1. Introduction
Data sharing helps the individual researcher and research organizations to run data analytics operations on published databases. However, the publishing of data may jeopardize personal privacy and disclose the sensitive values [
1]. In recent decades, the sharing of personal data has resulted in numerous incidents involving data privacy breaches [
2,
3], with disastrous results for the reputations and finances of organizations. Privacy-preserving data publishing methods are anonymizing the published data to preserve user privacy while allowing organizations to release their datasets [
4].
Personal privacy is ensured by privacy-preserving data publishing methods and anonymization of the data at the time of widespread publication. Although identifying attributes like social security numbers and names are never published for data mining purposes, sensitive data may still flow due to linking attacks, whereby an attacker may reveal hidden identities or sensitive data by linking the published data attributes with other publicly available data sources [
5]. The attributes that can be efficiently used to create such links, such as sex, zip code, and age, are called quasi-identifiers (
QIs). Anonymization requires the alteration of these attributes to prevent such attacks while preserving the maximum possible utility of the released data.
k-anonymity [
6] is the first privacy model for privacy-preserving data publishing which generalizes the attribute values of the quasi-identifiers so that each of the released records becomes indistinguishable from at least
k-1 other records when predicted on those attributes. As a result, each person can be associated only with sets of records of size at least
k in the anonymized table. While the goal of
k-anonymity is to prevent identity disclosure, the later privacy models
l-diversity [
7] and
t-closeness [
8] aim at preventing disclosure of sensitive attributes by requiring restrictions on the distribution of sensitive values in each subset of records that are indistinguishable by their
QIs.
Existing anonymization methods mainly concentrate on one-time data publication [
6,
7,
9], in which a data publisher anonymizes a dataset without considering other published datasets. In many cases, multiple views of a dataset [
10,
11] or a series of datasets in distinct time stamps [
12,
13,
14,
15,
16] are published. An example of the former case is the publication of data with different generalization schemes for different purposes, and an example of the latter is a quarterly publication of hospital data. Both examples are multiple-time data publications. Our previously published research [
17] concentrates on multiple-time data publishing for bike sharing datasets. When the information of an individual remains in multiple datasets, an adversary may examine the intersection of some anonymized datasets to reveal the individual’s private information even though it is preserved in each separate publication [
12,
18].
Let us look at an example of how multiple publications can lay information open to a composition attack, which uses the intersection of some published datasets to deduce the sensitive values of individuals whose records are in multiple datasets.
Table 1 and
Table 2 contain data segments from two hospitals, both including the same person’s health records. Assume that Boby’s personal information (Age = 22, Sex = Male, Zipcode = 47905), is known to the adversary. The adversary also knows that Boby visited two hospitals for medication. We can assume that the two hospitals published their data without consulting each other.
Table 3 and
Table 4 are the anonymized tables published by the two hospitals. We will see that this would result in an increased probability of breaching Boby’s privacy from their published data. It is true that the adversary cannot find a person’s sensitive information in either dataset since both satisfy
k-anonymity or
l-diversity. However, the intersection of
Table 3 and
Table 4 shown in
Table 5 comprises only those individuals who have visited both hospitals or have the same
QI and sensitive values. Now, from
Table 5, the adversary can link Boby’s
QI values with the sensitive value, breaching Boby’s personal privacy.
Multiple independent data publishing poses new challenges for data privacy and the utility of the published data. In multiple independent data publications, a data owner does not know which published dataset may be used for a composition attack. Multiple independent data publications are different from traditional multiple-time data publications, such as multiple-view data publication [
10,
11] and series data publication [
12,
13,
14], in which a data publisher is familiar with all the datasets (different views or previous versions of the current dataset) that could be used for composition attacks and can use information in the known datasets to anonymize the current dataset. Since there is no communication or information sharing between data owners in multiple independent data publications, collaborative privacy-preserving data publishing techniques [
19,
20,
21] cannot be used to protect privacy in this case. In addition, we published earlier research on privacy-preserving data publishing [
15,
17,
22]. To reduce the likelihood of composition attacks on published datasets, existing anonymization techniques [
2,
23,
24] utilize generalization and perturbation, which decrease the data utility.
In this paper, we use some ideas from [
17] and propose a new approach called Merging for protection against composition attack in various independent data publications while preserving better data utility. It partitions the data both vertically and horizontally. In the vertical partitions, highly correlated attributes are grouped into columns and each resulting column will then contain a subset of attributes. In the horizontal partition, the tuples are grouped in buckets or equivalence classes. In an equivalence class, the attribute values are randomly permuted to break the association between different columns. We introduce the cell generalization approach to increase the privacy of the published dataset. Hence each
QI value will be linked with
l distinct sensitive values, reducing the confidence that the adversary will have when breaching personal privacy.
Table 6 and
Table 7 are the published tables from the two hospitals, generated using the anonymization technique proposed in this paper.
The idea behind our approach is to increase the probability of false matches by linking the
QI values with the
l distinct sensitive values [
25]. When a person’s record is similar in two datasets, there will be common values in the intersection of the anonymized datasets, including
QI values and sensitive values. When a person’s record is not in the two datasets, there may still be a common record in both anonymized datasets, induced by two different patients having the same
QI and sensitive values. Such a match is called a false match. We consider the example as mentioned earlier where user privacy is breached by the intersection of two published datasets.
Table 6 and
Table 7 are published by the Merging method, and
Table 8 is the intersection of
Table 6 and
Table 7. From the intersection, the adversary cannot discover the actual
QI values of the user. In fact, the first bucket or equivalence class of
Table 8 contains 44
QI values. Now the adversary will need another publicly available data source to match his desired
QI values, which we call a true match. The adversary will want to link this true match with the sensitive value. However, in the sensitive values column, i.e., Disease, there are three distinct values. It will thus be difficult for him to deduce an exact sensitive value for the particular
QI values.
The essential aim of our proposed Merging anonymization technique is to increase the probability of false matches during a composition attack. In a real-world scenario, since there will be more records, there will be a stronger probability of producing a false match for a QI value. When we consider the ambiguity behind true and false matches, it is conceivable that the probability of a false match is higher than that of a true one. When a significant difference in such probabilities is achieved, the privacy of an individual is protected in multiple independent data publications. Putting this principle in the differential privacy context, the appearance of a common record in the published datasets is independent of whether or not the common record belongs to the same individual, and hence an adversary cannot be sure whether the sensitive value in the common record belongs to the person.
The main contributions of the paper are summarized as follows. Equivalence classes are created, and attribute values are randomly permuted in the equivalence class to break the cross-column relation to increasing the published data privacy. A cell generalization approach is introduced to protect the published datasets from composition attacks. In addition, we present the anonymization algorithm which can successfully anonymize the dataset to ensure the protection from composition attack and increase the data utility as well. The proposed method can protect the anonymized data from privacy breach by satisfying the l-diversity privacy requirements. We conduct the extensive experiments on real-world data to compare with the other state-of-art techniques to support the effectiveness of the Merging method.
The remainder of this paper is structured as follows. Background and related work are reviewed in
Section 2.
Section 3 and
Section 4 give the details of the proposed system and anonymization algorithm. We present experimental analysis in
Section 5 and conclude in
Section 6.
3. Preliminaries and Problem Definition
Given a microdata table T of records with d+1 attributes, and the attribute domains are . A tuple can be expressed as , where is the quasi-identifier of t and is the sensitive value of t.
We assume that a number of other microdata tables
are published by different independent publishers whose microdata tables are also defined by the same schema as
T and published using the same anonymization method. This is a reasonable assumption since public and private groups may have a standard method for data distribution. For example, all health care institutions in the USA follow one law, the HIPAA, for their distribution of
d-identified data [
2].
3.1. Equivalence Class and Match
In a published
l-diversity [
25] dataset, an equivalence class or bucket consists of
l distinct sensitive values from a particular sensitive value domain
S and highly similar
QI attribute values. In an equivalence class, any individual is linked with
l distinct sensitive values so that the adversary cannot learn the sensitive values of the individual with a probability greater than 1/
l.
Let and be two equivalence classes in the published datasets and , respectively. These two equivalence classes match if their attribute value pairs QI() and QI() are equal or have a non-empty intersection, and sensitive values S(. For example, and are two equivalence classes if QI() = (Age = 22, Sex = *, Zipcode = 47905) and QI() = (Age = 22, Sex = *, Zipcode = 47905). Suppose that the sensitive value domains are S() = (Ovarian Cancer, Gastritis, Flu, Breast Cancer) and S() = (Blood Cancer, Gastritis, Breast Cancer, Flu). The QI values of the two equivalence classes are 22, Male, 47905 or 22, Female, 47905. Therefore, . In addition, = (Gastritis, Breast Cancer, Flu ), and therefore, the equivalence classes and are matched.
Let t be the tuples of a user in T and F, s the possible sensitive value for t. The probability of a true match is defined as . In other words, the probability of a true match is the probability that the records of t are in both equivalence classes.
A match can be generated by two independent persons: this is called a false match. Even If the user is not in two published datasets, there is still a probability that two records match. This is the probability of a match in and that is generated by the uncertainty of two independent individuals, denoted by . For example, in the published dataset, two persons may have the same age, live in the same zip code area and even have suffered from the same disease, without having visited the same hospital for medication.
3.2. Composition Attack and Privacy Breach
Given two independently published tables, and , a composition attack consists in examining the intersection of the two tables to find the common QI values and the corresponding sensitive value s of a person. In the composition attack, and are from two different data publishers, and there is no information shared prior to data publishing. If there is only one common sensitive value shared by two equivalence classes of s in and , the privacy of the person is breached with 100% likelihood.
From the background knowledge, it is certain that the adversary already knows the QI values because the adversary has the published tables and . In addition, the adversary may gather knowledge about a particular individual from publicly available data sources such as voter registration lists. By using the QI values from the voter registration lists, the adversary may try to find the QI values from the intersection of tables and and finally uncover the sensitive values.
In order to protect the privacy of the individual, we break the association between QI values by segmenting the microdata table respectively into columns and rows. Breaking the association between the QI values will confuse an adversary looking for exact QI values from the intersection of published tables and .
5. Experimental Analysis
In this section, we present experiments on real-world datasets. The experiments are divided into two parts: the first part was designed to test the effectiveness of the proposed anonymization algorithm against composition attack, in comparison with the
[
41], Hybrid [
2], Probabilistic [
23], Composition [
24] and Mondrian [
44] methods. Our experimental results show that the Merging method also provides smaller privacy risks for the composition attacks. The results of this experiment are presented in
Composition Attack subsection.
In the second part, we evaluated the effectiveness of our Merging method in preserving data utility, as compared to the same set of competing methods. The experiment demonstrates that the Merging method preserves more data utility than the other methods. In addition, it has smaller relative query error and better classification accuracy than the competing methods. The results of this experiment are presented in Data Utility section.
