
Common Information Model-Oriented Ontology Database Framework for Improving Topology Processing Capability of Distribution Management Systems Considering Interoperability

Abstract
:1. Introduction
1.1. Framework and Motivation
1.2. Literature Review
1.3. Contributions and Content Summary
- The object–relational impedance mismatch between the object-oriented CIM and the table-based RDB structure
- The inflexibility to accommodate changes in the information model due to rigid schemas
- Performance degradation in TP stemming from inefficient graph traversal mechanisms in RDBs
2. CIM-Based DMS Platform Structure Considering Interoperability
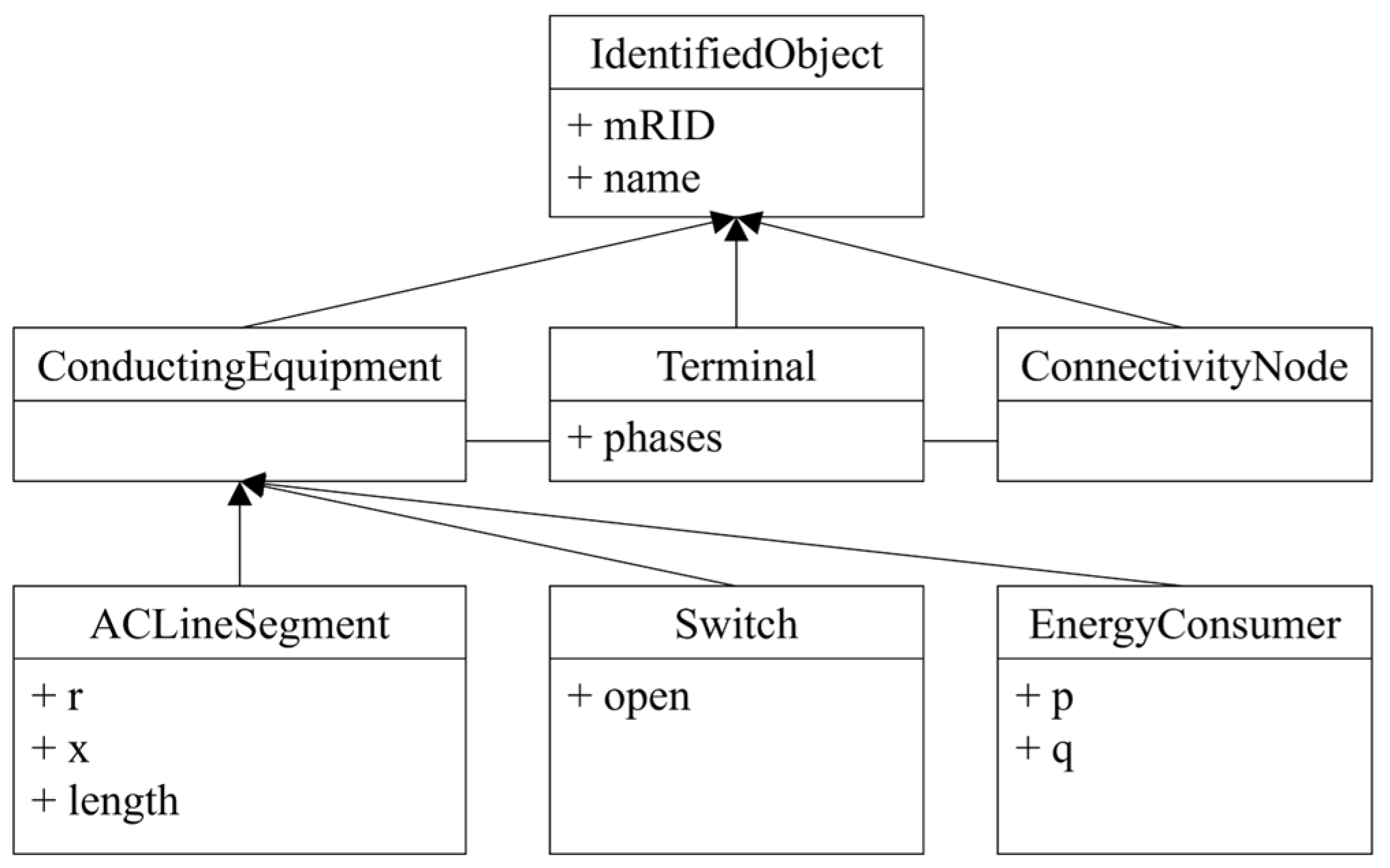
2.1. IEC TC57 CIM
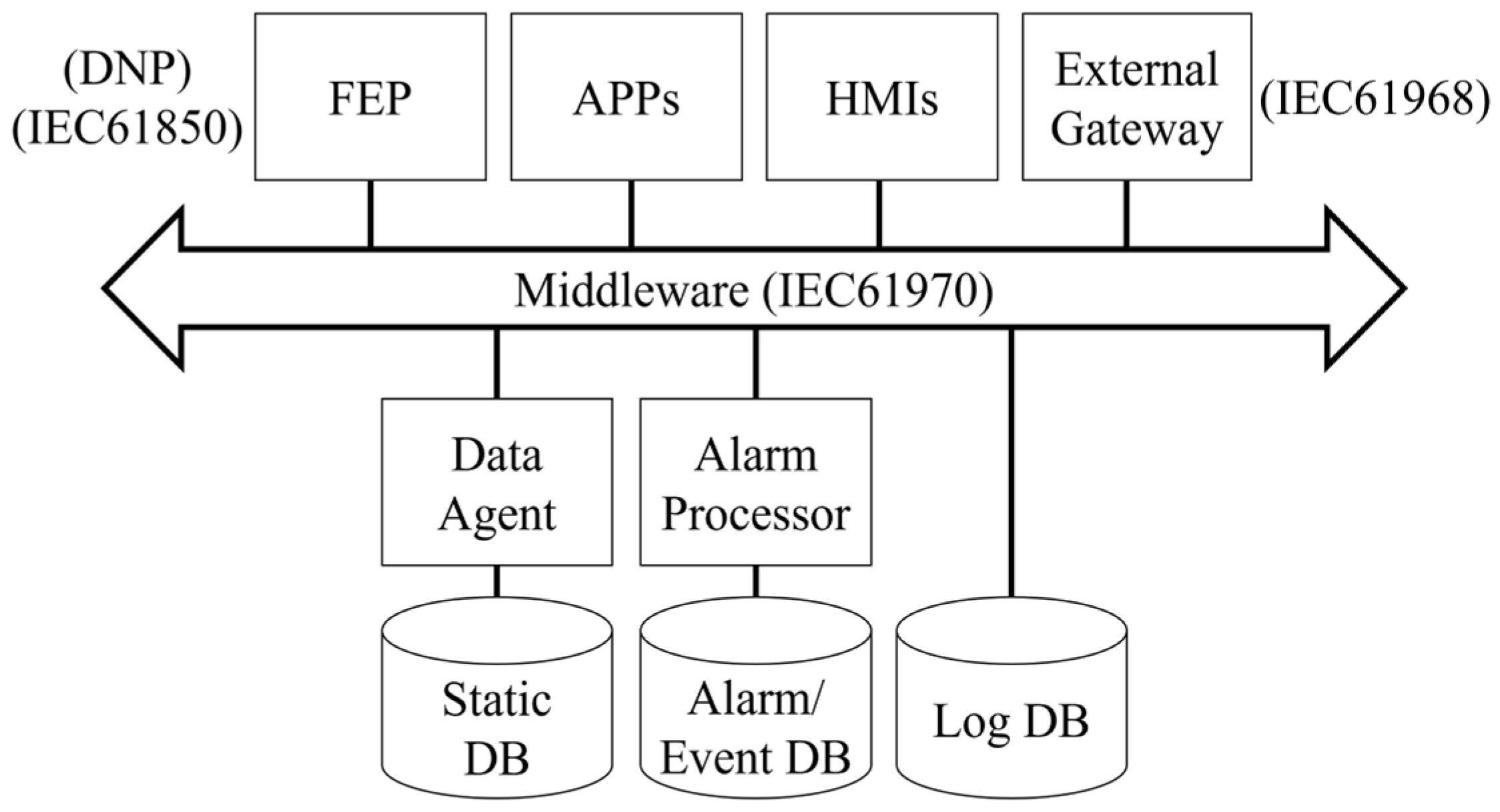
2.2. CIM-Based Distribution Management System
3. Comprehensive Analysis of Issues of CIM-Based DMS Using RDB
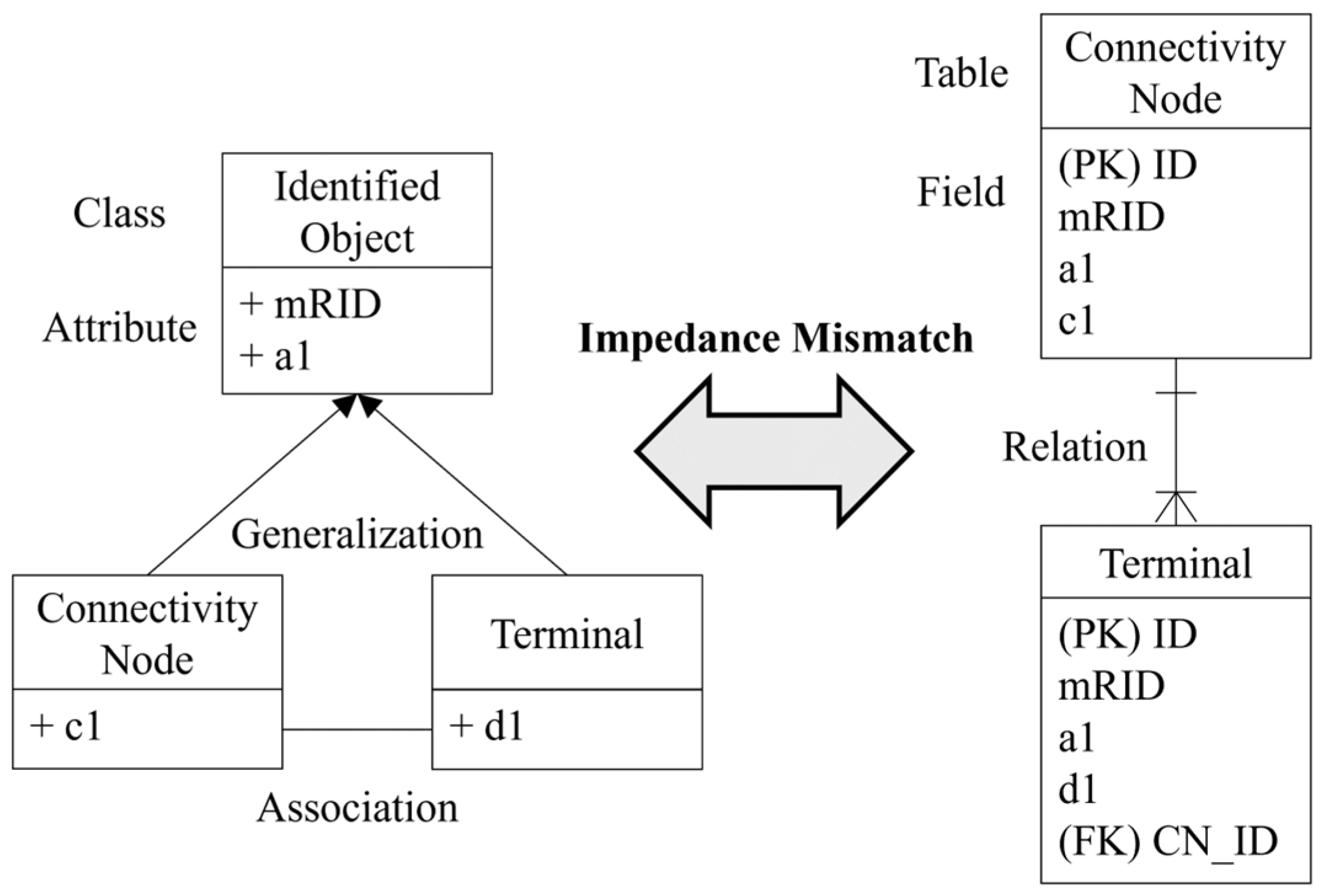
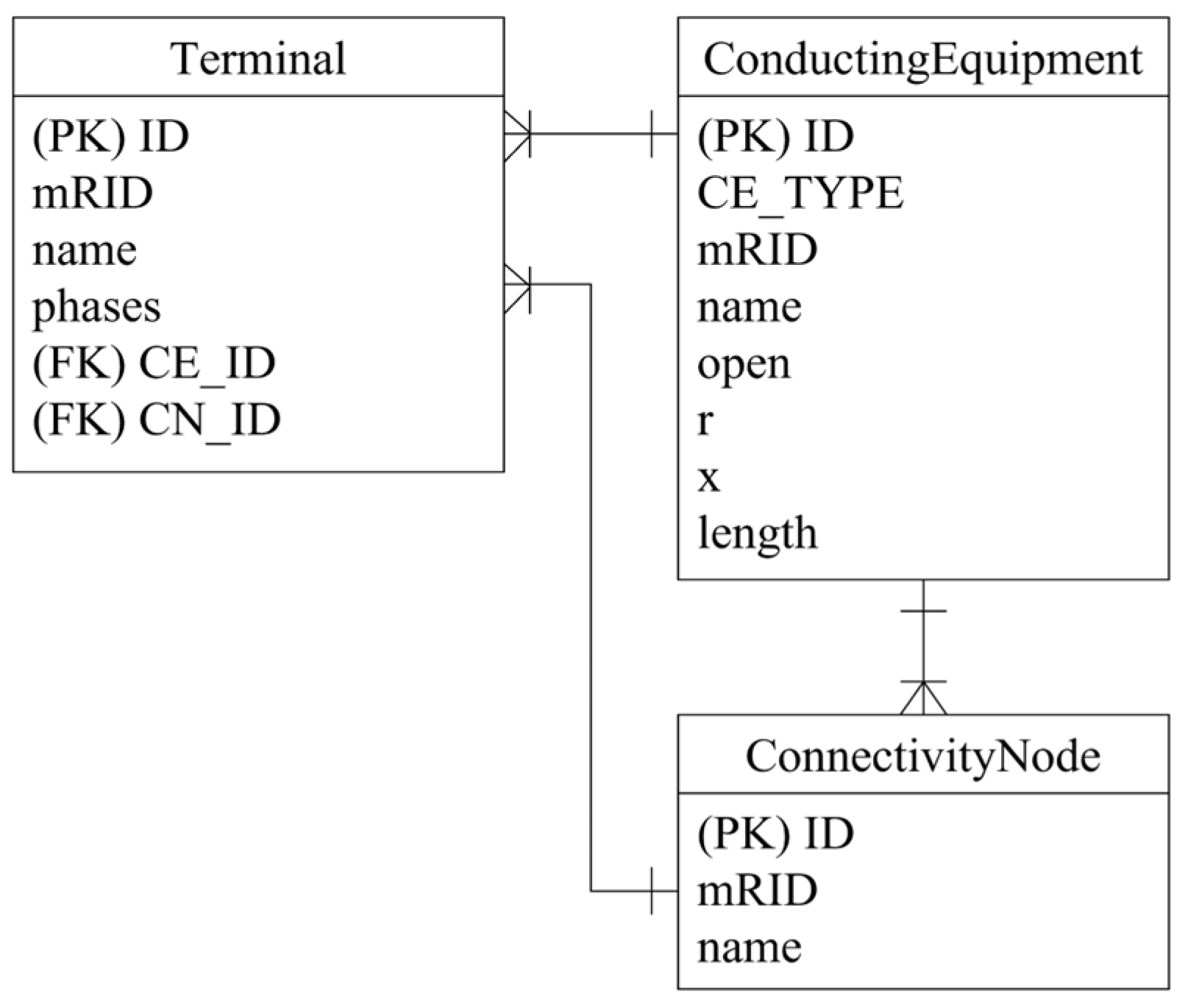
3.1. Object–Relational Impedance Mismatch
3.2. Difficulty of Changing Database Schema
3.3. Degradation of Topology Processing Performance
