1. Introduction
Autonomous navigation has drawn significant attention over the past years for its potential application in unmanned system. SLAM enables localization and mapping in GNSS-denied environments, making it a crucial and widely adopted technology for autonomous navigation across various applications [
1,
2]. Over the years, SLAM has undergone significant advancements, transitioning from pure vision-based approaches to more robust multi-sensor fusion methods that integrate LiDAR, inertial measurement units (IMU), and cameras to enhance localization accuracy and robustness. The most cutting-edge and advanced LIV-SLAM systems [
3,
4,
5,
6] exploit the depth accuracy of LiDAR, the motion constraints of IMU, and the feature richness of vision sensors to achieve high-precision and reliable localization and mapping in complex, real-world environments.
Despite the significant improvements achieved by the recent works, SLAM still faces several challenges. One major issue is the accumulation of errors over long-distance operation, leading to localization drift and map distortion. Additionally, global optimization for correcting accumulated errors in SLAM systems depends heavily on loop closure detection [
7,
8,
9,
10]. However, in many real-world scenarios, loop closures may be absent or challenging to detect.
Motivated by the limits of current methods and practical demands, we proposed a real-time geo-localizing navigation method for land vehicles that relies only on a LIV-SLAM and a referenced image. Our method is designed to function without GPS or loop closure. Instead, it estimates the global position by aligning the real-time constructed map to a referenced image with an efficient cross modal matching algorithm.
This paper makes three main contributions:
(1) A fast and robust cross-modal matching algorithm is proposed for the real-time geo-localization for land vehicles. The matching algorithm is designed to address the distortion caused by cross-modal, downward-view projection and cross-temporal scene variations, as shown in
Figure 1.
Figure 1a,b demonstrate cross-modal distortion, where the grayscale appearance of the same object varies significantly across modalities.
Figure 1c,d depict projecting distortion, in which the object’s appearance changes due to geometric transformation.
Figure 1e,f show scene variations resulting from temporal discrepancies between the projection image and the referenced image. Notably, all projection images contain invalid regions, typically visualized as black areas, which may introduce ambiguity and reduce the robustness of the matching process. We exploit Dense Structure Principal Direction (DSPD) [
11] to capture gradient-orientation-based texture patterns, which remains consistent for cross-domain images.
Furthermore, the similarity measurement is optimized, and the searching efficiency is significantly improved with a fast correlation in the frequency domain. The comparison in the ablation experiments demonstrates that the proposed cross-modal matching algorithm achieved the best result in both accuracy and efficiency. A detailed comparative evaluation of different matching algorithms is presented in
Section 4.3.1, which clearly shows the superior performance of our method in terms of matching precision and computational speed.
(2) This paper proposes an adaptive Kalman filter based on motion compensation (MC) and an Observation-Aware Gain Scaling (OAGS) mechanism. With motion compensation, the proposed AKF effectively eliminates prediction errors caused by observation delays and asynchronous updates. Ablation experiments demonstrate that MC effectively mitigates the adverse effects of observation delay, preventing degradation in fused localization accuracy, as detailed in the comparison of filters presented in
Section 4.3.2. The OAGS mechanism dynamically adjusts the Kalman gain based on the matching coefficient, prediction deviation, and matching inconsistency, minimizing the adverse impact of incorrect matches on state estimation. This enhancement enables the proposed matching-based autonomous navigation approach to more effectively adapt to complex environmental variations, ensuring robust and reliable localization, as validated by the experimental results in
Section 4.2 (Adaptability Evaluation) and
Section 4.3.2 (Comparison of Filters).
(3) Building on the contributions above, we propose a novel and practical long-distance autonomous navigation approach for land vehicles. The proposed method is evaluated on the R
3LIVE [
3,
4] and NCLT [
12] datasets, demonstrating its effectiveness in diverse real-world scenarios. Experimental results show that the proposed method enables real-time global localization and effectively addresses the issue of position drift in LIV-SLAM systems. It achieves an average RMSE of 2.03 m across all sequences of the NCLT dataset in outdoor environments and 2.64 m on the R
3LIVE dataset under the same condition.
To clarify the scope of this work, it should be noted that the goal of our research is not to present a universally optimal global localization solution. Rather, we aim to address a practical and increasingly common scenario: autonomous navigation in GNSS-denied environments where LiDAR and visual sensors are available.
