A Neural Networks Approach for Improving the Accuracy of Multi-Criteria Recommender Systems


Abstract
:1. Introduction
2. Related Background
2.1. Recommender Systems (RSs)
Collaborative Filtering
- Singular value decomposition (SVD): SVD is a latent factor model that aims to uncover latent features that determine the observed rating. The field of information retrieval usually applies SVD technique for identifying latent semantic factors. Koren and Bell explained the concept of SVD in [15] using a movie recommendation scenario. Similarly, we studied the Koren SVD [15] and used it to implement a traditional RS. The Koren SVD uses two vectors U and V in with d as the dimension of the latent factor space so that each item i is associated with vector and the user u is associated with . The resulting dot product represents the interaction between u and i. To estimate the final predicted rating of u on i, a baseline predictor that depends on item or user () needs to be added to have the relation in (1), where is the overall average rating.The model parameters ( and ) can be learned by regularized squared error minimization as , where S is the set of pairs for which the ratings of i given by u is known and is the regularization constant that controls the scope of the regularization and is normally obtained through cross-validation. The well-known popular gradient descent algorithm (GDA) [16] or alternating least squares optimization techniques [17] can typically be used to perform this minimization. Applying stochastic GDA for each rating , the predicted rating is obtained and the relative error is measured, then the GDA computes the parameters as:The parameters and can be assigned small positive real numbers such as 0.005 and 0.02, respectively [18].
- Slope one algorithm: The slope one is a model-based CF algorithm proposed by D. Lemire et al. [19], which was derived from item-based CF technique. It was named slope one algorithm and was proposed to overcome some of the issues encountered in CF-based RSs. Several experiments confirmed its efficiency, and it is easy to implement and maintain, which made it popular and attracted the attentions of the RSs community [20]. It approximates unknown ratings of users on items based on the differences between ratings of the user and those of similar users. In other words, the algorithm uses users who rated the same item or other items rated by the same user. The first of the two steps used for making predictions is to compute the mean deviation of two items as follows. For any two items and in the training set, slope one algorithm uses (2) to compute the mean deviation between them, where is the difference between ratings of and by the same user u and is the number of users who rated and , and S is the set of all users. The target rating of the user v on item j will be obtained finally from (3), where is the rating of v to other items c, and the total number of the user’s ratings . The recommendation follows the top-N technique.
2.2. Multi-Criteria Recommender Systems (MCRSs)
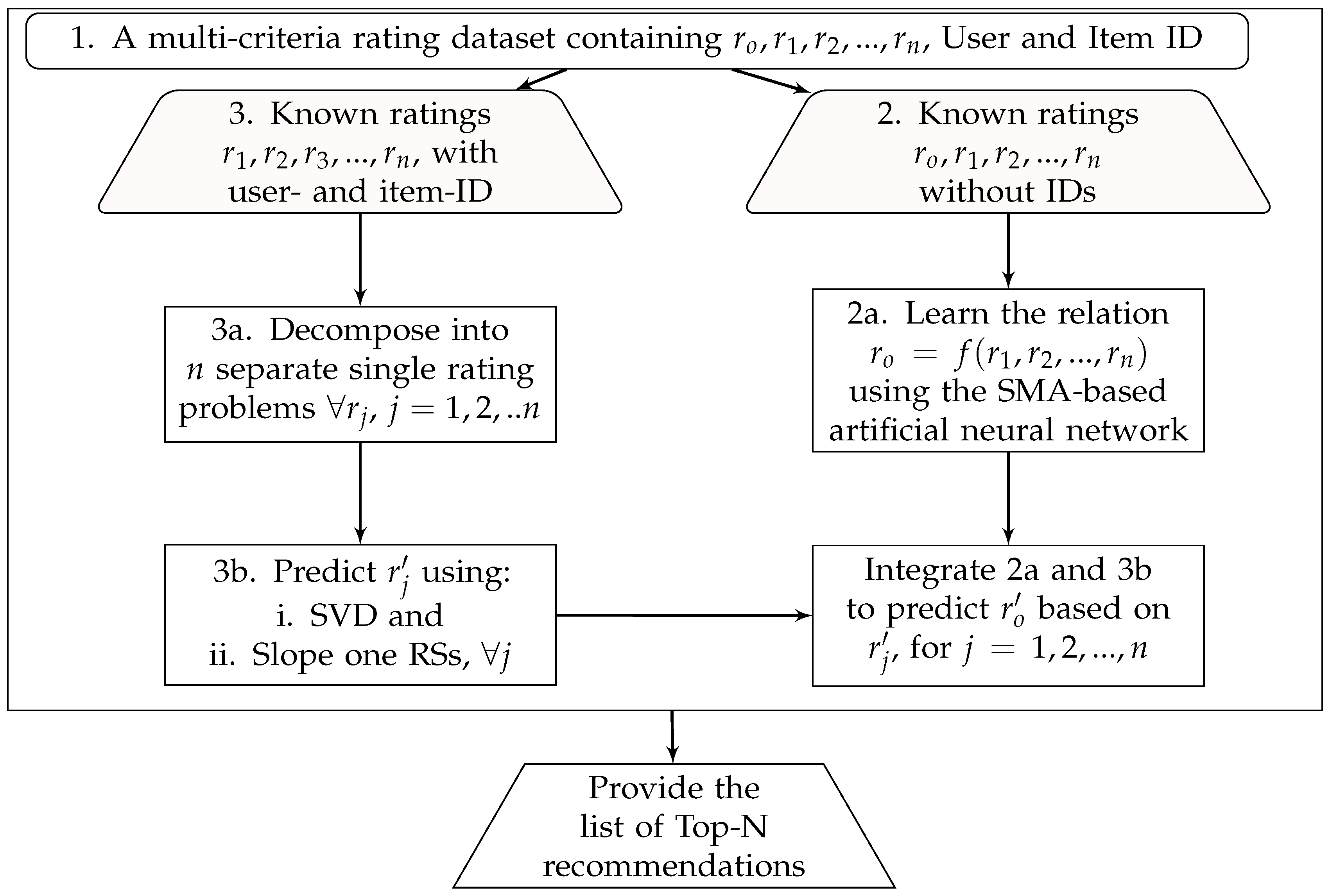
- Decompose the multi-criteria rating problem into single-rating problems.
