1. Motivation
This presented literature study systematically reviews existing literature related to equipment maintenance systems to elaborate the state of the art as well as to discover current research trends. In this context, predictive maintenance (
PdM) constitutes a specific method that aims to improve maintenance management methods, such as
run-to-failure [
1] or
preventive maintenance [
2], by including knowledge of the machine behavior with the goal to derive an optimal maintenance strategy. According to Mobley, the common target of
predictive maintenance applications (
PMA) constitutes “[...] regular monitoring of the actual mechanical condition, operating efficiency, and other indicators of the operating condition of machine-trains [...] to ensure the maximum interval between repairs as well as to minimize the number and cost of unscheduled outages created by machine-train failures ” [
3].
In general, literature reviews [
4] offer a technique to structure scientific articles. Existing review types focus on different strategies and should be chosen to fit best to the problem definition. Our requirements for reviewing the field of state of the art equipment maintenance systems are (1) to cover a wide range of articles, (2) to identify contemporary maintenance procedures and techniques, (3) to discover current trends, (4) to discover highly cited and influential articles, and (5) to include latest research on equipment maintenance systems. Other literature reviews do not always satisfy these requirements, e.g., the authors of [
5,
6] do not address Requirement 1. Concerning Requirement 2, for example, the authors of [
7,
8] do not consider recent research. In other works, in turn, the analyzed equipment maintenance strategy is too specific [
9,
10] or too general [
11] compared to the literature review presented in this paper. To properly address Requirements 1–5, the literature review we accomplished uses the
bibliometric analysis. In particular, the bibliometric analysis offers several advantages:
It visualizes relevant study articles based on various connection types, e.g., research fronts, knowledge bases, authors, and author affiliations.
It enables us to automatically cluster articles.
It enables quick recalculations of clusters based on different time periods.
Consequently, bibliometric analyses tend to be very effective when facing large and heterogeneous data sets. Thus, we apply the bibliometric analysis in the context of our literature review on equipment maintenance systems. We believe that this research field involves a multitude of research issues as well as complex interdependencies between them.
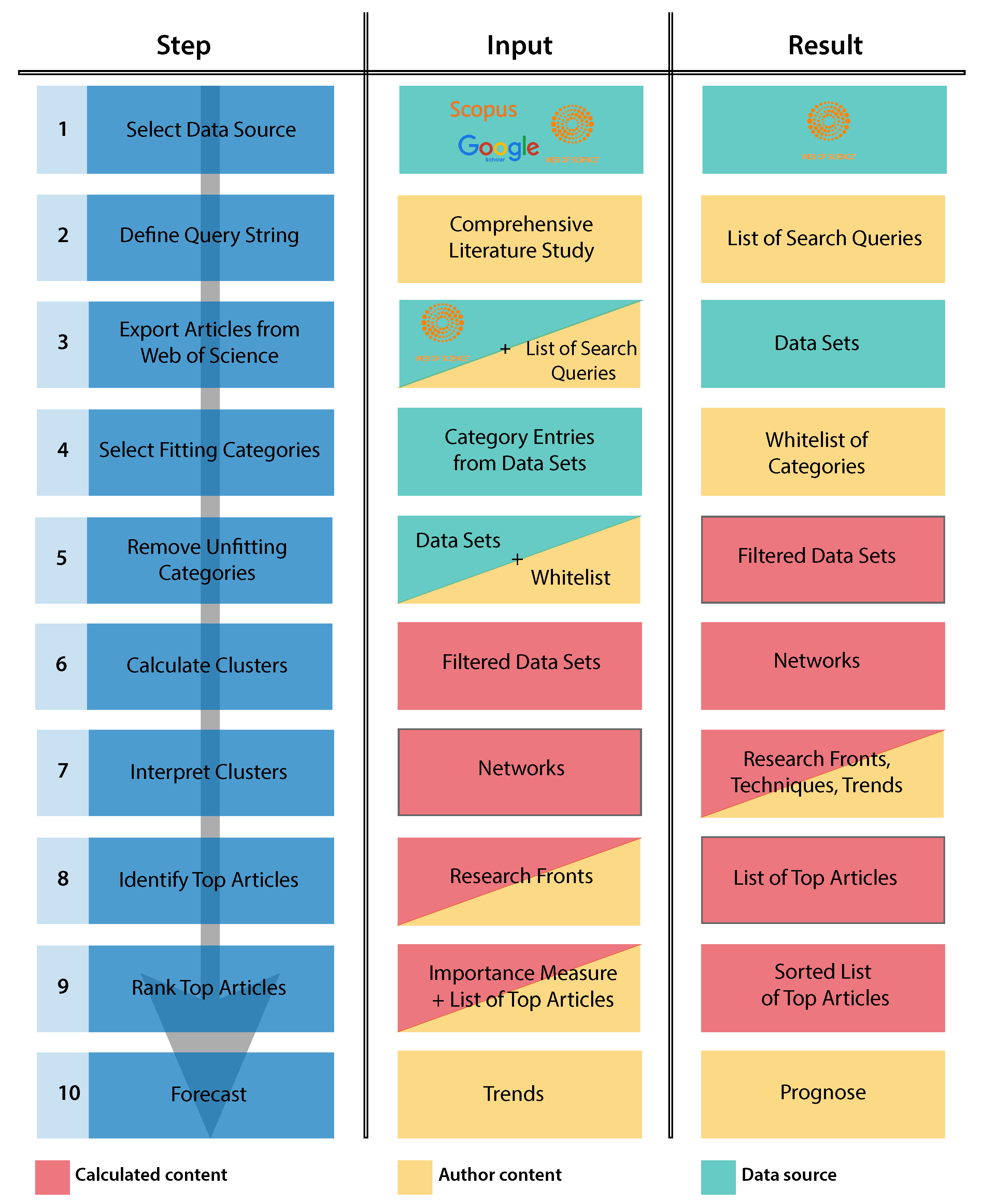
The procedure to accomplish the presented bibliometric analysis comprises ten steps as illustrated in
Figure 1 in the left column. (Please note that that
Figure 1 also shows in the middle and right columns, which steps have been actually accomplished for the present work.) The first step (cf.
Figure 1, 1) is to select the academic databases from which relevant works shall be obtained. Frequently, the following databases are used:
Google Scholar,
Scopus,
Web of Science, and
ScienceDirect. Despite the wide-spread use of Google Scholar in Computer Science, we decided to base our review on Web of Science for two reasons. First, Web of Science and Scopus (Scopus would be another valuable source for our approach. Please note that both Web of Science and Scopus are payment platforms [
12]. The reason we use just one is that our institution only has an account for Web of Science. In addition, according to [
12], the differences between the two platforms constitute no crucial threat to validity.) currently generate citation data that can be comfortably used with existing bibliometric analysis software tools. Second, Web of Science is compared to Google Scholar a so-called human-curated academic database, which leads to more controlled citation data. On the other hand, Google Scholar reflects a more current status of all published papers and theses in most cases. However, we still rely on Web of Science, as a visual inspection revealed that only a few recent papers can be found with Google Scholar, but not in Web of Science. Furthermore, an in-depth comparison of academic databases is a complex endeavor, which is beyond the scope of this paper. However, we are aware of this limitation regarding the presented review.
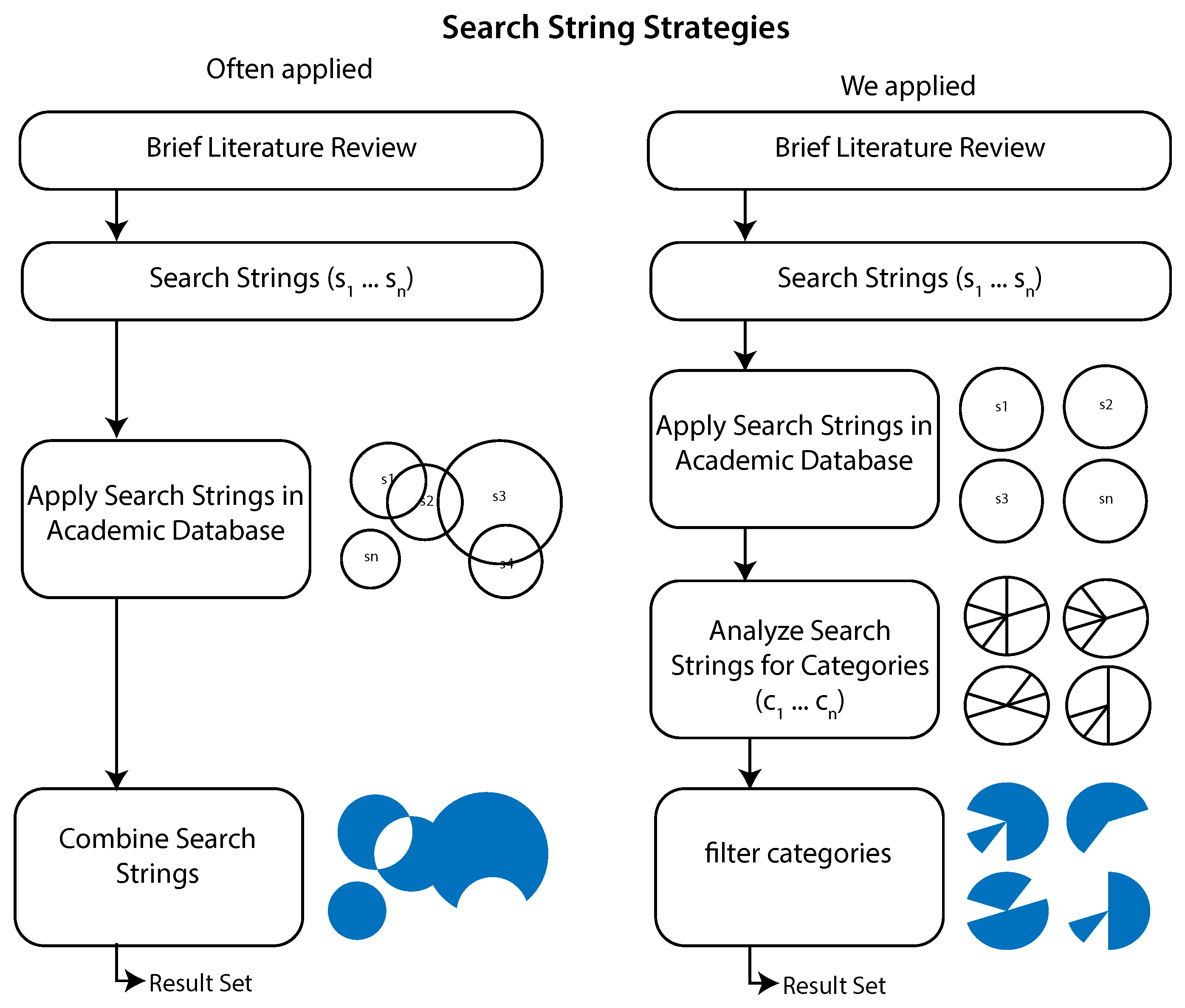
In the second step of a bibliometric analysis, one must specify the set of search strings to be applied to the used academic database (cf.
