1. Introduction
Bearing fault diagnosis is critical for the smooth operation of rotating machinery, which plays an essential role in various industries, from power generation to manufacturing. Bearings are fundamental components that facilitate rotation and support mechanical systems. In recent years, many scholars have researched how to extract information from vibration signals for fault diagnosis [
1,
2], proposing numerous advanced methods [
3], among which intelligent fault diagnosis based on deep learning has garnered particular attention in recent years [
4,
5].
Zhang et al. [
6] first designed a deep Convolutional Neural Network (CNN) with wide first-layer kernels (WDCNN) for fault diagnosis under the source domain setting, where both training and testing data were collected from the same set of bearing individuals. This architecture was tailored to enhance the network’s ability to capture long-range dependencies and extract detailed features from the vibration signals. Further, they proposed a convolutional neural network with training interference (TICNN) [
7] to enhance performance under noisy environmental conditions and different working loads, which better meets the need of practical industrial scenarios. Lin et al. [
8] proposed a novel meta-learning framework called generalized MAML to analyze the acceleration and acoustic signals obtained from bearings under different working conditions. Xu et al. [
9] introduced a zero-shot fault semantics learning model for diagnosing compound faults. Additionally, Chen et al. [
10] developed a dual adversarial learning-based multi-domain adaptation network for collaborative fault diagnosis across both bearings and gearboxes, with comparative results confirming its superior performance and effectiveness over other methods. Most current intelligent fault diagnosis models are trained and tested within the same individual. However, in practical industrial scenarios, the test objects are usually new components with potential individual differences [
