Attend It Again: Recurrent Attention Convolutional Neural Network for Action Recognition


Abstract
:1. Introduction
2. Related Work
2.1. ConvNet Architecture
2.2. LSTM-Like Architecture
2.3. Attention Mechanism
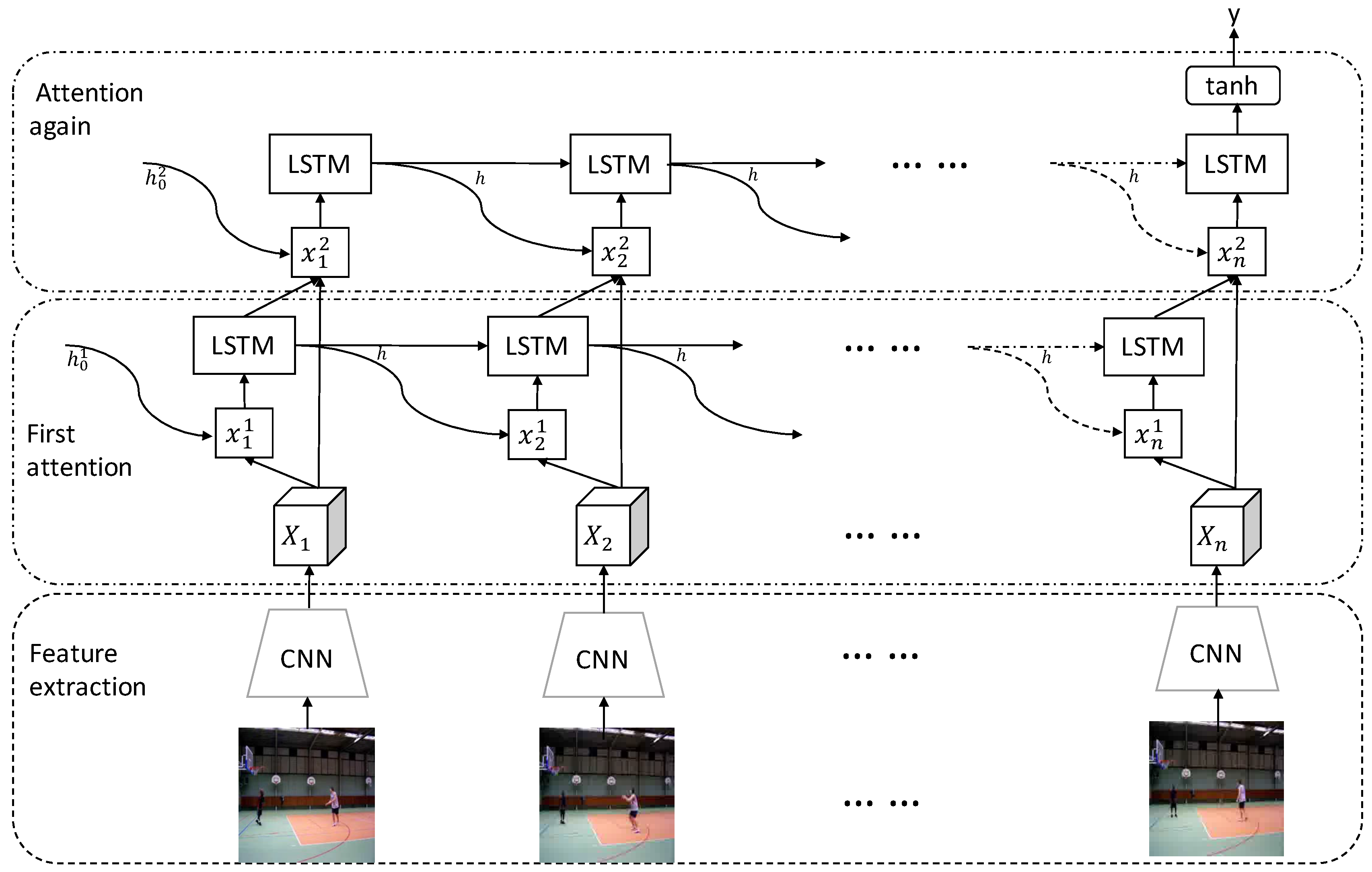
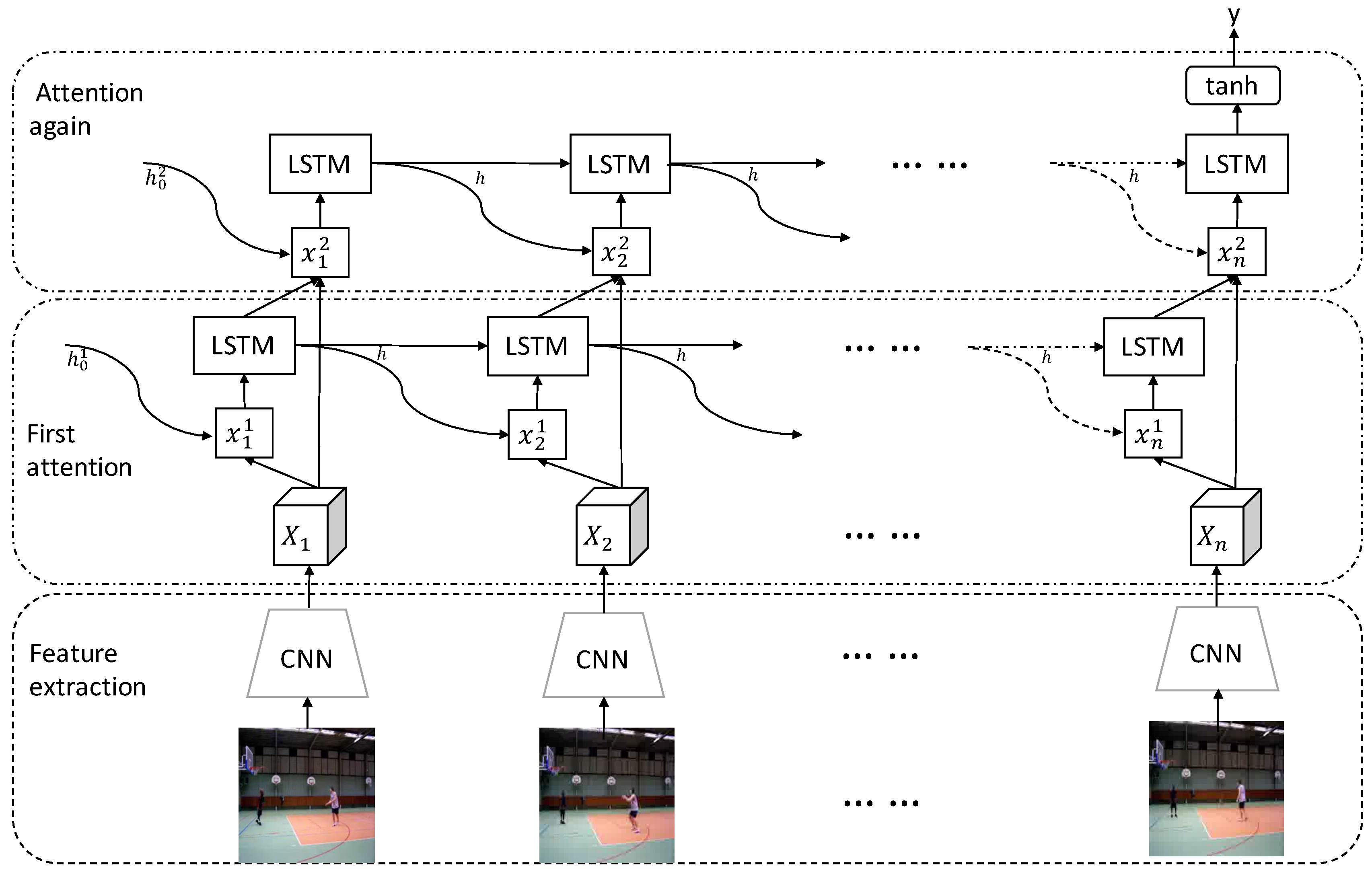
3. The Proposed Method
3.1. Convolutional Features Extractor
3.2. LSTM Sequence Modeling and Attention Model
3.2.1. LSTM Sequence Modeling
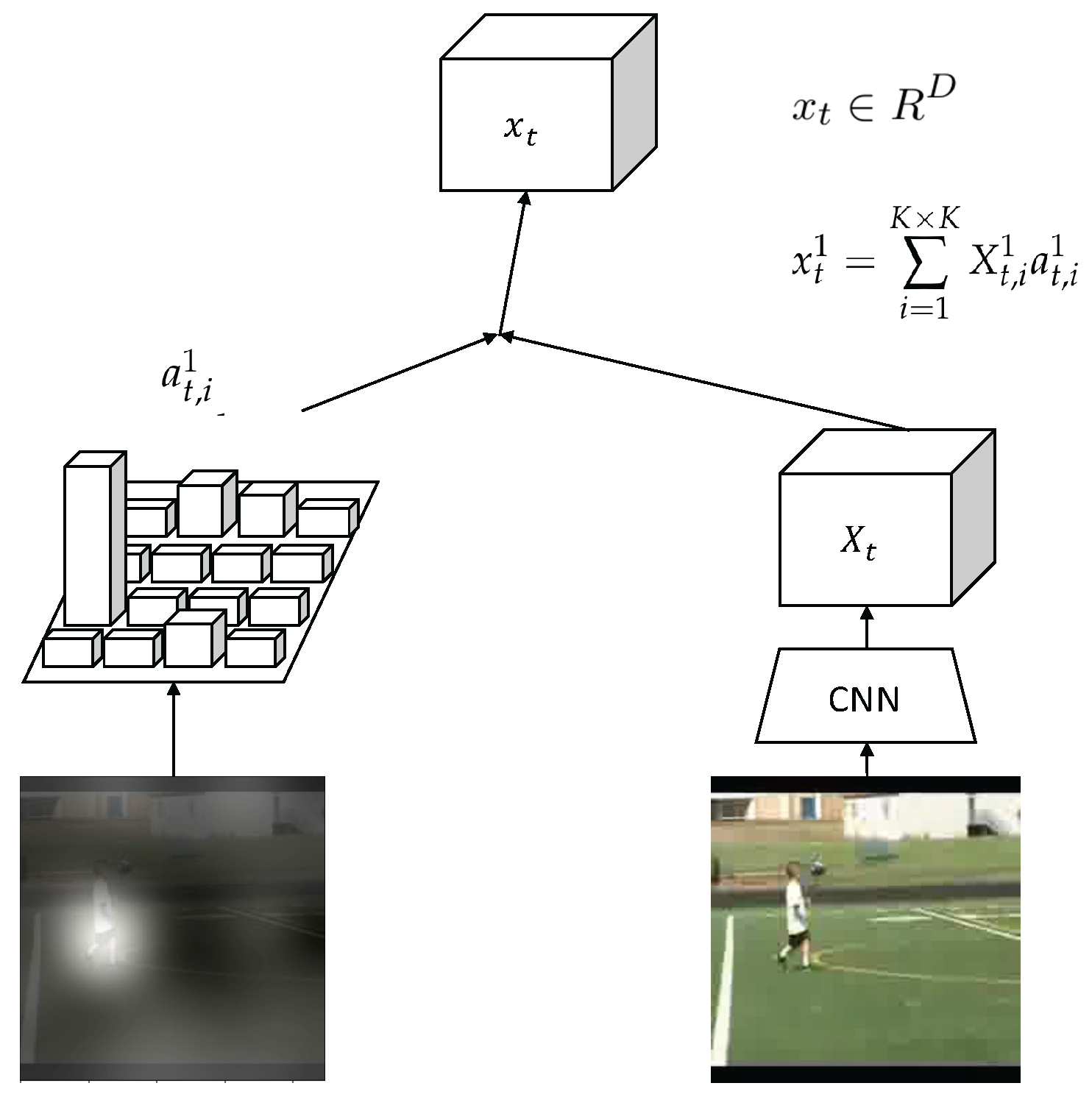
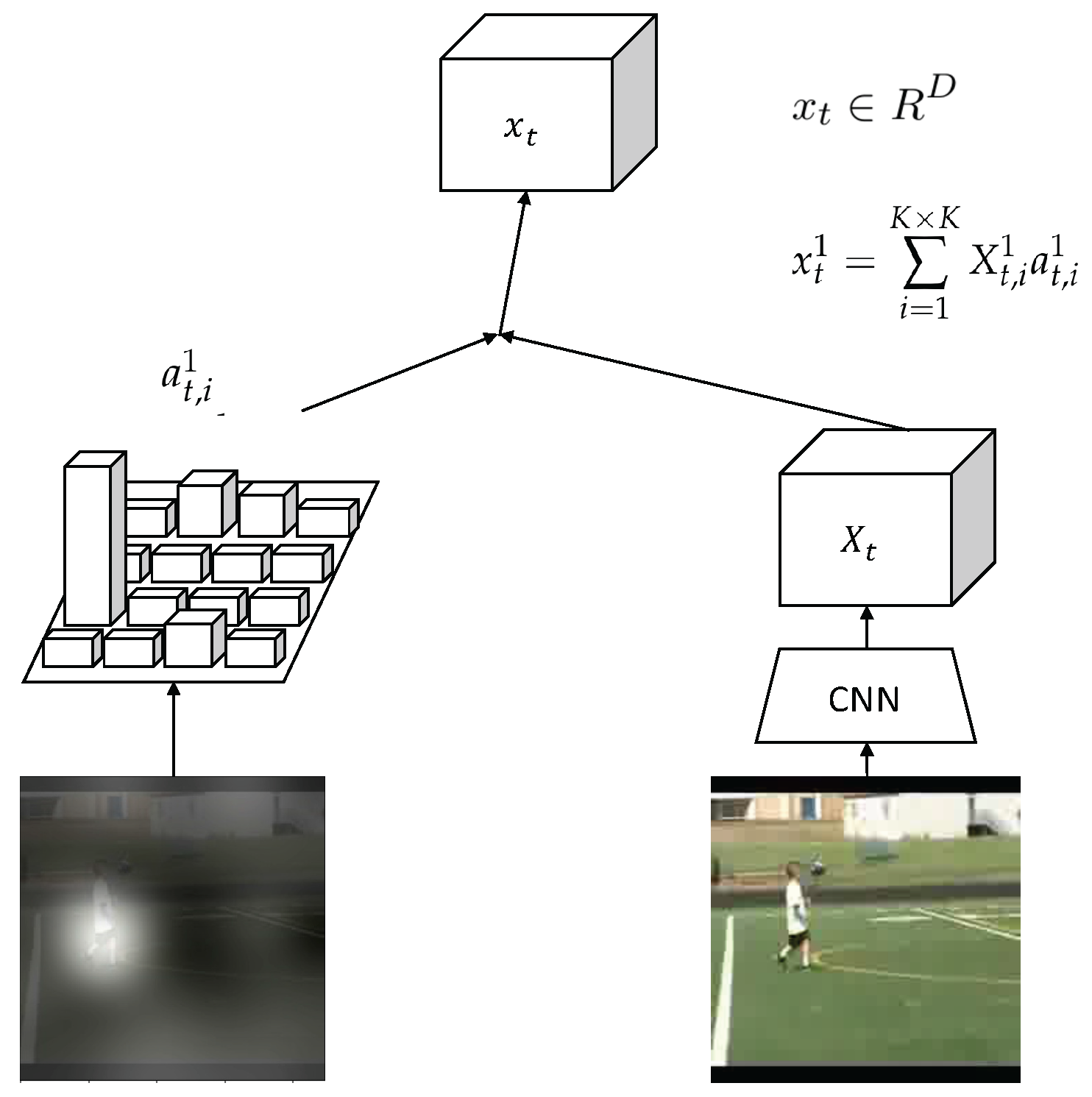
3.2.2. Attention Model
3.3. “Attention-Again” Model
3.4. Decode Network
4. Experiments
4.1. Datasets
4.2. Training Details
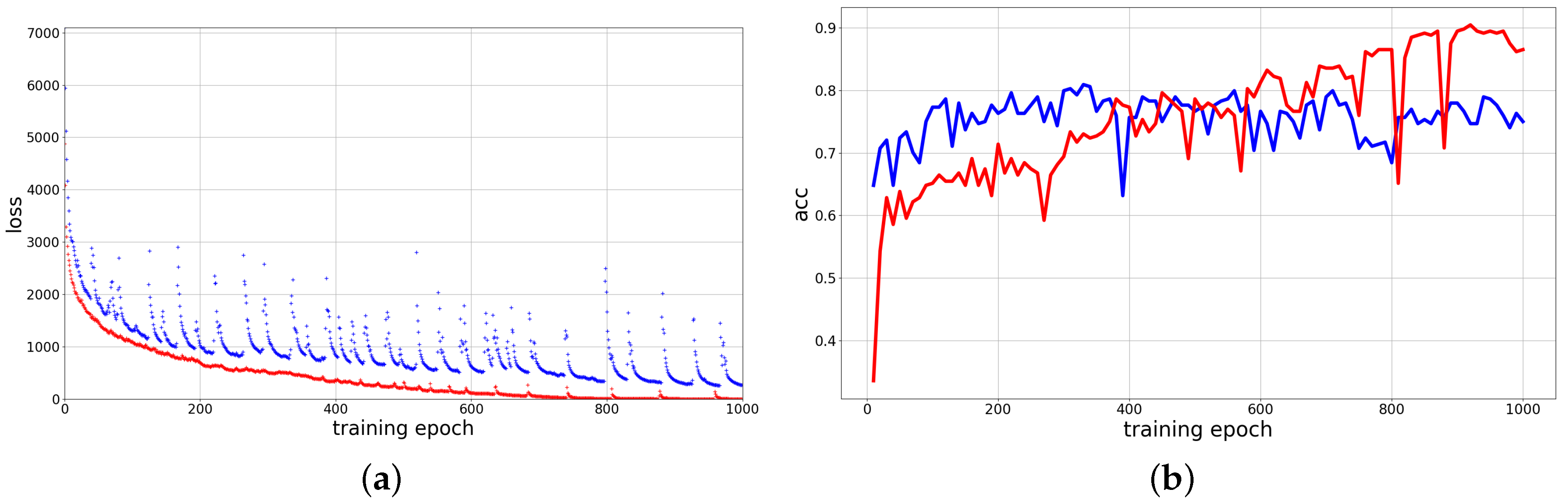
4.3. Results and Analysis
4.3.1. Quantitative Analysis
The Effect of Different CNN Encoders
The Effect of Every Component
Comparison with LSTM-like architecture
Comparison with state of the art
4.3.2. Qualitative Analysis
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yang, A.Y.; Iyengar, S.; Kuryloski, P.; Jafari, R. Distributed segmentation and classiffication of human actions using a wearable motion sensor network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Jalal, A.; Kamal, S. Real-time life logging via a depth silhouette-based human activity recognition system for smart home services. In Proceedings of the IEEE International Conference on Advanced Video and Signal-based Surveillance, Seoul, Korea, 26–29 August 2014; pp. 74–80. [Google Scholar]
- Jalal, A.; Sarif, N.; Kim, J.T.; Kim, T.S. Human activity recognition via recognized body parts of human depth silhouettes for residents monitoring services at smart homes. Indoor Built Environ. 2013, 22, 271–279. [Google Scholar] [CrossRef]
