Image Captioning with Word Gate and Adaptive Self-Critical Learning


Abstract
1. Introduction
- we introduce the word gate to dramatically reduce the valid action space of the text generation, which brings the reduced variance and easier learning.
- We present the adaptive SCST (ASCST), which incorporates two control parameters into the estimated baseline. We show that this simple yet novel approach significantly lowers the variance of the expected reward and gains improved stability and performance over the original SCST method.
- Experiments on MSCOCO dataset [8] show the outstanding performance of our method.
2. Related Work
2.1. Image Captioning
2.2. Image Captioning with Reinforcement Learning
3. Methodology
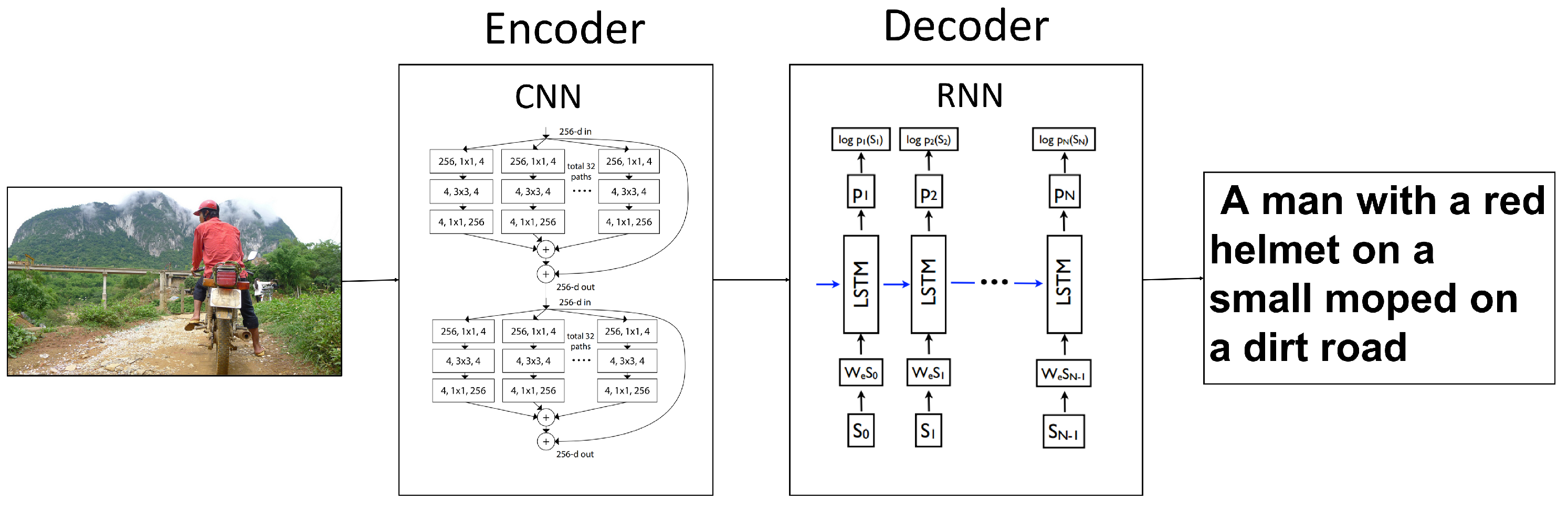
3.1. Overview of the Proposed Model
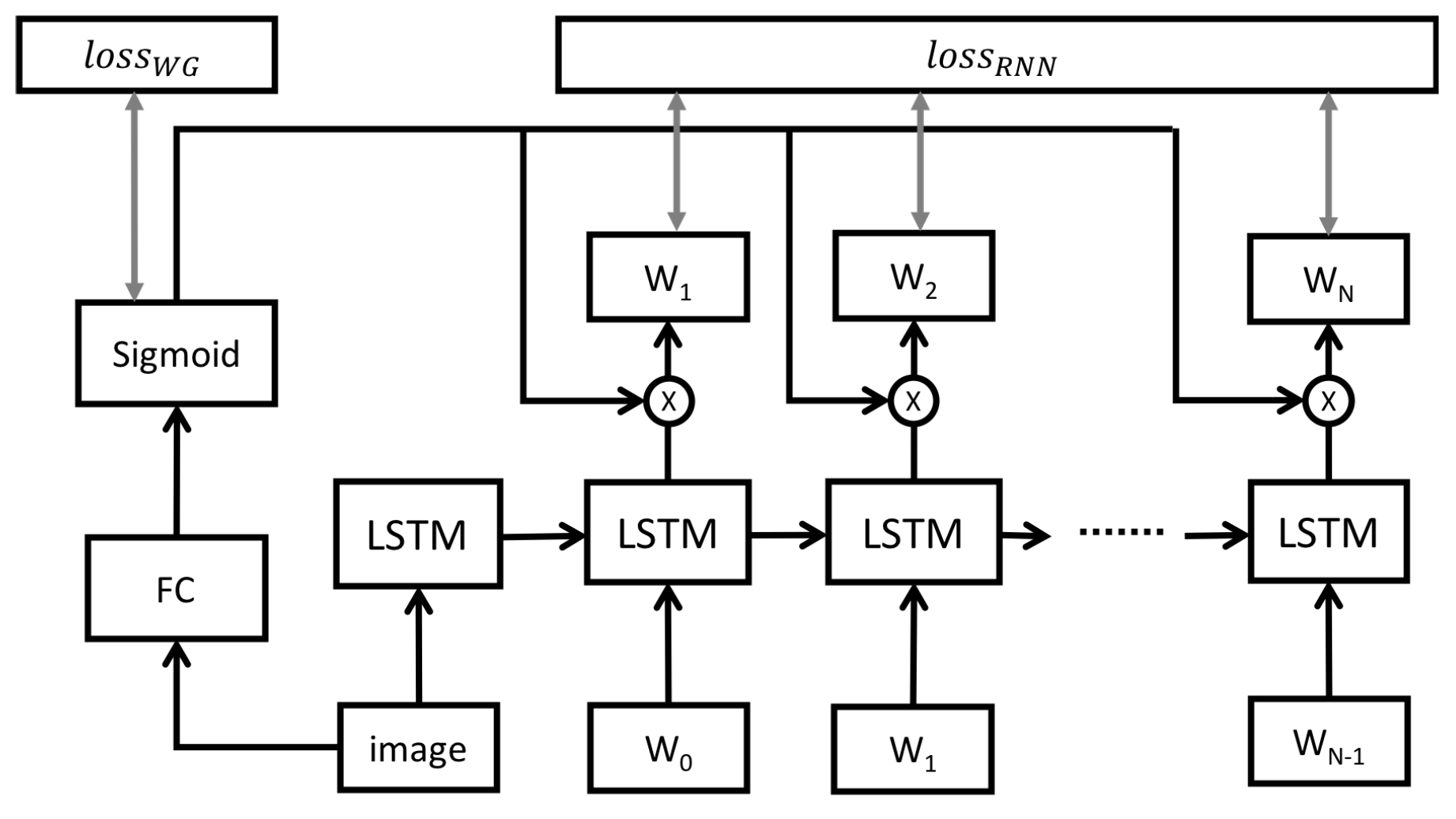
3.2. Word Gate
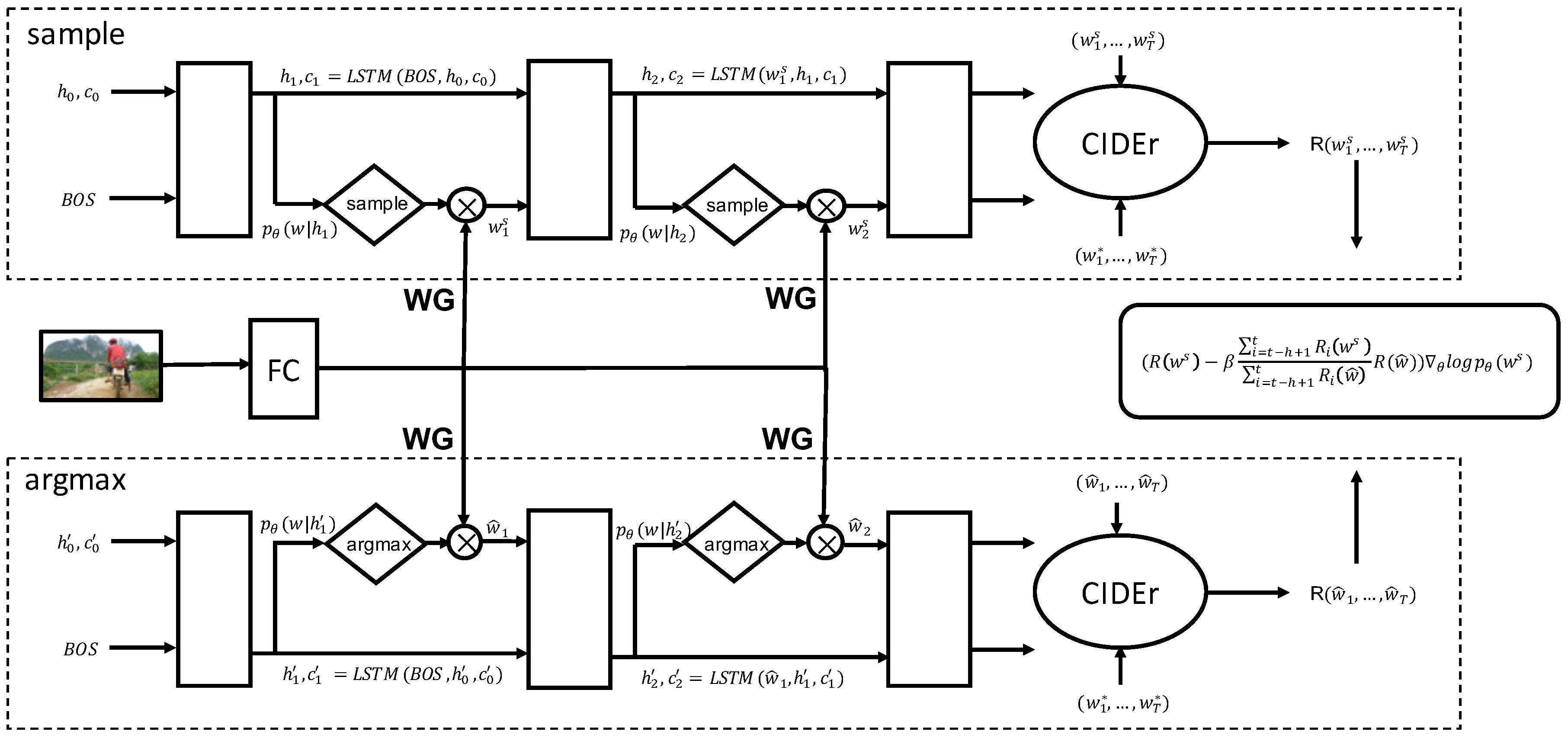
3.3. Adaptive Self-Critical Sequence Training
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Results
