
Sampling Method Based on Fuzzy Membership for Computing Negative Sample Credibility and Its Applications

Abstract
1. Introduction
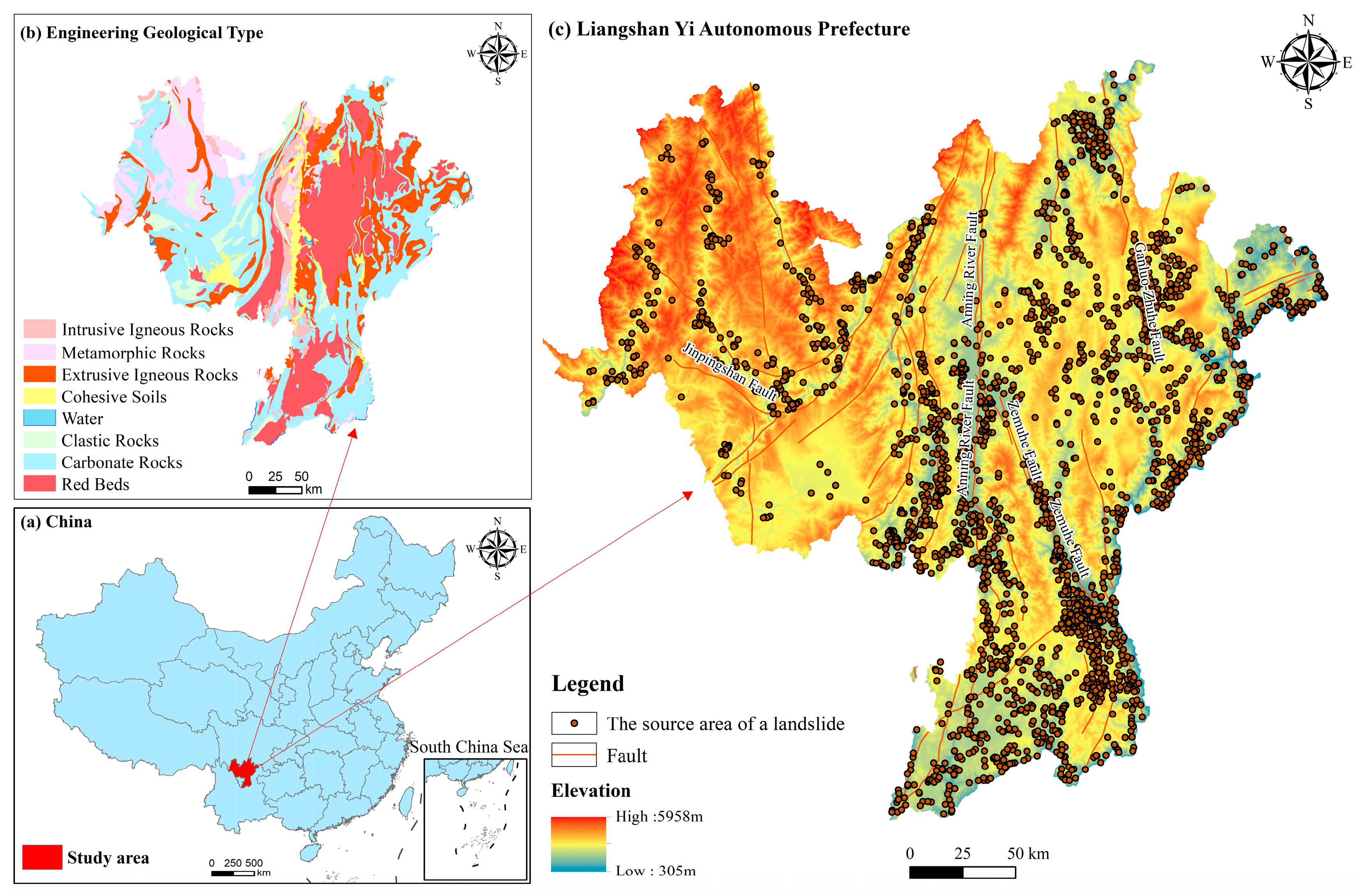
2. Study Areas and Data Sources
2.1. Study Areas
2.2. Data Sources
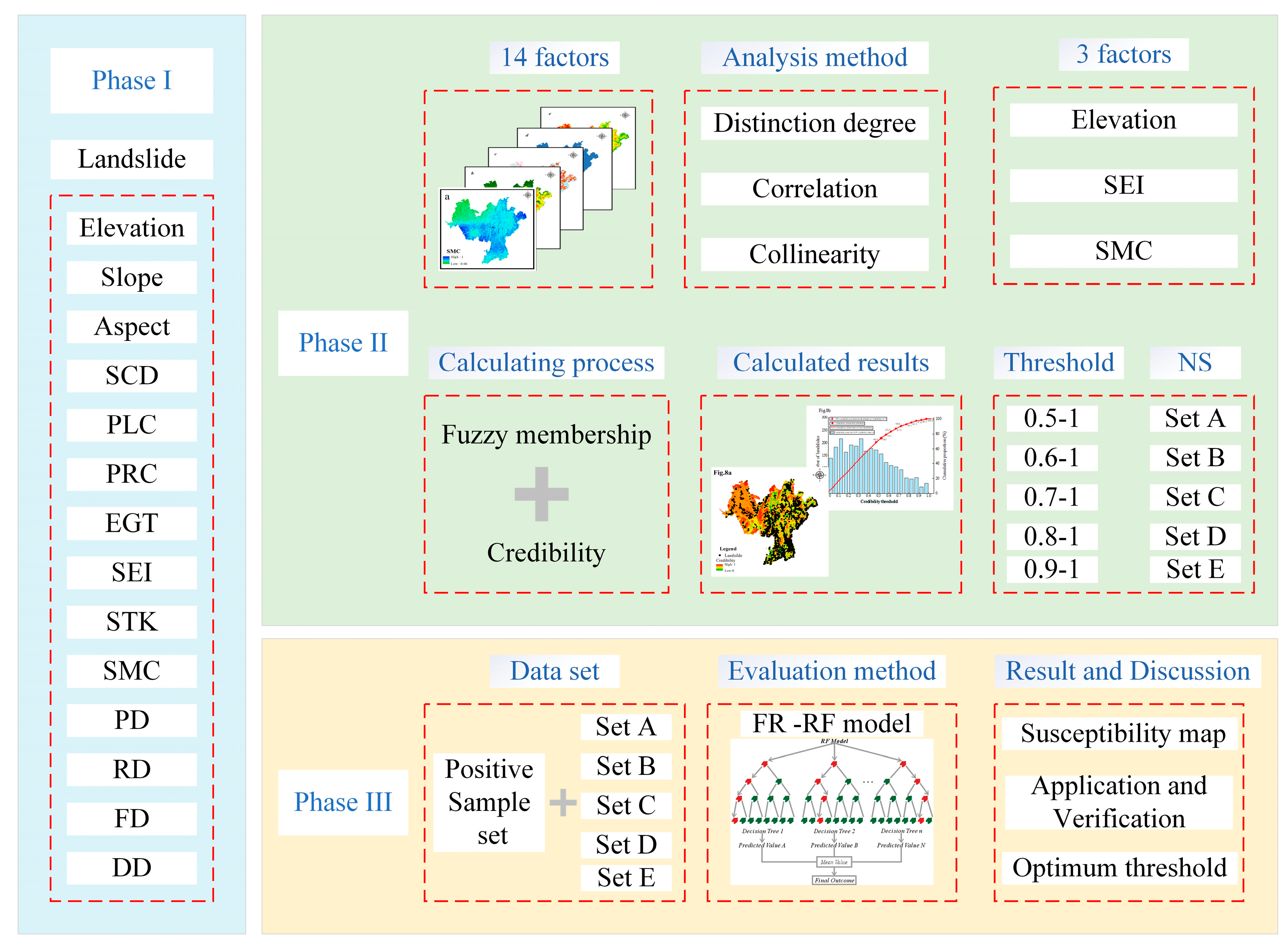
3. Methods
3.1. Evaluation Methods
3.1.1. Frequency Ratio Model
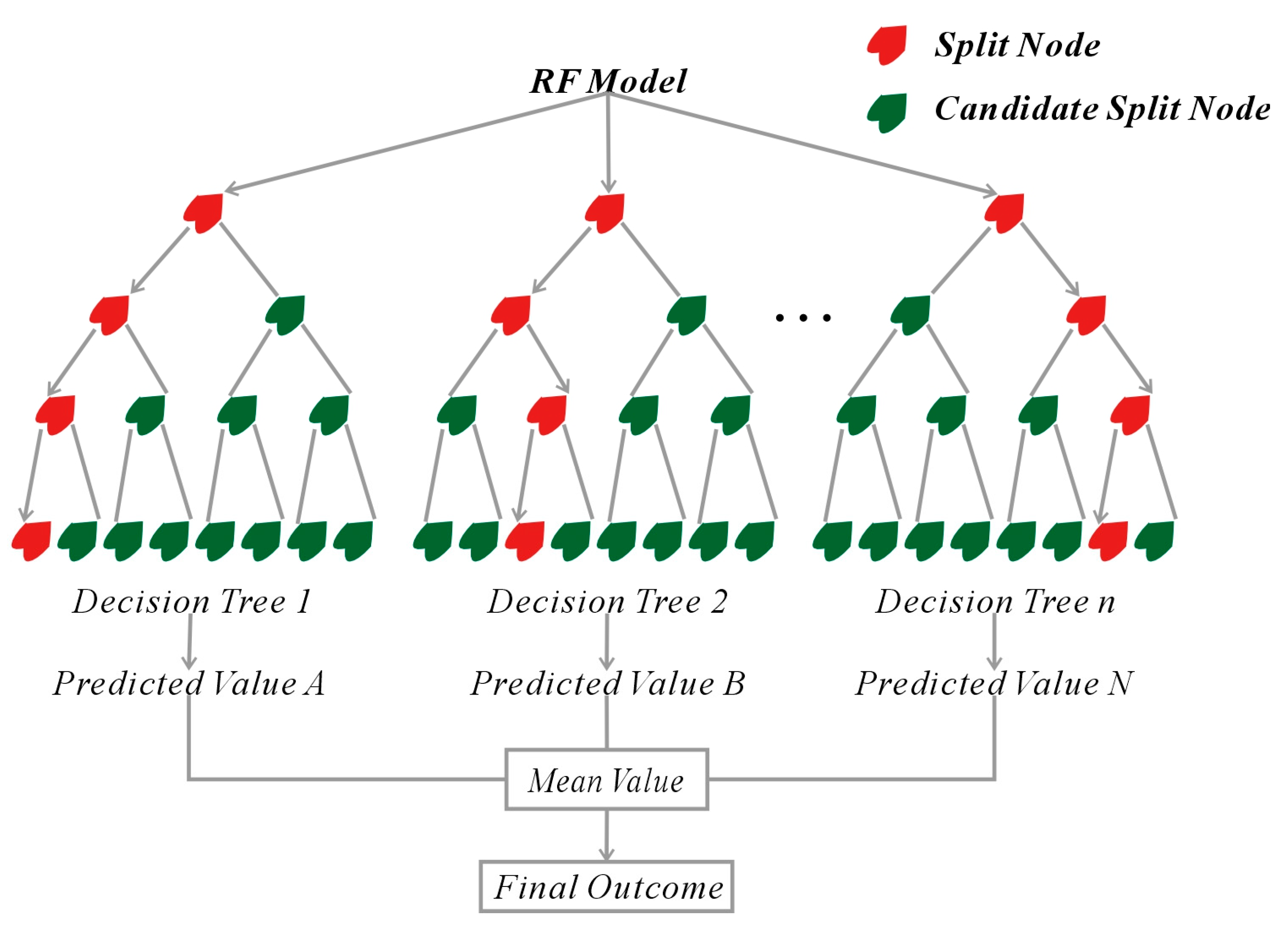
3.1.2. Random Forest Model
- (1)
- Multiple data subsets containing K samples are created by drawing samples with replacements from the original sample set;
- (2)
- When each sample has N attributes, m (where m << N) attributes are randomly selected. An information-gain strategy is then applied to identify a split attribute for the given node from the m selected attributes;
- (3)
- Decision trees are constructed by splitting each node according to Step 2 until further splits are no longer possible;
- (4)
- The above steps are repeated until the desired number of decision trees has been generated;
- (5)
- Samples are divided into training and test sets, with factor FRs as inputs and actual states (landslide or nonlandslide) as outputs. Each decision tree predicts an outcome for each sample, which is then averaged to obtain the final regression result (Equation (2)).
3.2. Evaluation Factor Selection Method
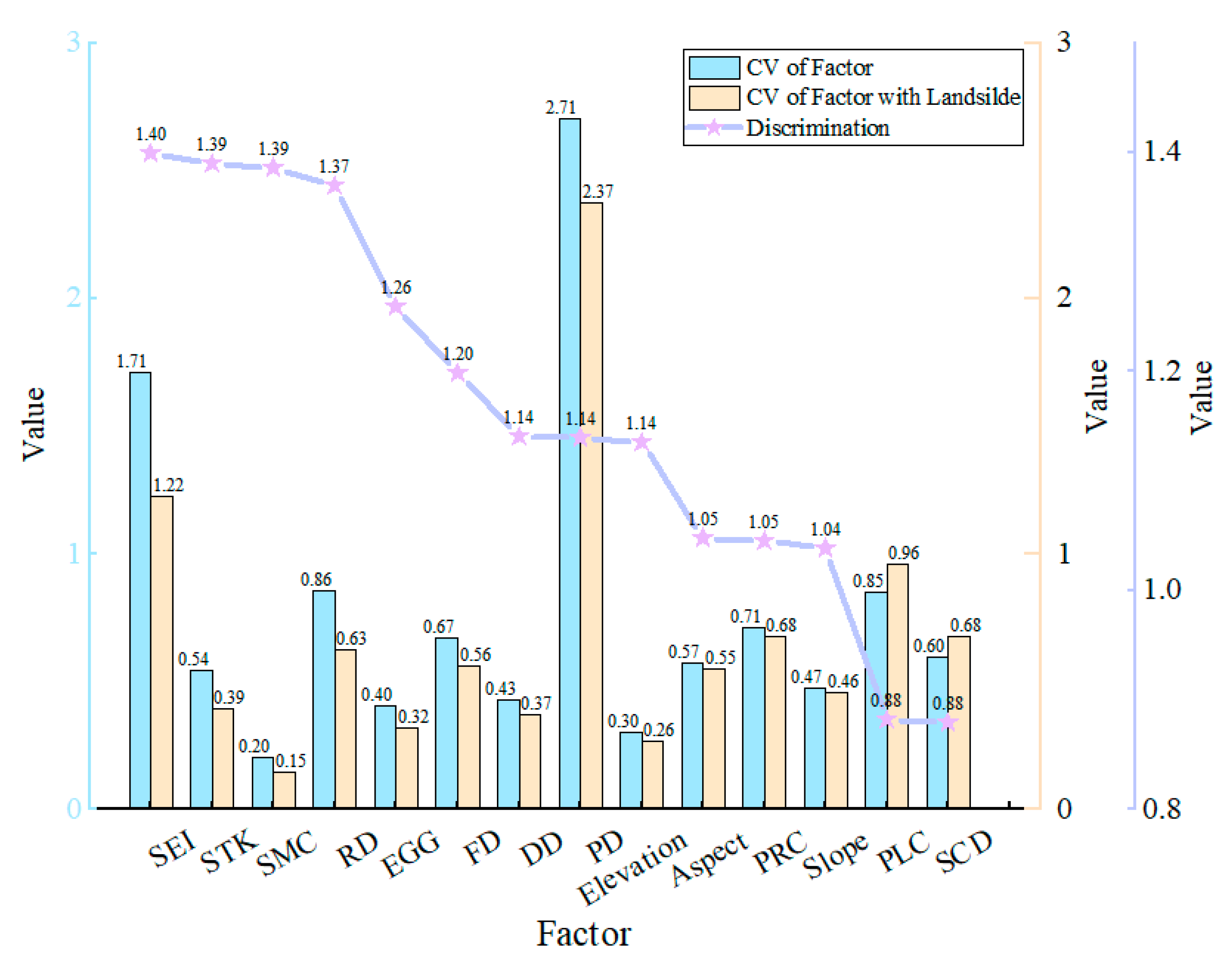
3.2.1. Differentiation
3.2.2. Maximum Mutual Information Coefficient Method
3.2.3. Collinearity Diagnosis
3.3. Negative Sample Selection Method
3.3.1. Geographical Information Similarity
3.3.2. Credibility Computational Method
3.4. Testing of the Evaluation Results
3.4.1. F1-Scores
3.4.2. AUC Value
4. Results
4.1. Selection of Evaluation Factors
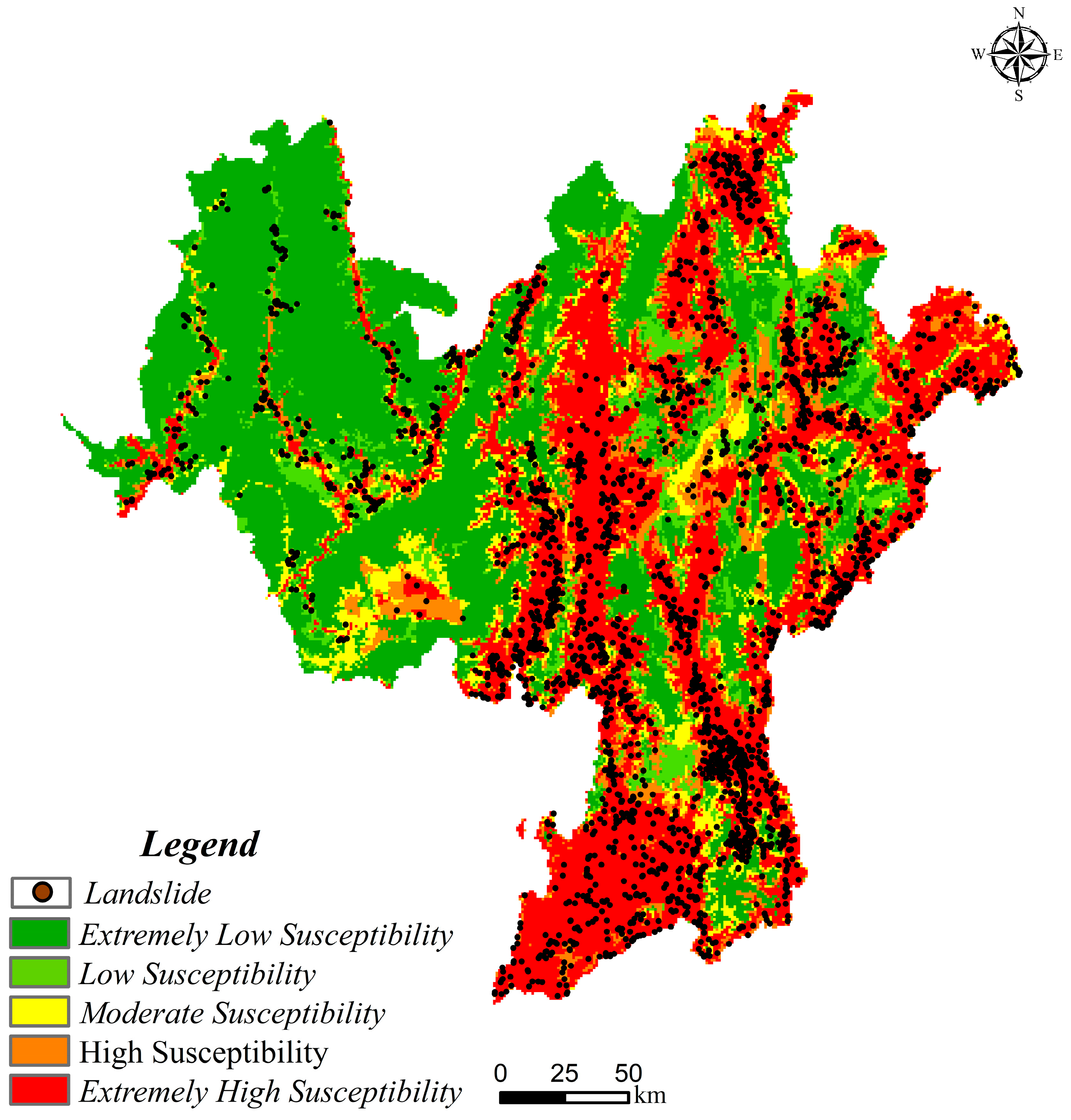
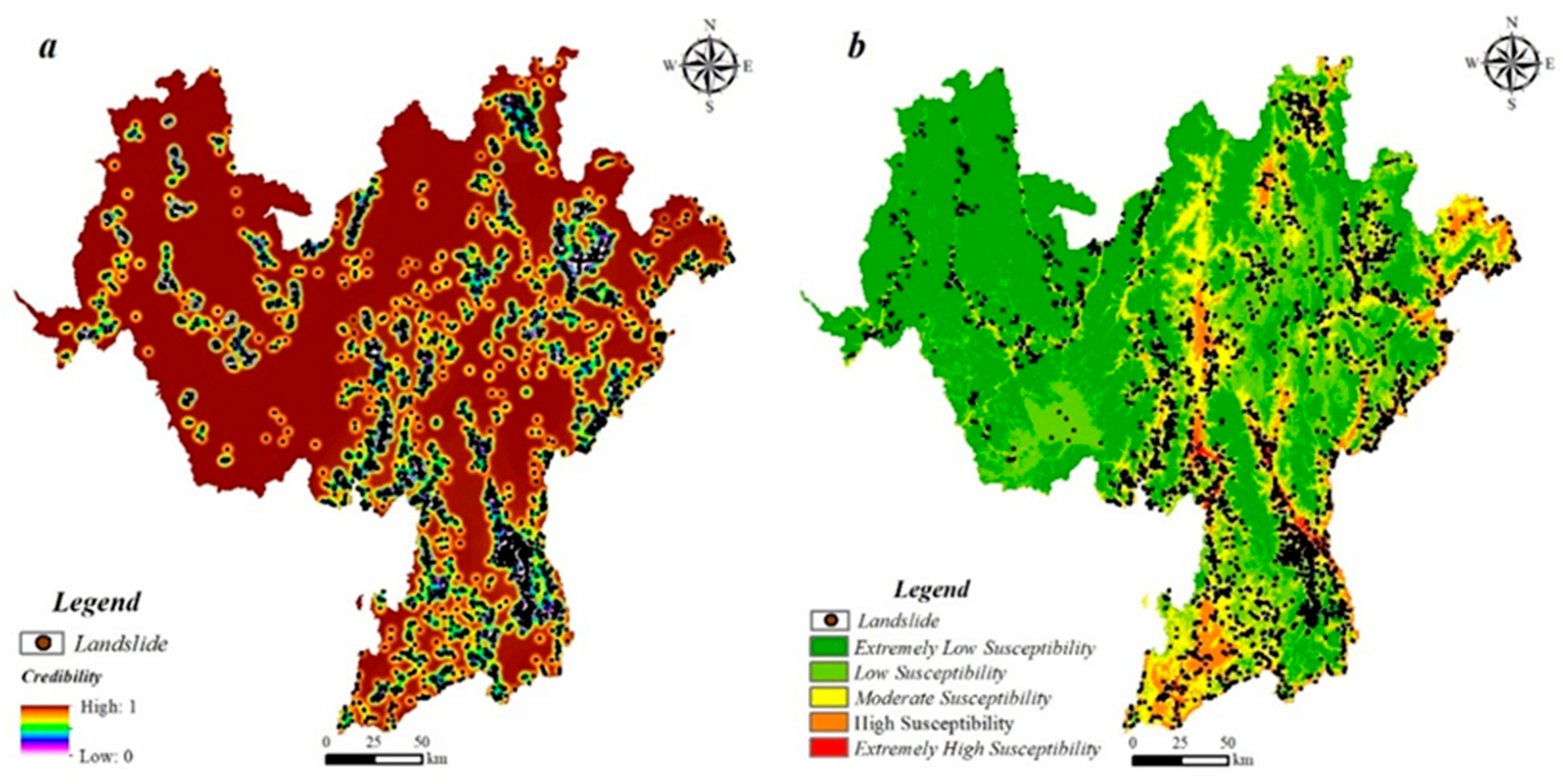
4.2. Spatial Distribution Map of Negative Sample Credibility
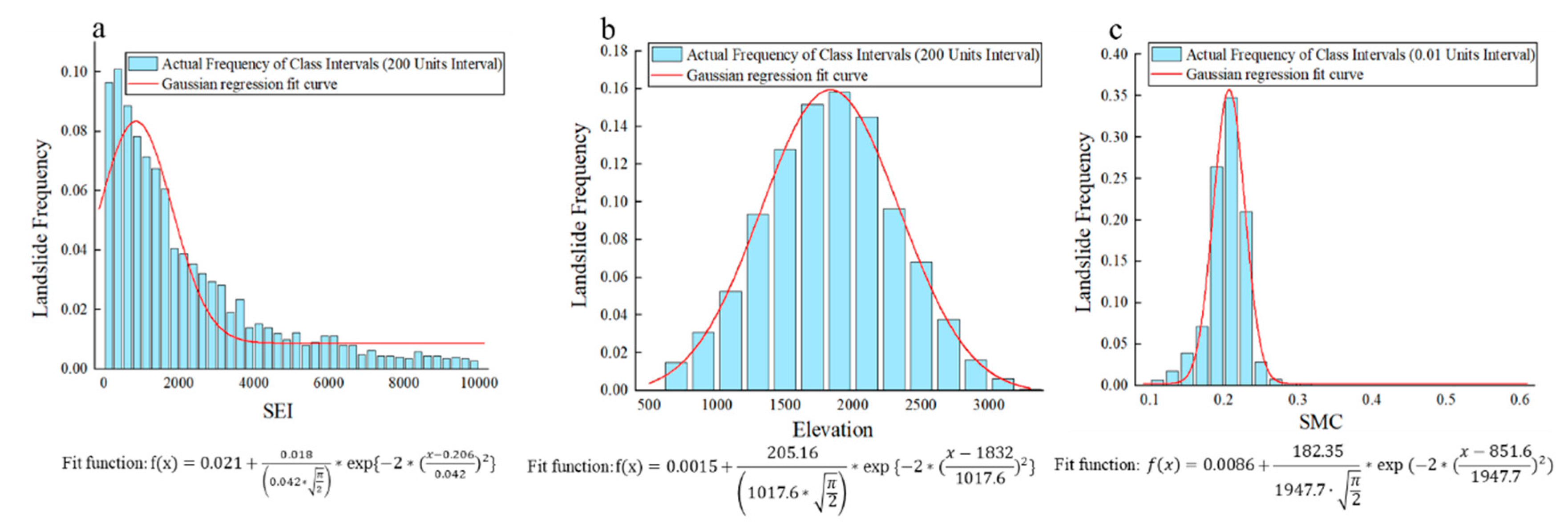
4.2.1. Calculation of the Membership Function
4.2.2. Negative Sample Credibility
4.3. Optimal Credibility Threshold
5. Discussion
