1. Introduction
With the emergence of innovative information technology, the increasing frequency and complexity of attacks on computer networks continue to threaten the security of cyberspace. The rapid evolution of cyber threats necessitates advanced intrusion detection methods that are able to model complex network interactions. Cyber attacks significantly threaten the assets and data security of individuals, enterprises, and even the country [
1,
2]. In order to combat this, enterprises utilize network intrusion detection systems (NIDSs) to protect critical infrastructure, data, and networks.
Network intrusion detection is a practical scheme for detecting attacks. Traditionally, NIDSs utilize rule-based methods to detect intrusions. The detection rule is generated from attack samples [
3,
4]. Ref. [
3] leverages both benign and malicious flow samples to generate detection rules. Meanwhile, ref. [
4] employs Bayesian networks to learn attack patterns and convert them into “IF-THEN” detection rules. These methods can detect attack types, but they cannot handle the interaction and variants between attack flows. In fact, attackers often use various techniques to conceal their attack behaviors to evade rule detection, making attack detection more difficult. Recently, there has been great progress in the application of new learning-based models for the development of new solutions [
5,
6]. Learning-based methods, on the other hand, rely on more complex operations, commonly involving machine learning (ML) to identify sophisticated attacks [
7,
8,
9,
10]. However, these approaches have generally barely considered the topological patterns of both benign and attack network flow, which is an important factor in network intrusion detection. NIDSs often fail to capture interdependencies between network entities, resulting in high false positive rates and limited interpretability. Therefore, we advocate using the network flow topology patterns to detect complex attacks such as Advanced Persistent Threat (APT) because APT attacks need to consider both the overall network graph topology patterns and lateral movement paths.
In order to explore topology patterns, graph neural networks (GNNs) [
11] are a potential method in deep learning. GNNs take advantage of the graph structures through the use of message passing between nodes or edges. This enables the neural network to learn and generalize effectively on graph-based data to output low-dimensional vector representations [
12]. For instance, studies such as [
13,
14,
15] have demonstrated the potential of GNNs in identifying attack patterns. However, despite the progress made by these methods, significant limitations remain when dealing with the importance of structure and detection grains.
Based on detection grains, the existing methods of detecting cyber attacks can be divided into two categories: anomaly-based binary classification [
7,
9,
14] and fine-grained multi-classification [
13,
16,
17]. Anomaly detection methods use benign samples for modeling, and any behavior patterns that deviate from expectations are identified as anomalies. For example, regularization and autoencoders are introduced in [
7] to improve potential representations for anomaly detection. OnlineBPCA is proposed in [
9], which converts network flow into a two-dimensional tensor and analyzes the changes in principal directions for anomaly detection. However, anomaly detection is rarely deployed in realistic situations due to the inability to provide detailed diagnostic information about attack types and the high false positive rate. Fine-grained detection methods are trained and evaluated using supervised learning based on predefined classes. In study [
13], the embedded representation of network flow is obtained by splicing the aggregated information of nodes. However, these methods require training from the scratch and predefined classes. Coarse-grained detection refers to binary classification of attack/benign flows, while fine-grained classification identifies specific attack types (e.g., DDoS, port scan). In a realistic network, attack classes sometimes only need to know benign or malicious, and sometimes need to know the specific attack category. If you train from scratch every time, it leads to a lot of computing power and time wasted.
Another emerging challenge is adversarial evasion. In recent years, adversarial attacks [
18,
19,
20] have emerged in several research fields, such as in computer vision [
19] and natural language processing [
20]. Attackers can induce deep learning models to make incorrect predictions by injecting tiny perturbations that are imperceptible to the human eye into the input data. We envision that when dealing with real network intrusion detection, network attacks change their features to evade existing detection rules and intrusion detection methods. For example, obfuscation techniques have been used to generate variants from known attacks that evade rule-based detection methods [
21]. Attackers often use techniques such as protocol camouflage (such as DNS covert tunnels) and flow feature obfuscation (such as modifying TCP window size) to construct adversarial network flow in order to evade detection systems. Such attacks can be regarded as edge feature perturbations on graph-structured data. Their goal is to modify the statistical features or protocol semantics of flow interactions so that malicious flow is misclassified as benign in the GNN model. Existing GNN-based intrusion detection methods (such as [
13,
14]) generally have adversarial vulnerabilities. In the model training process, these methods [
13,
14] assume that edge features are fixed and ignore the escape behavior of attackers actively perturbing features.
Overall, to propose a robust and multi-grained GNN intrusion detection method, three key challenges must be addressed:
Edge-aware aggregation: Existing methods do not distinguish the importance of nodes and edges in aggregation and message passing, using static aggregation strategies (such as mean/max pooling). So, they cannot adaptively distinguish key attack paths from noise edges.
Detection granularity: Current methods only focus on anomaly classification and lack a hierarchical detection framework to balance efficiency (coarse-grained screening) and accuracy (fine-grained classification).
Adversarial robustness: Detectors must anticipate and resist graph-structured perturbations that attackers use to evade models.
