1. Introduction
With the continuous reform in education, the importance of extracurricular education in the all-round development of students is gradually being recognized. Although the role of second-class activities in the education system is becoming more and more important, how to provide students with efficient and personalized learning paths is still a major challenge facing the current education system [
1]. The second classroom mentioned here refers to a series of activities and learning experiences outside formal classroom teaching, including but not limited to non-traditional teaching forms, such as club activities, interest groups, extracurricular skills training, and social practice activities. These activities aim to supplement and enhance regular classroom teaching content, promote students’ individualized development, and cultivate their innovative thinking, practical ability, and teamwork spirit [
2]. Although the role of second-class activities in the education system is becoming more and more important, how to provide students with efficient and personalized learning paths is still a major challenge facing the current education system.
Most existing learning path recommendation methods rely on static data analysis, which cannot effectively respond to changes in students’ interests and needs, and it is difficult to process multimodal information from different data sources [
3,
4]. Therefore, the recommendation system faces the problem of how to quickly and accurately recommend activities and learning paths that meet individual characteristics among many student needs. In particular, the inadequate processing of students’ long sequence data [
5,
6] and the lack of self-supervised learning capabilities have limited the effectiveness of other mainstream recommendation methods in the students’ learning process, and have failed to fully tap students’ potential and improve the efficiency of educational resource utilization. To address this problem, how to use large language model (LLM) technology [
7,
8] to improve the intelligence and personalization of learning path recommendations has become the key to improving the effectiveness of second-class education. Large-scale pre-trained models [
9,
10], especially technologies such as GPT-4 [
11,
12] that have strong advantages in generation capabilities and deep feature extraction [
13,
14], provide a new solution for personalized learning path recommendations. This paper aims to solve the shortcomings of the existing recommendation system based on LLM technology and proposes an innovative system that combines GPT-4 and generative adversarial networks [
15,
16]. It has far-reaching significance to provide accurate and personalized learning path recommendation methods for second-class education, extracurricular skills training, and other fields.
The purpose of this study is to solve the limitations of the existing learning path recommendation methods. The specific objectives include the following concepts: First, to improve the processing ability of long-sequence data, and to make full use of its advantages in long-sequence modeling by introducing a large-scale pre-training model GPT-4, so as to improve the processing ability of complex and changeable student behavior data [
17]. Secondly, enhance the accuracy of personalized recommendations, combine the multimodal data of students (such as physiological signals, facial expressions, activity levels, and emotional states), and use deep learning technology to extract features to generate learning paths that meet the current needs of students [
18]. Thirdly, realize dynamic adjustment and real-time feedback, and realize real-time feedback and dynamic adjustment through incremental learning technology and the self-attention mechanism of the model to ensure that the recommended content always matches the latest learning progress and personal needs of students [
19]. Finally, increase the diversity and innovation of the recommended content, enrich the diversity of recommended paths with the help of the GAN, and encourage students to try more diverse learning tasks [
20]. In order to achieve the above goals, this study proposes a personalized learning path recommendation system based on GPT-4. The system firstly collects and preprocesses data, cleans it up and normalizes it, then extracts and fuses features, extracts frequency features of time-series data by Fourier transform, and fuses multimodal data by the weighted summation method. Then, using the generated pre-training model and its training process, combined with the self-attention mechanism of GPT-4, the long-term dependence in the input sequence is captured and the personalized learning path is generated. Finally, innovation is introduced through incremental learning technology and the GAN to ensure that the learning path is dynamically adjusted according to the real-time feedback of students.
This paper mainly consists of six parts. The first part introduces the research background, challenges, objectives, methods, and significance of this study. The second part introduces the related literature research results. The third part describes the methods used in detail, including data collection, data preprocessing, feature extraction and fusion, generating a pre-training model and its training process based on GPT-4, generating the method of the personalized learning path, and real-time feedback and the dynamic adjustment mechanism. The fourth part shows the recommendation effect of the system and analyzes the performance of different models for recommendation accuracy, coverage, and recall rate through comparative experiments, which verifies the advantages of the system proposed in this study. The fifth part discusses the specific application of the method proposed in this study, as well as the limitations of this study and future solutions. Finally, in the conclusion, the main contributions of the research results are summarized. Through the application of large-scale pre-training model GPT-4, this study not only provides an innovative and effective solution for personalized learning path recommendations in the second classroom, but also lays a foundation for further exploring the application of AI technology in the field of education.
2. Related Work
With the development of AI technology [
21,
22], personalized learning path recommendations for the second classroom based on LLM technology has gradually become a research hotspot. Mu and Yuan [
23] reviewed the personalized learning path recommendation strategy, integrating the subject knowledge graph into the learning path recommendation model based on the individual characteristics and learning needs of learners and considering the logical relationship between knowledge points. He then combined the learner’s cognitive characteristics to plan the knowledge point path, sorted and filtered the related resources based on the knowledge point sequence and learner model, and obtained a sequence set of learning resources. Chen [
24] integrated the feedback data of teachers and learners into the policy function under the general framework of reinforcement learning, and then used the gradient descent algorithm to find the optimal solution for the joint parameters. In the experiment, a learning path recommendation based on videos and knowledge points was constructed, and the achievement of learning goals was evaluated through a test bank based on grouping. It was found that the feedback-based reinforcement learning recommendation algorithm can provide learners with more effective knowledge point learning paths. Ngo et al. [
25] proposed a personalized learning path (PLP) recommendation method, which integrated knowledge map embedding (KGE) technology, collaborative filtering (CF), and sequential pattern mining (SPM) to recommend video resource sequences. Their method constructs a MOOC-specific knowledge map (KG), and analyzes the learning path by combining courses, video resources, and users. Various learning trajectories can be expressed in detail by vectorizing the time sequence pattern of learners, thus generating highly personalized recommendations. The effectiveness of their method is proved by experiments. Liu et al. [
26] demonstrated that LLM significantly improves learning efficiency and student satisfaction in e-learning platforms by dynamically adjusting content and feedback, emphasizing the importance of data privacy and ethical issues. Ma et al. [
27] proposed a multi-algorithm collaborative recommendation model that combines multidimensional features, such as cognitive level and learning style, utilizing association rules and swarm intelligence algorithms to improve the personalization of learning paths and resource matching accuracy. Zhang et al. [
28] started from the perspective of recommendation systems and transformed user needs into natural language instructions, which were executed by the LLM to create a more intuitive and accurate recommendation experience. These three studies collectively point to the following trend: using artificial intelligence and big data analysis to build learner-centered intelligent education systems that can effectively address issues such as information overload and learning loss, thereby improving overall learning quality and user experience. These achievements not only provide theoretical support and technological paths for the development of educational technology, but also lay a solid foundation for the practice of personalized education in the future.
These studies show that LLM technology has great potential in learning path recommendation. However, the existing models mostly focus on recent data analysis and do not pay enough attention to the impact of students’ long-sequence data on the results. This paper introduces a large-scale pre-trained language model: GPT-4. Combining the powerful long-sequence data processing capabilities and self-supervised learning capabilities of the GPT-4 model [
29,
30] provides a new technical framework for learning path recommendation in the second classroom. Compared with traditional recommendation algorithms, the recommendation system based on GPT-4 can deeply analyze multimodal data, such as students’ interests, learning progress, and emotional state, and make accurate recommendations on learning paths. Technologies such as generative adversarial networks and incremental learning [
31,
32] are also introduced into the recommendation system. This not only optimizes the innovation and diversity of the recommended content, but also improves the system’s adaptive ability and real-time feedback capabilities [
33], ensuring that the learning path can be dynamically adjusted according to the changing needs of students. The experimental results show that the method proposed in this paper exceeds the existing mainstream models in multiple evaluation indicators, and the recommendation accuracy is significantly improved.
