
Pedestrian Re-Identification Algorithm Based on Unmanned Aerial Vehicle Imagery

Abstract
1. Introduction
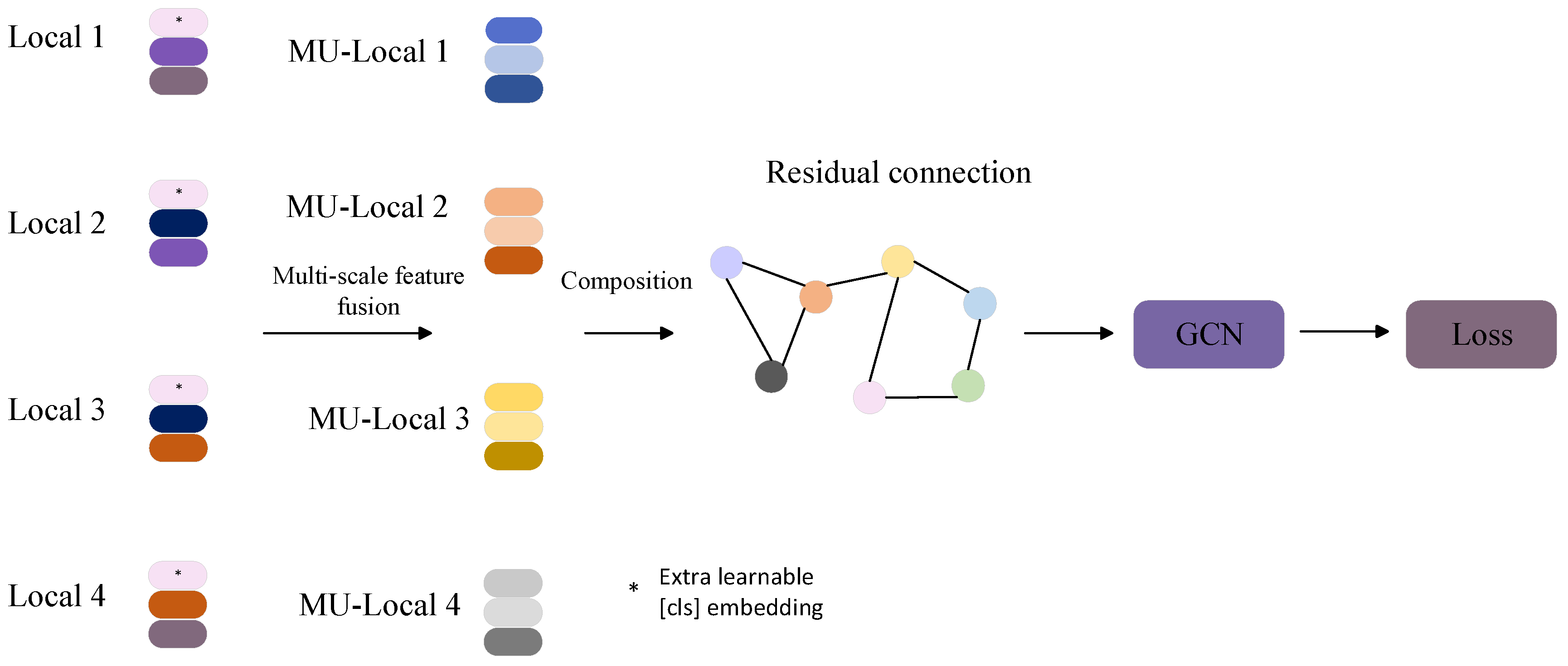
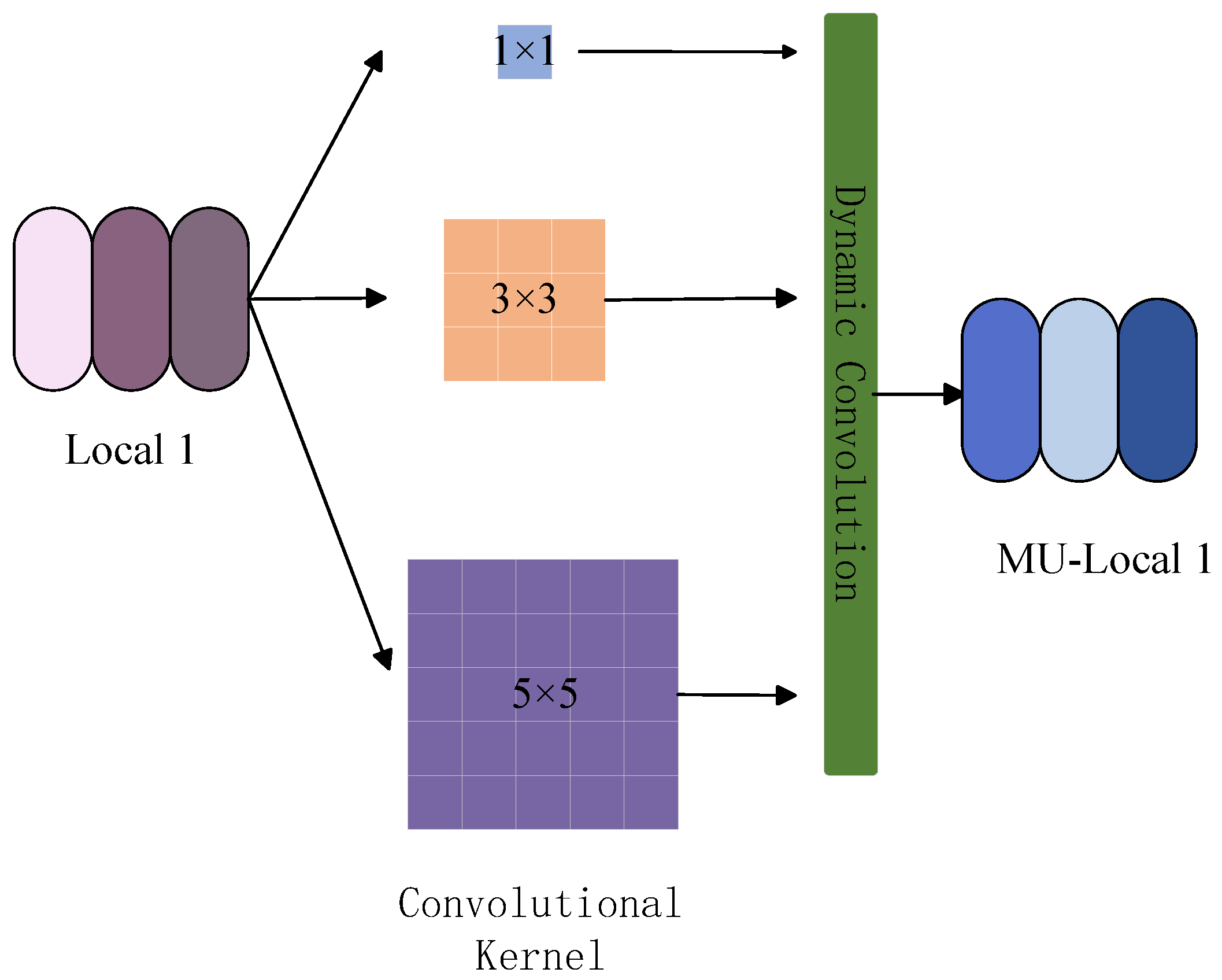
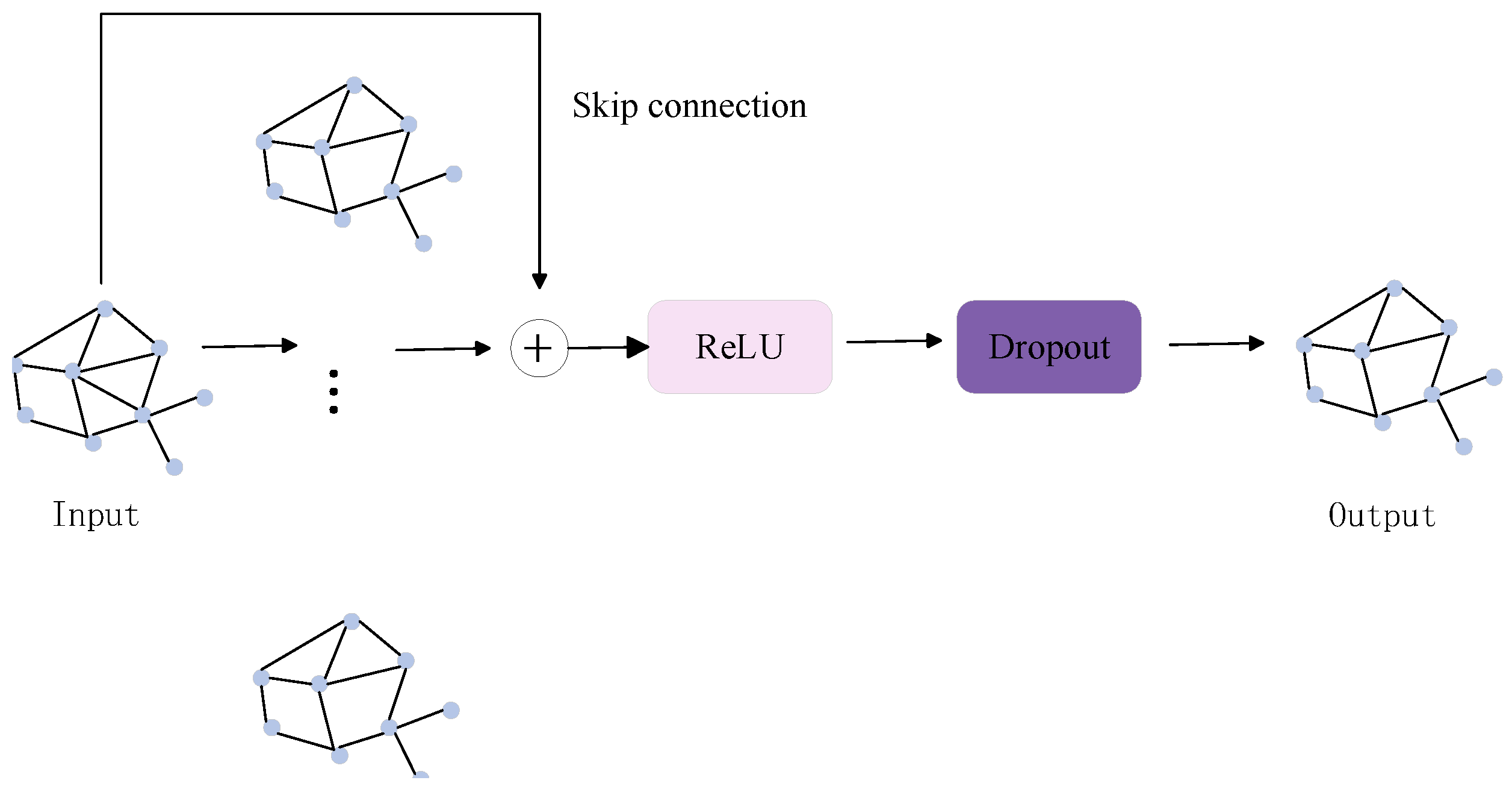
- The design of the multi-scale graph convolution network (MU-GCN): The MU-GCN is integrated into the stitching branch of the Transformer. This network captures detailed local features of pedestrian images using multi-scale convolutional kernels. It further enhances these features through graph convolutional networks. This approach is particularly effective at adapting to different feature scales, which is crucial for handling variable pedestrian poses and size changes in UAV views.
