1. Introduction
Amid the rapid pace of global urbanization, the generation of urban municipal garbage has increased exponentially, presenting unprecedented challenges to environmental protection and resource recovery. Traditional manual garbage classification methods, burdened by inefficiencies, high costs, and susceptibility to subjective biases, are increasingly inadequate to meet the demands of modern cities for efficient and precise garbage management within the framework of sustainable development. Consequently, deep learning-based intelligent garbage classification technologies, renowned for their superior performance in feature extraction and pattern recognition, have emerged as a pivotal and challenging research focus in recent years.
Early studies primarily focused on leveraging classical convolutional neural networks and their variants to enhance feature extraction and classification performance for garbage imagery. For instance, Jin et al. enhanced the MobileNetV2 model by incorporating an attention mechanism and extended its generalization capability via transfer learning, achieving a 90.7% classification accuracy on the Huawei Cloud dataset [
1]. Wang et al. fused the local feature extraction strength of ResNet with the global information capture of the Vision Transformer, further integrating Pyramid Pooling Module (PPM) and Convolutional Block Attention Module (CBAM) modules to improve both performance and accuracy in garbage classification [
2]. Additionally, Lee and Yeh employed an improved Single Shot MultiBox Detector (SSD) neural network, attaining a garbage detection accuracy of approximately 87%, thereby demonstrating the potential of object detection methods in this domain [
3]. Furthermore, Darwis et al. combined the deep features extracted from a 50-layer Residual Network (ResNet50) with traditional classification algorithms such as Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Random Forest, achieving a garbage classification performance of 91% [
4]. Li et al. built upon a 16-layer VGG network (VGG-16) by integrating content and boundary-aware mechanisms, which elevated the accuracy to 98% [
5]. Ren et al., after comparing various classical convolutional neural network models, recommended the utilization of ResNet18 [
6]. Similarly, both Ma et al. and Xie et al. optimized the MobileNetV2 architecture, each reporting classification accuracies exceeding 98% on their respective custom garbage datasets [
7,
8]. Yang et al. employed a compact convolutional neural network in conjunction with an adaptive image enhancement strategy, achieving high classification accuracy on a custom garbage dataset [
9]. Concurrently, Zhao et al. exploited the advanced architecture of MobileNetV3-Large by incorporating depthwise separable convolutions, inverted residual structures, lightweight attention mechanisms, and the hard_swish activation function to facilitate deep recognition of garbage images, attaining an accuracy of 81% [
10]. Qin et al. enhanced Inception V3 and integrated multi-source data, which resulted in a 4.80% improvement in classification accuracy on a real-world collected dataset [
11]. Additionally, Li et al. introduced feature fusion and depthwise separable convolutions into an improved ResNet-50, achieving an accuracy of 94.13% on the TrashNet dataset [
12].
While the aforementioned methods based on conventional convolutional neural network architectures have achieved remarkable success, challenges such as complex backgrounds, multi-label scenarios, and fine-grained classification in garbage images persist. To address these issues, some researchers have started exploring hybrid model designs to fully leverage the complementary advantages of diverse models. In this context, Goel et al. developed the Selective Enhanced Feature Weighted Attention Module (SEFWaM) framework, which employs transfer learning and algorithm fusion to achieve a 94.2% accuracy on the Trashnet 2.0 dataset [
13]. Wu et al. utilized the Vision Transformer (ViT-B/16) in combination with an innovative asymmetric loss function, resulting in an identification accuracy exceeding 92.36% on a self-collected dataset, thereby significantly enhancing garbage data classification performance [
14]. Kumar Lilhore et al. proposed a convolutional neural network (CNN) hybrid model that integrates Bidirectional Long Short-Term Memory (Bi-LSTM) with transfer learning, achieving a classification accuracy of 96.78% on the TrashNet dataset [
15]. Jain and Kumar adopted the EfficientNetB3 model for fine-grained classification of garbage bags, paper bags, and plastic bags, reaching an impressive accuracy of 97% [
16]. Wang et al. improved the overall discriminative power of their model by fusing the local features extracted by ResNet with the global information captured by the Vision Transformer, achieving an accuracy of 96.54% [
17]. Hossen et al. introduced the Garbage Classifier Deep Neural Network (GCDN-Net) deep neural network model, which demonstrated excellent performance in both single-label and multi-label classification of urban recyclable garbage [
18]. Finally, Yang et al. realized complementary model strengths by integrating ResNet, MobileNetV2, and You Only Look Once version 5 (YOLOv5), achieving an image classification accuracy of 98% [
19].
To further enhance the model’s feature aggregation and information propagation efficiency, researchers have embarked on new explorations in network architecture and attention mechanisms. Wang et al. augmented the Inception-V3 framework with Inverted Bottleneck and Contextual Transformer modules, thereby bolstering the model’s capability to manage complex backgrounds [
20]. Shang et al. optimized the structure of ShuffleNet V2 and integrated it with the MobileViT model to improve cross-channel information exchange, which in turn elevated garbage classification accuracy [
21]. Furthermore, Wang et al. introduced the Coordinate Attention (CA) mechanism into the YOLOv5 framework, complemented by data augmentation and adversarial sample generation, which significantly improved the recognition accuracy of garbage images [
22]. Yu et al. embedded multiple attention mechanisms within the YOLOv8 architecture and systematically assessed the impact of each module on overall performance [
23]. In addition, Yan et al. developed an automated garbage classification system based on an enhanced YOLOv5, achieving further gains in detection precision through structural optimization [
24].