3. Materials and Methods
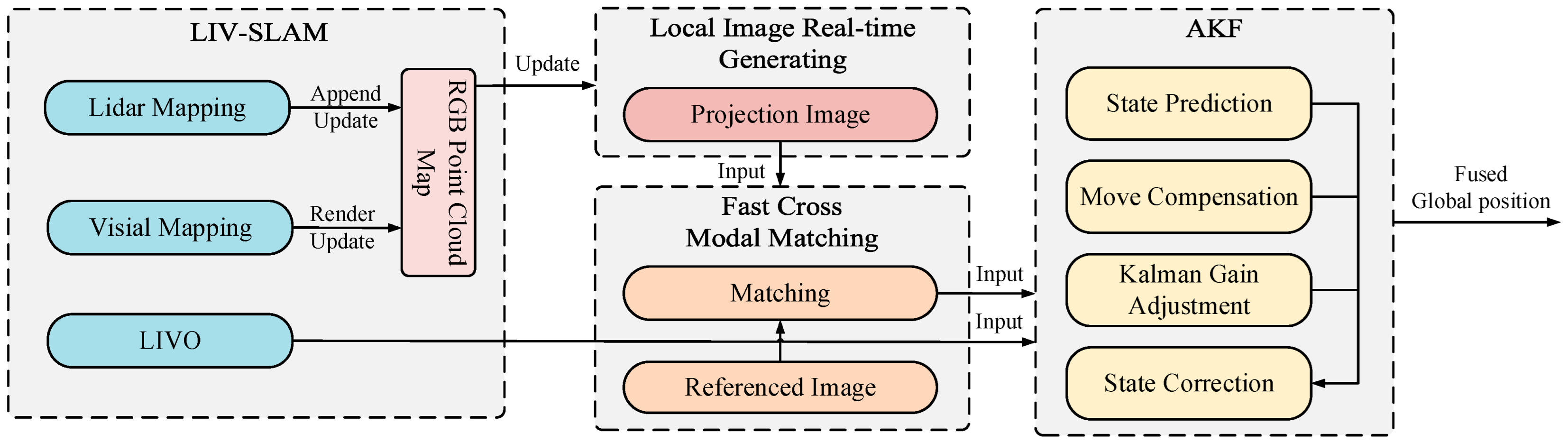
3.1. System Overview
The overall framework of our system is illustrated in
Figure 2, consisting of four main components: LIV-SLAM, local image real-time generating (
Section 3.2), fast cross-modal image matching (
Section 3.3), and AKF (
Section 3.4).
In our system, an existing LIV-SLAM framework is utilized for pose estimation and environment reconstruction. During the mapping process, the newly updated RGB point cloud, as shown in
Figure 3a, is fed into a local image real-time generating algorithm. This method effectively addresses the cross-view challenge by incrementally projecting the local observations into a vertical downward-view image, as shown in
Figure 3b. The fast cross-modal image matching module then aligns the projected image with the referenced image to get an absolute position in the referenced frame, as shown in
Figure 3c. Finally, the AKF module fuses the horizontal speed estimated by LIV-SLAM with the global position obtained from the fast cross-modal image matching algorithm. This integration provides a refined position expressed in the coordinate frame of the referenced image.
Notably, the LIV-SLAM module can be implemented using various state-of-the-art methods, such as Fast-LIO [
33,
34], R
3LIVE [
3], R
3LIVE++ [
4], Fast-LIVO [
6,
7] and so on. Although Fast-LIO is primarily a LiDAR-inertial odometry, the RGB point cloud map can be rendered through the extrinsic parameters obtained by the calibration between LiDAR and camera. The referenced satellite imagery used in our method is preloaded and stored locally on the onboard computer. No online map services or downloads are required during runtime.
3.2. Local Image Real-Time Generating
The local image generating algorithm integrates features from multiple LiDAR scans and camera frames, thereby significantly enhancing the feature richness compared to single-view approaches.
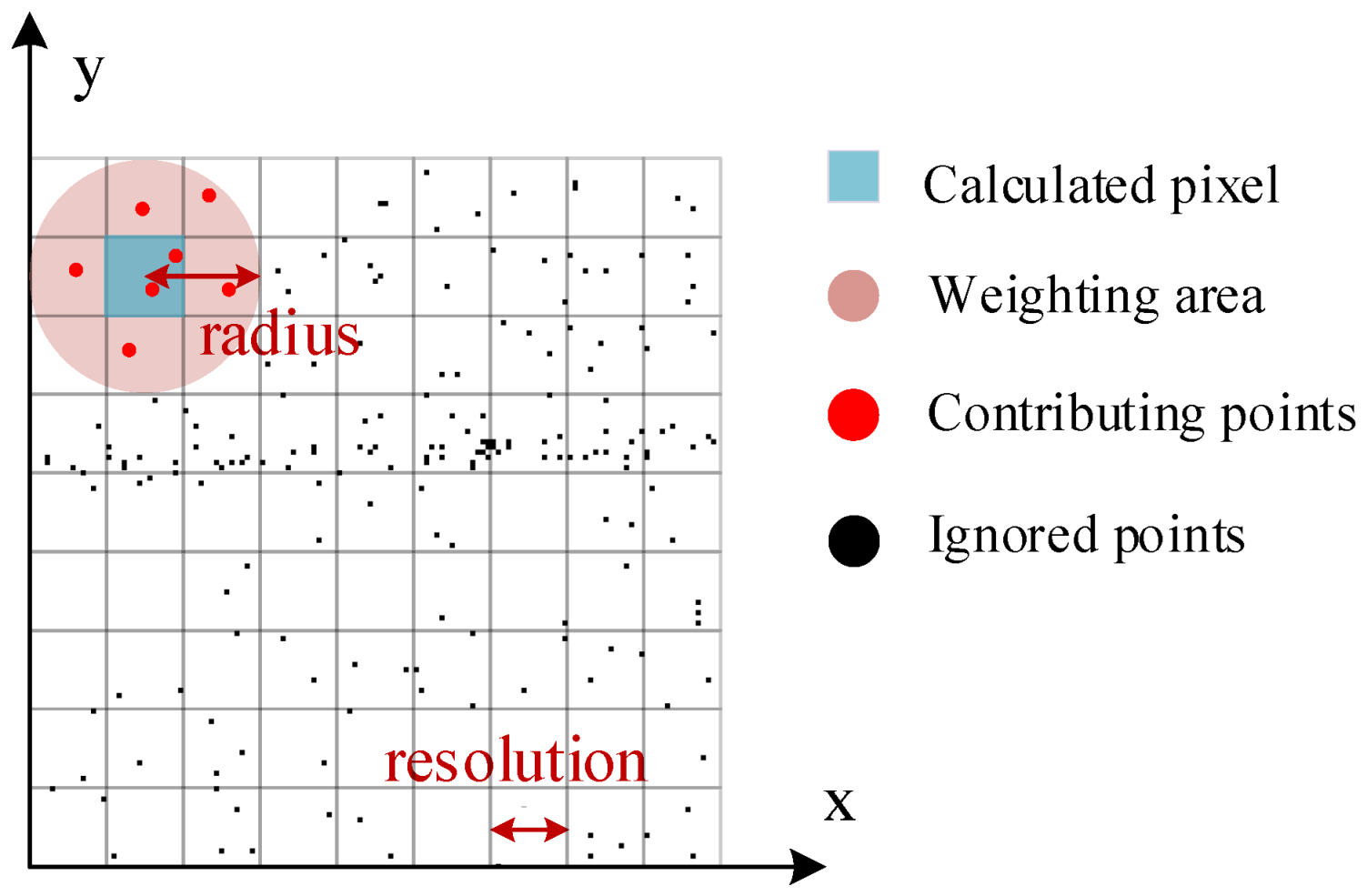
Figure 4 gives the details of the projection.
Given a point set:
where
represents the three-dimensional spatial coordinates, and
represents the corresponding color information. For each pixel at
, a subset of
within a radius is selected as contributing points, denoted as
. A projection map can be calculated using a Gaussian-weighted averaging method as follows:
where
denotes the Euclidean distance between point
and the calculated pixel
,
is the standard deviation, and
represents the color channel, as each channel of the color
is averaged in the same manner.
A straightforward implementation can be adopted. First, a projection image is determined based on the size of the projection area and the specified resolution. The color of each pixel is then computed using Equation (2), as illustrated in
Figure 4. Assuming the image size is
and there are
points within the projection area, the computational complexity of the approach is
