
A Scalable Parallel Architecture Based on Many-Core Processors for Generating HTTP Traffic


Abstract
:1. Introduction
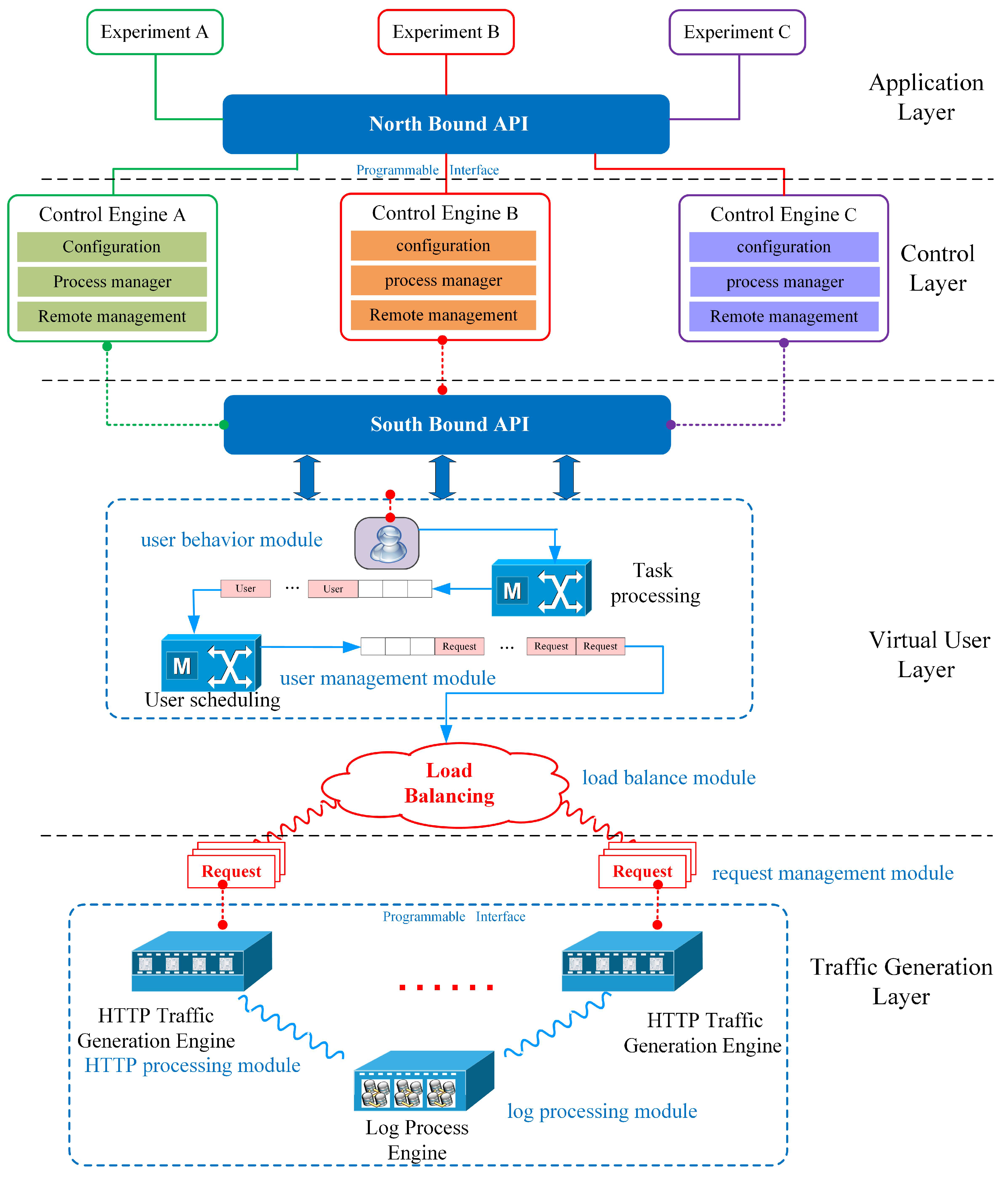
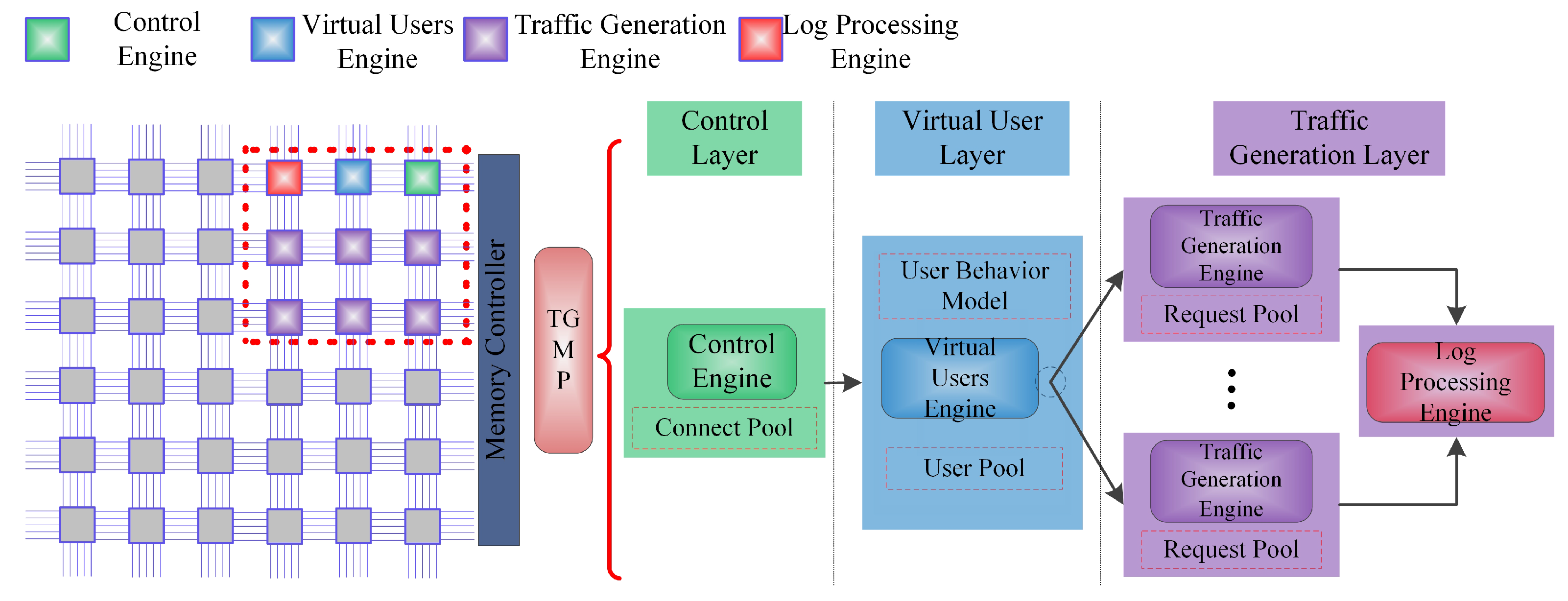
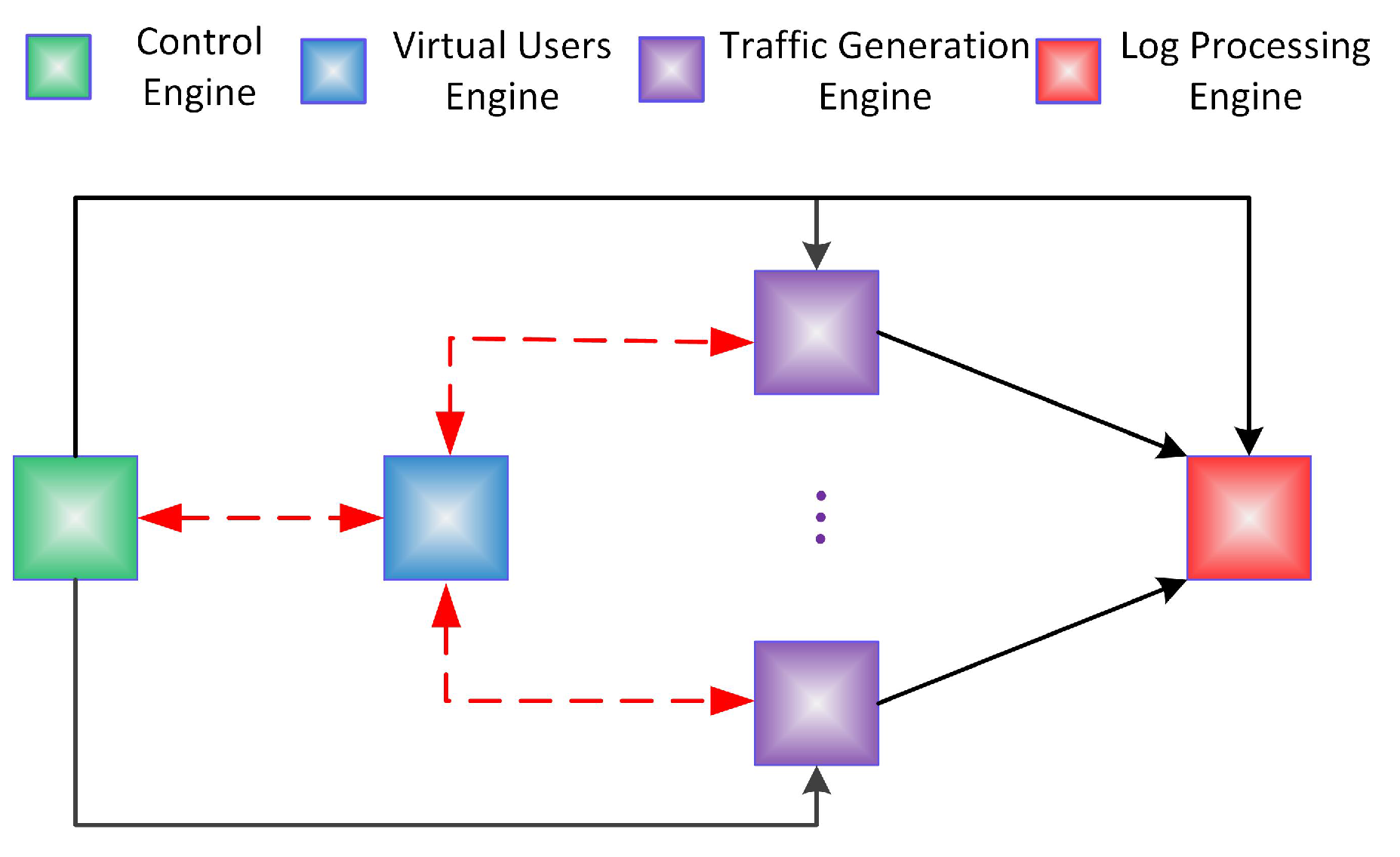
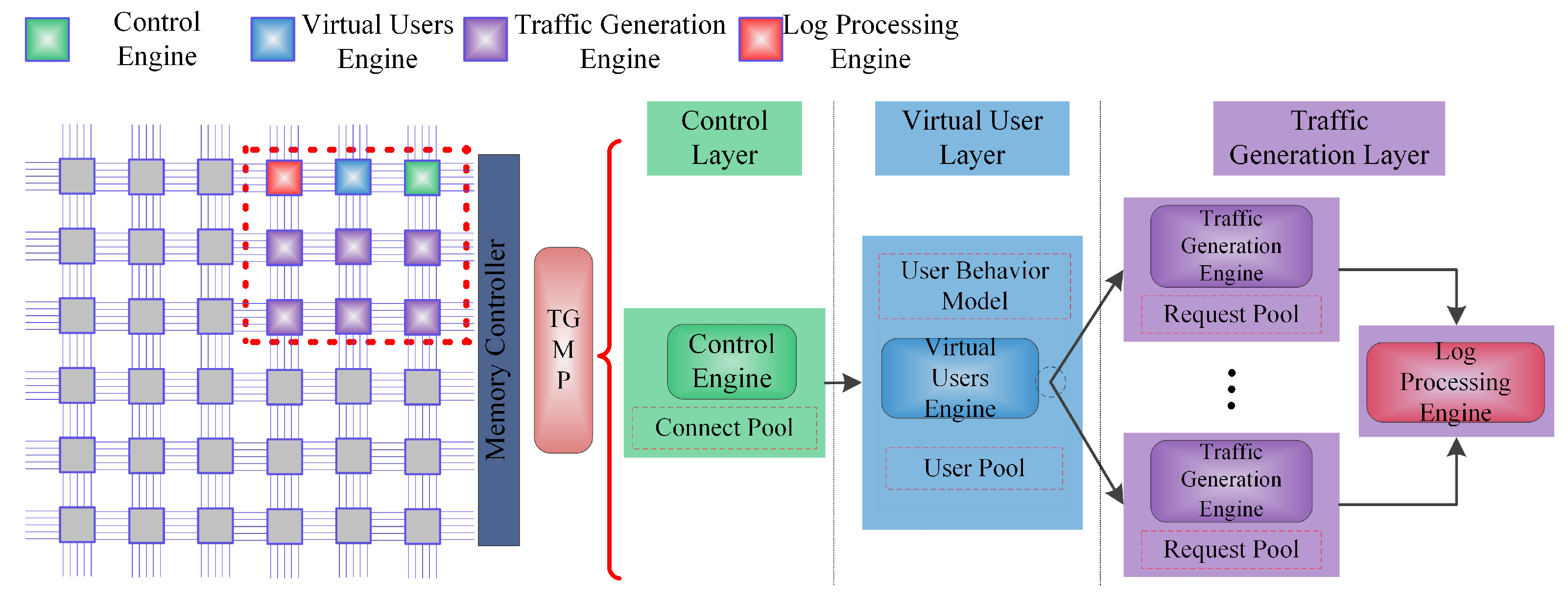
- The software architecture of a Web traffic generation system is proposed by using the hierarchical design methodology including the control layer, virtual user layer and traffic generation layer, to provide high scalability.
