A Novel Neural Network Framework for Automatic Modulation Classification via Hankelization-Based Signal Transformation



Abstract
1. Introduction
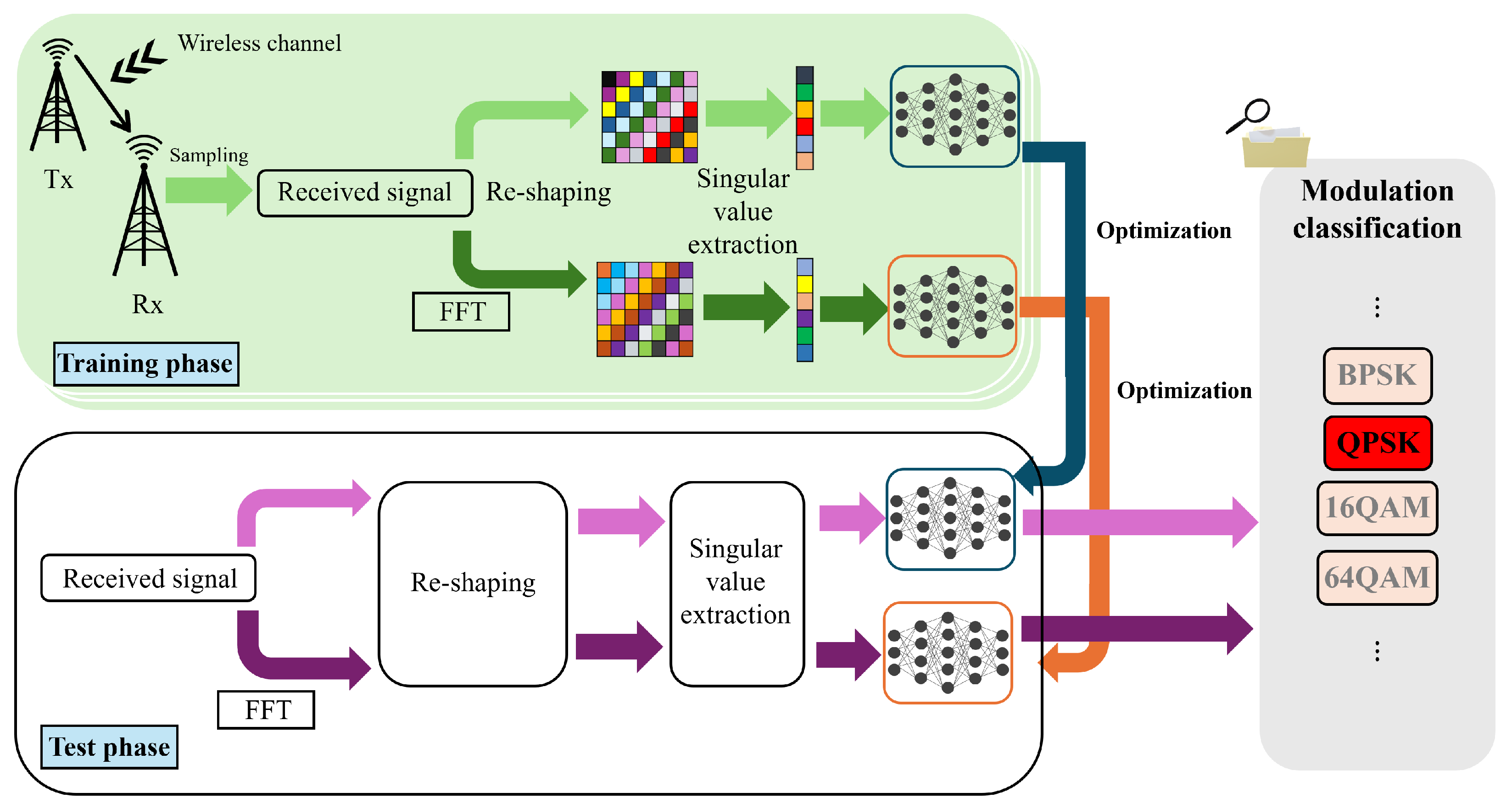
2. Proposed Framework
2.1. System Model and Problem Formulation
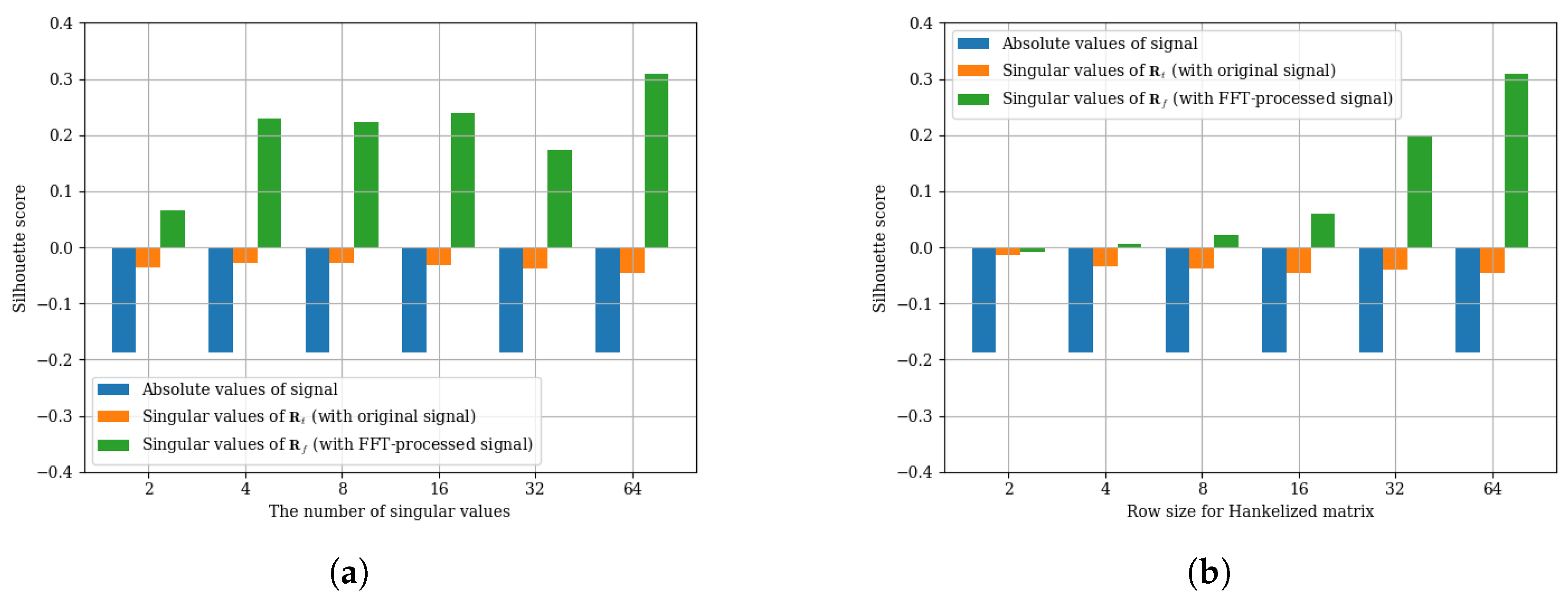
2.2. NN Design via Hankelization-Based Preprocessing
- : The loss function.
- : The collection of all trainable parameters, including weight matrices and bias vectors.
- : The parameter gradient computed with respect to .
- C: The number of modulation classes.
- M: The number of training datasets.
- N: The number of test datasets.