. It is evident that this complexity increases rapidly with larger projection areas and finer resolutions.
To reduce computational overhead, the projection process is designed in an incremental way, using only the updated point cloud from the LIV-SLAM module. Specifically, each new point is projected onto the pixels within its effective weighting area. The numerator and denominator of (2) are accumulated into a value map
and a weight map
, respectively. Then, the local projection image is generated by pixel-wise division of the value map by the weight map as follows:
The computational complexities of the first and second steps are and , respectively, where is the size of the effective weighting area for a single pixel, and represents the number of updated points. Typically, the weighting region for a single pixel is much smaller than the entire projection area (), and the number of updated points is significantly less than the total number of points within the projection area (). As a result, the incremental implementation is considerably more efficient. Moreover, the computational complexity remains invariant by increases in image size or resolution, which enhances matching reliability and accuracy by allowing larger projection images to capture more distinctive and detailed features.
3.3. Fast Cross-Modal Matching
To address the distortions illustrated in
Figure 1, we proposed a fast cross-modal matching algorithm based on DSPD [
11]. DSPD is a feature descriptor based on structural orientation of images, which can effectively adapt to nonlinear intensity variations across different imaging modalities. Although the DSPD feature is robust to cross-modal distortions, it does not consider the invalid regions caused by the projection as shown in
Figure 1. Besides, the matching algorithm proposed in [
11] suffers from high computational cost, as its similarity metric requires full searching in spatial domain and the affine searching, which in this algorithm leads to excessive search redundancy for the matching between local projection image and the referenced image, which only has translational uncertainty.
To enhance the computational efficiency, we optimize the similarity metric and employ translation full searching, which can be realized with fast correlations in the frequency domain. Specifically, the dissimilarity metric proposed in [
11] can be written to a similarity metric defined as follows:
where
denotes the DSPD at a pixel of the projection image, and
denotes the DSPD at the corresponding pixel of the referenced image.
To incorporate fast correlation in the frequency domain, we modify the similarity metric in (4) by introducing a double-angle cosine similarity as below:
Both metrics give minimal similarity when the two DSPDs are mutually orthogonal and maximal similarity when they are parallel. Actually, Equation (5) can be derived from Equation (4) according to Fourier expansion. The detailed derivation of the equations is provided in the
Supplementary Materials.
