
Deep Learning in Food Image Recognition: A Comprehensive Review

 , ,
, ,
Abstract
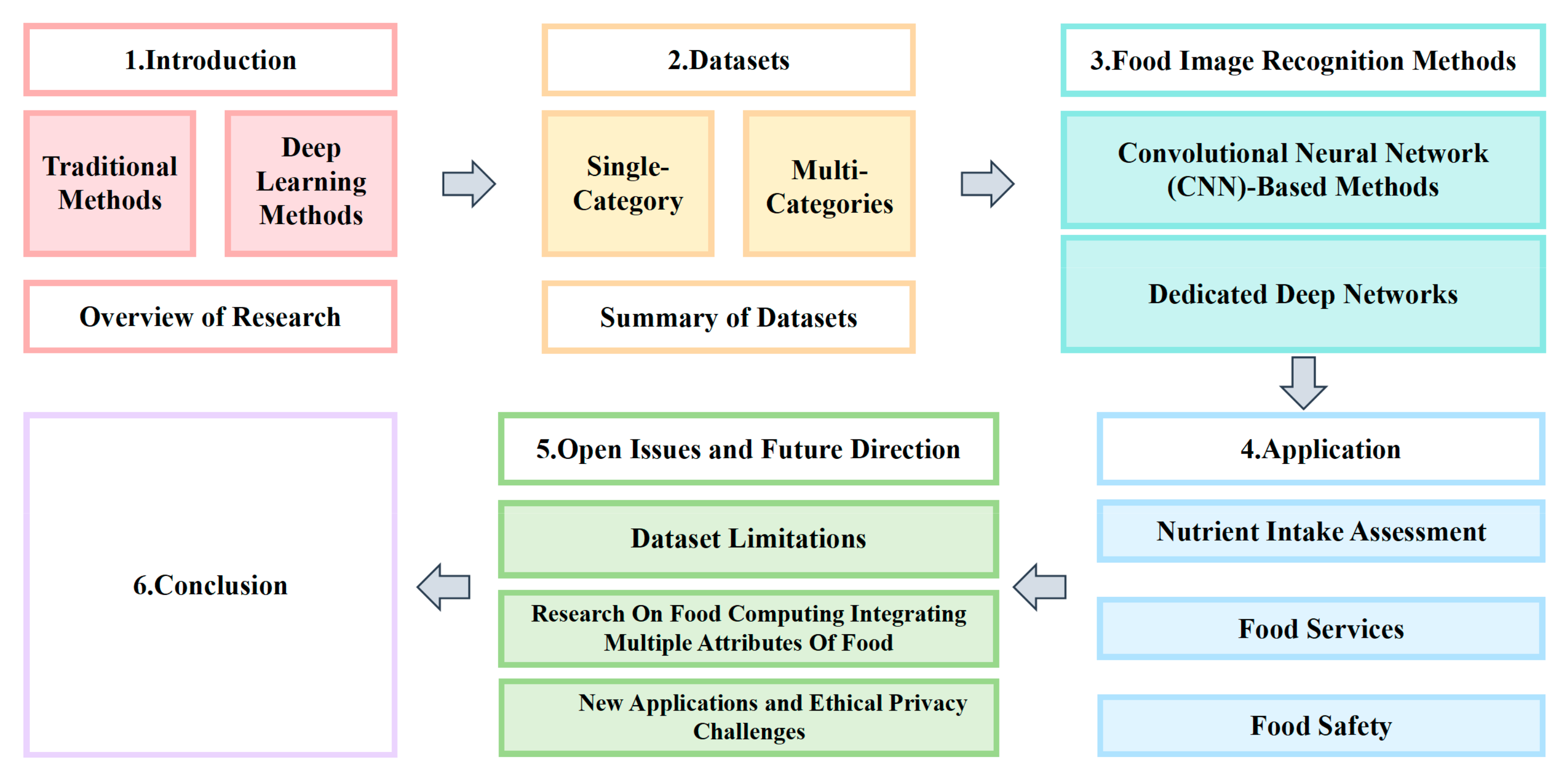
1. Introduction
- A comprehensive review of food image recognition methods, emphasizing deep learning models.
- A systematic organization of existing datasets to aid researchers in selecting appropriate resources.
- A discussion of practical applications in nutrition assessment, food services, and safety.
- An analysis of current challenges and future directions for research.
2. Datasets
- Low cultural coverage: The proportion of non-Western dishes in the mainstream dataset is relatively low, and the annotation standard does not consider the difference of national and regional names. For example, in the ETHZ Food-101 dataset, Asian dishes make up only 30% of the total, and African dishes make up even less, around 1%. The same is true for the ISIA Food-500 dataset, where Asian dishes make up about 40% of the total and African dishes make up only about 4%. In the single non-Western food dataset, there is still a lack of refinement of regional variants.
- Coarse annotation granularity: Most datasets only provide food category labels and lack fine-grained annotations such as ingredients and cooking methods, which limits the application of multi-task learning.
- Lack of authenticity: There are significant domain differences between the images taken in the laboratory environment and the blurred and occluded pictures actually taken by users, resulting in the performance degradation of the model in the real scene and the lack of dynamically updated datasets.