- For each , use a single-rating technique to predict unknown rating for each criterion separately.
- Learn the relationship between and using the selected algorithms, such as artificial neural networks.
- Integrate steps 2 and 3 to predict for .
2.3. Artificial Neural Networks (ANNs)
2.4. Simulated Annealing Algorithm (SMA)
3. Experimental Methodology
3.1. Analysis of the Dataset
3.1.1. Yahoo!Movie dataset
3.1.2. TripAdvisor Dataset
3.2. Systems Implementations and Evaluations
3.2.1. The Proposed MCRSs Framework
- An ANN was implemented and trained using SMA and the datasets to learn the relationship between the criteria ratings and the overall rating.
- Two traditional RSs were built using two different techniques (slope one and SVD); each of them can learn and predict the decomposed n-dimensional ratings separately from the dataset.
- Two MCRSs have been developed by integrating the SMA-based networks with the two traditional techniques separately.
3.2.2. Implementation
3.2.3. Evaluation Metrics
- Usage prediction: A which measures the segment of useful recommendations among those predicted as useful by the systems (Equation (10)). A , which is defined in a standard way by Adomavicius et al. [36] as a metric for estimating part of useful recommendations out of all the items acknowledged to be useful (Equation (11)). F-, which served as a harmonic mean of the precision and recall (Equation (12)), which are the most useful measures of interest for some number of recommendations were used in measuring usage predictions. In Equations (11) and (12), the term means the number of true positive, which indicates the number of useful predictions. The stands for the number of useful predictions that are not among the top-N recommendation list, and is the number of false positive that represents the total number of non-useful predictions.
