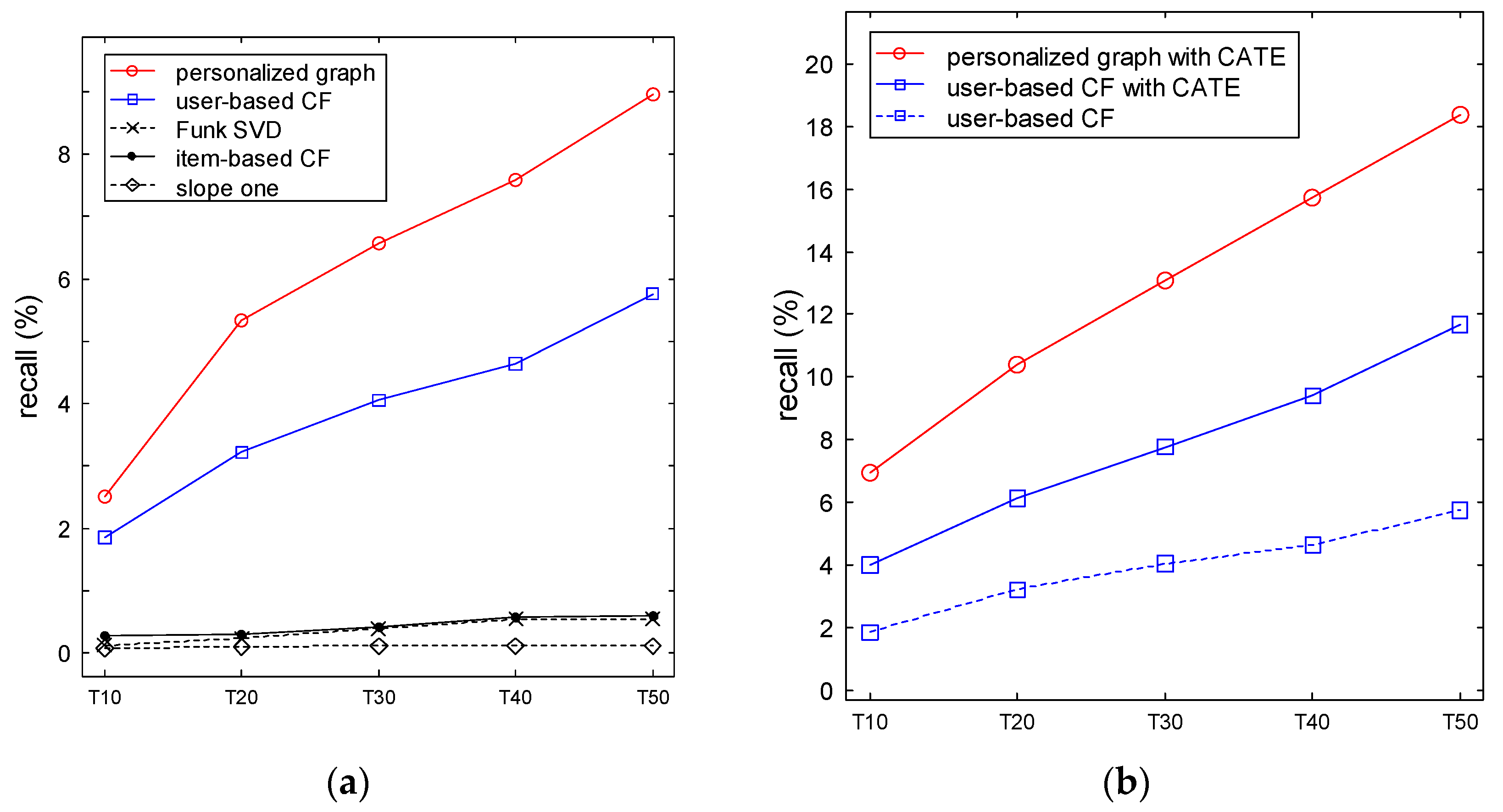
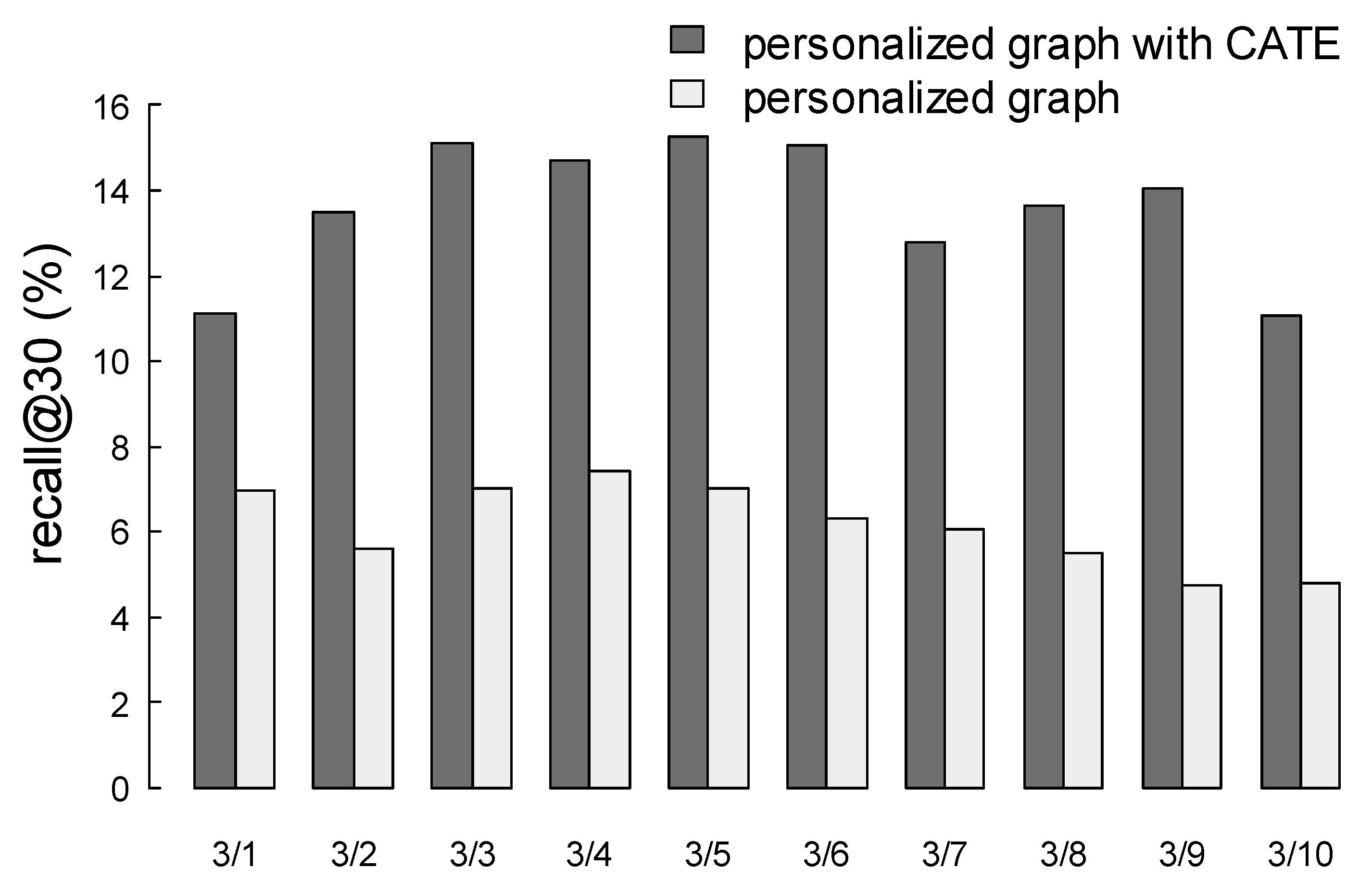
4.3. Results
5. Discussion
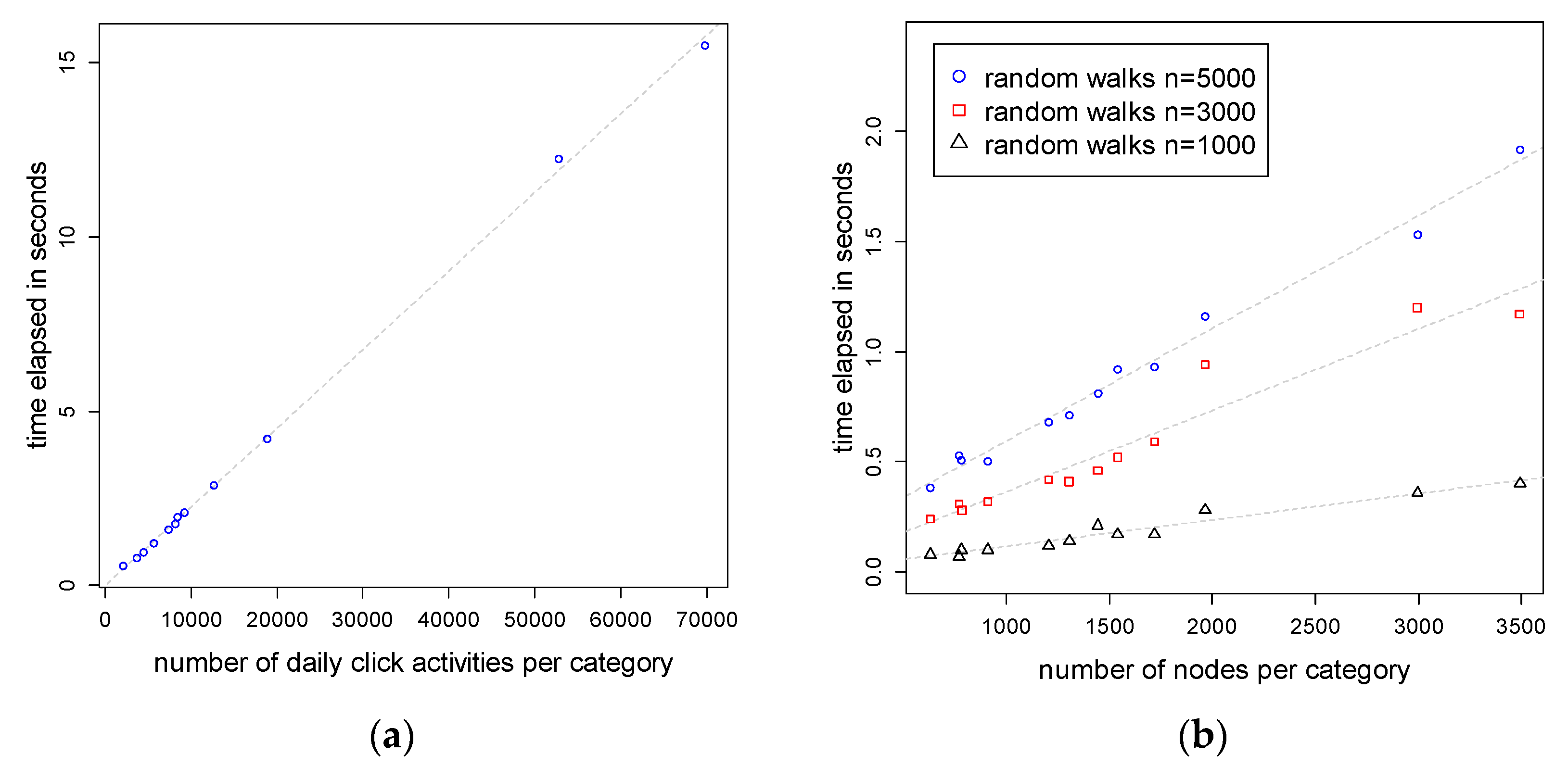
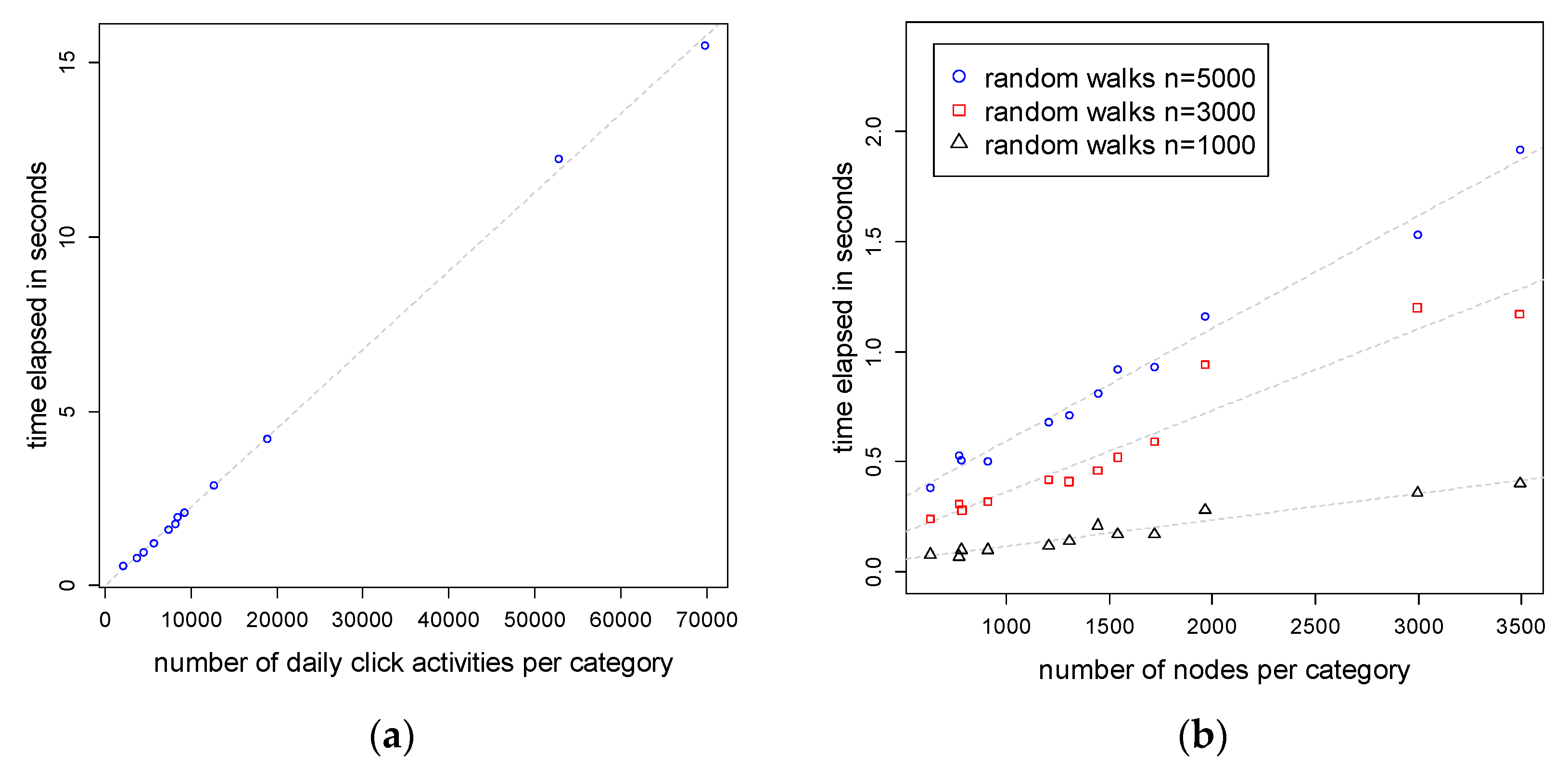
5.1. Computational Complexity
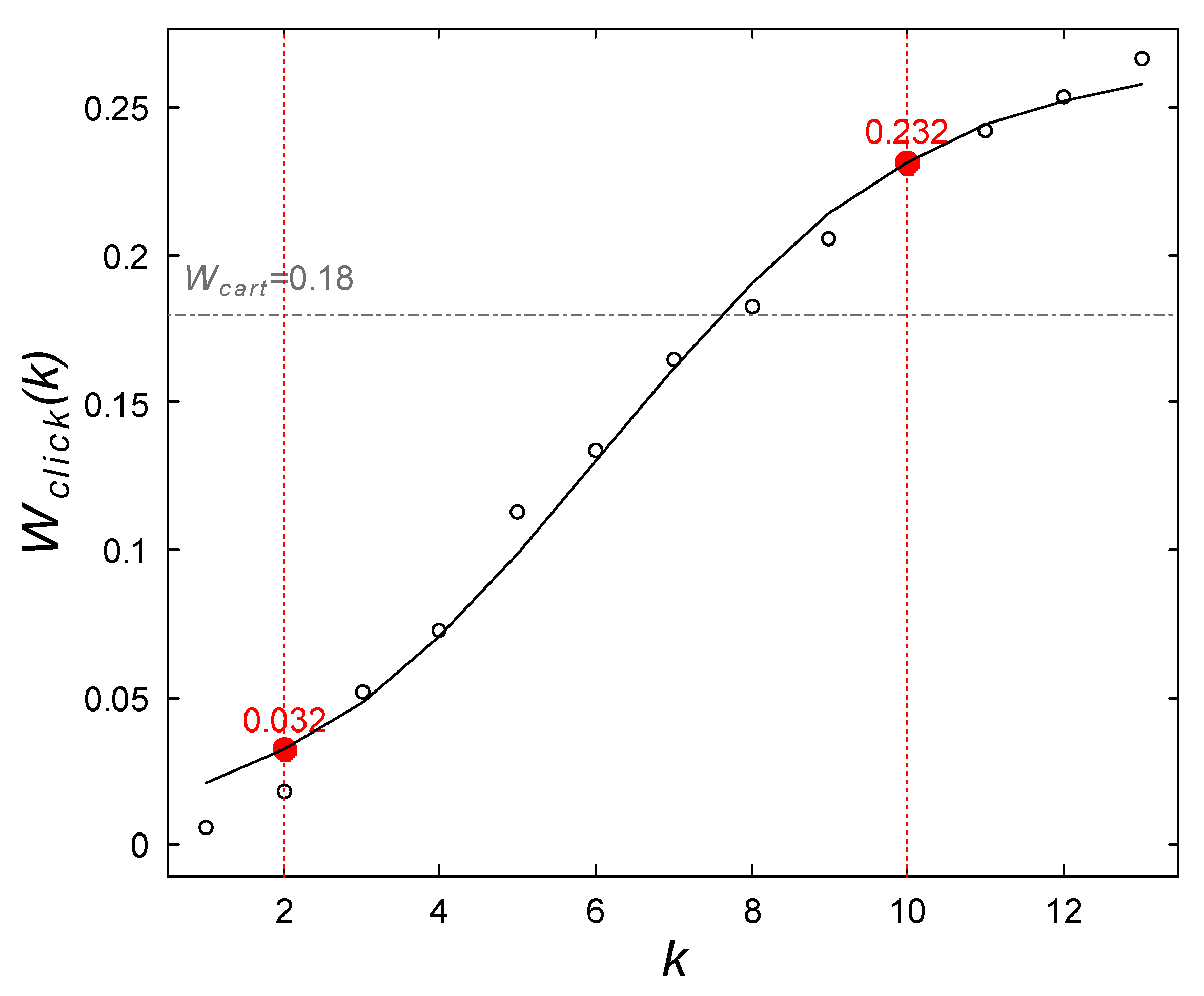
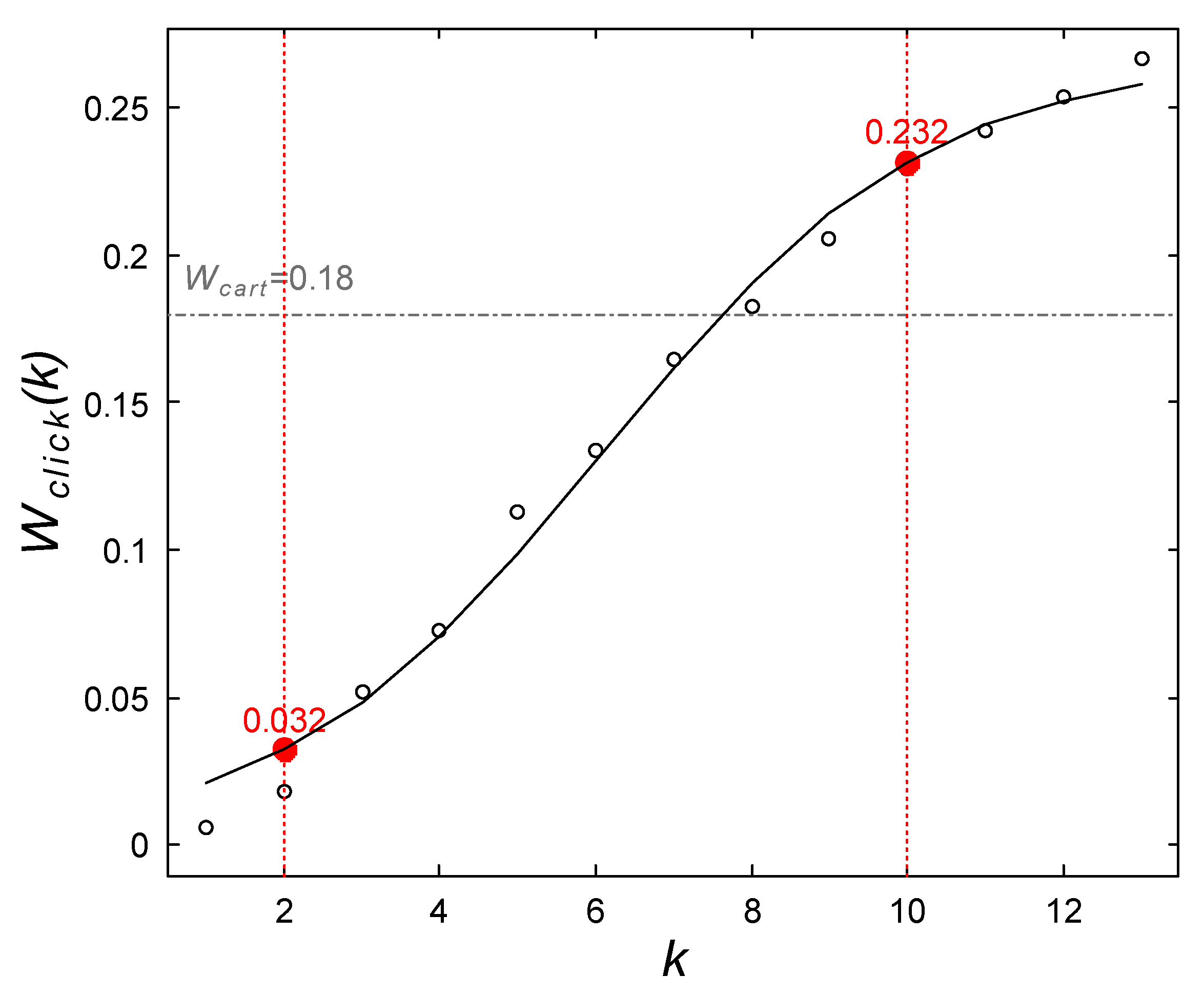
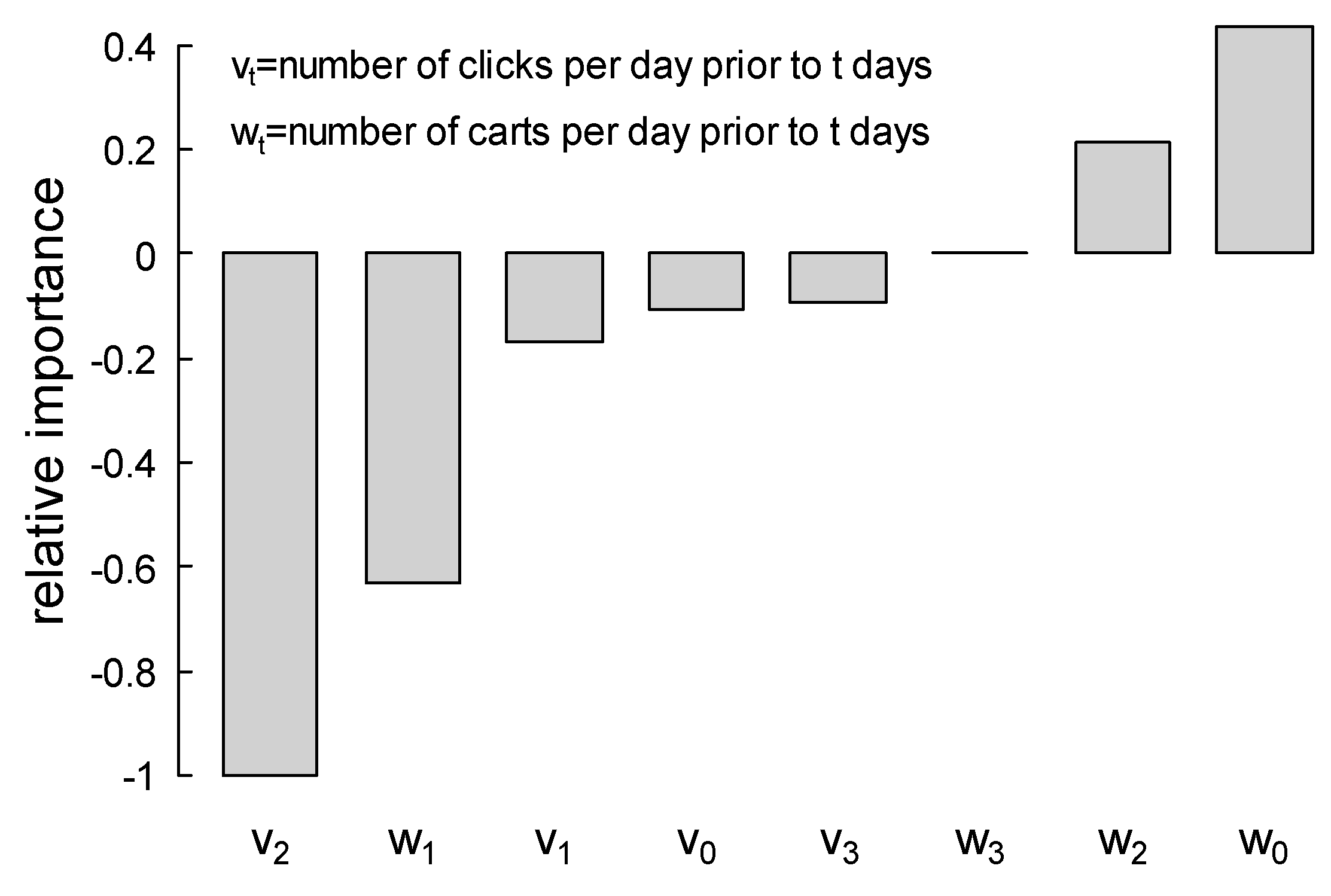
5.2. Analysis on Purchase Intention for Categories
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Statista. Share of Internet Users Who Have Ever Purchased Products Online as of NOVEMBER 2016, by Category. Available online: http://www.statista.com/statistics/276846 (accessed on 1 November 2017).
- Goto, M.; Mikawa, K.; Hirasawa, S.; Kobayashi, M.; Suko, T.; Horii, S. A new latent class model for analysis of purchasing and browsing histories on EC sites. Ind. Eng. Manag. Syst. 2015, 14, 335–346. [Google Scholar] [CrossRef]
- Golubtsov, N.; Galper, D.; Filchenkov, A. Active adaptation of expert-based suggestions in ladieswear recommender system LookBooksClub via reinforcement learning. In 1st International Early Research Career Enhancement School on Biologically Inspired Cognitive Architectures, FIERCES on BICA 2016; Klimov, V.V., Rybina, G.V., Samsonovich, A.V., Eds.; Springer Verlag: Berlin, Germany, 2016; Volume 449, pp. 61–69. [Google Scholar]
- Perkinian, C.; Vikkraman, P. An intelligent apparel recommendation system for online shopping using style classification. Int. J. Appl. Bus. Econ. Res. 2015, 13, 671–686. [Google Scholar]