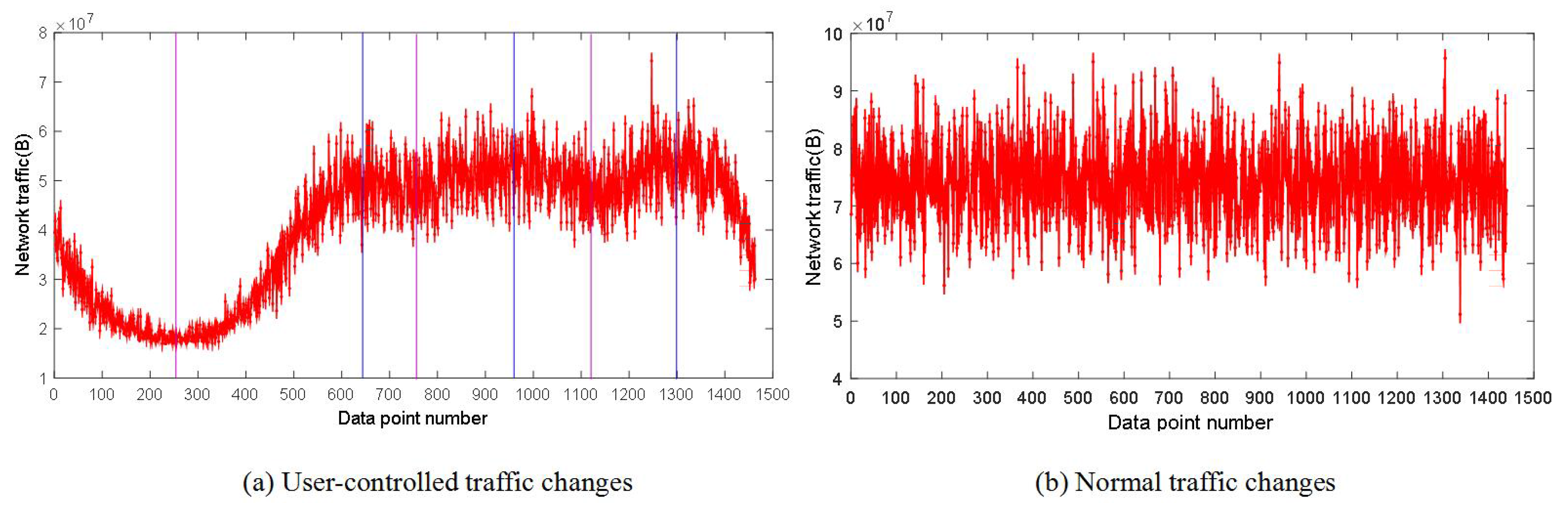
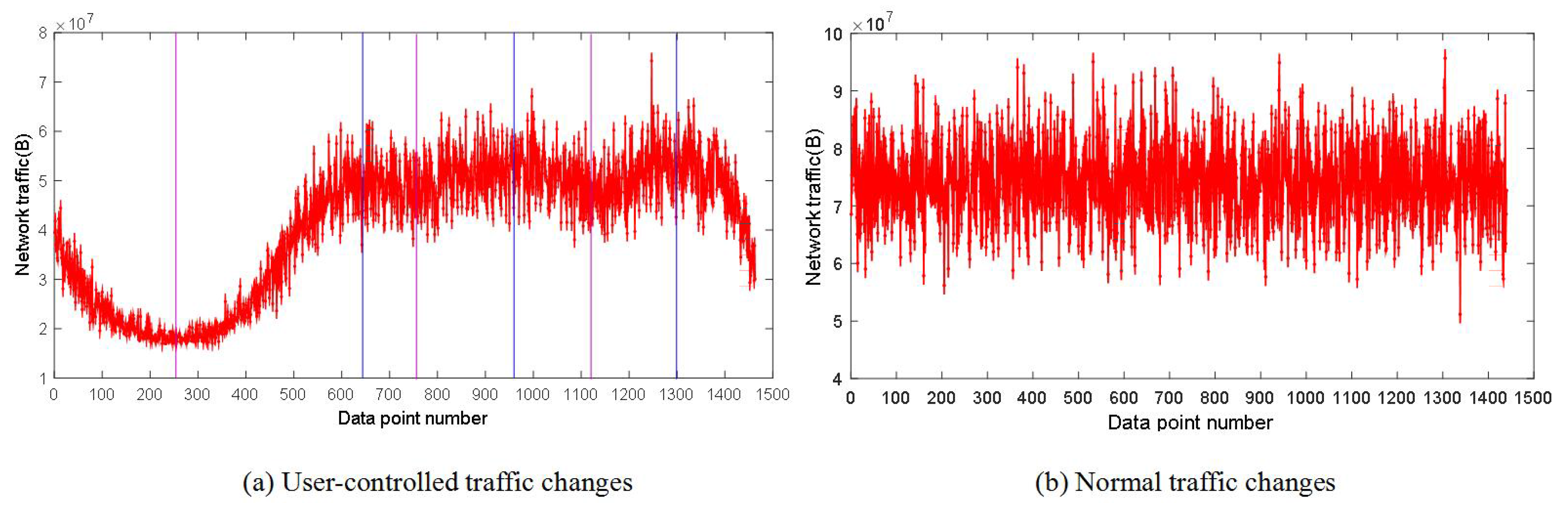
- We present a user-control method using the cubic spline interpolation based on the analysis of the Web user behavior simulation method of accessing the real server. The method enables the system to generate the background traffic with the characteristics of a real network over a long time scale according to the Internet user’s access time in different scenarios.
- In order to meet the requirements of concurrency, we have implemented a TGMP prototype. Three high concurrency strategies are employed, which enable the system to simulate a large number of virtual users at the same time, and generate more Web traffic.
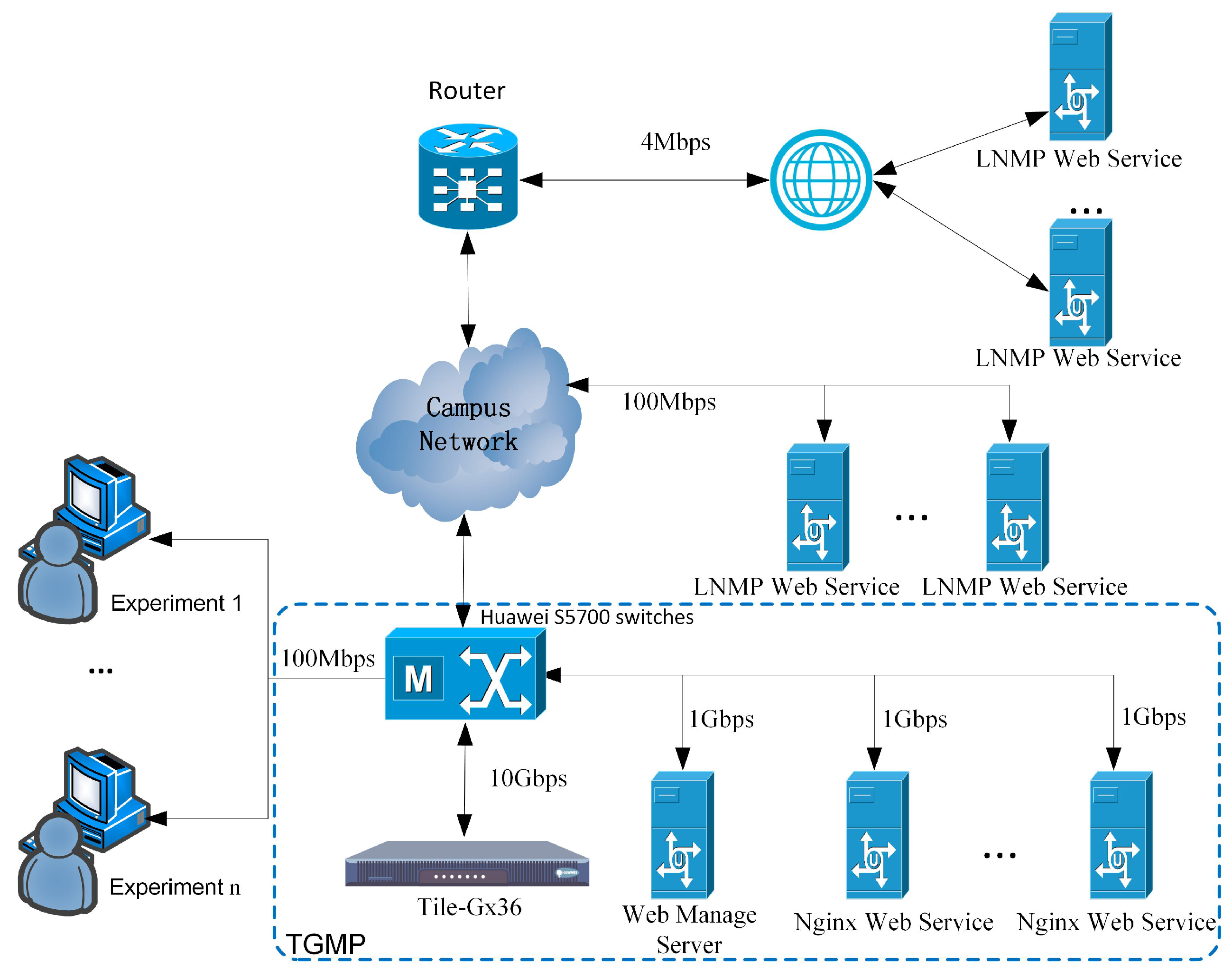
- We has been implemented and deployed in the real network at the third floor of the YiFu building in the CQUPT campus. The experiments show that compared with other systems, TGMP yields a more satisfactory performance in which 50,000 users access the Web server simultaneously.
