Abstract
Deep learning-based object detection technology is rapidly developing, and underwater object detection, an important subcategory, plays a crucial role in various fields such as underwater structure repair and maintenance, as well as marine scientific research. Some of the major challenges in underwater object detection are the relatively limited availability of underwater image and video datasets and the high cost of acquiring high-quality, diverse training data. To address this, we propose a novel underwater object detection method, SUD-YOLO, based on the Mean Teacher semi-supervised learning strategy. More specifically, it combines a small number of labeled samples with a large number of unlabeled samples, using the teacher model to guide the generation of pseudo-labels. In addition, a multi-scale pseudo-label enhancement module is developed specifically to address the issue of low-quality pseudo-labels. To overcome the model’s difficulty in learning underwater image feature extraction, we integrate a receptive-field attention mechanism with local spatial features and then design a lightweight detection head based on the task alignment concept to further improve the model’s feature extraction capability. Experimental results on the DUO dataset show that, by using only 10% of the labeled data, the proposed method achieves an average precision of 50.8, which is an improvement of 11.0% over the fully supervised YOLOv8 algorithm, 11.3% over the fully supervised YOLOv11 algorithm, 9.3% over the semi-supervised Efficient Teacher algorithm, and 3.4% on the semi-supervised Unbiased Teacher algorithm, while only 20% of the computational cost is required.
1. Introduction
The ocean covers a vast area and contains a rich array of natural resources. The rational development and utilization of marine resources will become a focal point in the future as land resources continue to be developed and consumed. Underwater robotic technology has gained an increasingly significant role as a key tool for exploring and evaluating underwater biological resources. Underwater robots are able to reach extreme environments, such as the deep sea, which are difficult for humans to access and perform a variety of tasks. These robots can capture high-definition images and accurately detect targets through integrated high-definition cameras or sophisticated sonar systems. In the field of underwater object detection based on acoustic vision, there are significant limitations in detecting and precisely identifying objects at a close range because of the high noise characteristics and long wavelengths of underwater sound signals [1]. In contrast, images captured in the visible-light spectrum provide richer information, with more prominent details, and are more closely aligned with the human visual system. For the effective development and utilization of marine resources, the requisite accuracy of underwater object detection technology is critical.
Existing underwater object detection algorithms can be broadly categorized into two subcategories: traditional methods and deep learning-based methods. Traditional methods rely on handcrafted feature extraction, which is not only time-consuming and expensive, but also limited in detection range. These methods often fail to capture the intricate features of objects effectively and perform particularly poorly when detecting small targets. Furthermore, the complexity of the underwater environment significantly limits its detection accuracy. With continuous advances in artificial intelligence (AI) and deep learning (DL) technologies, these methods have demonstrated outstanding capabilities in fields such as image recognition and object detection.
Deep learning-based object detection algorithms can be broadly classified into two categories: two-stage object detection algorithms [2,3,4] and one-stage object detection algorithms [5,6,7]. Two-stage object detection algorithms generally offer higher detection performance, but they require more time for both training and inference, making them unsuitable for underwater object detection tasks. In contrast, one-stage object detection algorithms do not require a region proposal network like two-stage algorithms. Instead, they directly predict bounding boxes on the image, resulting in higher detection speed and lower computational cost, which makes them more suitable for real-time object detection requirements.
In the field of underwater object detection, research on two-stage detectors has mainly focused on the Faster R-CNN model. Zeng et al. [8] proposed an underwater object detection algorithm based on Faster R-CNN and the Adversarial Occlusion Network (AON). This approach generates occlusion samples that are difficult to classify correctly during training, thus improving the robustness and generalization ability of the detection network in complex underwater environments. Dulhare et al. [9] introduced a method combining Faster R-CNN and data augmentation techniques to address the challenges of human detection in underwater environments. By applying three types of data augmentation—image degradation, perspective transformation, and lighting variation—this method enhances the model’s adaptability and detection accuracy under complex conditions.
Due to the limitations of underwater hardware, most underwater object detection tasks are currently designed using single-stage detection methods. Hu et al. [10] proposed a method for detecting uneaten feed pellets in aquaculture, based on an improved YOLO-V4 network, which addresses the issues of low contrast, small size, and the large number of feed pellets in underwater images. Liu et al. [11] employed a fuzzy network to process the dataset and made an improvement to YOLOv4 by incorporating an attention module, which enhanced the feature extraction ability of the backbone network. Furthermore, Zhang et al. [12] introduced an improved YOLOv5 object detection framework that significantly enhanced the accuracy and robustness of underwater organism detection by integrating the BoT3 self-attention mechanism and the MLLE image enhancement method. Song et al. [13] presented an enhanced algorithm based on YOLOv8 designed to address the challenges of poor image quality and suboptimal recognition accuracy in robotic underwater object detection. The proposed enhancements encompass the incorporation of Adaptive Deformable Convolution (DCNv3) and Spatial Pyramid Pooling with Cross-Stage Partial Connections (SPPFCSPC), as well as the utilization of the Weighted Intersection over Union (WIoU) loss function to refine detection performance. Zhang et al. [14] enhanced the YOLOv8 model by integrating Compact Inverted Blocks (CIB), the PSA self-attention mechanism, and a multi-scale feature fusion technique grounded in Gold-YOLO. These innovations significantly augment the precision and robustness of object recognition in intricate and challenging underwater environments.
The aforementioned studies have improved algorithms from different perspectives and achieved certain results. However, underwater object detection still faces several challenges. First, the underwater environment is complex, with dim lighting, and images are often blurry, making it difficult to accurately extract biological features. Second, underwater organisms are often concentrated in certain areas, leading to overlap and occlusion, which affects the accuracy of target recognition and presents challenges for annotation tasks. Lastly, the precise annotation of targets in underwater images requires specialized knowledge and technology, increasing both the cost and the difficulty of data preparation [15].
