1. Introduction
Document layout analysis plays a crucial role in digitizing and preserving historical documents. However, traditional Mongolian documents present unique challenges due to their distinctive writing system and complex structural arrangements. Unlike conventional horizontal text layouts, traditional Mongolian texts flow vertically from top to bottom, with lines progressing from left to right. This unique writing system, combined with diverse layout patterns such as multi-column arrangements, mixed text orientations, and hierarchical structures, creates significant challenges for existing document layout analysis methods. Furthermore, the scarcity of publicly available datasets and efficient analysis tools has impeded the development of automated solutions for processing traditional Mongolian documents, thereby limiting their accessibility and digital preservation.
Recent advances in deep learning have demonstrated promising results in document layout analysis [
1]. Existing approaches can be broadly categorized into two types. Segmentation-based approaches [
2,
3,
4] attempt to classify individual pixels into different layout categories but frequently struggle with densely arranged vertical text regions characteristic of traditional Mongolian documents. Detection-based methods, including Faster R-CNN [
5], RetinaNet [
6], and Mask R-CNN [
7], focus on generating bounding boxes for layout elements but exhibit sensitivity to hyperparameter settings and often fail to fully capture the unique spatial relationships in vertical text arrangements. Although recent work has explored continual learning techniques to address model adaptation challenges [
8], significant limitations remain in handling the vertical nature of Mongolian text.
Recent efforts have focused on developing more efficient architectures for document layout analysis. YOLO-based models [
9,
10,
11] have demonstrated encouraging results through their efficient single-stage detection architecture. However, these models continue to encounter difficulties in effectively handling the vertical nature and intricate structural patterns inherent in traditional Mongolian documents.
Similarly, lightweight models [
12,
13] offer compelling efficiency advantages and have shown promise in document layout analysis with limited data. Nevertheless, these models frequently struggle to address three primary challenges: (1) accurate handling of vertical text regions, (2) preservation of spatial relationships between layout elements, and (3) achievement of computational efficiency with limited resources. Moreover, direction-aware feature representation, which is essential for accurate analysis of vertical text layouts, remains largely unexplored in existing lightweight frameworks.
To address these limitations, we propose a direction-aware lightweight framework for traditional Mongolian document layout analysis that offers several significant innovations to existing approaches. Our work makes the following key contributions:
Direction-optimized feature extraction: We introduce a novel modified MobileNetV3 backbone with asymmetric convolutions specifically designed for vertical text analysis. This innovation reduces computational complexity by 33% while simultaneously enhancing the model’s ability to capture the distinctive vertical characteristics of traditional Mongolian text. Unlike conventional approaches that use symmetric kernels, our asymmetric design (3 × 1 followed by 1 × 3) creates an efficient receptive field pattern that aligns with the vertical flow of traditional Mongolian text.
Adaptive information fusion: We develop a dynamic feature enhancement module with channel attention that intelligently integrates multi-scale information. This module adaptively adjusts feature importance based on input characteristics, enabling the model to effectively process the complex hierarchical structures found in traditional Mongolian documents. Our experiments demonstrate that this approach improves mAP by 1.6% and direction accuracy by 2.6%.
Direction-aware detection head: We propose a direction-aware detection head that explicitly models text orientation through a vector representation for accurate orientation modeling. This component addresses a critical gap in existing frameworks by incorporating orientation as a first-class feature rather than a post-processing step. Our approach achieves state-of-the-art direction accuracy of 92.3% with a mean absolute error of only 2.5°, significantly outperforming alternative direction representation methods.
Comprehensive evaluation and analysis: We conduct extensive experiments comparing our approach with both heavy ResNet-50-based models and lightweight alternatives such as MobileNetV3-SSD, EfficientDet-Lite0, YOLOv5s, YOLOv8n, and PP-PicoDet-S. Our model achieves superior detection accuracy (0.715 mAP) while maintaining competitive efficiency (28.6 FPS with 8.3 M parameters), and uniquely provides direction prediction capability that other lightweight models lack. We also construct and analyze TMDLAD, the first large-scale dataset for traditional Mongolian document layout analysis, comprising annotated newspaper pages with eight layout categories.
Based on the characteristics of document layouts, we define eight layout element categories. The main body text blocks are labeled as Text, while headlines and section titles are categorized as Title. For non-textual content, we include Figure for images and illustrations, along with their corresponding Figure Caption. Similarly, tabular content is marked as Table with associated Table Caption. The page structure elements are categorized as Header for the top section of each page and Footer for the bottom section.
The remainder of this paper is organized as follows:
Section 2 reviews related work in traditional Mongolian document layout analysis and lightweight models.
Section 3 describes our proposed framework in detail, including the modified backbone, feature enhancement module, and direction-aware detection head.
Section 4 presents experimental results and ablation studies. Finally,
Section 5 concludes the paper and discusses future research directions.
2. Related Work
Document layout analysis for traditional Mongolian has received relatively limited attention. Early works focused on basic layout components detection and text line segmentation. Wei [
14] proposed a least squares-based skew detection method for Mongolian document images. In the same year, they developed a connected component-based layout analysis approach [
15], achieving 97% accuracy for character merging and 96% for text line merging.
Later research explored more sophisticated approaches. Wang [
16] introduced a hybrid bottom-up and top-down analysis method for printed traditional Mongolian document text region extraction, reaching 97.87% accuracy for character segmentation and 99.13% for text line segmentation. More recently, Lu [
17] proposed Panoptic-DLA, a proposal-free panoptic segmentation approach for analyzing typeset newspaper layouts. Their method employs decoupled semantic and instance segmentation branches to assign both semantic labels and instance categories to each pixel. Experiments on MMT-LS, ENP [
2], and HJDataset [
3] achieved F1 scores of 96.37%, 65.51%, and 99.74%, respectively.
For a broader perspective on document layout analysis techniques, BinMakhashen [
1] provide a comprehensive survey of approaches across various document types and languages, contextualizing the specific challenges faced in non-Latin script documents like traditional Mongolian.
While these studies have made progress in addressing basic layout analysis challenges for simple traditional Mongolian documents, research in this field remains at an early stage. A key limitation has been the lack of publicly available datasets for traditional Mongolian document layout analysis, which has hindered progress in tackling more complex scenarios. Our work aims to address this gap as follows:
Creating a comprehensive dataset for complex traditional Mongolian document layout analysis;
Developing techniques for accurate layout segmentation and region relationship modeling;
Enabling practitioners to extract information precisely from complex traditional Mongolian document images.