This paper applies the large-scale pre-trained model GPT-4 to personalized learning path recommendation, fully mining students’ behavioral data, learning progress, interest preferences, and other information to generate and accurate learning path. This paper combines GAN technology to enhance the diversity and exploratory nature of the recommended paths, enabling the system to recommend more innovative and challenging learning content, thereby improving students’ learning motivation and participation. Finally, through the real-time feedback mechanism and incremental learning strategy, the system can adjust the learning path in time according to the students’ learning progress, improving the intelligence and adaptability of the recommendation.
3. Methods
3.1. Research Design
The purpose of this study is to solve the problems in the existing learning path recommendation system, such as poor adaptability, insufficient personalization, and difficulty in handling long sequences of students’ behavior and interest data. By introducing LLM technology, especially GPT-4, the accuracy and efficiency of personalized learning path recommendation in the second classroom can be improved.
According to the experimental design principles proposed by Wohlin et al. [
34] and the qualitative research design framework proposed by Diggregorio and Davidson [
35], system planning was carried out. This study defines the demand for personalized learning path recommendation in the second classroom, and determines the function and technical framework of the system. These theoretical frameworks were chosen because they provide scientific research method guidance and help to ensure the rigor of the research process and the effectiveness of the results. Through user interviews and demand surveys, we can deeply understand user needs and provide a solid foundation for the subsequent design.
We made a systematic overall research plan, which is divided into the following stages.
Considering the complexity and diversity of students’ behavior data, a data source covering a variety of information was selected to fully reflect students’ learning status. The purpose of the preprocessing step is to improve the data quality, ensure that the data of different modes have the same weight in the model, and thus optimize the model’s performance.
The data source used a simulated student learning dataset (including 1200 records of 100 students), including multimodal data, such as physiological signals, facial expressions, activity levels, and emotional states. In the preprocessing step, the missing and abnormal values were eliminated, the frequency characteristics of time-series data were extracted by Fourier transform, and the Z-score method was used for standardization.
Effective features were extracted from multimodal data and fused to form a comprehensive student portrait. Feature extraction uses the GPT-4 model to extract the depth features of text data, combined with the features of other modal data (such as frequency domain features). Feature fusion uses the weighted summation method or other fusion techniques to integrate features of different modes to form a comprehensive portrait of students.
GPT-4 was selected for feature extraction because of its powerful long-sequence modeling ability and self-supervised learning ability, which can effectively capture the long-term dependence in students’ behavior. The feature fusion strategy was used to integrate information from different data sources, provide a comprehensive view of students, and generate personalized learning paths.
GPT-4 was selected as the basic model, and its long sequence modeling ability and self-attention mechanism were utilized. Pre-training was performed on simulation datasets, optimizing parameters to improve the model’s performance. The cross-entropy loss function was used to evaluate the error between the predicted path and the actual path, and the model parameters were updated by the Adam algorithm.
GPT-4 was chosen because of its excellent performance in natural language processing tasks and its ability to handle multimodal input. Specific parameter configuration was used to balance calculation efficiency and model performance and achieve the best results while ensuring efficient training.
According to students’ behavior data and feature vectors, personalized learning paths are generated. Based on the autoregressive modeling formula, the optimal learning path was generated by maximizing the conditional probability. Through incremental learning technology and the GAN to generate diversified recommendation paths, the novelty and exploration of the content were ensured.
Collect students’ feedback information, such as task completion, test scores, and emotional changes in real time. According to the feedback information, the recommendation strategy was adjusted immediately and the learning path was updated.
The introduction of the real-time feedback mechanism aims to ensure that the learning path can be dynamically adjusted according to the latest progress and personal needs of students and improve the accuracy and adaptability of recommendation. This mechanism is very important for promoting students’ continuous participation and improving learning efficiency.
The effectiveness of the system was verified by experiments and compared with other mainstream models. Using the control experiment method, the accuracy and recall of this model were compared with other benchmark models (such as BERT) under the TOP-N recommendation scenario. The accuracy, coverage, and recall of each model were counted and analyzed to verify the superiority of this system.
3.2. Data Collection
In this study, the simulated student learning dataset was used, which contains 1200 student session records and the learning behavior data of 100 students, including physiological signals (heart rate variability (HRV) [
36,
37], skin temperature), facial expressions, activity levels, as well as emotions and learning outcomes. The 15 session records collected in the simulated student learning dataset were used to collect some student learning behavior data, as shown in
Table 1.
Table 1 describes some of the student learning behavior data in the simulated student learning dataset, showing characteristics such as heart rate variability and frequency, skin temperature and frequency, emotions, learning outcomes, and participation.
Physiological signals (such as heart rate and skin temperature) can help to analyze students’ concentration and stress levels in the learning process, thus indirectly affecting the design of learning paths. For example, if students are detected to be in a state of high tension or fatigue, the system may recommend easier learning tasks to adjust the learning pace.
Emotional state (facial expression) has an important influence on learning efficiency. Understanding students’ emotional state helps to systematically recommend learning content suitable for their current psychological state. For example, when students are bored, the system can provide more challenging tasks to stimulate interest.
Activity level can reflect students’ participation and physical activity, which is very important for evaluating students’ overall learning attitude and habits. According to the data for activity level, the system can adjust the recommended learning path to ensure that it conforms to the students’ physical condition and meets the learning objectives.
Learning achievement provides important feedback on students’ learning effectiveness. By analyzing the performance changes after different learning tasks, the system can more accurately predict which types of activities are most beneficial to the progress of specific students and optimize the learning path accordingly.
3.3. Dataset Preprocessing
In the simulated student learning dataset, the data structure of each student’s learning behavior was unbalanced, with the same or similar session records being collected multiple times, and some missing values and outliers in the 1200 records. In order to improve the quality of the data and ensure that the weights of different modal data in the model were consistent, the data were cleaned by processing missing values and outliers [
38]. There were some missing values with a small proportion in the dataset. Delete the records with missing key fields (HRV or learning outcomes). For numerical features with a large proportion (such as HRV), use the mean to fill in the missing HRV values. The formula is shown in Equation (1). Use the most frequent value to fill in categorical features (such as emotions).
In Formula (1), is the non-missing value in the original data, and is the number of samples from the data.
In the dataset, the same student can have multiple conversation records, and the repeated conversation data can be deleted. For outliers, the IQR (interquartile range) method was used for detection. For numerical features, such as HRV and skin temperature, the IQR method calculates the quartiles of the data and sets the outliers as points that exceed 1.5 times the IQR range. Data normalization was used to provide different features with the same scale. For numerical data, especially features with different dimensions, such as HRV and skin temperature, the Z-score method was used to normalize the features, as shown in Equation (2):
In Equation (2), x, μ, and σ represent the raw data, mean, and standard deviation.
For categorical data, such as emotions, learning outcomes, and engagement, they can be converted to numerical types. Here, the four emotional features, interest, happiness, boredom, and confusion, were digitized into labels 0–3. Data normalization [
39] was used to scale numerical data to a fixed interval, which is very useful when processing data with different units and dimensions. For data such as HRV and skin temperature, Min-Max normalization was used to scale numerical features to the range of [0, 1], with Equation (3):
3.4. Feature Extraction and Fusion
For time-series data, such as HRV and skin temperature, Fourier transform [
40] was used to extract frequency features. The Fourier transform is shown in Equation (4):
In Formula (4), , , , and T represent frequency–domain, time–domain signals, frequency, and total signal duration, respectively. The frequency components of the signal were extracted through Fourier transform, and the corresponding frequency features were generated.