- Ranking accuracy: We used three evaluation metrics for measuring the ranking accuracy of RSs to evaluate the systems. The area under the curve () of a receiver operating characteristics () curve in Equation (13) for each user u, which measures how accurate the algorithms’ separate predictions into relevant and irrelevant by finding the area under the curve of the sensitivity rate (recall) against the specificity. The is the position of the kth relevant item among the N recommended items.The second ranking metric is the normalized discounted cumulative gain (), which is a ratio between the discounted cumulative gain () and the ideal () (see Equation (14)) that also measures the performance of RSs based on the graded relevance of the recommended entities. The shows the correctness of the ranking. It takes a real number between 0 and 1, and the larger the , the better the ranking accuracy of the algorithm. The is the maximum value for a given set of queries. The in the equation takes 1 if the item at position k is relevant, and 0 otherwise.Similarly, the fraction of concordant pairs () in Equation (15) was also used to ensure the correct measurement of the ranking accuracy. The represents the number of concordant pairs defined as , and is the corresponding number of discordant pairs calculated as . This means that the concordant pairs are predicted ratings and for some items i and j so that if , then their corresponding ratings and from the dataset must satisfy the same condition ; otherwise, the items i and j are called discordant pairs.
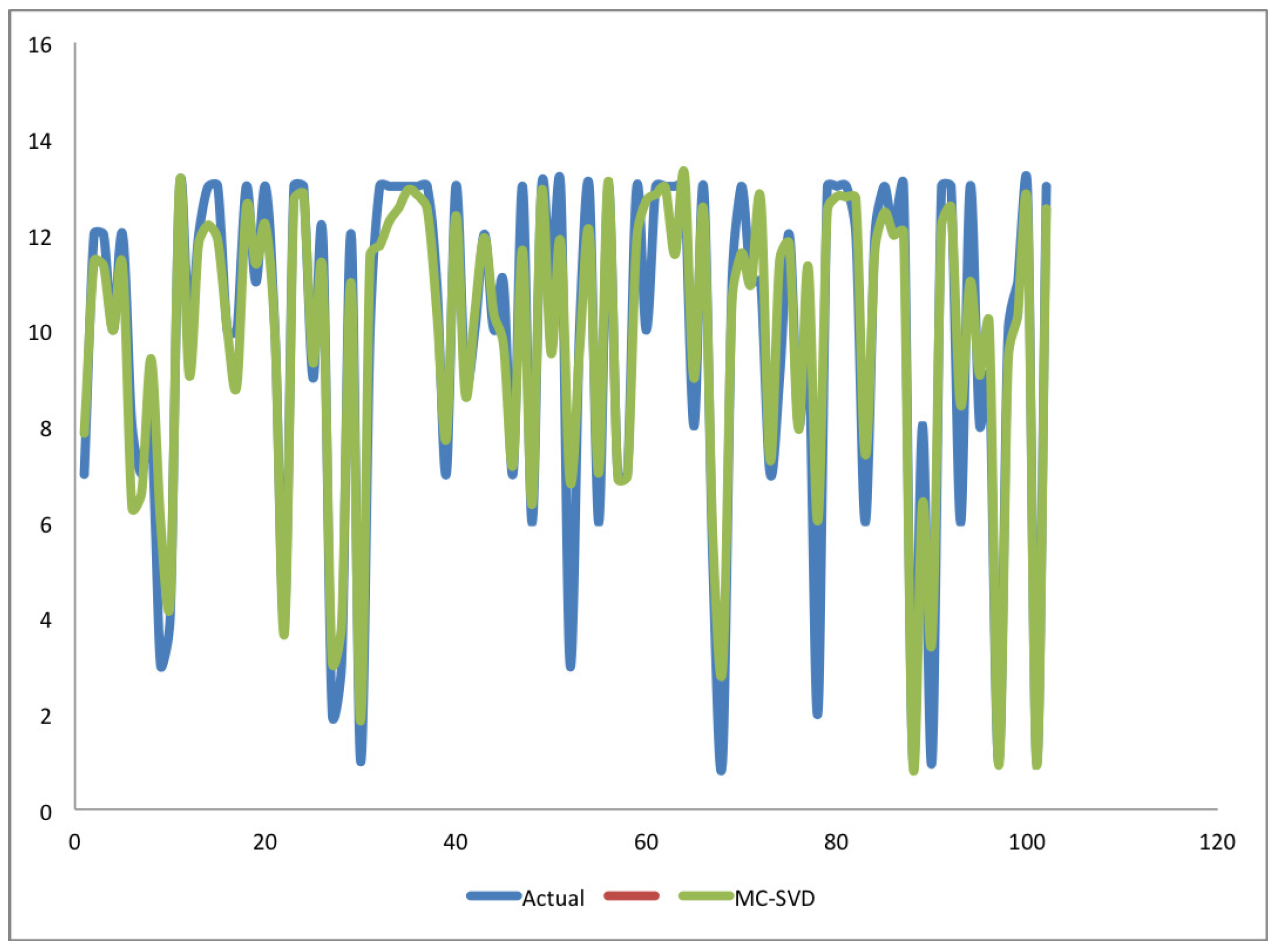
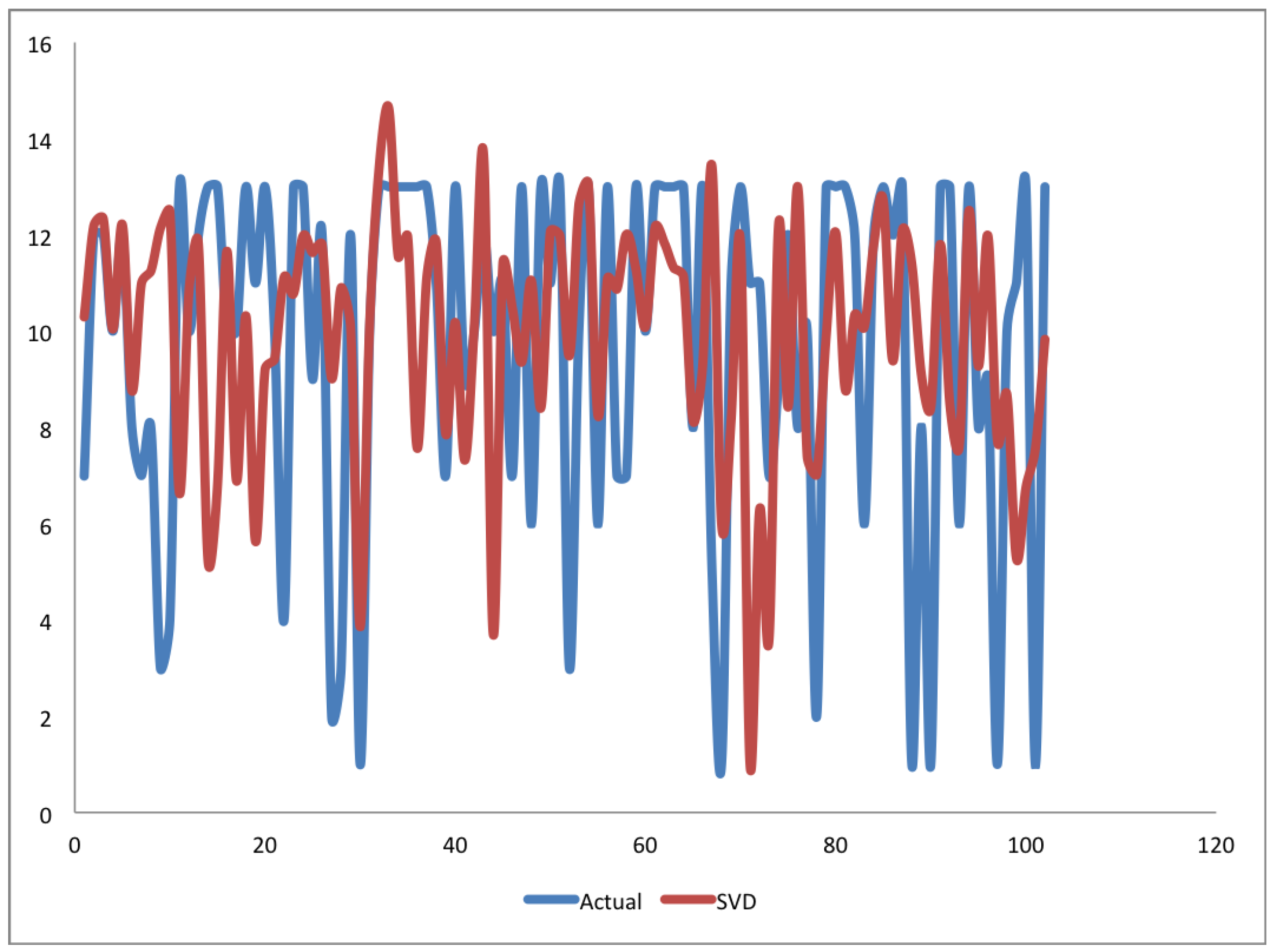
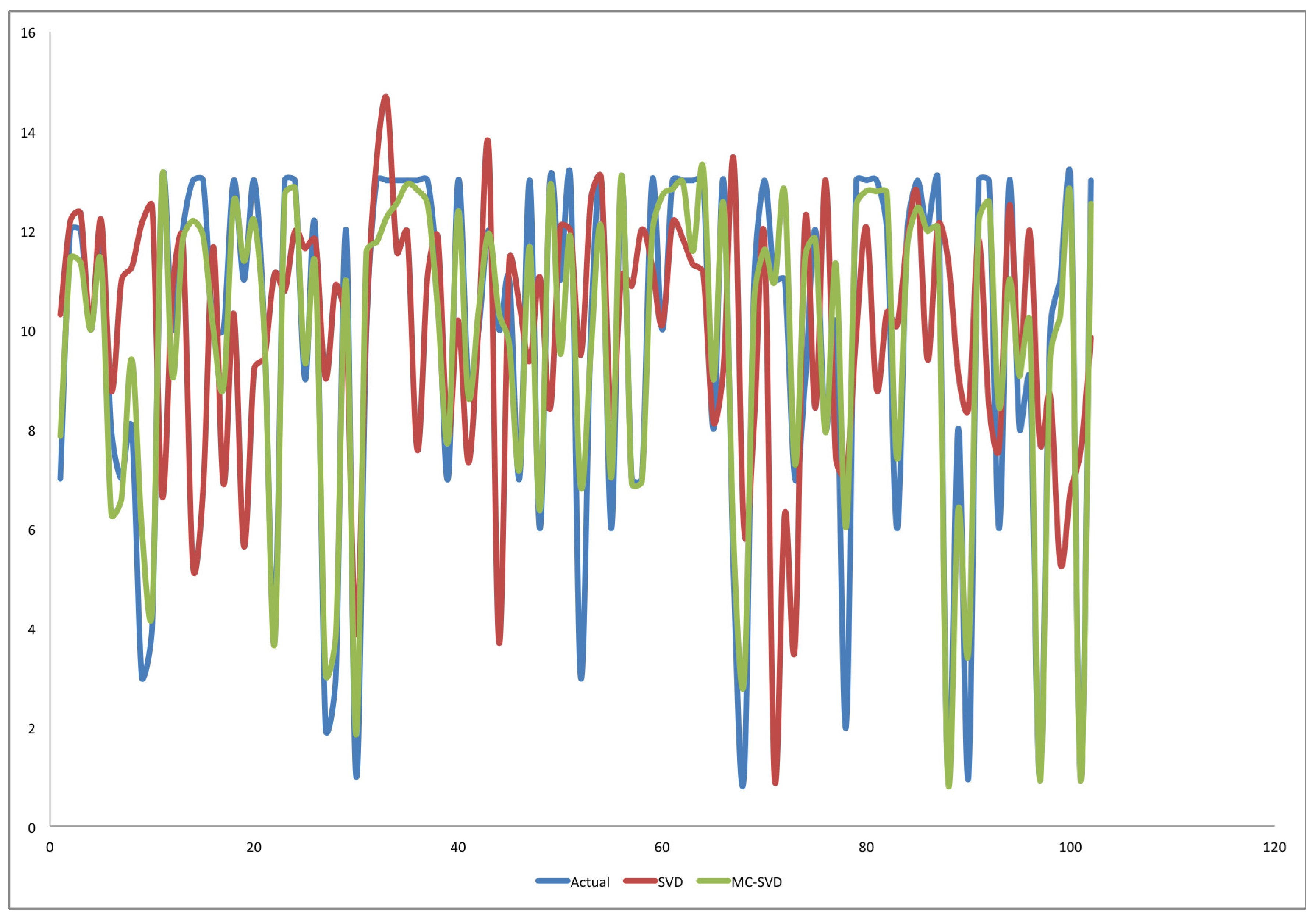
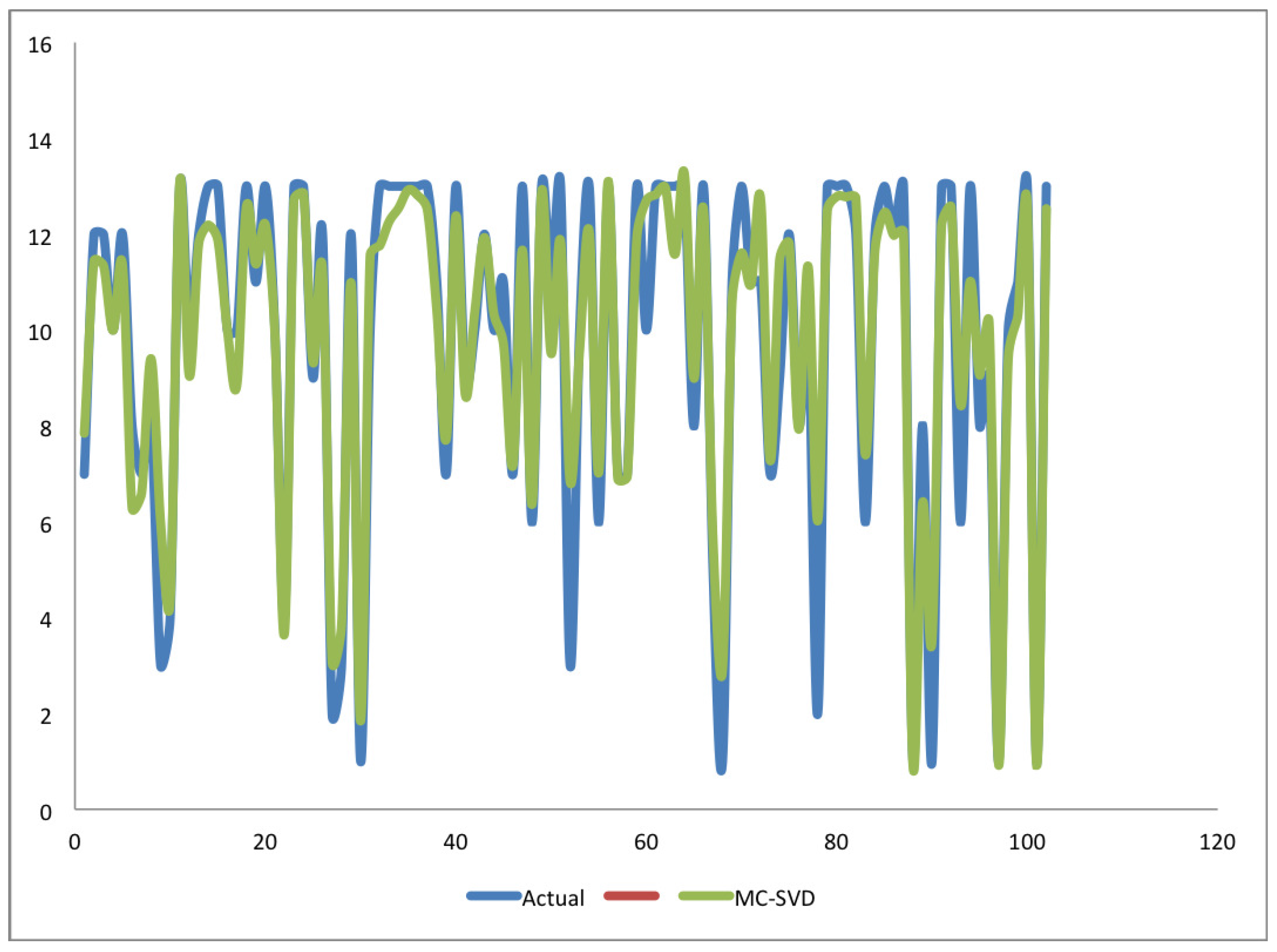
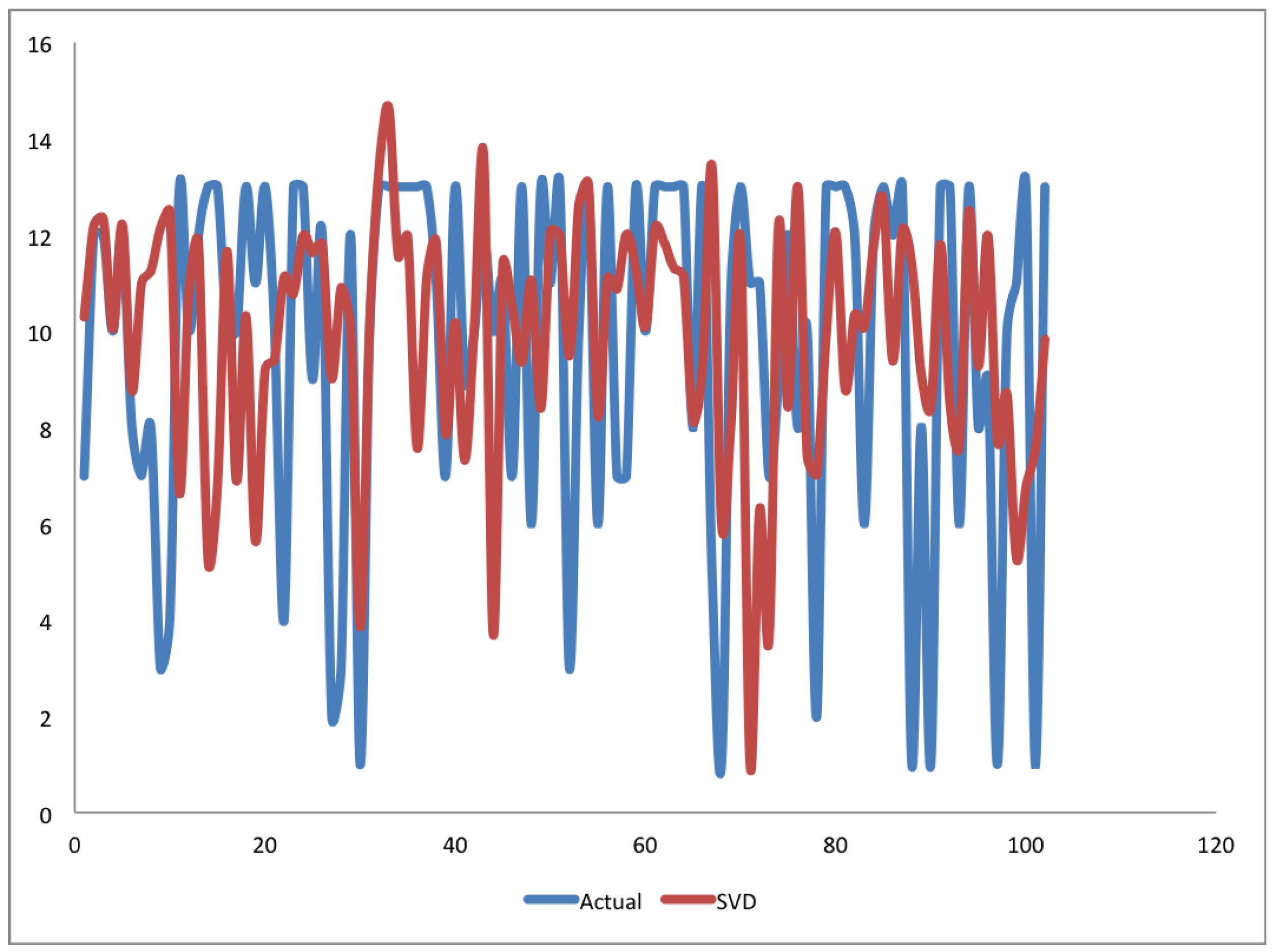
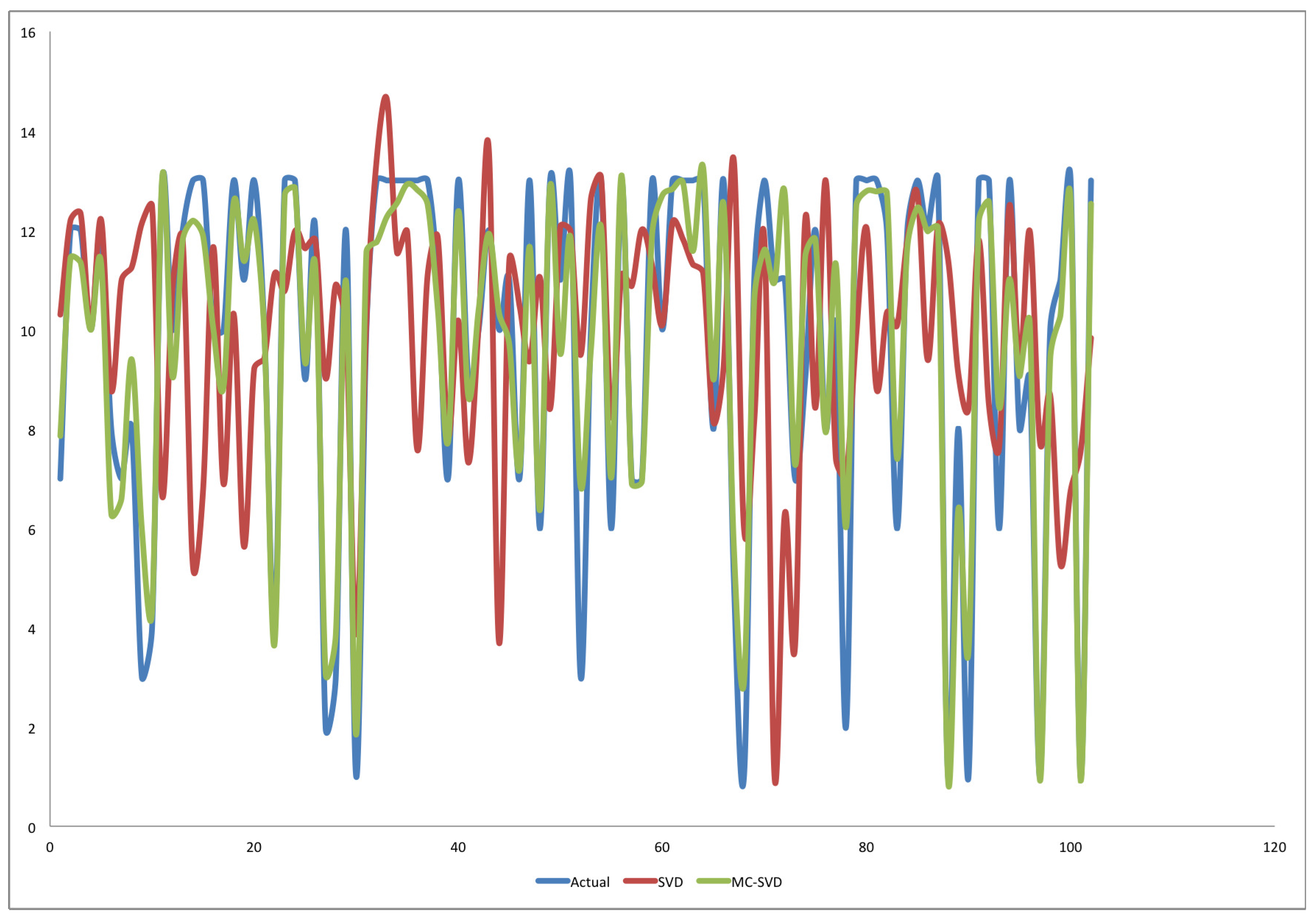
4. Results and Discussion
4.1. Experiment One
4.2. Experiment Two
