Abstract
Recent advancements in the detection Transformer model have demonstrated remarkable accuracy in real-time object detection using an end-to-end approach. DETR leverages the concept of object queries, which act as “questions” to determine the presence and location of objects. However, the excessive number of object queries significantly increases computational complexity, leading to higher training and inference times, greater memory consumption, and increased costs. To address this issue, this paper introduces the selected query detection Transformer, a novel approach that optimizes the selection of object queries in the decoder. By progressively filtering and reducing unnecessary queries, the selected query detection Transformer maintains model performance while significantly reducing computational overhead, resulting in faster training and inference times.
1. Introduction
Object detection plays a pivotal role in various applications, including autonomous driving, robotics, and drone technology. For instance, autonomous driving systems require precise detection of lanes, pedestrians, and obstacles to ensure safe navigation. Similarly, robotic arms must accurately detect and track objects for precise manipulation, while drones leverage object detection for tasks such as aerial photography, infrastructure inspection, and delivery services. Given the constraints of real-world environments—particularly on mobile devices and embedded systems—efficient and lightweight object detection models are crucial.
Recently, the detection Transformer (DETR) [1] has introduced a paradigm shift in object detection by eliminating the need for complex post-processing steps such as non-maximum suppression (NMS). This innovation not only enhances inference speed but also enables end-to-end optimization, simplifying the overall detection pipeline. Unlike traditional anchor-based or anchor-free methods that follow a one-to-many correspondence paradigm, DETR directly utilizes final prediction values through a one-to-one matching strategy. This simplification of the detection process has presented new possibilities for object detection model development.
The introduction of DETR has had a profound impact on academic research, leading to numerous studies aimed at improving its performance and convergence speed while preserving its architectural advantages. However, most existing research has focused on achieving state-of-the-art accuracy, with relatively little emphasis on reducing computational complexity for lightweight applications. One of the major bottlenecks in DETR’s efficiency is the excessive number of object queries processed by its decoder. These object queries are a type of proposal vector used by the DETR model to predict potential object locations and classes within an image. Since each query is designed to be matched one-to-one with a final prediction result, using a significantly larger number of queries than the actual number of objects in the image leads to unnecessary computations. Therefore, as DETR links object queries to final predictions in a one-to-one manner, surplus queries exceeding the actual number of objects become unnecessary. While the original DETR utilized 100 object queries, recent variants have increased this number to over 900 to ensure stable predictions [2,3]. However, real-world images rarely contain more than 50 objects, making a significant portion of these queries unnecessary. This redundancy leads to increased computational costs, prolonged training and inference times, and greater GPU memory consumption, posing challenges for practical deployment.
Although several studies have attempted to address this issue, most focus on improving query selection rather than directly reducing the query count. For example, models such as Efficient-DETR [4], DINO [2], and RT-DETR [5] prioritize selecting the most informative queries from encoder outputs rather than decreasing their total number. While these approaches have led to significant improvements in convergence speed and detection performance, they have not effectively reduced computational complexity. Some approaches, like Rank-DETR [6], attempt to sort queries to encourage the decoder to focus on the most relevant ones. While these methods can effectively limit the initial number of queries, they do not dynamically reduce query count during decoding, restricting their potential computational benefits. While DDQ [7] applies NMS at each decoder layer to remove unnecessary queries, leading to computational savings within the decoder and notable improvements in performance (particularly for small object detection), it introduces additional NMS operations. This contradicts DETR’s original goal of eliminating NMS, making it somewhat misaligned with the model’s intended design philosophy.
To address these challenges, we propose a novel approach called selected query (SQ), which directly reduces object queries in the decoder stage based on their importance. Our key hypothesis is that eliminating redundant object queries can improve both training efficiency and inference speed without compromising detection performance. However, simply reducing the number of queries risks degrading accuracy, particularly in complex scenes where objects vary in size or overlap. Thus, an effective query reduction strategy is required to balance efficiency and performance. We introduce a layer-wise query selection mechanism that evaluates the class probability of each query at each decoder layer. Queries with high confidence scores are retained, while low-confidence queries are gradually pruned. This adaptive selection process ensures that only the most relevant queries remain, thereby enhancing computational efficiency while maintaining detection accuracy.
This paper introduces significant contributions to enhance the efficiency of DETR-based object detection models, detailed as follows.