11], including manufacturing differences, production inconsistencies, assembly issues, and variations in fault manifestation. Consequently, differences in data distribution between the test and training individuals may hinder the model’s ability to accurately perform fault classification. Recently, scholars have begun to focus on more practical cross-domain issues beyond cross-condition scenarios, such as cross-machine problems [
12,
13], which are more closely aligned with real-world industrial applications. Cross-individual scenarios are practical, yet they remain insufficiently explored. This presents a challenging task that requires further attention [
14,
15].
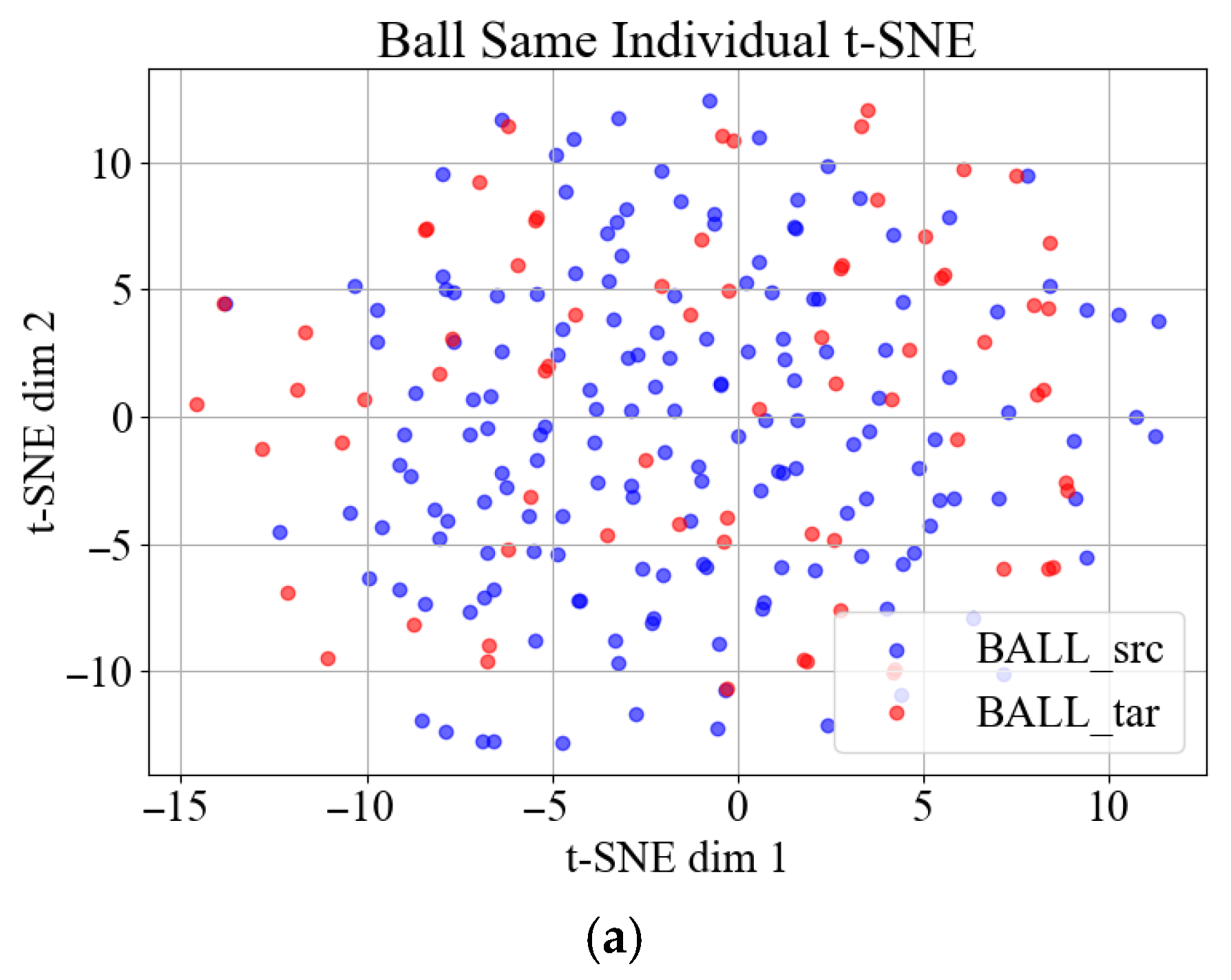
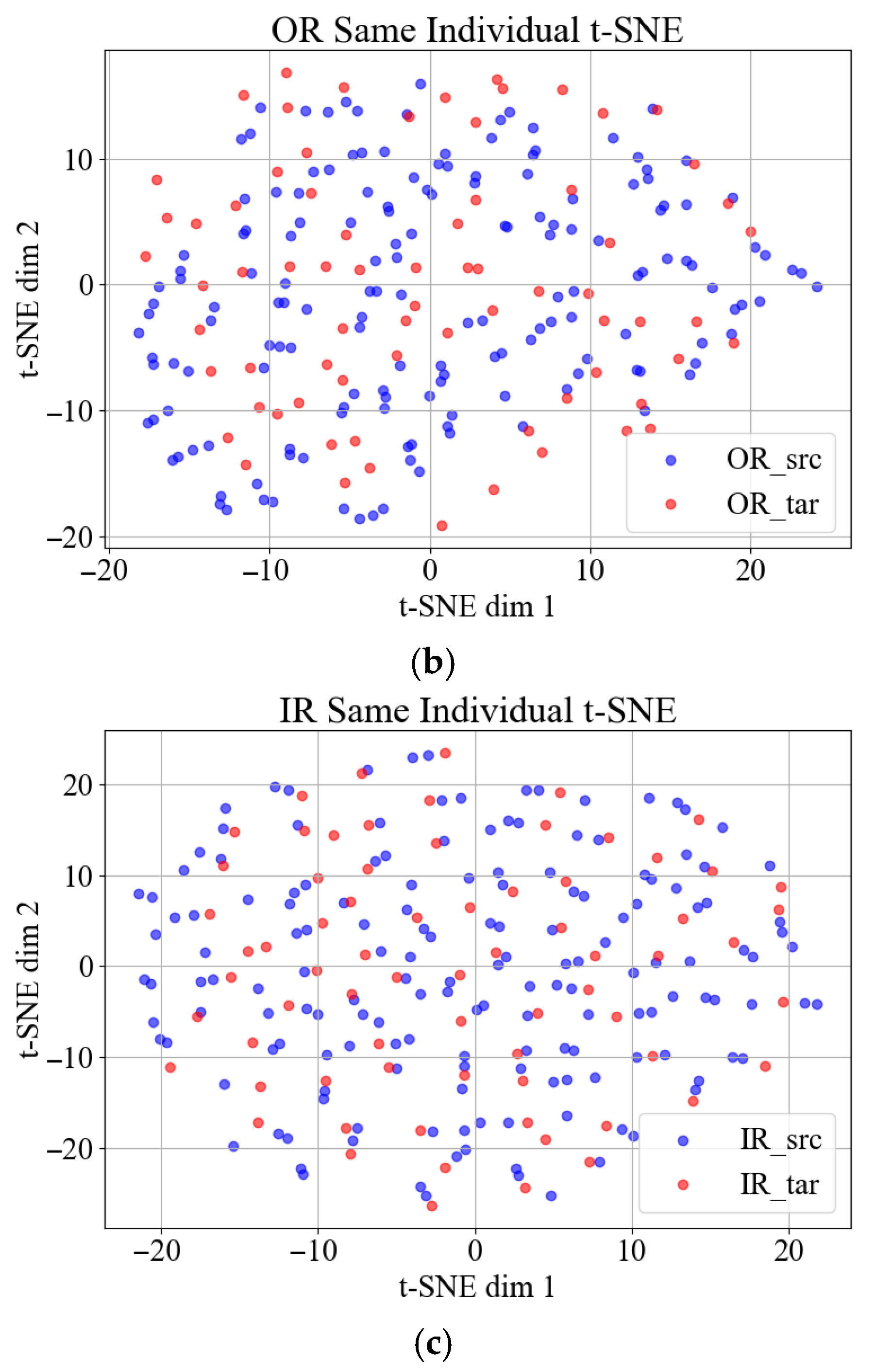
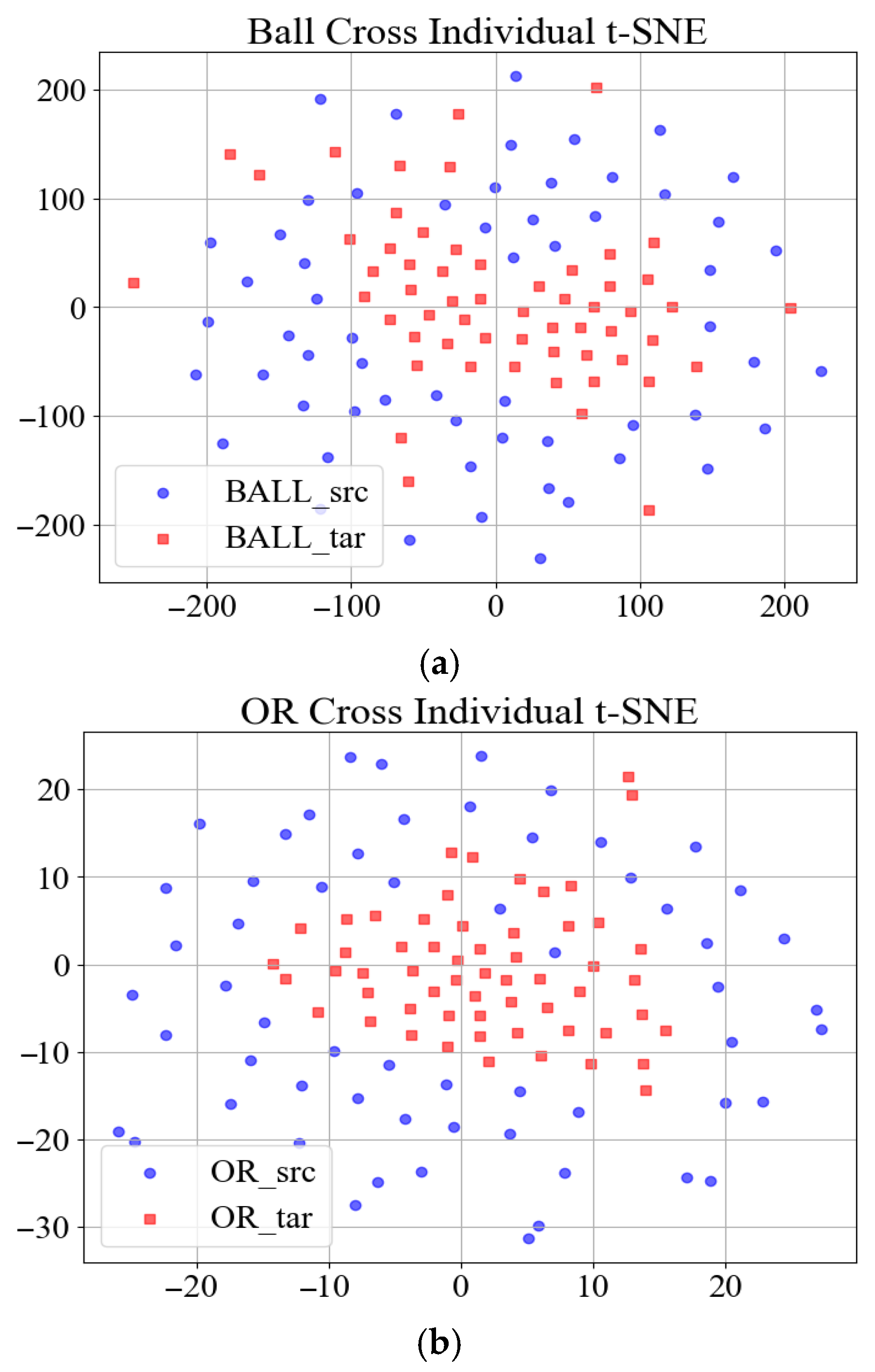
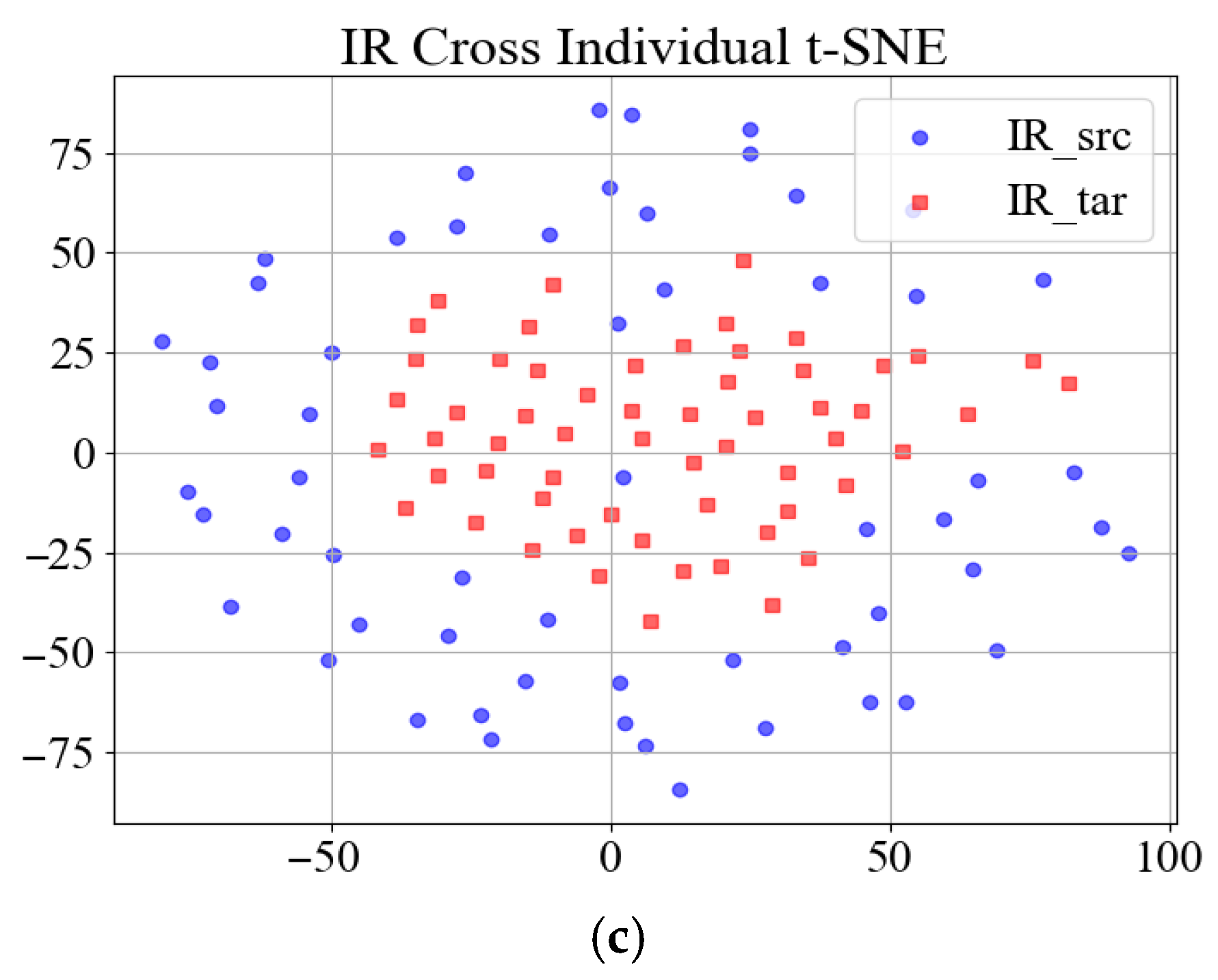
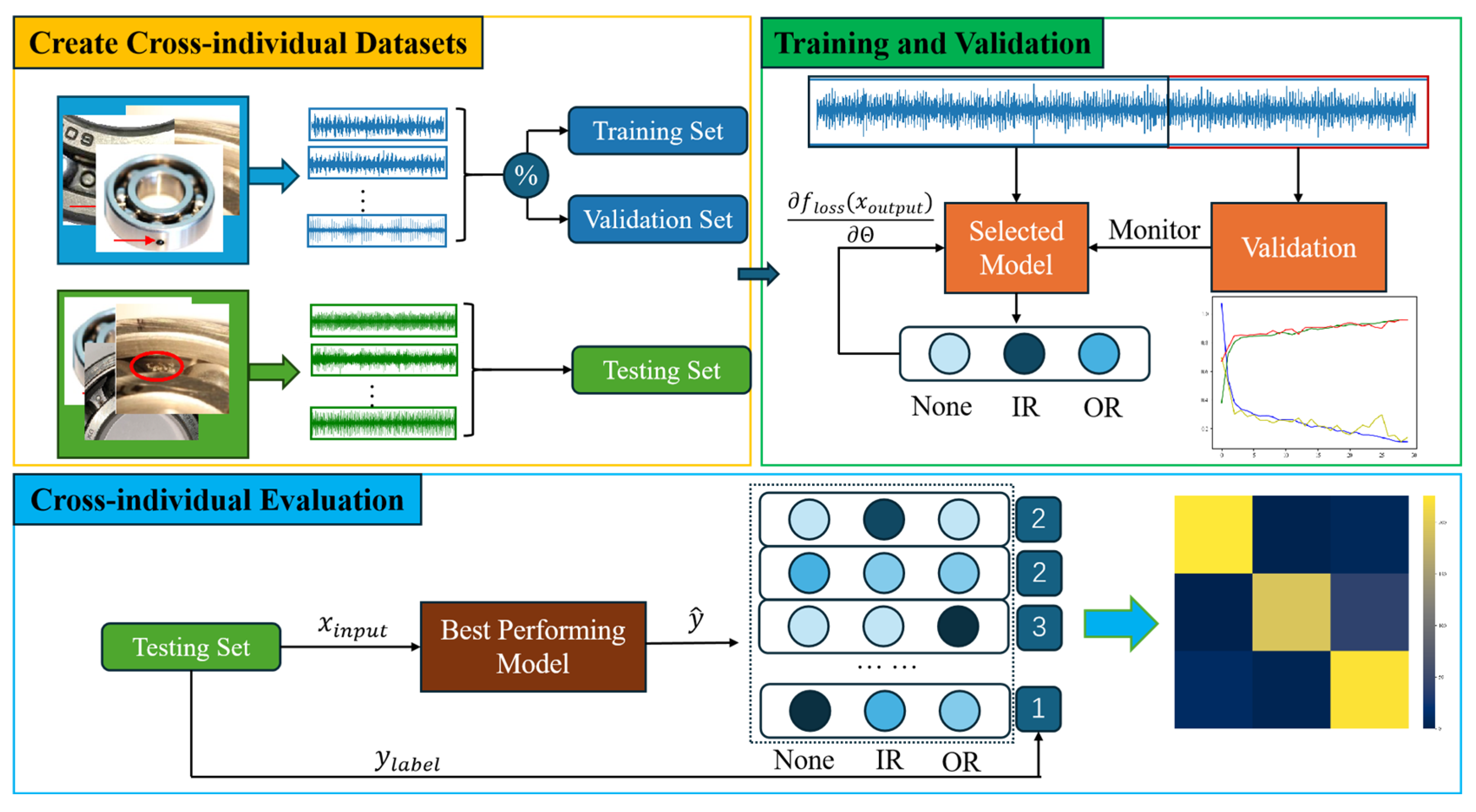
To demonstrate the challenge, the widely cited Case Western Reserve University (CWRU) bearing dataset serves as an illustrative example. Vibration signals corresponding to three distinct bearing fault types, Ball, Inner Race (IR), and Outer Race (OR) from the drive end (DE), were segmented using a sliding window approach to construct the source domain dataset. Respectively,
Figure 1a–c and
Figure 2a–c present the t-SNE [
16] (t-Distributed Stochastic Neighbor Embedding) visualization of the training and testing data distribution for the in-domain task and cross-individual task, where the blue markers represent the dimensionally reduced training set samples and the red markers denote the test set samples in the embedded space.
The t-SNE (t-Distributed Stochastic Neighbor Embedding) visualization reveals the following: (1) compact clustering of same-individual samples (intra-domain consistency), and (2) pronounced distribution shifts between the source (training) and target (testing) individuals, empirically demonstrating the cross-individual generalization challenge in bearing fault diagnosis.