To further enhance model robustness and generalization in complex scenarios, several studies have incorporated advanced optimization algorithms, dynamic construction strategies, and ensemble methods. Yulita et al. generated image embeddings using Inception V3 and combined them with Extreme Gradient Boosting (XGBoost v1.6.2) to realize efficient classification [
25]. Moreover, Wandre et al. explored an ensemble approach that integrated graph neural networks and recurrent neural networks based on feature extraction from VGG16 and ResNet50, effectively capturing the spatiotemporal characteristics of plastic garbage and achieving a classification accuracy of 81% [
26]. Lin et al. proposed a Dual-Branch Binarized Neural Network (DBBNN) that enhances garbage classification efficiency by refining both the network architecture and the loss function [
27]. Zucai et al. and Wang and Wen. conducted targeted optimizations on Inception V3 and YOLOv8, respectively [
28,
29]. Zhou et al. assembled a comprehensive dataset comprising 15,000 images and applied YOLOv8 to achieve a recognition accuracy of 90% [
30]. Liang and Guan introduced a novel FConvNet by integrating convolutions to augment spatial correlation [
31]. Furthermore, Li et al. developed a multi-subnetwork architecture by fusing Deconvolutional Single Shot Detector (DSSD), YOLOv4, and Faster Region-based Convolutional Neural Network (Faster-RCNN), and cascade classifiers [
32], while Gupta et al. achieved a detection accuracy of 98.5% on underwater images using an enhanced YOLOv8 [
33]. Ma et al. further advanced the field by improving SSD and the feature fusion module, replacing VGG16 with ResNet-101 and, thereby, surpassing the performance of several existing object detection algorithms [
34].
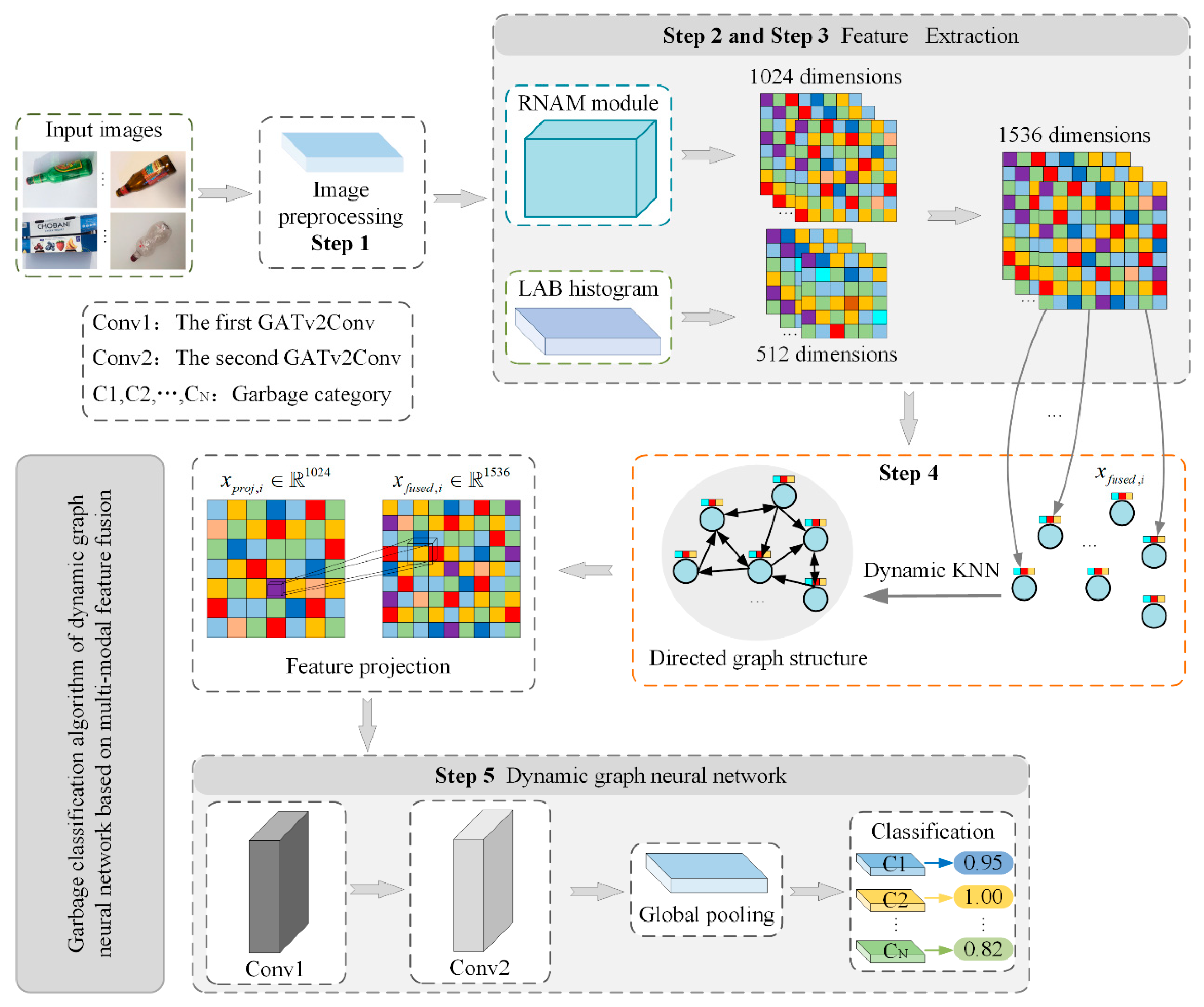
