1. Introduction
With the development of Autonomous Ground Vehicles (AGVs) in the last few decades, the demand for accuracy, maneuverability and controllability in vehicle’s navigation is ever increasing. For example, an AGV may be required to follow a path accurately under unstructured and uneven terrain conditions, where a significant amount of wheel slip and unpredictable disturbance forces occur at the vehicle’s wheels. The 4WS4WD vehicle, with four wheels that can be steered and driven independently, is a revolutionary platform that has great potential to perform high maneuverability and flexibility in harsh environments.
The main challenge in the control of 4WS4WD control is the number of control inputs (four steering angles and four drive torques), which results in an over-actuated system, where only three outputs including its degree of freedom (DOF) in the longitudinal, lateral and angular directions of the vehicle are concerned. How to allocate all eight control inputs to achieve high path following performance has not yet been effectively solved. The control allocation is proposed to handle the control problems of over-actuated systems [
1]. Generally, the control allocation can be treated as an optimization problem.
For controller designing, a model of the vehicle under control is generally required to facilitate the selection of future control inputs. A dynamic model describes the states of the vehicle based on the forces applied. However, the development of a detailed vehicle dynamic model is always a challenging task due to the uncertainty of parameters and the complex disturbances from the external forces. The majority of existing control methodologies for 4WS4WD vehicles are proposed based on the linearized dynamic model, which lead to the loss of input degree of freedom [
2,
3]. Meanwhile, some other methods use nonlinear dynamic models in the control of 4WS4WD vehicles [
4,
5], where control inputs are subjected to some relationship constraints to simplify the controller design. However, in practice, the four independent wheels may interact with different terrain conditions, where different slip, wheel forces and terrain disturbances are generated on the corresponding contact patches. Hence, it is desirable to make four wheels individually controlled, thereby limiting and/or overcoming different slip and disturbance on different contact patch.