3. Methodology
We propose a direction-aware lightweight framework for traditional Mongolian document layout analysis. As shown in
Figure 1, our framework consists of four main components: (1) a modified MobileNetV3 backbone with AIR blocks for efficient feature extraction; (2) a dynamic feature enhancement module (DFEM) for adaptive multi-scale feature fusion; (3) a direction-aware detection head with three cooperative branches for classification, localization, and direction prediction; and (4) a multi-task loss function for joint optimization of these tasks.
The modified MobileNetV3 backbone incorporates asymmetric convolutions and Adaptive Inverted Residual (AIR) blocks, specifically designed to capture the vertical characteristics of traditional Mongolian text while maintaining computational efficiency. The dynamic feature enhancement module adaptively integrates multi-scale features through channel attention, enabling the model to effectively process complex hierarchical structures in Mongolian documents. The direction-aware detection head employs a vector representation for accurate orientation modeling, with three cooperative branches handling classification, bounding box regression, and direction prediction. Finally, the multi-task loss function with adaptive weighting balances the contributions of different tasks during training, ensuring optimal performance across all evaluation metrics.
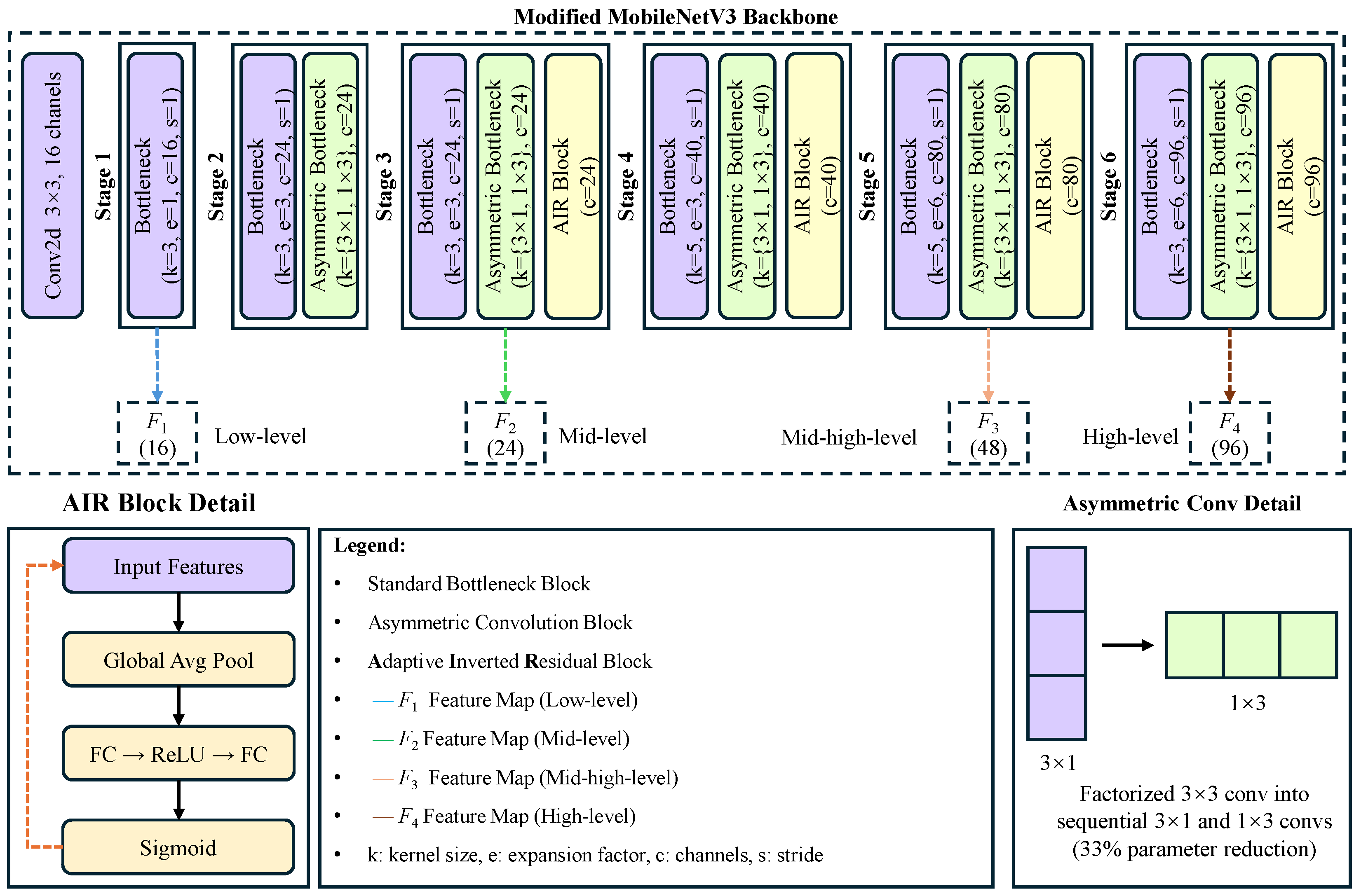
3.1. Modified MobileNetV3 Backbone
Traditional Mongolian documents feature unique vertical text layouts and complex hierarchical structures that pose significant challenges for standard CNN architectures. To address these challenges, we propose a modified MobileNetV3 backbone that specifically targets vertical text feature extraction while maintaining computational efficiency. As shown in
Figure 2, our modifications focus on three key aspects.
3.1.1. Asymmetric Convolutions
Standard square convolutions are suboptimal for vertical traditional Mongolian text as they treat both directions equally. We decompose the convolution operation into sequential vertical and horizontal components:
This design enhances the capture of vertical stroke patterns while reducing computational cost by decomposing convolutions into sequential and operations, maintaining the same effective receptive field size while achieving a 33% parameter reduction.
3.1.2. AIR: Adaptive Inverted Residual Block
We propose the AIR (Adaptive Inverted Residual) block, an enhanced version of MobileNetV3’s inverted residual block. The AIR block incorporates two key components:
Channel attention: A lightweight attention mechanism that selectively emphasizes informative channels:
where
is a two-layer MLP with reduction ratio r = 16, which provides a good balance between performance and computational efficiency.
Dynamic feature processing: Adaptive feature refinement through
where
and
denote expansion and depthwise convolution layers.