Figure 1, 2). In the context, we applied the following search strings to Web of Science:
predictive maintenance,
condition monitoring,
smart maintenance,
lean maintenance,
reliability-centered maintenance, and
predictive analytics. Those search strings were defined after an open search on various maintenance techniques. All those techniques can be also applied in the field of
Engineering Asset Management ([
13,
14]). Concerning the 12 functions of general asset management, as introduced by [
15], we are mainly interested in Risk Management, Condition Monitoring, Asset Usage Life Cycle, Performance Measures, and Information Systems. For example, the integration of a maintenance method into asset management, e.g., by using condition monitoring [
16], represents one typical workflow that is relevant for us.
After applying the search strings to Web of Science, we exported the results (cf.
Figure 1, 3) to apply several preprocessing steps (cf.
Figure 1, 4–5) to remove unfitting results (e.g., maintenance in a medical context) from the extracted data. Following this, the cleansed data was fed into a software for bibliometric analysis. As depicted in
Figure 1, the performed calculations and related interpretations comprise five steps (i.e., Steps 5–10 in
Figure 1). The obtained results, in turn, provide a valuable overview for state of the art maintenance systems in general and predictive maintenance in particular. Additionally, we were able to identify fundamental (i.e., distinguished) papers in this field. Moreover, to the best of our knowledge, the work at hand is the first one that applied bibliometric analysis in reviewing the research field of equipment maintenance systems. In addition, our results underlie that bibliometric analyses are able to gain valuable insights.
The remainder of this paper is structured as follows:
Section 2 provides deeper insight into the methodology applied, i.e., the bibliometric analysis. The result set obtained from the search strings applied to Web of Science are discussed in
Section 3. In
Section 4, results of the bibliometric analysis are presented. In turn,
Section 5 introduces a novel measure to rank single articles in a multi-dimensional way.
Section 6 predicts research trends based on the past development of related topics, whereas
Section 7 discusses threats to validity. Finally,
Section 8 concludes the paper and gives an outlook.
2. Bibliometric Analysis
Bibliometric analysis is a method from the field of
Bibliometrics [
17]. The latter, in turn, has connotations with the term
statistical bibliography and constitutes a quantitative approach to literature research. In the bibliometric analysis we performed with the goal to identify existing research fields in the context of state of the art equipment maintenance systems, we follow the basic idea presented in [
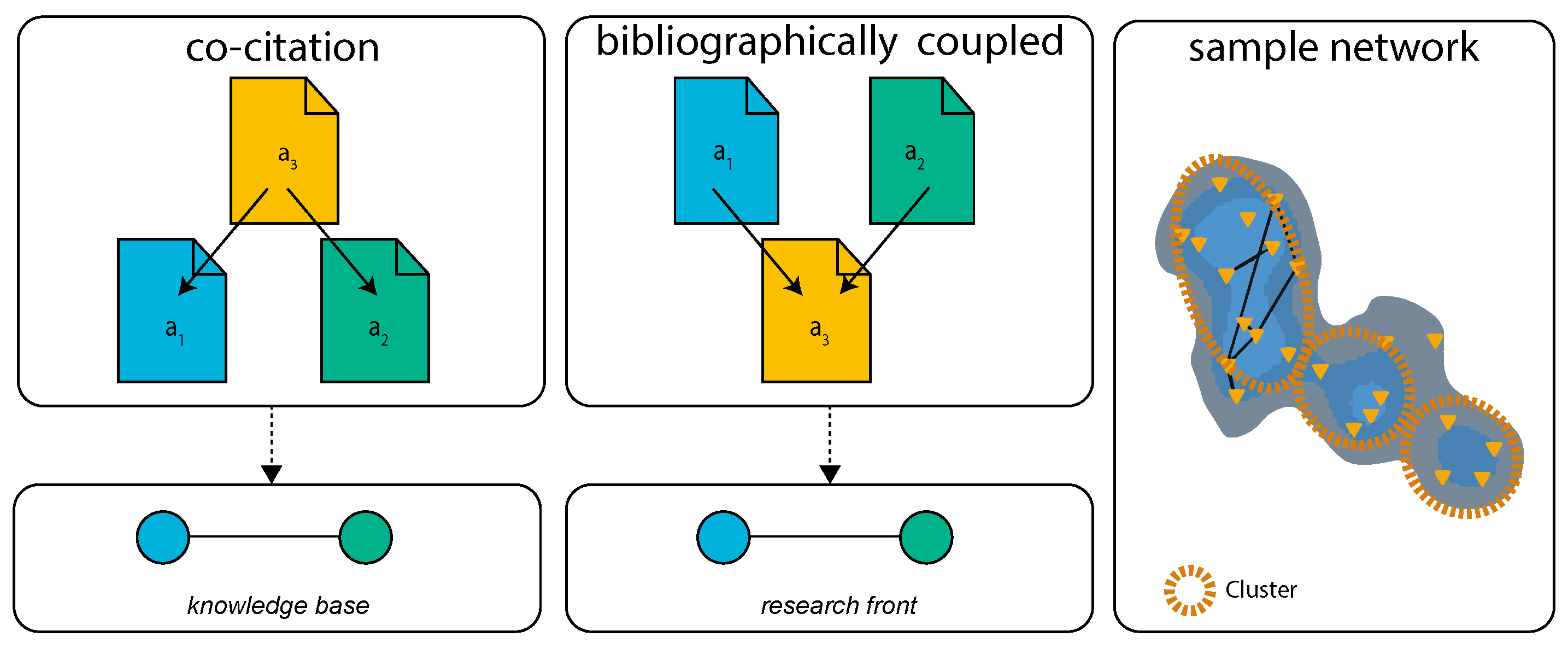
18], which introduced mathematical graphs, denoted as networks, as a suitable solution to represent a set of connected literature. In this network, each article is represented by a node, whereas edges constitute their bibliographic connections. In turn, connections can be established based on a multitude of similarity measures. In general, a similarity measure is based on the assumption that two articles pose a similarity in terms of thematic content. To identify entire research fields, denoted as clusters in a network (cf.
Figure 2), two similarity measures are of utmost importance:
Knowledge Bases and
Research Fronts [
19] (cf.
Figure 2). Two articles are bibliographically coupled (i.e., they are part of a research front) if they reference the same third article. Couplings between nodes become stronger (i.e., represented by a thicker line in the plotted network) if they co-cite multiple articles. By contrast, two references are connected by co-citation (i.e., they are part of a knowledge base) if they are both referenced by a third article. In addition to identify relevant research fields, we were interested in networks for authors [
20], countries, and organizations, which can be established by other similarity measures. Based on the evaluation of networks, valuable results can be obtained according to [
21]:
Identifying the research field structure
Detecting general contextual factors
Discovering developments in research
Forecasting coming trends
Another crucial aspect in performing a bibliometric analysis concerns the use of an appropriate software tool. In the field of bibliometrics, there exist tools that are specifically developed for for bibliometric analysis visualization techniques [
22]). We used NetCulator [
23] for the bibliometric analysis we conducted. NetCulator offers features to calculate the mentioned networks. Furthermore, it combines
bibliographic coupling with
lexical measures that, in turn, compare the similarity of terms (cf.
TF-IDF in
Appendix A.2). Next, NetCulator calculates
hybrid second-order similarities (See
Appendix A.2) with severe
edge cutting [
24]. The latter improves the calculation speed by ignoring all weak edges that result from weak coupling between nodes. Finally, NetCulator computes clusters based on
Louvain Clustering [
25]. Visualization and layouting for
research fronts and
knowledge bases either rely on the OpenOrd-Method [
26], which provides a quick overview by automatically summarizing clusters, or the Fruchterman-Reingold algorithm [
27] enabling a more detailed view. NetCulator offers many other valuable features, we utilized the context of our bibliometic analysis, e.g.,
Identifying core articles (i.e., significant papers within a research field).