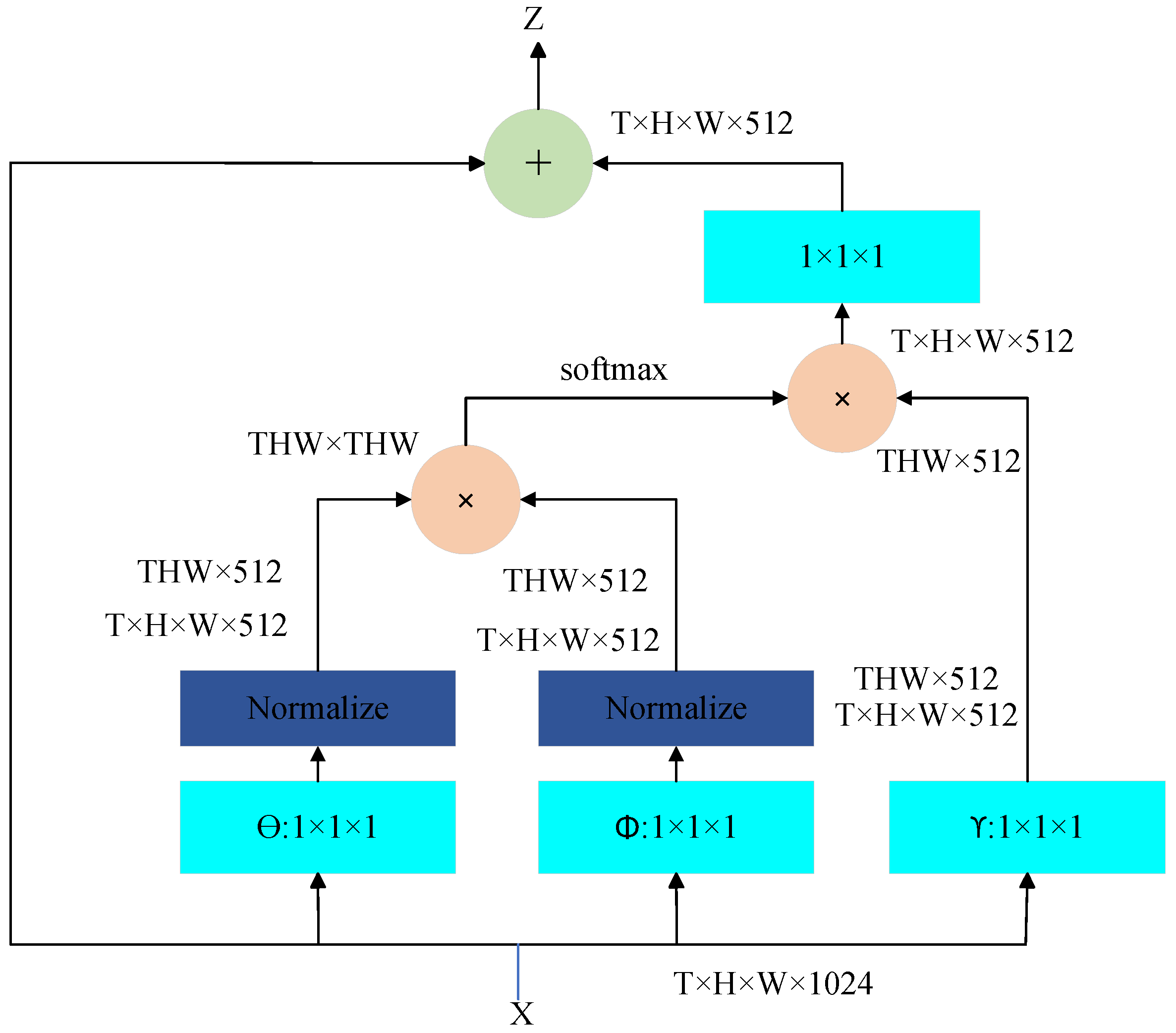
- The integration of the non-local attention mechanism: The non-local attention mechanism is introduced into the Transformer’s global branch. This mechanism overcomes the limitations of the traditional self-attention mechanism in capturing long-range dependencies. It significantly improves the model’s ability to integrate global contextual information, thereby enhancing performance in complex environments.
- Experimental validation on the UAV aerial image dataset: Experiments were conducted on a UAV aerial image dataset. The results show that the proposed model improves the mean Average Precision (mAP) by 9.5% and Rank-1 accuracy by 4.9% compared to the baseline model. These findings demonstrate the effectiveness of the proposed approach.
