1. Introduction
In the past few decades, three-dimensional video has been widely adopted in various applications. Free viewpoint video (FVV) is a novel display format that has evolved from 3D video that enables viewers to watch a scene from any position [
1]. This free navigation (FN) experience provides a rich and compelling immersive feeling that is much better than traditional 3D video [
2]. However, FVV has significant requirements for video acquisition, compression, and transmission technology. Due to the limitations on camera volume and bandwidth of the communication system, only a limited number of views can be transferred. View synthesis technology is proposed to support the FN capability of generating texture images that are not captured by a real camera. Depth image-based rendering (DIBR) [
3] is a crucial technology for view synthesis. DIBR utilizes one or more reference texture images and their associated depth images to synthesize virtual view images, wherein every pixel in the original reference image plane is projected to the 3D world coordinate system according to its associated depth value; thereafter the 3D world coordinates are projected onto the image plane in the virtual viewpoint [
4].
Although virtual view from an arbitrary viewpoint can be reconstructed by utilizing reference texture and depth information, DIBR still brings some artifacts due to the inaccurate depth images. The geometric misalignment between foreground objects and background regions causes boundary noise and wrapping position displacement. The projected float results lead to rounding errors, which further cause pinholes, cracks, and blurs. In addition to these artifacts, a critical problem also arises during the generation of virtual images, since the regions covered by foreground objects in the reference views may be disoccluded in the virtual viewpoints, and these areas will appear as large holes in the virtual view, also referred to as disocclusions.
In this paper, we propose a novel synthesis framework using two reference viewpoints. This method first determines whether the pixel-wise depth map is reliable or unreliable, then refines some of those unreliable depth values. Second, an adaptive background modeling method is employed to construct background information, aiming to fill the remaining empty regions after a proposed weighted blending. In addition, the proposed adaptive median filter and depth map processing method (DMPM) show satisfactory performance on reduction of noise and other unwanted effects while the texture images remain sharp and clear. This improvement comes from their focus on processing the target pixels instead of handling every pixel in the intermediate texture images. The paper is organized as follows. The related classical algorithms are discussed in
Section 2. In
Section 3, the proposed framework is described in detail. The experimental results and conclusions are provided in
Section 4 and
Section 5, respectively.
2. Related Work
Depth image-based rendering is one of the most common methods of generating virtual viewpoints at arbitrary locations [
3,
5]. Hence the accuracy of the depth map is very important for the directly warped image quality. Meanwhile, the associated depth maps are coarse because of the deficient stereo matching algorithm or low-precision depth acquisition instrument, and synthesized images are not capable of satisfying the visual perception. Initially, the common approach to eliminate pinholes, cracks, and other artifacts was to preprocess the depth maps before DIBR, aiming to reduce the disparity along the boundary between foreground and background. In [
6], Zhang and Tam used a symmetric Gaussian filter to smooth the whole depth map, and in [
7] they used an asymmetric filter to reduce the vertical edge artifacts. In [
8], Cheng used the background information to cover the holes after using a bilateral filter to preprocess the depth maps. In [
9], an edge-dependent Gaussian filter, which is capable of smoothing the depth map while preserving the boundary along the foreground and background, was presented. Based on the experimental results and subjective performance outcome, all of the filters in [
6,
7,
8,
9] easily caused geometrically distorted foreground objects, especially when the distance between the reference view and virtual view was large, and the artifacts and other unwanted effects could be seen as unsatisfactory. In this paper, depth consistency cross-checking is used to check whether the depth value of each pixel is reliable or unreliable. For the left reference view, each pixel in the texture image is warped to the right reference viewpoint to verify its similarity to the corresponding depth map. A pixel is marked as unreliable if it fails to match the corresponding texture pixel in another reference view. The cross-checking for the right view is similar.