In the multimodal data processing of student learning behavior, in addition to some structured data mentioned above, it is also necessary to integrate unstructured features, such as expressions, emotions, and learning outcomes, into a new comprehensive feature. This paper uses the weighted summation method for feature fusion. The formula is shown in Equation (5):
represents the fused features, X1, X2, …, Xn are the original features, and , , , are the weight coefficients of the features.
3.5. GPT-4 Generative Pre-Training Model and Model Training
- (1)
GPT-4 model
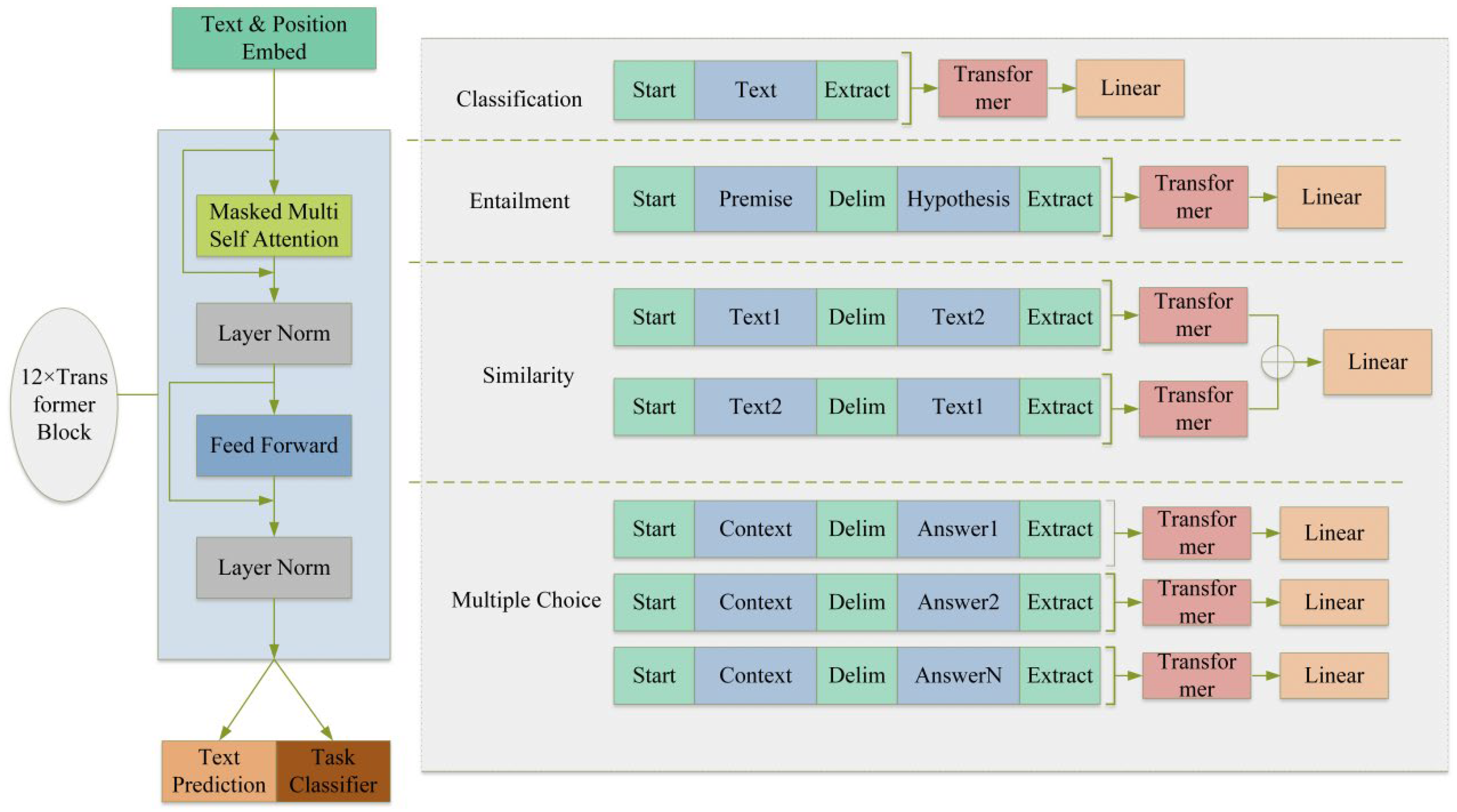
GPT-4 stands for the fourth generation of generative pre-trained transformation models. It performs well in natural language processing [
41] tasks and can generate response text for multimodal inputs of images and texts, as well as classify and analyze visual elements and extract implicit semantics from text. The multimodal architecture integrates visual, audio, and language information through a cross-attention mechanism [
42], extending the semantic understanding of the pure text model. The model is still based on Transformer architecture [
43], the core of which is the self-attention mechanism [
44], which enables the model to capture long-range dependencies by focusing on different parts of the input sequence. Transformer architecture consists of multiple encoders and decoders stacked together, while GPT series models use architecture that only includes a decoder. The overall model structure of GPT-4 is shown in
Figure 1.
Parameter setting: When using the GPT-4 model, we chose the default parameter configuration in the pre-training model, including 12 layers of Transformer structure; each layer contained 768 hidden units, and the number of heads was 12. In addition, the word embedding dimension was set to 768, and the feedforward neural network dimension was 3072. The optimizer adopted the Adam algorithm, the learning rate was set to 5 × 10−5, and the batch size was 32. These parameters were selected based on a previous research experience and preliminary experimental results.
Multimodal data integration: In order to integrate multimodal data (such as physiological signals, facial expressions, activity levels, and emotional states), we first standardized the data of each modality. For physiological signals (such as HRV and skin temperature), we applied Z-score standardization. For the emotional state, we converted it into a numerical label (for example, interest = 0, happiness = 1, boredom = 2, and confusion = 3). Then, the data of different modes were fused into a comprehensive feature vector by a weighted summation method. The formula is shown in Equation (6).
The overall model was divided into unsupervised pre-training and supervised downstream task fine-tuning. The processing student learning behavior data in this model was performed as follows: input the preprocessed long sequence data into the model and convert the behavior data into a series of input vectors in chronological order; each vector contained the multimodal features of the student. Each data item (such as the HRV value) was converted into a high-dimensional vector representation through the embedding layer, and these vectors were then sent to the Transformer model for processing. The multi-self attention mechanism, that is, a parallelized self-attention mechanism, can be used to generate multiple different attention weights; finally, based on the multimodal feature values of the students, the most suitable personalized learning path for the students at the moment was output.
The GPT-4 model captures the dependencies between positions in a long sequence through a self-attention mechanism. Specifically, for each input vector, GPT-4 converts it into a query, key, and value vector. The similarity between the query and key vectors determines which data information the model provides a higher attention weight when generating a learning path. The model calculates a weighted sum based on the correlation between the query and the key, and sends the weighted value vector to the next layer. The model can flexibly weigh each part of the input sequence through this mechanism to discover changes in interest and behavioral patterns during the learning process. The self-attention mechanism was modeled using Equation (7).
In Formula (6), Q, K, V, and represent the query vector, key vector, value vector, and key dimensions, respectively.