5. Conclusions and Future Work
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Meo, P.D.; Musial-Gabrys, K.; Rosaci, D.; Sarnè, G.M.; Aroyo, L. Using centrality measures to predict helpfulness-based reputation in trust networks. ACM Trans. Internet Technol. (TOIT) 2017, 17, 8. [Google Scholar] [CrossRef]
- Hassan, M.; Hamada, M. Performance Comparison of Featured Neural Network Trained with Backpropagation and Delta Rule Techniques for Movie Rating Prediction in Multi-criteria Recommender Systems. Informatica 2016, 40, 409–414. [Google Scholar]
- Moradi, P.; Ahmadian, S. A reliability-based recommendation method to improve trust-aware recommender systems. Expert Syst. Appl. 2015, 42, 7386–7398. [Google Scholar] [CrossRef]
- Bobadilla, J.; Serradilla, F.; Hernando, A.; MovieLens. Collaborative filtering adapted to recommender systems of e-learning. Knowl.-Based Syst. 2009, 22, 261–265. [Google Scholar] [CrossRef]
- Adomavicius, G.; Kwon, Y. Multi-criteria recommender systems. In Recommender Systems Handbook; Francesco, R., Lior, R., Bracha, S., Eds.; Springer: New York, NY, USA, 2015; pp. 854–887. [Google Scholar]
- Jannach, D.; Karakaya, Z.; Gedikli, F. Accuracy improvements for multi-criteria recommender systems. In Proceedings of the 13th ACM Conference on Electronic Commerce, Valencia, Spain, 4–8 June 2012; pp. 674–689. [Google Scholar]
- Cawley, G.C.; Talbot, N.L. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Zhang, L.; Suganthan, P.N. A survey of randomized algorithms for training neural networks. Inf. Sci. 2016, 364, 146–155. [Google Scholar] [CrossRef]
- Busetti, F. Simulated Annealing Overview. 2003. Available online: www.geocities.com/francorbusetti/saweb.pdf (accessed on 8 May 2017).
- Lu, J.; Wu, D.; Mao, M.; Wang, W.; Zhang, G. Recommender system application developments: A survey. Decis. Support Syst. 2015, 74, 12–32. [Google Scholar] [CrossRef]
