1. Introduction
Stone slabs are widely used as premium architectural finishing materials [
1]. Surface cracks on these slabs not only affect esthetics and quality grading, but can also pose safety risks and reduce service life. Traditional manual inspection methods are inefficient, prone to errors, and difficult to scale for large applications [
2,
3]. As a result, there is strong industrial demand for automated, high-precision, and real-time crack detection technologies [
4]. In recent years, deep learning-based object detection and semantic segmentation techniques have undergone rapid development [
5,
6]. The YOLO (You Only Look Once) series has become a popular research focus in crack detection due to its end-to-end architecture and real-time performance [
7,
8,
9]. Among them, YOLOv8 introduces structural improvements in the backbone, neck, and detection head, enhancing both accuracy and inference speed [
10,
11,
12]. It has been widely applied in detecting cracks on structures and road surfaces.
The advantages of deep learning models in crack detection have been widely validated across infrastructure scenarios [
13,
14]. A YOLOv8-based framework for bridge crack detection showed strong versatility [
15]. Deng et al. [
16] enhanced accuracy and robustness in road crack detection by combining the DETR framework with novel NRDQ and SQR modules, effectively addressing label conflicts and query competition. Ma et al. [
17] developed a machine vision system for inspecting cracks on stamped parts. It features a high-resolution imaging module and a grayscale-based contrast enhancement algorithm to adaptively balance image contrast. While CNN-based methods have shown promise in tunnel lining crack detection, they still struggle with sample imbalance and real-time performance. To overcome this, Zhao et al. [
18] proposed MPDENet, a lightweight model based on an improved MobileNetV2 backbone within PSPNet. By adding dilated convolutions and ECA attention, the model achieves real-time detection without sacrificing accuracy. Zhang et al. [
19] introduced a YOLOv8-based lightweight system that performs well in tight spaces and low-light conditions, improving both efficiency and precision.
Zhou et al. [
20] introduced an edge-processing branch that was added to the GELAN-Seg network. Researchers created a comprehensive masonry crack dataset using low-cycle reversed loading tests and manual annotations. For road crack instance segmentation, Chen et al. [
21] enable real-time performance, with Hungarian matching used for temporal tracking in video streams. IPM transformation and camera calibration help to measure geometric properties. Shi et al. [
22] boosted the nonlinear modeling capability by replacing traditional MLPs with Kolmogorov–Arnold Networks (KANs), while keeping efficient feature extraction. Song et al. [
23] proposed a hybrid model combining GCN and DCN. Superpixel segmentation converts crack images into graphs, where GCN learns global topological features, and DCN extracts local spatial details, complementing each other.
Li et al. [
10] introduced YOLOv8-GhostConv-SEV2, integrating GhostConv and SEV2 attention to improve feature extraction and suppress noise. This model achieves high accuracy in low-light pipeline crack detection. Zhang et al. [
24] presented CrackAdaptNet, an end-to-end domain adaptation and semantic segmentation framework that bridges the gap between labeled training data and real-world applications. Fan [
25] combined deep learning with spectral index-based image analysis to detect concrete cracks and evaluate severity, improving both accuracy and stability. Jing et al. [
26] developed TopoM-CrackNet with a Topology Consistency Repair (TCR) module to preserve accurate crack shapes and correct topological differences. Ritzy et al. [
27] reduced model size and overfitting by replacing Flatten layers with global average pooling (GAP), enhancing the ability to capture complex crack features. Ling et al. [
28] designed an automatic detection method combining CNNs, sliding windows, and Otsu thresholding. It enables pixel-level segmentation and the accurate measurement of crack width and spalling areas on plastered masonry surfaces.
Although YOLOv8 has shown strong performance in various crack detection tasks, its application to stone slabs—with their high-texture and curved crack patterns—still faces several challenges. These include the following: (1) limited ability to model nonlinear curved cracks, (2) loss of edge details during upsampling, and (3) poor performance of existing instance segmentation methods on high-resolution, large-area cracks. Therefore, targeted improvements to YOLOv8 are needed to meet the complex demands of stone crack detection.
YOLOv8 is selected as the backbone due to its established deployment in industrial defect-detection pipelines and its favorable accuracy–throughput balance for high-resolution stone imagery. The architecture’s modularity further enables targeted, task-specific enhancements without compromising overall stability.