- Song, Y.; Tang, J.; Liu, F.; Yan, S. Body surface Context: A new robust feature for action recognition from depth videos. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 952–964. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. Shape and motion features approach for activity tracking and recognition from Kinect video camera. In Proceedings of the 29th International Conference on Advanced Information Networking and Applications Workshops, Gwangiu, Korea, 24–27 March 2015; pp. 445–450. [Google Scholar]
- Jalal, A.; Kamal, S.; Kim, D. A depth video sensor-based life-logging human activity recognition system for elderly care in smart indoor environments. Sensors 2014, 14, 11735–11759. [Google Scholar] [CrossRef] [PubMed]
- Jalal, A.; Kim, J.T.; Kim, T.S. Development of a life logging system via depth imaging-based human activity recognition for smart homes. In Proceedings of the International Symposium on Sustainable Healthy Buildings, Seoul, Korea, 19 September 2012; pp. 91–95. [Google Scholar]
- Jalal, A.; Lee, S.; Kim, J.T.; Kim, T.S. Human activity recognition via the features of labeled depth body parts. In Proceedings of the 10th International Conference on Smart Homes and Health Telematics, Seoul, Korea, 22–24 June 2012; pp. 246–249. [Google Scholar]
- Jalal, A.; Kim, S. Global security using human face understanding under vision ubiquitous architecture system. World Acad. Sci. Eng. Technol. 2006, 13, 7–11. [Google Scholar]
- Jalal, A.; Rasheed, Y.A. Collaboration achievement along with performance maintenance in video streaming. In Proceedings of the IEEE Conference on Interactive Computer Aided Learning, Villach, Austria, 26–28 September 2007; pp. 1–8. [Google Scholar]
