
GCN-Former: A Method for Action Recognition Using Graph Convolutional Networks and Transformer


Abstract
1. Introduction
- A spatiotemporal graph convolutional network framework is proposed, combining the Transformer with GCNs. Additionally, we introduce the Contextual Temporal Attention (CTA) mechanism to more efficiently leverage contextual information, enhancing the expressive power of the output aggregated feature map.
- A Transformer Block-based time encoder with a self-attention mechanism is designed, effectively addressing the modeling challenge of long sequence data.
- Extensive experiments are conducted on multiple datasets, validating the effectiveness and superiority of the proposed model.
2. Methods
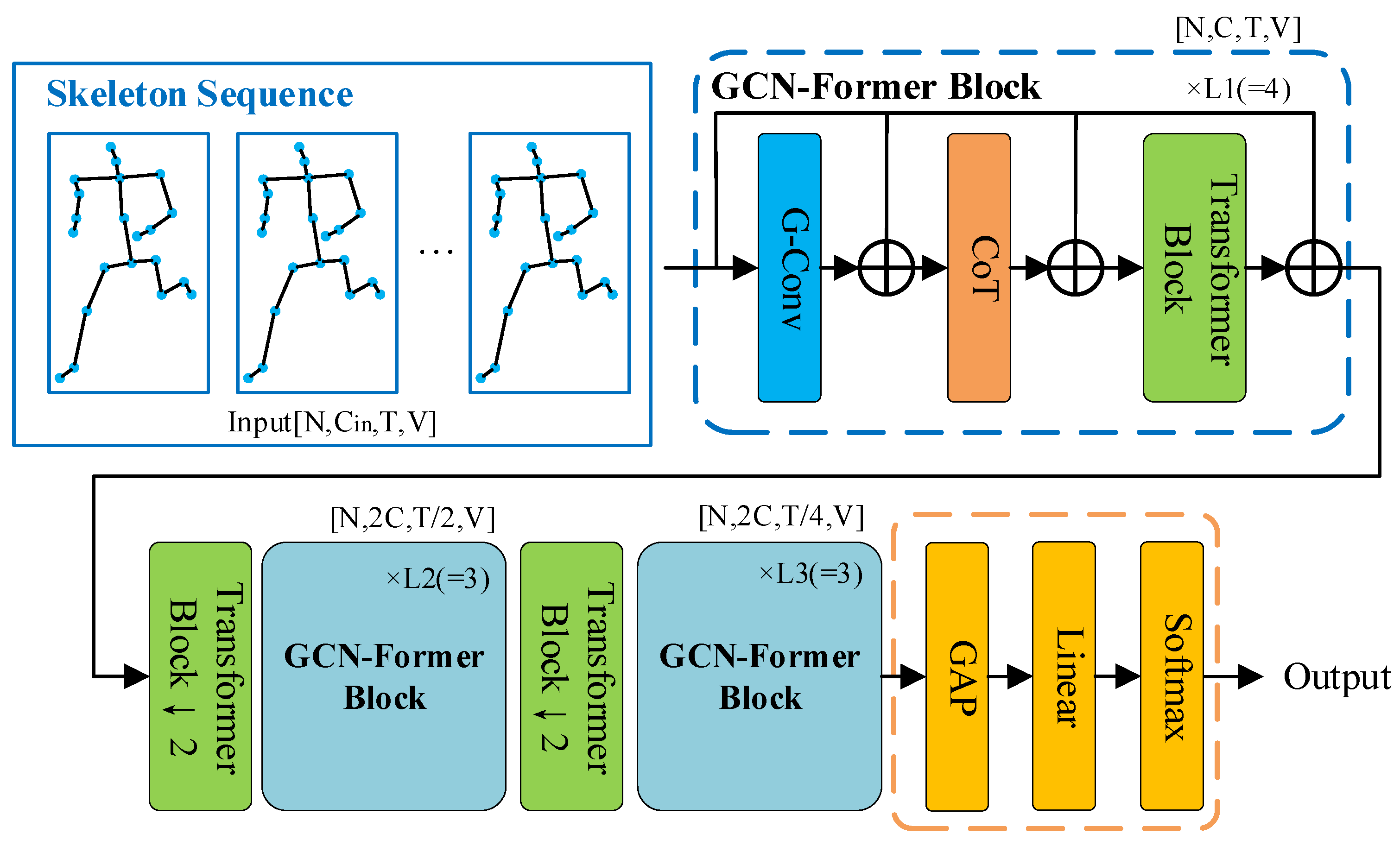
2.1. GCN-Former Architecture Overview
2.2. GCN-Former Block Architecture
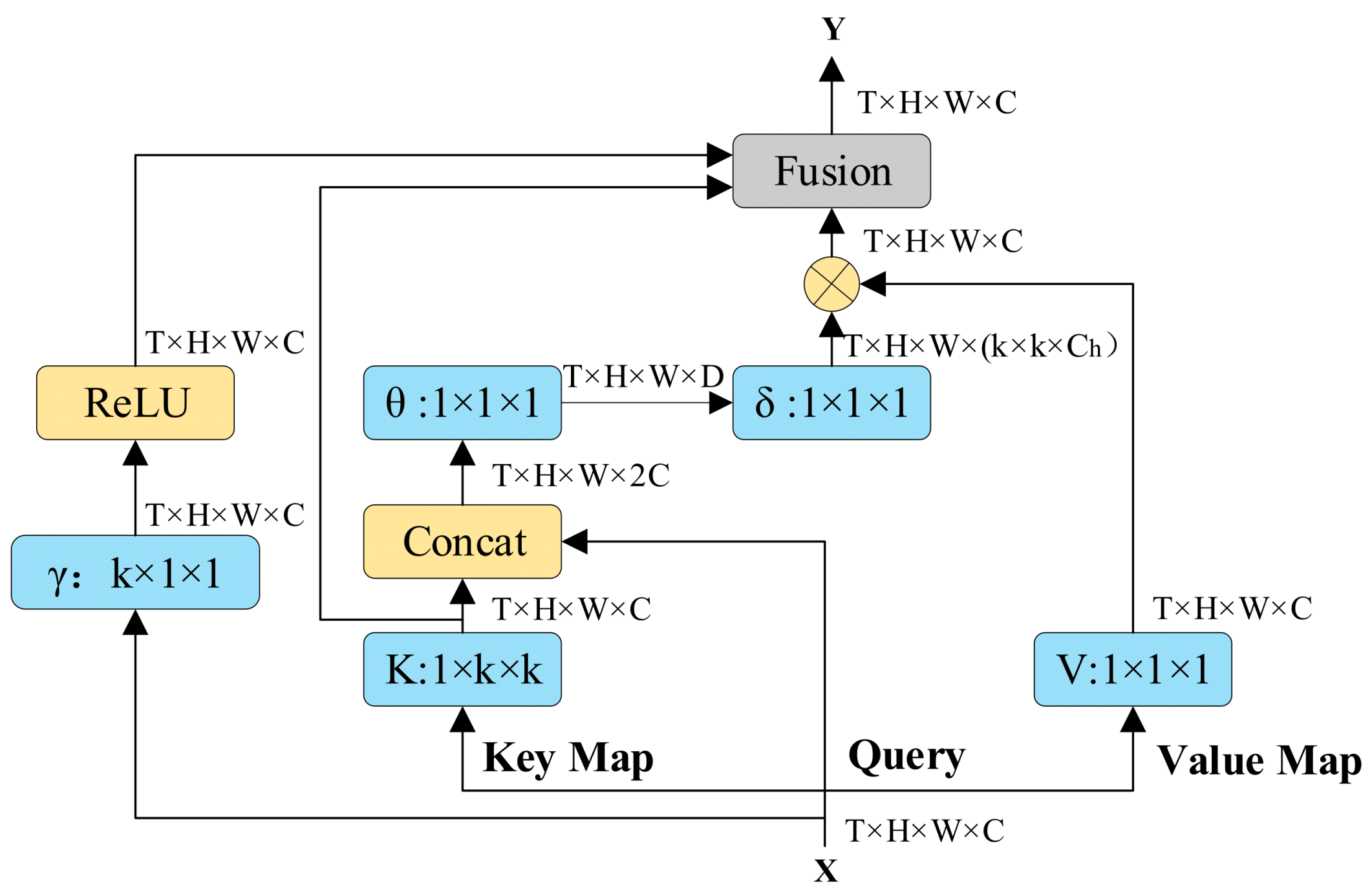
2.3. Contextual Temporal Attention
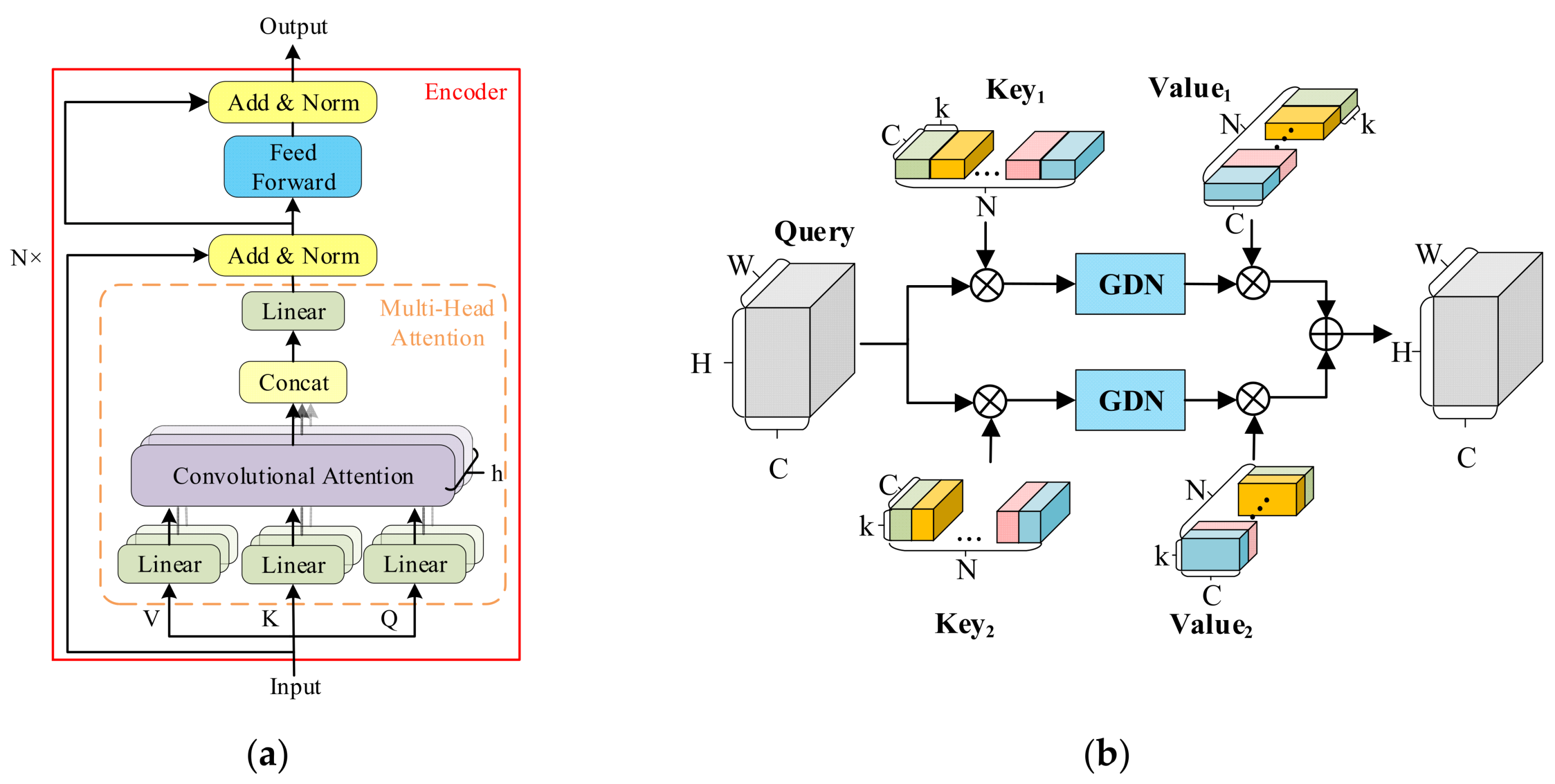
2.4. Transformer Block Module
3. Experiments
3.1. Datasets
3.2. Experiment Details
3.3. Comparison with State of the Art
3.4. Ablation Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing Human Actions: A Local SVM Approach. In Proceedings of the 17th International Conference on Pattern Recognition, 2004, ICPR 2004, Cambridge, UK, 26 August 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 3, pp. 32–36. [Google Scholar]
- Ahmad, M.; Lee, S.-W. HMM-Based Human Action Recognition Using Multiview Image Sequences. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 1, pp. 263–266. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A New Representation of Skeleton Sequences for 3d Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3288–3297. [Google Scholar]
- Liu, M.; Liu, H.; Chen, C. Enhanced Skeleton Visualization for View Invariant Human Action Recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar] [CrossRef]