4. The Proposed CIM-Oriented Ontology Database Framework for DMS
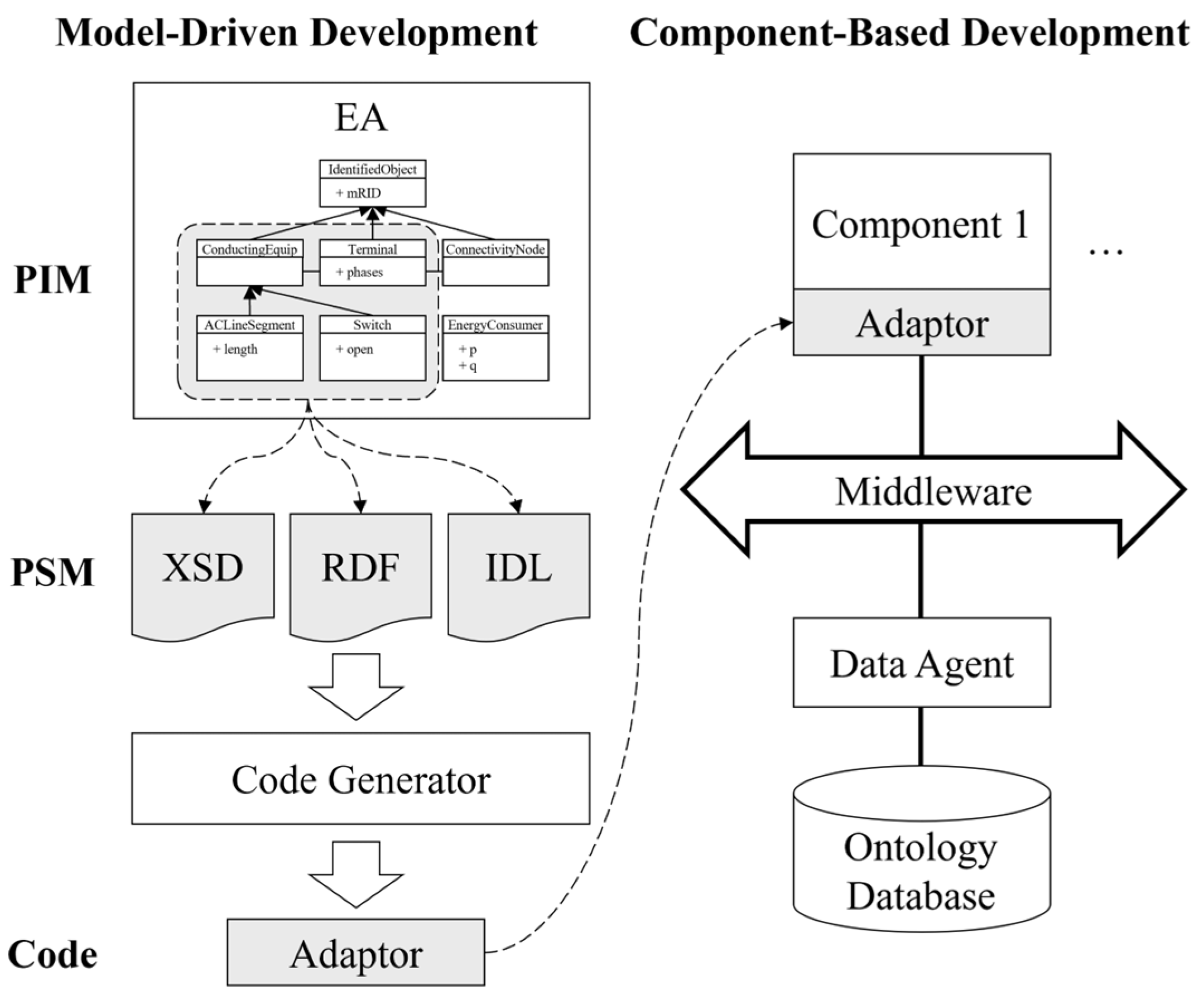
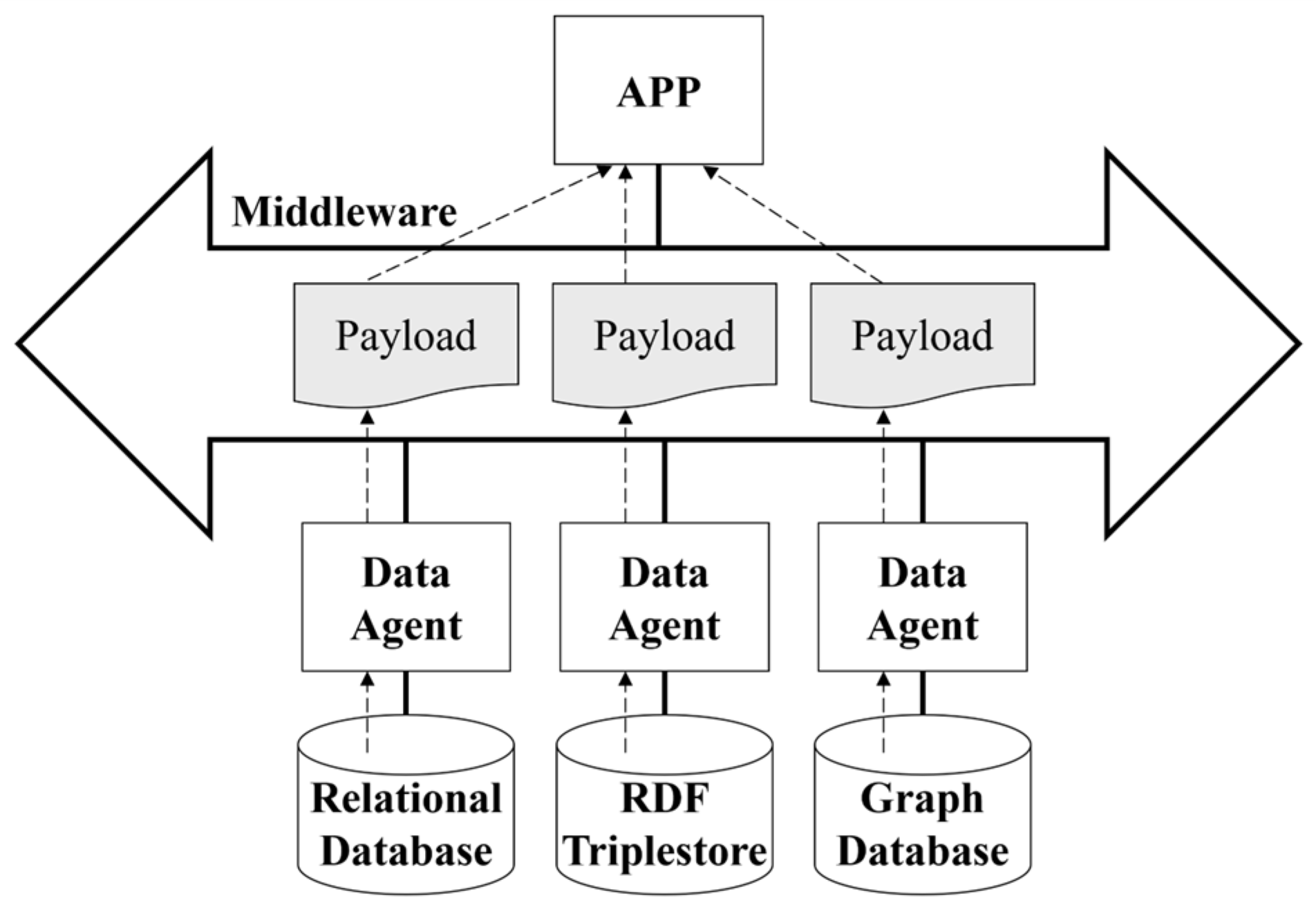
4.1. Development Process of the CIM-Oriented DMS Using an Ontology Database
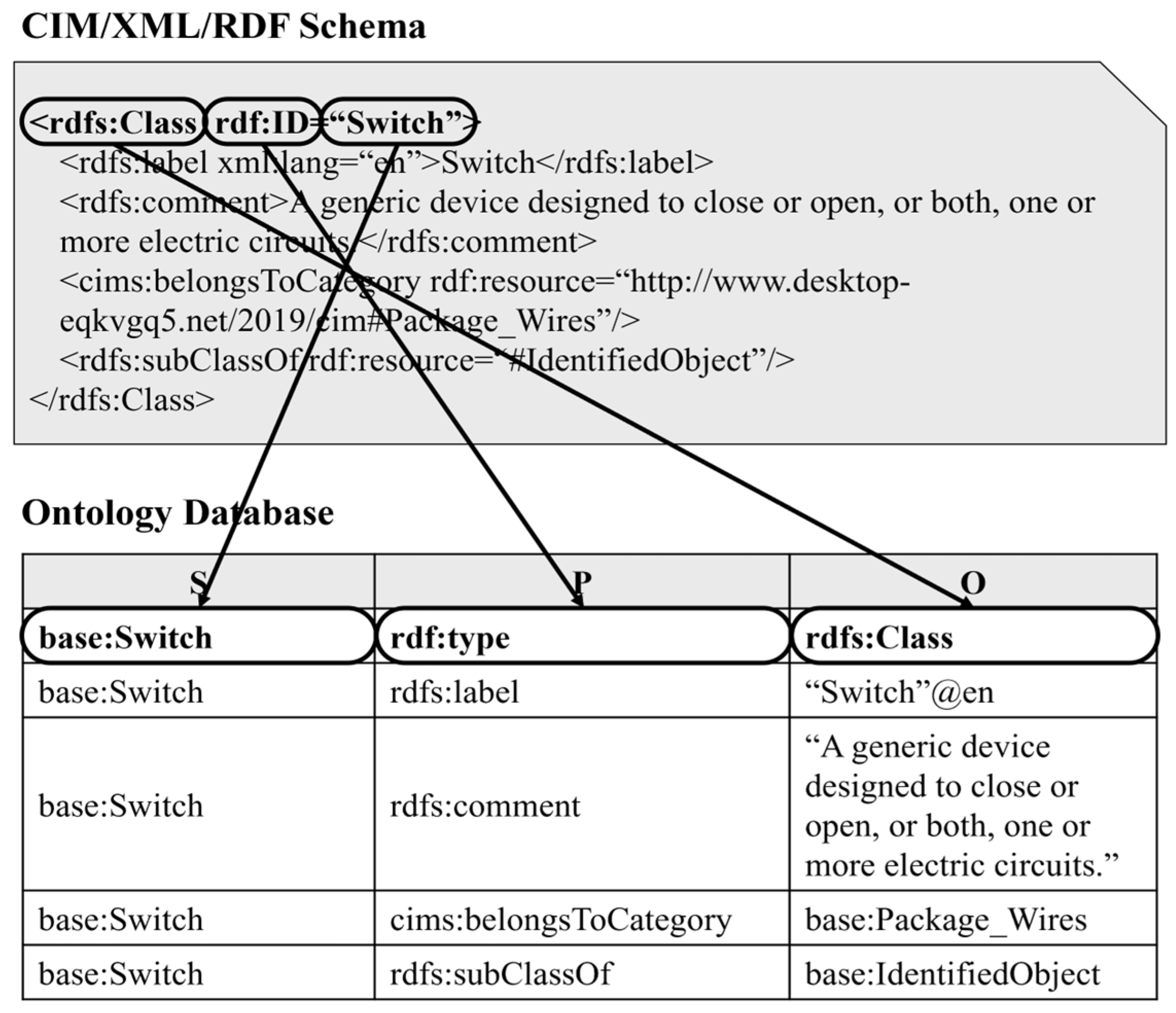
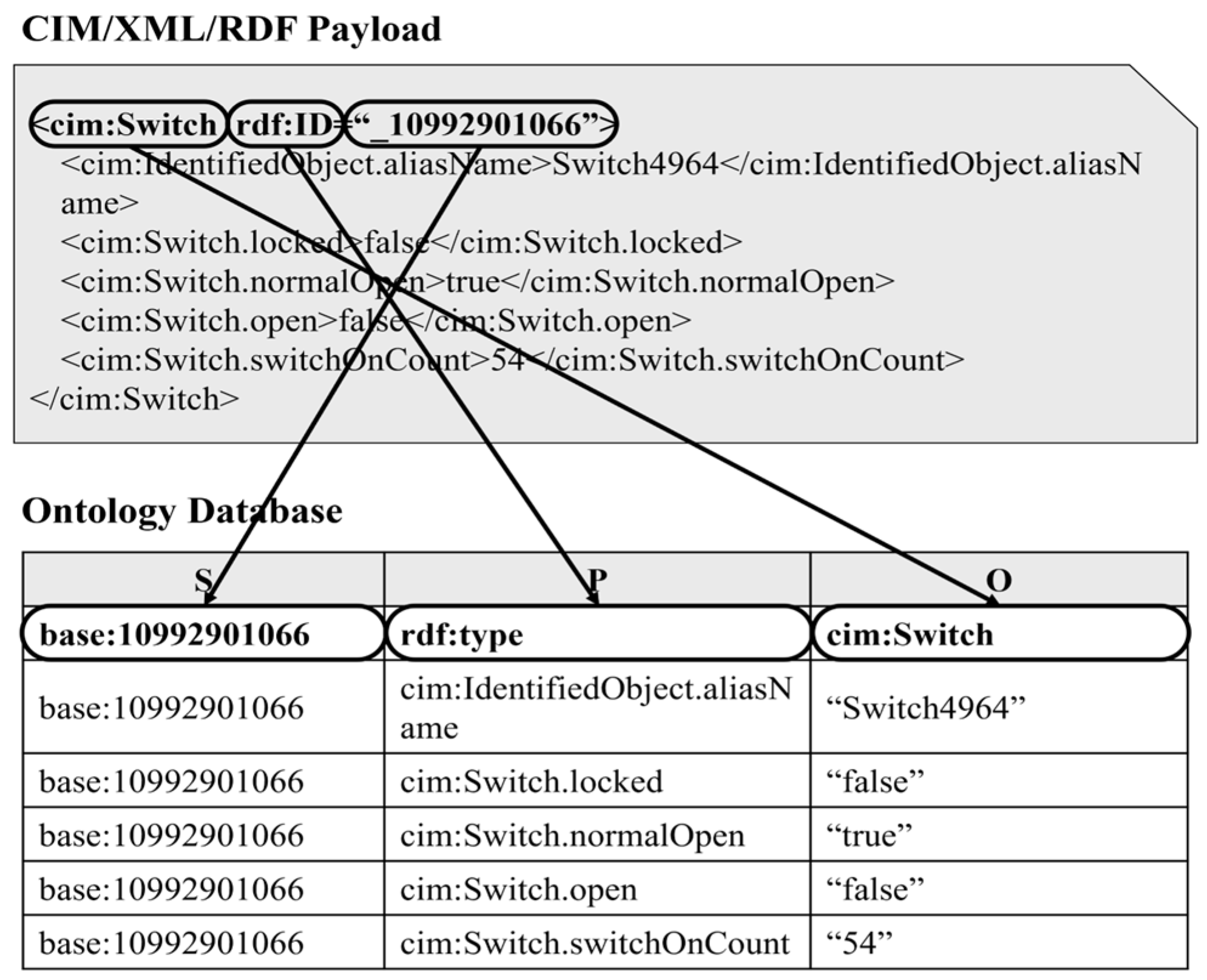
4.2. Details of Ontology Database Utilization
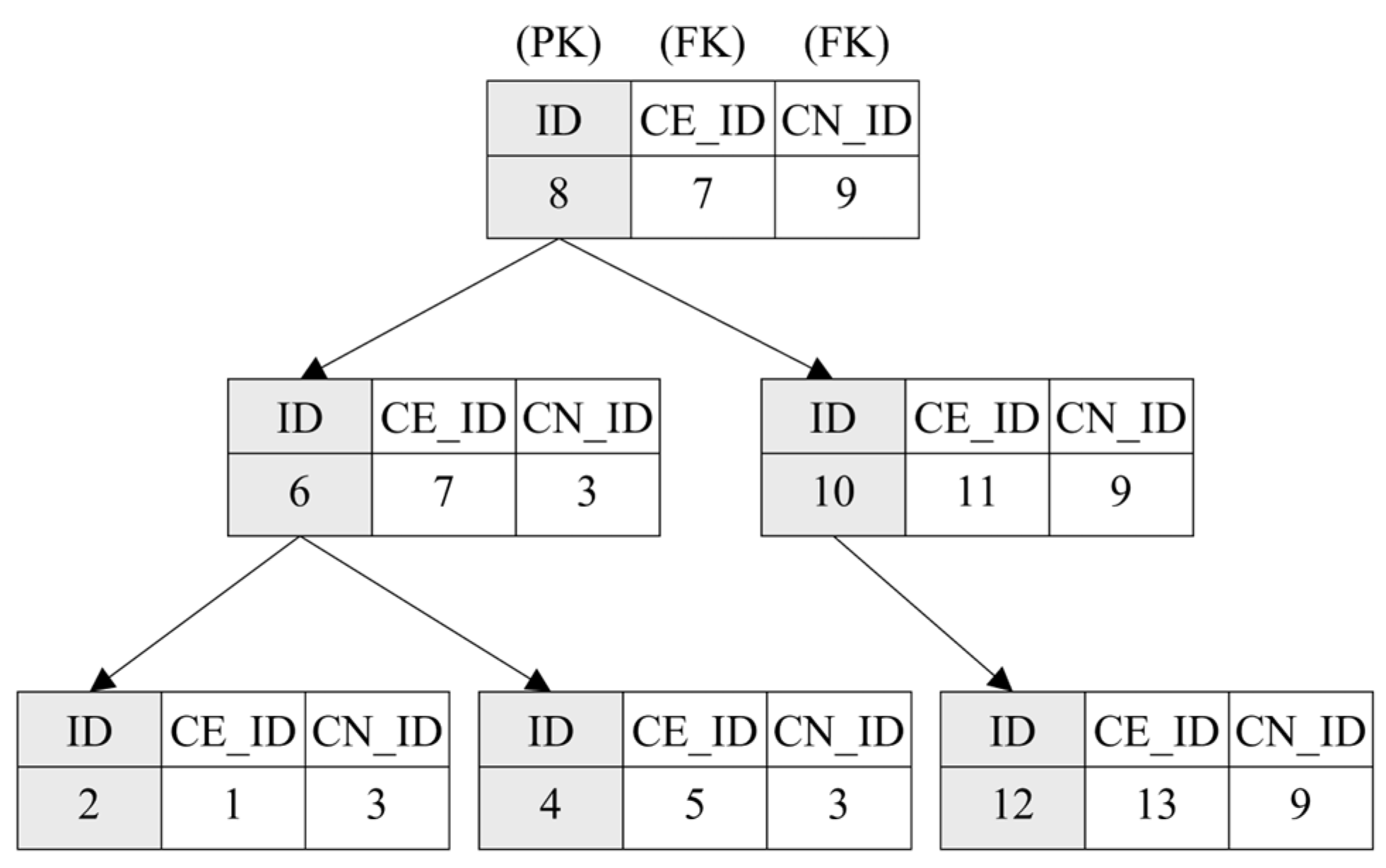
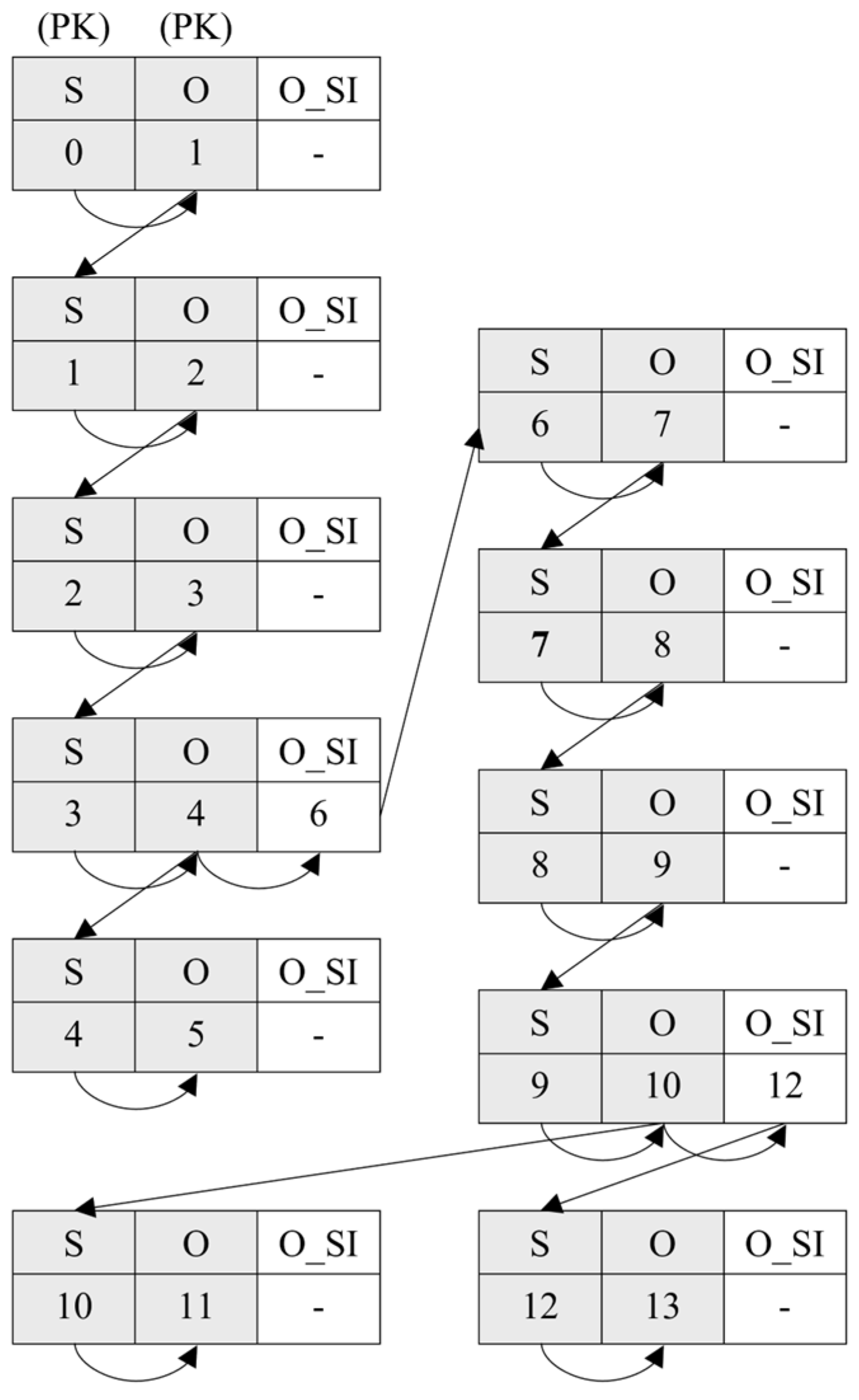
4.3. The Procedure of Topology Processing Using an Ontology Database
5. Case Studies
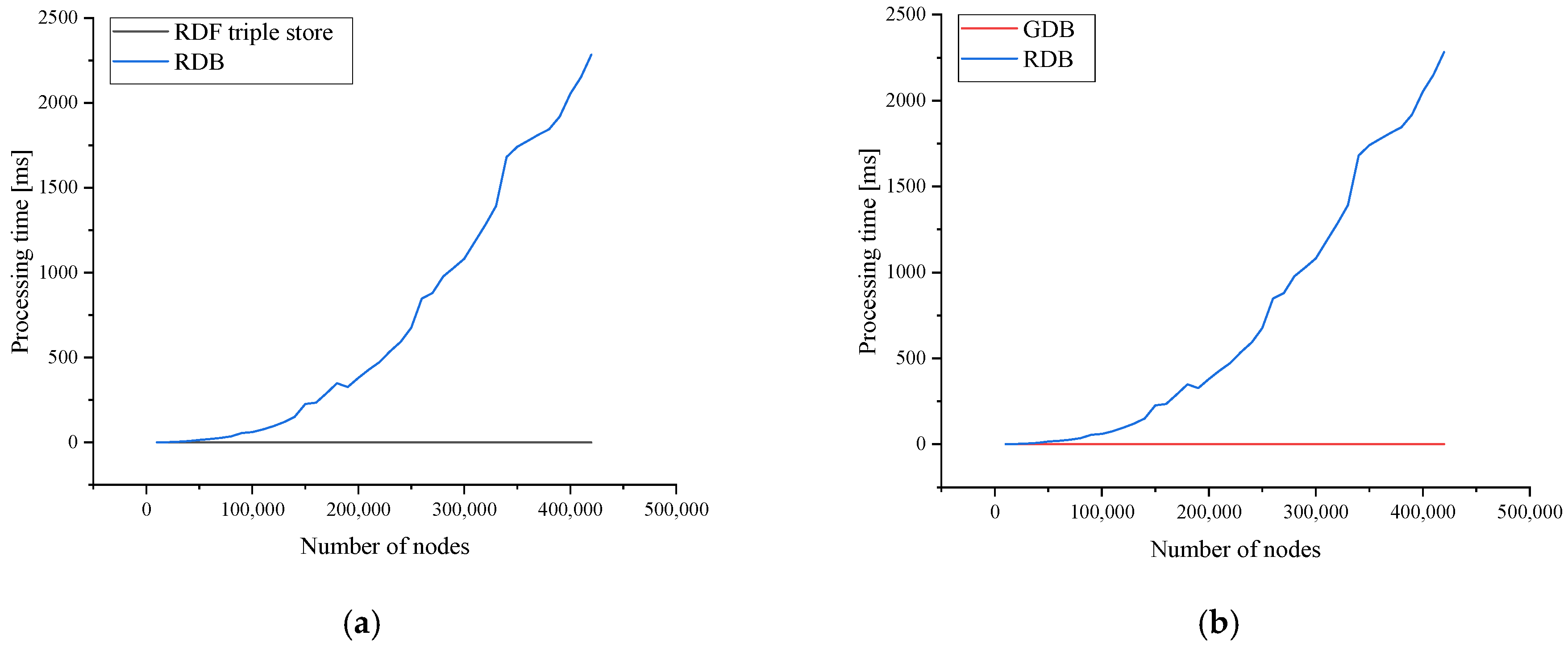
