MFEAM: Multi-View Feature Enhanced Attention Model for Image Captioning


Abstract
1. Introduction
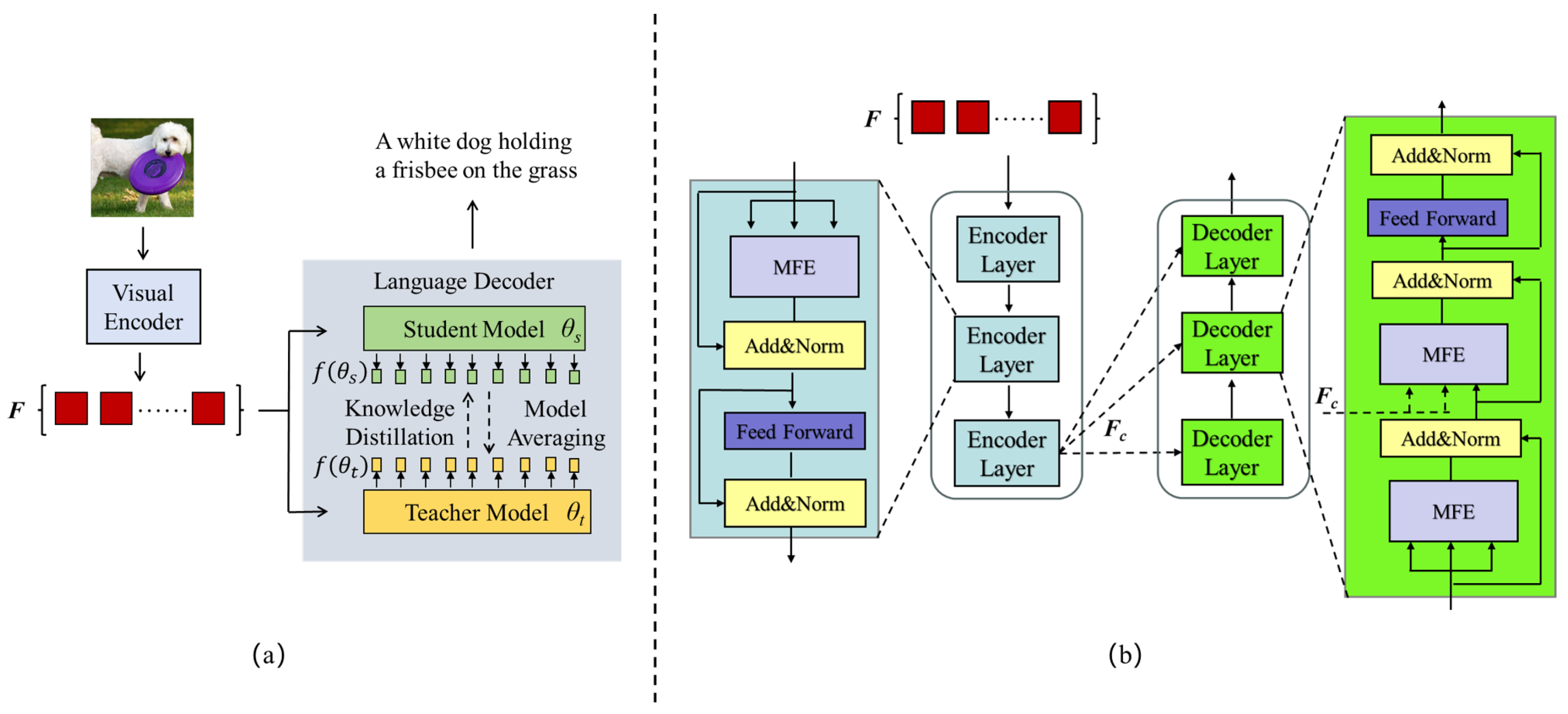
- We present a novel architecture called MFEAM, which incorporates the multi-view feature enhanced attention. By overcoming the limitations of relying on a single language model as the decoder and integrating the advanced Mean Teacher architecture, the model significantly improves upon baseline performance.