To address the above issues, this paper proposes a new method, SUD-YOLO, which combines the YOLOv8 object detection framework with the Mean Teacher semi-supervised learning strategy [16]. The main contributions of this paper are as follows:
- This study proposes a novel underwater object detection method based on the Mean Teacher semi-supervised learning method, which combines a limited number of labeled samples with a large number of unlabeled samples. The teacher model is used to guide the generation of pseudo-labels, and a multi-scale pseudo-label enhancement module is specially developed to address the issue of low-quality pseudo-labels.
- This study proposes a module that integrates the receptive-field attention mechanism with local spatial features, significantly improving the feature extraction capability in underwater images.
- This study proposes a lightweight detection head based on task alignment, which introduces shared convolution to reduce parameters while improving the feature delicacy in small target detection layers, allowing the model to observe more detailed features.
2. Related Works
2.1. Semi-Supervised Objection Detection
In the field of supervised learning, object detection algorithms have made considerable advancements. However, the high cost of manual annotation remains a significant bottleneck to their widespread application. To address this issue, semi-supervised learning methods have gradually become a focal point of research. These methods aim to make full use of limited labeled data in conjunction with a large amount of easily accessible unlabeled data, thereby enhancing model performance and offering great potential for the application of semi-supervised algorithms.
Semi-supervised object detection algorithms can be broadly categorized into two types: consistency-based methods [17] and pseudo-labeling methods [18]. STAC proposes a semi-supervised learning framework for visual object detection, which combines self-training and strong data augmentation consistency regularization, effectively leveraging unlabeled data to significantly boost model performance [19]. Unbiased Teacher, through a mutual learning mechanism between the teacher and student models, integrates techniques such as exponential moving average (EMA) training and focal loss, effectively mitigating issues of class imbalance and foreground/background disparity [20]. Soft Teacher introduces an innovative pseudo-label generation and selection mechanism, along with an efficient end-to-end training process, providing an effective new approach to address the challenges of semi-supervised object detection [21]. Efficient Teacher, specifically designed for one-stage anchor-based detectors, presents a semi-supervised object detection framework that optimizes the allocation of pseudo-labels through a Pseudo-Label Assigner. It also introduces an Epoch Adaptor to adjust the threshold and distribution adaptation of pseudo-labels, ensuring the efficiency and quality of the student model’s training process [22]. Humble Teacher [23] replaces hard pseudo-labels with soft pseudo-labels in semi-supervised learning, enabling the student to extract more comprehensive information from the teacher. MixTeacher [24] introduces a new approach involving mixed-scale teachers, aiming to improve pseudo-label generation and achieve scale-invariant learning, ultimately addressing the issue of scale variation during training. Subsequently, several studies [18,25] extended these existing methods to single-stage detectors, in pursuit of simpler and more effective solutions. Recently, Semi-DETR [26] explored the SSOD framework based on DETR, bringing new possibilities to the field of semi-supervised object detection.
2.2. Underwater Objection Detection
Underwater object detection tasks present distinct challenges compared to general object detection tasks. The complexity of the underwater environment leads to images being easily impacted by factors such as blur, noise, and color variations, which significantly hinder the performance of most conventional object detection methods in underwater scenarios.
A. Mahmood et al. proposed a CNN-based handcrafted method for classifying corals in the ocean [27,28]. K. Hu et al. introduced a cross-layer fusion network to improve the extraction capacity of feature [29]. This method combines the concepts of ResNet and SSD, achieving a 7.6% performance improvement over SSD. However, the network does not address issues related to heterogeneous noise. L. Chen et al. proposed the Sample-Weighted Hybrid Network (SWIPENet), which attempts to address issues related to heterogeneous noise and generates high-resolution, semantically rich feature maps [30]. This approach is optimized for noisy images, though it may still detect some unnecessary objects. CH Liu et al. used a fuzzy network to process the dataset and improved YOLOv4 by integrating an attention module, which strengthened the feature extraction capability of the backbone network [11].
3. Materials and Methods
3.1. Dataset Information
We used the DUO dataset [31], which consists of 7782 high-resolution underwater images in total, with 74,514 labeled aquatic organisms. The training set contains 6671 images while the test set contains 1111 images. Aquatic organisms are classified into four categories: holothurian, echinus, scallop, and starfish. The instances in the training and test datasets are presented in Table 1, and some sample images from the dataset are shown in Figure 1.

Table 1.
The number of instances for each category in the DUO dataset.

Figure 1.
Some examples from the DUO dataset.
3.2. The Proposed Detection Model, SUD-YOLO
This subsection provides a detailed explanation of the semi-supervised learning method applied to underwater object detection. Given the scarcity of labeled data available for training in current underwater object detection research, semi-supervised learning methods have become a research hotspot due to their ability to leverage a large amount of unlabeled data in combination with a small amount of labeled data to improve the model’s generalization ability. This method can mine the latent features in unlabeled data, helping the model gain a deeper understanding of the underwater environment. The overall framework of this paper is shown in Figure 2, and the design follows the Mean Teacher semi-supervised learning method [16].
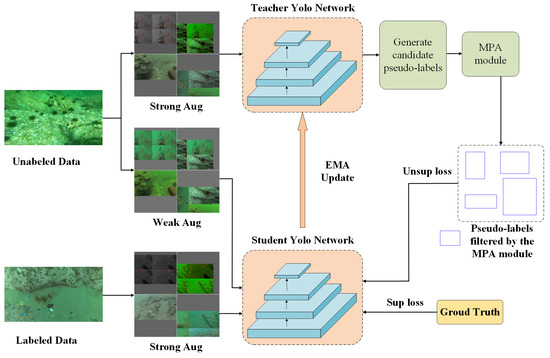
Figure 2.
The semi-supervised learning framework for underwater object detection algorithm we propose.