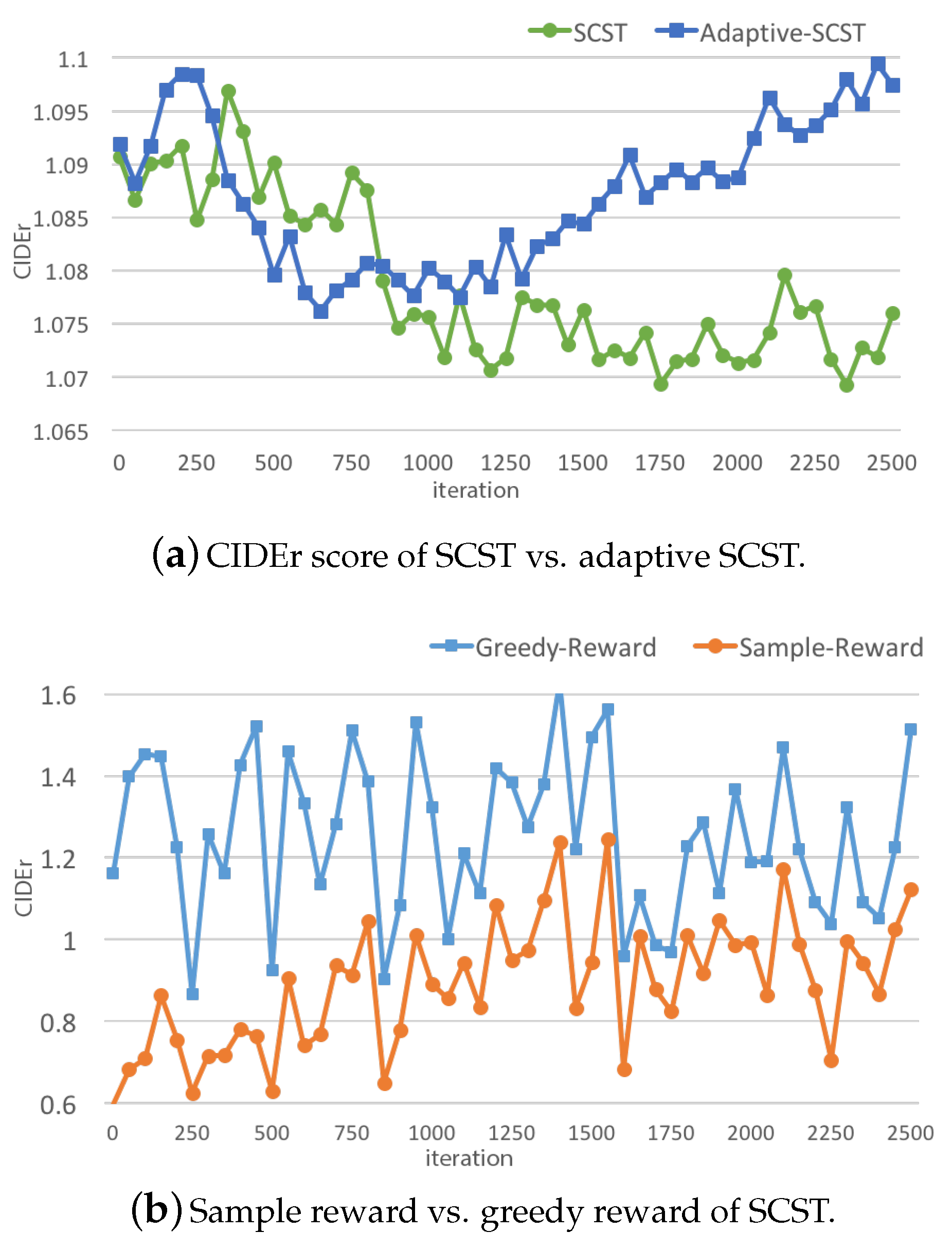
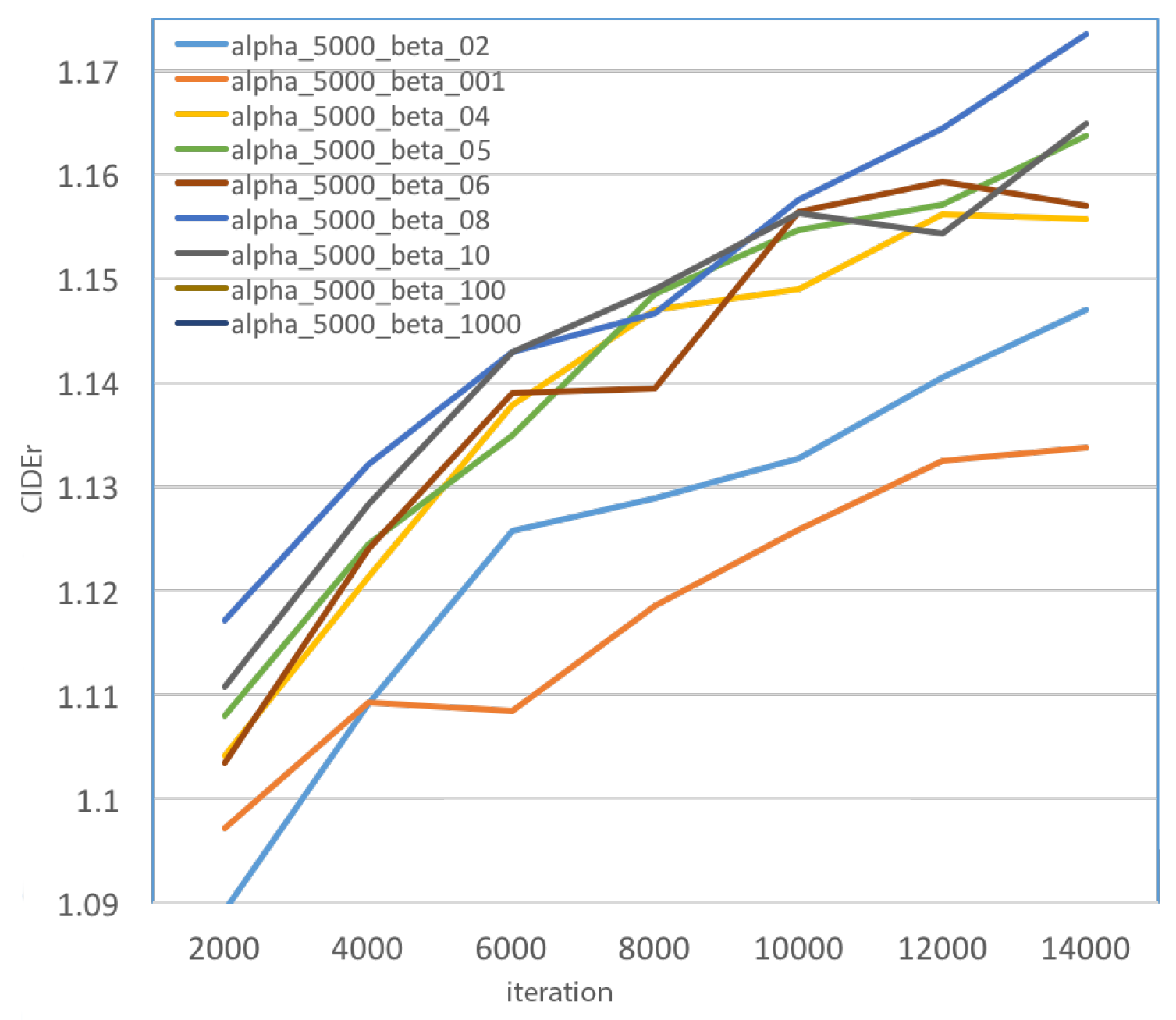
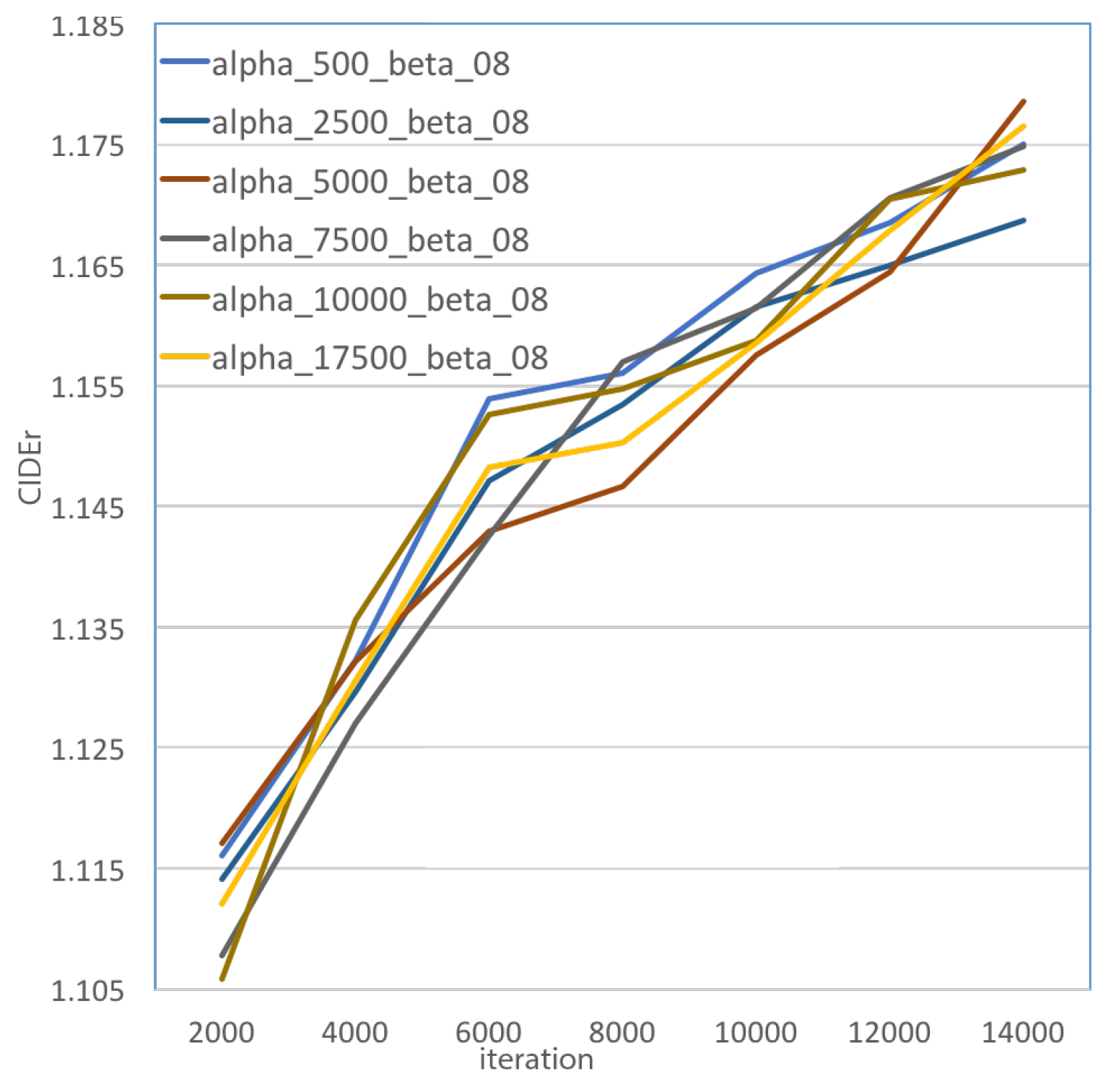
4.4. Quantitative Analysis
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Ranzato, M.; Chopra, S.; Auli, M.; Zaremba, W. Sequence level training with recurrent neural networks. arXiv 2015, arXiv:1511.06732. [Google Scholar]
- Bengio, S.; Vinyals, O.; Jaitly, N.; Shazeer, N. Scheduled sampling for sequence prediction with recurrent Neural networks. arXiv 2015, arXiv:1506.03099. [Google Scholar]
- Liu, S.; Zhu, Z.; Ye, N.; Guadarrama, S.; Murphy, K. Improved Image Captioning via Policy Gradient optimization of SPIDEr. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical Sequence Training for Image Captioning. arXiv 2016, arXiv:1612.00563. [Google Scholar]
- Vedantam, R.; Zitnick, C.L.; Parikh, D. CIDEr: Consensus-based image description evaluation. arXiv 2015, arXiv:1411.5726. [Google Scholar]
- Mnih, A.; Gregor, K. Neural Variational Inference and Learning in Belief Networks. arXiv 2014, arXiv:1402.0030. [Google Scholar]