- Du, Y.; Wang, W.; Wang, L. Hierarchical Recurrent Neural Network for Skeleton Based Action Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1110–1118. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; AAAI: Palo Alto, CA, USA, 2017; Volume 31. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View Adaptive Recurrent Neural Networks for High Performance Human Action Recognition from Skeleton Data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2117–2126. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; AAAI: Palo Alto, CA, USA, 2018; Volume 32. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-Structural Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3595–3603. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-Stream Adaptive Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 12026–12035. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Directed Graph Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 7912–7921. [Google Scholar]
- Zhang, X.; Xu, C.; Tao, D. Context Aware Graph Convolution for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 14333–14342. [Google Scholar]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Shift Graph Convolutional Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 183–192. [Google Scholar]
- Chi, H.; Ha, M.H.; Chi, S.; Lee, S.W.; Huang, Q.; Ramani, K. Infogcn: Representation Learning for Human Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 20186–20196. [Google Scholar]
- Chi, S.; Chi, H.; Huang, Q.; Ramani, K. InfoGCN++: Learning Representation by Predicting the Future for Online Human Skeleton-Based Action Recognition. arXiv 2023, arXiv:2310.10547. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Lee, M.; Lee, D.; Lee, S. Hierarchically Decomposed Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 10444–10453. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-Wise Topology Refinement Graph Convolution for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13359–13368. [Google Scholar]