- To strengthen the ability of the model in handling the entangled features of vision and text, we propose the multi-view feature enhanced attention (MFE). MFE is made up of the self-enhanced module and the sliding window module, which collaboratively assist the teacher model in comprehending entangled features from both visual and textual views.
- To mitigate performance degradation caused by overemphasis on certain features, a novel feature processing strategy is adopted in the student model. Specifically, the decoder layers are divided into two groups, with one focusing on processing instance features and the other responsible for capturing relational features between instances.
2. Related Work
2.1. Image Captioning
2.2. Knowledge Distillation
2.3. Vision-Language Pretrained Model
2.4. Dynamic Training Strategy
3. Method
3.1. Visual Encoder
3.2. Teacher Language Model
3.3. Student Language Model
3.4. Interaction Strategy
3.5. Training Strategy
4. Experiments
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Experimental Results
4.3. Ablation Study
4.4. Qualitative Studies
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3156–3164. [Google Scholar]
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3128–3137. [Google Scholar]
- Aneja, J.; Deshpande, A.; Schwing, A.G. Convolutional image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5561–5570. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6077–6086. [Google Scholar]
- Rennie, S.J.; Marcheret, E.; Mroueh, Y.; Ross, J.; Goel, V. Self-critical sequence training for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7008–7024. [Google Scholar]
- Wang, H.; Wang, H.; Xu, K. Evolutionary recurrent neural network for image captioning. Neurocomputing 2020, 401, 249–256. [Google Scholar] [CrossRef]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Wang, C.; Yang, H.; Bartz, C.; Meinel, C. Image captioning with deep bidirectional LSTMs. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 988–997. [Google Scholar]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing when to look: Adaptive attention via a visual sentinel for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 375–383. [Google Scholar]
- Zhu, X.; Li, L.; Liu, J.; Li, Z.; Peng, H.; Niu, X. Image captioning with triple-attention and stack parallel LSTM. Neurocomputing 2018, 319, 55–65. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PmLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Wang, C.; Shen, Y.; Ji, L. Geometry Attention Transformer with position-aware LSTMs for image captioning. Expert Syst. Appl. 2022, 201, 117174. [Google Scholar] [CrossRef]
- Barraco, M.; Stefanini, M.; Cornia, M.; Cascianelli, S.; Baraldi, L.; Cucchiara, R. CaMEL: Mean teacher learning for image captioning. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 4087–4094. [Google Scholar]
- Zhang, X.; Fan, M.; Hou, M. Mobilenet V3-transformer, a lightweight model for image caption. Int. J. Comput. Appl. 2024, 46, 1–9. [Google Scholar] [CrossRef]
- Chen, J.; Ge, C.; Xie, E.; Wu, Y.; Yao, L.; Ren, X.; Wang, Z.; Luo, P.; Lu, H.; Li, Z. PIXART-sigma: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2025; pp. 74–91. [Google Scholar]
- Moratelli, N.; Caffagni, D.; Cornia, M.; Baraldi, L.; Cucchiara, R. Revisiting Image Captioning Training Paradigm via Direct CLIP-based Optimization. arXiv 2024, arXiv:2408.14547. [Google Scholar] [CrossRef]
