A fusion strategy is employed to build the BIM structured query string generation model. Expert models can achieve high accuracy, but the generalization ability is generally not strong. Open-domain LLMs can help interpret human nature language points, but there are always “hallucination” problems. There are two main contributions of this work.
3.1. BIM Query Dataset
The dataset comprises 1680 samples, categorized into two main types: precise queries and fuzzy queries, to comprehensively assess the model’s parsing capabilities in different contexts. The natural language queries were constructed based on representative usage examples drawn from mainstream BIM software systems. These examples reflect frequently encountered information retrieval needs during real-world BIM operations. The query design was informed by domain knowledge embedded in these application scenarios to ensure practical relevance and authenticity.
The precise query dataset contains 1440 samples, each adhering strictly to IFC standard logic, with clear expression and well-structured format. These samples are primarily used to evaluate the model’s accuracy and stability when handling explicit query requirements.
In contrast, the fuzzy query test set includes 240 samples, which simulate natural language inputs from non-expert users. This dataset is primarily used to test the model’s robustness and generalization in real-world interaction scenarios. These queries may involve semantic ambiguity, incomplete expression, or colloquial descriptions.
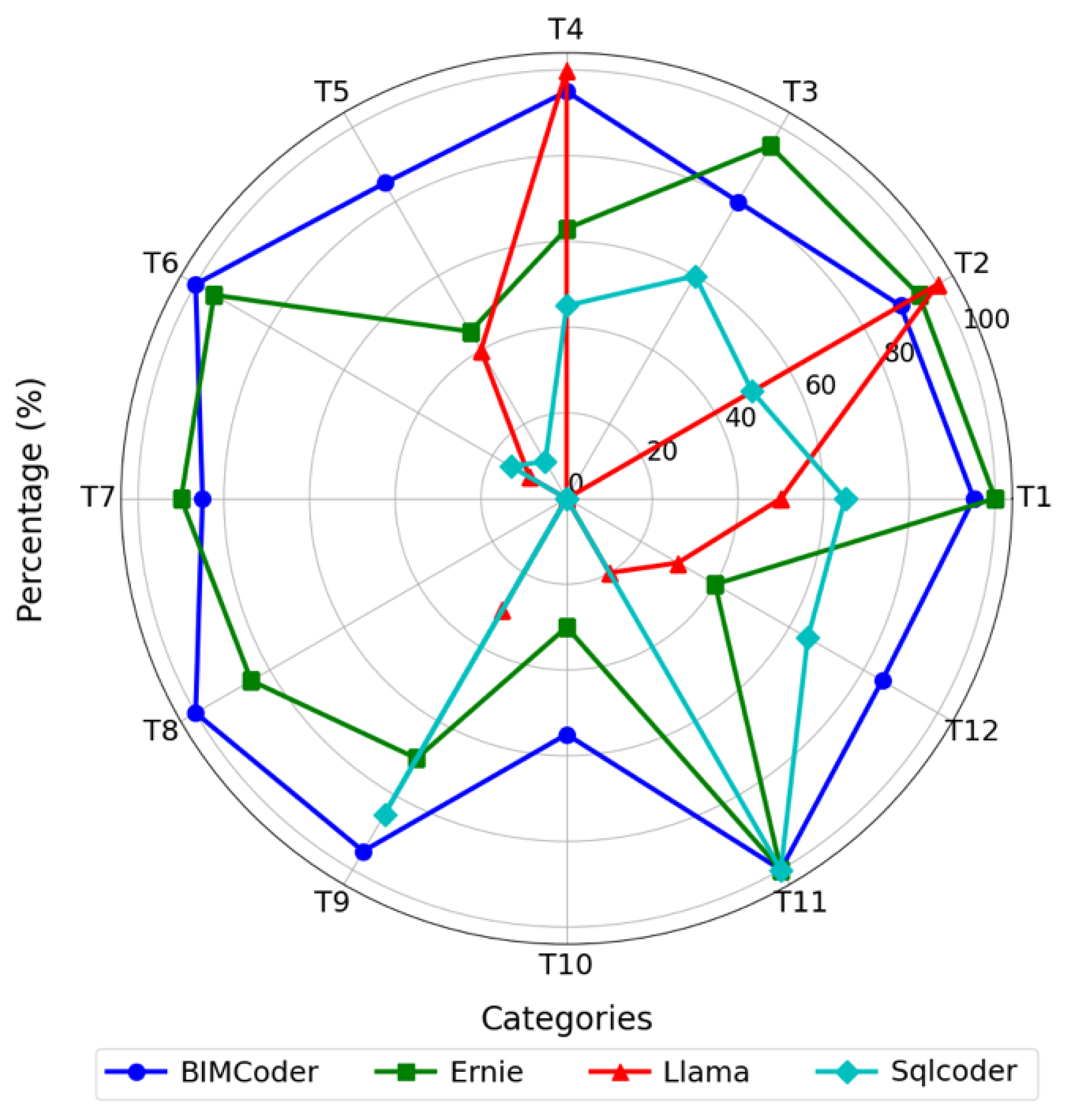
All queries in the dataset are divided into 12 standardized query types, corresponding to common query needs on BIMserver, covering core tasks in BIM data extraction. This design ensures both systematic and representative data, aiding in the training and evaluation of the model’s performance across different query categories and providing a high-quality testing benchmark for intelligent query systems in the BIM domain. The precise query dataset is further subdivided into 1200 training samples and 240 test samples, while the fuzzy query test set is exclusively used for validating the model’s flexibility in handling ambiguous queries. Initially, all query types were manually created and then augmented using GPT to generate 100 queries per type. The fuzzy query test set specifically aims to evaluate the system’s matching capability for fuzzy queries. All the source code and dataset can be obtained from
https://github.com/liubingru66/BIMcoder (accessed on 4 March 2025).
As shown in
Table 1, the dataset structure is as follows.
To better manage and understand the diversity of BIM queries, the 12 types of IFCQL query instructions can be classified based on the query target object, the query method, and its content. Grouping these queries according to their querying methods allows for clearer selection of query needs for users and ensures the scalability and flexibility of the query language. The classification reasons are as follows:
Object-Based Queries
These queries focus on filtering query targets based on different component types, such as walls, floors, doors, and windows. This category includes T1, T2, T3, and T12.
