1. Introduction
Large-scale music generation models [
1,
2,
3] can convert text or audio inputs into musical compositions, expanding music creation possibilities. These models provide a streamlined way to explore and produce music, making the process more accessible to a wide range of users.
Some music generation models generate audio output based on text or audio inputs, offering new possibilities for music generation. Specifically, text-to-music models, which translate textual descriptions into musical compositions, have gained significant attention for their ability to bridge natural language and music, but they face several key challenges.
First, text-to-music models [
1,
2,
3,
4,
5,
6,
7] perform well for genres that are well represented in their training data, but they fail to adequately represent rare genres or complex styles. The limitation stems from the biases caused by the limited generalizability of both the training data and the models themselves, making it challenging to adapt to new styles or genres [
4,
8].
Second, such models contain structural complexity. While various efforts have been made to improve them, text-to-music models face more challenges than text-to-text models due to the structural limitations in representing musical expressions. To address this, approaches [
5] have been proposed to effectively learn musical representations or reduce the gap between text and music representations.
Third, there is a lack of evaluation frameworks, which makes it difficult to reliably assess music generation models’ performance. Typically, they are evaluated subjectively or through experiments conducted on limited datasets. Although automated music evaluation approaches [
9,
10,
11,
12] have been proposed, eliminating subjective factors in music evaluation is still a challenge.
In particular, there are the following problems related to the issue of applying text-to-music models to specific genres and styles. First, the efforts to apply music generation models to diverse styles have primarily relied on traditional approaches like data augmentation [
7,
13,
14] and style transfer [
15,
16]. The former enhances diversity by modifying existing data, while the latter combines source and target styles to create new ones. However, ensuring the precision of complex style transfer remains a challenge. The traditional approach, MusicVAE [
17], leveraged a hierarchical structure in latent space to address these issues, but the lack of dataset diversity and the limited precision of style transfer techniques have not been resolved.
Second, there is a lack of precision in the reflection of user requirements. The text-to-music models aim to generate music based on text prompts, leveraging advanced techniques to bridge the gap between textual descriptions and musical outputs. Among these, MusicGen [
1] stands out as a model that uses text prompts as conditional inputs, utilizing compressed multi-stream representations to learn the semantic relationships between text and music and employing a transformer-based decoder. However, even this model struggles to fully incorporate detailed user requirements, such as specific tempos, instrument combinations, or complex styles. When user prompts are ambiguous or include multiple conditions, the generated outputs often reflect only partial requirements or fail to meet expectations [
2,
3].
Third, the large-scale generative models require significant computational resources for both training and inference. The additional training of pretrained models like MusicGen requires considerable computational power and costs. Transfer learning leverages the knowledge of traditional models to adapt to new tasks and reduce training costs, but it suffers from performance degradation when there is a domain gap. To address these challenges, research focusing on efficient training techniques such as parameter-efficient fine-tuning (PEFT) [
18,
19] is necessary.
We propose a method that adopts the soft prompt-tuning approach [
18] and tailors it to MusicGen by prepending a small learnable prompt embedding to each text input while keeping all original weights frozen, thereby boosting performance and overcoming the model’s longstanding difficulties with under-represented genres and complex styles. Prompt tuning involves adding a small set of datasets to enable fine adjustments for specific tasks without altering the original model parameters. The proposed method offers the following three benefits:
Enhanced adaptability for rare genres and styles: By applying prompt tuning, the proposed method significantly improves the adaptability of MusicGen, enabling it to generate high-quality music outputs even for underrepresented genres and intricate styles. This addresses traditional limitations in music generation and expands the model’s creative scope.
Improved semantic understanding of text prompts: The proposed method enhances the ability of MusicGen to accurately interpret text inputs. This leads to better alignment between user-defined attributes, such as tempo, instrumentation, and style, and the generated music, improving the overall user experience.
Efficient in model fine-tuning: By optimizing only a small set of trainable parameters, the proposed method reduces computational overhead while achieving significant performance improvements. This ensures scalability and efficiency, making it practical for large-scale applications.
This proposed method opens up new possibilities for improving the performance and efficiency of large-scale music generation models such as MusicGen. By integrating prompt tuning into these models, it underscores the potential of PEFT-based approaches to enhance generative tasks. This advancement paves the way for future research in AI-driven music generation, offering a promising direction for further exploration and innovation.
2. Related Work
This section reviews advancements in the text-to-music generation models, highlighting key developments in the field. It also explores various PEFT techniques, such as prompt tuning, and discusses the challenges of effectively applying them to improve such models’ adaptability and efficiency in handling diverse musical styles and user-specific requirements.
2.1. Text-to-Music Generation Models
Text-to-music generation systems [
5,
6,
7] have evolved rapidly as larger datasets and expressive neural architectures have become available. Early rule-based or sequence-to-sequence methods could not capture music’s rich temporal and harmonic structures. Transformer-based models, such as MusicGen [
1], alleviate many of these limitations. In MusicGen, textual conditioning is obtained by encoding the user prompt with a frozen transformer text encoder (adapted from a large language model). The resulting embeddings provide a fixed conditioning signal to a large autoregressive transformer decoder that operates over the discrete latent representations produced by a 32 kHz EnCodec audio tokenizer. Music is generated by predicting the sequence of multi-stream (codebook) EnCodec tokens autoregressively; these tokens are subsequently passed through the corresponding EnCodec decoder to reconstruct up to minute-long stereo waveforms that reflect the prompt-specified musical attributes (e.g., genre, mood, tempo).
Building on this baseline, subsequent studies have explored complementary directions (see
Table 1). Mustango [
6] shifts the focus to symbolic control: by emitting track-separated MIDI events from textual prompts, it enables precise editing, instrumentation changes, and rapid region-wise regeneration—capabilities that are difficult to realize in waveform models. AudioLDM [
5] pioneers the use of CLAP-guided latent diffusion for text-to-audio; its iterative denoising markedly improves timbral richness and reduces codec artefacts, demonstrating the value of diffusion processes for perceptual quality. Extending this paradigm, MusicLDM [
7] introduces a beat-synchronous mix-up augmentation that enlarges the rhythmic diversity of training data and thereby enhances the novelty and beat coherence of the generated music without increasing model size.
