
Research on X-Ray Weld Defect Detection of Steel Pipes by Integrating ECA and EMA Dual Attention Mechanisms


Abstract
1. Introduction
2. X-Ray Detection of Weld Defect Features and Dataset Construction
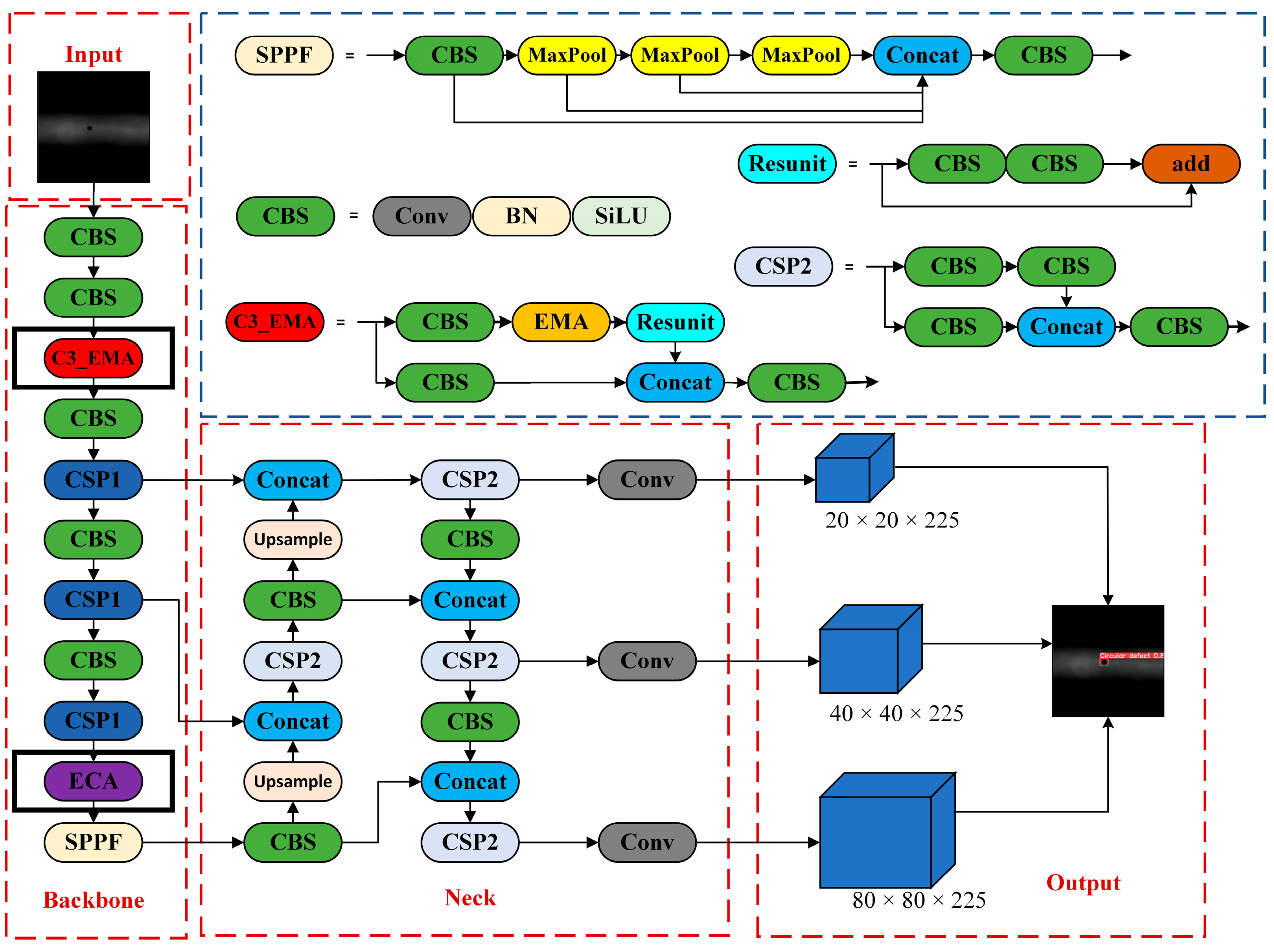
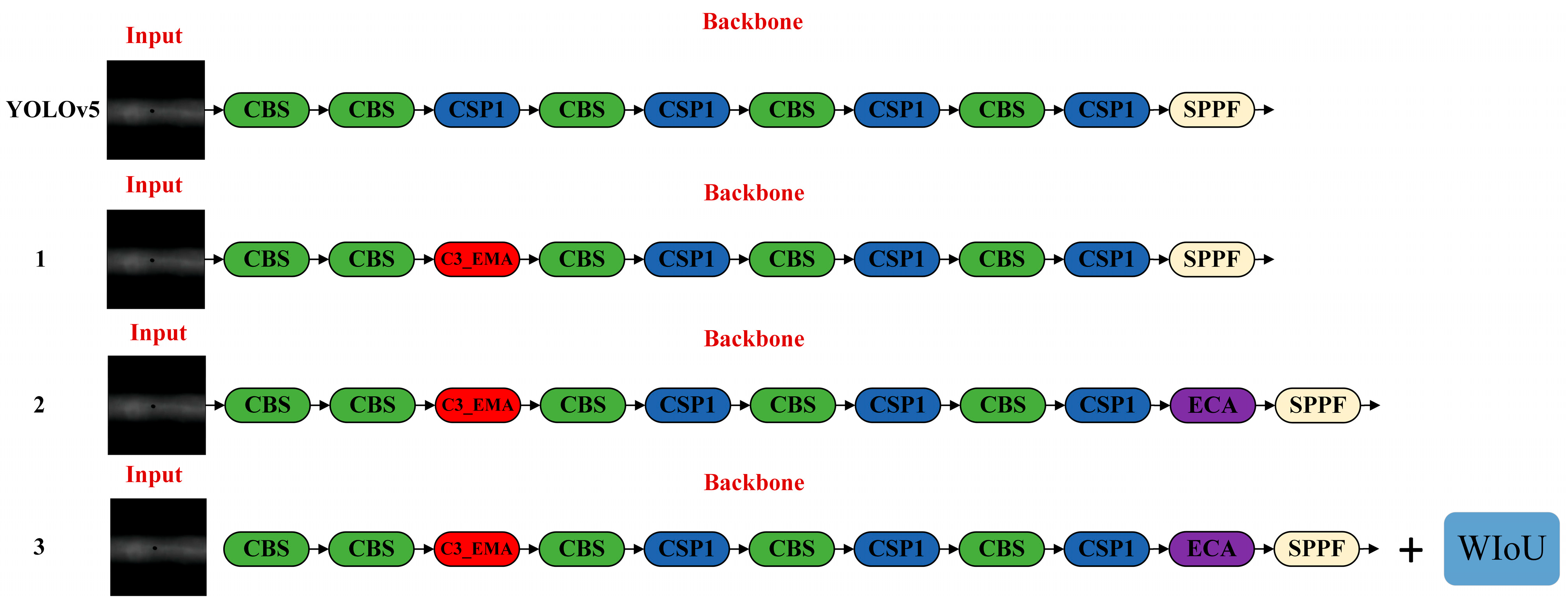
3. Establishment of YOLOv5-Based Optimized Detection Model and Evaluation Metrics
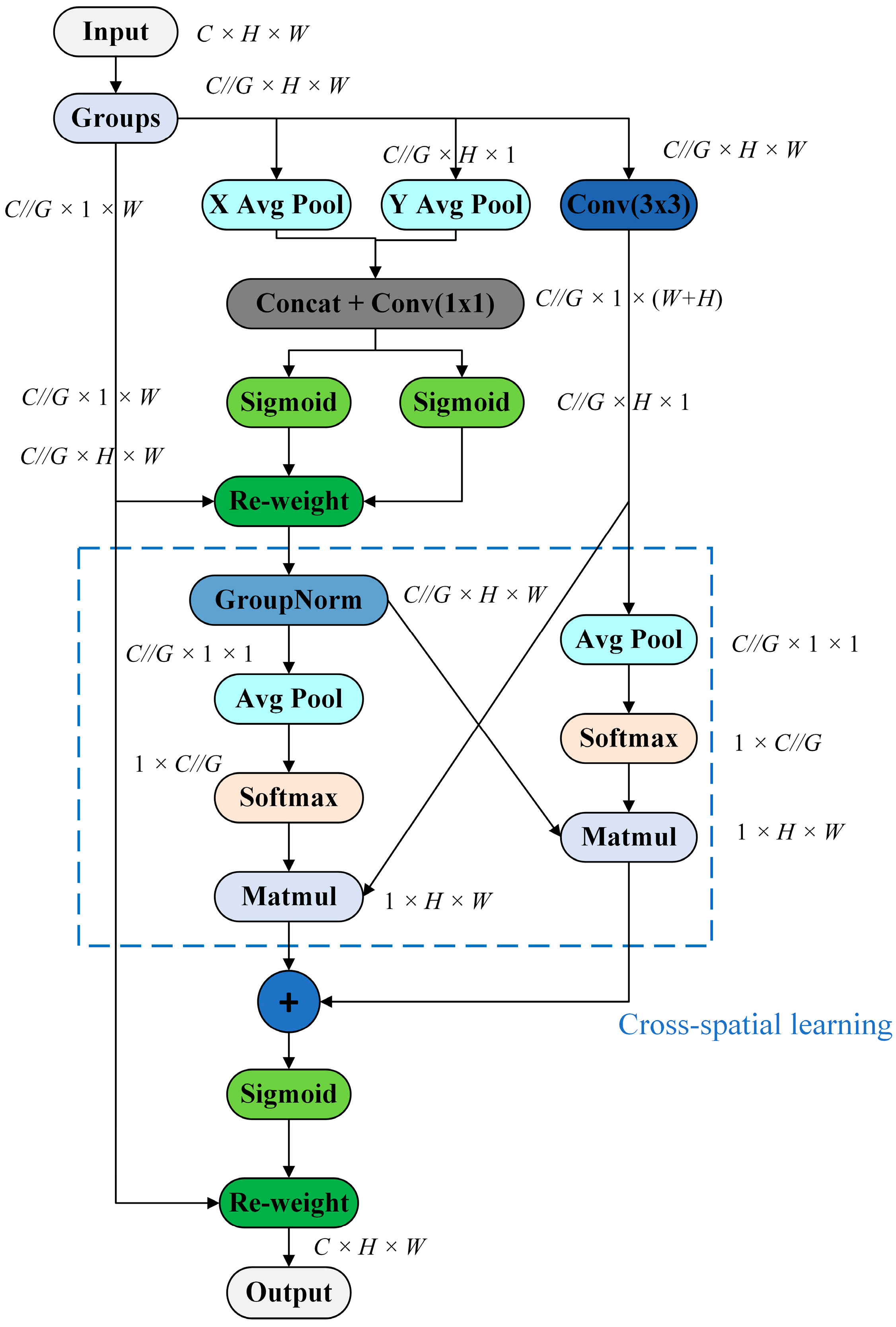
3.1. Efficient Multi-Scale Attention (EMA) Mechanism
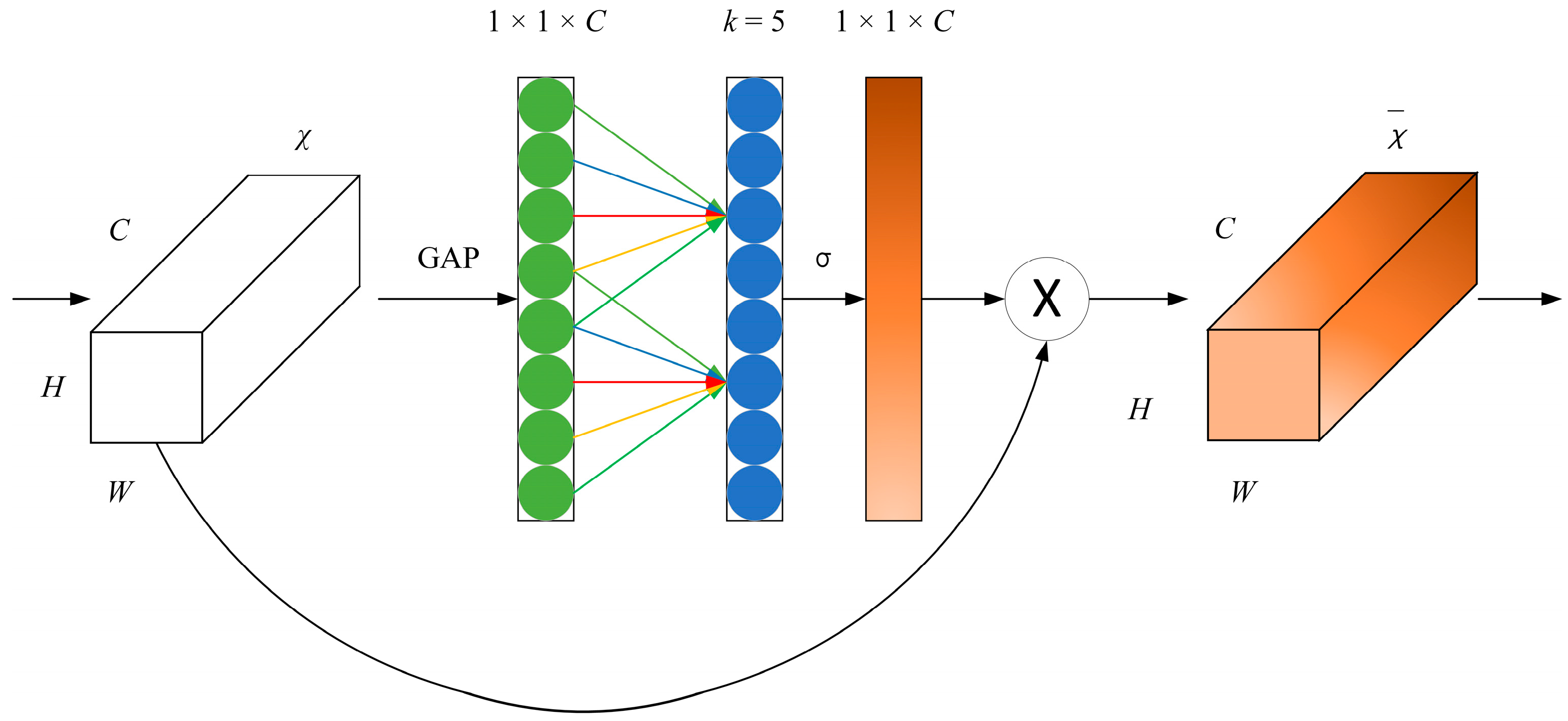
3.2. Efficient Channel Attention (ECA) Mechanism
3.3. Improvement of the Loss Function
3.4. Model Evaluation Index
4. Experiments and Result Analysis
4.1. Experimental Procedure and Experimental Setup
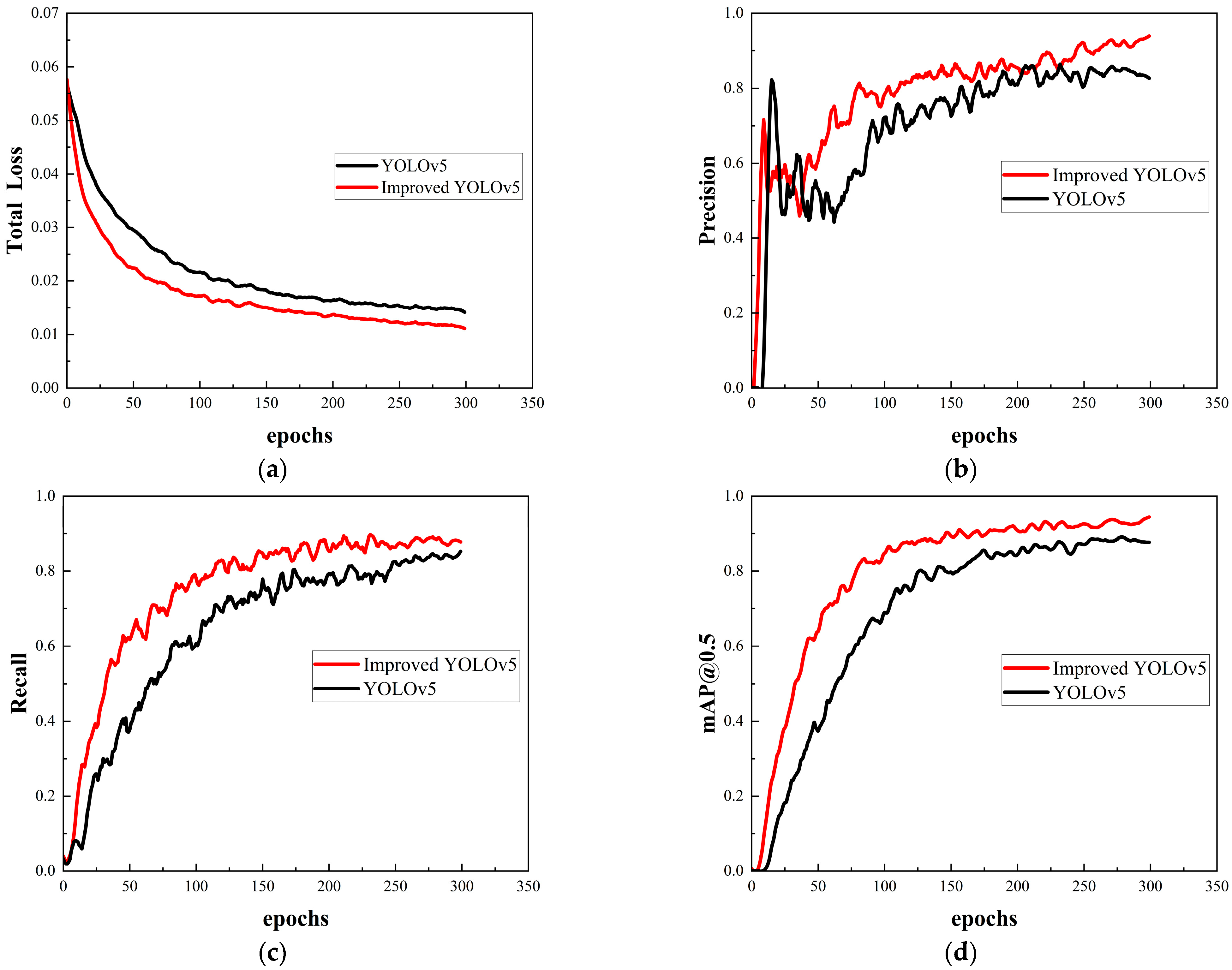
4.2. Result Analysis
4.3. Comparative Experiments
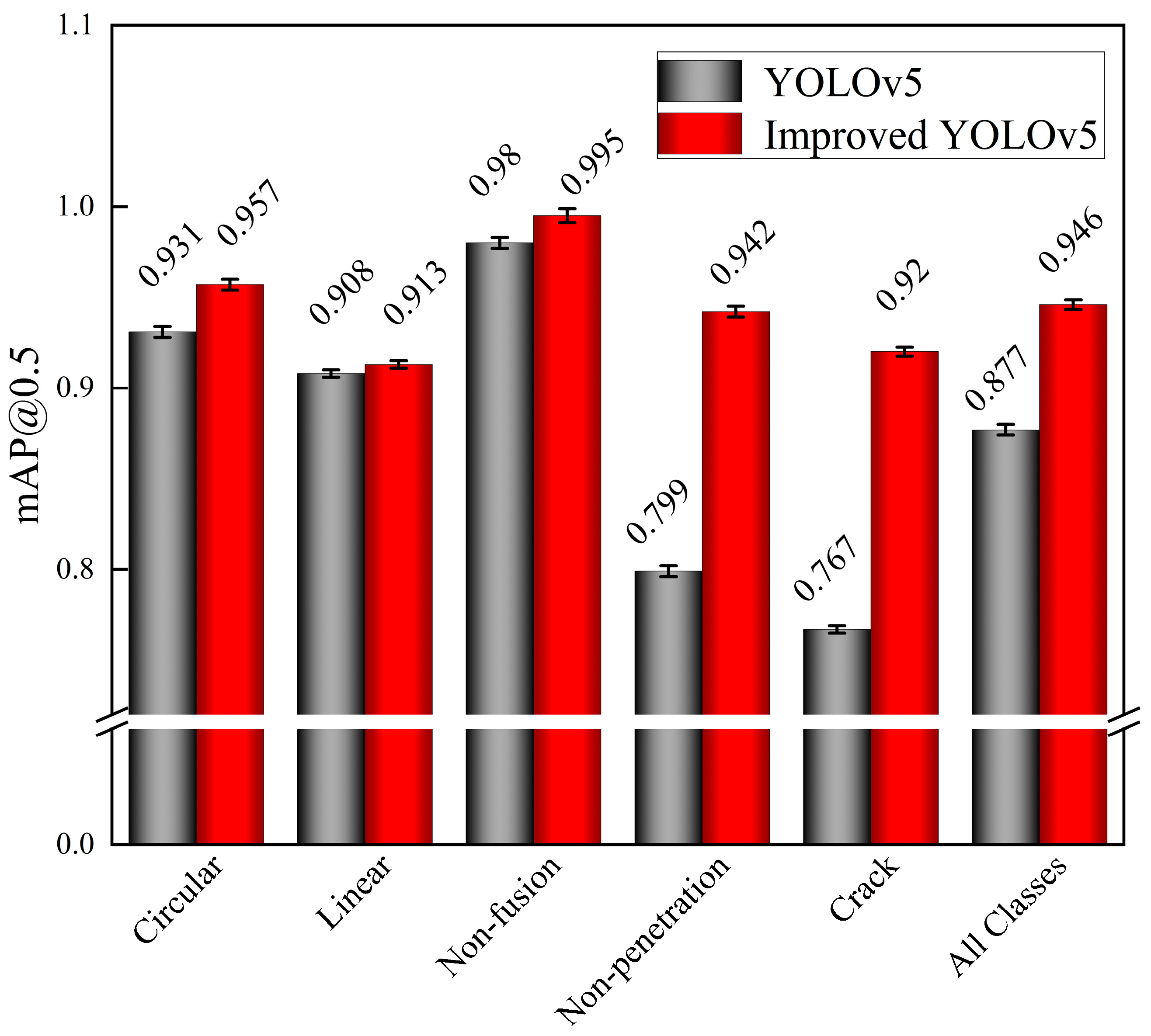
4.4. Ablation Experiment
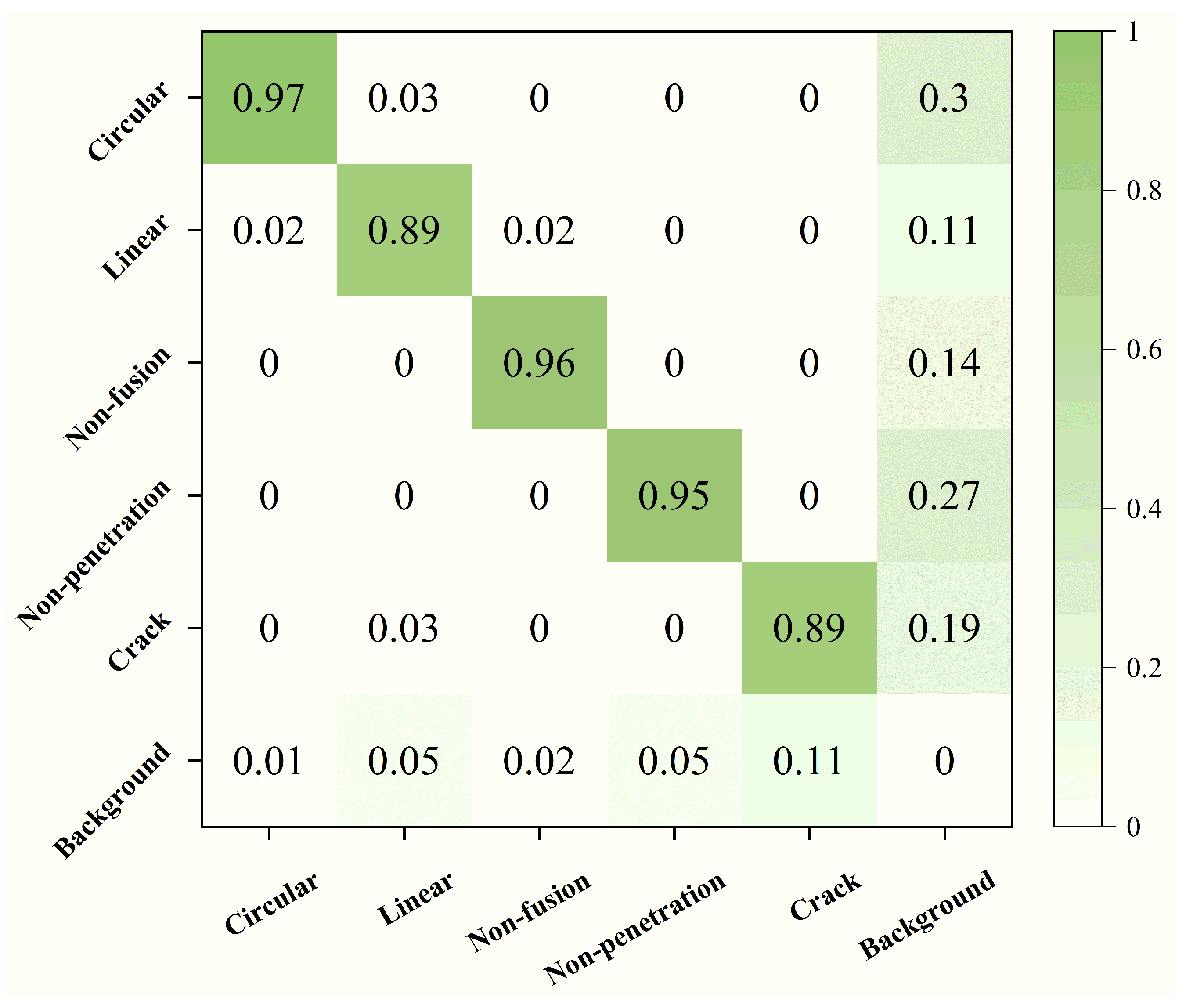
4.5. Confusion Matrix Analysis
4.6. Comparison of Actual Detection Effect