In this paper, we propose a novel combination of edge-aware attention with hierarchical coarse-to-fine detection under adversarial training, named AH-EAT, which systematically addresses the aforementioned challenges through three core mechanisms. The proposed method is able to learn an edge feature representation and exactly classify this edge into coarse-grained and fine-grained types with robustness against adversarial attacks. In detail, the method consists of three modules: an edge-based graph attention mechanism embedding module, a hierarchical multi-grained detection module, and an adversarial training module. The edge-based graph attention mechanism embedding module dynamically weights node-neighbor interactions by integrating edge features (e.g., flow protocols, interaction frequency) with attention mechanisms, adaptively distinguishing critical attack paths from noisy edges and capturing structural–semantic patterns vital for attack detection. The hierarchical multi-grained detection module is constructed with a two-stage pipeline: coarse-grained filtering of malicious flow followed by fine-grained classification of specific attack types, balancing detection efficiency and precision to overcome the limitation of single-granularity models. In the adversarial training module, a projected gradient descent (PGD)-based [
22] adversarial training strategy is proposed, adding edge feature perturbations and graph structure noise during training. This module can enhance the model’s robustness against graph-structural perturbations and edge-feature evasion attacks, significantly improving its resilience to evasion tactics in adversarial network environments. The synergistic effect of the three modules enables AH-EAT to efficiently capture deep features of critical attack interactions while maintaining stable detection performance in adversarial environments.
The contribution of this work is summarized as follows:
Edge-based Graph Attention Network: By integrating edge features and graph attention network mechanisms, AH-EAT dynamically weights node-neighbor interactions, capturing both structural and semantic patterns critical for attack detection.
Hierarchical Multi-grained Detection: A two-stage framework first filters malicious flows and then classifies specific attack types, addressing the limitations of single-grained models.
Adversarial Robustness: Leveraging PGD-based adversarial training, AH-EAT mitigates graph-structural perturbations and edge-feature evasion attacks and improves resilience for attack evasion tactics.
We also conduct extensive experiments on four benchmarks and the results demonstrate that AH-EAT significantly outperforms the baselines with significant advantages.
The rest of the paper is organized as follows.
Section 2 discusses related works, and
Section 3 provides the problem formulation and preliminaries. Our proposed AH-EAT method is introduced in
Section 4. Experimental evaluation results are presented in
Section 5.
Section 6 makes a conclusion.
3. Problem Formulation and Preliminaries
Graph learning is a rapidly evolving research field with a wide range of applications, including social and molecular networks. In recent years, GNNs have demonstrated outstanding performance in network attack detection, achieving state-of-the-art results, especially in the area of network intrusion detection [
13,
14].
3.1. Edge-Based Intrusion Detection
While existing GNNs excel at node-level tasks like social network analysis, they face two key limitations in edge-based intrusion detection:
GNNs extend deep learning to non-Euclidean graph data by propagating messages along topological structures. Formally, given a graph
with node features
and edge features
, the ll-th layer of a GNN can be defined as
where ⨁ is a permutation-invariant aggregation operator (e.g., mean, sum), and
and
are learnable functions.
Meanwhile, network intrusion detection systems (NIDSs) can be naturally formulated as an edge classification problem on network flow graphs. Nodes represent IP addresses with features . Edges are network flows , with features . The objective is learning a function that maps edge to labels
Existing GNN-based NIDSs [
13] primarily focus on binary edge classification (malicious vs. benign) or multi-class edge classification (different types of attacks) separately, by training two models. Therefore, we aim at hierarchical detection, which means to classify coarse-grained and fine-grained models with one model at the same time.
3.2. GNNs for Graph Edge Classification
GNNs can be treated as a deep learning approach for graph-based data. GNNs act as an extension of convolutional neural networks (CNNs) and can be generalized to non-Euclidean data. For each node in the graph, this means aggregating the adjacent node features as a new embedding of the current node, which takes into account the adjacent information. Therefore, node embeddings are capable of capturing the topological characteristics of the network structure where the nodes are located, as well as the unique properties of each individual node. Similarly, the embedding process can be applied to edges and graphs. By doing so, we can obtain edge embeddings and graph embeddings, which encode the relevant features of edges and entire graphs, respectively.
Since computer networks and the network flow can inherently be depicted in the form of graphs, leveraging GNNs for network intrusion and anomaly detection presents a highly promising method for identifying novel and sophisticated network attacks, like Advanced Persistent Threat (APT) attacks. In this scenario, we form a network flow graph. IP addresses can serve as representations of nodes, while the communication of packets or traffic flow between nodes can be used to represent edges.
Traditional GNNs, such as GCN, GraphSAGE, and GAT, have been successfully applied to a wide range of applications. However, these methods mainly focus on applying node features to node classification and graph classification tasks. Generally, the features of the edges in the graph cannot be considered in message passing and aggregation, so edge classification cannot be considered.
3.3. PGD Adversarial Training
Projected gradient descent (PGD) [
22] is a landmark adversarial training method that enhances model robustness. Deep neural networks are vulnerable to adversarial examples. Input samples are nearly indistinguishable from natural data but are misclassified by the network. The existence of adversarial attacks may be an inherent weakness of deep learning models. Madry et al. [
22] studies the adversarial robustness of neural networks from the perspective of robust optimization. Further more, in the field of cybersecurity, in order to avoid being detected, attacks usually obfuscate their behavioral characteristics, making them more similar to normal flow and thus evading network attack detection methods. Therefore, adversarial training is of great importance in cybersecurity.
The core idea is a natural saddle point (min-max) formulation to capture the notion of security against adversarial attacks to enhance the robustness:
where
is the adversarial perturbation, which is bounded by
.
f is the model parameter and
is the loss function. PGD generates adversarial examples through multi-step iteration.