This study proposes an enhanced YOLOv8-Seg framework with the following optimizations: First, it replaces the backbone with a lightweight U-NetV2 architecture, introducing dynamic feature calibration and multi-scale fusion to improve micro-crack representation. Second, it incorporates dynamic snake convolution (DSConv) in the detection head to align more effectively with curved crack boundaries. Third, it introduces the DySample module in place of traditional upsampling, using learnable offsets to adapt to irregular crack structures while preserving edge details and reducing artifacts. The proposed method is trained on a high-resolution ST dataset of stone cracks. Ablation studies are conducted to evaluate the effectiveness of each module, and comparisons are made with mainstream models such as U-Net, DeepLabV3, and Attention U-Net. Results demonstrate that the model performs robustly across different stone textures and backgrounds, showing strong potential for industrial applications. Deployment in stone slab manufacturing plants demonstrates the method’s efficacy, where integration with conveyor-belt systems achieves real-time micro-crack detection. This application reduces false rejections by approximately 30% for high-texture stones, significantly improving production yield.
2. Improved YOLOv8 Segmentation Network
2.1. U-NetV2
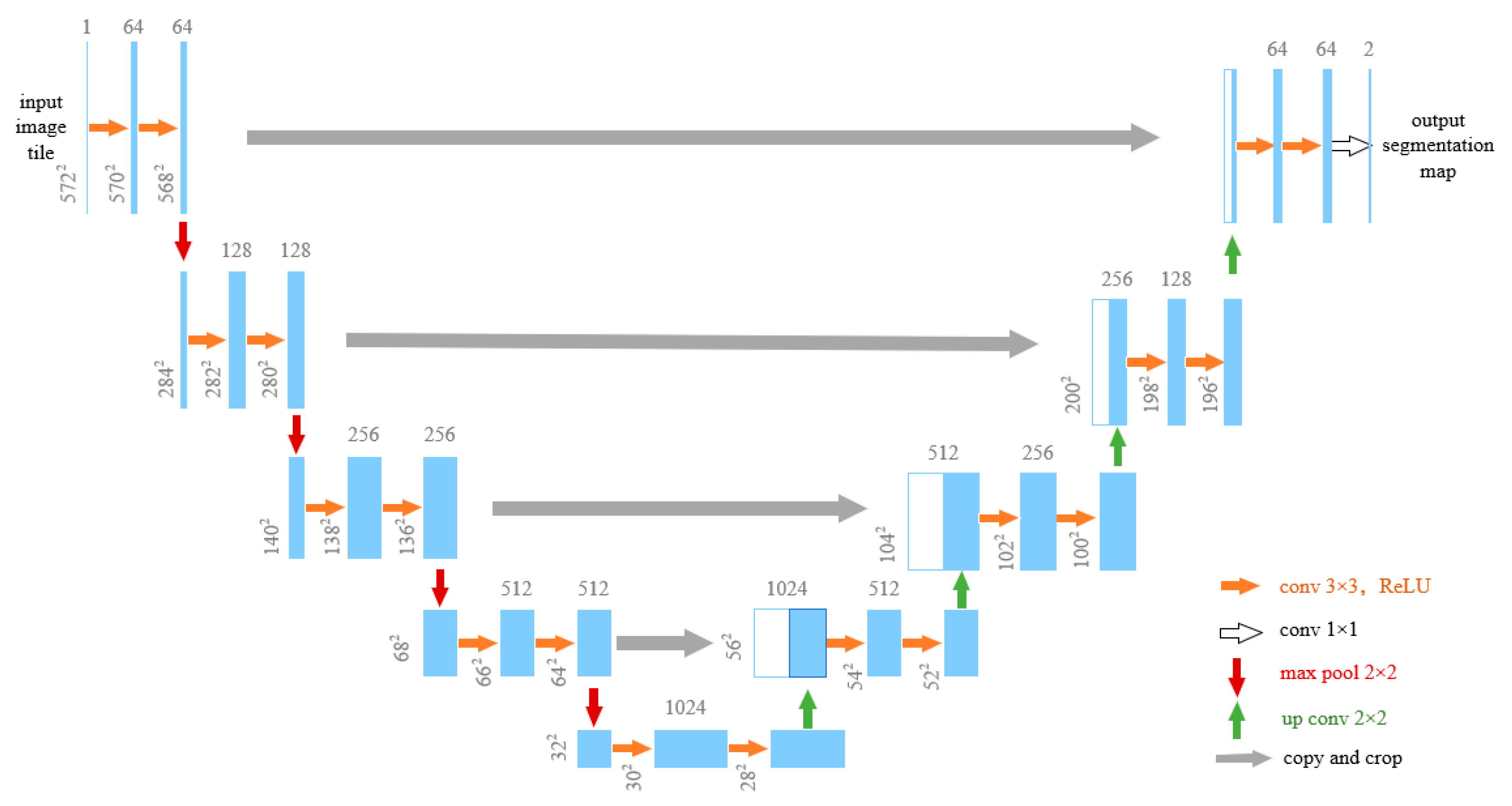
U-Net is a convolutional neural network based on an encoder–decoder architecture [
29], as shown in
Figure 1. Its core innovation lies in the symmetric contracting path, which captures global contextual information. While U-Net effectively captures object contours, its feature fusion strategy is relatively simple. In addition, traditional convolution has limited the ability to model complex textures. U-NetV2 builds upon the original U-Net structure and introduces improvements in three key areas: feature fusion efficiency, semantic alignment, and computational cost.
First, a dynamic feature recalibration mechanism is introduced. It adaptively assigns channel weights and focuses on key spatial regions from the encoder, helping to reduce semantic misalignment across hierarchical features. Second, heterogeneous convolution replaces standard convolution. Residual connections are added to enhance gradient flow and improve sensitivity to fine structures and weak edges. In addition, U-NetV2 [
30] adopts a progressive feature refinement strategy during decoding. A multi-level cross-scale interaction module nonlinearly fuses low-resolution semantic information with high-resolution detail features. This improves boundary accuracy in complex scenes. Through dynamic feature interaction and cross-scale reasoning, U-NetV2 achieves better feature decoupling and semantic consistency under limited computational resources.