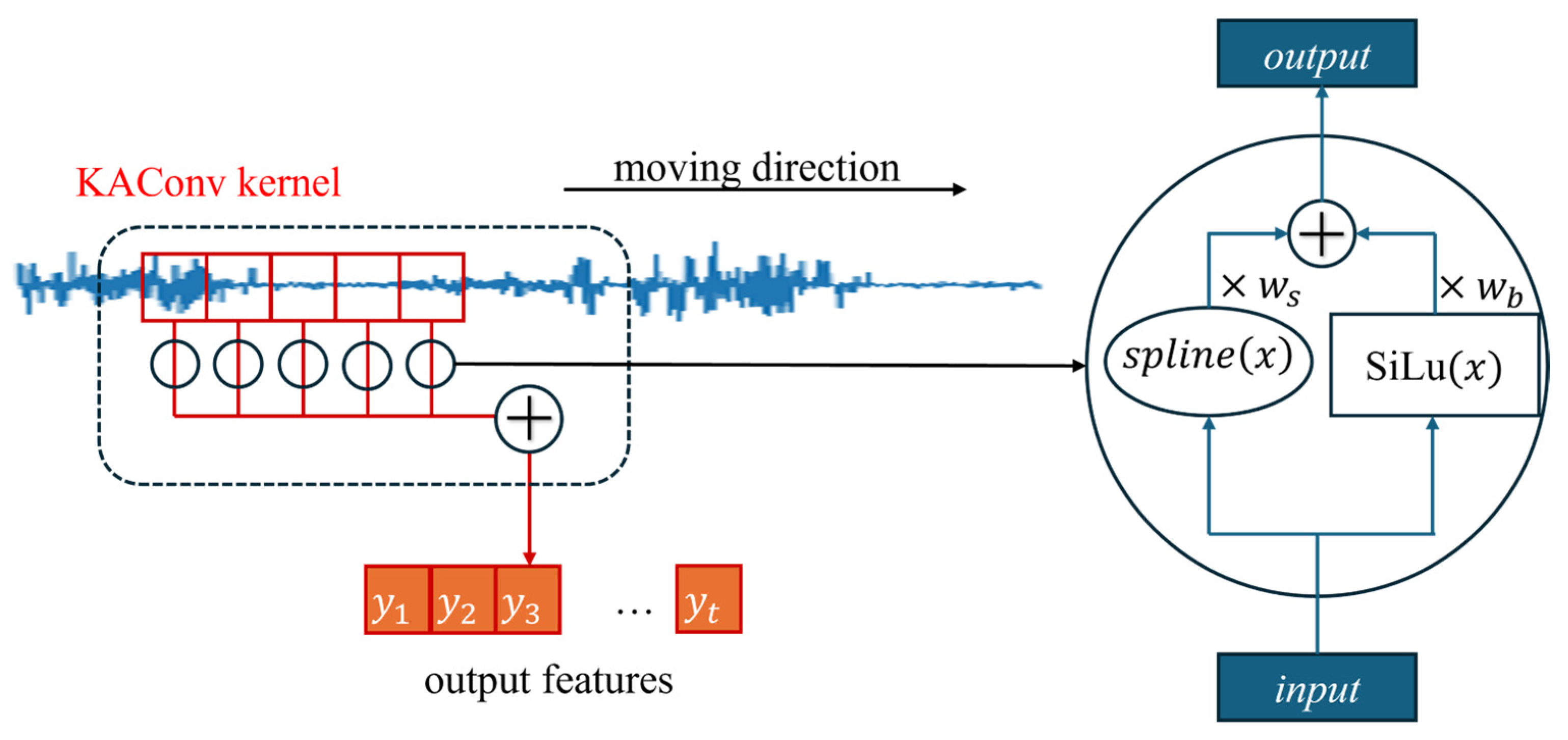
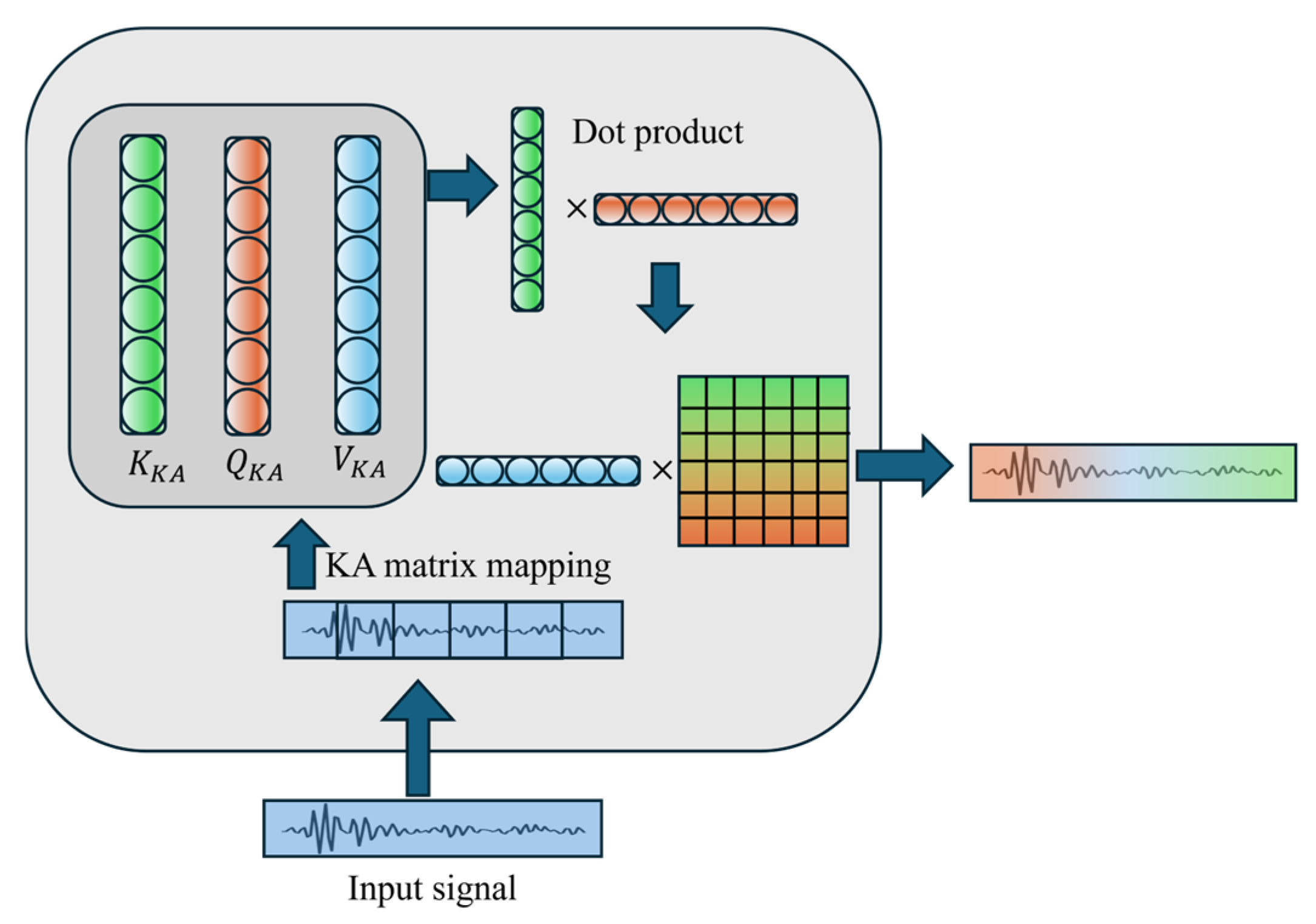
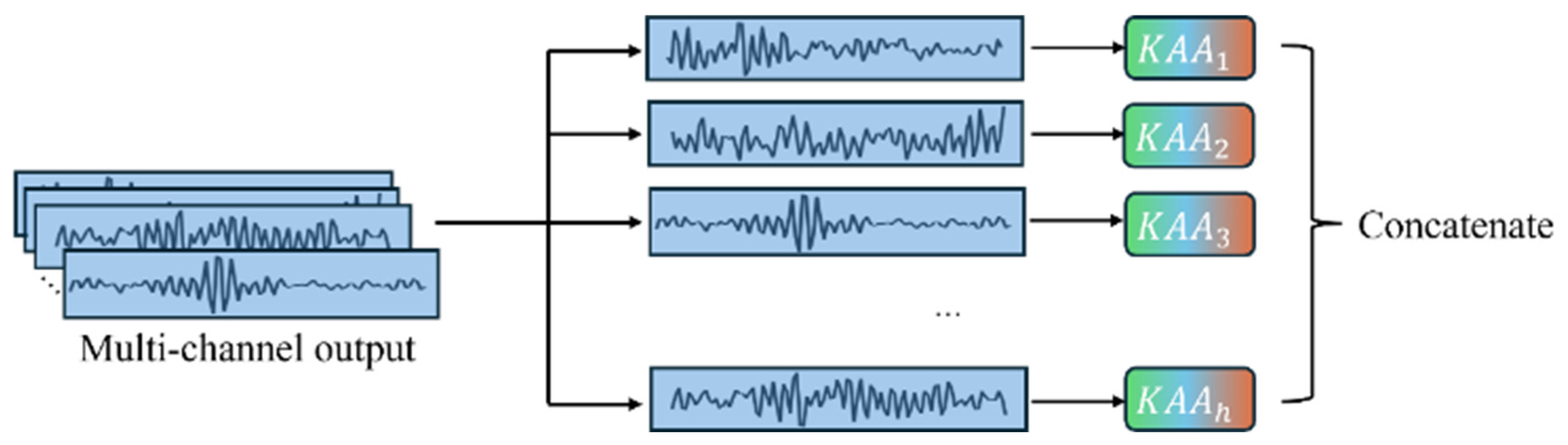
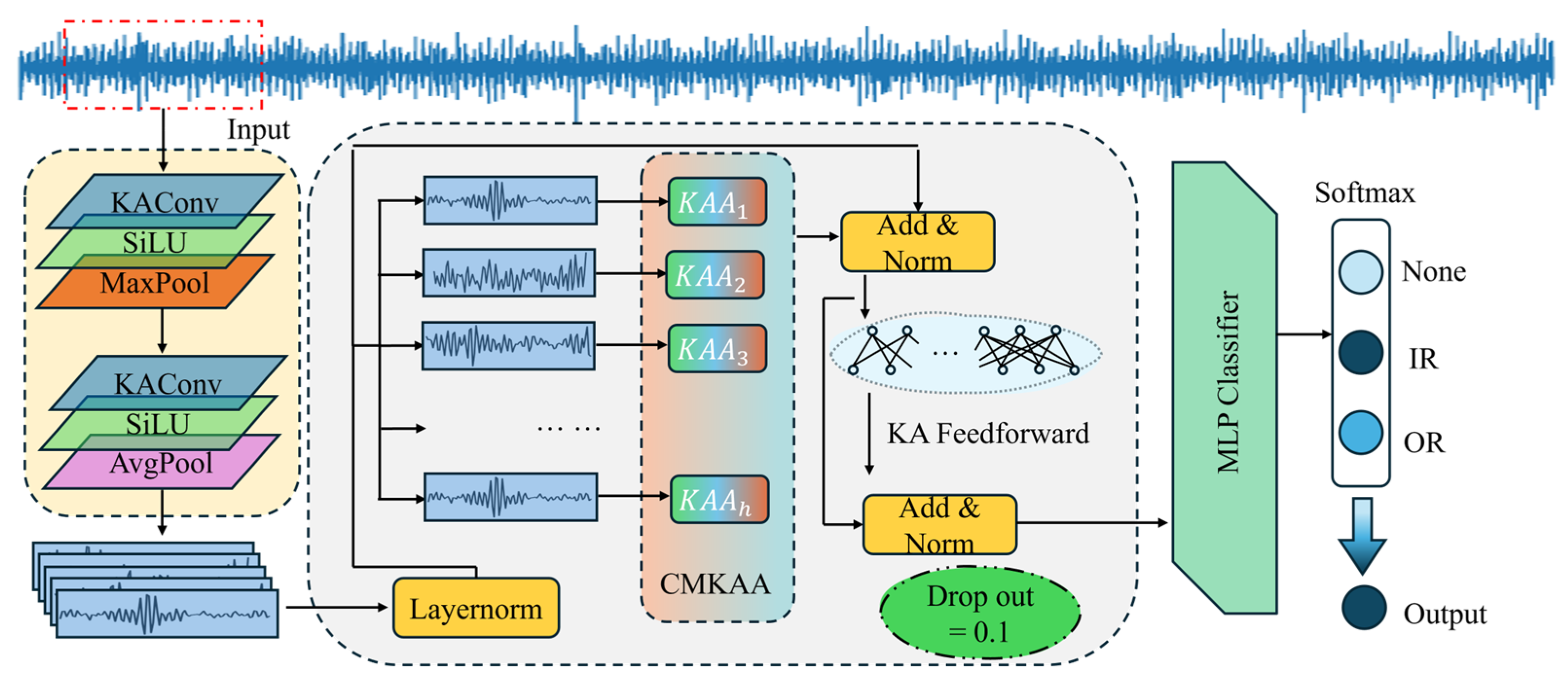
Inspired by the Kolmogorov–Arnold representation theorem (KART) [
17], Liu et al. proposed Kolmogorov–Arnold networks (KANs) as promising alternatives to multi-layer perceptrons (MLPs). With a fixed activation function and linear weights replaced by a univariate function parametrized as a spline, KANs tend to show a better nonlinearity expressive capability. This groundbreaking architecture offers promising potential for enhancing model generalization and accuracy. S. Ni et al. [
18] applied KANs to sEMG signal classification and achieved exceptionally high accuracy on three datasets, while Cheon et al. [
19] employed KANs in remote sensing to improve both efficiency and performance in RS applications. Building on these advancements, KANs hold promise for bearing fault diagnosis based on vibration signals. Considering that not all segments of the spectrum contribute equally to the fault characteristics [
20] and the inherent periodicity of vibration signal data, convolution operations and attention mechanisms each offer distinct advantages. The translational invariance of convolution enables the detection of similar local features at different positions, which is crucial for capturing periodic patterns in vibration signals. On the other hand, the attention mechanism, by weighing based on contextual information, captures long-range dependencies and important global information. So far, the architecture of combining CNN and Transformer has achieved remarkable progress in the field of fault diagnosis to enhance diagnostic accuracy and robustness [
21,
22]. Therefore, we consider integrating KART into classic CNN and Self-attention modules, proposing two novel modules, KAConv and KAA. This aims to improve the model’s capacity to learn fault types by boosting its ability to capture nonlinear features. The main contributions of this paper are as follows:
- (1)
Cross-individual scenarios are explored to provide a reasonable evaluation framework. Under this benchmark, models’ cross-individual generalization capability in real-world scenarios is effectively evaluated.