- Proposal of selected query, a novel object query reduction methodology: We propose selected query, a new method that systematically reduces the number of object queries in the decoder by selectively removing low-confidence queries. We provide a detailed analysis of the query selection mechanism and its layer-wise removal process, highlighting the simplicity and effectiveness of the methodology.
- Demonstration of selected query’s efficiency and performance: Through extensive experiments on major object detection benchmark datasets, we demonstrate that selected query significantly reduces computational cost and GPU memory usage while maintaining competitive detection performance. Key performance indicators, including FLOP reduction, inference time improvement, and average precision (AP) scores, are presented.
- Verification of accelerated model convergence: Our findings indicate that the proposed method accelerates model convergence, particularly in settings with a small number of decoder layers, further validating its potential for lightweight DETR-based architectures.
2. Related Work
In this section, we introduce the DETR and highlight its computational challenges. We then categorize existing research into two major directions: performance-oriented improvements and efficiency-oriented enhancements.
We summarize and compare representative DETR improvement methods based on their motivation in Table 1.

Table 1.
Comparison of DETR improvement approaches with an emphasis on motivation. ✓ indicates presence; X indicates absence.
2.1. Introduction to DETR and Its Computational Challenges
DETR [1] was the first end-to-end object detection model based on the Transformer architecture. Unlike conventional CNN-based object detectors [12,13,14,15,16,17,18,19], which rely on complex post-processing steps such as anchor generation and non-maximum suppression (NMS), DETR directly predicts objects using a Transformer-based encoder–decoder structure [20]. The model assigns object queries to final predictions through a one-to-one bipartite matching mechanism, enabling a streamlined detection pipeline without heuristic components. This approach provides several advantages, including end-to-end learning, a global attention mechanism for feature extraction, and an optimized assignment process that eliminates redundancy in object matching.
Despite these advantages, DETR suffers from significant computational inefficiencies, primarily due to the excessive number of object queries processed in the decoder. The original DETR model used 100 object queries, but subsequent studies have increased this number to over 900 to improve prediction stability [2,3]. However, in real-world applications, images rarely contain more than 50 objects, meaning that a large portion of these queries are redundant. This inefficiency increases computational costs, prolongs both training and inference times, and imposes a heavy burden on GPU memory, making DETR less suitable for resource-constrained environments. To address these challenges, researchers have proposed various modifications aimed at either improving DETR’s performance or enhancing its efficiency, which are discussed in the following sections.
2.2. Approaches to Enhancing DETR: Performance vs. Efficiency
2.2.1. Performance-Oriented Enhancements
Several studies have focused on improving DETR’s performance by refining its attention mechanism, enhancing the informativeness of queries, and introducing novel learning techniques. Deformable-DETR [8] improved DETR’s convergence speed and accuracy by modifying the attention mechanism to focus on specific regions of the image rather than attending to all features equally. Conditional-DETR [21] increased learning efficiency by ensuring that each object query contained information about a specific region, allowing the model to refine object predictions more effectively. Other works, such as Anchor-DETR [22] and DAB-DETR [9], introduced anchor-based query mechanisms to improve the spatial alignment of object predictions, leading to faster convergence.
Beyond improvements in attention mechanisms and query representation, several studies have explored denoising strategies and one-to-many matching to further enhance DETR’s learning efficiency. DN-DETR [10] introduced a denoising training approach in which noisy queries are systematically added and removed during training, improving model robustness against variations in object locations. DINO [2] extended this idea by incorporating contrastive denoising training, mixed query selection, and a look-forward-twice mechanism, leading to significant performance gains. To improve training efficiency while preserving DETR’s end-to-end inference structure, H-DETR [11] proposed hybrid matching, which combines one-to-one matching for confident objects with one-to-many matching for uncertain objects, ensuring a balanced learning process. Meanwhile, Co-DETR [3] adopted a multi-head assignment strategy, where multiple detection heads independently generate different object assignments, effectively leveraging one-to-many supervision across diverse feature representations.
While these performance-oriented approaches have successfully improved DETR’s accuracy and convergence speed, many of them achieve these gains by increasing the number of queries, which ultimately leads to higher computational overhead. Consequently, these methods do not address DETR’s inefficiency in resource-constrained environments, necessitating further research on computationally efficient solutions.