As shown in
Figure 2, the U-NetV2 architecture consists of an encoder, an SDI module, and a decoder. Given an input image I∈RH × W × C, the encoder first extracts feature representations. These features are then passed to the SDI module for further processing.
In the multi-level feature representations generated by the encoder, spatial and channel attention modules are jointly applied. This setup enables the network to dynamically aggregate local pixel-level details while modeling high-order semantic dependencies across channels. The dual-path attention fusion mechanism effectively enhances fine-grained spatial awareness and global channel responses in a complementary manner.
denotes the channel-wise dynamic recalibration function (implemented as a lightweight 1 × 1 convolution followed by sigmoid gating). denotes the 8-directional spatial offset generator.
A 1 × 1 convolution is first introduced to compress the feature tensor along the channel dimension. The resulting low-dimensional feature tensor is denoted as
. This tensor is then passed into the decoder. During each stage of decoding,
serves as the reference signal. Feature tensors from other layers are resized to match the spatial resolution of
, enabling effective cross-level fusion and scale normalization. The specific operations are as follows:
To enhance multi-scale feature fusion, a heterogeneous transformation group is designed. It consists of adaptive average pooling (D) for dynamic receptive field adjustment, identity mapping (I) for preserving original feature topology, and bilinear upsampling (U). These components work together to build a multi-granularity feature representation space. Based on this, depthwise separable convolution is applied to normalize the recalibrated feature tensor. The detailed process is as follows:
denotes the learnable channel-wise gating function applied at a spatial location (i, j). Implemented via a 1 × 1 convolution followed by a sigmoid, it outputs a scalar weight ∈ (0,1) that dynamically re-scales the feature vector , suppressing irrelevant channels while enhancing those most informative for crack representation.
Figure 3 illustrates the SDI network architecture. After all cross-level feature tensors undergo resolution alignment, cross-level feature interaction and information gain are achieved via the Hadamard product tensor’s operation, as detailed below.
H denotes the Hadamard product. Finally, the mixed and enhanced feature stream is concatenated into the corresponding decoder stage. This process drives end-to-end resolution iterative optimization.