2. Background and Challenges
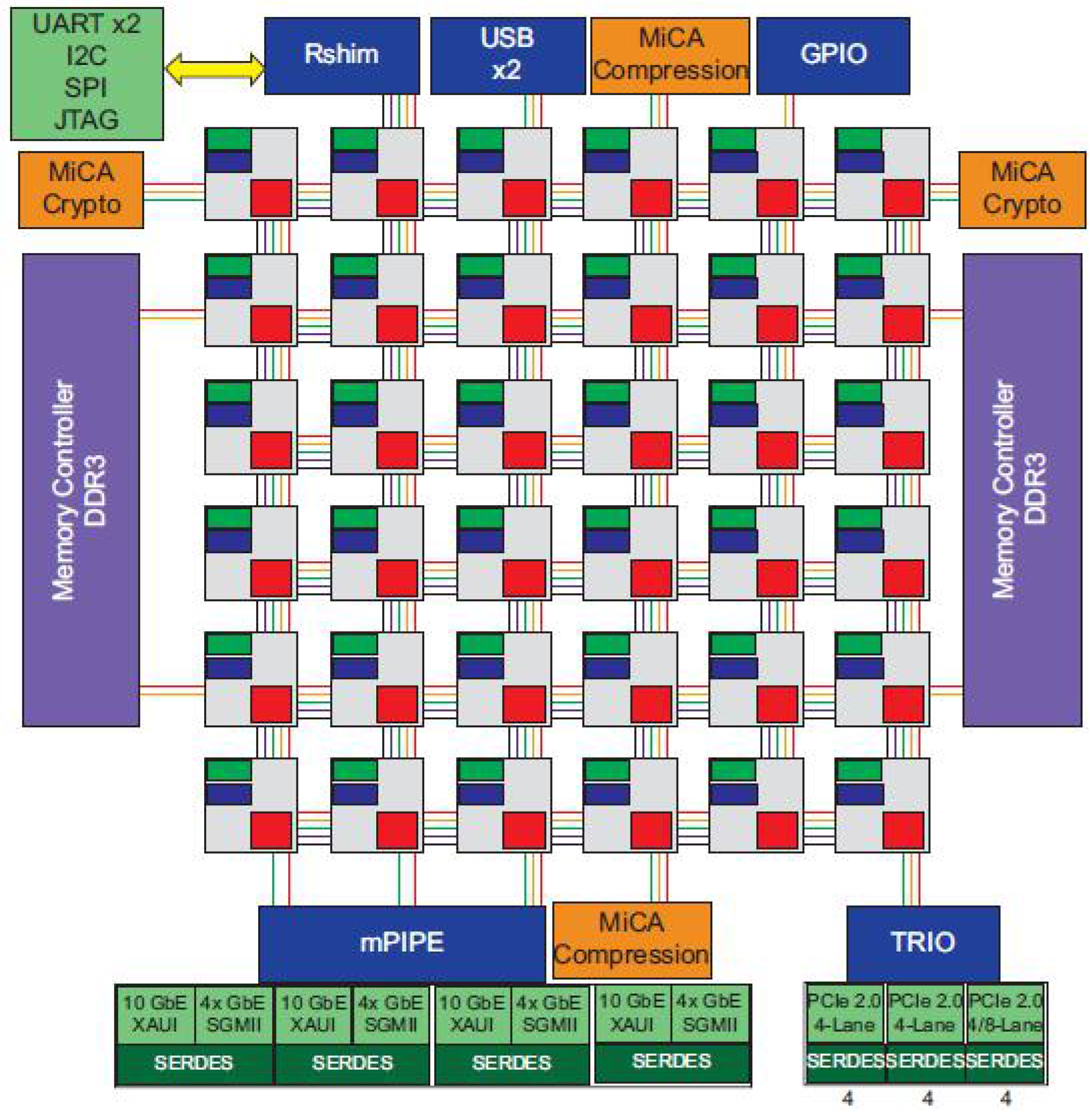
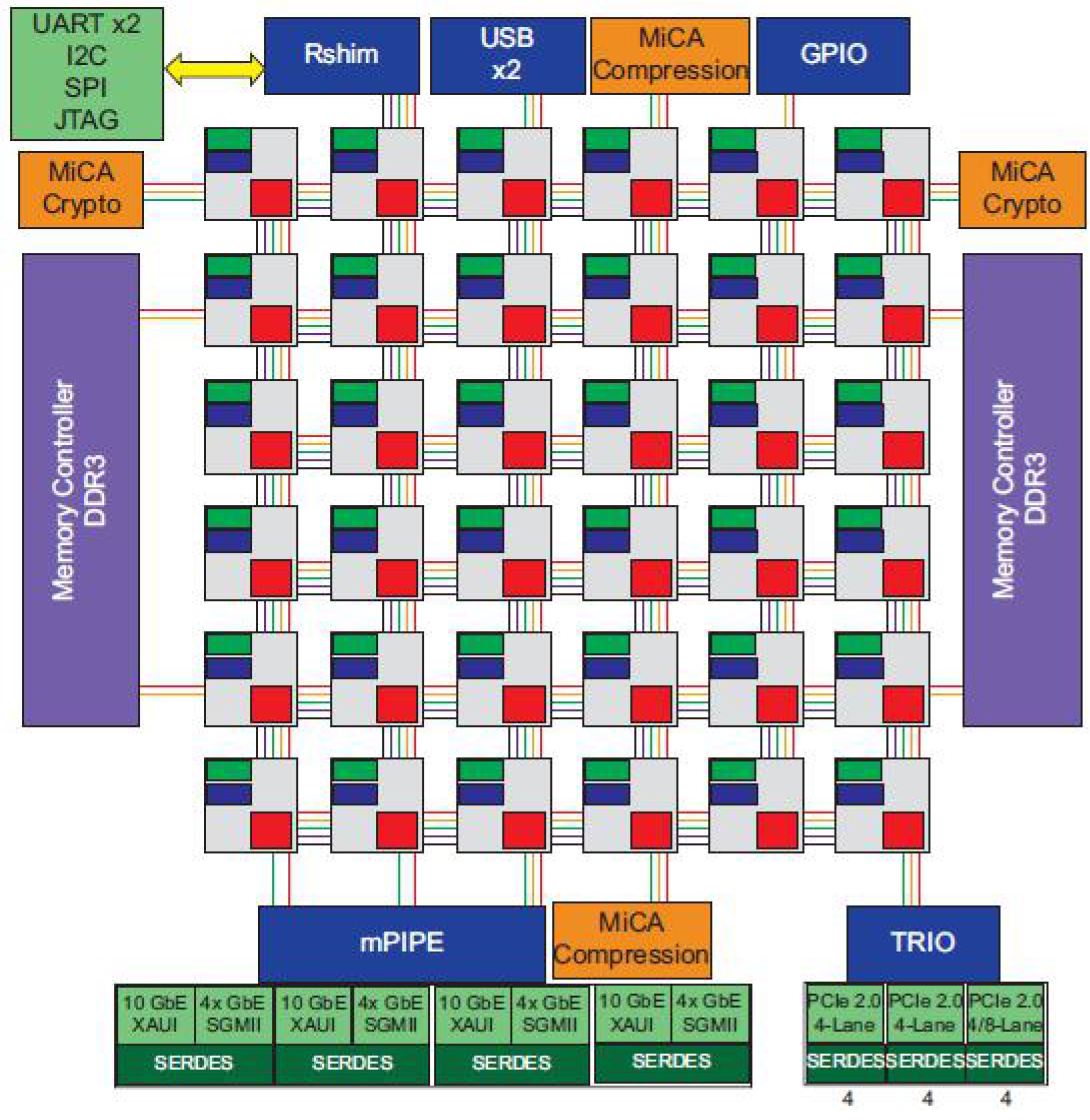
2.1. Overview of the TILEGX36 Architecture
2.2. The Existing Approaches of Traffic Generation
2.3. Challenges
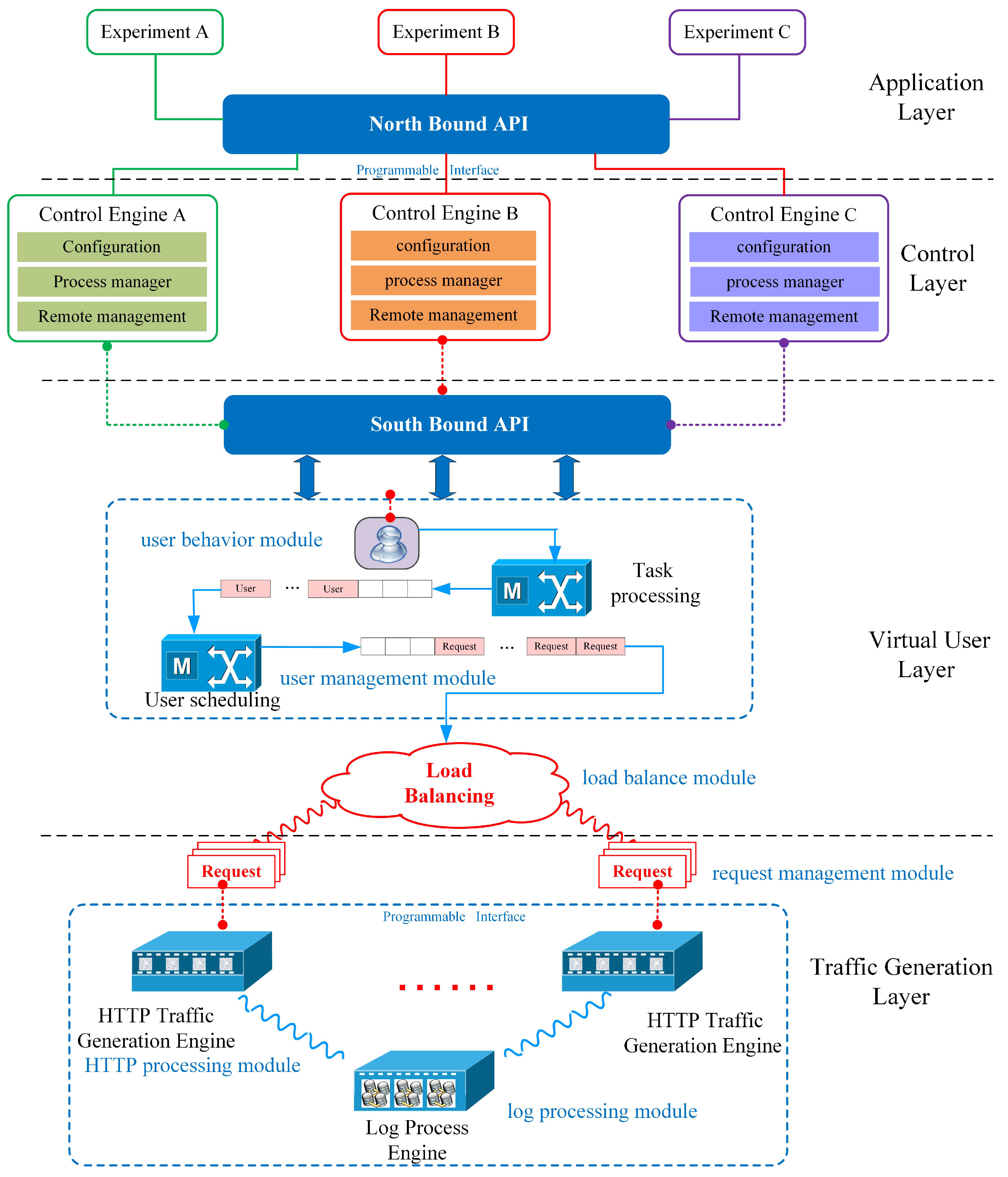
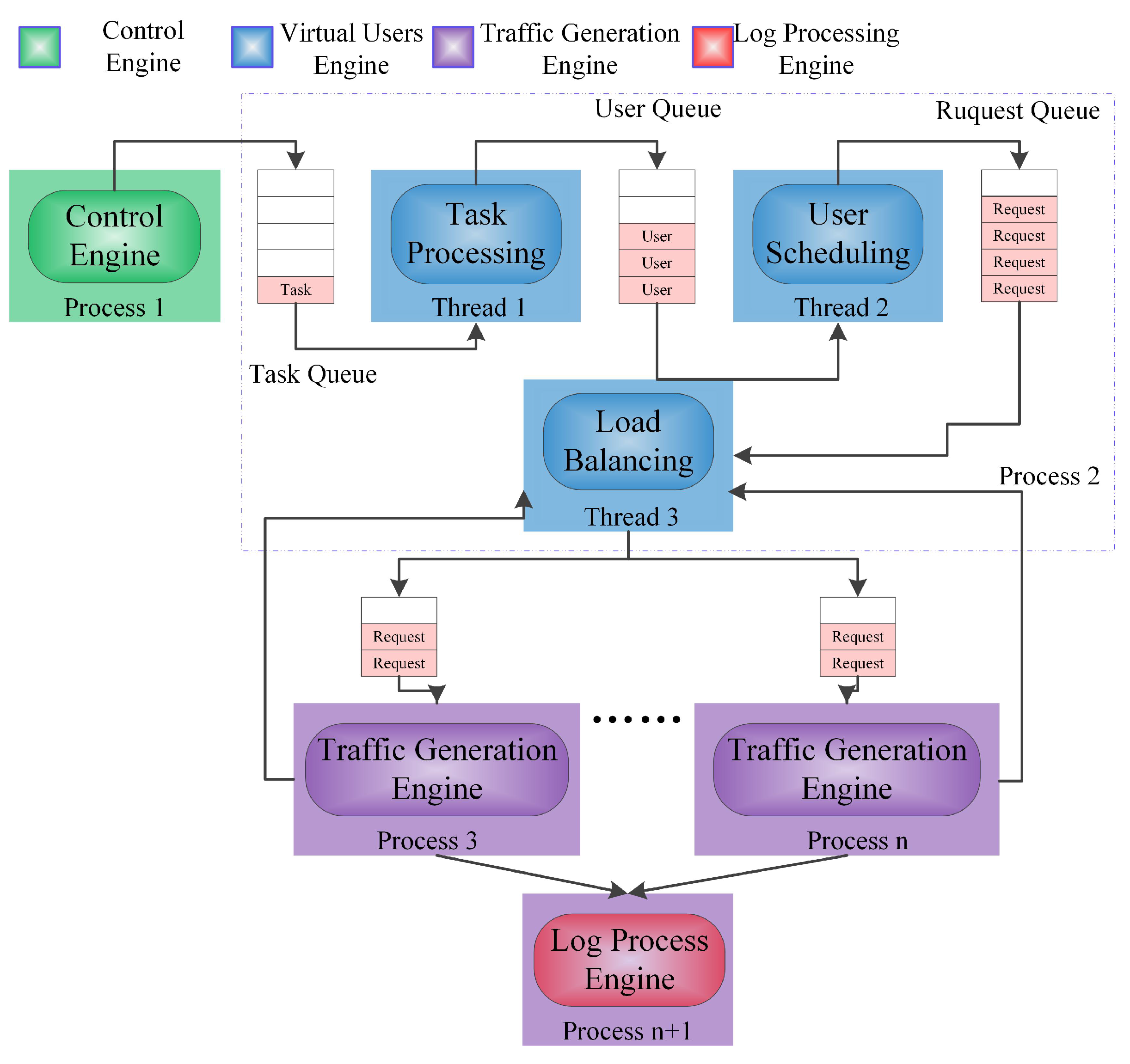
3. Traffic Generator Systems Architecture
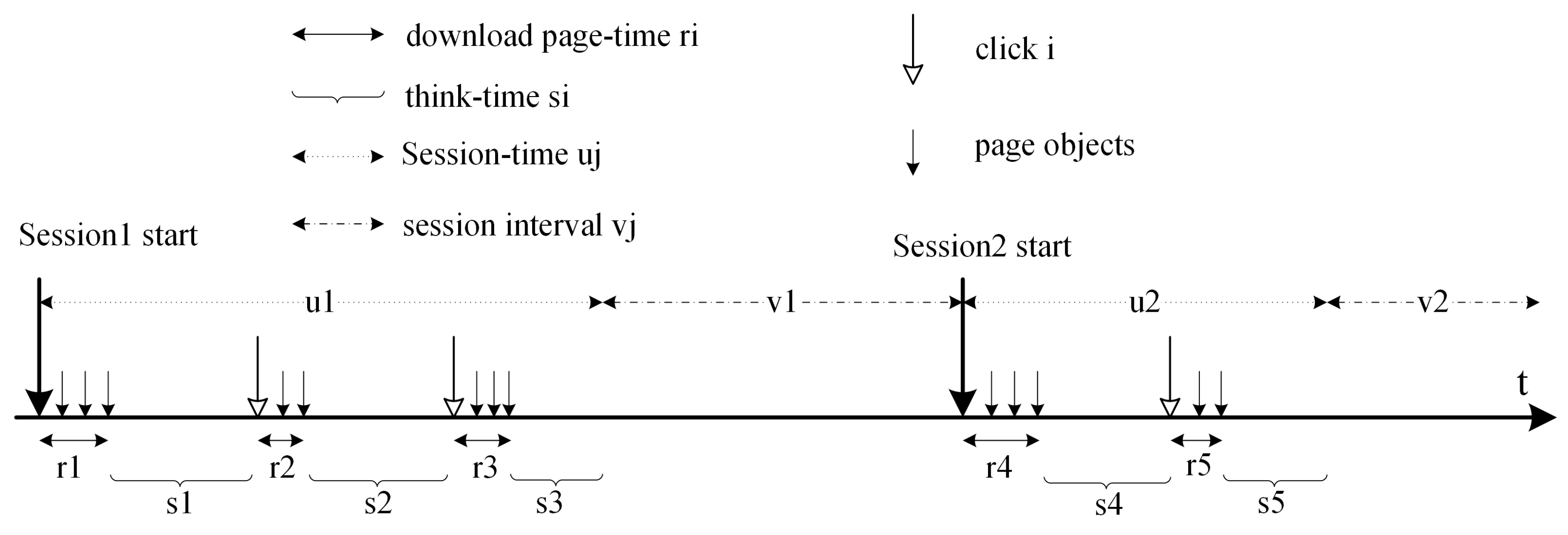