Identifying frequently used terms in a research field.
Identifying trends based on calculated timelines [
28] for research fronts.
Although the technique of bibliometric analysis is promising, it also comes with some limitations: First, the articles need to be published in an academic database. As a drawback, especially in the field of industrial production, articles are often represented as patents and internal enterprise documents. As another drawback, competition between companies leads to a large number of non-disclosure agreements. Second, any bibliometric analysis is dependent on the choice of the used search strings [
29]. Finally, a time lag must be considered, as it might take years for research to be published and cited.
4. Biblometric Analysis Results
We apply the bibliometric analysis to the data set described in
Section 3 using the NetCulator tool. Thereby, for each aspect to be evaluated (i.e., research fronts, knowledge bases, authors, organizations, countries, terms), several NetCulator parameters have to be defined.
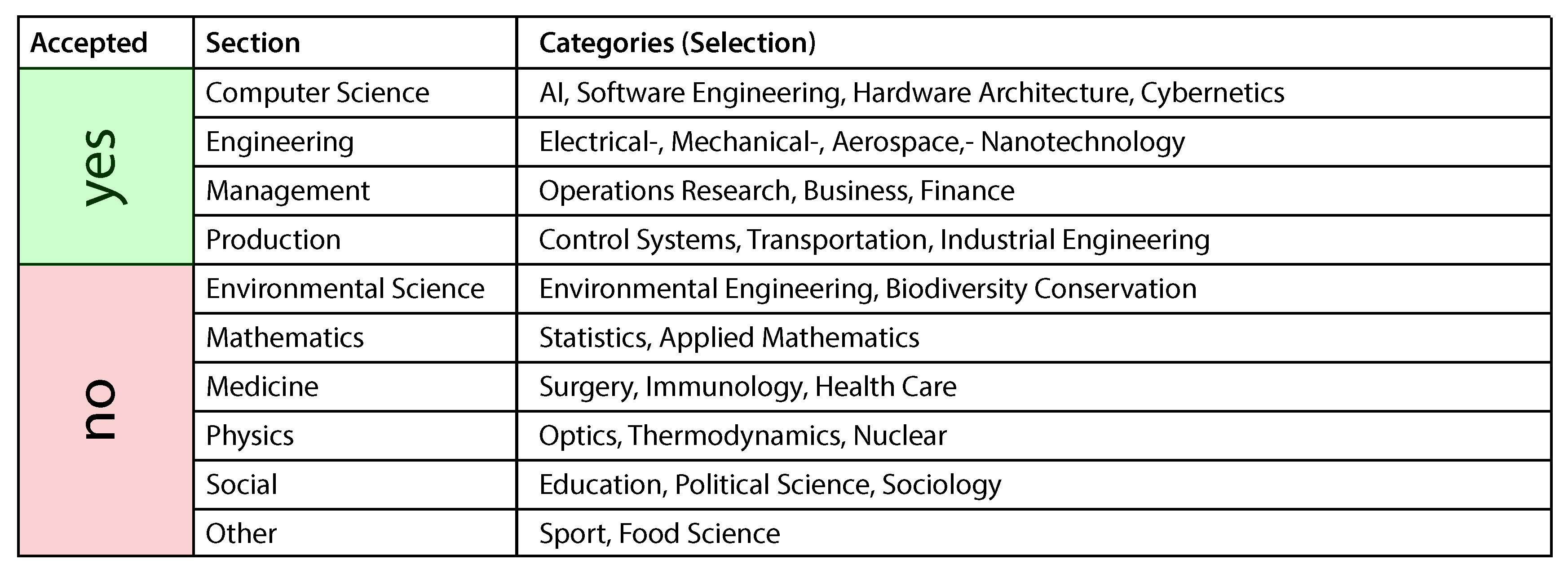
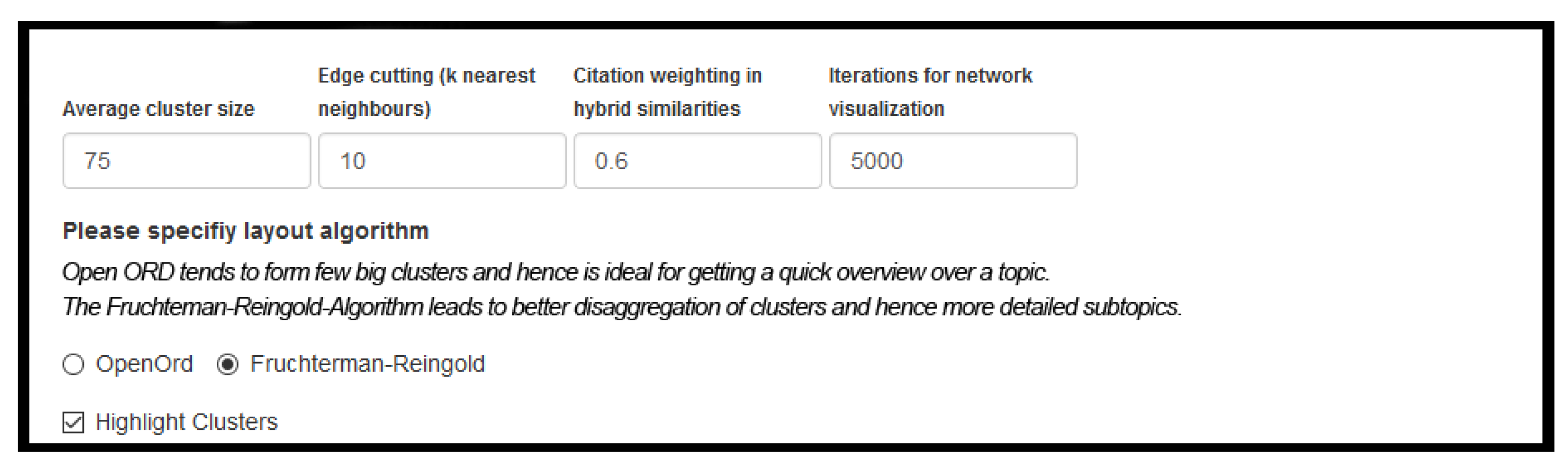
First of all, a time period needs to be specified. For our bibliometric analysis, we decided to do the calculations for different time periods in order to identify how the topic of predictive maintenance evolves over time. More specifically, we use three time periods: [1990–2000], [2000–2008], and [2008–2016]. These periods were defined using an iterative process in NetCulator and comparing emerging paper distributions. Please note that that this is a common way pursued in a bibliometric analysis. Then, the NetCulator user must define many more parameters (e.g., cluster size). Thereby, the user can either use default parameters or specifies his own parameter set. All parameters that can be specified are shown in
Figure 7. Finally, NetCulator presents the calculated networks to the user. Please note that that the
Figure 7 shows the actual parameters used for the presented bibliometric analysis in this work.
4.1. Predictive Maintenance
In the following, we provide a detailed analyses for
predictive maintenance in the aforementioned time periods (cf.
Figure 8).
4.1.1. Period 1990–2000
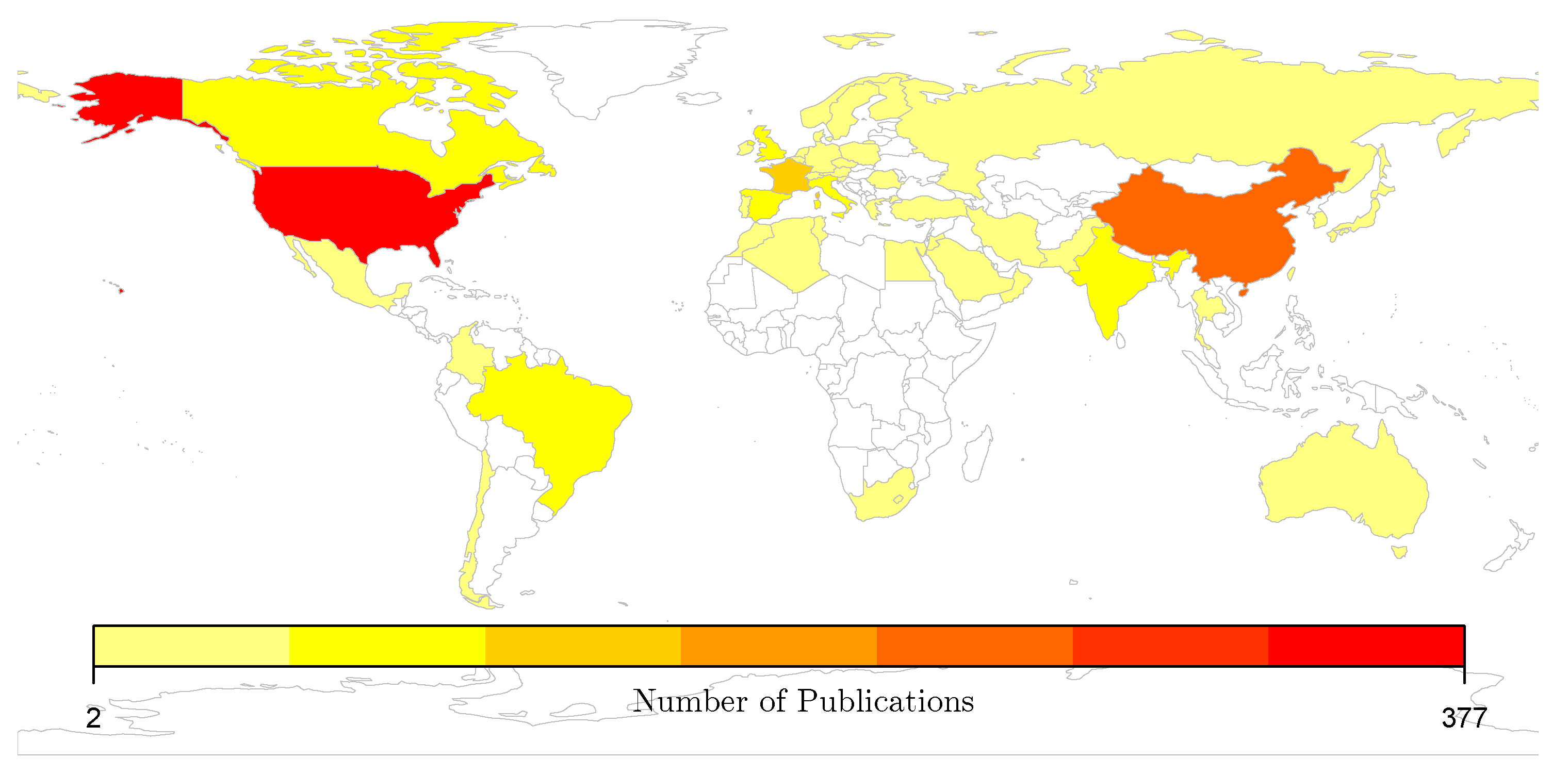
First of all, the results for the first period are based on 175 articles. The first work for this period was initiated by the American Association for Artificial Intelligence, whose subgroup, called
Special Interest in Manufacturing (SIGMAN), organized workshops collecting ideas in this context. Since an American organization was pioneering the topic of predictive maintenance in this period, the leading publication nation was the US (
), followed by France (
) and Canada (
). According to
Figure 9, we can observe an increasing cooperation of countries over time and a stronger thematic focus. More specifically, each data point in
Figure 9 represents a country, a close distance between them indicates researching in similar topics. However, closeness does not necessarily display collaborations, but constitutes an indicator of a high knowledge transfer between the involved countries. In general, the research in this first period did not reveal any outstanding research topic. Accordingly, no leading author or institution could be identified. The keyword analysis for the first period (cf.