2.2.2. Efficiency-Oriented Enhancements
To alleviate DETR’s computational burden, various studies have focused on reducing redundant computations and optimizing query processing. Deformable-DETR [8] introduced a sparse attention mechanism [23,24] that significantly reduces the computational complexity of self-attention. Unlike standard DETR, where each query attends to all spatial locations in the image, Deformable-DETR restricts attention to a small set of relevant key points. This modification not only lowers memory and computation costs but also improves scalability for high-resolution images. Building on this direction, RT-DETR [5] further optimized DETR’s efficiency by refining the encoder–decoder interaction. It introduced a hybrid encoder that combines CNN [25,26] and Transformer [20] architectures, effectively leveraging the strengths of both paradigms. By incorporating CNN-based feature extraction, RT-DETR enhances computational efficiency while retaining the global context modeling capability of Transformers, making it more suitable for real-time applications.
Other methods have focused on reducing the number of object queries processed in the decoder. Rank-DETR [6] proposed a query sorting mechanism, where queries are ranked at each decoder layer to help the model prioritize the most relevant ones. While this method effectively limits the initial number of queries, it does not dynamically adjust the query count during inference, restricting its potential for computational savings. DDQ [7] introduced a different strategy by applying NMS at each decoder layer to eliminate redundant queries, successfully reducing computational overhead and improving small object detection. However, because DDQ reintroduces NMS—a step that DETR originally sought to eliminate—it deviates from the model’s end-to-end learning paradigm and adds additional computational complexity.
Although these efficiency-oriented approaches achieve some level of computational reduction, they primarily focus on selecting more informative queries or modifying attention mechanisms rather than dynamically reducing the total number of queries throughout the decoding process. As a result, they do not fully resolve the inefficiencies arising from DETR’s excessive reliance on object queries, underscoring the need for a more direct and adaptive query reduction strategy.
3. Methodology: Selected Query DETR (SQ-DETR)
In this study, we propose selected query DETR (SQ-DETR), a novel approach that dynamically eliminates unnecessary object queries in the decoder to enhance computational efficiency. While DETR assigns a fixed number of queries regardless of the actual number of objects in an image, SQ-DETR introduces a query selection mechanism that adaptively prunes redundant queries at each decoder layer based on their importance. This strategy effectively reduces computational overhead while maintaining detection performance.
The key advantage of SQ-DETR lies in its ability to progressively refine object queries throughout the decoding process, ensuring that only the most informative queries remain. Unlike previous methods that either increase query numbers for stability, SQ-DETR performs layer-wise adaptive query selection, achieving a balance between computational efficiency and detection accuracy.
Figure 1 illustrates the overall architecture of SQ-DETR, which retains the fundamental DETR structure while integrating a query selection module within each decoder layer. The following sections describe the SQ-DETR architecture, query selection mechanism, training strategy, and inference process in detail.
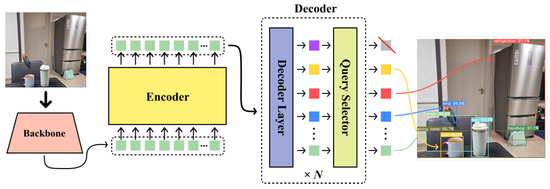
Figure 1.
SQ-DETR architecture.
3.1. Model Architecture and Layer-Wise Query Selection
3.1.1. Backbone and Encoder
Given an input image , a backbone network extracts n multi-scale feature maps,
where denote the spatial size and channel dimension of the i-th map. With a ResNet [27] backbone, we obtain scales. To enrich semantics, we adopt the hybrid encoder of RT-DETR [5]; the deepest map passes through a Transformer to inject global context. The result is fused with via a Path Aggregation Network (PaNet) [26],
3.1.2. Initial Query Pool
Before decoding, we generate an initial set of K object queries by selecting the most confident feature vectors from E. A lightweight classification head with parameters produces logits Z. The K elements with the highest foreground probability are kept:
3.1.3. Layer-Wise Selected Query (SQ) Function
The decoder refines predictions in L layers. At layer l (), we apply the SQ function to prune redundant queries adaptively (Figure 2). Given current queries , a layer-specific head yields class probabilities
where is the foreground confidence of . The top queries with highest survive:
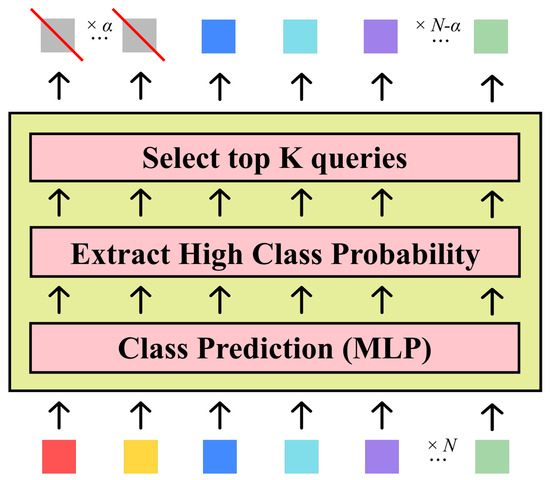
Figure 2.