- (2)
Model training and evaluation
Training environment: All experiments were conducted on a server equipped with NVIDIA Tesla V100 GPU, 128GB memory, and Intel Xeon Gold 6248R CPU. The operating system was Ubuntu 20.04 LTS, and the deep learning framework used PyTorch 1.9.0. In the training process, we used distributed training technology to accelerate the convergence of the model, and used mixed precision training to reduce memory occupation.
System verification process: After model training was completed, the whole dataset was divided into a training set, verification set, and test set according to the ratio of 8:1:1. The training set was used for model training, the verification set was used for parameter adjustment and model selection, and the test set was used for the final performance evaluation. Performance evaluation indicators use accuracy, recall, and coverage as the main evaluation indicators. In addition, the feedback adjustment time was calculated to evaluate the real-time response ability of the system. In order to verify the advantages of the system proposed in this paper compared with other mainstream models, comparative experiments were carried out under the same experimental conditions.
Cross-entropy loss [
45] was selected as the loss function to measure the error between the predicted path and the actual path. The loss function is shown in Equation (8).
In Formula (7), is the actual label, and is the probability value predicted by the model.
In the process of model optimization, the Adam algorithm was used to update the parameters, which combines the dual advantages of momentum mechanism and adaptive learning rate adjustment. The core mechanism lies in the adaptive adjustment of the parameter learning rate by dynamically calculating the first-order moment estimation and second-order moment estimation of each parameter gradient. This unique optimization method not only significantly improves the convergence efficiency of the model, but also effectively alleviates the gradient attenuation phenomenon common in deep neural networks. Specifically, the optimizer’s parameter update strategy can be expressed mathematically as Equations (9)–(11):
After model training was completed, the trained GPT-4 model was used to extract the feature vectors of the student data [
46]. These feature vectors contain a detailed representation of the student’s learning behavior and interests. In the evaluation stage of the model effect, multi-dimensional evaluation indicators were used for comprehensive analysis. Among them, the precision rate reflects the proportion of items in the recommendation list that are actually adopted by users, the recall rate represents the coverage degree of the correct items recommended by the system to the total number of users’ true preferences, and the coverage rate quantifies the breadth of potential resources of the system through the ratio of the recommendation directory to all recommended items. These three dimensions construct a complete evaluation system from the aspects of recommendation accuracy, demand matching, and service diversity.
3.6. Personalized Learning Path Generation
After the training of the GPT-4 model, the system recommends personalized learning paths based on the feature vectors of students’ learning behavior data and achieves accurate recommendations in the following ways. The system first obtains students’ multimodal learning data through the data collection layer, including behavioral data, emotional and physiological signal data, and learning outcome data. After preprocessing these data, the model can perform deep learning through a deep neural network, using the self-attention mechanism to model the dependencies of long sequences and extract potential features from them. GPT-4 deeply integrates these data to establish a comprehensive student portrait, taking into account factors such as students’ learning progress, interests, and emotions. After completing the student’s portrait, the system identifies the student’s current learning needs by analyzing the student’s behavior, interests, and other feature vectors; predicts the most appropriate learning path; and prioritizes relevant learning resources, such as learning tasks and supplementary courses, to help students improve their knowledge in this second-classroom area. The generated learning path is set as
L = [
,...,
], where each
is a recommended learning task or activity. The generation process is based on the autoregressive modeling of students’ historical data in Equation (12):
This formula indicates that, given the student feature vector, , the system generates the most appropriate learning path by maximizing the conditional probability, .
In order to avoid the learning path recommendation being too simplistic and to increase the diversity and exploratory nature of the recommendation, this system introduced the GAN to generate innovative learning paths.
Parameter setting: In the GAN, both the generator and the discriminator adopt Transformer architecture similar to GPT-4, but the number of layers and hidden units is reduced to reduce computational complexity. The specific parameters of generator and discriminator are as follows:
Generator: 4-layer Transformer; each layer contains 512 hidden units, the number of heads is 8, the word embedding dimension is 512, and the feedforward neural network dimension is 2048.
Discriminator: A total of 4 layers of the Transformer are also used; each layer contains 512 hidden units, the number of heads is 8, the word embedding dimension is 512, and the feedforward neural network dimension is 2048.
Loss function: The loss functions of the generator and discriminator are generation loss and discriminant loss, respectively, which are optimized by Binary Cross-Entropy Loss.
Multimodal data integration: In the GAN, we also need to integrate multimodal data. The specific method is to input the standardized multimodal feature vectors into the generator to generate new learning paths. The discriminator is responsible for evaluating the authenticity and quality of the generated learning path and providing feedback to improve the output of the generator. Through this way of confrontation training, we can ensure that the generated learning path not only meets the needs of students, but also has innovation and diversity.
The GAN consists of two networks. The generator is responsible for generating new learning paths from the input student feature vector and noise. Through continuous training, the generator gradually learns how to generate learning paths that meet the interests and needs of students. The discriminator is used to evaluate the conformity and quality of these paths and continuously optimize the generated paths through adversarial training with the generator. Specifically, the system uses the student behavior data feature vector and random noise, z, as the input of the GAN, and the generator generates the path by Equation (13):
is the generated learning path, is random noise, and is the student feature vector.
The role of the discriminator is to evaluate whether the generated learning path is reasonable and meets the needs of students, and to provide feedback to the generator through adversarial training. The discriminator scores the input path to determine whether it is “real” or “fake”. During the training process, the discriminator helps the generator optimize its learning path generation strategy by constantly competing with the generator.
The input of the discriminator includes the generated learning path,
, and the real learning path,
. The goal of the discriminator is to maximize the score of the real path while minimizing the score of the generated path. The specific discriminator calculation formula is shown in Equation (14):
is the score of the discriminator on the path, L, indicating the authenticity of the path; W is the weight of the discriminator; and is a Sigmoid activation function, which is used to output the probability value of the authenticity of the path. The discriminator calculates the difference between the generated path and the real path and back-propagates it to the generator, which drives the generator to continuously improve its ability to generate learning paths. The goal of adversarial training is to maximize the objective function of the generator and minimize the objective function of the discriminator.
The GAN’s adversarial training mechanism ensures the diversity and innovation of the recommended paths. When generating paths, the generator not only relies on the student’s feature vector, but also introduces random noise, z, so that each recommended path has a certain degree of exploratory nature. This allows the system to recommend not only familiar learning content to students, but also some new and inexperienced learning activities, thereby enhancing the diversity and innovation of learning paths.
3.7. Real-Time Feedback and Dynamic Adjustment
The real-time feedback mechanism is an important part of the system in this paper. The core is to transmit the data generated by students in the learning process, such as task completion, learning outcomes, emotional changes, etc., to the feedback module of the system in real time. After students complete a task or activity, the system collects relevant data and transmits them to the backend through an interface. The system quickly processes these data and applies them to recommendation strategies through a feedback mechanism. The specific process is as follows: feedback information, such as the completion of students’ learning tasks, test scores, and participation, is transmitted to the background in real time. The system updates the model through incremental learning methods and real-time data streams, evaluates the current learning status of students, and adjusts the learning path based on their behavioral data and emotional changes.
The dynamic adjustment mechanism is the core module for dynamically optimizing the recommended path based on real-time feedback. This ensures that the recommendation system can make real-time adjustments based on students’ feedback data, thereby improving the accuracy and adaptability of personalized recommendations. Incremental learning technology is the core of this mechanism, allowing the system to update the model in real time when new data are obtained without completely retraining the model. The system in this paper adapts to new data changes by fine-tuning model parameters. When students perform poorly in a certain learning module, the system can adjust the recommendation strategy by updating the model parameters and recommending more auxiliary learning materials. As student feedback data continue to accumulate, the recommendation system can continuously optimize its recommendation strategy to ensure that the recommended content always matches the student’s learning progress and needs.