Furthermore, the translation full searching-based matching with the double-angle cosine similarity metric can be expressed in the form of two correlations, as shown in (6):
where
is the mask of the projection image, which can be obtained during the projection process by binarizing the weight map. It is used to eliminate the influence of invalid regions in the projection image on the matching performance, as illustrated in
Figure 1.
According to the convolution theorem, the full searching in the correlation of spatial domains can be efficiently implemented in frequency domain with Fast Fourier Transform (FFT) [
35].
The translation full-searching with the similarity metric presented in Equation (4) has to be realized in the spatial domain. Given a projection image of size N × N and a search area of size M × M, the computational complexity of the full searching in the spatial domain is
. In contrast, the translation full-searching with the similarity metric presented in (6) can be realized in the frequency domain, where the FFT dominates the computational cost, resulting in an overall complexity of
[
35]. The comparison of matching algorithms in ablation experiments (
Section 4.3) demonstrates that the optimization significantly enhances the computational efficiency while maintaining the matching accuracy.
3.4. AKF Based on MC and OAGS
(1) Model: The system state
of the proposed AKF is given as below:
where the three sub-vectors
denote the position, velocity, and acceleration in a horizontal direction, respectively. The process model of the proposed AKF is a typical motion model, which can be expressed as follows:
where
and
represent the prior estimation and posterior estimate of the state at time
,
gives the transition of the system state over time, and the process noise
is attributed to uncertainties in acceleration.
The position observations are passed by the cross-modal matching algorithm, while the LIV-SLAM submodule provides the measurements of velocity, leading to the measurement model as follows:
where
contains the measurement of position and velocity,
represents an identity matrix, and the measurement noise
consists of position noise and velocity noise, defined as follows:
(2) Challenges: Since the observations are obtained from two independent submodules, there will be data latency and synchronization issues. Both the position and the velocity observations are subject to a certain delay due to the processing time before being input into the filter. Additionally, there is a discrepancy in update frequencies between position and velocity observations. Error position observation is another challenge. Although our cross-modal matching algorithm can adapt to image distortions to a certain extent, localization may degrade or even fail in the presence of significant scene changes or heavy occlusions or during transitions into indoor environments.
(3) Motion Compensation (MC): In the proposed method, historical observational data and the estimated navigation states output by the AKF are retained. The position observations are compensated using the past velocity observations, while the velocity observations are compensated based on historical acceleration estimations. This compensation mechanism enables the Kalman filter to process asynchronous data in a temporally consistent manner, ensuring fixed-frequency operation while minimizing the impact of observational delays, as shown in
Figure 5. The effectiveness of MC is validated in the comparison of filters in ablation experiments (
Section 4.3).
(4) Observation-Aware Gain Scaling (OAGS): To evaluate the confidence of position observations, we leverage the three indicators as follows:
Matching coefficient: This refers to the value of the similarity metric defined in (6), which is an indicator of matching reliability. A higher matching coefficient means a higher confidence level for a position observation, and vice versa.
Matching inconsistency: After the initial matching, the sub-patches of the projection image will be re-searched in corresponding sub-searching areas. The matching inconsistency
is calculated as follows:
where
is the translation estimated with the projection image, and
is the translation estimated with a sub-patch. A large matching inconsistency typically suggests that the associated position observation is incorrect.
The three indicators are normalized and utilized as input to the sigmoid function, which is defined as follows:
This function gives the relationship between the confidence of position and the three indicators (denoted as vector ). is a weighted vector, and and are linear transformation parameters. Based on the observation that the matching coefficient is positively correlated with the confidence of the matching result, while the latter two indicators are negatively correlated with it, the parameter is set as , the scaling factor is set to 10 to effectively amplify the effect of , and the bias term is set to 0. This configuration is fixed through all our experiments.
Based on the evaluation of position observation confidence, the OAGS is formulated as below:
where
represents the original Kalman gain, the position-related components of which are adaptively adjusted based on the confidence of the position observation, denoted as
. Consequently, the updates to the position state
and the covariance matrix
are modified accordingly, as shown in Equations (14) and (15).
Equations (13) and (14) show that the filter places greater reliance on the observation when the confidence is high, while reducing the influence of the erroneous position observation when the confidence is low.
4. Experiments
To evaluate the performance of the proposed method, we conduct extensive experiments in public datasets, including the NCLT dataset [
12] and R
3LIVE dataset [
3,
4]. Both datasets contain LiDAR, IMU, and camera data. To better evaluate the position drift correction of the proposed method, we selected 14 long-distance sequences covering diverse environmental conditions.
Table 1 and
Table 2 give the details of the selected sequences.
Localization accuracy is evaluated using the Absolute Position Error (APE), which is calculated in terms of RMSE:
where
denotes the estimated position of the proposed method and
is the corresponding position of ground truth.