Illustration of the layer-wise selected query (SQ) mechanism. At each decoder layer, only the queries with the highest foreground confidence are forwarded, reducing redundancy and accelerating inference.
The ratio can be fixed or adaptively tuned (see Section 4). Discarded queries are dropped permanently, so the decoder’s computational load shrinks layer by layer while focusing on increasingly promising object candidates.
3.1.4. Decoding and Prediction Heads
Each layer performs self-attention, deformable cross-attention, and a feed-forward network:
After the final layer, we obtain , from which two parallel heads predict classes and bounding boxes:
where a box is parameterized by center , width w, and height h.
3.1.5. Discussion
By unifying backbone, encoder, and query pruning into one pipeline, SQ-DETR progressively narrows the query set during decoding instead of fixing it a priori. This yields a favourable speed–accuracy trade-off; fewer tokens are processed in deeper layers, yet informative queries remain to preserve detection quality. The impact of different schedules and adaptive ratios is quantitatively analysed in Section 4.
3.2. Advantages of SQ-DETR
SQ-DETR enhances object detection by dynamically refining the query set throughout the detection process. Unlike traditional DETR-based models that rely on a fixed number of queries, SQ-DETR progressively reduces redundant queries while retaining the most informative ones. This adaptive approach improves detection efficiency and robustness without sacrificing accuracy.
A key advantage of SQ-DETR is its impact on computational efficiency. By processing a progressively smaller query set at each decoder layer, SQ-DETR significantly reduces memory consumption and inference time. This makes it well suited for real-time applications and deployment on resource-constrained devices.
Furthermore, SQ-DETR maintains strong detection performance while achieving substantial efficiency gains. By focusing on the most relevant queries, it enhances feature utilization and reduces unnecessary computations.
As illustrated in Figure 3, our proposed query selection method strategically eliminates fewer critical object queries at each layer stage. Within the DETR decoder’s internal operations, each layer refines the significance of queries through self-attention, elevating the scores of salient queries while diminishing those of less relevant ones. By selectively removing queries as depicted, we effectively prune redundant computations, leading to enhanced performance with reduced computational overhead. A closer examination of the figure reveals the removal of 25 queries per layer, indicating those queries that exhibit weaker mappings to objects and struggle to accurately predict specific classes.

Figure 3.
Visualization of queries dropped by SQ-DETR.
The modular design of the selection query module allows SQ-DETR to be seamlessly integrated into other DETR-based models. This adaptability extends its benefits to a wide range of Transformer-based object detection architectures, enabling broader applicability without requiring modifications to the backbone or encoder.
Artificial intelligence tools were utilized during the manuscript preparation process. Specifically, ChatGPT (OpenAI, GPT-4o) was used to assist with English language refinement and clarity.
4. Experiments
4.1. Experimental Setting
4.1.1. Dataset
In this experiment, we utilized the COCO [28] dataset, widely used in the field of object detection, to evaluate the performance of our proposed SQ-DETR model. The COCO dataset consists of 118,000 training images and 5000 validation images, covering 80 diverse object categories. The COCO dataset is suitable for measuring the performance of object detection models due to its real-world-like characteristics, such as objects of various sizes, complex backgrounds, and object overlaps. In particular, the high proportion of small objects and the large number of objects per image are useful for evaluating model performance in real-world applications.
4.1.2. Evaluation Metrics
To assess the performance of SQ-DETR, we employed the COCO evaluation protocol, which provides a comprehensive set of metrics for object detection. The primary metric used in our evaluation is average precision (AP), which quantifies the area under the precision–recall curve. COCO AP is computed by averaging precision values over multiple Intersection over Union (IoU) thresholds, ranging from 0.5 to 0.95 in 0.05 increments, offering a holistic measure of model performance.