5.1. Comparative Analysis of Application Effects and Novel Approach Advantages in Negative Sampling Methods
5.2. Application and Validation Based on Machine Learning Models
5.3. Limitations and Future Directions
6. Conclusions
- (1)
- This study successfully developed and applied a fuzzy membership-based method for calculating negative sample credibility for landslide susceptibility assessment. The proposed approach triggers a paradigm shift: from defining “where to select negative samples” to quantitatively evaluating “how reliable the selected samples are.” The proposed method not only overcomes the significant limitations of conventional sampling methods (such as inadequate spatial continuity and fragmented representations of environmental feature spaces) but also establishes an intuitive and quantifiable reliability metric (i.e., credibility) for negative landslide samples. The resulting credibility distribution map of the negative samples exhibits exceptional spatial continuity and effectively characterizes the nonlandslide spatial patterns, thereby substantially enhancing the scientific rigor and reliability of negative sample selection. Crucially, the proposed method provides robust theoretical and operational support for constructing high-precision landslide susceptibility models;
- (2)
- Systematic validation using SVM and RF models confirms that negative samples with credibility thresholds in the 0.7–1.0 range represent the optimal choice for balancing model performance and landslide distribution characteristics. Selecting negative samples within this threshold range enables the generation of scientifically robust landslide susceptibility maps. The results were systematically validated across two distinct ML models, demonstrating the broad applicability of the credibility mapping framework and the proposed sampling methodology. The proposed approach establishes a robust theoretical framework for selecting reliable negative samples in the study area and analogous regions;