These contributions delineate a design space in which high-fidelity waveform synthesis, symbolic editability, and perceptual richness via diffusion occupy different operating points. Despite these advances, all models continue to show reduced stylistic authenticity and weaker prompt alignment in under-represented genres (see
Table 2), motivating the parameter-efficient adaptation strategy proposed in this work.
2.2. Parameter-Efficient Fine-Tuning (PEFT)
PEFT methods [
18,
19,
20,
21,
22,
23,
24,
25] adapt large pretrained networks by updating only a tiny fraction of their parameters, thus reducing computational and storage costs (see
Table 3 and
Table 4). Soft prompt tuning learns task-specific embeddings prepended to the input, typically touching less than 0.1 % of the model weights; P-Tuning v2 extends the idea to deeper layers to stabilize long prompts. LoRA introduces low-rank updates (rank
is common) to weight projections, matching full fine-tuning quality with roughly 1 % trainable parameters, and has recently been applied to audio diffusion and music transformers. Adapter-style approaches insert lightweight feed-forward or prefix modules that can be swapped per task, enabling efficient model sharing without interference.
The proposed method enhances text-to-music models like MusicGen by applying the PEFT technique, improving efficiency and adaptability while addressing challenges like the semantic misalignment and narrow range of genres mentioned above. As a result, it enables scalable, high-quality AI-driven music generation.
3. MusicGen with Prompt-Tuning
This section introduces the proposed method for integrating prompt tuning into MusicGen. The core concept is the adaptation of learnable parameters, which acts as a bridge between user inputs and generated music, enabling improved results.
3.1. Overview
The proposed method centers on integrating learnable parameters into MusicGen to dynamically adapt its behavior based on the specific content of a text prompt. The learnable parameters are encoded with task-specific information and contextual nuances, enabling the model to generate audio files that are more accurately aligned with the text prompt. Instead of training all weights or relying solely on the base model’s parameters, the proposed method leverages the learnable parameters to enhance adaptability and representation. The proposed method consists of a data preprocessing phase as well as training and inference processes.
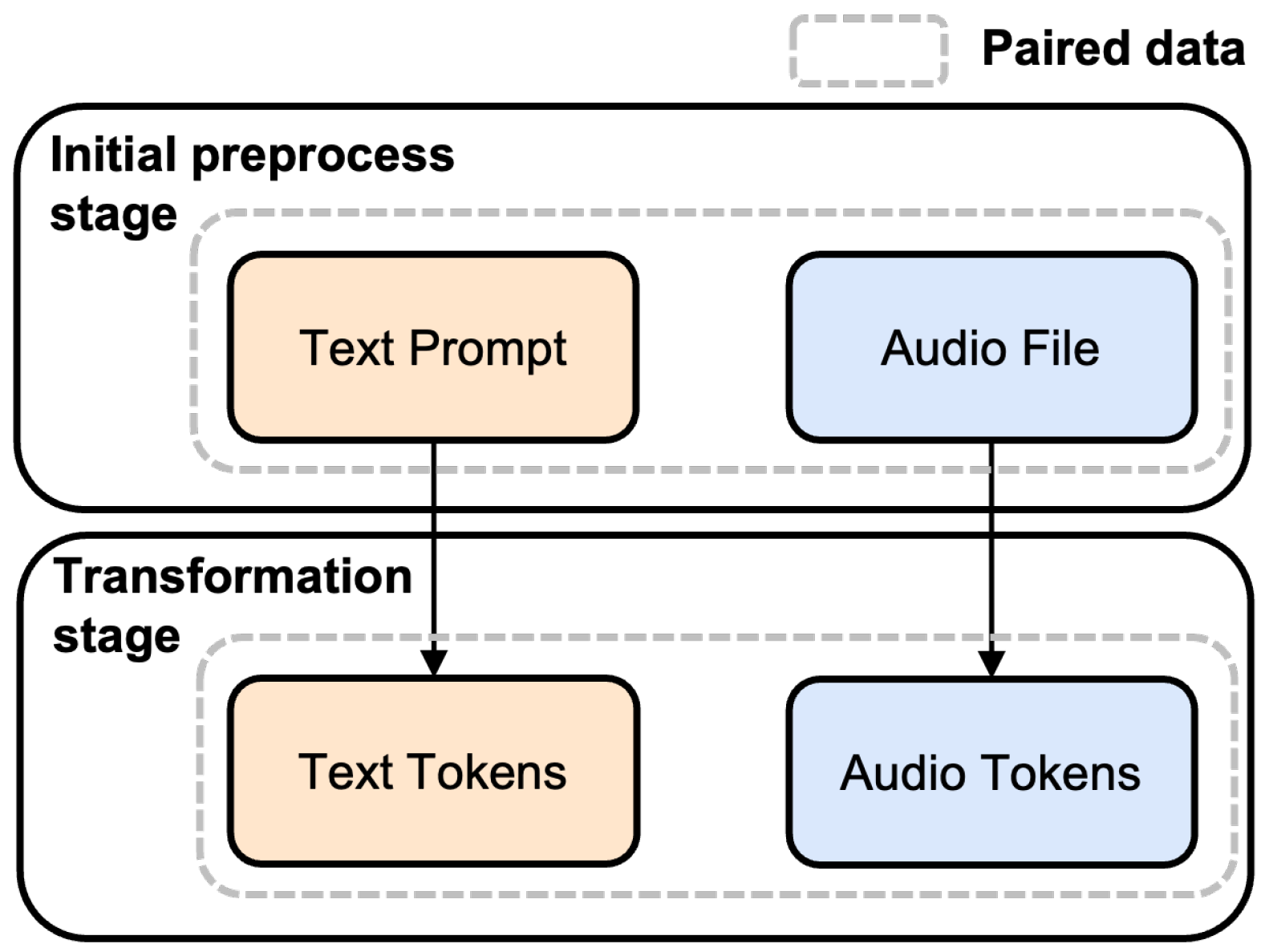
In the proposed method, a dataset consisting of text prompts and audio files that contain descriptions of the corresponding music is constructed. The data preprocessing phase involves two stages (see
Figure 1): an initial preprocessing stage and a subsequent transformation stage. During the first stage, audio files and text prompts are organized and processed. Each text prompt is carefully crafted to reflect the specific characteristics and attributes of the music, including details about instrumentation, tempo, and genre. This ensures that the textual information aligns closely with the corresponding audio features. All audio files are adjusted to a 30 s duration. This standardization ensures consistency in audio file data length, allowing MusicGen to process the audio files effectively and maintain compatibility with its architecture [
1]. Finally, pairs of text prompts and audio files are made in this stage.