In this study, the dataset is divided into two parts: labeled data and unlabeled data. Different augmentation techniques are applied to the labeled and unlabeled data. For labeled data, only strong augmentation is applied. When the teacher network generates pseudo-labels using unlabeled data, a weak augmentation is first applied. During the training of the student network, both labeled and unlabeled data are used, with the unlabeled data undergoing strong augmentation consistent with the labeled data. To ensure the quality of the generated pseudo-labels, we introduce a multi-scale pseudo-label augmentation module during the pseudo-label generation phase. The structure of this module is shown in Figure 3.

Figure 3.
Multi-scale Pseudo-label Box Augmentation Module (MPA).
The detection model we proposed in this paper is shown in Figure 4. First, the Backbone component incorporates our proposed receptive-field attention and Local Feature Fusion Module (RFEConv) and Spatial Pyramid Pooling Fast Module (SPPF). Figure 5 illustrates the specific structure of the RFEConv module.
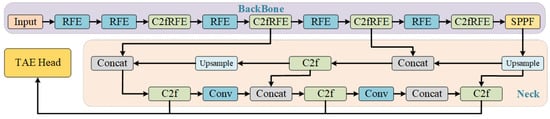
Figure 4.
The detection model for underwater object detection algorithm we propose.
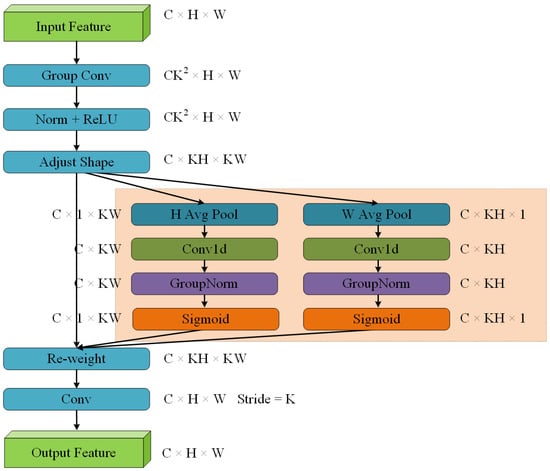
Figure 5.
RFEConv module architecture.
Next, the Neck component utilizes a Feature Pyramid Network (FPN) structure to perform multi-scale feature fusion using the feature maps from the Backbone.
Finally, the Head component introduces our proposed Task-Aligned Lightweight Detection Head Module (TAE). This object detection process adopts an anchor-free approach, eliminating the need for predefined anchor boxes, and is better suited to detect objects of varying scales and shapes. Figure 6 shows the structure of the TAE module. Upon receiving the feature maps from the Feature Pyramid Network (FPN), the detection head decomposes the task into two sub-tasks: classification and regression. The classification task aims to predict the category of the detected object, while the regression task is responsible for accurately predicting the position and dimensions of the bounding box enclosing the object.
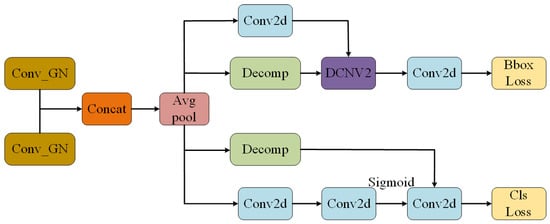
Figure 6.
TAE head module architecture.
3.2.1. The Proposed Semi-Supervised Learning Method for Training SUD-YOLO
In the task of underwater object detection, existing datasets have relatively few images, and manual labeling is costly in terms of both labor and financial resources. We introduced the Mean Teacher semi-supervised learning method [16] and proposed a multi-scale pseudo-label box enhancement method to improve the semi-supervised results, effectively utilizing a large amount of unlabeled data.
The semi-supervised object detection learning framework proposed in this paper is shown in Figure 2.
In this study, the data are divided into two parts: unlabeled data and labeled data. The labeled data undergo strong augmentation, while the unlabeled data undergo both weak and strong augmentations [32]. Weak augmentation includes mosaic augmentation, random flipping, and other augmentations that significantly affect the bounding boxes, while strong augmentation includes random color changes, grayscale changes, and other augmentations that affect the color significantly. The teacher network generates pseudo-labels using weakly augmented unlabeled data, treating these pseudo-labels as the ground truth for the unlabeled data to guide the student network’s learning. Specifically, the teacher network generates pseudo-labels for the weakly augmented unlabeled data, which serve as the learning reference for the student network. During training, the student network not only uses the strongly augmented labeled data for supervised learning but also leverages the pseudo-labels generated by the teacher network to perform unsupervised learning with the strongly augmented unlabeled data, thereby enabling the effective use of the unlabeled data.
To ensure that the pseudo-label generation is not affected by network fluctuations, the parameters of the teacher network are updated using the exponential moving average (EMA) of the student network’s parameters [18]. The EMA technique smooths the update process of the teacher network’s parameters, making the pseudo-labels more stable and reducing the uncertainty caused by sharp fluctuations in the teacher network’s parameters during training. This stability enhances the reliability of the pseudo-labels, thereby improving the overall performance of the semi-supervised learning framework.
The loss function of this semi-supervised learning framework consists of two parts: one part is the supervised learning loss, which measures the performance of the student network on the strongly augmented labeled data; the other part is the unsupervised learning loss, which evaluates the learning effectiveness of the student network on the strongly augmented unlabeled data and pseudo-labels.
where and denote the supervised loss and unsupervised loss, and denotes the weight of the unsupervised loss. is defined as
where denotes the classification supervised loss, denotes the bounding box supervised loss, and denotes the DFL supervised loss. is defined as
where denotes the classification unsupervised loss, denotes the bounding box unsupervised loss, and denotes the DFL unsupervised loss.