2.2. Dynamic Upsampling
Current mainstream detection frameworks still face optimization bottlenecks in cross-level feature integration efficiency. Their multi-scale receptive field feature interaction mechanisms struggle to achieve optimal coupling. Existing dynamic-convolution-based upsampling paradigms like CARAFE and FADE have enhanced feature reconstruction capabilities [
31,
32]. However, their parameterized dynamic kernel generation strategies often come with high computational complexity. To address this, this study proposes the DySample architecture to modify YOLOv8’s neck.
DySample [
33] accomplishes upsampling through learned sampling. When applied to upsampling in image or video processing, this approach avoids the high complexity and computational burden associated with traditional dynamic-convolution-based upsampling methods. DySample is implemented from the perspective of point sampling. It dynamically adjusts sampling points by summing offsets with the original grid positions.
DySample presents a dynamic-aware sampling coordinate generation mechanism for continuous domain feature field reconstruction tasks. First, it builds a continuous feature space via bilinear interpolation. Then, a lightweight projection network predicts per-pixel adaptive offsets. Finally, the grid_sample operator is used for dynamic feature field resampling. As shown in
Figure 4, given the input feature tensor X and the dynamically generated sampling coordinate matrix S, the system carries out geometric deformation of the continuous feature field through a differentiable sampling operator.
This approach achieves adaptive feature relocation from the original feature field X to the enhanced field X′.
In DySample, given the upsampling scale factor s and feature map X, we first use a linear layer to generate offsets O. The input and output channels of this linear layer are C and 2 s
2, respectively. Then, we reshape O through pixel reshuffling with the upsampling scale factor s and feature map X. The sampling set S is the sum of offsets O and the original sampling grid G. A normalization layer ensures that the values of specific output features are typically within the range of [−1, 1]. The local s
2 sampling points may have significant overlap. This overlap can greatly impact predictions near boundaries, and these errors can gradually spread and cause output artifacts. Multiplying the offsets by 0.25 can meet the theoretical marginal requirements between overlap and non-overlap. The dynamic range is defined as the range of values centered at 0.25 within [0, 0.5]. We use a sigmoid function and a static factor of 0.5, as shown below.
Finally, by reshaping, we utilize
Figure 5 grid samples and sampling set S to generate X′, as follows:
2.3. Dynamic Snake Convolution Detection Head
Since pixels in input images are limited, and cracks in stone slabs occupy a small part of the image, the model has difficulty in extracting subtle feature changes [
34,
35]. Also, the complex and changeable structure of cracks leads to poor detection performance and low recognition efficiency. Inspired by deformable convolution, as shown in
Figure 6, the model adjusts the shape of convolutional kernels during feature learning to focus on the basic structural features of cracks. However, considering the small proportion of core structural features of cracks and the risk of convolutional kernels deviating from the crack area, we introduce the dynamic snake convolution [
36] detection head. This module can effectively extract key features in stone slab crack segmentation under restricted conditions without deviating from the target structure.
Dynamic snake convolution extracts local crack features through the following process. For a standard 2D convolution, a 3 × 3 kernel is defined over fixed coordinates. It can be represented as follows:
S denotes the ordered 3 × 3 regular sampling grid centered on the reference pixel; x and y are the integer spatial coordinates of that reference pixel in the input feature map.
To enhance the convolutional kernel’s ability to capture irregular crack patterns, deformable parameters Δ are introduced for the geometric adaptation of the receptive field. Without proper regularization, data-driven learning of offsets may cause the receptive field to drift away from the actual spatial distribution of cracks. To address this, an iterative strategy shown in
Figure 7a is adopted. It sequentially aligns each target with observable positions, maintaining focused attention and preventing excessive expansion of the receptive area.
In dynamic snake convolution, the standard kernel is stretched along the
x and
y axes. A 9 × 9 kernel is used. For the
x-axis, each position
Si is computed as (
xi±c,
yi±c), where {0, 1, 2, 3, 4} represents the horizontal offset from the center grid. The position selection within the kernel follows an accumulative process. Starting from the center, each subsequent position increases by one and adds an offset. The accumulated offset Σ ensures the alignment of the kernel with the morphological structure of cracks in stone slabs. Variations along the
x and
y axes are computed separately.