- Wakita, Y.; Oku, K.; Huang, H.H.; Kawagoe, K. A Fashion-Brand Recommender System Using Brand Association Rules and Features. In Proceedings of the 4th IIAI International Congress on Advanced Applied Informatics (IIAI-AAI), Okayama, Japan, 12–16 July 2015; pp. 719–720. [Google Scholar]
- Chen, K.T.; Luo, J. When Fashion Meets Big Data: Discriminative Mining of Best Selling Clothing Features. In Proceedings of the 26th International World Wide Web Conference 2017, WWW 2017 Companion, Perth, Australia, 3–7 April 2017; pp. 15–22. [Google Scholar]
- Guan, C.; Qin, S.; Ling, W.; Ding, G. Apparel recommendation system evolution: An empirical review. Int. J. Cloth. Sci. Technol. 2016, 28, 854–879. [Google Scholar] [CrossRef]
- Jagadeesh, V.; Piramuthu, R.; Bhardwaj, A.; Di, W.; Sundaresan, N. Large scale visual recommendations from street fashion images. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD), New York, NY, USA, 8 January 2014; pp. 1925–1934. [Google Scholar]
- Yu, L.; Dong, A. Hybrid product recommender system for apparel retailing customers. In Proceedings of the 2010 WASE International Conference on Information Engineering (ICIE), Beidaihe, Hebei, China, 14–15 August 2010; pp. 356–360. [Google Scholar]
- Mu, W.; Meng, F.; Chu, D. A Collaborative Filtering Recommendation Algorithm Based on User Preferences on Service Properties. In Proceedings of the International Conference on Service Sciences (ICSS), Wuxi, China, 22–23 May 2014; pp. 43–46. [Google Scholar]
