Algorithm for Base Action Set Generation Focusing on Undiscovered Sensor Values

Abstract
1. Introduction
2. Base Action Set Generation Algorithm Focusing on Undiscovered Sensor Values
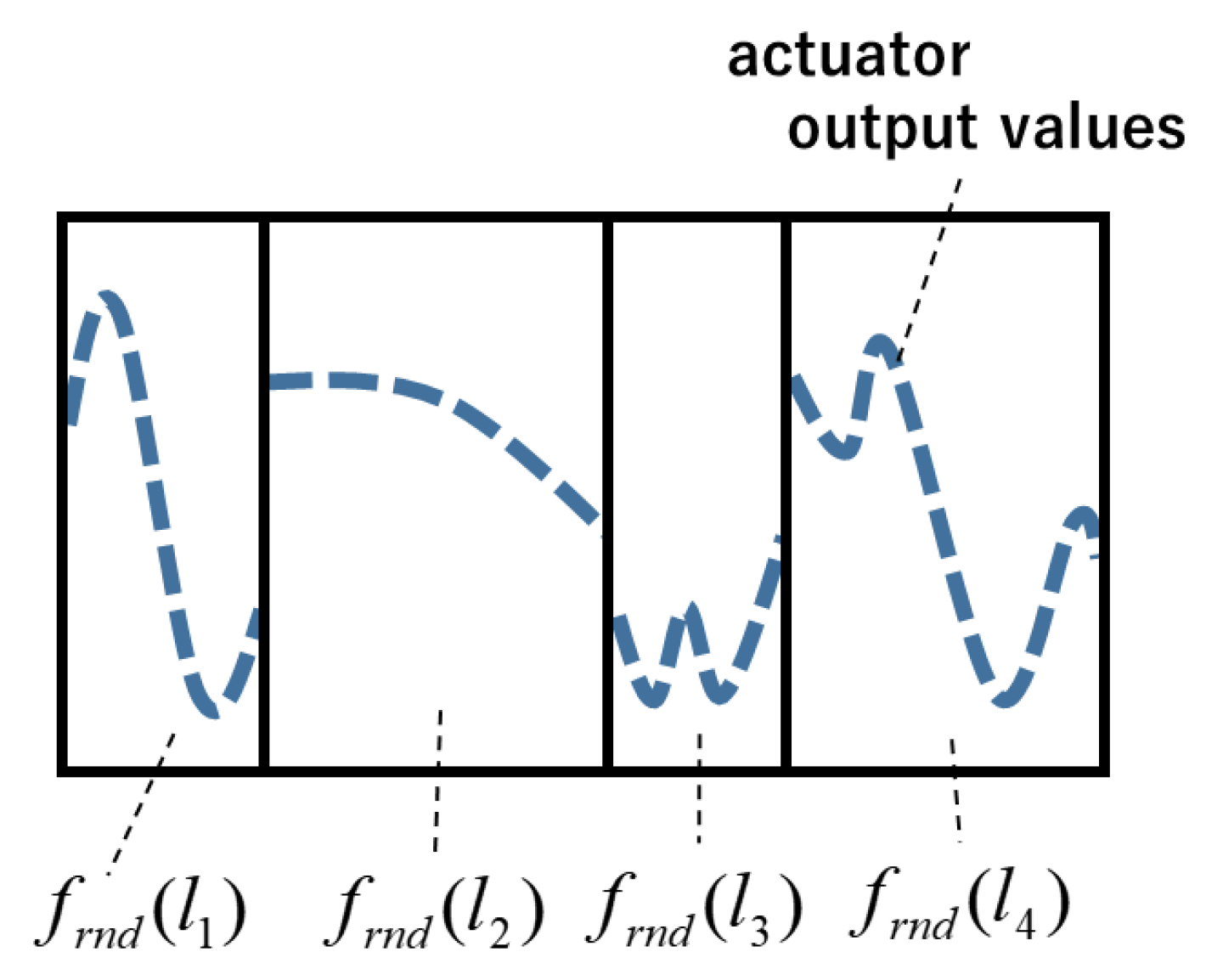
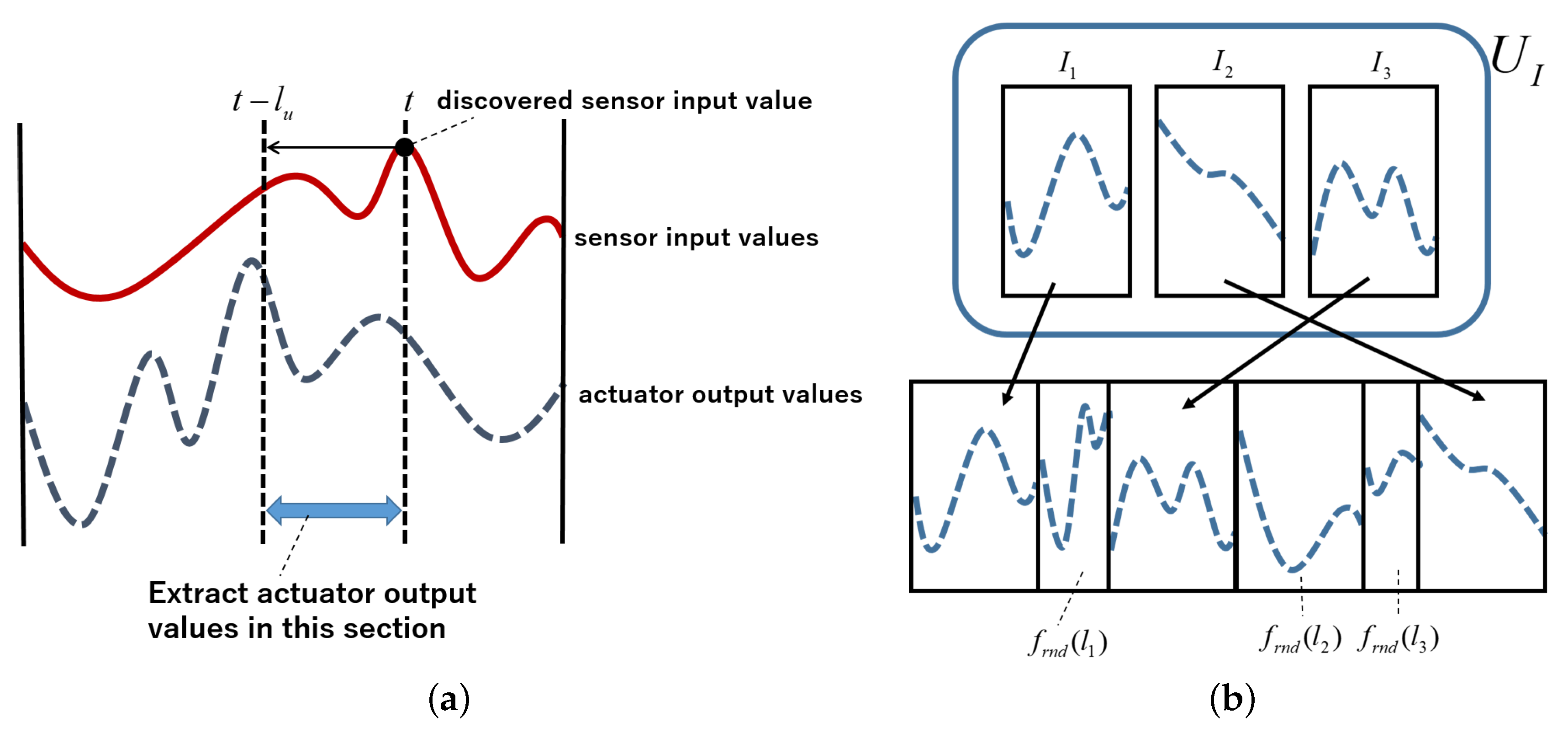
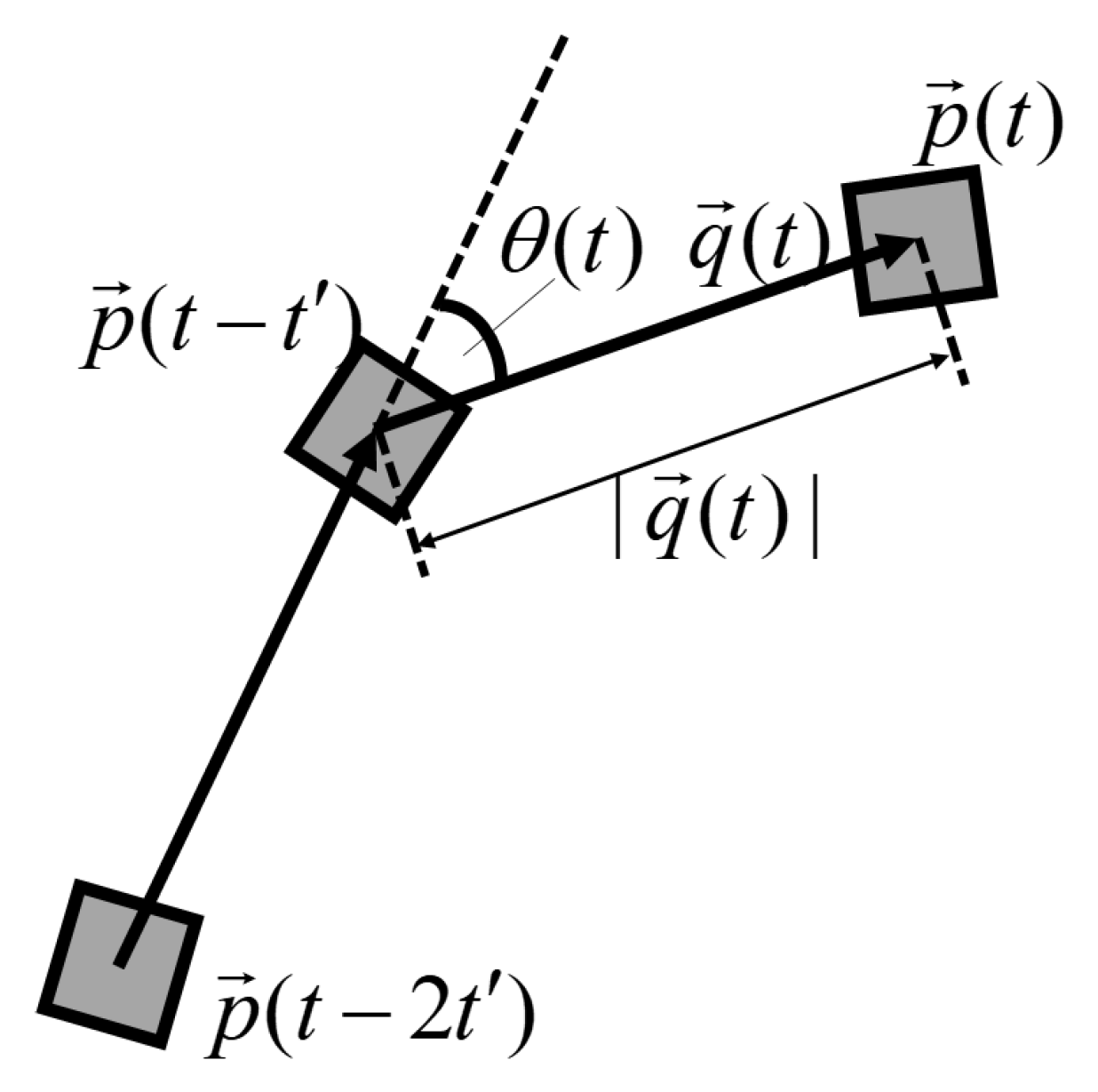
2.1. Definition of an Action Fragment
2.2. Action Fragment Operations
2.3. Random Motion Generation Algorithm for Comparison
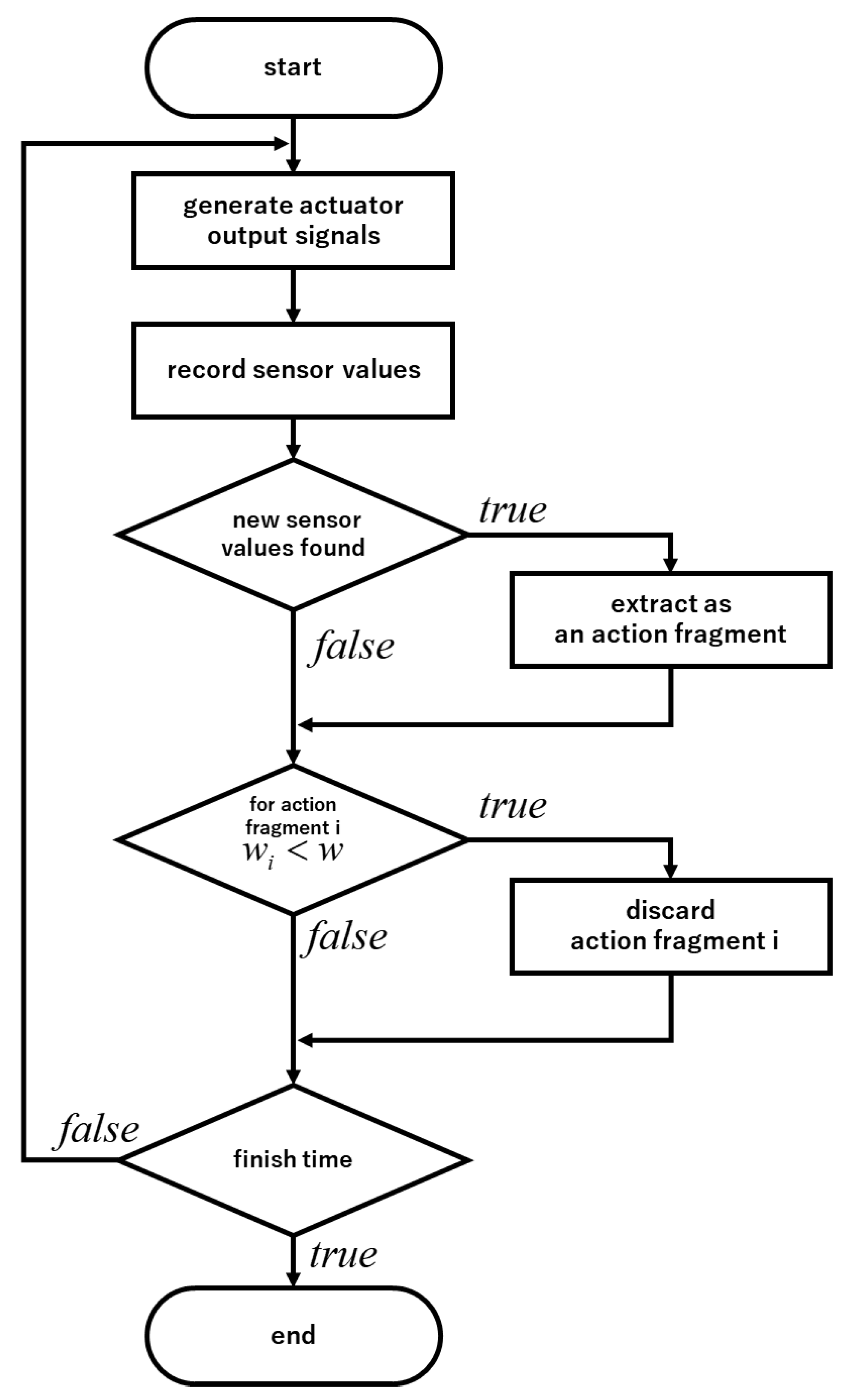
2.4. Base Action Set Generation Algorithm to Extract Actions That Cause Changes Effectively in the External Environment and to Combine Those Actions
2.5. Discard of Extracted Action Fragments
- : probability to use action fragment in a process of actuator output signal generation.
- : probability that a robot both uses in a process of actuator output signal generation and finds undiscovered sensor values.
- : probability that a robot finds undiscovered sensor values when it uses action fragment in a process of actuator output signal generation.