Table 2) shows a strong connection between the terms
predictive maintenance and
monitoring as they belong to the same cluster (i.e., Cluster
1 from
Table 2. Furthermore, as monitoring is represented by the two keywords
condition monitoring and
monitoring, this topic is a leading one in this period.
Interestingly, monitoring and predictive maintenance are in the same cluster, while this does not apply to condition monitoring, i.e., in this period, despite the thematic closeness of condition monitoring and predictive maintenance, they were addressed independently. Please note that that this result supports our decision to consider condition monitoring as a separate search string. In general, we assume the following order of complexity for tasks in the context of equipment maintenance systems:
Furthermore, we assume the technique monitoring needs mainly humans as decision makers and rarely relies on techniques of machine learning.
After calculating research fronts, we sort the articles based on the number of citations. The most popular paper, according to citations, is denoted as
lead document. In a manual inspection, used techniques of the lead document and a thematic field for each cluster have been identified. The collected information are shown in
Table 3, where the thematic field is denoted as
cluster label. The manual labeling of each cluster, denoted as cluster caption, and the identification of the used technique considers top terms, scanning the resulting articles. Please note that not every article in each research front needs to deal with the topic the cluster caption implies. In general, a bigger cluster size increases the probability of a
false-positive cluster classification. The research front clusters from
Table 3 are explained in the following. Cluster 1 deals with the continuous status monitoring. This cluster is coined by a joint project between the US and Egypt, as represented by the Alexandria National Iron & Steel Company. Second, in Cluster 2, items were found dealing with
vibration analysis. Here, vibrations caused by for example pumps, spindles and motors are used to refer to abnormal machine behavior. Cluster 3 assembles literature that deals with maintenance in risky environments, such as oil refinery and nuclear power plants. With a focus on special electronic equipment, such as radars and motors, Cluster 4 contains research based on the question how to predict electric systems behavior.
Cluster 5 represents the research field of stochastic approaches in various applications. Since not only machines need to be supervised, but also the software itself, the field of software maintenance 6 addresses these challenges with code metrics and fuzzy structures. Cluster 7 lists literature dealing with model predictive control (MPC). It is an advanced method of process control and it is frequently used in the context of lime production and kiln heating. Next, literature concerning emission control is collected in Cluster 8. Emission changes, e.g., caught by a infrared camera, indicate a changing machine behavior. Finally, Cluster 9 is labeled with the term hydroelectricity & photovoltaics. In this cluster, agent-based methods can be frequently found.
4.1.2. Period 2000–2008
First, research fronts and lead documents are extracted analogous to the way described in
Section 4.1.1 (cf.
Table A1). Some research front labels from the previous period can be reused, while new clusters are presented in the following. The topic of
predictive models (1) bundles general approaches to model and improve maintenance approaches, including even basic ideas (e.g., corporations between firms for data exchange). In the previous period, the keyword analysis recognized
monitoring (3) as being important, but no further cluster were identified for monitoring. In turn, during the second period, there exists a cluster with a focus on visualization. Third, when considering maintenance, costs constitute an important factor as well. The cluster of
cost-based models (4) emphasizes the costs for exchanging and maintaining machine parts. This cluster can be seen in contrast to the approach of
reliability-centered maintenance. Concerning abrasion and the condition of cables, the cluster
cable diagnostic (8) discusses solutions. With growing complexity of maintenance systems, the
management (9) aspect is evolving accordingly. In this cluster, the literature stresses the organization of maintenance strategies as well as the evaluation of their performance. Next, research on
motor fault prediction (10) grew forming a cluster. A widely used method in this context is the
root cause analysis. Moreover, a new cluster denoted as
generic approach (11) was found. Thereby, in most papers data-mining or machine-learning methods are utilized to enable adaptive maintenance systems. Finally, the cluster
sensor data (13) deals with the integration of sensors into maintenance systems.
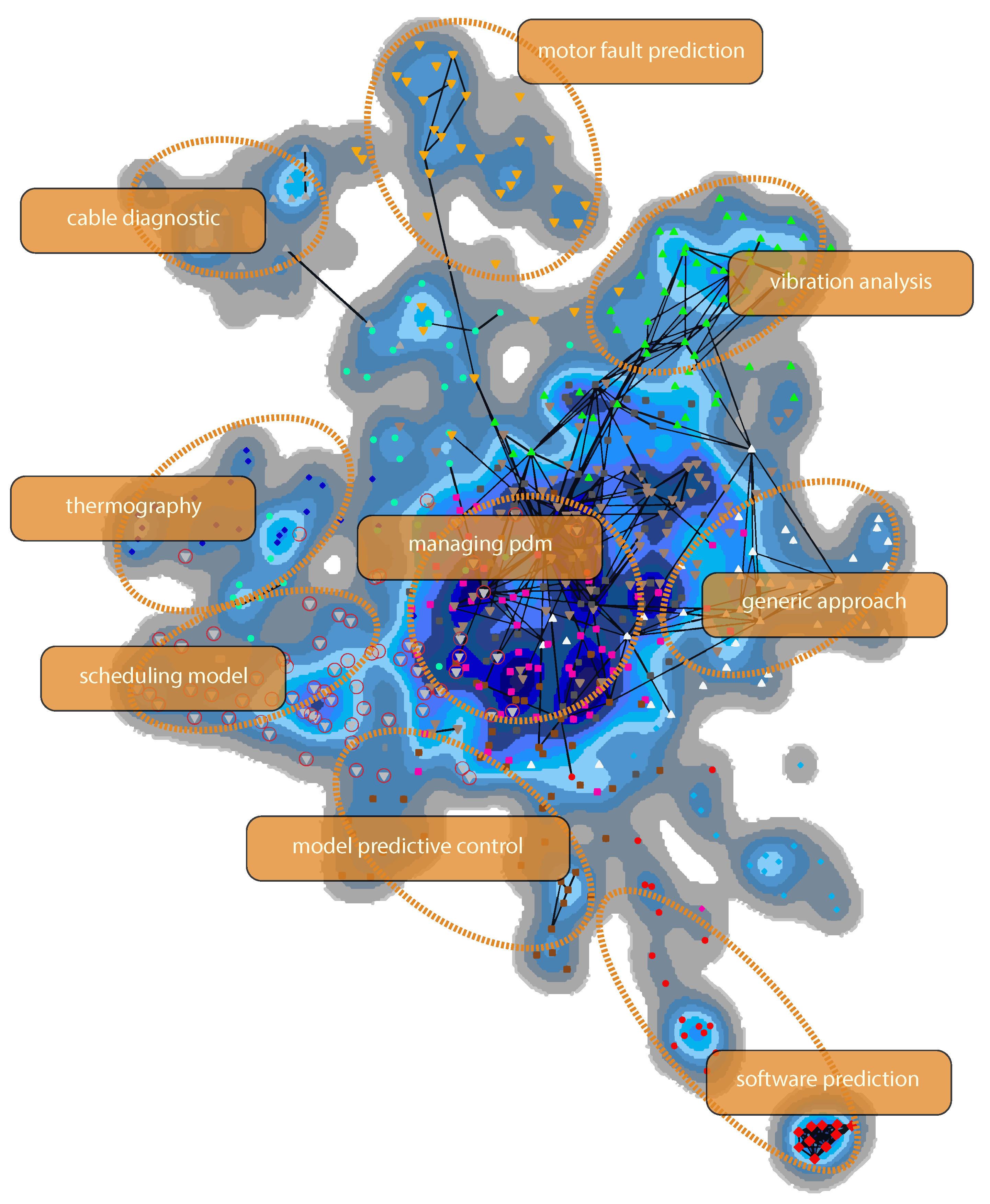
A visualization of the research fronts corresponding to
Table A1 is illustrated in
Figure 10. Articles from the same cluster are plotted with the same shape and color, whereas their proximity indicates a thematic similarity. Please note that a high article density is marked with dark blue.