- Sengottuvelan, P.; Gopalakrishnan, T.; Lokesh Kumar, R.; Kavya, M. A recommendation system for personal learning environments based on learner clicks. Int. J. Appl. Eng. Res. 2015, 10, 15316–15321. [Google Scholar]
- Ye, F.; Zhang, H. A collaborative filtering recommendation based on users’ interest and correlation of items. In Proceedings of the 5th International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 11–12 July 2016; pp. 515–520. [Google Scholar]
- Gan, M. COUSIN: A network-based regression model for personalized recommendations. Decis. Support Syst. 2016, 82, 58–68. [Google Scholar] [CrossRef]
- Su, C.; Yu, Y.; Xie, X.; Wang, Y. Data sensitive recommendation based on community detection. Found. Comput. Decis. Sci. 2015, 40, 143–159. [Google Scholar] [CrossRef]
- Xie, F.; Chen, Z.; Shang, J.; Huang, W.; Li, J. Item similarity learning methods for collaborative filtering recommender systems. In Proceedings of the 29th IEEE International Conference on Advanced Information Networking and Applications (AINA), Gwangiu, Korea, 24–27 March 2015; pp. 896–903. [Google Scholar]
- Kumar, R.; Bala, P.K. Recommendation engine based on derived wisdom for more similar item neighbors. Inf. Syst. e-Bus. Manag. 2017, 15, 661–687. [Google Scholar] [CrossRef]
- Lee, J.S.; Olafsson, S. Two-way cooperative prediction for collaborative filtering recommendations. Expert Syst. Appl. 2009, 36, 5353–5361. [Google Scholar] [CrossRef]