There is an abundance of literature that presents kinematic modelling of ground vehicles [
6,
7,
8], in which the vehicles are assumed to operate at low speeds to reduce the dynamic effects. Most vehicle kinematic models are developed based on the non-integrable kinematic constraints, known as non-holonomic constraints. As a result, the wheel slip has to be ignored with the assumption of zero relative velocity between wheels and terrain [
9,
10]. To utilize the kinematic model’s advantage of keeping the steering control relatively independent of velocity control [
11], it is desirable to incorporate wheel slip in the vehicle kinematic model so as to facilitate the accurate vehicle control in complex terrain conditions where the no-slip assumption is not applicable.
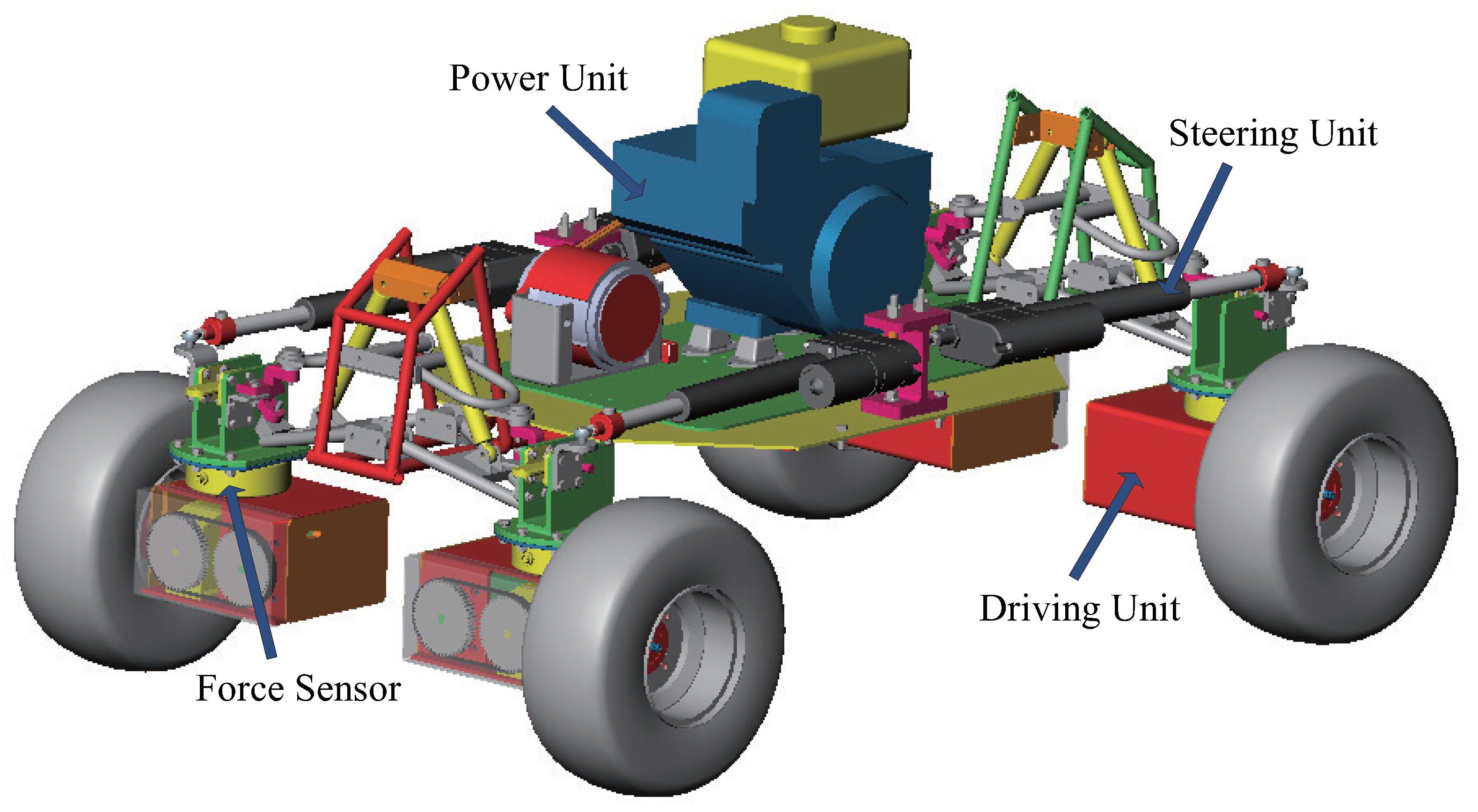
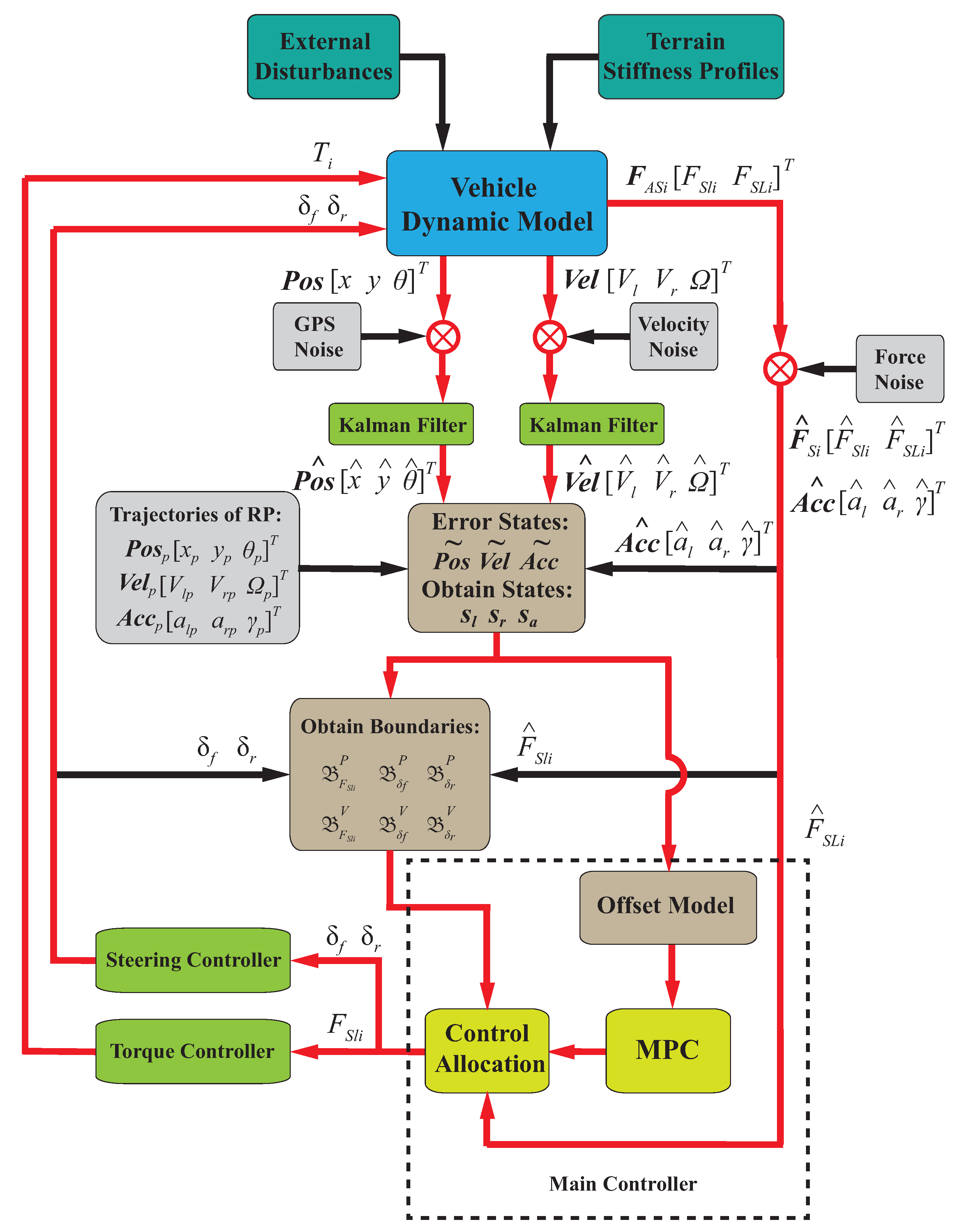
To realize force control, a novel type of 4WS4WD vehicle with force sensors at each wheel has been designed as shown in
Figure 1. This vehicle possesses the characteristics of independent steering and drive control at each wheel and force measurements. In this work, the dynamic model is partitioned into a hierarchy of three levels to facilitate the incorporation of force sensors and overcome uncertainties in the model. The force sensors at the drive unit allow the measurement of actual force data, while models of the drive unit and tire are used for simulation.
Model predictive control (MPC) is selected for its ability in handling linear constraints and time-varying systems as well as its good performance in tracking problems. Particle swarm optimization (PSO) is also selected for its fast searching speed in global optimization. MPC and PSO have been successfully applied in the controller design of real-time control systems [
12,
13,
14,
15,
16,
17]. In this work, MPC and PSO based control methods are proposed to realize the controlling aim of achieving good path following performance as well as high motion quality via vehicle steering control and independent force control at four wheels.
