HM3alD: Polymorphic Malware Detection Using Program Behavior-Aware Hidden Markov Model

Abstract
1. Introduction
1.1. Malware
1.2. Malware Analysis and Detection
1.3. Contributions
1.4. Paper Structure
2. Related Work
2.1. Static Analysis-Based Methods
2.2. Dynamic Analysis-Based Methods
3. Background
3.1. Malware Obfuscation
3.2. Hierarchical Clustering
3.3. Hidden Markov Model
4. Proposed Method:
4.1. Training Phase
4.1.1. Training Profiler
4.1.2. Preprocessing
4.1.3. Clustering Action Sequences
| Algorithm 1 : Preprocessing, generating an action sequence from a system call sequence | |
Input:
| |
Output:
| |
| 1: | Define an empty array such that each array element specifies a system call sequence during the execution of algorithm. |
| 2: | Initialize A with 26 base actions: |
| 3: | for each do |
| 4: | ℓ = OS_Handle() ▷ get the Operating System handle pointer of |
| 5: | insert(,) ▷ for any system call, insert it to |
| 6: | if is a releasing system call then ▷ A releasing system call releases the dependent resources and invalidate the handle. |
| 7: | v = Match(A,) ▷ Match to the corresponding action in A by a hash function |
| 8: | insert(,v) ▷ Insert action (v) to |
| 9: | end if |
| 10: | end for |
4.1.4. Training HMMs
4.1.5. Computing Decision Thresholds
| Algorithm 2 : HM3alD-Training phase | |
Input:
| |
Output:
| |
| 1: | ▷ an empty set |
| 2: | for to do |
| 3: | Estimate the number of states () for cluster |
| 4: | Initialize , and using the proposed program behavior-aware topology |
| 5: | Compute using Baum–Welch algorithm |
| 6: | Add to |
| 7: | end for |
| Algorithm 3 : Computing decision thresholds for all malware HMMs, | |
Input:
| |
Output:
| |
| 1: | for to k do |
| 2: | ▷ an empty set |
| 3: | ▷ an empty set |