- Zhou, Y.; Yan, X.; Cheng, Z.-Q.; Yan, Y.; Dai, Q.; Hua, X.-S. Blockgcn: Redefine Topology Awareness for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 2049–2058. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Plizzari, C.; Cannici, M.; Matteucci, M. Skeleton-Based Action Recognition via Spatial and Temporal Transformer Networks. Comput. Vis. Image Underst. 2021, 208, 103219. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, B.; Li, W.; Duan, L.; Gan, C. STST: Spatial-Temporal Specialized Transformer for Skeleton-Based Action Recognition. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, China, 20–24 October 2021; ACM: New York, NY, USA, 2021; pp. 3229–3237. [Google Scholar]
- Gao, Z.; Wang, P.; Lv, P.; Jiang, X.; Liu, Q.; Wang, P.; Xu, M.; Li, W. Focal and Global Spatial-Temporal Transformer for Skeleton-Based Action Recognition. In Proceedings of the Asian Conference on Computer Vision, ACCV, Macao, China, 4–8 December 2022; pp. 382–398. [Google Scholar]
- Shi, F.; Lee, C.; Qiu, L.; Zhao, Y.; Shen, T.; Muralidhar, S.; Han, T.; Zhu, S.-C.; Narayanan, V. STAR: Sparse Transformer-Based Action Recognition. arXiv 2021, arXiv:2107.07089. [Google Scholar]
- Zhou, Y.; Cheng, Z.-Q.; Li, C.; Fang, Y.; Geng, Y.; Xie, X.; Keuper, M. Hypergraph Transformer for Skeleton-Based Action Recognition. arXiv 2023, arXiv:2211.09590. [Google Scholar]
- Pang, Y.; Ke, Q.; Rahmani, H.; Bailey, J.; Liu, J. IGFormer: Interaction Graph Transformer for Skeleton-Based Human Interaction Recognition. In Computer Vision–ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Lecture Notes in Computer Science; Springer Nature: Cham, Switzerland, 2022; Volume 13685, pp. 605–622. ISBN 978-3-031-19805-2. [Google Scholar]
- Duan, H.; Xu, M.; Shuai, B.; Modolo, D.; Tu, Z.; Tighe, J.; Bergamo, A. Skeletr: Towards Skeleton-Based Action Recognition in the Wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 13634–13644. [Google Scholar]