- (2)
A novel Kolmogorov–Arnold enhanced convolutional transformer (KACFormer) model is proposed, which is inspired by KART. KAConv and KAA are designed to improve both general feature representation and cross-individual capabilities.
- (3)
Comprehensive comparative experiments are conducted on two public datasets, and experiment results demonstrate the effectiveness and superiority of the proposed method.
The structure of this paper is as follows:
Section 2 introduces the method proposed in this paper.
Section 3 carries on the experiment and analysis from different aspects.
Section 4 gives the main conclusion.
3. Experiments
To validate the effectiveness and the necessity of the proposed modules in the task, comprehensive experiments on two open datasets are conducted, including ablation study and contrast experiments. The code is written in Python 3.10.14 with Pytorch 2.4.1+cu124 on the computer, manufactured by Lenovo in Beijing, China, with an NVIDIA GeForce RTX 4060 Laptop GPU.
3.1. Task Setups
3.1.1. Task 1 on PU Dataset
The dataset for the first cross-individual task is sourced from the PU dataset from the Paderborn University Konstruktions und Antriebstechnik (KAt) data center [
26]. Vibration signals from the bearing housing are collected using piezoelectric accelerometers at a sampling frequency of 64 kHz. The experimental test platform, including a drive motor, load motor, flywheel, torque sensor, and module for testing bearing vibration data, is shown in
Figure 8.
A total of 32 different bearings are included in the PU dataset. These bearings vary in terms of their manufacturer, type, and severity of damage, aligning with the objectives of our cross-individual study. The bearing faults in the dataset are generated using two primary methods: electrical discharge machining (EDM) and life acceleration treatment. To ensure the experiments closely resemble real-world industrial scenarios, only the data obtained through life acceleration treatment is utilized. The fault positions considered in this study include Healthy (N), Outer Race (OR), and Inner Race (IR). Additionally, to avoid an imbalanced dataset, only a subset of the provided bearings is used. The chosen bearings for the training and validation sets are K001 (N), K002 (N), K003 (N), KA04 (OR), KA15 (OR), KA16 (OR), KI04 (IR), KI14 (IR), and KI16 (IR). For the testing sets, we selected K006 (N), KA22 (OR), and KI21 (IR).
All data is collected under the same working conditions, with a rotational speed of 900 rpm, load torque of 0.7 Nm, and radial force of 1000 N. The official working condition code is “N09_M07_F10”. Detailed information about the chosen bearings is provided on
Table 1.
3.1.2. Task 2 on CWRU Dataset
The dataset for Task 2 is derived from the highly cited CWRU dataset [
27]. The test bench consists of a 2 HP motor, a torque transducer, and a power dynamometer. The accelerometers are mounted on the drive side and the fan side of the housing to collect vibration signals, as shown in
Figure 9.
The CWRU dataset provides two distinct types of bearings for cross-individual task research, namely the drive end (DE) bearing (6205-2RS JEM SKF; deep groove ball bearing) and the fan end (FE) bearing (6203-2RS JEM SKF; deep groove ball bearing). According to official records, the parameters for the two different bearings are listed in
Table 2.
The CWRU dataset provides a relatively smaller scale of data for cross-individual fault diagnosis research. According to the relevant literature [
28], models tend to face greater challenges in distinguishing fault classes when subjected to higher loads. Regarding the difficulty caused by a relatively insufficient data volume, Task 2 was set on the working condition with 0 HP load. In Task 2, we utilize data collected from the DE bearings to train the model, while data from the FE bearings is used to test the model. Task 2 is also a three-class classification task, including Healthy, OR fault and IR fault.
3.1.3. Other Settings
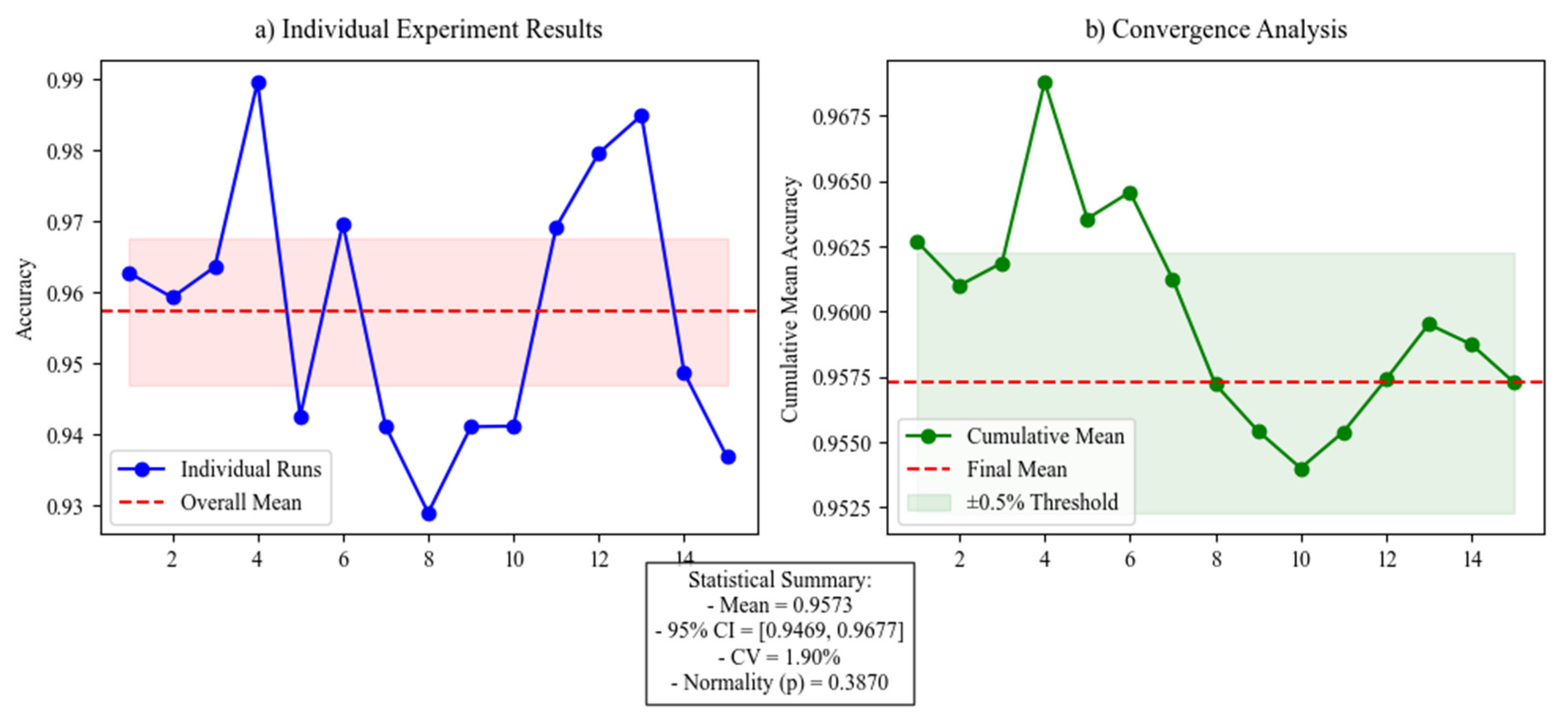
The sliding window has a length of 1024 and an overlapping rate of 0.5. All models are optimized using the Adam optimizer [
29] with the learning rate set to 0.001. Cross-entropy is used as the loss function to complete backpropagation and parameter updates for the models. To prevent model overfitting and achieve optimal performance on cross-individual tasks, multiple training runs are performed with different numbers of epochs, and the epoch number that yields the best accuracy on the target bearings is selected. Through experiments, the optimal number of epochs for different models ranges from 5 to 20. Additionally, to avoid the randomness of a single experiment, each model is run 15 times on the same task, and the average performance is taken as the result. The distribution of the training, validation, and testing data for both tasks is presented in
Table 3. As shown in
Figure 10, the statistical analysis using Shapiro–Wilk normality testing and confidence interval estimation demonstrates that 15 experimental repetitions yield sufficiently reliable results, with a narrow 95% CI [94.69%, 96.77%] and low variability (CV = 1.90%).
3.2. Model Selection
The hyperparameters of the model are listed in
Table 4.
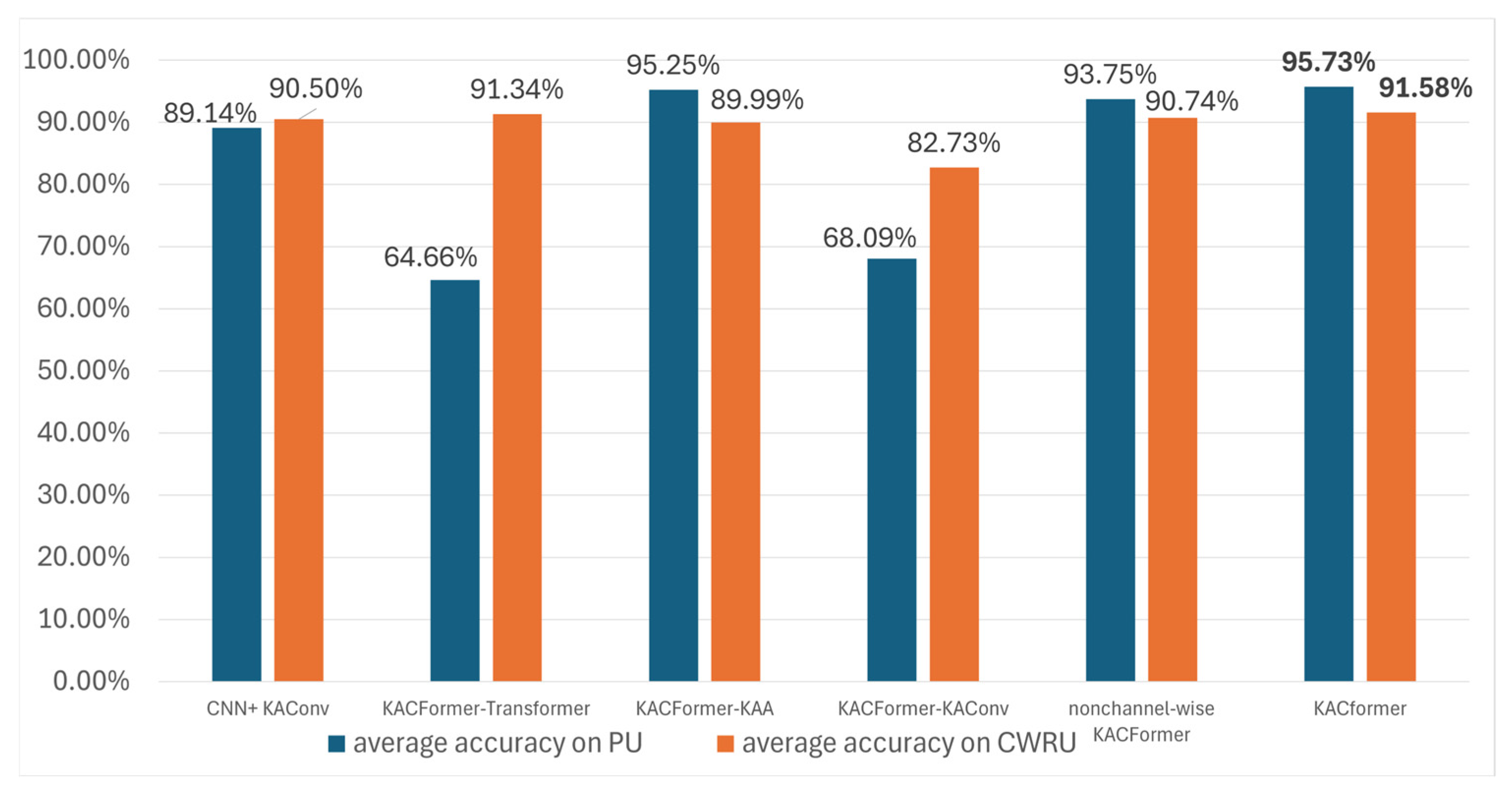
3.3. Ablation Experiment
To evaluate the efficacy of the proposed modules, the ablation experiment is carried out. The models participating in the ablation experiment are as follows:
- (A)
CNN+ KAConv. This model has the same structure as the classic WDCNN model. However, all conventional convolution modules are replaced by KAConv modules.
