1. Introduction
System deployment or system provisioning is the activity of making the operating system (OS) and applications that are available for use in the machine being deployed (i.e., the machine is put into the state of operational readiness) [
1,
2]. Because system deployment can be used for either physical or virtual machines, the term “bare-metal provisioning” [
3] can be used to describe the tasks that are related to the deployment of OSs and applications to physical machines. However, such deployment tasks are time-consuming because many sub-tasks are involved, including OS deployment, application installation, setting configuration, and performance adjustment, as well as the preparation and restoration of images [
2]. In addition, various OSs, including Microsoft (MS) Windows, Linux, Macintosh Operating System (MacOS), and FreeBSD (Berkeley Software Distribution), can be deployed. Hence, system deployment can be very complicated and tedious. However, system deployment is quite dominant due to its nature in ensuring the operational readiness of computer systems. Thus, system deployment can be regarded as the foundation of various computing environments.
The applications of system deployment vary. Infrastructure as a Service (IaaS) [
4] in cloud computing is one of the most dominant applications. Other typical cases include computing tasks accessing hardware devices that cannot be virtualized, while dedicated hardware is required for performance or security reasons. In addition, many applications can be found in high-performance computing clusters, content delivery networks, render farms, utility computing, large-scale web services, databases and file systems, appliances and network devices, and computer classrooms. IaaS has three types of architecture [
5]: bare metal, hypervisor, and container. Bare metal servers provide services on non-virtualized servers, so there is no overhead, as in the case for hypervisor servers. The overhead that is associated with a container-based virtual server is smaller than that associated with a hypervisor virtual server. Regardless of the IaaS architecture, the OS and basic applications on the host machine must be available. In addition, the emerging fog computing also relies on the hypervisor and container technologies [
6]. In a nutshell, without OSs and basic applications on the physical host machines, none of the mentioned scenarios of computing, including cloud computing and fog computing, can provide services. However, the installations of the OSs as well as applications are very time consuming. Therefore, the efficient deployment of OSs and applications to physical machines with all types of architectures is critical.
Open source means that the source code of the software is publicly available, thereby allowing for modification. The copyright owner of open source software allows for others to use, copy, modify, and distribute the source code [
7]. Because the open source approach allows for anyone to read and modify the source code(s), the modifications of such software can also be fed back to the developers. Therefore, all of the developers of open source software benefit each other. The model enabling developers to “stand on the shoulders of giants” facilitates the access, use, and improvement of existing software. Thus, a lot of high-quality software has been developed accordingly. Typical cases include the Linux kernel [
8] and the OpenStack [
9] for cloud computing platforms.
Although system deployment is dominant, to the best of the authors’ knowledge, no single open source program for system deployment exists, no matter if being from the aspect of single machine backup and recovery, the massive deployment of disks in a computer, or the massive deployment to large-scale computers. Furthermore, existing commercial proprietary system deployment software lacks a flexible architecture to handle various file systems being generated during the rapid evolution process of open source file systems due to software license or marketing issues.
Therefore, this paper aims to propose an open source massive deployment system that includes system architecture as well as associated software for system deployment. This massive deployment system can handle single machine backup and recovery, the massive deployment of disks in a computer, and massive deployment in large-scale computers. In addition, this system can deploy most dominant OSs, including Linux, MacOS, MS Windows, and FreeBSD. Once verified, the proposed mass deployment system can be promoted and applied in various scenarios of computing, thereby enhancing the efficiency of system deployment. To achieve this goal, the program “Clonezilla” [
10] was developed, which was based on the proposed architecture and following the open source developing model.
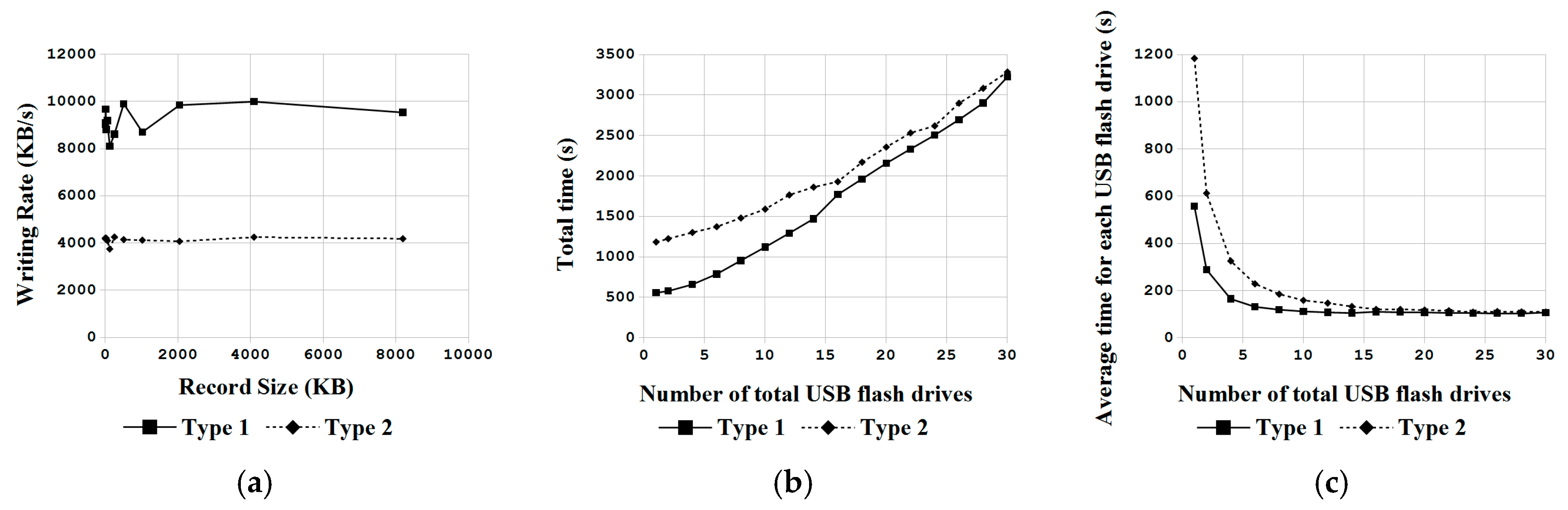
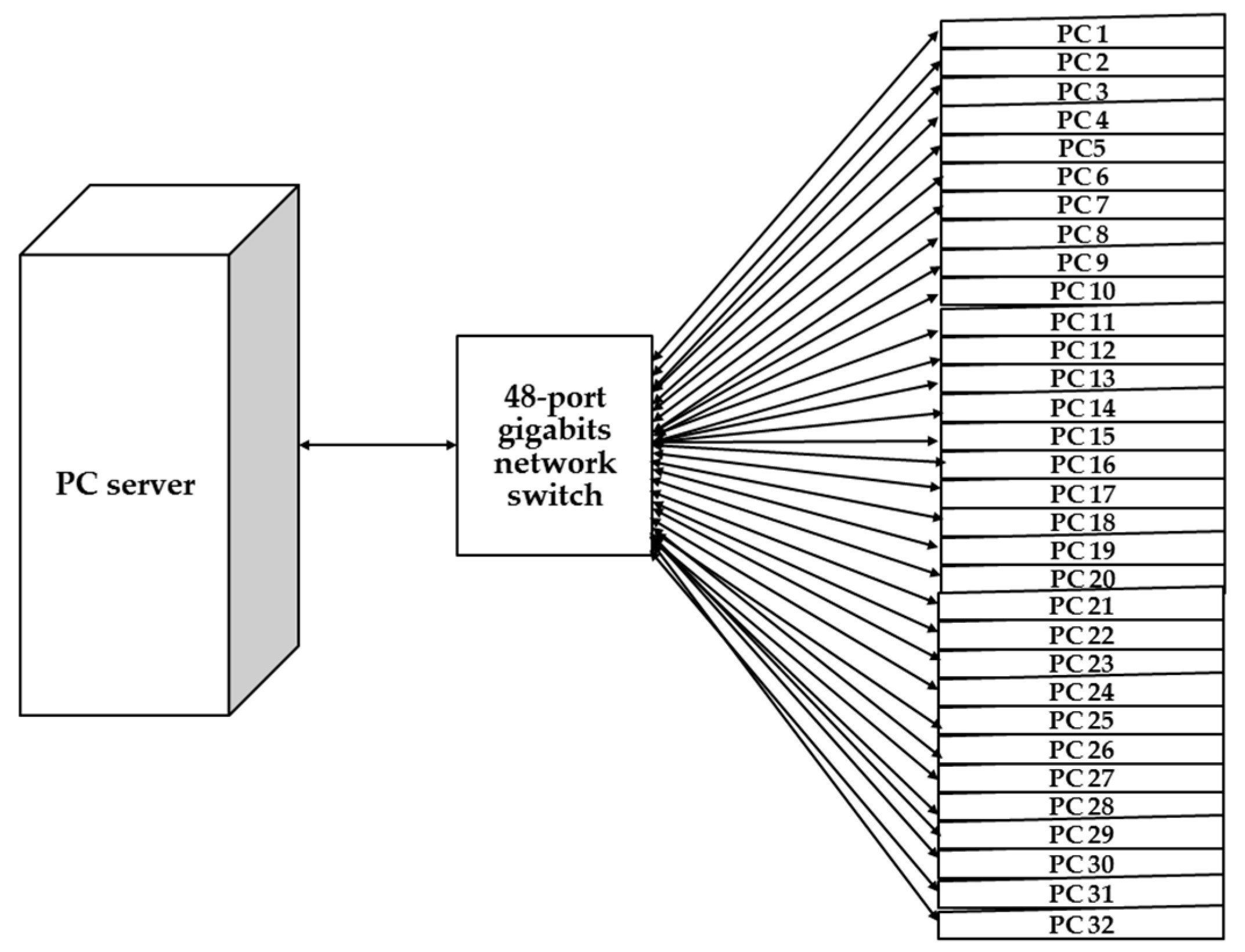
In order to demonstrate the feasibility of the proposed massive deployment system, the authors validated the system by deploying massive disks in a single machine. Clonezilla live was used to deploy Ubuntu Linux to a large quantity of USB flash drives in parallel on a single x86-64 based personal computer and USB 3.0 hubs. Various factors influence the input/output (I/O) throughputs (e.g., the number of disks, the bandwidth of system I/O bus, and the size of each I/O transfer). A governing equation to determine the optimal performance of the massive deployment system was also proposed and verified. In addition, cost comparisons between the proposed novel massive deployment system versus other widely adopted commercial proprietary solutions are provided. The software was also validated by deploying a Linux system to massive computers in a computer classroom via the multicast mechanism. The experimental results demonstrate the feasibility of massively deploying disks in a computer, and the use of massive deployment in large-scale computers. Nevertheless, the well-verified mass deployment system can also be used for single machine backup and recovery.
The rest of this paper is organized as follows.
Section 2 reviews and discusses related works.
Section 3 introduces the system architecture, software implementation, software packaging, massive deployment, and major changes and improvements of the developed software in the past decade. The experimental results are demonstrated in
Section 4. The results and comparisons are discussed in
Section 5. Conclusions and suggestions for future works are provided in
Section 6.
