
4KSecure: A Universal Method for Active Manipulation Detection in Images of Any Resolution



Abstract
1. Introduction
- Full flexibility—enables embedding integrity markers in images of virtually any resolution and aspect ratio without additional model retraining;
- High transparency—achieving an SSIM > 0.999 and PSNR > 60 dB ensures an almost imperceptible interference with the original image (especially for high/native resolutions);
- A simple yet effective model—even a standard UNet architecture, enhanced with a classification module, achieves excellent results in embedding and detecting signatures thanks to the original data flow. Using an “intermediate” resolution and upsampling allows such a straightforward network to handle high-quality and diverse image formats effectively;
- Economical memory management—introducing an “intermediate” resolution significantly reduces GPU usage, leading to lower hardware requirements and greater scalability. Moreover, shifting the most resource-intensive operations to system RAM further relieves the graphics card;
- No additional payload—the end-to-end pipeline does not require separate hidden data, considerably simplifying the process and reducing the computational costs.
2. Related Works
2.1. Deep Learning in Data Hiding
2.2. Deep Learning in Ensuring Image Integration
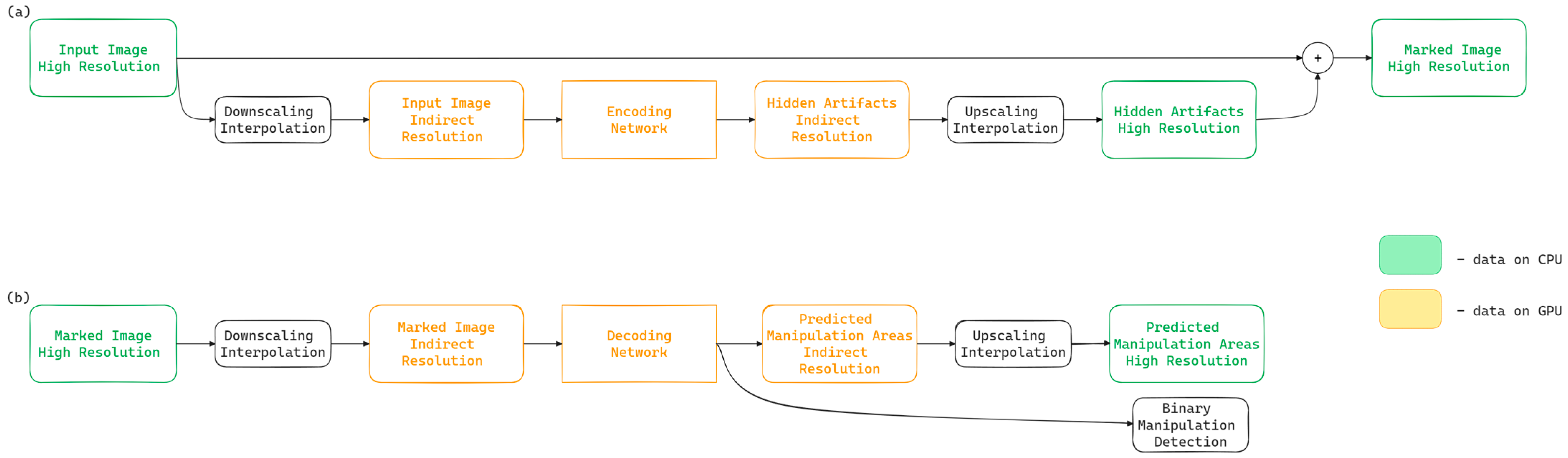
3. Method
3.1. Method Overview
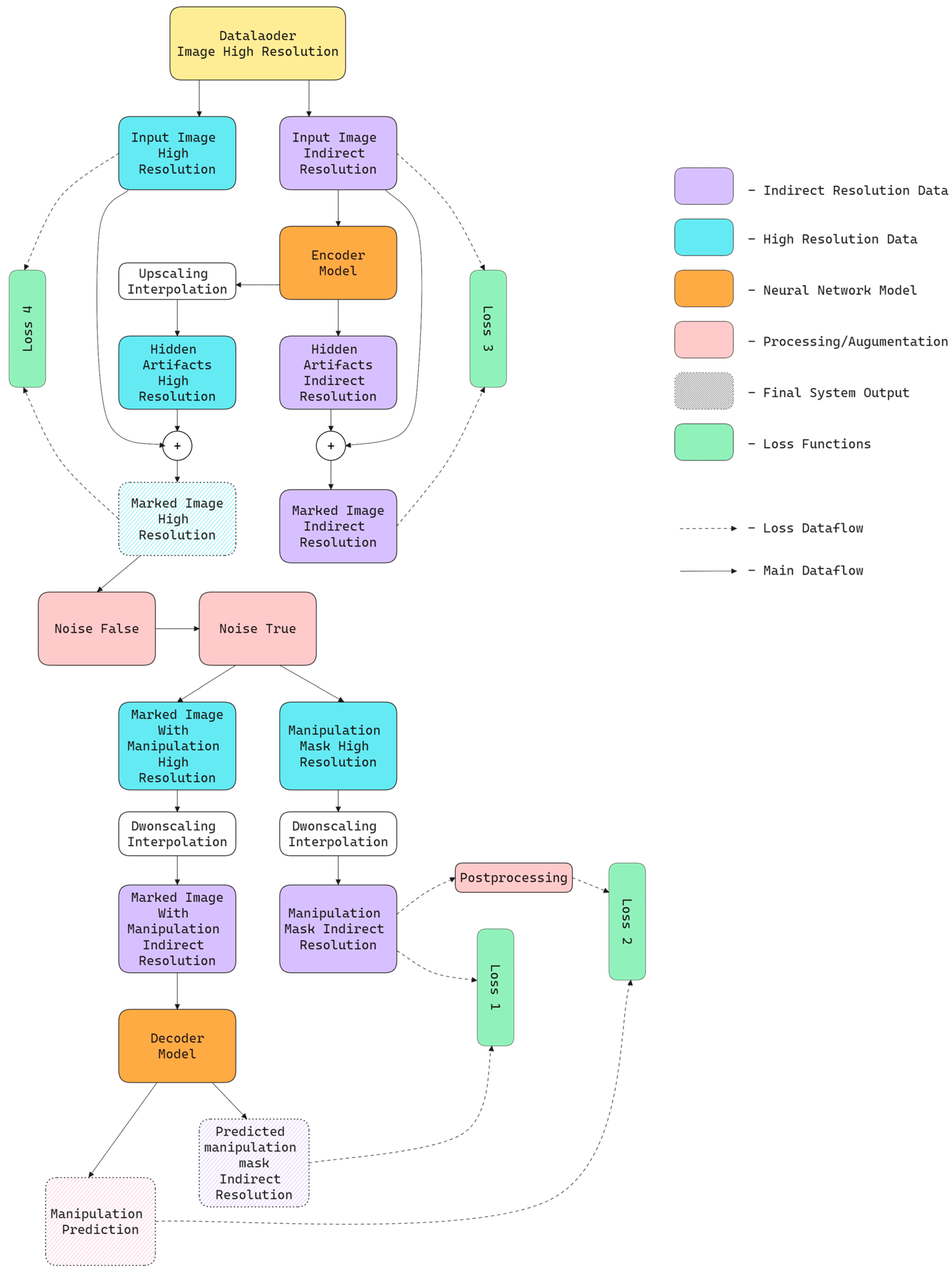
3.2. Method Implementation
3.3. Training Process
- Loss 1 is responsible for ensuring that the binary mask generated by the decoder aligns with the reference mask (ground truth). In this case, the classic Binary Cross-Entropy (BCE) function is used, as each pixel is classified into one of two categories: modified or unmodified. The reference mask is created by the attack module, which designates the manipulated regions. The mathematical formulation of BCE is as follows:where is the batch size;
- Loss 2 concerns the classification accuracy of the entire image. Similar to Loss 1, BCE is applied. Still, instead of operating on a pixel-wise matrix, it uses a single logit value that determines whether any manipulation is present in the entire image. The ground truth for this function is derived from the reference mask: if any modification is detected, the image is classified as “positive”;
- Loss 3 ensures high image transparency at the intermediate resolution stage. It evaluates artifacts introduced by the encoding network (combined with the input image), while considering the final predictions from the decoder. SSIM and LPIPS metrics are used to achieve this, as they provide a more perceptually accurate assessment of differences as perceived by the human eye compared to simple pixel-space error measures;
- Loss 4 serves a similar purpose to Loss 3, but it is calculated for the final high-resolution image (after upsampling). Due to the larger matrix size and higher computational demands, MSE and PSNR metrics are used instead of SSIM and LPIPS. These metrics balance quality assessment accuracy and computational efficiency, which is particularly important for large images.