2. Related Work
2.1. Conventional Pedestrian Re-Identification
2.2. Pedestrian Re-Identification for UAVs
3. Improvement of Transformer-Based Pedestrian Re-Identification Algorithm
3.1. Multi-Scale Graph Convolutional Networks
3.2. Non-Local Attention Mechanism
4. Experiment
4.1. Experimental Environment
4.2. Dataset
4.3. Evaluation Metrics
5. Results and Analysis
5.1. Ablation Experiments
5.2. Comparison Experiments
5.3. Robustness Experiments
5.4. Visualization Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Rybak, Ł.; Dudczyk, J. A geometrical divide of data particle in gravitational classification of moons and circles data sets. Entropy 2020, 22, 1088. [Google Scholar] [CrossRef] [PubMed]
- Rybak, Ł.; Dudczyk, J. Variant of data particle geometrical divide for imbalanced data sets classification by the example of occupancy detection. Appl. Sci. 2021, 11, 4970. [Google Scholar] [CrossRef]
- Ravindran, R.; Santora, M.J.; Jamali, M.M. Multi-object detection and tracking, based on DNN, for autonomous vehicles: A review. IEEE Sens. J. 2021, 21, 5668–5677. [Google Scholar] [CrossRef]
- Vitiello, F.; Causa, F.; Opromolla, R.; Fasano, G. Radar/visual fusion with fuse-before-track strategy for low altitude non-cooperative sense and avoid. Aerosp. Sci. Technol. 2024, 146, 108946. [Google Scholar] [CrossRef]
- Marques, T.; Carreira, S.; Miragaia, R.; Ramos, J.; Pereira, A. Applying deep learning to real-time UAV-based forest monitoring: Leveraging multi-sensor imagery for improved results. Expert Syst. Appl. 2024, 245, 123107. [Google Scholar] [CrossRef]
- Golcarenarenji, G.; Martinez-Alpiste, I.; Wang, Q.; Alcaraz-Calero, J.M. Illumination-aware image fusion for around-the-clock human detection in adverse environments from unmanned aerial vehicle. Expert Syst. Appl. 2022, 204, 117413. [Google Scholar] [CrossRef]
- Liu, F.; Shan, J.Y.; Xiong, B.Y.; Fang, Z. A real-time and multi-sensor-based landing area recognition system for UAVs. Drones 2022, 6, 118. [Google Scholar] [CrossRef]
- Liang, B.; Su, J.; Feng, K.; Liu, Y.; Hou, W. Cross-layer triple-branch parallel fusion network for small object detection in uav images. IEEE Access 2023, 11, 39738–39750. [Google Scholar] [CrossRef]
- Li, Y.; Li, Q.; Pan, J.; Zhou, Y.; Zhu, H.; Wei, H.; Liu, C. Sod-yolo: Small-object-detection algorithm based on improved yolov8 for UAV images. Remote Sens. 2024, 16, 3057. [Google Scholar] [CrossRef]
- Yue, M.; Zhang, L.; Huang, J.; Zhang, H. Lightweight and efficient tiny-object detection based on improved YOLOv8n for UAV aerial images. Drones 2024, 8, 276. [Google Scholar] [CrossRef]
- Sun, Y.; Zheng, L.; Deng, W.; Wang, S. Svdnet for pedestrian retrieval. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3800–3808. [Google Scholar]
- Zhang, X.; Luo, H.; Fan, X.; Xiang, W.; Sun, Y.; Xiao, Q.; Jiang, W.; Zhang, C.; Sun, J. Alignedreid: Surpassing human-level performance in person re-identification. arXiv 2017, arXiv:1711.08184. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-scale feature learning for person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3702–3712. [Google Scholar]
- Chen, T.; Ding, S.; Xie, J.; Yuan, Y.; Chen, W.; Yang, Y.; Ren, Z.; Wang, Z. Abd-net: Attentive but diverse person re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8351–8361. [Google Scholar]
- Zhu, C.; Zhou, W.; Ma, J. Person Re-Identification Network Based on Edge-Enhanced Feature Extraction and Inter-Part Relationship Modeling. Appl. Sci. 2024, 14, 8244. [Google Scholar] [CrossRef]
- An, F.; Wang, J.; Liu, R. Pedestrian Re-Identification Algorithm Based on Attention Pooling Saliency Region Detection and Matching. IEEE Trans. Comput. Soc. Syst. 2023, 11, 1149–1157. [Google Scholar] [CrossRef]