2. Related Works
The OS and applications in a physical machine are the basis for all of the computing scenarios. Therefore, many related works have been conducted concerning system deployment. At least three methods were proposed to deploy a system: (1) installing OS and applications from scratch with an automated installation and configuration program (hereafter referred to as “automated installation”) [
11]; (2) restoring previously saved files from a disk (hereafter referred to as “differential update”) [
12]; and, (3) restoring an image of the previously saved file system (hereafter referred to as “file system imaging”) [
13]. These three methods have specific advantages and disadvantages. The major advantage of the automated installation method is the flexibility to decide which packages will be installed. The system can also be configured in the deployment processes. The major disadvantage of this method is the comparatively longer time that is required. By using the automated installation method, every computer must be installed from scratch. The major advantage of the differential update method is the efficiency in file synchronization and the consumption of network bandwidth. However, the file system must be created before the system deployment starts so that files can be copied. Furthermore, not all of the file systems can be created when the OS is different. Therefore, the differential update method can support a very limited number of OSs. The major advantage of the file system imaging method is the highest efficiency of deployment. However, the method lacks flexibility because all of the systems being deployed are the same. Due to the different pros and cons that are associated with each deployment method, system administrators must choose the most appropriate one when deploying systems.
2.1. Automated Installation Method
Among the automated installation methods, Kickstart Installation [
1] and Fully Automatic Installation (FAI) [
14,
15] are two well-known open source projects. Both use a configuration file to define the steps in the system installation. Once the installation on a given computer is ready to be done, the Kickstart or FAI program takes over and performs the automatic installation without any manual intervention. Cobbler [
11] is open source software that is revised based on the Kickstart program. The major enhancement of Cobbler is the provision of a web user interface that allows for the provision of more features, so system administrators can automate many Linux-related tasks. Metal as a Service (MaaS) [
16] is another open source solution that is provided by Ubuntu Linux that was designed specifically for deploying Ubuntu Linux. All of the software mentioned here can only be used to deploy the Linux system. The deployment of other OSs (e.g., MS Windows, MacOS, or FreeBSD) requires other solutions. One typical example is open source software called Razor [
3], which can deploy both Linux and MS Windows systems. Another open source program is Crowbar [
17], which is supported by Dell Inc. and it also provides the ability to deploy both Linux and MS Windows systems.
2.2. Diffenrential Update Method
Regarding the previously mentioned system deployment software adopting differential update technology, “rsync” is the major open source software that provides fast incremental file transfer and a synchronization mechanism [
18]. However, more procedures than just copying files are required in system deployment. Such procedures include the creation of partition tables and file system(s) and interactions with the boot loader. However, because “rsync” lacks all of the functions that are required to deploy an entire system onto a disk, some other tools have been developed to cross the gap based on the differential update method. Mondo Rescue [
19] is open source software that can deploy Linux and FreeBSD systems. Mondo Rescue has been used by thousands of users and companies. Another open source software, called ReaR [
20], can also deploy the Linux system and has been expanded as Disaster Recovery Linux Manager (DRLM), which can support massive deployment [
21]. Storix System Backup Administrator (SBAdmin) [
22] is a commercial proprietary software with good graphical user interface (GUI), Web, and command-line interfaces. Therefore, system administrators can choose the interface that they prefer when conducting system deployment. Because SBAdmin can deploy the Linux system only, the application of SBAdmin is constrained.
2.3. File System Imaging Method
Many solutions are available for the file system imaging method. The Ghost [
23], which was commercialized in 1985, is one of the most famous examples of commercial proprietary software focusing on MS DOS (Disk Operating System) and Windows deployment. The enterprise version of Ghost supports the multicast function. Therefore, Ghost is suitable for massive deployment. True Image [
24] is another commercial proprietary software provided by Acronis. Two types of deployment methods are available in True Image: online/offline files backup and file system imaging. In addition, in previous years, many open source programs have been developed to fulfill the function of system deployment using the file system imaging method. The Partimage [
25], which was developed in 2001, supports the Linux and MS Windows system deployment. The development of Partimage was terminated in 2008 due to the development of another open source system deployment software, the FSArchiver [
26], by the same author. FSArchiver provides some new features that Partimage lacks. Redo Backup and Recovery [
27] is open source file system imaging software with a GUI; the software can be executed from a bootable Linux CD or a USB flash drive. The open source OpenGnSys (Open Genesis) [
13] system provides the functions that are required to deploy, manage, and maintain computers. OpenGnSys has been used in the computer lab in the Department of Electronic Engineering, Computer Systems, and Automatics at the University of Huelva (UHU) in Spain to improve teaching and learning in the classroom. FOG [
28] is an open source network computer cloning and management solution that provides a web interface. Microsoft also provides proprietary technology, Windows Deployment Services (WDS) [
29], for the automated installation of Windows operating systems. The WDS is especially suitable for Windows Vista, Windows Server 2008, and later versions of Windows. With WDS, system administrators can deploy Windows systems to new computers using network-based installations. Apple Software Restore (ASR) [
30] is the system image software that is provided by Apple Computer. ASR can be used for the massive deployment of Macintosh computers using two deployment methods: file-based and block-based modes. Normally, the block-based mode is faster due to the transactions that are not going through the OS file system. Frisbee [
31], or Emulab [
32,
33], is an open source system that was developed at the University of Utah. Frisbee aims to save and deploy entire disk images and has been used in the Utah Emulab testbed. Frisbee manages thousands of disk images for users. OpenStack [
9] is open source software that is dedicated for the IaaS in cloud computing. OpenStack supports bare-metal, virtual machine (VM), and container-based hosts [
34]. The integrated program in OpenStack for bare-metal machines is OpenStack Ironic [
9,
35], and it provides bare-metal provisioning for the Linux system.
2.4. Other Related Works
Some tools and mechanisms have been widely adopted in network-based massive deployment, including Preboot Execution Environment (PXE), Internet Protocol (IP), User Datagram Protocol (UDP), Dynamic Host Configuration Protocol (DHCP), and Trivial File Transfer Protocol (TFTP) [
36]. The PXE environment actually combines the UDP/IP, DHCP, and TFTP protocols. Because the image of the PXE firmware is quite small, it can be implemented on a variety of systems, including embedded systems, single-board computers (SBC), PCs and high-end servers. With the PXE environment enabled, bare-metal computers can be booted from network interface cards and initiate system deployment. UDPcast [
37] is an open source file transfer software that can transfer data simultaneously to many destinations in either the multicast or broadcast mechanism on a local area network (LAN). The multicast or broadcast method makes the file transfer in UDPcast more efficient than other methods, such as Network File System (NFS) and File Transfer Protocol (FTP). Therefore, UDPcast can be one of the best tools for network-based massive deployment.
Scholars or researchers have also dedicated many efforts to develop deployment software. The Silent Unattended Installation Package Manager (SUIPM) [
38] is a method that enables the automatic software installation and uninstallation processes, and generates silent unattended installation/uninstallation packages. Quiet [
39] is a framework for automatic installation and uninstallation over a network that is based on the SUIPM. Normally, SUIPM does not cover the OS installation; instead, the SUIPM focuses on software/application packaging and installation. Therefore, SUIPM is different from the open source massive deployment that is proposed in this work due to the lack of deployment for OS. Although the open source programs that are mentioned here aim to deploy systems, the focus is different. For example, FOG focuses on the system deployment using the server–client mechanism. Redo Backup and Recovery targets a single machine backup and restore, while OpenGnSys is dedicated to the management of massive computers in computer laboratories or classrooms.
The open source deployment system that is proposed in this paper is distinguished from the other software systems based on the following features: (1) one deployment system works for system backup and recovery, the massive deployment of disks in a computer, and the massive deployment to large-scale computers; (2) open design, with an easiness to change or add functions; (3) support for deployment of a wide variety of OSs, including Linux, MS Windows, MacOS, and FreeBSD; (4) fully automated, meaning that with proper pre-settings human interaction or intervention is not required; (5) a customization option enabling system administrators to assign different settings by boot parameters; and, (6) the provision of a live system that is ready to use (i.e., no installation required).
The major contribution of this research is that it proposes novel system architecture for system deployment. To accomplish this, a comprehensive program using the open source technique is developed. This architecture, and hence, the associated software can be used for three scenarios: (1) system backup and recovery; (2) massive deployment of disks in a computer; and, (3) massive deployment in large-scale computers. All three scenarios can be processed in one program system: Clonezilla live. Because Clonezilla live is a ready-to-use massive deployment system, no tedious installation or configuration is required before usage. Therefore, significant time can be saved in system deployment. The feasibility of Clonezilla live will be demonstrated in
Section 4 by deploying Ubuntu Linux to massive USB flash drives on a single machine and massive machines in a computer classroom.
3. Design and Implementation
This section describes topics that are related to the design and implementation of system deployment, including software architecture, software implementation, software packaging, massive deployment, and major changes and improvements of the software in the past decade.