3.3.1. Dataset
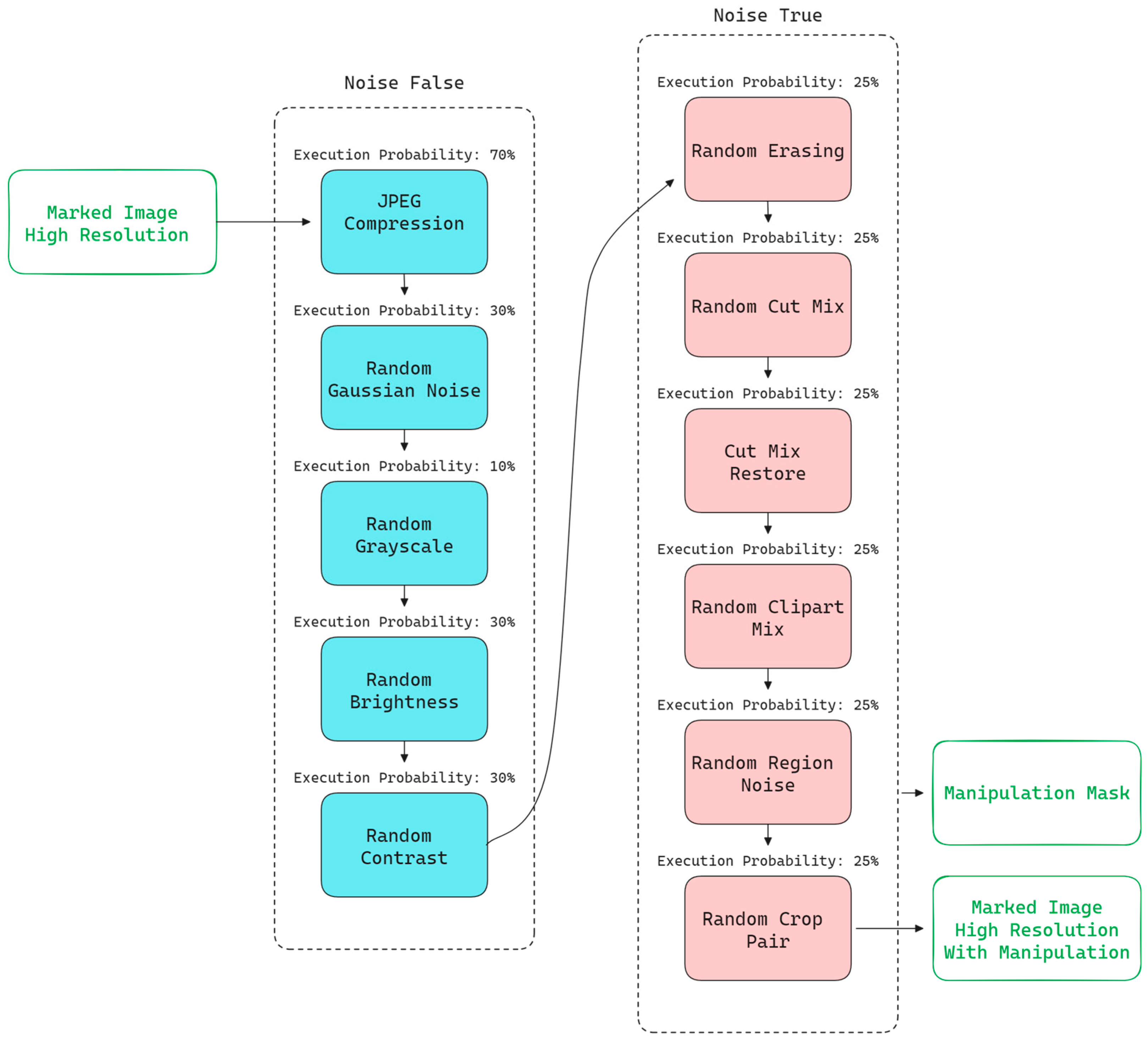
3.3.2. Noises
- Noise False
- This component is responsible for introducing various attacks or modifications that do not alter the semantics of the image. This means that, for a human observer, the image still conveys the same content and should not be classified as manipulated. In practice, this serves two main functions:
- (1) It acts as an additional augmentation technique, expanding the data distribution and increasing the diversity of sample scenes.
- (2) It trains the network to recognize that not every modification to an image should be classified as a manipulation, such as edits that enhance its visual appeal or improve its quality.
- The Noise False group includes operations such as the following:
- ○
- JPEG compression [48] with a randomly selected compression factor ranging from 64.0 to 99.0;
- ○
- Gaussian noise with random intensity and a standard deviation of std = 0.03;
- ○
- Conversion of the image to grayscale while preserving the number of channels;
- ○
- Brightness adjustment with random intensity in the range of 80% to 120%;
- ○
- Contrast adjustment with random intensity in the range of 80% to 120%.
- Each of these transformations can occur within an acceptable range of intensity, which does not significantly affect the semantics of the image and should not be interpreted as intentional manipulation.
- Noise True
- After passing through the Noise False module, the image enters the attack sequence labeled Noise True. These transformations actively alter the image’s content by modifying its semantics, such as removing, replacing or obscuring essential elements. As a result, the image deviates from the original to the extent that the network should detect the modification by identifying the manipulated area through binary classification as manipulated or non-manipulated. Each Noise True transformation also produces a binary mask indicating the modified areas, which serves as ground truth during training (see Figure 3). The Noise True sequence includes the following operations:
- ○
- Random Erasing: deletes a random portion of the image, filling it with zeros or a constant value. The affected area may range from 1% to 5% of the image’s surface;
- ○
- Random Cut Mix: swaps image fragments between samples in the batch by inserting part of one image into another. The affected area may range from 1% to 7% of the image’s surface;
- ○
- Cut Mix Restore: restores a fragment of the original image (without a hidden mark) in place of an already marked section. The affected area may range from 1% to 10% of the image’s surface;
- ○
- Random Clipart Mix: inserts randomly positioned, scaled and oriented clipart into the image. The clipart’s size may range from 8% to 25% of the image’s surface;
- ○
- Random Region Noise: applies noticeable blurring to selected image regions. The affected area may range from 8% to 25% of the image’s surface;
- ○
- Random Crop Pair: extracts a portion of the already noisy image and its corresponding mask and resizes it back to the original dimensions. The selected area may range from 60% to 99% of the image’s surface.