However, when confronted with the complexities and variabilities of real-world scenarios, single-model approaches or static feature extraction techniques still exhibit deficiencies in both generalization and real-time performance. Traditional feature extraction and fusion strategies often fail to fully capture the complementary information across different modalities, thereby limiting their effectiveness in handling complex backgrounds and fine-grained distinctions. Moreover, most attention mechanisms rely on static designs that are poorly equipped to adapt to dynamic changes in data distribution, which in turn undermines the model’s generalization capabilities in small-sample and extreme scenarios. Additionally, the majority of existing research continues to depend on conventional convolutional neural network architectures, missing opportunities to exploit the inter-sample relational information—most notably, the latent advantages of graph neural networks (GNNs) remain largely unexplored in the realm of garbage classification. To address these challenges, this paper proposes an innovative garbage classification method, with its primary contributions including the following:
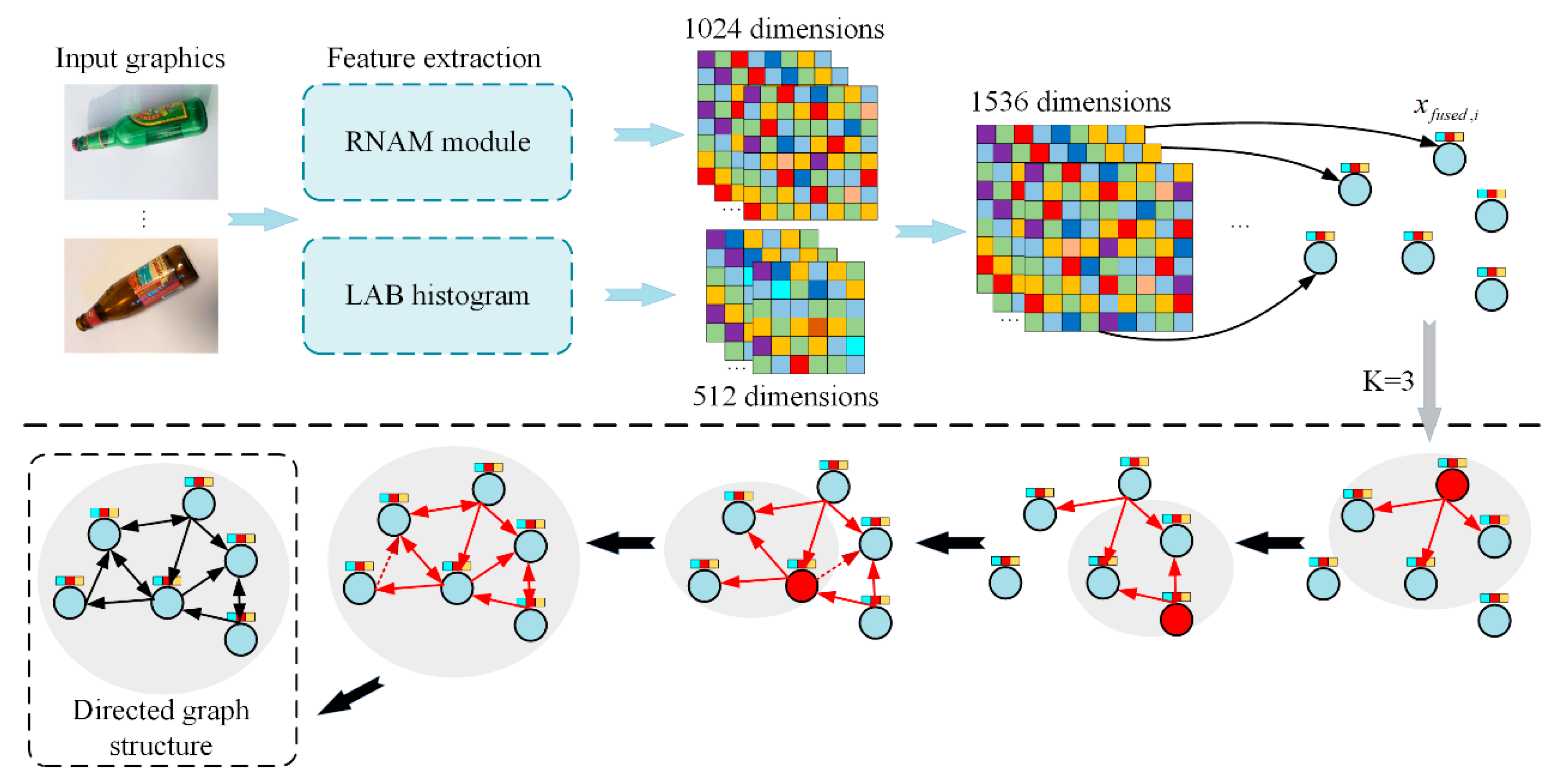
Multimodal Feature Fusion: An enhanced RNAM network model is employed to extract deep semantic features, while LAB histograms are utilized to capture color distribution information. This complementary integration of diverse modalities effectively bolsters the discriminative power of the feature representation.
Dynamic Graph Construction: Based on the fused features, a graph structure is constructed using a k-nearest neighbor algorithm. The value of k is dynamically adjusted to ensure the coherence and validity of the graph structure across varying batches, thereby effectively capturing local neighborhood relationships.
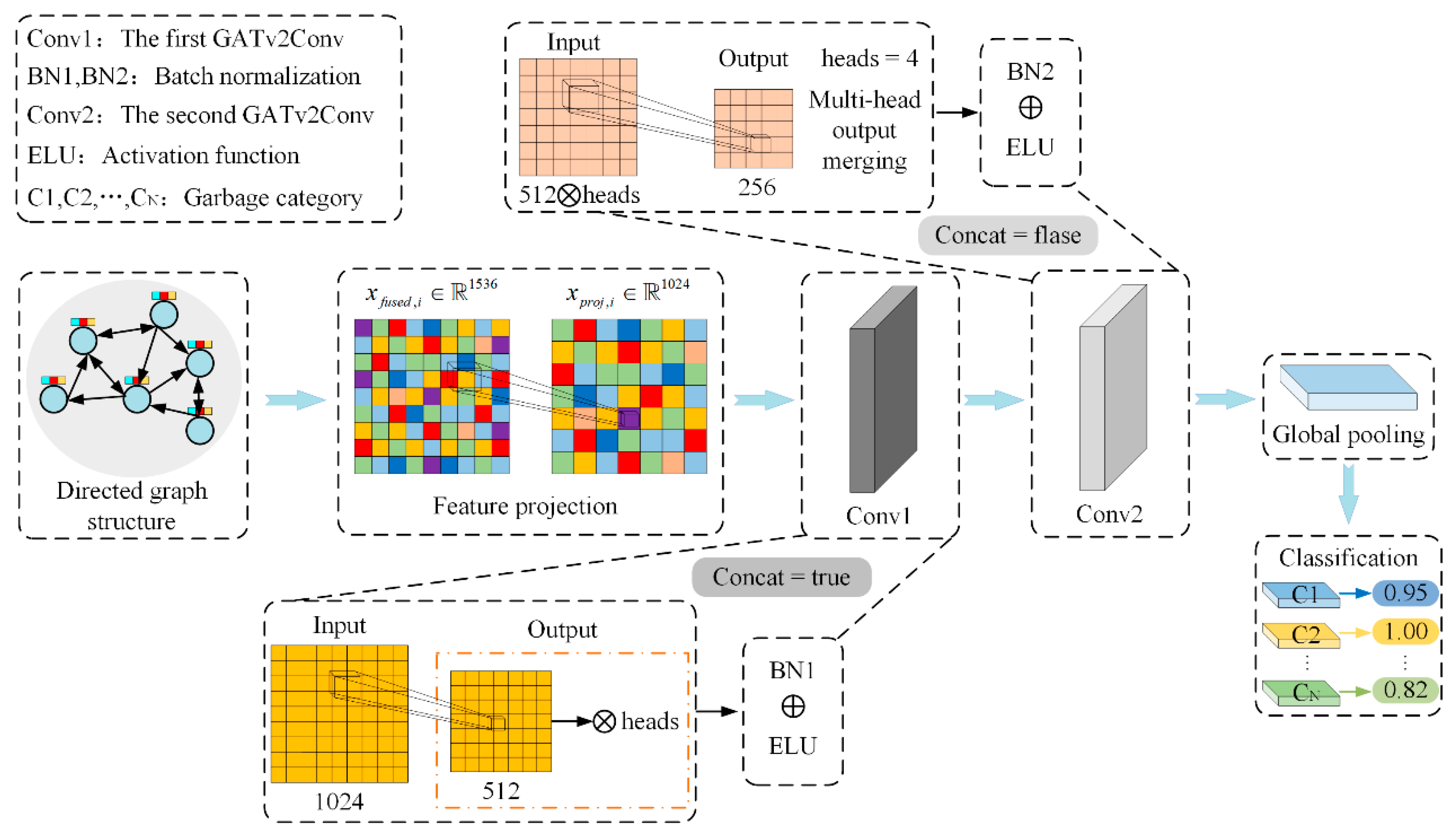
Dynamic Graph Neural Network Design: A Graph Attention Network v2 Convolution (GATv2Conv) layer is integrated into the graph structure, leveraging multi-head attention to adaptively aggregate neighborhood information. Concurrently, feature projection, batch normalization, and dropout are employed to alleviate the issue of heterogeneous feature scale mismatches, thereby effectively capturing both local and global relational features to further enhance the model’s capability for garbage image recognition.
