A Brief History of Cloud Application Architectures


Abstract
:Featured Application
Abstract
1. Introduction
- Practitioners prefer to transfer platforms (and not applications).
- Practitioners want to have the choice between platforms.
- Practitioners prefer declarative and cybernetic (auto-adjusting) instead of workflow-based (imperative) deployment and orchestration approaches.
- Practitioners are forced to make efficient use of cloud resources because more and more systems are migrated to cloud infrastructures causing steadily increasing bills.
- Practitioners rate pragmatism of solutions much higher than full feature coverage of cloud platforms and infrastructures.
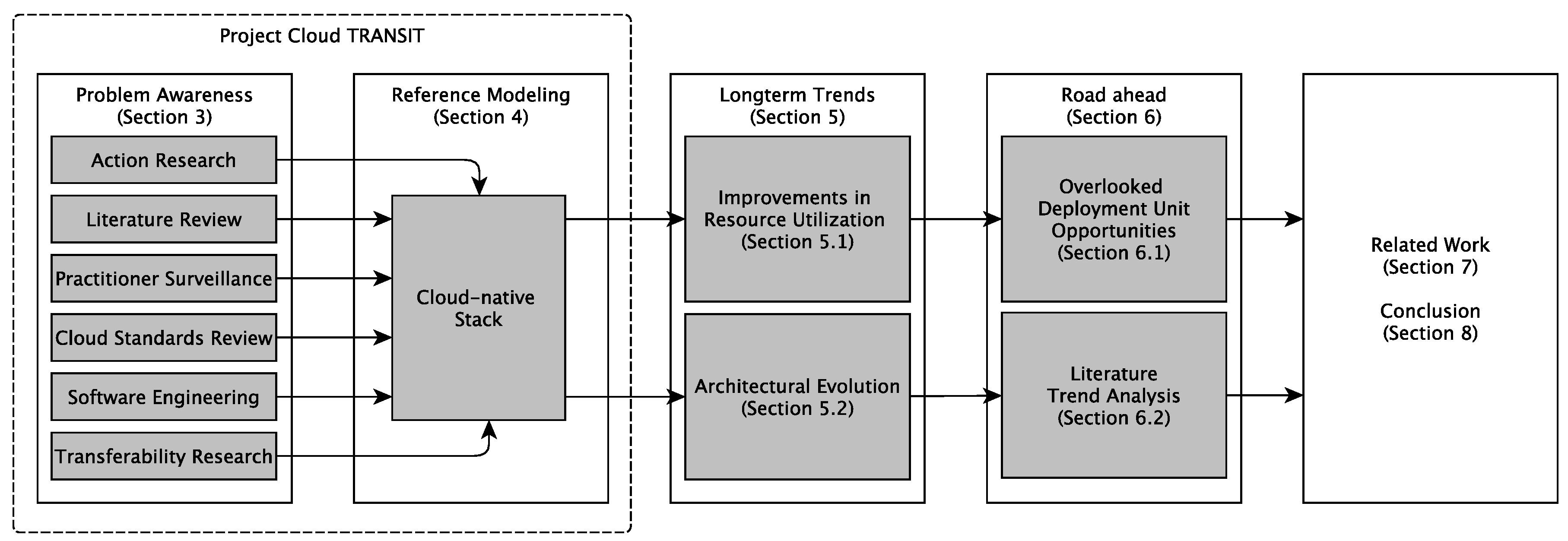
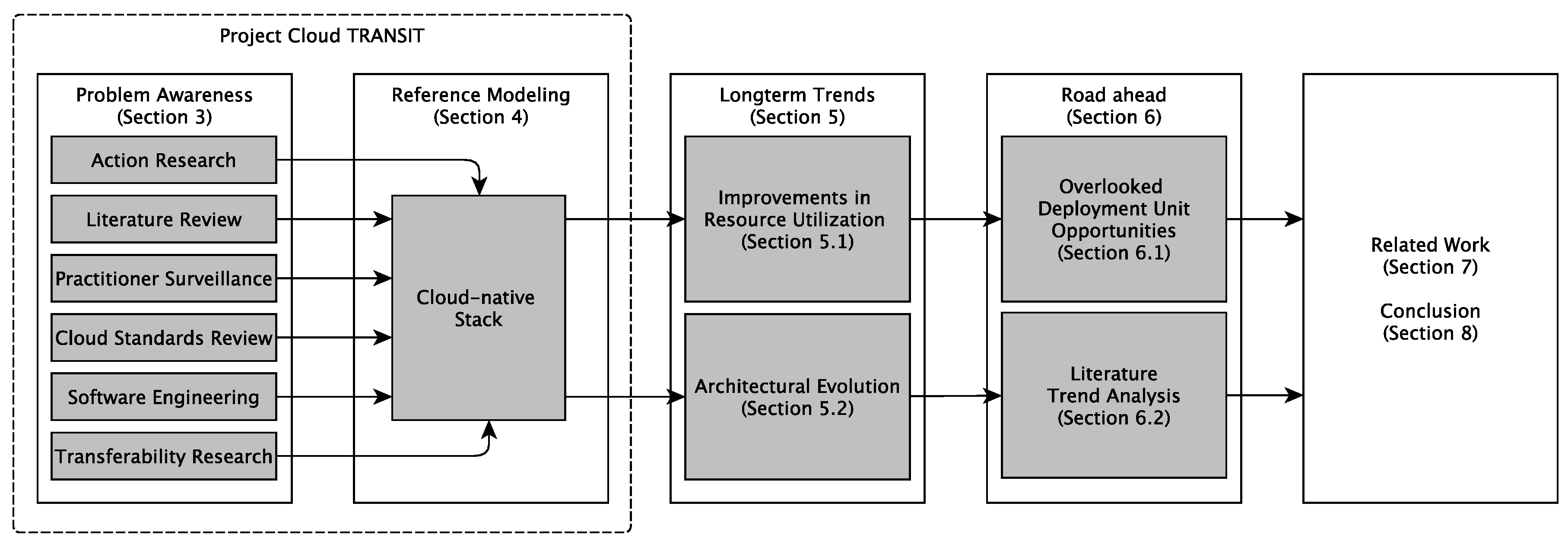
2. Methodology and Outline of This Paper
3. Problem Awareness (from the Research Project Cloud TRANSIT)
4. Reference Modeling—How Cloud Applications Look
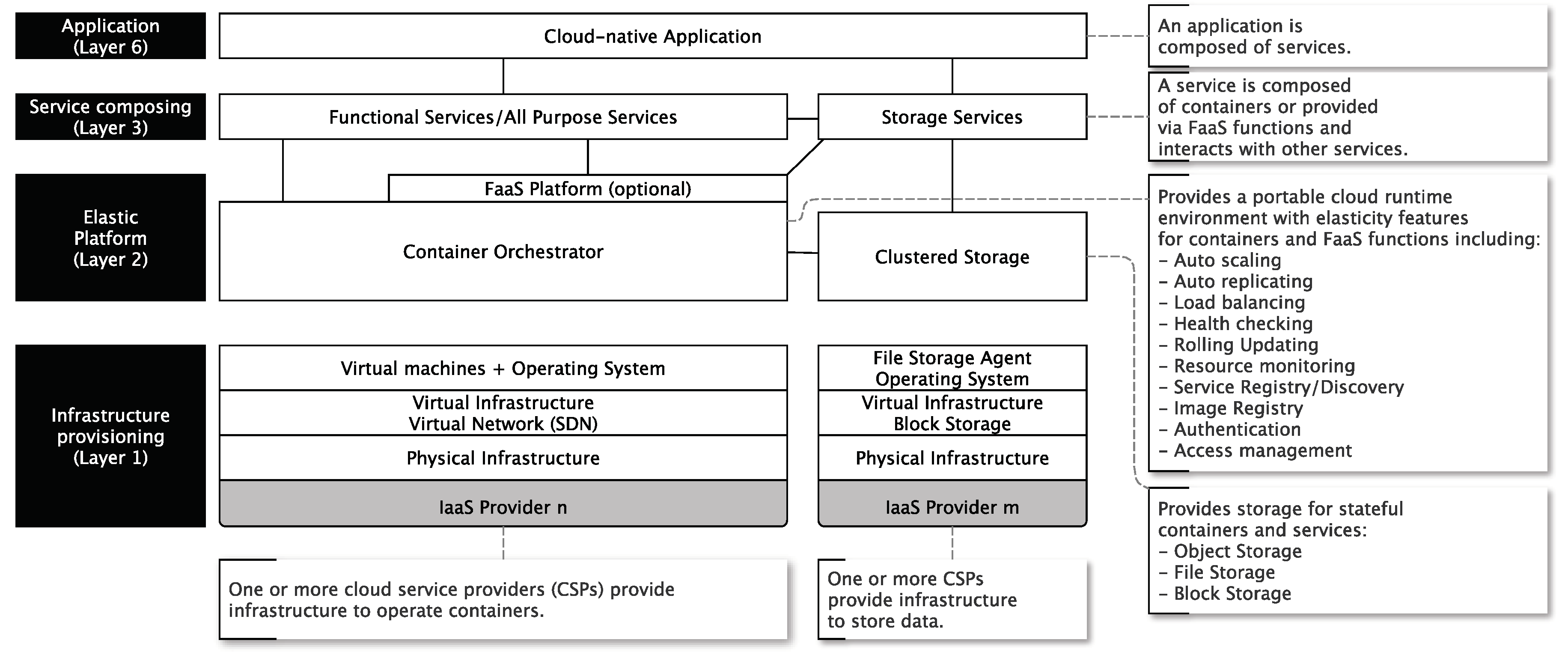
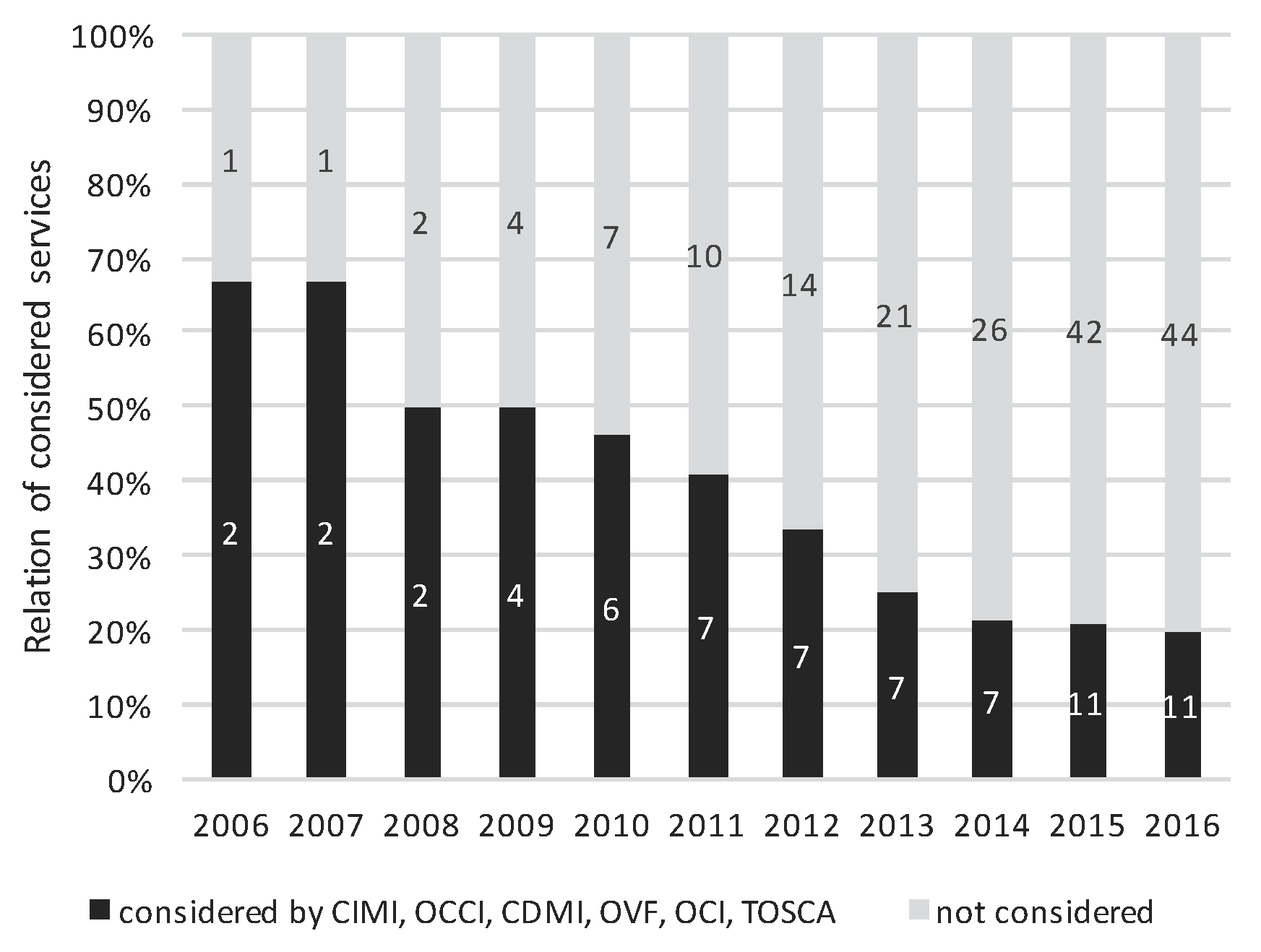
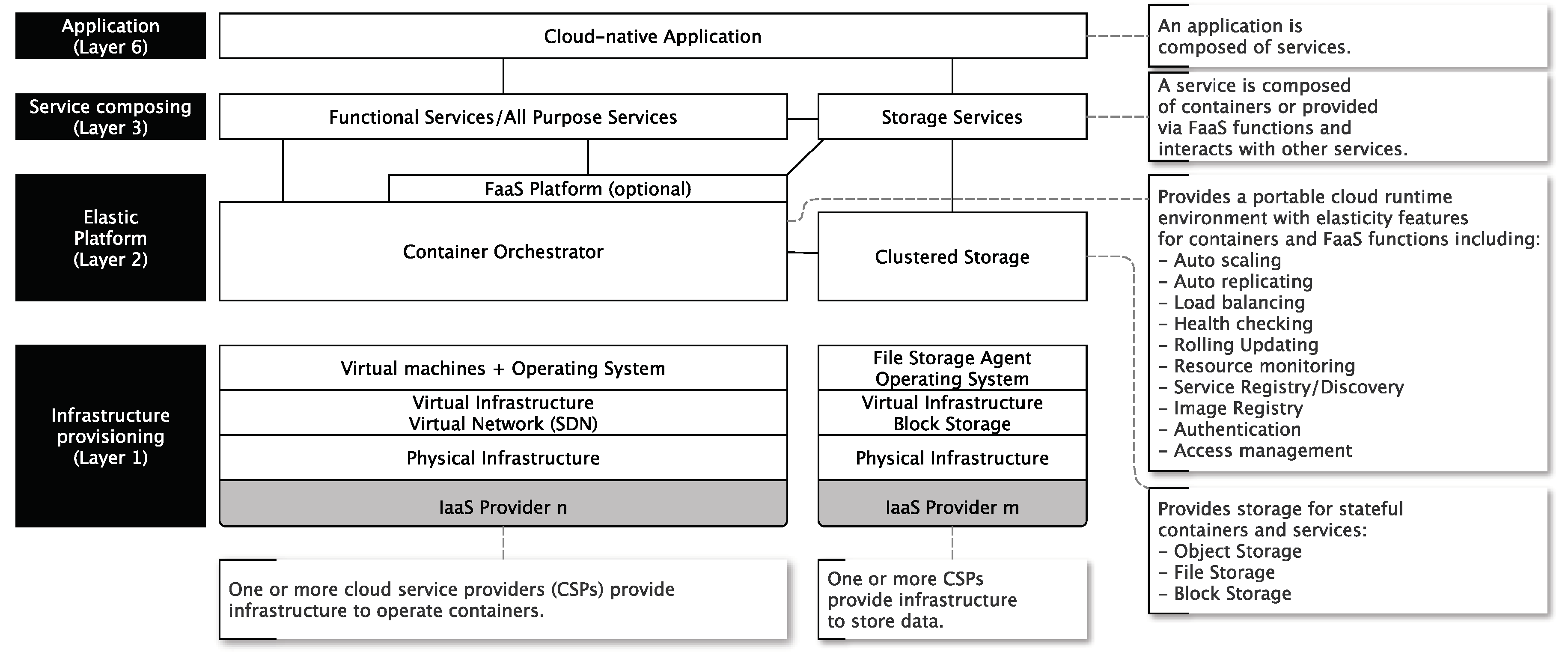
- Infrastructure provisioning: This is a viewpoint being familiar for engineers working on the infrastructure level and how IaaS is understood. IaaS deals with the deployment of separate compute nodes for a cloud consumer. It is up to the cloud consumer what he does with these isolated nodes (even if there are hundreds of them).