5.1. Data Set
The US-Census Adult dataset is derived from the UC Irvine Machine Learning Repository [
45], which is composed of data accumulated from the US census. Data sets are described in
Table 9. In our experiments, we extracted two independent datasets from the Adult dataset (i) Occupation and (ii) Education. The Adult dataset has 48842 tuples with six
QI attribute values: Age, Sex, Marital status, Work class, Relationship, and Salary. Occupation is used as the sensitive attribute value for the Occupation dataset, and Education for the Education dataset.
For the experiment, we needed independent datasets to simulate the independent data publishing environment. Therefore, 10 disjoint datasets were composed from each of the Education and Occupation datasets, each with 4 K randomly selected tuples. The remaining 8 K tuples were used to generate the overlapping tuples pool to check for composition attack. From the remaining tuples pool, we made five copies of each group, respectively inserting 100, 200, 300, 400, and 500 tuples into the Education and Occupation datasets. Finally, we obtained datasets with sizes of (4.1 K, 4.1 K), (4.2 K, 4.2 K), (4.3 K, 4.3 K), (4.4 K, 4.4 K) and (4.5 K, 4.5 K) for Education and Occupation datasets respectively.
In the experiment, each group of datasets was used as input to the
[
41], Hybrid [
2], Probabilistic [
23], Composition [
24], Mondrian [
44] and Merging algorithms to calculate the privacy risks and corresponding data utility. Privacy-preserving multiple independent data publishing is a non-interactive data publishing context, and for experimental analysis, we conduct the experiment on the non-interactive privacy settings. Conversely, the majority of the work in differential privacy [
37] follows the interactive settings and a user accesses a dataset through a numerical query, while the anonymization technique appends noise to the query answers. The interactive environments might not always support the entire situation because in most cases datasets need to be published in public. Therefore, we select a non-interactive setting for differential privacy experiment as discussed in [
41].
We compared the proposed Merging method with the
[
41], Hybrid [
2], Probabilistic [
23], Composition [
24] and Mondrian [
44] methods. To compute privacy risks, we execute all algorithms on the non-interactive privacy-preserving data publishing environment. In the non-interactive privacy settings,
, Hybrid, Probabilistic, Composition and Mondrian create
quasi-identifier equivalence class as