Figure 10 depicts all 574 papers from the second period. When regarding their connections, however, only the strongest 242 out of 4826 are shown. The research front
managing pdm is the central cluster, as it is an indirect part of many other research fields. By contrast, the
software prediction cluster is outside of the center as it is not thematically connected to most other clusters.
Concerning participating countries in research, the increase of Chinese publications is noticeable. More specifically, the number of publications grew from 0 to 54 (cf.
Figure 11), making China the second most publishing country in this field. Remarkable seems to be the fairly low participation in research of highly industrialized countries like Japan and Germany. The United States remain the most active country in the research field of predictive maintenance and the University Cincinnati (Ohio) constitutes the driving force.
4.1.3. Period 2008–2016
Again, first of all, research fronts are calculated and evaluated (cf.
Table A2). The newly emerging clusters are presented in the following. First, one of the added clusters deals with
multi-component applications (1), that aim to combine data of multiple production units into one predictive model.
With increasing interest in alternative energies, wind turbines (4) come into the focus of predictive maintenance systems. Third, the discipline known as prognostics and health management (5), which links failure mechanisms to system life cycle management, forms a cluster as well. Furthermore cluster Cloud and IoT (6) aims at better production results by, first and foremost, including recent developments from Big Data Analytics and Distributed Systems. Dealing with certain machine components, the analyzes of rolling bearings (7) and capacitors (8) form other clusters. Literature referring to the prediction of metal deterioration due to corrosion is collected in (11), whereas rail maintenance (14) monitors the current state of roads and rails. Finally, by analyzing changes in oil (15) consistency and consumption, a changing machine behavior must be considered. Concerning the publishing countries, China increases its number of publications, while the US remain number one. In turn, the Tsinghua University (Peking) constitutes now the driving force for publications in this topic.
After discussing the results of the periods separately, keywords, research fronts, and techniques over all three periods are juxtaposed in the following.
Keyword Ranking
A first possibility of showing the development of research during the time periods is the comparison of top keywords.
Table 4 shows the top mentioned key words, their percentage distribution, and their difference in ranking position compared to the previous period (cf.
Section 4.1.1). The ranking difference is denoted as
, whereby a positive
denotes growing importance of this keyword. Furthermore, letter
n stands for
not mentioned yet, meaning that this keyword was not introduced in a previous period. Two particular developments can be obtained from
Table 4. First, the complexity of predictive maintenance systems rises over time. During the first period, there is a focus on rather simple methods, such as monitoring and preventive maintenance, while their importance decrease during the last period, in which more complex issues (e.g., prediction and prognostics) are addressed. An example of this development can be seen in the ratio between
fault detection and
fault diagnosis. During the first period, they are equally important, while in the last period the diagnostic part is more important. As a second aspect, the used techniques are not explicitly mentioned anymore in the last period. The disappearance of techniques like
neural networks and
genetic algorithms, which had an outstanding ranking position before, indicates that they are now in a rather major state, i.e., they are no longer explicitly mentioned.
Research Front Development
To gain insights into the development of research fronts, we sort all identified research fronts according to their relative size in the period and search for recurrences (cf.
Figure 12). Furthermore, we identify highly overlapping subjects, using the graphical representation of research fronts, and put related research fronts in brackets. As vibration analysis is constantly present in all periods, it is being revealed as the most important research field. In addition, we discovered that the thematic field
Internet of Things gains importance over time and it is connected to generic approaches as well.
Technique Identification
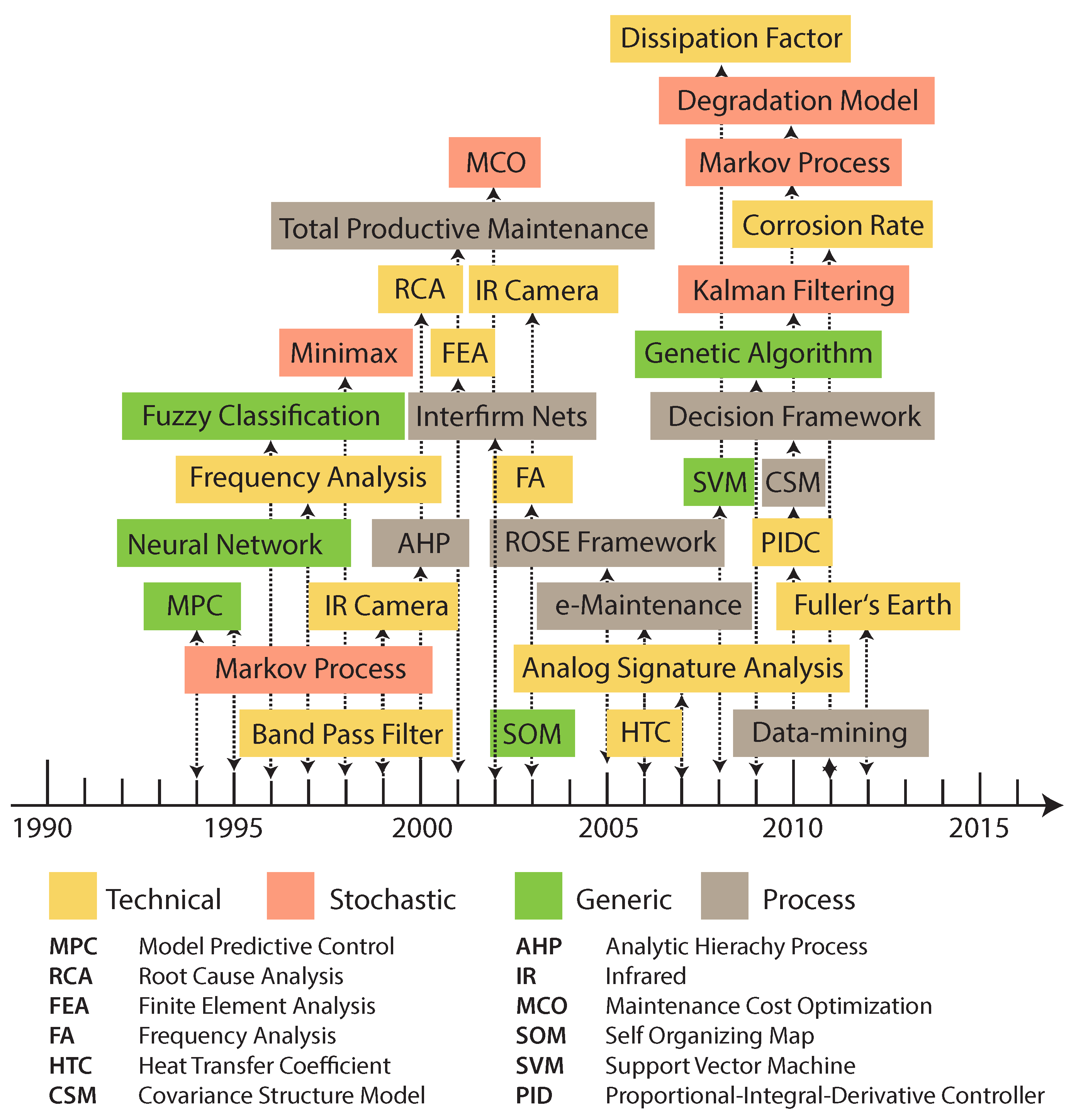
A final comparison over all three time periods aims to identify the techniques applied in the maintenance approaches. Thereby, for the lead document of each cluster, the used technique is extracted from the abstract and keywords as well as by evaluating the context of the document. In addition, the identified techniques were manually classified into the following four categories:
Technical. The approach focuses on application-specific technical parameters.
Stochastic. The approach emphasizes the importance of stochastic issues.
Generic. The approach deals with adaptive and learning methods.
Process. The approach focuses on the maintenance lifecycle.
Based on these categories, the identified techniques are visualized in a timeline (cf.
Figure 13) to obtain further insights. In general, we can observe a dominance of technical approaches. Thereby, most research focuses on concrete machine use cases, whereas general frameworks are less considered.