| 4: | for each do |
| 5: | |
| 6: | insert(,) |
| 7: | end for |
| 8: | sort() ▷ sort in ascending order |
| 9: | =round() |
| 10: | |
| 11: | Compute by using Equation (3) |
| 12: | if then |
| 13: | |
| 14: | else |
| 15: | |
| 16: | end if |
| 17: | insert(,) |
| 18: | end for |
4.2. Detection Phase
4.3. Time Complexity Analysis
4.3.1. Training Phase
4.3.2. Detection Phase
| Algorithm 4 : HM3alD-Detection phase | |
Input:
| |
Output:
| |
| 1: | for to k do |
| 2: | =forward(,) |
| /* The forward() is presented as Algorithm 5 in Appendix B.*/ | |
| 3: | if then |
| 4: | return “Malware” & exit ▷ returns “Malware” and then exit. |
| 5: | end if |
| 6: | end for |
| /* If none of the malware HMMs detect the program as malware, then the algorithm decides that it is a benign program. */ | |
| 7: | return “Benign” |
5. Experimental Evaluation
5.1. Dataset
5.2. Experimental Setup
5.3. Evaluation Metrics
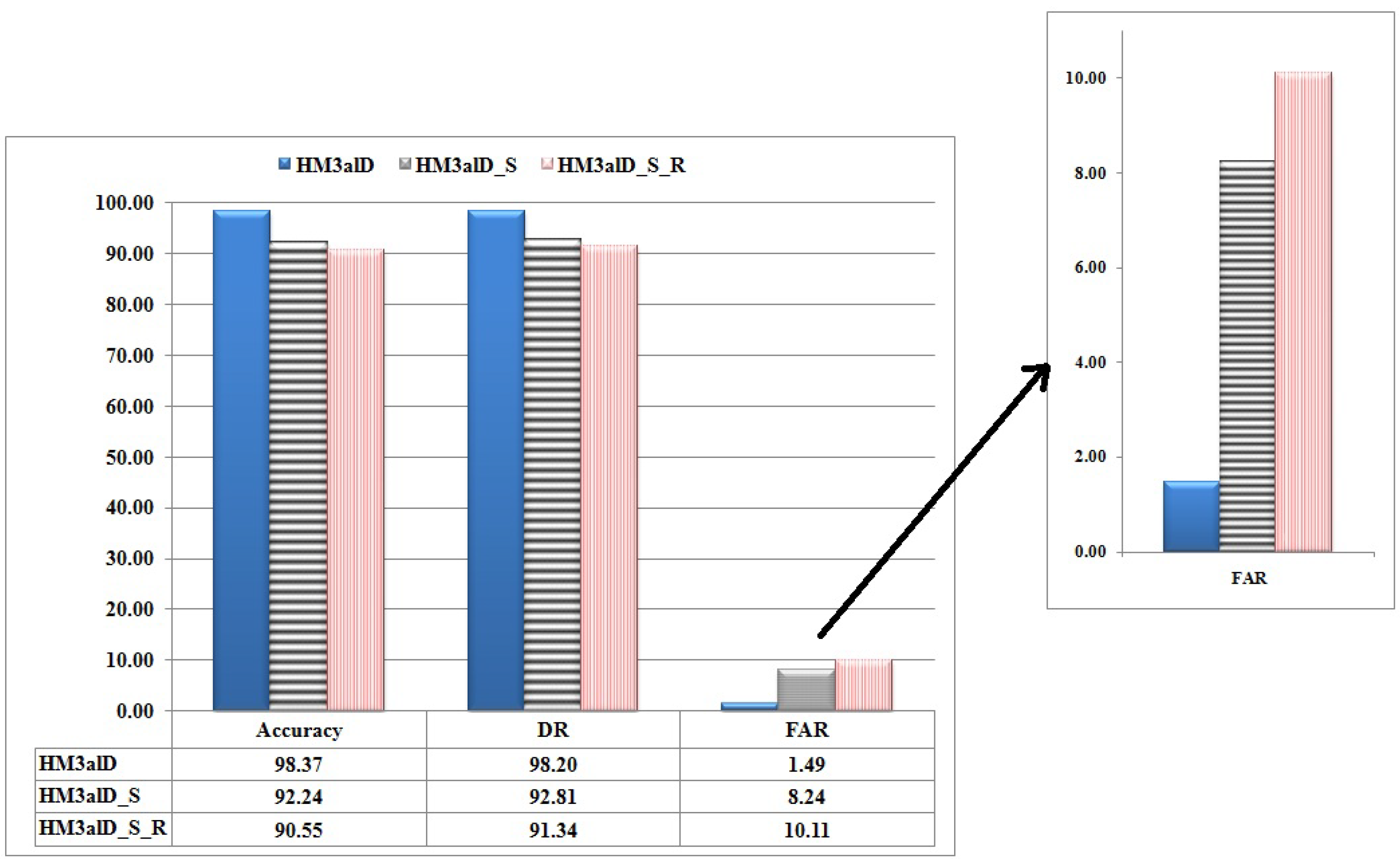
5.4. The Performance of
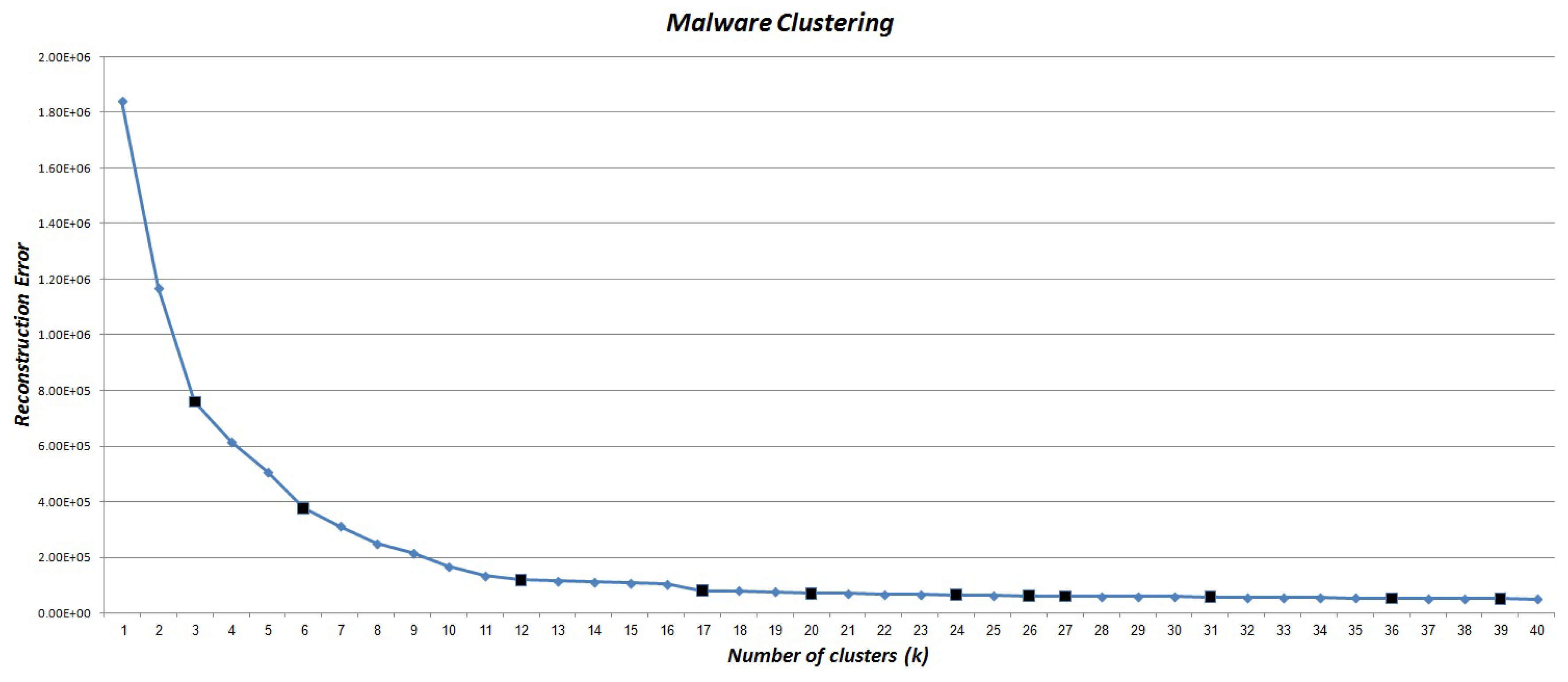
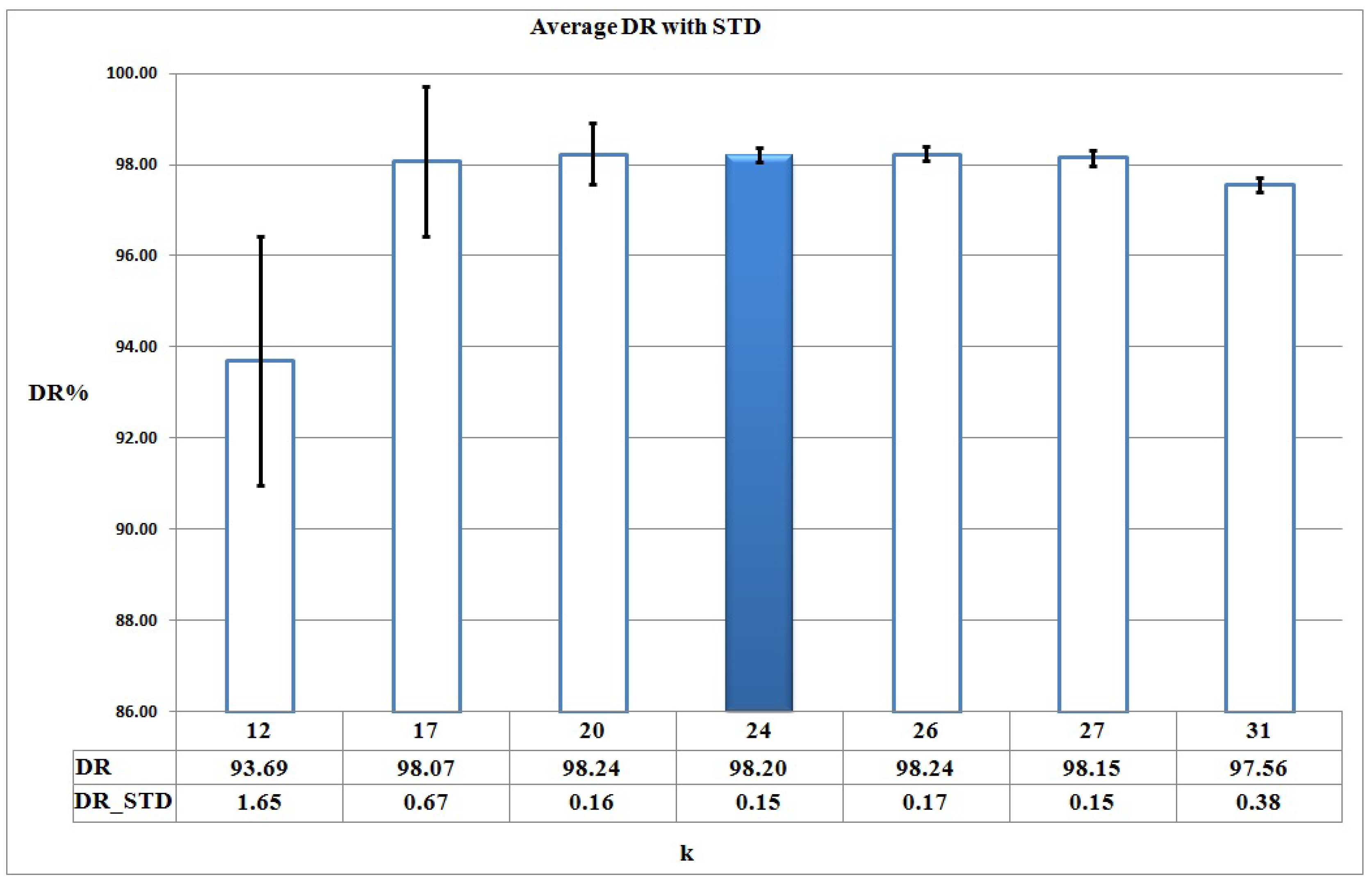
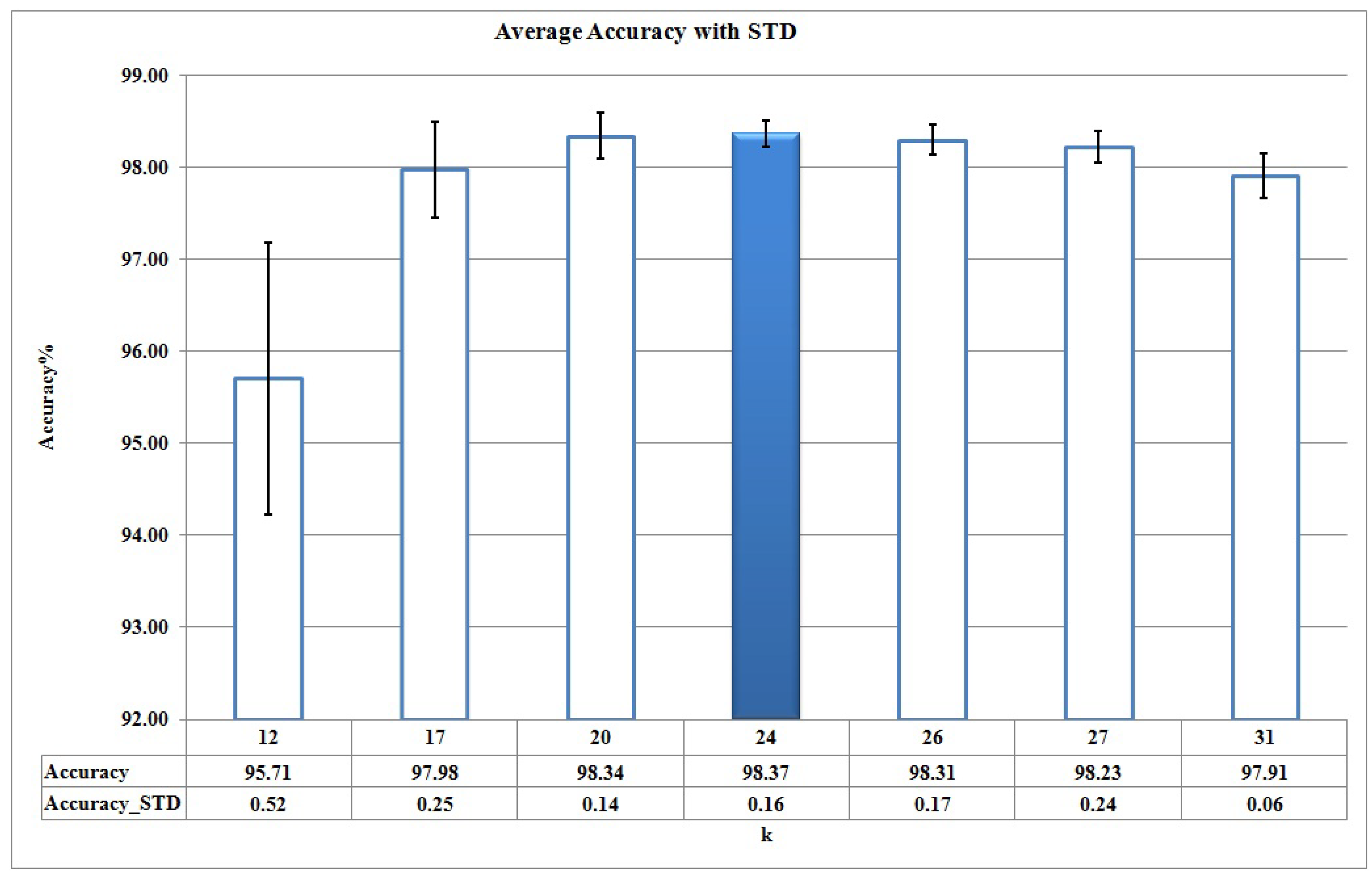
5.4.1. Training Phase
5.4.2. Detection Phase
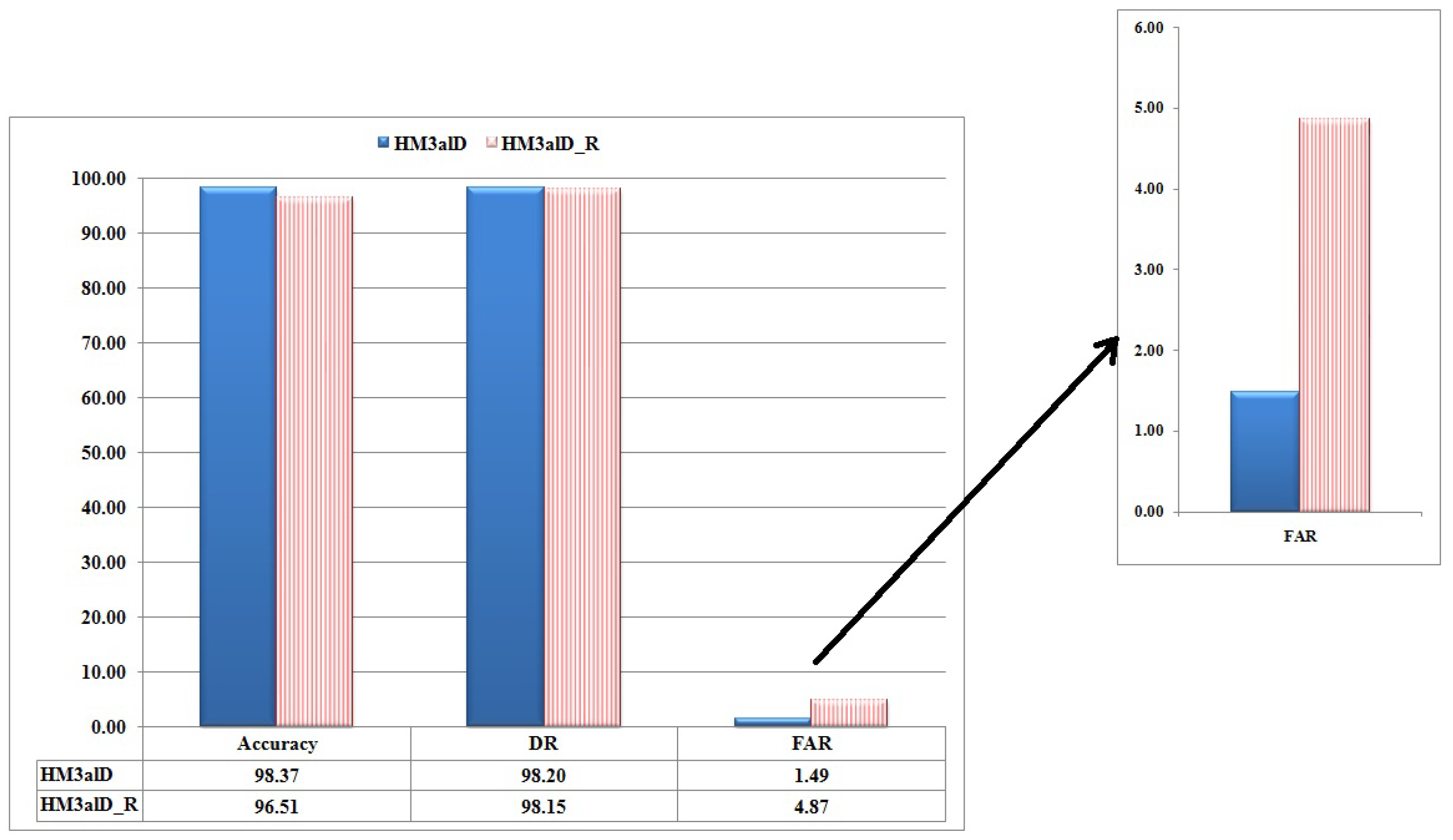
5.5. Comparing with Other Work
6. Analysis and Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A. Mapping a Subsequence of System Calls to Actions
- File Actions include “write file”, “read file”, “delete file”, “execute file”, “copy file”, and “move file”.
- Registry Actions indicate the program behavior regarding the registry of Windows operating system (OS), which includes writing, reading, and deleting in the registry.
- Service Actions relate to the registered services in Windows OS. These actions include creating, deleting, and executing a service in Windows.
- Network Actions cover the behavior of executing sample in the transport layer. This Action set is formed based on the state diagram in the TCP protocol, which includes opening and closing a connection (socket), listening on a socket, binding a socket, accepting a socket, sending and receiving on a socket, etc.
- Internet Actions include all actions that occur during communications of a running program in the Application Layer. These actions include opening a session, session connection, and sending and reading files via the network.
- System Actions consist of the sequence of system calls which express a system operation to begin the execution. Load library, memory allocation, address allocation to procedures, etc. are some examples of system actions.
- Process Actions include all the actions related to process and threads, (e.g., creating, executing, and killing a thread.)