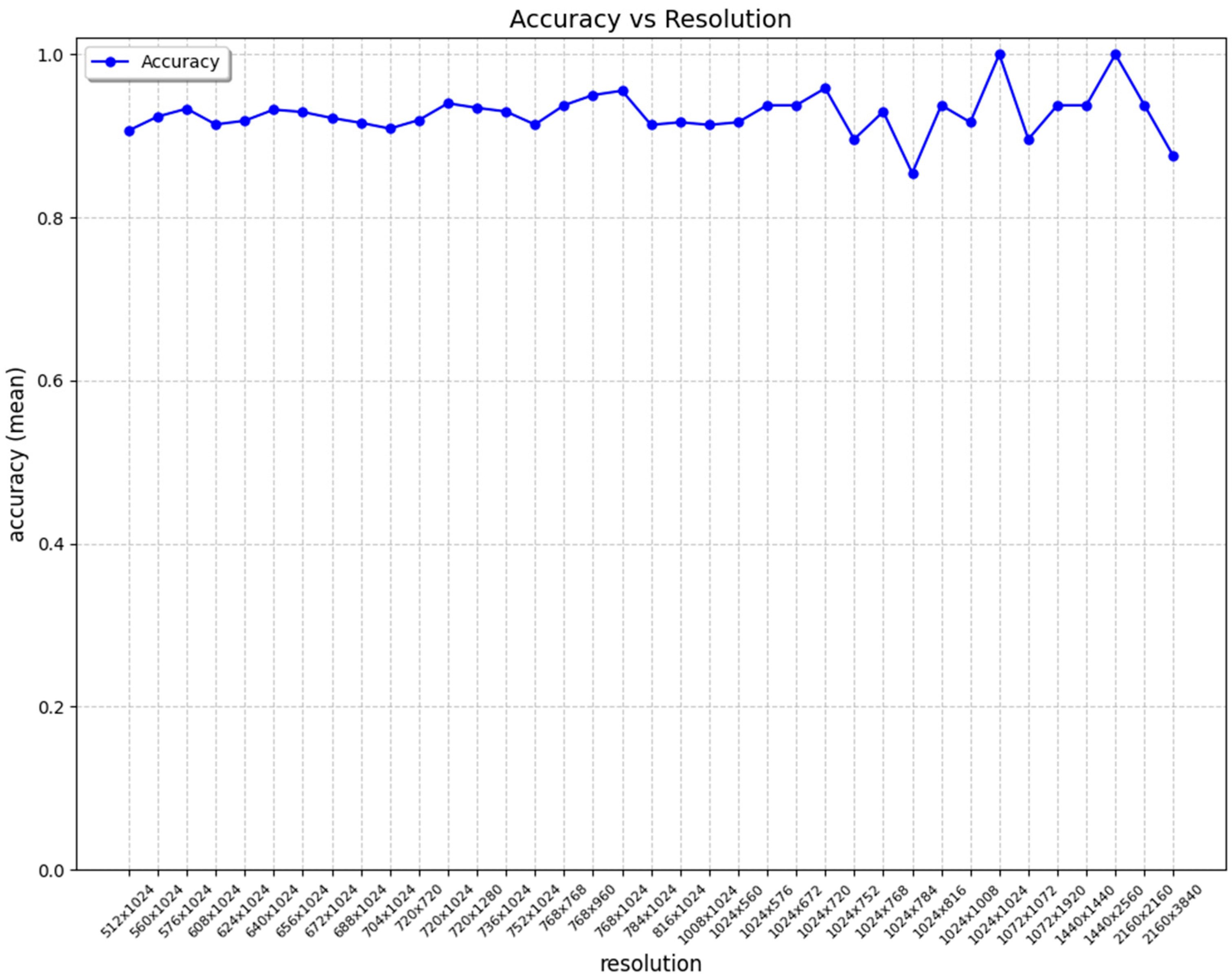
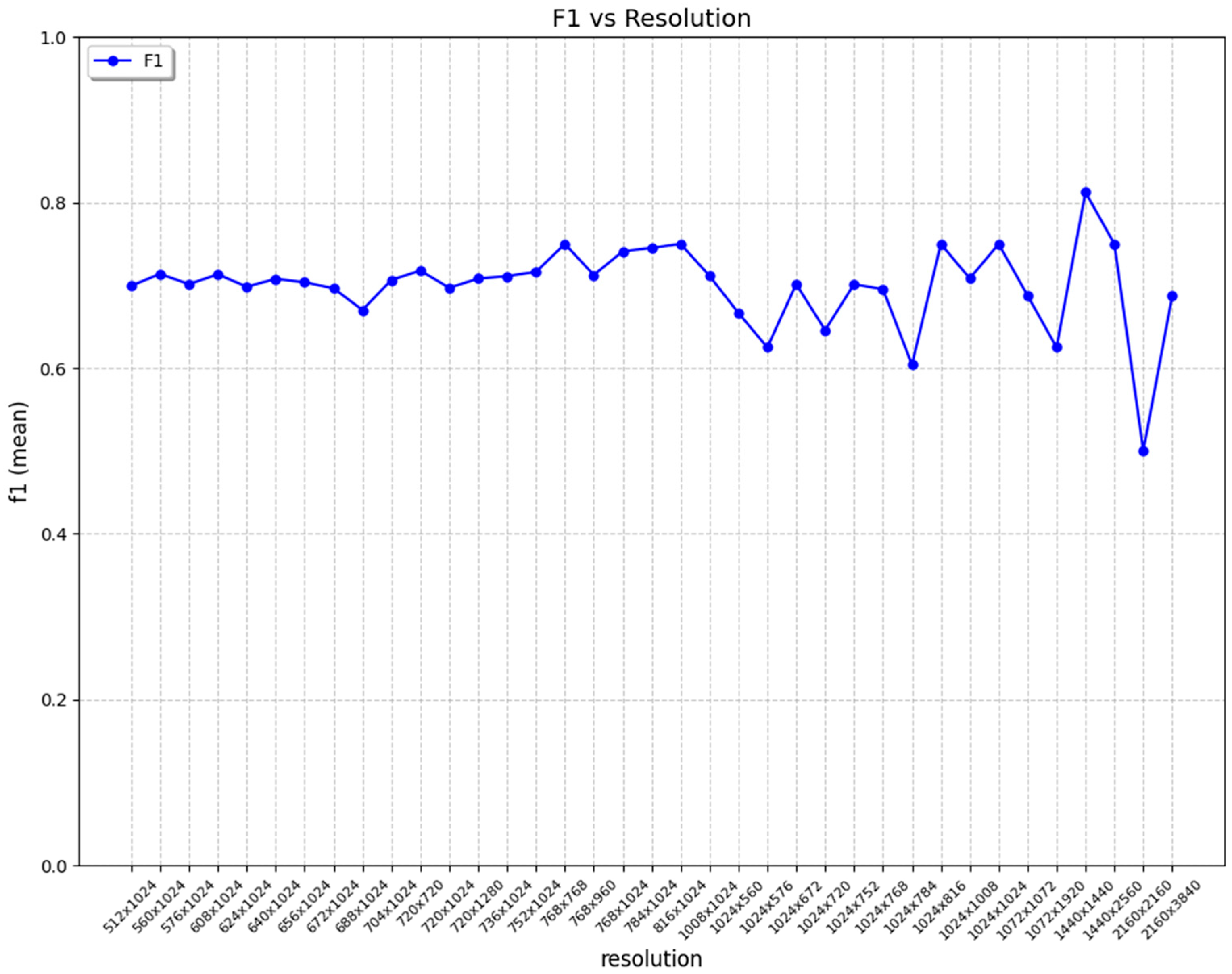
3.4. Evaluation
3.4.1. Transparency Metrics Obtained
- SSIM (Structural Similarity Index) is a metric used to evaluate the similarity between two images, considering factors such as luminance, contrast and structural details. It ranges from 0 to 1, where 1 represents perfect similarity between the images.