- Guo, L.; Liang, J.; Zhao, X. Collaborative filtering recommendation algorithm incorporating social network information. Pattern Recognit. Artif. Intell. 2016, 29, 281–288. [Google Scholar] [CrossRef]
- Huang, T.C.K.; Chen, Y.L.; Chen, M.C. A novel recommendation model with Google similarity. Decis. Support Syst. 2016, 89, 17–27. [Google Scholar] [CrossRef]
- Kim, K.J.; Ahn, H. Recommender systems using cluster-indexing collaborative filtering and social data analytics. Int. J. Prod. Res. 2017, 55, 5037–5049. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, Y.; Lin, M.; Liu, J. An effective collaborative filtering algorithm based on user preference clustering. Appl. Intell. 2016, 45, 230–240. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Almenningen, T.; Havig, M.; Schistad, H.; Kofod-Petersen, A.; Langseth, H.; Ramampiaro, H. Learning to rank for personalised fashion recommender systems via implicit feedback. In 2nd International Conference on Mining Intelligence and Knowledge Exploration (MIKE 2014); Prasath, R., O’Reilly, P., Kathirvalavakumar, T., Eds.; Springer Verlag: Berlin, Germany, 2014; Volume 8891, pp. 51–61. [Google Scholar]
- Reusens, M.; Lemahieu, W.; Baesens, B.; Sels, L. A note on explicit versus implicit information for job recommendation. Decis. Support Syst. 2017, 98, 26–35. [Google Scholar] [CrossRef]
- Mishra, R.; Kumar, P.; Bhasker, B. A web recommendation system considering sequential information. Decis. Support Syst. 2015, 75, 1–10. [Google Scholar] [CrossRef]