3.1. Software Architecture for System Deployment
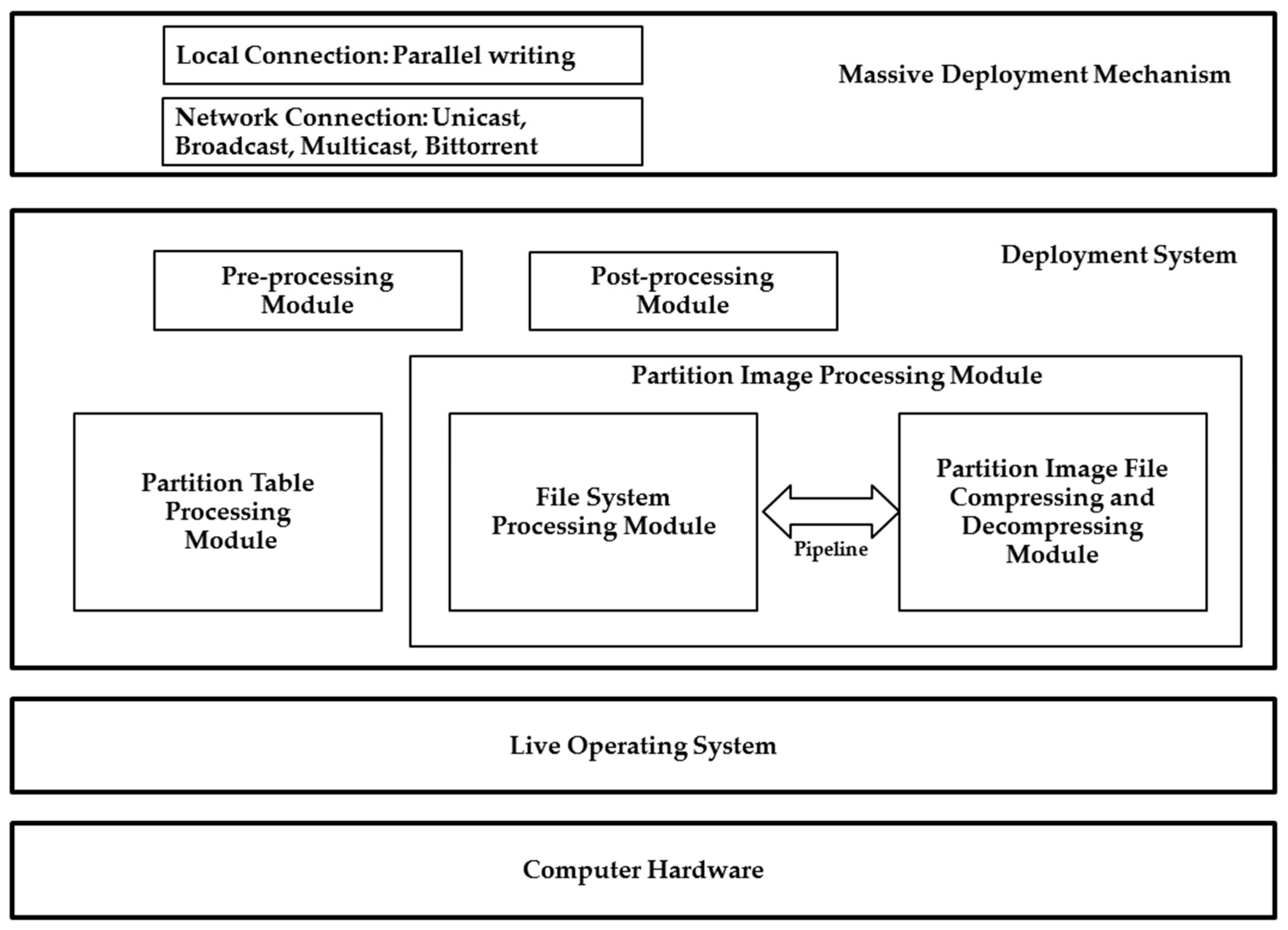
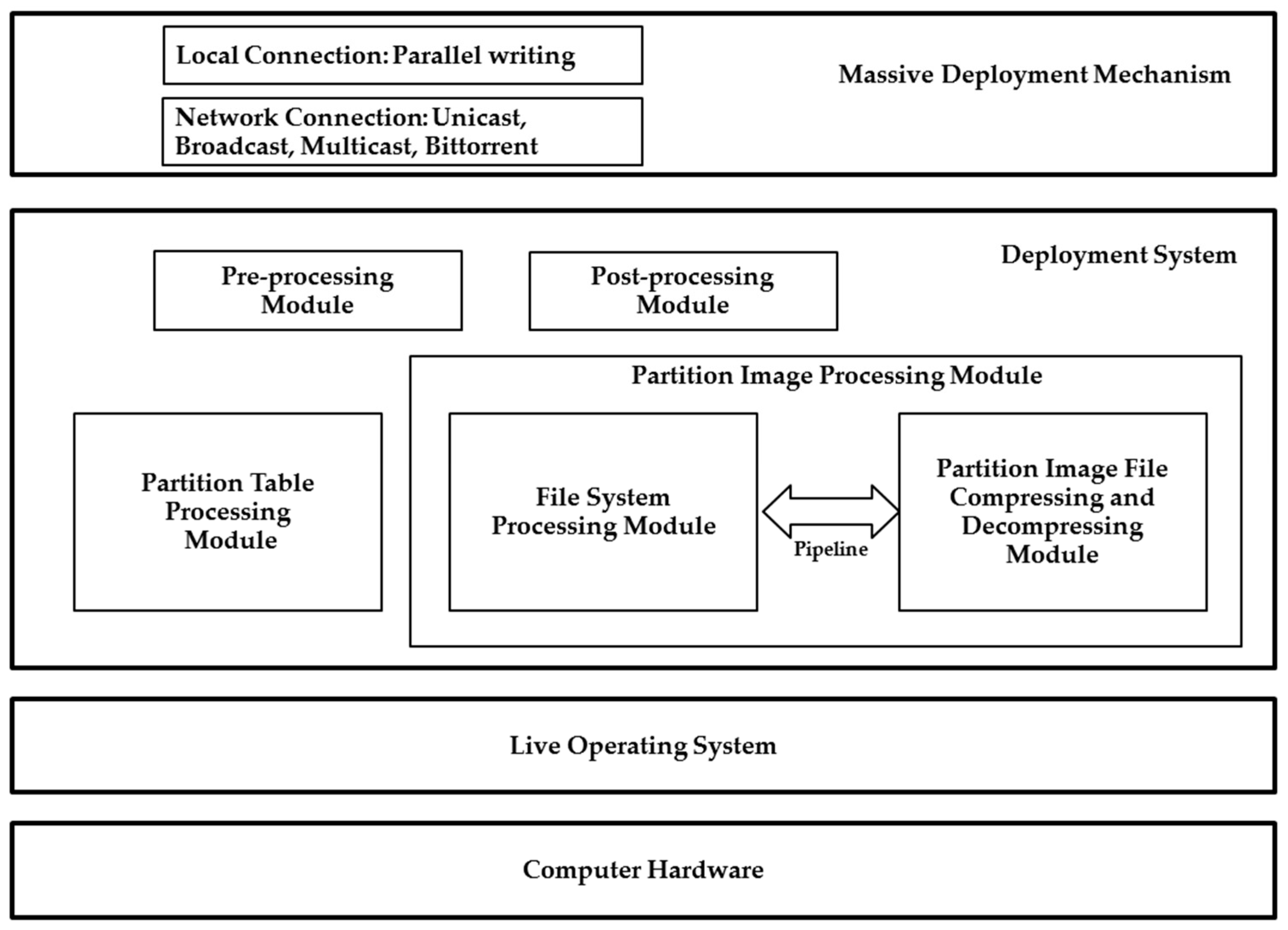
The proposed system architecture consists of computer hardware, live OS, deployment system, and massive deployment mechanism (refer to
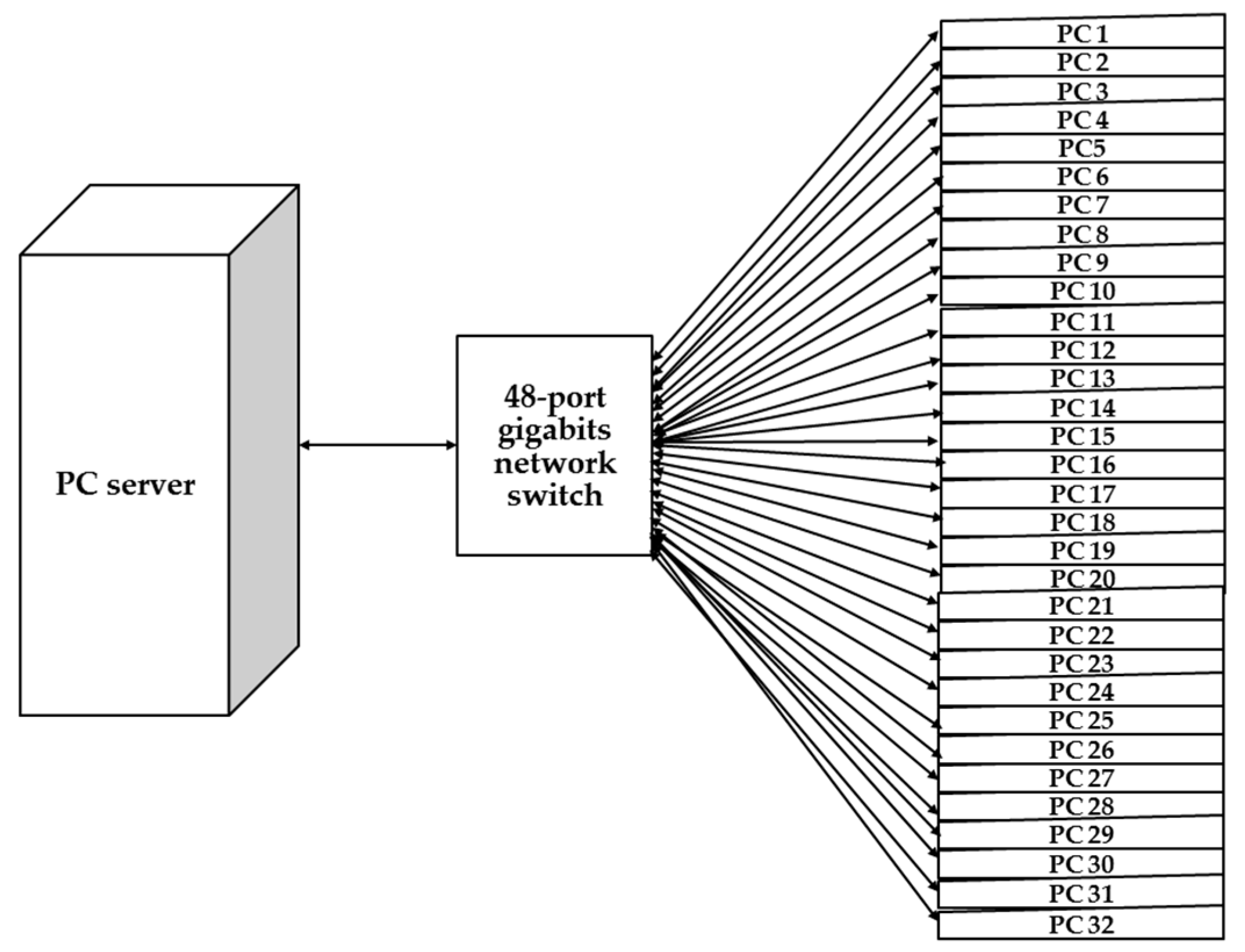
Figure 1). Four modules are included in the system architecture: (1) partition table processing; (2) partition image processing; (3) pre-processing; and, (4) post-processing modules. Two sub-modules exist in the second partition image processing module: file system process module and partition image file compressing and decompressing module. The massive deployment mechanism can support either local or network connections. The former one enables the connections of massive disks to the system buses, such as the USB or the external Serial Advanced Technology Attachment (eSATA) bus. The latter one (i.e., network connection mechanism) is for massive machines connected to network switches.
In addition, several principles are used when developing the system deployment system based on the existing free and open source software. First, the image is a directory. All of the information about the disk as well as the partitions, boot loaders, and file systems is stored in the directory. As a result, the design provides the flexibility to add more information by putting files in the image directory in the future. Traditionally, a system deployment program normally uses a file to store the file system image. However, when a new mechanism must be added in the future, the image file format has to be redefined. Hence, future maintenance is not easy. Defining an image as a directory can greatly reduce the maintenance efforts in the future. Second, all information in the image directory should be the output or input of existing open source software, unless such a program does not exist or is in short of the required functionalities. If either one of these criteria is fulfilled, a suitable program has to be developed in order to resolve the identified issue(s). Third, the UNIX philosophy, “write programs to handle text streams, because that is a universal interface” [
40], should be followed. Therefore, in most programs, pipelines are used to enable these programs to work together. This principle has a very good feature because, for example, adding a new compression format for the image is extremely easy.