The remainder of this paper is organized as follows. In
Section 2, we provide an in-depth discussion of the multimodal feature fusion strategy for image preprocessing and feature enhancement.
Section 3 elaborates on the graph construction process and details the implementation of the dynamic graph neural network. In
Section 4, the design of the loss function and the corresponding optimization strategies are presented.
Section 5 introduces and discusses the experimental results, and finally,
Section 6 summarizes the main contributions of this work and outlines potential future research directions.
2. Multimodal Feature Fusion for Image Preprocessing and Feature Enhancement
2.1. Image Preprocessing
In the process of preprocessing and augmenting garbage images, various random transformations were applied to the images in the training set to diversify the scenes encountered during model training, enhance its generalization across different distributions, and effectively mitigate the risk of overfitting. The implemented code encompasses the following data augmentation operations: adjustments of brightness, contrast, saturation, and hue; random grayscaling; Gaussian blurring; random rotations; as well as random horizontal and vertical flipping.
2.2. Attention Module
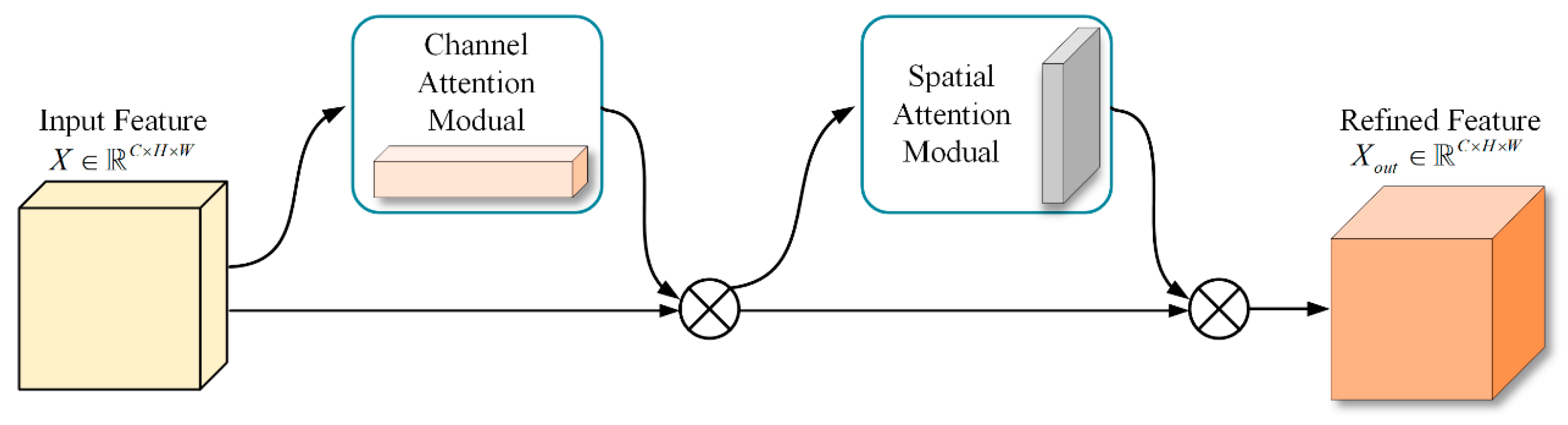
The attention module comprises two components, channel attention and spatial attention, which are designed to enhance feature representations along the channel and spatial dimensions, respectively. As illustrated in
Figure 1, this schematic depicts the attention module architecture utilized in our study.