- Jalal, A.; Kim, S. Advanced performance achievement using multi-algorithmic approach of video transcoder for low bit rate wireless communication. ICGST Int. J. Gr. Vis. Image Process. 2005, 5, 27–32. [Google Scholar]
- Jalal, A.; Kim, Y. Dense depth maps-based human pose tracking and recognition in dynamic scenes using ridge data. In Proceedings of the IEEE International Conference on Advanced Video and Signal-based Surveillance, Seoul, Korea, 26–29 August 2014; pp. 119–124. [Google Scholar]
- Jalal, A.; Kim, Y.; Kim, D. Ridge body parts features for human pose estimation and recognition from RGB-D video data. In Proceedings of the IEEE International Conference on Computing, Communication and Networking Technologies, Hefei, China, 11–13 July 2014; pp. 1–6. [Google Scholar]
- Jalal, A.; Kamal, S.; Kim, D. Human depth sensors-based activity recognition using spatiotemporal features and hidden markov model for smart environments. J. Comput. Netw. Commun. 2016, 2016, 1–11. [Google Scholar] [CrossRef]
- Jalal, A.; Kamal, S.; Kim, D. Depth map-based human activity tracking and recognition using body joints features and self-organized map. In Proceedings of the IEEE International Conference on Computing, Communication and Networking Technologies, Hefei, China, 11–13 July 2014; pp. 1–6. [Google Scholar]
- Jalal, A.; Kim, Y.H.; Kim, Y.J. Robust human activity recognition from depth video using spatiotemporal multi-fused features. Pattern Recognit. 2017, 61, 295–308. [Google Scholar] [CrossRef]
- Jalal, A.; Kim, Y.; Kamal, S. Human daily activity recognition with joints plus body features representation using Kinect sensor. In Proceedings of the IEEE International Conference on Informatics, Electronics and Vision, Fukuoka, Japan, 15–18 June 2015; pp. 1–6. [Google Scholar]