In the second stage, the pairs of text prompts and audio files are transformed into a training-ready input-output format. The text prompts are tokenized into text tokens using MusicGen’s tokenizer. Simultaneously, the audio files are encoded into audio tokens using Encodec [
26], a tool integrated within the MusicGen framework. This encoding converts the audio features into a format suitable for model training.
3.2. Architecture
The integration of prompt tuning into MusicGen is structured around two key processes: training and inference. During the training process, learnable parameters are optimized to capture the characteristics of specific genres and styles, providing the foundation for improved music generation. In the inference process, the learnable parameters refine the interpretation of user text prompts and generate music that aligns with the desired attributes. The following sections detail these two processes.
3.2.1. Training Process
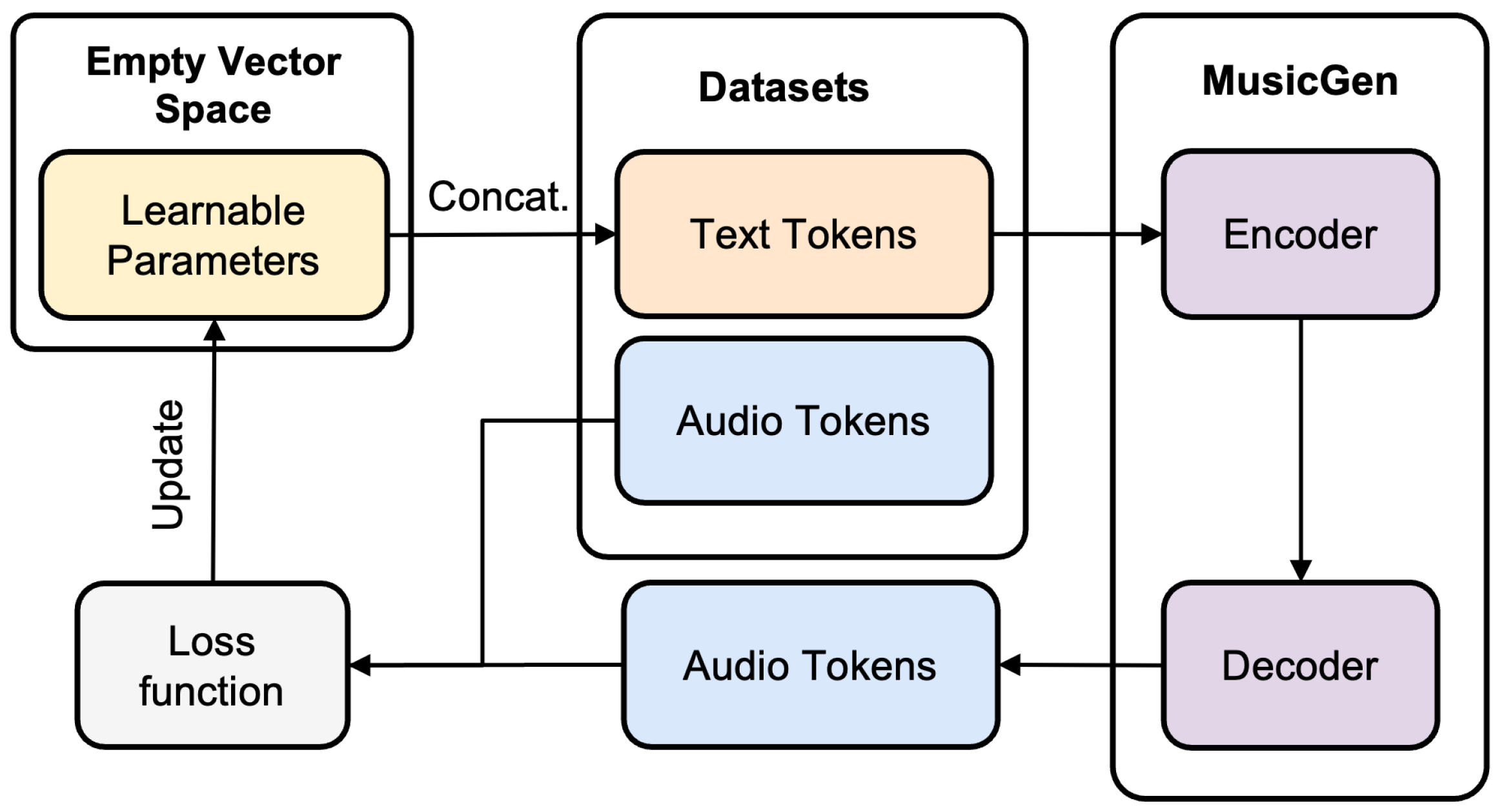
In the training process (see
Figure 2), new learnable parameters are initialized with random noise values to allow adaptation from diverse initial conditions. These learnable parameters enhance the representation of the text prompt by serving as additional trainable parameters that interact with the model during training. The training process leverages the transformer library’s Trainer module, where the model’s prediction function is repeatedly called.