- Bahdanau, D.; Brakel, P.; Xu, K.; Goyal, A.; Lowe, R.; Pineau, J.; Courville, A.; Bengio, Y. An actor-critic algorithm for sequence prediction. arXiv 2016, arXiv:1607.07086. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: Lessons learned from the 2015 mscoco image captioning challenge. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 652–663. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.L.; Kiros, R.; Cho, K.; Courville, A.C.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. arXiv 2015, arXiv:1502.03044. [Google Scholar]
- Wu, Q.; Shen, C.; Liu, L.; Dick, A.R.; Den Hengel, A.V. What Value Do Explicit High Level Concepts Have in Vision to Language Problems. arXiv 2016, arXiv:1506.01144. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Qiu, Z.; Mei, T. Boosting Image Captioning with Attributes. arXiv 2016, arXiv:1611.01646. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Zhang, L.; Sung, F.; Liu, F.; Xiang, T.; Gong, S.; Yang, Y.; Hospedales, T.M. Actor-Critic Sequence Training for Image Captioning. arXiv 2017, arXiv:1706.09601. [Google Scholar]
- Zaremba, W.; Sutskever, I. Reinforcement Learning Neural Turing Machines-Revised. arXiv 2015, arXiv:1505.00521. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; Volume 1. [Google Scholar]
- Karpathy, A.; Feifei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Xie, S.; Girshick, R.B.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv 2016, arXiv:1611.05431. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A method for automatic evaluation of machine translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Denkowski, M.; Lavie, A. Meteor Universal: Language Specific Translation Evaluation for Any Target Language. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MA, USA, 26–27 June 2014; pp. 376–380. [Google Scholar]
- Jia, X.; Gavves, E.; Fernando, B.; Tuytelaars, T. Guiding the Long-Short Term Memory Model for Image Caption Generation. arXiv 2015, arXiv:1509.04942. [Google Scholar]