5. Conclusions and Prospect
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, D.; Cui, Y.; Yu, Z.; Yuan, H. Deep learning based steel pipe weld defect detection. Appl. Artif. Intell. 2021, 35, 1237–1249. [Google Scholar] [CrossRef]
- Yang, L.; Wang, H.; Huo, B.; Li, F.; Liu, Y. An automatic welding defect location algorithm based on deep learning. NDT E Int. 2021, 120, 102435. [Google Scholar] [CrossRef]
- Ji, C.; Wang, H.; Li, H. Defects detection in weld joints based on visual attention and deep learning. NDT E Int. 2023, 133, 102764. [Google Scholar] [CrossRef]
- Zuo, F.; Liu, J.; Fu, M.; Wang, L.; Zhao, Z. An X-Ray-based multiexpert inspection method for automatic welding defect assessment in intelligent pipeline systems. IEEE/ASME Trans. Mechatron. 2024, 1–12. [Google Scholar] [CrossRef]
- Li, Y.; Liu, C.; Wu, Z.; Sun, Q.; Zhu, Y.; Li, K. One-stage identification method for weld defects based on deep learning network. J. Guangxi Univ. 2021, 46, 362–372. [Google Scholar]
- Yang, L.; Wang, Z.; Gao, S. Pipeline magnetic flux leakage image detection algorithm based on multiscale SSD network. IEEE Trans. Ind. Inform. 2019, 16, 501–509. [Google Scholar] [CrossRef]
- Wu, Y.; Yan, S.; Zhao, X. Weld defect detection model based on machine vision. In Proceedings of the Third International Conference on Advanced Manufacturing Technology and Electronic Information (AMTEI 2023), Tianjin, China, 22–24 December 2023; Volume 13081, pp. 170–174. [Google Scholar]
- Kwon, J.-E.; Park, J.-H.; Kim, J.-H.; Lee, Y.-H.; Cho, S.-I. Context and scale-aware YOLO for welding defect detection. NDT E Int. 2023, 139, 102919. [Google Scholar] [CrossRef]
- Yao, J.; Qi, J.; Zhang, J.; Shao, H.; Yang, J.; Li, X. A real-time detection algorithm for Kiwifruit defects based on YOLOv5. Electronics 2021, 10, 1711. [Google Scholar] [CrossRef]
- Zhang, Y.; Ni, Q. A novel weld-seam defect detection algorithm based on the s-yolo model. Axioms 2023, 12, 697. [Google Scholar] [CrossRef]