As novel contributions, the MPC methodology is applied to achieve precise path tracking of 4WS4WD vehicle. Based on the MPC theory, an offline control law is proposed to guarantee the stability of the upper controller. An sequential quadratic programming (SQP) based control allocation is developed to control the 4WS4WD vehicle in the lower controller. The inclusion of full independent force control and steering control on all four wheels enable the maximization of performance. In this work, comparison of MPC and PSO on the same vehicle model is provided, in which the proposed PSO control methodology is a further refinement of the PSO methodology presented previously in [
18]. The PSO control methodology in this paper simplifies the derivation and gives an algorithm in a more general form, which facilitates the comparison with other control methods. In addition, both methodologies are compared with the kinematic model based method proposed in [
19].
The paper is organized as follows:
Section 2 describes the 4WS4WD vehicle modelling. The MPC and PSO control methodologies are presented in
Section 3. In
Section 4, simulation setup and the reference path are presented. The result of the two controllers are compared. In
Section 5, the discussion about two methodologies are provided based on their theoretical analysis and simulation results. Finally, conclusions are provided in
Section 6.
3. Control Methodology
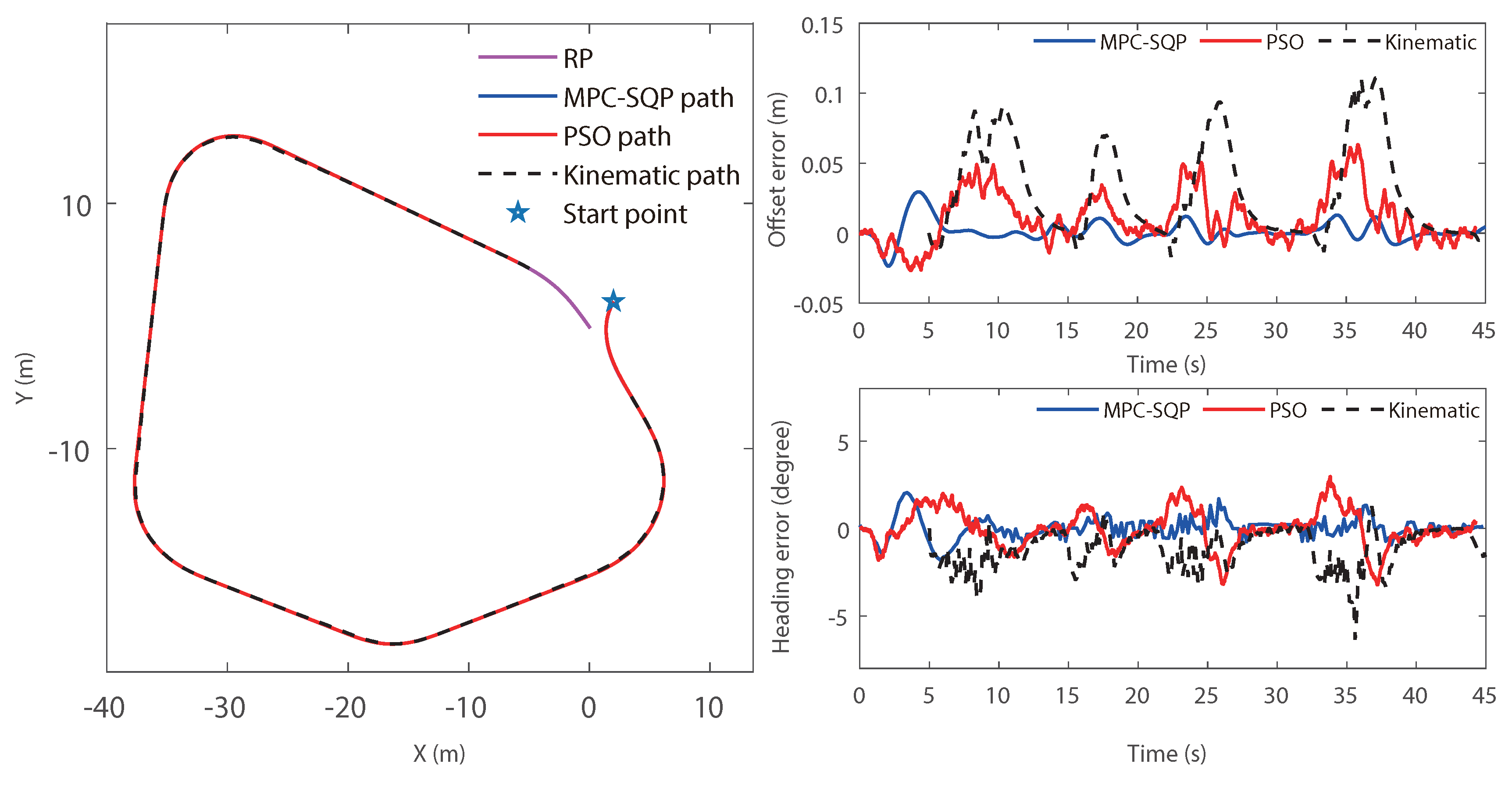
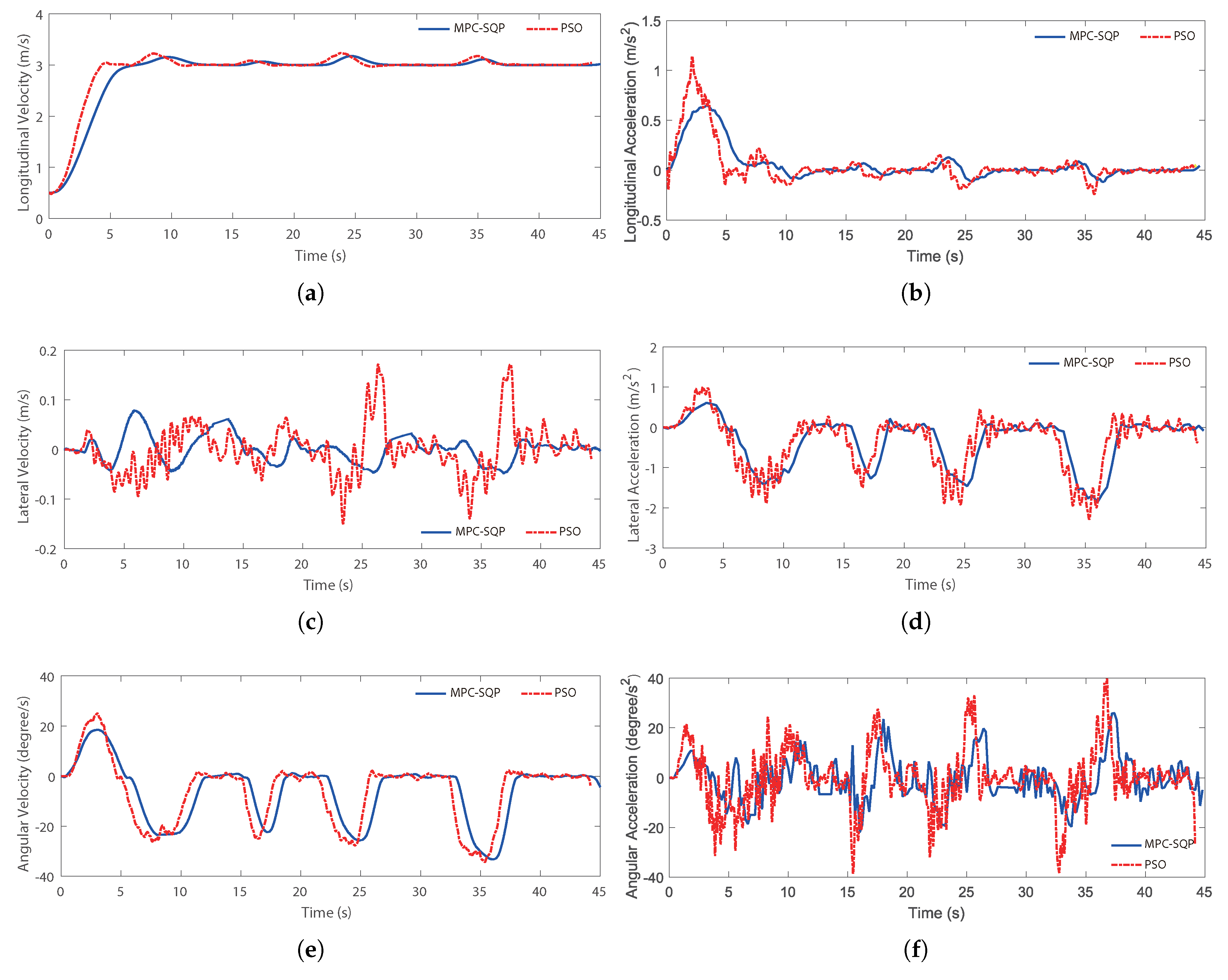
Two methods of finding the optimal control inputs for steering angles (i.e., and ) and drive forces are developed. The first method used model predictive control (MPC) with a sequential quadratic programming (SQP) solver. The second method is particle swarm optimization (PSO). The objective of the controller is to accurately follow a predetermined path through multiple terrain types.
3.1. MPC-SQP Method
3.1.1. Offset Model Linearization