- Zhou, L.; Xu, C.; Koch, P.; Corso, J.J. Image caption generation with text-conditional semantic attention. arXiv 2016, arXiv:1606.04621. [Google Scholar]
- Yang, Z.; Yuan, Y.; Wu, Y.; Salakhutdinov, R.; Cohen, W.W. Review Networks for Caption Generation. arXiv 2016, arXiv:1605.07912. [Google Scholar]
- You, Q.; Jin, H.; Wang, Z.; Fang, C.; Luo, J. Image Captioning with Semantic Attention. arXiv 2016, arXiv:1603.03925. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | CIDEr-D | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 | ROUGEL | METEOR |
|---|---|---|---|---|---|---|---|
| NICv2 [9] | 0.998 | - | - | - | 0.321 | - | 0.257 |
| Hard-Attention [10] | - | 0.718 | 0.504 | 0.357 | 0.25 | - | - |
| Soft-Attention [10] | - | 0.707 | 0.492 | 0.344 | 0.243 | - | - |
| e2e-gLSTM [24] | 0.951 | 0.712 | 0.54 | 0.401 | 0.292 | - | - |
| Sentence-condition [25] | 0.959 | 0.72 | 0.546 | 0.404 | 0.298 | - | - |
| Att2in [4] | 1.013 | - | - | - | 0.313 | 0.543 | 0.260 |
| Att2in + SCST [4] | 1.114 | - | - | - | 0.333 | 0.553 | 0.263 |