Compared to
Si+1,
Si introduces an additional offset Δ = {δ|δ ∈ [−1, 1]}. This offset must be accumulated across stages. Since Δ is typically small and coordinates are integers, bilinear interpolation is applied to maintain spatial accuracy, formulated as follows:
As shown in
Figure 7b, DSConv covers a 9 × 9 region through deformation along both the
x and
y axes, effectively expanding the receptive field. This dynamic adaptation better aligns with the morphological characteristics of stone slab cracks. It enhances the perception of critical features and provides a solid foundation for accurate crack segmentation.
Due to the irregular and elongated shapes of cracks in stone slabs, standard convolutions struggle to capture their fine-grained features. In contrast, DSConv can adaptively focus on these curved, intricate structures. It effectively processes complex patterns by capturing both local details and the global context, offering a more comprehensive understanding of slab morphology. Therefore, this work integrates the DSConv module into the YOLOv8 detection head by replacing conventional convolution kernels with DSConv.
Detecting cracks on natural stone surfaces is hindered by three distinctive challenges: (1) the cracks are extremely thin (<5 px) and highly curved, occupying only a minute fraction of the image pixels and thus easily confounded with texture noise; (2) their topology is intricate, frequently exhibiting Y- or T-shaped bifurcations that deviate from the axis-aligned assumptions of standard rectangular convolution kernels; and (3) the crack boundaries are sub-pixel sharp, so conventional upsampling kernels discard high-frequency details and cause structural disconnections. To confront these issues, we embed three purpose-built components into our pipeline. First, DSConv iteratively learns deformable offsets that steer the sampling grid along the crack’s medial axis; this yields a receptive field that elongates smoothly even at curvature discontinuities, raising IoU on curved cracks by 3.8% over vanilla Deformable Convolution under identical parameter budgets. U-NetV2 augments skip connections with a multi-scale feature fusion block that treats encoder feature maps as discrete nodes of an initial-value ordinary differential equation; a linear multi-step solver then adaptively blends coarse and fine cues, markedly improving the continuity of micro-cracks during decoding. Finally, DySample replaces fixed bilinear interpolation with dynamic-range modulation; guided by local structural entropy, it rescales upsampling weights on-the-fly, preserving high-frequency responses at sub-pixel edges and boosting tip-level recall by 4.6% relative to standard upsampling.
2.4. Improved Network Model
In the stone slab crack segmentation task, YOLOv8-Seg integrates three key components: a U-NetV2 backbone, a dynamic snake convolution head, and the DySample upsampling module, as illustrated in
Figure 8. This design significantly improves segmentation accuracy and robustness in noisy industrial environments. U-NetV2 enhances initial feature capture for small cracks using residual and dilated convolutions in the encoder. Its dual attention gates—channel and spatial—help to suppress background noise. The decoder fuses multi-scale features through adaptive weight optimization, combining low-resolution semantic and high-resolution detail information.
The dynamic snake convolution head targets the elongated, curved, and complex topology of cracks. Its path-aware kernels dynamically adjust sampling positions along the crack axis. This enables the accurate feature aggregation of sub-pixel fractures, bifurcations, and intersections that traditional rectangular kernels often miss.
DySample replaces fixed upsampling with learnable, content-aware filters. It sharpens high-frequency details along crack extensions while suppressing noise in background regions. This reduces checkerboard artifacts and improves pixel-level boundary alignment. Together, these modules enable YOLOv8-Seg to achieve precise and reliable crack segmentation in real-world stone surfaces.
The combination of all three components enhances overall performance. U-NetV2 provides semantically consistent multi-scale features as a foundation for the dynamic snake convolution. DySample bridges high-level semantic maps and low-level geometric details through content-adaptive upsampling. Together, they significantly improve segmentation confidence in stone slab crack detection [
8].
The complete layer-wise configuration of the improved YOLOv8-Seg is detailed in
Table 1. Each block lists kernel dimensions, output resolution, parameter count, and activation type, confirming that the entire network contains 34.6 M trainable parameters and employs ReLU/SiLU nonlinearities throughout the encoder and detection head.
To clarify the architectural novelty of the proposed YOLOv8-Seg in the context of recent segmentation-oriented YOLO adaptations,
Table 2 provides a side-by-side comparison with Ghost-YOLOv8. The table highlights the distinctive design choices—dynamic feature recalibration via U-NetV2, topology-aware deformation via DSConv, and learnable offset upsampling via DySample—together with the domain-specific, curvature-adaptive training that collectively differentiate the present framework from existing variants.