At each step, the learnable parameters are inserted into the predefined empty parameter space in the datasets, prepared during data preprocessing. This combined input, consisting of the text tokens and the learnable parameters, passes through MusicGen’s encoder, where the learnable parameters influence representation learning by adjusting how the input text is interpreted within the model’s architecture. The encoder’s output, which now includes the information contributed by the learnable parameters, then passes to the decoder to predict the target output.
The loss function, typically computed between the generated and ground-truth audio tokens, updates the learnable parameters. Since only the learnable parameters are trainable while the rest of MusicGen’s parameters remain frozen, the training process focuses solely on adjusting the learnable parameters to better align the input representation with the desired output. Over multiple iterations, the learnable parameters become increasingly specialized, effectively capturing the nuances of the training data and enhancing the model’s ability to adapt to specific tasks or genres.
Throughout this iterative process, the learnable parameters are optimized to better represent the context and characteristics of the input text. Positioned at the input of the text encoder, the optimized learnable parameters enhance the information passed through the encoder, ensuring that the decoder receives a more enriched and precise representation. By the end of training, the learnable parameters tailor themselves to specific genres and styles, encapsulating the necessary information to guide the model in generating outputs aligned with the desired attributes. This architecture maintains the original parameters of MusicGen, offering flexibility for new genres and styles without requiring full retraining.
3.2.2. Inference Process
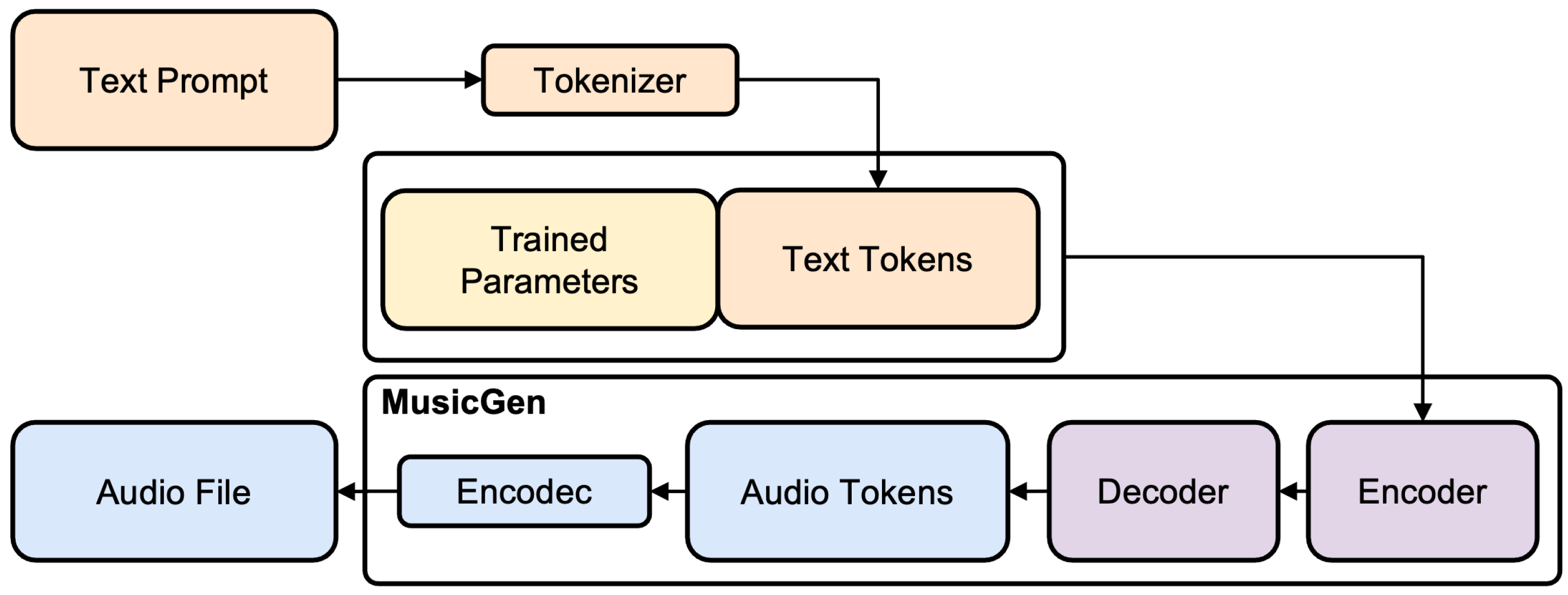
When a user provides a text prompt, the tokenizer processes it to generate text tokens to which the learnable parameters are prepended (see
Figure 3). Together, this combined input passes to MusicGen’s encoder and decoder for further processing. The decoder generates a sequence of audio tokens that correspond to the characteristics represented in the combined input. These tokens leverage patterns and relationships learned from the training dataset, enabling the decoder to produce audio tokens that accurately reflect the intended genre or style. Finally, the audio tokens pass through Encodec [
26], which reconstructs them into a continuous waveform, resulting in playable music.
By leveraging the learnable parameters, the proposed method enables MusicGen to produce audio files that are more precise, coherent, and aligned with specific genres and styles. This integration significantly enhances its adaptability and performance, allowing it to handle a wider variety of user requirements and music types.
4. Experimental Results
This section outlines the experimental setup, including the experimental design and evaluation metrics. It also demonstrates experimental results that contrast the effectiveness of the proposed method with that of the traditional MusicGen. This evaluation demonstrates the effectiveness of the proposed method in capturing the characteristics of traditional Korean instruments and musical genres and improving the semantic understanding of user input texts.
4.1. Datasets and Environmental Setup
The dataset and experimental environment played a crucial role in ensuring the success of the experiments. A high-quality, well-curated dataset provided reliable input for model training and validation, while a well-designed experimental environment ensured consistent and reproducible results. Together, these factors significantly impacted the accuracy and reliability of the findings.