- Wen, Y.; Tang, Z.; Pang, Y.; Ding, B.; Liu, M. Interactive Spatiotemporal Token Attention Network for Skeleton-Based General Interactive Action Recognition. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 7886–7892. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual Transformer Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Wu, D.; Yu, C.; Chu, X.; Sang, N.; Gao, C. Sctnet: Single-Branch Cnn with Transformer Semantic Information for Real-Time Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; AAAI: Washington, DC, USA, 2024; Volume 38, pp. 6378–6386. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.-T.; Wang, G. Ntu Rgb+ d: A Large Scale Dataset for 3d Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1010–1019. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.-Y.; Kot, A.C. Ntu Rgb+ d 120: A Large-Scale Benchmark for 3d Human Activity Understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef] [PubMed]
- Xia, L.; Chen, C.-C.; Aggarwal, J.K. View Invariant Human Action Recognition Using Histograms of 3D Joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA; pp. 20–27. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Zhang, P.; Lan, C.; Zeng, W.; Xing, J.; Xue, J.; Zheng, N. Semantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1112–1121. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and Unifying Graph Convolutions for Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 143–152. [Google Scholar]
- Chen, Z.; Li, S.; Yang, B.; Li, Q.; Liu, H. Multi-Scale Spatial Temporal Graph Convolutional Network for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Conference, 2–9 February 2021; AAAI: Palo Alto, CA, USA, 2021; Volume 35, pp. 1113–1122. [Google Scholar]
- Song, Y.-F.; Zhang, Z.; Shan, C.; Wang, L. Constructing Stronger and Faster Baselines for Skeleton-Based Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1474–1488. [Google Scholar] [CrossRef] [PubMed]