- Data Augmentation Techniques:
- Geometric transformation: By rotating, flipping, scaling, and performing other operations on the image, it can simulate the food form under different shooting angles and perspectives and effectively alleviate the problem of model recognition bias caused by different shooting angles.
- Color perturbation: Adjusting the color parameters of the image such as brightness and contrast can reduce the influence of light changes on the visual characteristics of the food image and enhance the robustness of the model under different lighting conditions.
- Generative data augmentation: Ito et al. [20] utilized the Conditional Generative Adversarial Network (CGAN) for food image generation. In the experiment, the CGAN was trained using the “ramen” image dataset and the recipe image dataset. Through generative data augmentation, the diversity of the data was enriched. A plate discriminator was added to the “ramen” GAN to make the shape of the dishes in the generated image more rounded. The “recipe” GAN was used to generate dish images from cooking ingredients and use them for image search in the recipe database.
- Domain adaptation method
- Transfer learning: This approach pretrains models on large-scale general-purpose datasets such as ImageNet and then fine-tunes them to the task of food image recognition. This method reduces the dependence of the model on large-scale labeled food data and makes full use of the common visual features learned by the pre-trained model.
- Self-supervised learning: In the case of masked image modeling, large amounts of unlabeled data can be effectively utilized to improve the generalization ability of the model by occlusion part of the image region and letting the model predict the occluded content.
- Multi-source data fusion
- Combining auxiliary information such as recipe texts and geolocation with visual data of food images can make up for the cultural bias problem existing in pure visual data. Herranz et al. [21] simplified the classification problem by using context information such as geolocation and proposed a food recognition framework including semantic feature learning and location-adaptive classification. Experiments showed that using geographical location could improve the recognition performance by approximately 30%.
3. Food Image Recognition Methods
3.1. Convolutional Neural Network (CNN)-Based Methods
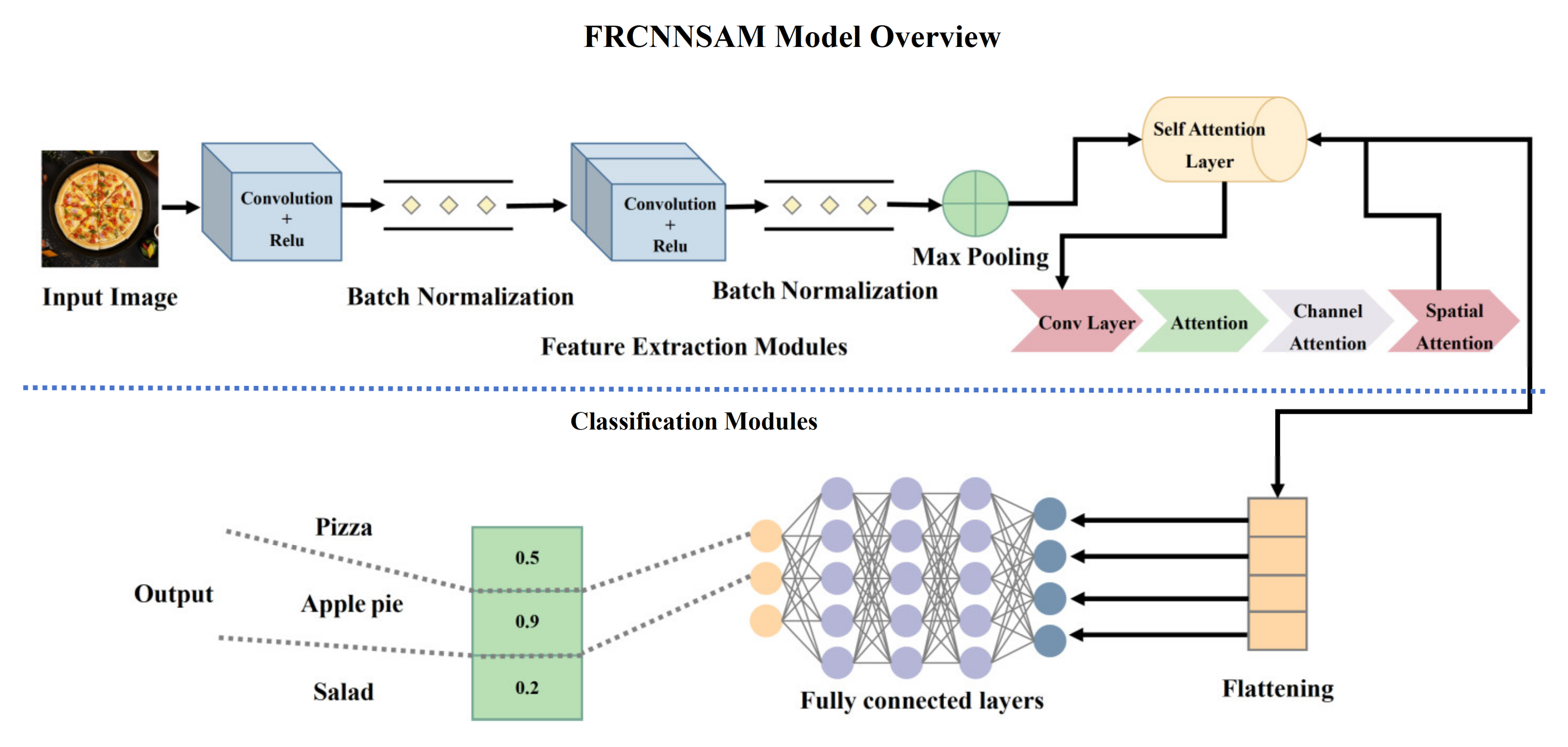
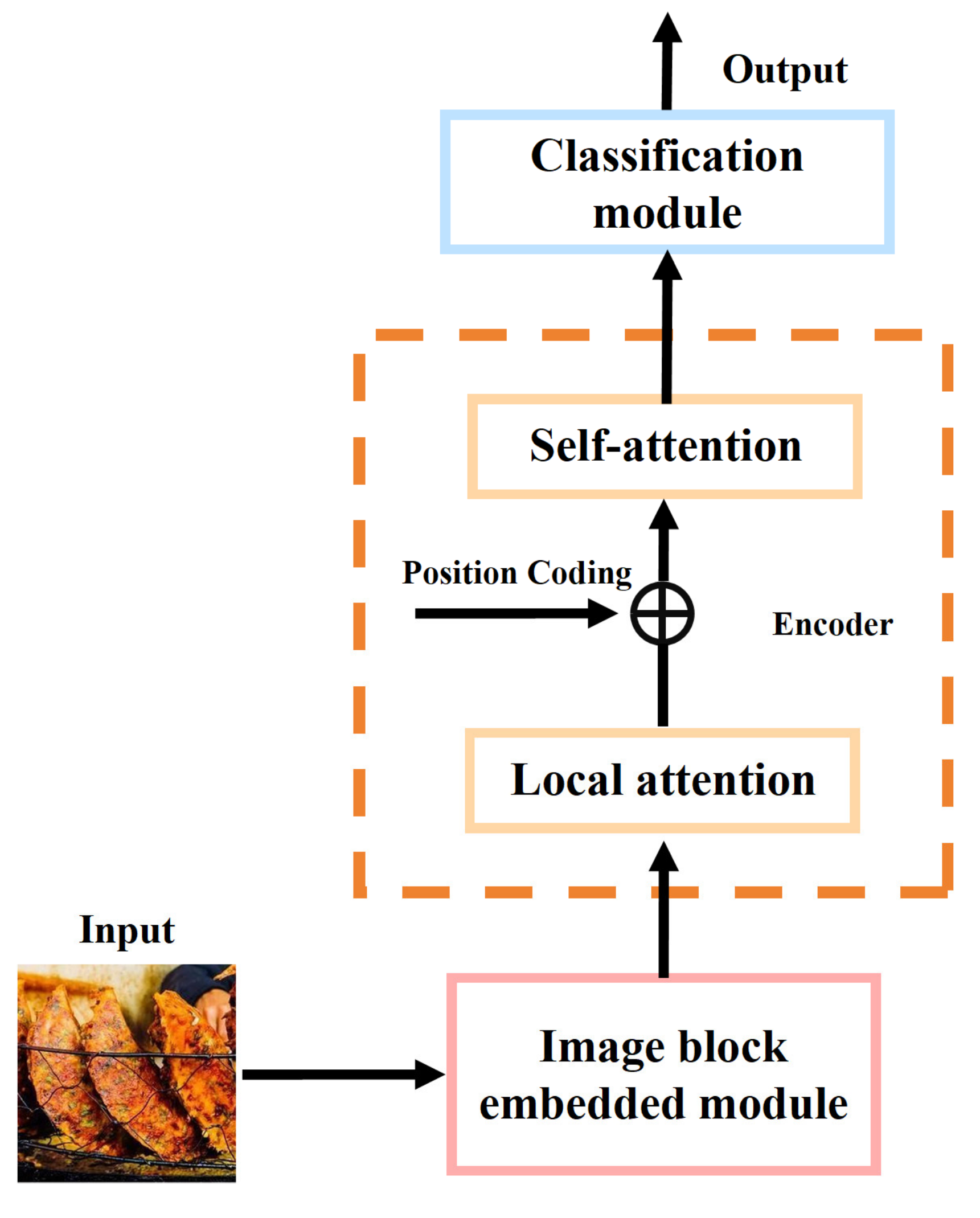
- Attention-Augmented Architectures: Abiyev et al. [22] introduced the FRCNNSAM framework, integrating self-attention mechanisms with deep CNNs through weight-sharing and data compression. Ensemble predictions from multiple FRCNNSAM variants via averaging achieved state-of-the-art accuracies of 96.40% on Food-101 and 95.11% on MA Food-121, outperforming transfer learning baselines by 8.12% (Figure 3).