- Clustered elastic platforms: This is a viewpoint being familiar for engineers who are dealing with horizontal scalability across nodes. Clusters are a concept to handle many Layer 1 nodes as one logical compute node (a cluster). Such kind of technologies is often the technological backbone for portable cloud runtime environments because they are hiding complexity (of hundreds or thousands of single nodes) appropriately. Additionally, this layer realizes the foundation to define services and applications without reference to particular cloud services, cloud platforms or cloud infrastructures. Thus, it provides a foundation to avoid vendor lock-in.
- Service composing: This is a viewpoint familiar for application engineers dealing with Web services in service-oriented architectures (SOA). These (micro)-services operate on a Layer 2 cloud runtime platform (like Kubernetes, Mesos, Swarm, Nomad, and so on). Thus, the complex orchestration and scaling of these services are abstracted and delegated to a cluster (cloud runtime environment) on Layer 2.
- Application: This is a viewpoint being familiar for end-users of cloud services (or cloud-native applications). These cloud services are composed of smaller cloud Layer 3 services being operated on clusters formed of single compute and storage nodes.
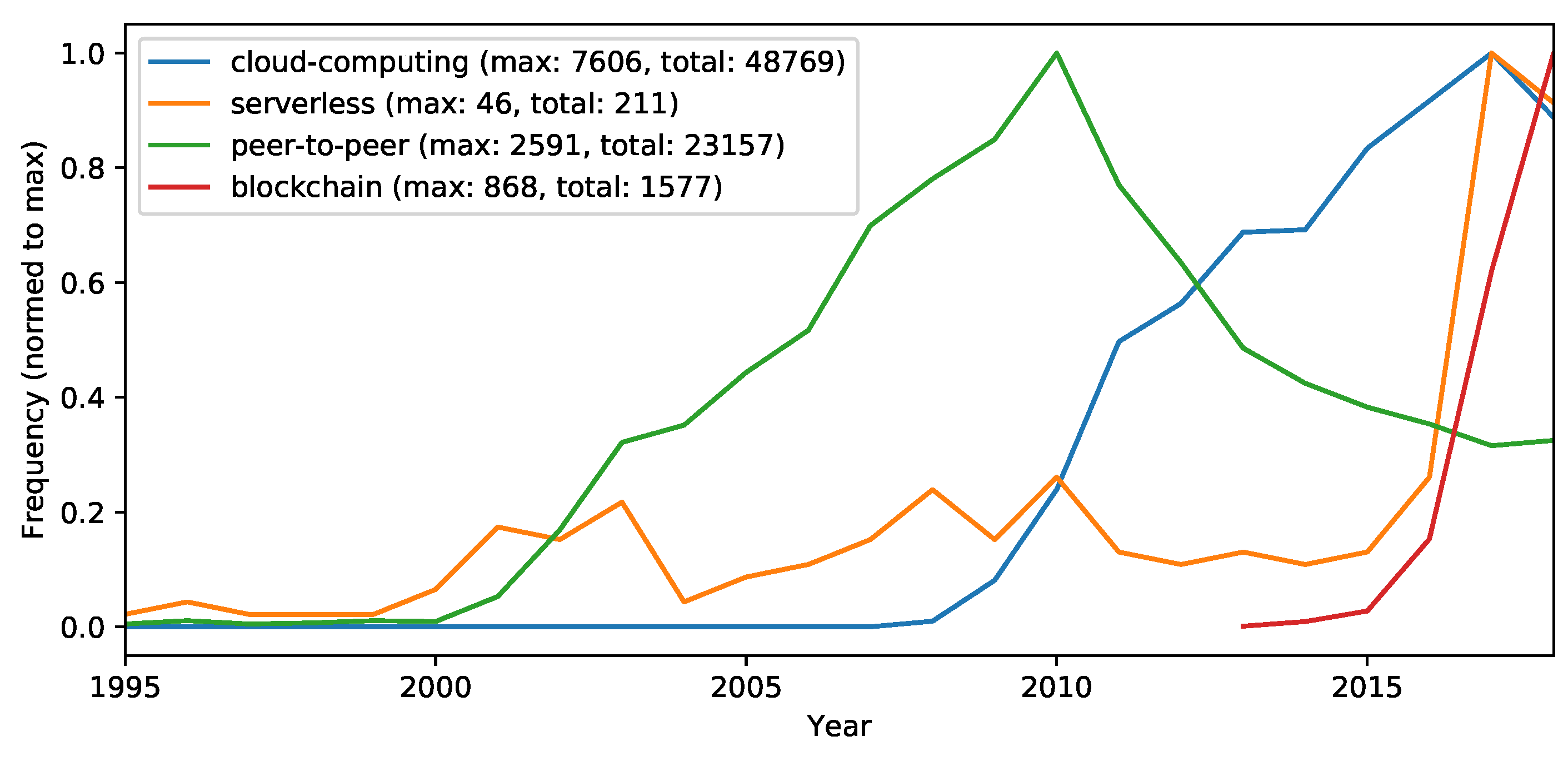
5. Observable Long-Term Trends in Cloud Systems Engineering
- In Section 5.1, we will investigate cloud application architectures from a resource utilization point of view over time.