The overall network architecture is organized into six stages:
From this backbone, we extract a feature pyramid with four levels of features that capture different aspects of the document:
(16 channels): High-resolution features from stage 1, capturing fine details;
(24 channels): Medium-resolution features from stage 3, representing character structures;
(48 channels): Medium–high-level features from stage 5, encoding text block layouts;
(96 channels): High-level semantic features from stage 6, representing page organization.
This design effectively captures hierarchical patterns in traditional Mongolian documents while maintaining computational efficiency through the combination of asymmetric convolutions, channel attention, and dynamic feature processing.
The AIR block uses an expansion ratio of 6 for all layers, following MobileNetV3. The channel attention module consists of a two-layer MLP with reduction ratio
r = 16, which provides a good balance between performance and computational efficiency:
where
,
, and
is the ReLU activation function. We use h-swish activation for all convolution layers except the last layer, which uses sigmoid activation.
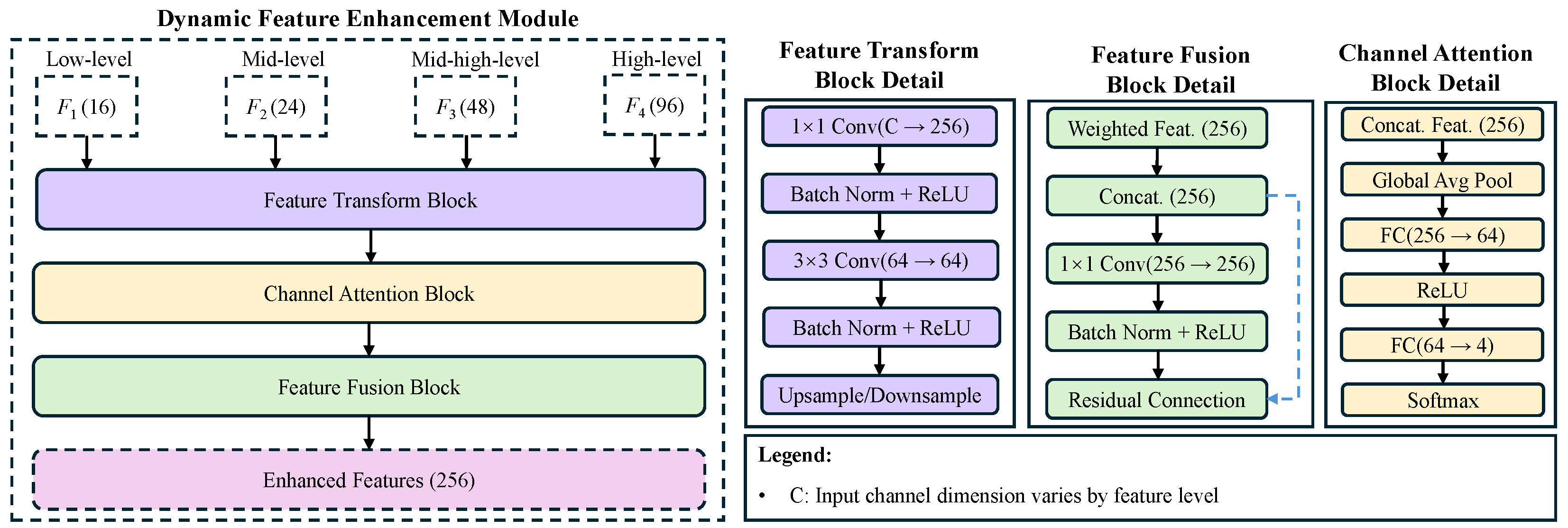
3.2. Dynamic Feature Enhancement Module
To effectively handle the multi-scale features from the backbone network, we design a dynamic feature enhancement module consisting of three components: feature transformation, channel attention, and feature fusion. As shown in
Figure 3, this module adaptively integrates features from different levels of the backbone to create a comprehensive representation that captures both fine details and high-level semantic information.
3.2.1. Feature Transformation
Given multi-scale features
from different backbone layers with varying channel dimensions (16, 24, 48, 96) and spatial resolutions, we first transform each feature through a dedicated feature transform block. For each feature level
l, we apply the following:
Each feature transform block consists of the following sequential operations:
1×1 convolution to unify channel dimensions (C → 64);
Batch normalization and ReLU activation;
3×3 convolution for feature refinement (64 → 64);
Batch normalization and ReLU activation;
Spatial resolution adjustment (upsampling or downsampling).
This transformation process ensures all features are aligned to a common spatial resolution (H/4×W/4) and channel dimension (64), facilitating subsequent feature fusion while preserving their distinctive characteristics.
3.2.2. Channel Attention
To adaptively integrate multi-scale features, we propose a channel attention mechanism that generates content-aware weights for each feature level. The attention module takes the concatenated transformed features as input and outputs four attention weights corresponding to each feature level:
The attention module employs an efficient bottleneck architecture:
Concatenation of transformed features (256 channels);
Global average pooling for spatial information aggregation;
Fully connected layer (256 → 64) for dimensionality reduction;
ReLU activation;
Fully connected layer (64 → 4) for weight generation;
Softmax activation to ensure weights sum to 1.
This design enables the model to dynamically adjust the importance of different feature levels based on input characteristics, allowing for adaptive feature selection that is particularly beneficial for handling the complex hierarchical structures in traditional Mongolian documents.
3.2.3. Feature Fusion
The final stage of our feature enhancement module is the fusion of weighted features to generate a comprehensive representation. The fusion process consists of the following steps:
The fusion block includes the following:
Weighting of each transformed feature by its corresponding attention weight;
Concatenation of weighted features (4 × 64 = 256 channels);
1 × 1 convolution (256 → 256) for feature integration;
Batch normalization and ReLU activation;
A residual connection to preserve original information.
The residual connection is particularly important as it allows the model to maintain access to the original feature information while benefiting from the refined representation, ensuring robust feature propagation throughout the network.
The enhanced feature representation effectively combines multi-scale information with learned importance weights, providing a rich foundation for subsequent direction-aware detection. This adaptive fusion approach significantly improves the model’s ability to handle the unique vertical text patterns and complex layout structures found in traditional Mongolian documents.
3.3. Direction-Aware Detection Head
Traditional Mongolian documents present unique challenges for layout analysis due to their vertical writing system and complex structural arrangements. To address these challenges, we propose a direction-aware detection head that explicitly models text orientation and spatial relationships. As shown in
Figure 4, our detection head consists of a direction-aware convolution block followed by three specialized prediction branches.