In the second period, there are two methods to solve large-hole region problems, spatial correlation and temporal correlation [
5]. In the spatial domain, some methods utilize texture information in the neighboring regions of the frame that are selected at the same moment. Criminisi et al. [
10] proposed an exemplar-based method that iteratively fills the disocclusions using the neighboring information; nowadays, this method denotes a classical inpainting algorithm. Experimental results show that inpainting obtains good performance when holes appear as narrow gaps, but the texture information is easily lost when holes are large. In fact, experiments indicate that large holes are always caused by disocclusions. In [
11], Ahn and Kim presented a novel virtual view synthesis method with a single viewpoint plus depth (SVD) format, which can cover disoccluded regions in a visually plausible manner. This improved texture synthesis is realized by exemplar-based texture synthesis, including a new priority term and a new best exemplar selection based on both texture and depth information. Actually, these spatial methods always focus on filling the narrow gaps or small holes in the texture image, while texture synthesis can fill the large-scale holes [
12,
13,
14]. Since large holes are observed when areas that are occluded by foreground objects in the reference view become exposed in the synthesized view, view-blending approaches can be used to alleviate this problem, as two adjacent cameras can cover a relatively wider viewing angle [
15,
16,
17].
As to exploiting the temporal correlation, Scheming and Jiang [
18] tried to determine the background information using a background subtraction method, but this approach relies on good performance of the foreground segmentation method, so it cannot be adopted in complex circumstances. Chen explored the motion vector of H.264/AVC bit stream to render disocclusions in the virtual view [
19]. In [
20,
21], a background sprite was generated by the original texture and synthesized images from the temporal previous frames using disocclusion filling, but the temporal consistency of the synthesized images needs further investigation, as described in [
22]. In [
23], Yao proposed a disocclusion filling approach based on temporal correlation and depth information. Experimental results showed that this approach yields better subjective and objective performance beyond the above-mentioned spatial methods of filling disocclusions. However, the SVD format limits its wide usage because of the small baseline. Besides, some disocclusion regions that are not included in a single reference view may easily be spotted in another virtual viewpoint, and reverse mapping [
4] may be more reliable. In [
23], Luo and Zhu et al. proposed the use of a constructed background video with a modified Gaussian mixture model (GMM) to eliminate the holes in synthesized video. The foreground objects are detected and removed, then motion compensation and modified GMMs are applied to construct a stable background. Results indicated that a clean background without artifacts of foreground objects can be generated by using the proposed background model, so that the blurry effect or artifacts in disoccluded regions can be eliminated and the sharp edges along the foreground boundaries can be preserved with realistic appearance [
24].
Although [
17] indicates that large holes in a target virtual view can be greatly reduced by using other more neighboring complementary views in addition to the two (commonly used) most neighboring primary views, we still employ only two reference views to render virtual views in our proposed framework. The occlusions that appear on one warped image will be filled by another reference viewpoint in the weighted blending process.
In this paper, a multiview plus depth (MVD) format is employed for view synthesis. Two reference views are selected to interpolate virtual views located between them. Occlusions that appear on one warped image will be filled by another reference viewpoint. In addition, an adaptive background modeling method is proposed to construct background intensity distribution. The stable constructed reference background image helps to fill the remaining unfilled regions that are left due to the unreliable depth map. Another novelty of the proposed algorithm relates to depth refinement, which has the advantage of eliminating some noise caused by the coarse depth map. We also present a weighted blending process to blend two warped images from reference views based on the reliability of each pixel. An adaptive median filter and a depth map processing method are utilized before generating the synthesized virtual image.