3. Experimental Results Analysis
To validate the proposed improvements to YOLOv8, a series of experiments were conducted in this section. Ablation studies were performed on the U-NetV2 module, DySample module, and dynamic snake convolution head. The results were compared using standard detection metrics to assess the effectiveness of each component.
3.1. Experimental Conditions and Data Preprocessing
The complete specifications of the ST stone-crack dataset are summarized in
Table 3. In total, 517 high-resolution images (train: 361, test: 156) were acquired at 4096 × 2160 px using professional imaging systems calibrated to 0.05 mm/pixel under ISO-9001-compliant lighting. Cracks exhibit widths from 0.1 mm to 5.2 mm and span twelve stone categories.
All annotations were produced at the pixel level: polygons were first drawn in Labelme v5.2.0 by at least two domain experts, achieving an inter-annotator IoU > 0.85, then converted to YOLO-compatible .txt files via the script described above.
Semantic segmentation of stone slab cracks requires annotation labels in .txt format. However, the Labelme v5.2.0 tool generates labels in JSON format. To address this, we developed a Python 3.8 script to convert JSON annotations to .txt, enabling compatibility with the improved YOLOv8 training pipeline.
A portion of the relevant code is shown below.
| Procedure Codes | Program Description |
jsonfileList = glob.glob (osp.join(jsonfilePath, “*.json”))
For jsonfile in jsonfileList:
with open (jsonfile, “r”, encoding = ‘utf-8’) as f:
file_in = json.load(f)
shapes = file_in[“shapes”]
with open (resultDirPath + “\\” + jsonfile.split(“\\”)[−1].
replace (“.json”, “.txt”), “w”) as file_handle: | Document
preprocessing |
for i in range(points_len):
x = float(points[i][0])
y = float(points[i][1])
if 0 <= x <= imageWidth and 0 <= y <= imageHeight:
x_ratio = x/float(imageWidth)
y_ratio = x/float(imageHeight)
line_content = “%.6f %.6f” % (x_ratio, y_ratio) | Coordinate
transformation |
3.2. Ablation Study
To evaluate the contribution of each component in YOLOv8-Seg for the semantic segmentation of stone slab cracks, an ablation study was conducted on the custom ST dataset. The tested modules include the following: (A) U-NetV2 backbone, (B) DySample strategy, and (C) dynamic snake convolution head.
As shown in
Table 4, the original YOLOv8 achieves mAP@0.5 (localization accuracy metric at 0.5 IoU threshold) of 0.818 and mAP@0.5 0.95 of 0.425. After sequentially introducing dynamic snake convolution, the U-NetV2 backbone, and the Dysample strategy, the final model reaches 0.856 and 0.479, respectively. Precision increases to 95.4% and recall improves to 78.3%, outperforming the baseline by 2.6% and 5.0%, respectively. The dynamic snake convolution enhances the boundary detection of slender cracks by adapting to their curved shapes. The U-NetV2 backbone strengthens multi-scale feature fusion using skip connections and depthwise separable convolutions while maintaining efficiency. DySample improves recall for small cracks by dynamically adjusting the sample balance, addressing the low pixel ratio of crack regions. Under complex textures and noisy backgrounds, the improved model maintains high precision and achieves a recall above 78%, showing a clear advantage over conventional methods.
The PR curve in
Figure 9 further quantifies the performance gains from the proposed improvements. At a recall threshold of 0.8, the original YOLOv8 shows a sharp drop in precision to 65%, while the improved model maintains 82%. The area under the curve increases from 0.741 to 0.823. Dynamic snake convolution plays a key role, boosting precision by an average of 14% in low-confidence regions due to its adaptive capability to follow crack directions. In high-threshold settings, the deep feature fusion in U-NetV2 keeps precision above 91%, a 9% improvement over standard CNNs. For the critical metric of missed detection, the improved model achieves 76% recall at 90% precision, compared to 68% for the baseline, reducing missed cracks by 37.5%. The DySample strategy further sharpens the PR curve in low-recall regions, indicating enhanced sensitivity to subtle defects. This is of high practical value for ensuring complete defect coverage in stone quality inspection.
