
A Progressive Semantic-Aware Fusion Network for Remote Sensing Object Detection


Abstract
1. Introduction
- In summary, the key contributions of our work are as follows:
- We propose ProSAF-Net, a progressive semantic-aware fusion network tailored for remote sensing object detection. This approach effectively addresses key challenges such as complex background interference and substantial variations in object scales.
- To leverage the complementary advantages of fine-grained details from shallow features and high-level semantics from deep features, we design the shallow detail aggregation module (SDAM) and deep semantic fusion module (DSFM). These modules enable effective collaboration between detail extraction and semantic enhancement, improving overall detection performance in complex backgrounds.
- To comprehensively exploit contextual information, we introduce a spatial context awareness module (SCAM) that filters out background noise effectively and optimizes the recognition of small targets.
- To better handle objects of varying scales, we design an auxiliary dynamic loss function that adaptively adjusts the loss weights for different object scales, thereby optimizing detection across diverse scale variations.
2. Related Work
2.1. Feature Fusion
2.2. Contextual Information Exploration
3. Proposed Method
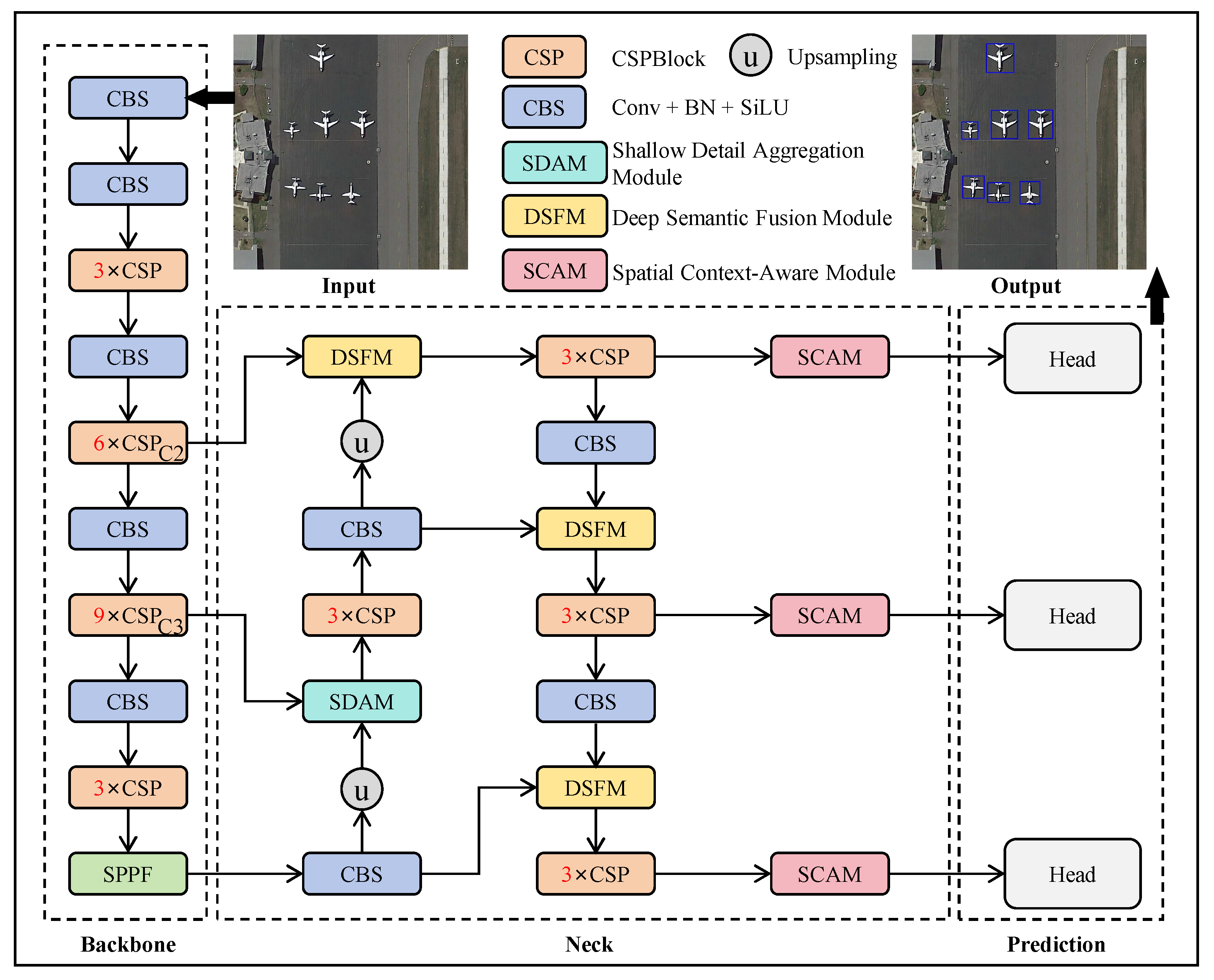
3.1. Overall Framework
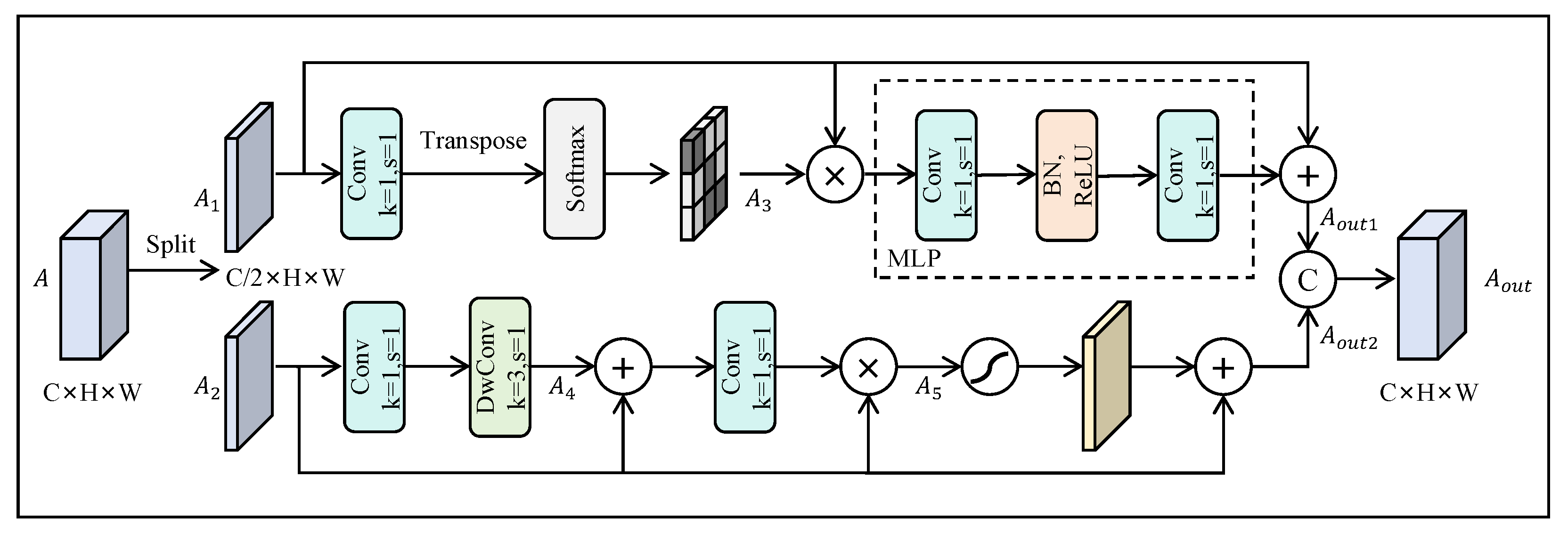
3.2. Shallow Detail Aggregation Module
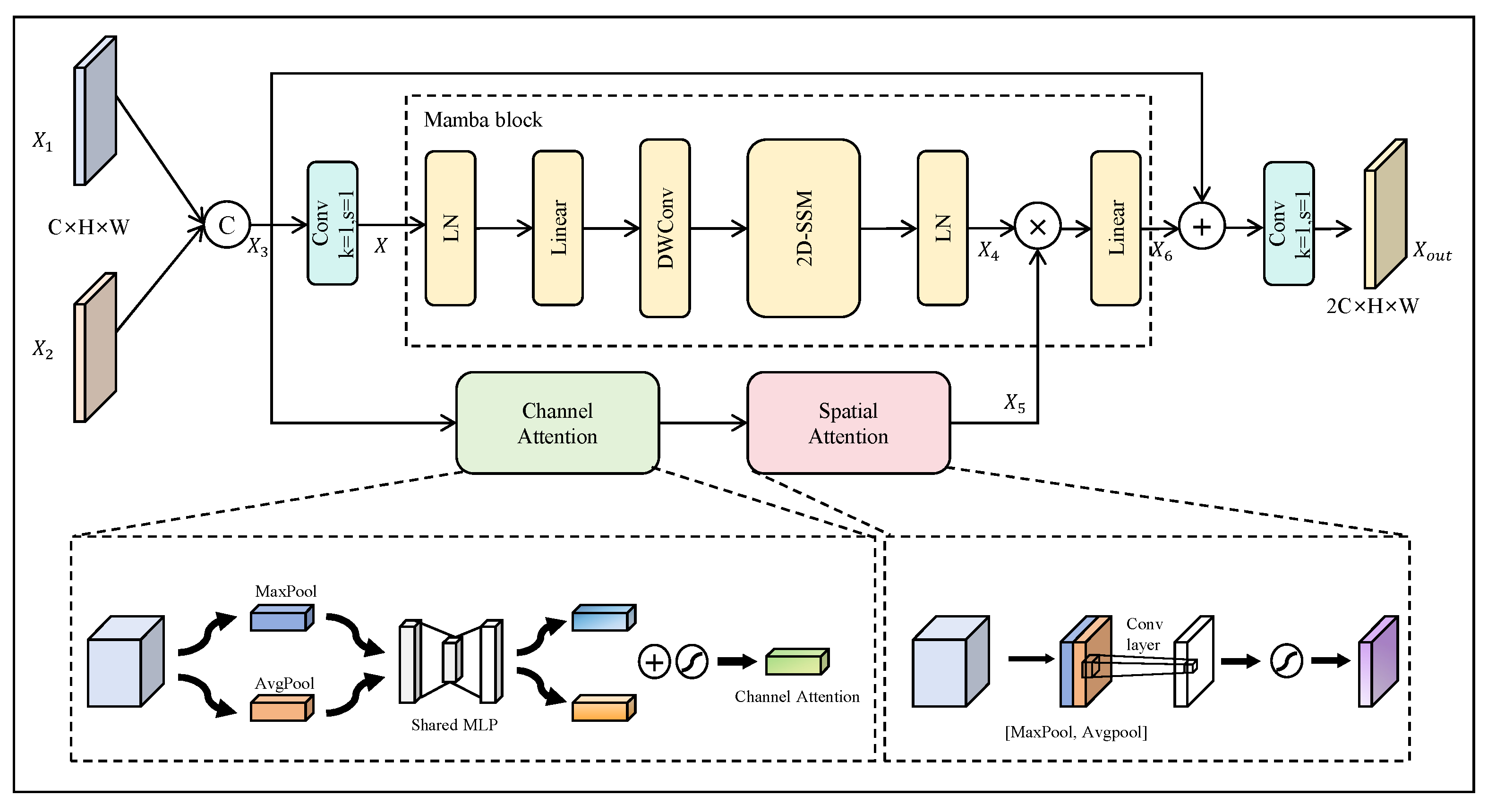
3.3. Deep Semantic Fusion Module
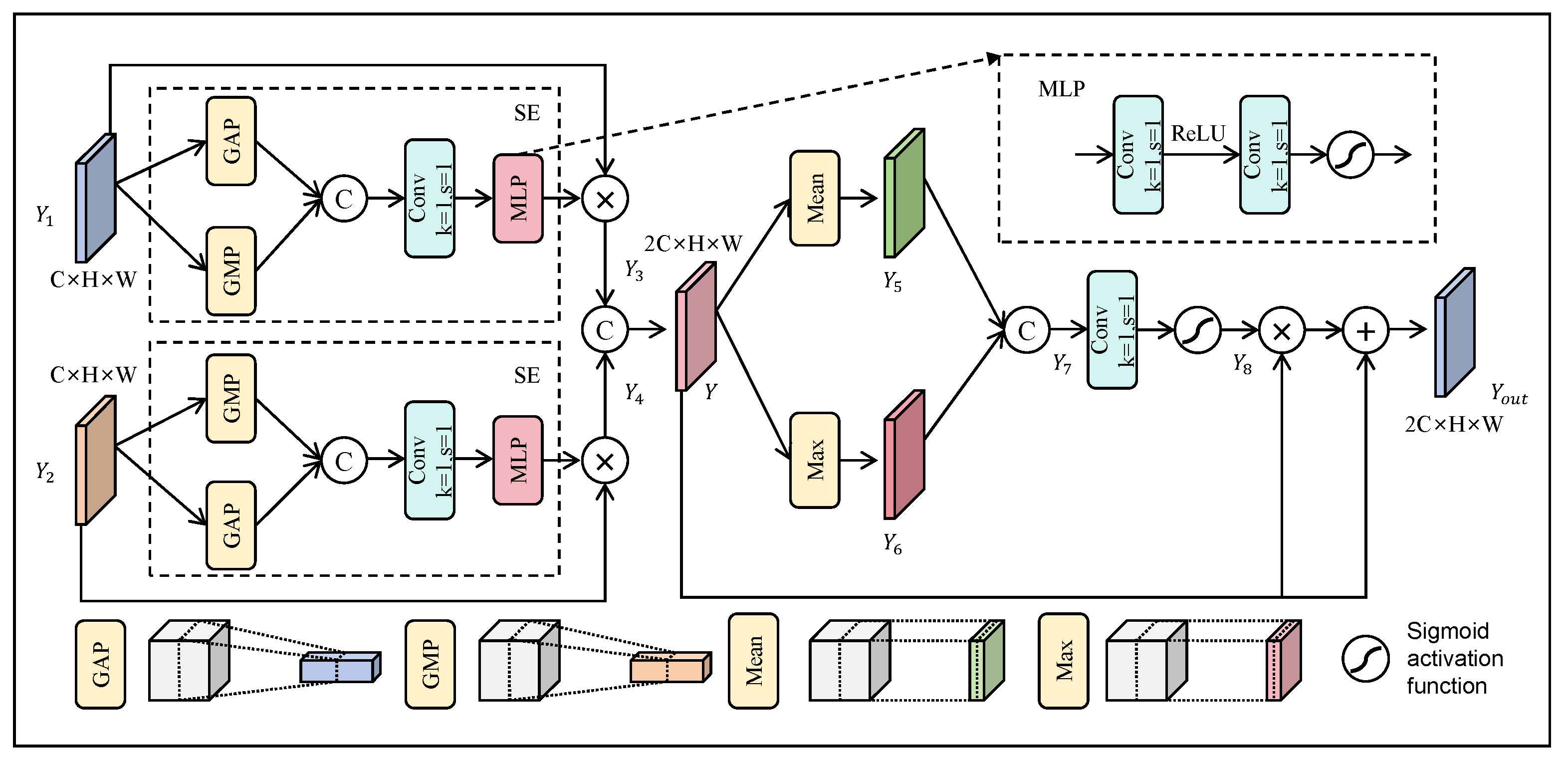
3.4. Spatial Context Awareness Module
3.5. Auxiliary Dynamic Loss Function
4. Experimental Results and Discussion
4.1. Datasets
4.1.1. RSOD Dataset
4.1.2. NWPU VHR-10 Dataset
4.1.3. DIOR Dataset
4.2. Experimental Details
4.3. Evaluation Metrics
4.4. Experimental Results and Discussion
4.4.1. Results on the RSOD Dataset
4.4.2. Results on the NWPU VHR-10 Dataset
4.4.3. Results on the DIOR Dataset
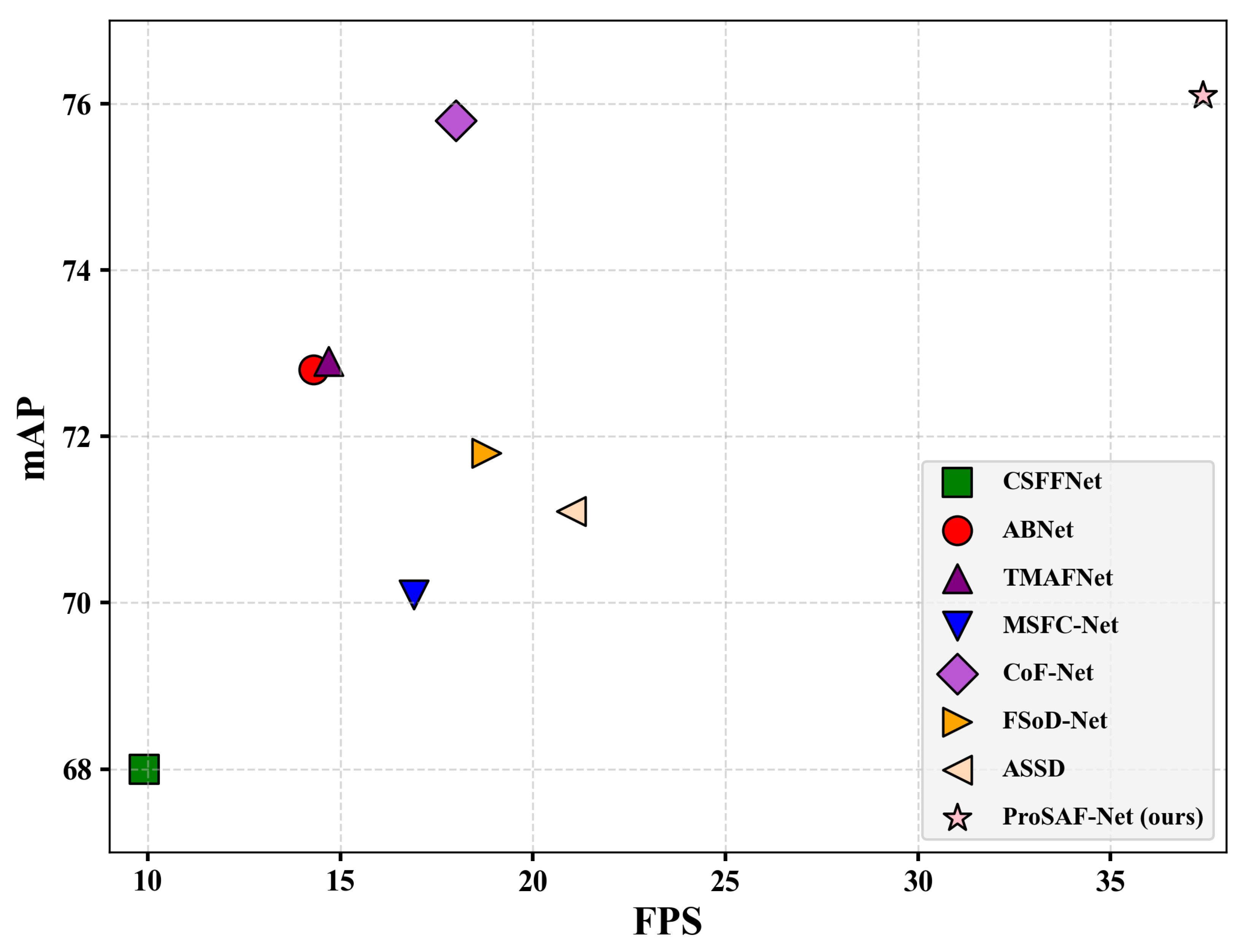
4.4.4. Computational Efficiency Analysis
4.5. Ablation Study
4.5.1. Effect of SDAM
4.5.2. Effect of DSFM
4.5.3. Effect of SCAM
4.5.4. Effect of ADIoU
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ProSAF-Net | Progressive Semantic-Aware Fusion Network |
| SDAM | Shallow Detail Aggregation Module |
| DSFM | Deep Semantic Fusion Module |