- Wang, Y.; Shang, W. Personalized news recommendation based on consumers’ click behavior. In Proceedings of the 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; pp. 634–638. [Google Scholar]
- Zhu, G.; Cao, J.; Li, C.; Wu, Z. A recommendation engine for travel products based on topic sequential patterns. Multimedia Tools Appl. 2017, 76, 17595–17612. [Google Scholar] [CrossRef]
- Ahmed, A.A.; Salim, N. Markov Chain Recommendation System (MCRS). Int. J. Nov. Res. Comput. Sci. Softw. Eng. 2016, 3, 11–26. [Google Scholar]
- Eirinaki, M.; Vazirgiannis, M.; Kapogiannis, D. Web path recommendations based on page ranking and Markov models. In Proceedings of the Interntational Workshop on Web Information and Data Management (WIDM), Bremen, Germany, 4 Novembe 2005; pp. 2–9. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of the 19th International World Wide Web Conference (WWW2010), Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Haveliwala, T.H. Topic-sensitive PageRank. In Proceedings of the 11th International Conference on World Wide Web (WWW ’02), Honolulu, HI, USA, 7–11 May 2002; pp. 517–526. [Google Scholar]
- Lee, S.; Song, S.I.; Kahng, M.; Lee, D.; Lee, S.G. Random walk based entity ranking on graph for multidimensional recommendation. In Proceedings of the 5th ACM Conference on Recommender Systems (RecSys), Chicago, IL, USA, 23–27 October 2011; pp. 93–100. [Google Scholar]