- Kamal, S.; Jalal, A. A hybrid feature extraction approach for human detection, tracking and activity recognition using depth sensors. Arabian J. Sci. Eng. 2016, 41, 1043–1051. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv, 2015; arXiv:1409.0473. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A.; Kavukcuoglu, K. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D convolutional neural networks for human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei, L.F. Large-scale video classification with convolutional neural networks. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhutdinov, R. Unsupervised learning of video representations using lstms. arXiv, 2015; arXiv:1502.04681. [Google Scholar]
- Sharma, S.; Kiros, R.; Salakhutdinov, R. Action recognition using visual attention. arXiv, 2015; arXiv:1511.04119. [Google Scholar]
- Hochreiter, S.; Schmid Huber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Dar-rell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 2625–2634. [Google Scholar]
- Shi, Y.; Tian, Y.; Wang, Y.; Huang, T. Sequential deep trajectory descriptor for action recognition with three-stream cnn. IEEE Trans. Multimed. 2017, 19, 1510–1520. [Google Scholar] [CrossRef]
- Ng, J.Y.; Hausknecht, M.; Vijayanarasimhan, S.; Vinyals, O.; Monga, R.; Toderici, G. Beyond short snippets: Deep networks for video classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–10 June 2015; pp. 4694–4702. [Google Scholar]
- Baradel, F.; Wolf, C.; Mille, J. Pose-conditioned Spatio-Temporal Attention for Human Action Recognition. arXiv, 2017; arXiv:1703.10106. [Google Scholar]