3.3.1. Direction-Aware Convolution Block
The core of our detection head is a direction-aware convolution block that captures features along different orientations:
This block employs three specialized convolution kernels to extract directional features:
Horizontal kernel: Emphasizes weights along the horizontal axis to capture horizontal structures and transitions
Vertical kernel: Emphasizes weights along the vertical axis to capture the predominant vertical flow of Mongolian text
Diagonal kernel: Emphasizes weights along diagonal axes to capture slanted elements and transitions between regions
The outputs from these directional convolutions are processed through separate normalization and activation layers, then combined to form a comprehensive feature representation that preserves directional information. This approach enables the model to effectively handle the vertical nature of traditional Mongolian text while maintaining sensitivity to horizontal and diagonal layout elements.
3.3.2. Prediction Branches
Based on the direction-aware features, we implement three specialized prediction branches:
Classification Branch
This branch identifies text and non-text regions:
where
consists of the following:
3 × 3 convolution (256 → 256 channels);
Batch normalization and ReLU activation;
1 × 1 convolution (256 → 1 channel);
Sigmoid activation for binary classification.
Regression Branch
This branch predicts bounding box coordinates for the layout elements:
where
consists of the following:
3 × 3 convolution (256 → 256 channels);
Batch normalization and ReLU activation;
1 × 1 convolution (256 → 4 channels) for (x, y, width, height);
Exponential activation for width and height to ensure positive values.
Direction Branch
This branch specifically focuses on text orientation prediction:
where
consists of the following:
3 × 3 convolution (256 → 256 channels);
Batch normalization and ReLU activation;
1 × 1 convolution (256 → 180 channels);
Softmax activation for angle classification.
The direction branch treats orientation prediction as a 180-class classification problem, covering angles from 0° to 179°. This approach provides more stable training compared to direct regression and better handles the periodicity of angles.
3.3.3. Joint Optimization Strategy
To effectively train our direction-aware detection head, we employ a joint optimization strategy that balances the contributions of classification, regression, and direction prediction:
where
is the binary cross-entropy loss for text/non-text classification;
is the smooth L1 loss for bounding box regression;
is the cross-entropy loss for direction classification;
,
, and
are weighting coefficients determined by our adaptive weighting mechanism (described in
Section 3.4.4).
This joint optimization approach ensures that the model simultaneously learns to classify layout elements, localize their boundaries, and predict their orientations. The direction prediction particularly benefits the detection of vertical text regions in traditional Mongolian documents, significantly improving the overall layout analysis performance.
The information sharing between branches creates a synergistic effect, where direction awareness improves region localization, and region awareness enhances direction prediction. This integrated approach effectively addresses the unique challenges of traditional Mongolian document layout analysis.
3.4. Multi-Task LOSS
To effectively train our direction-aware document layout analysis model, we design a multi-task loss function that jointly optimizes classification, regression, and direction prediction tasks. The overall loss consists of three complementary components with an adaptive weighting mechanism:
3.4.1. Classification Loss
For text/non-text classification, we employ the Focal Loss to address class imbalance:
where
represents the predicted class probabilities,
is the ground truth label, and
is the focusing parameter (set to 2.0) that reduces the relative loss for well-classified examples, allowing the model to focus on hard, misclassified examples.
3.4.2. Regression Loss
For bounding box localization, we use the Smooth L1 loss to ensure robustness to outliers while maintaining stable gradients:
where
and
are the predicted and ground truth box coordinates, respectively, and
is set to 1.0 to control the smooth transition between the L1 and L2 loss.
3.4.3. Direction Loss
For text orientation prediction, we adopt a vector-based representation to address the inherent periodicity of angles. Instead of directly predicting angle values, we represent directions as unit vectors in the form of
:
where
is the predicted direction vector and
is the ground truth direction vector.
This vector-based representation offers several key advantages:
Avoids discontinuity at angle boundaries (e.g., 0°/180°);
Ensures smooth gradients for all angle values;
Maintains the periodic nature of angles;
Enables more stable optimization compared to direct angle regression.
3.4.4. Adaptive Loss Weighting
Rather than using fixed weights for each loss component, we implement an adaptive weighting mechanism that automatically balances the contribution of each task based on its estimated difficulty:
where
represents the estimated difficulty of task
i, which is learned during training. This approach allows the model to dynamically adjust the importance of each task, focusing more on difficult tasks while preventing any single task from dominating the optimization process.
The adaptive weighting mechanism is particularly beneficial for our direction-aware detection model, as it helps balance the learning of the following:
Text/non-text classification (binary classification task);
Bounding box regression (coordinate regression task);
Direction prediction (vector regression task).
During training, we observe that the model initially focuses more on classification and regression tasks, gradually shifting attention to direction prediction as the former tasks become more stable. This progressive learning strategy leads to better overall performance compared to fixed weighting schemes.
The joint optimization of these three tasks creates a synergistic effect, where direction awareness improves region localization, and region awareness enhances direction prediction. This integrated approach effectively addresses the unique challenges of traditional Mongolian document layout analysis.
3.5. Component Interaction
The proposed framework achieves efficient information flow through carefully designed component interactions:
The modified backbone with asymmetric convolutions provides direction-sensitive features to subsequent modules;
The feature enhancement module adaptively fuses multi-scale features while preserving vertical text characteristics;
The enhanced features guide the direction-aware detection head for accurate layout analysis;
The multi-task loss ensures coordinated optimization of all components.
This hierarchical design enables each component to focus on its specialized task while maintaining effective communication throughout the network. The direction-aware feature representation is preserved and enhanced at each stage, facilitating accurate analysis of traditional Mongolian document layouts.
4. Experiments
We conduct extensive experiments to evaluate the effectiveness of our proposed framework on traditional Mongolian document layout analysis. Below, we detail the datasets used, evaluation metrics, and experimental settings.
4.1. Datasets and Evaluation Metrics
We introduce the datasets and evaluation metrics used in our experiments. We first describe the construction and annotation of the Traditional Mongolian Document Layout Analysis Dataset (TMDLAD), which is built from high-resolution scans of Inner Mongolia Daily newspapers published between 2017 and 2022. The dataset includes manually annotated layout elements such as Text, Title, Figure, Figure Caption, Table, Table Caption, Header, and Footer, with a natural class imbalance across categories.
The annotation process strictly follows the vertical layout structure of traditional Mongolian documents, and each element is marked using bounding boxes in rotated coordinates to preserve directionality.