k-anonymity method [
6]. For creating equivalence class, we select
k = 4 and
k = 6. In an equivalence class for the differential privacy, Laplacian noise is appended to the count of sensitive values [
23]. To create the equivalence class for Merging method
l-diversity [
7] is chosen as discussed earlier, and we select
l = 4 and
l = 6. We select
for the
budget.
The Merging method creates n = 1 fake tuples. For this reason, the output size of the Merging method will be larger than the all other methods. In the experimental comparison, we have therefore calculated the percentage of the respective output for each group of datasets.
In our experiments, we used the anonymization algorithm to anonymize the datasets. Composition attack was performed on all pairs of datasets, and data utility was measured after anonymization of the datasets.
5.2. Composition Attack
We checked the effectiveness of an anonymization algorithm in reducing the privacy risk due to composition attack. Privacy risk is measured by the ratio of true matches to total matches and expressed as [
2]:
Composition attacks were measured by calculating privacy risk for all pairs of the extracted dataset with identical overlapping records. In the Merging method, the false matches will be increased because of l distinct sensitive values linked with the QI values, and it will decrease the privacy risk.
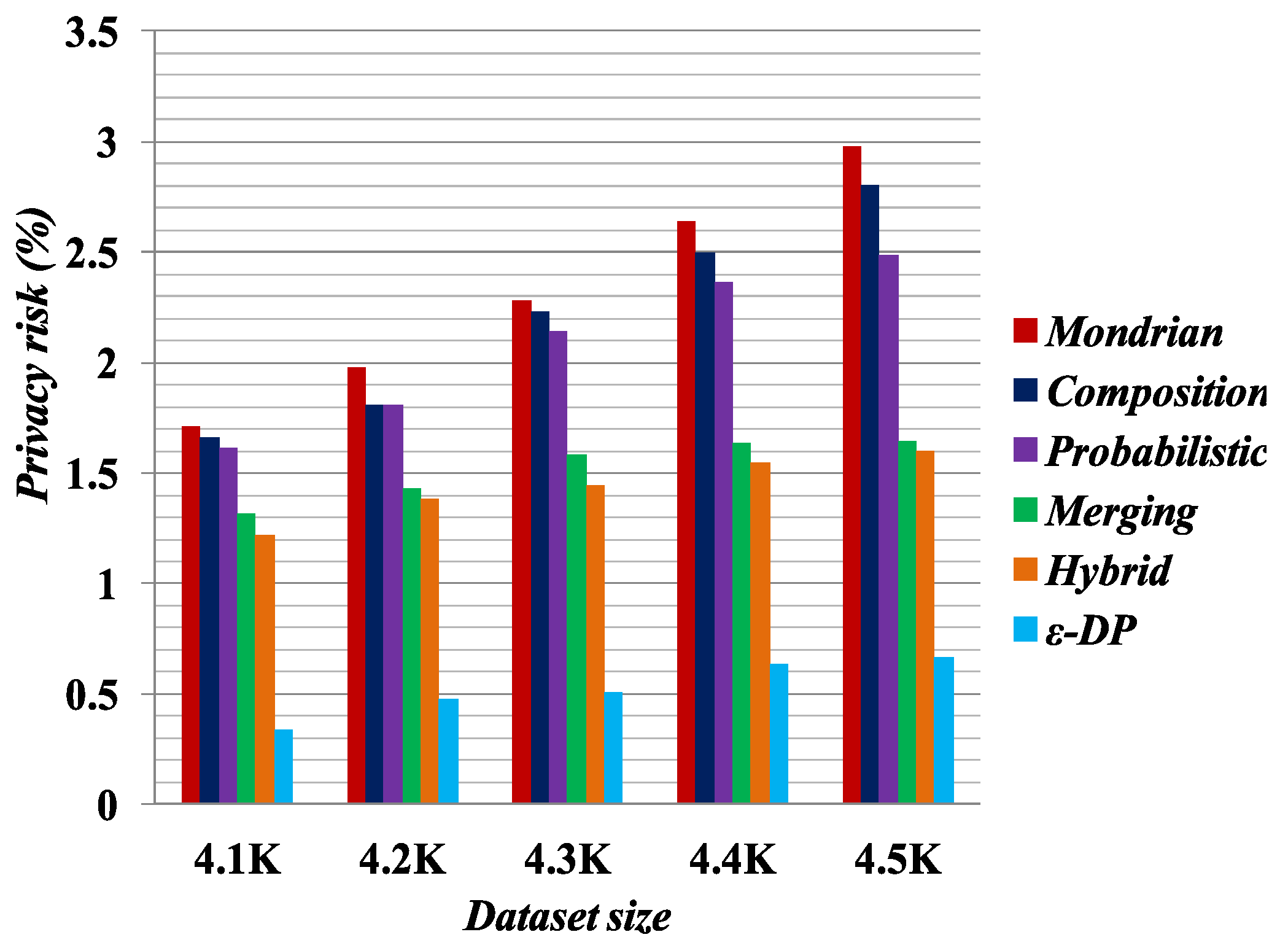
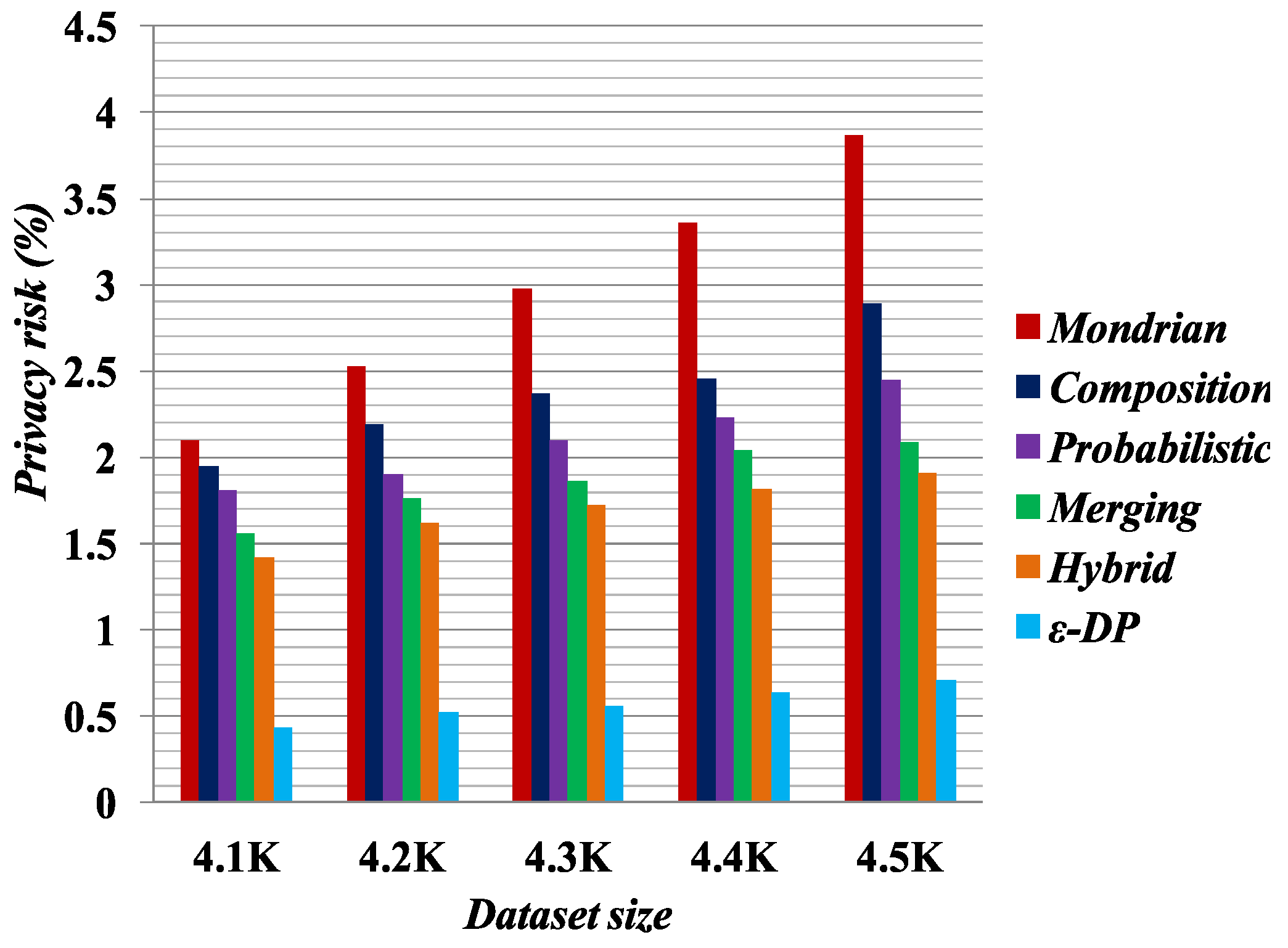
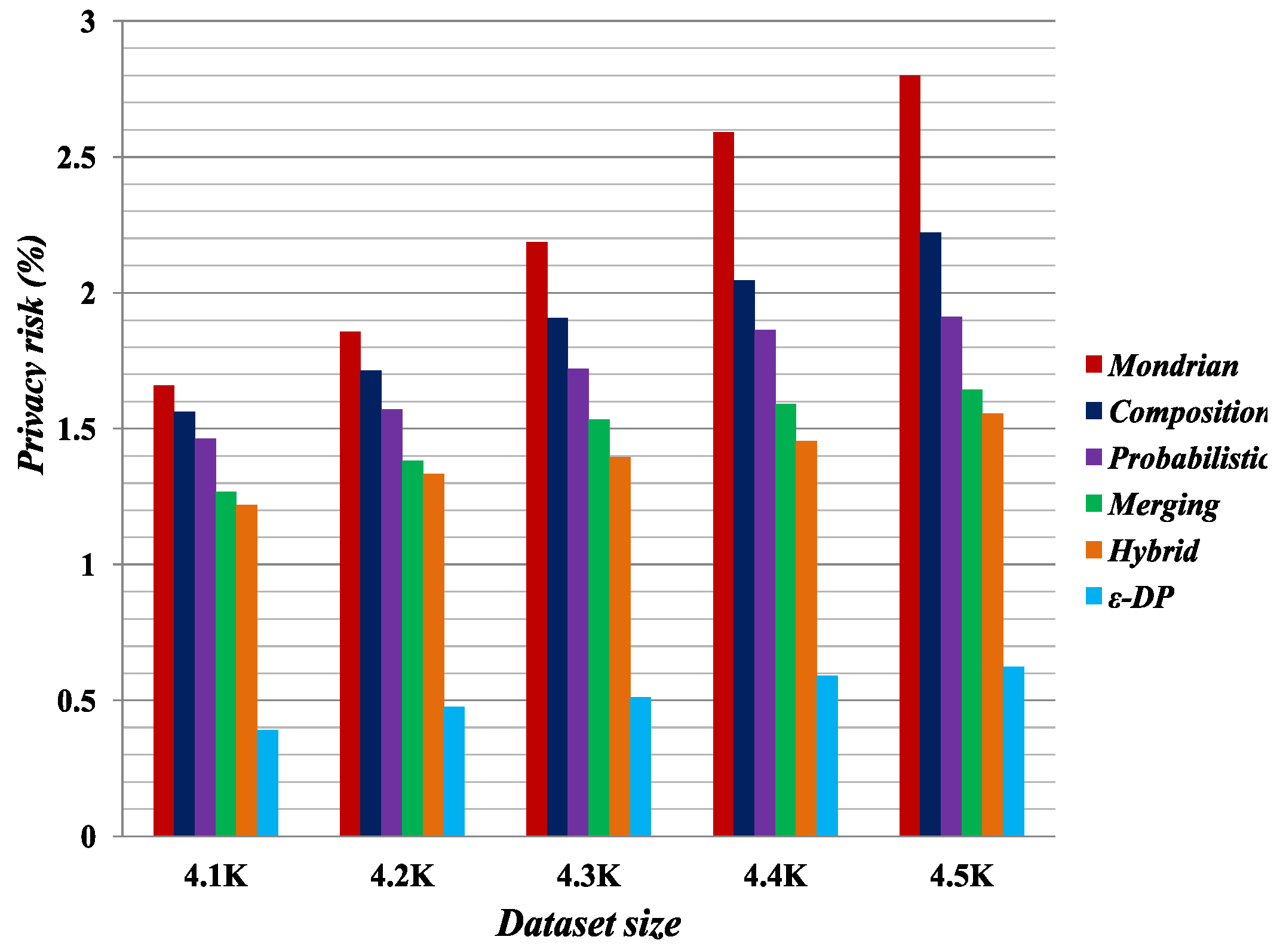
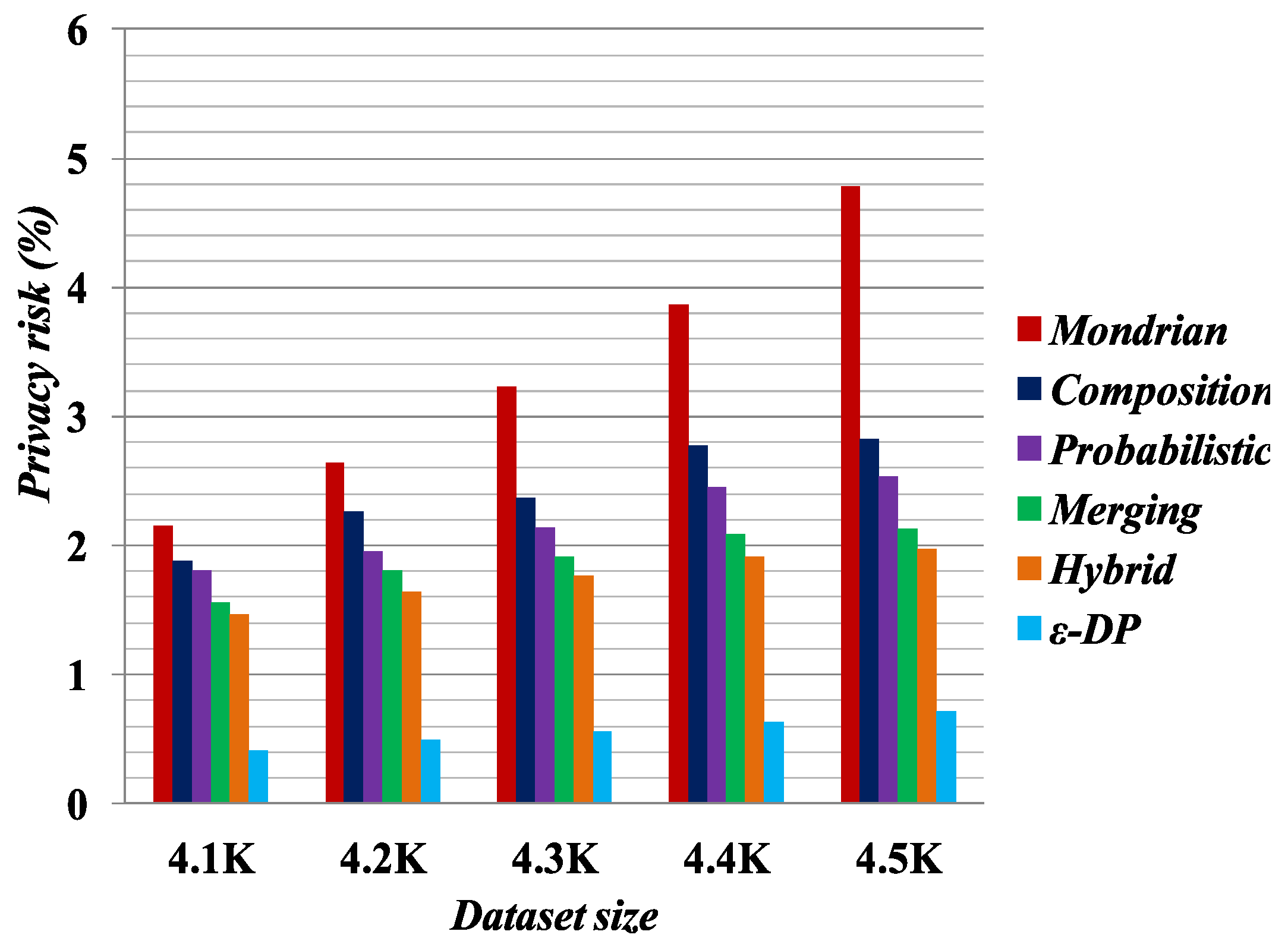
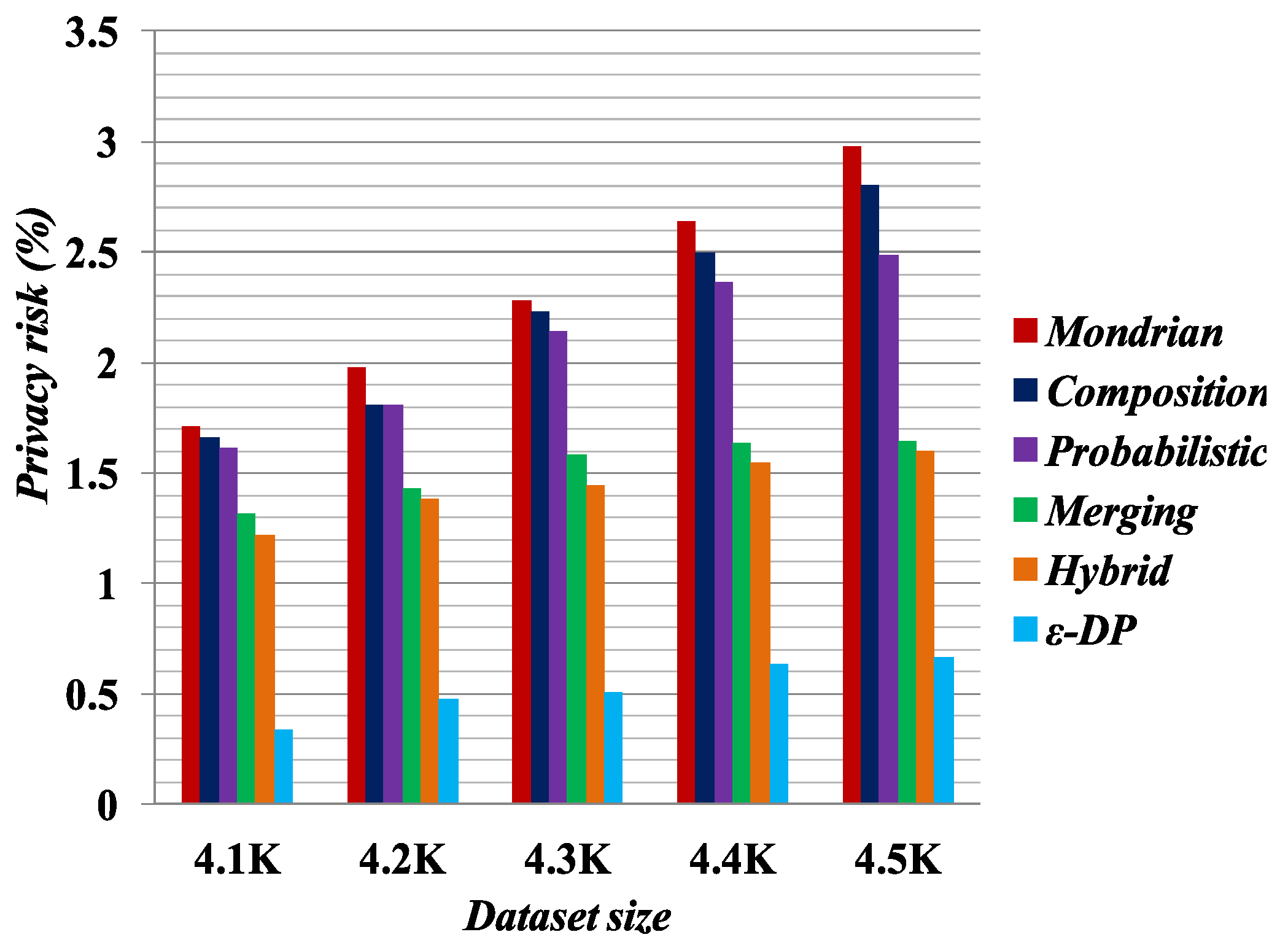
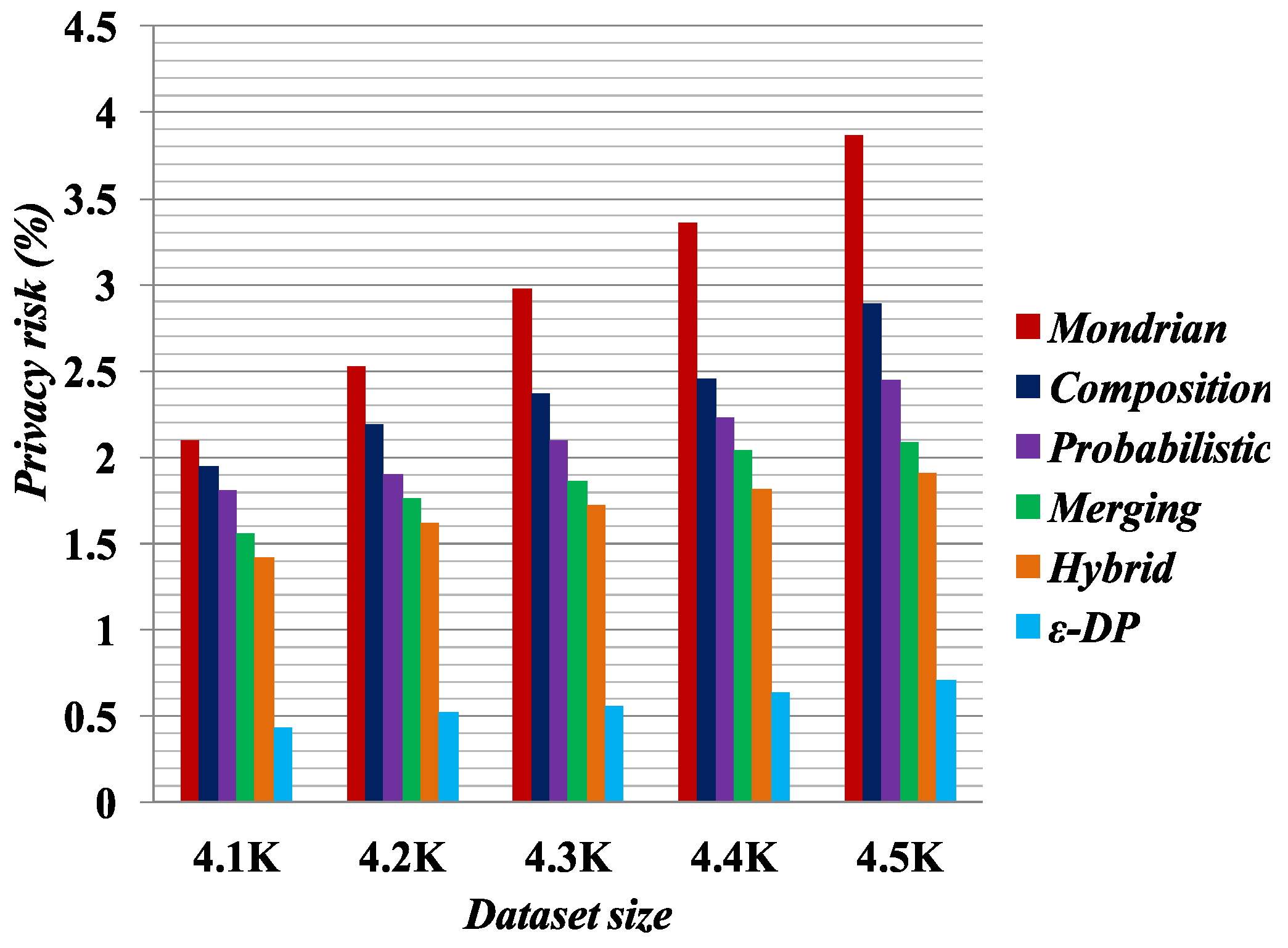
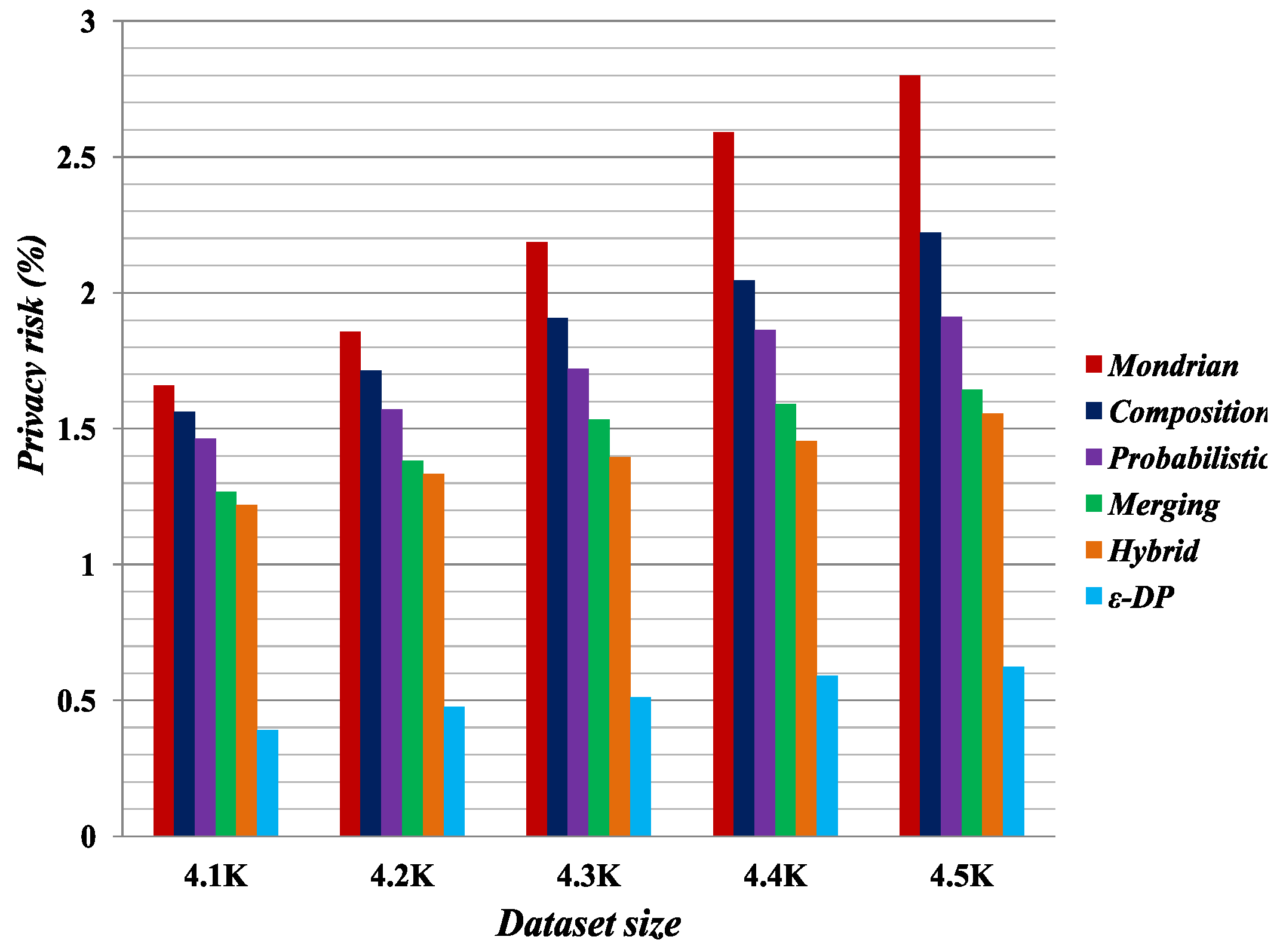
Figure 1,
Figure 2,
Figure 3 and
Figure 4 present the experimental results on the Occupation and Education datasets, respectively. They illustrate the privacy risk resulting from different anonymization techniques. Privacy risk indicates how confidently an adversary can learn sensitive values of a user from the multiple independent datasets.
[
41] provides the lowest privacy risk for composition attacks among all the compared methods. Privacy risk gets smaller by increasing the false matches in the published datasets. The breaking of cross-column relation increases the probability of false matches in the anonymized datasets by the Merging method. As reported by the privacy risk shown in the result, Merging yields a lower probability of inferring the user’s private information than the Probabilistic [
23], Composition [
24] and Mondrian [