- Pan, L.; Lu, J.; Tang, X. Spatial-Temporal Graph Neural ODE Networks for Skeleton-Based Action Recognition. Sci. Rep. 2024, 14, 7629. [Google Scholar] [CrossRef] [PubMed]
- Kang, M.-S.; Kang, D.; Kim, H. Efficient Skeleton-Based Action Recognition via Joint-Mapping Strategies. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 3403–3412. [Google Scholar]
- Wu, L.; Zhang, C.; Zou, Y. SpatioTemporal Focus for Skeleton-Based Action Recognition. Pattern Recognit. 2023, 136, 109231. [Google Scholar] [CrossRef]
- Gedamu, K.; Ji, Y.; Gao, L.; Yang, Y.; Shen, H.T. Relation-Mining Self-Attention Network for Skeleton-Based Human Action Recognition. Pattern Recognit. 2023, 139, 109455. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, J.; Cai, J.; Xu, Z. HybridNet: Integrating GCN and CNN for Skeleton-Based Action Recognition. Appl. Intell. 2023, 53, 574–585. [Google Scholar] [CrossRef]
- Bavil, A.F.; Damirchi, H.; Taghirad, H.D. Action Capsules: Human Skeleton Action Recognition. Comput. Vis. Image Underst. 2023, 233, 103722. [Google Scholar] [CrossRef]
- Lu, J.; Huang, T.; Zhao, B.; Chen, X.; Zhou, J.; Zhang, K. Dual-Excitation Spatial–Temporal Graph Convolution Network for Skeleton-Based Action Recognition. IEEE Sens. J. 2024, 24, 8184–8196. [Google Scholar] [CrossRef]
- Ke, L.; Peng, K.-C.; Lyu, S. Towards To-at Spatio-Temporal Focus for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Conference, 22 February–1 March 2022; AAAI: Palo Alto, CA, USA, 2022; Volume 36, pp. 1131–1139. [Google Scholar]
- Livieris, I.E.; Karacapilidis, N.; Domalis, G.; Tsakalidis, D. An Advanced Explainable and Interpretable ML-Based Framework for Educational Data Mining. In Methodologies and Intelligent Systems for Technology Enhanced Learning, Workshops Proceedings of the 13th International Conference, Guimaraes, Portugal, 12–14 July 2023; Kubincová, Z., Caruso, F., Kim, T., Ivanova, M., Lancia, L., Pellegrino, M.A., Eds.; Springer Nature: Cham, Switzerland, 2023; pp. 87–96. [Google Scholar]