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl.-Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Yera, R.; Martınez, L. Fuzzy Tools in Recommender Systems: A Survey. Int. J. Comput. Intell. Syst. 2017, 10, 776–803. [Google Scholar] [CrossRef]
- Nazemian, A.; Gholami, H.; Taghiyareh, F. An improved model of trust-aware recommender systems using distrust metric. In Proceedings of the 2012 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Istanbul, Turkey, 26–29 August 2012; pp. 1079–1084. [Google Scholar]
- Aggarwal, C.C. Recommender Systems; Springer International Publishing: Basel, Switzerland, 2016. [Google Scholar]
- Koren, Y.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: New York, NY, USA, 2011; pp. 145–186. [Google Scholar]
- Paterek, A. Improving regularized singular value decomposition for collaborative filtering. In Proceedings of the KDD Cup and Workshop, San Jose, CA, USA, 12 August 2007; Volume 2007, pp. 5–8. [Google Scholar]
- Hastie, T.; Mazumder, R.; Lee, J.D.; Zadeh, R. Matrix completion and low-rank SVD via fast alternating least squares. J. Mach. Learn. Res. 2015, 16, 3367–3402. [Google Scholar]
- Bennett, J.; Lanning, S. The netflix prize. In Proceedings of the KDD Cup and Workshop, San Jose, CA, USA, 12 August 2007; Volume 2007, p. 35. [Google Scholar]
- Lemire, D.; Maclachlan, A. Slope One Predictors for Online Rating-Based Collaborative Filtering. In Proceedings of the 2005 SIAM International Conference on Data Mining, Beach, CA, USA, 21–23 April 2005; Volume 5, pp. 1–5. [Google Scholar]
- Sun, M.; Zhang, H.; Song, S.; Wu, K. USO-a new Slope One algorithm based on modified user similarity. In Proceedings of the 2012 International Conference on Information Management, Innovation Management and Industrial Engineering, Sanya, China, 20–21 October 2012; Volume 2, pp. 335–340. [Google Scholar]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Gao, S.; Wang, J.; Chu, C.; Todo, Y.; Tang, Z. Financial time series prediction using a dendritic neuron model. Knowl.-Based Syst. 2016, 105, 214–224. [Google Scholar] [CrossRef]