Appendix B. The Forward Algorithm
| Algorithm 5 : Forward algorithm | |
| It implements the scaled forward algorithm and returns: | |
| (1) log(); (2) scale factor set F = ; and (3) scale forward variables, . | |
Input:
| |
Outputs:
| |
| Initialization: | |
| 1: | |
| 2: | for to N do |
| 3: | |
| 4: | |
| 5: | |
| 6: | end for |
| 7: | |
| 8: | for to N do |
| 9: | |
| 10: | end for |
| Induction: | |
| 11: | for to T do |
| 12: | |
| 13: | for to N do |
| 14: | |
| 15: | for to N do |
| 16: | |
| 17: | end for |
| 18: | |
| 19: | |
| 20: | end for |
| 21: | |
| 22: | for to N do |
| 23: | |
| 24: | end for |
| 25: | end for |
| Termination | |
| 26: | |
| 27: | for to T do |
| 28: | |
| 29: | end for |
| 30: | |
| 31: | return |
References
- Kang, B.; Han, K.S.; Kang, B.; Im, E.G. Malware categorization using dynamic mnemonic frequency analysis with redundancy filtering. J. Digit. Investig. 2014, 11, 323–335. [Google Scholar] [CrossRef]
- Shin, S.; Zhaoyan, X.; Guofei, G. EFFORT: A new host–network cooperated framework for efficient and effective bot malware detection. Comput. Netw. 2013, 57, 2628–2642. [Google Scholar] [CrossRef]
- Symantec. Available online: http://www.symantec.com/threatreport/ (accessed on 25 June 2018).
- Lu, H.; Wang, X.; Zhao, B.; Wang, F.; Su, J. ENDMal: An anti-obfuscation and collaborative malware detection system using syscall sequences. J. Math. Comput. Model. 2013, 58, 1140–1154. [Google Scholar] [CrossRef]
- Shahid, A.; Horspool, R.N.; Traore, I.; Sogukpinar, I. A framework for metamorphic malware analysis and real-time detection. J. Comput. Secur. 2015, 48, 212–233. [Google Scholar]
- Cha, S.K.; Moraru, I.; Jang, J.; Truelove, J.; Brumley, D.; Andersen, D.G. SplitScreen: Enabling efficient, distributed malware detection. J. Commun. Netw. 2011, 13, 187–200. [Google Scholar] [CrossRef]
- Egele, M.; Scholte, T.; Kirda, E.; Kruegel, C. A survey on automated dynamic malware-analysis techniques and tools. ACM Comput. Surv. 2012, 44, 6. [Google Scholar] [CrossRef]
- Bruschi, D.; Martignoni, L.; Monga, M. Code normalization for self-mutating malware. IEEE J. Secur. Priv. 2007, 5, 46–54. [Google Scholar] [CrossRef]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. J. ACM Comput. Surv. 2009, 41, 15. [Google Scholar] [CrossRef]
- Grill, M.; Pevny, T. Learning combination of anomaly detectors for security domain. Comput. Netw. 2016, 107, 55–63. [Google Scholar] [CrossRef]
- Preda, M.D.; Christodorescu, M.; Jha, S.; Debray, S. A semantics-based approach to malware detection. ACM Trans. Program. Lang. Syst. 2008, 30, 25. [Google Scholar] [CrossRef]
- Faruki, P.; Laxmi, V.; Gaur, M.S.; Vinod, P. Mining control flow graph as API call-grams to detect portable executable malware. In Proceedings of the ACM International Conference on Security of Information and Networks, Jaipur, India, 25–27 October 2012. [Google Scholar]
- Kalbhor, A.; Austin, T.H.; Filiol, E.; Josse, S.; Stamp, M. Dueling hidden Markov models for virus analysis. J. Comput. Virol. Hacking Tech. 2015, 11, 103–118. [Google Scholar] [CrossRef]
- Wong, W.; Stamp, M. Hunting for metamorphic engines. J. Comput. Virol. 2006, 2, 211–229. [Google Scholar] [CrossRef]
- Austin, T.H.; Filiol, E.; Josse, S.; Stamp, M. Exploring hidden markov models for virus analysis: A semantic approach. In Proceedings of the 46th Hawaii International Conference on System Sciences, Wailea, HI, USA, 7–10 January 2013. [Google Scholar]
- Song, F.; Touili, T. Efficient malware detection using model-checking. J. Formal Methods (FM) 2012, 7436, 418–433. [Google Scholar]
- Ding, Y.; Yuan, X.; Tang, K.; Xiao, X.; Zhang, Y. A fast malware detection algorithm based on objective-oriented association mining. J. Comput. Secur. 2013, 39, 315–324. [Google Scholar] [CrossRef]
- Hellal, A.; Lotfi, B.R. Minimal contrast frequent pattern mining for malware detection. J. Comput. Secur. 2016, 62, 19–32. [Google Scholar] [CrossRef]
- Park, Y.; Reeves, D.S.; Stamp, M. Deriving common malware behavior through graph clustering. J. Comput. Secur. 2013, 39, 419–430. [Google Scholar] [CrossRef]