Since matching-based positioning is infeasible indoors, some accuracy evaluations exclude all indoor results. Columns labeled as “outdoor” report statistics for outdoor localization only, while others include all results.
In our implementation, the projection area is set to 150 m × 150 m with an image resolution of 0.1 m/pixel, and the matching search radius is 20 m. The R3LIVE dataset was collected in August 2021, and the corresponding referenced imagery was collected in April 2022. The NCLT dataset used in our experiments was recorded in 2012 from February to November, and the corresponding referenced imagery was captured in April 2015. All referenced imagery was acquired from Google Earth at zoom level 19, with an approximate ground resolution of 0.2986 m/pixel. During processing, the referenced imagery was resampled to 0.1 m/pixel to maintain consistency with the resolution of the projection map.
4.1. Outdoor Accuracy Evaluation
To evaluate the localization accuracy of our proposed system, we conducted experiments on the NCLT dataset and compared the results with two representative SLAM algorithms: R
3LIVE++ [
4] and FAST-LIO2 [
34]. None of the compared methods employed loop closure. Our method utilizes FAST-LIO2 as the odometry backbone.
The experimental results are shown in
Table 1, demonstrating that the proposed method significantly improves localization accuracy compared to R
3LIVE++ and FAST-LIO2. This improvement is primarily attributed to the use of global localization based on image matching, which effectively eliminates error accumulation over time.