- Caudill, M. Neural nets primer, part VI. AI Expert 1989, 4, 61–67. [Google Scholar]
- Goffe, W.L.; Ferrier, G.D.; Rogers, J. Global optimization of statistical functions with simulated annealing. J. Econom. 1994, 60, 65–99. [Google Scholar] [CrossRef]
- Sexton, R.S.; Dorsey, R.E.; Johnson, J.D. Beyond backpropagation: Using simulated annealing for training neural networks. J. Organ. End User Comput. (JOEUC) 1999, 11, 3–10. [Google Scholar] [CrossRef]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Lakiotaki, K.; Matsatsinis, N.F.; Tsoukias, A. Multicriteria user modeling in recommender systems. IEEE Intell. Syst. 2011, 26, 64–76. [Google Scholar] [CrossRef]
- Wang, H.; Lu, Y.; Zhai, C. Latent aspect rating analysis without aspect keyword supervision. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 618–626. [Google Scholar]
- Owen, S.; Anil, R.; Dunning, T.; Friedman, E. Mahout in Action; Manning: Shelter Island, NY, USA, 2011. [Google Scholar]
- Jannach, D.; Lerche, L.; Gedikli, F.; Bonnin, G. What recommenders recommend—An analysis of accuracy, popularity, and sales diversity effects. In Proceedings of the International Conference on User Modeling, Adaptation, and Personalization, Rome, Italy, 10–14 June 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 25–37. [Google Scholar]
- Picault, J.; Ribiere, M.; Bonnefoy, D.; Mercer, K. How to get the Recommender out of the Lab? In Recommender Systems Handbook; Springer: New York, NY, USA, 2011; pp. 333–365. [Google Scholar]
- Gunawardana, A.; Shani, G. Evaluating Recommender Systems. In Recommender Systems Handbook; Springer: New York, NY, USA, 2015; pp. 265–308. [Google Scholar]