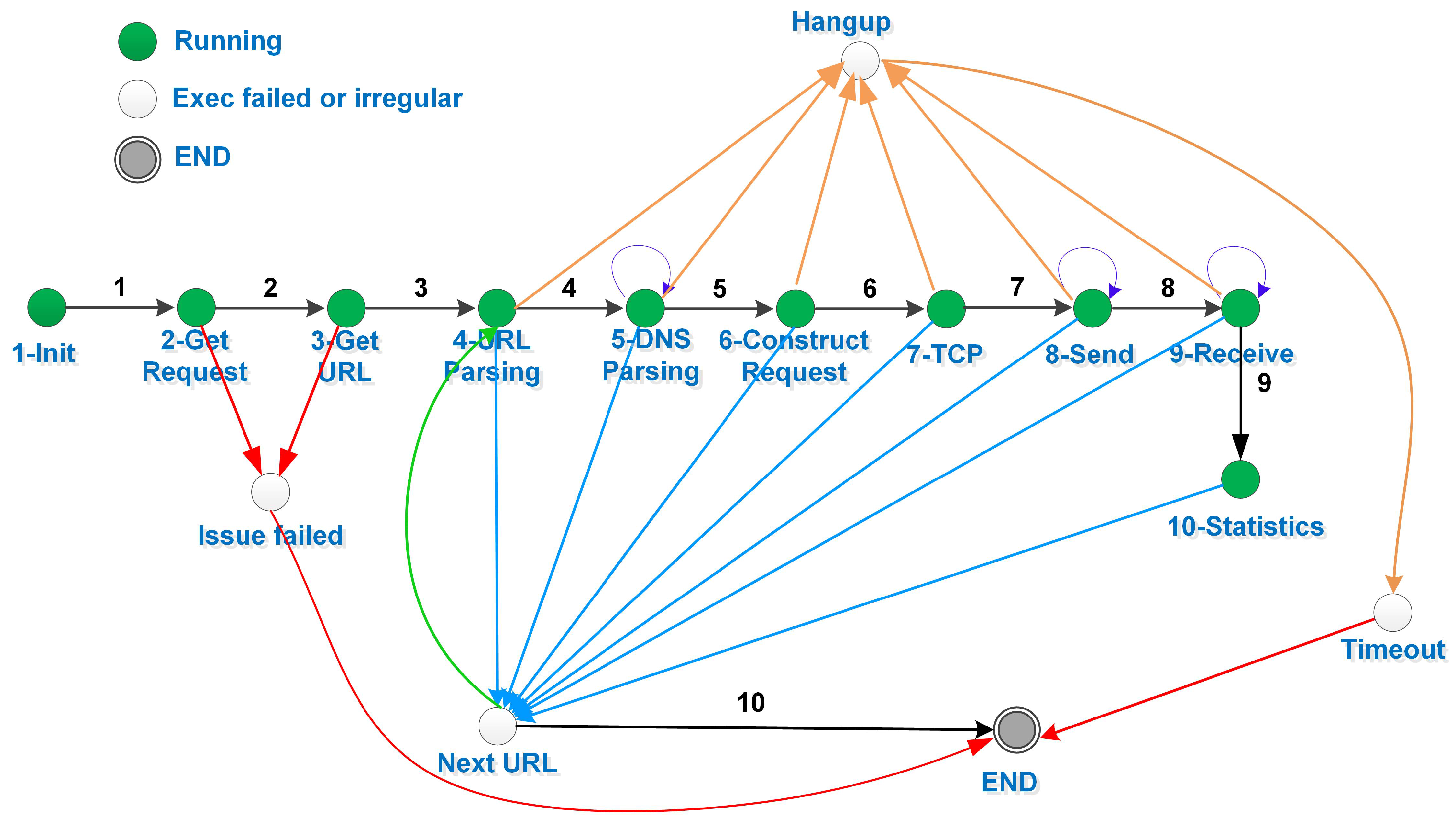
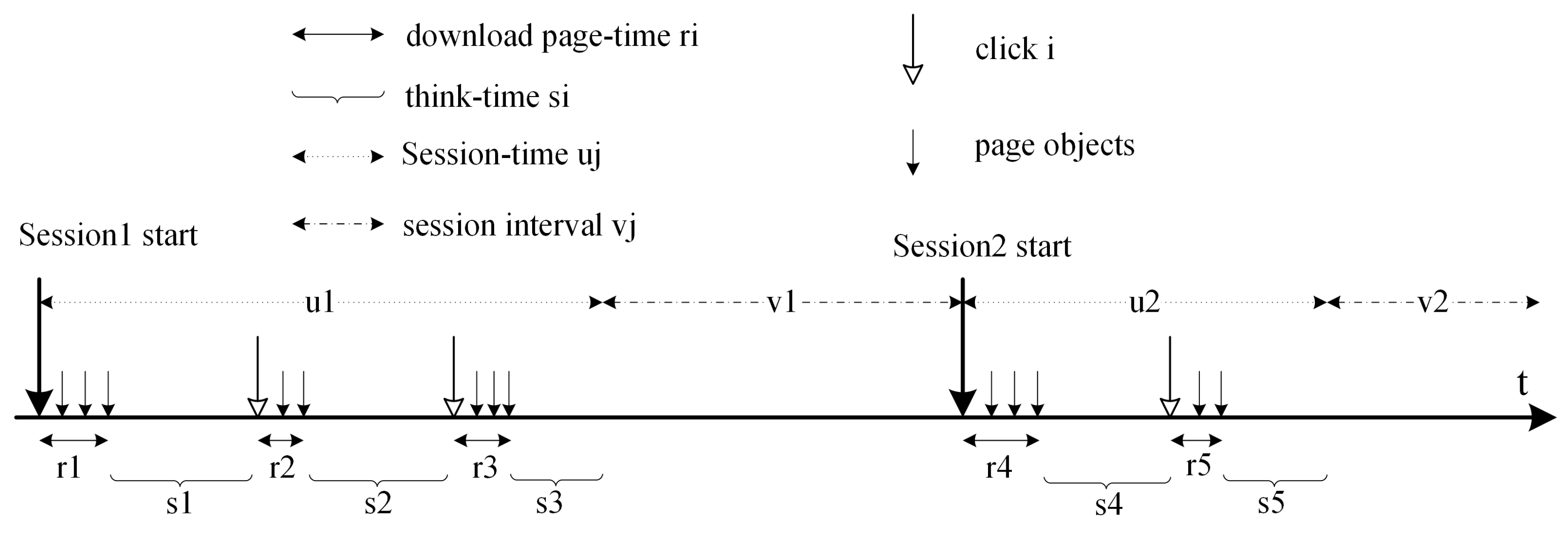
4. User Control Method by Cubic Spline Interpolation
5. The High Concurrency Strategy
5.1. Optimization of Parameters
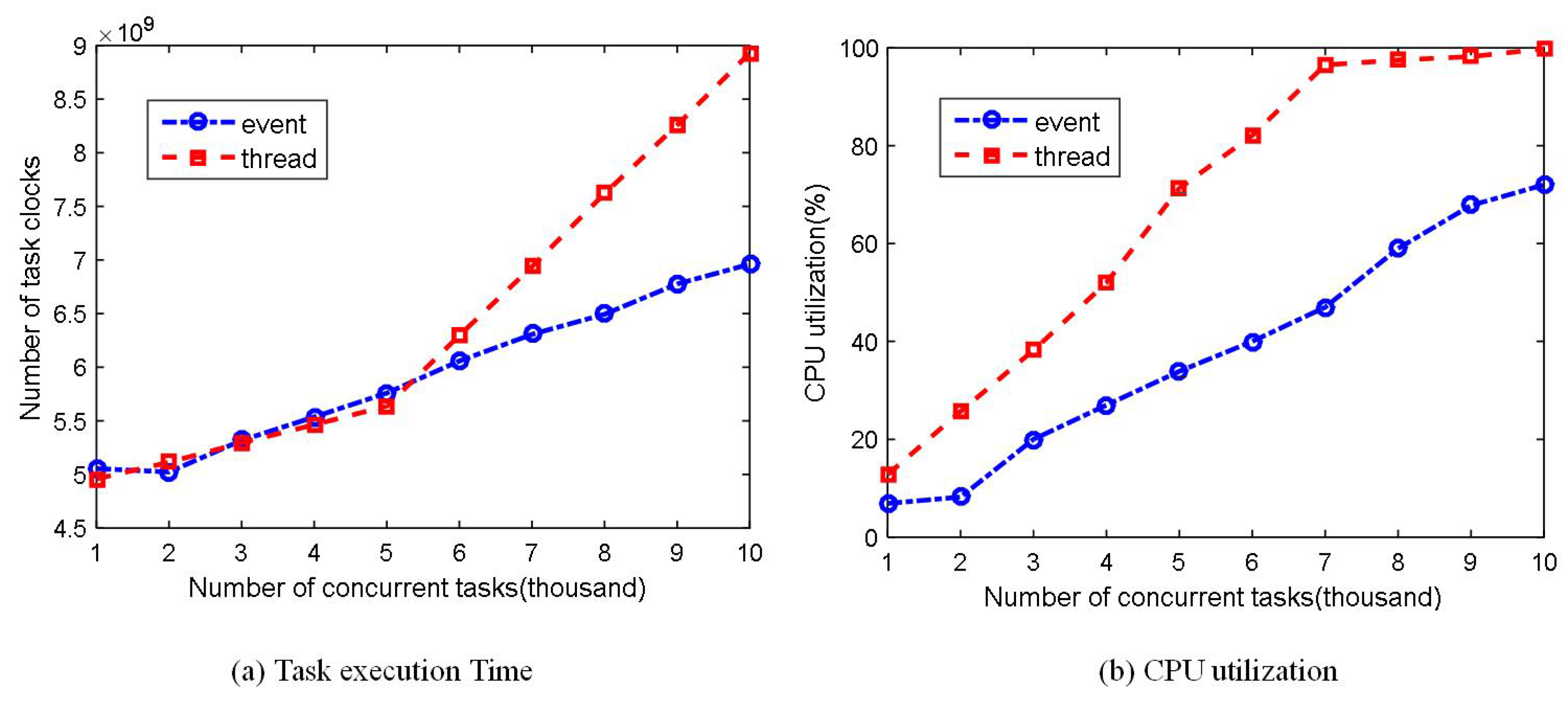
5.2. Event-Driven
5.3. Parallel Architectures on TILERAGX36
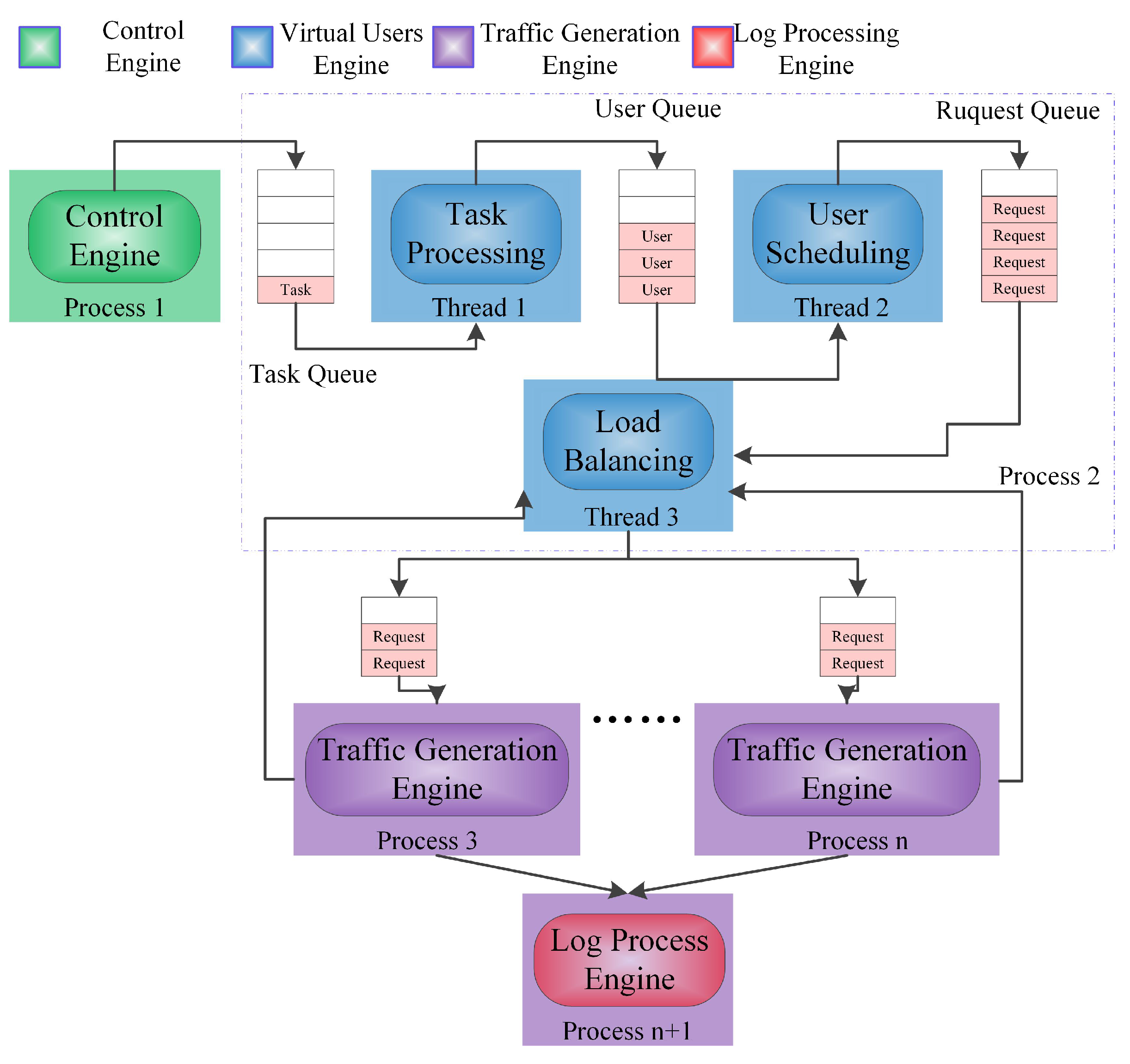