- Cai, Z.; Wang, L.; Peng, X.; Qiao, Y. Multi-view super vector for action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 596–603. [Google Scholar]
- Zeng, W.; Luo, W.; Fidler, S.; Urtasun, R. Efficient summarization with read-again and copy mechanism. arXiv, 2016; arXiv:1611.03382. [Google Scholar]
- Liu, J.; Luo, J.; Shah, M. Recognizing realistic actions from videos “in the wild”. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 25–25 June 2009. [Google Scholar]
- Kuehne, H.; Jhuang, H.; Garrote, E.; Poggio, T.; Serre, T. HMDB: A large video database for human motion recognition. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2556–2563. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A Dataset of 101 human action classes from videos in the wild. arXiv, 2012; arXiv:1212.0402. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montréal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Shi, Y.; Zeng, W.; Huang, T.; Wang, Y. Learning deep trajectory descriptor for action recognition in videos using deep neural networks. In Proceedings of the IEEE International Conference on Multimedia and Expo, Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. ACM Trans. Inf. Syst. 2016, 22, 20–36. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computter Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar]
- Mahasseni, B.; Todorovic, S. Regularizing long short term memory with 3D human-skeleton sequences for action recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Baccouche, M.; Mamalet, F.; Wolf, C.; Garcia, C.; Baskurt, A. Sequential deep learning for human action recognition. In Human Behavior Understanding; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 29–39. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. arXiv, 2015; arXiv:1506.02025. [Google Scholar]