4.2. Predictive Analytics, Reliability-Centered Maintenance, Predictive Analytics, and Smart Maintenance
We combine the datasets of four search strings in order to obtain cluster sizes comparable to the ones for search strings
predictive maintenance and
condition monitoring. The resulting dataset, in turn, contains 2330 items. Concerning countries, similar to the results we obtained for
predictive maintenance, the US is the driving force in this research field, with the Universities of Washington, Illinois and Cincinnati being leading organizations for the time between 1990 and 2016. Please note that the University of Cincinnati was another driving force in the field of predictive maintenance in the period from 2000 to 2008. Finally,
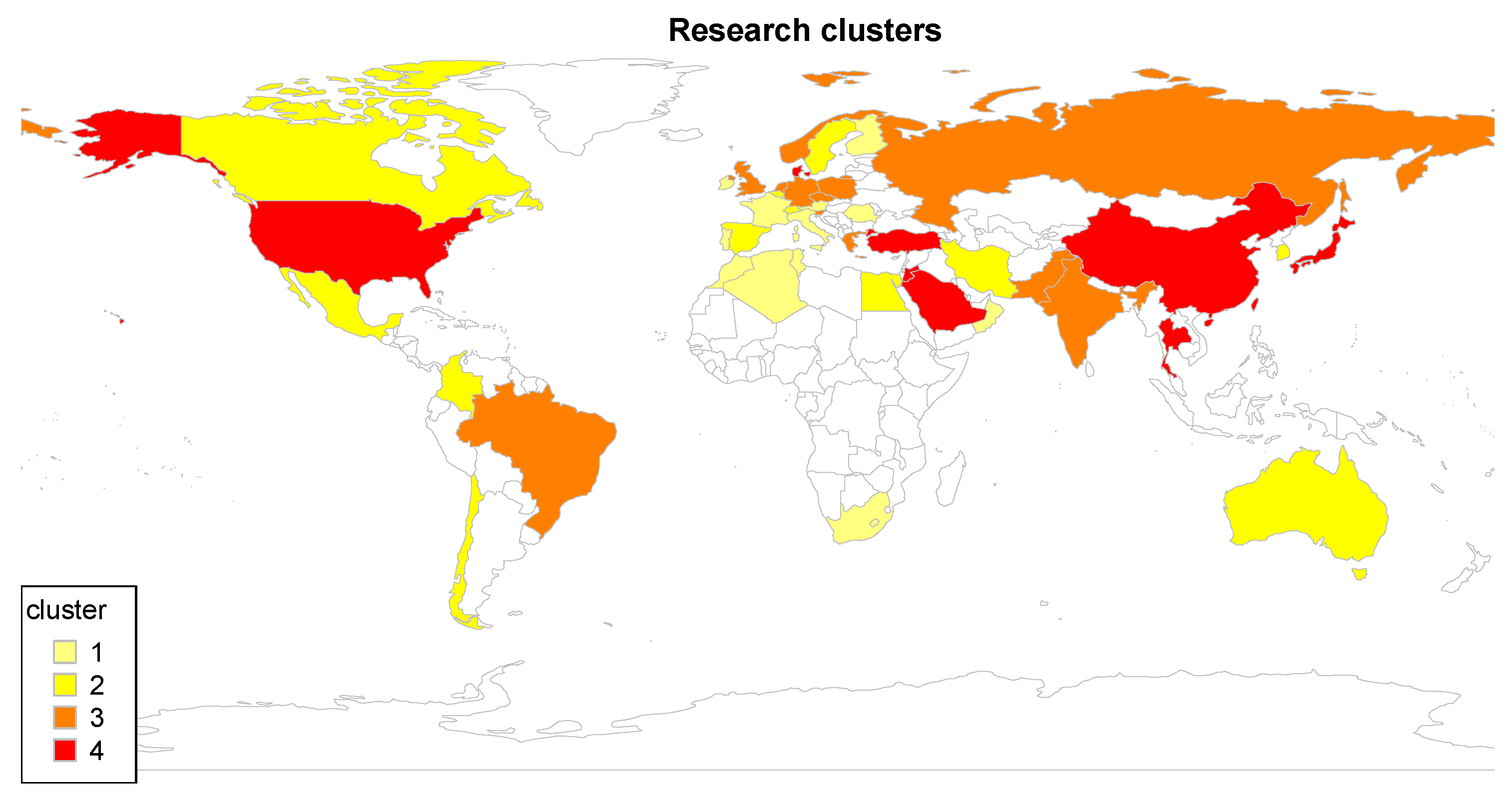
Figure 14 reveals corporations of countries from 2008 to 2016.
4.2.1. Period 1990–2000
Analogous to the approach used for
predictive maintenance, research fronts are calculated and evaluated (cf.
Table 5). If a research field for this evaluated search string was also identified in
Section 4.1, it gets marked with (1)–(3). The numbers (1)–(3) represent periods. For example, the research field
sensors from
Table 5 was found in the second period of predictive maintenance, with the following results obtained: First,
lean networks (1) deal with the process optimization for maintenance, especially for companies that want apply the method of
lean production.
Reliability-centered maintenance, in turn, can be frequently found in
aircraft (2) applications due to the high safety standards required in this field. Finally, explanations on
nuclear power plants (3) and
sensors (4) can be already found in
Section 4.1.
4.2.2. Period 2000–2008
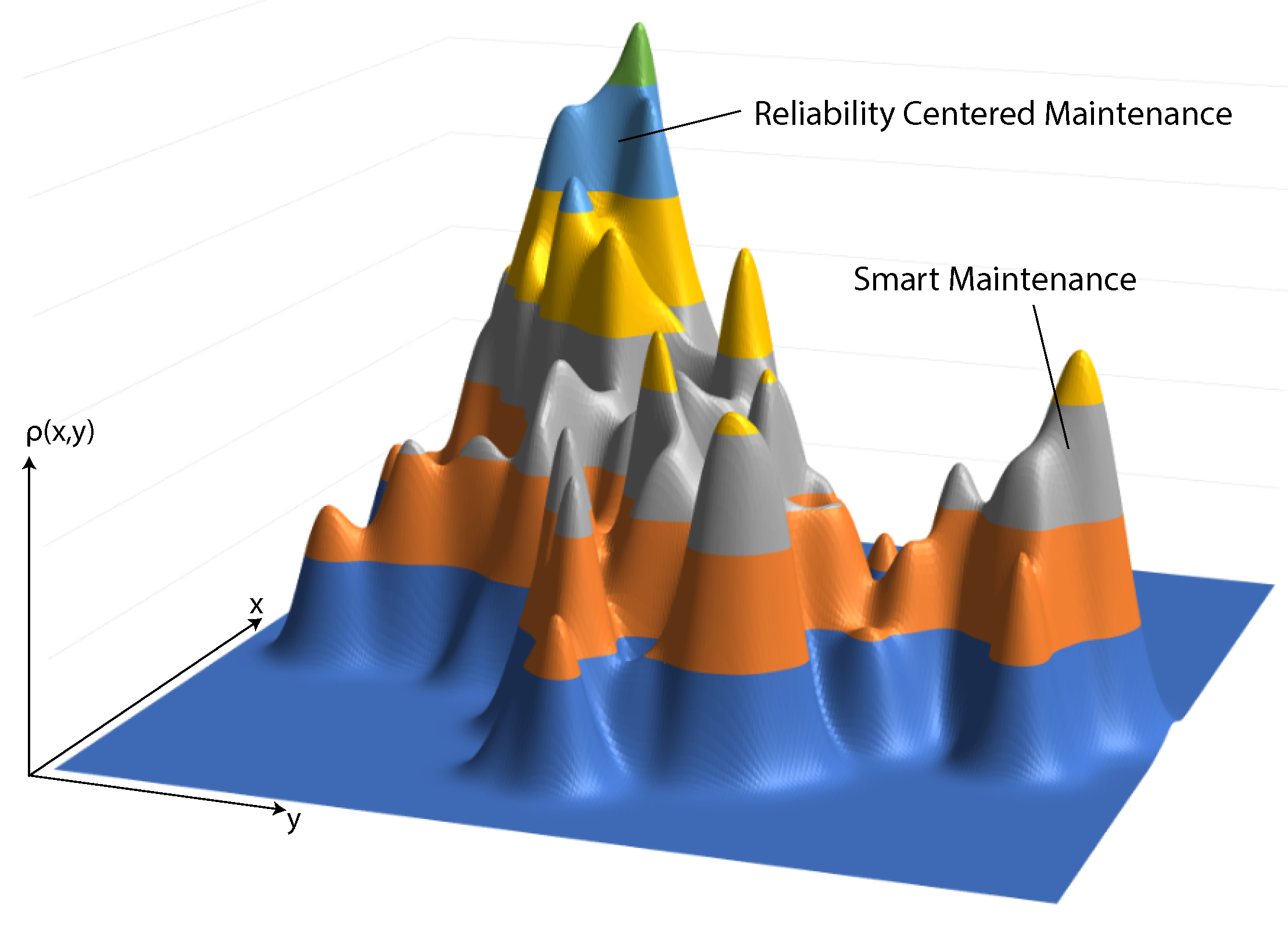
For the second period, the research fronts are shown in a 3D visualization (cf.
Figure 15).
Figure 15 is based on the same calculated data as
Figure 10 (cf.
Section 4.1). However, the article density, denoted as
, is represented through the height of the 3D surface plot. Thereby, local peaks in the surface plot represent research fields. The latter, in turn, are partly aggregated to finally form seven research fronts of this period (cf.
Table 6)). Please note that the results of the search strings
reliability centered maintenance and
smart maintenance can be clearly separated.
The first cluster revealed is denoted as lean manufacturing (1). It is strongly connected to cluster lean maintenance discovered in the previous period. Second, a main cluster deals with maintainable systems (2). Process-oriented approaches, in turn, are collected in cluster lifecycle management (3). Moreover, clusters condition-based maintenance (4) and reliability-centered maintenance (5) are considered. Finally, smart networks (7) often integrate smart sensors in the production lifecycle.
4.2.3. Period 2008–2016
Table 7 shows the results for this period.