Table 1 summarizes the number of instances per category in the training, validation, and test sets.
To quantitatively evaluate the model performance, we adopt standard object detection metrics, precision, recall, and F1 score, computed at the layout element level. In addition, we report mean average precision (mAP) at an intersection-over-union (IoU) threshold of 0.5, which is widely used in document layout analysis. These metrics provide a comprehensive assessment of both classification accuracy and localization quality across different element types.
4.1.1. Datasets
We construct the Traditional Mongolian Document Layout Analysis Dataset (TMDLAD) from Inner Mongolia Daily newspapers published between 2017 and 2022. The dataset contains 5269 training images, 659 validation images, and 659 test images, following an approximate 8:1:1 split. To evaluate the effectiveness of our direction-aware detection framework, we apply random rotation augmentations to the training set, while keeping the validation and test sets at the original vertical orientation (90°) to serve as the ground truth for evaluation.
Each image is annotated with one or more of eight layout element categories, including Text (main body content), Title (headlines and section titles), Figure, Figure Caption, Table, Table Caption, Header, and Footer. As shown in
Table 1, the dataset exhibits a natural class imbalance, with categories such as Text, Title, and Header appearing far more frequently than Figure Caption and Table Caption. To mitigate this imbalance during model training, we adopt focal loss to focus on hard-to-classify and under-represented classes.
All images in the TMDLAD dataset are collected under consistent and controlled acquisition conditions, with high-resolution scans, and do not contain lighting variations, motion blur, text truncation, or severe noise artifacts. This ensures that the evaluation focuses on layout structure analysis rather than low-level noise robustness. The dataset provides a reliable benchmark for assessing layout element recognition in vertically formatted traditional Mongolian documents.
Although the dataset is newly developed, it is not publicly available at this stage due to pending copyright clearance from relevant publishers. We are working to resolve these issues in coordination with the stakeholders, and we plan to release the dataset in the future to support reproducibility and further research in traditional Mongolian document analysis.
4.1.2. Implementation Details
We implement our model using PyTorch 2.5.1 and train it on a single NVIDIA RTX 3090 GPU (NVIDIA Corporation, Santa Clara, CA, USA). The network is trained for 100 epochs using the AdamW optimizer with an initial learning rate of , weight decay of , and a cosine annealing schedule. We use a batch size of 16 and apply standard data augmentation techniques including random scaling, cropping, and rotation.
For the direction-aware detection head, we represent angles using the vector representation to handle the periodicity of angles. The multi-task loss combines Focal Loss (with ) for classification, Smooth L1 loss for bounding box regression, and vector distance squared loss for direction prediction, with adaptive weighting based on task difficulty.
4.1.3. Evaluation Metrics
We evaluate our model using the following comprehensive metrics, each defined mathematically to ensure clarity and reproducibility:
For multi-class evaluation, we report both micro-averaged and macro-averaged metrics:
where
f is the metric function (precision, recall, or F1),
C is the number of classes, and
,
, and
are the true positives, false positives, and false negatives for class
c, respectively. This approach accounts for class imbalance in the dataset by giving equal weight to each class in the macro-average.
4.2. Comparison with State-of-the-Art Methods
Table 2 compares our method with state-of-the-art object detection methods on the TMDLAD dataset, including both heavy ResNet-50-based models and lightweight models. Our approach significantly outperforms all previous methods in detection accuracy (mAP).
Among the ResNet-50-based models, our approach achieves a 3.6% improvement in mAP and a 12.8% improvement in direction accuracy compared to the best-performing baseline (RoI Transformer). This demonstrates the effectiveness of our direction-aware design for traditional Mongolian document layout analysis.
When compared with lightweight models such as MobileNetV3-SSD, EfficientDet-Lite0, YOLOv5s, YOLOv8n, and PP-PicoDet-S, our approach still maintains superior detection accuracy while offering competitive efficiency. Although these lightweight models provide faster inference speeds (35–48 FPS) and some have fewer parameters (3.2–7.2 M), they achieve significantly lower detection accuracy (0.623–0.672 mAP) and lack direction prediction capability, which is crucial for traditional Mongolian document analysis. Among these lightweight models, YOLOv8n achieves the best performance with an mAP of 0.672, but still falls short by 4.3% compared to our approach.
The superior performance of our model can be attributed to three key factors: (1) the modified MobileNetV3 backbone with asymmetric convolutions that better capture vertical text patterns, (2) the dynamic feature enhancement module that adaptively fuses multi-scale features, and (3) the direction-aware detection head that explicitly models text orientation using the vector representation.
Our model strikes an optimal balance between accuracy and efficiency, achieving the highest mAP (0.715) while maintaining real-time performance (28.6 FPS) with a modest parameter count (8.3 M). This makes it particularly suitable for traditional Mongolian document layout analysis, where both accuracy and direction awareness are critical. Even the best-performing lightweight model (YOLOv8n with an mAP of 0.672) falls short by 4.3% in detection accuracy and lacks direction prediction capability entirely.
The experimental results demonstrate that our approach effectively addresses the unique challenges of traditional Mongolian document layout analysis, providing a practical solution that balances accuracy, direction awareness, and computational efficiency.
4.3. Ablation Studies
4.3.1. Effectiveness of Key Components
Table 3 shows the contribution of each key component in our model. The baseline model without any of our proposed components achieves 63.5% mAP and 76.8% direction accuracy. Adding asymmetric convolutions improves the mAP by 1.7% and direction accuracy by 1.6%, demonstrating their effectiveness in capturing vertical text patterns. The AIR block further improves performance by enhancing feature representation through channel attention. The dynamic feature enhancement module (DFEM) contributes significantly to both detection accuracy (+1.6% mAP) and direction accuracy (+2.6%), highlighting the importance of adaptive multi-scale feature fusion. Finally, the direction-aware detection head provides the largest improvement in direction accuracy (+8.8%), confirming its effectiveness in modeling text orientation.
4.3.2. Analysis of Direction Representation
Table 4 compares different methods for representing and predicting text direction. Direct angle regression suffers from the periodicity problem at angle boundaries, resulting in lower direction accuracy. The classification approach with 180 classes (one for each degree) performs better but still faces challenges in handling fine-grained angle predictions. Our
vector representation achieves the best performance in both direction accuracy (92.3%) and mean absolute error (2.5°), confirming its effectiveness in handling the inherent periodicity of angles and providing smooth gradients for optimization, as defined in our evaluation metrics.