One significant change in YOLOv8 compared to YOLOv5 is the transition from an anchor-based to an anchor-free approach. Without prior anchors, YOLOv8 generates fewer anchor boxes, which is disadvantageous for semi-supervised learning because this approach relies on the pseudo-anchor boxes generated by the model. With fewer pseudo-anchor boxes, the model is more likely to learn incorrect knowledge, leading to a decrease in both accuracy and recall [33]. Therefore, the semi-supervised improvement effect in YOLOv8 is relatively smaller than that in YOLOv5. To address this issue, we propose a multiscale pseudo-label bounding box enhancement module, as shown in Figure 4.
In general semi-supervised object detection algorithms, a teacher model is responsible for generating pseudo-labels on unlabeled images, which are then treated as ground truth and incorporated into the semi-supervised training process. During this process, the quality of the generated pseudo-labels plays a crucial role in determining the success of the entire semi-supervised training. For instance, if the generated pseudo-labels are very close to the ground truth (GT), the semi-supervised training process can essentially be treated as supervised training, leading to highly effective results. Conversely, if the generated pseudo-labels are incorrect, it is akin to training on a mislabeled dataset in a supervised manner, which will inevitably result in poor performance.
A key parameter that controls the quality of pseudo-label generation is the confidence threshold when generating predictions for pseudo-labels. High-confidence bounding boxes indicate that the model is highly confident that the detected box likely contains a correct object, while low-confidence bounding boxes suggest that the box is more likely to be incorrect—it may either not contain any object or fail to properly classify the object it contains. While a high confidence threshold ensures that the generated bounding boxes are generally correct, it can also lead to some correct objects being overlooked, as they might not achieve a high enough confidence score due to insufficient feature learning by the model.
In this study, for the training images, we first apply flipping and scale transformation, followed by inference prediction. Once the model’s prediction results are obtained, they are resized back to their original dimensions, and the results are then aggregated for further selection. In contrast to the approach of lowering the confidence threshold to increase the number of pseudo-labels, which may introduce low-quality pseudo-labels, the proposed method not only ensures that the generated pseudo-labels are more accurate but also facilitates the acquisition of more meaningful pseudo-label information. This allows the network to become more confident during training and amitigates the risk of incorrect learning due to the presence of low-quality pseudo-labels.
3.2.2. Receptive-Field Attention and Local Feature Fusion Module
Xu et al. proposed Efficient Local Attention (ELA) [34], which is designed to overcome issues in existing attention mechanisms, such as the insufficient use of spatial information, information loss caused by reduced channel dimensions, and the high complexity of the attention generation process.
Liu et al. proposed Receptive Field Block (RFB) [35], which simulates the relationship between the receptive field size and eccentricity in the human visual system. It captures multi-scale information by utilizing multi-branch convolutional layers and dilated convolutional layers, thereby enhancing the feature representation capability of lightweight CNN models. Each branch uses kernels of different sizes combined with specific dilation rates to adjust the eccentricity of the receptive field, and the outputs from all branches are concatenated and integrated through a 1 × 1 convolution layer, generating a receptive field configuration similar to that of the human visual system. The RFB module is designed to improve feature discriminability and robustness, and it can be easily integrated into existing CNN architectures, such as the SSD detector, thereby enhancing detection accuracy without adding excessive computational cost.
Liu et al. proposed the receptive-field attention (RFA) mechanism [36] and the corresponding convolution operation RFAConv, which focuses on the receptive field’s spatial features to address the issue of parameter sharing in large convolution kernels. This approach significantly improves network performance with almost no increase in computational cost.
Inspired by these, we designed the Receptive-Field Attention and Local Spatial Feature Fusion Convolution Module (RFEConv). The structure of this module is shown in Figure 5. First, 3 × 3 grouped convolutions are used to quickly extract receptive field features. The normalization and ReLU activation functions are applied to accelerate convergence speed and improve the expressive ability of the network. Next, the generated feature maps are reshaped, and the input feature map is globally average-pooled in both the width and height directions to obtain feature maps in these two directions. A one-dimensional convolution is then applied to process the sequential signals, followed by GroupNorm for normalization. After passing through a sigmoid activation function, local spatial feature weights (w) are obtained. These weights are used to perform a weighted summation on the reshaped feature maps, and finally, a 3 × 3 convolution is applied to generate the output feature map.
RFEConv particularly focuses on the spatial features of the receptive field, not limited to traditional spatial dimensions, enabling the network to more effectively understand and process local regions in images, thereby improving the precision of feature extraction. RFEConv dynamically generates receptive field feature spaces and adaptively adjusts the shape and range of the receptive field according to the size of the convolution kernels, so as to accommodate aquatic organisms of different sizes. A smaller receptive field is generated for smaller aquatic organisms to preserve finer details, while a larger receptive field is generated for larger aquatic organisms to capture global features.
3.2.3. Task-Aligned Lightweight Detection Head Module (TAE)
The detection head in YOLOv8 exhibits certain limitations that impact its efficiency and performance. First, the detection head consists of a considerable number of parameters, accounting for about one-fifth of the model’s total computational load. Specifically, each of the three detection heads includes two 3 × 3 convolutional layers and one 1 × 1 convolutional layer, leading to a notable increase in the parameter count. Second, the original algorithm employs a single-scale prediction strategy, which is inadequate for detecting objects at multiple scales. This approach restricts predictions to a single scale of the feature map, ignoring the valuable contributions of features from other scales that could potentially improve detection performance.
In the context of underwater object detection, where small objects are common, traditional detection methods face significant challenges. A typical single-stage detector uses three detection heads to capture objects at various scales, specifically, large, medium, and small. Among these, the small object detection head is especially crucial for underwater target detection due to the prevalence of small objects. To enhance the detection capability for small objects, this study proposes increasing the number of channels in the small object detection layer. However, this adjustment leads to an increase in both the parameter count and the computational cost of the model.