Smart meters (1) constitute the first newly discovered research field. These intelligent electronic devices enable two-way communication between meter and production system. Furthermore,
Big Data Analysis (3) and
Data Science (4) are focusing on data analytics. The increasing capabilities of distributed systems increase the potential for
automation systems (4). Finally,
total productive maintenance (7) constitutes a method including
key performance indicators (KPI) for production control.
4.3. Condition Monitoring
Papers related to condition monitoring contribute the largest dataset. To allow for a comparability with the other data sets, calculation parameters have to be adapted. To be more precise, the average cluster size is increased to 200, whereas each period of time is limited to one year. Hence, the periods differ from the previously defined ones. Following this approach, twelve research fronts were calculated.
Table 8 lists the discovered lead documents and techniques for each year. Interestingly, many known research fields from previous Sections could be observed and only two new research fields were discovered at the end: First,
data-driven systems (8) enrich production workflows by including data evaluation methods. Second,
cyber-physical systems (12) focus on the combination of physical and software components.
4.4. Engineering Asset Management
As we also consider that the revealed maintenance methods should be applicable in the field of Engineering Asset Management, which is not used as a direct search string, we discuss this connection briefly. Therefore, we show connections between revealed papers and this research field using the definition of general asset management functions as presented by the authors in [
15]. First,
Risk Management is the process of identifying risks and taking steps to reduce the latter [
71]. In case of equipment maintenance, this would be the identification of the
Remaining Useful Life (RUL) [
72]. It is evident that
Condition Monitoring can be directly found in our revealed papers, e.g., as shown by [
73]. Next, the
Asset Usage Life Cycle is of paramount importance and [
70] uses this concept for energy storage systems. Moreover, maintenance strategies have a great impact on Performance Measures, as shown, for example, by the authors of [
74]. Finally, Intelligent
Information Systems enrich maintenance approaches by improving the reliability [
66]. In conclusion, our revealed papers cover many parts of the Engineering Asset Management field.
5. Importance Measure
By collecting all lead documents for each time period, we obtain lists with potentially relevant papers. Please note that the importance of literature entries in these lists is not directly comparable for two reasons. First of all, when judging the importance of a paper, not only the number of its citations should be considered. Additionally, for two papers with same number of citations, their date of publication should be considered as well. For this purpose, we introduce a correction factor
(cf. Equation (
2)). Second, the
citing culture differs across the various research fields. For example, in economics, the mean number of citations is higher than in computer science. In line with the latter observation, regarding the results of search string
Lean Maintenance, we obtain articles with high numbers of citations that mainly focus on management-oriented issues ([
46,
50]). To reduce these two effects and to express aspects from the bibliometric analysis more properly, we propose an alternative impact measure. (For a general overview of impact measures see [
86]).
The first part of the importance measure represents anomalies caused by the different search strings (Predictive Maintenance (PDM), Condition Monitoring (CM), Predictive Analytics (PA), Reliability-centered Maintenance (RCM), Lean Maintenance (LM), and Smart Maintenance (SM)). Assuming that the search strings differ in their relevance for state of the art equipment maintenance systems, we express their importance on scale from 0 to 1. This factor is denoted as
topic neighborhood(tn) assigned to each article
a:
As opposed to the
h-index [
36], which cannot decrease over time, we apply a logarithmic reduction (cf .
Figure 16) for the value of a citation. For example,
Figure 16 shows a decreasing, normalized influence value for 88 fictive citations over a time span of 18 years.
Since the bibliometric analysis is based on clustering, it seems to be appropriate to include the relative
cluster size (cs) of a cluster
c in period
p as well. In addition, the average
h-index of the first and last author will be part of the importance measure to express that literature from authors widely read is very important. Finally, graph-based indicators contribute to the importance measure. The important papers from a cluster can be identified using the
article degree, also named as well valency [
87]. Besides, according to the graph theory, a cluster can be denoted as a graph
G, with each article representing a vertex
v, where
deg(v) is the number of edges incident to the vertex. A second graph unit is
betweenness [
88], which constitutes a
centrality measure. Betweenness represents the number of shortest paths in the cluster that cross
v. Clusters containing a high number of items automatically produce large betweenness values and. Hence, the betweenness needs to be calculated relatively to the cluster size.
In a nutshell, the importance index of an article, suggested by us, considers the following attributes:
age t [2016-publish year]
times cited tc
cluster size cs
number of items in the assigned period p
h-index mean () of the first and last author
topic neighbourhood tn
degree d
betweenness b
The newly introduced importance measure refers to five different variables (cf. Equation (
2)), whereby each term is weighted according to the preferences of the study leader. For our analysis, we stress the importance of the centrality measures. (cf. Equation (
3)).
The resulting impact factor for each article is then calculated as follows:
The impact measures of selected articles and the parameters involved are shown in
Table 9 (all values are normalized), accompanied by the statistical measures
average (avg),
median (med), and
standard deviation (std). Please note that the high weight of the centrality measures leads to top positions for articles showing excellent degree and betweenness values. Exemplarly, we will discuss the first row of
Table 9. The paper was cited 53 times and was 5 years old when the collection process took place. It is indirectly connected to maintenances and receives therefore the topic neighbourhood of 0.4. According to Equation (
2), the value
is calculated and is 0.03. This number indicates that this paper is relatively seldom cited among all papers. Next, the paper was revealed as the most important paper in a cluster of size 318 in a period with 1813 entries. This results in a relative cluster size of about 17% and a normalized value of 0.43. According to Web of Science the h-Index of the first and last author are 17 and 15, which produces a normalzed value of 0.4. Both degree and degreeness are the highest values among all papers and therefore represented by the normalized value 1. Using Equation (
3), the final importance measure for this paper is 0.59.
Finally, two other aspects need to be mentioned. First, the presented ranking can be easily parameterized by changing the values of tn and the used weights. Second, the introduced importance measure is well suited for a complex bibliometric analysis including various research areas.
6. Forecast
We forecast the development of identified research fronts based on the history of scientific and public interest. According to [
90],
scanning constitutes a prerequisite of forecasting. Scanning involves “collecting information: the system, history, and context of the issue [...]”. We collected the required information from our bibliometric analysis. For this forecast, we only include those research fields connected to search string
predictive maintenance. Thereby, we assume that a higher interest in the topic will result in more publications. Furthermore, we distinguish between
scientific and
public interest. To describe the
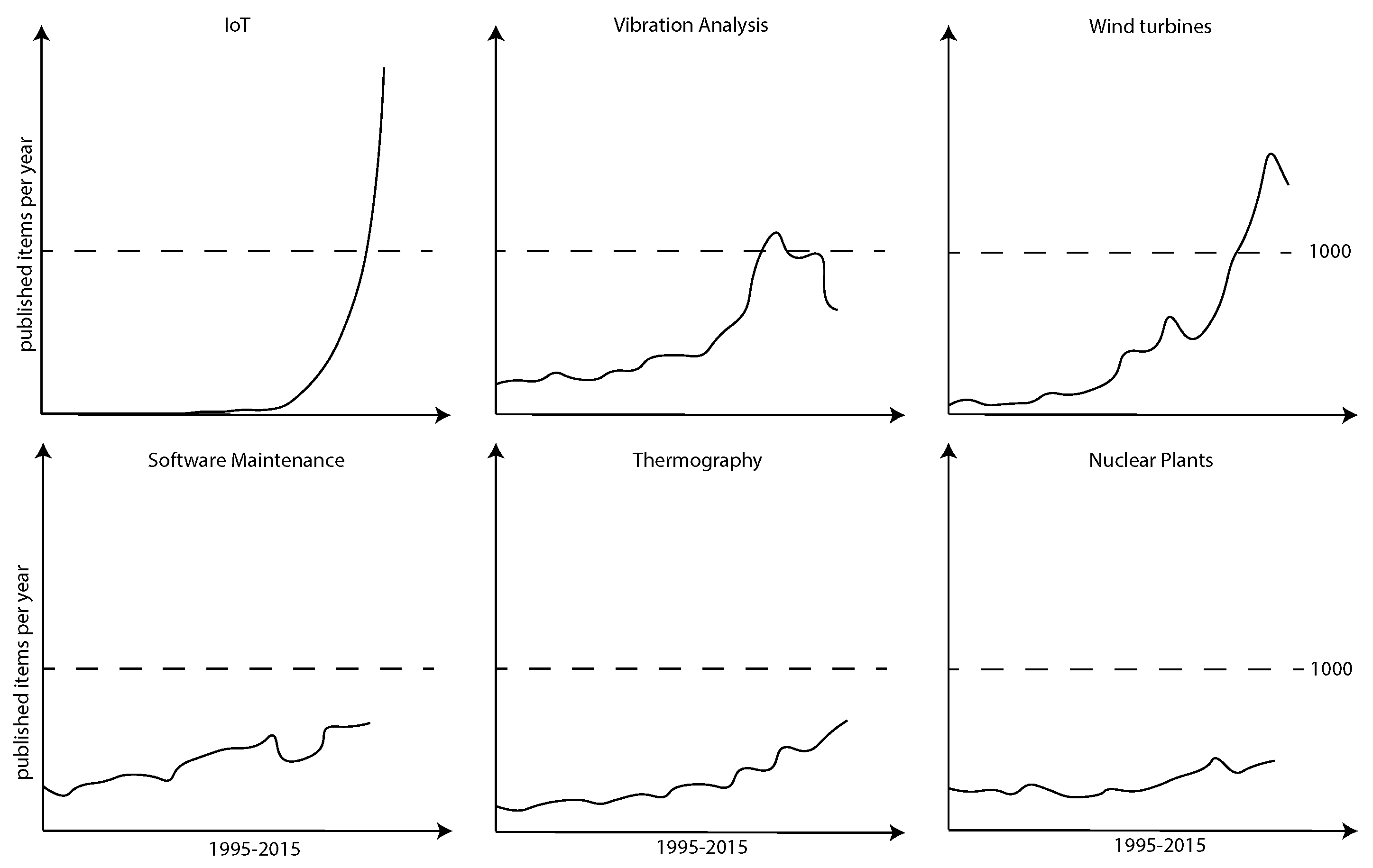
scientific interest, six research fronts from the period 2008–2016 were chosen and their names were used as new search queries for Web of Science. This period constitutes the latest one and, hence, the most important period for us. From this period, we take six important research fronts and analyze their development over the last 20 years; i.e., according to the published items per year. . This time, we were not interested in extracting literature, but in measuring the published items per year (cf.