It is worth noting that the original R3LIVE++ paper does not report experimental results on the 2012-03-25 sequence. Our experiments further indicate that Fast-LIO2 exhibits significant drift on this sequence, with an RMSE of 19.30 m. However, our proposed method effectively corrects the drift by integrating matching-based observations.
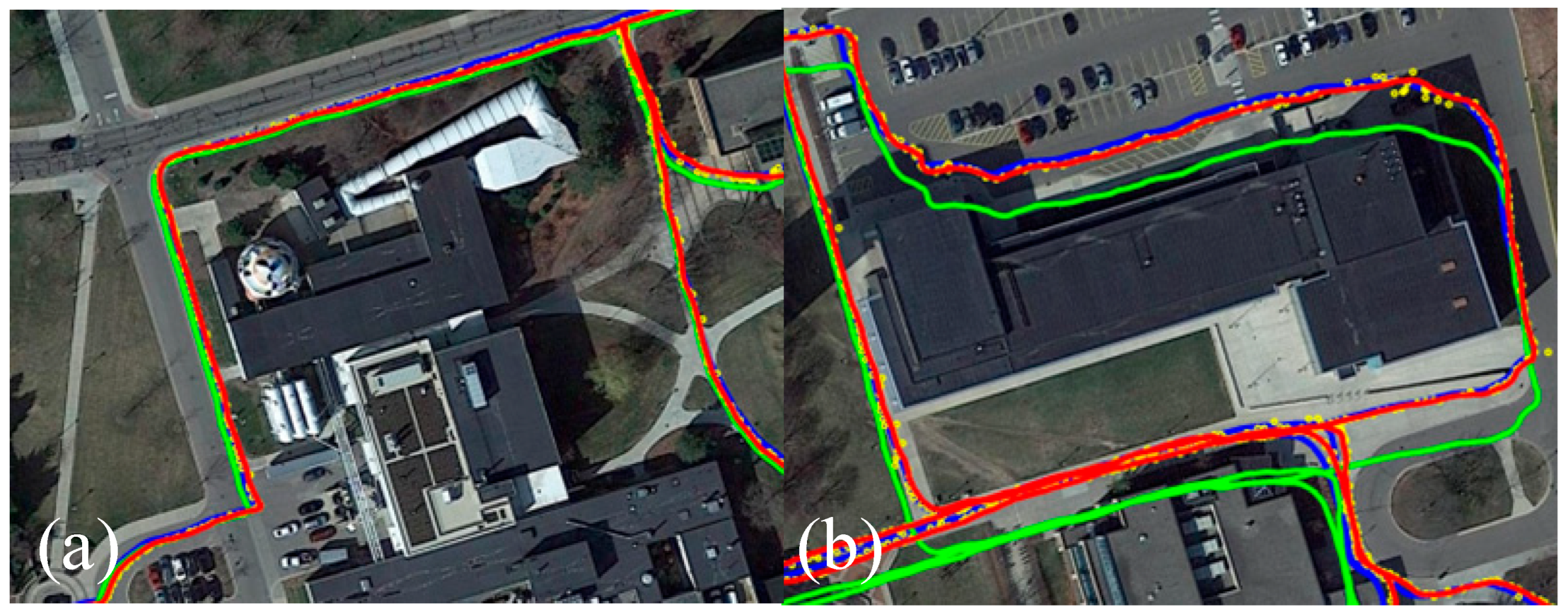
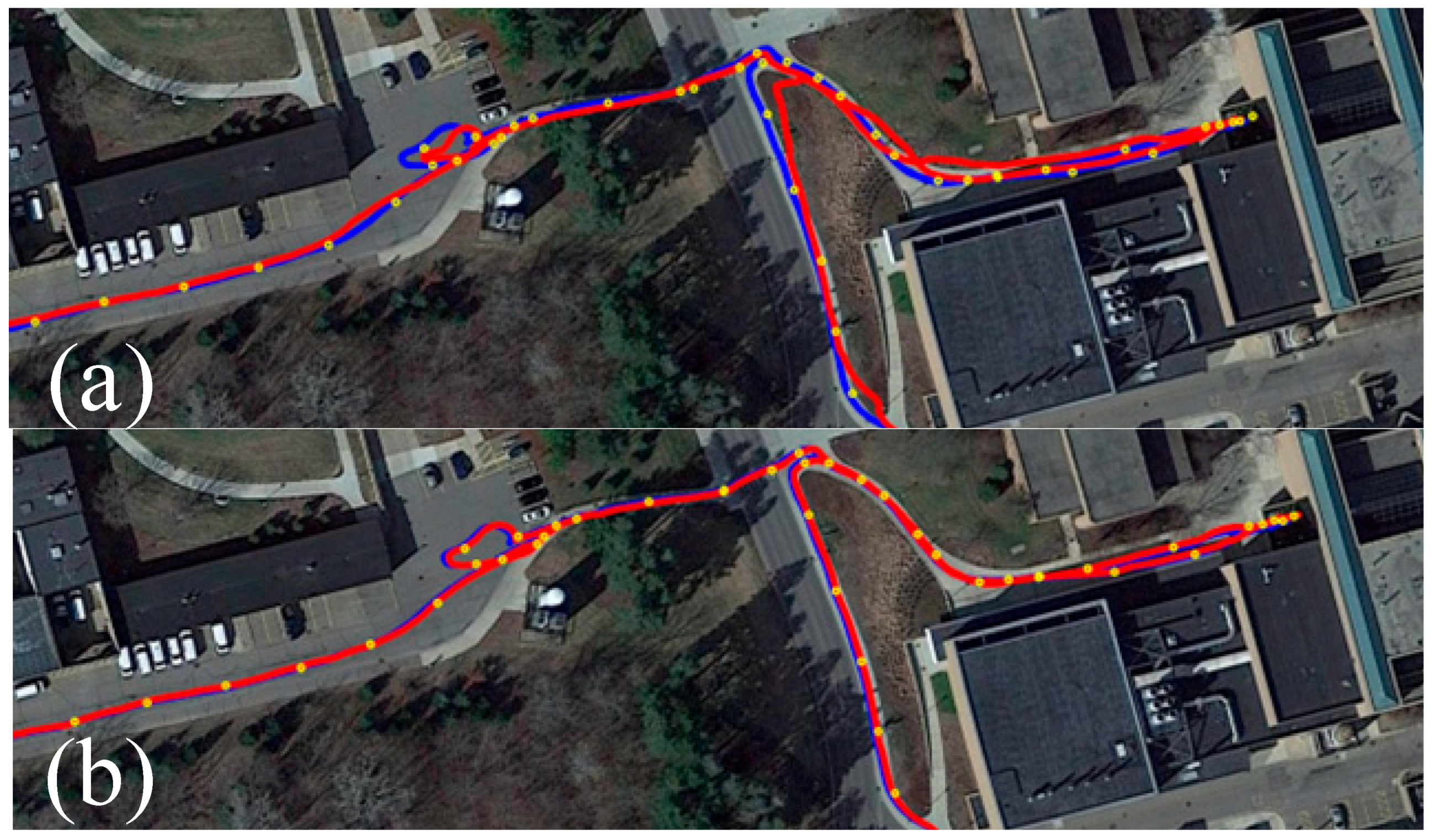
Figure 6 presents a comparison between the proposed method and FAST-LIO2 on a representative segment from the NCLT dataset. As shown in
Figure 6, the green, red, and blue lines represent the trajectories estimated by LIV-SLAM (FAST-LIO2), the proposed method, and the ground truth, respectively, while the yellow points indicate the localization results obtained from the matching algorithm. This color convention is consistently used throughout the paper. In
Figure 6a, the initial segment of a sequence from the NCLT dataset shows that FAST-LIO2 maintains low drift and achieves localization accuracy comparable to our method. However, in
Figure 6b, after approximately 1800 s, FAST-LIO2 begins to exhibit significant position drift due to accumulated odometry error. In contrast, our method continuously corrects this drift through matching-based global localization, thereby achieving improved overall localization accuracy.
We also conducted comparative experiments on two sequences from the R
3LIVE dataset, evaluating the proposed method against R
3LIVE and Fast-LIVO2. Since the original R
3LIVE, under default parameters, has been reported to achieve a localization accuracy of approximately 0.1 m [
3], we use its trajectory as the ground truth reference for evaluation.