- (B)
KACFormer–Transformer. The output of KAConv Encoder is sent directly into the MLP classifier.
- (C)
KACFormer–KAA. This model is equipped with the WD-KAConv Encoder, followed by a traditional transformer layer.
- (D)
KACFormer–KAConv. Replace the WD-KAConv Encoder with the same structured convolution encoder.
- (E)
Non-channel-wise KACFormer (N-KACFormer). Assign more channels to each KAA head.
- (F)
KACFormer. The proposed model.
3.4. Contrast Experiment
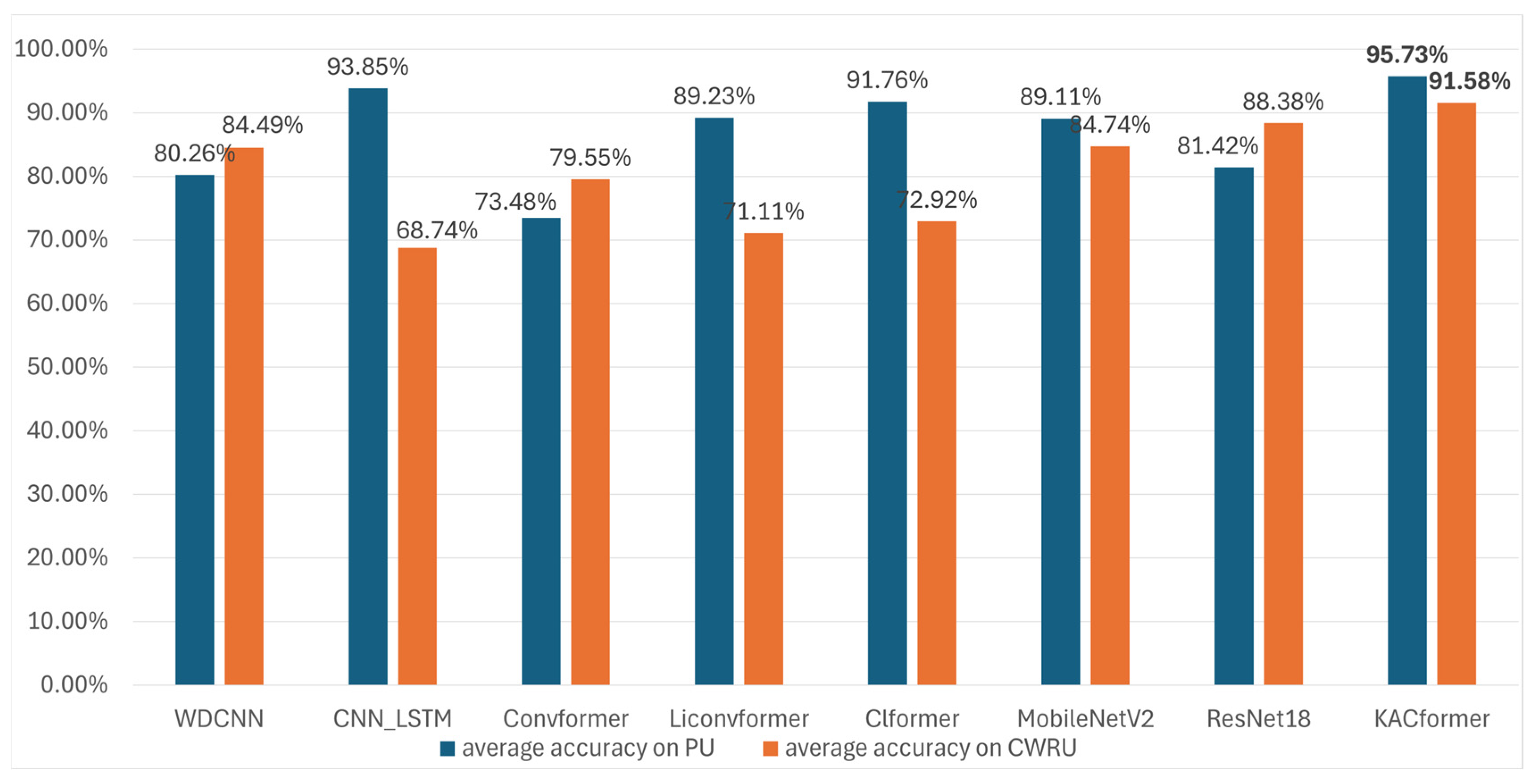
To validate the advancement of our proposed KACFormer model, we conducted a comprehensive comparative experiment involving both traditional classic models and modern advanced models, ranging from CNN-based methods to contemporary Transformers. The compared models include classic CNN architecture as well as frameworks that share a similar CNN-Transformer structure to our approach. Below are detailed descriptions of the contrasted models:
- (A)
WDCNN. Pioneering work in the field of fault diagnosis, serving as the baseline model [
6].
- (B)
CNN-LSTM. A fault diagnosis model utilizing the CNN module and the LSTM module with 100 neurons set for calculation [
30].
- (C)
Convformer. A network designed to extract robust features by integrating both global and local information, with the goal of enhancing the end-to-end fault diagnostic performance of gearboxes under high levels of noise [
21]. To better adapt to the mission, the small version of the Conformer is utilized.
- (D)
Liconvformer. A novel advanced lightweight fault diagnosis model with separable multiscale convolution and broadcast Self-attention [
22].
- (E)
Clformer. A transformer based on convolutional embedding and Self-Attention mechanisms [
31].
- (F)
MobileNetV2. This neural network enhances the state-of-the-art performance of mobile models across various tasks, benchmarks, and a wide range of model sizes [
32].
- (G)
ResNet18. ResNet18 is a convolutional neural network architecture known for its use of residual connections, enabling efficient training of deeper models while maintaining strong performance in image classification and other computer vision tasks [
33].
- (H)
KACFormer. The proposed model.
3.5. Results and Analysis
3.5.3. Analysis
Other Evaluations
While fault diagnosis accuracy remains the primary industrial concern, a comprehensive model evaluation requires multi-dimensional metrics. In addition to accuracy and confusion matrix metrics, we have incorporated other domain-generalization-specific evaluations: Precision, Recall, and F1-score (all macro-averaged). The relevant data is shown in
Table 7.
Learning Dynamics
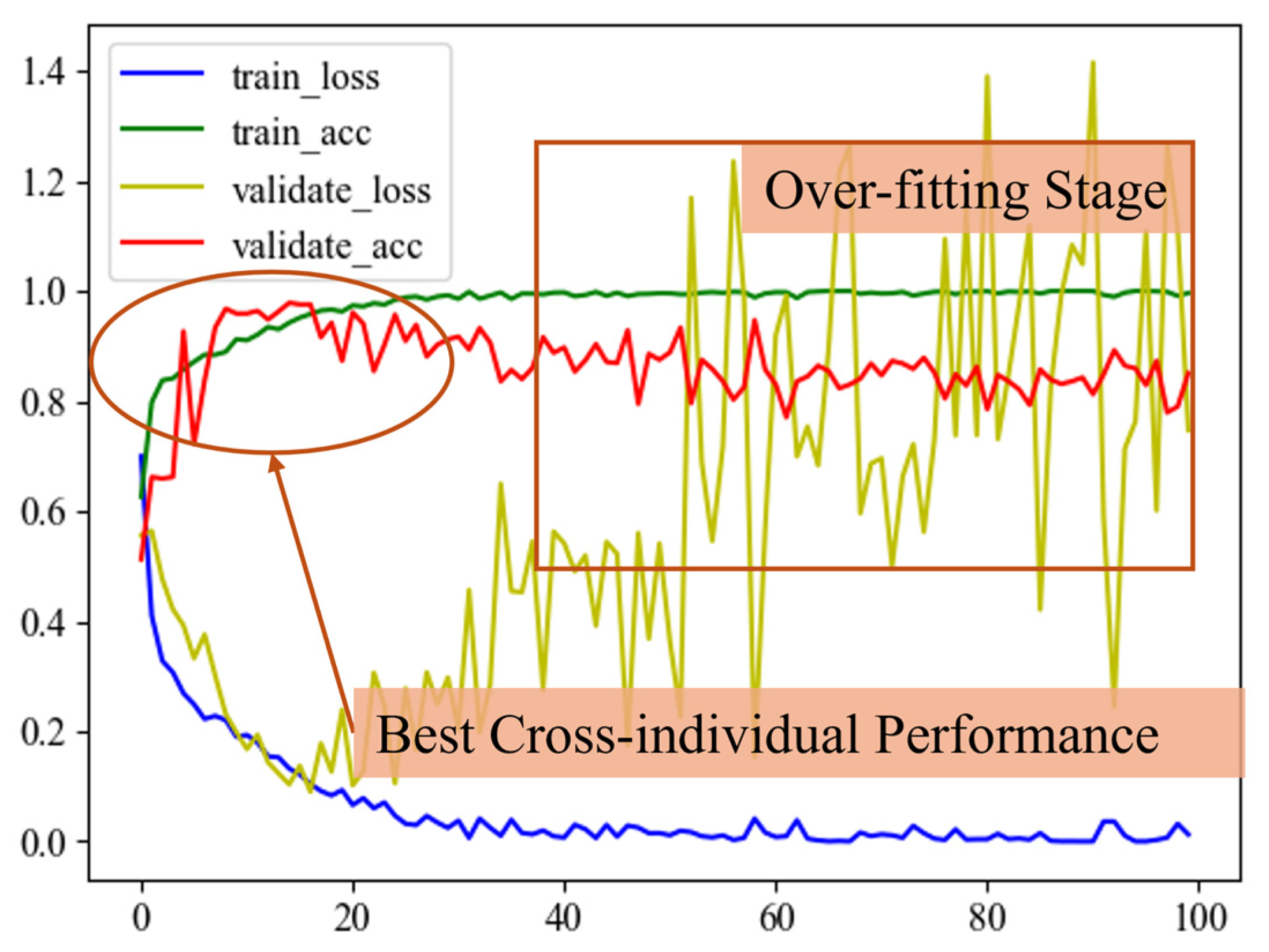
To obtain a deeper understanding of the learning dynamics of KACFormer in cross-individual learning tasks, the following experiments are conducted: the model is tested on the testing set to observe phenomena such as convergence and potential overfitting after each epoch. The number of epochs is set to be 100.