- In Section 5.2, we will investigate cloud application architectures more from an evolutionary architecture point of view focusing mainly functional stability and reliability but also addressing compatibility, maintainability, and portability according to [26].
5.1. A Review of the Resource Utilization Evolution and Its Impact on Cloud Technology Architectures
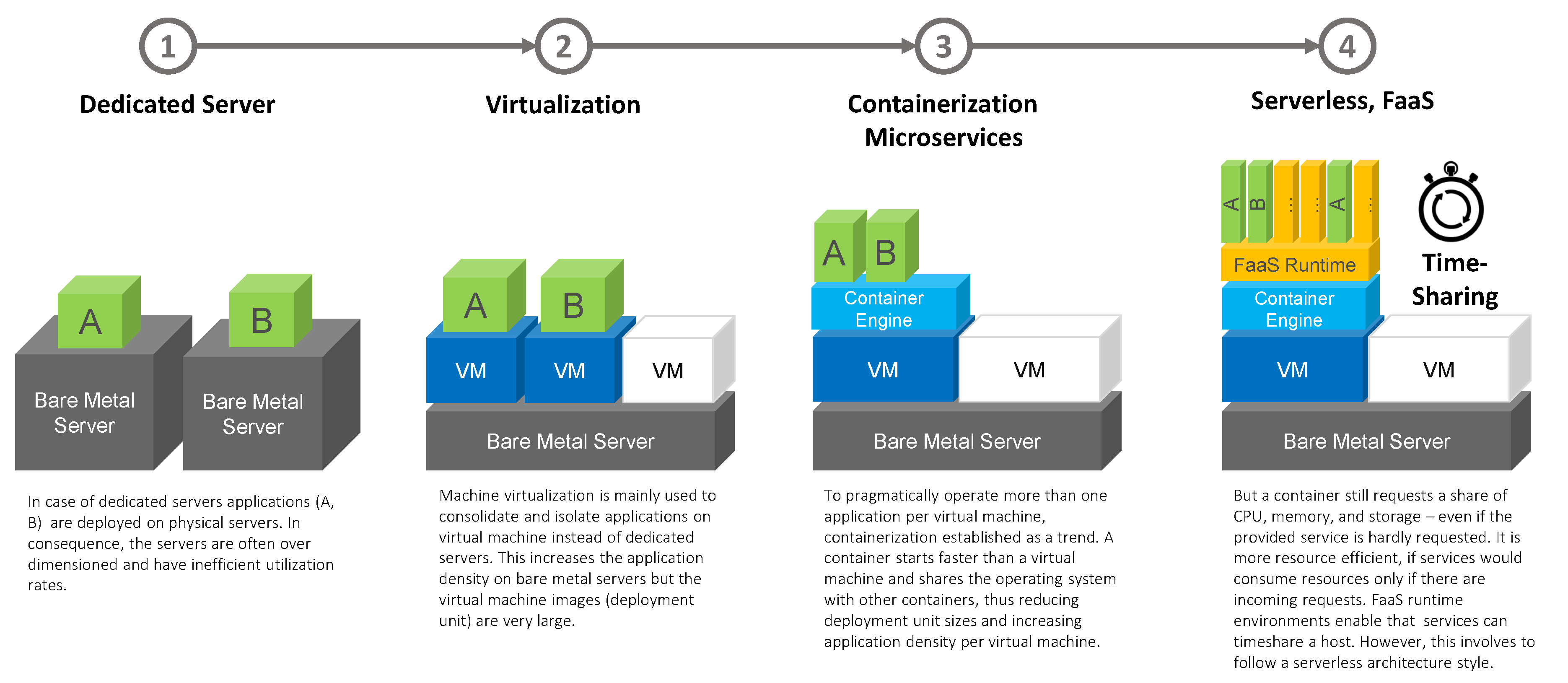
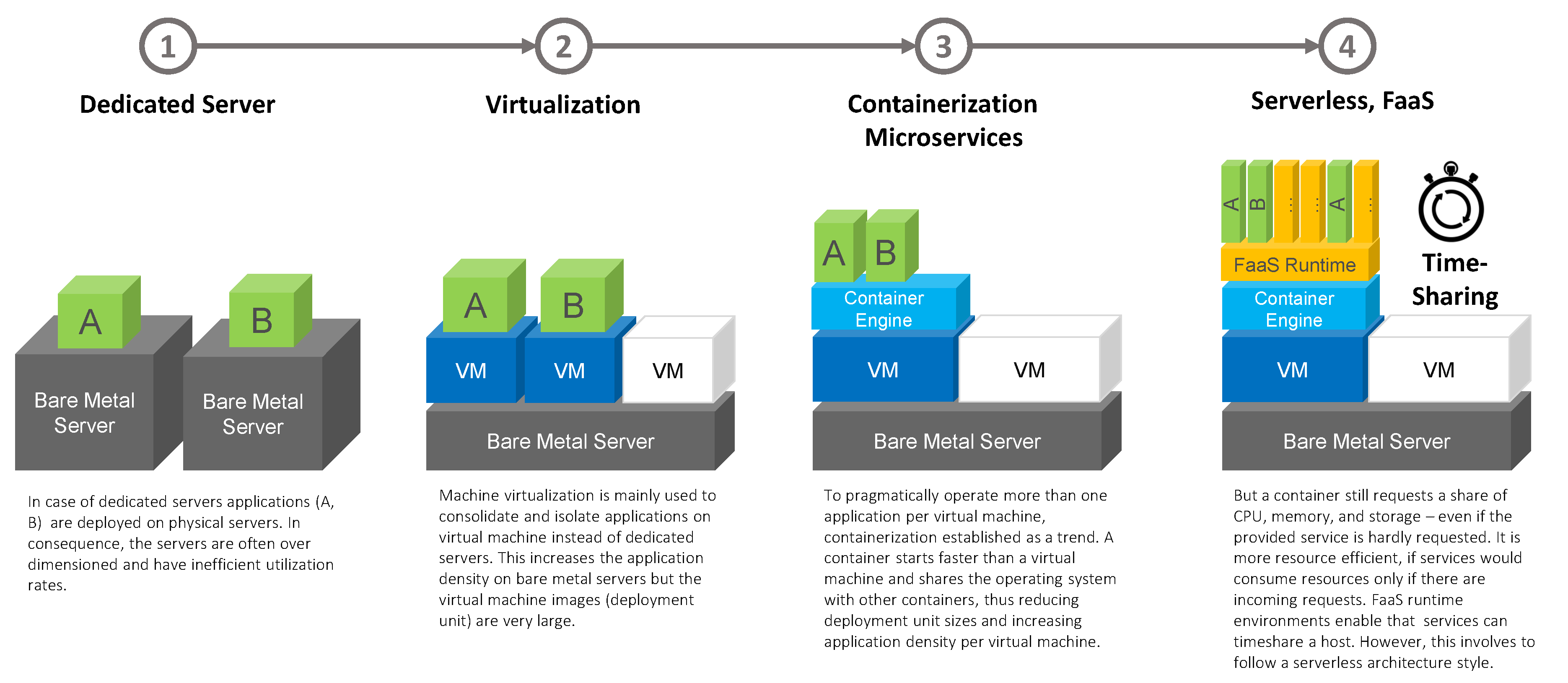
5.1.1. Service-Oriented Deployment Monoliths
“A monolithic software application is a software application composed of modules that are not independent of the application to which they belong. Since the modules of a monolith depend on said shared resources, they are not independently executable. This makes monoliths difficult to naturally distribute without the use of specific frameworks or ad hoc solutions [...]. In the context of cloud-based distributed systems, this represents a significant limitation, in particular, because previous solutions leave synchronization responsibilities to the developer ”.[45]
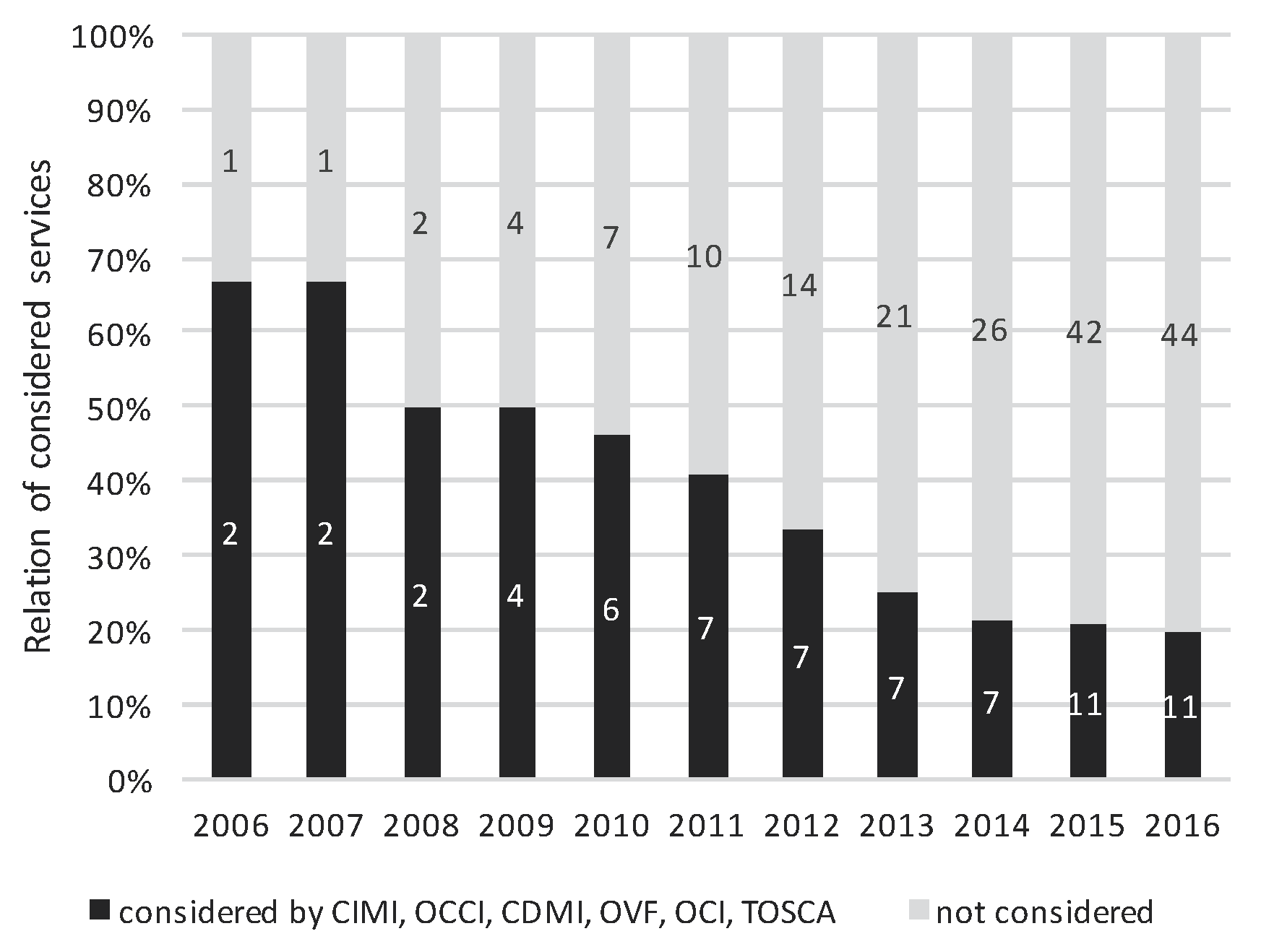
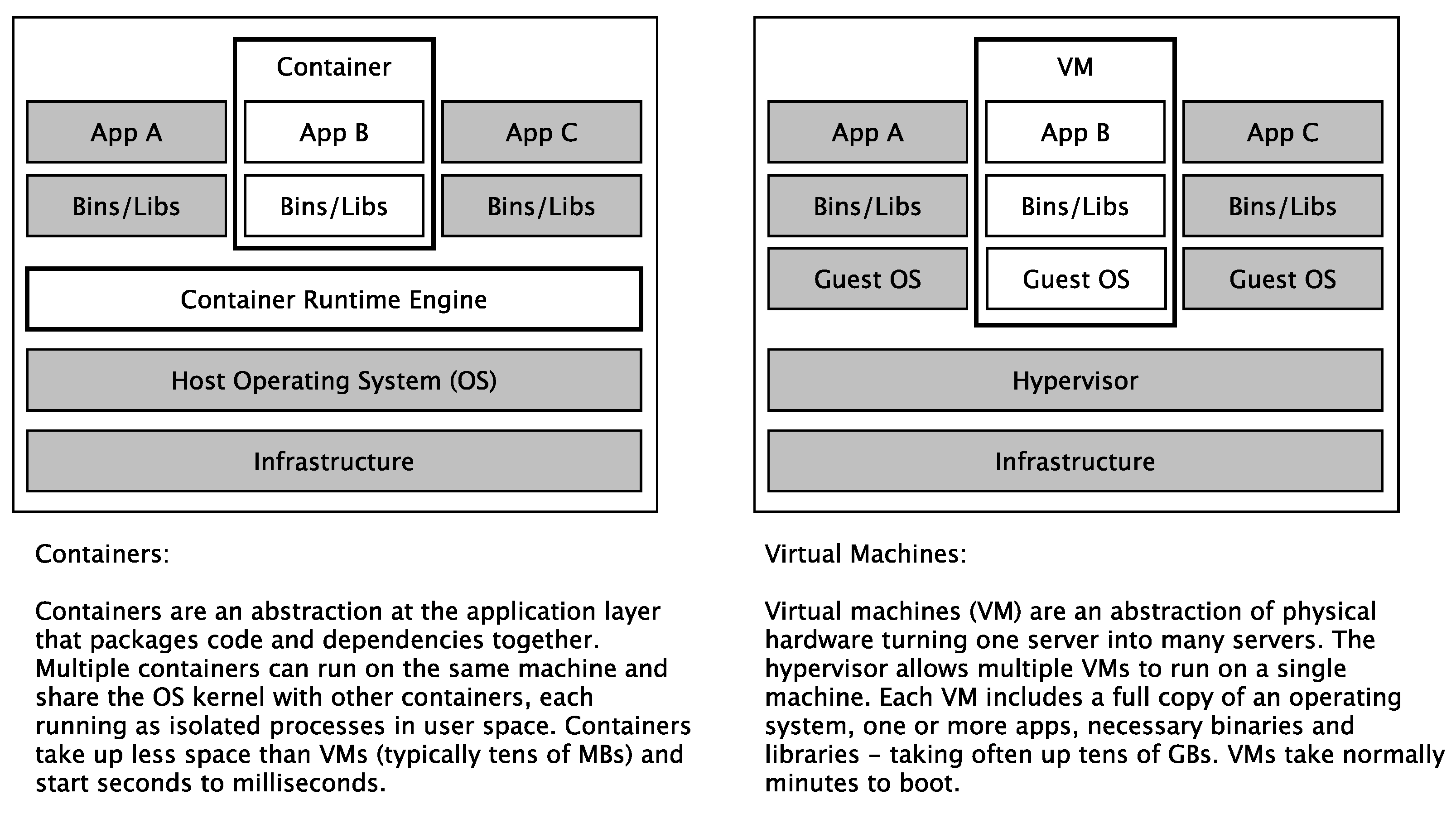
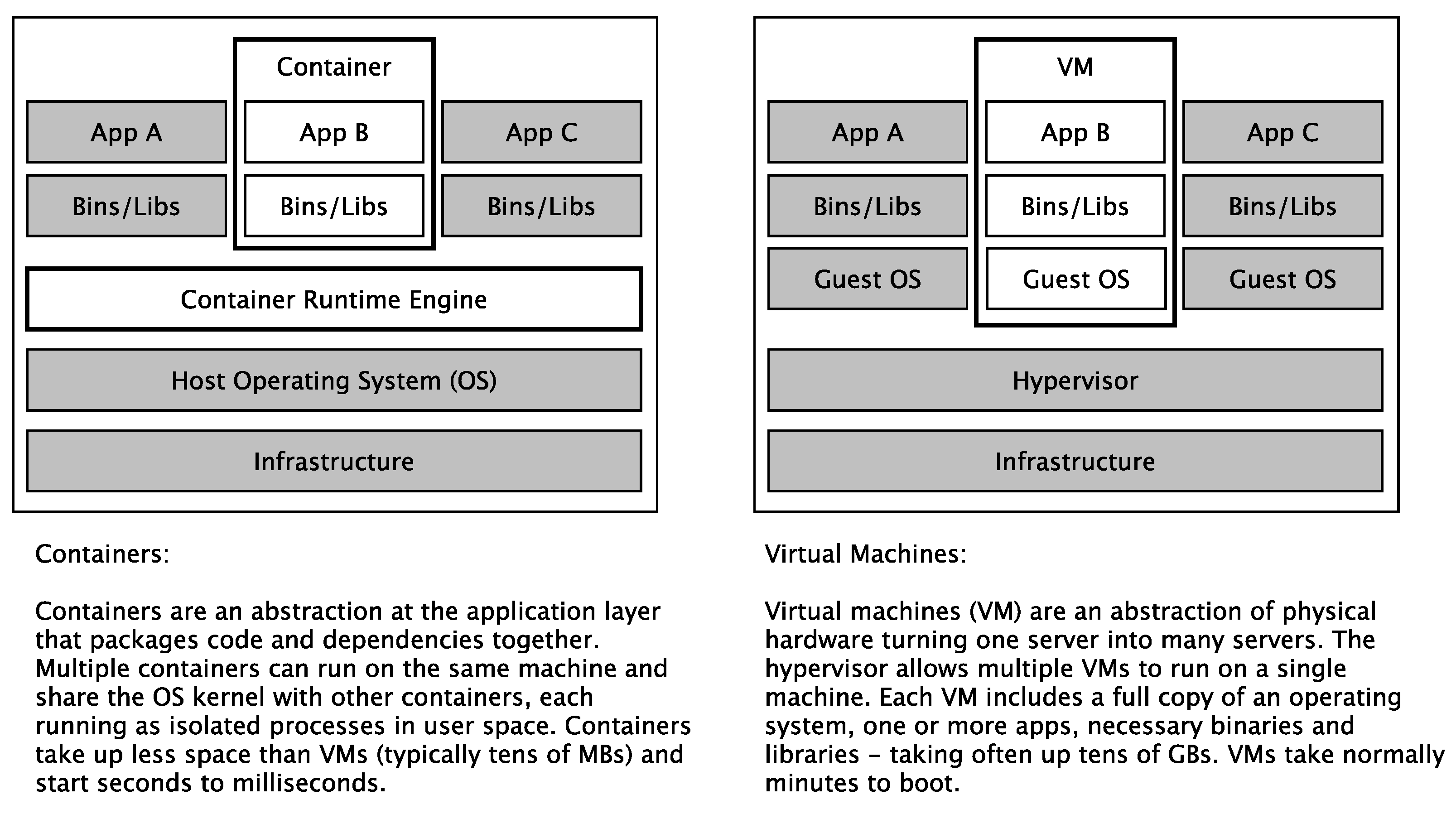
5.1.2. Standardized and Self-Contained Deployment Units
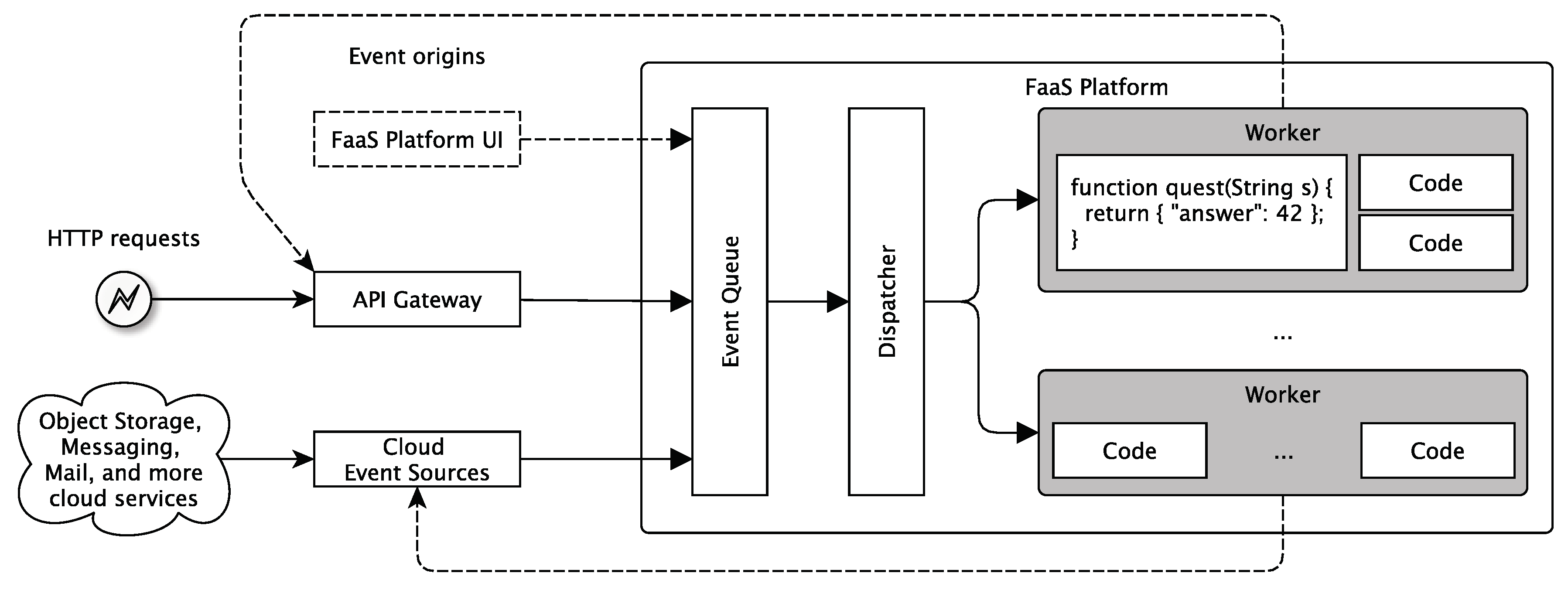
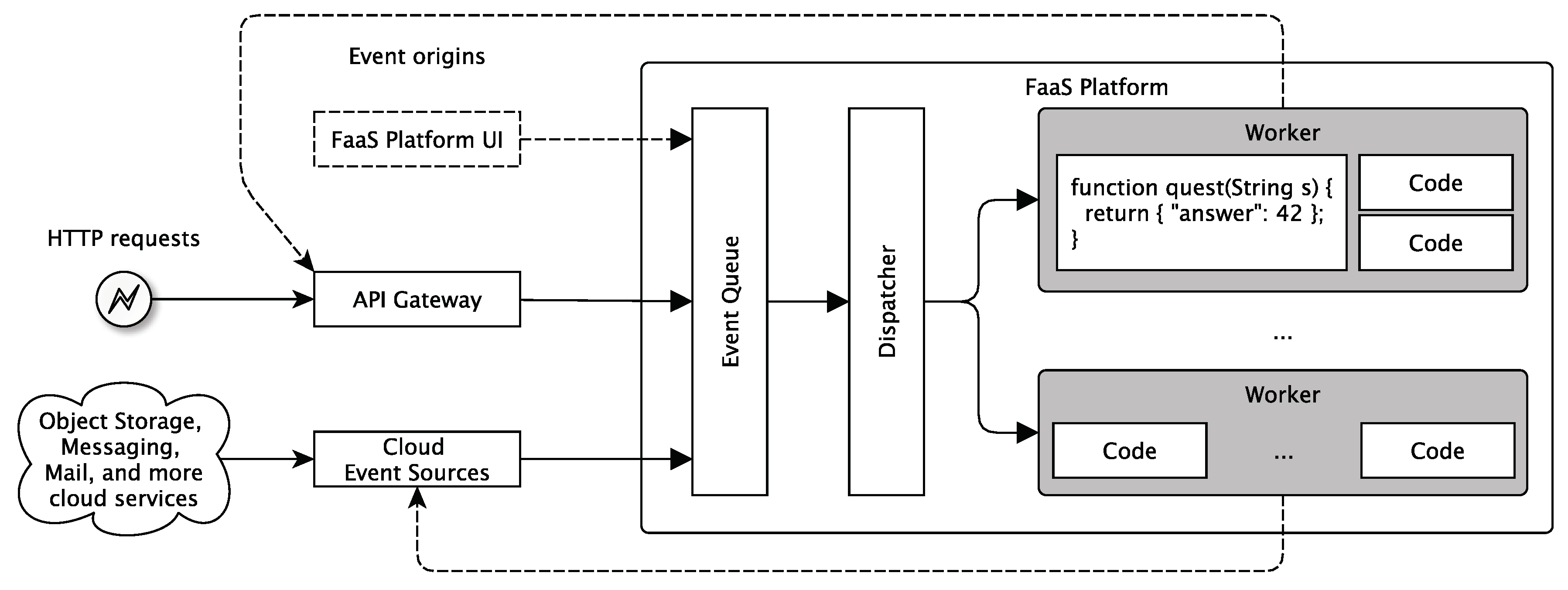
5.1.3. Function-as-a-Service
- “Serverless was first used to describe applications that significantly or fully incorporate third-party, cloud-hosted applications and services, to manage server-side logic and state. These are typically “rich client” applications—think single-page web apps, or mobile apps—that use the vast ecosystem of cloud-accessible databases, authentication services, and so on. These types of services can be described as “Backend as a Service (BaaS) [40]”.