5.3.1. Task Decomposition
5.3.2. Task Mapping
5.3.3. IPC Scheme
5.3.4. Dynamic Load-Balancing Based on the Minimum Number of Requests (DMR)
6. Evaluation
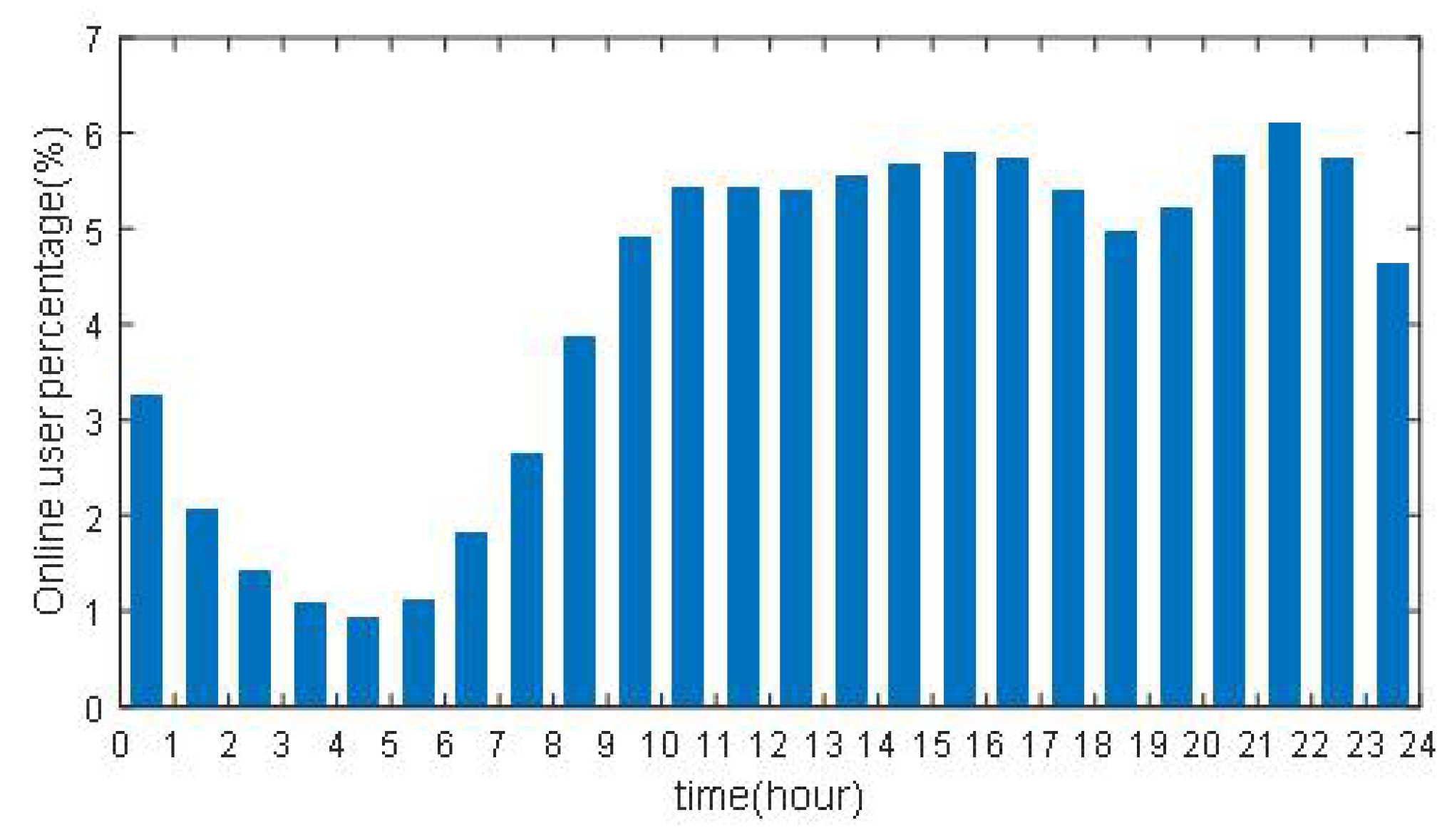
6.1. Experimental Setup
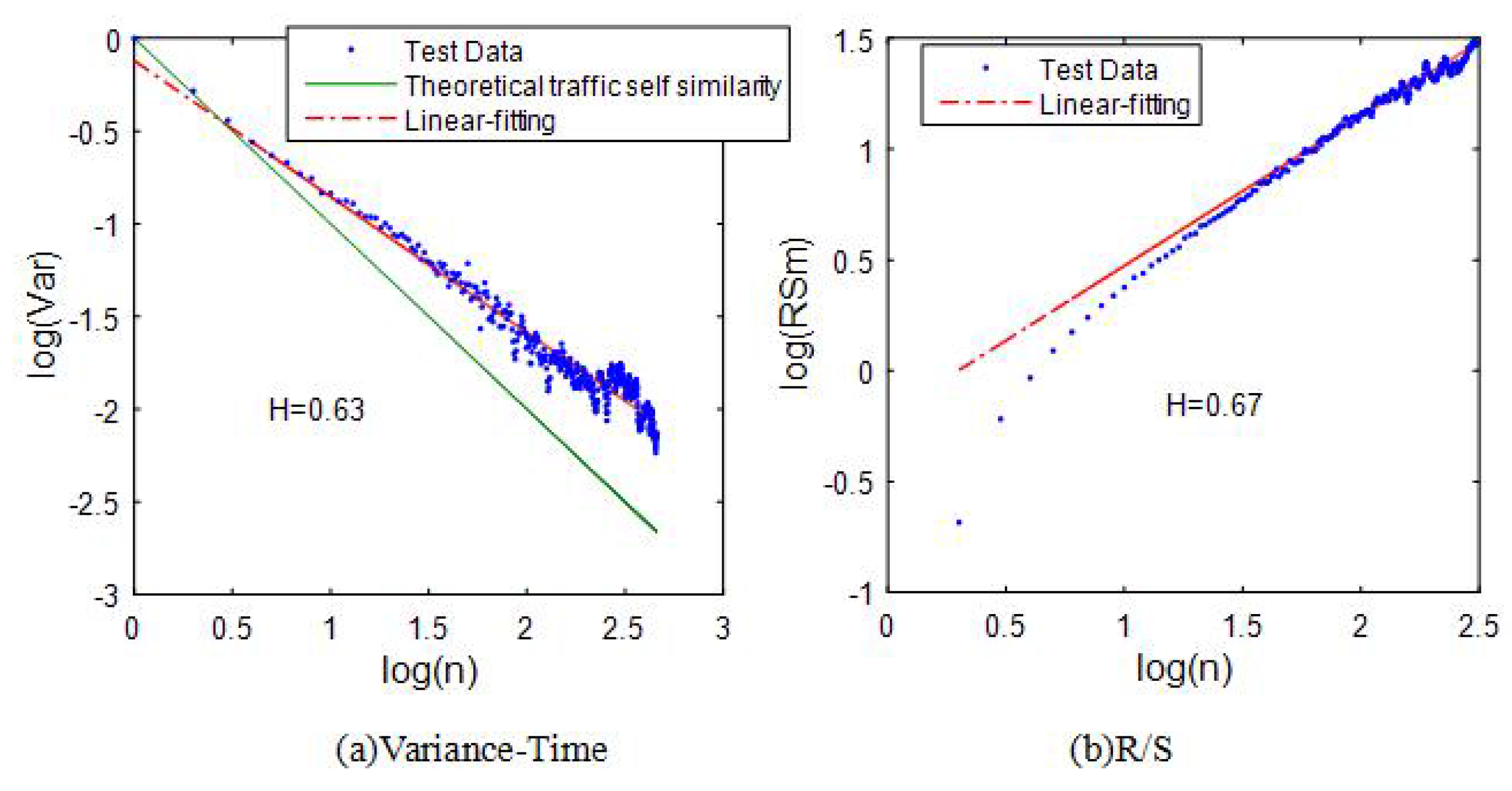
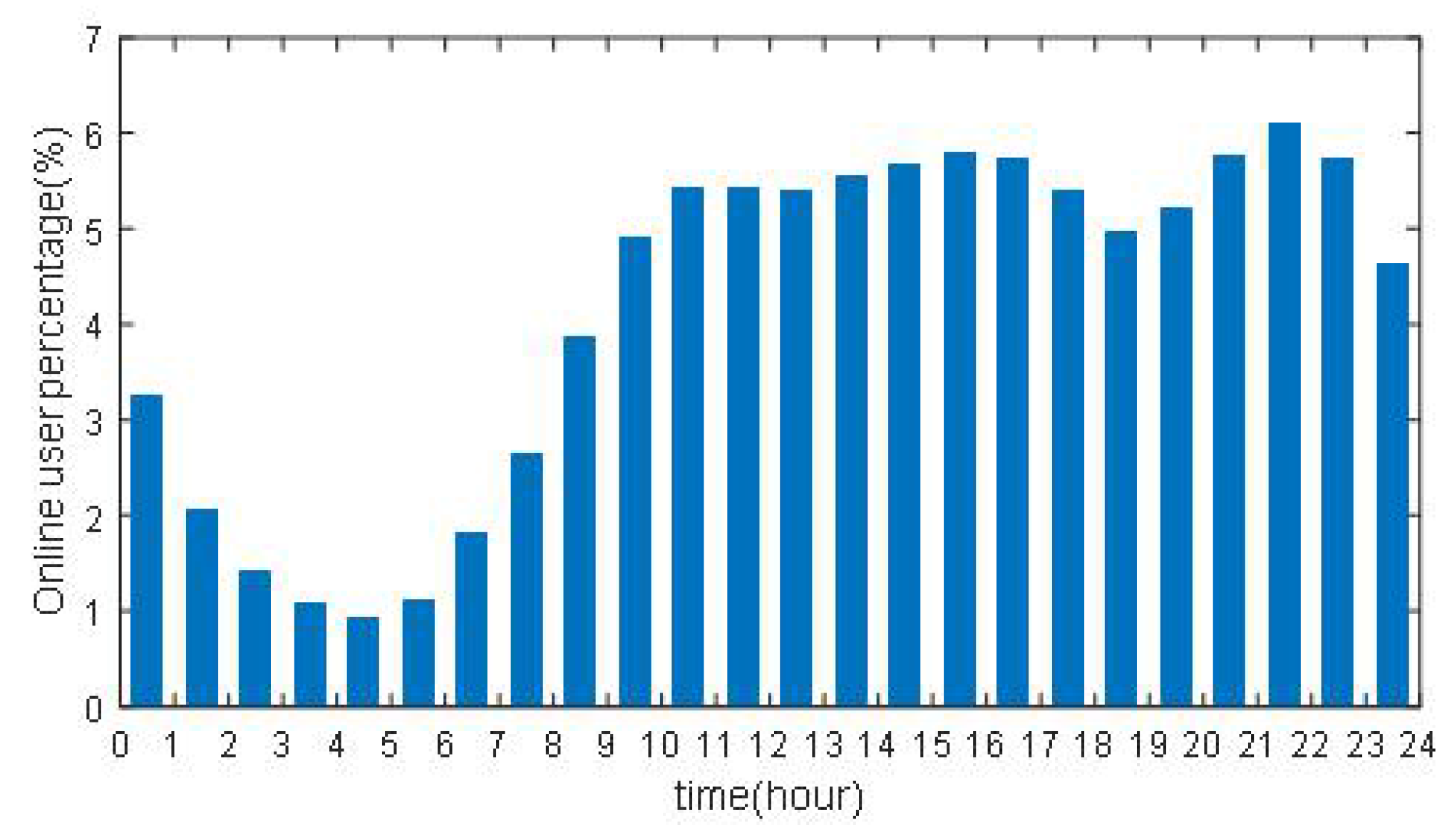
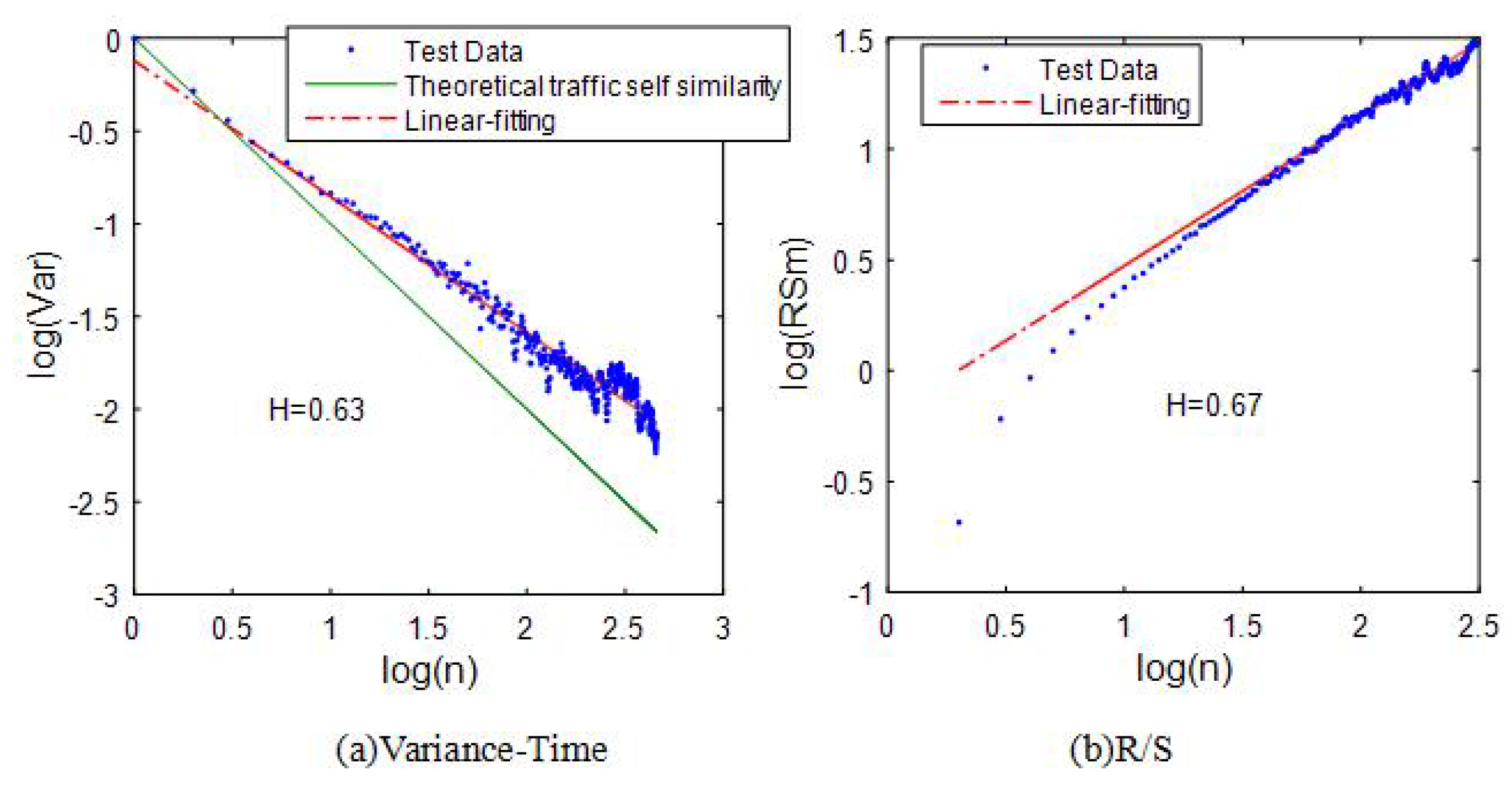
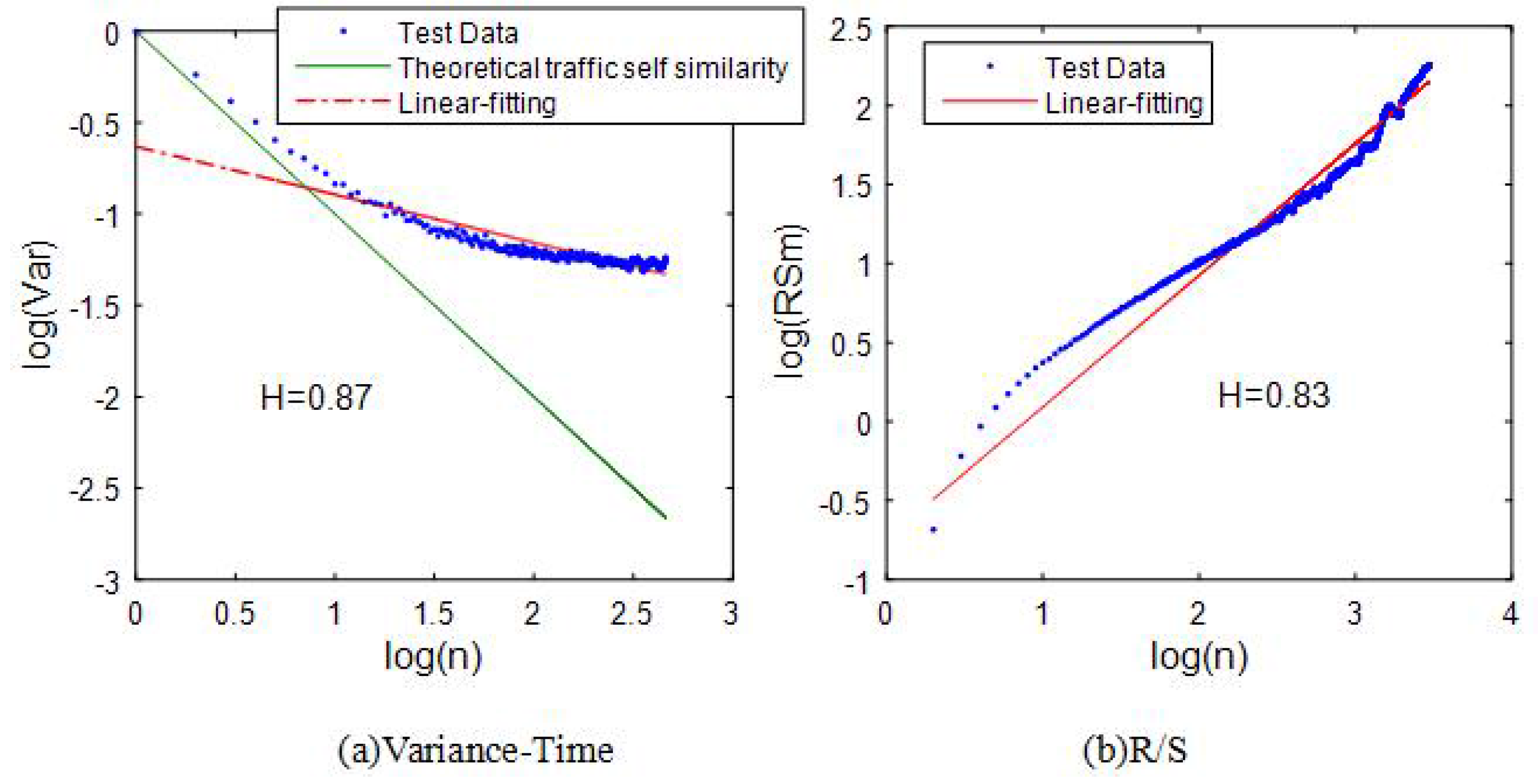