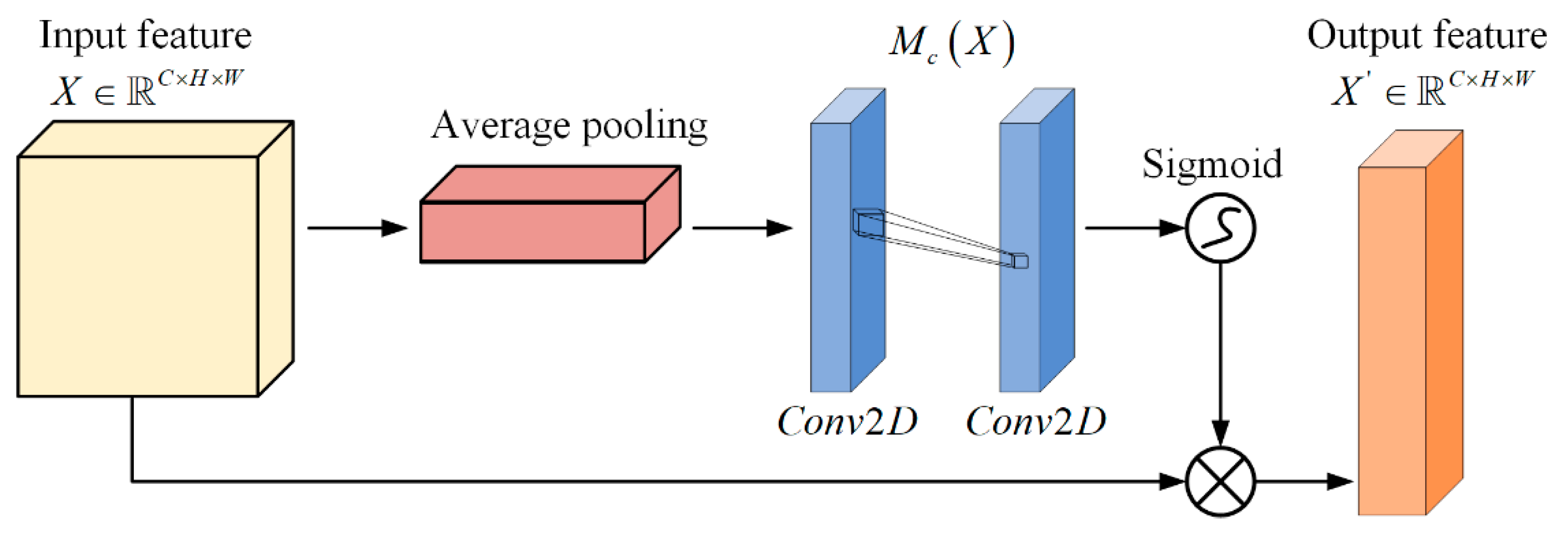
Channel attention enables the network to learn which channels are most discriminative based on the global responses of each channel, thereby enhancing these channels while suppressing less informative ones. Unlike the channel attention module in CBAM [
35], which employs both average and max pooling, we exclusively utilize average pooling. The rationale is that the global feature distribution information provided by average pooling is entirely sufficient for effective channel attention learning and helps to avoid neglecting other crucial information due to local extreme values. Global average pooling:
Here, represents the input feature map, and a global average is computed for each channel to yield the vector .
Here, denotes the ReLU activation function, represents the Sigmoid activation function, and corresponds to a fully connected layer that outputs the channel attention.
Element-wise Multiplication:
Here,
corresponds to the channel-wise weighting, while
represents the channel-enhanced features. The structure of our channel attention module is depicted in
Figure 2.
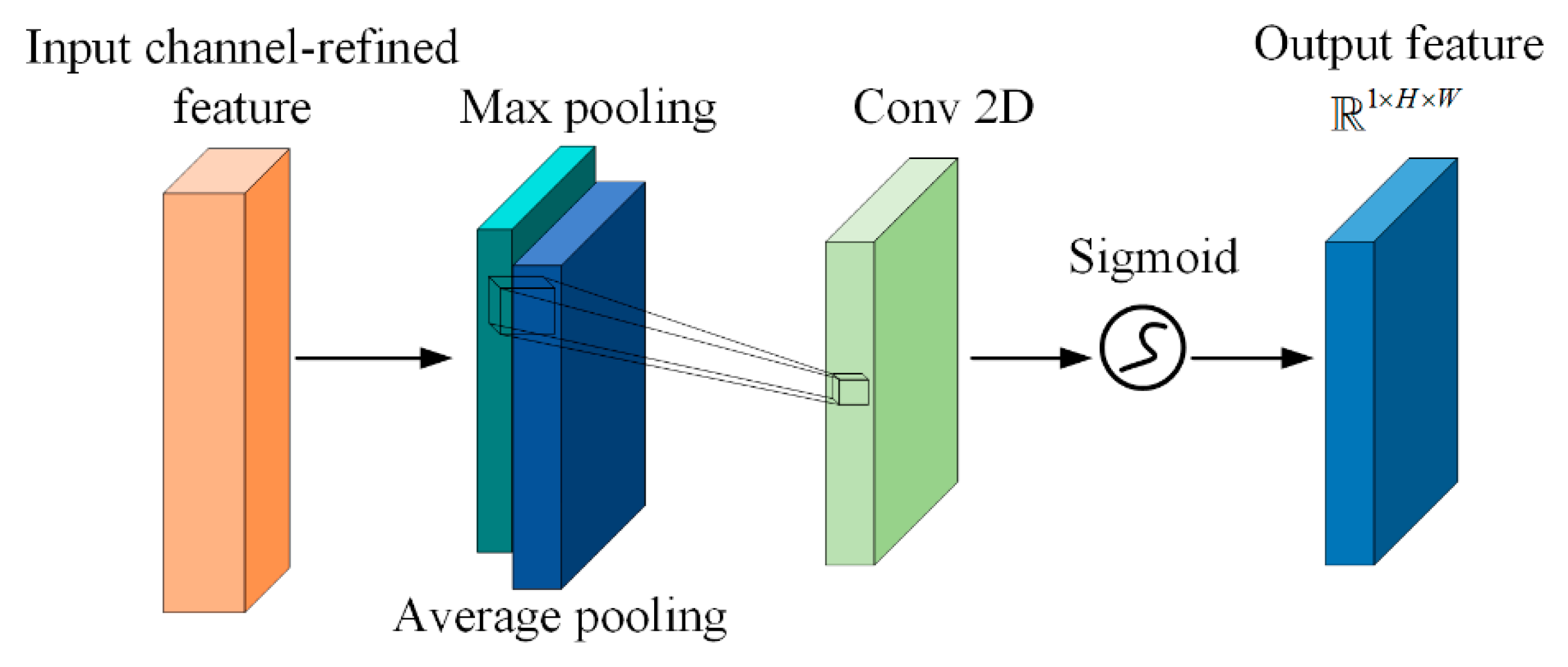
Spatial attention further weights the internal pixel positions within each channel, guiding the network to focus on regions of significant relevance. We adopt the spatial attention module from CBAM because spatial information exhibits strong local distinctiveness. The combination of max pooling and average pooling more comprehensively captures the fine-grained variations in key regions, thereby enhancing the model’s sensitivity and accuracy in localizing critical spatial features.