- “Serverless can also mean applications where server-side logic is still written by the application developer, but, unlike traditional architectures, it is run in stateless compute containers that are event-triggered, ephemeral (may only last for one invocation), and fully managed by a third party. One way to think of this is “Functions as a Service” or “FaaS.” AWS Lambda is one of the most popular implementations of a Functions-as-a-Service platform at present, but there are many others, too [40]”.
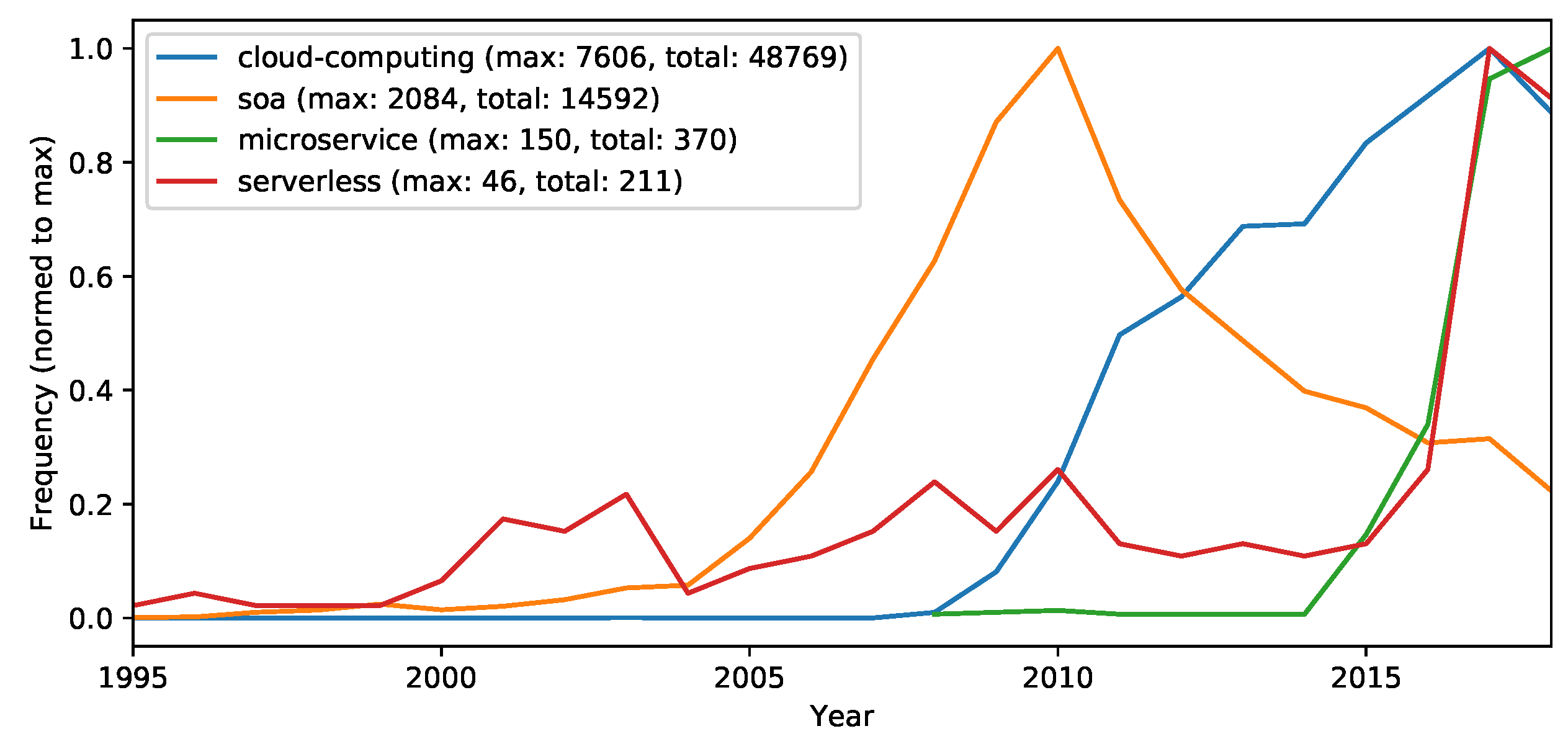
5.2. A Review of the Architectural Evolution
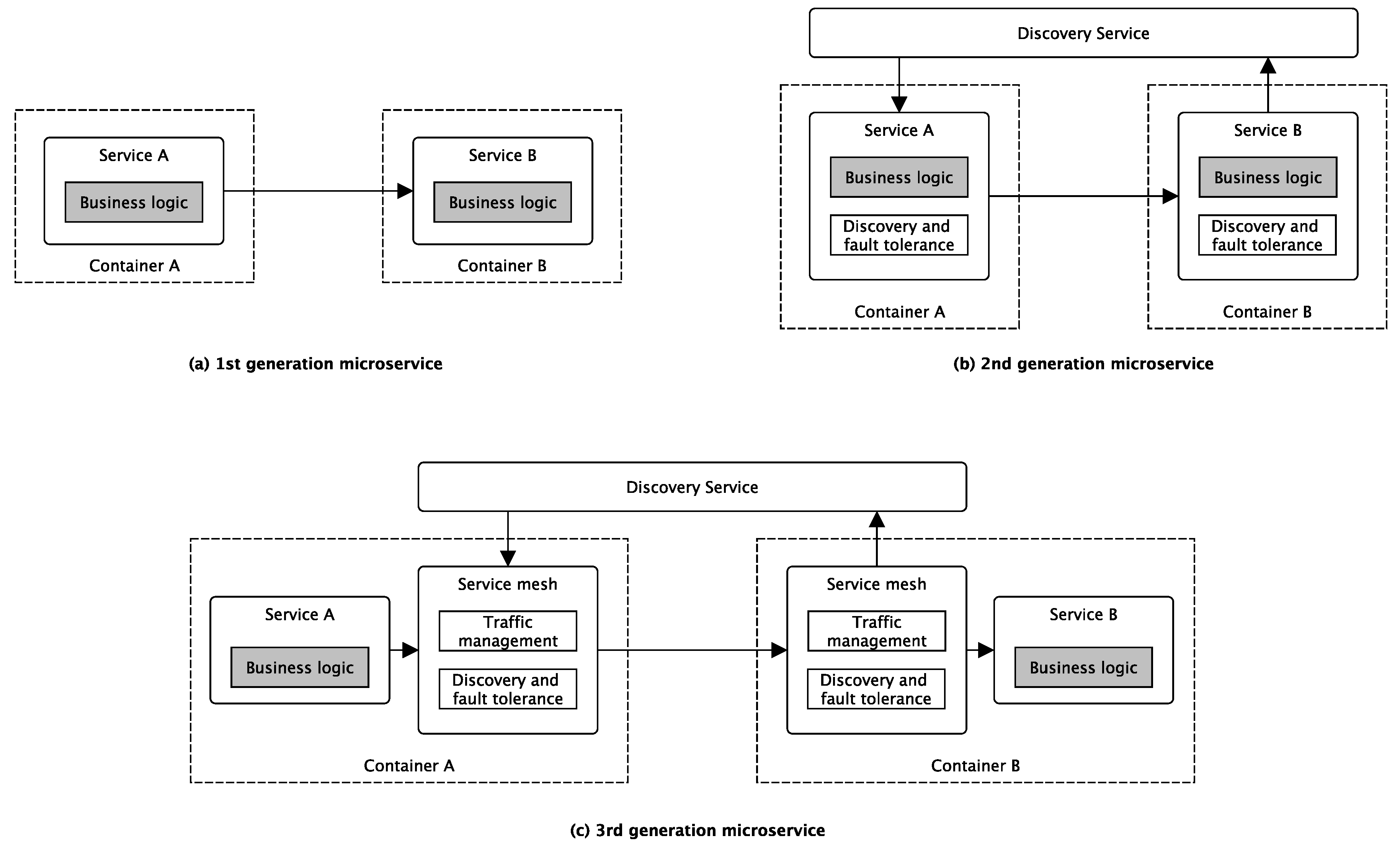
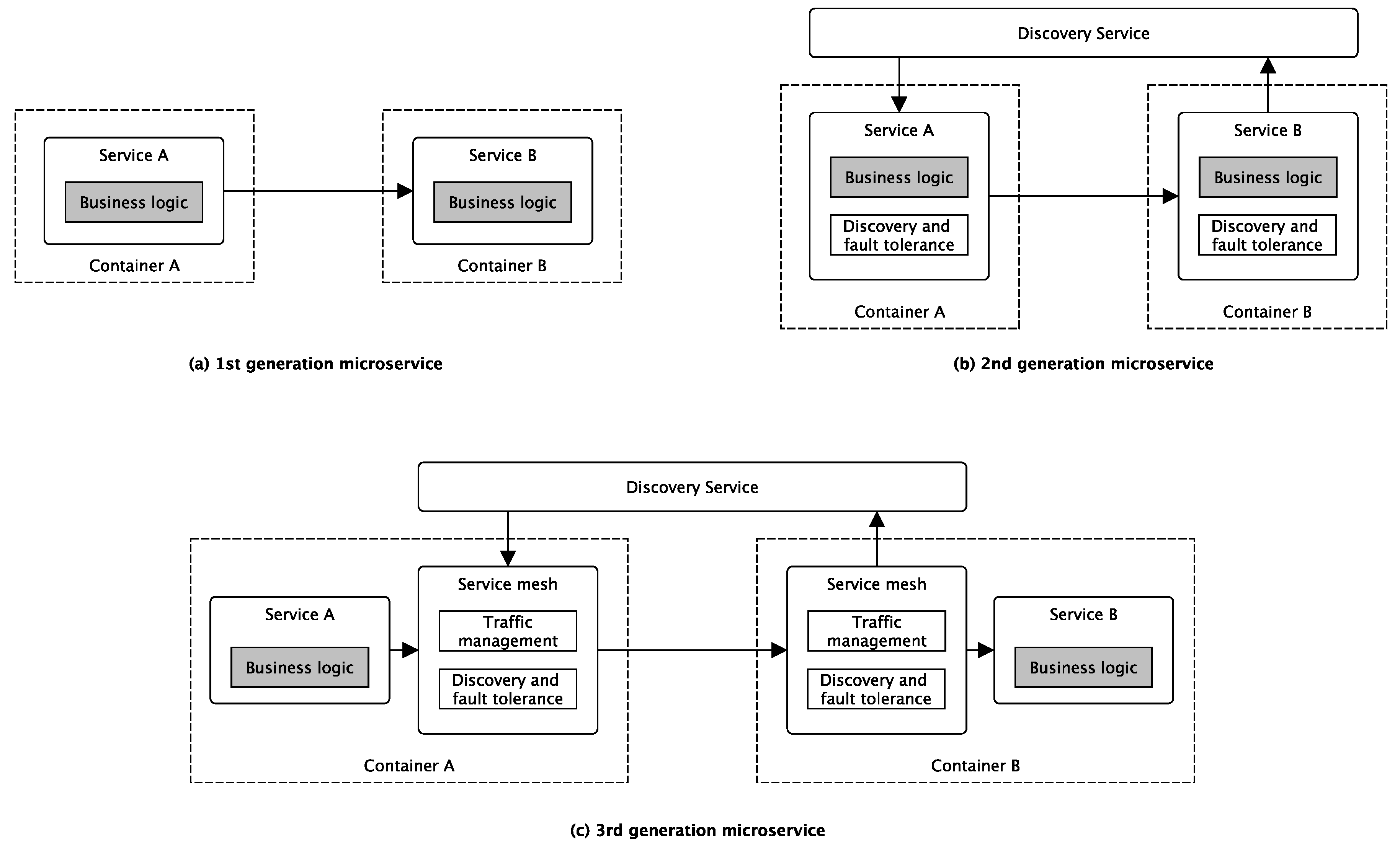
5.2.1. Microservice Architectures
- Service discovery technologies let services communicate with each other without explicitly referring to their network locations.