This classification is intuitive and aligns with real-world applications where users often need to perform precise queries for different component types (e.g., walls, floors, doors). For instance, T1 and T2 allow the retrieval of entire buildings and individual component types, respectively, while T3 can handle combined queries for multiple component types. These operations are commonly seen in practical BIM applications.
Component Identification or Location-Based Queries
This category of queries focuses on retrieving target components through their unique identifiers (GUIDs) or spatial location ranges. It includes T4, T5, T6 and T10.
Queries based on GUIDs or spatial ranges help users locate specific components or areas. For example, T4 and T5 support locating components via their GUID or spatial range, which is a common query need in architectural design and construction.
Although end users typically do not directly interact with GUIDs in daily operations, GUIDs serve as unique identifiers in the BIM context, ensuring the accuracy and traceability of component queries. In practice, users often start queries based on physical or attribute information of components and later use GUIDs to pinpoint specific components for more refined queries. This method not only enhances query accuracy but also reduces computational overhead from repeated queries, enabling users to efficiently access the required information.
Component Attribute or Relationship-Based Queries
These queries focus on filtering based on the attributes of components or their interrelationships. They are primarily used to extract detailed component information or to query the dependencies between components in the BIM model. This category includes T7, T8, T9, and T11.
Attribute and relationship queries concentrate on retrieving details about the components themselves or the logical relationships between them. These types of queries are theoretically sound because in a BIM model, component attributes (such as material, size, load-bearing capacity) and component relationships (such as containment or relative positioning) are critical elements of the model. By querying component attributes and relationships, users can gain in-depth insights into the components’ functionality, performance, and interactions with other components.
Based on the information presented in
Table 2, the following examples illustrate Precise Queries and Fuzzy Queries.
In BIM query tasks, precise queries and fuzzy queries represent two different user interaction modes, corresponding to structured professional query requirements and more natural, colloquial expressions, respectively. Precise queries typically have well-defined query targets and clear parameter definitions, such as specifying a spatial range, component type, or GUID for retrieval. Due to their strong directionality, models usually achieve high accuracy in understanding and executing such tasks.
In contrast, fuzzy queries are closer to the natural language expressions of non-expert users and may include vague descriptions, colloquial phrasing, or context-dependent query needs. For example, users may not directly provide specific values or GUIDs but instead use vague instructions like “see what you can find in this area” or “help me find that wall section.” These queries are semantically more flexible and require the model to possess a stronger ability to understand context and reason, in order to correctly translate fuzzy expressions into executable queries.