Max Pooling and Average Pooling:
Specifically for , max pooling and average pooling are each applied along the channel dimension to obtain , which are then concatenated along the channel dimension to yield .
Convolution-Based Spatial Attention Learning:
The output, , denotes the importance of each spatial location.
Element-wise Multiplication:
Here,
is the final feature map enhanced along both the channel and spatial dimensions. The structure of our spatial attention module is illustrated in
Figure 3.
2.3. RNAM
A typical residual block comprises two convolution operations, batch normalization, and activation function processing. By employing a skip connection to add the input features to the transformed features, it effectively alleviates the vanishing gradient problem as the network depth increases. The overall structure can be represented as follows:
Here, denotes the input feature map. and represent the two convolution operations, and BN stands for batch normalization. and are the ReLU activation functions. By stacking multiple residual blocks, higher-order features can be obtained.
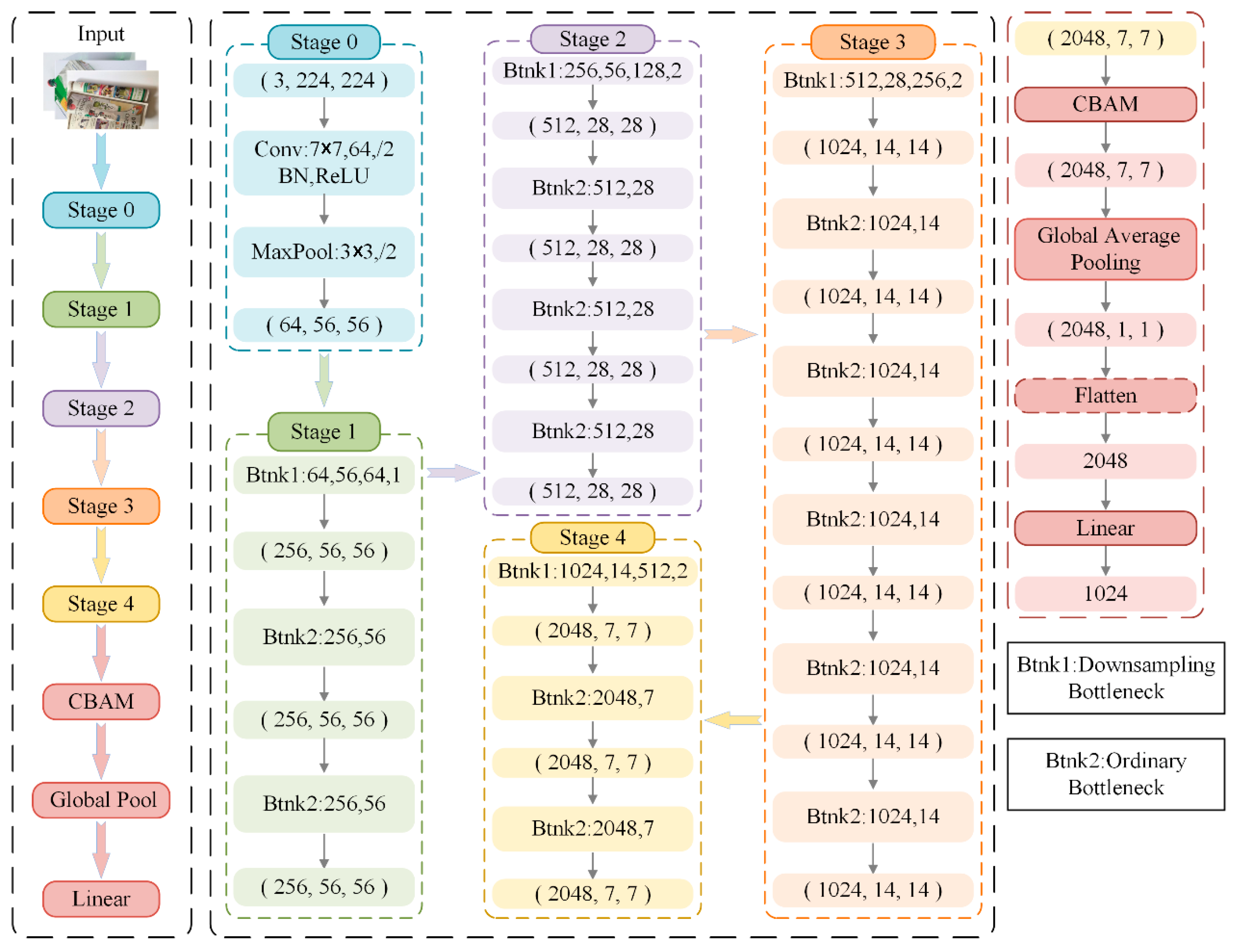
The classical ResNet50 architecture can be structurally divided into three stages. In the initial feature extraction stage, a 7 × 7 convolution kernel with a stride of 2 is employed to perform preliminary feature extraction, quickly reducing the spatial resolution. A subsequent max pooling layer with a kernel size of 3 × 3 and a stride of 2 further diminishes the feature map dimensions, laying the groundwork for the following residual units. In the multi-stage residual feature extraction phase, the network comprises four residual stages, each constructed from multiple stacked Bottleneck residual units. The first Bottleneck unit in each stage performs downsampling of the feature map, while the number of channels increases stage by stage to enhance the representational capacity. Specifically, Stage 1 contains three residual units; Stage 2 contains four; Stage 3 contains six; and Stage 4 contains three, culminating in 2048 channels in the final stage. Within these stages, the convolutional layers, batch normalization (BN), and ReLU activation functions collectively form the core feature extraction backbone of ResNet50.
The last stage employs global average pooling and a fully connected (FC) layer. While this configuration effectively reduces feature dimensionality, it struggles to adequately focus on critical regions and channels within the feature maps. To address these shortcomings, we introduce an innovative convolutional attention module and a customized global pooling architecture to replace the original fully connected layer, thereby enhancing the model’s ability to attend to crucial feature regions and improving both classification accuracy and generalization. Finally, the feature map
produced by the convolutional attention module undergoes global average pooling to yield
, which is then reduced in dimensionality via a linear layer:
Here,
converts
to
,
reduces the dimensionality from 2048 to 1024, and
serves as the final CNN representation. The detailed network structure of our improved RNAM is presented in
Figure 4.