As illustrated in
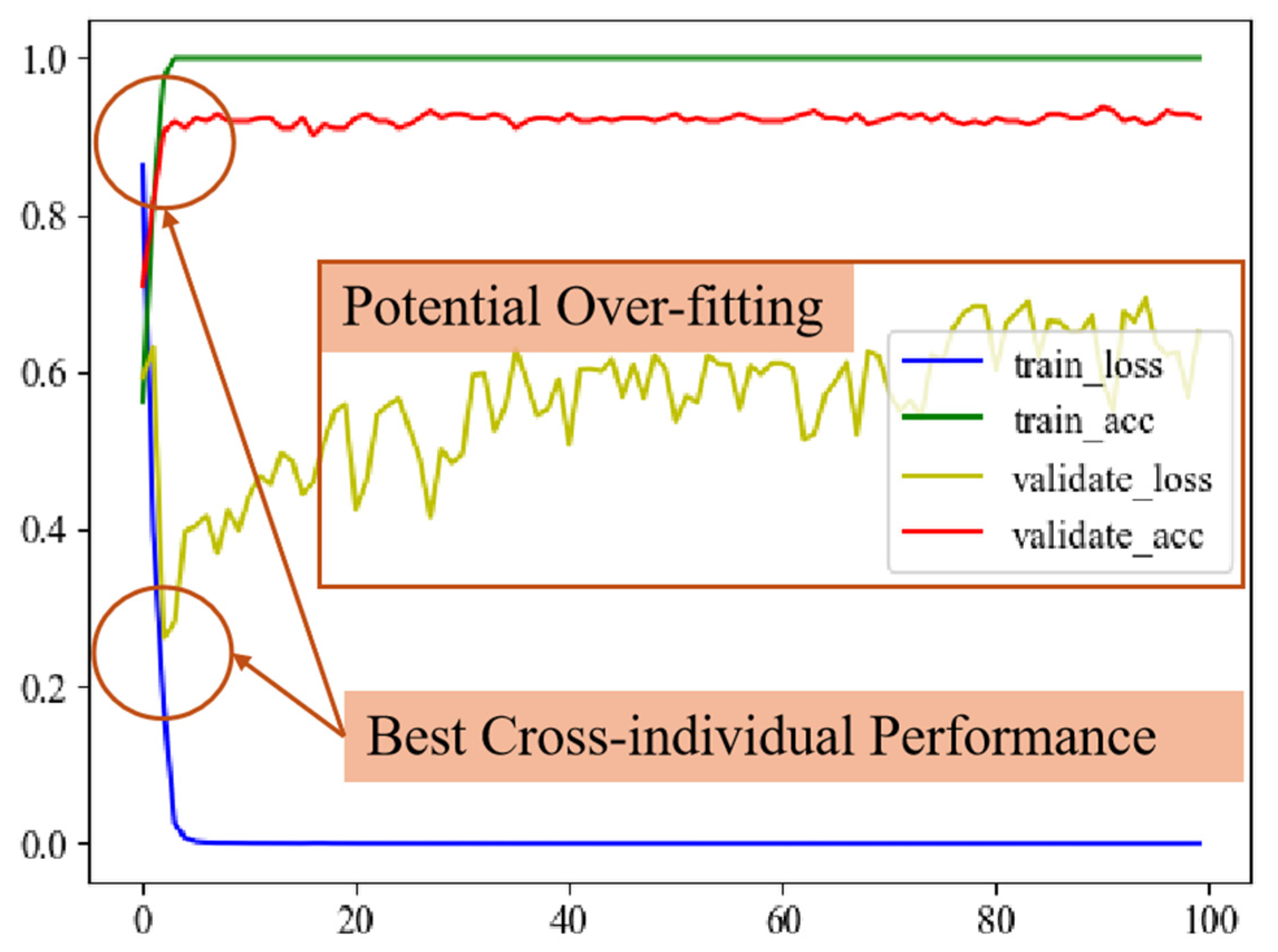
Figure 17, on Task 1, the KACFormer network achieves its best accuracy on the target domain when it begins to converge on the source domain, typically around 5 to 20 epochs. After the 20th epoch, as training continues, the model’s performance on the target domain begins to degrade. Such a phenomenon is not as pronounced on Task 2. As illustrated in
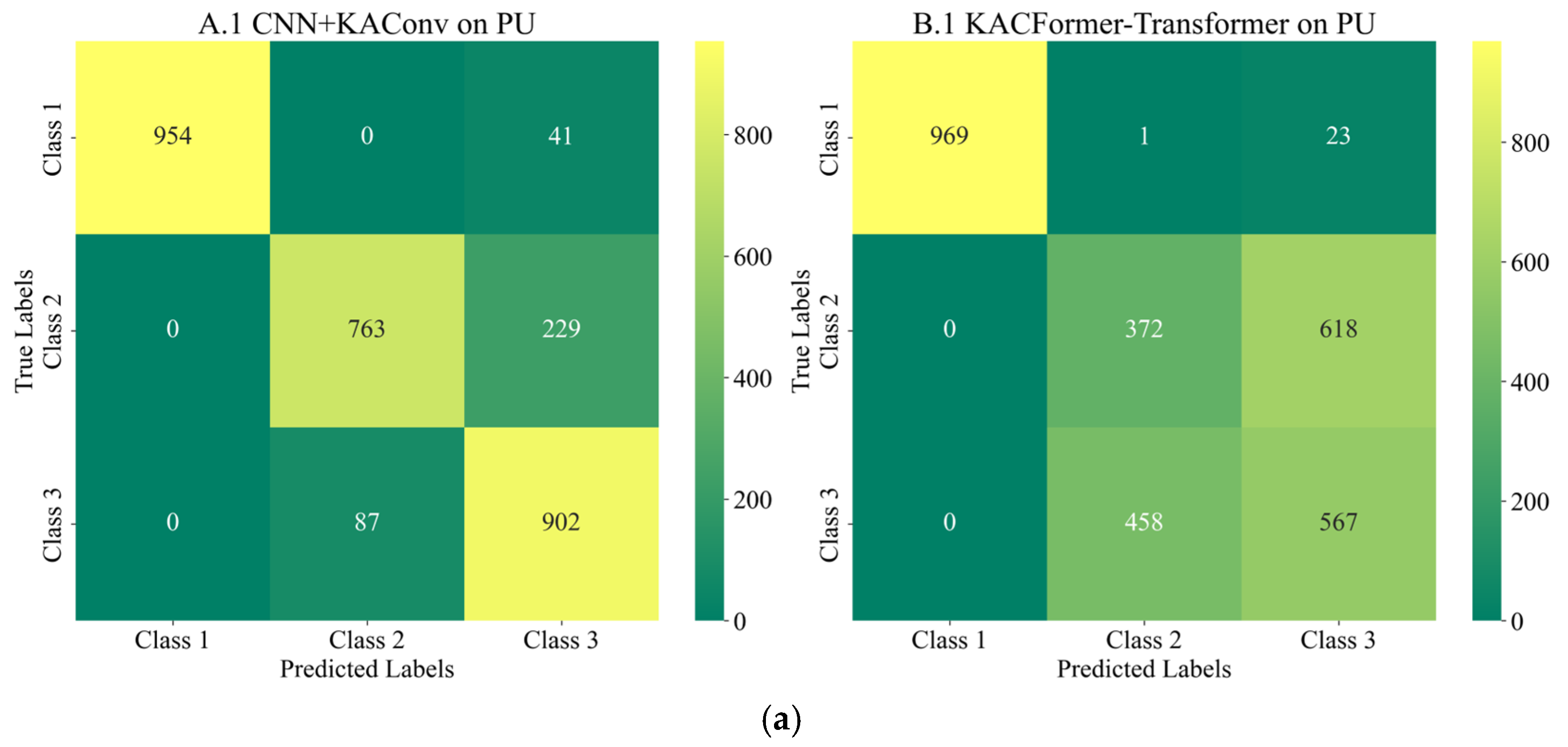
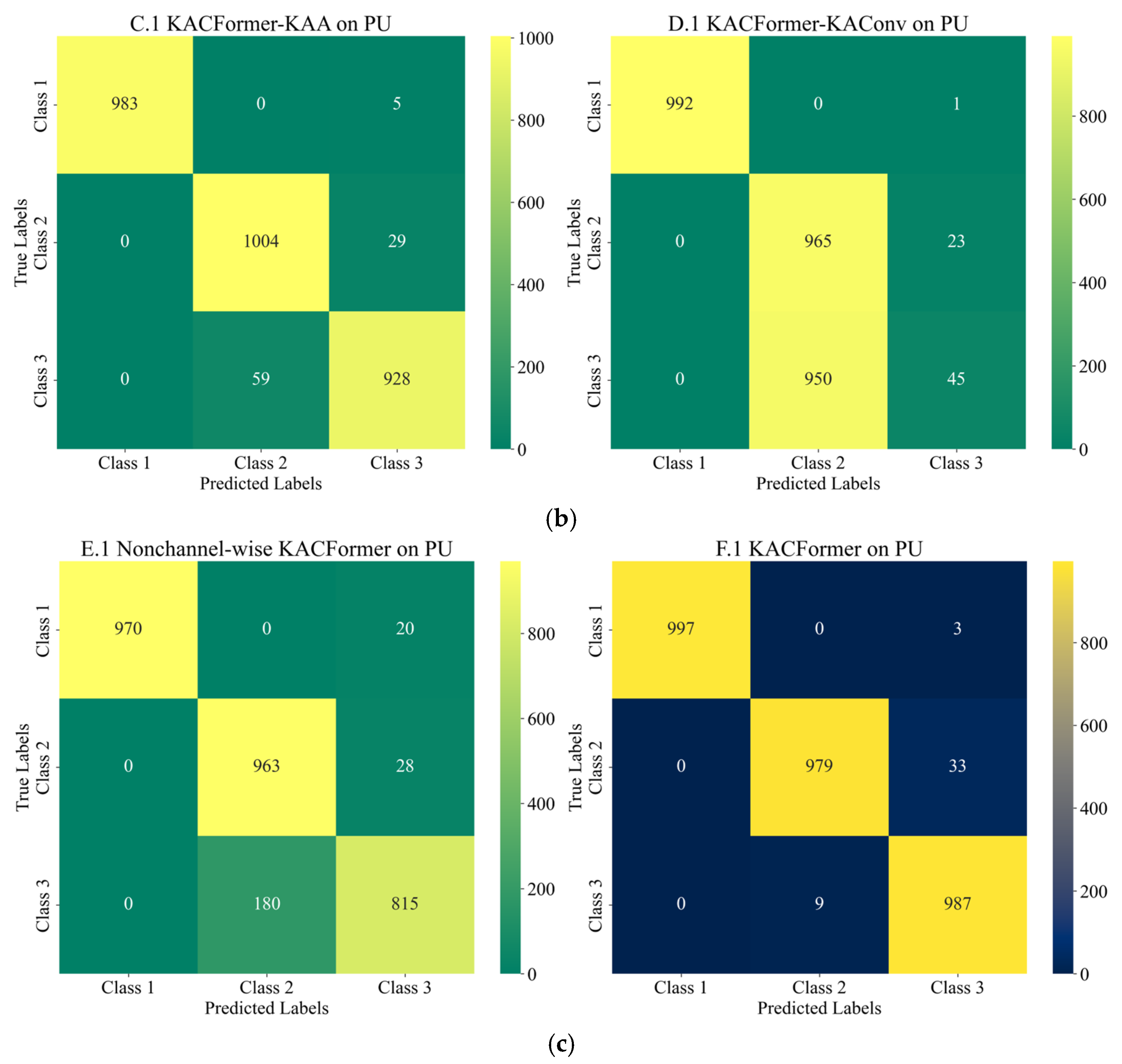
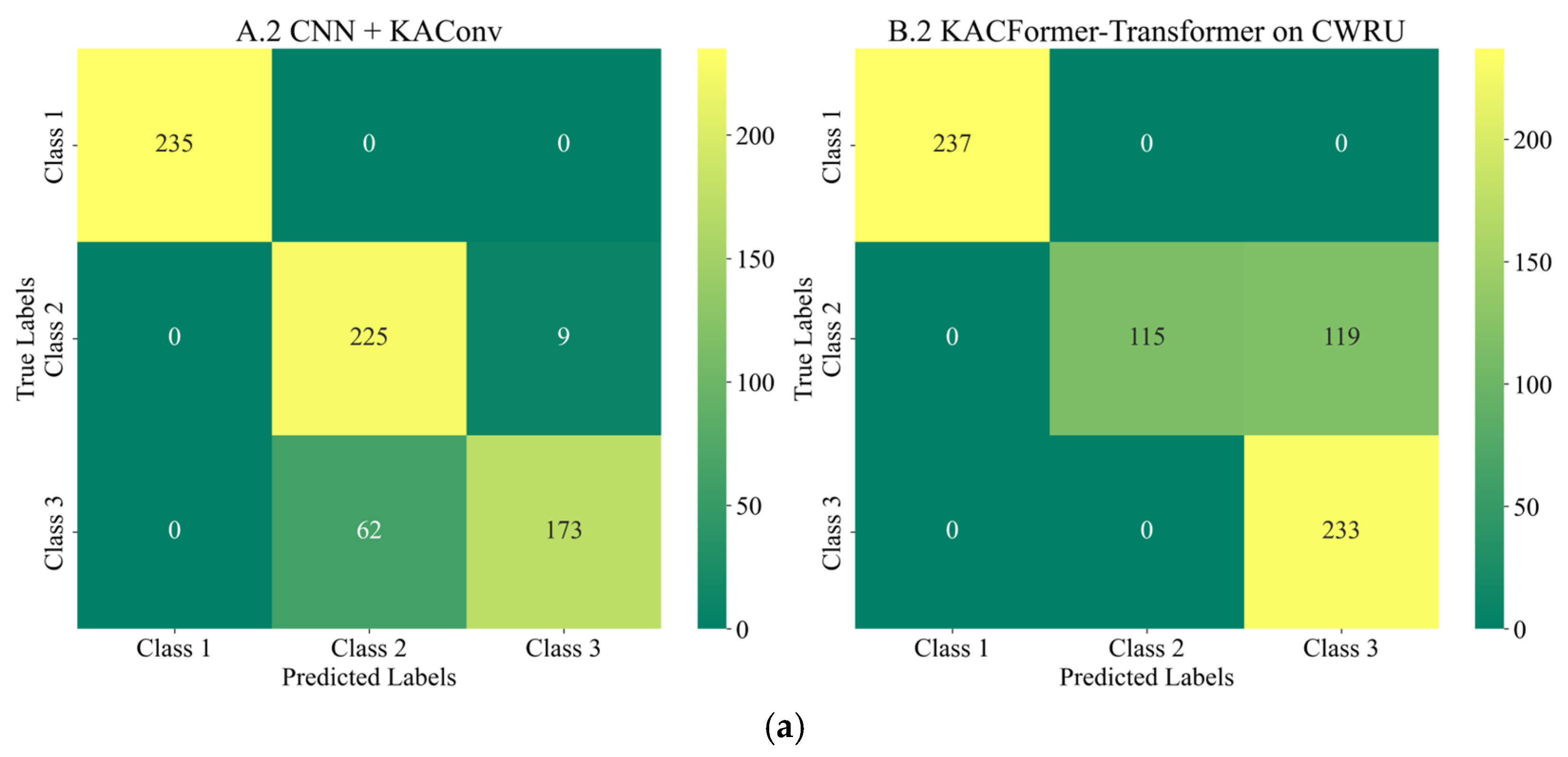
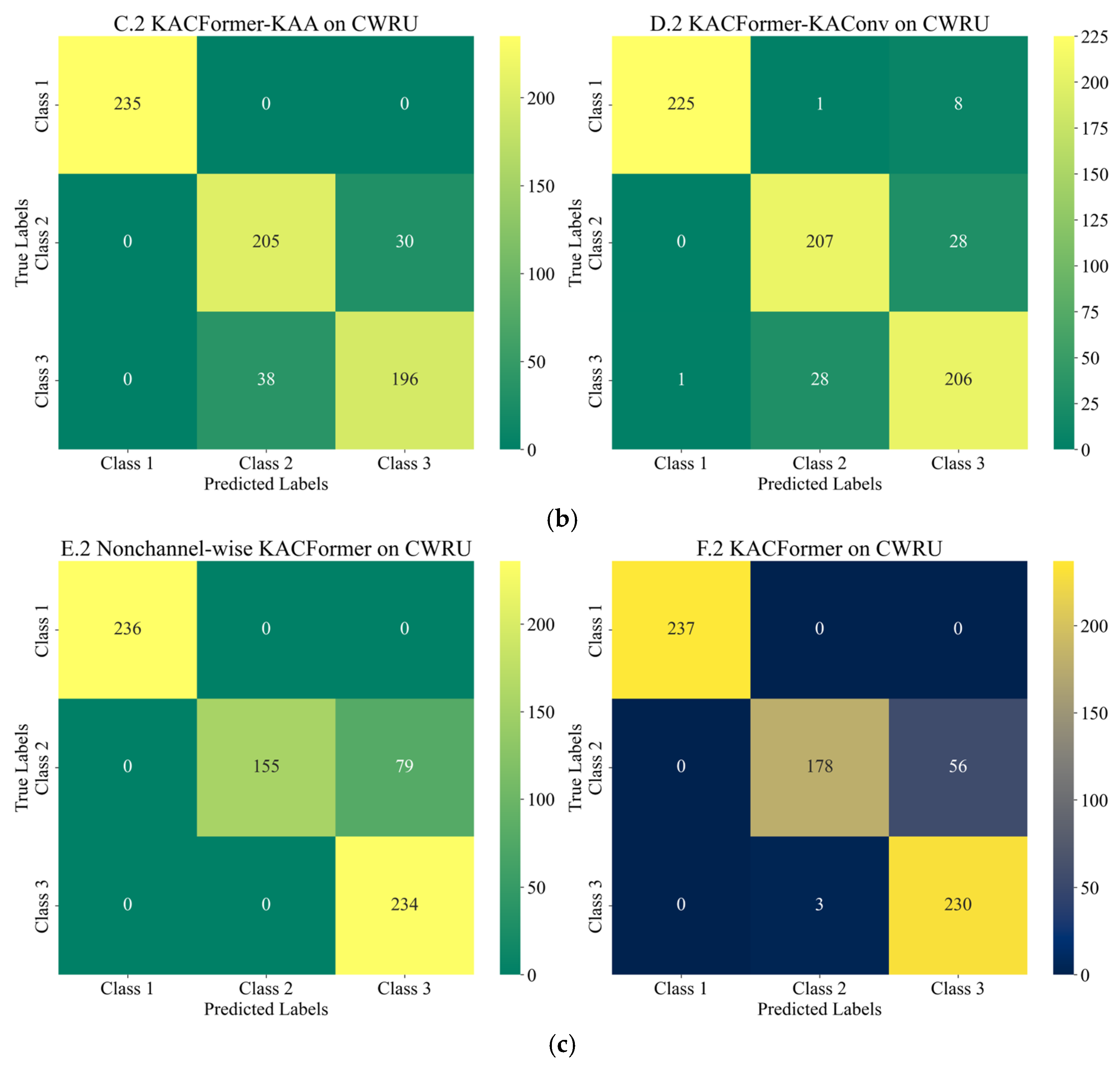
Figure 18, the model converges quickly and demonstrates relatively strong stability on the target dataset. However, the rising validation loss may indicate a potential over-fitting risk. Such a difference may be due to the volume of data and the inherent differences between the individuals in target and training datasets. Moreover, as shown in the confusion matrixes listed in
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
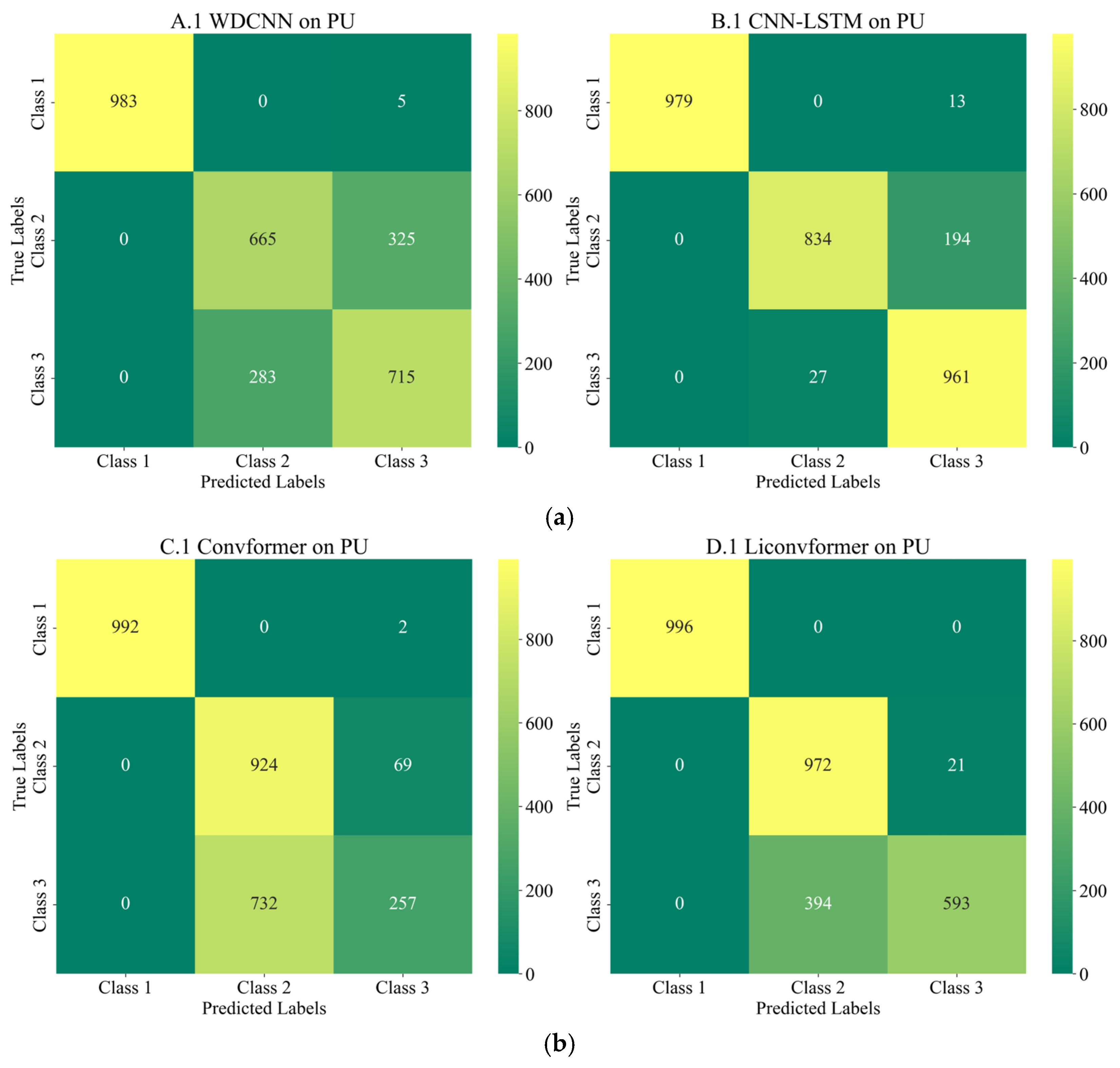
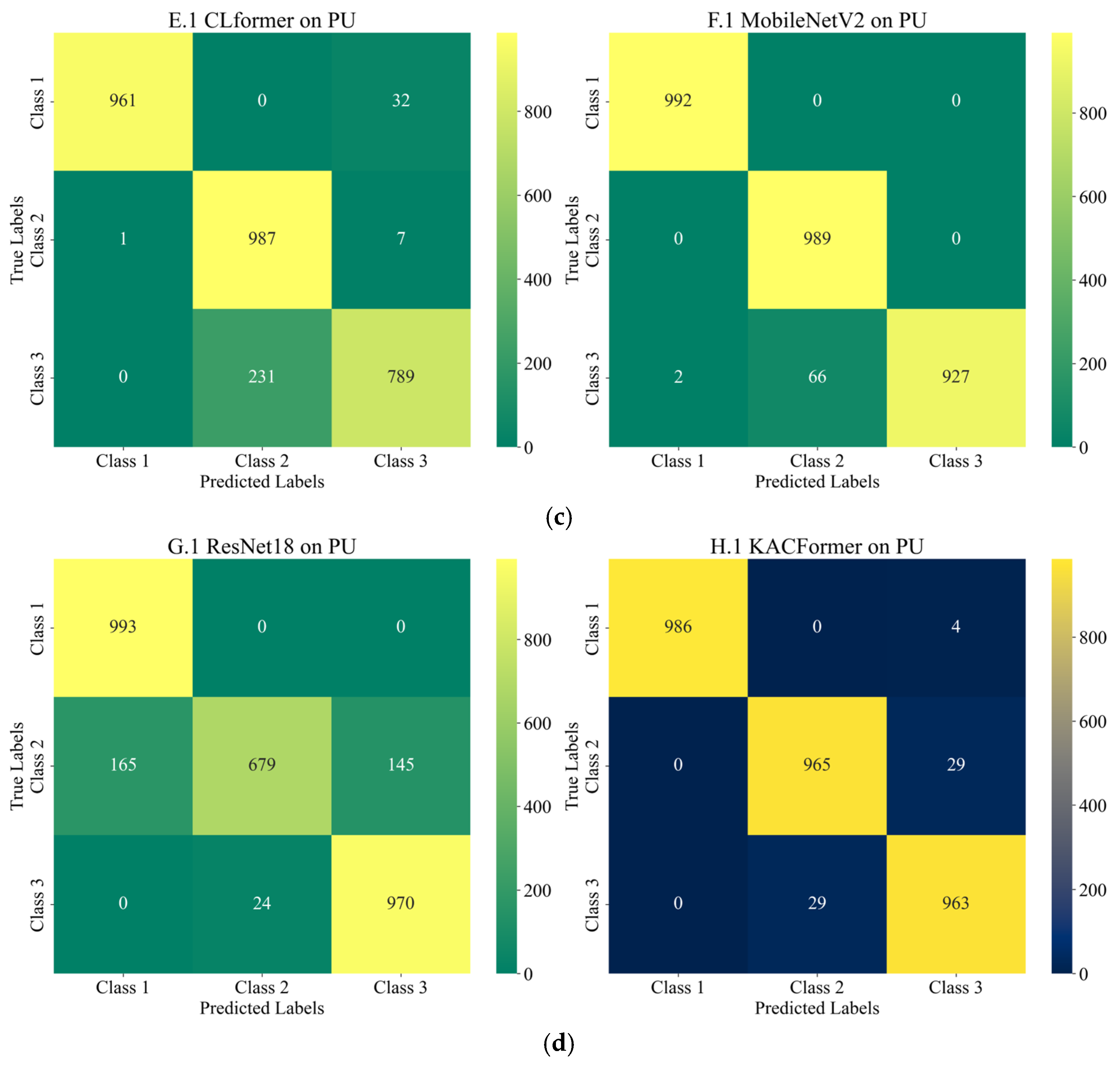
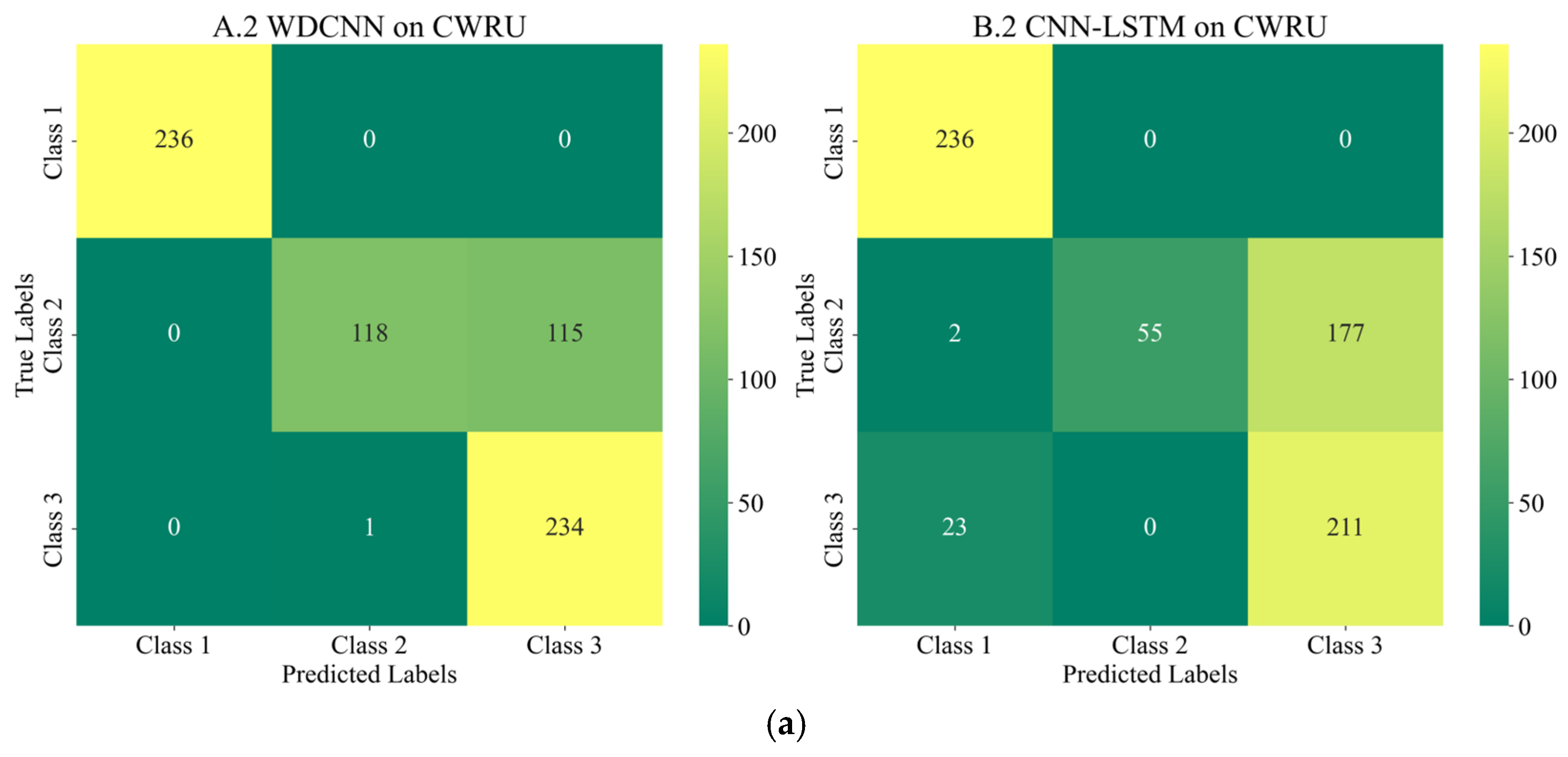
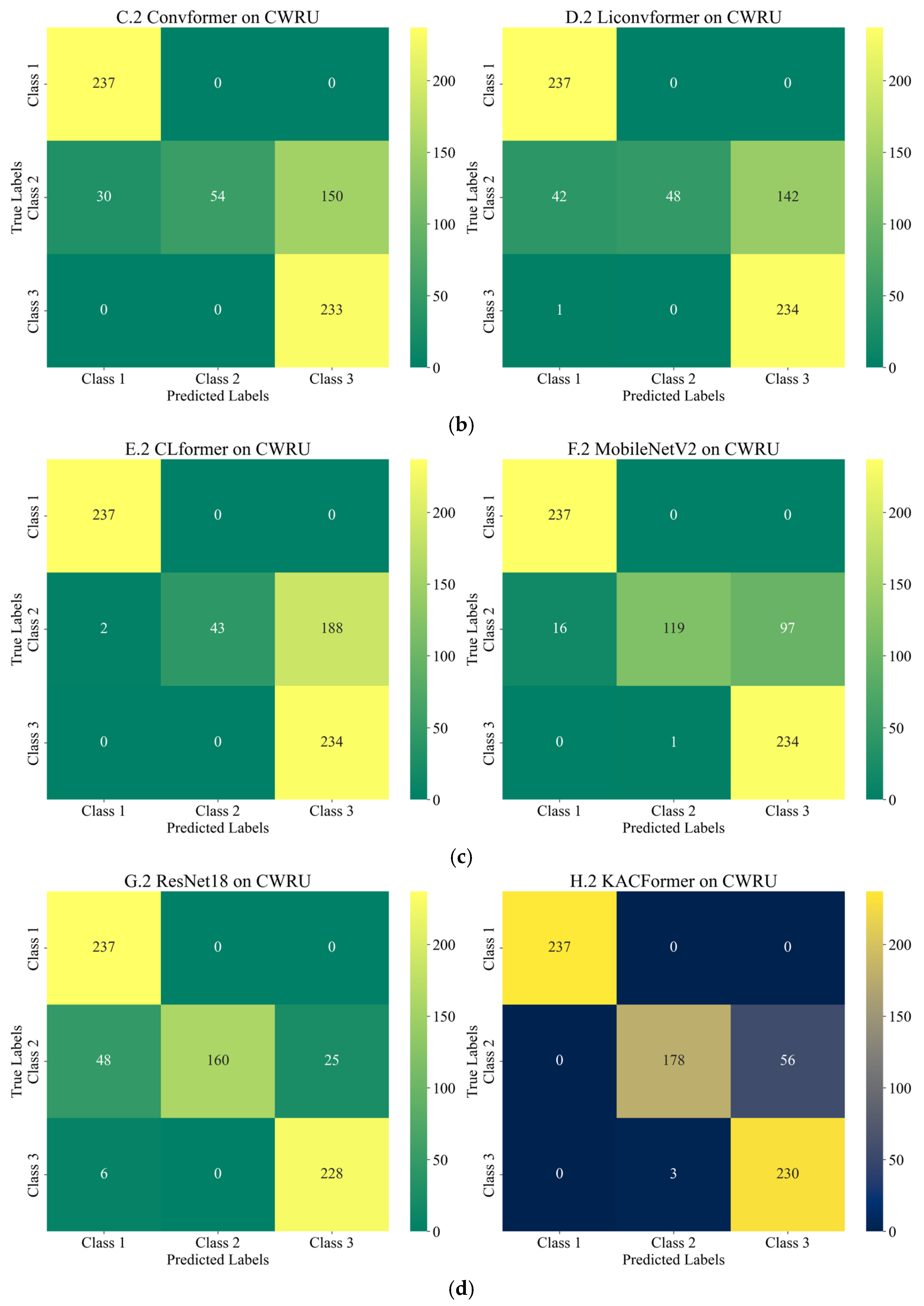
Figure 16, the features of healthy bearings in the PU and CWRU dataset are more distinct compared to the other two categories, and models participating in the experiment demonstrate strong cross-domain performance. However, there is a significant degree of confusion between Inner Race (IR) and Outer Race (OR) faults.
Why SiLU