- (3)
- The primary contribution of this study lies in its pioneering application of fuzzy membership theory to spatialized quantitative representation of negative sample credibility, which provides a novel and effective technical solution to the long-standing challenge of negative sample quality in landslide susceptibility modeling. The generated continuous, high-resolution credibility distribution map deepens our understanding of the spatial heterogeneity in “nonlandslide areas” and its latent association with landslide occurrence mechanisms. This result provides a reliable tool for geoscientists to select high-credibility negative samples and provides critical technical support for disaster managers in generating high-fidelity susceptibility maps and robust scientific foundations for land-use planning and disaster risk reduction policy formulation across diverse regions.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, J.; He, Y.; Zhang, L.; Zhang, Q.; Tang, J.; Huo, T.; Zhang, Y. A synergistic CNN-DF method for landslide susceptibility assessment. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 6584–6599. [Google Scholar] [CrossRef]
- Tekin, S.; Quesada Román, A.; Çan, T. Landslide susceptibility assessment of the Asi watershed, southern Türkiye. Turk. J. Earth Sci. 2024, 33, 208–223. [Google Scholar] [CrossRef]
- Kudaibergenov, M.; Nurakynov, S.; Iskakov, B.; Iskaliyeva, G.; Maksum, Y.; Orynbassarova, E.; Akhmetov, B.; Sydyk, N. Application of Artificial Intelligence in Landslide Susceptibility Assessment: Review of Recent Progress. Remote Sens. 2025, 17, 34. [Google Scholar] [CrossRef]
- Zhu, Y.; Liu, S.; Yin, K.; Zeng, T.; Guo, Z.; Liu, Z.; Yang, H. Impact of negative sampling strategies on landslide susceptibility assessment. Adv. Space Res. 2025. [Google Scholar] [CrossRef]
- Li, M.; Tian, H. Insights from Optimized Non-Landslide Sampling and SHAP Explainability for Landslide Susceptibility Prediction. Appl. Sci. 2025, 15, 1163. [Google Scholar] [CrossRef]