In addition to overall , we report and , which represent precision at fixed IoU thresholds of 0.5 and 0.75, respectively. These metrics highlight model robustness across varying localization requirements. Furthermore, we evaluate performance across object scales using , , and , which correspond to small ( pixels), medium ( pixels), and large ( pixels) objects.
Through these various evaluation metrics, we can comprehensively analyze the performance of the proposed model and determine the performance improvement by comparing it with existing models.
4.1.3. Training Details
All baseline detectors in Table 2 are trained for the exact number of epochs reported in their original papers (500 for DETR-DC5, 108 for Conditional-DETR, 50 for Anchor-DETR, 36 for Efficient-DETR, 50 for Deformable-DETR, etc.). SQ-DETR follows a 72-epoch schedule by default, but its validation AP peaks at epoch 62 and drops slightly thereafter, indicating overfitting. We therefore report both the best checkpoint at 62 epochs and the final checkpoint at 72 epochs, and we use the former for subsequent ablation studies.
Table 2.
Comparison with other object detectors in COCO.
4.2. Experiment Results
4.2.1. Comparison with Recent DETR
Table 2 shows the results of comparing and analyzing the performance of various object detection models on the COCO 2017 validation dataset. As shown in the table, our proposed SQ-DETR (Ours) model, using the ResNet-50 backbone network and trained for 72 epochs, demonstrated outstanding performance comparable to other DETR-based models.
SQ-DETR achieved an average precision (AP) of 52.6%, which is among the top-performing results compared to other models presented in the table. In particular, AP50, the average precision at an IoU threshold of 0.5, recorded a very high value of 71.3%. This indicates that SQ-DETR’s ability to accurately predict object locations even under relatively loose IoU criteria is excellent. Even at AP75, which raises the IoU threshold more strictly, it maintained a respectable performance of 56.7%, showing that SQ-DETR exhibits stable performance even under difficult conditions that require very accurate object location prediction.
Looking at the performance by object size, SQ-DETR recorded 34.6% in small object (S) AP, 57.1% in medium-sized object (M) AP, and 70.1% in large object (L) AP. In particular, the high AP value for large objects (70.1%) shows that SQ-DETR has the ability to detect large objects very effectively. Although the small object AP (34.6%) is relatively low, considering that small object detection is generally a difficult task, it can be interpreted that SQ-DETR has secured a certain level of detection ability for small objects as well.
In Table 2, the number of parameters (Params) and FLOP information are not explicitly provided for SQ-DETR. However, since the core of the proposed SQ-DETR in the paper is to reduce the amount of computation by efficiently reducing the number of queries in the decoder stage, it is expected that efficiency will be improved compared to the existing DETR model in terms of the number of parameters and FLOPs. This will be covered in more detail in the subsequent experimental results analysis section.
Overall, the performance analysis results in Table 2 show that SQ-DETR is a model with strengths in overall object detection performance, especially accuracy with high IoU criteria and large object detection ability. These performance results suggest that SQ-DETR can successfully maintain object detection performance while improving computational efficiency through the query selection method.
To further verify the generalizability of SQ-DETR under different scenarios, we conducted additional experiments on the CrowdHuman dataset, which is known for its high-density pedestrian instances and frequent occlusions. This dataset poses a significantly more challenging setting than COCO and serves as a strong benchmark for evaluating detection robustness in crowded scenes.
As shown in Table 3, SQ-DETR achieved performance on par with the baseline RT-DETR models across all metrics, while reducing the decoder FLOPs by up to 7.8% (from 12.8G to 11.8G for ResNet-18 and by 6.6% from 21.1G to 19.7G for ResNet-50). Notably, SQ-DETR with ResNet-50 recorded an of 81.8%, matching the performance of RT-DETR under the same training configuration, but with improved efficiency. The most significant reduction in computational cost was observed in the ResNet-18 configuration, where SQ-DETR lowered the decoder FLOPs by 7.8% while maintaining identical detection performance.
Table 3.
Evaluation of SQ-DETR on the CrowdHuman Dataset for assessment of generalizability.
These results confirm that SQ-DETR maintains strong detection performance even in densely crowded and highly occluded environments, while also reducing computational cost. This supports the method’s robustness and practicality across diverse real-world scenarios.