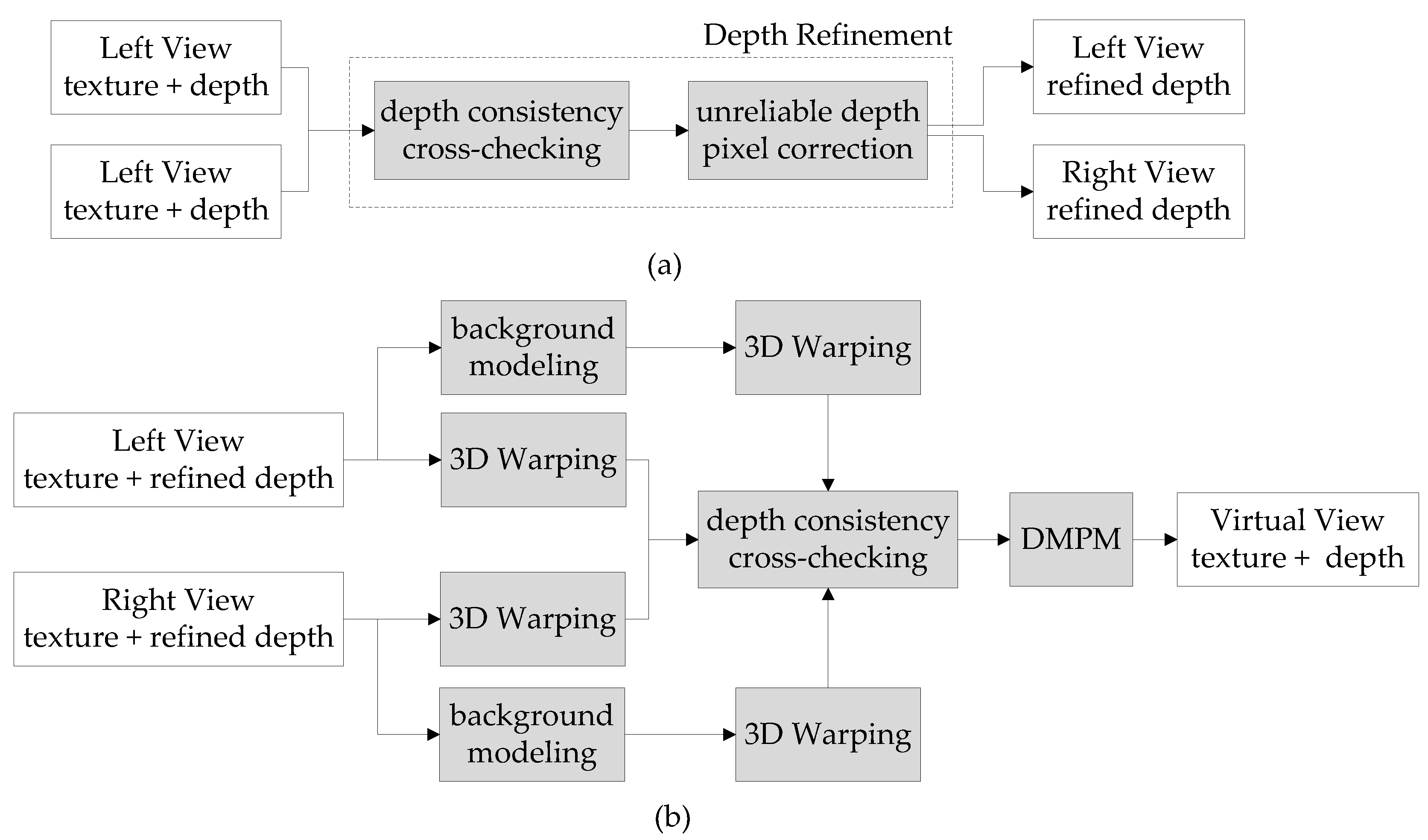
3. Proposed Framework
In this section, the proposed approach will be presented in detail. The framework of the proposed synthesis algorithm is illustrated in
Figure 1. There are mainly four techniques proposed in this framework: depth refinement, background modeling, reliability-based blending, and depth map processing method. These approaches will be discussed in
Section 3.
3.1. Depth Refinement
There are two steps in the depth refinement process, as illustrated in
Figure 1a. In the first step, depth consistency cross-checking is used to check whether each pixel’s depth value is reliable or unreliable. Second, depth refinement is employed to interpolate the depth values of unreliable pixels. The details of the first step are as follows. For depth consistency cross-checking of the left reference view: let (
u,
v) be the coordinate of one pixel from the left reference view, then its corresponding pixel (
uw,
vw) in the right reference view is obtained through the classical DIBR technology [
2]. The texture value
I and depth value
D of these two pixels are verified; the subscript
L and
R indicate left view and right view, respectively.