- Wang, F.; Mei, J.; Yuille, A. Sclip: Rethinking self-attention for dense vision-language inference. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2025; pp. 315–332. [Google Scholar]
- Moratelli, N.; Cornia, M.; Baraldi, L.; Cucchiara, R. Fluent and Accurate Image Captioning with a Self-Trained Reward Model. In Proceedings of the International Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2025; pp. 209–225. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the 31st International Conference on Neural Information Processing System, Long Beach, CA, USA, 4–9 December 2017; pp. 1195–1204. [Google Scholar]
- Gu, Y.; Dong, L.; Wei, F.; Huang, M. MiniLLM: Knowledge distillation of large language models. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna Austria, 7–11 May 2024. [Google Scholar]
- Kang, M.; Lee, S.; Baek, J.; Kawaguchi, K.; Hwang, S.J. Knowledge-augmented reasoning distillation for small language models in knowledge-intensive tasks. Adv. Neural Inf. Process. Syst. 2024, 36, 48573–48602. [Google Scholar]
- Li, Z.; Li, X.; Fu, X.; Zhang, X.; Wang, W.; Chen, S.; Yang, J. Promptkd: Unsupervised prompt distillation for vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26617–26626. [Google Scholar]
- Nguyen, T.; Gadre, S.Y.; Ilharco, G.; Oh, S.; Schmidt, L. Improving multimodal datasets with image captioning. Adv. Neural Inf. Process. Syst. 2024, 36, 22047–22069. [Google Scholar]
- Mahmoud, A.; Elhoushi, M.; Abbas, A.; Yang, Y.; Ardalani, N.; Leather, H.; Morcos, A.S. Sieve: Multimodal dataset pruning using image captioning models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 22423–22432. [Google Scholar]
- Awadalla, A.; Xue, L.; Shu, M.; Yan, A.; Wang, J.; Purushwalkam, S.; Shen, S.; Lee, H.; Lo, O.; Park, J.S.; et al. BLIP3-KALE: Knowledge Augmented Large-Scale Dense Captions. arXiv 2024, arXiv:2411.07461. [Google Scholar]
- Yu, Q.; Sun, Q.; Zhang, X.; Cui, Y.; Zhang, F.; Cao, Y.; Wang, X.; Liu, J. Capsfusion: Rethinking image-text data at scale. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–20 June 2024; pp. 14022–14032. [Google Scholar]
- Chen, L.; Li, J.; Dong, X.; Zhang, P.; He, C.; Wang, J.; Zhao, F.; Lin, D. Sharegpt4v: Improving large multi-modal models with better captions. In Proceedings of the European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2025; pp. 370–387. [Google Scholar]
- Liao, Y.; Zhang, A.; Lu, M.; Wang, Y.; Li, X.; Liu, S. Gen-vlkt: Simplify association and enhance interaction understanding for hoi detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20123–20132. [Google Scholar]
- Li, J.; Wang, Y.; Zhao, D. Layer-wise enhanced transformer with multi-modal fusion for image caption. Multimed. Syst. 2023, 29, 1043–1056. [Google Scholar] [CrossRef]
- Yang, C.; Li, Z.; Zhang, L. Bootstrapping interactive image-text alignment for remote sensing image captioning. IEEE Trans. Geosci. Remote Sens. 2024, 62, 1–12. [Google Scholar] [CrossRef]
- Ansari, K.; Srivastava, P. An efficient automated image caption generation by the encoder decoder model. Multimed. Tools Appl. 2024, 83, 66175–66200. [Google Scholar] [CrossRef]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 684–699. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 17, 6000–6010. [Google Scholar]
- Hinton, G. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Zhou, Y.; Zhang, Y.; Hu, Z.; Wang, M. Semi-autoregressive transformer for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 3139–3143. [Google Scholar]