4.2.2. SQ-DETR Inference Testing
Figure 4 presents the object detection results of the SQ-DETR model across various scenes. Overall, the model demonstrates a strong capability to accurately detect and classify a wide range of objects. Notably, in the first image, the model successfully identifies and categorizes a tennis player, with precise bounding boxes around both the person and the tennis racket. Similarly, in the second image, multiple individuals are accurately detected and classified, again with precise bounding boxes. The model also accurately detects and classifies a refrigerator, birds, and cups in the third image, with well-fitted bounding boxes. In the fourth image, the model correctly identifies and classifies a person skiing, with accurate bounding boxes for both the person and their ski boots. The fifth image showcases the model’s ability to detect and classify a truck and several people, with accurate bounding boxes for the truck, individuals, and a car. The model once again demonstrates its ability to detect a refrigerator in the sixth image, with a precise bounding box. In the seventh image, the model successfully identifies and classifies a boat, a person, and a handbag, with accurate bounding boxes for each. Finally, in the eighth image, the model accurately detects and classifies a person surfing, with precise bounding boxes for the person and their surfboard.

Figure 4.
SQ-DETR inference results.
In general, the SQ-DETR model exhibits a high level of proficiency in accurately detecting and classifying objects across diverse scenes. The model is capable of detecting a variety of objects, including people, vehicles, furniture, and sports equipment. The bounding boxes generated by the model are typically accurate and effectively represent the location and size of the detected objects.
The SQ-DETR model consistently demonstrates the ability to detect objects under varying lighting conditions and viewpoints. It also effectively detects objects that are partially obscured and objects of different sizes. These capabilities make the SQ-DETR model primed for effective application in a variety of real-world object detection scenarios.
4.2.3. Ablation Study: Comparison with Backbone and Query Drop Setting
In this study, we conducted an ablation study to deeply analyze the performance changes of the SQ-DETR model according to the backbone network. In particular, we compared the object detection performance difference when applying ResNet-18 (R-18) and ResNet-50 (R-50) backbones to SQ-DETR and aimed to clarify the impact of the backbone network on model performance.
Table 4 summarizes the best SQ-DETR results for the ResNet-18 and ResNet-50 backbones under several drop ratio configurations, that is, the number of object queries discarded at each decoder layer.
Table 4.
Comparison with backbone and query drop ratio.
SQ-DETR Based on ResNet-18 Backbone (SQ-DETR-R18-Dec3)
The SQ-DETR-R18-Dec3 variant (ResNet-18 backbone, three-layer decoder) was evaluated under several drop ratio configurations. The best result was obtained with the ‘50, 50, 50’ setting, which discards 50 queries at every decoder layer.
Even with the lightweight ResNet-18 backbone, this configuration achieved a strong AP of 47.3.
SQ-DETR Based on ResNet-50 Backbone (SQ-DETR-R50-Dec6)
The SQ-DETR-R506 variant (ResNet-50 backbone, six-layer decoder) was evaluated under several drop ratio configurations. The best result was obtained with the ‘25, 25, 25, 25, 25, 25’ setting, which discards 25 queries at every decoder layer.
The SQ-DETR-R506 model achieved a higher optimal AP score compared to SQ-DETR-R18-Dec3. Notably, under certain settings, it also reached similar AP performance in fewer training epochs.
In conclusion, the results of this ablation study demonstrate that SQ-DETR is well applied to both ResNet-18 and ResNet-50 backbones. Considering its advantages of lightweightness, the ResNet-18 backbone shows potential value for the efficient implementation of SQ-DETR. In future research, we plan to further explore various lightweighting and performance enhancement techniques, focusing on the ResNet-18 backbone-based SQ-DETR model, to further expand its applicability in the field of object detection.
5. Limitations and Future Work
This study has several limitations. First, although SQ-DETR ranks queries purely by their class-probability scores, it currently ignores complementary cues such as bounding box scale, the spatial distribution of proposals, and inter-object geometric relations; incorporating these factors could yield a more reliable importance metric. While SQ-DETR does not use an explicit relation module, Transformer self-attention inherently captures pair-wise dependencies, and our query selection strategy keeps high-confidence representatives, making complete loss of an object’s relational cues unlikely in practice.