Ith is a large preset threshold value for texture comparison and
Dth is a small preset threshold value for depth comparison. The consistency checking produces five results, as follows:
- (1)
If and are both satisfied, this implies that these two pixels are matched. This depth pixel in the left reference depth map is reliable only in this situation, and it is marked as black in its cross-checking mask.
- (2)
If and are both satisfied, this implies that these two pixels fail to match. In this situation, there is a high probability that the pixel belongs to the occlusion area and the depth pixel in the left reference depth map fails to check whether it is reliable or not, then it is marked as blue in its cross-checking mask.
- (3)
If and are both satisfied, this implies that these two pixels fail to match. Either an erroneous texture pixel or an unreliable depth value causes this situation. We will check its surrounding depth distribution to find the real reason in the second step. The depth pixel in the left reference depth map is unreliable and it is marked as red in its cross-checking mask.
- (4)
If and are both satisfied, this also implies that the depth pixel is unreliable, and it is marked as green in its cross-checking mask.
- (5)
Some pixels in the left reference view are not able to project into the right reference view, because their corresponding pixels are located outside the image boundary. These areas are marked as white.
Figure 2 shows a result of the depth consistency check; because pixels in the white and blue regions fail to get a chance to verify their reliability, they are all determined to be unreliable and a specific weight is given when they are interpolated into virtual view. Several measures are implemented to refine other unreliable pixels, especially for the red and green regions. The main idea for the refinement is to find the most appropriate reliable pixel value to interpolate the depth value of unreliable pixels. Neighboring pixels from four directions are utilized here, and both the inverse proportion of distance and the reliability of the depth value are considered in calculating the weighting factors. If the reliable depth pixel maps to a reliable pixel in the other view, this indicates that this depth pixel is highly reliable. On the contrary, if the corresponding pixel in the other view is unreliable, the reliability of the pixel is lower.
Let
WDt, WDb,
WDl, and
WDr be the weighting factors calculated by the distance from the current unreliable depth value to the nearest reliable depth pixel in top, bottom, left, and right directions, respectively.
WH and
WL are the weighting values with high reliability and low reliability, respectively. The weighting factor for each direction can be formulated as:
where the subscript
direction can be either
t,
b,
l, or
r. The four weighting factors are normalized as
WNdirection, then the unreliable depth value
Dr can be interpolated by Equation (2):
where
Dd is the nearest reliable depth value in one of four directions.
3.2. Adaptive Background Modeling
In the previous step, a refined depth map was obtained. In
Section 3.2, we propose to apply an adaptive background modeling method evolving from Gaussian mixture model (GMM) to generate a reference image. GMM is commonly used in video processing to detect moving objects because of its capacity to identify foreground and background pixels [
7]. In previous research, GMM was utilized to construct a stable background image aiming to fill large empty regions. However, GMM is not suitable for scenes that contain periodic or reciprocating foreground objects; these foreground moving objects are easily detected as erroneous background pixels, thus generating an inaccurate background image. In addition, some background pixels might have slight changes, for example, pixel densities are different while shadows caused by foreground objects appear or move. Thus, the stable background images generated by previous approaches always had blurring effects and were not accurate. In our proposed adaptive background modeling method, both the texture images and their associated depth maps are utilized to explore the temporal correlation. In addition, we propose to apply a reliability-based view synthesis method using background information to interpolate the intermediate image and fill the disocclusions.