In order to be applied in the MPC controller design, the offset model is linearized by a feedback linearization method. By defining the state vector
, as
,
,
,
and
, the offset model can be written in the following form:
In this model,
,
and
are considered as the inputs while other constants including reference accelerations and velocities can be obtained from the vehicle states. The nonlinearity of the model comes from trigonometric terms of
. For accurate path tracking problems, the yaw error is assumed to vary smoothly within [−10° 10°]. Then, the model can be linearized by feedback linearization. Define the input vector
; then, the new input vector at time
is obtained as
and the offset model is expressed as
where
It can be seen that the model is time-varying but can be treated as a linear model at each sampling step. The output vector is denoted by
and the equation is written as
where
3.1.2. Model Predictive Control
To develop the MPC controller, the offset model as given in Equations (
27) and (
28) needs to be discretized and its discrete-time state vector form can be written as
where
,
and
are the state vector, output vector and input vector, respectively. The coefficient matrices
,
and
are updated after discretization.
To eliminate undesirable oscillations, embedded integrator vectors
,
are defined, thereby an augmented state-space model can be expressed as
where
is a zero matrix, and
represents the identity matrix.
Defining the new state vector
, the augmented model can be written in the following matrix form:
where
Theorem 1. Given a discrete time system following the form of Equation (31), the asymptotic stabilization of the closed-loop system can be realized by substituting the first item of as the control input , when is the optimal solution of the following optimization problem:where denotes the predicted output sequence, denotes the future input sequence, and is the prediction horizon. is the sequence of the control target vector. represents the error between the final predicted output and target. Proof of Theorem 1.