- Fu, Y.; Fan, Z.; Li, X.; Wang, P.; Sun, X.; Ren, Y.; Cao, W. The Influence of Non-Landslide Sample Selection Methods on Landslide Susceptibility Prediction. Land 2025, 14, 722. [Google Scholar] [CrossRef]
- Zhang, Q.; He, Y.; Zhang, Y.; Lu, J.; Zhang, L.; Huo, T.; Tang, J.; Fang, Y.; Zhang, Y. A Graph–Transformer Method for Landslide Susceptibility Mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 14556–14574. [Google Scholar] [CrossRef]
- Ke, C.; Sun, P.; Zhang, S.; Li, R.; Sang, K. Influences of non-landslide sampling strategies on landslide susceptibility mapping: A case of Tianshui city, Northwest of China. Bull. Eng. Geol. Environ. 2025, 84, 123. [Google Scholar] [CrossRef]
- Guo, Z.; Tian, B.; Zhu, Y.; He, J.; Zhang, T. How do the landslide and non-landslide sampling strategies impact landslide susceptibility assessment?—A catchment-scale case study from China. J. Rock Mech. Geotech. Eng. 2024, 16, 877–894. [Google Scholar] [CrossRef]
- Jiang, W.; Li, L.; Niu, R. Impact of Non-Landslide Sample Sampling Strategies and Model Selection on Landslide Susceptibility Mapping. Appl. Sci. 2025, 15, 2132. [Google Scholar] [CrossRef]
- Li, M.; Li, L.; Lai, Y.; He, L.; He, Z.; Wang, Z. Geological Hazard Susceptibility Analysis Based on RF, SVM, and NB Models, Using the Puge Section of the Zemu River Valley as an Example. Sustainability 2023, 15, 11228. [Google Scholar] [CrossRef]
- Ahmed, S.; Fatma, O.; Yacine, S.; Fatna, M.; Youcef, B.; Said, G.M. Statistical-based methods for landslides susceptibility mapping in the Wilaya of Mila (northeast Algeria). J. Earth Syst. Sci. 2025, 134, 21. [Google Scholar] [CrossRef]
- Pham, B.T.; Vu, V.D.; Costache, R.; Phong, T.V.; Ngo, T.Q.; Tran, T.-H.; Nguyen, H.D.; Amiri, M.; Tan, M.T.; Trinh, P.T.; et al. Landslide susceptibility mapping using state-of-the-art machine learning ensembles. Geocarto Int. 2025, 37, 5175–5200. [Google Scholar] [CrossRef]