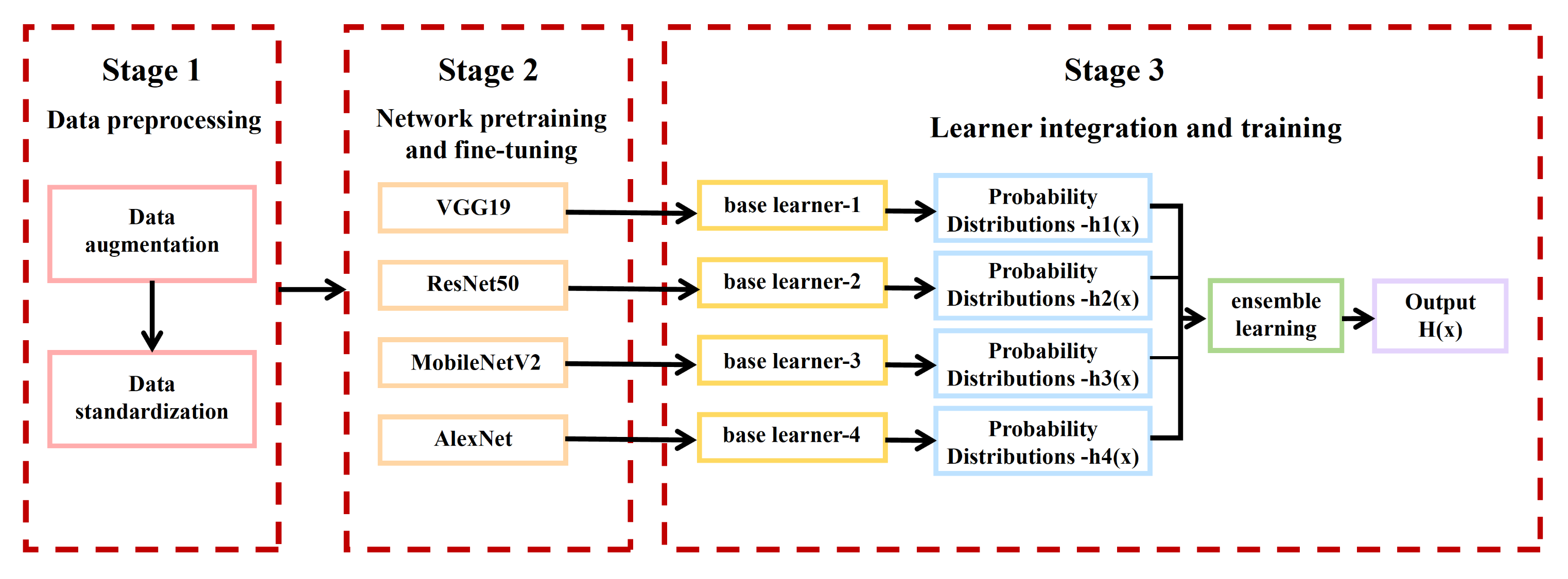
- Transfer Learning Ensembles: Bu et al. [23] developed an ensemble model leveraging ImageNet-pretrained networks (VGG19, ResNet50, MobileNetV2, AlexNet) for generic feature extraction. Fine-tuning and strategic combination of base learners through feature-space fusion yielded 96.88% accuracy on FOOD-11, demonstrating superior generalization over individual models (Figure 4).
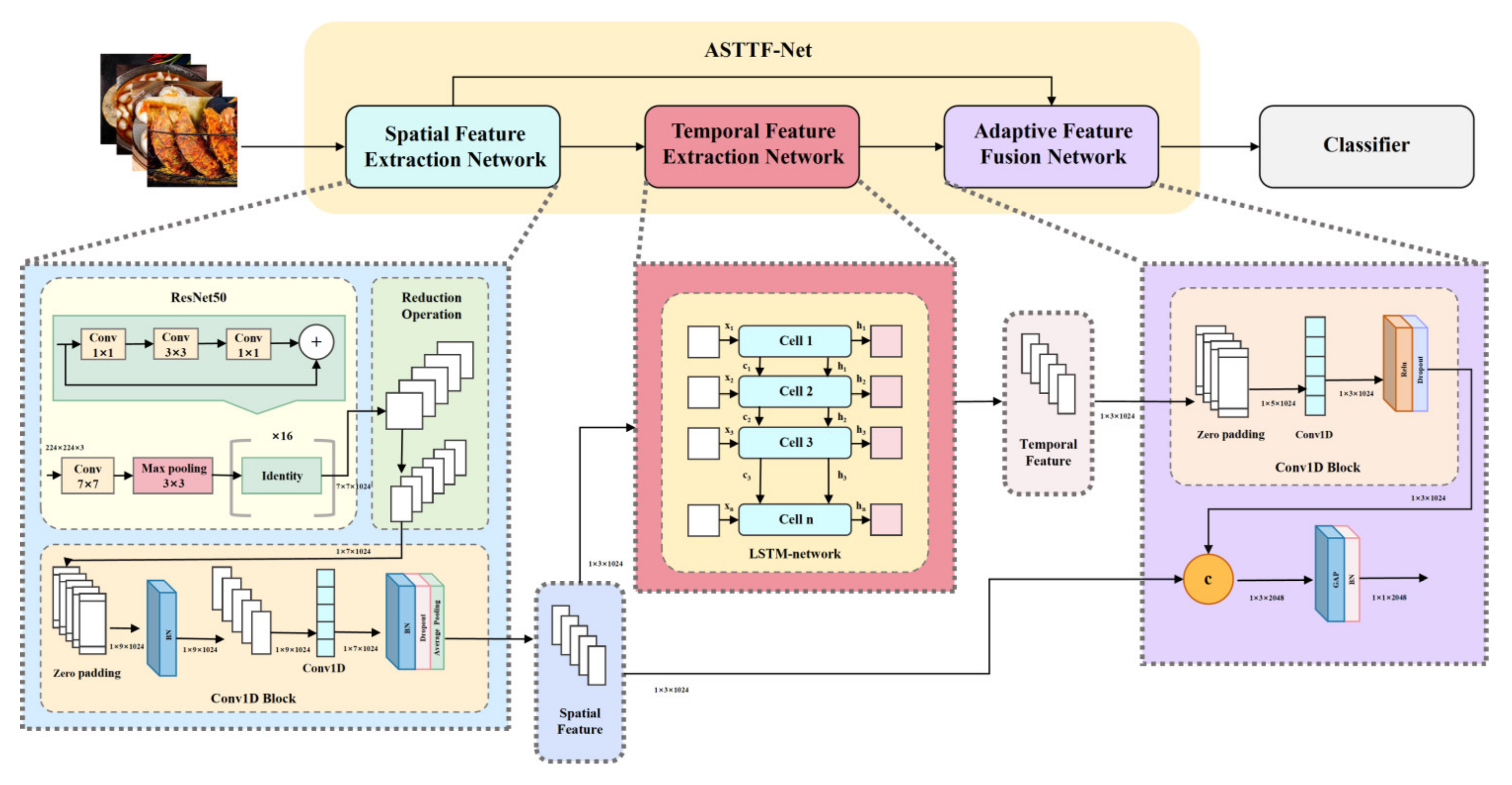
- Spatiotemporal Fusion Networks: Phiphitphatphaisit et al. [24] proposed ASTFF-Net, a novel architecture combining the following (Figure 5):
- Spatial encoder: ResNet50 with parameter reduction for robust feature extraction.
- Temporal processor: LSTM-enhanced Conv1D layers for sequential pattern learning.
- Adaptive fusion module: Softmax-optimized spatiotemporal feature integration. This framework addresses key challenges in food recognition-including occlusions, image blur, and inter-class similarity while maintaining computational efficiency. Benchmark evaluations across Food11, UEC FOOD-100/256, and ETH Food-101 confirm its competitive performance.
3.2. Dedicated Deep Networks
4. Application
4.1. Nutrient Intake Assessment
4.2. Food Services
4.3. Food Safety
5. Open Issues and Future Direction
- Dataset Limitations
- Research on Food Computing Integrating Multiple Attributes of Food
- New Applications and Ethical Privacy Challenges
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Min, W.; Liu, L.; Liu, Y.; Luo, M.; Jiang, S. A Survey on Food Image Recognition. Chin. J. Comput. 2022, 45, 542–566. [Google Scholar]
- Parrish, E.A.; Goksel, A.K. Pictorial Pattern Recognition Applied to Fruit Harvesting. Trans. ASABE 1977, 20, 822–0827. [Google Scholar] [CrossRef]
- Bolle, R.M.; Connell, J.H.; Haas, N.; Mohan, R.; Taubin, G. VeggieVision: A produce recognition system. In Proceedings of the Third IEEE Workshop on Applications of Computer Vision, WACV’96, Sarasota, FL, USA, 2–4 December 1996; pp. 244–251. [Google Scholar]
- Kitamura, K.; Yamasaki, T.; Aizawa, K. Food log by analyzing food images. In Proceedings of the ACM Multimedia, Vancouver, BC, Canada, 27–31 October 2008. [Google Scholar]
- Yang, S.; Chen, M.; Pomerleau, D.; Sukthankar, R. Food recognition using statistics of pairwise local features. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2249–2256. [Google Scholar]
- Kagaya, H.; Aizawa, K.; Ogawa, M. Food Detection and Recognition Using Convolutional Neural Network. In Proceedings of the 22nd ACM international conference on Multimedia 2014, Orlando, FL, USA, 3–7 November 2014. [Google Scholar]
- Kawano, Y.; Yanai, K. FoodCam: A real-time food recognition system on a smartphone. Multimed. Tools Appl. 2015, 74, 5263–5287. [Google Scholar] [CrossRef]