The dataset used in the proposed method consisted of audio files representing traditional Korean instruments and musical genres. A total of 2402 training samples were used. Similarly, the 329 validation samples also consisted of traditional Korean instruments and musical genres. Each sample has a 30 s duration. The dataset was grouped as below. First, traditional Korean instruments (gayageum, haegeum, daegeum, janggu, etc.) were considered. These data captured both solo performances and ensemble compositions, allowing the model to learn each instrument’s unique timbres and playing styles. Second, traditional Korean musical genres, specifically minyo, sanjo, muak, jeryeak, boheosa, etc., were considered. Minyo represents traditional folksongs characterized by regional melodies and rhythms, while sanjo features an improvised and fluid playing style, highlighting the diversity of traditional instrumental techniques. Third, a traditional Korean historical story. Fourth, Korean traditional cultural themes such as han, a unique emotion often associated with sorrow or the feeling of loss.
Each audio file in the dataset was paired with a text prompt (e.g., “Haegeum sanjo performance” or “Minyo is a traditional Korean genre played with gayageum”) to facilitate text-to-music learning. This dataset was designed to enable learning of not only the distinct sounds of traditional Korean instruments but also the broader musical context of these genres.
4.2. Experimental Environment
The baseline model was MusicGen, a transformer-based model designed to generate music based on text input by learning the mapping between text and audio. Moreover, prompt tuning was applied to extend its capabilities to better reflect the characteristics of traditional Korean music and instruments.
Hyperparameters in the proposed method were configured with a learnable parameter length of 30, a batch size of 32, and a maximum epoch number of 100. The learning rate was set to “ 1 × 10−5” to ensure stable and efficient training. Early stopping was employed, enabling the training to terminate if no further performance improvement was observed on the validation data, thereby avoiding unnecessary computations and overfitting.
Regarding the hardware environments, training was conducted on an NVIDIA A100 SXM4 80 GB GPU, while testing was performed on an NVIDIA Tesla T4 GPU. These environments provided the computational resources required for large-scale deep learning training and validation.
4.3. Evaluation Metrics
Since music is inherently subjective and influenced by individual preferences, it is not easy to evaluate its quality using purely numerical metrics. However, by utilizing models that represent the characteristics of music as vectors, it becomes possible to quantitatively compare the similarity between music and texts or music and music. In the proposed method, we adopt two models: Contrastive Language-Audio Pretraining (CLAP) [
27] to assess the alignment between text and music and Kullback–Leibler Divergence (KLD) [
28] to represent the characteristics of music.
In addition to semantic alignment, we observed that the audio quality of the generated music was preserved even for underrepresented or rare genres. Although subjective perception plays a role, the similarity in audio feature distributions quantified through low KLD values suggests that the proposed method maintains consistent audio characteristics across diverse musical styles. This indicates the model’s capability not only to semantically align with textual prompts but also to generate sonically coherent outputs regardless of genre frequency in the training data.
The performance of the proposed method was evaluated using the CLAP model [
27], which quantifies the semantic alignment between text and audio. The CLAP model extends the idea of aligning text and visual representations to the domain of audio, enabling it to evaluate the semantic consistency between textual descriptions and audio signals. Specifically, the CLAP model was used to map both text and audio into a shared vector space, where their semantic similarity was assessed using cosine similarity. This metric provided a robust measure of the relevance of the generated music to the given text.
Cosine similarity, ranging from −1 to 1, was used to evaluate the semantic alignment between text prompts and generated music. Negative values indicated semantic opposition (e.g., generating piano sounds for a “guitar sounds” prompt), while values closer to 1 signified strong alignment between the prompt and the music. As the similarity score shifted from negative to positive, it reflected the model’s progression toward generating music that better matched the intended semantic content. Despite its simplicity, cosine similarity effectively captured the degree of alignment and was thus adopted as a key metric in this proposed method.
The KLD is a fundamental metric that measures the similarity between two probability distributions. Specifically, it quantifies how one probability distribution differs from another reference distribution by calculating their relative entropy. In information theory, the KLD is particularly useful for comparing the statistical characteristics of different distributions, where a lower value indicates greater similarity between them.
In the proposed method, we utilized the KLD to evaluate the performance of our tuning method by comparing the audio characteristics of both the traditional and tuned models. We extracted four key audio features from the samples: Mel-frequency cepstral coefficients (MFCCs) [
29] to capture timbral characteristics, chroma features [
30] to represent pitch class distributions, spectral features [
31] to analyze frequency spectrum characteristics, and the zero-crossing rate [
32] to measure temporal properties. To establish a baseline for comparison, we first extracted these features from 336 evaluation dataset samples and computed their average distributions. We then used the KLD to calculate scores between this reference distribution and the features extracted from both the traditional model’s outputs and our proposed model’s outputs. This allowed us to quantitatively assess whether our tuning process improved the alignment of generated audio characteristics with those of the evaluation dataset, with lower scores indicating better alignment with the reference distribution.
For a comprehensive analysis of audio characteristics, we extracted four key audio features: MFCCs, chroma features, spectral features, and the zero crossing rate. MFCCs capture the timbral and textural characteristics of the audio signal by representing the short-term power spectrum based on human auditory perception. Chroma features represent the distribution of musical pitch classes, providing insights into the harmonic and melodic content of the audio. Spectral features, including spectral centroid, bandwidth, and rolloff, describe the overall shape and energy distribution of the frequency spectrum, reflecting the brightness and spectral characteristics of the sound. Finally, the zero crossing rate measures the rate at which the audio signal changes from positive to negative, indicating rhythmic and percussive elements in the audio.