| Algorithm 1 The Procedure of the Proposed Method |
| [Training phase] |
| 1: Collect training dataset . |
| 2: Select domain for all samples: (time-domain) or (frequency-domain via FFT). |
| 3: for to M do |
| 4: Build Hankelized matrix: |
| 5: Compute SVD based on (3): . |
| 6: Extract the vector consisting of singular values based on (6) . |
| 7: end for |
| 8: Optimize NN based on (7), (8), and (9). |
| [Test phase] |
| 9: Collect test dataset . |
| 10: Employ the same domain as chosen during training phase. |
| 11: for to N do |
| 12: Build Hankelized matrix as in Step 4. |
| 13: Make the input vector referring to Step 5 and 6. |
| 14: Predict modulation class index based on (10) and (11):, . |
| 15: end for |
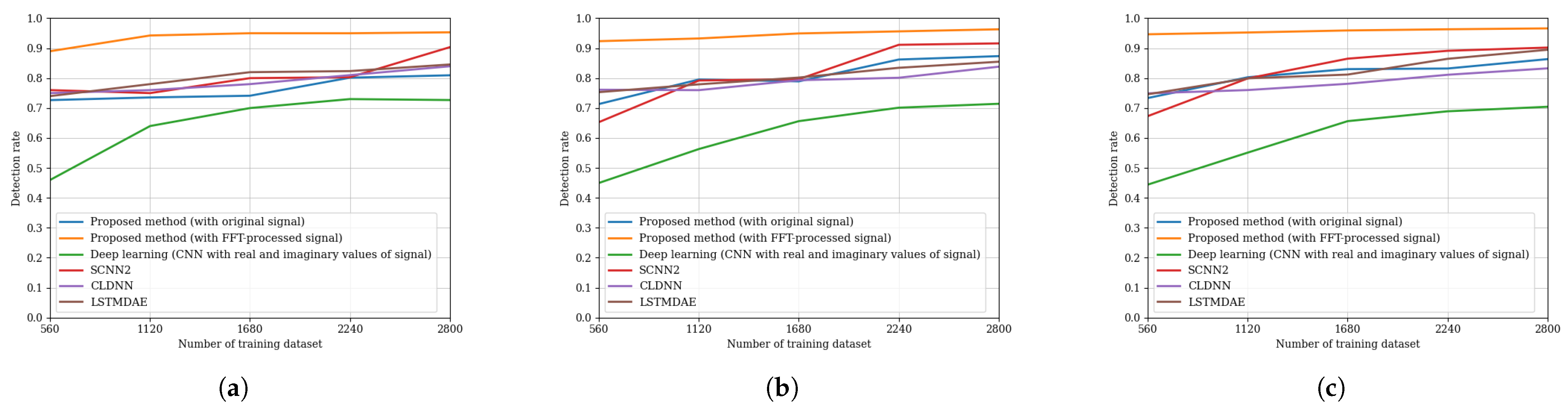
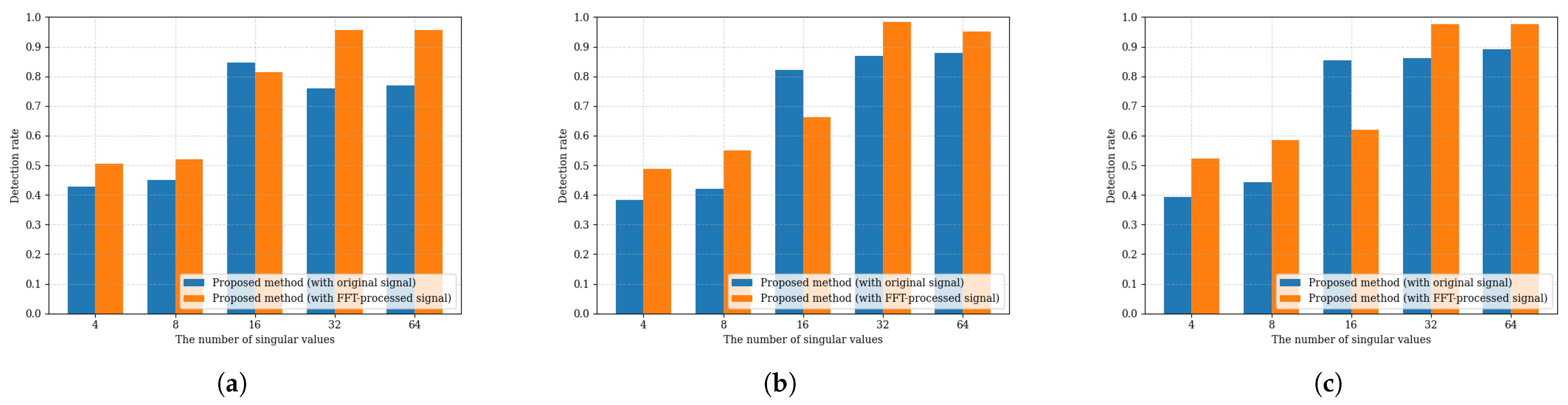
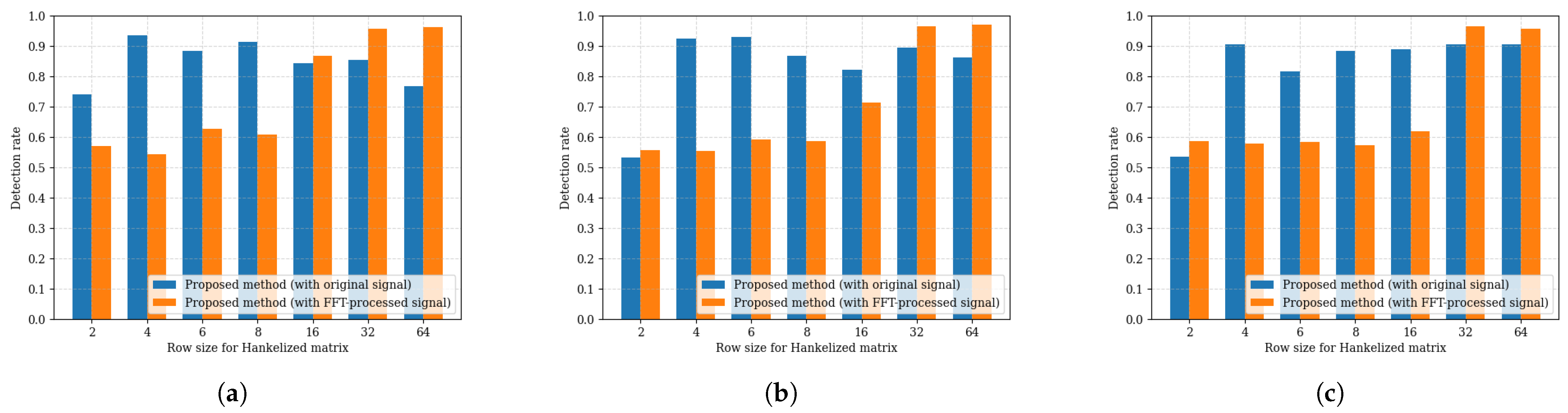
3. Simulation Results
3.1. Simulation Configurations
- Deep learning (CNN with real and imaginary values of the signal: The NN-based method that utilizes a CNN architecture, in which the real and imaginary parts of the input signal are treated as two separate input channels. This structure follows the design presented in [24].
- SCNN2: The NN-based method that transforms raw complex signals into spectrogram images via discrete short-time Fourier transform (STFT), applies Gaussian filtering for noise reduction, and performs classification using a dedicated CNN architecture optimized for time-frequency representations, as described in [14].
- CLDNN: The NN-based method that combines convolutional layers for local feature extraction, long short-term memory (LSTM) layers for modeling temporal dependencies, and FC layers for classification. This hybrid architecture leverages both spatial and temporal information embedded in the received signal, following the design principles in [16].