- Sameni, S.; Kafle, K.; Tan, H.; Jenni, S. Building Vision-Language Models on Solid Foundations with Masked Distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 14216–14226. [Google Scholar]
- Ren, K.; Hu, C.; Xi, H.; Li, Y.; Fan, J.; Liu, L. EDIR: An expert method for describing image regions based on knowledge distillation and triple fusion. Appl. Intell. 2025, 55, 62. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, M.; Liu, D.; Hu, Z.; Zhang, H. More grounded image captioning by distilling image-text matching model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4777–4786. [Google Scholar]
- Bajpai, D.J.; Hanawal, M.K. CAPEEN: Image Captioning with Early Exits and Knowledge Distillation. arXiv 2024, arXiv:2410.04433. [Google Scholar] [CrossRef]
- Cohen, G.H. ALIGN: A program to superimpose protein coordinates, accounting for insertions and deletions. Appl. Crystallogr. 1997, 30, 1160–1161. [Google Scholar] [CrossRef]
- Xiao, B.; Wu, H.; Xu, W.; Dai, X.; Hu, H.; Lu, Y.; Zeng, M.; Liu, C.; Yuan, L. Florence-2: Advancing a unified representation for a variety of vision tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 4818–4829. [Google Scholar]
- Vedantam, R.; Lawrence Zitnick, C.; Parikh, D. Cider: Consensus-based image description evaluation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4566–4575. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision—ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the acl Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Ann Arbor, MI, USA, 29 June 2005; pp. 65–72. [Google Scholar]
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 22 July 2004; pp. 74–81. [Google Scholar]
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. Spice: Semantic propositional image caption evaluation. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part V 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 382–398. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural machine translation of rare words with subword units. arXiv 2015, arXiv:1508.07909. [Google Scholar]
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Hierarchy parsing for image captioning. In Proceedings of the IEEE/CVF INTERNATIONAL Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2621–2629. [Google Scholar]
- Wu, M.; Zhang, X.; Sun, X.; Zhou, Y.; Chen, C.; Gu, J.; Sun, X.; Ji, R. Difnet: Boosting visual information flow for image captioning. In Proceedings of the IEEE/CVF Conference on Computer vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2022; pp. 18020–18029. [Google Scholar]
- Huang, L.; Wang, W.; Chen, J.; Wei, X.Y. Attention on attention for image captioning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4634–4643. [Google Scholar]
- Pan, Y.; Yao, T.; Li, Y.; Mei, T. X-linear attention networks for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10971–10980. [Google Scholar]
- Luo, Y.; Ji, J.; Sun, X.; Cao, L.; Wu, Y.; Huang, F.; Lin, C.W.; Ji, R. Dual-level collaborative transformer for image captioning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 2286–2293. [Google Scholar]
- Zhang, X.; Sun, X.; Luo, Y.; Ji, J.; Zhou, Y.; Wu, Y.; Huang, F.; Ji, R. Rstnet: Captioning with adaptive attention on visual and non-visual words. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15465–15474. [Google Scholar]