In the proposed method, we leverage two complementary metrics to comprehensively assess both the quality and alignment of the generated music. CLAP quantifies the semantic similarity between text prompts and music outputs by embedding both modalities into a shared vector space and calculating their cosine similarity, as defined in (
1) [
27]:
This provides a clear and interpretable measure of how well the generated music matches the intended textual description. On the other hand, KLD measures the statistical similarity between the distributions of music features extracted from the generated samples and those of the reference dataset. It is computed as shown in (
2) [
28]:
4.4. Result
The experimental results, including CLAP and KLD scores, demonstrated that the proposed method achieved significant improvements over the traditional MusicGen. The evaluations were conducted using four types of text prompts (see
Table 5): one set containing the names of 20 traditional Korean instruments, another referencing traditional Korean musical genres, 20 prompts, a third set focusing on traditional Korean cultural themes and natural landscapes 20 prompts covering hanok courtyards, temples, bamboo forests, and seasonal elements, and a fourth set exploring Korean traditional emotional narratives and historical stories. Twenty prompts featuring deep cultural concepts such as ’han’ (deep sorrow), ’jeong’ (affection), and tales from the Joseon Dynasty, including gisaeng, scholars, and folk heroes. For each type, 20 prompts were evaluated, and the average scores were calculated for comparison.
4.4.1. CLAP Socre
For prompts containing traditional Korean instrument names, the proposed method produced music that closely matched the characteristics described in the text, with the largest improvement observed with the prompt “Create a cheerful melody with the high-pitched kkwaenggwari,” achieving a CLAP score increase of 0.3691 compared with the baseline and an average improvement of approximately 0.1270 in this category. Similarly, for prompts referencing traditional Korean musical genres, the proposed method exhibited substantial improvements, with the most significant enhancement seen with the prompt “Design a variation based on the classic boheosa,” achieving a CLAP score increase of 0.3941 and an average improvement of 0.1613 across all prompts in this category. In the remaining groups, while the average improvements were not as pronounced in the story-based prompts and traditional cultural theme prompts due to the dataset being biased toward genres and instruments, individual prompts containing Korean traditional vocabulary showed improvements (see
Table 6).
In conclusion, across a total of 80 data points, the cosine similarity value increased by an average of 0.0752. The proposed method demonstrated the ability to address the limitations of traditional approaches by capturing the unique aspects of traditional Korean music, showing remarkable improvements, particularly in traditional Korean instruments and genres. By strengthening the semantic alignment between text and music, the proposed method broadened the possibilities for generating culturally enriched and contextually accurate music.
4.4.2. KLD Score
For audio samples generated with traditional Korean instrument prompts, the KLD demonstrated significant improvements in distributional similarity (see
Table 7), with the most notable one observed in a specific sample, where the KLD score decreased by 0.02384, indicating substantially better alignment with the reference distribution, and overall, 15 out of 20 samples showed reduced KLD scores, with an average improvement of 0.00403. Similarly, for prompts specifying traditional Korean music genres, the KLD revealed consistent improvements in distributional similarity, with the most significant enhancement observed in a particular sample, showing a KLD score reduction of 0.01300, and among the 20 samples, 13 demonstrated decreased KLD scores, with an average improvement of 0.00401. For the additional comparison groups, the story-based prompts showed an average improvement of 0.00552 with a maximum reduction of 0.02368, while the traditional cultural theme prompts demonstrated an average improvement of 0.00438 with a maximum reduction of 0.00823. These reductions suggest that our tuning method effectively captures and preserves the distinctive characteristics of traditional Korean music while maintaining the statistical properties of the generated music.
The comprehensive evaluation using both CLAP and the KLD demonstrates the effectiveness of our proposed method across multiple dimensions. For instrument-related prompts, the proposed method achieved significant improvements in semantic understanding, with CLAP scores increasing by an average of 0.1270, and the most notable enhancement of 0.3691 was observed in the kkwaenggwari-related prompt. This semantic improvement was complemented by better distributional similarity, as evidenced by a reduction in the average KLD score from 0.01019 to 0.00616 (improvement of 0.00403). Similarly, for genre-related prompts, the proposed method showed even more substantial enhancements, with CLAP scores improving by an average of 0.1613, peaking at a 0.3941 increase for the boheosa variation prompt. The KLD evaluation for genres revealed a comparable improvement, with the average score decreasing by 0.00401, from 0.01155 to 0.00754. For the additional comparison groups, the story-based prompts showed modest CLAP improvements with an average of 0.0002 and KLD improvements of 0.00552, while the traditional cultural theme prompts demonstrated CLAP improvements of 0.0121 and KLD improvements of 0.00438. These consistent improvements across both evaluation metrics and categories demonstrate that the proposed method successfully enhances adaptability for rare genres and styles and the semantic understanding of text prompts.
5. Discussion
The results obtained from the experiments revealed that the proposed method effectively addresses key limitations of traditional approaches, particularly the narrow range of genres and styles and the misunderstanding of text prompts. By employing prompt tuning, the proposed method consistently improves the alignment between text prompts and generated music, enabling more accurate and reliable outputs. These improvements are evident across diverse test cases, with notable gains in both semantic alignment and structural coherence. The results highlight the adaptability and robustness of the proposed method, establishing its potential as a scalable solution for enhancing generative music models across a wide range of applications.
The proposed method contributes to society by enhancing the accessibility and diversity of music creation. By enabling generative models to produce high-quality outputs for under-represented genres, such as traditional Korean music, the method supports the preservation and appreciation of cultural heritage. Furthermore, its improved alignment between text prompts and generated music lowers barriers for users, allowing a broader audience to explore and engage with music creation, regardless of their level of expertise. This demonstrates the potential of AI technologies to complement human creativity and support cultural expression in meaningful ways.
Reflecting on the challenges identified in the introduction, the limitations of traditional approaches in handling diverse musical styles and user requirements are addressed through the integration of prompt tuning into MusicGen. By building upon prior research in text-to-music generation and PEFT methods, the proposed method demonstrates its ability to overcome biases in training data and inefficiencies in fine-tuning. This study highlights how prompt tuning, as a lightweight yet powerful technique, can adapt generative models to specific genres, such as traditional Korean music, while maintaining scalability and efficiency. Together, these contributions underscore the potential of combining foundational research with innovative methodologies to advance generative AI in creative and culturally significant directions.