In BIM information retrieval, it is crucial to support both precise and fuzzy queries. Precise queries ensure efficiency and reliability in professional environments, while supporting fuzzy queries enhances the user interaction experience for non-expert users, making BIM data access more intuitive and natural.
To ensure the validity and practicality of the constructed dataset, it is essential to verify whether the designed query issues can be correctly executed in a real BIM environment. The verification process serves not only to validate the dataset content but also to assess the practical applicability of the query language and the query framework used. For the 12 query types proposed in the dataset, the verification is carried out by executing the queries within the BIMserver open-source project.
The executable IFC files for real-world scenarios can be accessed in the dataset available on GitHub (tested using BIMserver v1.5.187).
3.2. Fusion-Based BIM Structured Query Strings Generation
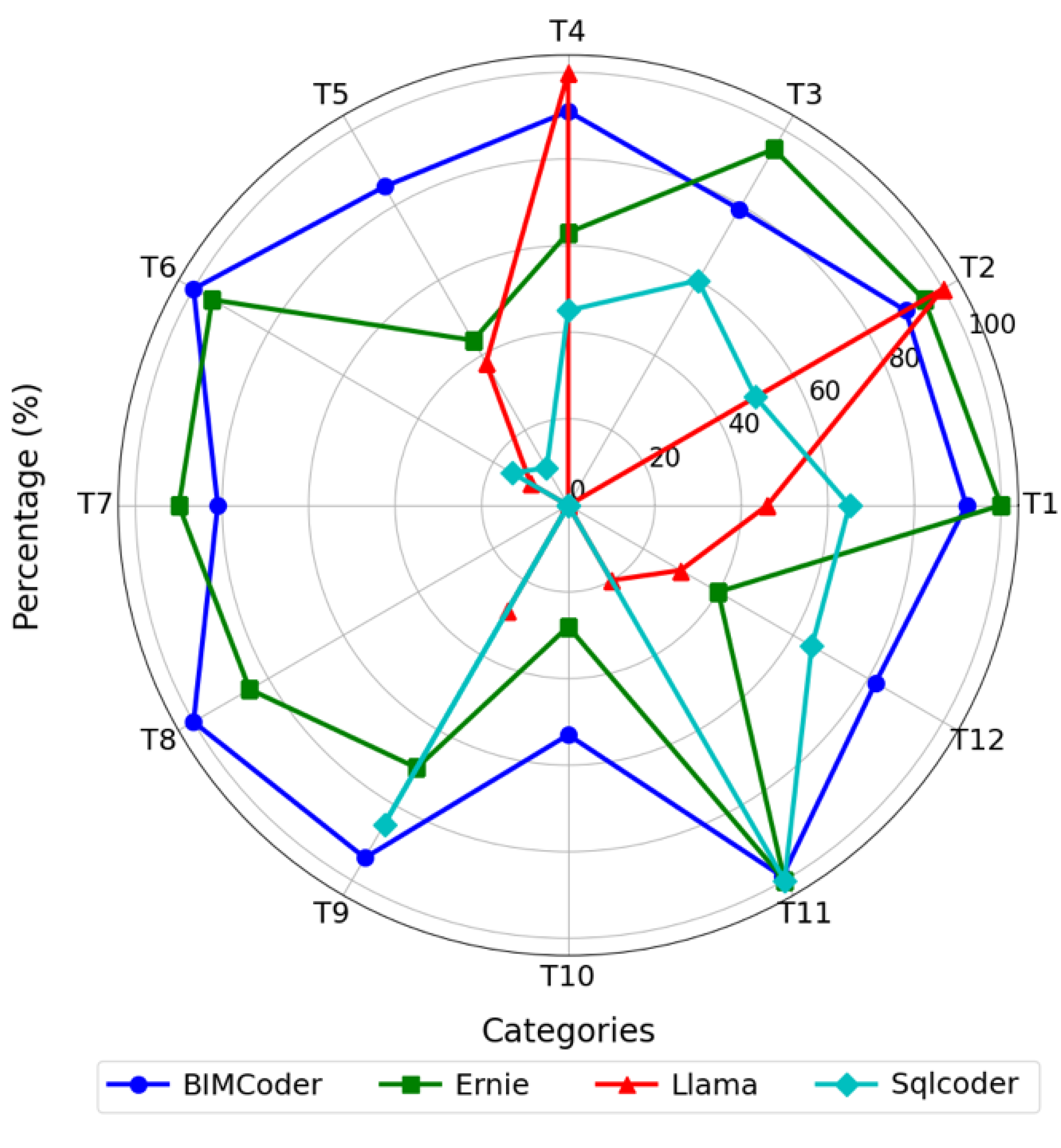
The proposed model, termed BIMCoder, is a fusion-based architecture designed to translate natural language BIM queries into executable structured commands. It integrates the domain expertise of fine-tuned models with the flexibility of open-domain language models and adds a verification layer to ensure output quality. The architecture consists of three key components: an expert model, a wrapper model, and a validator.