- Wang, Q.; Cheng, M.; Huang, S.; Cai, Z.; Zhang, J.; Yuan, H. A deep learning approach incorporating YOLO v5 and attention mechanisms for field real-time detection of the invasive weed Solanum rostratum Dunal seedlings. Comput. Electron. Agric. 2022, 199, 107194. [Google Scholar] [CrossRef]
- Xu, L.; Dong, S.; Wei, H.; Ren, Q.; Huang, J.; Liu, J. Defect signal intelligent recognition of weld radiographs based on YOLO V5-IMPROVEMENT. J. Manuf. Process. 2023, 99, 373–381. [Google Scholar] [CrossRef]
- Cheng, S.; Yang, H.; Xu, X.; Li, M.; Chen, Y. Improved lightweight X-ray aluminum alloy weld defects detection algorithm based on YOLOv5. Chin. J. Lasers 2022, 49, 2104005. [Google Scholar]
- Xu, X.; Li, X. Research on surface defect detection algorithm of pipeline weld based on YOLOv7. Sci. Rep. 2024, 14, 1881. [Google Scholar] [CrossRef] [PubMed]
- Wu, L.; Chu, Y.; Yang, H.; Chen, Y. Sim-YOLOv8 Object Detection Model for DR Image Defects in Aluminum Alloy Welds. Chin. J. Lasers 2024, 51, 29–38. [Google Scholar]
- Cheng, K.; Hu, X.; Chen, H.; Li, H. Remote Sensing Object Detection Methods Based on Improved YOLOv5s. Laser Optoelectron. Prog. 2024, 61, 285–291. [Google Scholar]
- Wang, D.; Xiao, B.; Yao, C.; Zhao, W.; Zhu, R. Improved YOLOv5-Based Deeplearning Method for Detecting “Hot Spot Effect” in Phtotvoltaic Modules. Acta Energiae Solaris Sin. 2024, 45, 342–348. [Google Scholar]
- Wang, X.; Zhang, B.; Cui, J.; Wu, J.; Li, Y.; Li, J.; Tan, Y.; Chen, X.; Wu, W.; Yu, X. Image analysis of the automatic welding defects detection based on deep learning. J. Nondestruct. Eval. 2023, 42, 82. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Li, Y.; Zhong, X.; Yao, Z.; Hu, B. Detection of dress code violations based on improved YOLOv5s. J. Graph. 2024, 45, 433–455. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Cao, Y.; Liu, F.; Jiang, L.; Cheng, B.; You, M.; Chen, C. Detection of wood surface defects using YOLOv5-LW model. J. For. Eng. 2024, 9, 144–152. [Google Scholar]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Zhao, X.; Fang, J.; Zhao, Y. Tomato Potting Seedling Classification and Recognition Model Based on Improved YOLOv5s. Sci. Technol. Eng. 2024, 24, 11774–11785. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Loss | Precision/% | Recall/% | mAP@0.5/% | Params | FPS |
|---|---|---|---|---|---|---|
| YOLOv5 | 0.014 | 82.6 ± 0.2 | 83.8 ± 0.1 | 87.7 ± 0.2 | 7,023,610 | 227.27 |
| Improved YOLOv5 | 0.011 | 94.1 ± 0.3 | 89.2 ± 0.1 | 94.6 ± 0.2 | 7,023,789 | 208.83 |
| Model | AP/% | mAP@0.5/% | Params/M | FPS | ||||
|---|---|---|---|---|---|---|---|---|
| Circular | Linear | Non-Fusion | Non-Penetration | Crack | ||||
| Faster-RCNN | 57.72 | 78.83 | 93.91 | 98.60 | 69.47 | 79.7 ± 0.5 | 41.14 | 42.20 |
| SSD | 69.15 | 67.54 | 94.55 | 97.08 | 79.57 | 81.6 ± 0.4 | 24.28 | 51.60 |