This system monitors students’ learning behavior data in real time and combines GPT-4, GAN, and other technologies to generate personalized learning paths based on students’ learning outcomes and emotional changes. The system collects and processes student feedback. Based on the latest feedback data, the system updates model parameters through an incremental learning mechanism, dynamically adjusts the recommendation strategy, and achieves the long-term adaptive adjustment of personalized recommendation paths.
4. Results and Discussion
4.1. System Recommendation Effects
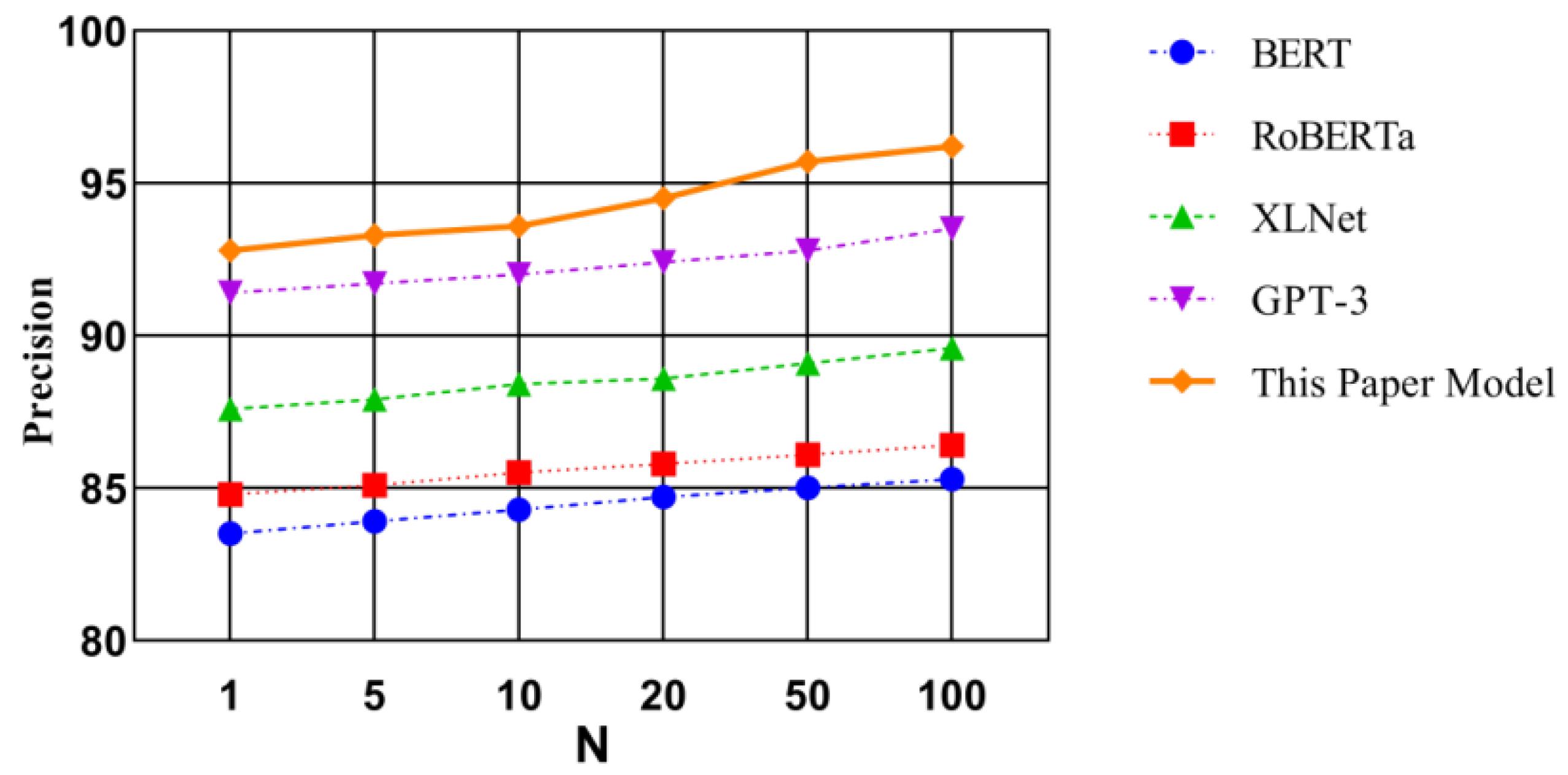
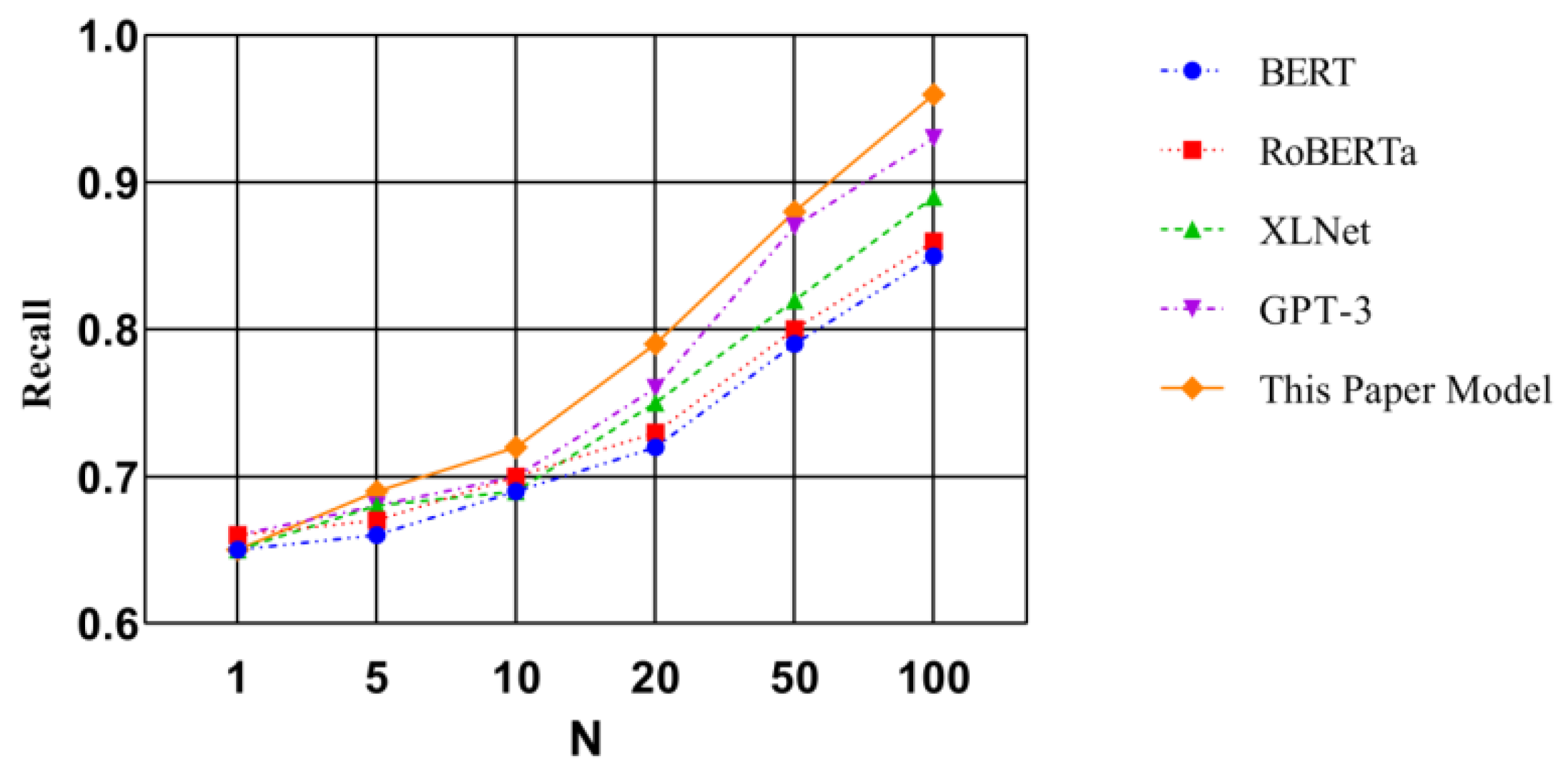
Using a controlled experimental method, this study compares the proposed model with benchmark models, such as BERT, across different models, and quantitatively evaluates the recommendation effectiveness through precision and recall metrics in the TOP-N recommendation scenario. The precision and recall results for each model are shown in
Figure 2 and
Figure 3.