- Huang, F.; Liu, K.; Jiang, S.; Catani, F.; Liu, W.; Fan, X.; Huang, J. Optimization method of conditioning factors selection and combination for landslide susceptibility prediction. J. Rock Mech. Geotech. Eng. 2025, 17, 722–746. [Google Scholar] [CrossRef]
- Huang, F.; Yang, Y.; Jiang, B.; Chang, Z.; Zhou, C.; Jiang, S.-H.; Huang, J.; Catani, F.; Yu, C. Effects of different division methods of landslide susceptibility levels on regional landslide susceptibility mapping. Bull. Eng. Geol. Environ. 2025, 84, 276. [Google Scholar] [CrossRef]
- Mirus, B.B.; Belair, G.M.; Wood, N.J.; Jones, J.; Martinez, S.N. Parsimonious High-Resolution Landslide Susceptibility Modeling at Continental Scales. AGU Adv. 2024, 5, e2024AV001214. [Google Scholar] [CrossRef]
- Ning, Z.; Tie, Y.; Sun, C.; Xu, W. Geohazard susceptibility mapping considering spatial heterogeneity: A case study of Xide County in Sichuan Province. Nat. Hazards 2024. [Google Scholar] [CrossRef]
- Aldiansyah, S.; Wardani, F. Assessment of resampling methods on performance of landslide susceptibility predictions using machine learning in Kendari City, Indonesia. Water Pract. Technol. 2024, 19, 52–81. [Google Scholar] [CrossRef]
- Tan, S.-Q.; Zhang, X.; Li, Q.; Ai, C. Information push model-building based on maximum mutual information coefficient(Article). J. Jilin Univ. 2018, 48, 558–563. [Google Scholar] [CrossRef]
- Dunlong, L.; Qian, X.; Xuejia, S.; Shaojie, Z.; Hongjuan, Y. Landslide susceptibility prediction method based on HSOM and IABPA-CNN in Wenchuan earthquake disaster area. J. Mt. Sci. 2024, 21, 4001–4018. [Google Scholar]
- Hong, H.; Wang, D.; Zhu, A.-X.; Wang, Y. Landslide susceptibility mapping based on the reliability of landslide and non-landslide sample. Expert Syst. Appl. 2024, 243, 122933. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, G.; Wei, L.; Ding, J.; Zhang, Z. Landslide Susceptibility Assessment Using the Geographical-Optimal-Similarity Model. Appl. Sci. 2025, 15, 1843. [Google Scholar] [CrossRef]