To mitigate the adverse effects of the increased parameter count and computational load, we introduce a shared convolution mechanism into the detection head structure. This not only reduces the number of parameters in the network but also effectively enhances its generalization ability, as demonstrated by previous research [36]. This technique effectively reduces the overall number of parameters, promotes a sparser network, and improves its translational invariance.
In this paper, a task-aligned structure [37] is designed in the detection head. The feature extractor learns the interaction features of the task from multiple convolutional layers. This design not only facilitates task interaction, but also provides multi-level features and multi-scale effective receptive fields for both tasks. The localization branch uses DCNv2 (Deformable Convolutional Networks v2) [38], an enhanced convolution technique that adaptively modifies the shape of the convolution kernels to more effectively fit the deformation or multi-scale features of the target. DCNv2 introduces biases to achieve dynamic feature extraction, dynamically adapting to each feature extraction location and incorporating weights to express features uniquely at each position. The introduction of DCNv2 into the detection head significantly improves the localization capability of the model. The complete design of the TAE detection head is shown in Figure 6.
The complete workflow of the semi-supervised algorithm proposed in this paper is shown in Algorithm 1.
| Algorithm 1 The semi-supervised algorithm for training SUD-YOLO. |
|
1. Data Preparation: The underwater object detection dataset consists of both labeled and unlabeled data, with a total of samples, where I is the number of labeled samples and J is the number of unlabeled samples, with typically . represents the labeled dataset, and represents the unlabeled dataset. Here, x and y represent the sample images and the annotation boxes, respectively. 2. Pre-training: Use the small labeled dataset to train the model and obtain the M initial supervised model weights. 3. Input: , , and the initial weights M. 4. Output: The final weights file F of the underwater object detection model. 5. Repeat:
6. Until: The model training converges. 7. Return: Weights F. 8. End. |
4. Results
4.1. Evaluation Criteria
This paper integrates the YOLO evaluation metrics [6] with the COCO evaluation metrics [39]. The COCO evaluation metrics are employed for comparative analysis with other models. The evaluation metrics include the number of parameters, floating-point operations (FLOPS), and mean average precision (mAP). To compute mAP, precision and recall need to be calculated first. The formulas for these calculations are provided in Equations (4) and (5).
where denotes the number of true positive samples, denotes the number of false positive samples, and denotes the number of false negative samples.
The main metric in the COCO evaluation [6] is AP (Average Precision), which is the average precision for all object categories and 10 IoU thresholds, ranging from 0.5 to 0.95 with a step size of 0.05. The final mAP is obtained by averaging the AP values across all categories and thresholds, and it is the primary evaluation metric in the COCO challenge. It is worth noting that, although the COCO evaluation also provides other metrics, all AP values refer to mAP.
4.2. Implementation Details
- Experimental EnvironmentThe hardware configuration for this experiment includes an Intel(R) Xeon(R) Platinum 8457C processor and a single L20 GPU. The operating system is Linux, and PyTorch 2.0.1 is used as the deep learning framework, with CUDA version 11.8.
- Experimental Parameter SettingsThe model’s input size is 640 × 640, and the batch size is set to 64. The optimizer is SGD, with an initial learning rate of 0.01, a momentum of 0.937, and a weight decay of 0.0005. The hyper-parameters for semi-supervised learning framework are set as follows: weight of the semi-supervised loss weight, 0.5; pseudo-label’s confidence threshold, 0.5.
4.3. Experimental Results
To verify the effectiveness of the proposed method for underwater object detection tasks, we utilized the DUO dataset, with 10% designated as the labeled dataset and the remaining 90% as the unlabeled dataset. The results are shown in Table 2. The proposed method was compared against state-of-the-art general object detection algorithms and two leading semi-supervised object detection methods. These methods include Faster R-CNN [2], ATSS [40], YOLOv7 [41], YOLOv8, YOLOv9 [42], YOLOv10 [43], YOLOv11 [44], Unbiased Teacher [18], and Efficient Teacher [22].
Table 2.
Comparison with other algorithms on the 10% labeled DUO dataset.
On the 10% labeled DUO dataset, our method outperforms the current state-of-the-art one-stage object detection algorithms. Compared to YOLOv8, our method exceeds by 11.0%, 12.5%, 13.5%, 9.7%, 11.9%, and 9.6% in , , , , , and , respectively. When compared to YOLOv11, our approach achieves improvements of 14.8%, 18.0%, 18.5%, 4.7%, 15.4%, and 14.3% in the same metrics. Additionally, in comparison to YOLOv11, our model surpasses by 11.3%, 12.1%, 14.7%, 8.0%, 12.2%, and 10.4%. From the comparison with YOLOv8, it is evident that our method shows more significant improvements in detecting medium and small objects, indicating that our model is better suited to underwater environments, which are typically filled with a large number of medium and small targets.
Among the three two-stage object detection algorithms, ATSS performs the best. However, our model still outperforms ATSS by 13.1%, 10.7%, 17.9%, 0.5%, 14.6%, and 11.1% in , , , , , and , respectively. The difference in the metric is minimal, suggesting that there is still room for improvement in small object detection performance. For other metrics, our model maintains a clear advantage, and it also has significantly fewer parameters and lower computational cost. Specifically, the computation cost of our model is only 22.2% of that of ATSS.
We conducted a comparison with two general semi-supervised object detection algorithms on the same dataset. One is the Unbiased Teacher, designed for two-stage object detection, and the other is Efficient Teacher, tailored for one-stage detection. Compared to the Unbiased Teacher model, the proposed method achieves improvements of 3.4%, 0.8%, 5.4%, 0.9%, 4.9%, and 1.2% in , , , , , and , respectively. Furthermore, the number of parameters in the proposed model is only 23% that of the Unbiased Teacher, and its computational complexity (FLOPs) is reduced to just 19.6%. This demonstrates that our approach not only retains the advantages in parameter efficiency and computational cost of one-stage algorithms but also significantly enhances detection performance.