44] methods. It has almost identical privacy risk to that of the Hybrid [
2] method. Therefore, we can say Merging also reduces the probability of composition attack on published datasets.
According to the privacy risk shown in
Figure 1,
Figure 2,
Figure 3 and
Figure 4, we see that the
method achieves the best result for composition attacks because in an equivalence class it appends Laplacian noise to the count of sensitive values. It thus has the highest probability of yielding false matches. However, it reduces data utility, as discussed in
Section 5.3. Conversely, the Merging method preserves more data utility compared with all the other methods.
5.3. Data Utility
In the experiments in this subsection, we measured the data quality by the distortion ratio and the aggregate query answering error. In addition, we conducted an experiment on classifier learning of the published datasets. We observed that the Merging method has lower data loss, less relative error and better classification accuracy than the all other methods.
5.3.1. Data Utility Comparison
There are many methods [
46] for calculating the information loss in the published data. Here we describe a simple method to illustrate the basic information loss metric.
We estimate that each attribute value of the microdata table is correlated with a generalized taxonomy tree. The cost is calculated from the published dataset and is called the distortion ratio. If the attribute value of a tuple is at the leaf node of the taxonomy tree, then the value is not generalized, and the distortion of that value is 0. Consequently, if the attribute value is generalized and does not represent the leaf node, then the distortion is defined by the position of the generalized attribute value and the height of the taxonomy tree. For instance, the age 22 is not generalized, and it stands at the leaf node; therefore, the height is 0, and the distortion is likewise equal to 0. While the attribute value is generalized one level up in the taxonomy tree, the distortion is equal to
1/H. Here
H represents the height of the taxonomy tree. Let
is the distortion of the attribute
of tuple
. The distortion of the entire published microdata table is equal to the sum of the distortions of all values in the generalized dataset. In addition, the distortion is defined as discussed in [
46]:
The distortion ratio is , where is the distortion ratio, is the distortion of the published table, and is the distortion of the fully generalized (i.e., all attribute values are generalized by the root of the taxonomy trees) dataset.