- Li, L.; Zheng, L.; Yang, F.; Li, T. Modeling and broadening temporal user interest in personalized news recommendation. Expert Syst. Appl. 2014, 41, 3168–3177. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, F.; Wen, J.R.; Li, Z. Bring user interest to related entity recommendation. In 4th International Workshop on Graph Structures for Knowledge Representation and Reasoning (GKR 2015); Rudolph, S., Croitoru, M., Marquis, P., Stapleton, G., Eds.; Springer Verlag: Berlin, Germany, 2015; Volume 9501, pp. 139–153. [Google Scholar]
- He, R.; McAuley, J. Fusing similarity models with markov chains for sparse sequential recommendation. In Proceedings of the 16th IEEE International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 191–200. [Google Scholar]
- Su, Q.; Chen, L. A method for discovering clusters of e-commerce interest patterns using click-stream data. Electron. Commer. Res. Appl. 2015, 14, 1–13. [Google Scholar] [CrossRef]
- Zhao, Y.; Yao, L.; Zhang, Y. Purchase prediction using Tmall-specific features. Concurr. Comput. 2016, 28, 3879–3894. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef]
- Elbadrawy, A.; Karypis, G. Domain-aware grade prediction and top-n course recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems (RecSys 2016), Boston, MA, USA, 15–19 September 2016; pp. 183–190. [Google Scholar]
- Guo, Y.; Wang, M.; Li, X. An interactive personalized recommendation system using the hybrid algorithm model. Symmetry 2017, 9, 216. [Google Scholar] [CrossRef]
- Tuan, T.X.; Phuong, T.M. 3D convolutional networks for session-based recommendation with content features. In Proceedings of the 11th ACM Conference on Recommender Systems (RecSys), Como, Italy, 27–31 August 2017; pp. 138–146. [Google Scholar]