- LSTMDAE: The NN-based method that employs a denoising autoencoder (DAE) based on LSTM networks, which learns robust latent representations of noisy signals through temporal masking and reconstruction. The decoder output is jointly optimized with a modulation classification objective, thereby improving classification performance under noisy conditions, as introduced in [25].
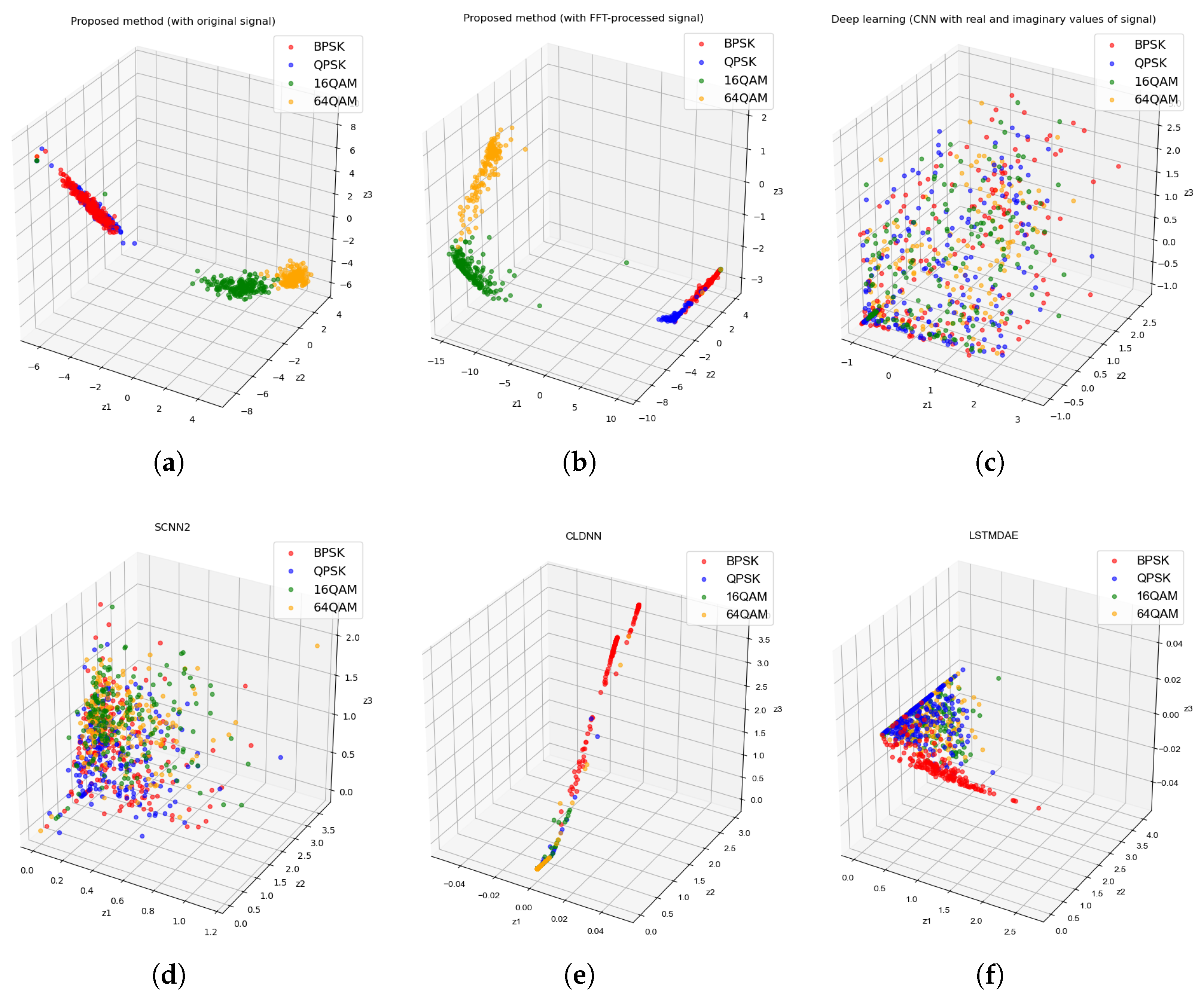
3.2. Empirical Latent Space Comparison Across Models
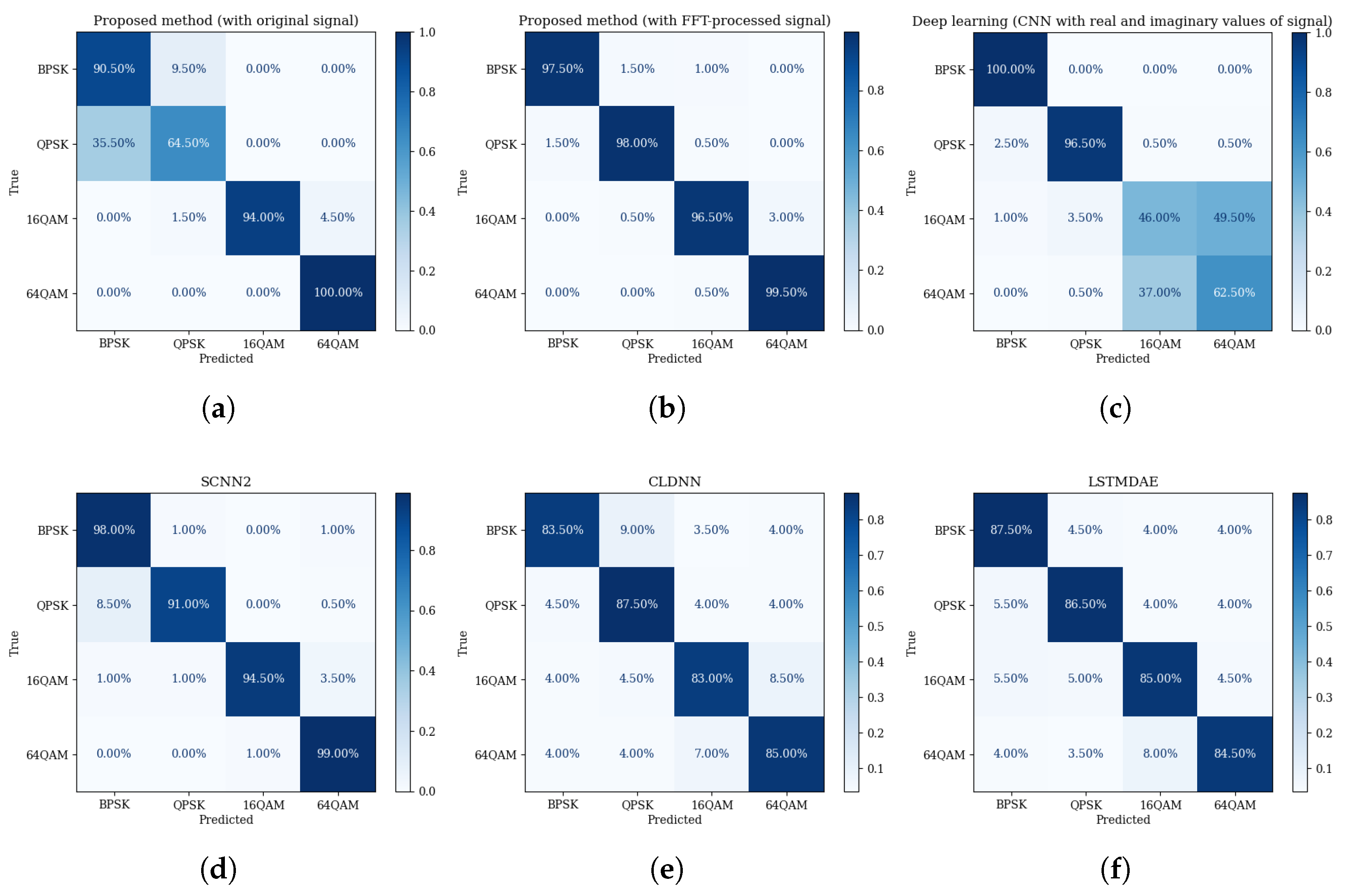
3.3. Performance Evaluation for Modulation Recognition
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AMC | Automatic modulation classification |
| ML | Machine learning |
| SVM | Support vector machine |
| k-NN | k-nearest neighbors |
| NN | Neural network |
| CNN | Convolutional neural network |
| RNN | Recurrent neural network |
| DL | Deep learning |
| SNR | Signal-to-noise ratio |
| SVD | Singular value decomposition |
| SISO | Single-input single-output |
| CIR | Channel impulse response |
| AWGN | Additive white Gaussian noise |
| FFT | Fast Fourier transform |
| t-SNE | t-distributed stochastic neighbor embedding |
| FC | Fully connected |
| Adam | Adaptive moment estimation |
| RMSProp | Root mean square propagation |
| MLP | Multilayer perceptron |
| STFT | Short-time Fourier transform |
| LSTM | Long short-term memory |
| DAE | Denoising autoencoder |
| FLOP | Floating-point operation |
References
- Gui, G.; Liu, M.; Tang, F.; Kato, N.; Adachi, F. 6G: Opening new horizons for integration of comfort, security, and intelligence. IEEE Wirel. Commun. 2020, 27, 126–132. [Google Scholar] [CrossRef]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef]