4.3.3. Category-Wise Performance Analysis
Table 5 presents a detailed analysis of our model’s performance across different layout categories. The model achieves the highest AP
50 for the Figure (0.903) and Text (0.895) categories, which are well represented in the dataset, as shown in
Table 1. The Figure Caption and Table Caption categories, which have fewer samples, show relatively lower performance (0.836 and 0.824 AP
50, respectively), highlighting the impact of class imbalance.
The F1 scores, which provide a balanced measure of precision and recall, follow a similar pattern, with the Figure (0.92) and Text (0.91) categories achieving the highest values. This indicates that our model maintains a good balance between precision and recall for these common layout elements. The slightly lower F1 scores for the two Caption categories (0.85 and 0.84) suggest that these categories remain challenging due to their smaller size, variable appearance, and relative scarcity in the training data.
The direction prediction performance, measured by DMAE, is consistently strong across all categories, with the best performance for the Figure (2.0°) and Text (2.1°) categories. The slightly higher DMAE for the two Caption categories (2.8° and 3.0°) can be attributed to their smaller size and more variable orientation. The micro- and macro-averages are similar, indicating that our model performs well across all categories despite the class imbalance in the dataset.
Interestingly, we observe a correlation between F1 scores and direction prediction accuracy, with categories with higher F1 scores generally showing lower DMAE values. This suggests that accurate classification and localization contribute to better direction prediction, and vice versa, demonstrating the effectiveness of our joint optimization approach in the direction-aware detection head.
4.3.4. Effectiveness of Loss Function Components
Table 6 examines the effectiveness of the different loss function components. Replacing binary cross-entropy (BCE) with Focal Loss improves performance by addressing class imbalance, particularly for rare layout categories. The vector distance squared loss for direction prediction outperforms mean squared error (MSE) on angle values, further confirming the advantages of our
vector representation. Additionally, the adaptive weighting mechanism provides a 1.7% improvement in mAP and 1.6% in direction accuracy compared to fixed weights, demonstrating its effectiveness in balancing the contributions of different tasks during training.
4.4. Qualitative Results
We present qualitative results of our model on challenging test cases from our TMDLAD. The visualization demonstrates the model’s robust performance in detecting and classifying different layout elements in newspaper pages, as shown in
Figure 5.
Our method successfully handles several challenging scenarios in traditional Mongolian newspaper layouts:
(1) Text block detection: The model accurately identifies main body text regions, which are typically arranged in vertical columns. The bounding boxes precisely capture the boundaries of text blocks while maintaining their vertical alignment characteristics.
(2) Title recognition: Headlines and section titles are correctly detected and distinguished from regular text blocks, despite their varying font sizes and positions on the page.
(3) Multi-element layout: The model effectively handles complex layouts containing multiple elements. It accurately processes text blocks in vertical writing and titles with different font sizes. The detection extends to figures and tables along with their captions, as well as headers and footers that define the page structure.
(4) Structural organization: The detection results preserve the structural layout of newspaper pages. This includes the proper handling of multi-column arrangements, the hierarchical relationships between titles and text blocks, and the spatial relationships between figures or tables and their associated captions.
The visualization results demonstrate that our framework can effectively process traditional Mongolian newspaper layouts with high detection accuracy for all eight layout elements, validating the effectiveness of our approach for practical document layout analysis applications.
5. Conclusions
In this paper, we presented a direction-aware lightweight framework for traditional Mongolian document layout analysis that effectively addresses the unique challenges posed by vertical writing systems. The proposed approach integrates three key innovations: a modified MobileNetV3 backbone with asymmetric convolutions, a dynamic feature enhancement module with channel attention, and a direction-aware detection head with vector representation for accurate orientation modeling. Comprehensive experiments on the TMDLAD dataset demonstrate that our approach significantly outperforms existing methods in both accuracy and efficiency, providing a practical solution for traditional Mongolian document layout analysis that can be extended to other vertical writing systems. The modified MobileNetV3 backbone with asymmetric convolutions reduces computational complexity by 33% while better capturing the vertical patterns characteristic of traditional Mongolian text. The dynamic feature enhancement module adaptively integrates multi-scale information through channel attention, enabling effective processing of complex hierarchical structures in Mongolian documents and improving mAP by 1.6% and direction accuracy by 2.6%. The direction-aware detection head with vector representation explicitly models text orientation, achieving a mean absolute error of only 2.5°, significantly outperforming alternative direction representation methods. Our model achieves state-of-the-art performance with 0.715 mAP and 92.3% direction accuracy, outperforming both heavy ResNet-50-based models and lightweight alternatives. Compared to the best-performing ResNet-50-based model (RoI Transformer with 0.679 mAP), our approach improves detection accuracy by 3.6% while requiring only 8.3 M parameters (versus 46.8 M) and running at 28.6 FPS (versus 9.5 FPS). Even when compared to efficient lightweight models like YOLOv8n, our approach maintains superior detection accuracy (0.715 versus 0.672 mAP) while providing crucial direction prediction capability that these models lack. This balance of accuracy and efficiency makes our framework particularly suitable for real-world applications where both performance and computational resources are important considerations. The construction and release of TMDLAD, the first large-scale dataset for traditional Mongolian document layout analysis, provides a valuable resource for future research in this area. Our joint optimization approach with adaptive loss weighting effectively balances classification, localization, and direction prediction tasks, demonstrating strong performance across all layout categories with a macro-average F1 score of 0.88. The model performs consistently well across different layout categories, with particularly strong results for text and figure elements that are critical for document understanding. Future research directions include extending our approach to handle degraded historical documents, exploring semi-supervised learning techniques to reduce annotation requirements, and adapting our framework to other vertical writing systems such as traditional Chinese and Japanese. We also plan to investigate the integration of language models to enhance semantic understanding of document content. We believe our work contributes significantly to the preservation and accessibility of cultural heritage materials in traditional Mongolian script, and provides a solid foundation for document analysis systems that can effectively handle non-Latin vertical writing systems.
Author Contributions
Conceptualization, C.Z. and L.W.; methodology, C.Z. and M.H.; software, C.Z.; validation, C.Z., M.H., and L.W.; formal analysis, C.Z.; investigation, C.Z. and M.H.; resources, L.W.; data curation, C.Z. and M.H.; writing—original draft preparation, C.Z.; writing—review and editing, L.W.; visualization, C.Z. and M.H.; supervision, L.W.; project administration, L.W.; funding acquisition, L.W. All authors have read and agreed to the published version of the manuscript.