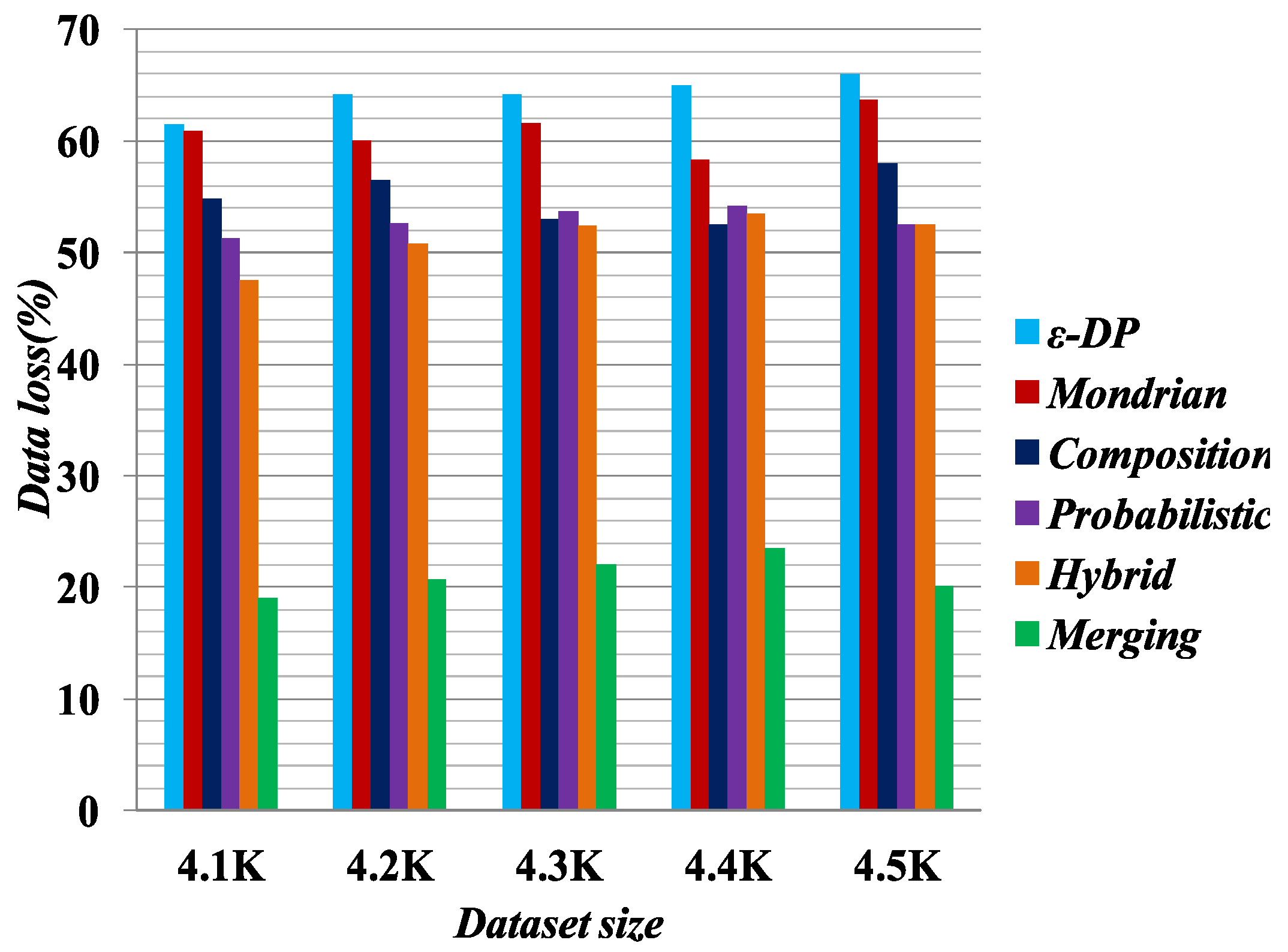
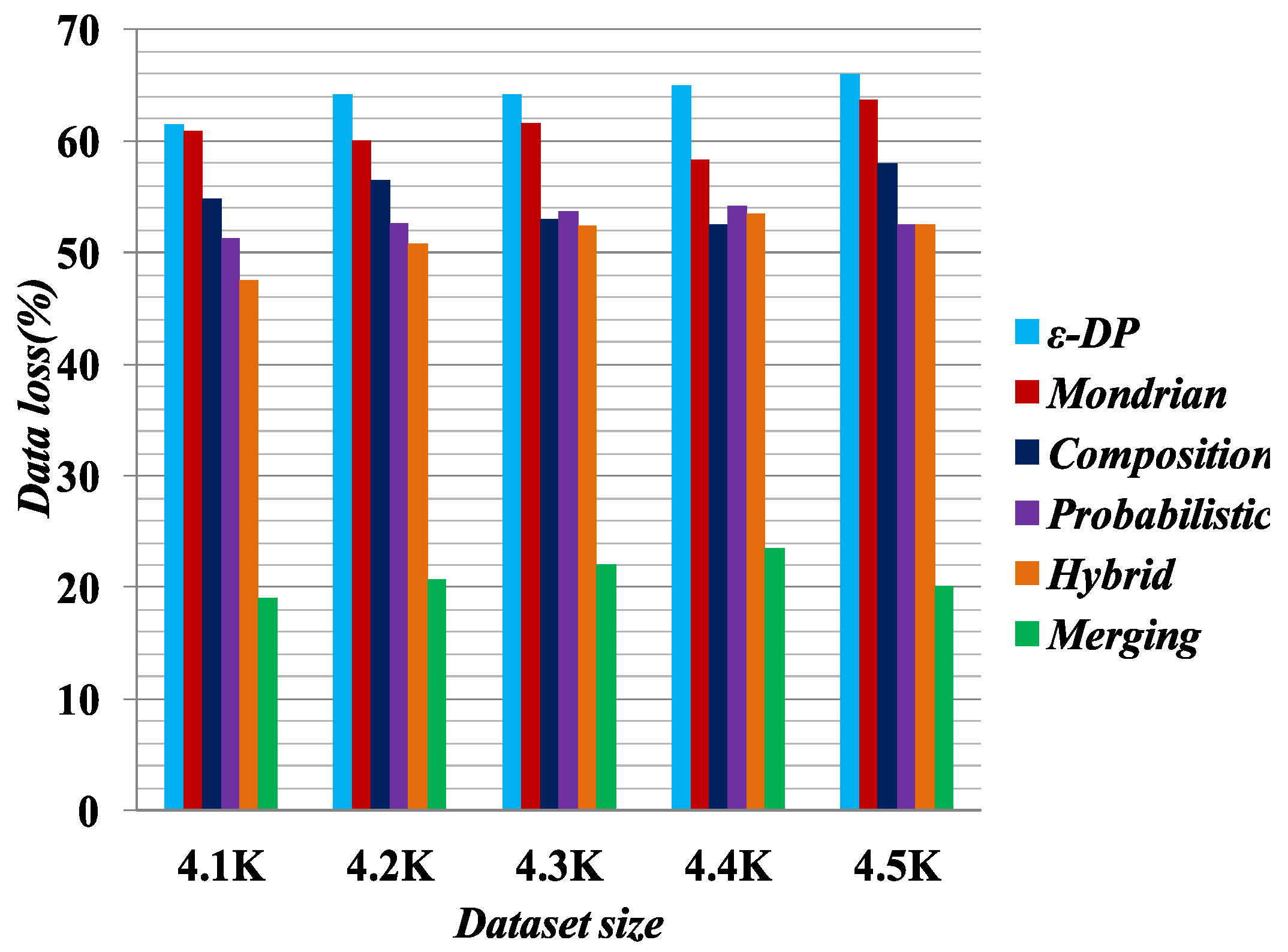
Figure 5 illustrates the experimental result for data utility, based on data loss in the published datasets. For the data loss experiment, we selected a 4.5K dataset with
6-anonymity for the Hybrid [
2],
[
41], Probabilistic [
23], Composition [
24] and Mondrian [
44] methods, and
6-diversity for the Merging method. The results show that the Merging method yields less data loss than all the other methods. We know the full generalization of the attribute values reduces the published data utility [
25]. The Merging method employs selective generalization in the cell if it is necessary to meet the privacy requirements. Therefore, it preserves more data utility than the other methods.