- Huynh-The, T.; Pham, Q.V.; Nguyen, T.V.; Nguyen, T.T.; Ruby, R.; Zeng, M.; Kim, D.S. Automatic modulation classification: A deep architecture survey. IEEE Access 2021, 9, 142950–142971. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-air deep learning based radio signal classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef]
- Häring, L.; Chen, Y.; Czylwik, A. Efficient modulation classification for adaptive wireless OFDM systems in TDD mode. In Proceedings of the 2010 IEEE Wireless Communications and Networking Conference, Sydney, Australia, 18–21 April 2010; pp. 1–6. [Google Scholar]
- Harper, C.A.; Thornton, M.A.; Larson, E.C. Automatic modulation classification with deep neural networks. Electronics 2023, 12, 3962. [Google Scholar] [CrossRef]
- Fu, X.; Gui, G.; Wang, Y.; Gacanin, H.; Adachi, F. Automatic modulation classification based on decentralized learning and ensemble learning. IEEE Trans. Veh. Technol. 2022, 71, 7942–7946. [Google Scholar] [CrossRef]
- Su, W.; Xu, J.L.; Zhou, M. Real-time modulation classification based on maximum likelihood. IEEE Commun. Lett. 2008, 12, 801–803. [Google Scholar] [CrossRef]
- Xu, J.L.; Su, W.; Zhou, M. Likelihood-ratio approaches to automatic modulation classification. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2010, 41, 455–469. [Google Scholar] [CrossRef]
- Ozdemir, O.; Li, R.; Varshney, P.K. Hybrid maximum likelihood modulation classification using multiple radios. IEEE Commun. Lett. 2013, 17, 1889–1892. [Google Scholar] [CrossRef]
- Li, J.; Meng, Q.; Zhang, G.; Sun, Y.; Qiu, L.; Ma, W. Automatic modulation classification using support vector machines and error correcting output codes. In Proceedings of the 2017 IEEE 2nd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 December 2017; pp. 60–63. [Google Scholar]
- Orlic, V.D.; Dukic, M.L. Automatic modulation classification algorithm using higher-order cumulants under real-world channel conditions. IEEE Commun. Lett. 2009, 13, 917–919. [Google Scholar] [CrossRef]