- Arnold, B.C. Pareto Distribution; Wiley Online Library: Boca Raton, FL, USA, 2015. [Google Scholar]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B (Methodol.) 1974, 36, 111–147. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-validation. In Encyclopedia of Database Systems; Springer: New York, NY, USA, 2009; pp. 532–538. [Google Scholar]
- Adomavicius, G.; Sankaranarayanan, R.; Sen, S.; Tuzhilin, A. Incorporating contextual information in recommender systems using a multidimensional approach. ACM Trans. Inf. Syst. (TOIS) 2005, 23, 103–145. [Google Scholar] [CrossRef]
- Adomavicius, G.; Kwon, Y. New recommendation techniques for multicriteria rating systems. IEEE Intell. Syst. 2007, 22, 48–55. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User ID | Movie ID | Direction | Action | Story | Visual | Overall |
|---|---|---|---|---|---|---|
| 101 | 1 | C | ||||
| 3 | B | |||||
| 5 | ||||||
| 102 | 3 | |||||
| 5 | C | |||||
| 6 | C | B | ||||
| 101 | 1 | 13 | 6 | 5 | 8 | 5 |
| 3 | 9 | 10 | 10 | 11 | 8 | |
| 5 | 8 | 11 | 10 | 11 | 11 | |
| 102 | 3 | 13 | 13 | 13 | 13 | 13 |
| 5 | 5 | 6 | 13 | 13 | 13 | |
| 6 | 6 | 9 | 7 | 8 | 8 |
| Value | Frequency | Percentage | CumFreq |
|---|---|---|---|
| 1 | 3395 | ||
| 2 | 1340 | ||
| 3 | 1522 | ||
| 4 | 1329 | ||
| 5 | 2051 | ||
| 6 | 2428 | ||
| 7 | 2489 | ||
| 8 | 3251 | ||
| 9 | 5586 | ||
| 10 | 7006 | ||
| 11 | 6702 | ||
| 12 | 12,153 | ||
| 13 | 12,904 |
| User ID | Hotel ID | Value | Rooms | Location | Cleanliness | Check-in Desk | Service | Overall |
|---|---|---|---|---|---|---|---|---|
| 27 | 1 | 1 | 5 | 4 | 5 | 5 | 5 | 4 |
| 9 | 1 | 5 | 5 | 5 | 5 | 4 | 3 | 5 |
| 22 | 6 | 3 | 2 | 4 | 3 | 3 | 3 | 3 |
| 27 | 6 | 4 | 5 | 4 | 5 | 5 | 4 |
| Overall | Value | Rooms | Location | Cleanliness | Check-in Desk | Service | |
|---|---|---|---|---|---|---|---|