6.2. The Traffic Self-Similarity
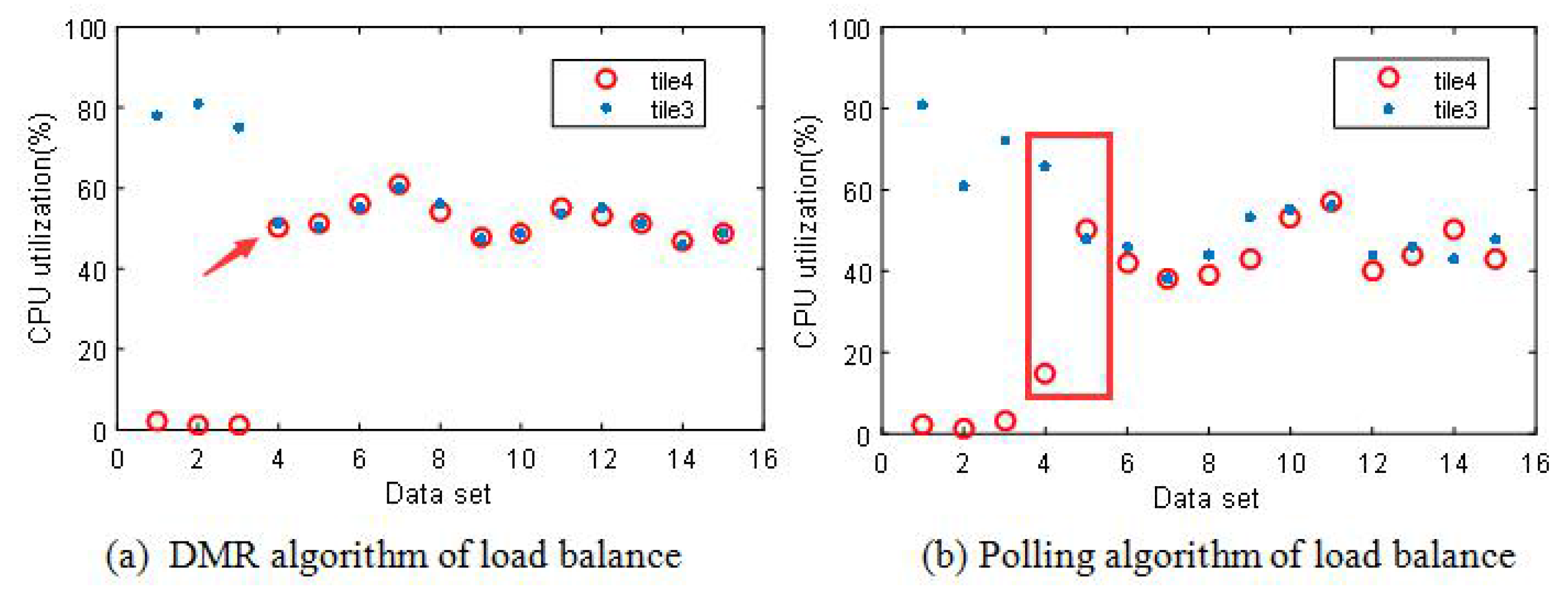
6.3. Load Balancing
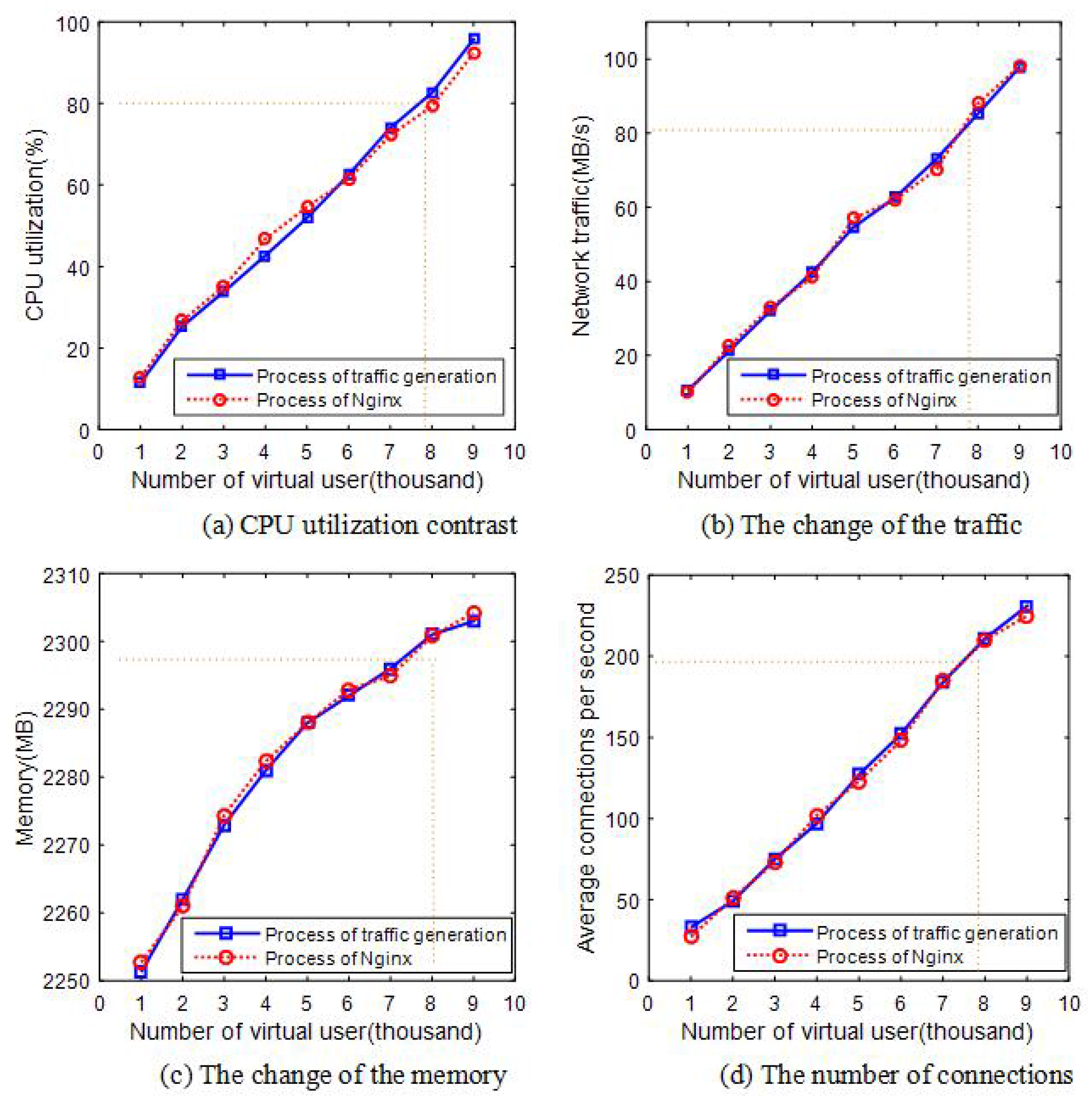
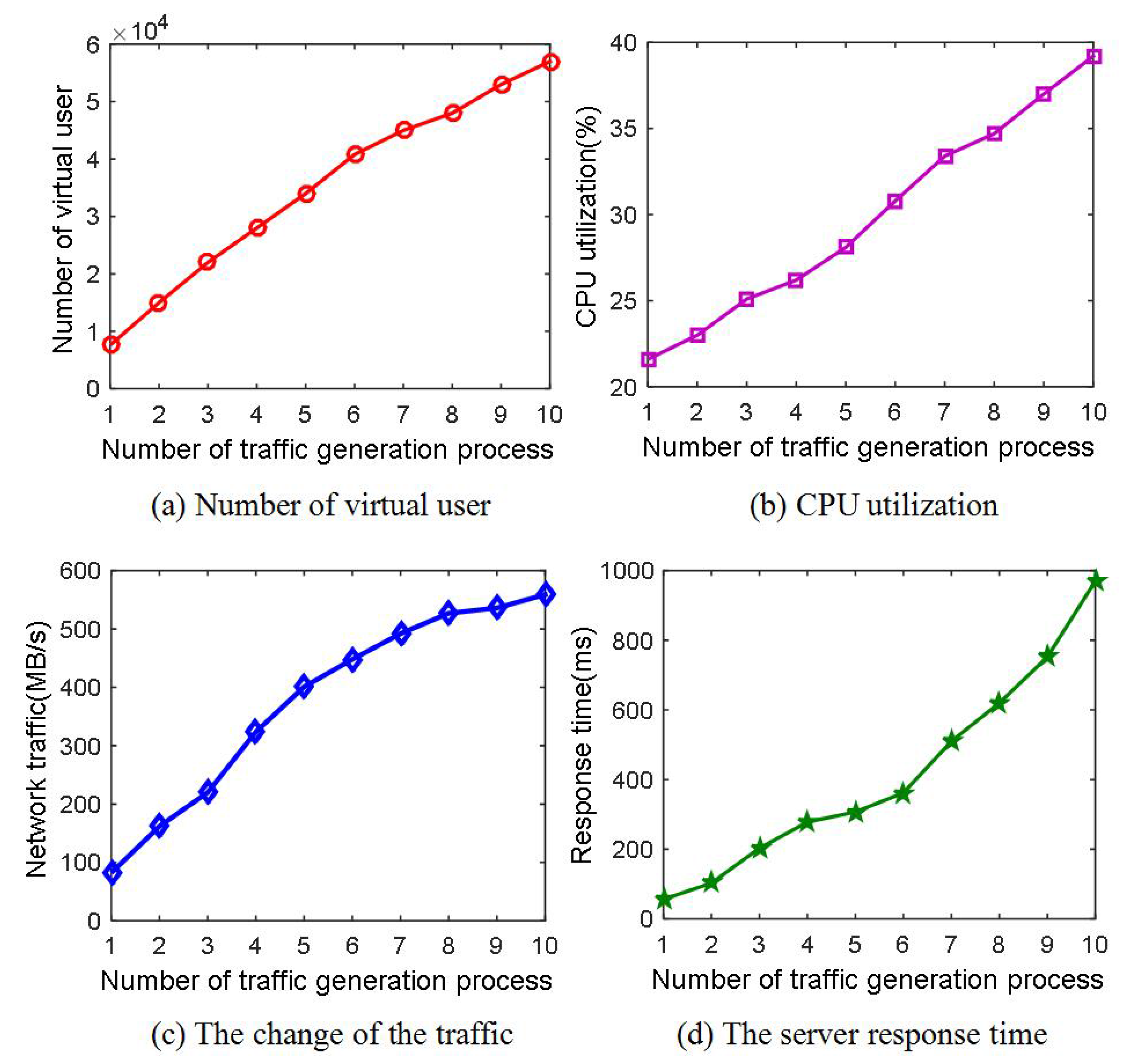
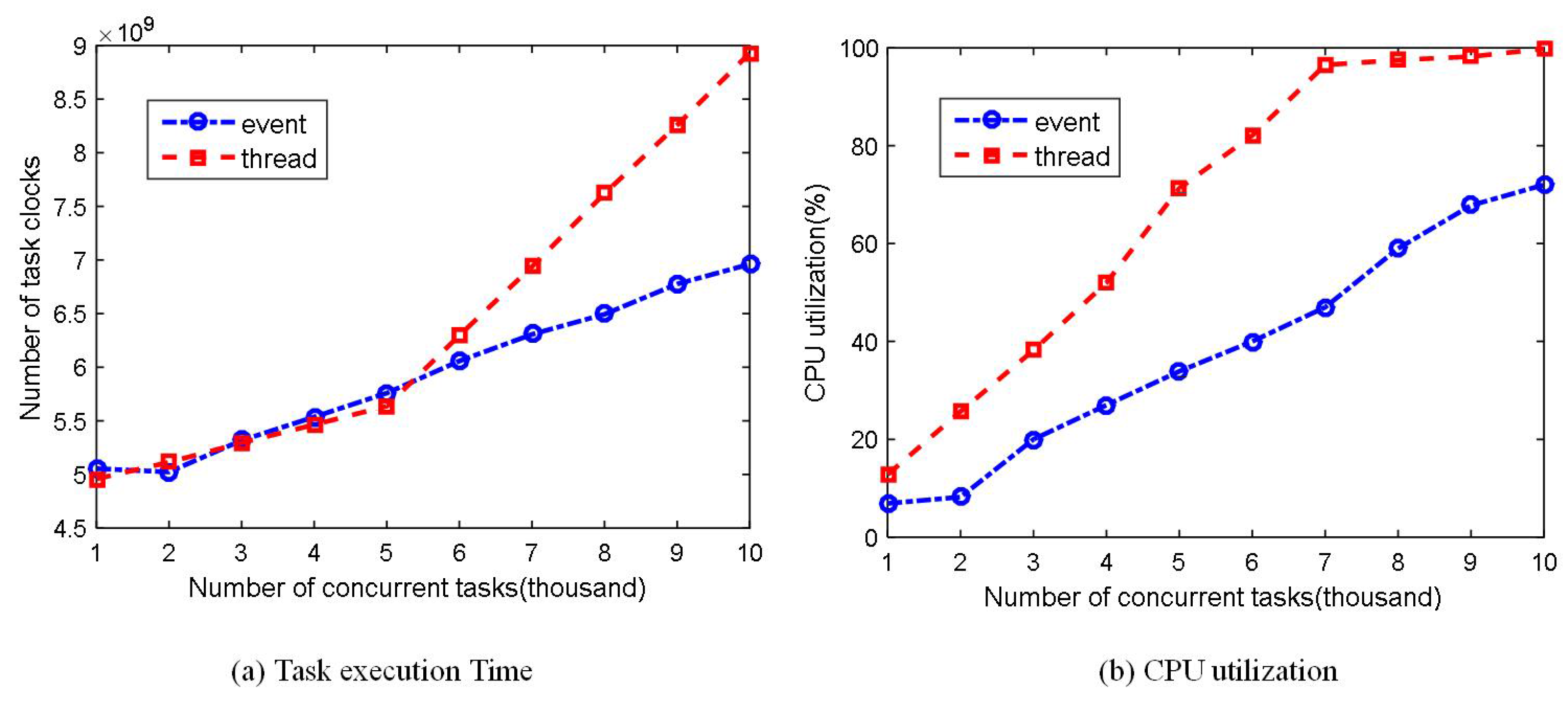
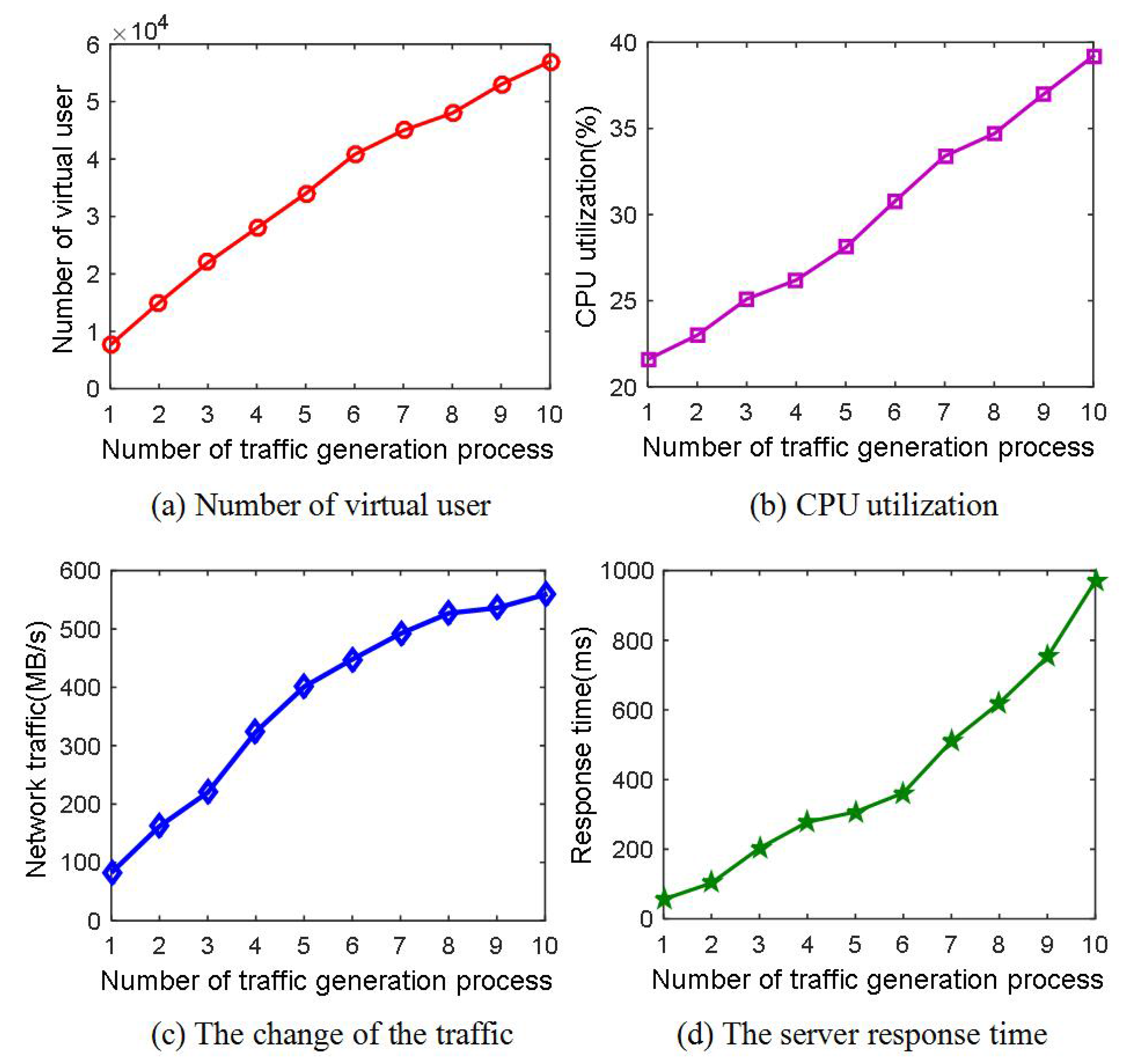
6.4. Concurrent Performance
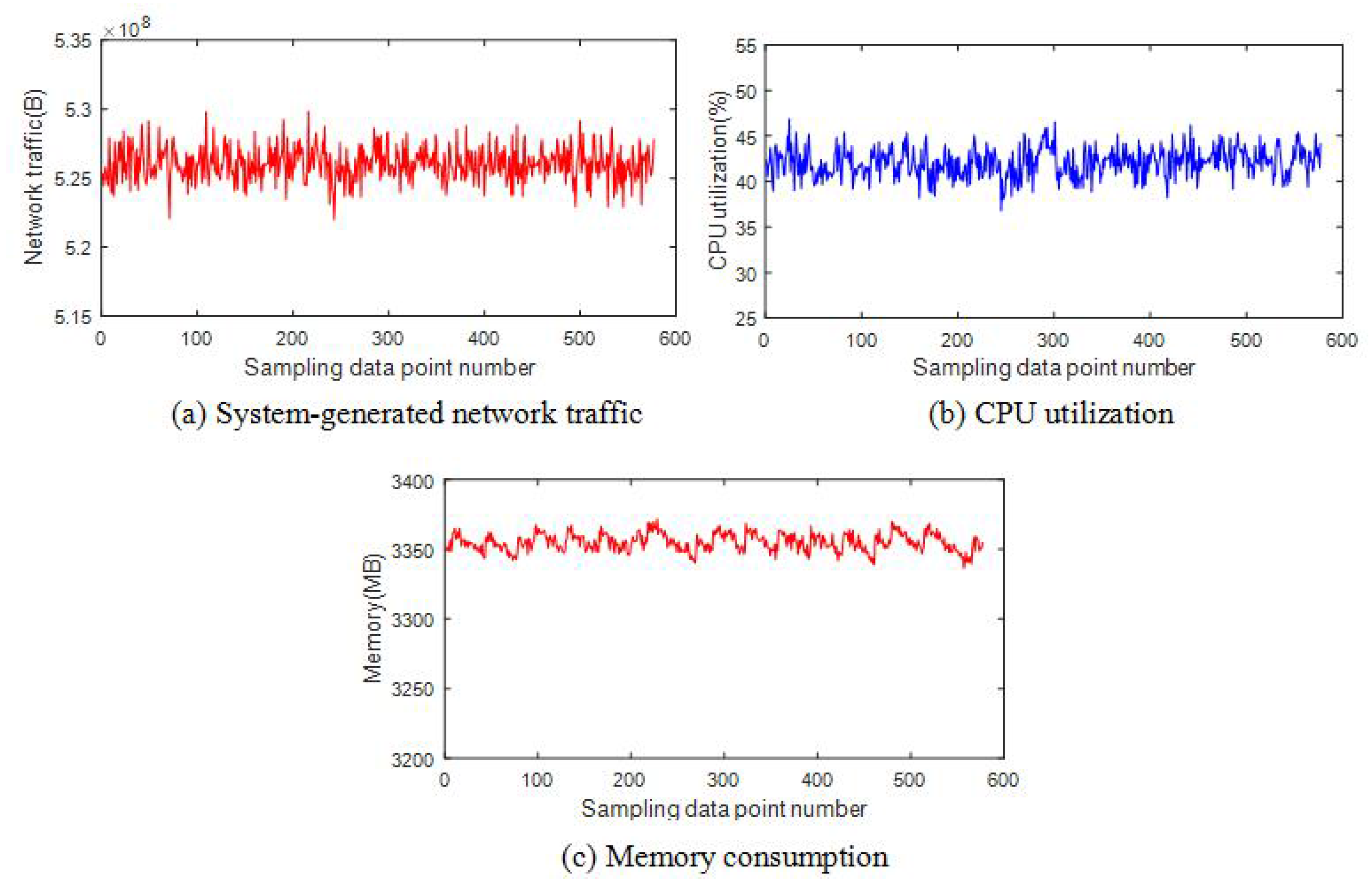
6.5. System Stability
6.6. Comparison with Existing System
7. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Feknous, M.; Houdoin, T.; Guyader, B.L.; de Biasio, J.; Gravey, A.; Torrijos Gijón, J.A. Internet traffic analysis: A case study from two major European operators. In Proceedings of the International Symposium on Computers and Communications, Funchal, Madeira, Portugal, 23–26 June 2014; pp. 1–7.