| NIC (Resnext_101_64x4d) | 1.009 | 0.724 | 0.556 | 0.418 | 0.314 | 0.537 | 0.259 |
| Soft-Attention (Resnext_101_64x4d) | 1.046 | 0.737 | 0.571 | 0.433 | 0.326 | 0.550 | 0.263 |
| Soft-Attention + SCST | 1.148 | 0.771 | 0.610 | 0.465 | 0.349 | 0.561 | 0.266 |
| Soft-Attention + ASCST | 1.170 | 0.777 | 0.616 | 0.471 | 0.354 | 0.564 | 0.269 |
| Soft-Attention + WG | 1.092 | 0.757 | 0.595 | 0.456 | 0.347 | 0.558 | 0.272 |
| Soft-Attention + WG + SCST | 1.187 | 0.779 | 0.620 | 0.470 | 0.349 | 0.569 | 0.274 |
| Soft-Attention + WG + ASCST | 1.212 | 0.785 | 0.630 | 0.486 | 0.368 | 0.571 | 0.277 |
| Methods | CIDEr | METEOR | ROUGE-L | Bleu-1 | Bleu-2 | Bleu-3 | Bleu-4 |
|---|---|---|---|---|---|---|---|
| MSM@MSRA [12] | 0.984 | 0.256 | 0.542 | 0.739 | 0.575 | 0.436 | 0.330 |
| Review Net [26] | 0.965 | 0.256 | 0.533 | 0.720 | 0.550 | 0.414 | 0.313 |
| ATT [27] | 0.943 | 0.250 | 0.535 | 0.731 | 0.565 | 0.424 | 0.316 |
| Google [9] | 0.943 | 0.254 | 0.530 | 0.713 | 0.542 | 0.407 | 0.309 |