Table 2 shows the localization accuracy of the three methods on the R
3LIVE dataset, also demonstrating that the proposed approach achieves the minimum RMSE among all tested methods. In
Table 2, R
3LIVE- is a degraded version of R
3LIVE, which operates with reduced point cloud resolution and a smaller number of tracked visual features, resulting in degraded odometry performance. When comparing with the outputs of R
3LIVE-, the LIV-SLAM module implemented in our system is also R
3LIVE-. Therefore, the observed improvements in localization accuracy are solely attributed to the proposed method.
4.2. Adaptability Evaluation
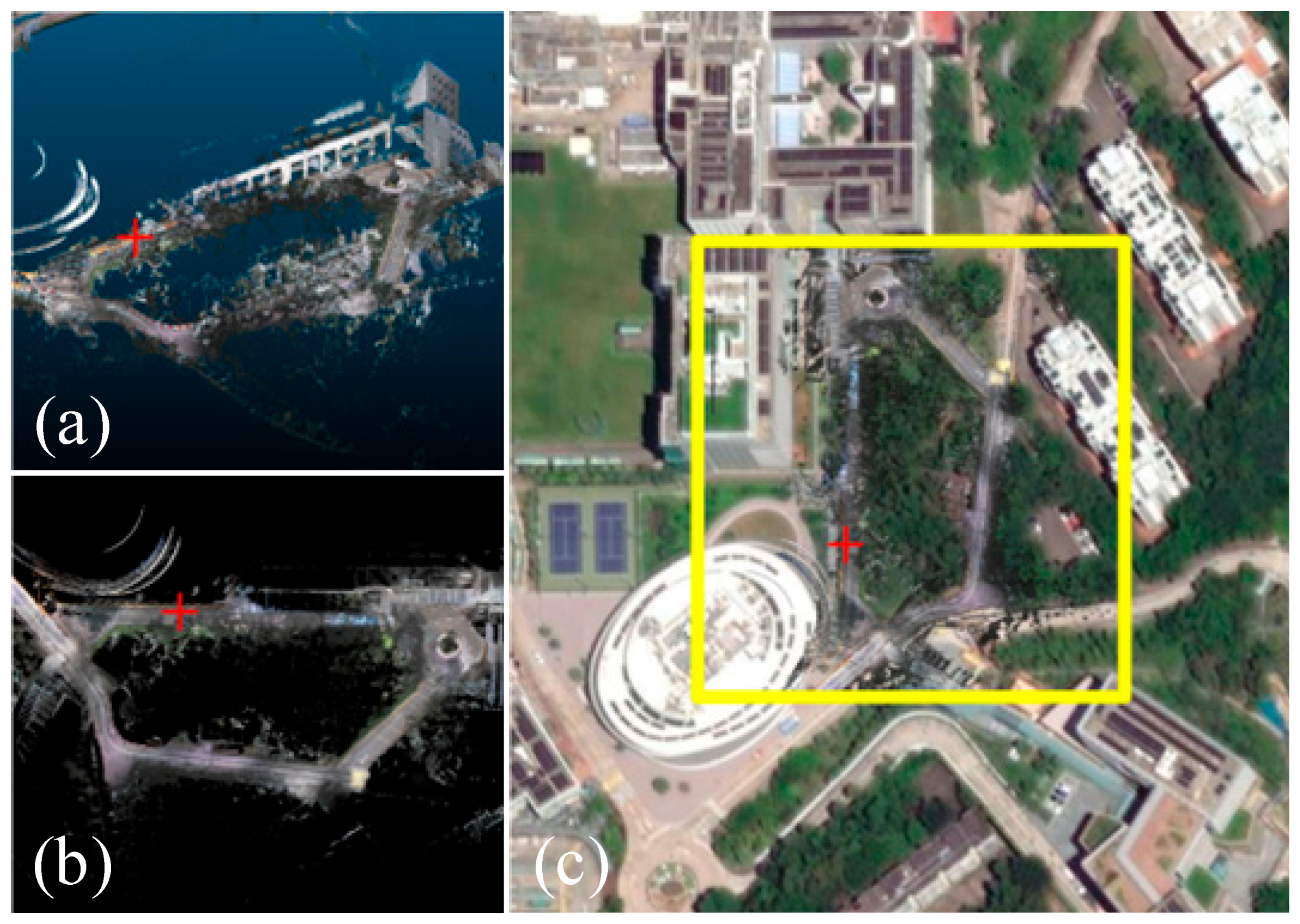
Significant scene variations and transitions into indoor environments may cause substantial discrepancies between real-time projection images and referenced images, thereby greatly reducing the reliability of image matching. To address this issue, two strategies can be adopted. First, enlarging the projection image area can help include more corresponding features, thus improving matching robustness.
Figure 7 presents an example of indoor environment, where the red cross represents the current localization,
Figure 7a,b show the projection image of the local region and its corresponding reference map, respectively. Compared to the 100 m × 100 m projection image, the 150 m × 150 m projection image includes a larger portion of the surrounding outdoor area, thereby capturing more features that effectively correspond to the reference image. Additionally, increasing the search range allows the matching algorithm to relocate the correct position after passing through disturbed or occluded regions.