3.2. Software Implementation
The key functionality of the proposed system architecture is the file system processing module. Instead of automated installation or differential update methods, the file system imaging method was chosen as the approach for system deployment because the system imaging method is more general, robust, and faster than the automated installation and differential update mechanisms [
31]. The system imaging method is more general because users do not need the file system-related knowledge regarding directory structure, file ownership, etc. Instead, users can use the system imaging method-based software for system deployment. Regarding the robustness of the system imaging method-based software, the deployment does not depend on the existing contents of the destination disk because the software just reads or overwrites the whole file system. As for the speed advantage of the system imaging method that was specified earlier, the deployment does not have to go through the OS file system for every single file. Hence, the file system imaging method that reads or writes an entire disk image is faster than the other two methods that were used to decide the files to be copied or updated. As previously mentioned, the file system imaging mechanism is not perfect due to the shortage of flexibility and the requirement for more network bandwidth. In terms of flexibility shortage, all of the deployed systems should be configured or fine-tuned after deployment. Furthermore, more network bandwidth is required than the differential update mechanism. However, the advantages outweigh the disadvantages when the file system imaging method is compared with automated installation and differential update methods. Therefore, the file system imaging mechanism was chosen in the proposed open source massive deployment system.
Based on the proposed system architecture and principles, the program Partclone, as the engine for the file system processing module, was developed, and it is licensed under GNU General Public License (GPL) [
41]. The Partclone is designed to support as many file systems as possible for the major OSs. Existing open source imaging software, like Partimage or FSArchiver, cannot support some of the major file systems (e.g., the imaging Hierarchical File System Plus (HFS+) of MacOS). Partclone aims to solve this problem by leveraging the libraries of file systems to obtain the used blocks of a file system and outputting the data of the used blocks to a file. Nowadays, Partclone can support most file systems, including ext2, ext3, ext4, reiserfs, reiser4, xfs, jfs, btrfs, f2fs, nilfs2, File Allocation Table (FAT), New Technology File System (NTFS), HFS+, Unix File System (UFS), minix, Virtual Machine File System 3 (VMFS3), and VMFS5.
The Clonezilla program consisting of all the modules of the proposed massive deployment system (refer to