| SCAM | Spatial Context-Aware Module |
| ADL | Auxiliary Dynamic Loss |
| RCNN | Region Convolutional Neural Network |
| RPN | Region Proposal Network |
| mAP | Mean Average Precision |
| GAP | Global Average Pooling |
| GMP | Global Max Pooling |
| RSI | Remote Sensing Image |
References
- Zhang, X.; Zhang, T.; Wang, G.; Zhu, P.; Tang, X.; Jia, X.; Jiao, L. Remote sensing object detection meets deep learning: A metareview of challenges and advances. IEEE Geosci. Remote Sens. Mag. 2023, 11, 8–44. [Google Scholar] [CrossRef]
- Ganci, G.; Cappello, A.; Bilotta, G.; Del Negro, C. How the variety of satellite remote sensing data over volcanoes can assist hazard monitoring efforts: The 2011 eruption of Nabro volcano. Remote Sens. Environ. 2020, 236, 111426. [Google Scholar] [CrossRef]
- Xie, W.; Zhang, X.; Li, Y.; Lei, J.; Li, J.; Du, Q. Weakly supervised low-rank representation for hyperspectral anomaly detection. IEEE Trans. Cybern. 2021, 51, 3889–3900. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Gao, J.; Yuan, Y. A joint convolutional neural networks and context transfer for street scenes labeling. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1457–1470. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint Triplets for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Wu, Y.; Zhang, K.; Wang, J.; Wang, Y.; Wang, Q.; Li, X. GCWNet: A global context-weaving network for object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5619912. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, C.; Zhang, T.; Liu, Y.; Zheng, Y. Self-attention guidance and multiscale feature fusion-based UAV image object detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6004305. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–23 June 2023; pp. 7464–7475. [Google Scholar]
- Ruan, H.; Qian, W.; Zheng, Z.; Peng, Y. A Decoupled Semantic–Detail Learning Network for Remote Sensing Object Detection in Complex Backgrounds. Electronics 2023, 12, 3201. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Q.; Yuan, Y.; Du, Q.; Wang, Q. ABNet: Adaptive balanced network for multiscale object detection in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5614914. [Google Scholar] [CrossRef]
- Gao, T.; Niu, Q.; Zhang, J.; Chen, T.; Mei, S.; Jubair, A. Global to local: A scale-aware network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5615614. [Google Scholar] [CrossRef]