In comparison to Efficient Teacher, which is designed for one-stage detection tasks, the proposed model achieves improvements of 9.3%, 8.6%, 12.1%, 8.8%, 10.5%, and 7.2% in , , , , , and , respectively. Efficient Teacher, based on YOLOv5, retains the computational and parameter efficiency of YOLOv5; however, this design inherently limits its overall performance.
To validate the generalization ability of the proposed method, we conducted model comparison experiments on the URPC dataset. Similar to the data partitioning in the DUO dataset, we also selected 10% of the labeled data from the URPC dataset for the experiment. The detailed experimental results are shown in Table 3.
Table 3.
Comparison with other algorithms on the 10% labeled URPC dataset.
In fully supervised methods, compared to our baseline YOLOv8, our approach outperforms it by 4.9%, 6.4%, 6.7%, 1.9%, 4.3%, and 6.4% in , , , , , and , respectively. This demonstrates that our method also yields improvements on other underwater datasets. Compared with semi-supervised methods, our approach surpasses Efficient Teacher by 8.6%, 9.9%, 12%, 5.0%, 8.0%, and 9.4% in , , , , , and , respectively. The results of Efficient Teacher show minimal improvement compared to YOLOv5, indicating poor performance on this dataset. In contrast, the substantial improvements over YOLOv8 demonstrate the effectiveness of our method on this dataset.
On this dataset, our method slightly lags behind Unbiased Teacher, but we outperform it in terms of performance. Despite having only 22% of the parameters and 20% of the computational load of Unbiased Teacher, we achieve comparable experimental results, highlighting that our method is a more favorable choice for devices with limited resources, such as underwater drones.
4.4. Visual Analysis
In this section, we performed a visual experiment to demonstrate the effectiveness of our detection model.
Figure 7 presents the comparison of the detection results between the proposed model and the Efficient Teacher model. The left column shows the original images, the middle column shows the detection results from the Efficient Teacher model, and the right column shows the detection results from the proposed model. The areas where the detection differences between the two models are highlighted are enlarged below the non-original images, with the magnified areas corresponding to the green boxes in the detection images.

Figure 7.
Visual analysis of fully supervised SOTA methods. (a,d) are the original images, (b,e) are the detection results of Efficient Teacher, and (c,f) are the detection results of the proposed method.
Compared to Figure 7b,c, when we zoom in on the darker areas in the image, it becomes apparent that Efficient Teacher failed to detect two starfish and one echinus in the region. In general, our method demonstrates better detection performance. Furthermore, compared to Figure 7e,f, Efficient Teacher missed a significant number of echinuses, especially in the selected zoomed-in areas.
From the experimental results, it is clear that the proposed model performs better than the Efficient Teacher model in both quantitative evaluation metrics and qualitative detection results for underwater object detection tasks.
4.5. Ablation Studies
This section will progressively validate the effectiveness of the key components of the proposed model, specifically analyzing the impact of the following factors on the performance of the underwater object detection model: (1) the impact of different modules on the model; (2) the impact of different pseudo-label filtering thresholds on the model.
Ablation experiments are conducted on the DUO dataset, where 10% of the data are used as labeled data. A total of six network models were validated, and the ablation experiment results are shown in Table 4. The baseline model is a semi-supervised object detection model based on YOLOv8s using the Mean Teacher method.
Table 4.
Ablation experiments on the 10% labeled DUO dataset.
Starting from the baseline model, the RFEConv module was first added, leading to improvements of 1.9% in , 2.5% in , and 2.7% in . Next, the TAE detection head was added, resulting in an increase of 2.7% in , 3.7% in , and 3.8% in . Finally, the multi-scale pseudo-label augmentation module was incorporated, which further improved the performance by 2.2% in , 2.5% in , and 1.8% in .
Ablation experiments on the 10% labeled DUO dataset.
In this ablation study, the baseline model is YOLOv8 equipped with the semi-supervised detection framework proposed in this paper, without any additional modules. The experimental results indicate that, after incorporating the RFEConv module, the model’s performance in detecting medium and large objects is significantly improved. This suggests that the RFEConv module enhances the feature extraction capabilities for larger objects, though it may overlook smaller targets. Upon introducing the TAE module, the model demonstrates a substantial improvement in detecting small and medium-sized objects, with a moderate enhancement in the detection of larger objects. This highlights that the TAE module effectively improves the model’s ability to detect smaller targets, thereby contributing to an overall increase in detection performance. Lastly, the addition of the MPA module further enhances the model’s detection capabilities for large and medium-sized objects, suggesting that MPA facilitates the generation of larger pseudo-labels during the semi-supervised training process. Overall, each module plays a distinct role, and their combined effects have collectively contributed to the superior performance of our method. Table 5 shows the effect of using different thresholds for pseudo-label filtering in the model.
Table 5.
The effect of different thresholds on MPA.
In this study, we selected a threshold of 0.5 for pseudo-label filtering. This threshold was chosen based on extensive experimental evaluations, demonstrating that it strikes a reasonable balance between the quality and quantity of pseudo-labels. Specifically, a lower threshold may introduce too many low-quality pseudo-labels, which could negatively impact the training process and degrade model performance. Conversely, a higher threshold, while ensuring better quality pseudo-labels, significantly reduces the amount of training data available, which compromises the effectiveness of semi-supervised learning. Thus, a threshold of 0.5 serves as an effective compromise, ensuring both high-quality pseudo-labels and sufficient training data.