- Shahzad, F.; Shahzad, M.; Farooq, M. In-execution dynamic malware analysis and detection by mining information in process control blocks of Linux OS. J. Inf. Sci. 2013, 231, 45–63. [Google Scholar] [CrossRef]
- Elhadi, A.A.E.; Maarof, M.A.; Barry, B.I.; Hamza, H. Enhancing the detection of metamorphic malware using call graphs. J. Comput. Secur. 2014, 46, 62–78. [Google Scholar] [CrossRef]
- Shehata, G.H.; Mahdy, Y.B.; Atiea, M.A. Behavior-based features model for malware detection. J. Comput. Virol. Hacking Tech. 2015, 12, 59–67. [Google Scholar]
- Salehi, Z.; Sami, A.; Ghiasi, M. MAAR: Robust features to detect malicious activity based on API calls, their arguments and return values. J. Eng. Appl. Artif. Intell. 2017, 59, 93–102. [Google Scholar] [CrossRef]
- Christodorescu, M.; Jha, S.; Kruegel, C. Mining specifications of malicious behavior. In Proceedings of the the 6th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering, Dubrovnik, Croatia, 3–7 September 2007. [Google Scholar]
- Kolbitsch, C.; Comparett, P.M.; Kruegel, C.; Kirda, E.; Zhou, X.; Wang, X. Effective and efficient malware detection at the end host. In Proceedings of the International Conference on USENIX Security Symposium, Montreal, QC, Canada, 10–14 August 2009. [Google Scholar]
- Ding, Y.; Xiaoling, X.; Sheng, C.; Ye, L. A malware detection method based on family behavior graph. J. Comput. Secur. 2018, 73, 73–86. [Google Scholar] [CrossRef]
- Schrittwieser, S.; Stefan, K.; Johannes, K.; Georg, M.; Edgar, W. Protecting software through obfuscation: Can it keep pace with progress in code analysis? ACM Comput. Surv. 2016, 49, 4:1–4:37. [Google Scholar] [CrossRef]
- Cohen, Y.; Danny, H. Scalable Detection of Server-Side Polymorphic Malware. Knowl.-Based Syst. 2018, 156, 113–128. [Google Scholar] [CrossRef]
- Alpaydin, E. Introduction to Machine Learning; MIT Press: London, UK, 2014. [Google Scholar]
- Camastra, F.; Vinciarelli, A. Machine Learning for Audio, Image, and Video Analysis; Springer: London, UK, 2008. [Google Scholar]
- Francis, H.; Chen, H.; Ristenpart, T.; Li, J.; Su, Z. Back to the future: A framework for automatic malware removal and system repair. In Proceedings of the 22nd Annual Computer Security Applications Conference, Miami Beach, FL, USA, 11–15 December 2006. [Google Scholar]
- Cuckoo Foundation. Available online: https://www.cuckoosandbox.org (accessed on 25 June 2018).
- Murtagh, F. A survey of recent advances in hierarchical clustering algorithms. Comput. J. 1983, 26, 354–359. [Google Scholar] [CrossRef]
- Yujian, L.; Bo, L. A normalized Levenshtein distance metric. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 1091–1095. [Google Scholar] [CrossRef] [PubMed]
- VxHeavens. Available online: http://vxheaven.org/vl.php (accessed on 1 March 2016).
- Sourceforge. Available online: https://sourceforge.net/ (accessed on 25 June 2018).
- GHMM Library. Available online: http://www.ghmm.org/ (accessed on 25 June 2018).
- Giacinto, G.; Perdisci, R.; Del Rio, M.; Roli, F. Intrusion detection in computer networks by a modular ensemble of one-class classifiers. J. Inf. Fusion 2008, 9, 69–82. [Google Scholar] [CrossRef]
- Lanzi, A.; Balzarotti, D.; Kruegel, C.; Christodorescu, M.; Kirda, E. Accessminer: Using system-centric models for malware protection. In Proceedings of the 17th ACM conference on Computer and communications security, Chicago, IL, USA, 4–8 October 2010; pp. 399–412. [Google Scholar]
- Das, S.; Liu, Y.; Zhang, W.; Chandramohan, M. Semantics-Based Online Malware Detection: Towards Efficient Real-Time Protection Against Malware. IEEE Trans. Inf. Forensics Secur. 2016, 11, 289–302. [Google Scholar] [CrossRef]
- Maggi, F.; Matteucci, M.; Zanero, S. Detecting intrusions through system call sequence and argument analysis. IEEE Trans. Dependable Secur. Comput. 2010, 7, 381–395. [Google Scholar] [CrossRef]
- Virus Bulletin. Available online: https://www.virusbulletin.com (accessed on 25 June 2018).