- Dong, X.; Qin, Y.; Fu, R.; Gao, Y.; Liu, S.; Ye, Y.; Li, B. Multiscale deformable attention and multilevel features aggregation for remote sensing object detection. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6510405. [Google Scholar] [CrossRef]
- Zhao, W.; Kang, Y.; Chen, H.; Zhao, Z.; Zhao, Z.; Zhai, Y. Adaptively attentional feature fusion oriented to multiscale object detection in remote sensing images. IEEE Trans. Instrum. Meas. 2023, 72, 5008111. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, T.; Yu, P.; Wang, S.; Tao, R. SFSANet: Multiscale Object Detection in Remote Sensing Image Based on Semantic Fusion and Scale Adaptability. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4406410. [Google Scholar] [CrossRef]
- Wang, G.; Zhuang, Y.; Chen, H.; Liu, X.; Zhang, T.; Li, L.; Dong, S.; Sang, Q. FSoD-Net: Full-scale object detection from optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5602918. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Luo, Y.; Cao, X.; Zhang, J.; Guo, J.; Shen, H.; Wang, T.; Feng, Q. CE-FPN: Enhancing channel information for object detection. Multimed. Tools Appl. 2022, 81, 30685–30704. [Google Scholar] [CrossRef]
- Liu, N.; Celik, T.; Li, H.C. Gated ladder-shaped feature pyramid network for object detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 6001505. [Google Scholar] [CrossRef]
- Yu, L.; Hu, H.; Zhong, Z.; Wu, H.; Deng, Q. GLF-Net: A target detection method based on global and local multiscale feature fusion of remote sensing aircraft images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 4021505. [Google Scholar] [CrossRef]
- Jiang, L.; Yuan, B.; Du, J.; Chen, B.; Xie, H.; Tian, J.; Yuan, Z. Mffsodnet: Multi-scale feature fusion small object detection network for uav aerial images. IEEE Trans. Instrum. Meas. 2024, 21, 5015214. [Google Scholar] [CrossRef]
- Yi, Q.; Zheng, M.; Shi, M.; Weng, J.; Luo, A. AFANet: A Multi-Backbone Compatible Feature Fusion Framework for Effective Remote Sensing Object Detection. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6015805. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Zhou, Y.; Hu, H.; Zhao, J.; Zhu, H.; Yao, R.; Du, W.L. Few-shot object detection via context-aware aggregation for remote sensing images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6509605. [Google Scholar] [CrossRef]