- Container orchestration technologies automate container allocation and management tasks and abstracting away the underlying physical or virtual infrastructure from service developers. This is the reason that we see this technology as an essential part of any cloud-native application stack (see Figure 3).
- Monitoring technologies that are often based on time-series databases to enable runtime monitoring and analysis of the behavior of microservice resources at different levels of detail.
- Latency and fault-tolerant communication libraries let services communicate more efficiently and reliably in permanently changing system configurations with plenty of service instances permanently joining and leaving the system according to changing request stimuli.
- Continuous-delivery technologies integrate solutions often into third-party services that automate many of the DevOps practices typically used in a web-scale microservice production environment [32].
- Service proxy technologies encapsulate mainly communication-related features such as service discovery and fault-tolerant communication and expose them over HTTP.
- Finally, latest service mesh technologies built on sidecar technologies to provide a fully integrated service-to-service communication monitoring and management environment.
5.2.2. Serverless Architectures
- Public (commercial) serverless services of public cloud service providers provide computational runtime-environments, also known as a function as a service (FaaS) platforms. Some well-known type representatives include AWS Lambda, Google Cloud Functions, or Microsoft Azure Functions. All of the mentioned commercial serverless computing models are prone to create vendor lock-in (to some degree).
- Open (source) serverless platforms like Apache’s OpenWhisk or OpenLambda might be an alternative with the downside that these platforms need infrastructure.
- Provider agnostic serverless frameworks provide a provider and platform agnostic way to define and deploy serverless code on various serverless platforms or commercial serverless services. Thus, these frameworks are an option to avoid (or reduce) vendor lock-in without the necessity to operate an own infrastructure.
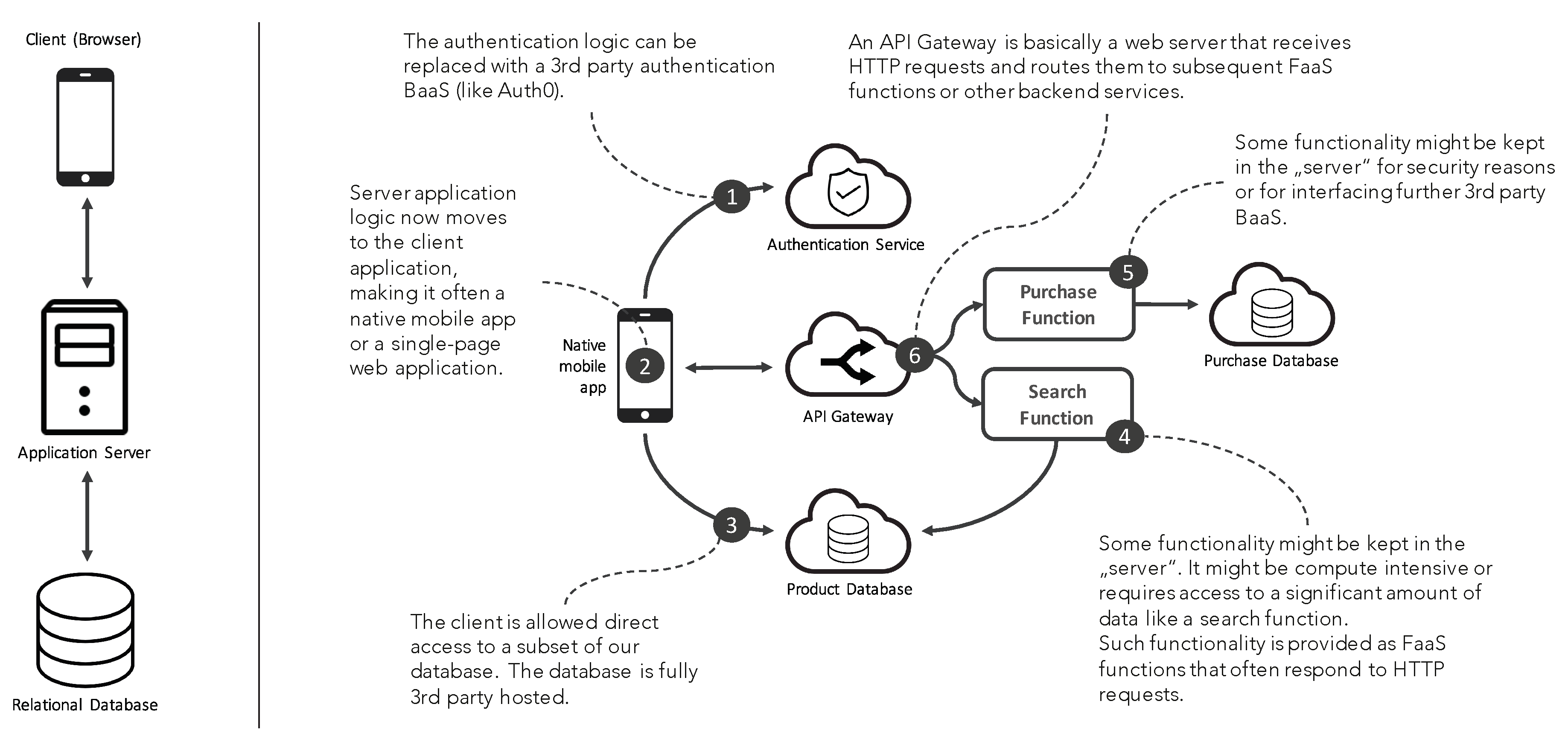
- Former cross-sectional but service-internal (or via a microservice provided) logic like authentication or storage is sourced to external third party services.
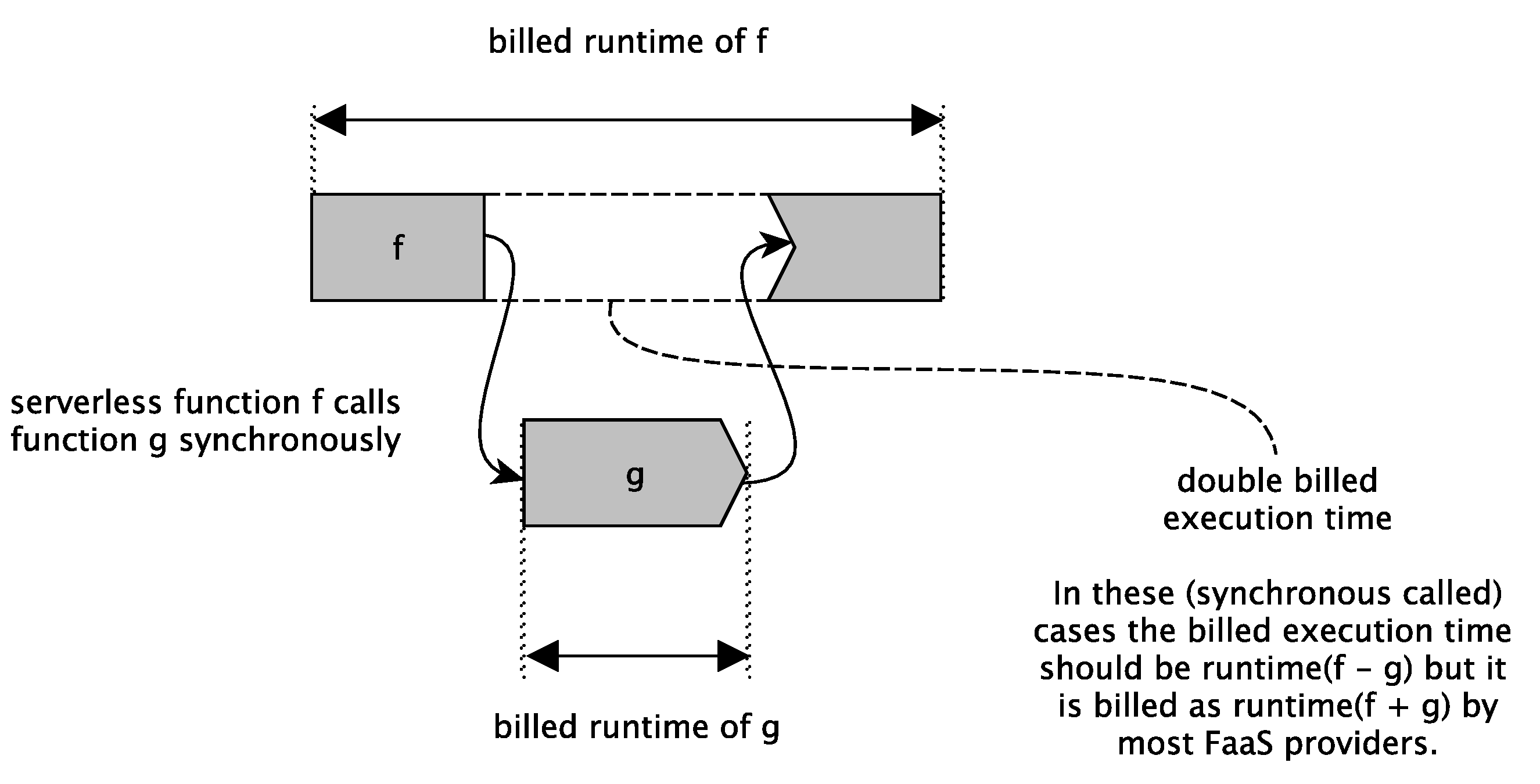
- Even nano- and microservice composition is shifted to end-user clients or edge devices. This means that even service orchestration is not done anymore by the service provider itself but by the service consumer via provided applications. This end-user orchestration has two interesting effects: (1) the service consumer now provides resources needed for service orchestration; (2) because the service composition is done outside the scope of the FaaS platform, still unsolved FaaS function composition problems (like the double spending problem) are avoided.
- Such client or edge devices are interfacing third party services directly.
- Endpoints of very service specific functionality is provided via API gateways. Thus, HTTP- and REST-based/REST-like communication protocols are generally preferred.
- Only very domain or service specific functions are provided on FaaS platforms. Mainly, when this functionality is security relevant and should be executed in a controlled runtime environment by the service provider, or the functionality is too processing or data-intensive to be executed on consumer clients or edge devices, or the functionality is so domain-, problem-, or service-specific that simply no external third-party service exists.
6. The Road Ahead
6.1. Unikernels—The Overlooked Deployment Unit?
- Because unikernels make operating systems and container runtime engines obsolete, this could further increase resource utilization rates.
- FaaS platforms workers are normally container based. However, unikernels are a deployment option as well. Interesting research and engineering directions would be how to combine unikernels with FaaS platforms to apply the same time-sharing principles.