- AV-Comparatives. Available online: http://www.av-comparatives.org/false-alarm-tests (accessed on 1 September 2016).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster No. | Cluster Size | Centroid |
|---|---|---|
| 1 | 273 | 0.65 |
| 2 | 1638 | 0.59 |
| 3 | 243 | 0.89 |
| 4 | 318 | 0.41 |
| 5 | 311 | 0.82 |
| 6 | 268 | 0.81 |
| 7 | 376 | 0.56 |
| 8 | 510 | 0.62 |
| 9 | 372 | 0.73 |
| 10 | 588 | 0.68 |
| 11 | 592 | 0.83 |
| 12 | 860 | 0.95 |
| Cluster No. | Cluster Size | Centroid |
|---|---|---|
| 1 | 468 | 0.79 |
| 2 | 1170 | 0.61 |
| 3 | 54 | 0.13 |
| 4 | 264 | 0.58 |
| 5 | 492 | 0.90 |
| 6 | 100 | 0.63 |
| 7 | 92 | 0.72 |
| 8 | 284 | 0.59 |
| 9 | 308 | 0.79 |
| 10 | 64 | 0.56 |
| 11 | 273 | 0.65 |
| 12 | 243 | 0.89 |
| 13 | 311 | 0.82 |
| 14 | 268 | 0.81 |
| 15 | 510 | 0.62 |
| 16 | 588 | 0.68 |
| 17 | 860 | 0.95 |
| Cluster No. | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21 | 22 | 17 | 18 | 16 | 15 | 17 | 23 | 26 | 23 | 15 | 21 | 20 | 19 | 22 | 18 | 14 | 23 | 23 | 10 | 12 | 16 | 21 | 9 |
| Approaches | Dataset Size (Benign/Malware) | DR(%) | FAR(%) | Accuracy (%) |
|---|---|---|---|---|
| Shahzad (2013) [20] | 105/114 | 93.7 | 0 | 96.65 |
| 105/114 | 100 | 0 | 100 | |
| Elhadi (2014) [21] | 98/416 | 97.57 | 0 | 98.05 |
| 98/416 | 100 | 0 | 100 | |
| Salehi (2017) [23] | 1359/3009 | 98.4 | 4.6 | — |
| 1359/3009 | 98.89 | 1.12 | 98.88 | |
| Shehata (2015) [22] | 2000/2000 | 97.6 | 2.37 | 96.89 |
| 2000/2000 | 98.83 | 1.18 | 98.87 |
| Methods | Dataset Size (Benign/Malware) | DR(%) | FAR(%) | Accuracy (%) |
|---|---|---|---|---|
| Kalbhor (2015) [13] | 370/760 | 88.95 | 0.2 | 97.58 |
| 370/760 | 99.12 | 0.23 | 99.38 | |
| Song (2012) [16] | 8/200 | 100 | 12.5 | 99.52 |
| 8/200 | 100 | 0 | 100 | |
| Shahid (2015) [5] | 2330/1020 | 98.9 | 4.5 | — |
| 2330/1020 | 98.99 | 1.27 | 98.85 | |
| Furuki (2012) [12] | 2595/3639 | 98.4 | 2.7 | 97.85 |
| 2595/3639 | 98.81 | 1.36 | 98.70 | |
| Ding (2013) [17] | 3760/4410 | 97.3 | — | 91.2 |
| 2676/4410 | 98.79 | 1.85 | 98.39 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tajoddin, A.; Jalili, S. HM3alD: Polymorphic Malware Detection Using Program Behavior-Aware Hidden Markov Model. Appl. Sci. 2018, 8, 1044. https://doi.org/10.3390/app8071044
Tajoddin A, Jalili S. HM3alD: Polymorphic Malware Detection Using Program Behavior-Aware Hidden Markov Model. Applied Sciences. 2018; 8(7):1044. https://doi.org/10.3390/app8071044
Chicago/Turabian StyleTajoddin, Asghar, and Saeed Jalili. 2018. "HM3alD: Polymorphic Malware Detection Using Program Behavior-Aware Hidden Markov Model" Applied Sciences 8, no. 7: 1044. https://doi.org/10.3390/app8071044
APA StyleTajoddin, A., & Jalili, S. (2018). HM3alD: Polymorphic Malware Detection Using Program Behavior-Aware Hidden Markov Model. Applied Sciences, 8(7), 1044. https://doi.org/10.3390/app8071044