- Zhang, Z.; Gong, P.; Sun, H.; Wu, P.; Yang, X. Dynamic local and global context exploration for small object detection. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Zhao, Z.; Du, J.; Li, C.; Fang, X.; Xiao, Y.; Tang, J. Dense tiny object detection: A scene context guided approach and a unified benchmark. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5606913. [Google Scholar] [CrossRef]
- Ultralytics. ultralytics/yolov5: v7.0—YOLOv5 SOTA Realtime Instance Segmentation. 2022. [CrossRef]
- Tian, Y.; Ye, Q.; Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv 2025, arXiv:2502.12524. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, I.; Polosukhin, Ł. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; Jiao, J.; Liu, Y. Vmamba: Visual state space model. Adv. Neural Inf. Process. Syst. 2024, 37, 103031–103063. [Google Scholar]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. UnitBox: An Advanced Object Detection Network. In Proceedings of the 24th ACM International Conference on Multimedia (ACM MM), Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and a Loss for Bounding Box Regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, C.; Zhang, S. Inner-iou: More effective intersection over union loss with auxiliary bounding box. arXiv 2023, arXiv:2311.02877. [Google Scholar]
- Yang, J.; Liu, S.; Wu, J.; Su, X.; Hai, N.; Huang, X. Pinwheel-shaped Convolution and Scale-based Dynamic Loss for Infrared Small Target Detection. arXiv 2024, arXiv:2412.16986. [Google Scholar] [CrossRef]
- Zhang, W.; Cong, M.; Wang, L. Algorithms for optical weak small targets detection and tracking. In Proceedings of the International Conference on Neural Networks and Signal Processing, Nanjing, China, 14–17 December 2003; Volume 1, pp. 643–647. [Google Scholar]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote. Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS: Improving Object Detection with One Line of Code. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Zhou, Z.; Zhu, Y. KLDet: Detecting tiny objects in remote sensing images via kullback-leibler divergence. IEEE Trans. Geosci. Remote Sens. 2024, 62, 4703316. [Google Scholar] [CrossRef]
- Guo, Y.; Tong, X.; Xu, X.; Liu, S.; Feng, Y.; Xie, H. An anchor-free network with density map and attention mechanism for multiscale object detection in aerial images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6516705. [Google Scholar] [CrossRef]