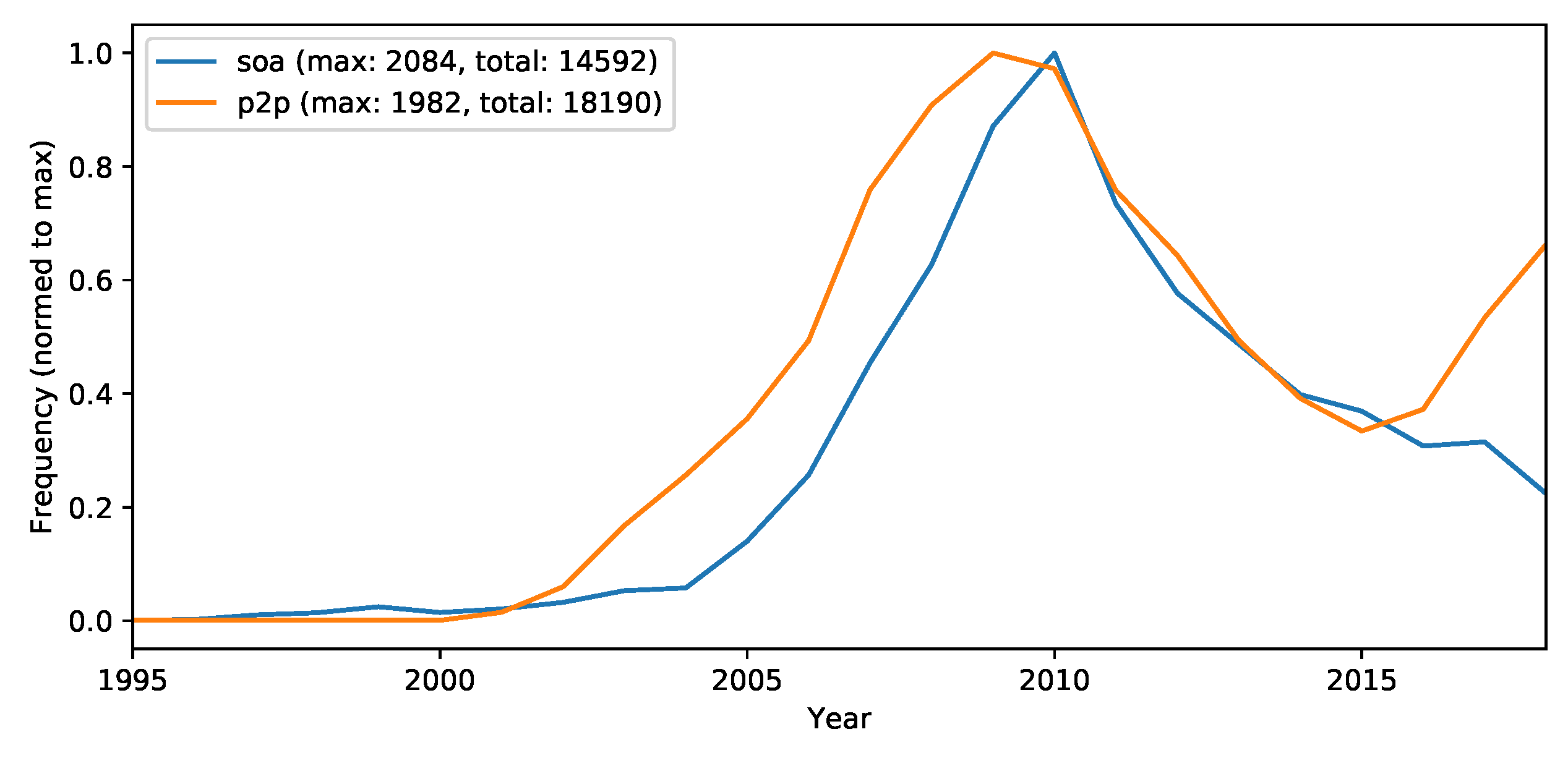
6.2. Overcoming Conceptual Centralized Approaches
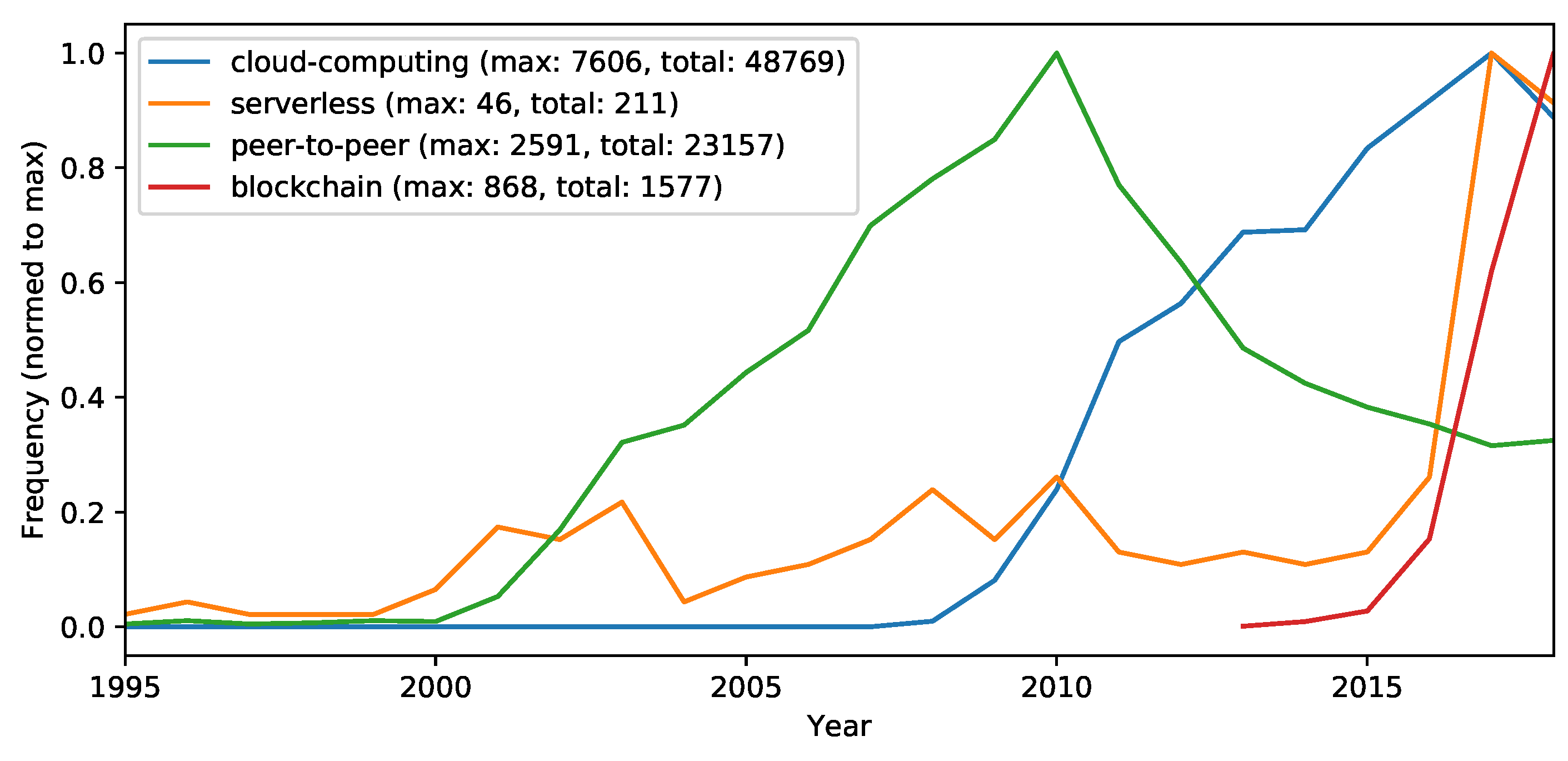
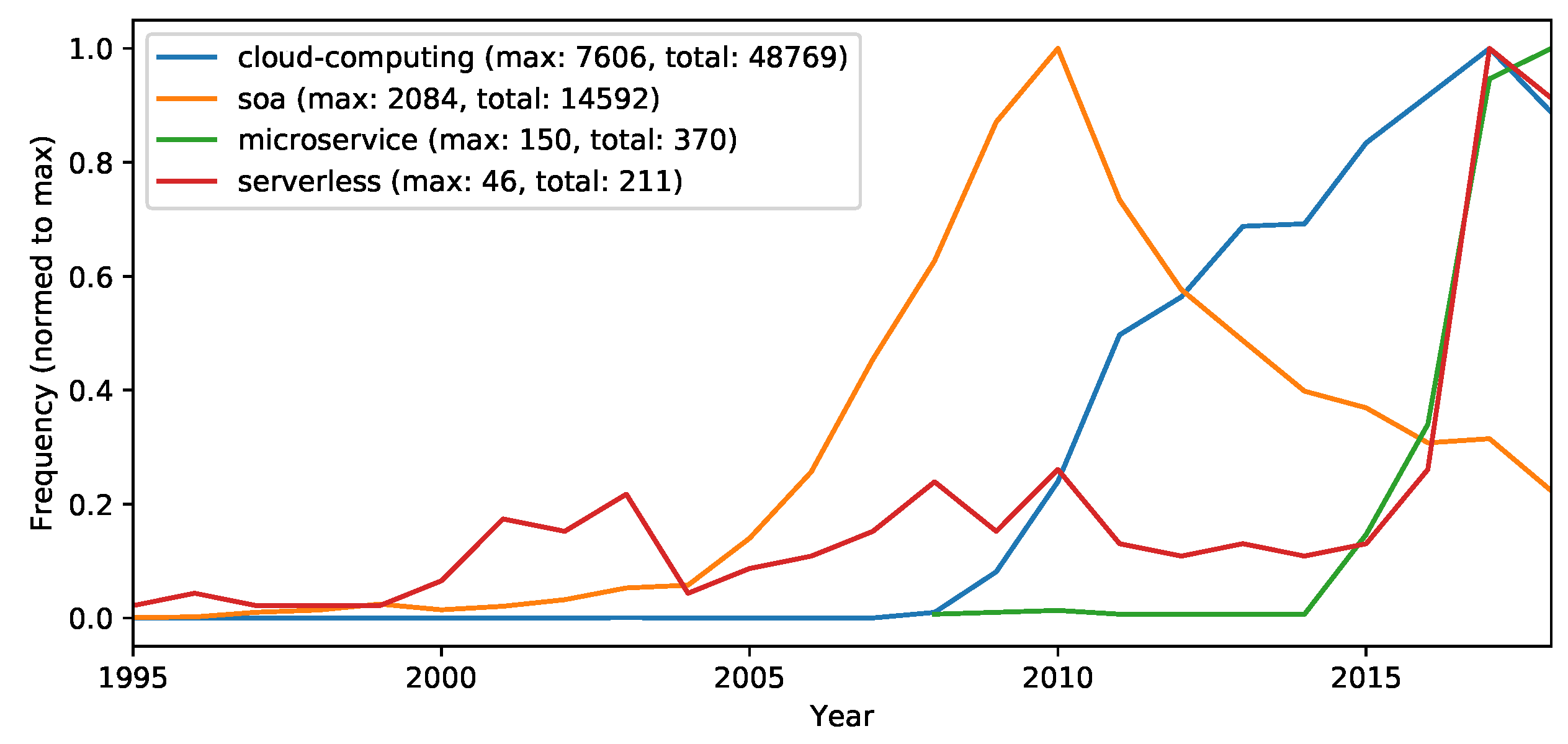
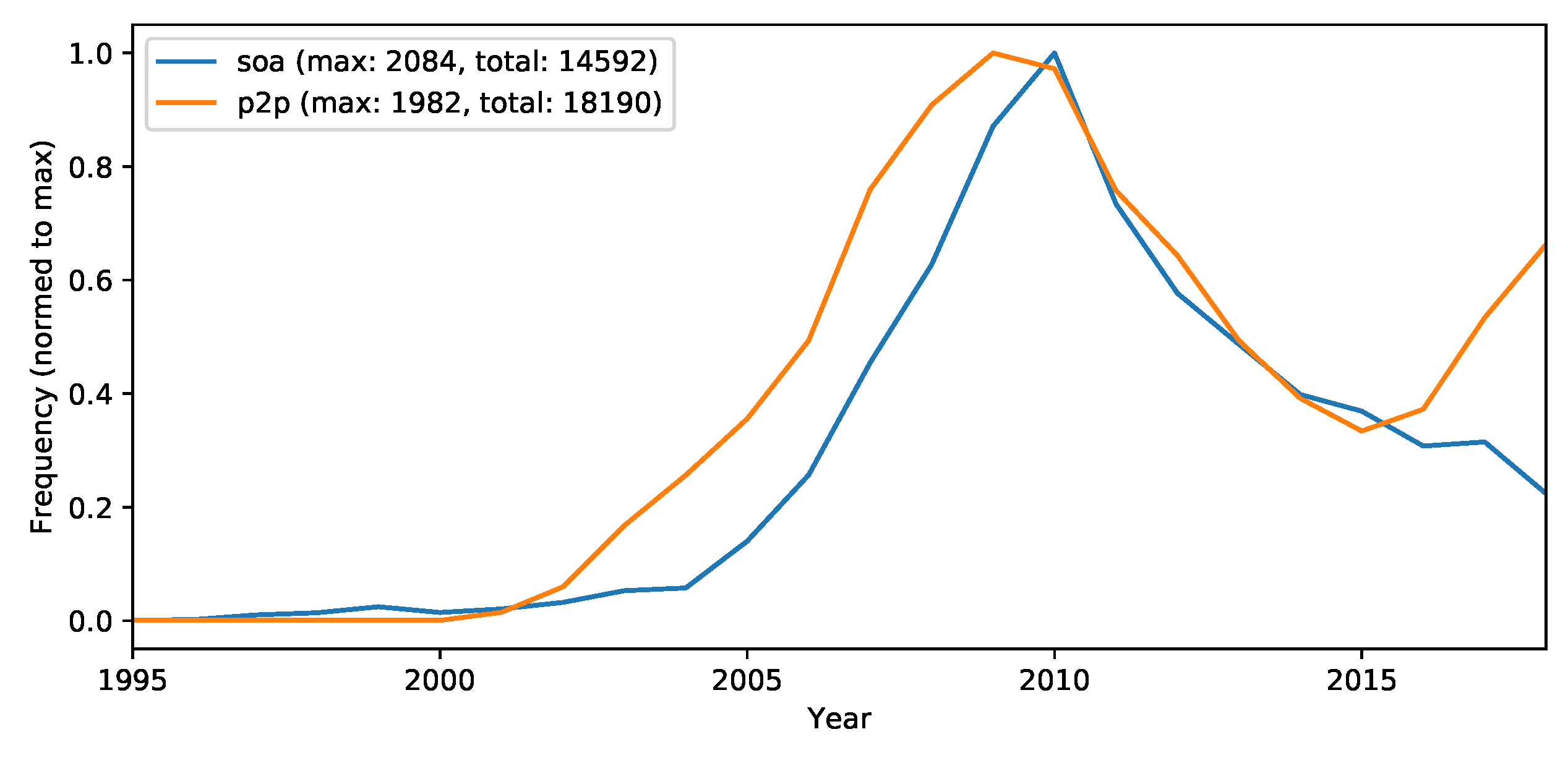
- Cloud computing—to collect the amount of cloud computing-related research in general.
- SOA—to collect the service computing related research, which is still a major influencing concept in cloud computing.
- Microservices—to collect microservice related research (which is more modern and pragmatic interpretation of SOA and very popular in cloud computing).
- Serverless—to collect serverless architecture related research (which is the latest observable architecture trend in cloud computing).
- Peer-to-peer (P2P)—to collect P2P related research (because recently more decentralizing concepts are entering cloud computing).
- Blockchain—to collect blockchain related research (which is the latest observable P2P related research trend/hype).
7. Related Work
- Resource utilization optimization approaches like containerization and FaaS approaches have been investigated in Section 5.1.
- The architectural evolution of cloud applications that is dominated by microservices and evolving into serverless architectures. Both architectural styles have been investigated in Section 5.2.
8. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AMQP | Advanced Message Queuing Protocol |
| API | Application Programming Interface |
| GCE | Google Compute Engine |
| CDMI | Cloud Data Management Interface |
| CIMI | Cloud Infrastructure Management Interface |
| CNA | Cloud-Native Application |
| DLT | Distributed Ledger Technology (aka blockchain) |
| IaaS | Infrastructure as a Service |
| IoT | Internet of Things |
| FaaS | Function as a Service |
| HTTP | Hypertext Transfer Protocol |
| NIST | National Institute of Standards and Technology |
| OCI | Open Container Initiative |
| OCCI | Open Cloud Computing Interface |
| OVF | Open Virtualization Format |
| OS | Operating System |
| P2P | Peer-to-Peer |
| PaaS | Platform as a Service |
| QoS | Quality of Service |
| REST | Representational State Transfer |
| SaaS | Software as a Service |
| SOA | Service-Oriented Architecture |
| SOC | Service-Oriented Computing |
| TOSCA | Topology and Orchestration Specification for Cloud Applications |
| UCAML | Unified Cloud Application Modeling Language |
| VM | Virtual Machine |
| WS-BPEL | Web Service-Business Process Execution Language |
References
- Weinmann, J. Mathematical Proof if the Inevitability of Cloud Computing. 2011. Available online: http://joeweinman.com/Resources/Joe_Weinman_Inevitability_Of_Cloud.pdf (accessed on 10 July 2018).