- In a simplified form, the SSIM can be defined by the following equation:where
- ○
- ;
- ○
- ;
- ○
- .
- PSNR (Peak Signal-to-Noise Ratio) measures image quality based on the difference between pixel values in the original and distorted images. It is typically expressed in decibels (dB) and is widely used to evaluate image perceptual similarity. A higher PSNR value indicates better image quality and less distortion.
- For 8-bit images, the PSNR is commonly calculated using the following formula:where
- ○
- ;
- ○
- .
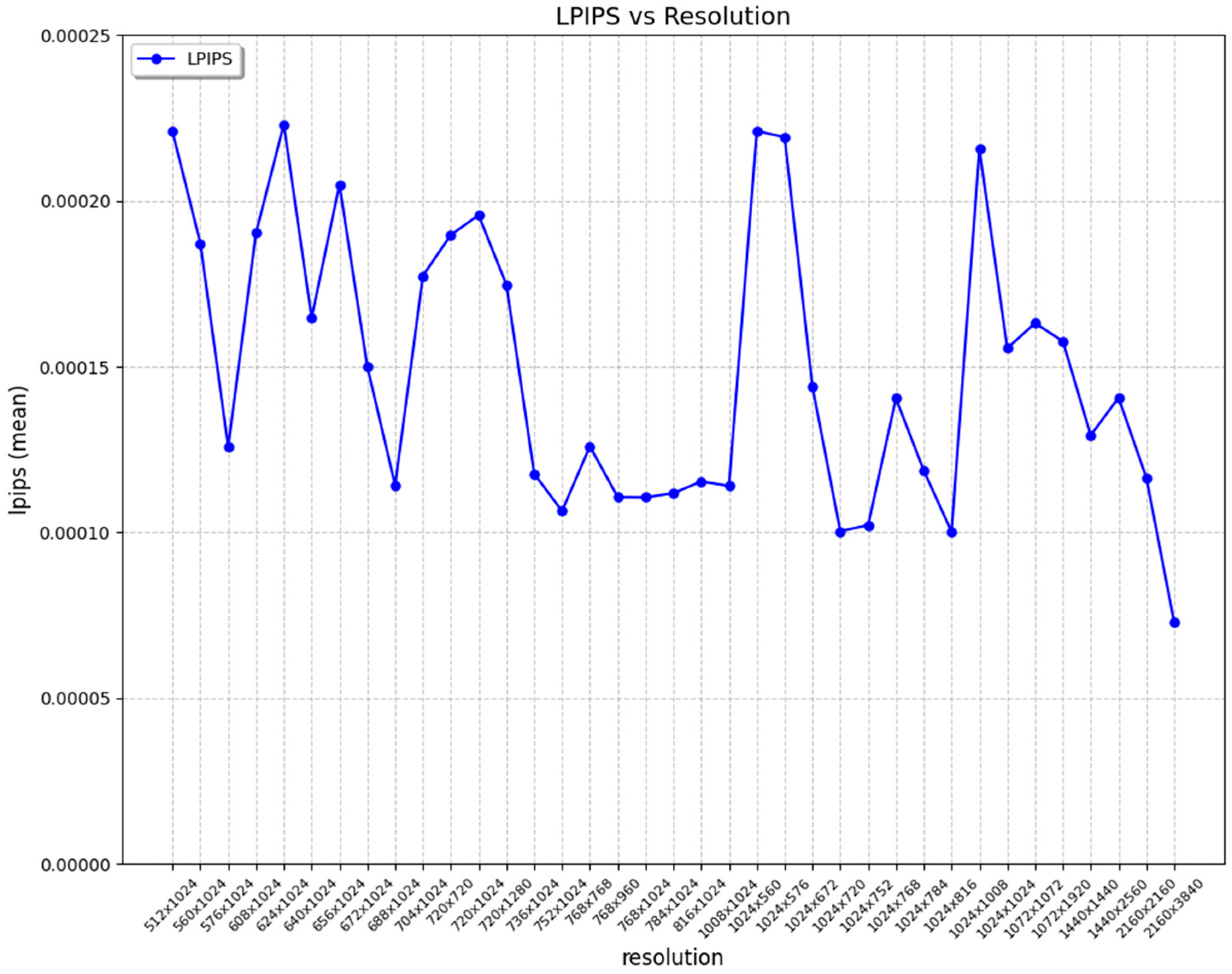
- LPIPS (Learned Perceptual Image Patch Similarity) uses deep neural networks to assess differences between images, like human perception. Instead of comparing pixel values, LPIPS compares embedding values in the layers of a neural network trained on a large number of image examples. It takes values in the range of 0 to 1, where 0 indicates a perfect similarity between images. The AlexNet [49] backbone was selected as the feature extractor.