4. Methodology
AH-EAT integrates a graph attention mechanism and adversarial training to solve the problems encountered by existing graph-based NIDSs, such as the lack of a fusion mechanism of node embedding edge features and topology, single detection granularity, and adversarial vulnerability. Therefore, we aim to leverage edge-level feature information and learning edge embedding by GAT, hierarchical detection, and adversarial learning.
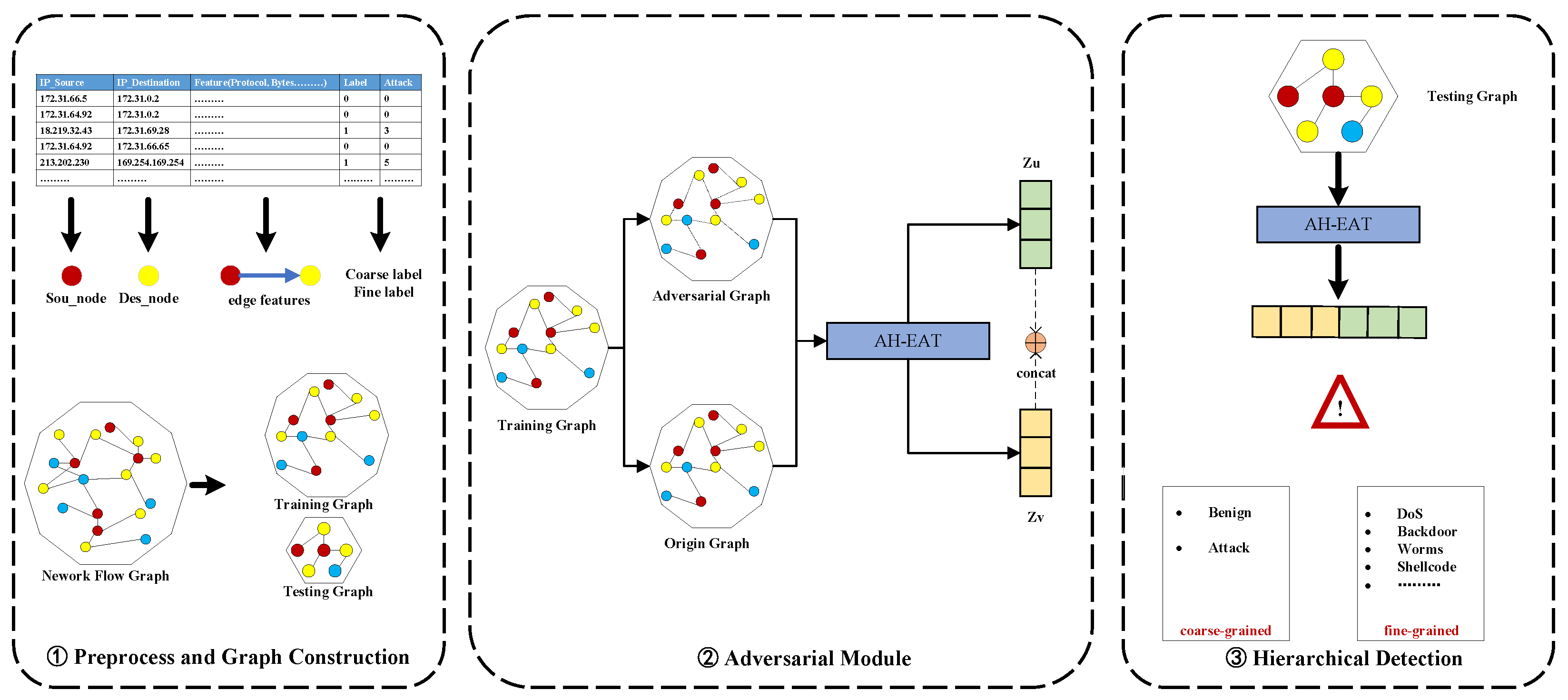
Figure 1 presents an overview of the anomaly detection process performed using AH-EAT, which comprises three organized modules designed to address multi-grained network intrusion detection. The pipeline initiates with a sophisticated graph construction phase (left panel), where raw network flows transform into network flow graph representations. We use the IP address of each network flow as a node and other features as edge features to construct the graph. At the same time, we construct training and testing graphs while preserving both coarse-grained (e.g., attack categories) and fine-grained labels (e.g., specific attack variants), thus maintaining hierarchical threat intelligence crucial for multi-level detection. Finally, we divide the training graph and test graph according to the defined ratio. The core innovation resides in the adversarial graph generation module (central panel), where we implement a graph adversarial training that injects perturbation patterns constrained by attack semantics. Unlike conventional adversarial methods, our model employs edge feature perturbation and feature masking to simulate sophisticated evasion tactics while preserving the integrity of genuine attack flow signatures. This adversarially augmented graph is subsequently fed into a graph neural network equipped with edge-based attention mechanisms. Afterwards, the embedding vectors obtained from the origin graph and the adversarial graph are concatenated and used as the embedding representation of the edge at the same time, so that the representation features obtained by each network flow training have both the original features and the adversarial perturbation feature information. The final detection phase (right panel) implements a hierarchical classification architecture that synergistically combines coarse-grained anomaly detection with fine-grained label prediction. The system first performs coarse-grained detection to identify fundamental attack categories (benign and attack flow), then executes fine-grained classification using multi-scale feature fusion that correlates with global graph properties. This dual-detection approach enables simultaneous macro-pattern (coarse-grained) recognition and micro-anomaly (fine-grained) localization, effectively addressing the challenge of detecting both malicious intent and broad attack types. The entire process is optimized through adversarial training, ensuring robustness against adversarial attack patterns. This results in a highly robust model that considers the possibility of being applied to actual NIDSs in the future to protect network security.