To prove the stability, the Lyapunov function
is defined equal to the value of the objective function
subjected to its optimal solution, which can be expressed as
where,
are obtained by the optimal solution of future inputs, and
represent the corresponding error sequence between future outputs and target.
is the nonnegative gain matrix.
According to the definition in Equation (
33), the Lyapunov function at the next sample
is written as
To facilitate the comparison between two neighboring Lyapunov function values, a intermediate function
is defined, which is formed by evaluating
with a defined inputs sequence, which is obtained by shifting the optimal inputs sequence of
one step forward, and setting its last input
as zero. It is obvious that the objective function value of non-optimal inputs sequence has to be no less than
, which can be expressed as
thereby,
Since
shares the same future inputs sequence and the predictive outputs sequence with
for the sample time
, it can be easily derived that the difference between these two functions is
As is given in Equation (
32), the optimization problem is subjected to the constraint
. Then, it can be obtained that
Then, the monotonicity of the Lyapunov function can be obtained by
which can prove the asymptotic stability of the system. □
The model predictive control algorithm is realized by receding optimization. In order to apply the MPC efficiently, we assume that the predicted outputs sequence is in a finite prediction horizon
and the inputs sequence is in a control horizon
, which is less than
. The sequences mentioned above can be expressed in the matrix form:
where
denotes the predicted outputs at time
based on the states at time
k. Based on Theorem 1 and the assumption above, the corollary about finite-time unconstrained MPC can be obtained as follows.
Corollary 1. Given the system without input and output constraints, the prediction and control horizon are and , respectively. Then, the following feedback control law can asymptotically stabilize the closed-loop system, whereand, Proof of Corollary 1.
According to Equations (
31) and (
40), the predicted output sequence
can be expressed by
Meanwhile, the final item of
can be expressed as
By substituting Equations (
43) and (
44) into Theorem 1, the optimization problem turns into the following form:
where
is a weighting matrix.
Note that in the application of offset model based path tracking, the target vector