- Livieris, I.E. A Novel Forecasting Strategy for Improving the Performance of Deep Learning Models. Expert Syst. Appl. 2023, 230, 120632. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13713–13722. [Google Scholar]
- Kiriakidou, N.; Livieris, I.E.; Pintelas, P. Mutual Information-Based Neighbor Selection Method for Causal Effect Estimation. Neural Comput. Appl. 2024, 36, 9141–9155. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Methods | Parameters | FLOPs | NTU RGB+D 60 | NTU RGB+D 120 | ||
|---|---|---|---|---|---|---|
| X-Sub (%) | X-View (%) | X-Sub (%) | X-Set (%) | |||
| MS-G3D [36] | 2.8 M | 5.22 G | 91.5 | 96.2 | 86.9 | 88.4 |
| MST-GCN [37] | 12 M | - | 91.5 | 96.6 | 87.5 | 88.8 |
| CTR-GCN | 1.5 M | 1.97 G | 92.4 | 96.4 | 88.9 | 90.4 |
| EfficientGCN-B4 [38] | 2.0 M | 15.2 G | 91.7 | 95.7 | 88.3 | 89.1 |
| STG-NODE [39] | - | - | 84.0 | 91.1 | - | - |
| AM-GCN [40] | - | - | 90.3 | 95.2 | 86.9 | 88.2 |
| 4s-STF-Net [41] | 6.8 M | - | 91.1 | 96.5 | 86.5 | 88.2 |
| RSA-Net [42] | 3.5 M | 3.84 G | 91.8 | 96.8 | 88.4 | 89.7 |
| 4s-HybridNet [43] | - | - | 91.4 | 96.9 | 87.5 | 89.0 |
| Action Capsules [44] | - | 3.84 G | 90.0 | 96.3 | - | - |
| JPA-DESTGCN [45] | 4.41 M | 5.2 G | 91.6 | 96.9 | 87.5 | 88.5 |
| STF [46] | - | - | 92.5 | 96.9 | 88.9 | 89.9 |
| InfoGCN | 1.6 M | 1.84 G | 92.3 | 96.7 | 89.2 | 90.7 |
| HDGCN | 1.7 M | 1.77 G | 93.0 | 97.0 | 89.8 | 91.2 |
| BlockGCN | 1.3 M | 1.63 G | 93.1 | 97.0 | 90.3 | 91.5 |
| Ours | 1.8 M | 1.92 G | 93.5 | 97.3 | 90.7 | 91.9 |
| Action | ST-GCN | BlockGCN | Ours | |||
|---|---|---|---|---|---|---|
| AUC | G-Mean | AUC | G-Mean | AUC | G-Mean | |
| Walk | 96.98 | 96.96 | 98.69 | 98.66 | 98.35 | 98.33 |
| Sit Down | 89.37 | 89.21 | 94.29 | 94.14 | 94.42 | 94.24 |
| Standup | 90.05 | 89.92 | 94.52 | 94.49 | 94.17 | 94.12 |
| Pickup | 90.29 | 90.24 | 92.46 | 92.28 | 92.61 | 92.57 |
| Carry | 89.34 | 89.17 | 91.18 | 90.77 | 95.54 | 94.95 |
| Throw | 92.24 | 92.24 | 95.25 | 95.23 | 94.75 | 94.69 |