2.4. Color Histogram Features
To preserve global color distribution information and supplement the color cues that a CNN might otherwise overlook, especially for objects with similar appearances yet distinct coloration, we compute a 3D histogram in the LAB color space:
Here, , , and denote the three channels in the LAB color space. Each channel is divided into eight intervals, where indicates the corresponding index is indicated, and the total number of counting bins is .
Next, normalization is performed as follows:
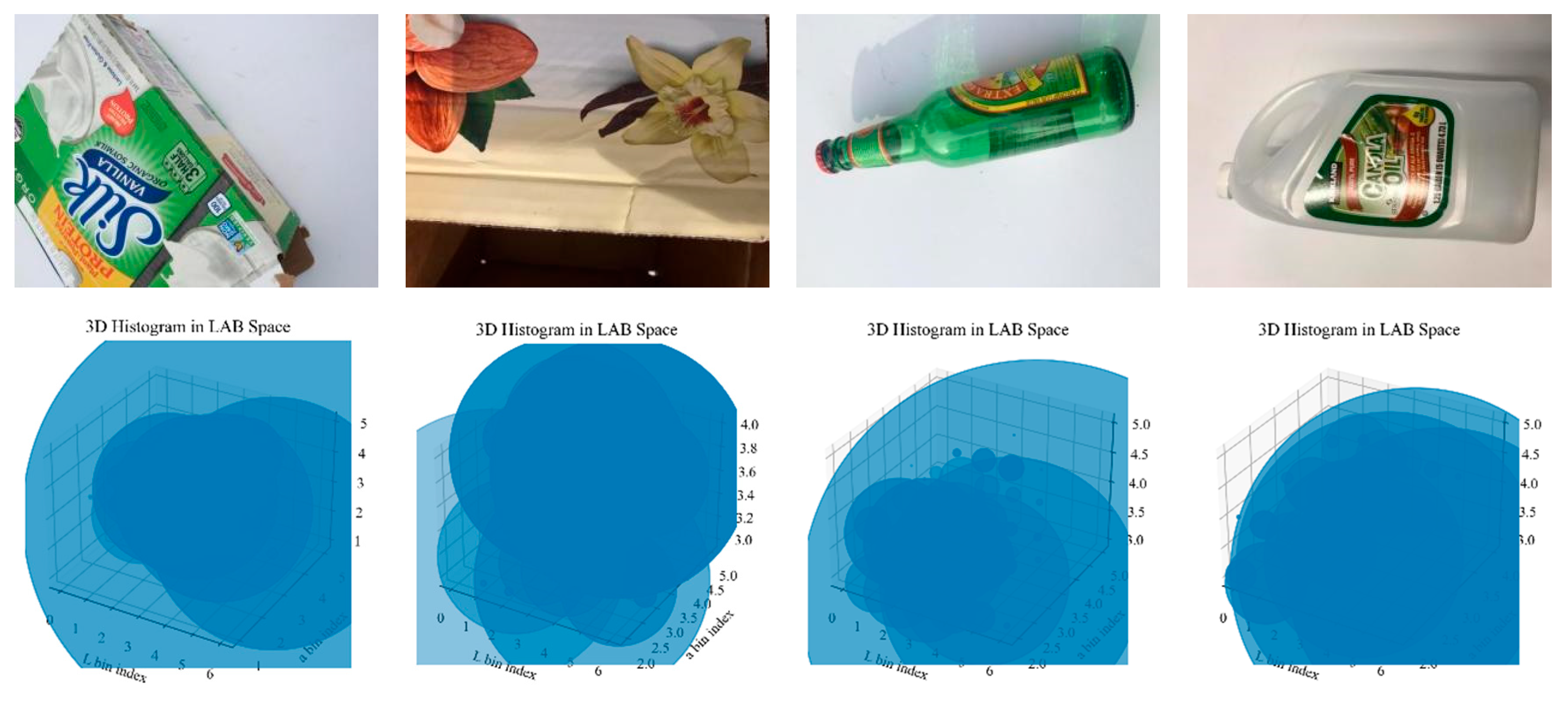
The resulting features preserve overall color distribution and complement the texture and semantic features extracted by the CNN. As illustrated in
Figure 5, the upper row presents our original garbage images, and the lower row shows the 3D histograms in LAB color space. From these visualizations, it is evident that each image contains several aggregation regions in the LAB color space. The position, shape, and size of these regions vividly reflect the image’s primary brightness and chromaticity features. Taking the third image as an example, the main subject is a green bottle with a small area of colorful labeling. Most pixels are distributed near negative values on the a axis, indicating green; some pixels appear at positive values on the b axis, denoting a greenish-yellow region. Meanwhile, the L axis predominantly signifies illumination intensity and generally exhibits a lower distribution. The histogram displays one or two relatively concentrated clusters, suggesting that the color is fairly uniform and predominantly green.
2.5. Multimodal Feature Fusion
After data augmentation and CNN-based extraction, the resulting 1024-dimensional features are concatenated with the 512-dimensional features obtained via LAB histogram calculation and normalization, forming a 1536-dimensional feature vector. This concatenation operation retains the strengths of both feature sets, encompassing deep semantic information as well as statistical color information, thereby enabling the subsequent graph neural network to build and classify graphs using a richer feature representation.