5.1. Comparison of Topology Processing Time by the Number of Nodes
5.2. Expansion to Three Distribution Networks of the Republic of Korea
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DMS | distribution management system |
| DER | distributed energy resource |
| TP | topology processing |
| ODB | ontology database |
| RDB | relational database |
| CIM | common information model |
| EV | electric vehicle |
| MVDC | medium-voltage direct current |
| DSO | distribution system operator |
| IEC | International Electrotechnical Commission |
| TC | Technical Committee |
| EMS | energy management systems |
| TSO | transmission system operator |
| ICT | information and communication technology |
| ORM | object–relational mapping |
| ORDB | object–relational database |
| GDB | graph database |
| MDD | model-driven development |
| CBD | component-based development |
| CCAPI | control center API |
| UML | unified modeling language |
| FEP | front-end processor |
| HMI | human–machine interface |
| FLISR | fault location, isolation, and service restoration |
| EA | Enterprise Architect |
| SOP | soft-open point |
| OWL | web ontology language |
| PIM | Platform-Independent Model |
| PSM | Platform-Specific Model |
| RDFS | RDF Schema |
| XSD | XML Schema |
| IDL | Interface Definition Language |
References
- Asmus, P.; Lawrence, M.; Metz, A.; Gunjan, P.; Labastida, R.R.; Shepard, S.; Woods, E. Integrated DER: Orchestrating the Grid’s Last Mile; Guide House: McLean, VA, USA, 2020. [Google Scholar]
- Navigant Research. Optimization DER Integration & Grid Management with ADMS and DERMS. 2019.