To assess the broader applicability of these benefits, we next examine how the same prompt-tuning principle could be extended beyond MusicGen to other text-to-music architectures. Although our experiments focus on MusicGen, the same soft prompt-tuning strategy can, in principle, be ported to symbolic-token transformers (e.g., Mustango [
6]) or diffusion-based systems such as AudioLDM [
5]. However, two practical challenges arise. First, different models operate in distinct representation spaces—symbolic MIDI tokens, spectrogram latents, or audio codecs—so the prompt embedding must be inserted at architecture-specific positions (for example, the text encoder of a diffusion U-Net) and resized to match layer widths. Second, some frameworks do not freeze the text encoder by default, meaning that isolating a small set of trainable parameters may require additional gating or adapter layers. Addressing these issues could involve minor architectural modifications or combining prompt tuning with low-rank adapters; a systematic investigation of such variants is left to future work.
A further limitation concerns the audio representation itself. The Encodec quantizer embedded in MusicGen was pre-trained primarily on Western-instrument datasets such as Jamendo, whereas traditional Korean instruments (e.g., gayageum, haegeum, and taepyeongso) display spectral envelopes characterized by strong odd harmonics, micro-tonal vibrato, and high-Q resonances that are scarcely represented in that corpus. A preliminary log-spectral-distance probe on a small set of solo clips indicates that Encodec reconstructs these timbres with slightly higher distortion than comparable Western strings, hinting at a codec mismatch. While the present study shows that prompt tuning can compensate for semantic misalignment, the absolute ceiling on audio fidelity may ultimately be bounded by the expressiveness of the underlying codec. Future work could mitigate this gap by fine-tuning Encodec on a balanced corpus of Korean timbres, replacing it with a higher-bit-rate VQ-VAE trained domain-specifically, or adopting diffusion decoders that bypass codec quantization altogether; clarifying the relative impact of codec choice versus prompt–text alignment remains an open research question.
6. Conclusions
The proposed method addresses the challenges of generating music for underrepresented genres by enhancing MusicGen through prompt tuning. It demonstrates its effectiveness in improving the adaptability and quality of music generation while maintaining efficiency. By fine-tuning only a small set of parameters, it preserves the integrity of the traditional MusicGen, highlighting the potential of the PEFT technique in optimizing large-scale generative models.
The findings illustrate that PEFT techniques, such as prompt tuning, can be successfully applied to complex models like MusicGen, enabling targeted improvements without extensive computational resources. The proposed method highlights a practical pathway for advancing generative AI systems across various domains, providing scalability and versatility in handling diverse creative tasks. By exploring the integration of the lightweight fine-tuning technique, the proposed method enables the adaptation of sophisticated AI models to specialized applications.
This paper highlights several avenues for future research that could advance generative music models in the following focused directions:
Enhanced Evaluation Methodologies: Although CLAP and KLD provide objective benchmarks, they do not fully capture musical expressiveness (e.g., emotional nuance, creativity, cultural context). Developing music-specific evaluation frameworks that integrate both objective and subjective criteria remains a pressing need.
Broader Parameter-Efficient Adaptation: Beyond prompt tuning, techniques such as meta-learning, contrastive learning, and reinforcement learning could further improve adaptability to rare genres and complex styles while preserving computational efficiency.
Expanded Conditioning Modalities: Extending input beyond text or audio—e.g., images, sketches, or symbolic scores—would enable more intuitive, cross-modal interaction with generative systems and broaden their creative applications.
Author Contributions
Conceptualization, H.S., J.I. and Y.S.; methodology, H.S., J.I. and Y.S.; software, H.S.; validation, H.S.; formal analysis, H.S. and J.I.; investigation, H.S. and J.I.; writing—original draft preparation, H.S. and J.I.; writing—review and editing, H.S., J.I. and Y.S.; visualization, H.S. and J.I.; supervision, Y.S.; project administration, H.S. and J.I. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Institute of Information & communications Technology Planning & Evaluation (IITP) under the Artificial Intelligence Convergence Innovation Human Resources Development (IITP-2025-RS-2023-00254592) grant funded by the Korean government (MSIT). This work was supported by the Ministry of Education of the Republic of Korea and the National Research Foundation of Korea (NRF-2021R1F1A1063466).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Restrictions apply to the availability of these data. Data were obtained from AI Hub and are available AI Hub with the permission of AI Hub (
https://www.aihub.or.kr/, accessed on 1 July 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Copet, J.; Kreuk, F.; Gat, I.; Remez, T.; Kant, D.; Synnaeve, G.; Adi, Y.; Défossez, A. Simple and controllable music generation. Adv. Neural Inf. Process. Syst. 2024, 36, 47704–47720. [Google Scholar]