- Ma, W.; Wang, X.; Zhu, H.; Yang, X.; Yi, X.; Jiao, L. Significant feature elimination and sample assessment for remote sensing small objects’ detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5615115. [Google Scholar] [CrossRef]
- Li, Z.; Wang, Y.; Xu, D.; Gao, Y.; Zhao, T. TBNet: A texture and boundary-aware network for small weak object detection in remote-sensing imagery. Pattern Recogn. 2025, 158, 110976. [Google Scholar] [CrossRef]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-merged single-shot detection for multiscale objects in large-scale remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3377–3390. [Google Scholar] [CrossRef]
- Tian, S.; Kang, L.; Xing, X.; Tian, J.; Fan, C.; Zhang, Y. A relation-augmented embedded graph attention network for remote sensing object detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1000718. [Google Scholar] [CrossRef]
- Shi, L.; Kuang, L.; Xu, X.; Pan, B.; Shi, Z. CANet: Centerness-aware network for object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5603613. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, W.; Gao, Y.; Hou, X.; Bi, F. A dense feature pyramid network for remote sensing object detection. Appl. Sci. 2022, 12, 4997. [Google Scholar] [CrossRef]
- Xu, T.; Sun, X.; Diao, W.; Zhao, L.; Fu, K.; Wang, H. ASSD: Feature aligned single-shot detection for multiscale objects in aerial imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5607117. [Google Scholar] [CrossRef]
- Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A cross-scale feature fusion pyramid network based remote sensing target detection. Remote Sens. 2021, 13, 847. [Google Scholar] [CrossRef]
- Cheng, G.; Si, Y.; Hong, H.; Yao, X.; Guo, L. Cross-scale feature fusion for object detection in optical remote sensing images. IEEE Geosci. Remote Sens. Lett. 2020, 18, 431–435. [Google Scholar] [CrossRef]
- Sagar, A.S.; Chen, Y.; Xie, Y.; Kim, H.S. MSA R-CNN: A comprehensive approach to remote sensing object detection and scene understanding. Expert Syst. Appl. 2024, 241, 122788. [Google Scholar] [CrossRef]
- Gao, T.; Liu, Z.; Zhang, J.; Wu, G.; Chen, T. A task-balanced multiscale adaptive fusion network for object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5613515. [Google Scholar] [CrossRef]