- Myers, A.; Johnston, N.; Rathod, V.; Korattikara, A.; Gorban, A.; Silberman, N.; Guadarrama, S.; Papandreou, G.; Huang, J.; Murphy, K. Im2Calories: Towards an Automated Mobile Vision Food Diary. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1233–1241. [Google Scholar]
- Song, G.; Tao, Z.; Huang, X.; Cao, G.; Liu, W.; Yang, L. Hybrid Attention-Based Prototypical Network for Unfamiliar Restaurant Food Image Few-Shot Recognition. IEEE Access 2020, 8, 14893–14900. [Google Scholar] [CrossRef]
- Feng, J.; Lili, Z. Method for Recognition of Food Images Based on Improved Attention Model. J. Comput. Eng. Appl. 2024, 60, 153. [Google Scholar]
- Liang, H.; Wen, G.; Hu, Y.; Luo, M.; Yang, P.; Xu, Y. MVANet: Multi-Task Guided Multi-View Attention Network for Chinese Food Recognition. IEEE Trans. Multimed. 2021, 23, 3551–3561. [Google Scholar] [CrossRef]
- Sheng, G.; Sun, S.; Liu, C.; Yang, Y. Food recognition via an efficient neural network with transformer grouping. Int. J. Intell. Syst. 2022, 37, 11465–11481. [Google Scholar] [CrossRef]
- Sheng, G.; Min, W.; Zhu, X.; Xu, L.; Sun, Q.; Yang, Y.; Wang, L.; Jiang, S. A Lightweight Hybrid Model with Location-Preserving ViT for Efficient Food Recognition. Nutrients 2024, 16, 200. [Google Scholar] [CrossRef]
- Sheng, G.; Min, W.; Yao, T.; Song, J.; Yang, Y.; Wang, L.; Jiang, S. Lightweight Food Image Recognition with Global Shuffle Convolution. IEEE Trans. AgriFood Electron. 2024, 2, 392–402. [Google Scholar] [CrossRef]
- Min, W.; Wang, Z.; Liu, Y.; Luo, M.; Kang, L.; Wei, X.; Wei, X.; Jiang, S. Large Scale Visual Food Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 9932–9949. [Google Scholar] [CrossRef]
- Chen, M.; Dhingra, K.; Wu, W.; Yang, L.; Sukthankar, R.; Yang, J. PFID: Pittsburgh fast-food image dataset. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 289–292. [Google Scholar]
- Taichi, J.; Keiji, Y. A food image recognition system with Multiple Kernel Learning. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; pp. 285–288. [Google Scholar]
- Hoashi, H.; Joutou, T.; Yanai, K. Image Recognition of 85 Food Categories by Feature Fusion. In Proceedings of the 2010 IEEE International Symposium on Multimedia, Taichung, Taiwan, 13–15 December 2010; pp. 296–301. [Google Scholar]
- Bossard, L.; Guillaumin, M.; Van Gool, L. Food-101—Mining Discriminative Components with Random Forests. In Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 446–461. [Google Scholar]
- Ito, Y.; Shimoda, W.; Yanai, K. Food image generation using a large amount of food images with conditional GAN: ramenGAN and recipeGAN. In Proceedings of the Joint Workshop on Multimedia for Cooking and Eating Activities and Multimedia Assisted Dietary Management, Stockholm, Sweden, 15 July 2018. [Google Scholar] [CrossRef]