- Lemire, D.; Maclachlan, A. Slope one predictors for online rating-based collaborative filtering. In Proceedings of the 2005 SIAM International Conference on Data Mining (SDM), Newport Beach, CA, USA, 21–23 April 2005; pp. 471–475. [Google Scholar]
- Funk, S. Netflix Update: Try This at Home. Available online: https://sifter.org/~simon/journal/20061211.html (accessed on 28 June 2019).
- Cacheda, F.; Carneiro, V.; Fernández, D.; Formoso, V. Comparison of collaborative filtering algorithms: Limitations of current techniques and proposals for scalable, high-performance recommender systems. ACM Trans. Web 2011, 5, 2. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User ID | Item ID | Gender | Category | Activity | Time Stamp |
|---|---|---|---|---|---|
| W | CLICK | 2017-01-09 20:59 | |||
| W | CLICK | 2017-01-09 21:00 | |||
| W | CLICK | 2017-01-09 21:01 | |||
| W | CLICK | 2017-01-09 21:17 | |||
| W | CLICK | 2017-01-10 19:05 | |||
| W | ORDER | 2017-01-10 19:07 | |||
| W | CLICK | 2017-01-09 11:24 | |||
| W | CLICK | 2017-01-09 11:31 | |||
| W | CART | 2017-01-09 11:36 | |||
| W | CLICK | 2017-01-10 15:27 | |||
| W | CLICK | 2017-01-10 15:31 | |||
| W | CLICK | 2017-01-10 16:02 | |||
| W | ORDER | 2017-01-09 13:37 | |||
| W | CLICK | 2017-01-10 17:18 | |||
| M | CLICK | 2017-01-10 18:09 |
| User | Item | Gender | Category | #Clicks | Cart | Order | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| W | 2 | 0.032 | 0.032 | |||||||