- Liu, J.; Li, S.; Zhou, C.; Cao, X.; Gao, Y.; Wang, B. SRAF-Net: A scene-relevant anchor-free object detection network in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5405914. [Google Scholar] [CrossRef]
- Zhang, T.; Zhuang, Y.; Wang, G.; Dong, S.; Chen, H.; Li, L. Multiscale semantic fusion-guided fractal convolutional object detection network for optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5608720. [Google Scholar] [CrossRef]
- Zhang, C.; Lam, K.M.; Wang, Q. Cof-net: A progressive coarse-to-fine framework for object detection in remote-sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5600617. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP | Aircraft | Oil Tank | Overpass | Playground |
|---|---|---|---|---|---|
| soft-NMS [48] | 86.60 | 76.10 | 90.30 | 81.30 | 98.80 |
| Faster R-CNN [10] | 88.10 | 71.30 | 90.7 | 90.90 | 99.70 |
| YOLOv3 [12] | 89.40 | 88.60 | 94.50 | 75.90 | 99.90 |
| FPN [13] | 90.91 | 90.58 | 94.47 | 80.18 | 98.49 |
| Cascade R-CNN [49] | 91.30 | 94.20 | 96.10 | 83.20 | 99.00 |
| KLDet [50] | 93.22 | 94.46 | 94.88 | 86.58 | 96.95 |
| YOLOv5 [33] | 93.64 | 95.58 | 97.79 | 81.68 | 99.50 |
| ABNet [16] | 94.17 | 91.49 | 96.14 | 89.61 | 99.44 |
| DA2FNet [51] | 94.78 | 95.72 | 97.73 | 90.56 | 95.12 |
| SESA-Net [52] | 95.15 | 95.69 | 97.89 | 90.23 | 96.82 |
| TBNet [53] | 96.98 | 95.24 | 96.76 | 95.92 | 100 |
| ProSAF-Net (Ours) | 97.12 | 96.56 | 98.37 | 94.71 | 98.86 |
| Method | mAP | AP | SH | ST | BD | TC | BC | GTF | HA | BR | VE |
|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv3 [12] | 87.27 | 99.55 | 81.82 | 80.30 | 98.26 | 80.56 | 81.82 | 99.47 | 74.31 | 89.61 | 86.98 |
| Faster R-CNN [10] | 88.30 | 99.70 | 85.58 | 99.27 | 95.93 | 88.22 | 92.08 | 99.73 | 92.11 | 43.37 | 86.60 |
| FMSSD [54] | 90.40 | 99.70 | 89.90 | 90.30 | 98.20 | 86.00 | 96.80 | 99.60 | 75.60 | 80.10 | 88.20 |
| CAD-Net [29] | 91.50 | 97.00 | 77.90 | 95.60 | 93.60 | 87.60 | 87.10 | 99.60 | 100 | 86.20 | 89.90 |
| EGAT [55] | 92.01 | 97.32 | 96.72 | 97.16 | 96.51 | 86.64 | 94.46 | 94.18 | 86.18 | 80.14 | 90.79 |
| Cascade R-CNN [49] | 92.19 | 99.54 | 88.53 | 95.98 | 94.46 | 94.02 | 88.21 | 97.16 | 91.45 | 82.30 | 90.25 |
| YOLOv7 [14] | 92.94 | 99.52 | 92.60 | 96.61 | 97.78 | 93.85 | 90.78 | 95.60 | 89.54 | 83.72 | 89.38 |
| YOLOv5 [33] | 93.30 | 99.50 | 94.80 | 84.75 | 97.94 | 97.36 | 94.79 | 99.00 | 89.22 | 86.76 | 88.84 |