should be zero all the time. It can be seen that
J meets an equality constrained quadratic programming. Then, the objective function is expanded by Lagrange expression and simplified by omitting the constant term,
where
is the Lagrange multiplier.
According to the Lagrange multiplier method, the optimal control input vector
can be found by solving the following equation system. The solution is obtained by taking the first partial derivatives of
J with respect to the vectors
and
, and then equating these derivatives to zero:
Then, its optimal solution can be obtained:
where
According to the receding horizon control principle, the first increment of
is applied as the control inputs. Then, the control law in Equation (
41) can be obtained. □
It can be seen that Corollary 1 gives an offline solution of the MPC algorithm, which significantly improves its computing efficiency. Based on Corollary 1, the desired accelerations can be obtained by integrating the optimal solution .
3.1.3. Sequential Quadratic Programming Based Control Allocation
Considering the vehicle body with the mass
M and inertia
J in this work, the command force vector
is defined as
where
,
and
are the longitudinal and lateral forces and the moment about a vertical axis of the vehicle, respectively.
According to the vehicle body dynamic model given in Equation (
1), the actual actuating forces come from the longitudinal forces
and lateral forces
on each wheel. Let the command forces
produced jointly by the wheel forces and steering angles be expressed as
where the
i-th column of
and
can be written as
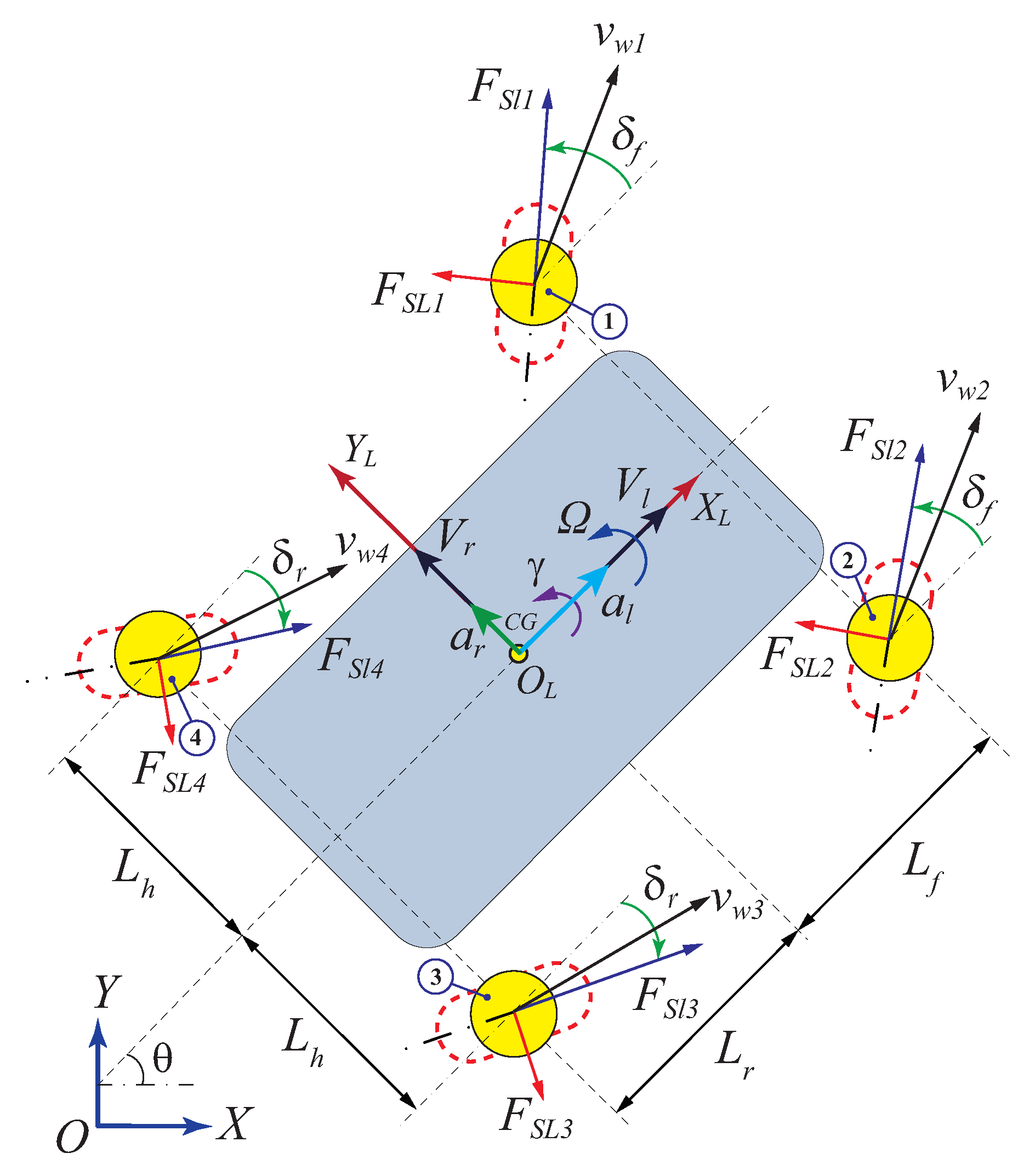
represents the location of each wheel in a coordinate system with its origin at the centre of gravity and positive
x-axis forward.
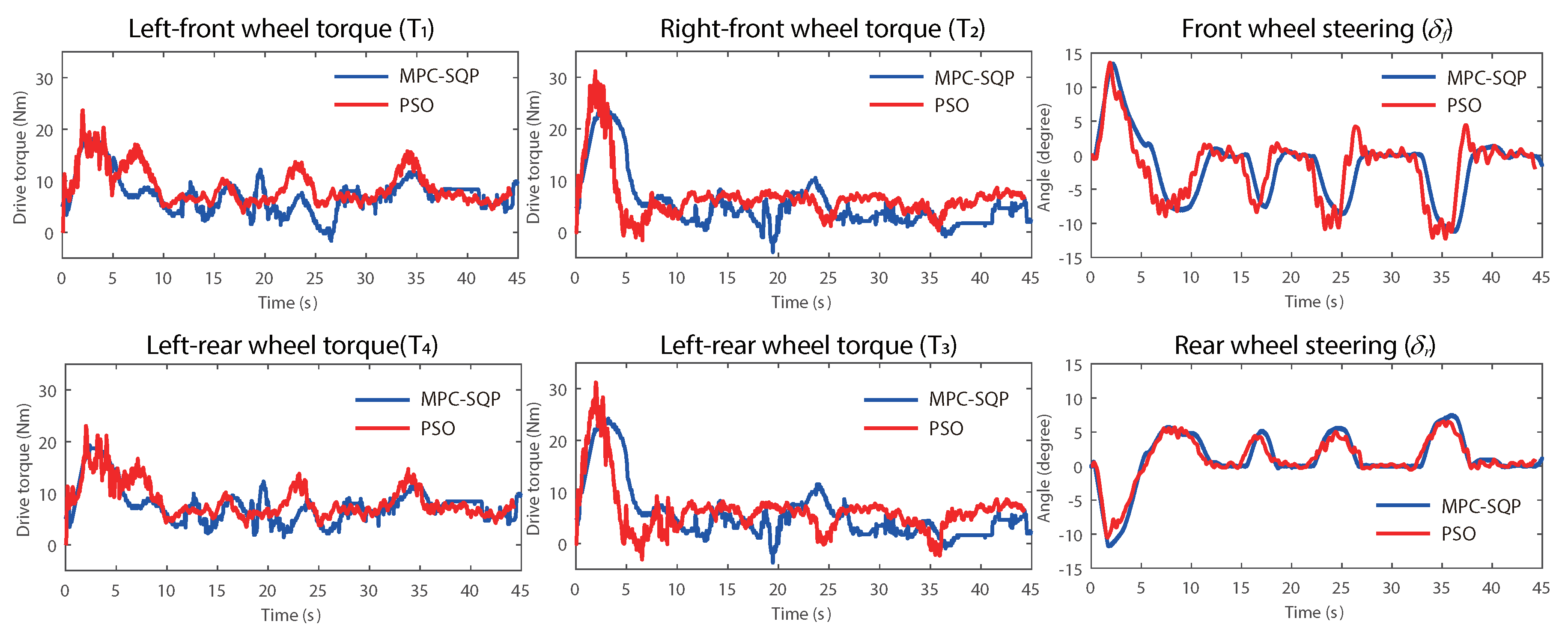
On a 4WS4WD vehicle, the drive forces
and the steering angles
are the direct inputs while the lateral forces
obtained from sensors are considered as a measured disturbance. In this work, the steering angles
are composed of
and
, which represent the front and rear steering inputs, respectively. Thus, the control problem is reduced to obtaining the feasible solution of Equation (
50). In order to facilitate the computation, a slack vector
is defined by
which denotes the error between the commanded and actual generalized forces. The slack variable
s guarantees that there always exists a feasible solution in the following optimization [
26].