| W | 1 | T | 0.021 | 1 | 1 | |||||
| W | 1 | 0.021 | 0.021 | |||||||
| W | 1 | 0.021 | 0.021 | |||||||
| W | 3 | 0.049 | 0.049 | |||||||
| W | 1 | T | 0.021 | 0.18 | 0.18 | |||||
| W | 1 | 0.021 | 0.021 | |||||||
| . | W | 0 | T | 0 | 1 | 1 | ||||
| W | 1 | 0.021 | 0.021 | |||||||
| M | 1 | 0.021 | 0.021 |
| User | Category | Order | ||||
|---|---|---|---|---|---|---|
| 0 | 0 | 4 | 0 | 1 | ||
| 1 | 0 | 0 | 0 | 0 | ||
| 0 | 0 | 0 | 0 | 1 |
| Method | Training | Prediction |
|---|---|---|
| Proposed | ||
| User-based | - | |
| Item-based | ||
| Slope one | ||
| Funk SVD |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ok, M.; Lee, J.-S.; Kim, Y.B. Recommendation Framework Combining User Interests with Fashion Trends in Apparel Online Shopping. Appl. Sci. 2019, 9, 2634. https://doi.org/10.3390/app9132634
Ok M, Lee J-S, Kim YB. Recommendation Framework Combining User Interests with Fashion Trends in Apparel Online Shopping. Applied Sciences. 2019; 9(13):2634. https://doi.org/10.3390/app9132634
Chicago/Turabian StyleOk, Minjae, Jong-Seok Lee, and Yun Bae Kim. 2019. "Recommendation Framework Combining User Interests with Fashion Trends in Apparel Online Shopping" Applied Sciences 9, no. 13: 2634. https://doi.org/10.3390/app9132634
APA StyleOk, M., Lee, J.-S., & Kim, Y. B. (2019). Recommendation Framework Combining User Interests with Fashion Trends in Apparel Online Shopping. Applied Sciences, 9(13), 2634. https://doi.org/10.3390/app9132634