Although the correct position can be relocated by increasing the search range, the fused localization accuracy will be still degraded due to the incorrect matching results. To mitigate this, the proposed OAGS mechanism adaptively adjusts the Kalman gain based on the matching confidence, thereby significantly suppressing the adverse impact of incorrect observations. As illustrated in
Figure 8a, erroneous observations from image matching could lead to significant localization errors, while
Figure 8b shows the result after applying the proposed OAGS mechanism. By effectively suppressing unreliable observations during indoor environments, the fusion trajectory with OAGS remains significantly closer to the ground truth, indicating a clear improvement in both localization robustness and accuracy.
4.3. Ablation Experiments
In this section, we conduct ablation experiments to evaluate the performance of the individual modules within the proposed framework.
4.3.1. Comparison of Matching Algorithm
The proposed matching algorithm is compared against other matching methods, including Scale Invariant Feature Transform (SIFT), omniGLUE [
36], MI [
37], and CFOG [
38]. Among them, SIFT is a classic local feature-based algorithm, while omniGLUE is a more recent and deep learning-based feature matching method that can be applied to cross-modal matching tasks. Both MI and CFOG are designed for cross-modal matching. Similar to our method, they adopt a translation-based full-search strategy for the matching. Two variants of our method are included in the comparison: ASD, a spatial-domain search based on the absolute difference metric (4), and CFD, a frequency-domain search utilizing the double-angle cosine similarity metric (6).
A total of 100 matching pairs, each consisting of a real-time projection image and the corresponding reference search region, were randomly sampled from 14 sequences. A matching result is considered incorrect if its distance to the ground truth exceeds 5 m. The results in
Table 3 demonstrate that our method achieves the best performance in terms of both matching accuracy rate and computational efficiency. Examples of the above matching method are provided in
Figure 9.
4.3.2. Comparison of Filters
In this section, we compare the performance of three variants of the Kalman filter: the standard Kalman filter (KF), the Kalman filter with motion compensation (KF + MC), and the Kalman filter with both motion compensation and the proposed Observation-Aware Gain Scaling (KF + MC + OAGS). The standard KF and KF + MC were each evaluated under three different positioning update frequencies to assess the impact of observation delay on localization performance.
The evaluation results are summarized in
Table 4. The results show that as the localization observation frequency decreases (corresponding to increased observation delay from 1 s to 10 s), the standard KF suffers from significant degradation in localization accuracy. In contrast, KF with MC maintains better performance due to the integration of motion compensation.
Figure 10 illustrates the trajectory segments of KF and KF + MC, highlighting the performance difference under a 10-s observation delay. Specifically, (a) shows the result of the standard KF, while (b) presents the corresponding trajectory obtained using KF + MC. The improvement is particularly evident in turning scenarios, where motion compensation effectively mitigates the impact of delayed observations.
Table 5 presents the comparison between KF + MC and KF + MC + OAGS. The results show that enabling OAGS further reduces the overall RMSE. This improvement is primarily due to the ability of OAGS to suppress the influence of incorrect matching results, which can otherwise degrade the fused localization accuracy, particularly in indoor environments where the referenced image is unavailable.
4.4. Computational Efficiency
In this section, we evaluate the average processing time of the proposed method. The experiments were conducted on a PC equipped with an Intel i7-1360P CPU and 64 GB of RAM, without any GPU acceleration.
The main computational cost of the proposed algorithm lies in the projection and matching modules. Enabling the OAGS mechanism introduces additional overhead due to the evaluation of matching inconsistency.
Table 6 reports the average processing time of each submodule in single-threaded implementation. On the testing platform, the system runs at approximately 14 Hz with OAGS enabled and around 30 Hz without it.
5. Conclusions
This paper presents a global localization algorithm based on real-time map projection and cross-modal image matching, which can effectively correct the drift in existing LIV-SLAM systems such as Fast-LIO, R3LIVE++, and Fast-LIVO2. In addition, we propose an AKF incorporating MC and OAGS mechanisms, which fuses the outputs of the LIV-SLAM module with global localization results to achieve a novel and practical long-distance autonomous navigation approach for land vehicles.
Compared to existing cross view-based autonomous navigation approaches [
32], which achieves an average localization accuracy of about 20 m and operates at a relatively low frequency of 0.5–1 Hz, the proposed method achieves pixel-level alignment, resulting in significantly improved localization accuracy (RMSE of about 2 m) and real-time performance (approximately 14 Hz with OAGS enabled and around 30 Hz without it).
However, the proposed method has several limitations. First, it requires accumulating a sufficient amount of point cloud data before generating a projection image, thus it cannot support one-shot localization. Second, the system relies on the output of a LIV-SLAM module; if the SLAM fails completely (e.g., due to extreme motion or sensor degradation), the localization may fail. Additionally, in environments lacking structural or texture features, such as open grasslands or deserts, the image matching process may be unreliable.
Future work will focus on extending the proposed framework to a purely vision-based solution that eliminates the dependency on LiDAR sensors. This adaptation will improve the system’s applicability to a broader range of platforms.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}