5.3.2. Aggregate Query Answering Error
In this experimental analysis, the accuracy of aggregate query answering [
47] was also evaluated as a measure of data utility. It is possible to compute aggregate query operators such as “COUNT”, “MAX”, “AVERAGE” and so on. In the experiment, only the “COUNT” operator was evaluated, for queries whose predicates involved the sensitive values. The query is considered in the following form:
where
is the quasi-identifier value for attribute
and
is the domain for attribute
,
s is the sensitive attribute value,
and
is the domain for the sensitive attribute S. A query predicate is characterized by predicate dimension
and query selectivity
,
indicating the number of quasi-identifiers in the predicate and
indicating the number of values in each
. The size of
was randomly chosen from
. Each query was executed on seven tables: the original and those generated by the Merging,
, Hybrid, Probabilistic, Composition and Mondrian methods. Count is indicated for the original and anonymized tables, the original count denoted by
and the anonymized count by
, where
is Merging,
, Hybrid, Probabilistic, Composition and Mondrian respectively. To measure the average relative error in the anonymized dataset, we compute all queries as described in [
47]:
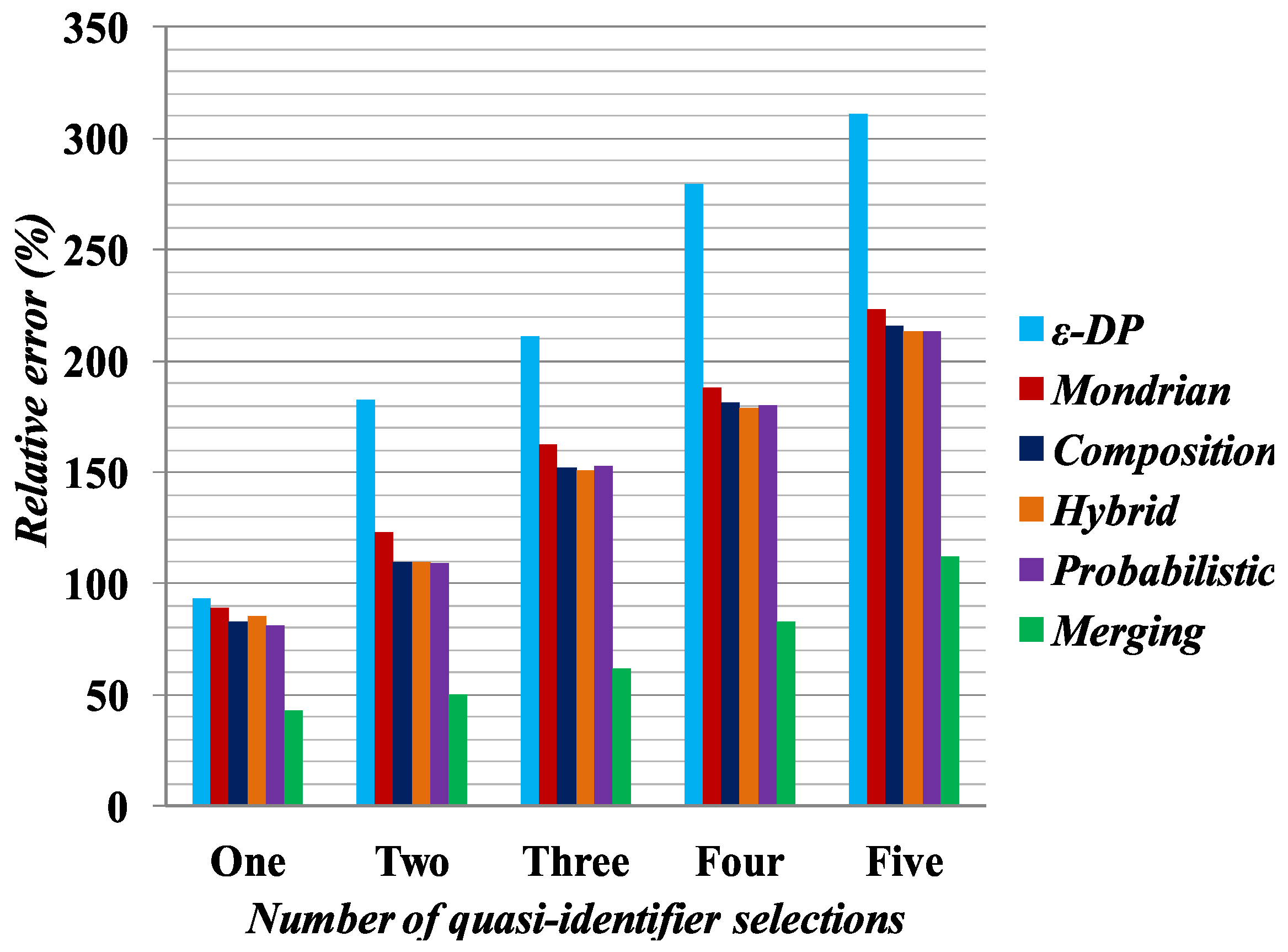
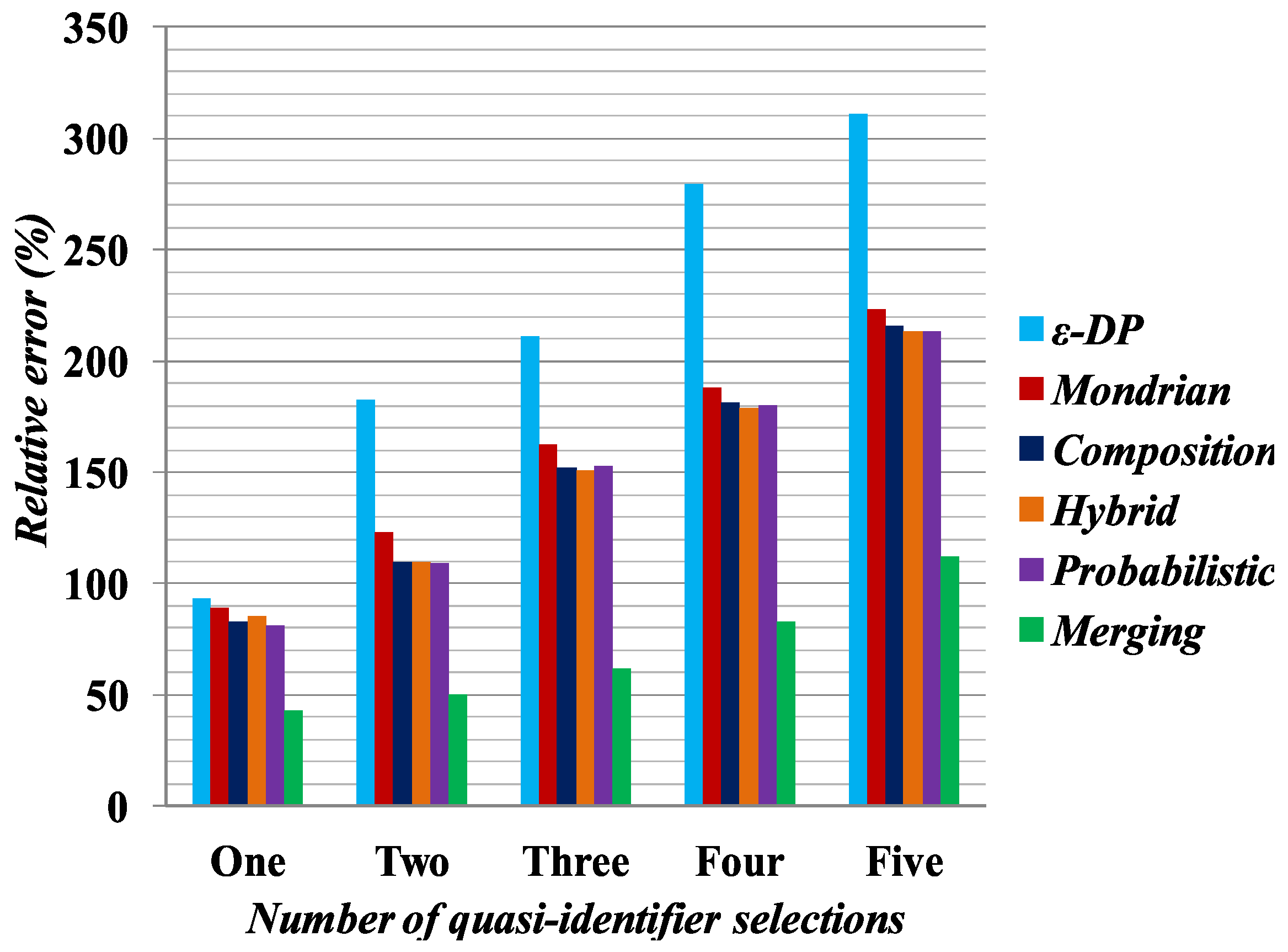
In
Figure 6, relative query error is plotted on the Y-axis based on the quasi-identifier selection. In the experiment, we selected one, two, three, four or five attributes as quasi-identifiers and calculated the relative query error on the anonymized tables generated by Merging,
[
37], Hybrid [
2], Probabilistic [
23], Composition [
24] and Mondrian [
44] methods. For example, suppose we want to calculate the relative query error by Merging for
Table 6, and the corresponding query is
From the query answer, there is only one female person suffering from Fever. However, from the original table, i.e.,
Table 1, the query answer will be two persons. Using a relative error formula, it could be shown that Merging has a 50% relative query error for one attribute selection. For the experiment, all possible combinations of the query were generated and executed across anonymization tables for the 4.5 K Occupation dataset and the average relative query error was calculated, with
k set to 6 for the Mondrian, Hybrid,
, Probabilistic, Composition methods and
l set to 6 for Merging. The relative query error was calculated and is shown in
Figure 6, where the value on the
Y-axis denotes relative error percentage and those on
X-axis stand for different quasi-identifier selections. While the Merging method creates fake tuples in the anonymization, it can be seen from the experimental result that Merging still has small relative error compared with all other methods. For the generalization of attribute values, one needs to consider all possible combinations for a particular query answer. Therefore, the competing methods demonstrate the higher relative query error for the anonymized datasets.