The proposed method works at the pixel level, and every pixel is modeled independently by a mixture of
K Gaussian distributions, where
K is usually between 3 and 5. By using this distribution, pixel values that have a high probability of occurring are saved if their associated depth values show they belong to the background. The Gaussian mixture distribution with
K components can be written as [
25]:
where
denotes the probable density of value
of pixel
j at time
t;
η is the Gaussian density function with three dependent variables:
,
, and
, where
denotes the mean value of pixel
; and
is the variance value of the pixel. Further,
is the weight of the
ith Gaussian distribution at time
t of pixel
j, with
. The function
η is given by:
Before texture information is modeled by Gaussian distribution, we propose to verify each novel pixel to ensure that it is not from a foreground region. If the depth value is much bigger than the stored depth buffer (which means this pixel is nearer to a captured device), the pixel is considered as a foreground pixel. Otherwise, if the depth value is much smaller than the stored buffer, the pixel is considered as a background pixel, and the modeled distribution is not reliable and should be restarted. The detailed process to generate the reference background distribution is as follows:
Initialization. The model is initialized at the beginning of the generation (time
t0):
where the variance value
is set to a certain large number,
is the stored depth buffer for pixel
j, and
is the depth value of pixel
j at time
.
Update. In the next frame, i.e., at time , we first check the depth level of this pixel, and is compared with the existing depth buffer . There are three situations for the depth comparison results:
- (a)
If the condition is satisfied ( is a predefined threshold depth value), this indicates that the new pixel belongs to the foreground objects, it will be discarded, and background distribution will not be updated.
- (b)
If
is verified,
is searched to match with
K Gaussian models. From each model
i from 1 to
K, if the condition
is satisfied, the matching process will stop, and the matched Gaussian model will be updated as follows:
where
α is the model learning rate (
α = 0.01), and
. The other parameters of the Gaussian models remain unchanged except:
These two parameters reflect the rate of model convergence. If pixel fails to match all the current Gaussian models, a new Gaussian model is introduced to evict the Gaussian model with the smallestvalue. The mean and variance values of the other Gaussian models remain unchanged, while the new model is set with , , . Finally, the weights of K Gaussian models are normalized to .
- (c)
In the third situation, if the condition is satisfied, this indicates that the new input pixel belongs to the background and the previous Gaussian distributions need to be abandoned. The first step is executed for.
Convergence. The remaining frames are processed by repeating step 2. The value of background pixels is derived by μ, and the most stable pixels in the time domain are modeled as background image; meanwhile, the number of Gaussian models of each pixel is obtained to determine whether the pixel experiences similar intensities over time or not.
Figure 3 shows two examples of adaptive background modeling.
Figure 3a presents the
Ballet background image generated with a small baseline, where
cam03 is chosen as a target virtual viewpoint that is interpolated by the reference viewpoints
cam02 and
cam04.
Figure 3b presents the
Breakdancers modeling result, where the background image at virtual viewpoint
cam04 is projected from reference viewpoints
cam02 and
cam06. Although some foreground objects are stored in a stable temporal background reference using the mechanism of the proposed framework, these effects would not affect the quality of the final synthesized image, since the filling of remaining empty regions always occurs in the background areas. Thus, the temporal stable background information can be obtained by both large and small baseline instances. This adaptive background modeling approach can be widely adopted in applications with unchanged scenes.
3.3. Reliability-Based Weighted Blending
As the background distribution for each reference view is obtained by the proposed background modeling method discussed in
Section 3.2, two background images are projected into virtual viewpoint and then blended into one background image in virtual viewpoint (represented by
IB). Previous research shows that GMM has an inherent capacity to capture background and foreground pixel intensities; missing pixel intensities of an occluded area are successfully recovered by exploiting temporal correlation.
In our proposed method, weighting factors are also applied to blend two reference views and one background image into a synthesized image. Two reference texture images are projected to virtual view using their corresponding refined depth maps, and two intermediate texture images IL, IR and depth images DL, DR are obtained. The reliability-based weighted blending process to produce a virtual image IV is as follows:
- (1)
If a pixel is filled in both
IL and
IR, first two depth values are compared. If the depth value of one pixel is much bigger than the other, this indicates that one pixel is obviously nearer to the capturing device.
IV is filled by the pixel with a bigger associated depth value. If two depth values are very close, weighting factors are utilized.