- Su, W. Feature space analysis of modulation classification using very high-order statistics. IEEE Commun. Lett. 2013, 17, 1688–1691. [Google Scholar] [CrossRef]
- Zeng, Y.; Zhang, M.; Han, F.; Gong, Y.; Zhang, J. Spectrum analysis and convolutional neural network for automatic modulation recognition. IEEE Wirel. Commun. Lett. 2019, 8, 929–932. [Google Scholar] [CrossRef]
- Huynh-The, T.; Hua, C.H.; Pham, Q.V.; Kim, D.S. MCNet: An efficient CNN architecture for robust automatic modulation classification. IEEE Commun. Lett. 2020, 24, 811–815. [Google Scholar] [CrossRef]
- West, N.E.; O’shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; pp. 1–6. [Google Scholar]
- Hamidi-Rad, S.; Jain, S. Mcformer: A transformer based deep neural network for automatic modulation classification. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Chen, Y.; Dong, B.; Liu, C.; Xiong, W.; Li, S. Abandon locality: Frame-wise embedding aided transformer for automatic modulation recognition. IEEE Commun. Lett. 2022, 27, 327–331. [Google Scholar] [CrossRef]
- Mao, Q.; Hu, F.; Hao, Q. Deep learning for intelligent wireless networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2018, 20, 2595–2621. [Google Scholar] [CrossRef]
- Sathyanarayanan, V.; Gerstoft, P.; El Gamal, A. RML22: Realistic dataset generation for wireless modulation classification. IEEE Trans. Wirel. Commun. 2023, 22, 7663–7675. [Google Scholar] [CrossRef]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- O’shea, T.J.; West, N. Radio machine learning dataset generation with GNU radio. In Proceedings of the GNU Radio Conference, Charlotte, NC, USA, 20–24 September 2016; Volume 1. [Google Scholar]