4.1. Graph Construction
Before training, convert the data into table format using the raw Netflow format. NetFlow format is an IP flow collection tool that utilizes network elements (such as routers and switches) to collect encountered IP flows and export them to external devices. These IP flows can be defined as a unidirectional sequence of packets encountered on a network device and contain a variety of important network information, including IP addresses, port numbers, number of packets and bytes, and other useful packet statistics. Pre-process the tabular data, including operations such as data standardization. Use IP as a node, and all attributes except IP as edge attributes to construct a graph, and divide it into training graphs and testing graphs. While building the training graph and testing graph, retain the coarse-grained labels and fine-grained labels so that it is possible to detect whether it is an attack flow and what kind of attack flow it is during the training process.
Here is the process of Netflow format from each dataset into training and testing graphs. First, we split the tabular data into train and test samples. Then, source and destination port information is removed from each flow record. After that, target encoding is performed on categorical features in both the training and testing set. The training set is used to train a target encoder on categorical data. Encoding is then performed again using the fully trained encoder on both the training and testing sets. Meanwhile, any empty or infinite values arising from this process are replaced with a value of 0. Before finally generating graphs, training and testing sets are normalized using an L2 normalization approach. Similarly to the approach taken in target encoding, the normalizer is trained using the training set to guarantee a learning process. Finally, each graph’s node features are set to a constant vector containing ones with the same dimensions as those of the edge features, for example, if 10 edge features are used, node features will be vectors of 10 ones.
4.2. Edge Attention Mechanism Embedding
GNNs have been successfully applied in various application domains. However, these approaches mainly focus on node features for message propagation and are currently unable to consider edge features for edge classification. Therefore, we propose an edge attention mechanism that integrates edge-specific semantics into the message-passing process, enabling the model to dynamically weigh node-neighbor interactions while incorporating edge features. The attention mechanism provides a new idea for graph modeling by dynamically assigning node–edge interaction weights. For example, hierarchical attention network (HAN) [
29] uses predefined meta-paths to capture the semantic information of heterogeneous graphs (such as the “author-paper-conference” relationship in academic networks), but its performance is highly dependent on manually designed meta-paths and is difficult to adapt to the variability and concealment of network attack patterns (such as the unknown propagation path of zero-day attacks).
The core of our approach is a two-stage process: attention coefficient calculation and edge-aware message aggregation, as formalized in Algorithm 1.
where
and
are the node features of
u and
v at the
-th layer. This vector is then fed into a linear layer with a LeakyReLU activation to generate the attention coefficient.
is a weight matrix that parameterizes the attention mechanism, enabling the model to learn the importance of node pairs adaptively.
| Algorithm 1 Attention-Based Graph Edge Embedding. |
Input: Graph
Parameter: Node features
Parameter: Edge features
Parameter: Weight matrices , ,
Parameter: Nonlinearity
Output: Edge embeddings , Node embeddings - 1:
for layer to K do - 2:
Compute attention coefficients: - 3:
for edge do - 4:
- 5:
- 6:
end for - 7:
Normalize attention: - 8:
- 9:
Aggregate messages: - 10:
for node do - 11:
- 12:
end for - 13:
- 14:
Update Edge features: - 15:
for node do - 16:
- 17:
end for - 18:
end for - 19:
return ,
|
After Softmax normalization for neighbor weights, we fuse node and edge features during message propagation, rather than traditional GNNs that ignore edge semantics.
This step embeds edge-specific information (e.g., flow protocols, interaction frequency) into the node representation, enhancing the model’s ability to distinguish critical attack paths from noisy edges. This formulation explicitly incorporates edge features during neighborhood aggregation, preserving protocol-specific semantics critical for network intrusion detection.
Finally,
K layers of message-passing edge embeddings are generated by concatenating the features of their incident nodes.
This ensures that each edge embedding captures the collaborative representation of its source and destination nodes, enriched by the edge attention mechanism.
The architecture achieves three key advantages: (1) Edge feature preservation through integration prevents information loss common in conventional GNNs. (2) Adaptive attention weights suppress benign flow patterns while amplifying suspicious connections. (3) Layer propagation captures multi-grained attack, with shallow layers detecting anomalies and deeper layers identifying attack types.
4.3. Hierarchical Detection Framework
Generally, NIDSs using graph embedding usually use coarse labels to predict whether the network flow is an attack or benign [
14]. However, such a model is not able to further explore the attack type to facilitate network defenders in conducting research. Lo et al. [
13] classifies the attack fine-grained labels while training coarse-grained detection, and then trains a second model for attack type recognition, but this will cause a lot of training resources to be wasted.
Therefore, we add both fine-grained and coarse-grained objectives to the training objective. For coarse-grained loss,
is calculated using the cross-entropy loss function:
For fine-grained loss the steps are as follows: First, create a mask
to mark samples whose coarse-grained labels are positive (assuming the positive label is 1):
If , that is, there are no samples with coarse-grained labels as positive, then the fine-grained loss . If the opposite holds, perform the following steps:
Compute fine-grained prediction probability distribution
:
where
i is the coarse-grained positive sample index and
j is the fine-grained category index,
.