| Overall | |||||||
| Value | |||||||
| Rooms | |||||||
| Location | |||||||
| Cleanliness | |||||||
| Check-in desk | |||||||
| Service |
| Settings | Algorithms | F-Measure | AUC | NDCG | FCP | ||||
|---|---|---|---|---|---|---|---|---|---|
| 10–10 | |||||||||
| - | |||||||||
| - | |||||||||
| 5–10 | |||||||||
| - | |||||||||
| - | |||||||||
| 10–5 | |||||||||
| - | |||||||||
| - | |||||||||
| 5–5 | |||||||||
| - | |||||||||
| - | |||||||||
| 5–4 | |||||||||
| - | |||||||||
| - | |||||||||
| Average | |||||||||
| - | * | * | * | * | * | * | * | * | |
| - |
| Algorithm | * | * | - ** | ** | ** | ** |
|---|---|---|---|---|---|---|
| Algorithm | * | * | - ** | ** | ** | ** |
|---|---|---|---|---|---|---|
| Measure | - | - | ||
|---|---|---|---|---|
| Algorithms | RMSE | MAE | F-Measure | AUC | NDCG | FCP | ||
|---|---|---|---|---|---|---|---|---|
| - | ||||||||
| - |
| Algorithm | * | * | - ** | ** | ** | ** |
|---|---|---|---|---|---|---|
| Algorithm | * | * | - ** | ** | ** | ** |
|---|---|---|---|---|---|---|
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassan, M.; Hamada, M. A Neural Networks Approach for Improving the Accuracy of Multi-Criteria Recommender Systems. Appl. Sci. 2017, 7, 868. https://doi.org/10.3390/app7090868
Hassan M, Hamada M. A Neural Networks Approach for Improving the Accuracy of Multi-Criteria Recommender Systems. Applied Sciences. 2017; 7(9):868. https://doi.org/10.3390/app7090868
Chicago/Turabian StyleHassan, Mohammed, and Mohamed Hamada. 2017. "A Neural Networks Approach for Improving the Accuracy of Multi-Criteria Recommender Systems" Applied Sciences 7, no. 9: 868. https://doi.org/10.3390/app7090868
APA StyleHassan, M., & Hamada, M. (2017). A Neural Networks Approach for Improving the Accuracy of Multi-Criteria Recommender Systems. Applied Sciences, 7(9), 868. https://doi.org/10.3390/app7090868