IV is formulated as follows:
where
WD is the weighting factor for the inversely proportional distance between reference view and virtual view, and
WR is the weighting factor for the previously defined reliability of depth value. One of three values (
rH,
rM, or
rL) is assigned to
WR when a pixel in this reference intermediate image is mapped by a reliable, refined, or unreliable depth value, respectively. It should be noted that
WL and
WR need to be normalized by
so that
.
- (2)
If only one pixel is filled in two reference views, for example only IL is filled, the reliability of IL is taken into consideration. If IL is mapped by a reliable depth value, IV can simply be filled with IL (). Otherwise, background information is used to generate IV. If DL is close to the background depth value, then ; if DL is much bigger than DB, .
- (3)
If pixels in both reference views are not filled, we use the constructed background image to deal with the hole-filling challenge. First, we check the surrounding depth value of IV and find the filled depth value to determine a proper depth value range. Then IV is filled by the background pixel if its depth value is in the obtained range. Otherwise, inverse warping and classical inpainting are applied to fill IV.
We propose this hole-filling method to ensure that background pixels are appropriate to fill the remaining hole regions. Because they adopt depth information, background pixels can be chosen to improve the rendered image quality even when the hole is surrounded by foreground objects.
3.4. Depth Map Processing Method
After weighted blending is completed, the warped texture image and depth map become entirely filled. However, in the previous process, cracks and pinholes could be observed in the rendered image. With the previous method, a classical median filter was applied to smooth the texture image or remove these artifacts. In our framework, a depth map processing method is proposed. Not only the above-mentioned artifacts, but also the background pixels in cracks of foreground regions (shown in
Figure 4a,b) can be removed. This method has advantages in preserving the texture details, since it is only performed on the detected coordinates.
The main idea of DMPM is based on the fact that pixel value in depth maps always changes smoothly in a large area, except in the case of sharp edges in the boundary area between foreground objects and background. These features allow easy detection of noise in depth maps. In fact, most artifacts and noise caused by inaccurate depth values are reduced because of the previously introduced depth refinement, but some unreliable or undetected depth values remain in the reference depth map, most of them in out-of-boundary areas and occluded areas. Therefore, DMPM is still necessary. Details of the depth map processing method are as follows:
- (1)
A conventional median filter is proposed to apply to the coarse depth map to obtain an improved depth map . It is capable of removing the existing noise and preserves the sharp boundary information.
- (2)
The texture image
is refined according to the improvement of its associated depth map. If the condition
is satisfied (
is a threshold value for depth difference), this indicates that the depth value of the pixel is unreliable and it is renewed after the median filter. An inverse mapping process using the updated depth value is employed to find an appropriate texture pixel. A depth range
is used as a candidate to find its corresponding pixel in two reference views. In Equations (11) and (12), we can get a corresponding reference pixel location (
ur,
vr) through pixel (
x,
y) and the associated depth values
zv and
zr;
A and
b denote rotation matrix and translation matrix, respectively. Several measurements are used to make sure a highly reliable pixel is obtained by using backward warping. First, the depth value of the obtained pixel should be close to the updated depth value
. Second, the disparity between (
x,
y) and (
ur,
vr) should not be too large according to the alignment of the reference viewpoint and virtual viewpoint:
In our previous method, we simply used a median filter on (
x,
y), and this turned out to be very effective when the texture of this area was smooth. However, a median filter easily produces blurring effects when the scene has detailed textures. Unlike the texture images, the smooth regions in the depth map are invulnerable to the filter with gray value distributions. After the renovation is conducted, the associated texture image is updated according to the improvement of its depth map.
Figure 4d shows the updated version of the integrated depth map, where the infiltration errors and unnatural depth distribution are eliminated by the classical median filter, while the sharp edges are preserved. Comparing
Figure 4a,c, the DMPM generates desirable improvement and avoids filtering of the entire image at the same time.
4. Experimental Results
In this section, the proposed framework is implemented in C++ based on OpenCV, and the tested multiview video plus depth sequences include two Microsoft datasets: Ballet and Breakdancers. In all video sequences, the size of each frame is 1024 × 768 pixels, and each video contains 100 frames with an unmoved background. The baseline between two adjacent cameras is 20 cm for both Ballet and Breakdancers. The associated depth maps and camera parameters are provided with the sequences. The format of all video sequences is avi, while texture images contain three channels (RGB).