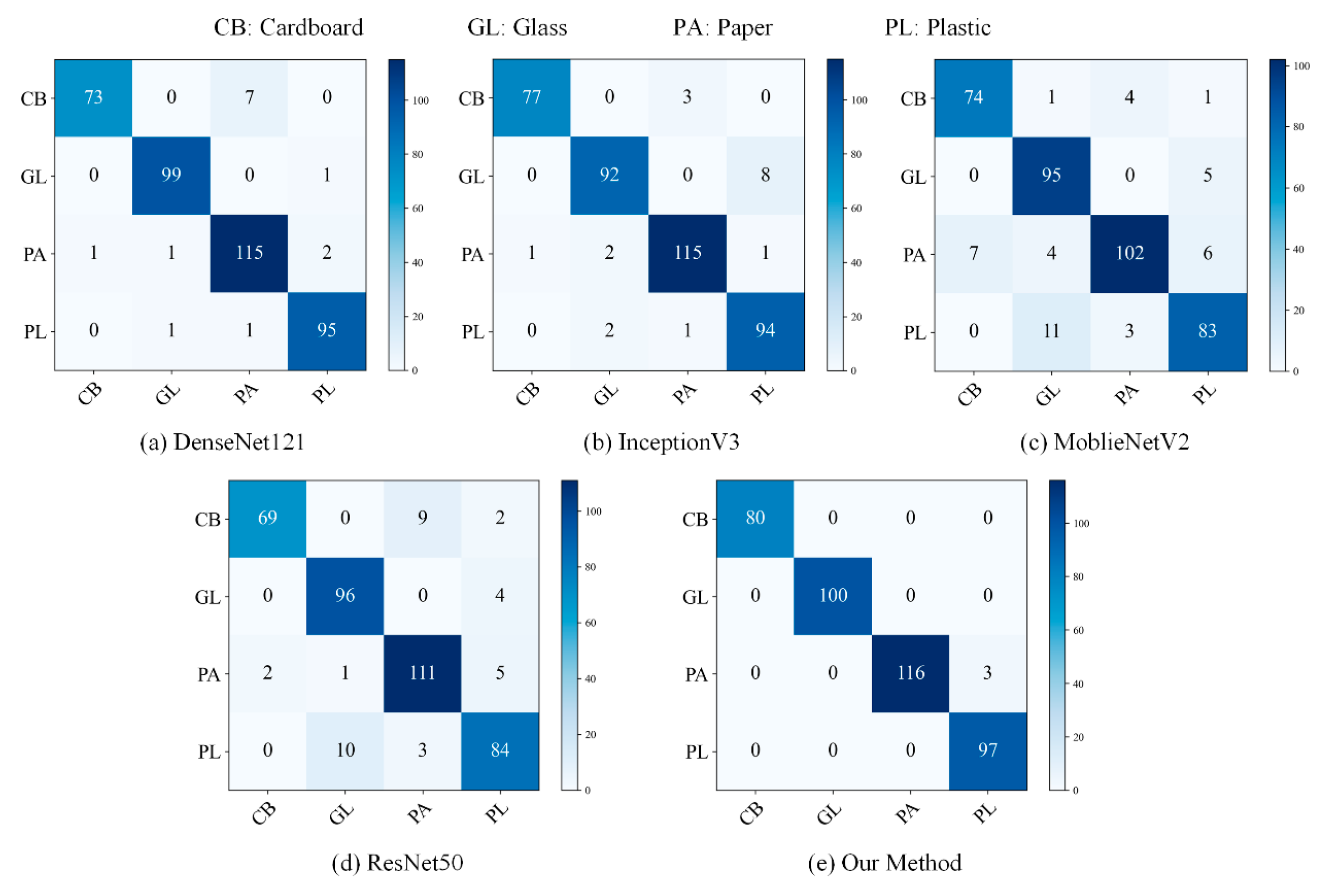
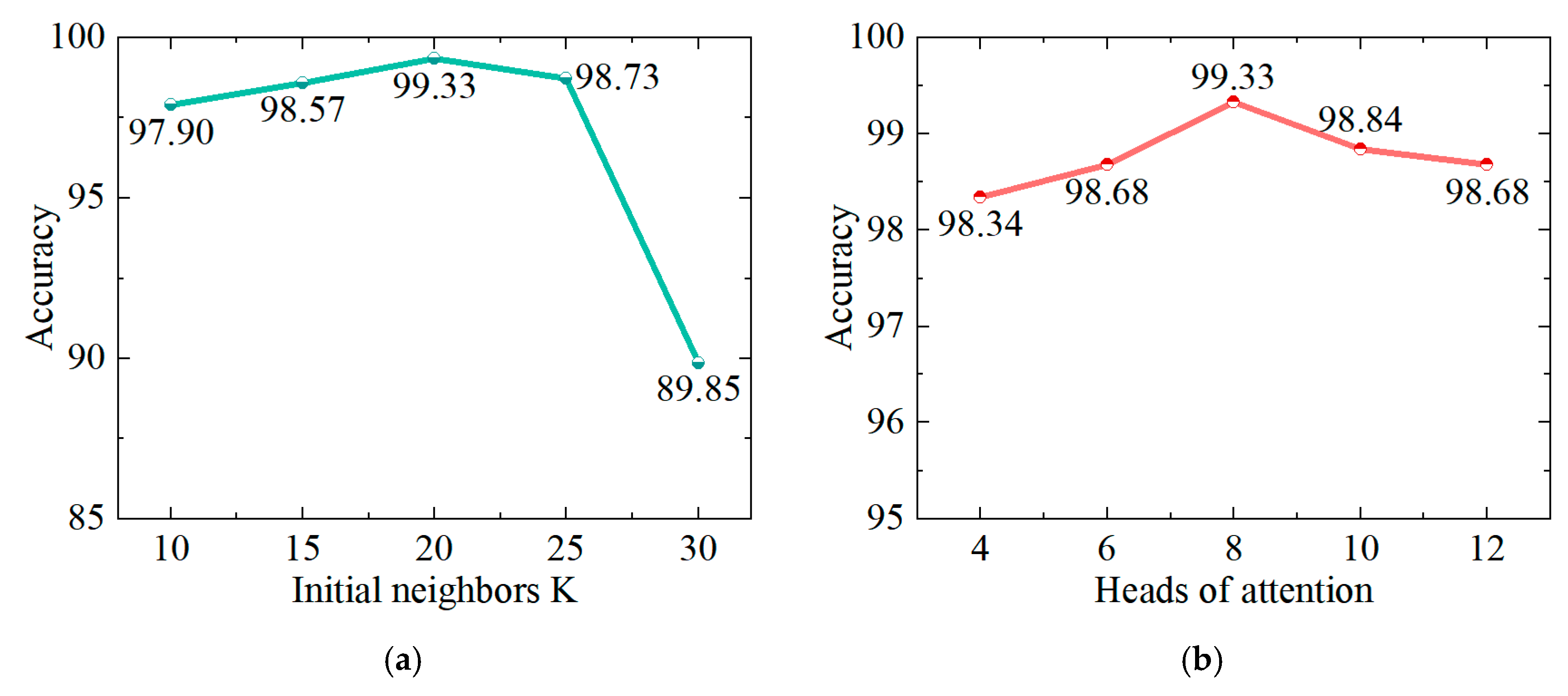

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}