In order to solve this control allocation problem, the objective function is defined with respect to
,
and
,
where
,
and
are the search bounds of each variable.
In this function, the first term minimizes the magnitudes of the drive forces; the second term is used to ensure the steering angle to search around its previous value. By penalizing the slack variable in the third term, the actual generalized force vector coincides as much as possible with the commanded forces . The matrix , and are used to tune the objective. The search bounds of all variables (i.e. , and s) are specified by the constraints.
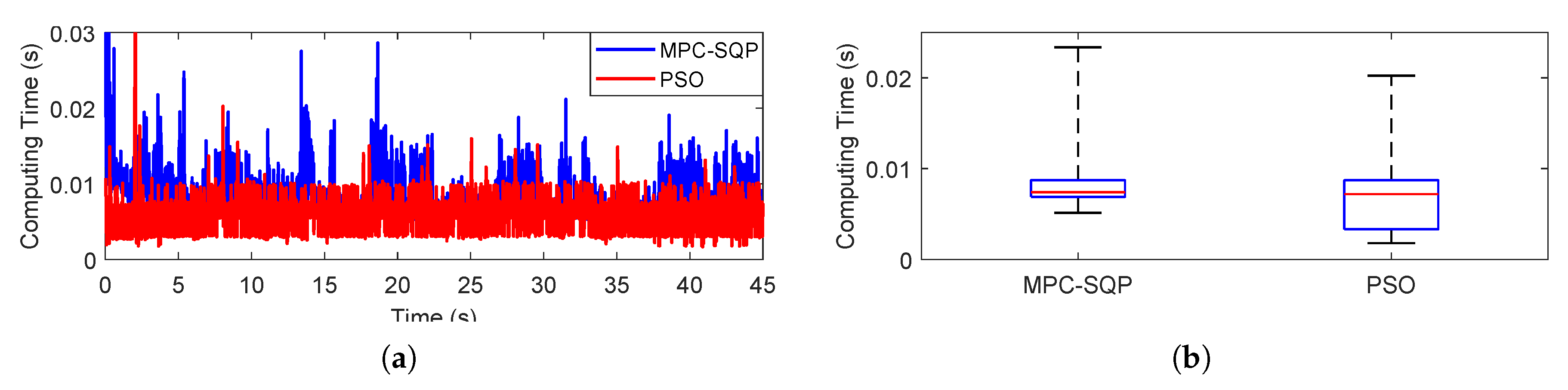
Based on the objective function presented above, the control allocation is converted to a nonlinear constrained optimization problem. Using the sequential quadratic programming (SQP), the optimal solution can be computed efficiently and reliably by standard numerical software.
3.2. PSO-Based Method
For the PSO-based method, an objective function including vehicle error states is proposed using the sliding surfaces. In Sliding Mode Control (SMC), the time-varying sliding surface is normally defined by the scalar equation
, in which
is expressed by [
27],
where
is a positive constant and
is the error state vector.
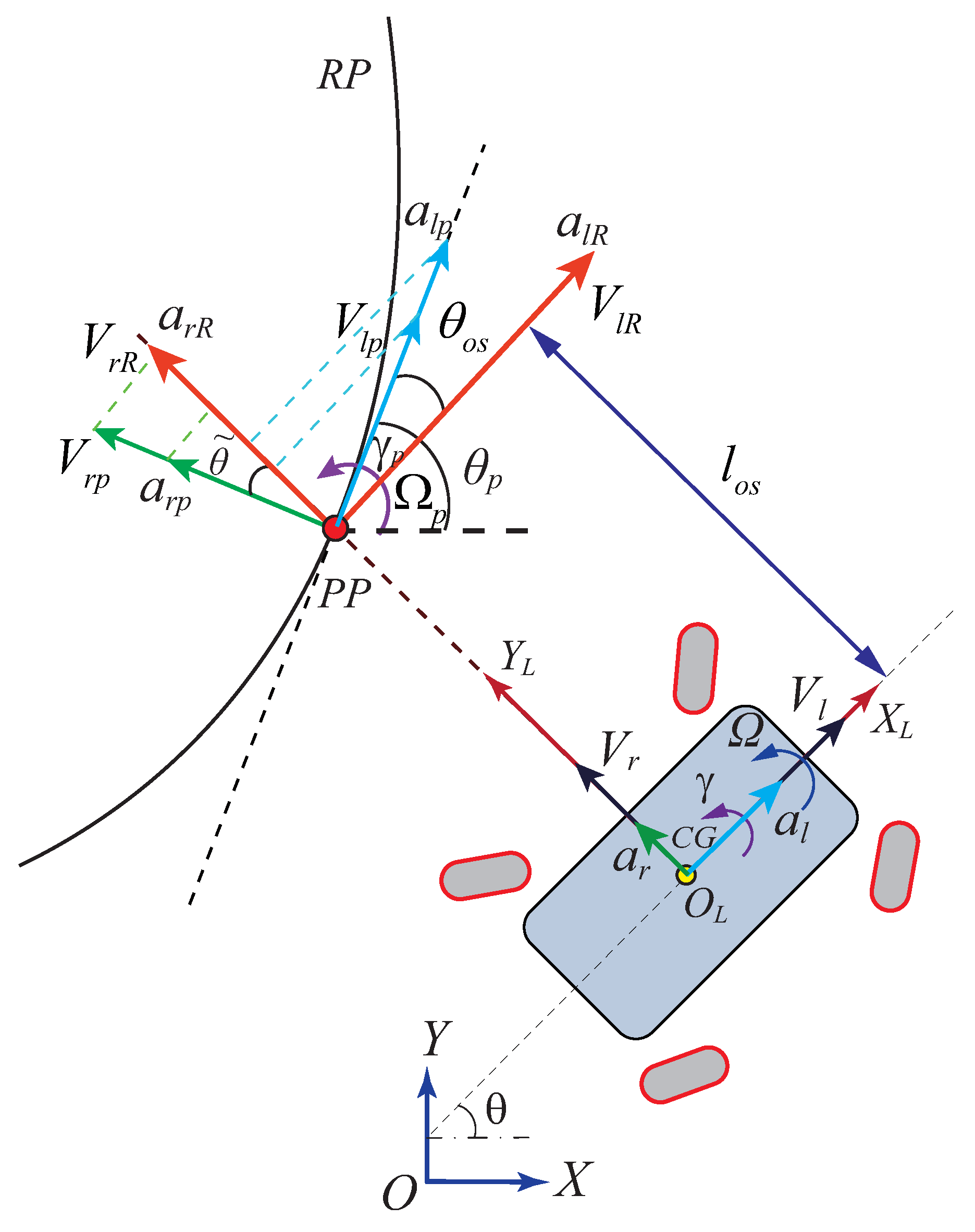
According to the idea of SMC, the problem of maintaining is transformed into keeping . In this work, the scalar quantities composed of vehicle error states are introduced into the definition of objective function. Instead of designing the switching control law in SMC, the optimization is used to maintain the scalar quantities on the sliding surface . The vehicle error state vectors including , and are following the definitions in the offset model. Therefore, to track the trajectories of the RP, the vector needs to be defined correspondingly. Note that vector follows a different definition than that in SQP. It is defined to facilitate the notations in the local boundary part.
For
presented in Equation (
17), its first component, which represents the position error in the longitudinal direction, is always zero. Therefore, according to Equation (
53), the longitudinal scalar quantity
can be obtained as
where
and
are the longitudinal components of
and
, which are given in Equations (
22) and (
19), respectively.
To maintain the vehicle on the RP geometrically, another first order scalar quantity
is designed as
which aims to minimize the offset errors
and
.
The angular acceleration error
is included to consider the effects of forces and yaw movements of vehicle, and thus a second order scalar quantity is chosen as
where
,
and
are given in Equations (
17), (
19) and (
22), respectively.
Then, the problem of following the trajectories of RP is transformed into maintaining
at 0. Using the linear scalarization, an objective function is defined as
where
,
and
are the weighting coefficients strictly positive and constrained by
The variables of objective function in Equation (
57) consist of the forces
, steering angles
and
, which can be written as a variable vector,
First invented by Kennedy and Eberhart (1995), PSO has been successfully applied to solve problems featuring nonlinearity, non-differentiable, and multiple optima. PSO is found to be capable of generating high quality solutions with more stable and faster convergence characteristics, and shorter calculation times than other stochastic methods [