- Wang, W.; Duan, P.; Zhang, W.; Gong, F.; Zhang, P.; Rao, Y. Towards a Pervasive Cloud Computing Based Food Image Recognition. In Proceedings of the 2013 IEEE International Conference on Green Computing and Communications and IEEE Internet of Things and IEEE Cyber, Physical and Social Computing, Beijing, China, 20–23 August 2013; pp. 2243–2244. [Google Scholar]
- Abiyev, R.; Adepoju, J. Automatic Food Recognition Using Deep Convolutional Neural Networks with Self-attention Mechanism. Hum. Centric Intell. Syst. 2024, 4, 171–186. [Google Scholar] [CrossRef]
- Bu, L.; Hu, C.; Zhang, X. Recognition of food images based on transfer learning and ensemble learning. PLoS ONE 2024, 19, e0296789. [Google Scholar] [CrossRef] [PubMed]
- Phiphitphatphaisit, S.; Surinta, O. Multi-layer adaptive spatial-temporal feature fusion network for efficient food image recognition. Expert Syst. Appl. 2024, 255, 124834. [Google Scholar] [CrossRef]
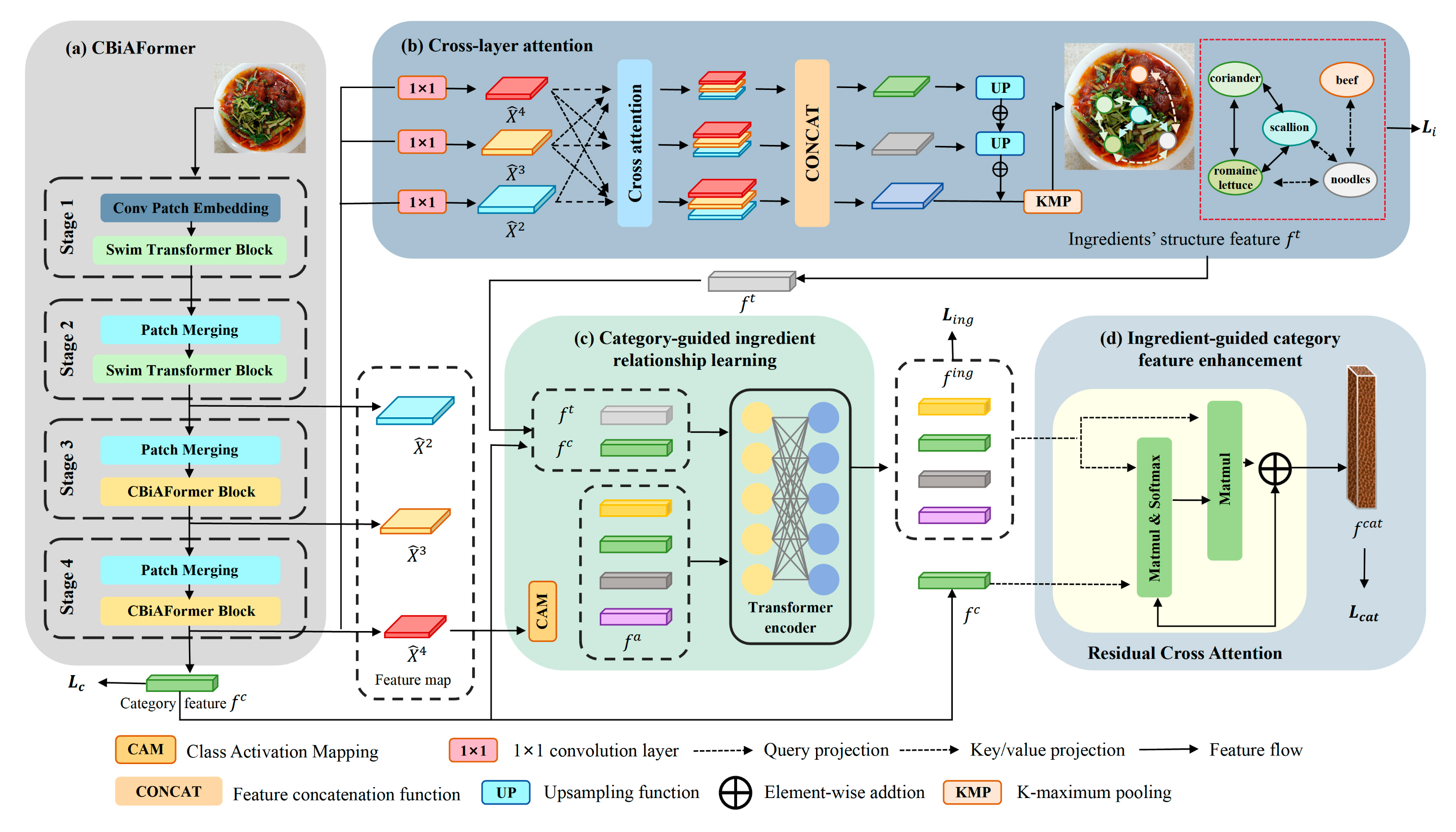
- Liu, Y.; Min, W.; Jiang, S.; Rui, Y. Convolution-Enhanced Bi-Branch Adaptive Transformer with Cross-Task Interaction for Food Category and Ingredient Recognition. IEEE Trans. Image Process. 2024, 33, 2572–2586. [Google Scholar] [CrossRef]
- Nadeem, M.; Shen, H.; Choy, L.; Barakat, J. Smart Diet Diary: Real-Time Mobile Application for Food Recognition. Appl. Syst. Innov. 2023, 6, 53. [Google Scholar] [CrossRef]
- Xiao, G.; Wu, Q.; Chen, H.; Cao, D.; Guo, J.; Gong, Z. A Deep Transfer Learning Solution for Automating Food Material Procurement using Electronic Scales. IEEE Trans. Ind. Inform. 2019, 16, 2290–2300. [Google Scholar] [CrossRef]
- Mohammad, I.; Mazumder, M.S.I.; Saha, E.K.; Razzaque, S.T.; Chowdhury, S. A Deep Learning Approach to Smart Refrigerator System with the assistance of IOT. In Proceedings of the International Conference on Computing Advancements, Dhaka, Bangladesh, 10–12 January 2020; p. 57. [Google Scholar]
- Herranz, L.; Ruihan, X.; Shuqiang, J. A probabilistic model for food image recognition in restaurants. In Proceedings of the 2015 IEEE International Conference on Multimedia and Expo (ICME), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Wang, Y.; Wu, J.; Deng, H.; Zeng, X. Food Image Recognition and Food Safety Detection Method Based on Deep Learning. In Computational Intelligence and Neuroscience; John Wiley & Sons Ltd.: Hoboken, NJ, USA, 2021; pp. 1–13. [Google Scholar]