3. Validation of Base Action Set Generation Process Using the Proposed Algorithm through Experiments with a Differential Wheeled Robot
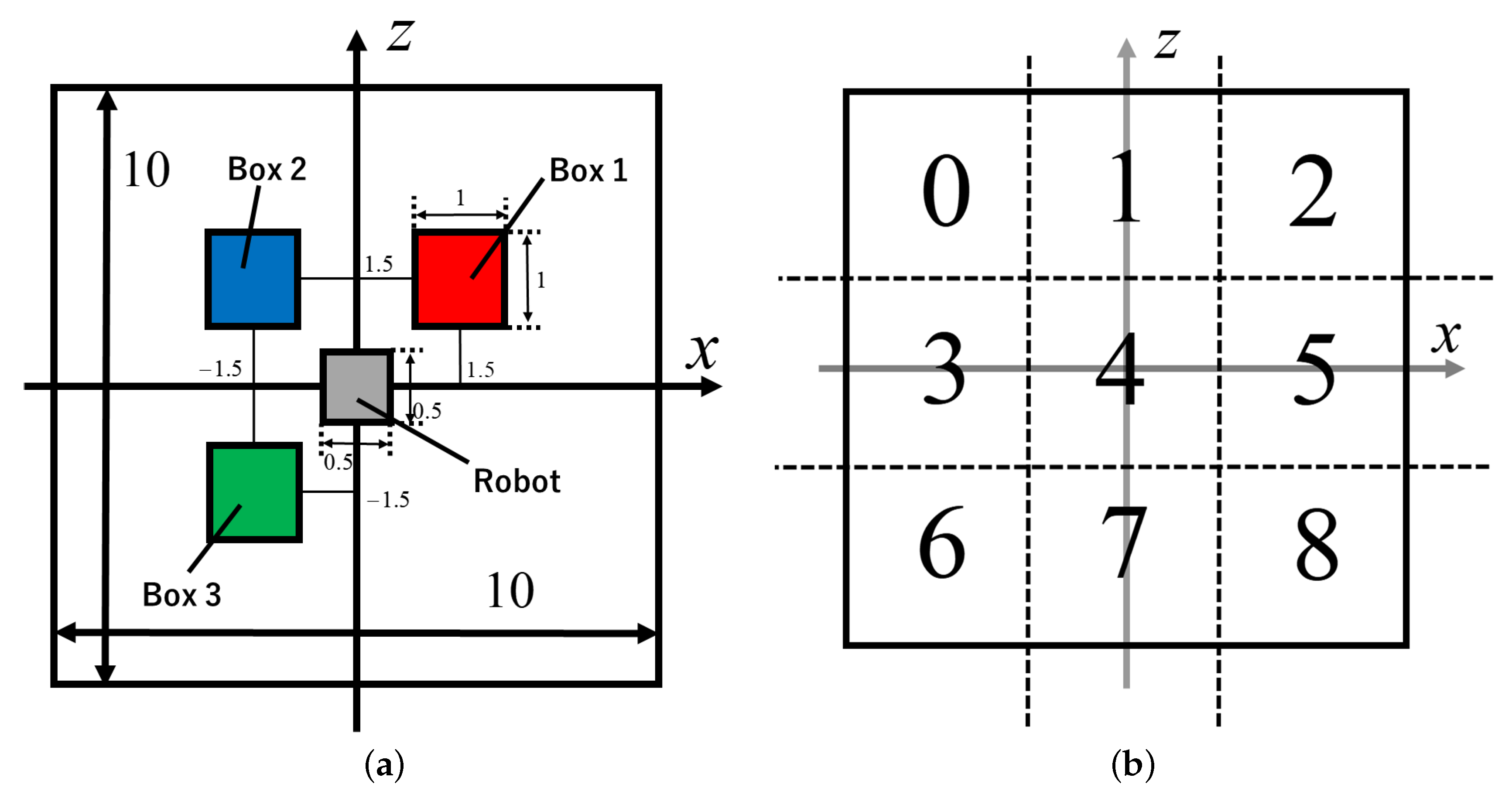
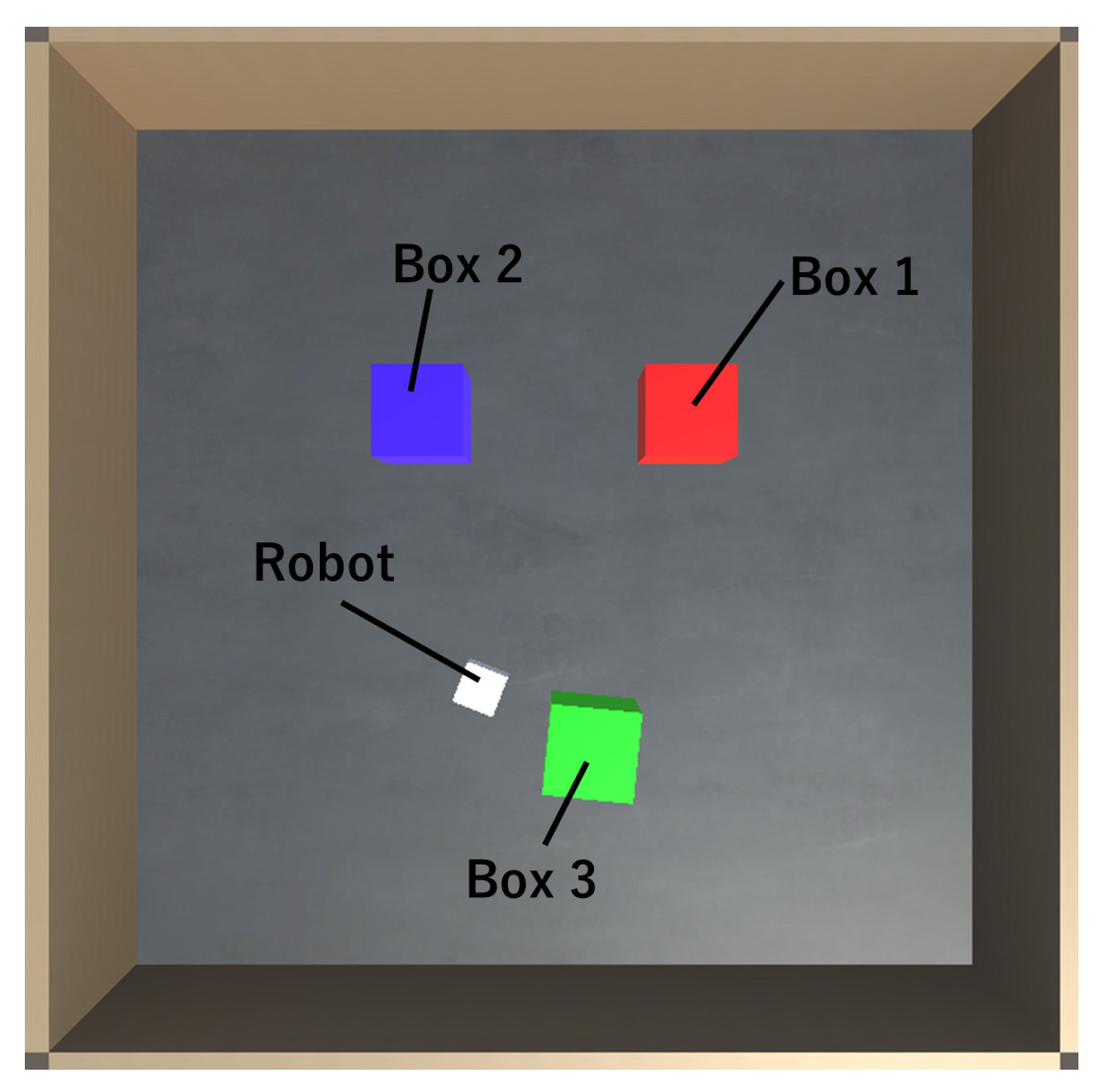
3.1. Experiment Using a Differential Wheeled Robot
3.2. Viewpoints of the Experiment
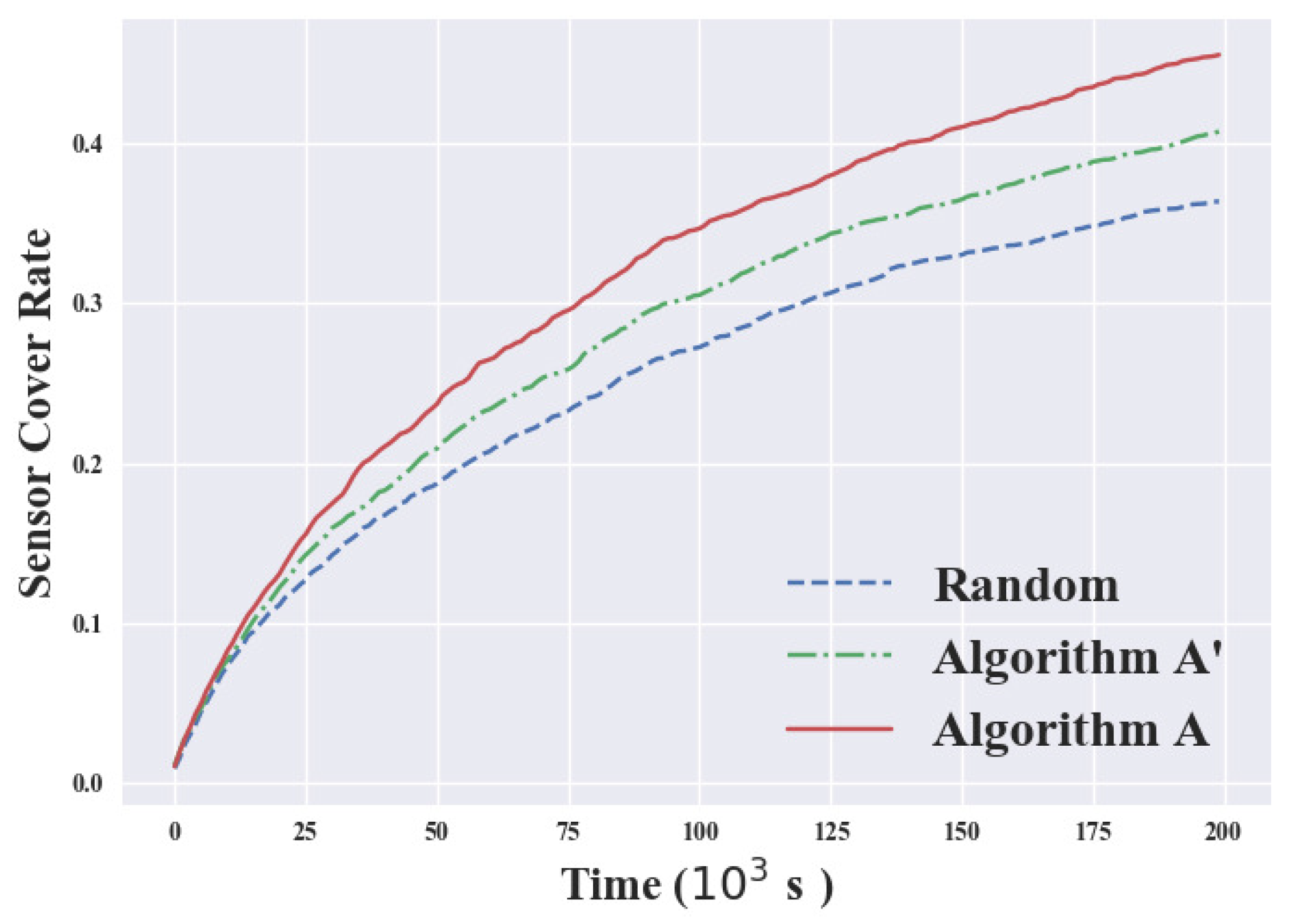
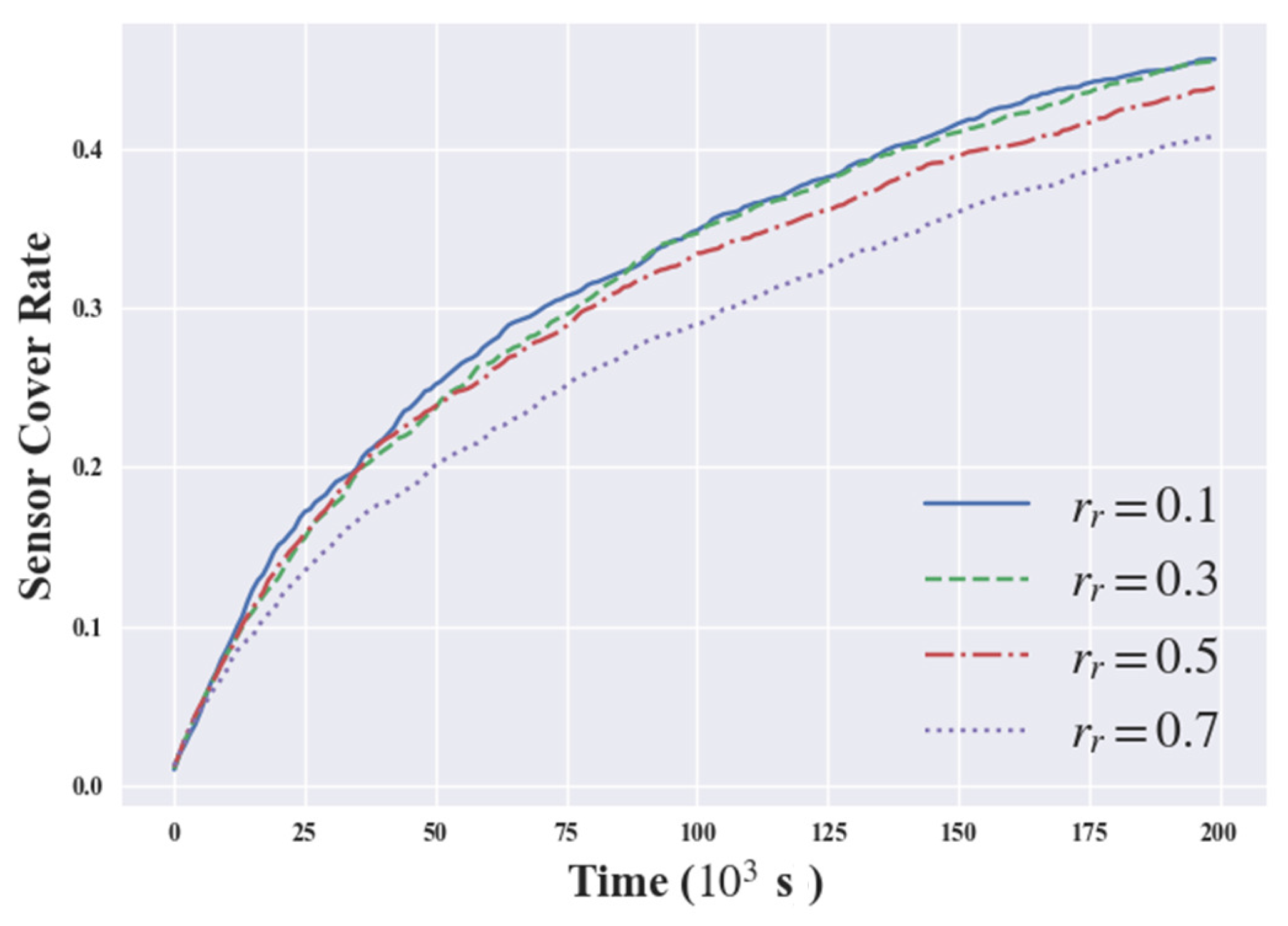
3.2.1. Sensor Cover Rate
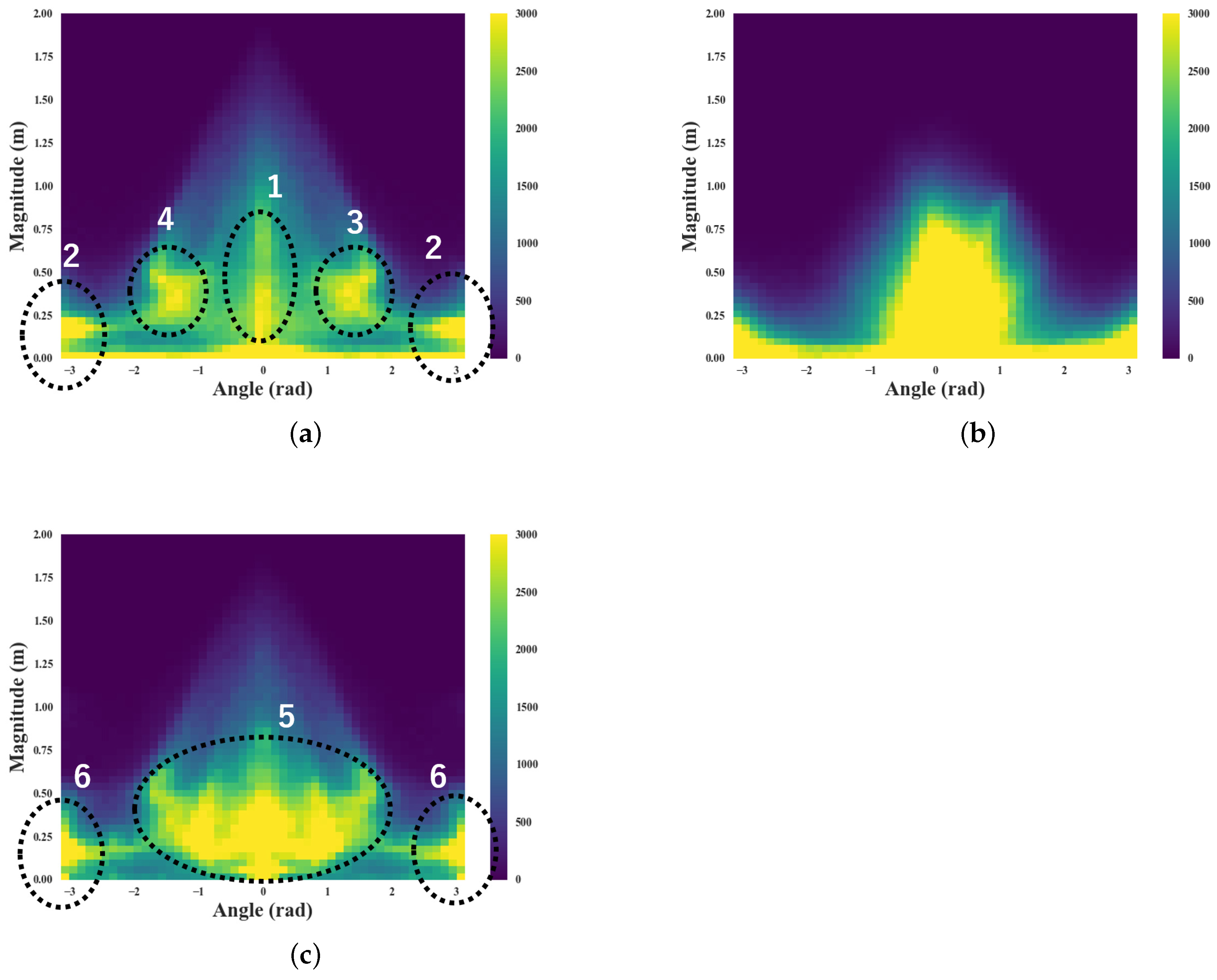
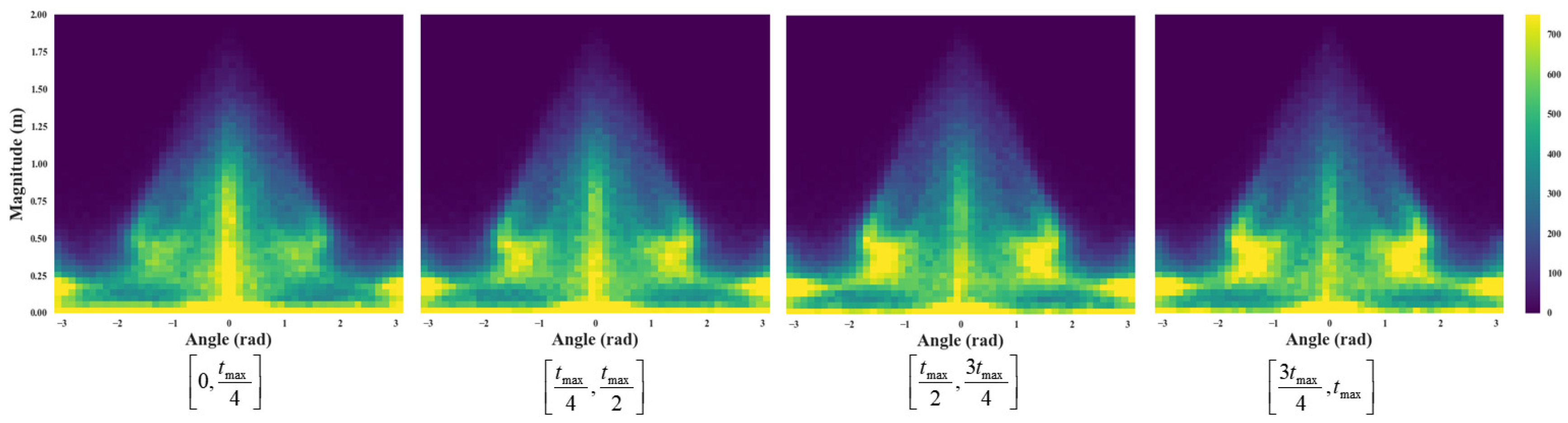
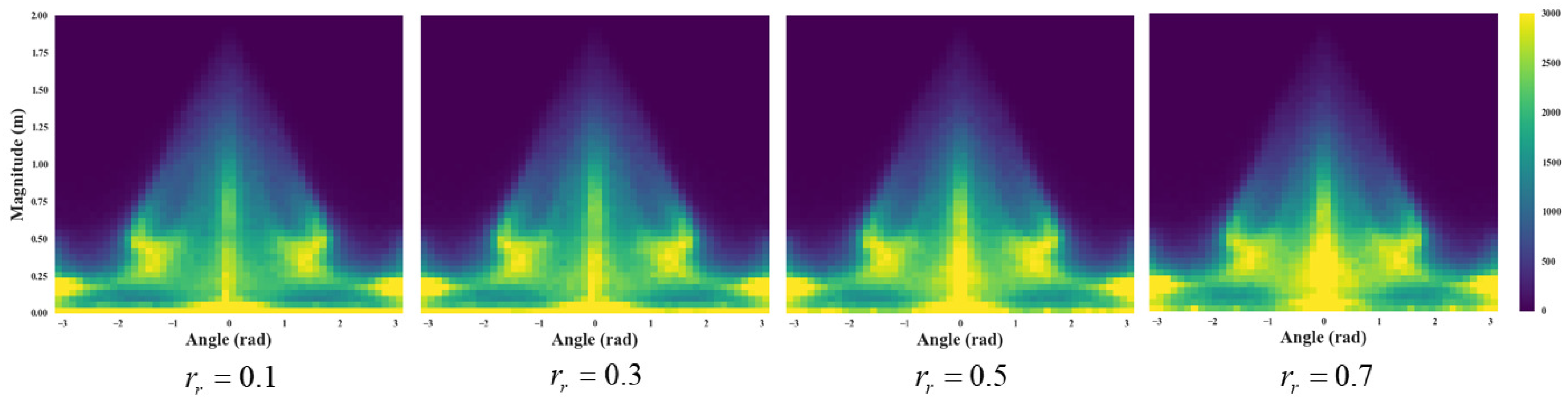
3.2.2. Distribution of the Robot’s Motion Vectors
3.3. Parameters Settings
4. Experimental Results
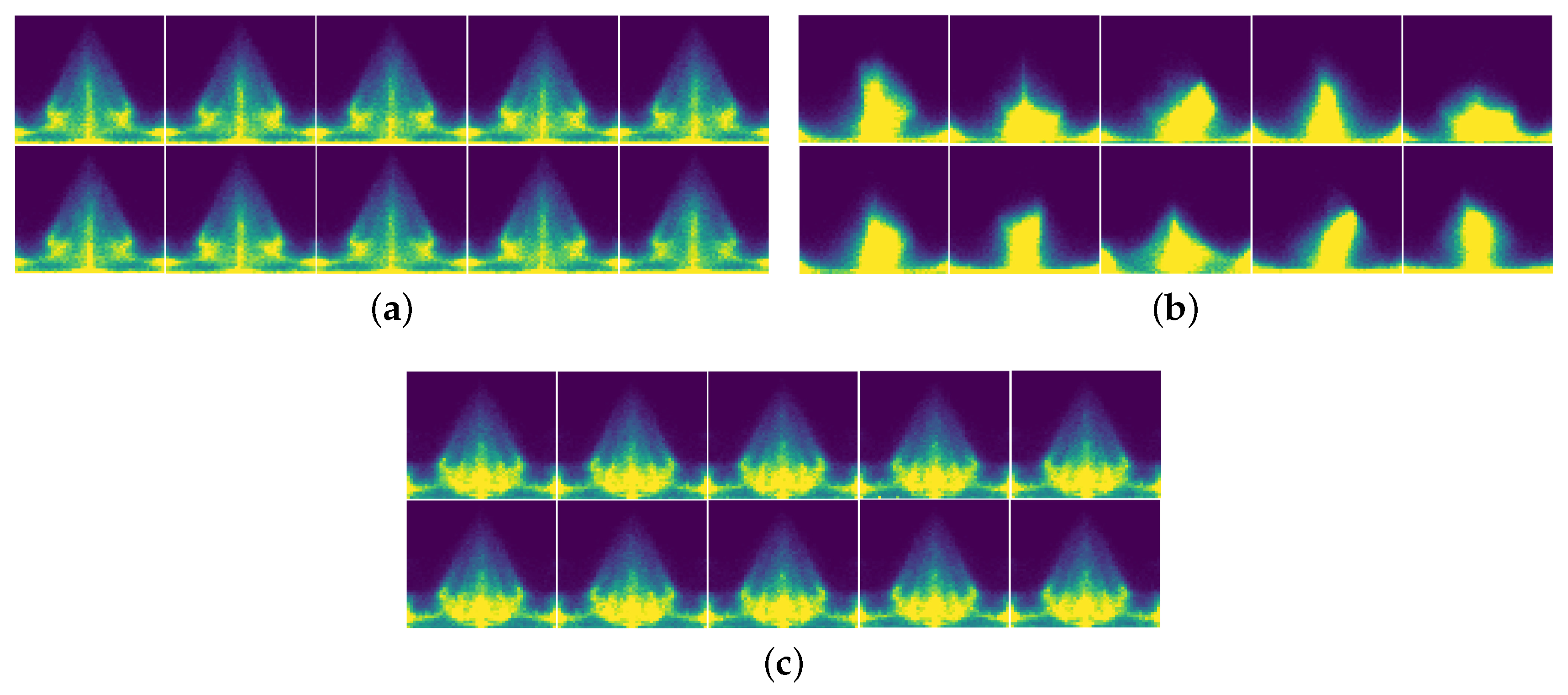
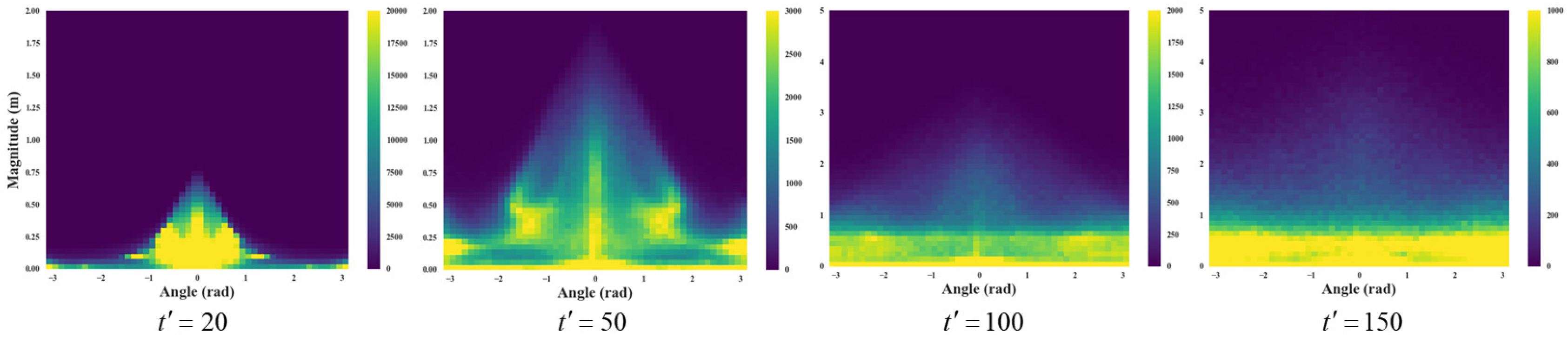
4.1. Visualization of Robot’s Motion Vectors
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Lungarella, M.; Metta, G.; Pfeifer, R.; Sandini, G. Developmental robotics: A survey. Connect. Sci. 2003, 15, 151–190. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Scheier, C.; Pfeifer, R. Classification as sensory-motor coordination. In Proceedings of the Third European Conference on Artificial Life, Granada, Spain, 4–6 June 1995; Springer: Berlin, Germany, 1995; pp. 657–667. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Li, F.F.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3357–3364. [Google Scholar]
- Qureshi, A.H.; Nakamura, Y.; Yoshikawa, Y.; Ishiguro, H. Robot gains social intelligence through multimodal deep reinforcement learning. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 745–751. [Google Scholar]
- Lei, T.; Ming, L. A robot exploration strategy based on q-learning network. In Proceedings of the IEEE International Conference on Real-time Computing and Robotics (RCAR), Angkor Wat, Cambodia, 6–10 June 2016; pp. 57–62. [Google Scholar]
- Riedmiller, M.; Gabel, T.; Hafner, R.; Lange, S. Reinforcement learning for robot soccer. Auton. Robot. 2009, 27, 55–73. [Google Scholar] [CrossRef]
- Matarić, M.J. Reinforcement Learning in the Multi-robot Domain. Auton. Robot. 1997, 4, 73–83. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G.; Barto, A.G.; Bach, F. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Mitchell, T.M.; Thrun, S.B. Explanation-based neural network learning for robot control. In Proceedings of the 5th International Conference on Neural Information Processing Systems, Denver, CO, USA, 30 November–3 December 1992; pp. 287–294. [Google Scholar]
- Pfeiffer, M.; Nessler, B.; Douglas, R.J.; Maass, W. Reward-modulated hebbian learning of decision making. Neural Comput. 2010, 22, 1399–1444. [Google Scholar] [CrossRef] [PubMed]
- Hafner, R.; Riedmiller, M. Neural reinforcement learning controllers for a real robot application. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 2098–2103. [Google Scholar]
- Kormushev, P.; Calinon, S.; Caldwell, D.G. Reinforcement learning in robotics: Applications and real-world challenges. Robotics 2013, 2, 122–148. [Google Scholar] [CrossRef]