- Ministry of Trade, Industry, and Energy. The 10th Basic Plan of Long-Term Electricity Supply and Demand. 2023. Available online: https://nsp.nanet.go.kr/plan/subject/detail.do?nationalPlanControlNo=PLAN0000033810 (accessed on 30 March 2025).
- Government of the Republic of Korea. 2050 Long-Term Low Greenhouse Gas Emission Development Strategies (LEDS) Carbon Neutral Strategy of the Republic of Korea: Towards a Sustainable and Green Society. 2020. Available online: https://unfccc.int/documents/267683 (accessed on 30 March 2025).
- The Number of EV Chargers Exceeds 70,000… Concerns Over Shortage as EVs Reach 230,000 Units. Available online: https://www.mk.co.kr/news/society/10299536 (accessed on 30 March 2025).
- Ministry of Trade, Industry, and Energy. The 4th Energy Technology Development Plan (2019~2028). 2019. Available online: https://www.korea.kr/archive/expDocView.do?docId=39159 (accessed on 30 March 2025).
- IEC 61970-301; International Standard: Energy Management System Application Program Interface (EMS-API)—Part 301: Common Information Model (CIM) Base. IEC Standards: Geneva, Switzerland, 2022.
- IEC 61968-1; International Standard: Application Integration at Electric Utilities—System Interfaces for distribution Management—Part 1: Interface Architecture and General Recommendations. IEC Standards: Geneva, Switzerland, 2020.
- IEC 62325-301; International Standard: Framework for Energy Market Communications—Part 301: Common Information Model (CIM) Extensions for Markets. IEC Standards: Geneva, Switzerland, 2018.
- Worighi, I.; Maach, A.; Hafid, A.; Hegazy, O.; Mierlo, J.V. Integrating renewable energy in smart grid system: Architecture, virtualization and analysis. Sustain. Energy Grids Netw. 2019, 18, 100226. [Google Scholar] [CrossRef]
- Shen, F.; López, J.C.; Wu, Q.; Rider, M.J.; Lu, T.; Hatziargyriou, N.D. Distributed self-healing scheme for unbalanced electrical distribution systems based on alternating direction method of multipliers. IEEE Trans. Power Syst. 2020, 35, 2190–2199. [Google Scholar] [CrossRef]
- Jabr, R.A.; Džafić, I. Distribution Management Systems for Smart Grid: Architecture, Work Flows, and Interoperability. J. Mod. Power Syst. Clean Energy 2022, 10, 300–308. [Google Scholar] [CrossRef]
- Melton, R.B.; Schneider, K.P.; Lightner, E.; Mcdermott, T.E.; Sharma, P.; Zhang, Y.; Ding, F.; Vadari, S.; Podmore, R.; Dubey, A.; et al. Leveraging standards to create an open platform for the development of advanced distribution applications. IEEE Access 2018, 6, 37361–37370. [Google Scholar] [CrossRef]
- Melton, R.B.; Schneider, K.P.; Vadari, S. GridAPPS-DTM a distribution management platform to develop applications for rural electric utilities. In Proceedings of the IEEE Rural Electric Power Conference (REPC), Bloomington, MN, USA, 28 April–1 May 2019. [Google Scholar] [CrossRef]
- Anderson, A.; Barr, J.; Vadari, S.; Dubey, A. Real-time distribution simulation and application development for power systems education. In Proceedings of the IEEE Power & Energy Society General Meeting (PESGM), Denver, CO, USA, 17–21 July 2022. [Google Scholar] [CrossRef]
- Sharma, P.; Reiman, A.P.; Anderson, A.A.; Poudel, S.; Allwardt, C.H.; Fisher, A.R.; Slay, T.E.; Mukherjee, M.; Dubey, A.; Ogle, J.P.; et al. GridAPPS-D Distributed App Architecture and API for Modular and Distributed Grid Operations. IEEE Access 2024, 12, 39862–39875. [Google Scholar] [CrossRef]
- Poudel, S.; Sharma, P.; Dubey, A.; Schneider, K.P. Advanced FLISR with intentional islanding operations in an ADMS environment using GridAPPS-D. IEEE Access 2020, 8, 113766–113778. [Google Scholar] [CrossRef]
- Anderson, A.A.; Podmore, R.; Sharma, P.; Reiman, A.P.; Jinsiwale, R.A.; Allwardt, C.H.; Black, G.D. Distributed application architecture and LinkNet topology processor for distribution networks using the common information model. IEEE Access 2022, 10, 120765–120780. [Google Scholar] [CrossRef]
- Soares, T.; Carvalho, L.; Morais, H.; Bessa, R.J.; Abreu, T.; Lambert, E. Reactive power provision by the DSO to the TSO considering renewable energy sources uncertainty. Sustain. Energy Grids Netw. 2020, 22, 100333. [Google Scholar] [CrossRef]
- Uslar, M.; Rohjans, S.; Neureiter, C.; Andrén, F.P.; Velasquez, J.; Steinbrink, C.; Efthymiou, V.; Migliavacca, G.; Horsmanheimo, S.; Brunner, H.; et al. Applying the smart grid architecture model for designing and validating system-of-systems in the power and energy domain: A european perspective. Energies 2019, 12, 258. [Google Scholar] [CrossRef]
- Robinson, I.; Webber, J.; Eifrem, E. Graph Databases; OReilly Media Inc.: Newton, MA, USA, 2013. [Google Scholar]
- McDermott, T.E.; Stephan, E.G.; Gibson, T.D. Alternative database designs for the distribution common information model. In Proceedings of the IEEE/PES Transmission and Distribution Conference and Exposition (T&D), Denver, CO, USA, 16–19 April 2018. [Google Scholar] [CrossRef]
- Wu, J.; Schulz, N.N. Overview of CIM-oriented database design and data exchanging in power system applications. In Proceedings of the 37th Annual North American Power Symposium, Ames, IA, USA, 25 October 2005. [Google Scholar] [CrossRef]
- Barros, J.V.; Leite, J.B. Development of a relational database oriented on the common information model for power distribution networks. In Proceedings of the IEEE URUCON, Montevideo, Uruguay, 24–26 November 2021. [Google Scholar] [CrossRef]
- Ravikumar, G.; Khaparde, S.A.; Pradeep, Y. CIM oriented database for topology processing and integration of power system applications. In Proceedings of the IEEE Power & Energy Society General Meeting, Vancouver, BC, Canada, 21–25 July 2013. [Google Scholar] [CrossRef]
- Elbattah, M.; Roushdy, M.; Aref, M.; Salem, A.M. Large-scale ontology storage and query using graph database-oriented approach: The case of freebase. In Proceedings of the IEEE Seventh International Conference on Intelligent Computing and Information Systems, Cairo, Egypt, 12–14 December 2015. [Google Scholar] [CrossRef]
- Ravikumar, G.; Khaparde, S.A. A common information model oriented graph database framework for power systems. IEEE Trans. Power Syst. 2017, 32, 2560–2569. [Google Scholar] [CrossRef]
- EPRI. CIM Primer, 8th ed.; EPRI: Palo Alto, CA, USA, 2022. [Google Scholar]