Figure 1) is implemented in a bash shell script. The components of Clonezilla include: (1) pre-processing module: including read the input parameters, check the disk device, and execute the customized job if assigned by user; (2) partition table processing module: including deal with the partition table and the master boot record (MBR) of a disk; (3) partition image processing system: including checking the file system on a partition and save or restoring the file system on the partition using Partclone; and (4) post-processing module: including process the boot loader on the disk, tune the deployed system (e.g., remove hardware info files from the hard drive), and execute the customized job if assigned by the user.
An example is given here to show how the developed programs and the existing software work together in UNIX pipelines in the Clonezilla program. To save the image of a new technology file system (NTFS) file in the partition, /dev/sda1, the image will be compressed using the parallel gz compression program pigz in a 16-core central processing unit (CPU). Any output files that are larger than 4096 Mega Byte (MB) will be split into smaller 4069 MB pieces. Each piece is output to a file, entitled “sda1.ntfs-ptcl-img.gz” in the /home/partimag/vmware-windows-7 directory. The following command will be executed inside the main Clonezilla program:
partclone.ntfs -z 10485760 -N -L /var/log/partclone.log -c -s /dev/sda1 --output - | pigz -c --fast -b 1024 -p 16 --rsyncable | split -a 2 -b 4096MB - /home/partimag/vmware-windows-7/sda1.ntfs-ptcl-img.gz.
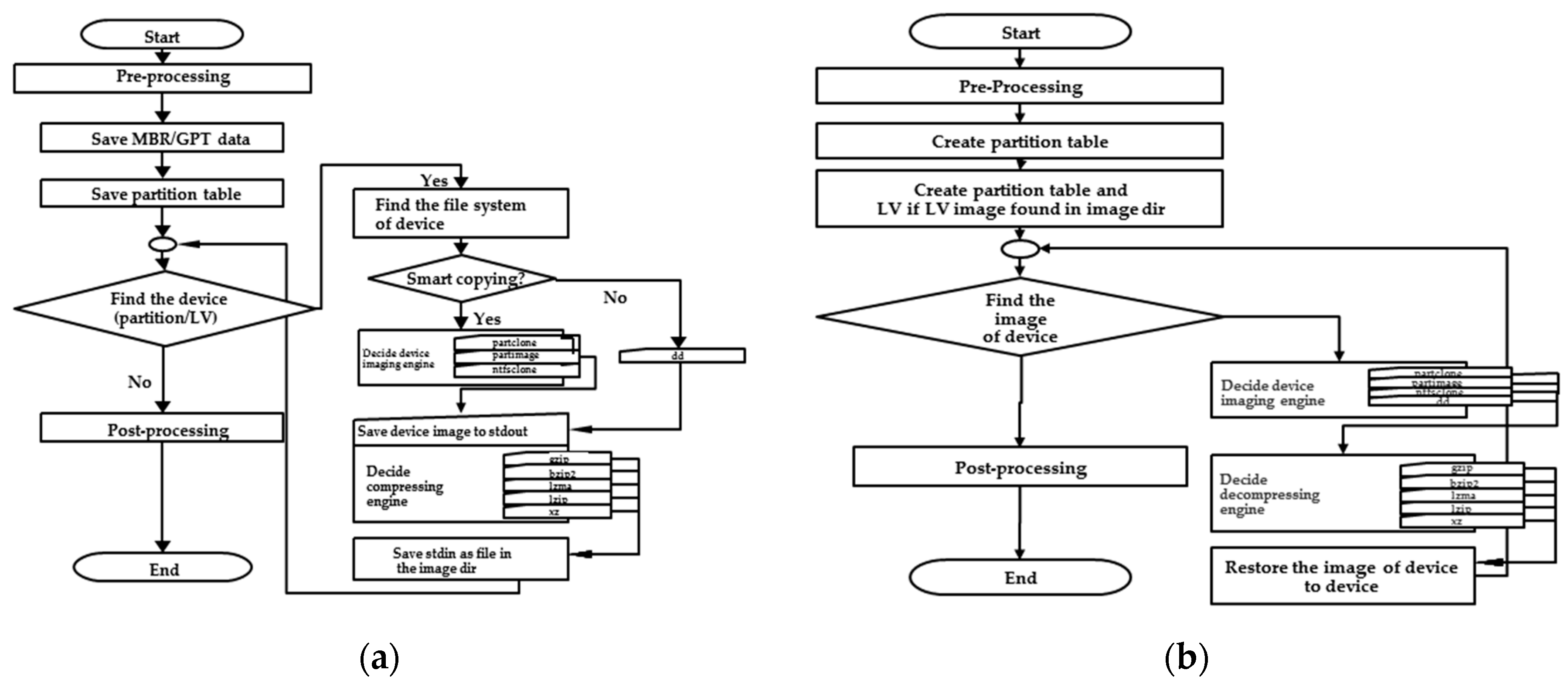
In this example, partclone.ntfs is the program that was developed in this research, while the programs pigz and split are the existing programs from the Linux system. The procedures for saving an image from a drive and restoring the image to another drive are shown in
Figure 2a,b, respectively.
Figure 2a shows the imaging engines for a different file system, which includes Partclone, Partimag, ntfsclone, and dd. Among them, Partclone is the default engine for Clonezilla. In addition, the sequential compressing programs from the Linux system, which include gzip, bzip2, lzma, lzip, or xz, could be used to compress the image. By default, gzip is chosen. If the CPU on the system has multiple cores, the corresponding parallel program, like pigz, pbzip2, plzip, or pixz, can be used when such a program is available from the Linux system. However, if the corresponding program is unavailable, then Clonezilla will roll back to use the sequential program. As an image is restored, the image should be decompressed by the corresponding program and then written to a partition, according to the format of the image, as described in
Figure 2b.
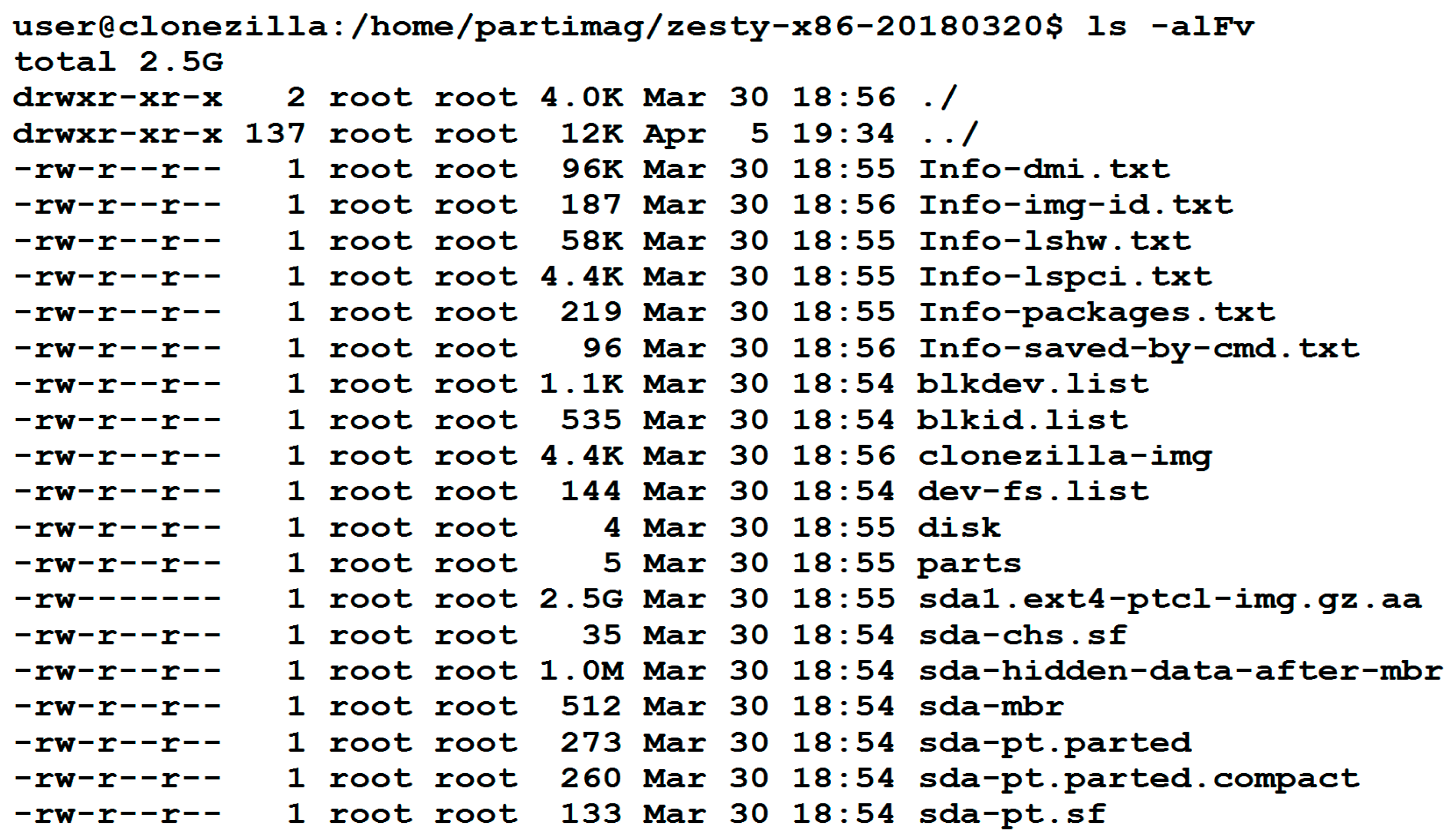
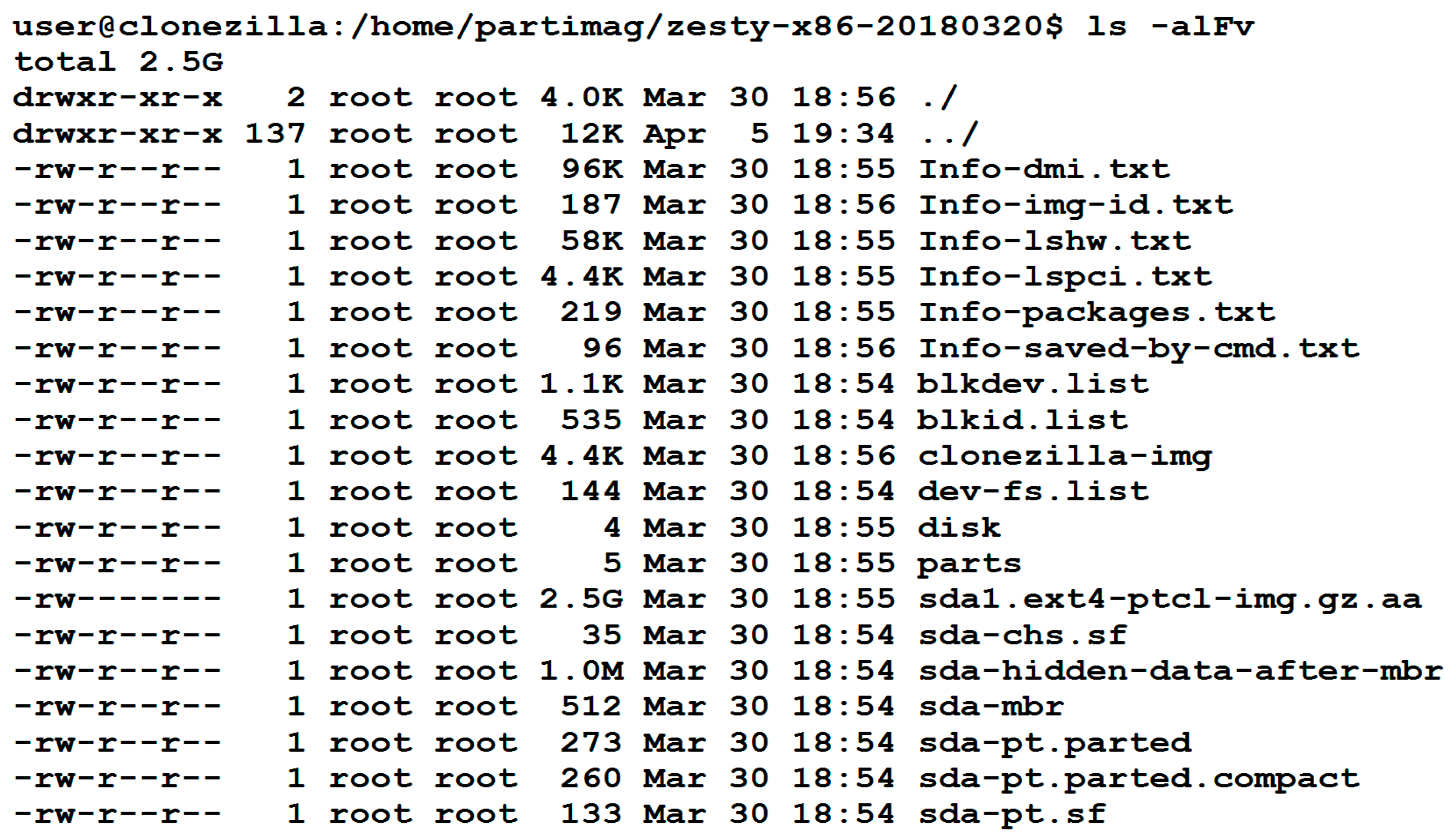
A screenshot about the image directory from Clonezilla is presented in
Figure 3. One can easily identify the file(s) by reading its name. For example, sda-mbr is the MBR data of disk sda, where sda is the device name under Linux for the first hard drive in the system. Meanwhile, sda1.ext4-ptcl-img.gz.aa is the image of sda1 being saved by the imaging program Partclone. Here, sda1 is the first partition on the first drive. After being compressed by the gzip or pigz program, the image file is split into several volumes. The default limit of each volume is 4 Giga Byte (GB). Because the image size of the example is only 2.5 GB, and there is only one volume, then the suffix is aa. If more volumes exist in the image, the suffixes ab, ac, etc., will be used, respectively. The complete list of the file formats supported is provided in