- Kober, J.; Peters, J.R. Policy search for motor primitives in robotics. In Advances in Neural Information Processing Systems; Curran Associates: Vancouver, BC, Canada, 2009; pp. 849–856. [Google Scholar]
- Shen, H.; Yosinski, J.; Kormushev, P.; Caldwell, D.G.; Lipson, H. Learning fast quadruped robot gaits with the RL power spline parameterization. Cybern. Inf. Technol. 2012, 12, 66–75. [Google Scholar] [CrossRef]
- Ijspeert, A.J.; Nakanishi, J.; Schaal, S. Learning attractor landscapes for learning motor primitives. In Advances in Neural Information Processing Systems; Curran Associates: Vancouver, BC, Canada, 2003; pp. 1547–1554. [Google Scholar]
- Kimura, H.; Yamashita, T.; Kobayashi, S. Reinforcement learning of walking behavior for a four-legged robot. IEEJ Trans. Electron. Inf. Syst. 2002, 122, 330–337. [Google Scholar]
- Shibata, K.; Okabe, Y.; Ito, K. Direct-Vision-Based Reinforcement Learning Using a Layered Neural Network. Trans. Soc. Instrum. Control Eng. 2001, 37, 168–177. [Google Scholar] [CrossRef]
- Goto, Y.; Shibata, K. Emergence of higher exploration in reinforcement learning using a chaotic neural network. In Proceedings of the International Conference on Neural Information Processing, Siem Reap, Cambodia, 13–16 December 2018; Springer: Berlin, Germany, 2016; pp. 40–48. [Google Scholar]
- Dutta, A.; Dasgupta, P.; Nelson, C. Adaptive locomotion learning in modular self-reconfigurable robots: A game theoretic approach. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 3556–3561. [Google Scholar] [CrossRef]
- Lample, G.; Chaplot, D.S. Playing FPS Games with Deep Reinforcement Learning. In Proceedings of the Conference on Artificial Intelligence AAAI, San Francisco, CA, USA, 4–9 February 2017; pp. 2140–2146. [Google Scholar]
- Sallab, A.E.; Abdou, M.; Perot, E.; Yogamani, S. Deep reinforcement learning framework for autonomous driving. Electron. Imaging 2017, 2017, 70–76. [Google Scholar] [CrossRef]
- Ran, L.; Zhang, Y.; Zhang, Q.; Yang, T. Convolutional neural network-based robot navigation using uncalibrated spherical images. Sensors 2017, 17, 1341. [Google Scholar] [CrossRef] [PubMed]