- Hwang, J.; Oh, Y.; Song, J.; An, J.; Jeon, J. Development of a platform for securing interoperability between components in a carbon-free island microgrid energy management system. Energies 2021, 14, 8525. [Google Scholar] [CrossRef]
- Beydeda, S.; Book, M.; Gruhn, V. Model-Driven Software Development; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Panic, S.; Petrovic, V.; Kontrec, N.; Milojevic, S. Performance analysis of hybrid FSO/RF communication system with receive diversity in the presence of chi-square/gamma turbulence and rician fading. Univ. Kragujev. Digit. Arch. 2023, 4, 304–313. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. No. | Key Contribution | Strengths | Limitations |
|---|---|---|---|
| [10,11] | Introduction of communication standards and CIM for data modeling | Provides a foundational understanding of CIM | Lacks practical implementation aspects |
| [12] | Application of CIM-based interoperability in smart grid DMS | Emphasizes integration importance in advanced DMS | Does not focus on data storage or performance |
| [13,14,15,16] | Development of GridAPPS-D, a CIM-based open platform | Enables advanced DMS application development and reuse | Mainly focused on application logic, not database performance |
| [17,18] | Implementation of new CIM-based advanced DMS applications | Demonstrates the practical utility of CIM | No analysis on data processing efficiency |
| [19,20] | TDX-ASSIST project for TSO–DSO CIM-based data exchange | Extends CIM interoperability across system boundaries | Not directly related to real-time DMS database design |
| [21,22] | Issues of using RDB with CIM: object–relational mismatch | Maintains reliability and structure in legacy systems | Schema rigidity, low TP performance, complex queries |
| [23,24] | Analysis of TP performance degradation in CIM-based RDBs | Highlights the need for flexible modeling | Limited ability for topological search and model updates |
| [25] | Proposal of CIM-based ORDB with ORM tools | Bridges object–relational paradigm | ORM-related complexity, optimization limitations |
| [26,27] | GDB-based framework for storing large-scale CIM ontologies | Suitable for semantic modeling and scalability | Lacks real-time DMS implementation or TP focus |
| Standard | Application Domain | Description |
|---|---|---|
| IEC 61970 | Transmission Systems | Defines the CIM for energy management system (EMS) integration and information exchange. |
| IEC 61968 | Distribution Systems | Supports data exchange between distribution management systems (DMS) and other utility applications. |
| IEC 62325 | Electricity Markets | Provides models and messages for electricity market communications based on CIM. |
| Modification of Information Models | Class Tabulation | Object Tabulation | |
|---|---|---|---|
| Change | class name | table name | table name (depending on the case) |
| attribute name | field name | field name | |
| correlation between classes | change | Not changed | |
| Delete | class | table (deleting the inheritance relationship and foreign key relationship between tables) | table or related field (depending on the case) |
| attribute | field | field | |
| correlation between classes | foreign key relationship between tables | foreign key relationship between tables (depending on the case) | |
| Add | subclass/superclass | table and set a foreign key relationship | related table or field (depending on the case) |
| attribute | field | field | |
| correlation between classes | foreign key relationship | field of inheritance relationship; otherwise, foreign key relationship | |
| Category | Binary Tree | B−Tree | B+Tree |
|---|---|---|---|
| Number of child nodes | Up to 2 child nodes | Multiple child nodes (the number can be defined) | Multiple child nodes (the number can be defined) |
| Data storage location | Key and value are stored at the node | Key and value are stored at both the internal and leaf nodes | Only the key is stored at the internal node, and the actual data are stored at the leaf node |
| Index structure |
|
|
|
| CIM Object | Number of Nodes | |
|---|---|---|
| Terminal | 441,284 | |
| ConnectivityNode | 164,222 | |
| ConductingEquipment | EnergySource | 13,992 |
| EnergyConsumer | 9110 | |
| Switch | 58,113 | |
| Junction | 64,994 | |
| ACLineSegment | 122,561 | |
| PowerTransformer | 176 | |
| BusBarSection | 322 | |
| Total ConductingEquipment | 269,268 | |
| Total CIM Objects | 874,774 | |
| Number of Terminals | RDB [ms] | RDF Triple Store [ms] | GDB [ms] |
|---|---|---|---|
| 10,000 | 0.557 | 0.003 | 0.001 |
| 100,000 | 60.200 | 0.022 | 0.005 |
| 200,000 | 379.238 | 0.044 | 0.014 |
| 300,000 | 1081.562 | 0.078 | 0.021 |
| 400,000 | 2053.510 | 0.104 | 0.028 |
| Area | Terminal | Connectivity Node | Conducting Equipment | Total Objects |
|---|---|---|---|---|
| A | 441,284 | 164,222 | 269,268 | 874,774 |
| B | 265,981 | 95,544 | 163,223 | 524,748 |
| C | 112,205 | 39,849 | 68,396 | 220,450 |
| Area | RDB [ms] | RDF Triple Store [ms] | GDB [ms] |
|---|---|---|---|
| A | 2283.725 | 0.113 | 0.029 |
| B | 707.889 | 0.072 | 0.018 |
| C | 82.840 | 0.024 | 0.007 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hwang, J.; Kim, G.-H.; Seo, S.-A.; Song, J.-U.; Lim, S.-I.; Oh, Y.-S. Common Information Model-Oriented Ontology Database Framework for Improving Topology Processing Capability of Distribution Management Systems Considering Interoperability. Appl. Sci. 2025, 15, 4105. https://doi.org/10.3390/app15084105
Hwang J, Kim G-H, Seo S-A, Song J-U, Lim S-I, Oh Y-S. Common Information Model-Oriented Ontology Database Framework for Improving Topology Processing Capability of Distribution Management Systems Considering Interoperability. Applied Sciences. 2025; 15(8):4105. https://doi.org/10.3390/app15084105
Chicago/Turabian StyleHwang, Jihui, Gyeong-Hun Kim, Sang-A Seo, Jin-Uk Song, Seong-Il Lim, and Yun-Sik Oh. 2025. "Common Information Model-Oriented Ontology Database Framework for Improving Topology Processing Capability of Distribution Management Systems Considering Interoperability" Applied Sciences 15, no. 8: 4105. https://doi.org/10.3390/app15084105
APA StyleHwang, J., Kim, G.-H., Seo, S.-A., Song, J.-U., Lim, S.-I., & Oh, Y.-S. (2025). Common Information Model-Oriented Ontology Database Framework for Improving Topology Processing Capability of Distribution Management Systems Considering Interoperability. Applied Sciences, 15(8), 4105. https://doi.org/10.3390/app15084105