Figure 17). Interestingly, the development over the last 20 years has shown a significant growth in almost all connected research fields. In particular, the research front
Internet of Things is identified to be a potential driving force for publications in the context of predictive maintenance.
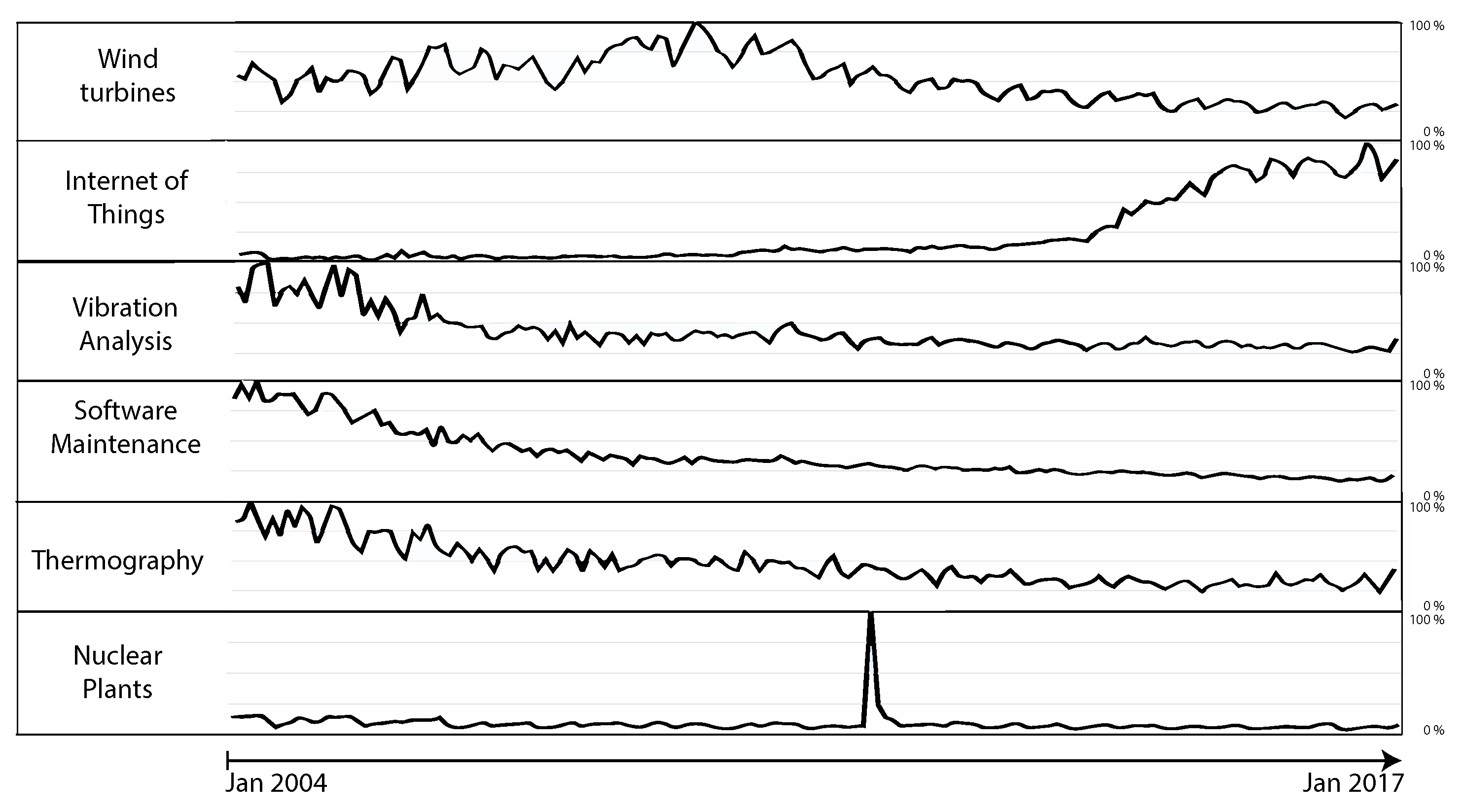
As an indicator for
public interest, we choose the Google trend analysis. (
https://www.google.de/trends/explore) Interest, as measured by Google searches, is visualized in a normalized form for the period from 2004 to 2017 (cf.
Figure 18). The topic
Internet of Things grew significantly during the last years. The greatest difference between scientific and public interest can be observed in the graphs related to
software maintenance. Please note that the Fukushima Daiichi nuclear disaster in March 2001 distorts the graph for
nuclear power plants. The public interest was enormous due to this event, causing a peak in the graph.
Furthermore, we link upcoming developments in the field of predictive maintenance to the development of the Internet of Things. Three aspects are of particular interest in this context:
Algorithm Development. Current success stories on
deep learning have not affected research yet. In particular, neural networks were used in all periods. Please note that the introduction of
convolutional neural networks (cnn) might improve predictions. So far, this technique has been widely used for image classification [
91], but the tendency of bringing more and more sensors into industrial applications will make this multidimensional approach more attractive as well.
Trust. Using predictive systems, the importance of
planning algorithms for industrial production is increasing. Decisions are based on algorithm results and a evolution of these systems is leveraged if people agree on calculations and if they trust their predictive systems. According to [
92], high agreement rates can be achieved by trust, which, in turn, depends on reliability. Following the theory that improvements in algorithm result in a better reliability of predictive systems, we expect better trust and acceptance rates as well.
Alliances. From
Figure 14, it can be discovered that in Clusters 3 and 4, the countries working in the same cluster are in a conflicting state. If deteriorating country relations influences research progress, the pairs US-China, Russia-Germany, and Great Britain-Germany (Brexit) might complicate research cooperations and consequently slow down the scientific progress due to reduced knowledge exchange.
Altogether, we expect a further growth in the number of research publications in the field of Predictive Maintenance.
7. Threats to Validity
The bibliometric analysis is a powerful tool. Though, some limitations need to be considered. First, a general quality measure for choosing search queries is challenging. As the total number of all published papers is unknown, it cannot be measured how good we cover the state of the art. Furthermore, the comparison with other search query choices is difficult as we use preprocessing filters. Our search strings result in many papers. Therefore, we improve the significance of centrality measures, such as betweenness and degree. On the other hand, we take the risk to include irrelevant papers in the analysis. Next, as there is an unlimited number of combinations for the parameters of the bibliometric analysis, we cannot guarantee optimal cluster sizes. When the cluster size is too small, related research fields are likely not to be representative for the dataset, i.e., they are too specific. By contrast, by conducting the analysis with too large cluster sizes, we might merge two different cluster labels and loose information as well as precision. Another thread to validity concerns the choice of the number of citations as an indicator for the importance of research, since quality is not necessarily expressed by public attention. Finally, the bibliometric analysis solely covers the academic part of approaches. Knowledge that is present within enterprises, but which is not publicly available, is not included in the analysis. Therefore, we cannot evaluate the feasibility of the presented approaches and techniques.
8. Summary and Outlook
This work identified important papers and techniques used in the field of state of the art equipment maintenance systems based on a bibliometric analysis. The latter covers temporal, geographical, author-related, and technique-related issues. For this analysis, we used search strings from contemporary maintenance methods to extract sets of papers from an academic database.
This work provides an overview on maintenance strategies on one hand and serves as a schema to categorize future research results on the other by providing look-up tables for research fields and techniques. The techniques, which were mostly identified by keywords, indicate how researchers approach the topic of state of the art equipment maintenance systems. Furthermore, each research field is represented by the most important paper, whose importance is determined by the number of citations. The collection of lead documents extracted from different search strings is not comparable due to different time periods and research fields.
We further introduced an importance measure to compare the papers by standardizing their properties and by expressing their relevance in a more cluster-independent way. The weighting of each parameter needed for calculating of the importance measure can be chosen by the conductor of the analysis. Therefore, this procedure is adaptive and can be reused in other bibliometric analyses. Since state of the art equipment maintenance systems, mainly represented by predictive maintenance, constitute a growing research field, it is important to stay informed about the current research. This work allows for the classification of emerging works as well as for the comparison with existing literature. As shown, the topic of equipment maintenance systems consists of many different research fields and various applied techniques. For our future work, we will focus our research on modular predictive maintenance applications. These applications, in turn, need to scale up with an increasing number of sensors, as particularly required in the context of the Internet of Things. We will evaluate the integration of the revealed techniques into new equipment maintenance systems modules. Finally, further research will emphasize the modular design of predictive maintenance applications to support scaling applications and flexible procedures.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