- Yun, X.; Ge, M.; Sun, Y.; Dong, K.; Hou, X. Margin CosReid Network for Pedestrian Re-Identification. Appl. Sci. 2021, 11, 1775. [Google Scholar]
- Khaldi, K.; Mantini, P.; Shah, S.K. Unsupervised person re-identification based on skeleton joints using graph convolutional networks. In Proceedings of the International Conference on Image Analysis and Processing, Bologna, Italy, 6–10 September 2022; pp. 135–146. [Google Scholar]
- Dai, Z.; Wang, G.; Yuan, W.; Zhu, S.; Tan, P. Cluster contrast for unsupervised person re-identification. In Proceedings of the Asian Conference on Computer Vision, Macau, China, 4–8 December 2022; pp. 1142–1160. [Google Scholar]
- Wang, X.; Sun, Z.; Chehri, A.; Jeon, G.; Song, Y. Margin CosReid Network for Pedestrian Re-Identification. Pattern Recognit. 2024, 146, 110045. [Google Scholar] [CrossRef]
- Luo, J.; Liu, L. Improving unsupervised pedestrian re-identification with enhanced feature representation and robust clustering. IET Comput. Vis. 2024, 18, 1097–1111. [Google Scholar] [CrossRef]
- Lin, Y.; Dong, X.; Zheng, L.; Yan, Y.; Yang, Y. A bottom-up clustering approach to unsupervised person re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8738–8745. [Google Scholar]
- Zeng, K.; Ning, M.; Wang, Y.; Guo, Y. Hierarchical clustering with hard-batch triplet loss for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13657–13665. [Google Scholar]
- Bai, Z.; Wang, Z.; Wang, J.; Hu, D.; Ding, E. Unsupervised multi-source domain adaptation for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 13–19 June 2020; pp. 12914–12923. [Google Scholar]
- An, F.P.; Liu, J.E. Pedestrian re-identification algorithm based on visual attention-positive sample generation network deep learning model. Cinform. Fusion 2022, 86, 136–145. [Google Scholar] [CrossRef]
- Alexey, D. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. Transreid: Transformer-based object re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Cision, Montreal, BC, Canada, 10–17 October 2021; pp. 15013–15022. [Google Scholar]
- Xu, L.; Peng, H.; Lu, X.; Xia, D. Meta-transfer learning for person re-identification in aerial imagery. In Proceedings of the CCF Conference on Computer Supported Cooperative Work and Social Computing, Taiyuan, China, 23–25 November 2022; pp. 634–644. [Google Scholar]
- Xu, L.; Peng, H.; Lu, X.; Xia, D. Learning to generalize aerial person re-identification using the meta-transfer method. Concurr. Comput. Pract. Exp. 2023, 35, e7687. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, Q.; Yang, Y.; Wei, X.; Wang, P.; Jiao, B.; Zhang, Y. Person re-identification in aerial imagery. IEEE Trans. Multimed. 2020, 23, 281–291. [Google Scholar] [CrossRef]
- Lu, Z.; Chen, H.; Lai, J.H.; Jiao, B.; Zhang, Y. Region Aware Transformer with Intra-Class Compact for Unsupervised Aerial Person Re-identification. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Wulumuqi, China, 18–20 October 2024; pp. 243–257. [Google Scholar]
- Khaldi, K.; Nguyen, V.D.; Mantini, P. Unsupervised person re-identification in aerial imagery. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 260–269. [Google Scholar]
- Khaldi, K.; Nguyen, V.D.; Mantini, P.; Shah, S. Adapted deep feature fusion for person re-identification in aerial images. In Autonomous Systems: Sensors, Vehicles, Security, and the Internet of Everything; SPIE: Orlando, FL, USA, 2018; pp. 128–133. [Google Scholar]
- Huang, M.; Hou, C.; Zheng, X.; Wang, Z. Multi-resolution feature perception network for UAV person re-identification. Multimed. Tools Appl. 2024, 83, 62559–62580. [Google Scholar] [CrossRef]