Table 1. The names denoted in brackets are assigned according to the name of the device (disk, partition, or Logical Volume Manager (LVM)), file system, compression format, or suffix. The other names without brackets are fixed styles.
3.3. Software Packaging
The Clonezilla program depends on many programs, because, as described in
Section 3.2, it uses the UNIX pipelines to make Partclone and the existing open source software work together. Hence, it is tedious for users to collect all of the required programs when they want to use Clonezilla. In addition, most of the system deployment is executed in the so-called bare metal way—that is, the machine may have only one hard drive without any OS or software. An extra OS is required to conduct the system deployment. Thus, the best way for system deployment is to have a live system [
42] that includes all of the required programs and has the capability to boot from a machine. A live system is the complete bootable computer software, including OS, which allows for users to boot from removable media and run applications without affecting the contents of the computer. This is why Clonezilla live was designed for system deployment [
10] in this research. In order to make use of the open source software, Debian live [
42], which is a live system based on Debian Linux, was chosen as the underlying system because its software repository provides thousands of open source software packages. The file size of the developed Clonezilla live system is about 200 to 300 MB. In addition, a mechanism is required to predefine all of the steps required by an unattended mode in Clonezilla live. The kernel boot parameters mechanism [
43] was used to predefine the steps in Clonezilla live. Additional parameters that were developed and implemented in Clonezilla live include ocs_live_prerun*, ocs_live_run, ocs_live_postrun*, and ocs_daemonon. The ocs_live_prerun* parameter provides the commands to be executed before the main program, ocs_live_run, can be executed. The ocs_live_postrun* parameter provides the commands to be executed after the main program, ocs_live_run, can be executed. Finally, ocs_daemonon predefines the services that are to be started after the system is booted. The boot parameters mentioned could be used to customize the unattended mode of a deployment system. An example of automatically configuring the network settings by the DHCP, mounting the NFS file server as an image repository, starting the ssh service, and then running a restoring job using the boot parameters of Clonezilla live is demonstrated, as follows:
ocs_live_prerun1=”dhclient -v eth0” ocs_live_prerun2=”mount -t nfs 192.168.100.254:/home/partimag /home/partimag” ocs_daemonon=”ssh” ocs_live_run=”ocs-sr -g auto -e1 auto -e2 -batch -r -j2 -p poweroff restoredisk my-xenial-img sda”
3.4. Massive Deployment
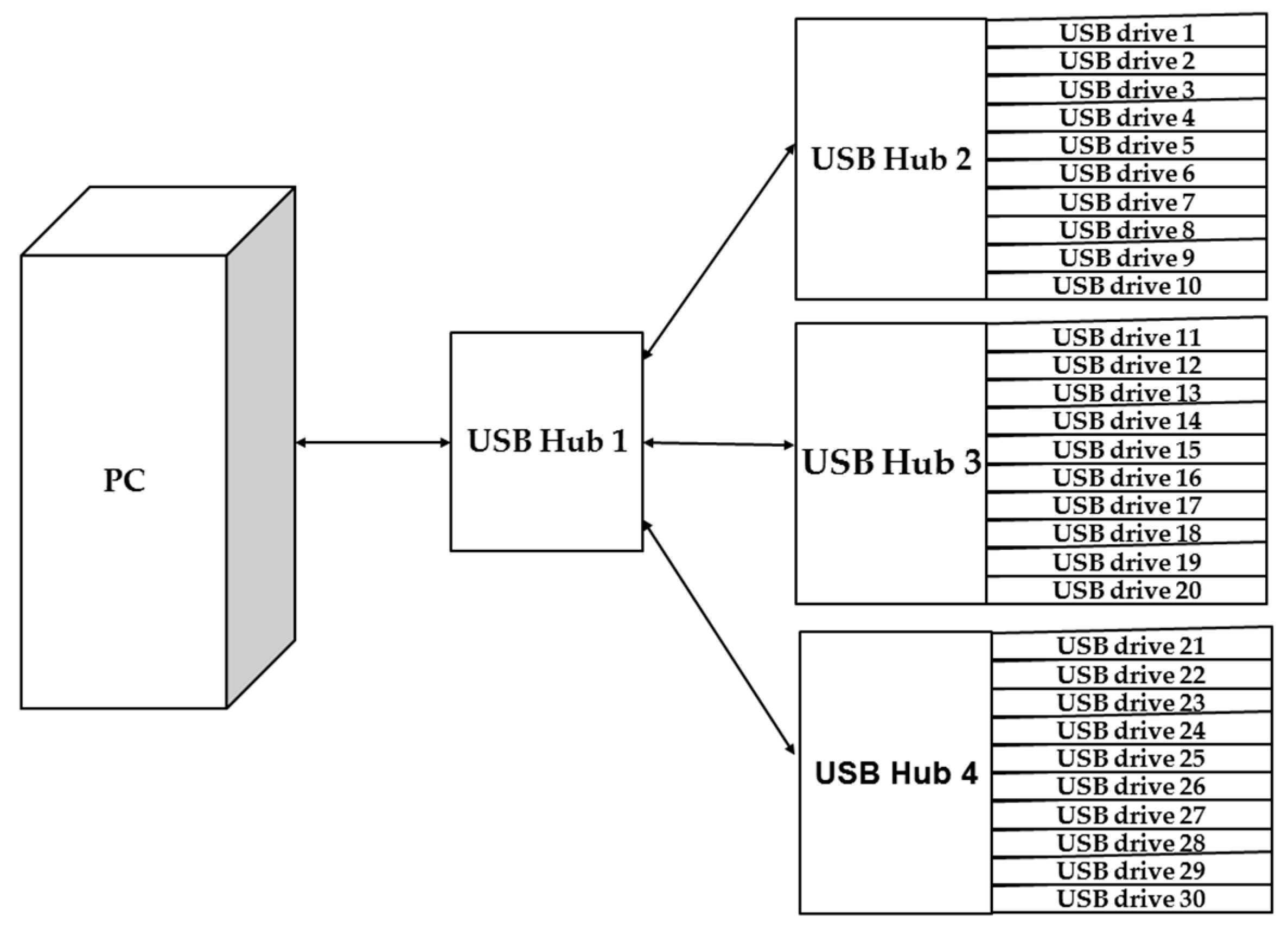
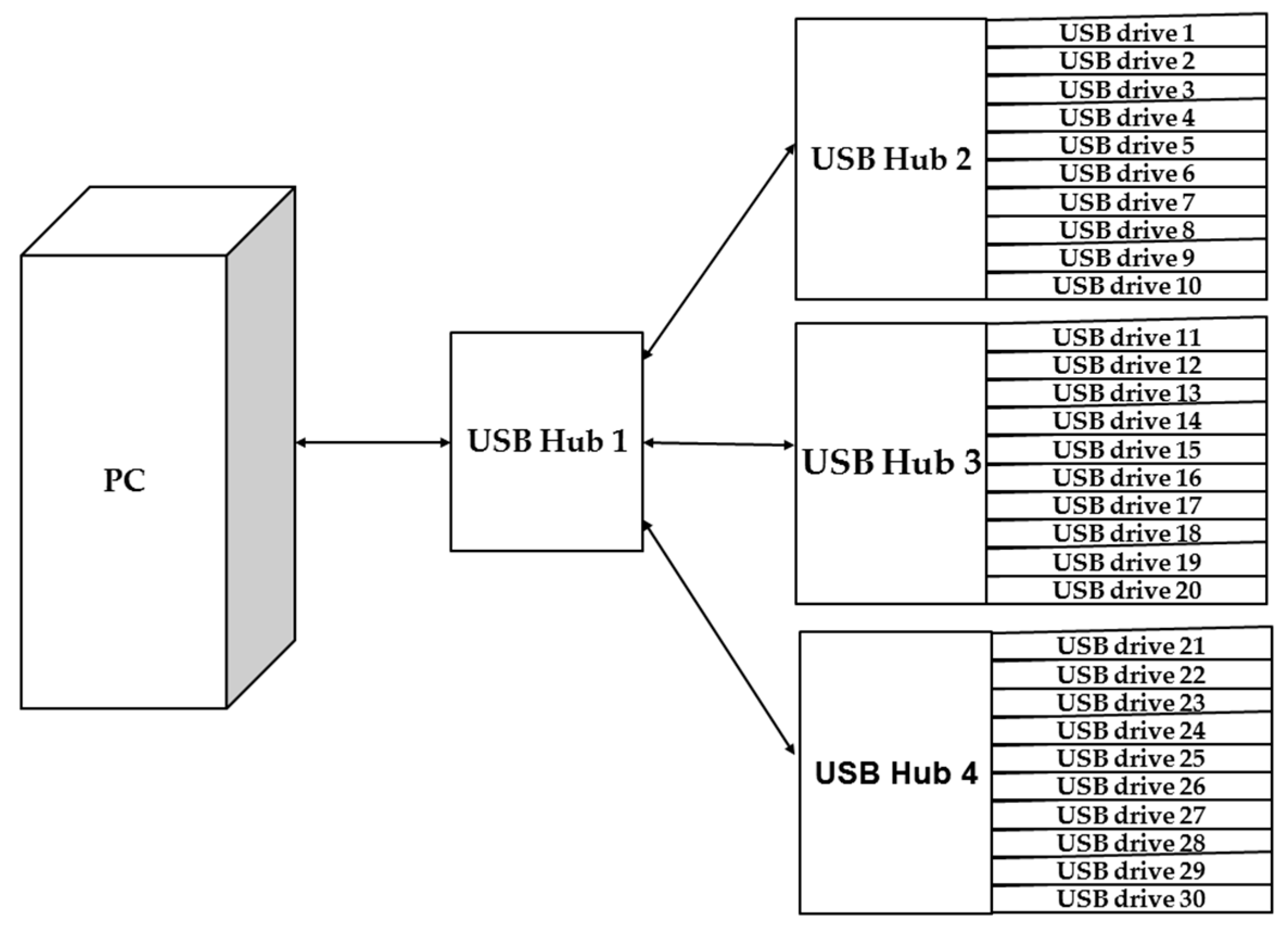
As mentioned in