- Mell, P.M.; Grance, T. The NIST Definition of Cloud Computing; Technical Report; National Institute of Standards & Technology: Gaithersburg, MD, USA, 2011. [Google Scholar]
- Kratzke, N.; Quint, P.C. Preliminary Technical Report of Project CloudTRANSIT—Transfer Cloud-Native Applications at Runtime; Technical Report; Preliminary Technical Report; Lübeck University of Applied Sciences: Lübeck, Germany, 2018. [Google Scholar]
- Kratzke, N.; Quint, P.C. Understanding Cloud-native Applications after 10 Years of Cloud Computing—A Systematic Mapping Study. J. Syst. Softw. 2017, 126, 1–16. [Google Scholar] [CrossRef]
- Kratzke, N.; Peinl, R. ClouNS—A Cloud-Native Application Reference Model for Enterprise Architects. In Proceedings of the 2016 IEEE 20th International Enterprise Distributed Object Computing Workshop (EDOCW), Vienna, Austria, 5–9 September 2016; pp. 1–10. [Google Scholar] [CrossRef]
- Kratzke, N. Smuggling Multi-Cloud Support into Cloud-native Applications using Elastic Container Platforms. In Proceedings of the 7th International Conference on Cloud Computing and Services Science (CLOSER 2017), Porto, Portugal, 24–26 April 2017; pp. 29–42. [Google Scholar]
- Kratzke, N. About the Complexity to Transfer Cloud Applications at Runtime and how Container Platforms can Contribute. In Cloud Computing and Services Science (Revised Selected Papers); Helfert, M., Ferguson, D., Munoz, V.M., Cardoso, J., Eds.; Communications in Computer and Information Science (CCIS); Springer: Berlin, Germany, 2018. [Google Scholar]
- Quint, P.C.; Kratzke, N. Towards a Description of Elastic Cloud-native Applications for Transferable Multi-Cloud-Deployments. In Proceedings of the 1st International Forum on Microservices Odense, Denmark, 25–26 October 2017. [Google Scholar]
- Quint, P.C.; Kratzke, N. Towards a Lightweight Multi-Cloud DSL for Elastic and Transferable Cloud-native Applications. In Proceedings of the 8th International Conference on Cloud Computing and Services Science Madeira, Portugal, 19–21 March 2018. [Google Scholar]
- Aderaldo, C.M.; Mendonça, N.C.; Pahl, C.; Jamshidi, P. Benchmark Requirements for Microservices Architecture Research. In Proceedings of the 1st International Workshop on Establishing the Community-Wide Infrastructure for Architecture-Based Software Engineering, Buenos Aires, Argentina, 20–28 May 2017; IEEE Press: Piscataway, NJ, USA, 2017; pp. 8–13. [Google Scholar] [CrossRef]
- OASIS. Advanced Message Queueing Protocol (AQMP), version 1.0; OASIS: Manchester, UK, 2012. [Google Scholar]
- Kratzke, N. Lightweight Virtualization Cluster—Howto overcome Cloud Vendor Lock-in. J. Comput. Commun. 2014, 2. [Google Scholar] [CrossRef]
- Kratzke, N.; Quint, P.C.; Palme, D.; Reimers, D. Project Cloud TRANSIT—Or to Simplify Cloud-native Application Provisioning for SMEs by Integrating Already Available Container Technologies. In European Project Space on Smart Systems, Big Data, Future Internet—Towards Serving the Grand Societal Challenges; Kantere, V., Koch, B., Eds.; SciTePress: Setubal, Portugal, 2016. [Google Scholar]
- Hogan, M.; Fang, L.; Sokol, A.; Tong, J. Cloud Infrastructure Management Interface (CIMI) Model and RESTful HTTP-Based Protocol, Version 2.0.0c; Distributed Management Task Force; 2015. Available online: https://www.dmtf.org/sites/default/files/standards/documents/DSP0263_1.0.1.pdf (accessed on 13 August 2018).
- Nyren, R.; Edmonds, A.; Papaspyrou, A.; Metsch, T. Open Cloud Computing Interface (OCCI)—Core, Version 1.2; Open Grid Forum; 2016. Available online: https://www.ogf.org/documents/GFD.221.pdf (accessed on 13 August 2018).
- Metsch, T.; Edmonds, A. Open Cloud Computing Interface (OCCI)—Infrastructure, Version 1.2; Open Grid Forum; 2016. Available online: https://www.ogf.org/documents/GFD.224.pdf (accessed on 13 August 2018).
- SNIA. Cloud Data Management Interface (CDMI), Version 1.1.1; SNIA, 2016. Available online: https:////www.snia.org/sites/default/files/CDMI_Spec_v1.1.1.pdf (accessed on 13 August 2018).
- System Virtualization, Partitioning, and Clustering Working Group. Open Virtualization Format Specification, Version 2.1.1; Distributed Management Task Force, 2015. Available online: https://www.dmtf.org/sites/default/files/standards/documents/DSP0243_2.1.1.pdf (accessed on 13 August 2018).
- OCI. Open Container Initiative. 2015. Available online: https://github.com/opencontainers/runtime-spec (accessed on 13 August 2018).
- OASIS. Topology and Orchestration Specification for Cloud Applications (TOSCA), version 1.0; OASIS, 2013. Available online: http://docs.oasis-open.org/tosca/TOSCA/v1.0/os/TOSCA-v1.0-os.pdf (accessed on 13 August 2018).
- Opara-Martins, J.; Sahandi, R.; Tian, F. Critical review of vendor lock-in and its impact on adoption of cloud computing. In Proceedings of the International Conference on Information Society (i-Society 2014), London, UK, 10–12 November 2014; pp. 92–97. [Google Scholar] [CrossRef]
- Ashtikar, S.; Barker, C.; Clem, B.; Fichadia, P.; Krupin, V.; Louie, K.; Malhotra, G.; Nielsen, D.; Simpson, N.; Spence, C. Open Data Center Alliance Best Practices: Architecting Cloud-Aware Applications Rev. 1.0; Technical Report. Open Data Center Alliance, 2014. Available online: https://oaca-project.github.io/files/Architecting%20Cloud-Aware%20Applications%20Best%20Practices%20Rev%201.0.pdf (accessed on 13 August 2018).
- Bohn, R.B.; Messina, J.; Liu, F.; Tong, J.; Mao, J. NIST Cloud Computing Reference Architecture. In World Congress on Services (SERVICES 2011); IEEE Computer Society: Washington, DC, USA, 2011; pp. 594–596. [Google Scholar]
- Quint, P.C.; Kratzke, N. Overcome Vendor Lock-In by Integrating Already Available Container Technologies—Towards Transferability in Cloud Computing for SMEs. In Proceedings of the 7th International Conference on Cloud Computing, GRIDS and Virtualization, Rome, Italy, 20–24 March 2016. [Google Scholar]
- Ardagna, D.; Casale, G.; Ciavotta, M.; Pérez, J.F.; Wang, W. Quality-of-service in cloud computing: Modeling techniques and their applications. J. Internet Serv. Appl. 2014, 5, 11. [Google Scholar] [CrossRef] [Green Version]
- White, G.; Nallur, V.; Clarke, S. Quality of service approaches in IoT: A systematic mapping. J. Syst. Softw. 2017, 132, 186–203. [Google Scholar] [CrossRef]
- Newman, S. Building Microservices; O’Reilly Media: Sebastopol, CA, USA, 2015. [Google Scholar]
- Namiot, D.; Sneps-Sneppe, M. On micro-services architecture. Int. J. Open Inf. Technol. 2014, 2, 24–27. [Google Scholar]
- Cerny, T.; Donahoo, M.J.; Pechanec, J. Disambiguation and Comparison of SOA, Microservices and Self-Contained Systems. In Proceedings of the International Conference on Research in Adaptive and Convergent Systems—RACS ’17, Krakow, Poland, 20–23 September 2017. [Google Scholar] [CrossRef]
- Taibi, D.; Lenarduzzi, V.; Pahl, C. Architectural Patterns for Microservices: A Systematic Mapping Study. In Proceedings of the 8th International Conference on Cloud Computing and Services Science (CLOSER’18), Madeira, Portugal, 19–21 March 2018. [Google Scholar]
- Jamshidi, P.; Pahl, C.; Mendonça, N.C.; Lewis, J.; Stefan Tilkov, T. Microservices The Journey So Far and Challenges Ahead. IEEE Softw. 2018, 35, 24–35. [Google Scholar] [CrossRef]
- Balalaie, A.; Heydarnoori, A.; Jamshidi, P. Microservices Architecture Enables DevOps: Migration to a Cloud-Native Architecture. IEEE Softw. 2016. [Google Scholar] [CrossRef]
- Jabbari, R.; bin Ali, N.; Petersen, K.; Tanveer, B. What is DevOps? A Systematic Mapping Study on Definitions and Practices. In Proceedings of the Scientific Workshop Proceedings of XP2016, Scotland, UK, 24 May 2016. [Google Scholar] [CrossRef]
- Bergmayr, A.; Breitenbücher, U.; Ferry, N.; Rossini, A.; Solberg, A.; Wimmer, M.; Kappel, G.; Leymann, F. A Systematic Review of Cloud Modeling Languages. ACM Comput. Surv. 2018, 51, 39. [Google Scholar] [CrossRef]
- Adam Wiggins. The Twelve-Factor App. 2014. Available online: https://12factor.net (accessed on 13 August 2018).
- Martin Fowler. Circuit Breaker. 2014. Available online: https://martinfowler.com/bliki/CircuitBreaker.html (accessed on 11 August 2018).
- Fehling, C.; Leymann, F.; Retter, R.; Schupeck, W.; Arbitter, P. Cloud Computing Patterns; Springer: Berlin, Germany, 2014. [Google Scholar]
- Erl, T.; Cope, R.; Naserpour, A. Cloud Computing Design Patterns; Springer: Berlin, Germany, 2015. [Google Scholar]
- Verma, A.; Pedrosa, L.; Korupolu, M.; Oppenheimer, D.; Tune, E.; Wilkes, J. Large-scale cluster management at Google with Borg. In Proceedings of the Tenth European Conference on Computer Systems—EuroSys’15, Zhangjiajie, China, 18–20 November 2015; pp. 1–17. [Google Scholar] [CrossRef]
- Michael Roberts and John Chapin. What Is Serverless? O’Reilly: Sebastopol, CA, USA, 2016. [Google Scholar]
- Baldini, I.; Cheng, P.; Fink, S.J.; Mitchell, N.; Muthusamy, V.; Rabbah, R.; Suter, P.; Tardieu, O. The serverless trilemma: Function composition for serverless computing. In Proceedings of the 2017 ACM SIGPLAN International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software, Vancouver, BC, Canada, 25–27 October 2017. [Google Scholar] [CrossRef]
- Baldini, I.; Castro, P.; Chang, K.; Cheng, P.; Fink, S.; Ishakian, V.; Mitchell, N.; Muthusamy, V.; Rabbah, R.; Slominski, A.; et al. Serverless Computing: Current Trends and Open Problems. In Research Advances in Cloud Computing; Springer: Singapore, 2017; pp. 1–20. [Google Scholar] [Green Version]
- Martin Fowler. Microservices—A Definition of this new Architectural Term. 2014. Available online: https://martinfowler.com/articles/microservices.html (accessed on 13 August 2018).