- Baharvand, S.; Rahnamarad, J.; Soori, S.; Saadatkhah, N. Landslide susceptibility zoning in a catchment of Zagros Mountains using fuzzy logic and GIS. Environ. Earth Sci. 2020, 79, 204. [Google Scholar] [CrossRef]
- Oleng, M.; Ozdemir, Z.; Pilakoutas, K. Co-seismic and rainfall-triggered landslide hazard susceptibility assessment for Uganda derived using fuzzy logic and geospatial modelling techniques. Nat. Hazards 2024, 120, 14049–14082. [Google Scholar] [CrossRef]
- Xu, Q.; Li, W.; Liu, J.; Wang, X. A geographical similarity-based sampling method of non-fire point data for spatial prediction of forest fires. For. Ecosyst. 2023, 10, 195–214. [Google Scholar] [CrossRef]
- Zhao, P.; Wang, Y.; Xie, Y.; Uddin, M.G.; Xu, Z.; Chang, X.; Zhang, Y. Landslide susceptibility assessment using information quantity and machine learning integrated models: A case study of Sichuan province, southwestern China. Earth Sci. Inform. 2025, 18, 190. [Google Scholar] [CrossRef]
- Cao, W.-g.; Fu, Y.; Dong, Q.-y.; Wang, H.-g.; Ren, Y.; Li, Z.-y.; Du, Y.-y. Landslide susceptibility assessment in Western Henan Province based on a comparison of conventional and ensemble machine learning. China Geol. 2023, 6, 409–419. [Google Scholar]
- Khabiri, S.; Crawford, M.M.; Koch, H.J.; Haneberg, W.C.; Zhu, Y. An Assessment of Negative Samples and Model Structures in Landslide Susceptibility Characterization Based on Bayesian Network Models. Remote Sens. 2023, 15, 3200. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Li, M.; Qi, Z.; Li, C.; Qi, H.; Zhang, X. Improved landslide susceptibility assessment: A new negative sample collection strategy and a comparative analysis of zoning methods. Ecol. Indic. 2024, 169, 112948. [Google Scholar] [CrossRef]
- Huang, F.; Teng, Z.; Yao, C.; Jiang, S.-H.; Catani, F.; Chen, W.; Huang, J. Uncertainties of landslide susceptibility prediction: Influences of random errors in landslide conditioning factors and errors reduction by low pass filter method. J. Rock Mech. Geotech. Eng. 2024, 16, 213–230. [Google Scholar] [CrossRef]