The comparative analysis of the data confirms that the model has the best performance in precision and recall. In the precision measurement chart, the precision of the model in this paper in the TOP-N tasks is above 90%. From the overall curve, when the number of samples increases, the recommendation accuracy of the model in this paper increases slightly, indicating that the path recommended by the model in this paper can effectively meet the learning needs of students. In contrast, the recommendation accuracy of BERT and RoBERTa is around 85%, and the increase in accuracy is almost unchanged under low and high sample numbers. When the number of samples is low, the recall rates of several models in the experiment are around 0.65. When the number of recommended students increases, the recall rate improvement of the model in this paper is more intuitive. GPT-4 considers the deep meaning of feature data when generating feature vectors and can extract features that have a more obvious impact on learning effects, highlighting the key directions of recommendations and increasing the accuracy of recommendations. In general, the system model in this paper performs well in both precision and recall, has strong comprehensive capabilities, and can provide students with efficient learning support.
4.2. System Coverage Results for Different Students
This paper takes junior high-school, high-school, and university student groups as the research objects, and compares different models. The coverage results of each model for different student groups are shown in
Figure 4.
Overall, the model performed best among the three student groups (middle school, high school, and college), especially in the college group, where the coverage of the model in this paper reaches the highest level. The model proposed in this paper can provide higher-quality learning path recommendations for students of different grades, covering more learning content and with a higher degree of personalization. Among junior high-school students, the performance of GPT-3 and the model proposed in this paper is relatively close, with a coverage difference of less than 20%, but the coverage is still not as good as the model proposed in this paper. The BERT model performed the most mediocre, with a coverage rate of only 87%. The results show that in this group, the recommendation system in this paper can provide students with learning path options with wider content coverage. In the high-school group, the coverage rate of all models is significantly lower than that of the other two groups. This shows that although the recommendation system based on the LLM has the advantages of personalization and high accuracy, the task and content coverage of the recommended path in the second-class learning of high-school students still needs to be improved. Among college students, the performance of this model is the most outstanding, with a coverage rate of 94.4%, which exceeds other models and is significantly higher than BERT. This shows that as students’ learning level improves, the model in this paper can still meet the learning needs in complex environments and provide richer and more customized learning paths.
Overall, the model in this paper can simultaneously process students’ multimodal information, thereby providing more personalized recommendations. Especially in the university population, students’ learning content is more diverse and complex, and the model in this paper can provide more accurate and diverse learning paths. The system can adjust the recommendation strategy based on students’ real-time feedback to ensure that students always receive the learning content that best suits their current needs. This dynamic adjustment capability enables the system to maintain a high coverage rate in different groups. By introducing GAN technology, the model in this paper can generate innovative and exploratory learning paths to avoid the monotony of recommended content. In different student groups, the system’s recommended content is both rich and in-depth, and the content coverage is more extensive.
4.3. Changes in Students’ Second-Classroom Grades
From the experimental data, 50 students were selected as the experimental group and the other 50 students were selected as the control group. The students in the experimental group used the path recommendation system for learning throughout the second-classroom learning period, while students in the control group used the conventional method for learning. The system recommends personalized learning paths in real time based on students’ historical behavior data, learning progress, interests, and emotional states, and dynamically adjusts and optimizes the paths through incremental learning technology and generative adversarial networks. By comparing the scores of the two groups of students in the mid-term final exam, it found that the scores of students using this system improved significantly, especially in the final exams. The changes in the grades of the two groups of students in the mid-term final exams are shown in
Table 2.
As can be seen from
Table 2, the experimental-group students’ mid-term exam score was 70.5 and the final exam score was 85.2, with a score improvement of 20.8%. In contrast, the control-group students’ mid-term exam score was 69.2 and the final exam score was 72.3, with a score improvement of only 4.5%. Compared with the control group, the performance of the students in the experimental group significantly improved, indicating that the personalized learning path recommendation system had a significant effect on the students’ academic performance.
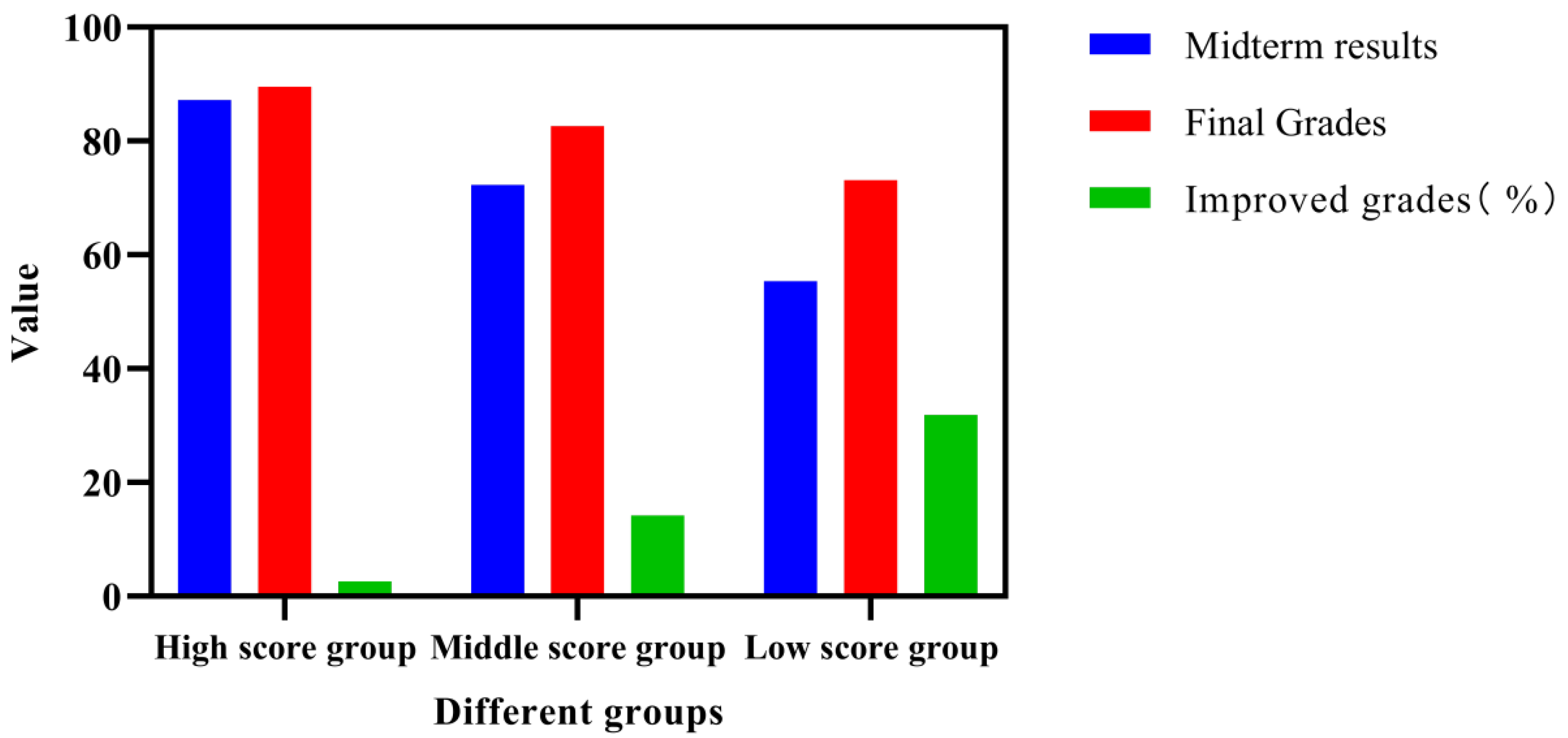
In order to gain a deeper understanding of the effect of the recommendation system on different student groups, the students in the experimental group were grouped according to their grades, divided into high-score groups (above 85 points), medium-score groups (70–85 points), and low-score groups (below 70 points). After analyzing the changes in the grades of different groups after using the recommendation system, the following results were obtained.