- Yeung, S.; Russakovsky, O.; Jin, N.; Andriluka, M.; Mori, G.; Li, F.F. Every moment counts: Dense detailed labeling of actions in complex videos. arXiv, 2015; arXiv:1507.05738. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.C.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent neural network regularization. arXiv, 2014; arXiv:1409.2329. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2015; arXiv:1412.6980. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv, 2016; arXiv:1603.04467. [Google Scholar]
- Li, Z.; Gavves, E.; Jain, M.; Snoek, C.G.M. VideoLSTM Convolves, Attends and Flows for Action Recognition. Comput. Vis. Image Underst. 2018, 166, 41–50. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W. Convolutional lstm network: A machine learning approach for precipitation nowcasting. arXiv, 2015; arXiv:1506.04214. [Google Scholar]
- Shi, Y.; Tian, Y.; Wang, Y.; Huang, T. Joint Network based Attention for Action Recognition. arXiv, 2016; arXiv:1611.05215. [Google Scholar]
- Sun, L.; Jia, K.; Chen, K.; Yeung, D.Y.; Shi, B.E.; Savarese, S. Lattice Long Short-Term Memory for Human Action Recognition. arXiv, 2017; arXiv:1708.03958. [Google Scholar]
- Girdhar, R.; Ramanan, D. Attentional Pooling for Action Recognition. arXiv, 2017; arXiv:1711.01467. [Google Scholar]
- Wang, X.; Farhadi, A.; Gupta, A. Actions transformations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2658–2667. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | UCF11 | HMDB51 | UCF101 |
|---|---|---|---|
| GoogLeNet | 89.7 | 52.3 | 85.4 |
| VGG | 90.1 | 52.6 | 85.8 |
| ResNet-101 | 90.9 | 53.8 | 87.2 |