Section 3.1, two types of mechanisms were considered and implemented in the massive deployment system. When dealing with the local connection (i.e., massive disks are connected to a system bus belonging to a computer), writing the data of the system image to massive disks in parallel was developed. The program in Clonezilla that can execute such a massive deployment is called ocs-restore-mdisks. According to the flowchart that is shown in
Figure 2b, a system deployment is executed for each drive. The multiple executions of writing images to USB drives in parallel by using the ocs-restore-mdisks program is executed by using the “for loop” on the Linux system.
When dealing with the network connection where massive machines are connected to network switches, at least four types of communication protocols (i.e., unicast, broadcast, multicast [
37], and peer-to-peer (P2P) networking [
44], such as BitTorrent [
45]) can be used to deploy the system image to each machine. These four protocols were implemented in Clonezilla. Basically, the flowchart for deploying each machine is similar to the one in
Figure 2b. The only difference is how the client machine to be deployed receives the system image from different protocols. Hence, the steps for such a massive deployment can be defined according to Lee et al. [
37]: (1) save a system image from the template machine; (2) start the required services for the client machines, including DHCP, TFTP, and the data-distributing service (unicast, broadcast, multicast, or BitTorrent); and, (3) boot the client machines from PXE, receive the system image data, and then write to the disks.
As mentioned in
Section 3.3, Clonezilla live is the software that is used for system backup and recovery, the massive deployment of disks in a computer, and the massive deployment in large-scale computers. Clonezilla live contains the server programs (e.g., DHCP, TFTP, and UDPcast), as well as the programs for system deployment in client machines (e.g., sfdisk, gunzip, Partclone, and Clonezilla). Clonezilla live also provides the mechanism for clients to boot from the PXE. Therefore, Clonezilla live can be used in massive deployment on both the server machine and the client machines by appropriate configurations.
3.5. Major Changes and Improvements of the Software
Since the initial release of Clonezilla live, the software has been revised several times to enhance its functionalities.
Table 2 summarizes these major revisions, indicating the version number, revision time (year), and major changes or improvements. As demonstrated in
Table 2, in the past decade, the Clonezilla live has been upgraded from the initial single machine version to the latest version, which can support the massive deployment in large-scale computers. The initial single machine version 1.0.0 could support backup and recovery in a computer. The latest version 2.5.2, which can support massive deployment in large-scale computers, was rolled out in 2017. The three types of system deployment (i.e., single machine backup and recovery, massive deployment of disks in a computer, and massive deployment in large-scale computers) were integrated into one program, Clonezilla live. All three modes of system deployment were developed based on the proposed system architecture.