As can be seen from
Figure 5, the recommendation system has different effects on students of different grades. The grades of the high-score group show a limited improvement of only 2.6%; the grades of the middle-score group improve by 14.2%, and the grades of the low-score group improve the most, reaching 31.9%. This shows that the recommendation system has a more significant learning promotion effect on students with low and medium scores. Low-scoring students receive more help through personalized recommendations, and the system adjusts the learning content according to their characteristic data to fill their knowledge gaps. For high-scoring students, the role of the system is mainly reflected in the recommendation of innovative and challenging learning tasks, which can help high-scoring students improve considerably, so the improvement in a single course is relatively minor.
This study suggests that physiological signals (such as heart rate variability and skin temperature) and emotional variables (such as interest, happiness, boredom, and confusion) can be transformed into specific educational actions. First of all, the system can dynamically adjust the difficulty of learning tasks according to the HRV of students. A higher HRV indicates that students are in a better state of concentration and are suitable for recommending more challenging tasks. Lower HRV indicates that students may need simple tasks or rest time to regain their energy. It is also very important to choose suitable learning content based on emotional classification. When students show interest, they can recommend extended reading materials, increase interactive activities when they are happy, introduce new stimulating elements when they are bored, and provide more explanations and supporting materials when they are confused.
These signals have important educational value in the learning environment. By monitoring students’ physiological and emotional states in real time, the system can provide personalized learning paths for each student, ensure that the learning content and difficulty meet their actual needs and ability level, and thus improve learning motivation and participation. In addition, monitoring physiological signals, such as HRV, can help students identify their stress state and take timely measures to relieve stress, such as providing relaxation training or psychological counseling resources. Analyzing students’ emotional state can also provide emotional support and adjustment strategies in time to help students maintain a positive attitude and a good emotional state. Using the real-time feedback mechanism, teachers and parents can keep abreast of students’ learning status and progress, and provide corresponding intervention and support. Through the analysis of a large number of students’ data, schools and educational institutions can formulate more scientific and reasonable teaching plans and resource allocation schemes to improve the overall quality of education.
4.4. Performance Evaluation and Result Analysis
This study used a behavioral dataset of 100 students, which covers students’ behavior, physiological signals, emotional state, task completion, etc. In order to comprehensively evaluate the effect of path recommendation of the model in this paper, the model in this paper is compared with other mainstream models for the following evaluation indicators, and the results are shown in
Table 3.
With an accuracy of 95.2%, the calculated 95% confidence interval ranges from approximately 93.85% to 96.55%. This indicates that at a 95% confidence level, the true accuracy is within this interval. The 95% confidence interval for a coverage rate of 96.4% ranges from approximately 95.22% to 97.58%, while the 95% confidence interval for a recall rate of 96% ranges from approximately 94.76% to 97.24%. This means that at a 95% confidence level, the true coverage and recall rates are likely to fall within these intervals. For continuous variables, such as response time, with an average of 1.5 s and a standard deviation of 0.2 s, the 95% confidence interval ranges from approximately 1.4876 s to 1.5124 s.
Table 3 shows the comparison results of the model in this paper and other mainstream models in the personalized learning path recommendation task. The model cited in this paper is superior to other comparison models in multiple evaluation indicators. It not only accurately recommends paths and proposes appropriate learning tasks, but also achieves an efficient performance at multiple levels. In particular, the performance of this paper’s model for recall and coverage is 0.96 and 96.4%, respectively, which is much higher than other models. This shows that this paper’s model presents a significant improvement in accuracy in TOP-N recommendation tasks. The system response time and system stability of the model in this paper reached 1.5s and 0.97, respectively, which are values far superior to other models. This shows that the system can complete the recommendation of learning paths and feedback of behavioral data in a very short time, and the system can maintain a trouble-free operation under long-term or high-concurrency operations. In contrast, the BERT model is at the lowest level for all indicators, especially in precision (85.3%) and recall (0.91), indicating that its recommended path accuracy is low and it cannot provide students with effective learning paths and tasks. Although RoBERTa has improved over BERT in terms of precision and recall, it still has a large gap in coverage and response time indicators compared with the model in this paper, indicating that its coverage of different types of students and its response speed in the system are not as good as the model in this paper.
The application of the GPT-4 model enables the system to effectively explore the dependencies between features in data sequences and effectively improves the ability of multimodal feature extraction. After combining the self-attention mechanism of the model, it is easier for the system to find the features that have the most influence on the recommendation effect, making the model’s path recommendations more accurate in a variety of complex feature data. Combining the real-time feedback mechanism with incremental learning technology, the system can dynamically adjust the learning strategy based on the data fed back by the background, thus improving the real time and accuracy of the recommendation effect. In addition, although traditional language training models (such as BERT) can process contextual information data, they often have limitations when processing complex multimodal signals and long sequence data, especially in exploring the interactive relationship between different modalities and extracting key features. GPT-4 combines the self-attention mechanism and feature extraction capabilities to achieve more accurate processing in this regard, and through real-time feedback and dynamic adjustment, it greatly improves the adaptability and real-time performance of recommendations. The model in this paper can significantly surpass other mainstream models in various evaluation indicators. It is enough to prove its superiority and practical application value.
The personalized learning path recommendation system based on GPT-4 proposed in this paper shows remarkable advantages in many aspects. First of all, using the powerful long-sequence modeling ability of GPT-4, the system can deal with students’ complex and changeable behavior data more effectively and improve the accuracy of recommendation. Secondly, by fusing multimodal data, the system can fully understand students’ learning status and needs and provide highly personalized learning paths. In addition, the system introduces incremental learning technology and a self-attention mechanism to realize real-time feedback and dynamic adjustment to ensure that the recommended content always matches the latest progress of students. The experimental results show that the personalized recommendation accuracy of the system is over 92%; the coverage rate and recall rate are over 91% and 93%, respectively; and the feedback adjustment time is controlled within 1.5 s, which is superior to other mainstream models. These advantages make this system not only improve the effect of personalized recommendation, but also enhance the diversity and innovation of the recommended content.