| ResNet-152 | 91.2 | 54.4 | 87.7 |
| Model | HMDB51 | UCF101 |
|---|---|---|
| LSTM | 41.3 | 77.5 |
| ALSTM | 40.9 | 77.0 |
| ConvLSTM | 41.8 | 77.6 |
| ConvALSTM | 43.3 | 79.6 |
| ConvLSTM + hierarchical LSTM (Three layers) | 45.2 | 81.7 |
| ConvLSTM + hierarchical LSTM (Two layers) | 46.6 | 82.4 |
| + attention mechanism | 50.9 | 84.1 |
| + “attention-again” model | 52.6 | 85.8 |
| Method | Pre-Train | Networks | UCF11 | HMDB51 | UCF101 | ||
|---|---|---|---|---|---|---|---|
| ImageNet | GoogLeNet | VGG-M | VGG16 | ||||
| LRCN [27] | ✓ | - | ✓ | - | - | - | 82.9 |
| Soft-attention [25] | ✓ | ✓ | - | - | 84.86 | 41.31 | 77 |
| VideoLSTM [48] | ✓ | - | - | ✓ | - | 43.3 | 79.6 |
| JAN [50] | ✓ | - | - | ✓ | - | 50.2 | 81.6 |
| [51] | ✓ | - | - | ✓ | - | * | 83.2 |
| Ours | ✓ | - | - | ✓ | 90.1 | 52.6 | 85.8 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Zhang, J.; Li, S.; Lei, J.; Chen, S. Attend It Again: Recurrent Attention Convolutional Neural Network for Action Recognition. Appl. Sci. 2018, 8, 383. https://doi.org/10.3390/app8030383
Yang H, Zhang J, Li S, Lei J, Chen S. Attend It Again: Recurrent Attention Convolutional Neural Network for Action Recognition. Applied Sciences. 2018; 8(3):383. https://doi.org/10.3390/app8030383
Chicago/Turabian StyleYang, Haodong, Jun Zhang, Shuohao Li, Jun Lei, and Shiqi Chen. 2018. "Attend It Again: Recurrent Attention Convolutional Neural Network for Action Recognition" Applied Sciences 8, no. 3: 383. https://doi.org/10.3390/app8030383
APA StyleYang, H., Zhang, J., Li, S., Lei, J., & Chen, S. (2018). Attend It Again: Recurrent Attention Convolutional Neural Network for Action Recognition. Applied Sciences, 8(3), 383. https://doi.org/10.3390/app8030383