- Min, W.; Liu, L.; Wang, Z.; Luo, Z.; Wei, X.; Wei, X.; Jiang, S. ISIA Food-500: A Dataset for Large-Scale Food Recognition via Stacked Global-Local Attention Network. In Proceedings of the 28th ACM International Conference on Multimedia 2020, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Chen, J.; Ngo, C.-W. Deep-based Ingredient Recognition for Cooking Recipe Retrieval. In Proceedings of the 24th ACM international conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 32–41. [Google Scholar]
- Majil, I.; Yang, M.T.; Yang, S. Augmented Reality Based Interactive Cooking Guide. Sensors 2022, 22, 8290. [Google Scholar] [CrossRef]
- Haque, R.U.; Khan, R.; Shihavuddin, A.; Syeed, M.; Uddin, F. Lightweight and Parameter-Optimized Real-Time Food Calorie Estimation from Images Using CNN-Based Approach. Appl. Sci. 2022, 12, 9733. [Google Scholar] [CrossRef]
- Kaur, P.; Sikka, K.; Wang, W.; Belongie, S.J.; Divakaran, A. FoodX-251: A Dataset for Fine-grained Food Classification. arXiv 2019, arXiv:1907.06167. [Google Scholar]
- Sahoo, D.; Wang, H.; Ke, S.; Wu, X.; Le, H.; Achananuparp, P.; Lim, E.-P.; Hoi, S.C.H. FoodAI: Food Image Recognition via Deep Learning for Smart Food Logging. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining 2019, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2019. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Mezgec, S.; Koroušić Seljak, B. NutriNet: A Deep Learning Food and Drink Image Recognition System for Dietary Assessment. Nutrients 2017, 9, 657. [Google Scholar] [CrossRef] [PubMed]
- Pornpanomchai, C.; Srikeaw, K.; Harnprasert, V.; Promnurakkit, K. Thai fruit recognition system (TFRS). In Proceedings of the International Conference on Internet Multimedia Computing and Service, Kunming, China, 23–25 November 2009. [Google Scholar]
- Wen, W.; Jie, Y. Fast food recognition from videos of eating for calorie estimation. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–3 July 2009; pp. 1210–1213. [Google Scholar]
- Kong, F.; Tan, J. DietCam: Regular Shape Food Recognition with a Camera Phone. In Proceedings of the 2011 International Conference on Body Sensor Networks, Dallas, TX, USA, 23–25 May 2011; pp. 127–132. [Google Scholar]
- Matsuda, Y.; Hoashi, H.; Yanai, K. Recognition of Multiple-Food Images by Detecting Candidate Regions. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, VIC, Australia, 9–13 July 2012; pp. 25–30. [Google Scholar]
- Chen, M.-Y.; Yang, Y.-H.; Ho, C.-J.; Wang, S.-H.; Liu, S.-M.; Chang, E.; Yeh, C.-H.; Ouhyoung, M. Automatic chinese food identification and quantity estimation. In SIGGRAPH Asia 2012 Technical Briefs; Machinery: New York, NY, USA, 2012; pp. 1–4. [Google Scholar]
- Anthimopoulos, M.M.; Gianola, L.; Scarnato, L.; Diem, P.; Mougiakakou, S.G. A Food Recognition System for Diabetic Patients Based on an Optimized Bag-of-Features Model. IEEE J. Biomed. Health Inform. 2014, 18, 1261–1271. [Google Scholar] [CrossRef] [PubMed]