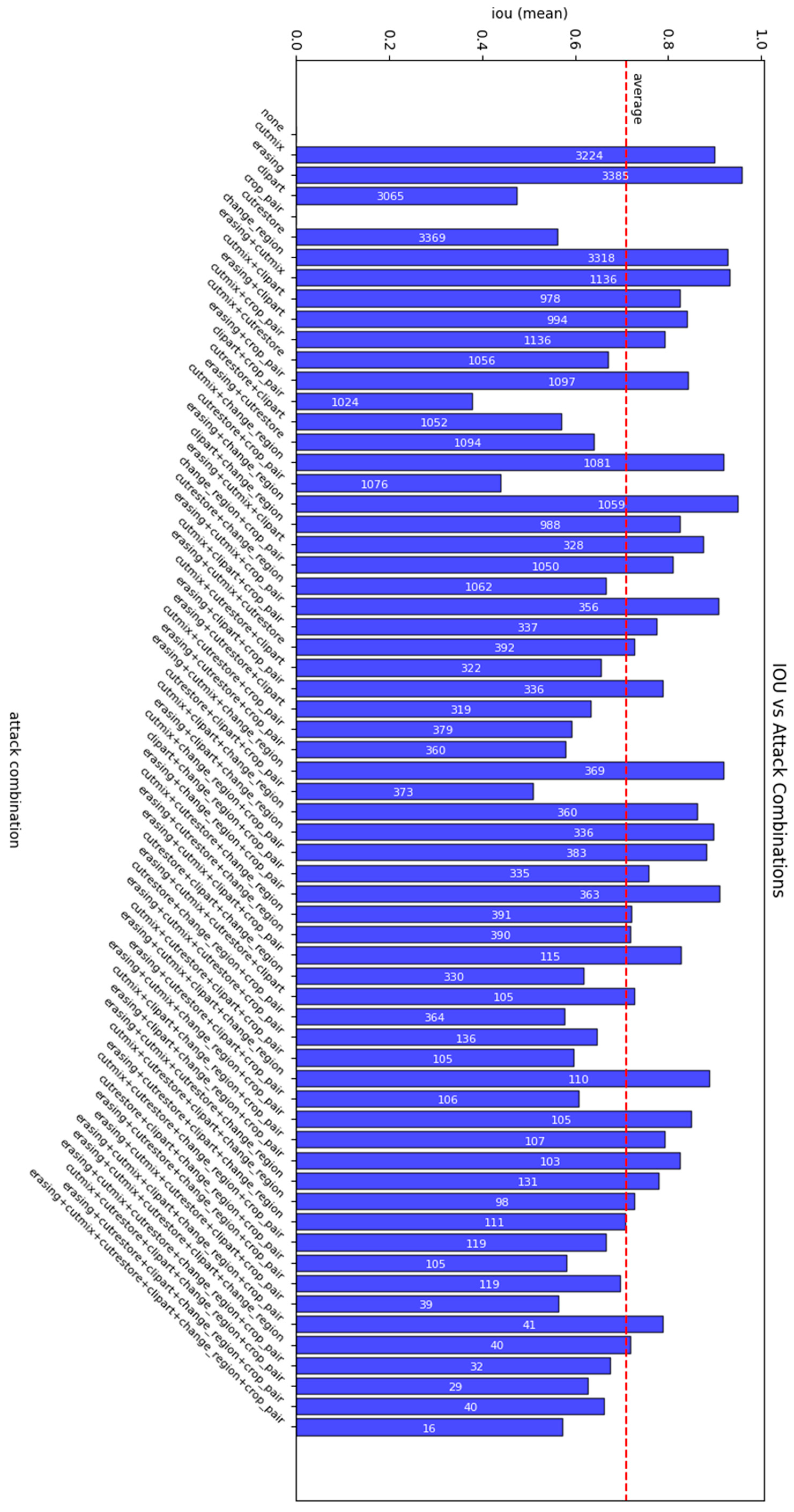
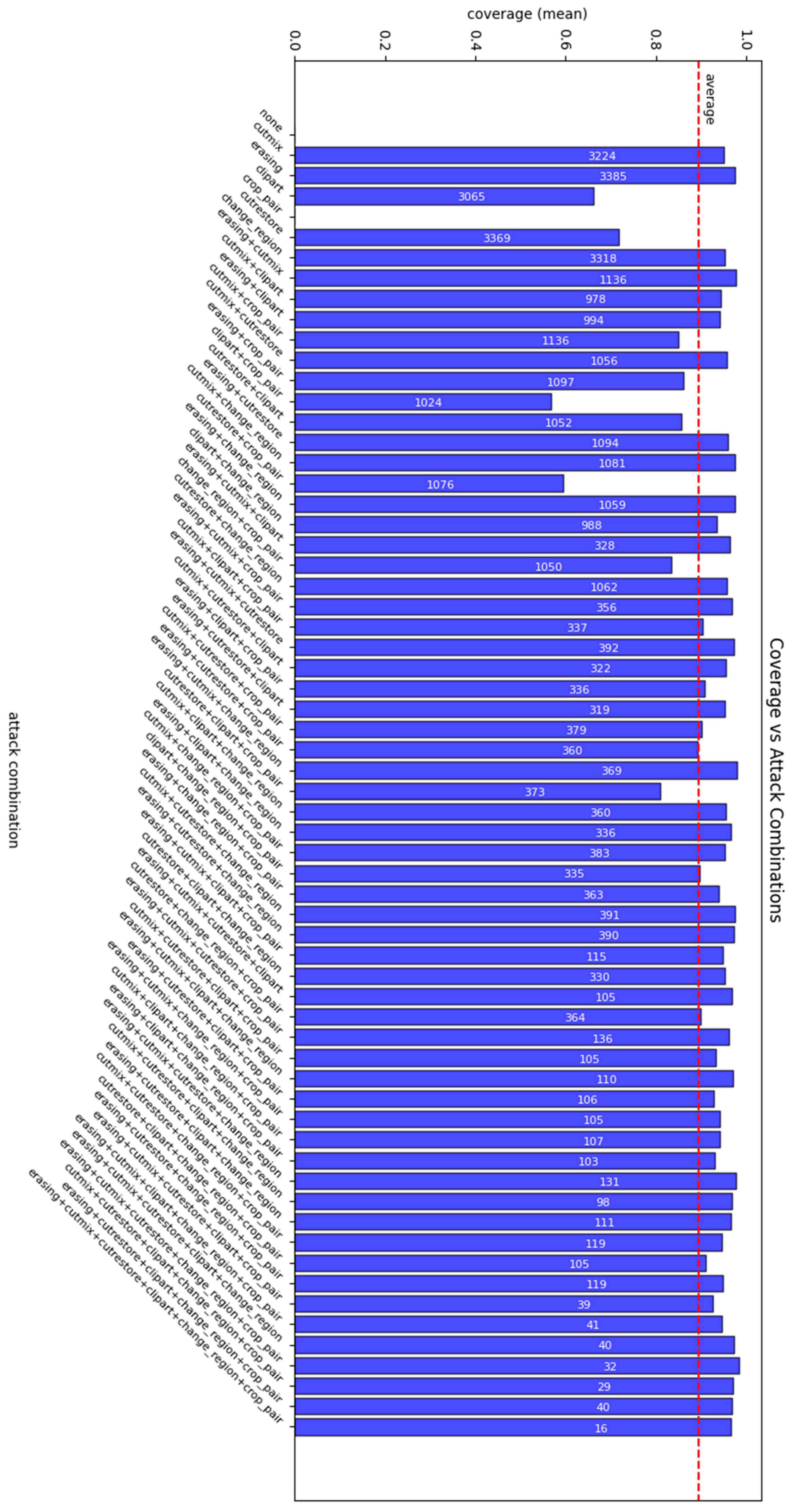
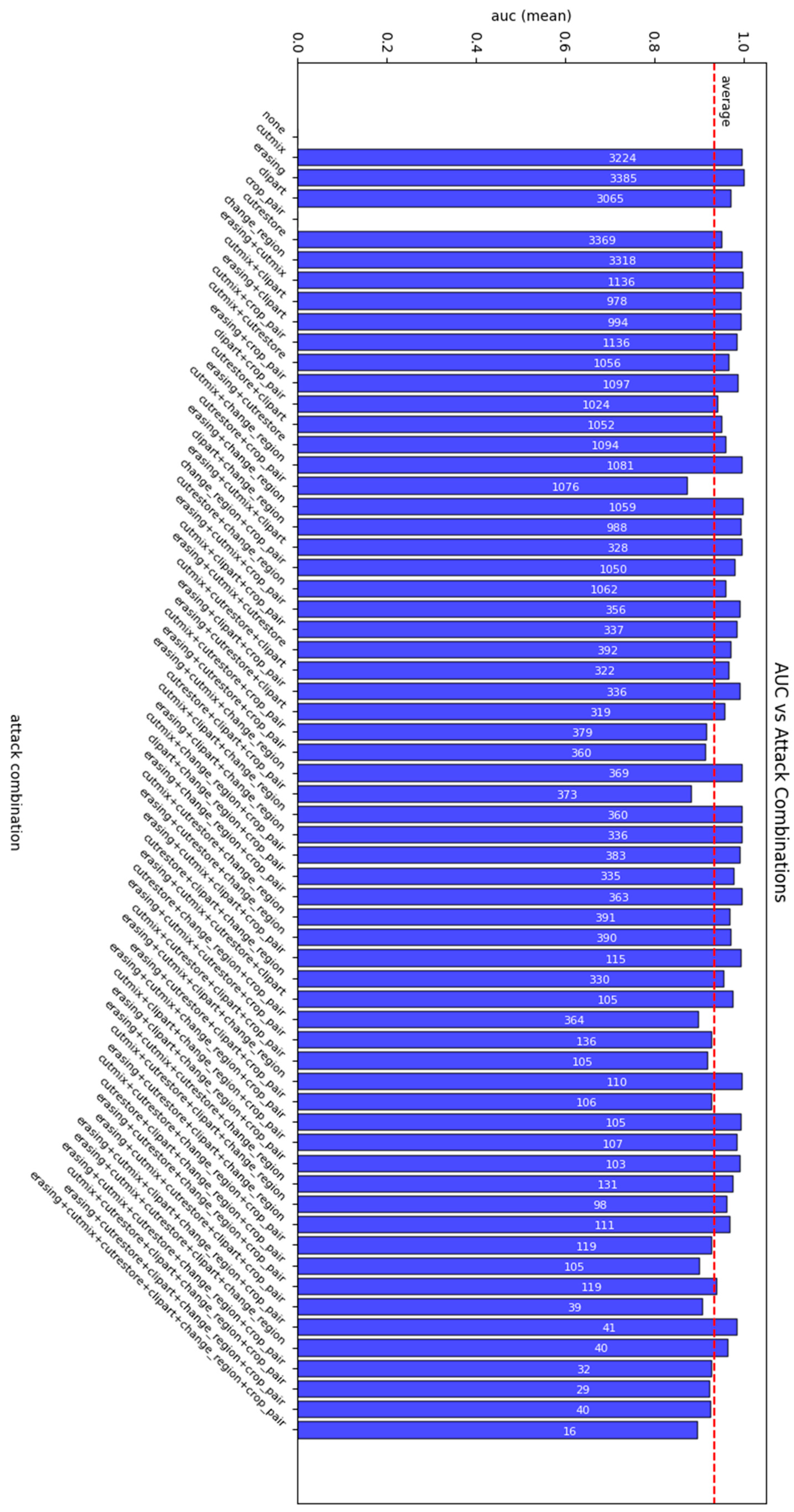
3.4.2. Detection Metrics Obtained
Image Manipulation Detection Metrics Obtained
- ;
- .
Image Manipulation Detection Metrics Obtained
- IoU—measures the proportion of correctly detected pixels (the intersection of the predicted and actual manipulation area) relative to the total number of pixels present in both sets. The formula is given bywhere
- ○
- ○
- Dice—similar to IoU, measures the overlap between the predicted manipulation area and the actual manipulation area but places greater emphasis on overall coverage. This formulation gives more weight to the consistency between predictions and the ground truth. The formula is given by
- Coverage—measures the fraction of all pixels predicted as “manipulated” that actually overlap with the manipulated region in the ground truth. This metric answers the question of how accurate the detection was from the perspective of the predicted manipulation area, indicating what percentage of predicted pixels were truly modified. The formula is given by
- AUC—measures the performance of a binary classifier by calculating the area under the ROC (Receiver Operating Characteristic) curve. It indicates how well the model distinguishes between classes. The AUC value falls within the range (0, 1), where 1.0 represents perfect classification, 0.5 corresponds to random predictions, and 0.0 indicates completely incorrect classification.where
- ○
- (True Positive Rate): ;
- ○
- .
- The first row contains the original images;
- The second row presents the images after the integrity markers have been applied;
- The third row shows the artifacts introduced by the encoding network, which have been normalized (0–1) to make them visible;
- The fourth row includes false and actual manipulations introduced into the previously marked images, with some highlighted using orange arrows for better readability;
- The fifth row displays binary ground truth masks indicating areas of actual manipulation (true attacks);
- The last row presents the raw output of the decoding model (without any thresholds or filters), attempting to reconstruct the manipulated regions.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, S.; Saharia, C.; Montgomery, C.; Pont-Tuset, J.; Noy, S.; Pellegrini, S.; Onoe, Y.; Laszlo, S.; Fleet, D.J.; Soricut, R.; et al. Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18359–18369. [Google Scholar]
- Duszejko, P.; Walczyna, T.; Piotrowski, Z. Detection of Manipulations in Digital Images: A Review of Passive and Active Methods Utilizing Deep Learning. Appl. Sci. 2025, 15, 881. [Google Scholar] [CrossRef]
- Farid, H. Image Forgery Detection. IEEE Signal Process. Mag. 2009, 26, 16–25. [Google Scholar] [CrossRef]
- Tyagi, S.; Yadav, D. A Detailed Analysis of Image and Video Forgery Detection Techniques. Vis. Comput. 2023, 39, 813–833. [Google Scholar] [CrossRef]
- Kaczyński, M.; Piotrowski, Z. High-Quality Video Watermarking Based on Deep Neural Networks and Adjustable Subsquares Properties Algorithm. Sensors 2022, 22, 5376. [Google Scholar] [CrossRef]
- Bistroń, M.; Piotrowski, Z. Efficient Video Watermarking Algorithm Based on Convolutional Neural Networks with Entropy-Based Information Mapper. Entropy 2023, 25, 284. [Google Scholar] [CrossRef]
- Lenarczyk, P.; Piotrowski, Z. Parallel Blind Digital Image Watermarking in Spatial and Frequency Domains. Telecommun. Syst. 2013, 54, 287–303. [Google Scholar] [CrossRef]