5.3.3. Classifier Learning
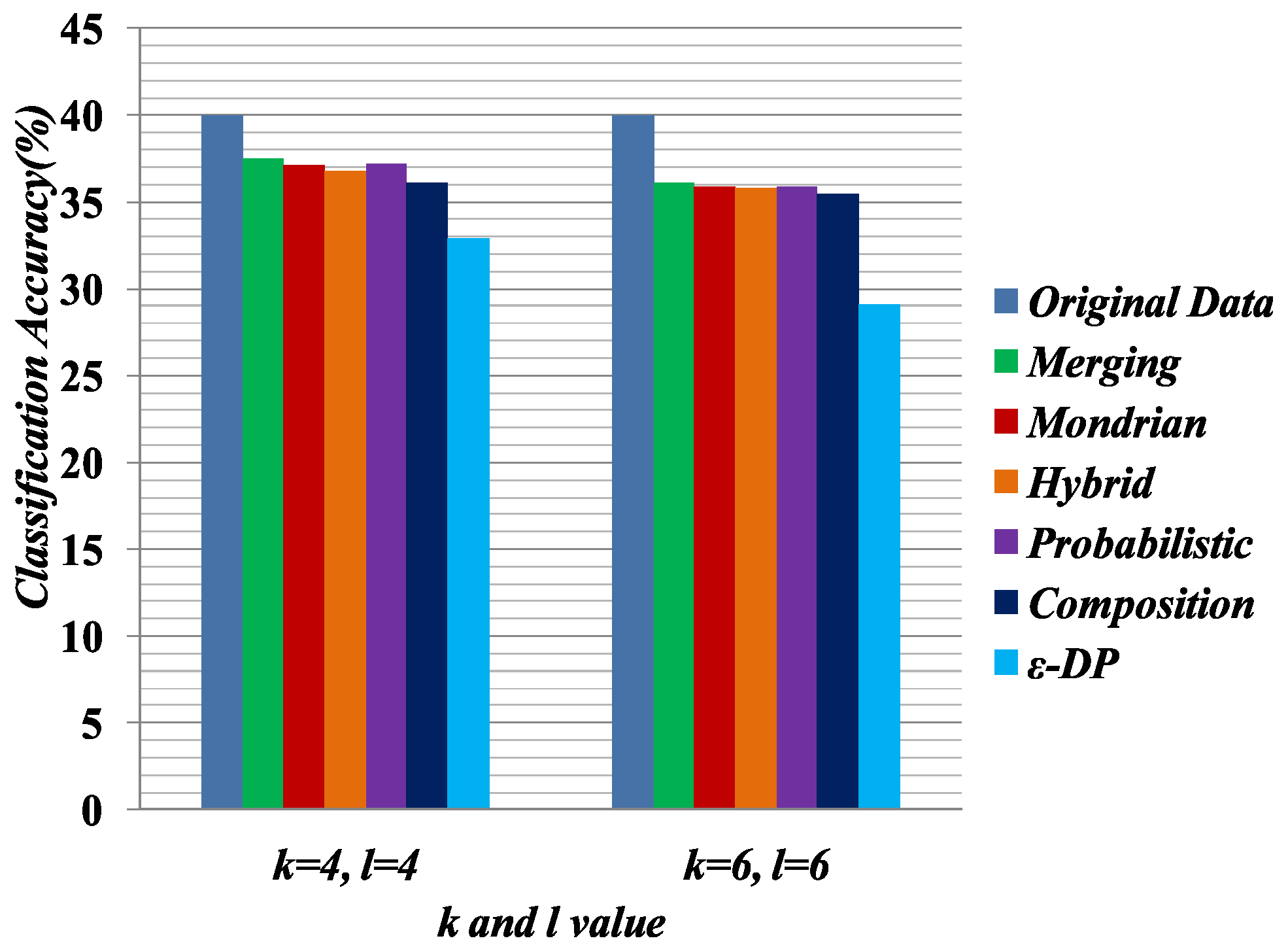
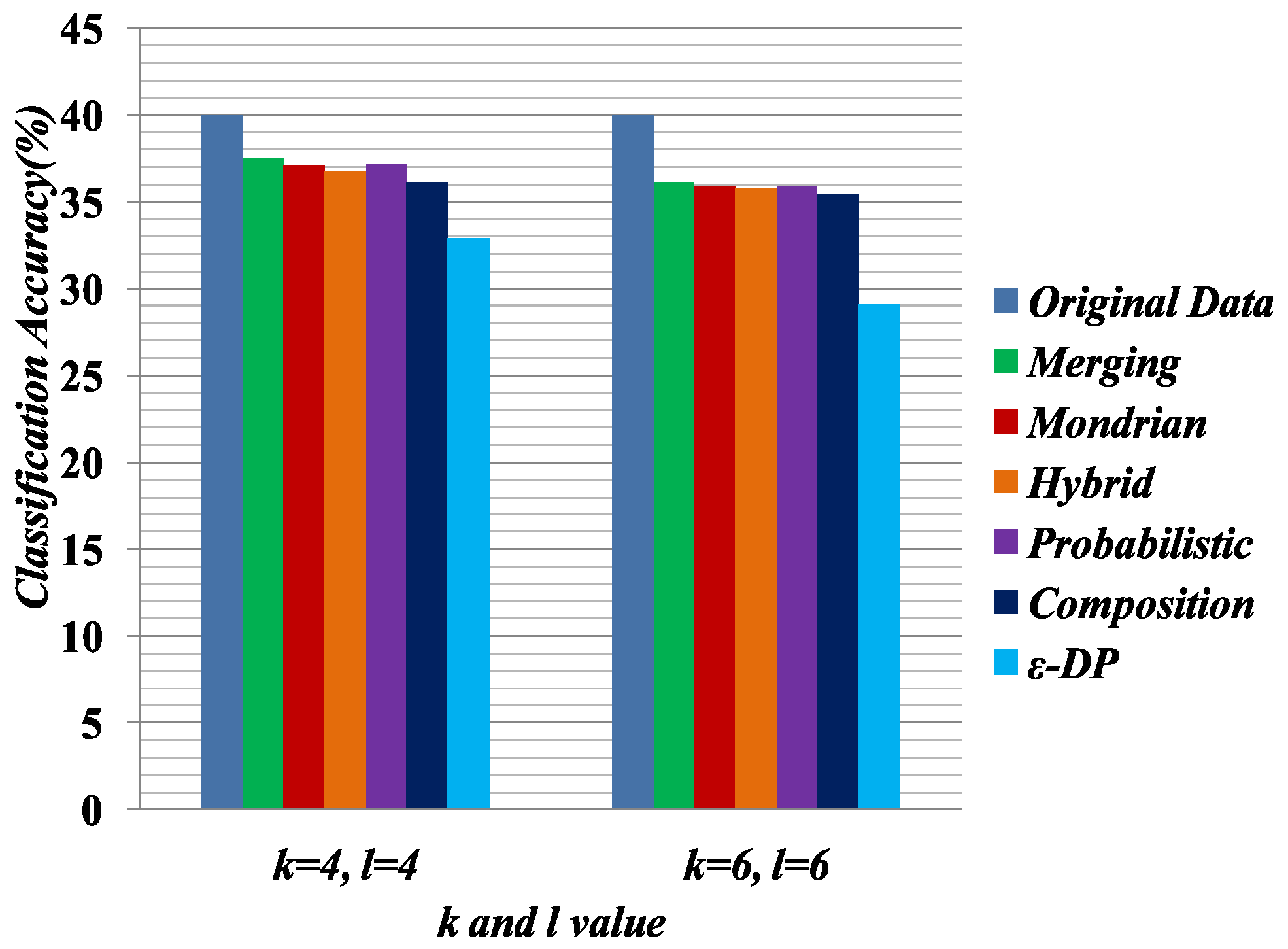
Some preprocessing steps were applied on the anonymized data for classifier learning. The data anonymized by Merging contains multiple columns, and the linking between columns is broken. In Merging, attributes are partitioned into two or more columns. For an equivalence class that contains k tuples and c columns, the k tuples were generated as follows: first, randomly permute the values in each column; second, generate the tuple by linking the value in each column. This procedure was applied to all equivalence classes and generated all of the tuples. The procedure generates the linking between the two columns in a random fashion.
We measure the quality of anonymized data for classifier learning, which has been used in [
25]. The Weka [
48] software package was used to evaluate the classification accuracy for C4.5 (J48). Default settings were used to do the classification task. In the experiment, we used 10-fold cross-validation. In each experiment, one attribute was chosen as the target attribute and the others served as predictor attributes. For performance evaluation, we selected 4,6 diversity of the Merging table and the 4,6-anonymized versions of the
, Hybrid, Probabilistic, Composition and Mondrian tables. In the classifier learning, Education was chosen as the sensitive attribute and Relationship was chosen as the
QI attribute.
In this experiment, we built two classifiers based on sensitive attribute Education and
QI attribute Relationship. All other attributes are predictor attributes.
Table 10 and
Table 11 present the classifier learning for sensitive attribute Education and
QI attribute Relationship, respectively.
Figure 7 compares the quality of the anonymized datasets with the comparison of original data when the target attribute is Education.
Figure 8 presents the quality of the anonymized datasets with the comparison of original data when the target attribute is Relationship. Classifier learning indicates the quality of the dataset in terms of the attribute associations. We know that in the generalization, the attribute values have to consider all possible combinations of association. Therefore, it shows the lower performance of the classifier learning. In all experiments for classifier learning, the Merging method shows the better classification accuracy than the other methods because it only generalizes the required cell to satisfy the privacy requirement.
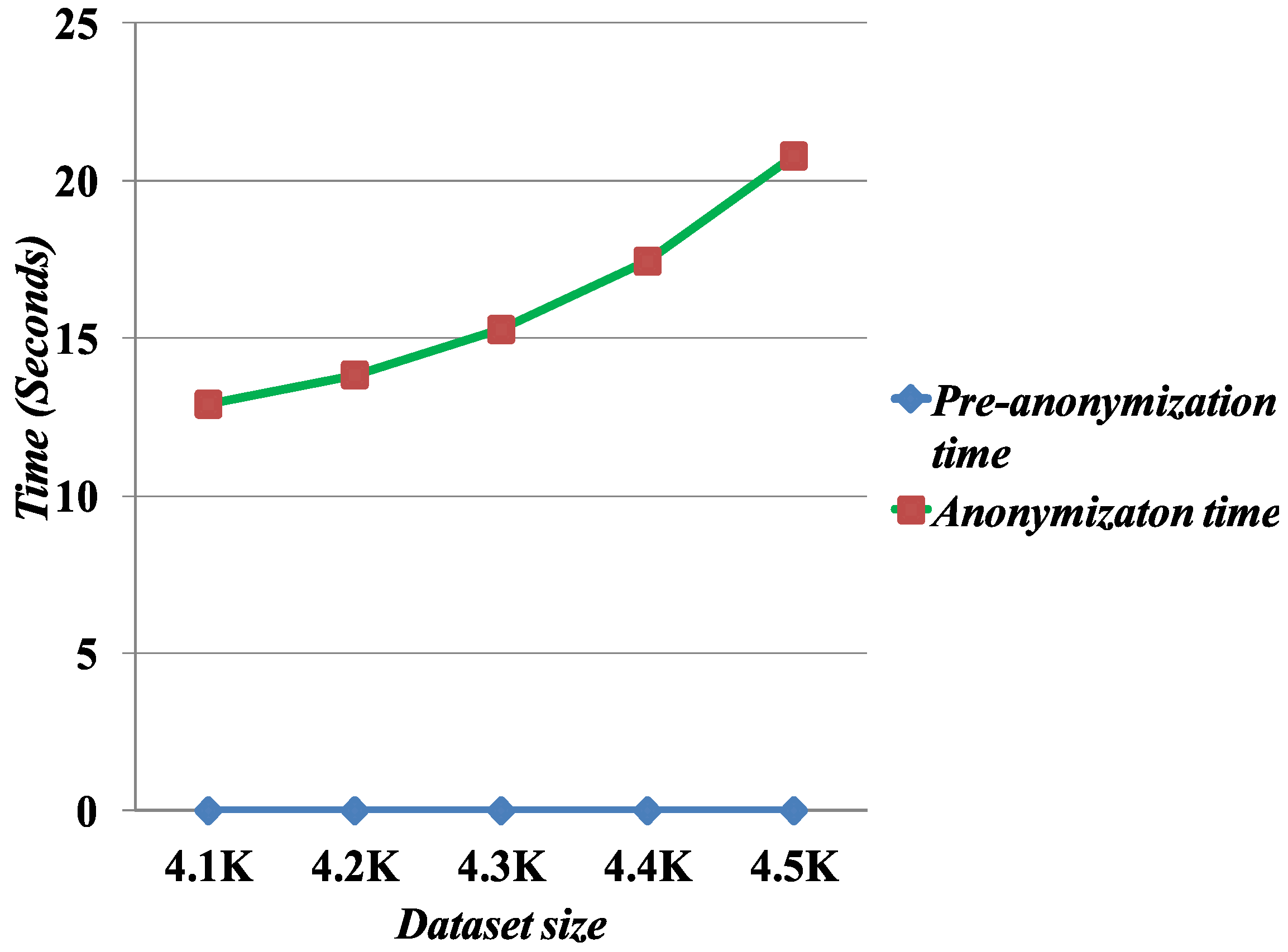
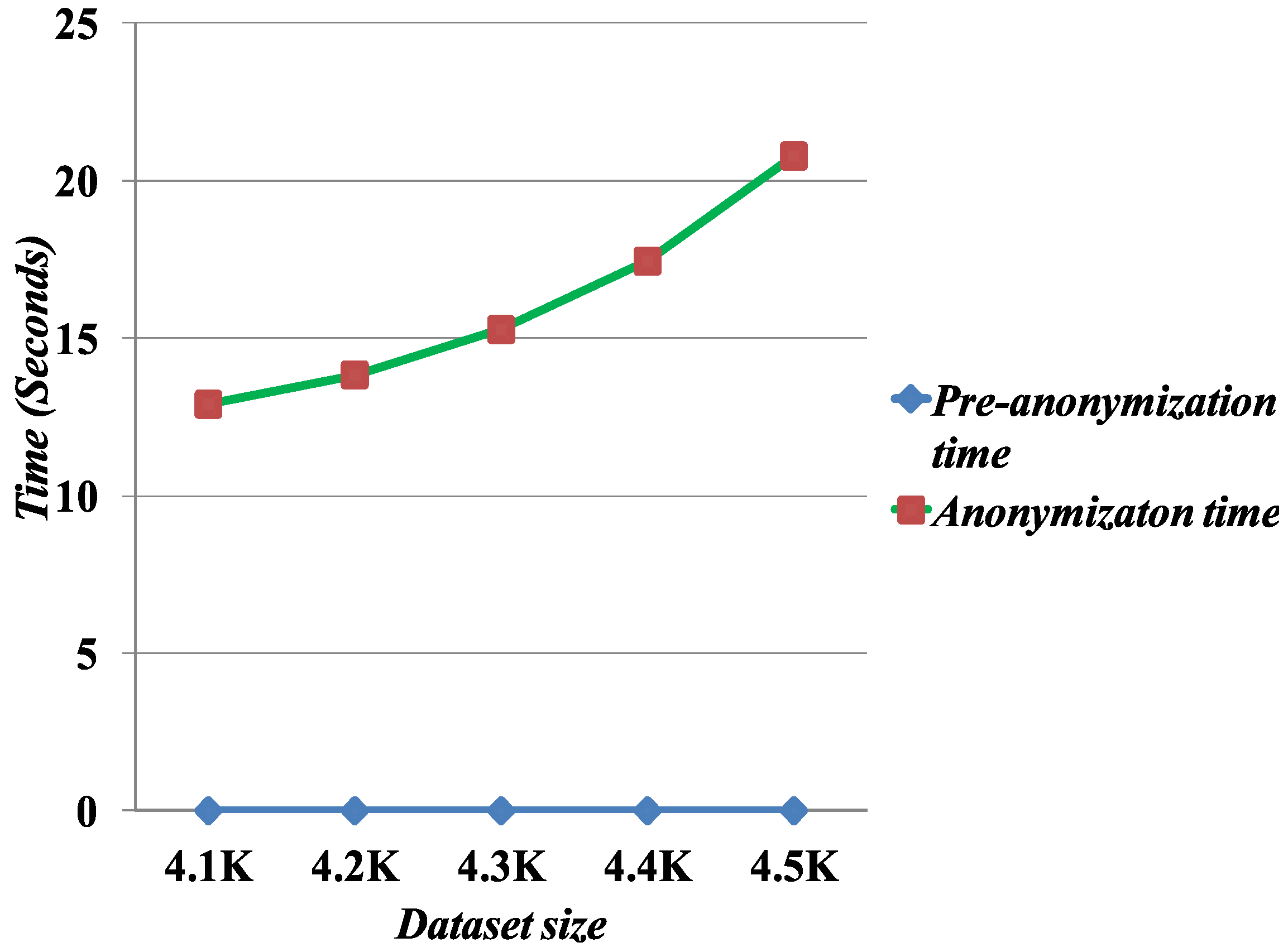
5.4. Execution Time
We measure the scalability of the Merging method by evaluating the computation time to run the anonymization algorithm. To measure the computation time, we fix
l = 6 and increase the dataset sizes for the execution time.