The expert model is fine-tuned using a carefully constructed BIM query dataset to capture domain-specific syntactic and semantic patterns. The wrapper model, built upon a general-purpose large language model (LLM), serves as a preprocessing module that standardizes user inputs and enhances compatibility with the expert model. Finally, the validator ensures that the output query strings conform to IFC-based JSON syntax and can be successfully executed within BIM platforms.
The overall workflow is illustrated in
Figure 1.
The detailed process is as follows:
Input: The system receives user-provided natural language queries targeting BIM-related information.
Wrapper Model: A large language model (LLM) reformulates the input queries into standardized, disambiguated forms suitable for domain-specific parsing.
Expert Model: The expert model, trained on BIM query data, converts the preprocessed input into structured BIM query strings in JSON format.
Validator: The validator checks the syntax and executability of the generated queries to ensure compatibility with downstream BIM platforms.
Output: Validated structured query strings, ready to be executed in BIM systems (e.g., IFCQL-compliant JSON), are returned to the user or interfaced applications.
This fusion-based design improves the robustness, interpretability, and domain adaptability of BIM query generation. By leveraging general-purpose LLMs for preprocessing and domain-specific models for generation, BIMCoder effectively bridges the gap between natural language flexibility and structured query precision.
3.2.1. SQLCoder Fine-Tuning-Based Expert Model
Fine-tuning SQLCoder, as the expert model, accepts natural language queries and generates structured BIM queries. It trained with Supervised Fine-Tuning (SFT) on the SQLCoder model. SQLCoder employs the Mistral model architecture, which excels at structured string generation.
The constructed dataset (presented in
Section 3.1) was employed in the fine-tuning stage. Twelve types of precisely formulated and well-structured questions and their corresponding answers were used. These question categories were carefully designed to ensure specificity and accuracy. A total of 10% of the dataset was set aside for validation, while full-scale updates were employed for training. Given the small sample size of the dataset, the number of epochs was set to 10, with a learning rate of 0.000001 and a batch size of 2. The model learned and absorbed language patterns and query construction techniques from the structured dataset through fine-tuning training.
3.2.2. LLM-Based Wrapper
In real-world situations, applying the trained SQLCoder model directly to informal or vaguely worded questions often yields unsatisfactory results. Therefore, a pre-trained large language model is utilized to transform imprecise user queries into clearly formulated questions.
The ERNIE model was employed to convert raw queries into well-structured and explicitly directed queries. A specifically designed prompt was attached to guide the large language model in processing every raw query. Although this prompt is used with the ERNIE model, it does not mean ERNIE is the only choice. Any large language model that supports prompts can be used as a Wrapper model.
Table 3 presents the prompt for the LLM-based Wrapper model.
As shown in
Table 4, once questions are transformed in this manner—more structured and directed—they can be passed on to the specialized BIMcoder model to generate more accurate query statements.