- Taki, R.; Maeda, Y.; Takahashi, Y. Generation Method of Mixed Emotional Behavior by Self-Organizing Maps in Interactive Emotion Communication. J. Jpn. Soc. Fuzzy Theory Intell. Inform. 2012, 24, 933–943. [Google Scholar] [CrossRef]
- Gotoh, M.; Kanoh, M.; Kato, S.; Kunitachi, T.; Itoh, H. Face Generation Using Emotional Regions for Sensibility Robot. Trans. Jpn. Soc. Artif. Intell. 2006, 21, 55–62. [Google Scholar] [CrossRef]
- Matsui, Y.; Kanoh, M.; Kato, S.; Nakamura, T.; Itoh, H. A Model for Generating Facial Expressions Using Virtual Emotion Based on Simple Recurrent Network. JACIII 2010, 14, 453–463. [Google Scholar] [CrossRef]
- Yano, Y.; Yamaguchi, A.; Doki, S.; Okuma, S. Emotional Motion Generation Using Emotion Representation Rules Modeled for Human Affection. J. Jpn. Soc. Fuzzy Theory Intell. Inform. 2010, 22, 39–51. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Action fragment extraction length | |
| Action generation random rate | |
| Discard criterion threshold | |
| Time interval of motion vectors | |
| Minimum length of random motion generation | |
| Maximum length of random motion generation |
| Algorithm | Standard Deviation |
|---|---|
| Algorithm A | 0.0261 |
| Algorithm A’ | 0.1443 |
| Algorithm Random | 0.0102 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yamauchi, S.; Suzuki, K. Algorithm for Base Action Set Generation Focusing on Undiscovered Sensor Values. Appl. Sci. 2019, 9, 161. https://doi.org/10.3390/app9010161
Yamauchi S, Suzuki K. Algorithm for Base Action Set Generation Focusing on Undiscovered Sensor Values. Applied Sciences. 2019; 9(1):161. https://doi.org/10.3390/app9010161
Chicago/Turabian StyleYamauchi, Sho, and Keiji Suzuki. 2019. "Algorithm for Base Action Set Generation Focusing on Undiscovered Sensor Values" Applied Sciences 9, no. 1: 161. https://doi.org/10.3390/app9010161
APA StyleYamauchi, S., & Suzuki, K. (2019). Algorithm for Base Action Set Generation Focusing on Undiscovered Sensor Values. Applied Sciences, 9(1), 161. https://doi.org/10.3390/app9010161