To evaluate the performance of the proposed method, we implemented two state-of-the-art methods and my previous work in [
26], in order to compare this with the proposed approach. One of these two methods is a commonly used reference software, VSRS 3.5 [
27], which mainly contains a simple DIBR method [
3] and a classical inpainting technique [
10]. The other is a hole-filling method exploiting temporal correlations based on GMM [
5]. These two methods [
5,
27] represent the exploitation of spatial correlation and temporal correlation, respectively. In each experiment, the test sequence was composed of three real video sequences from three reference viewpoints. The coded left and right views with their associated depth videos were projected to interpolate the virtual video in the target viewpoint between them. The rendered sequence was compared with the actual video on the target viewpoints to measure the peak signal-noise ratio (PSNR) and structural similarity index (SSIM). In order to show wide practical applicability of the proposed synthesis algorithm, each view synthesis method was performed on both small baseline and large baseline instances.
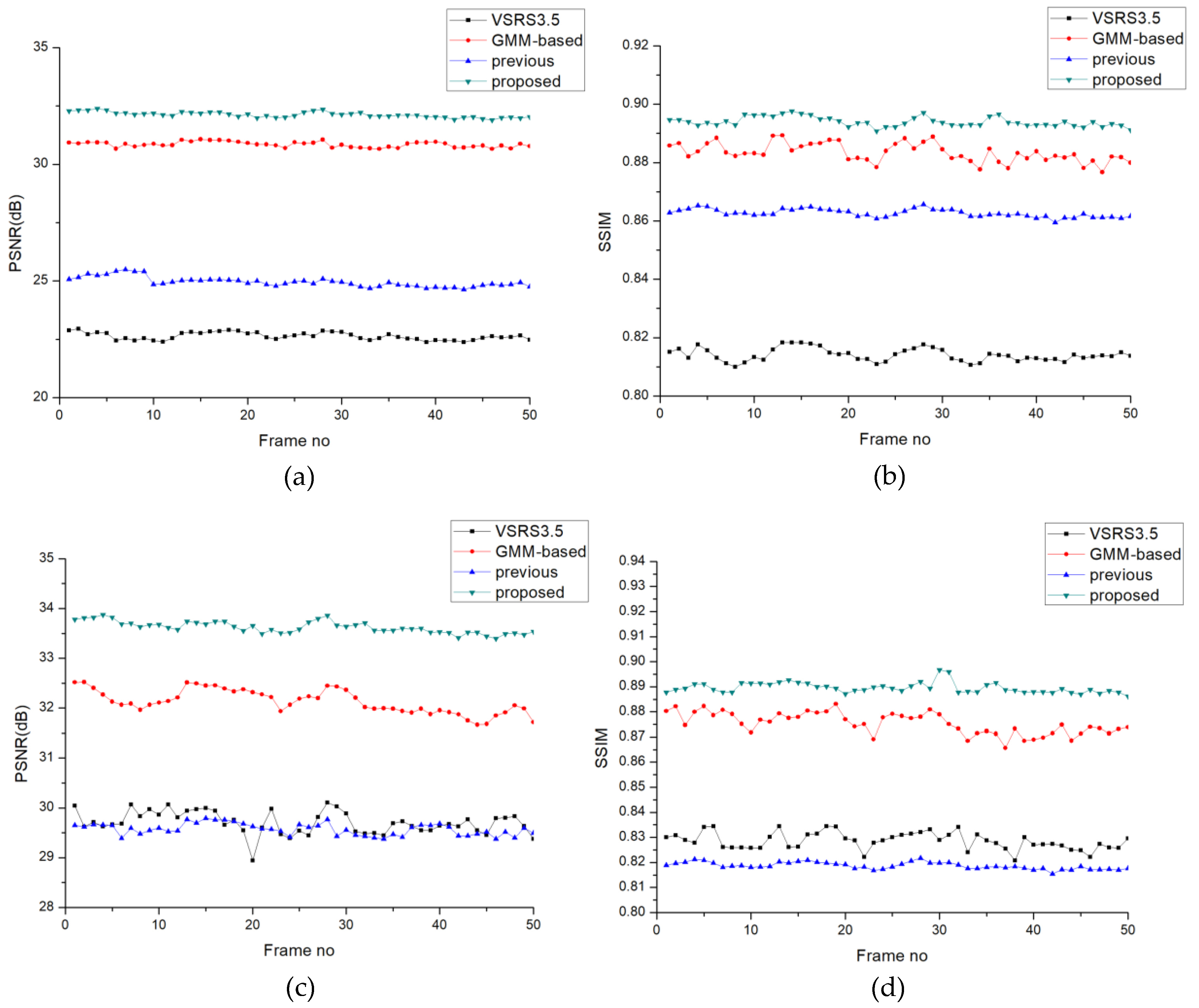
Table 1 and
Table 2 show the average PSNR and SSIM values for 100 frames.