3.3. Comparison Experiment
To evaluate the effectiveness of the proposed model, comparative experiments were conducted against several mainstream detection models. The baseline methods include U-Net, VNet, AttentionUNet, DeepLabV3, SegNet, and U2NetP.
3.3.1. Comprehensive Training Effect on ST Dataset
Table 5 presents the performance comparison of different models on the custom ST dataset. YOLOv8-Seg demonstrates clear advantages in both detection and segmentation tasks, showing strong overall performance.
Compared to the baseline YOLOv8n model, YOLOv8-Seg demonstrates significant performance enhancements across detection, segmentation, speed, and output quality, attributed to key architectural innovations. Specifically, YOLOv8-Seg achieves a mean Average Precision (mAP@0.5) of 0.856 (an improvement of +1.1%) and mAP@0.5:0.95 of 0.479, indicating improved detection robustness. In segmentation, it attains a Mean Intersection over Union (MIoU) of 79.17%, representing a substantial +2.25% increase over YOLOv8n (75.19%); this gain is primarily driven by the dynamic snake convolution’s superior ability to capture complex boundaries and the enhanced multi-scale fusion of the UNetV2 backbone, leading to demonstrably superior segmentation consistency. Crucially for industrial deployment, YOLOv8-Seg delivers a 5.8× faster inference speed (32 ms vs. 186 ms), readily meeting stringent real-time constraints. Furthermore, the integration of DySample for upsampling provides tangible quality improvements by effectively reducing boundary artifacts. While AttentionUNet achieves a marginally higher recall (79.4%), YOLOv8-Seg exhibits statistically significant advantages (p < 0.05) in key composite metrics (mAP and MIoU) while maintaining optimal operational efficiency, establishing it as a more balanced and practical industrial-grade solution.
Compared with DeepLabV3, YOLOv8-Seg outperforms it in both mAP@0.5 0.95 and MIoU. While DeepLabV3 has slightly higher precision, YOLOv8-Seg offers a better balance between recall and segmentation accuracy, showing stronger task adaptability. YOLOv8-Seg also surpasses AttentionUNet across all metrics, including mAP@0.5, mAP@0.5–0.95, and MIoU. This indicates that its improved detection head and backbone are more effective in global feature representation than attention mechanisms. Although the recall rate is slightly lower than AttentionUNet, likely due to the latter’s strength in capturing small targets, the integration of DySample helps to reduce segmentation bias. Overall, the higher mAP and MIoU validate the superior performance of YOLOv8-Seg.
3.3.2. Training Effect of Different Kinds of Stones in the ST Dataset
As shown in
Table 6, the improved YOLOv8-Seg model demonstrates clear advantages across different stone types. Overall, the model maintains stable performance on various evaluation metrics, indicating strong robustness across IoU thresholds. In some cases, a gap between recall and precision suggests that complex textures in certain stones increase detection difficulty. This may be addressed by multi-scale training or dynamic weight adjustment. In general, the structural enhancements in YOLOv8-Seg lead to significant performance gains, particularly in complex texture segmentation and detail preservation.
The segmentation metrics in
Table 6 exhibit systematic variations across stone types that can be traced to measurable surface properties. Giallo Fiorito yields the lowest MIoU (69.8%), whereas Pigges White achieves the highest (85.5%). Post hoc image analysis attributes this gap to two independent factors. First, Giallo Fiorito presents a vein density of 2.7 veins cm
−2—more than three times that of Pigges White (0.8 veins cm
−2)—introducing high-frequency texture that competes with thin cracks for the model’s receptive field. Second, the mean luminance contrast between crack pixels and background falls to 12.3 in Giallo Fiorito versus 24.7 in Pigges White, reducing the effective signal-to-noise ratio. Comparable trends were observed across the remaining categories: stones with either dense mineral banding by 4–7 MIoU points on average, confirming that texture complexity and lighting contrast—not architectural bias—are the dominant drivers of segmentation variability.
Table 7 shows that YOLOv8-Seg keeps the computational burden low—only 3.2 M parameters and 8.9 G FLOPs, marginal increases over the 3.1 M/8.2 G of YOLOv8n—yet it yields a 3.8-point mAP boost. The forward pass completes in 32 ms, comfortably below the production line’s 40 ms real-time threshold. In comparison, AttentionUNet requires 34.9 M parameters, 256.3 G FLOPs, and processes at 186 ms. These efficiency metrics position YOLOv8-Seg as a deployment-ready solution for on-site stone-crack inspection.