Although the 0.5 threshold has yielded promising results in our experiments, we acknowledge that it may not be optimal for all datasets and tasks. Future work could explore the implementation of dynamic thresholding strategies that adjust the threshold based on the model’s learning progress and training conditions. For instance, the threshold could be dynamically tuned according to the model’s performance on the validation set or the distribution of pseudo-label confidence, allowing the model to optimize the filtering process based on the evolving training needs. This adaptive thresholding approach holds the potential to further enhance the effectiveness of semi-supervised learning, particularly in cases where data quality and model confidence fluctuate during training.
5. Discussion and Conclusions
This paper proposes a semi-supervised learning algorithm suitable for the YOLOv8 model, effectively addressing the limitations brought about by the scarcity of labeled data. By incorporating a multi-scale pseudo-label module, the quality of the pseudo-labels generated during the semi-supervised training process is further improved, thereby enhancing the reliability of the semi-supervised training. Additionally, the YOLOv8 algorithm is modified to make it more suitable for underwater object detection tasks. The RFEConv module significantly improves the model’s feature extraction ability in underwater images, while the TAE detection head enables the model to effectively detect targets of various scales in underwater environments. Through comparative experiments, the effectiveness of the proposed semi-supervised learning algorithm on YOLOv8 is validated. Ablation experiments were also conducted based on the semi-supervised learning framework. The experimental results show that, on the same dataset, the proposed method achieved an AP of 50.8%, which is an improvement of 11.0% over the fully supervised YOLOv8 algorithm, 12.0% over the fully supervised YOLOv9 algorithm, 14.8% over the fully supervised YOLOv10 algorithm, 11.3% over the fully supervised YOLOv11 algorithm, 9.3% over the semi-supervised Efficient Teacher algorithm, and 3.4% over the semi-supervised Unbiased Teacher algorithm, while requiring only 20% of the computational cost. This demonstrates that the method proposed in this paper is effective for underwater object detection.
In summary, the proposed SUD-YOLO method has made significant strides in underwater object detection, showcasing its exceptional performance in addressing the complex factors of underwater environments. By incorporating semi-supervised learning techniques and carefully designed modular optimizations, we have significantly enhanced the model’s detection accuracy in data-scarce conditions, providing a more reliable and efficient solution for future underwater object detection tasks. For example, in underwater robotics, the ability to accurately and efficiently detect and classify objects in real time can significantly enhance autonomous navigation and task execution, such as underwater exploration, infrastructure inspection (e.g., pipelines and cables), and marine conservation efforts. This not only reduces the reliance on human divers but also ensures safety and cost-effectiveness in various underwater operations. In particular, in applications such as Autonomous Underwater Vehicles (AUVs) and aquaculture monitoring, this method not only improves detection accuracy across various scales of underwater targets but also substantially reduces the cost of manual labeling in practical applications, thereby facilitating the widespread deployment of underwater intelligent systems.
Although our method has demonstrated significant results in various experiments, it still has certain limitations. One notable shortcoming is the lack of pre-training. Pre-training typically leverages large-scale, general-purpose datasets to initialize the model’s weights, which can accelerate the training process and enhance the model’s generalization ability. Without pre-training, our model relies on training from scratch, which may result in suboptimal performance, particularly when there is a scarcity of data or limited training time.
Future work could explore incorporating pretraining strategies into our approach, utilizing expansive, general datasets to initialize the model and then fine-tuning it to improve performance in underwater environments. In addition, pre-training could enable the model to better adapt to diverse datasets, particularly when significant differences exist between datasets. Through transfer learning, the model could quickly adapt to specific tasks and environments, further enhancing detection performance. This could be especially beneficial in tasks where the environmental conditions or data characteristics vary significantly, providing a more robust solution across different domains.
In addition, we plan to further validate its performance in more complex and dynamic underwater environments. These include more challenging scenarios such as deep-sea conditions, underwater structures with intricate topology, and seasonal variations in water quality. Moreover, as the demands of underwater tasks become increasingly diverse, we intend to adapt the existing architecture to better accommodate the variety and complexity of underwater environments.
Furthermore, future research will explore the integration of the SUD-YOLO method with underwater hardware systems, such as Autonomous Underwater Vehicles, unmanned underwater robots, and sonar detection systems, to evaluate its performance in real-world underwater missions. This will not only help verify the practical application potential of the method but also lay a solid foundation for the industrial application of underwater object detection technology.