In the PSNR evaluation, the proposed approach obtained 4–10 dB better results than VSRS 3.5 on Ballet for a large baseline instance. In the case of a small baseline, the results for both Ballet and Breakdancers were also better. The proposed method also showed better results beyond GMM-based disocclusion filling method and my previous work. Inpainting is an effective algorithm to fill narrow gaps and other small empty regions when the baseline is small, however, it is not practical for fill large empty regions. Moreover, my previous work did not perform well for both Ballet and Breakdancers sequences. This is due to the fact that simple GMM is not capable to deal with the scenes which foreground objects are with reciprocating motion.
Consequently, the proposed approach yielded better results on both tested sequences. The larger the baseline, the better the results. In addition to the objective measurements,
Figure 5 shows a subjective comparison.
Figure 5a presents the synthesized results generated by a simple DIBR technology, where the disocclusion regions and pinholes remain to be filled.
Figure 5b shows the performance of VSRS 3.5, where large empty regions are filled based on neighboring texture information. Blurring effects are observed, in contrast to our proposed method in
Figure 5e. This improvement comes from our idea of avoiding global processing for every pixel to handle the noise. Hence, our method shows desirable results in reducing errors and removing unwanted effects, while texture remains sharp and clear.
Figure 5c shows an enlarged part of the synthesis result produced by the GMM-based disocclusion filling method; the temporal correlation method shows better performance in filling large empty areas beyond the inpainting method. Depth refinement and weighted blending lead to much more satisfactory interpolation results, as shown in
Figure 5e.
Frame-by-frame comparisons of PSNR and SSIM are shown in
Figure 6.
Figure 6a,b show a synthesis result with a large baseline: viewpoint
cam03 is interpolated by
cam01 and
cam 07. Another PSNR and SSIM comparison (
Figure 6c,d) comes from a small baseline; two reference viewpoints,
cam03 and
cam05, were utilized to render target virtual view
cam04. Both instances are from the sequence
Ballet. Obviously, exploring temporal correlations to fill the disocclusions yields better performance beyond the inpainting-based view synthesis method, which only explores the spatial correlation, especially when the baseline is large. In all the frames, our proposed framework shows more stable output than the GMM-based method.
In this article, we additionally tested the computation time for all the four approaches. Greater improvements in subjective and objective image quality are brought by much more complex computation. In our proposed method, 3D warping process is performed six times and adaptive background modeling is applied twice, that is the reason why the computation cost of my proposed method is high. The first reason is that the GPU-accelerated algorithm is commonly used for image processing and the hardware performance is growing rapidly, the increased computation time for one frame will not increase too much time for synthesizing the whole sequence if parallel algorithm is adopted. The second reason is that due to the mechanism of our proposed approach, we mainly explore the contribution of depth refinement technique and adaptive background modeling, the time can be shortened if this method is applied in practical applications. After all, our proposed method is implemented using OpenCV library, the computation time is capable to reduce a lot if we carefully using coding skills.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}