- Yan, P.; Li, Z.; Hu, R.; Cao, X. BENet: Bi-directional enhanced network for image captioning. Multimed. Syst. 2024, 30, 48. [Google Scholar] [CrossRef]
- Wei, J.; Li, Z.; Zhu, J.; Ma, H. Enhance understanding and reasoning ability for image captioning. Appl. Intell. 2023, 53, 2706–2722. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | B-1 | B-4 | M | R | C | S |
|---|---|---|---|---|---|---|
| Up-Down [4] | 79.8 | 36.3 | 27.7 | 56.9 | 120.1 | 21.4 |
| GCN-LSTM [9] | 80.5 | 38.3 | 28.5 | 58.3 | 127.6 | 22.0 |
| AoANet [51] | 80.2 | 38.9 | 29.2 | 58.8 | 129.8 | 22.4 |
| EURAIC [56] | 80.9 | 39.5 | 29.4 | 59.4 | 130.3 | - |
| HIP [49] | - | 39.1 | 28.9 | 59.2 | 130.6 | 22.3 |
| VAT [29] | 81.2 | 39.0 | 29.3 | 59.4 | 131.8 | 22.8 |
| X-Transformer [52] | 80.9 | 39.7 | 29.5 | 59.1 | 132.8 | 23.4 |
| DLCT [53] | 81.4 | 39.8 | 29.5 | 59.1 | 133.8 | 23.0 |
| RSTNet [54] | 81.8 | 40.1 | 29.8 | 59.5 | 135.6 | 23.3 |
| DIFNet [50] | 81.7 | 40.0 | 29.7 | 59.4 | 136.2 | 23.2 |
| BENet [55] | 82.1 | 40.3 | 30.0 | 59.7 | 137.6 | 23.6 |
| MFEAM | 82.8 | 40.8 | 30.5 | 60.2 | 140.1 | 24.3 |
| SEM | SWM | B-1 | B-4 | M | R | C | S |
|---|---|---|---|---|---|---|---|
| - | - | 77.8 | 37.7 | 28.6 | 57.5 | 122.8 | 21.5 |
| - | √ | 78.2 | 38.1 | 28.9 | 57.8 | 123.5 | 21.8 |
| √ | - | 78.6 | 38.9 | 29.1 | 58.6 | 125.3 | 22.1 |
| √ | √ | 79.2 | 39.7 | 29.3 | 59.1 | 127.3 | 22.4 |
| Model | Model Averaging | B-1 | B-4 | M | R | C | S |
|---|---|---|---|---|---|---|---|
| CLIP-VIT-B/16 | - | 78.0 | 38.1 | 28.9 | 58.2 | 123.1 | 21.8 |
| CLIP-VIT-B/32 | - | 76.3 | 36.6 | 28.1 | 56.8 | 118.3 | 21.1 |
| CLIP-RN50 | - | 75.9 | 36.3 | 27.8 | 56.6 | 115.9 | 20.6 |
| CLIP-RN101 | - | 76.6 | 37.1 | 28.1 | 57.1 | 118.7 | 21.0 |
| CLIP-RN50×4 | - | 77.3 | 37.8 | 28.5 | 57.7 | 122.0 | 21.5 |
| CLIP-RN50×16 | - | 78.7 | 39.1 | 29.1 | 58.8 | 126.7 | 22.3 |
| MFEAM | √ | 79.2 | 39.7 | 29.3 | 59.1 | 127.3 | 22.4 |
| Model | MFEAM | B-1 | B-4 | M | R | C | S |
|---|---|---|---|---|---|---|---|
| CLIP-VIT-B/16 | - | 77.8 | 38.0 | 29.1 | 58.0 | 122.5 | 21.8 |
| CLIP-VIT-B/16 | √ | 78.8 | 38.9 | 29.2 | 58.6 | 125.7 | 22.0 |
| CLIP-VIT-B/32 | - | 76.5 | 36.7 | 28.1 | 56.9 | 118.1 | 21.0 |
| CLIP-VIT-B/32 | √ | 76.5 | 36.9 | 27.9 | 56.9 | 119.7 | 21.1 |
| CLIP-RN50 | - | 75.7 | 36.2 | 28.1 | 56.7 | 115.7 | 20.8 |
| CLIP-RN50 | √ | 76.3 | 36.6 | 28.2 | 56.8 | 116.2 | 20.7 |
| CLIP-RN101 | - | 76.5 | 37.2 | 28.4 | 57.2 | 118.6 | 21.2 |
| CLIP-RN101 | √ | 77.1 | 37.4 | 28.5 | 57.5 | 119.0 | 21.1 |
| CLIP-RN50×4 | - | 77.2 | 37.6 | 28.7 | 57.6 | 121.9 | 21.6 |
| CLIP-RN50×4 | √ | 77.9 | 38.3 | 28.6 | 58.0 | 122.4 | 21.7 |
| CLIP-RN50×16 | - | 78.0 | 38.8 | 29.4 | 58.6 | 125.0 | 22.2 |
| CLIP-RN50×16 | √ | 79.2 | 39.7 | 29.3 | 59.1 | 127.3 | 22.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, Y.; Zhang, J. MFEAM: Multi-View Feature Enhanced Attention Model for Image Captioning. Appl. Sci. 2025, 15, 8368. https://doi.org/10.3390/app15158368
Cui Y, Zhang J. MFEAM: Multi-View Feature Enhanced Attention Model for Image Captioning. Applied Sciences. 2025; 15(15):8368. https://doi.org/10.3390/app15158368
Chicago/Turabian StyleCui, Yang, and Juan Zhang. 2025. "MFEAM: Multi-View Feature Enhanced Attention Model for Image Captioning" Applied Sciences 15, no. 15: 8368. https://doi.org/10.3390/app15158368
APA StyleCui, Y., & Zhang, J. (2025). MFEAM: Multi-View Feature Enhanced Attention Model for Image Captioning. Applied Sciences, 15(15), 8368. https://doi.org/10.3390/app15158368