- Shu, H.; Qi, S.; Liu, X.; Shao, X.; Wang, X.; Sun, D.; Yang, S.; He, J. Relationship between continuous or discontinuous of controlling factors and landslide susceptibility in the high-cold mountainous areas, China. Ecol. Indic. 2025, 172, 113313. [Google Scholar] [CrossRef]
- Sun, X.; Yuan, L.; Tao, S.; Liu, M.; Li, D.; Zhou, Y.; Shao, H. A novel landslide susceptibility optimization framework to assess landslide occurrence probability at the regional scale for environmental management. J. Environ. Manag. 2022, 322, 116108. [Google Scholar] [CrossRef] [PubMed]
- Topaçli, Z.K.; Ozcan, A.K.; Gokceoglu, C. Performance Comparison of Landslide Susceptibility Maps Derived from Logistic Regression and Random Forest Models in the Bolaman Basin, Türkiye. Nat. Hazards Rev. 2024, 25, 04023054. [Google Scholar] [CrossRef]
- Xu, W.; Xu, W.; Cui, Y.; Wang, J.; Gong, L.; Zhu, L. Landslide susceptibility zoning with five data models and performance comparison in Liangshan Prefecture, China. Front. Earth Sci. 2024, 12, 1417671. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Source | Data Type | Scale |
|---|---|---|---|
| Landslides | Chengdu Geological Survey Center | Shop | |
| DEM | Global digital elevation model(GDEM) | Tiff | 90 m |
| Geological information | National Geological Data Center | Shop | 1:200,000 |
| Roads | Digital Earth Science Platform | Shop | 1:100,000 |
| Rivers | Resource and Environmental Science Data Platform | Shop | 1:100,000 |
| Faults | National Earthquake Data Center | Shop | 1:100,000 |
| Factor | Significance | VIF |
|---|---|---|
| Elevation | 0 | 1.287 |
| PD | 0.078 | 1.05 |
| SEI | 0 | 1.02 |
| RD | 0.183 | 1 |
| SMC | 0 | 1.229 |
| Verification Method | Model A | Model B | Model C | Model D | Model E |
|---|---|---|---|---|---|
| Precision | 0.928 | 0.926 | 0.938 | 0.975 | 0.974 |
| Recall | 0.839 | 0.936 | 0.942 | 0.883 | 0.889 |
| F1-score | 0.881 | 0.926 | 0.940 | 0.927 | 0.928 |