- Grigorev, A.; Tian, Z.; Rho, S.; Xiong, J.; Liu, S.; Jiang, F. Deep person re-identification in UAV images. EURASIP J. Adv. Signal Process. 2019, 2019, 1–10. [Google Scholar] [CrossRef]
- Zhang, S.; Li, Y.; Wu, X.; Chu, Z.; Li, L. MRG-T: Mask-Relation-Guided Transformer for Remote Vision-Based Pedestrian Attribute Recognition in Aerial Imagery. Remote Sens. 2024, 16, 1216. [Google Scholar] [CrossRef]
- Hu, H.F.; Ni, Z.Y.; Zhao, H.T. Transformer based light weight person re-identification in unmanned aerial vehicle images. J. Nanjing Univ. Posts Telecommun. 2024, 44, 48–62. [Google Scholar]
- Peng, H.; Lu, X.; Xu, L.; Xia, D.; Xie, X. Parameter instance learning with enhanced vision transformers for aerial person re-identification. Concurr. Comput. Pract. Exp. 2024, 36, e8045. [Google Scholar] [CrossRef]
- Xu, S.; Luo, L.; Hong, H.; Hu, J.; Yang, B.; Hu, S. Multi-granularity attention in attention for person re-identification in aerial images. Vis. Comput. 2024, 40, 4149–4166. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP/% | Rank-1/% | Rank-10/% |
|---|---|---|---|
| ResNet50 | 73.2 | 86.0 | 94.3 |
| +Multi-scale Fusion | 75.4 | 88.5 | 95.7 |
| +GCN | 74.3 | 87.3 | 95.3 |
| +MU-GCN | 80.1 | 89.8 | 96.6 |
| Method | FLOPS/G | Parameter/M | Self-Constructed Dataset | PRAI-1581 | ||||
|---|---|---|---|---|---|---|---|---|
| mAP/% | Rank-1/% | Rank-10/% | mAP/% | Rank-1/% | Rank-10/% | |||
| Baseline | 101.2 | 96.8 | 79.4 | 89.9 | 95.7 | 50.7 | 56.2 | 67.1 |
| +Multi-scale Fusion | 124.6 | 102.6 | 84.1 | 92.9 | 97.0 | 52.4 | 60.1 | 67.4 |
| +GCN | 134.3 | 105.8 | 83.4 | 90.9 | 97.2 | 51.6 | 61.8 | 63.4 |
| +MU-GCN | 141.6 | 108.8 | 85.9 | 93.3 | 96.8 | 55.8 | 63.8 | 74.6 |
| +Non-attention mechanism | 137.5 | 106.5 | 82.3 | 91.2 | 95.9 | 53.7 | 62.9 | 71.8 |
| MNTReID | 143.2 | 110.1 | 88.9 | 94.8 | 97.4 | 58.5 | 70.9 | 83.2 |
| Method | mAP/% | Rank-1/% |
|---|---|---|
| OSNet [14] | 42.1 | 54.4 |
| SVDNet [12] | 36.7 | 46.1 |
| AlignedReID [13] | 37.6 | 48.5 |
| Pretrained ViT [39] | 57.3 | 65.3 |
| Cluster Contrast REID [33] | 21.8 | 23.5 |
| LTReID [38] | 58.7 | 66.3 |
| Meta-Learning [30] | 38.1 | 64.9 |
| GCCReID [29] | 25.5 | 31.3 |
| Subspace Pooling [36] | 39.6 | 49.8 |
| MGAiA [40] | 42.7 | 55.3 |
| MNTReID | 58.5 | 70.9 |
| Method | mAP/% | Rank-1/% |
|---|---|---|
| OSNet [14] | 79.7 | 88.6 |
| ABDNet [15] | 81.9 | 90.5 |
| AlignedReID [13] | 78.1 | 88.3 |
| TransREID [28] | 79.4 | 89.9 |
| Cluster Contrast REID [33] | 52.1 | 49.6 |
| MNTReID | 88.9 | 94.8 |
| Environmental Condition | mAP/% | Rank-1/% | Rank-10/% |
|---|---|---|---|
| Low light | 81.3 | 89.2 | 96.1 |
| Low resolution | 84.7 | 92.8 | 95.2 |
| Foggy and rainy weather | 84.1 | 92.4 | 96.6 |
| Normal weather | 88.9 | 94.8 | 97.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, L.; Jin, X.; Han, J.; Yao, J. Pedestrian Re-Identification Algorithm Based on Unmanned Aerial Vehicle Imagery. Appl. Sci. 2025, 15, 1256. https://doi.org/10.3390/app15031256
Song L, Jin X, Han J, Yao J. Pedestrian Re-Identification Algorithm Based on Unmanned Aerial Vehicle Imagery. Applied Sciences. 2025; 15(3):1256. https://doi.org/10.3390/app15031256
Chicago/Turabian StyleSong, Lili, Xin Jin, Jianfeng Han, and Jie Yao. 2025. "Pedestrian Re-Identification Algorithm Based on Unmanned Aerial Vehicle Imagery" Applied Sciences 15, no. 3: 1256. https://doi.org/10.3390/app15031256
APA StyleSong, L., Jin, X., Han, J., & Yao, J. (2025). Pedestrian Re-Identification Algorithm Based on Unmanned Aerial Vehicle Imagery. Applied Sciences, 15(3), 1256. https://doi.org/10.3390/app15031256