Calculate the information entropy of each sample
:
Calculate the weight of each sample
:
where the
is the temperature coefficient.
Normalize weights and calculate fine-grained losses
:
Finally, automatically balance the weights of the loss function. The total loss function
is a combination of the coarse-grained loss function and the fine-grained loss function.
The hierarchical design effectively addresses class imbalance by first filtering out the majority of benign samples through coarse-grained detection, thus reducing the imbalance ratio for fine-grained classification. The dynamic weighting mechanism based on information entropy further ensures that rare attack types are assigned higher training weights, preventing the model from being dominated by dominant attack categories. This dual strategy not only enhances detection efficiency but also significantly improves the model’s ability to recognize rare attack types in imbalanced datasets.
4.4. Adversarial Training Module
In response to the defense requirements against escape attacks in network intrusion detection, this work proposes an edge feature perturbation generation framework based on projected gradient descent (PGD) [
22]. PGD is adopted for its proven effectiveness as a universal first-order adversary, capable of generating strong adversarial examples that systematically expose model vulnerabilities. Unlike traditional nodes, focus on centric perturbation methods. Our approach leverages PGD to target edge features. Attackers often obfuscate protocol fields, port numbers, or flow timing to evade detection (e.g., DNS tunneling via modified UDP payloads or TCP flag order manipulation).
Given the original edge feature matrix
, this paper generates adversarial perturbations
through multiple steps of iteration. The perturbed edge feature
maximizes the loss function of the detection model under the premise of satisfying the
norm constraint
.
where ∏ represents the projection operation,
is the step size, and
is the hierarchical cross-entropy loss function.
The adversarial training formalized in Algorithm 2 alternates between adversarial perturbation crafting and model optimization throughout each training epoch. The process is initiated by generating edge feature perturbations through multi-step projected gradient descent (PGD). Starting from uniformly sampled noise within the prescribed bound, the perturbation undergoes iterative refinement by ascending the gradient direction of the detection model’s loss function. Following perturbation generation, the model parameters are updated using the adversarially perturbed graph features, thereby hardening the detector against evasion tactics while preserving topological relationships essential for contextual analysis.
Our approach focuses on edge feature manipulation, such as payload content and inter-packet timing. These are key vectors for evasion in real-world attacks. By prioritizing edge features over static node attributes like IP geolocation, we ensure the training process aligns with realistic adversarialtactics. We preserve the topological integrity of the network graph, such as IP communication patterns, through edge-centric perturbation. This allows the model to learn how to distinguish malicious behaviors while retaining structural context. Additionally, the iterative nature of PGD is beneficial. For example, 10–20 steps are designed to capture incremental edge feature modifications in advanced attacks. For example, it can model APTs’ gradual protocol shifting from HTTP to DNS. This capability forces the model to generalize across evolving evasion strategies.
| Algorithm 2 Adversarial Training with PGD. |
Input: Training graph G, model , perturbation bound , step size , iterations T, total epochs N, robust model parameters
- 1:
for epoch to N do - 2:
Generate adversarial examples: - 3:
Initialize - 4:
for to T do - 5:
Compute gradient: - 6:
Update perturbation: - 7:
Project to ball: - 8:
Apply protocol constraints: - 9:
end for - 10:
Update model parameters: - 11:
- 12:
end for
|
By integrating edge feature perturbation into the PGD framework, this module enhances the detection model’s robustness against real-world escape tactics, ensuring reliable performance in adversarial network environments.
4.5. Computational Complexity Analysis
4.5.1. Time Complexity
The Edge Attention Mechanism has two main computational steps. First, the attention coefficient calculation for each edge involves concatenating node features and passing them through a linear layer, leading to a time complexity of . is the number of edges and is the node feature. Then, the message aggregation process for each node v involves integrating neighboring edge features, resulting in a complexity of . The h is the hidden layer dimension.
The Hierarchical Detection Framework consists of two stages. Coarse-grained classification employs a Softmax function, with a complexity . Fine-grained classification is performed only on positive samples from the coarse-grained stage, leading to a complexity of .
The Adversarial Training Module utilizes projected gradient descent (PGD) for generating adversarial perturbations. Each perturbation generation requires T iterations of gradient calculations, resulting in a time complexity of .
4.5.2. Space Complexity
The space complexity of AH-EAT is determined by the storage requirements for model components and intermediate results:
Node Embedding Storage: , where is the number of nodes.
Edge Feature Matrix: The edge feature matrix requires space.
Adversarial Perturbation Cache: Storing adversarial perturbation vectors for edges incurs a space complexity of , which is the same as the edge feature matrix.
5. Experiments and Results
We evaluate the effectiveness and efficiency of AH-EAT using four datasets, including UNSW-NB15, CSE-CIC-IDS2018, BoT-IoT, and ToN-IoT.
We first describe our experimental settings (
Section 5.1). Then we elaborate on the performance compared with other state-of-art methods (
Section 5.2). We conduct the robustness performance study (
Section 5.3). Finally, we perform an ablation study (
Section 5.4).
5.1. Experimental Setting
5.1.1. Implementation
We implement AH-EAT in Python 3.8. The graph representation module is implemented using PyTorch [
30], PyG [
31], Scikit-learn [
32], and NetworkX [
33]. For each dataset, we divide the training set and testing set into the conventional 70% and 30%, respectively. The number of training epochs is 2000 iterations. Experiments are run on a server with an Intel CPU and an NVIDIA V100 GPU. The operating system is Linux. We will release the source code after this paper is published.