Second, the drop ratio (i.e., the number of queries discarded at each decoder layer) is treated as a fixed hyper-parameter. An adaptive scheduler—driven by image complexity, per-layer uncertainty, or reinforcement learning—may further improve the accuracy–efficiency trade-off. Third, our evaluation is confined to the COCO benchmark; we have not yet tested on widely used alternatives such as LVIS or CrowdHuman. Additional experiments on datasets with denser crowds or domain-specific imagery (e.g., CrowdHuman and aerial or medical datasets) are required to verify the generality of SQ-DETR.
In future work, we therefore plan to (i) enrich the query-scoring function with multi-scale positional features and cross-query geometric relations; (ii) devise an uncertainty-guided or reinforcement learning strategy that dynamically selects the drop ratio or absolute query budget in accordance with run time;and (iii) conduct large-scale cross-dataset studies, including LVIS and CrowdHuman, to validate robustness and real-world applicability.
Author Contributions
Conceptualization, C.-Y.C.; methodology, S.-J.H.; software, S.-J.H.; formal analysis, S.-J.H.; writing—original draft preparation, C.-Y.C. and S.-J.H.; writing—review and editing, C.-Y.C., S.-J.H. and S.-W.L.; data analysis, S.-J.H.; supervision, S.-W.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Challengeable Future Defense Technology Research and Development Program through the Agency For Defense Development (ADD) funded by the Defense Acquisition Program Administration (DAPA) in 2025 (No.915073201) and also supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIT) (RS-2025-00520064).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets used in this study, COCO and CrowdHuman, are publicly available.
Acknowledgments
The authors acknowledge the use of ChatGPT (OpenAI, GPT-4o) for English editing support during the preparation of this manuscript.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.Y. DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Zong, Z.; Song, G.; Liu, Y. Detrs with collaborative hybrid assignments training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6748–6758. [Google Scholar]
- Yao, Z.; Ai, J.; Li, B.; Zhang, C. Efficient detr: Improving end-to-end object detector with dense prior. arXiv 2021, arXiv:2104.01318. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- Pu, Y.; Liang, W.; Hao, Y.; Yuan, Y.; Yang, Y.; Zhang, C.; Hu, H.; Huang, G. Rank-DETR for high quality object detection. Adv. Neural Inf. Process. Syst. 2023, 36, 16100–16113. [Google Scholar]
- Zhang, S.; Wang, X.; Wang, J.; Pang, J.; Lyu, C.; Zhang, W.; Luo, P.; Chen, K. Dense Distinct Query for End-to-End Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; Volume 2023-June. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable Detr: Deformable Transformers for End-to-End Object Detection. In Proceedings of the ICLR 2021—9th International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. Dab-Detr: Dynamic Anchor Boxes Are Better Queries for Detr. In Proceedings of the ICLR 2022—10th International Conference on Learning Representations, Virtual Event, 25–29 April 2022. [Google Scholar]
- Li, F.; Zhang, H.; Liu, S.; Guo, J.; Ni, L.M.; Zhang, L. DN-DETR: Accelerate DETR Training by Introducing Query DeNoising. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; Volume 2022-June. [Google Scholar] [CrossRef]
- Jia, D.; Yuan, Y.; He, H.; Wu, X.; Yu, H.; Lin, W.; Sun, L.; Zhang, C.; Hu, H. Detrs with hybrid matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19702–19712. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Volume 2016-December. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 2015-January. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Zhang, S.; Chi, C.; Yao, Y.; Lei, Z.; Li, S.Z. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9759–9768. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A simple and strong anchor-free object detector. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Łukasz, K.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 2017-December. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3651–3660. [Google Scholar]
- Wang, Y.; Zhang, X.; Yang, T.; Sun, J. Anchor detr: Query design for transformer-based detector. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 2567–2575. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable convnets v2: More deformable, better results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9308–9316. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Volume 2016-December. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2014; Volume 8693 LNCS. [Google Scholar] [CrossRef]
- Gao, P.; Zheng, M.; Wang, X.; Dai, J.; Li, H. Fast Convergence of DETR with Spatially Modulated Co-Attention. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Yang, J.; Zhang, P.; Yuan, L.; Zhang, L. Dynamic DETR: End-to-End Object Detection with Dynamic Attention. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar] [CrossRef]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. DETRs beat YOLOs on real-time object detection (2023). arXiv 2023, arXiv:2304.08069. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).