| AUC | 0.887 | 0.925 | 0.941 | 0.932 | 0.937 |
| Model | Factor | Zone I | Zone II | Zone III | Zone IV | Zone V |
|---|---|---|---|---|---|---|
| Model A | A | 0.02 | 0.10 | 0.08 | 0.08 | 0.72 |
| B | 0.40 | 0.20 | 0.07 | 0.04 | 0.29 | |
| A/B | 0.05 | 0.51 | 1.10 | 1.89 | 2.47 | |
| Model B | A | 0.03 | 0.03 | 0.10 | 0.09 | 0.76 |
| B | 0.44 | 0.09 | 0.09 | 0.06 | 0.32 | |
| A/B | 0.06 | 0.34 | 1.07 | 1.46 | 2.38 | |
| Model C | A | 0.02 | 0.03 | 0.04 | 0.10 | 0.82 |
| B | 0.38 | 0.08 | 0.08 | 0.10 | 0.37 | |
| A/B | 0.05 | 0.36 | 0.51 | 1.00 | 2.24 | |
| Model D | A | 0.04 | 0.04 | 0.03 | 0.04 | 0.85 |
| B | 0.37 | 0.09 | 0.04 | 0.04 | 0.45 | |
| A/B | 0.10 | 0.43 | 0.84 | 0.90 | 1.88 | |
| Model E | A | 0.04 | 0.03 | 0.03 | 0.02 | 0.88 |
| B | 0.38 | 0.07 | 0.03 | 0.02 | 0.50 | |
| A/B | 0.10 | 0.45 | 1.03 | 0.99 | 1.77 |
| Verification Method | Model a | Model b | Model c | Model d | Model e |
|---|---|---|---|---|---|
| Precision | 0.855 | 0.854 | 0.938 | 0.946 | 0.966 |
| Recall | 0.891 | 0.912 | 0.942 | 0.896 | 0.792 |
| F1 score | 0.873 | 0.882 | 0.940 | 0.920 | 0.870 |
| AUC | 0.872 | 0.885 | 0.939 | 0.902 | 0.874 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ning, Z.; Tie, Y. Sampling Method Based on Fuzzy Membership for Computing Negative Sample Credibility and Its Applications. Appl. Sci. 2025, 15, 7646. https://doi.org/10.3390/app15147646
Ning Z, Tie Y. Sampling Method Based on Fuzzy Membership for Computing Negative Sample Credibility and Its Applications. Applied Sciences. 2025; 15(14):7646. https://doi.org/10.3390/app15147646
Chicago/Turabian StyleNing, Zhijie, and Yongbo Tie. 2025. "Sampling Method Based on Fuzzy Membership for Computing Negative Sample Credibility and Its Applications" Applied Sciences 15, no. 14: 7646. https://doi.org/10.3390/app15147646
APA StyleNing, Z., & Tie, Y. (2025). Sampling Method Based on Fuzzy Membership for Computing Negative Sample Credibility and Its Applications. Applied Sciences, 15(14), 7646. https://doi.org/10.3390/app15147646