To clearly distinguish the differences and benefits of using AH-EAT embeddings in NIDSs, our results compare the accuracy and F1-score for both coarse-grained detection and fine-grained detection. The F1-score is used as a key performance indicator for our experiments, as this metric combats the problem of potential imbalance within datasets. Additionally, accuracy (Acc) is also used for comparison.
In the robustness study, we use the accuracy degradation before and after adversarial attack and the adversarial success rate (ASR) as research indicators. The ASR is the proportion of input samples that are misclassified by the model under adversarial attacks. Specifically, it is the ratio of the number of perturbed samples that are misclassified by the model to the total number of perturbed samples after adding adversarial perturbations to the original samples. It measures the vulnerability of the model to adversarial attacks. The higher the ASR, the more vulnerable the model is to adversarial attacks and the worse its robustness.
where the
is the number of misclassified adversarial samples and
is the total number of adversarial samples.
5.1.2. Datasets
We evaluate our approach on four NIDSs datasets.
UNSW-NB15 [
34] has 43 standardized features. Out of the 2,390,275 flows, 2,295,222 (96.02%) samples are benign flows, and the remaining 95,053 (3.96%) samples are attack flows. Nine attack types are distributed across the 3.98% of the flows representing attacks.
CSE-CIC-IDS2018 [
35] contains 18,893,708 flows distributed between 16,635,567 (88.05%) benign samples and 2,258,141 (11.95%) attack samples. Within the 11.95% of attack samples are 6 different attack methods.
ToN-IoT [
36] is a netflow-based IoT network dataset, which includes different types of IoT data, such as operation system logs and telemetry data of IoT/IIoT services. The dataset consists of 796,380 (3.56%) benign flows and 21,542,641 (96.44%) attack flows, with a total of 22,339,021 flows.
BoT-IoT [
37] is comprised of 6 types of attacks and a total of 47 features with corresponding class labels. The dataset contains only 477 (0.01%) benign flows and 3,668,045 (99.99%) attack flows, with a total of 3,668,522 flows. These datasets are all updated versions of existing NIDS datasets that have been standardized into a NetFlow format [
38].
5.1.3. Baseline
We have four comparison methods. E-GraphSAGE [
13] is an improved GNN model designed for edge features in IoT. Through the message-passing mechanism, source node features and edge features (such as protocol type and flow statistics) are aggregated to generate node embeddings. The two node embeddings of an edge are concatenated to obtain edge embeddings. Anomal-E [
14] is a GNN-based intrusion and anomaly detection method that uses edge features and graph topology in a self-supervised manner. This method allows for the incorporation of both edge features and topological patterns to detect attack patterns, without the need for labeled data. E-GCN is a model we modified based on E-GraphSAGE, changing the embedding model from GraphSAGE [
26] to the standard convolution operation of GCN [
11], which is used to compare the sampling effect of GraphSAGE. In network flow data with rich edge features, the complete aggregation of global topological information is richer than what can be learned by random sampling.
Table 1 shows the differences between the baselines in detail.
5.2. Comparison with SOTA Methods
The coarse-grained and fine-grained classification capabilities of GNNs are crucial in the field of network security.
Table 2 and
Table 3 show the performance comparison of different models on coarse-grained (binary classification: normal/attack) and fine-grained (multi-classification: specific attack type) tasks, respectively.
In coarse-grained detection, AH-EAT shows significant advantages on the IoT datasets BoT-IoT and ToN-IoT. For BoT-IoT, AH-EAT’s accuracy (98.44%) and F1-score (98.05%) are both higher than E-GraphSAGE (93.76%, 95.45%) and E-GCN (94.35%, 95.73%), indicating that it has a stronger ability to identify complex attacks in IoT environments. On the ToN-IoT dataset, although E-GraphSAGE has a slightly higher accuracy (81.47% vs. 80.42%), AH-EAT’s F1-score (71.68%) far exceeds Anomal-E (16.37%), showing better classification balance. Anomal-E completely fails on BoT-IoT and ToN-IoT (F1 < 20%) due to its unsupervised design. Since these two datasets were not experimented on in the original Anomal-E paper, the unsupervised method Anomal-E is not adaptable enough to IoT data and the limitations of the algorithm.
Fine-grained classification can better reflect the model’s ability to identify attack subclasses. Since Anomal-E cannot support fine-grained tasks,
Table 3 focuses on the comparison of E-GraphSAGE, E-GCN, and AH-EAT. AH-EAT’s fine-grained accuracy (22.77%) and F1-score (34.34%) on the CSE-CIC-IDS2018 dataset are significantly higher than E-GraphSAGE (9.41%, 11.35%) and E-GCN (1.41%, 1.29%), indicating that it has stronger feature extraction capabilities in complex attack scenarios. In BoT-IoT and ToN-IoT, AH-EAT’s fine-grained F1-scores reach 83.84% and 25.38%, respectively, far exceeding similar models.
Overall, AH-EAT effectively balances the generalization of coarse-grained detection and the specificity of fine-grained classification through hierarchical detection mechanisms, so that it can perform very well in most cases for both coarse and fine granularity scenarios. Compared with the self-supervised method Anomal-E, it shows better adaptability; compared with traditional GNN models (such as E-GraphSAGE, E-GCN), its innovative edge-based graph attention network and feature fusion strategies significantly improve the ability to identify attack types, providing a more reliable solution for actual network security deployment.