| CANet [56] | 93.33 | 99.99 | 85.99 | 99.27 | 97.28 | 97.80 | 84.77 | 98.38 | 90.38 | 89.16 | 90.25 |
| ABNet [16] | 94.21 | 100 | 92.58 | 97.77 | 97.76 | 99.26 | 95.98 | 99.86 | 94.26 | 69.04 | 95.62 |
| TBNet [53] | 95.44 | 100 | 95.09 | 97.35 | 97.35 | 97.55 | 98.96 | 100 | 94.64 | 80.77 | 92.71 |
| ProSAF-Net (Ours) | 96.56 | 99.50 | 98.01 | 98.07 | 98.73 | 89.56 | 95.18 | 98.60 | 94.05 | 91.69 | 93.68 |
| Method | mAP | AL | AT | BF | BC | BG | CM | DM | EA | ES | GC | GF | HB | OP | SP | SD | ST | TC | TS | VH | WM |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN [10] | 54.1 | 53.6 | 49.3 | 78.8 | 66.2 | 28.0 | 70.9 | 62.3 | 69.0 | 55.2 | 68.0 | 56.9 | 50.2 | 50.1 | 27.7 | 73.0 | 39.8 | 75.2 | 38.6 | 23.6 | 45.4 |
| YOLOv3 [12] | 57.1 | 72.2 | 29.2 | 74.0 | 78.6 | 31.2 | 69.7 | 56.9 | 48.6 | 54.4 | 31.1 | 61.1 | 44.9 | 49.7 | 87.4 | 70.6 | 68.7 | 87.3 | 29.4 | 48.3 | 78.7 |
| CenterNet [7] | 63.9 | 73.6 | 58.0 | 69.7 | 88.5 | 36.2 | 76.9 | 47.9 | 52.7 | 53.9 | 60.5 | 62.6 | 45.7 | 52.6 | 88.2 | 63.7 | 76.2 | 83.7 | 51.3 | 54.4 | 79.5 |
| CF2PN [59] | 67.3 | 78.3 | 78.3 | 76.5 | 88.4 | 37.0 | 71.0 | 59.9 | 71.2 | 51.2 | 75.6 | 77.1 | 56.8 | 58.7 | 76.1 | 70.6 | 55.5 | 88.8 | 50.8 | 36.9 | 86.4 |
| CSFFNet [60] | 68.0 | 57.2 | 79.6 | 70.1 | 87.4 | 46.1 | 76.6 | 62.7 | 82.6 | 73.2 | 78.2 | 81.6 | 50.7 | 59.5 | 73.3 | 63.4 | 58.5 | 85.9 | 61.9 | 42.9 | 86.9 |
| DFPN-YOLO [57] | 69.3 | 80.2 | 76.8 | 72.7 | 89.1 | 43.4 | 76.9 | 72.3 | 59.8 | 56.4 | 74.3 | 71.6 | 63.1 | 58.7 | 81.5 | 40.1 | 74.2 | 85.8 | 73.6 | 49.7 | 86.5 |
| SRAF-Net [63] | 69.7 | 88.4 | 76.5 | 92.6 | 87.9 | 35.8 | 83.8 | 58.6 | 86.8 | 66.8 | 76.4 | 82.8 | 16.2 | 58.0 | 59.4 | 80.9 | 55.6 | 90.6 | 52.0 | 53.2 | 91.0 |
| MSFC-Net [64] | 70.1 | 85.8 | 76.2 | 74.4 | 91.1 | 44.2 | 78.1 | 55.5 | 60.9 | 59.5 | 76.9 | 73.7 | 49.6 | 57.2 | 89.6 | 69.2 | 76.5 | 86.7 | 51.8 | 55.2 | 84.3 |
| ASSD [58] | 71.1 | 85.6 | 82.4 | 75.8 | 89.5 | 40.7 | 77.6 | 64.7 | 67.1 | 61.7 | 80.8 | 78.6 | 62.0 | 58.0 | 84.9 | 76.7 | 65.3 | 87.9 | 62.4 | 44.5 | 76.3 |
| FSoD-Net [21] | 71.8 | 88.9 | 66.9 | 86.8 | 90.2 | 45.5 | 79.6 | 48.2 | 86.9 | 75.5 | 67.0 | 77.3 | 53.6 | 59.7 | 78.3 | 69.9 | 75.0 | 91.4 | 52.3 | 52.0 | 90.6 |
| YOLOv5 [33] | 72.0 | 81.3 | 81.2 | 74.0 | 90.1 | 45.9 | 79.7 | 59.7 | 64.2 | 63.8 | 78.7 | 74.9 | 61.3 | 61.3 | 89.6 | 69.2 | 79.3 | 89.0 | 58.8 | 57.5 | 80.9 |