6. Conclusions and Future Work
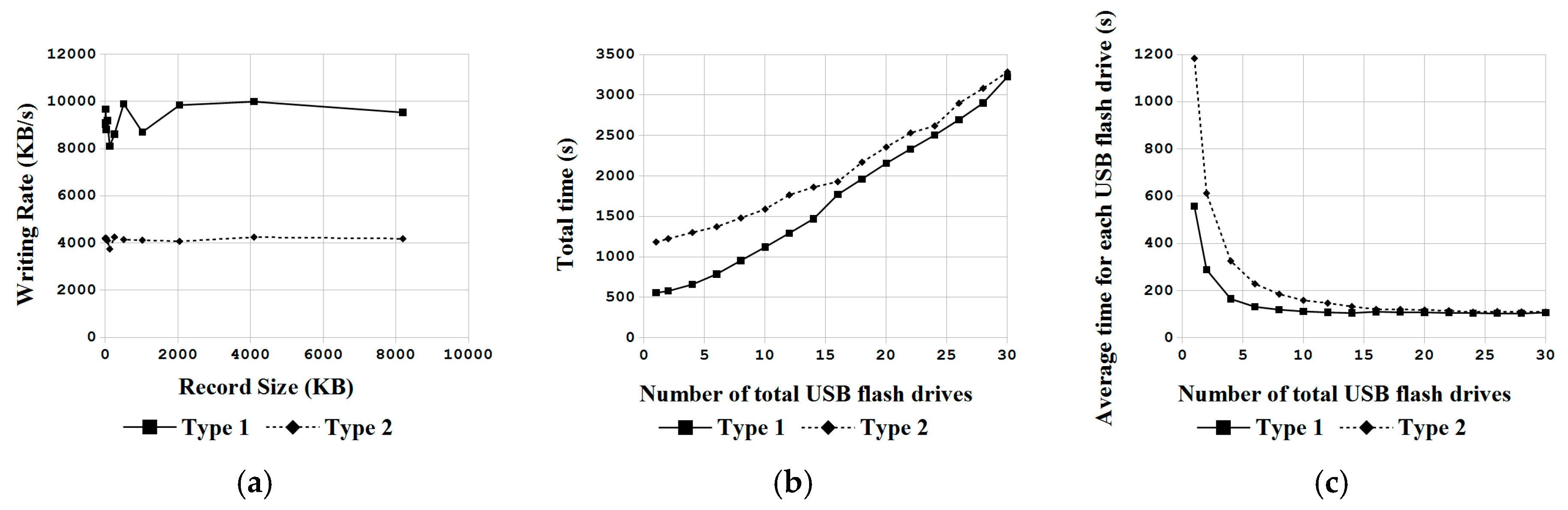
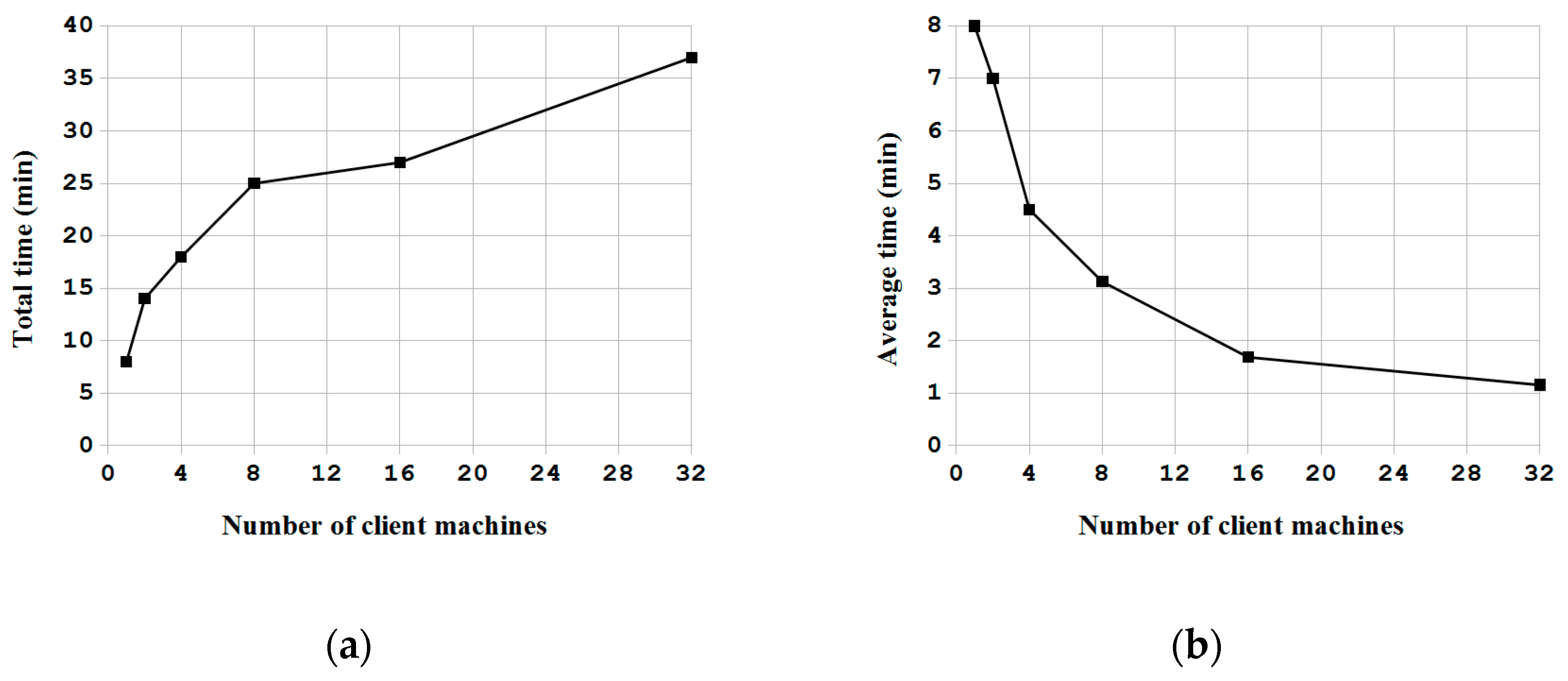
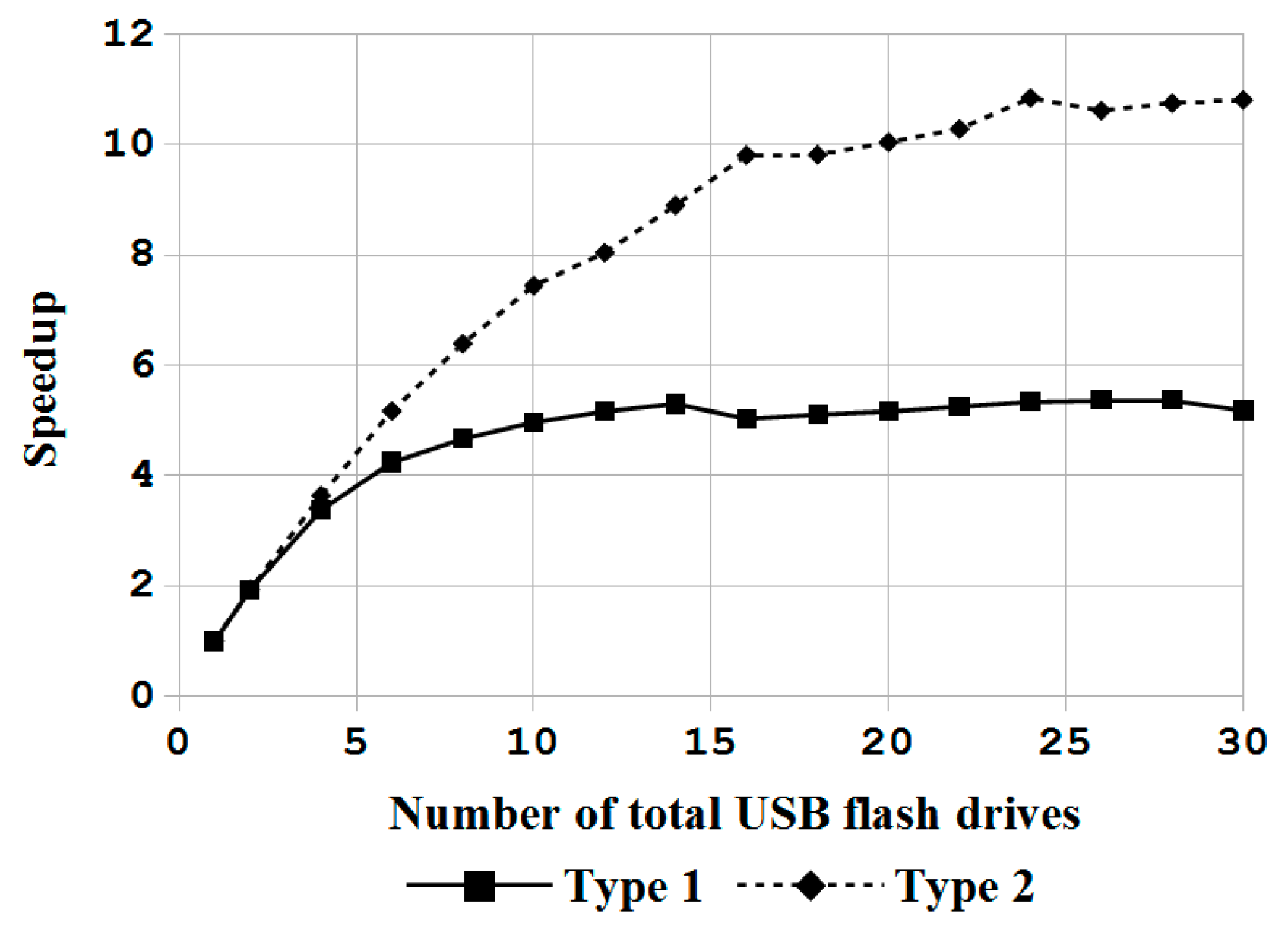
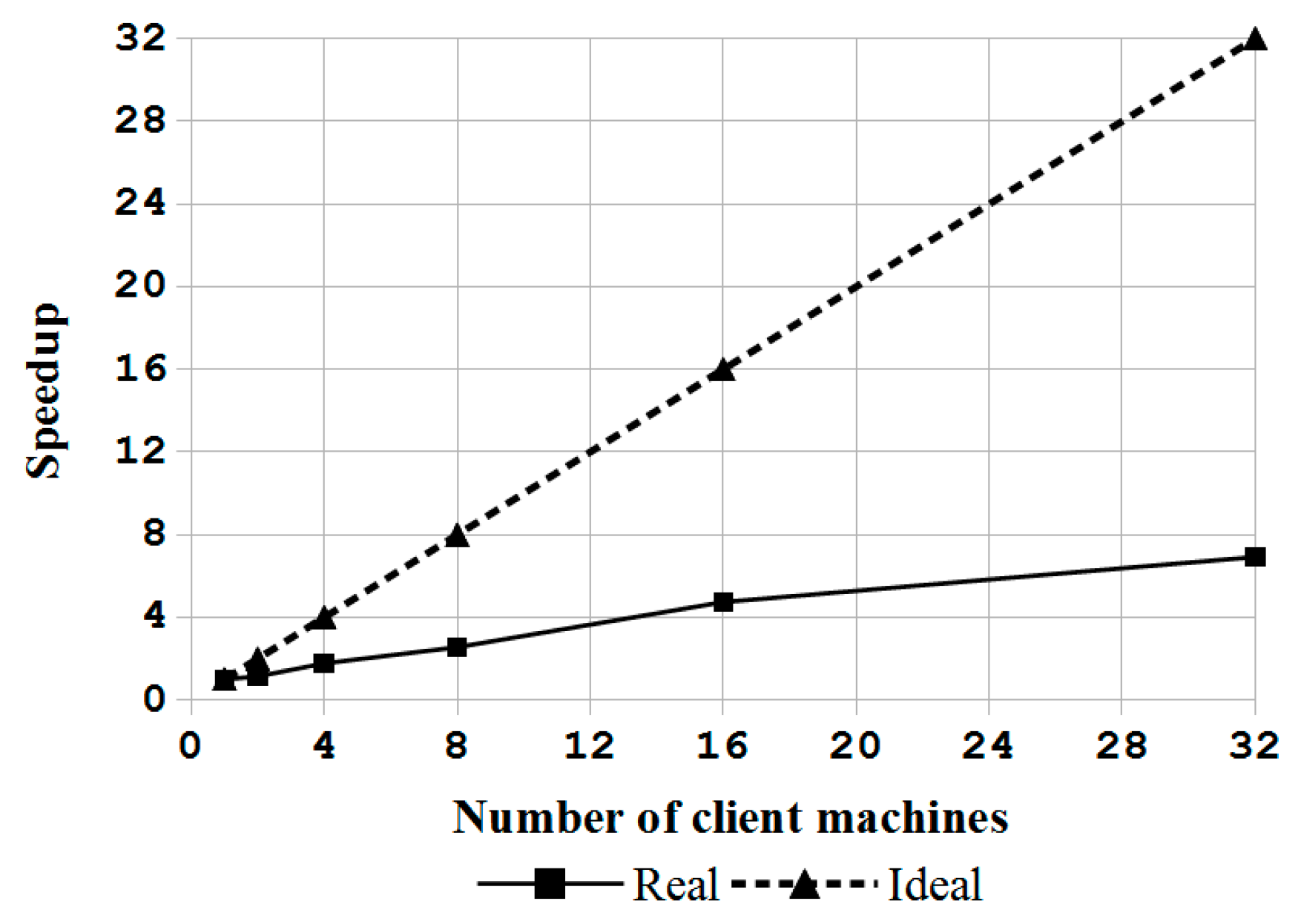
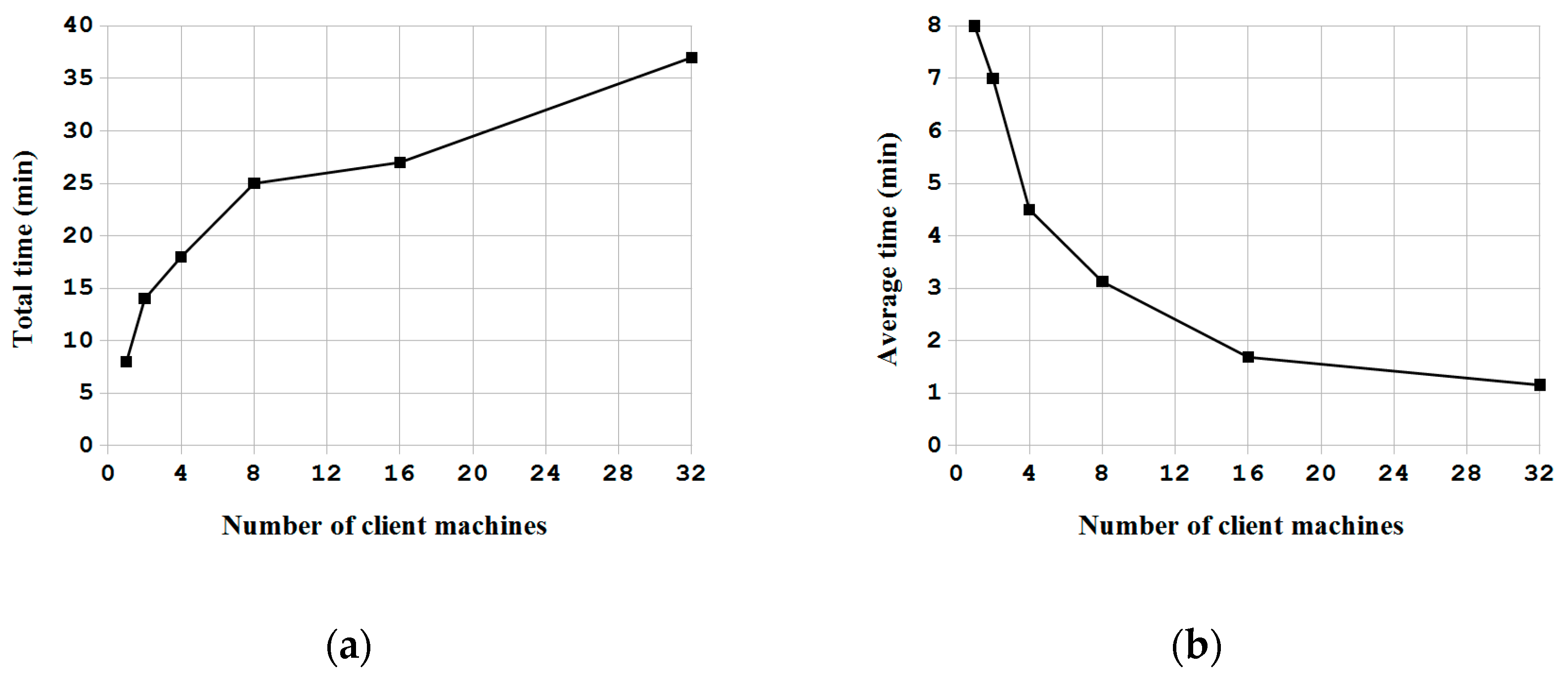
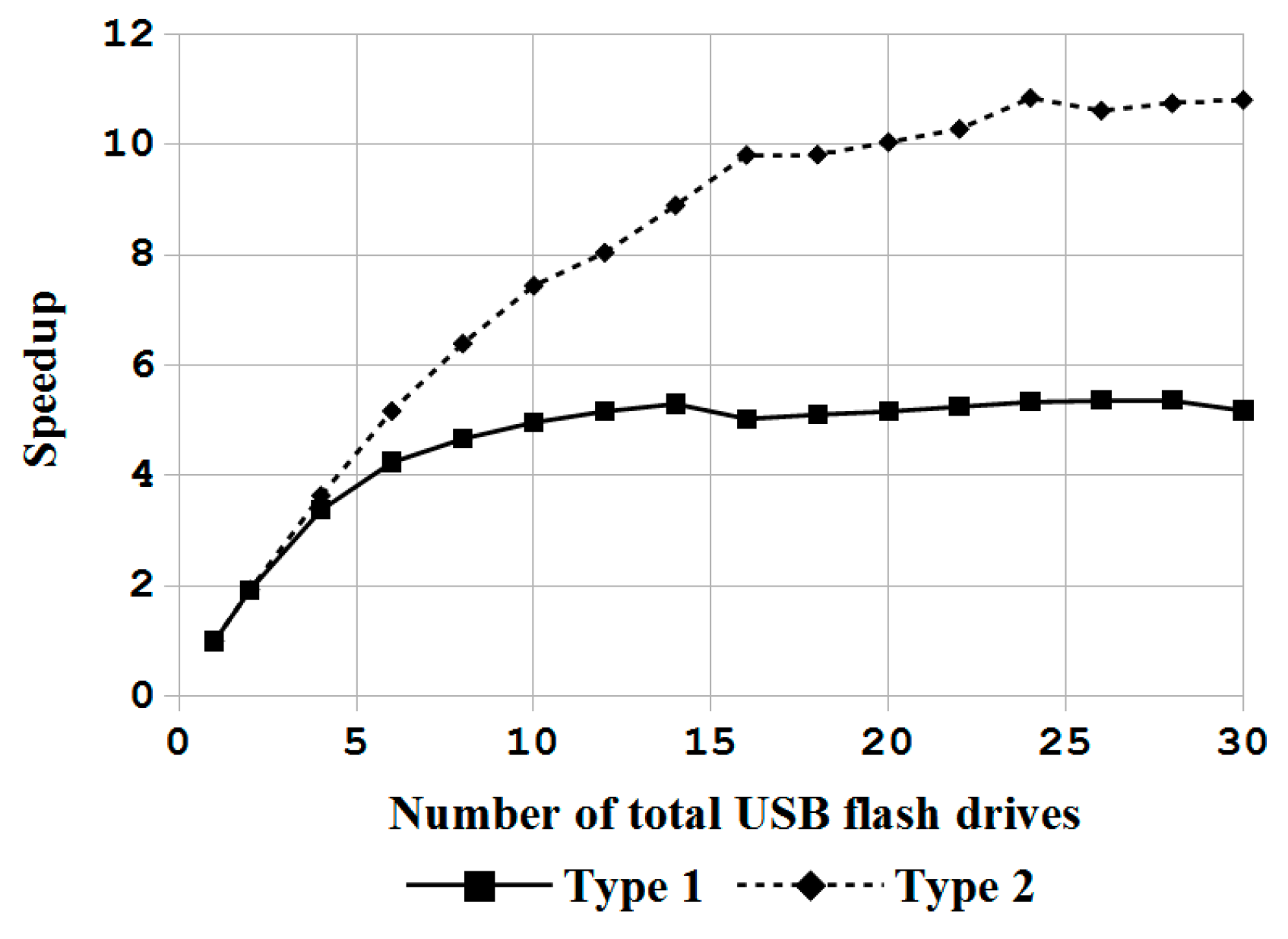
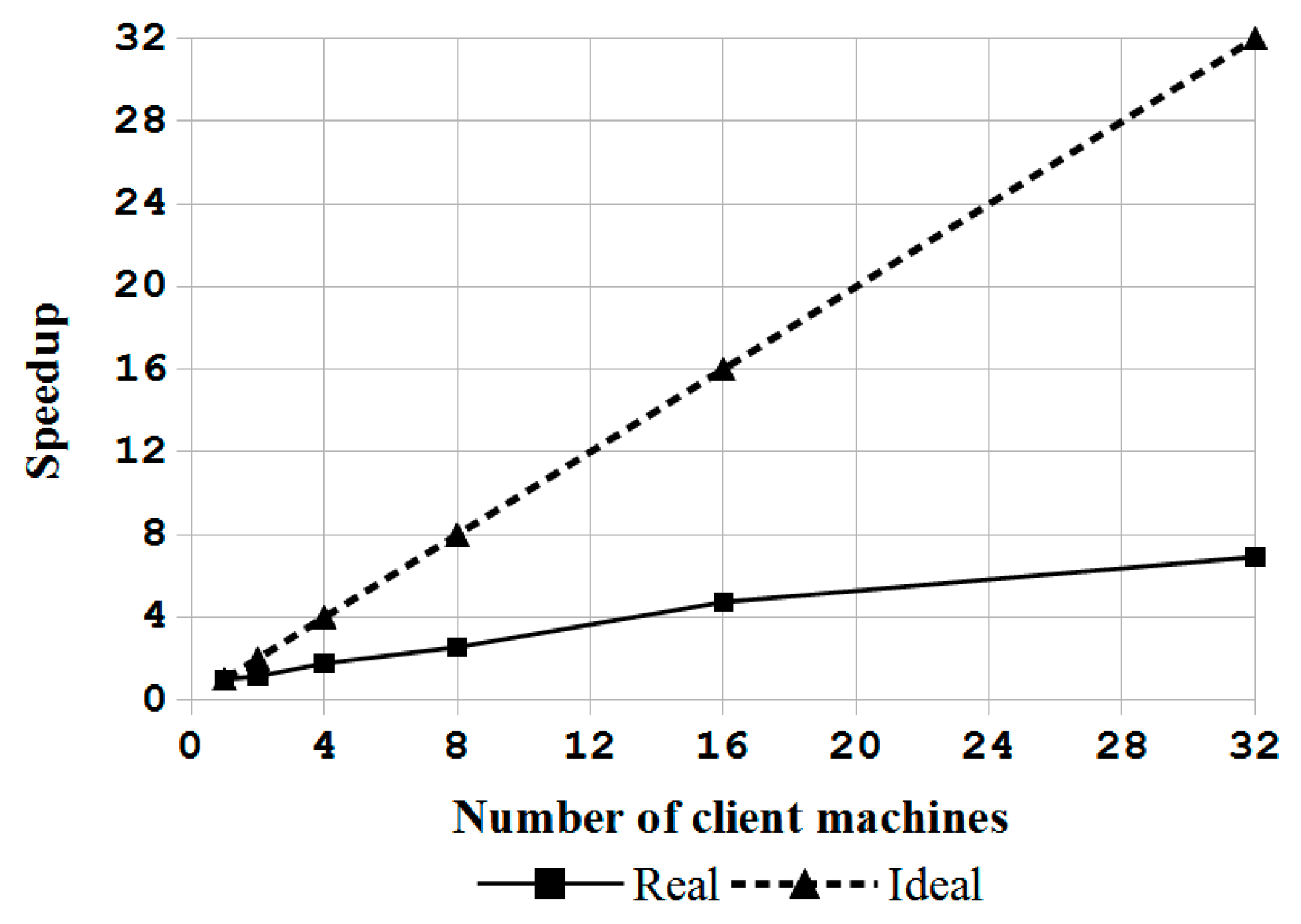
In this paper, a novel system architecture was proposed and developed in an open source manner to support single machine backup and recovery, massive deployment of disks in a computer, and massive deployment in large-scale computers. To the best of the authors’ knowledge, this is the first open source system deployment program that can provide these three types of functions. In addition, this system deployment software can support various OSs, including Linux, MacOS, MS Windows and FreeBSD. A comparison between Clonezilla live with other commercial proprietary or open source software was provided. Regardless, whether considered through the aspect of the file system being support, the capability of starting from a live OS, the support of massive deployment of disks in a computer, and the provision of the client-server mechanism for massive deployment in large-scale computers, the proposed mass deployment system is a better choice. The experiments that were performed by deploying a Linux system to 1 to 30 USB flash drives in a single machine and to 1 to 32 machines in a network using the software being developed in this work have demonstrated the feasibility and efficiency of the proposed work. A comparison between the cost of the USB drive duplicator that was developed in this research, which is $200, is 92% lower than the cost of commercial proprietary products with similar functionalities. In addition, due to the open source nature, this USB drive duplicator can be upgraded easily. The experiments also validated the capabilities of Clonezilla live to conduct massive deployment in large-scale computers. The result is consistent with previous works. In general, the comparisons with other utilities and the experiment results have proved and demonstrated that the proposed architecture and the software being developed in this study are highly efficient and cost-effective for system deployment.
For future research possibilities, more file systems can be supported. Meanwhile, the multicast mechanism and the support of BitTorrent to distribute images to large-scale computers can be further improved. Also, systems can be upgraded to support non-x86 CPU (e.g., the ARM processor) based systems and support for the massive deployment in these non-x86 computer systems, as well as the Open Network Install Environment (ONIE) network switch systems [
54], because this will allow for all of the facilities in a cabinet inside a data center to be ready for use after they are deployed. In addition, the proposed novel open source massive deployment system can further be expanded to support the fog computing or even the fog of everything [
6] in the future.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}