| SCST [4] | 1.147 | 0.270 | 0.563 | 0.781 | 0.619 | 0.470 | 0.352 |
| WG-ASCST | 1.179 | 0.275 | 0.572 | 0.786 | 0.630 | 0.485 | 0.368 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, X.; Li, L.; Liu, J.; Guo, L.; Fang, Z.; Peng, H.; Niu, X. Image Captioning with Word Gate and Adaptive Self-Critical Learning. Appl. Sci. 2018, 8, 909. https://doi.org/10.3390/app8060909
Zhu X, Li L, Liu J, Guo L, Fang Z, Peng H, Niu X. Image Captioning with Word Gate and Adaptive Self-Critical Learning. Applied Sciences. 2018; 8(6):909. https://doi.org/10.3390/app8060909
Chicago/Turabian StyleZhu, Xinxin, Lixiang Li, Jing Liu, Longteng Guo, Zhiwei Fang, Haipeng Peng, and Xinxin Niu. 2018. "Image Captioning with Word Gate and Adaptive Self-Critical Learning" Applied Sciences 8, no. 6: 909. https://doi.org/10.3390/app8060909
APA StyleZhu, X., Li, L., Liu, J., Guo, L., Fang, Z., Peng, H., & Niu, X. (2018). Image Captioning with Word Gate and Adaptive Self-Critical Learning. Applied Sciences, 8(6), 909. https://doi.org/10.3390/app8060909