| RT-DETR | 91.00 | 86.10 | 87.60 | 94.00 | 83.80 | 88.5 ± 0.1 | 31.99 | 81.97 |
| YOLOv3 | 83.73 | 68.92 | 79.82 | 85.42 | 58.29 | 75.2 ± 0.3 | 12.13 | 62.89 |
| YOLOv5 | 93.10 | 90.80 | 98.00 | 79.90 | 76.70 | 87.7 ± 0.2 | 7.02 | 227.27 |
| YOLOv8 | 91.90 | 88.60 | 95.60 | 91.40 | 70.00 | 87.5 ± 0.2 | 11.13 | 108.70 |
| YOLOv9 | 92.5 | 91.5 | 91.1 | 82.00 | 78.40 | 87.1 ± 0.3 | 7.17 | 107.53 |
| YOLOv10 | 94.20 | 90.20 | 86.10 | 75.60 | 73.20 | 83.9 ± 0.3 | 2.70 | 217.39 |
| Ours | 95.70 | 91.30 | 99.50 | 94.20 | 92.00 | 94.6 ± 0.2 | 7.02 | 208.33 |
| ECA | EMA | WIoU | AP/% | mAP@0.5/% | ||||
|---|---|---|---|---|---|---|---|---|
| Circular | Linear | Non-Fusion | Non-Penetration | Crack | ||||
| — | — | — | 93.1 | 90.8 | 98.0 | 79.9 | 76.7 | 87.7 ± 0.2 |
| √ | — | — | 91.2 | 92.5 | 95.5 | 85.3 | 81.7 | 89.2 ± 0.1 |
| √ | √ | — | 95.2 | 94.3 | 98.8 | 91.5 | 84.3 | 92.8 ± 0.3 |