Since AH-EAT does not perform well on the ToN-IoT dataset in fine-grained detection, we focus on analyzing
Figure 2a,b (t-SNE visualization). T-SNE visualization reveals key insights into AH-EAT’s performance limitations on ToN-IoT. With more than 80% attack samples across nine fine-grained types (e.g., <0.1% Ransomware), ToN-IoT imposes extreme classification imbalance. While t-SNE shows clear separation between benign and attack clusters at the coarse-grained level, attack clusters overlap significantly due to semantically similar flow patterns (e.g., DoS and DDoS). Compared to traditional network flow datasets, the Internet of Things dataset exhibits fewer features. Most of them are dominated by basic UDP/TCP protocols and repetitive traffic timings. This forces AH-EAT to struggle with intra-attack-type discrimination. On the other hand, although AH-EAT’s fine-grained accuracy (42.25%) lags behind E-GraphSAGE (49.36%), AH-EAT has two training targets, namely coarse-grained and fine-grained training targets, so it may not be as effective as focusing on only one training target (E-GraphSAGE). However, the difference between the two is not large, which is a limitation shared by all methods in this paper, but is more significant in IoT data due to its constrained feature space.
To further illustrate AH-EAT’s effectiveness across datasets, we conducted a false positive/negative rate analysis. As shown in
Figure 2c, traditional network datasets CIC-IDS2018 and UNSW-NB15 exhibit superior performance, attributed to their diverse protocols (e.g., HTTP, DNS) and complex attack patterns. These enable AH-EAT’s edge attention mechanism to capture topological differences and avoid attack-type confusion. Specifically, CIC-IDS2018 achieves a perfect True Positive Rate (TPR = 1.0) with a near-zero False Positive Rate (FPR) and False Negative Rate (FNR), while UNSW-NB15 shows a high TPR of 0.9477 with low FPR (0.0046) and FNR (0.0523). Conversely, AH-EAT’s poor performance on ToN-IoT is reaffirmed by its relatively high FNR, indicating limited feature diversity in this IoT dataset. BoT-IoT, another IoT dataset, outperforms ToN-IoT but still lags behind traditional datasets, highlighting that the constrained feature space of IoT data—dominated by basic UDP/TCP protocols—hinders discriminability compared to rich traditional network flows.
To gain insights into the underlying mechanisms of AH-EAT’s performance, we conducted an analysis of the model’s learned features. The edge attention mechanism in AH-EAT assigns varying weights to different edges in the network flow graph, with higher weights typically given to edges that exhibit abnormal flow statistics, such as unusually high packet counts or rare port pairs. This indicates that the model has learned to prioritize attack propagation paths and critical topological interactions, which are essential for distinguishing malicious flows from benign ones.
5.3. Compare Robustness
Adversarial robustness is a core indicator to measure whether a model can maintain stable performance under adversarial attacks.
Table 4 and
Table 5 show the robustness performance of different models on the CIC-IDS2018 and ToN-IoT datasets, including clean sample accuracy (clean accuracy), adversarial sample robust accuracy (robust accuracy) and adversarial success rate (ASR).
E-GCN achieves the highest clean accuracy (98.91%) on clean samples but collapses under adversarial attacks, with robust accuracy dropping to 53.50% and ASR reaching 46.50%, indicating severe sensitivity to adversarial perturbations. E-GraphSAGE performs better than E-GCN with a robust accuracy of 81.66% and ASR of 18.34%, though still showing significant degradation. Anomal-E performs worst, with robust accuracy as low as 11.97% and ASR as high as 88.03%, reflecting its inability to maintain classification ability in adversarial environments, likely due to poor feature extraction for IoT data using a self-supervised method. AH-EAT demonstrates overwhelming advantages on CIC-IDS2018: its clean accuracy (98.55%) is identical to robust accuracy, with an ASR of only 1.45%. This means the model’s accuracy remains unchanged after adding adversarial perturbations, proving its strong resistance to adversarial attacks.
As a dataset for low-resource IoT devices, ToN-IoT imposes stricter robustness requirements. E-GraphSAGE and E-GCN suffer drastic drops in robust accuracy to 19.58% and 30.64%, respectively, with ASR exceeding 60%, indicating that traditional GNNs struggle to defend against attacks in resource-constrained scenarios. In contrast, AH-EAT maintains consistent robust accuracy (84.38%) with an ASR of only 15.62%, which is far lower than peer models. This benefits from its hierarchical adversarial training, which suppresses the impact of perturbations on classification decisions while preserving original feature representations.
AH-EAT constructs a multi-layer defense against adversarial perturbations through gradient alignment constraints and feature space robust regularization. On CIC-IDS2018, its ASR is only of E-GCN, and on ToN-IoT, it reduces ASR by over 80% compared to E-GraphSAGE. This advantage is particularly critical for resource-constrained IoT scenarios, proving that AH-EAT can maintain stable detection performance under real-world attacks, providing a solid foundation for industrial deployment.
The adversarial training module in AH-EAT also plays a key role in enhancing the model’s robustness. By generating adversarial perturbations during training, the model has learned to focus on invariant features that are less susceptible to evasion attacks. This is evident from the model’s consistent performance across different datasets, even when faced with adversarial examples.
5.4. Ablation Study
The ablation experiment removes the core modules (attention, hierarchical detection framework, adversarial training) to quantify the independent contribution of each component to the model performance (accuracy, robustness) and reveal the synergy between modules. By comparing the performance of the complete model with the variant model, the necessity of each module design and its unique value in complex tasks are verified, providing a theoretical basis for model optimization.