3.2.3. Validator
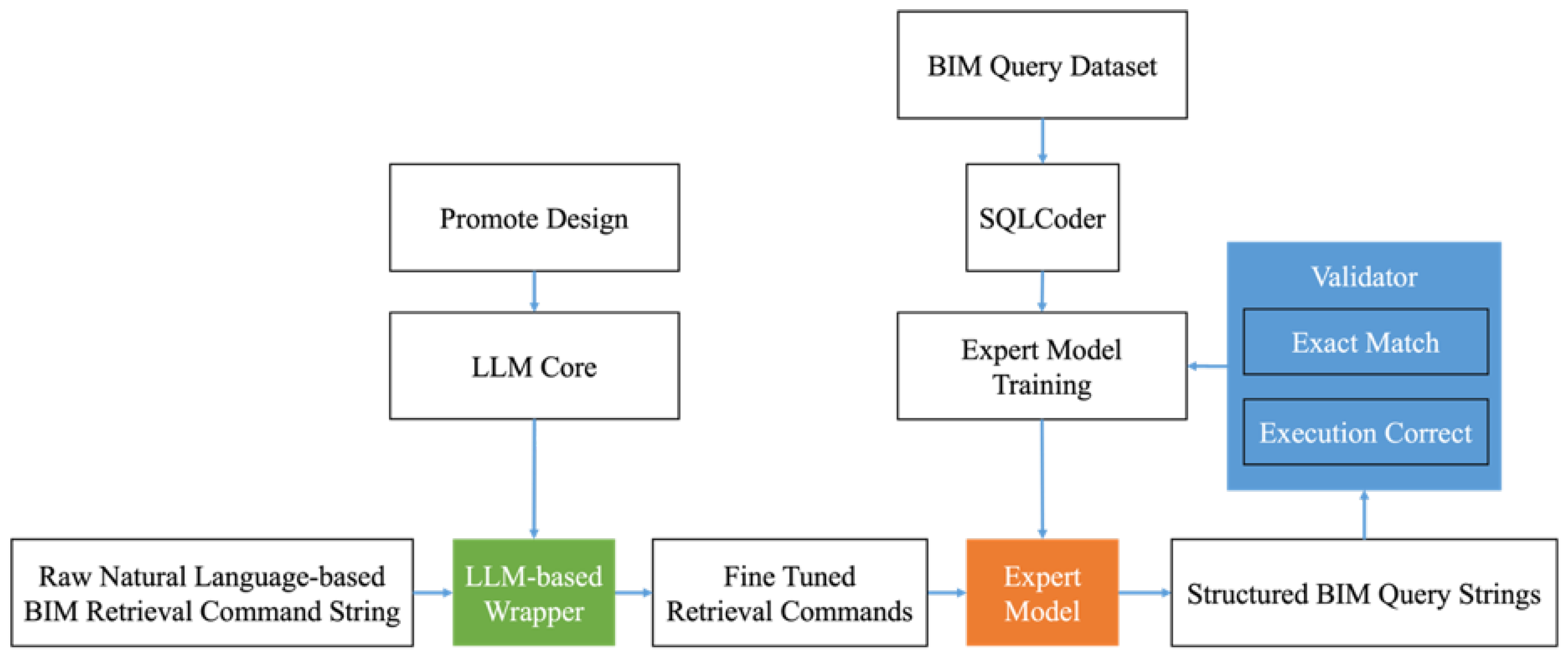
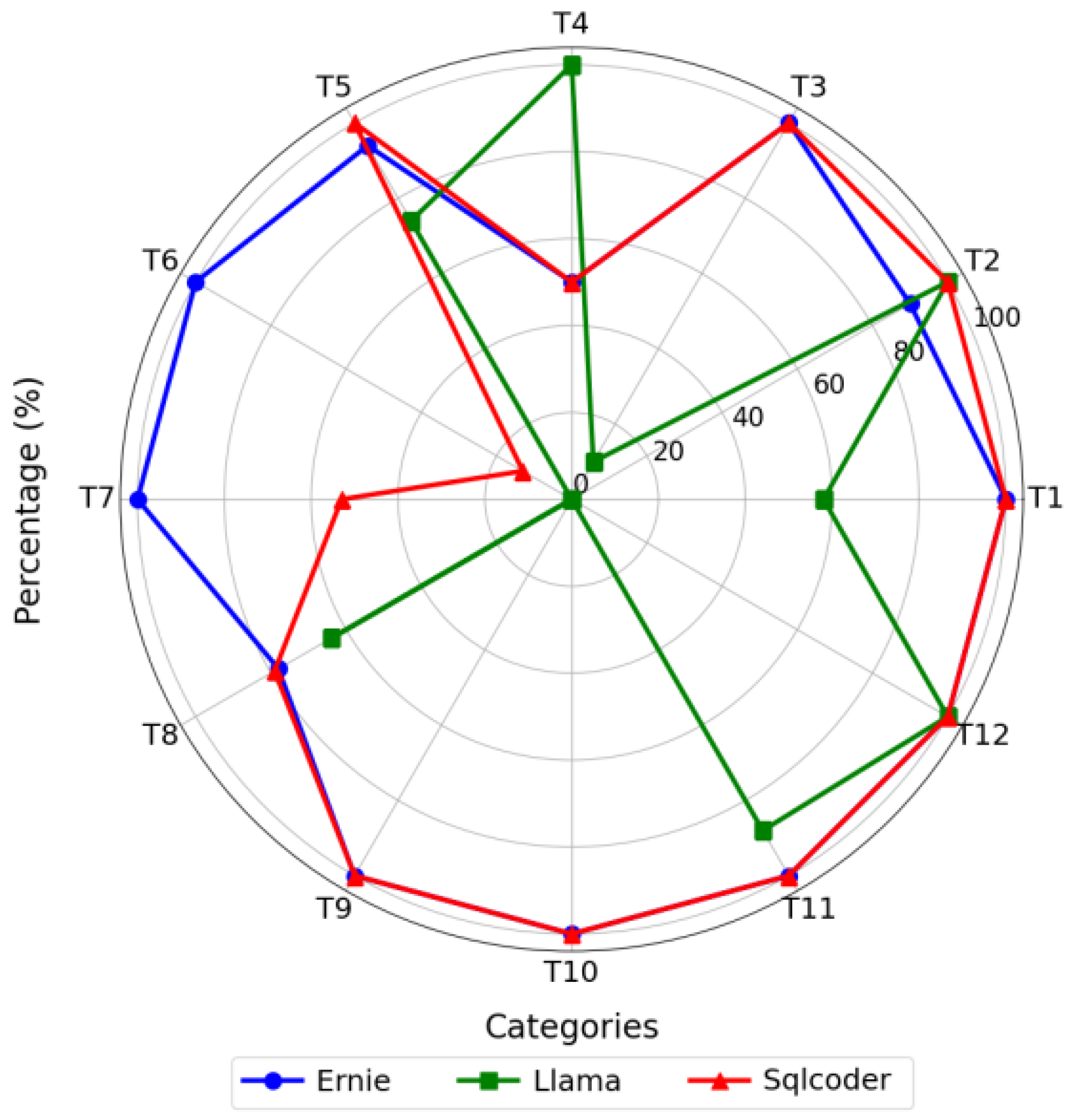
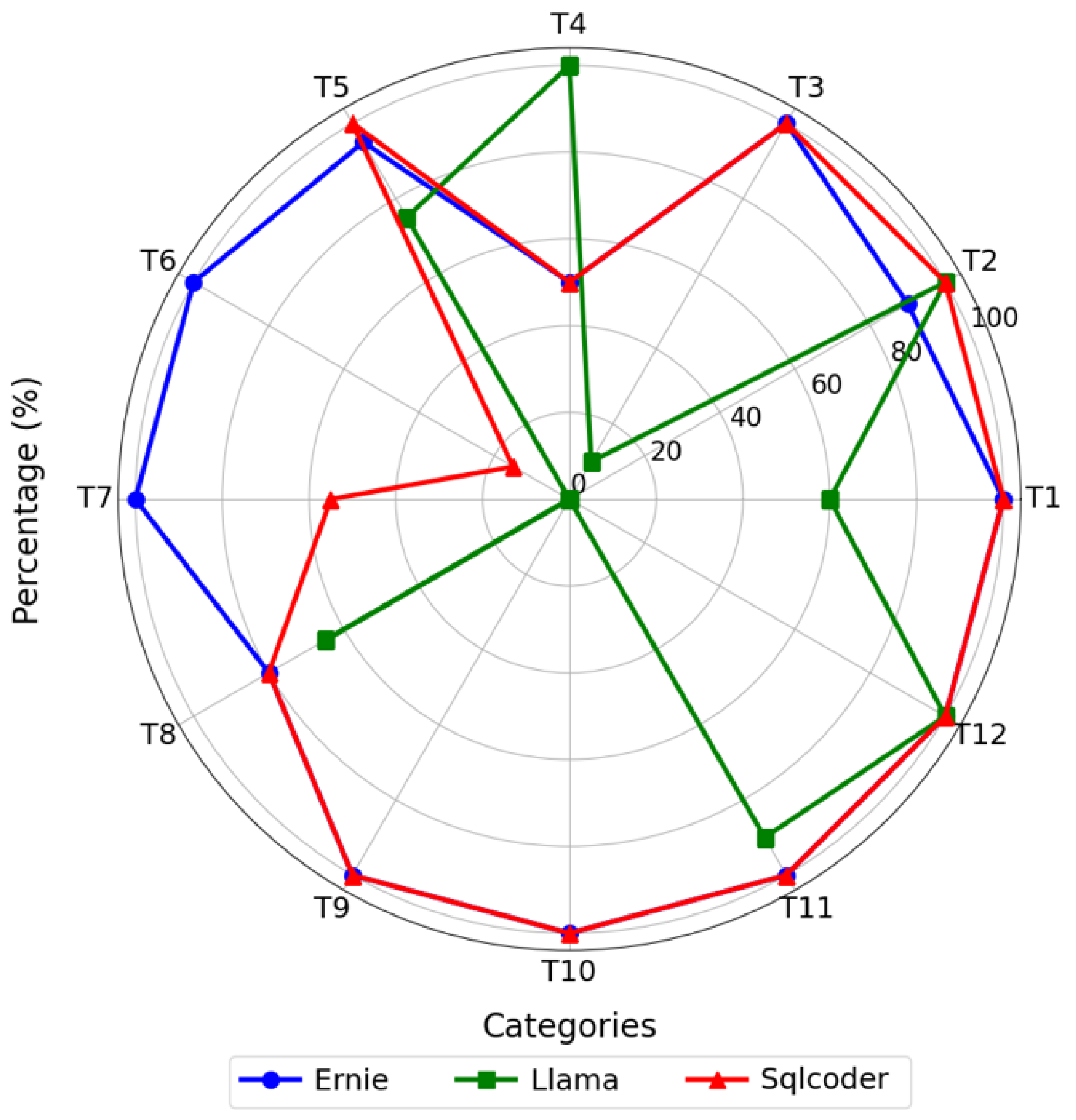
In NL2SQL tasks, models are required to comprehend the semantics of natural language and generate SQL queries that are both syntactically valid and semantically accurate. To rigorously evaluate model performance, this study adopts two widely recognized evaluation metrics: Exact Match Accuracy (EM) and Execution Accuracy (EX), both of which are adapted to the context of structured query generation for Building Information Modeling (BIM).
Exact Match Accuracy measures the proportion of predictions that are exactly identical to the gold-standard SQL query. Formally, for each prediction, if the generated SQL query matches the reference SQL query token by token and structure by structure, the output is counted as correct. This metric places a strong emphasis on syntactic fidelity and full semantic coverage, and is particularly effective for detecting whether the model can completely and precisely encode all elements of a user’s query, such as specific entity names, attribute constraints, and logical connectors.