| Push | 87.69 | 87.18 | 89.41 | 88.92 | 89.26 | 88.86 |
| Pull | 85.73 | 85.39 | 86.74 | 86.35 | 86.83 | 86.51 |
| Wave Hands | 92.56 | 92.44 | 95.23 | 95.16 | 96.18 | 96.09 |
| Clap Hands | 90.65 | 90.16 | 94.72 | 94.58 | 94.95 | 94.62 |
| Average | 90.49 | 90.29 | 93.25 | 93.06 | 93.71 | 93.50 |
| Net | Param | FLOPs | Acc (%) | |||
|---|---|---|---|---|---|---|
| GCN | TCN | CTA | Transformer Block | |||
| √ | √ | 1.5 M | 1.97 G | 88.9 | ||
| √ | √ | √ | 1.6 M | 1.99 G | 89.2 | |
| √ | √ | 1.7 M | 1.88 G | 90.5 | ||
| √ | √ | √ | 1.8 M | 1.92 G | 91.3 | |
| Settings | Param | FLOPs | Acc (%) |
|---|---|---|---|
| GCN-Former (Ours) | 1.7 M | 1.88 G | 90.5 |
| +SE [49] | 1.9 M | 1.89 G | 90.8 |
| +CBAM [50] | 1.8 M | 1.89 G | 90.8 |
| +CA [51] | 1.9 M | 1.95 G | 91.0 |
| +CoT | 1.7 M | 1.90 G | 91.0 |
| +CTA(Ours) | 1.8 M | 1.92 G | 91.3 |
| GCN | Convolution Attention | Acc (%) | ||
|---|---|---|---|---|
| h = 1 | h = 2 | h = 4 | ||
| √ | √ | 90.4 | ||
| √ | √ | 90.9 | ||
| √ | √ | 91.3 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, X.; Zhang, J.; He, Y.; Wang, Z.; Zhao, W. GCN-Former: A Method for Action Recognition Using Graph Convolutional Networks and Transformer. Appl. Sci. 2025, 15, 4511. https://doi.org/10.3390/app15084511
Cui X, Zhang J, He Y, Wang Z, Zhao W. GCN-Former: A Method for Action Recognition Using Graph Convolutional Networks and Transformer. Applied Sciences. 2025; 15(8):4511. https://doi.org/10.3390/app15084511
Chicago/Turabian StyleCui, Xueshen, Jikai Zhang, Yihao He, Zhixing Wang, and Wentao Zhao. 2025. "GCN-Former: A Method for Action Recognition Using Graph Convolutional Networks and Transformer" Applied Sciences 15, no. 8: 4511. https://doi.org/10.3390/app15084511
APA StyleCui, X., Zhang, J., He, Y., Wang, Z., & Zhao, W. (2025). GCN-Former: A Method for Action Recognition Using Graph Convolutional Networks and Transformer. Applied Sciences, 15(8), 4511. https://doi.org/10.3390/app15084511