Figure 9 presents the computation time as a function of the number of records. The results show that the Merging algorithm scales well with the data sizes.





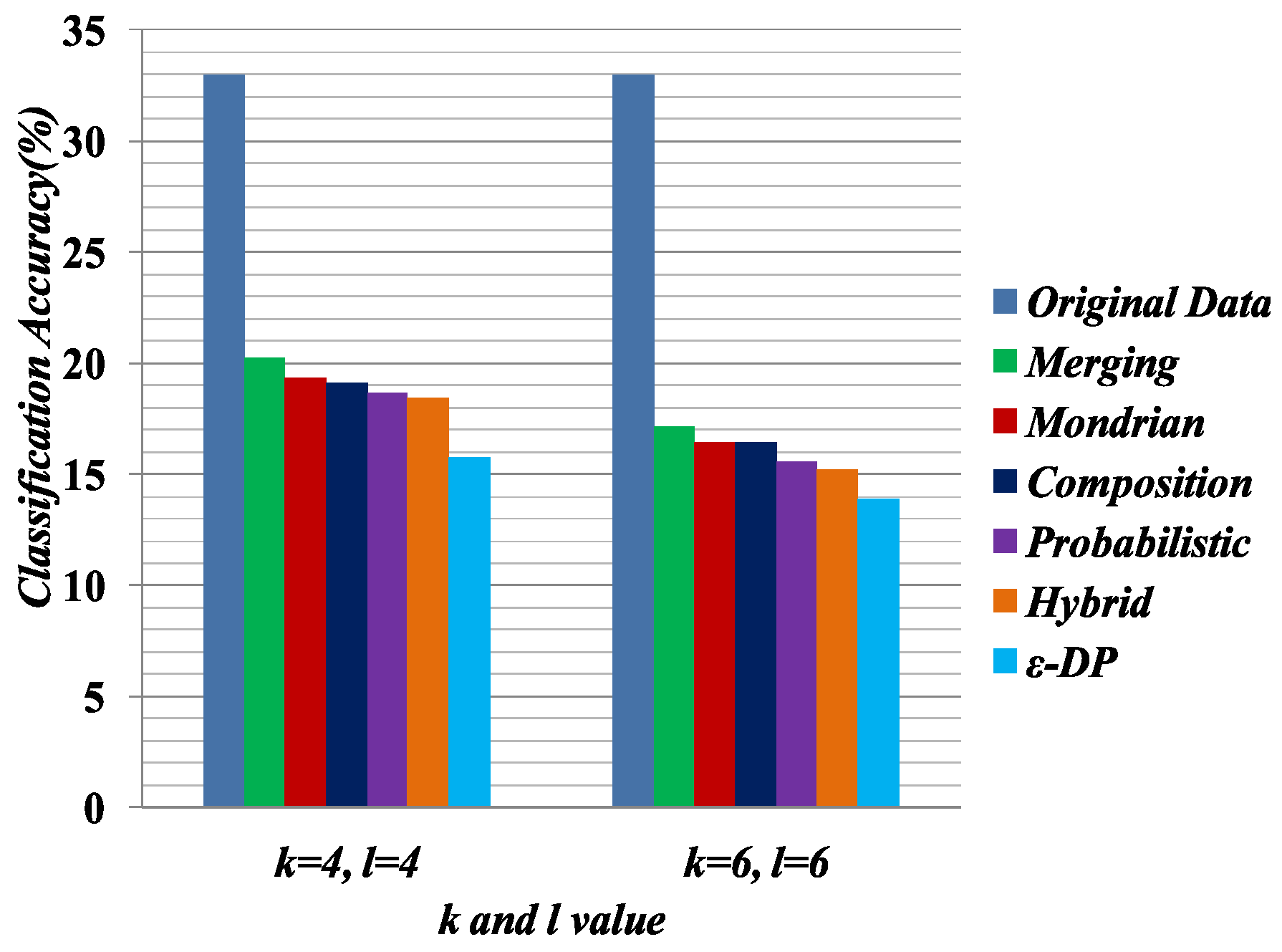

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
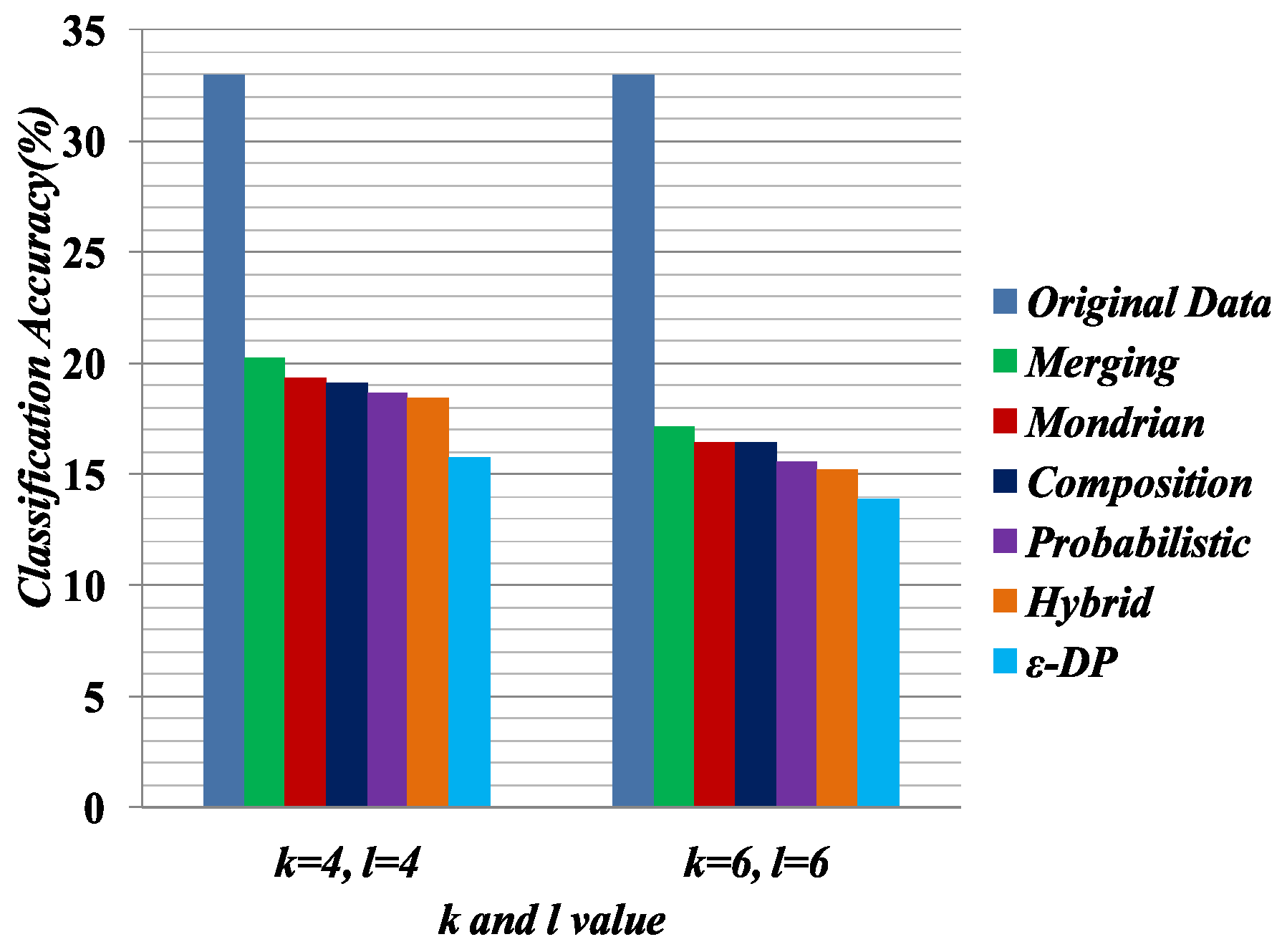{kind=link}
{kind=link}
{kind=link}