- Tekbıyık, K.; Ekti, A.R.; Görçin, A.; Kurt, G.K.; Keçeci, C. Robust and fast automatic modulation classification with CNN under multipath fading channels. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Ke, Z.; Vikalo, H. Real-time radio technology and modulation classification via an LSTM auto-encoder. IEEE Trans. Wirel. Commun. 2021, 21, 370–382. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Channel model | Rician fading |
| K-factor | 4 dB |
| Sampling rate | 200 kHz |
| Number of multipaths L | 3 |
| Doppler frequency | max = 1 Hz |
| Initial phase error | U(0, ) |
| Frequency offset | Standard deviation per sample = , Maximum deviation: 500 Hz |
| Timing offset | Standard deviation per sample = , Maximum deviation: 500 Hz |
| Number of samples per modulation per SNR | 1000 |
| Length of samples | 128 |
| SNR | to 20 dB in steps of 2 dB |
| Parameter | Value |
|---|---|
| Data split (per modulation class) | 70% training/10% validation/20% testing |
| NN depth d | 3 |
| NN width | 24 |
| Epochs | 120 |
| Mini-batch size | 64 |
| NN connection type | FC |
| Learning rate | |
| Activation function | Hyperbolic tangent function |
| Loss function | Cross-entropy |
| Optimizer | Adam |
| , | , |
| Experimental setup | Python 3.10.16, PyTorch 2.5.1, CUDA 12.1, cuDNN 9.1.0, NVDIA RTX A4000 GPU, Intel Core i9-11900K CPU |
| SNR [dB] | Proposed Method (with Original Signal) | Proposed Method (with FFT-Processed Signal) | Deep Learning (CNN with Real and Imaginary Values of Signal) | SCNN2 | CLDNN | LSTMDAE |
|---|---|---|---|---|---|---|
| −20 | 0.2545 ± 0.0113 | 0.2490 ± 0.0123 | ||||
| −18 | 0.2529 ± 0.0099 | 0.2454 ± 0.0066 | ||||
| −16 | 0.3394 ± 0.0138 | 0.2476 ± 0.0054 | ||||
| −14 | 0.4627 ± 0.0282 | 0.2984 ± 0.0692 | ||||
| −12 | 0.5888 ± 0.0176 | 0.6123 ± 0.0145 | ||||
| −10 | 0.6834 ± 0.0176 | 0.6912 ± 0.0131 | ||||
| −8 | 0.7140 ± 0.0077 | 0.7251 ± 0.0078 | ||||
| −6 | 0.7292 ± 0.0146 | 0.7329 ± 0.0148 | ||||