17]. For standard PSO at time
t, the updating velocity
and position
of the
i-th particle are presented in the following equations:
where
and
are vectors in multi-dimensional space.
and
denote the local optimal position and the global optimal position, respectively. The particle inertia weight is represented by
. The particle cognitive acceleration and social acceleration are denoted by
and
, which are defined as positive constants.
and
are two stochastic parameters within [0 1].
The search space of PSO in this work is defined as a six-dimensional space corresponding to the dimension of
. Therefore, the particle position vector
in Equation (
60) represents a possible solution of the objective function in Equation (
57).
3.3. Boundary Definition
Given that both methods are reduced to the optimization problems, the definition of the search space determines the quality of the solution.
3.3.1. Global Boundaries
In this work, the global boundaries can be assigned based on the properties of each actuator, which is defined as
where
and
are the minimum and maximum steering angles of each wheel.
and
are the minimum and maximum drive forces provided by the driving unit, which can be calculated by
where
is the maximum torque that can be achieved by the driving unit of the vehicle.
3.3.2. Local Boundaries
To realize real-time optimization, the computing time obtaining optimal values for variables needs to be constrained within the sample time of controller . According to the properties of each actuator, the maximum variations of within can be obtained. In this work, to improve the computing efficiency, the local boundaries are also determined by the states of .
According to
in Equation (
1), when
, the forces
need to be increased, thereby dragging
in Equation (
54) towards the surface
. Similarly, when
, the forces
need to be decreased. Therefore, the local boundaries of
can be written as
where
is the maximum change of
that can be achieved within
. At the time
,
are the possible optimal solutions.
For the steering angles
and
in
, they affect the vehicle lateral and angular motions in a coupled way. To solve this problem, an allocating method is specified that the vehicle lateral error determines searching direction of
, while
is related to vehicle angular error. When
,
needs to be increased to drive
back to the surface
, and vice versa. Thus, the local boundary of
is summarized as,
where
is the maximum change of steering angle that can be achieved within
. At the time
, the possible optimal solution of front steering angle is
.
Similarly, based on
, the local boundary of
is defined as
For the PSO in particular, its particle velocity boundaries define the range of speed that particles can achieve to search for the optimal solution. To improve search performance in PSO, the absolute maximum particle velocity is normally set as a certain percentage of particle position range [
28]. According to Equations (
63)–(
65), the particle velocity boundaries can be obtained as
where
,
and
are the particle velocity coefficients for
,
and
, respectively.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}