Author Contributions
Conceptualization, S.X.; methodology, S.X.; software, S.X.; validation, S.X.; formal analysis, S.X.; investigation, S.X.; resources, S.X. and J.W.; data curation, S.X.; writing—original draft preparation, S.X.; writing—review and editing, Q.S. and J.W.; visualization, S.X.; supervision, Q.S. and J.W.; project administration, Q.S. and J.W.; funding acquisition, Q.S. and J.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The dataset used in this paper is provided by a third party and can be accessed at https://github.com/chongweiliu/duo (accessed on 10 April 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Fayaz, S.; Parah, S.A.; Qureshi, G.J. Underwater object detection: Architectures and algorithms—A comprehensive review. Multimed. Tools Appl. 2022, 81, 20871–20916. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 14. [Google Scholar]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A simple and strong anchor-free object detector. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar] [CrossRef] [PubMed]
- Zeng, L.; Sun, B.; Zhu, D. Underwater target detection based on Faster R-CNN and adversarial occlusion network. Eng. Appl. Artif. Intell. 2021, 100, 104190. [Google Scholar] [CrossRef]
- Dulhare, U.N.; Ali, M.H. Underwater human detection using Faster R-CNN with data augmentation. Mater. Today Proc. 2023, 80, 1940–1945. [Google Scholar] [CrossRef]
- Hu, X.; Liu, Y.; Zhao, Z.; Liu, J.; Yang, X.; Sun, C.; Chen, S.; Li, B.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106135. [Google Scholar] [CrossRef]
- Liu, C.-H.; Lin, C.H. Underwater object detection based on enhanced YOLOv4 architecture. Multimed. Tools Appl. 2024, 83, 53759–53783. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Zhou, K.; Zhang, Y.; Chen, H.; Yan, X. An improved YOLOv5-based underwater object-detection framework. Sensors 2023, 23, 3693. [Google Scholar] [CrossRef]
- Song, G.; Chen, W.; Zhou, Q.; Guo, C. Underwater Robot Target Detection Algorithm Based on YOLOv8. Electronics 2024, 13, 3374. [Google Scholar] [CrossRef]
- Zhang, F.; Cao, W.; Gao, J.; Liu, S.; Li, C.; Song, K.; Wang, H. Underwater Object Detection Algorithm Based on an Improved YOLOv8. J. Mar. Sci. Eng. 2024, 12, 1991. [Google Scholar] [CrossRef]
- Liu, L.; Hua, Y.; Zhao, Q.; Huang, H.; Bovik, A.C. Blind Image Quality Assessment by Relative Gradient Statistics and AdaBoosting Neural Network. Signal Process. Image Commun. 2016, 40, 1–15. [Google Scholar] [CrossRef]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Jeong, J.; Lee, S.; Lee, J.; Park, H. Consistency-Based Semi-Supervised Learning for Object Detection. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Liu, Y.C.; Ma, C.Y.; Kira, Z. Unbiased teacher v2: Semi-supervised object detection for anchor-free and anchor-based detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022; pp. 9819–9828. [Google Scholar]
- Sohn, K.; Kim, Y.; Lee, D.; Kim, H.; Yoo, J. A Simple Semi-Supervised Learning Framework for Object Detection. arXiv 2020, arXiv:2005.04757. [Google Scholar]
- Liu, Y.-C.; Chen, C.-H.; Chou, C.-P. Unbiased Teacher for Semi-Supervised Object Detection. arXiv 2021, arXiv:2102.09480. [Google Scholar]
- Xu, M.; Zhang, Z.; Hu, H.; Wang, J.; Wang, L.; Wei, F.; Bai, X.; Liu, Z. End-to-End Semi-Supervised Object Detection with Soft Teacher. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Xu, B.; Chen, M.; Guan, W.; Hu, L. Efficient Teacher: Semi-Supervised Object Detection for YOLOv5. arXiv 2023, arXiv:2302.07577. [Google Scholar]
- Tang, Y.; Chen, W.; Luo, Y.; Zhang, Y. Humble Teachers Teach Better Students for Semi-Supervised Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Liu, L.; Zhang, B.; Zhang, J.; Zhang, W.; Gan, Z.; Tian, G.; Zhu, W.; Wang, Y.; Wang, C. MixTeacher: Mining Promising Labels with Mixed Scale Teacher for Semi-Supervised Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Zhou, H.; Ge, Z.; Liu, S.; Mao, W.; Li, Z.; Yu, H.; Sun, J. Dense Teacher: Dense Pseudo-Labels for Semi-supervised Object Detection. arXiv 2022, arXiv:2207.02541. [Google Scholar]
- Zhang, J.; Lin, X.; Zhang, W.; Wang, K.; Tan, X.; Han, J.; Ding, E.; Wang, J.; Li, G. Semi-DETR: Semi-Supervised Object Detection with Detection Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Mahmood, A.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F.; Hovey, R.; Kendrick, G.; Fisher, R.B. Coral Classification with Hybrid Feature Representations. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 519–523. [Google Scholar]
- Mahmood, A.; Bennamoun, M.; An, S.; Sohel, F.A.; Boussaid, F.; Hovey, R.; Kendrick, G.A.; Fisher, R.B. Deep Image Representations for Coral Image Classification. IEEE J. Ocean. Eng. 2018, 44, 121–131. [Google Scholar] [CrossRef]
- Hu, K.; Lu, F.; Lu, M.; Deng, Z.; Liu, Y. A Marine Object Detection Algorithm Based on SSD and Feature Enhancement. Complexity 2020, 2020, 5476142. [Google Scholar] [CrossRef]
- Chen, L.; Liu, Z.; Tong, L.; Jiang, Z.; Wang, S.; Dong, J.; Zhou, H. Underwater Object Detection Using Invert Multi-Class Adaboost with Deep Learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: New York, NY, USA, 2020; pp. 1–8. [Google Scholar]
- Liu, C.; Li, H.; Wang, S.; Zhu, M.; Wang, D.; Fan, X.; Wang, Z. A dataset and benchmark of underwater object detection for robot picking. In Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Lin, J.; Lin, H.; Wang, F. A Semi-Supervised Method for Real-Time Forest Fire Detection Algorithm Based on Adaptively Spatial Feature Fusion. Forests 2023, 14, 361. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Xu, W.; Wan, Y. ELA: Efficient Local Attention for Deep Convolutional Neural Networks. arXiv 2024, arXiv:2403.01123. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, X.; Liu, C.; Yang, D.; Song, T.; Ye, Y.; Li, K.; Song, Y. RFAConv: Innovating spatial attention and standard convolutional operation. arXiv 2023, arXiv:2304.03198. [Google Scholar]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. Tood: Task-aligned One-Stage Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; IEEE Computer Society: New York, NY, USA, 2021. [Google Scholar]
- Wang, R.; Shivanna, R.; Cheng, D.Z.; Jain, S.; Lin, D.; Hong, L.; Chi, E.H. DCN v2: Improved Deep & Cross Network and Practical Lessons for Web-Scale Learning to Rank Systems. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: New York, NY, USA, 2014; pp. 740–755. [Google Scholar] [CrossRef]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the Gap Between Anchor-Based and Anchor-Free Detection via Adaptive Training Sample Selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: New York, NY, USA, 2020. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. In Proceedings of the European Conference on Computer Vision, London, UK, 15–16 January 2025; Springer: Cham, Switzerland, 2025. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).