Table 6 and
Table 7 show the results on the BoT-IoT (fine-grained) and UNSW-NB15 (coarse-grained) datasets, respectively.
The three models are designed as follows:
AH-EAT-NA (removes attention mechanism). This variant removes the attention mechanism and uses the mean aggregation of neighbor features instead. The goal is to verify the key role of hierarchical attention in the fusion of graph structure features. By comparing the original model, whether mean aggregation leads to a decrease in feature discrimination (such as ignoring the structural information of key nodes) is observed. Therefore, it clarifies the irreplaceable role of the attention mechanism in screening high-value neighbor features and suppressing noise interference.
AH-EAT-NH (remove hierarchical detection framework). This variant removes the hierarchical framework of “coarse-grained detection → fine-grained classification” and directly performs multi-classification on all samples. Its core goal is to verify the dual improvement of hierarchical detection on efficiency and accuracy: whether the coarse-grained stage can effectively filter normal samples to reduce the computational load, and whether the fine-grained stage can alleviate the category imbalance problem through hierarchical decision-making.
AH-EAT-NADV (remove adversarial training). This variant turns off the adversarial training module and only uses the original clean data for training, aiming to verify the core impact of adversarial training on model robustness. By comparing the performance under adversarial samples (such as ASR, robust accuracy), it quantifies the cornerstone role of adversarial training in resisting perturbations. It enhances the robustness of feature space and reveals its decisive impact on the stability of the model in real attack scenarios.
Table 6 shows the effects on a fine-grained dataset. Attention mechanism (AH-EAT-NA): After removal, the F1-score dropped by 1.16% (83.84%→82.68%), but accuracy unexpectedly increased by 0.8% (81.46%→82.26%). This shows that although mean aggregation improves overall accuracy, it weakens the ability to capture hidden attack features (such as the time series pattern of DNS tunnels). Its ASR decreased by 1.88% (18.85%→17.97%), reflecting that the attention mechanism may introduce slight vulnerabilities, so the effect of the attention mechanism is limited in a small-scale dataset such as BoT-IoT. Hierarchical detection framework (AH-EAT-NH): direct multi-classification caused the F1-score to plummet by 14.75% (83.84%→69.09%), and ASR increased by 2.97% (18.85%→21.82%). It is proved that the hierarchical framework effectively protects fine-grained modules from noise interference through coarse-grained screening (filtering 85% of benign flow) and improves the identification accuracy of key attack paths. Adversarial training (AH-EAT-NADV): after closing, robust F1 drops by 12.51% (83.52%→71.01%), and ASR surges by 8.34% (18.85%→27.19%). It shows that adversarial training improves the model’s defense capability against edge feature perturbations by more than 3 times, highlighting the necessity of adversarial training.
Table 7 shows the effects on a coarse-grained dataset. Attention mechanism (AH-EAT-NA): the F1-score drops by 0.56% (97.23%→96.67%) and ASR increases slightly by 0.24% (2.64%→2.88%). It shows that in coarse-grained tasks, global topological information is more important than local attention. However, the attention mechanism still contributes to the recognition ability of key information. Hierarchical detection framework (AH-EAT-NH): direct multi-classification leads to a 3.15% drop in F1-score (97.23%→94.08%), and a 1.34% increase in ASR (2.64%→3.98%). Adversarial training (AH-EAT-NADV): after turning it off, the model completely collapses (robust F1 = 2.56% vs. 97.10%), and ASR soars to 88.03%. It proves that adversarial training is the core guarantee of robustness. It enables the model to learn the protocol semantic invariance (such as HTTP method legality constraints) through edge feature perturbation generation.
In summary, the attention mechanism provides high-discrimination features for hierarchical detection, and the hierarchical framework reduces the interference of invalid samples in adversarial training (such as fine-grained adversarial optimization only for samples that are judged as attacks at a coarse-grained level). Adversarial training feeds back feature learning, forming a positive cycle of “feature screening → hierarchical decision → robust enhancement”.
6. Conclusions
In this paper, we propose AH-EAT, an adversarial hierarchical-aware edge attention learning method. AH-EAT collaborates with an edge attention mechanism, a hierarchical detection framework, and an adversarial training module to construct a detection system with accuracy, efficiency, and robustness. It solves the defects of existing NIDSs in static feature aggregation, single-granularity detection, and adversarial vulnerability. We integrate edge features (such as flow protocol and interaction frequency) with an attention mechanism, adaptively distinguish key attack paths from noise edges, and effectively capture structures and feature patterns. It solves how traditional static aggregation strategies (such as mean/max pooling) cannot intelligently filter features, and lays a feature foundation for accurate detection. Through the hierarchical multi-grained detection, malicious and benign flows are quickly distinguished through coarse-grained detection. Then fine-grained attack detection is used to identify malicious flows. This framework breaks through the limitations of single-granularity detection, alleviating the problem of imbalanced attack class samples. It avoids the waste of resources of traditional methods of training from scratch. The adversarial training strategy is based on projected gradient descent (PGD), which generates adversarial samples of edge features. It forces the model to learn robust decision boundaries that are insensitive to perturbations, significantly improving the stability of the model in adversarial environments. Experiments have shown that AH-EAT has both accurate detection and strong robustness, providing a feasible technical solution for intrusion detection in complex network environments.





{kind=link}
{kind=link}