- Teca, G.; Natkaniec, M. StegoBackoff: Creating a Covert Channel in Smart Grids Using the Backoff Procedure of IEEE 802.11 Networks. Energies 2024, 17, 716. [Google Scholar] [CrossRef]
- Natkaniec, M.; Kępowicz, P. StegoEDCA: An Efficient Covert Channel for Smart Grids Based on IEEE 802.11e Standard. Energies 2025, 18, 330. [Google Scholar] [CrossRef]
- Jekateryńczuk, G.; Jankowski, D.; Veyland, R.; Piotrowski, Z. Detecting Malicious Devices in IPSEC Traffic with IPv4 Steganography. Appl. Sci. 2024, 14, 3934. [Google Scholar] [CrossRef]
- Teca, G.; Natkaniec, M. A Novel Covert Channel for IEEE 802.11 Networks Utilizing MAC Address Randomization. Appl. Sci. 2023, 13, 8000. [Google Scholar] [CrossRef]
- Wang, Z.; Byrnes, O.; Wang, H.; Sun, R.; Ma, C.; Chen, H.; Wu, Q.; Xue, M. Data Hiding With Deep Learning: A Survey Unifying Digital Watermarking and Steganography. IEEE Trans. Comput. Soc. Syst. 2023, 10, 2985–2999. [Google Scholar] [CrossRef]
- Ye, C.; Tan, S.; Wang, J.; Shi, L.; Zuo, Q.; Feng, W. Social Image Security with Encryption and Watermarking in Hybrid Domains. Entropy 2025, 27, 276. [Google Scholar] [CrossRef]
- Cao, F.; Ye, H.; Huang, L.; Qin, C. Multi-Image Based Self-Embedding Watermarking with Lossless Tampering Recovery Capability. Expert Syst. Appl. 2024, 258, 125176. [Google Scholar] [CrossRef]
- Zhu, J.; Kaplan, R.; Johnson, J.; Li, F.-F. HiDDeN: Hiding Data With Deep Networks. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11219, pp. 682–697. ISBN 978-3-030-01266-3. [Google Scholar]
- Luo, X.; Zhan, R.; Chang, H.; Yang, F.; Milanfar, P. Distortion Agnostic Deep Watermarking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 13548–13557. [Google Scholar]
- Tancik, M.; Mildenhall, B.; Ng, R. StegaStamp: Invisible Hyperlinks in Physical Photographs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Jing, J.; Deng, X.; Xu, M.; Wang, J.; Guan, Z. HiNet: Deep Image Hiding by Invertible Network. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; IEEE: Montreal, QC, Canada, 2021; pp. 4713–4722. [Google Scholar]
- Yang, H.; Xu, Y.; Liu, X. DKiS: Decay Weight Invertible Image Steganography with Private Key. Neural Netw. 2025, 185, 107148. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Liu, Y.; Guo, M.; Zhang, J.; Zhu, Y.; Xie, X. A Novel Two-Stage Separable Deep Learning Framework for Practical Blind Watermarking. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1509–1517. [Google Scholar]
- Lyu, S.; Pan, X.; Zhang, X. Exposing Region Splicing Forgeries with Blind Local Noise Estimation. Int. J. Comput. Vis. 2014, 110, 202–221. [Google Scholar] [CrossRef]
- Fan, Y.; Carré, P.; Fernandez-Maloigne, C. Image Splicing Detection with Local Illumination Estimation. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 2940–2944. [Google Scholar]
- Chen, J.; Kang, X.; Liu, Y.; Wang, Z.J. Median Filtering Forensics Based on Convolutional Neural Networks. IEEE Signal Process. Lett. 2015, 22, 1849–1853. [Google Scholar] [CrossRef]
- Bayar, B.; Stamm, M.C. Constrained Convolutional Neural Networks: A New Approach towards General Purpose Image Manipulation Detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2691–2706. [Google Scholar] [CrossRef]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. Mantra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries with Anomalous Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9543–9552. [Google Scholar]