- Parker, J.D.; Spijkervet, J.; Kosta, K.; Yesiler, F.; Kuznetsov, B.; Wang, J.C.; Avent, M.; Chen, J.; Le, D. StemGen: A music generation model that listens. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 1116–1120. [Google Scholar]
- Lam, M.W.; Tian, Q.; Li, T.; Yin, Z.; Feng, S.; Tu, M.; Ji, Y.; Xia, R.; Ma, M.; Song, X.; et al. Efficient neural music generation. Adv. Neural Inf. Process. Syst. 2024, 36, 17450–17463. [Google Scholar]
- Mittal, G.; Engel, J.; Hawthorne, C.; Simon, I. Symbolic music generation with diffusion models. arXiv 2021, arXiv:2103.16091. [Google Scholar] [CrossRef]
- Liu, H.; Chen, Z.; Yuan, Y.; Mei, X.; Liu, X.; Mandic, D.; Wang, W.; Plumbley, M.D. Audioldm: Text-to-audio generation with latent diffusion models. arXiv 2023, arXiv:2301.12503. [Google Scholar]
- Melechovsky, J.; Guo, Z.; Ghosal, D.; Majumder, N.; Herremans, D.; Poria, S. Mustango: Toward controllable text-to-music generation. arXiv 2023, arXiv:2311.08355. [Google Scholar]
- Chen, K.; Wu, Y.; Liu, H.; Nezhurina, M.; Berg-Kirkpatrick, T.; Dubnov, S. Musicldm: Enhancing novelty in text-to-music generation using beat-synchronous mixup strategies. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 1206–1210. [Google Scholar]
- Ji, S.; Luo, J.; Yang, X. A comprehensive survey on deep music generation: Multi-level representations, algorithms, evaluations, and future directions. arXiv 2020, arXiv:2011.06801. [Google Scholar] [CrossRef]
- Wu, C.W.; Gururani, S.; Laguna, C.; Pati, A.; Vidwans, A.; Lerch, A. Towards the objective assessment of music performances. In Proceedings of the International Conference on Music Perception and Cognition (ICMPC), San Francisco, CA, USA, 5–9 July 2016; pp. 99–103. [Google Scholar]
- Guo, Y.; Liu, Y.; Zhou, T.; Xu, L.; Zhang, Q. An automatic music generation and evaluation method based on transfer learning. PLoS ONE 2023, 18, e0283103. [Google Scholar] [CrossRef]
- Xiong, Z.; Wang, W.; Yu, J.; Lin, Y.; Wang, Z. A Comprehensive Survey for Evaluation Methodologies of AI-Generated Music. arXiv 2023, arXiv:2308.13736. [Google Scholar] [CrossRef]
- Deng, Y.; Xu, Z.; Zhou, L.; Liu, H.; Huang, A. Research on AI composition recognition based on music rules. In Proceedings of the 8th Conference on Sound and Music Technology: Selected Papers from CSMT; Springer: Berlin/Heidelberg, Germany, 2021; pp. 187–197. [Google Scholar]
- Schlüter, J.; Grill, T. Exploring data augmentation for improved singing voice detection with neural networks. In Proceedings of the ISMIR, Málaga, Spain, 26–30 October 2015; pp. 121–126. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A simple data augmentation method for automatic speech recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar] [CrossRef]
- Dong, H.W.; Hsiao, W.Y.; Yang, L.C.; Yang, Y.H. Musegan: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Brunner, G.; Konrad, A.; Wang, Y.; Wattenhofer, R. MIDI-VAE: Modeling dynamics and instrumentation of music with applications to style transfer. arXiv 2018, arXiv:1809.07600. [Google Scholar] [CrossRef]
- Roberts, A.; Engel, J.; Raffel, C.; Hawthorne, C.; Eck, D. A hierarchical latent vector model for learning long-term structure in music. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4364–4373. [Google Scholar]
- Lester, B.; Al-Rfou, R.; Constant, N. The power of scale for parameter-efficient prompt tuning. arXiv 2021, arXiv:2104.08691. [Google Scholar] [CrossRef]
- Hu, E.J.; Shen, Y.; Wallis, P.; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. Lora: Low-rank adaptation of large language models. arXiv 2021, arXiv:2106.09685. [Google Scholar]
- Liu, X.; Zheng, Y.; Du, Z.; Ding, M.; Qian, Y.; Yang, Z.; Tang, J. GPT understands, too. AI Open 2024, 5, 208–215. [Google Scholar] [CrossRef]
- Liu, X.; Ji, K.; Fu, Y.; Tam, W.L.; Du, Z.; Yang, Z.; Tang, J. P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks. arXiv 2021, arXiv:2110.07602. [Google Scholar]
- Li, X.L.; Liang, P. Prefix-tuning: Optimizing continuous prompts for generation. arXiv 2021, arXiv:2101.00190. [Google Scholar] [CrossRef]
- Choi, D.; Im, J.; Sung, Y. LoRA Fusion: Enhancing Image Generation. Mathematics 2024, 12, 3474. [Google Scholar] [CrossRef]
- Cho, M.; Kim, S.; Choi, D.; Sung, Y. Enhanced BLIP-2 Optimization Using LoRA for Generating Dashcam Captions. Appl. Sci. 2025, 15, 3712. [Google Scholar] [CrossRef]
- Choi, Y.; Kim, S.; Bassole, Y.C.F.; Sung, Y. Enhanced retrieval-augmented generation using low-rank adaptation. Appl. Sci. 2025, 15, 4425. [Google Scholar] [CrossRef]
- Défossez, A.; Copet, J.; Synnaeve, G.; Adi, Y. High fidelity neural audio compression. arXiv 2022, arXiv:2210.13438. [Google Scholar] [CrossRef]
- Elizalde, B.; Deshmukh, S.; Al Ismail, M.; Wang, H. Clap learning audio concepts from natural language supervision. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Loughran, R.; Walker, J.; O’Neill, M.; O’Farrell, M. The Use of Mel-Frequency Cepstral Coefficients in Musical Instrument Identification; International Computer Music Association: San Francisco, CA, USA, 2008. [Google Scholar]
- Muller, M.; Kurth, F.; Clausen, M. Chroma-based statistical audio features for audio matching. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 16–19 October 2005; pp. 275–278. [Google Scholar]
- Tzanetakis, G.; Cook, P. Musical genre classification of audio signals. IEEE Trans. Speech Audio Process. 2002, 10, 293–302. [Google Scholar] [CrossRef]
- Liu, Z.; Huang, J.; Wang, Y.; Chen, T. Audio feature extraction and analysis for scene classification. In Proceedings of the First Signal Processing Society Workshop on Multimedia Signal Processing, Princeton, NJ, USA, 23–25 June 1997; pp. 343–348. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).





{kind=link}
{kind=link}
{kind=link}