| −4 | 0.7274 ± 0.0082 | 0.7409 ± 0.0138 | ||||
| −2 | 0.7264 ± 0.0098 | 0.7428 ± 0.0609 | ||||
| 0 | 0.7297 ± 0.0655 | 0.7316 ± 0.0119 | ||||
| 2 | 0.8229 ± 0.0843 | 0.8408 ± 0.0097 | ||||
| 4 | 0.8396 ± 0.0614 | 0.8456 ± 0.0196 | ||||
| 6 | 0.8306 ± 0.0560 | 0.8508 ± 0.0120 | ||||
| 8 | 0.8316 ± 0.0607 | 0.8545 ± 0.0112 | ||||
| 10 | 0.8482 ± 0.0125 | 0.8448 ± 0.0182 | ||||
| 12 | 0.8341 ± 0.0159 | 0.8512 ± 0.0281 | ||||
| 14 | 0.8336 ± 0.0535 | 0.8619 ± 0.0221 | ||||
| 16 | 0.8326 ± 0.0676 | 0.8945 ± 0.0196 | ||||
| 18 | 0.8403 ± 0.0687 | 0.8898 ± 0.0159 |
| Method | FLOPs | # Params |
|---|---|---|
| Proposed method (with original signal) | ||
| Proposed method (with FFT-processed signal) | ||
| Deep learning (CNN with real and imaginary values of signal) | ||
| SCNN2 | ||
| CLDNN | ||
| LSTMDAE |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-H.; Lee, J.-H.; Shin, O.-S.; Lee, W.-H. A Novel Neural Network Framework for Automatic Modulation Classification via Hankelization-Based Signal Transformation. Appl. Sci. 2025, 15, 7861. https://doi.org/10.3390/app15147861
Kim J-H, Lee J-H, Shin O-S, Lee W-H. A Novel Neural Network Framework for Automatic Modulation Classification via Hankelization-Based Signal Transformation. Applied Sciences. 2025; 15(14):7861. https://doi.org/10.3390/app15147861
Chicago/Turabian StyleKim, Jung-Hwan, Jong-Ho Lee, Oh-Soon Shin, and Woong-Hee Lee. 2025. "A Novel Neural Network Framework for Automatic Modulation Classification via Hankelization-Based Signal Transformation" Applied Sciences 15, no. 14: 7861. https://doi.org/10.3390/app15147861
APA StyleKim, J.-H., Lee, J.-H., Shin, O.-S., & Lee, W.-H. (2025). A Novel Neural Network Framework for Automatic Modulation Classification via Hankelization-Based Signal Transformation. Applied Sciences, 15(14), 7861. https://doi.org/10.3390/app15147861