- Security Test Solution for App-Aware Devices. Available online: https://www.spirent.com/Products/Avalanche/ (accessed on 20 September 2016).
- Measure the Quality of Experience of Real-Time, Business-Critical Applications With Converged Multiplay Service Emulations. Available online: https://www.ixiacom.com/products/ixload (accessed on 20 September 2016).
- Thorndale, C.W. Webstone: The first generation in http server benchmarking. Geophys. Prospect. 1995, 29, 541–549. [Google Scholar]
- Busari, M.; Williamson, C. ProWGen: A synthetic workload generation tool for simulation evaluation of web proxy caches. Comput. Netw. 2002, 38, 779–794. [Google Scholar] [CrossRef]
- Katsaros, K.V.; Xylomenos, G.; Polyzos, G.C. GlobeTraff: A traffic workload generator for the performance evaluation of future Internet architectures. In Proceedings of the 2012 5th International Conference on New Technologies, Mobility and Security (NTMS), Istanbul, Turkey, 7–10 May 2012; pp. 1–5.
- Kant, K.; Tewari, V.; Iyer, R.K. Geist: A generator for e-commerce and internet server traffic. In Proceedings of the 2001 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Tucson, AZ, USA, 4–6 November 2001; pp. 49–56.
- Veloso, E.; Almeida, V.; Meira, W. A hierarchical characterization of a live streaming media workload. In Proceedings of the 2nd ACM SIGCOMM Workshop on Internet Measurment, Marseille, France, 6–8 November 2002; pp. 117–130.
- Abhari, A.; Soraya, M.; Meira, W. Workload generation for YouTube. Multimed. Tools Appl. 2010, 46, 91. [Google Scholar] [CrossRef]
- Zinke, J.; Habenschuss, J.; Schnor, B. Servload: Generating representative workloads for web server benchmarking. In Proceedings of the 2012 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS), Genoa, Italy, 8–11 July 2012; pp. 1–8.
- Cheng, Y.; Çetinkaya, E.K.; Sterbenz, J.P.G. Transactional traffic generator implementation in ns-3. In Proceedings of the 6th International ICST Conference on Simulation Tools and Techniques, Cannes, France, 5–7 March 2013; pp. 182–189.
- Botta, A.; Dainotti, A.; Pescapé, A. A tool for the generation of realistic network workload for emerging networking scenarios. Comput. Netw. 2012, 56, 3531–3547. [Google Scholar] [CrossRef]
- Nedjah, N.; Calazan, R.M.; de Macedo Mourelle, L.; Wang, C. Parallel Implementations of the Cooperative Particle Swarm Optimization on Many-Core and Multi-core Architectures. Int. J. Parallel Program. 2016, 44, 1173–1199. [Google Scholar] [CrossRef]
- Jiang, H.; Zhang, G.; Xie, G.; Salamatian, K.; Mathy, L. Scalable high-performance parallel design for network intrusion detection systems on Many-Core processors. In Proceedings of the Ninth ACM/IEEE Symposium on Architectures for Networking and Communications Systems, San Jose, CA, USA, 21–22 October 2013; pp. 137–146.
- Qiao, S.; Xu, C.; Xie, L.; Yang, J.; Hu, C.; Guan, X.; Zou, J. Network recorder and player: FPGA-based network traffic capture and replay. In Proceedings of the 2014 International Conference on Field-Programmable Technology (FPT), Shanghai, China, 10–12 December 2014; pp. 342–345.
- Huang, C.Y.; Lin, Y.D.; Liao, P.Y.; Lai, Y.C. Stateful traffic replay for web application proxies. Secur. Commun. Netw. 2015, 8, 970–981. [Google Scholar] [CrossRef]
- Xu, L.; Zhang, W.; Chen, L. Modeling Users’ Visiting Behaviors for Web Load Testing by Continuous Time Markov Chain. In Proceedings of the 2010 Seventh Web Information Systems and Applications Conference (WISA), Huhehot, China, 20–22 August 2010; pp. 59–64.
- Web Polygraph. Available online: http://web-polygraph.org (accessed on 20 November 2016).
- Mosberger, D.; Jin, T. Httperf: A tool for measuring web server performance. In Proceedings of the First Workshop on Internet Server Performance (WISP), Madison, WI, USA, 23 June 1998; ACM: New York, NY, USA, 1998; Volume 26, pp. 31–37. [Google Scholar]
- Varet, A.; Larrieu, N. How to generate realistic network traffic. In Proceedings of the 2014 IEEE 38th Annual Computer Software and Applications Conference (COMPSAC), Vasteras, Sweden, 21–25 July 2014; pp. 299–304.
- Pries, R.; Magyari, Z.; Tran-Gia, P. An HTTP web traffic model based on the top one million visited web pages. In Proceedings of the 2012 8th EURO-NGI Conference on Next Generation Internet (NGI), Karlskrona, Sweden, 25–27 June 2012; pp. 33–139.
- Howell, F.W.; Williams, R.; Ibbett, R.N. Hierarchical Architecture Design and Simulation Environment. In Proceedings of the Second International Workshop on Modeling, Analysis, and Simulation of Computer and Telecommunication Systems, Durhan, NC, USA, 31 January–2 February 1994; Volume 94, pp. 970–981.
- Emmerich, P.; Gallenmüller, S.; Raumer, D.; Wohlfart, R.; Carle, G. MoonGen: A Scriptable High-Speed Packet Generator. In Proceedings of the 2015 ACM Conference on Internet Measurement Conference, Tokyo, Japan, 28–30 October 2015; pp. 275–287.
- TRex realistic traffic generator. Available online: https://trex-tgn.cisco.com/ (accessed on 25 November 2016).
- Baidu Statistics. Available online: http://tongji.baidu.com/data/hour (accessed on 21 September 2016).
- Wentzlaff, D.; Griffin, P.; Hoffmann, H. On-chip interconnection architecture of the tile processor. IEEE Micro 2007, 27, 15–31. [Google Scholar] [CrossRef]
- Reimers, S.O. Protothreads: Simplifying Event-Driven Programming of Memory-Constrained Embedded Systems. In Proceedings of the 4th International Conference on Embedded Networked Sensor Systems, Boulder, CO, USA, 31 October–3 November 2006.
- Duffy, C.; Roedig, U.; Herbert, J.; Sreenan, C. An experimental comparison of event driven and multi-threaded sensor node operating systems. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications Workshops, White Plains, NY, USA, 19–23 March 2007; pp. 267–271.
- Shao, Q.F.; Yang, T.C.; Hou, W. The design of high available single sign-on server of Nginx-based. Appl. Mech. Mater. 2013, 241, 2411–2416. [Google Scholar] [CrossRef]
- Litz, H.; Braun, B.; Cheriton, D. EXCITE-VM: Extending the Virtual Memory System to Support Snapshot Isolation Transactions. In Proceedings of the 2016 International Conference on Parallel Architectures and Compilation ACM, Haifa, Israel, 11–15 September 2016; pp. 401–412.
- Tripakis, S.; Limaye, R.; Ravindran, K.; Wang, G.; Andrade, H.; Ghosal, A. Tokens vs. Signals: On Conformance between Formal Models of Dataflow and Hardware. J. Signal Process. Syst. 2016, 85, 23–43. [Google Scholar] [CrossRef]
- Vuchener, C.; Esnard, A. Dynamic load-balancing with variable number of processors based on graph repartitioning. In Proceedings of the 2012 19th International Conference on High Performance Computing (HiPC), Pune, India, 18–22 December 2012; pp. 1–9.
- Sundaramoorthy, K. Adaptive Load-Balancing Algorithm with Rainbow Mechanism to Avoid Connectivity Holes in Wireless Sensor Networks. Middle-East J. Sci. Res. 2015, 23, 974–980. [Google Scholar]
- Kourdis, P.D.; Bellan, J. Highly Reduced Species Mechanisms for iso-Cetane Using the Local Self-Similarity Tabulation Method. Int. J. Chem. Kinet. 2015, 48, 974–980. [Google Scholar] [CrossRef]
- Zhu, F.; Ding, M.; Zhang, X. Self-similarity inspired local descriptor for non-rigid multi-modal image registration. Inf. Sci. 2016, 372, 16–31. [Google Scholar] [CrossRef]
- Chen, J.; Tan, X.; Jia, Z. Performance analysis of seven estimate algorithms about the Hurst coefficient. J. Comput. Appl. 2006, 4, 059. [Google Scholar]
- Zhang, H.F.; Shu, Y.T.; Yang, O. Estimation of Hurst parameter by variance-time plots. In Proceedings of the IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, Victoria, BC, Canada, 20–22 August 1997; Volume 2, pp. 883–886.
- Fu, L.Y.; Wang, R.C.; Wang, H.Y.; Ren, X.Y. Implementation and Application of Computing Self-Similar Parameter by R/S Approach to Analyze Network Traffic. J. Nanjing Univ. Aeronaut. Astronaut. 2007, 3, 016. [Google Scholar]
- Pruthi, P.; Erramilli, A. Heavy-tailed on/off source behavior and self-similar traffic. Communications 1995, 1, 445–450. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm 1. Cubic Spline Interpolation Algorithm. |
|---|
| Input: the number of actual users N, actual online user percentage . |
| Output: the virtual user reference set B, the number of active virtual user A. |
| 1. Compute the number of virtual users which satisfies |
| where ; |
| 2. Obtain virtual users-time percent data in each time slot i calculated as |
| ; |
| 3. Use the cubic spline interpolation algorithm, and compute continuous time |
| function based on interpolation processing ; |
| 4. Identify the time slot j which divides 24 h into 30 s; |
| 5. Initialize ; |
| 6. while h do |
| 7. ; |
| 8. ; |
| 9. end while |
| 10. Obtain the virtual user reference set B in chronological order; |
| 11. Assume the number of active virtual user in time slot j; |
| 12. while h do |
| 13. if then |
| 14. Delete out of active users. |
| 15. else |
| 16. Add extra active users. |
| 17. end if |
| 18. end while |
| //procuring the CPU affinity |
| cpu_set_t cpus; |
| if (tmc_cpus_get_my_affinity(&cpus) != 0) |
| tmc_task_die(“tmc_cpus_get_my_affinity() failed.”); |
| //bind to the allocated CPU |
| if (tmc_cpus_set_my_cpu(tmc_cpus_find_nth_cpu(&cpus, rank)) < 0) |
| tmc_task_die(“tmc_cpus_set_my_cpu() failed.”); |
| Tools | Performance | Method | Scalability | Technology | Platform |
|---|---|---|---|---|---|
| TRex | 200 Gb/s | Traffic Replay | Good | DPDK | Intel DPDK 1/10/40 Gbps interface support |
| TGMP | Simulate 50,000 users User Behavior | User Behavior | Good | Many-core processor | TILERAGX36 |
| MoonGen | Up to 178.5 Mpps at 120 Gbit/s | Traffic Model | General | DPDK | Modern commodity NICs is support for multi-core CPUs |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Xu, C.; Jin, W.; Wang, J.; Wang, Q.; Zhao, G. A Scalable Parallel Architecture Based on Many-Core Processors for Generating HTTP Traffic. Appl. Sci. 2017, 7, 154. https://doi.org/10.3390/app7020154
Wang X, Xu C, Jin W, Wang J, Wang Q, Zhao G. A Scalable Parallel Architecture Based on Many-Core Processors for Generating HTTP Traffic. Applied Sciences. 2017; 7(2):154. https://doi.org/10.3390/app7020154
Chicago/Turabian StyleWang, Xinheng, Chuan Xu, Wenqiang Jin, Jiajie Wang, Qianyun Wang, and Guofeng Zhao. 2017. "A Scalable Parallel Architecture Based on Many-Core Processors for Generating HTTP Traffic" Applied Sciences 7, no. 2: 154. https://doi.org/10.3390/app7020154
APA StyleWang, X., Xu, C., Jin, W., Wang, J., Wang, Q., & Zhao, G. (2017). A Scalable Parallel Architecture Based on Many-Core Processors for Generating HTTP Traffic. Applied Sciences, 7(2), 154. https://doi.org/10.3390/app7020154