- Hu, X.; Zhang, Z.; Jiang, Z.; Chaudhuri, S.; Yang, Z.; Nevatia, R. SPAN: Spatial Pyramid Attention Network for Image Manipulation Localization. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12366, pp. 312–328. ISBN 978-3-030-58588-4. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Wang, J.; Wu, Z.; Chen, J.; Han, X.; Shrivastava, A.; Lim, S.-N.; Jiang, Y.-G. ObjectFormer for Image Manipulation Detection and Localization. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New Orleans, LA, USA, 2022; pp. 2354–2363. [Google Scholar]
- Zhao, Y.; Liu, B.; Zhu, T.; Ding, M.; Yu, X.; Zhou, W. Proactive Image Manipulation Detection via Deep Semi-Fragile Watermark. Neurocomputing 2024, 585, 127593. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Walczyna, T.; Piotrowski, Z. Fast Fake: Easy-to-Train Face Swap Model. Appl. Sci. 2024, 14, 2149. [Google Scholar] [CrossRef]
- Duan, X.; Liu, N.; Gou, M.; Wang, W.; Qin, C. SteganoCNN: Image Steganography with Generalization Ability Based on Convolutional Neural Network. Entropy 2020, 22, 1140. [Google Scholar] [CrossRef] [PubMed]
- Riba, E.; Mishkin, D.; Ponsa, D.; Rublee, E.; Bradski, G. Kornia: An Open Source Differentiable Computer Vision Library for PyTorch. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Li, Y.; Wang, H.; Barni, M. A Survey of Deep Neural Network Watermarking Techniques. Neurocomputing 2021, 461, 171–193. [Google Scholar] [CrossRef]
- Zhong, X.; Das, A.; Alrasheedi, F.; Tanvir, A. A Brief, In-Depth Survey of Deep Learning-Based Image Watermarking. Appl. Sci. 2023, 13, 11852. [Google Scholar] [CrossRef]
- Singh, H.K.; Singh, A.K. Digital Image Watermarking Using Deep Learning. Multimed. Tools Appl. 2024, 83, 2979–2994. [Google Scholar] [CrossRef]
- Langguth, J.; Pogorelov, K.; Brenner, S.; Filkuková, P.; Schroeder, D.T. Don’t Trust Your Eyes: Image Manipulation in the Age of DeepFakes. Front. Commun. 2021, 6, 632317. [Google Scholar] [CrossRef]
- Capasso, P.; Cattaneo, G.; De Marsico, M. A Comprehensive Survey on Methods for Image Integrity. ACM Trans. Multimedia Comput. Commun. Appl. 2024, 20, 347. [Google Scholar] [CrossRef]
- Zheng, L.; Zhang, Y.; Thing, V.L.L. A Survey on Image Tampering and Its Detection in Real-World Photos. J. Vis. Commun. Image Represent. 2019, 58, 380–399. [Google Scholar] [CrossRef]
- Open Images V7. Available online: https://storage.googleapis.com/openimages/web/index.html (accessed on 15 January 2025).
- Marcin Marsza{\l}ek and Ivan Laptev and Cordelia Schmid. HOLLYWOOD2 Human Actions and Scenes Dataset. Available online: https://www.di.ens.fr/~laptev/actions/hollywood2/ (accessed on 15 January 2025).
- Free SVG Clip Art and Silhouettes for Cricut Cutting Machines. Available online: https://freesvg.org/ (accessed on 15 January 2025).
- Bghira/Photo-Concept-Bucket·Datasets at Hugging Face. Available online: https://huggingface.co/datasets/bghira/photo-concept-bucket (accessed on 23 January 2025).
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Shin, R. JPEG-Resistant Adversarial Images. In Proceedings of the Advances in Neural Information Processing SystemsWorksh, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Li, G.; Li, S.; Luo, Z.; Qian, Z.; Zhang, X. Purified and Unified Steganographic Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024. [Google Scholar]
- Neekhara, P.; Hussain, S.; Zhang, X.; Huang, K.; McAuley, J.; Koushanfar, F. FaceSigns: Semi-Fragile Neural Watermarks for Media Authentication and Countering Deepfakes. arXiv 2022, arXiv:2204.01960. [Google Scholar]
- CelebA Dataset. Available online: https://mmlab.ie.cuhk.edu.hk/projects/CelebA.html (accessed on 31 January 2025).