In the model, the SiLU activation function is employed in the encoder based on experimental validation. This implementation is consistent with the original KAN authors’ use of SiLU activation in their work [
16], further validating our design choice. As demonstrated in
Table 8, using ReLU activation resulted in accuracy degradation in both tasks compared to SiLU. This performance gap may be attributed to SiLU’s superior properties: smoothness, non-monotonicity, and boundedness below (unbounded above), which make it particularly suitable for approximating smooth functions, and this may be a latent characteristic exhibited in vibration signal processing.
Working Condition
Working condition variability is a widely discussed challenge in fault diagnosis, with numerous scholars dedicated to cross-condition diagnosis [
34,
35,
36]. Since model performance may vary under different operating conditions, considering data availability, experiments are conducted on Task 1 based on the PU dataset—evaluating the same bearing samples under different conditions.
Table 9 presents KACFormer’s accuracy for Task 1 across these three distinct working conditions.
From the experimental data, it can be concluded that when the source domain and target domain individuals work under the same working conditions, the robustness of the algorithm will not be affected.
4. Conclusions
In this work, a cross-individual bearing fault diagnosis scenario is explored. By integrating KART into traditional convolution and attention mechanisms, a novel model, KACFormer, is proposed to explore the potential of leveraging the nonlinear modeling capabilities and individual generalization of KANs. KACFormer enhances feature representation while preserving the translation invariance of convolution and the context-aware semantic modeling ability of attention mechanisms. Extensive experiments on two public datasets demonstrate the superior generalization performance of KACFormer, achieving state-of-the-art accuracy rates of 95.73% and 91.58% in cross-individual scenarios. These results highlight the potential effectiveness of KACFormer in improving fault diagnosis under varying operational conditions and individual differences. Beyond bearing fault diagnosis, the proposed KACFormer framework exhibits potential for generalization to other similar industrial scenarios involving vibration signal processing and domain adaptation, such as health monitoring for gearboxes and wind turbine condition monitoring [
37].
Despite the advancement achieved, limitations remain. (1) Compared to MLP-based models, KANs-embedded models take a relatively longer time to train. Further study will be carried out to reduce the complexity of the model while maintaining the cross-individual accuracy. (2) Furthermore, the model should prioritize detecting smaller, incipient faults to better align with industrial requirements, as early-stage fault diagnosis is crucial for predictive maintenance and to minimize machine downtime. However, due to limitations in the current datasets, experiments regarding the model’s minimum detectable fault size were not conducted. This constitutes an important direction for future research.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}