- Villamizar, M.; Garcés, O.; Ochoa, L.; Castro, H.; Salamanca, L.; Verano, M.; Casallas, R.; Gil, S.; Valencia, C.; Zambrano, A.; et al. Cost comparison of running web applications in the cloud using monolithic, microservice, and AWS Lambda architectures. Serv. Oriented Comput. Appl. 2017. [Google Scholar] [CrossRef]
- Dragoni, N.; Giallorenzo, S.; Lafuente, A.L.; Mazzara, M.; Montesi, F.; Mustafin, R.; Safina, L. Microservices: Yesterday, Today, and Tomorrow. In Present and Ulterior Software Engineering; Mazzara, M., Meyer, B., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 195–216. [Google Scholar] [Green Version]
- Pahl, C.; Brogi, A.; Soldani, J.; Jamshidi, P. Cloud Container Technologies: A State-of-the-Art Review. IEEE Trans. Cloud Comput. 2017, 1. [Google Scholar] [CrossRef]
- Hindman, B.; Konwinski, A.; Zaharia, M.; Ghodsi, A.; Joseph, A.D.; Katz, R.; Shenker, S.; Stoica, I. Mesos: A Platform for Fine-grained Resource Sharing in the Data Center. In Proceedings of the 8th USENIX Conference on Networked Systems Design and Implementation, Boston, MA, USA, 30 March–1 April 2011; USENIX Association: Berkeley, CA, USA, 2011; pp. 295–308. [Google Scholar]
- Pérez, A.; Moltó, G.; Caballer, M.; Calatrava, A. Serverless computing for container-based architectures. Future Gener. Comput. Syst. 2018, 83, 50–59. [Google Scholar] [CrossRef]
- Baldini, I.; Castro, P.; Cheng, P.; Fink, S.; Ishakian, V.; Mitchell, N.; Muthusamy, V.; Rabbah, R.; Suter, P. Cloud-native, event-based programming for mobile applications. In Proceedings of the International Conference on Mobile Software Engineering and Systems, Austin, TX, USA, 16–17 May 2016; pp. 287–288. [Google Scholar]
- Cozzolino, V.; Ding, A.Y.; Ott, J. FADES: Fine-grained edge offloading with unikernels. In Proceedings of the Workshop on Hot Topics in Container Networking and Networked Systems, Los Angeles, CA, USA, 25 August 2017; pp. 36–41. [Google Scholar]
- Koller, R.; Williams, D. Will Serverless End the Dominance of Linux in the Cloud? In Proceedings of the 16th Workshop on Hot Topics in Operating Systems, Whistler, BC, Canada, 8–10 May 2017; pp. 169–173. [Google Scholar]
- Bratterud, A.; Happe, A.; Duncan, R.A.K. Enhancing cloud security and privacy: The Unikernel solution. In Proceedings of the 8th International Conference on Cloud Computing, GRIDs, and Virtualization, Athens, Greece, 19–23 February 2017. [Google Scholar]
- Happe, A.; Duncan, B.; Bratterud, A. Unikernels for Cloud Architectures: How Single Responsibility Can Reduce Complexity, Thus Improving Enterprise Cloud Security; SciTePress: Setubal, Portugal, 2017; Volume 2016, pp. 1–8. [Google Scholar]
- Duncan, B.; Happe, A.; Bratterud, A. Cloud Cyber Security: Finding an Effective Approach with Unikernels. In Security in Computing and Communications; IntechOpen: London, UK, 2017; p. 31. [Google Scholar]
- Compastié, M.; Badonnel, R.; Festor, O.; He, R.; Lahlou, M.K. Unikernel-based Approach for Software-Defined Security in Cloud Infrastructures. In Proceedings of the NOMS 2018-IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018. [Google Scholar]
- Rahimi, M.R.; Ren, J.; Liu, C.H.; Vasilakos, A.V.; Venkatasubramanian, N. Mobile Cloud Computing: A Survey, State of Art and Future Directions. MONET 2014, 19, 133–143. [Google Scholar] [CrossRef]
- Pooranian, Z.; Abawajy, J.H.; P, V.; Conti, M. Scheduling Distributed Energy Resource Operation and Daily Power Consumption for a Smart Building to Optimize Economic and Environmental Parameters. Energies 2018, 11, 1348. [Google Scholar] [CrossRef]
- Pooranian, Z.; Chen, K.C.; Yu, C.M.; Conti, M. RARE: Defeating side channels based on data-deduplication in cloud storage. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Honolulu, HI, USA, 15–19 April 2018; pp. 444–449. [Google Scholar] [CrossRef]
- Liu, M.; Koskela, T.; Ou, Z.; Zhou, J.; Riekki, J.; Ylianttila, M. Super-peer-based coordinated service provision. Advanced Topics in Cloud Computing. J. Netw. Comput. Appl. 2011, 34, 1210–1224. [Google Scholar] [CrossRef]
- Westerlund, M.; Kratzke, N. Towards Distributed Clouds—A review about the evolution of centralized cloud computing, distributed ledger technologies, and a foresight on unifying opportunities and security implications. In Proceedings of the 16th International Conference on High Performance Computing and Simulation (HPCS 2018), Orléans, France, 16–20 July 2018. [Google Scholar]
- Kaur, T.; Chana, I. Energy Efficiency Techniques in Cloud Computing: A Survey and Taxonomy. ACM Comput. Surv. 2015, 48, 22:1–22:46. [Google Scholar] [CrossRef]
- Tosatto, A.; Ruiu, P.; Attanasio, A. Container-Based Orchestration in Cloud: State of the Art and Challenges. In Proceedings of the 2015 Ninth International Conference on Complex, Intelligent, and Software Intensive Systems, Blumenau, Brazil, 8–10 July 2015; pp. 70–75. [Google Scholar] [CrossRef]
- Peinl, R.; Holzschuher, F.; Pfitzer, F. Docker Cluster Management for the Cloud—Survey Results and Own Solution. J. Grid Comput. 2016, 14, 265–282. [Google Scholar] [CrossRef]
- Spillner, J. Practical Tooling for Serverless Computing. In Proceedings of the10th International Conference on Utility and Cloud Computing, Austin, TX, USA, 5–8 December 2017; ACM: New York, NY, USA, 2017; pp. 185–186. [Google Scholar] [CrossRef] [Green Version]
- Lynn, T.; Rosati, P.; Lejeune, A.; Emeakaroha, V. A Preliminary Review of Enterprise Serverless Cloud Computing (Function-as-a-Service) Platforms. In Proceedings of the 2017 IEEE International Conference on Cloud Computing Technology and Science (CloudCom), Hong Kong, China, 11–14 December 2017; pp. 162–169. [Google Scholar] [CrossRef]
- Van Eyk, E.; Toader, L.; Talluri, S.; Versluis, L.; Uta, A.; Iosup, A. Serverless is More: From PaaS to Present Cloud Computing. Sep/Oct issue. IEEE Internet Comput. 2018, 22. Available online: https://atlarge-research.com/pdfs/serverless-history-now-future18ieeeic.pdf (accessed on 13 August 2018).
- Van Eyk, E.; Iosup, A.; Abad, C.L.; Grohmann, J.; Eismann, S. A SPEC RG Cloud Group’s Vision on the Performance Challenges of FaaS Cloud Architectures. In Proceedings of the 8th ACM/SPEC on International Conference on Performance Engineering, ICPE 2018, Berlin, Germany, 9–13 April 2018. [Google Scholar]
- Ylianttila, M.; Riekki, J.; Zhou, J.; Athukorala, K.; Gilman, E. Cloud Architecture for Dynamic Service Composition. Int. J. Grid High Perform. Comput. 2012, 4, 17–31. [Google Scholar] [CrossRef] [Green Version]
- Zhou, J.; Riekki, J.; Sun, J. Pervasive Service Computing toward Accommodating Service Coordination and Collaboration. In Proceedings of the 2009 4th International Conference on Frontier of Computer Science and Technology, Shanghai, China, 17–19 December 2009; pp. 686–691. [Google Scholar] [CrossRef]
- Huhns, M.N.; Singh, M.P. Service-Oriented Computing: Key Concepts and Principles. IEEE Internet Comput. 2005, 9, 75–81. [Google Scholar] [CrossRef]
- Dustdar, S.; Schreiner, W. A survey on web services composition. Int. J. Web Grid Serv. 2005, 1, 1–30. [Google Scholar] [CrossRef]
- Papazoglou, M.P.; Traverso, P.; Dustdar, S.; Leymann, F. Service-Oriented Computing: State of the Art and Research Challenges. Computer 2007, 40, 38–45. [Google Scholar] [CrossRef] [Green Version]
- Papazoglou, M.P.; van den Heuvel, W.J. Service oriented architectures: Approaches, technologies and research issues. VLDB J. 2007, 16, 389–415. [Google Scholar] [CrossRef]
- Razavian, M.; Lago, P. A Survey of SOA Migration in Industry; Springer: Berlin, Germany, 2011. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Maturity | Criteria |
|---|---|---|
| 3 | Cloud | - Transferable across infrastructure providers at |
| native | runtime and without interruption of service. | |
| - Automatically scale out/in based on stimuli. | ||
| 2 | Cloud | - State is isolated in a minimum of services. |
| resilient | - Unaffected by dependent service failures. | |
| - Infrastructure agnostic. | ||
| 1 | Cloud | - Composed of loosely coupled services. |
| friendly | - Services are discoverable by name. | |
| - Components are designed to cloud patterns. | ||
| - Compute and storage are separated. | ||
| 0 | Cloud | - Operated on virtualized infrastructure. |
| ready | - Instantiateable from image or script. |
| Trend | Rationale |
|---|---|
| Microservices | Microservices can be seen as a “pragmatic” interpretation of SOA. In addition to SOA, microservice architectures intentionally focus and compose small and independently replaceable horizontally scalable services that are “doing one thing well.” [27,28,29,30,31] |
| DevOps | DevOps is a practice that emphasizes the collaboration of software developers and IT operators. It aims to build, test, and release software more rapidly, frequently, and more reliably using automated processes for software delivery [32,33]. DevOps foster the need for independent replaceable and standardized deployment units and therefore pushes microservice architectures and container technologies. |
| Cloud Modeling Languages | Softwareization of infrastructure and network enables to automate the process of software delivery and infrastructure changes more rapidly. Cloud modeling languages can express applications and services and their elasticity behavior that shall be deployed to such infrastructures or platforms. There is a good survey on this kind of new “programming languages” [34]. |
| Standardized Deployment Units | Deployment units wrap a piece of software in a complete file system that contains everything needed to run: code, runtime, system tools, system libraries. Thus, it is guaranteed that the software will always run the same, regardless of its environment. This deployment approach is often made using container technologies (OCI standard [19]) Unikernels would work as well but are not yet in widespread use. A deployment unit should be designed and interconnected according to a collection of cloud-focused patterns like the twelve-factor app collection [35], the circuit breaker pattern [36] or cloud computing patterns [37,38]. |
| Elastic Platforms | Elastic platforms like Kubernetes [39], Mesos [47], or Swarm can be seen as a unifying middleware of elastic infrastructures. Elastic platforms extend resource sharing and increase the utilization of underlying compute, network and storage resources for custom but standardized deployment units. |
| Serverless | the term serverless is used for an architectural style that is used for cloud application architectures that deeply depend on external third-party-services (Backend-as-a-Service, BaaS) and integrating them via small event-based triggered functions (Function-as-a, FaaS). FaaS extend resource sharing of elastic platforms by simply by applying time-sharing concepts [40,41,42]. |
| State Isolation | Stateless components are easier to scale up/down horizontally than stateful components. Of course, stateful components cannot be avoided, but stateful components should be reduced to a minimum and realized by intentional horizontal scalable storage systems (often eventual consistent NoSQL databases) [37]. |
| Versioned REST APIs | REST-based APIs provide scalable and pragmatic communication, means relying mainly on already existing internet infrastructure and well defined and widespread standards [43]. |
| Loose coupling | Service composition is done by events or by data [43]. Event coupling relies on messaging solutions (e.g., AMQP standard). Data coupling often relies on scalable but (mostly) eventual consistent storage solutions (which are often subsumed as NoSQL databases) [37]. |
| Benefits | Drawbacks |
|---|---|
| RESOURCE EFFIENCY (service side) | |
| - auto-scaling based on event stimulus | - maximum function runtime is limited |
| - reduced operational costs | - startup latencies of functions must be considered |
| - scale to zero capability (no always-on) | - function runtime variations |
| - functions can not preserve a state across function calls | |
| - external state (cache, key/value stores, etc.) can compensate this but is a magnitude slower | |
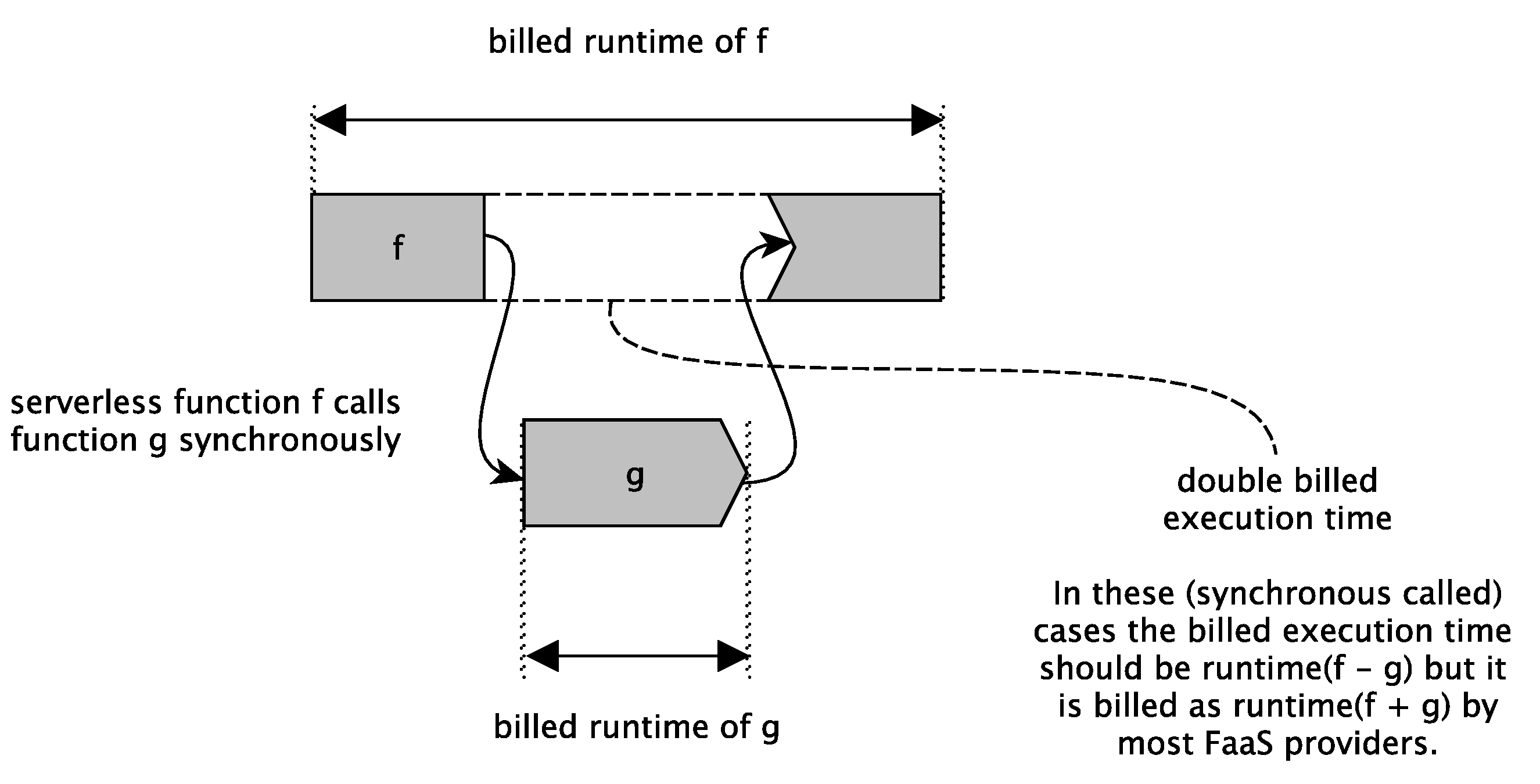
| - double spending problems (FaaS functions call other FaaS functions) | |
| OPERATION (service side) | |
| - simplified deployment | - increased attack surfaces |
| - simplified operation (see auto-scaling) | - each endpoint introduces possible vulnerabilities |
| - missing protective barrier of a monolithic server application | |
| - parts of the application logic are shifted to the client-side (that is not under control of the service provider) | |
| - increased vendor lock-in (currently no FaaS standards for API gateways and FaaS runtime environments) | |
| DEVELOPMENT SPEED (service side) | |
| - development speed | - increased client complexity |
| - simplified unit testing of stateless FaaS functions | - application logic is shifted to the client-side |
| - better time to market | - code replication on client side across client platforms |
| - control of application workflow on client side to avoid double-sending problems of FaaS computing | |
| - increased integration testing complexity | |
| - missing integration test tool-suites |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kratzke, N. A Brief History of Cloud Application Architectures. Appl. Sci. 2018, 8, 1368. https://doi.org/10.3390/app8081368
Kratzke N. A Brief History of Cloud Application Architectures. Applied Sciences. 2018; 8(8):1368. https://doi.org/10.3390/app8081368
Chicago/Turabian StyleKratzke, Nane. 2018. "A Brief History of Cloud Application Architectures" Applied Sciences 8, no. 8: 1368. https://doi.org/10.3390/app8081368
APA StyleKratzke, N. (2018). A Brief History of Cloud Application Architectures. Applied Sciences, 8(8), 1368. https://doi.org/10.3390/app8081368