5. Discussion
The personalized learning path recommendation system for the second classroom proposed in this paper, which combines the large language model (such as GPT-4) and GAN technology, can provide students with personalized and dynamically adjusted learning paths. Taking a student who is interested in programming as an example, the system will collect their behavior data in the programming club, including physiological signals (such as heart rate and body temperature) and emotional state reflected by facial expressions, and carry out preprocessing, such as removing abnormal values and extracting features, for generating learning paths. In the analysis stage, the system fuses multimodal data to construct a comprehensive portrait of students. GPT-4 analyzes students’ learning behavior according to portraits and recommends the content that is most suitable for the current level. If students encounter difficulties in learning advanced programming, the system will automatically recommend basic courses to help them understand it. At the same time, the GAN will also generate new learning tasks, such as robot programming or open source projects, to encourage students to try new approaches.
The system also has a real-time feedback mechanism. When students complete tasks or have unsatisfactory test scores, the system will immediately receive feedback information and update the learning path through incremental learning to ensure that the recommended content always meets the needs of the students. This dynamic adjustment improves the accuracy of recommendation and also enhances the adaptability of the system and students’ enthusiasm to learn, thus making more efficient use of educational resources and promoting students’ all-round development.
When comparing the personalized learning path recommendation system of GPT-4 proposed in this paper with other educational tools and methods, we can find that this method has obvious advantages in many aspects. First of all, compared with the learning path recommendation method based on the knowledge map, the latter relies on static data analysis and is difficult to adapt to the changes in students’ interests and needs. The GPT-4 system can be dynamically adjusted to provide more personalized learning paths and better meet the real-time needs of students. Secondly, compared with the method based on reinforcement learning, although both of them can optimize the learning path according to feedback, the GPT-4 system not only improves the diversity and innovation of recommended content, but also enhances the adaptive ability of the system by introducing incremental learning technology and the GAN. Furthermore, compared with the methods of collaborative filtering and sequential pattern mining, the GPT-4 system not only processes video resource sequences, but also fuses physiological signals, facial expressions, and other data, thus providing more accurate personalized suggestions. Finally, the personalized services provided by traditional online education platforms, such as Coursera or edX, are usually based on simple rules or limited datasets. In contrast, the system based on GPT-4 can provide a highly customized learning experience according to each student’s unique learning progress and interest preference. Although its implementation cost is high, it far exceeds the traditional platform in personalization and accuracy.
However, this study also has certain limitations. The system’s recommendation effect is still affected by data quality and student feedback and requires more extensive data support and verification. If the input data are noisy or missing, they may affect the model’s accurate judgment of the learner’s state. In order to solve this problem, the dataset can be further expanded in the future to collect more diverse and multi-scene student behavior data, so as to enhance the generalization ability and robustness of the model.
Moreover, as a large-scale model, GPT-4 has high computational complexity and may be difficult to deploy in resource-constrained environments. In this regard, the future research can explore the use of lightweight LLMs (such as DistilGPT and TinyLLM) or model compression technology (such as knowledge distillation and quantification) to reduce the computational overhead and improve the system’s deployment in the actual teaching environment. At the same time, the combination of edge computing architecture also helps to alleviate the pressure on the server side.
Thirdly, in order to further improve the personalization and accuracy of recommendation, the system can introduce more advanced technologies in the future, such as self-supervised learning, to reduce the dependence on labeled data, and the knowledge map to model the relationship between knowledge points, so as to realize more intelligent knowledge path planning.
In addition, when discussing the personalized learning path recommendation system based on LLM technology, this paper has to face the ethical dilemma and practical consideration presented by using physiological signals and emotional variables. First of all, at the ethical level, privacy protection has become the primary concern. Because highly sensitive personal information is involved, it is very important to ensure that these data are stored safely and used only for the intended purpose. It is an essential step to formulate a clear data use policy and obtain the informed consent of students or their guardians. At the same time, there is also the risk of data misuse, which requires the establishment of a strict supervision mechanism to prevent such abuse and prevent physiological and emotional data from being used for non-educational evaluation or discriminatory purposes. Continuous monitoring of students’ emotional state may also place extra psychological pressure to students, so we must consider the possible negative impact of this practice on mental health and take measures to alleviate any potential harm. From the practical feasibility point of view, although the system shows great potential, it faces technical challenges to collect high-quality physiological and emotional data in the actual educational environment. Therefore, it is particularly important to understand and solve these concerns before popularizing this kind of system. Implementing such a complex personalized learning path recommendation system requires not only advanced technical support, but also adequate training and support services to help educators make effective use of these tools. Therefore, before popularizing the system, it is necessary to carry out field experiments to verify its feasibility in real teaching scenarios. In addition, a supporting teacher training and technical support system is needed to help educators better understand and use these intelligent tools.
6. Conclusions
This paper proposes a personalized learning path recommendation system for the second classroom. By introducing the AI model GPT-4, taking advantage of its long-sequence data processing advantages and self-attention mechanism, and deeply analyzing students’ multimodal behavior data, it provides students with more accurate and personalized learning suggestions. By generating adversarial networks to optimize recommended content, the diversity and innovation of recommended paths are improved. The experimental results show that the system performs well in several evaluation indexes: the accuracy of personalized recommendation reaches 92%, the coverage reaches 91%, and the recall rate reaches 93%. In addition, the real-time feedback adjustment time of the system does not exceed 1.5 s, which shows that it not only responds to the changes of students’ needs quickly, but also shows an excellent ability to dynamically adjust learning paths. Compared with other mainstream models, the system in this study has significantly improved in adaptability, accuracy, and real-time feedback ability.
The main contribution of this study is the innovative introduction of GPT-4, a LLM technology, which fully explores the potential features in students’ multimodal data. The system combines GAN technology to enhance the diversity and innovation of recommendation paths. At the same time, the system has real-time feedback and dynamic adjustment functions, which can adjust the recommendation strategy according to students’ real-time feedback data to ensure that the path is highly matched with students’ latest needs. This paper not only provides a new technical framework for personalized learning path recommendation in the second classroom, but also provides practical guidance for the application of intelligent recommendation systems in the field of education. This study can provide a more accurate, efficient, and real-time learning path recommendation system for the fields of intelligent education and personalized training, and promote the efficient use of educational resources and the personalized development of students.
Based on the above research, although remarkable achievements have been made, there are still many directions worth exploring in the continuous optimization of personalized learning path recommendation systems. In the future research, we plan to further explore how to enhance the cross-cultural adaptability of personalized learning path recommendation systems and the diversity of data sources, for example, by integrating data with additional dimensions, such as social network behavior and online discussion participation, so as to capture students’ interests and needs more comprehensively. At the same time, we will devote ourselves to developing a more intelligent and interactive user interface, so that the system can communicate with students more naturally and adjust learning suggestions immediately. In addition, it is also one of the important research directions to evaluate the influence of the system on the long-term learning effect. With the development of emerging technologies, such as quantum computing and edge computing, we will explore the potential of these technologies in improving the processing speed and recommendation accuracy of the system, and on this basis, we will continue to optimize our technical framework to better serve educational practices and promote the progress of educational fairness and personalized learning.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}