Execution Accuracy, on the other hand, evaluates whether the result returned by executing the generated SQL query matches that of the reference query. Even if the predicted SQL differs in structure (e.g., uses different but equivalent expressions or JOIN orders), it is considered correct as long as the execution results are the same. This metric emphasizes functional correctness and reflects the model’s ability to understand the user’s intent and generate an executable query with equivalent semantics.
In the BIM domain, these metrics are calculated across 12 representative question categories, each corresponding to a specific application scenario—such as project cost estimation, component tracking, construction progress, spatial conflict detection, and compliance verification. For each category, we compute both EM and EX separately. The overall Exact Match Accuracy and Execution Accuracy are then derived by averaging across all question types, providing a holistic evaluation of model performance on BIM-oriented NL2SQL tasks.
To further enhance the reliability of structured query generation, we introduce a validator module that plays a critical role in ensuring both syntactic correctness and execution validity. The validator first checks whether the generated query conforms to the required IFCQL format using a built-in query format checker embedded in the BIM server platform. If the query fails to pass the syntax check or yields invalid execution results, the system provides immediate feedback to the user, indicating the cause of failure (e.g., unrecognized attributes, incorrect nesting, or unsupported filtering conditions). This feedback mechanism effectively mitigates hallucination issues and guides the user toward more accurate query reformulation, thus improving overall user experience and system robustness.
It is worth noting that certain challenges in the dataset may influence the robustness of these metrics. Specifically, queries involving GUID-based filtering or deeply nested IFC entities may introduce noise, as different syntactic representations may yield the same results (affecting EM) or produce execution discrepancies due to incomplete data linkage (affecting EX). Additionally, since some fuzzy queries were derived from usage examples without expert annotation, there is potential for label bias or intent ambiguity.
To mitigate these factors, we performed basic data normalization and cleaning, including de-duplication, query canonicalization, and entity disambiguation. However, further improvements—such as integrating expert validation, filtering ambiguous queries, and implementing robust canonicalization pipelines—remain promising directions to enhance dataset quality and evaluation reliability in future work.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}