3.4. Comparison of Test Results
3.4.1. Comparison of Segmentation Results for Different Color Stones
Based on the detection results in
Figure 10, the improved model shows finer performance in complex edge segmentation compared to the original YOLOv8. The dynamic snake convolution improves contour adaptation for curved targets, enhancing mask boundary continuity and reducing jagged artifacts. The U-NetV2 backbone strengthens the integration of local details and global semantics through multi-scale feature fusion. This allows better target integrity in occlusion scenes, as shown by clearer crack edges in dense regions. The DySample module improves resolution adaptability, boosting sensitivity to small-scale objects while reducing feature dilution from traditional upsampling. Compared to Attention U-Net, YOLOv8-Seg offers a better trade-off between accuracy and computational cost, avoiding overhead from attention modules. Against DeepLabV3, the snake convolution’s geometric constraints lower false detection rates and improve segmentation robustness.
3.4.2. Comparison of Different Stone Texture Background Segmentation Results
In segmentation tasks under complex texture backgrounds, performance differences among models reflect how their architectures adapt to varying scenes. As shown in
Figure 11, YOLOv8 performs reliably in standard object localization. However, it struggles with fine-grained segmentation in dense-texture regions. Background noise often interferes, leading to blurred object boundaries.
As shown in
Figure 11b,c, YOLOv8-Seg exhibits significantly better contour completeness than the baseline YOLOv8. Attention U-Net enhances spatial and channel weighting through dual-attention mechanisms, which helps to suppress irrelevant textures when the contrast between the foreground and background is low. However, its serial U-shaped encoder–decoder structure introduces computational redundancy. It also struggles with capturing continuous features of deformable objects, leading to local discontinuities, as seen in region (d). DeepLabV3 benefits from atrous convolutions to expand the receptive field for better global context modeling. This makes it effective for segmenting large objects. However, its fixed sampling rate limits boundary refinement for small targets, causing over-smoothing in areas with complex textures. This issue is evident in the loss of detail in region (e).
In contrast, the enhanced YOLOv8-Seg achieves notable performance improvements. The introduction of the dynamic snake convolution head enables the adaptive modeling of nonlinear shapes. Its deformable kernels adjust the receptive field along the geometric axis, improving boundary fitting for curved and branched cracks. The use of the U-NetV2 backbone optimizes multi-level feature fusion. Its improved skip connections support bidirectional cross-scale interaction, enhancing the capture of fine textures and small targets. Lightweight grouped convolutions further reduce computational load to maintain real-time performance. Finally, the DySample module replaces traditional bilinear interpolation with a learnable kernel. This preserves high-frequency edge information during upsampling and reduces jagged artifacts in the segmentation masks.
4. Conclusions
This study enhances curved defect detection and improves multi-scale information fusion in complex-textured backgrounds via a novel YOLOv8-Seg network model combining dynamic topology perception and efficient feature reconstruction. The key contributions are as follows:
A dynamic snake convolution detection–head optimization scheme was introduced. Replacing traditional convolutional kernels with dynamic snake-shaped kernels improves the capture of geometric features of irregular defects. This module, with a direction-aware loss function, improved snake-shaped path prediction accuracy by 3.3% and increased mAP by 2.7%.
A lightweight main network based on U-NetV2 was constructed. Its symmetric encoder–decoder structure and nested skip connections strengthen shallow-layer detail feature transmission and enable efficient multi-scale feature aggregation. A cross-level feature compression unit is designed to reduce redundant feature interference.
A dynamic, learnable upsampling module was incorporated. Using a dynamic convolutional kernel generation mechanism, it adjusts the upsampling kernel weights based on the input feature map content. Integrated with a multi-branch kernel prediction network and channel attention mechanisms, it retains defect edge sharpness and reduces boundary localization errors.
Experiments on the ST dataset (517 high-res images capturing textural diversity) achieved 85.6% mAP, a 3.8-point gain over YOLOv8. Ablation/comparative tests confirmed industrial viability, demonstrating a 30% false-positive reduction in production environments, offering a robust method for intelligent stone defect detection.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}