| √ | √ | √ | 95.7 | 91.3 | 99.5 | 94.2 | 92.0 | 94.6 ± 0.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, G.; Su, X.; Wang, Q.; Luo, W.; Lu, W. Research on X-Ray Weld Defect Detection of Steel Pipes by Integrating ECA and EMA Dual Attention Mechanisms. Appl. Sci. 2025, 15, 4519. https://doi.org/10.3390/app15084519
Su G, Su X, Wang Q, Luo W, Lu W. Research on X-Ray Weld Defect Detection of Steel Pipes by Integrating ECA and EMA Dual Attention Mechanisms. Applied Sciences. 2025; 15(8):4519. https://doi.org/10.3390/app15084519
Chicago/Turabian StyleSu, Guanli, Xuanhe Su, Qunkai Wang, Weihong Luo, and Wei Lu. 2025. "Research on X-Ray Weld Defect Detection of Steel Pipes by Integrating ECA and EMA Dual Attention Mechanisms" Applied Sciences 15, no. 8: 4519. https://doi.org/10.3390/app15084519
APA StyleSu, G., Su, X., Wang, Q., Luo, W., & Lu, W. (2025). Research on X-Ray Weld Defect Detection of Steel Pipes by Integrating ECA and EMA Dual Attention Mechanisms. Applied Sciences, 15(8), 4519. https://doi.org/10.3390/app15084519