| ABNet [16] | 72.8 | 66.8 | 84.0 | 74.9 | 87.7 | 50.3 | 78.2 | 67.8 | 85.9 | 74.2 | 79.7 | 81.2 | 55.4 | 61.6 | 75.1 | 74.0 | 66.7 | 87.0 | 62.2 | 53.6 | 89.1 |
| TMAFNet [62] | 72.9 | 92.2 | 77.7 | 75.0 | 91.3 | 47.1 | 78.6 | 53.6 | 67.1 | 66.2 | 78.5 | 76.3 | 64.9 | 61.4 | 90.5 | 72.2 | 75.4 | 90.7 | 62.1 | 55.2 | 83.2 |
| MSA R-CNN [61] | 74.3 | 92.9 | 73.8 | 93.2 | 87.3 | 43.0 | 90.6 | 58.9 | 69.2 | 58.0 | 83.3 | 84.2 | 57.3 | 62.4 | 68.8 | 91.8 | 81.3 | 90.9 | 53.7 | 72.2 | 74.5 |
| SESA-Net [52] | 74.6 | 93.5 | 78.2 | 91.9 | 82.2 | 46.8 | 89.3 | 61.4 | 67.2 | 67.5 | 73.3 | 76.7 | 55.8 | 62.0 | 78.8 | 84.8 | 82.4 | 89.8 | 54.4 | 76.7 | 79.1 |
| CoF-Net [65] | 75.8 | 84.0 | 85.3 | 82.6 | 90.0 | 47.1 | 80.7 | 73.3 | 89.3 | 74.0 | 84.5 | 83.2 | 57.4 | 62.2 | 82.9 | 77.6 | 68.2 | 89.9 | 68.7 | 49.3 | 85.2 |
| ProSAF-Net (Ours) | 76.1 | 76.3 | 85.6 | 82.7 | 90.3 | 48.9 | 80.2 | 68.0 | 86.8 | 80.6 | 79.9 | 80.7 | 61.5 | 62.5 | 90.2 | 73.4 | 74.4 | 90.9 | 62.3 | 56.2 | 90.0 |
| Exp | SDAM | PSFM | SCAM | ADIoU | mAP (R) (%) | mAP (N) (%) | Params(M) | FLOPs(G) |
|---|---|---|---|---|---|---|---|---|
| 1 | ✗ | ✗ | ✗ | ✗ | 93.64 | 93.30 | 7.03 | 16.0 |
| 2 | ✓ | ✗ | ✗ | ✗ | 95.37 | 94.39 | 8.01 | 18.3 |
| 3 | ✗ | ✓ | ✗ | ✗ | 95.08 | 94.47 | 7.45 | 16.3 |
| 4 | ✗ | ✗ | ✓ | ✗ | 94.73 | 94.71 | 7.47 | 16.6 |
| 5 | ✓ | ✓ | ✗ | ✗ | 95.93 | 95.30 | 8.41 | 18.6 |
| 6 | ✓ | ✓ | ✓ | ✗ | 96.79 | 96.01 | 8.85 | 19.2 |
| 7 | ✓ | ✓ | ✓ | ✓ | 97.12 | 96.56 | 8.85 | 19.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, L.; Wang, J.; Liao, Y.; Qian, W. A Progressive Semantic-Aware Fusion Network for Remote Sensing Object Detection. Appl. Sci. 2025, 15, 4422. https://doi.org/10.3390/app15084422
Li L, Wang J, Liao Y, Qian W. A Progressive Semantic-Aware Fusion Network for Remote Sensing Object Detection. Applied Sciences. 2025; 15(8):4422. https://doi.org/10.3390/app15084422
Chicago/Turabian StyleLi, Lerong, Jiayang Wang, Yue Liao, and Wenbin Qian. 2025. "A Progressive Semantic-Aware Fusion Network for Remote Sensing Object Detection" Applied Sciences 15, no. 8: 4422. https://doi.org/10.3390/app15084422
APA StyleLi, L., Wang, J., Liao, Y., & Qian, W. (2025). A Progressive Semantic-Aware Fusion Network for Remote Sensing Object Detection. Applied Sciences, 15(8), 4422. https://doi.org/10.3390/app15084422