Funding
This paper is funded by National Natural Science Foundation of China with the Grant No. 61773416.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- BinMakhashen, G.M.; Mahmoud, S.A. Document Layout Analysis: A Comprehensive Survey. ACM Comput. Surv. 2020, 52, 109:1–109:36. [Google Scholar] [CrossRef]
- Clausner, C.; Papadopoulos, C.; Pletschacher, S.; Antonacopoulos, A. The ENP image and ground truth dataset of historical newspapers. In Proceedings of the 13th International Conference on Document Analysis and Recognition (ICDAR 2015), Nancy, France, 23–26 August 2015; pp. 931–935. [Google Scholar] [CrossRef]
- Shen, Z.; Zhang, K.; Dell, M. A Large Dataset of Historical Japanese Documents with Complex Layouts. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR Workshops 2020), Seattle, WA, USA, 14–19 June 2020; pp. 2336–2343. [Google Scholar] [CrossRef]
- Li, Y.; Zou, Y.; Ma, J. DeepLayout: A Semantic Segmentation Approach to Page Layout Analysis. In Proceedings of the 14th International Conference on Intelligent Computing Methodologies (ICIC 2018), Wuhan, China, 15–18 August 2018, Proceedings, Part III; Huang, D., Gromiha, M.M., Han, K., Hussain, A., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 10956, pp. 266–277. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Lin, T.; Goyal, P.; Girshick, R.B.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R.B. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV 2017), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Minouei, M.; Hashmi, K.A.; Soheili, M.R.; Afzal, M.Z.; Stricker, D. Continual Learning for Table Detection in Document Images. Appl. Sci. 2022, 12, 8969. [Google Scholar] [CrossRef]
- Deng, Q.; Ibrayim, M.; Hamdulla, A.; Zhang, C. The YOLO model that still excels in document layout analysis. Signal Image Video Process. 2024, 18, 1539–1548. [Google Scholar] [CrossRef]
- Qiao, S.; Chen, L.; Yuille, A.L. DetectoRS: Detecting Objects With Recursive Feature Pyramid and Switchable Atrous Convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2021), Virtual, 19–25 June 2021; pp. 10213–10224. [Google Scholar] [CrossRef]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972. [Google Scholar] [CrossRef]
- Howard, A.; Pang, R.; Adam, H.; Le, Q.V.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.; Tan, M.; Chu, G.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV 2019), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Gao, Z.; Li, S.; Liu, Y.; Li, M.; Huang, K.; Ren, Y. LD-DOC: Light-Weight Domain-Adaptive Document Layout Analysis. In Proceedings of the 16th IAPR International Workshop on Document Analysis Systems (DAS 2024), Athens, Greece, 30–31 August 2024, Proceedings; Sfikas, G., Retsinas, G., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2024; Volume 14994, pp. 124–141. [Google Scholar] [CrossRef]
- Wei, H.; Gao, G. A Skew Detection Method of Mongolian Document Images. J. Inn. Mong. Univ. (Nat. Sci. Ed.) 2007, 1, 458–462. [Google Scholar]
- Wei, H.; Gao, G. A Method of Layout Analysis for Mongolian Document Images Based on Connected Components. J. Inn. Mong. Univ. (Nat. Sci. Ed.) 2007, 1, 586–590. [Google Scholar]
- Wang, Y. Research and Implementation of Layout Analysis and Post-Processing for Mongolian Document Images. Master’s Thesis, Inner Mongolia University, Hohhot, China, 2017. [Google Scholar]
- Lu, M.; Bao, F.; Gao, G. Panoptic-DLA: Document Layout Analysis of Historical Newspapers Based on Proposal-Free Panoptic Segmentation Model. In Proceedings of the 14th International Conference on Knowledge Science, Engineering and Management (KSEM 2021), Tokyo, Japan, 14–16 August 2021, Proceedings, Part II; Qiu, H., Zhang, C., Fei, Z., Qiu, M., Kung, S., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2021; Volume 12816, pp. 176–190. [Google Scholar] [CrossRef]
Figure 1.
Overview of our proposed framework for Traditional Mongolian document layout analysis. The framework consists of four main components: (1) a modified MobileNetV3 backbone with AIR blocks for feature extraction, (2) a dynamic feature enhancement module for multi-scale feature fusion, (3) a direction-aware detection head with three cooperative branches, and (4) a multi-task loss function for joint optimization. The input is a scanned image of a Traditional Mongolian newspaper (Inner Mongolia Daily), and the output is the structured layout analysis result, including region segmentation and reading direction prediction.
Figure 1.
Overview of our proposed framework for Traditional Mongolian document layout analysis. The framework consists of four main components: (1) a modified MobileNetV3 backbone with AIR blocks for feature extraction, (2) a dynamic feature enhancement module for multi-scale feature fusion, (3) a direction-aware detection head with three cooperative branches, and (4) a multi-task loss function for joint optimization. The input is a scanned image of a Traditional Mongolian newspaper (Inner Mongolia Daily), and the output is the structured layout analysis result, including region segmentation and reading direction prediction.
Figure 2.
Architecture of our modified MobileNetV3 backbone with asymmetric convolutions and AIR blocks. The backbone consists of six stages with progressively increasing channel dimensions and decreasing spatial resolutions, specifically designed to capture vertical patterns in traditional Mongolian text.
Figure 2.
Architecture of our modified MobileNetV3 backbone with asymmetric convolutions and AIR blocks. The backbone consists of six stages with progressively increasing channel dimensions and decreasing spatial resolutions, specifically designed to capture vertical patterns in traditional Mongolian text.
Figure 3.
Architecture of our dynamic feature enhancement module (DFEM). The module consists of three main components: (1) feature transformation blocks that align multi-scale features to a common dimension, (2) a channel attention mechanism that generates content-aware weights for each feature level, and (3) a feature fusion block that integrates the weighted features. The adaptive weighting enables the model to focus on the most informative features for each specific input.
Figure 3.
Architecture of our dynamic feature enhancement module (DFEM). The module consists of three main components: (1) feature transformation blocks that align multi-scale features to a common dimension, (2) a channel attention mechanism that generates content-aware weights for each feature level, and (3) a feature fusion block that integrates the weighted features. The adaptive weighting enables the model to focus on the most informative features for each specific input.
Figure 4.