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, X.; Li, R.; Yu, J.; Xu, Y.; Li, W.; Zhang, J. EditGuard: Versatile Image Watermarking for Tamper Localization and Copyright Protection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2014, arXiv:1405.0312. [Google Scholar]
- Asnani, V.; Yin, X.; Hassner, T.; Liu, X. MaLP: Manipulation Localization Using a Proactive Scheme. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023. [Google Scholar]
- Zhang, X.; Tang, Z.; Xu, Z.; Li, R.; Xu, Y.; Chen, B.; Gao, F.; Zhang, J. OmniGuard: Hybrid Manipulation Localization via Augmented Versatile Deep Image Watermarking. arXiv 2024, arXiv:2412.01615. [Google Scholar]
- The MIRFLICKR Retrieval Evaluation. Available online: https://press.liacs.nl/mirflickr/ (accessed on 31 January 2025).
- Wang, Y.; Zhu, X.; Ye, G.; Zhang, S.; Wei, X. Achieving Resolution-Agnostic DNN-Based Image Watermarking: A Novel Perspective of Implicit Neural Representation. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024. [Google Scholar]
- Zhang, X.; Xu, Y.; Li, R.; Yu, J.; Li, W.; Xu, Z.; Zhang, J. V2A-Mark: Versatile Deep Visual-Audio Watermarking for Manipulation Localization and Copyright Protection. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, VIC, Australia, 28 October–1 November 2024. [Google Scholar]
- Xue, T.; Chen, B.; Wu, J.; Wei, D.; Freeman, W.T. Video Enhancement with Task-Oriented Flow. Int. J. Comput. Vis. 2019, 127, 1106–1125. [Google Scholar] [CrossRef]
- Perazzi, F.; Pont-Tuset, J.; McWilliams, B.; Van Gool, L.; Gross, M.; Sorkine-Hornung, A. A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; IEEE: Las Vegas, NV, USA, 2016; pp. 724–732. [Google Scholar]
- Feng, J.; Wu, Y.; Sun, H.; Zhang, S.; Liu, D. Panther: Practical Secure Two-Party Neural Network Inference. IEEE Trans. Inf. Forensics Secur. 2025, 20, 1149–1162. [Google Scholar] [CrossRef]
- Zhao, P.; Lai, L. Minimax Optimal Q Learning With Nearest Neighbors. IEEE Trans. Inf. Theory 2025, 71, 1300–1322. [Google Scholar] [CrossRef]
- Zhang, P.; Fang, X.; Zhang, Z.; Fang, X.; Liu, Y.; Zhang, J. Horizontal Multi-Party Data Publishing via Discriminator Regularization and Adaptive Noise under Differential Privacy. Inf. Fusion 2025, 120, 103046. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Name | Year | Dataset Used for Testing | Cover Size (Used in Paper) | SSIM | PSNR [dB] |
|---|---|---|---|---|---|
| HiDDeN [15] | 2018 | ImageNet | 256 × 256 | 0.9234 | 28.87 |
| StegaStamp [17] | 2020 | ImageNet | 400 × 400 | 0.930 | 29.88 |
| SteganoCNN [35] | 2020 | ImageNet | 256 × 256 | 0.981 | 35.852 |
| HiNet [18] | 2021 | ImageNet | 256 × 256 | 0.9920 | 46.88 |
| DKiS [19] | 2024 | ImageNet | 256 × 256 | 0.9948 | 41.91 |
| PUSNet [50] | 2024 | ImageNet | 256 × 256 | 0.9756 | 38.94 |
| Ours (indirect-resolution) | 2025 | ImageNet | 144 × 256 | 0.9995 | 58.9127 |
| Ours (indirect-resolution) | 2025 | Our dataset | 144 × 256 | 0.9995 | 58.3834 |
| Ours (high-resolution) | 2025 | ImageNet | Potentially any commercial size (tested up to 1936 × 2592) | 0.9996 | 60.7743 |
| Ours (high-resolution) | 2025 | Our dataset | Potentially any commercial size (tested up to 3840 × 2160) | 0.9996 | 60.2165 |
| Method Name | Year | Dataset Used for Train/Test |
Image Size (Used in Paper) | AUC | SSIM | PSNR [dB] | Comments |
|---|---|---|---|---|---|---|---|
| FaceSigns [51] | 2022 | CelebA [52] FFHQ [53] | 256 × 256 | 0.996 | 0.975 | 36.08 | This method primarily works with face datasets (CelebA, FFHQ, etc.). |
| EditGuard [54] | 2023 | COCO [55] CelebA | 512 × 512 | 0.933 | 0.949 | 37.77 | |
| MaLP [56] | 2023 | COCO CelebA | 256 × 256 | 1.0 | 0.7312 | 23.02 | |
| OmniGuard [57] | 2024 | MIR-FlickR [58] | 512 × 512 | 0.991 | 0.989 | 41.78 | |
| Wang et al. [59] | 2024 | COCO | Potentially any commercial size (tested up to 1920 × 1080) | - | - | 39.61 | The method can only work at the specific resolution on which it was trained. The authors achieved an accuracy of 99.90%. |
| V2A-Mark [60] | 2024 | Vimeo-90K [61] DAVIS [62] | 448 × 256 | 0.972 | 0.983 | 40.83 | A separate and coordinated watermark for the video track and audio, plus a “cross-modal” mechanism—the final key can combine what is decoded from both the image and the sound. |
| Zhao et al. [31] | 2024 | FFHQ CelebA | 256 × 256 | 0.95 | 0.94 | 38.05 | |
| Ours (high-resolution) | 2025 | Our dataset | Potentially any commercial size (tested up to 3840 × 2160) | 0.9668 | 0.9996 | 60.2165 | |
| Ours (high-resolution) | 2025 | ImageNet-1K | Potentially any commercial size (tested up to 1936 × 2592) | 0.9783 | 0.9996 | 60.7743 | (1936 × 2592) is the maximum image resolution in the ImageNet-1K dataset. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duszejko, P.; Piotrowski, Z. 4KSecure: A Universal Method for Active Manipulation Detection in Images of Any Resolution. Appl. Sci. 2025, 15, 4469. https://doi.org/10.3390/app15084469
Duszejko P, Piotrowski Z. 4KSecure: A Universal Method for Active Manipulation Detection in Images of Any Resolution. Applied Sciences. 2025; 15(8):4469. https://doi.org/10.3390/app15084469
Chicago/Turabian StyleDuszejko, Paweł, and Zbigniew Piotrowski. 2025. "4KSecure: A Universal Method for Active Manipulation Detection in Images of Any Resolution" Applied Sciences 15, no. 8: 4469. https://doi.org/10.3390/app15084469
APA StyleDuszejko, P., & Piotrowski, Z. (2025). 4KSecure: A Universal Method for Active Manipulation Detection in Images of Any Resolution. Applied Sciences, 15(8), 4469. https://doi.org/10.3390/app15084469