Architecture of our direction-aware detection head. The head consists of a direction-aware convolution block followed by three specialized prediction branches: (1) a classification branch for identifying layout categories, (2) a regression branch for bounding box localization, and (3) a direction branch that employs a vector representation for accurate orientation modeling. The joint optimization of these three branches enables precise layout analysis with explicit direction awareness.
Figure 4.
Architecture of our direction-aware detection head. The head consists of a direction-aware convolution block followed by three specialized prediction branches: (1) a classification branch for identifying layout categories, (2) a regression branch for bounding box localization, and (3) a direction branch that employs a vector representation for accurate orientation modeling. The joint optimization of these three branches enables precise layout analysis with explicit direction awareness.
Figure 5.
Example detection results on a traditional Mongolian document page. The bounding boxes show accurate localization of all eight layout elements (Text, Title, Figure, Figure Caption, Table, Table Caption, Header, and Footer) in their typical arrangement.
Figure 5.
Example detection results on a traditional Mongolian document page. The bounding boxes show accurate localization of all eight layout elements (Text, Title, Figure, Figure Caption, Table, Table Caption, Header, and Footer) in their typical arrangement.
Table 1.
Statistics of layout elements in the TMDLAD dataset.
Table 1.
Statistics of layout elements in the TMDLAD dataset.
| Category | Training | Validation | Test | Total |
|---|
| Text | 42,148 | 5269 | 5182 | 52,599 |
| Title | 21,074 | 2635 | 2569 | 26,278 |
| Figure | 15,806 | 1976 | 1881 | 19,663 |
| Figure Caption | 3287 | 411 | 384 | 4082 |
| Table | 2484 | 311 | 297 | 3092 |
| Table Caption | 2286 | 286 | 268 | 2840 |
| Header | 22,128 | 2766 | 2693 | 27,587 |
| Footer | 12,644 | 1581 | 1488 | 15,713 |
| Total | 121,857 | 15,235 | 14,762 | 151,854 |
Table 2.
Comparison with state-of-the-art methods on the TMDLAD dataset.
Table 2.
Comparison with state-of-the-art methods on the TMDLAD dataset.
| Method | Backbone | AP50 ↑ | mAP ↑ | DA ↑ | Params ↓ | FPS ↑ |
|---|
| Faster R-CNN | ResNet-50 | 0.762 | 0.591 | - | 41.5 M | 12.5 |
| Mask R-CNN | ResNet-50 | 0.778 | 0.613 | - | 44.2 M | 9.8 |
| Cascade R-CNN | ResNet-50 | 0.795 | 0.638 | - | 69.2 M | 8.7 |
| FCOS | ResNet-50 | 0.783 | 0.624 | - | 32.1 M | 14.3 |
| Oriented R-CNN | ResNet-50 | 0.821 | 0.667 | 0.782 | 43.7 M | 10.2 |
| RoI Transformer | ResNet-50 | 0.834 | 0.679 | 0.795 | 46.8 M | 9.5 |
| MobileNetV3-SSD | MobileNetV3 | 0.723 | 0.623 | - | 4.3 M | 35.2 |
| EfficientDet-Lite0 | EfficientNet-B0 | 0.742 | 0.645 | - | 3.2 M | 30.5 |
| YOLOv5s | CSPNet | 0.756 | 0.658 | - | 7.2 M | 45.7 |
| YOLOv8n | CSPNet | 0.768 | 0.672 | - | 3.2 M | 48.3 |
| PP-PicoDet-S | ESNet | 0.749 | 0.651 | - | 3.5 M | 42.1 |
| Ours | Modified MobileNetV3 | 0.867 | 0.715 | 0.923 | 8.3 M | 28.6 |
Table 3.
Ablation study on key components of our model.
Table 3.
Ablation study on key components of our model.
Asymmetric
Conv | AIR
Block | DFEM | Direction-Aware
Detection | AP50 ↑ | mAP ↑ | DA ↑ |
|---|
| | | | | 0.793 | 0.635 | 0.768 |
| ✓ | | | | 0.815 | 0.652 | 0.784 |
| ✓ | ✓ | | | 0.832 | 0.671 | 0.809 |
| ✓ | ✓ | ✓ | | 0.849 | 0.687 | 0.835 |
| ✓ | ✓ | ✓ | ✓ | 0.867 | 0.715 | 0.923 |
Table 4.
Comparison of different direction representation methods.
Table 4.
Comparison of different direction representation methods.
| Direction Representation | mAP ↑ | DA ↑ | DMAE ↓ (°) |
|---|
| Direct Angle Regression | 0.693 | 0.857 | 4.8 |
| Classification (180 classes) | 0.702 | 0.895 | 3.2 |
| Vector | 0.715 | 0.923 | 2.5 |
Table 5.
Category-wise performance analysis on the TMDLAD dataset.
Table 5.
Category-wise performance analysis on the TMDLAD dataset.
| Category | AP50 ↑ | Precision ↑ | Recall ↑ | F1 ↑ | DMAE ↓ (°) |
|---|
| Text | 0.895 | 0.92 | 0.90 | 0.91 | 2.1 |
| Title | 0.872 | 0.89 | 0.88 | 0.88 | 2.3 |
| Figure | 0.903 | 0.94 | 0.91 | 0.92 | 2.0 |
| Figure Caption | 0.836 | 0.86 | 0.84 | 0.85 | 2.8 |
| Table | 0.851 | 0.88 | 0.85 | 0.86 | 2.4 |
| Table Caption | 0.824 | 0.85 | 0.83 | 0.84 | 3.0 |
| Header | 0.887 | 0.91 | 0.89 | 0.90 | 2.2 |
| Footer | 0.868 | 0.89 | 0.87 | 0.88 | 2.5 |
| Micro-avg | 0.867 | 0.90 | 0.88 | 0.89 | 2.5 |
| Macro-avg | 0.867 | 0.89 | 0.87 | 0.88 | 2.4 |
Table 6.
Ablation study on loss function components.
Table 6.
Ablation study on loss function components.
| Loss Configuration | AP50 ↑ | mAP ↑ | DA ↑ |
|---|
| BCE + Smooth L1 + MSE | 0.842 | 0.689 | 0.885 |
| Focal + Smooth L1 + MSE | 0.858 | 0.703 | 0.901 |
| Focal + Smooth L1 + Vector Distance | 0.867 | 0.715 | 0.923 |
| Fixed Weights | 0.853 | 0.698 | 0.907 |
| Adaptive Weighting | 0.867 | 0.715 | 0.923 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}