- Song, X.; Jiang, S.; Xu, R.; Herranz, L. Semantic Features for Food Image Recognition with Geo-Constraints. In Proceedings of the 2014 IEEE International Conference on Data Mining Workshop, Shenzhen, China, 14 December 2014; pp. 1020–1025. [Google Scholar]
- Tammachat, N.; Pantuwong, N. Calories analysis of food intake using image recognition. In Proceedings of the 2014 6th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 7–8 October 2014; pp. 1–4. [Google Scholar]
- Yanai, K.; Kawano, Y. Food image recognition using deep convolutional network with pre-training and fine-tuning. In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Ahmed, A.; Ozeki, T. Food Image Recognition by Using Bag-of-SURF Features and HOG Features. In Proceedings of the 3rd International Conference on Human-Agent Interaction 2015, Daegu, Republic of Korea, 21–24 October 2015. [Google Scholar]
- Bi, Y.; Lv, M.; Song, C.; Xu, W.; Guan, N.; Yi, W. AutoDietary: A Wearable Acoustic Sensor System for Food Intake Recognition in Daily Life. IEEE Sens. J. 2016, 16, 806–816. [Google Scholar] [CrossRef]
- Singla, A.; Yuan, L.; Ebrahimi, T. Food/Non-food Image Classification and Food Categorization using Pre-Trained GoogLeNet Model. In Proceedings of the 2nd International Workshop on Multimedia Assisted Dietary Management, Amsterdam, The Netherlands, 16 October 2016. [Google Scholar]
- Liu, C.; Cao, Y.; Luo, Y.; Chen, G.; Vokkarane, V.; Ma, Y. DeepFood: Deep Learning-Based Food Image Recognition for Computer-Aided Dietary Assessment. In Proceedings of the Inclusive Smart Cities and Digital Health, Wuhan, China, 25–27 May 2016; pp. 37–48. [Google Scholar]
- Zheng, J.; Wang, Z.J.; Ji, X. Superpixel-based image recognition for food images. In Proceedings of the 2016 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Vancouver, BC, Canada, 15–18 May 2016; pp. 1–4. [Google Scholar]
- Tatsuma, A.; Aono, M. Food Image Recognition Using Covariance of Convolutional Layer Feature Maps. IEICE Trans. Inf. Syst. 2016, 99, 1711–1715. [Google Scholar] [CrossRef]
- Pouladzadeh, P.; Shirmohammadi, S. Mobile multi-food recognition using deep learning. ACM Trans. Multimed. Comput. Commun. Appl. 2017, 13, 1–21. [Google Scholar] [CrossRef]
- Giovany, S.; Putra, A.; Hariawan, A.S.; Wulandhari, L.A. Machine Learning and SIFT Approach for Indonesian Food Image Recognition. Procedia Comput. Sci. 2017, 116, 612–620. [Google Scholar] [CrossRef]
- Termritthikun, C.; Muneesawang, P.; Kanprachar, S. NU-InNet: Thai Food Image Recognition Using Convolutional Neural Networks on Smartphone. J. Telecommun. Electron. Comput. Eng. 2017, 9, 2289–8131. [Google Scholar]
- Zheng, J.; Wang, Z.J.; Zhu, C. Food Image Recognition via Superpixel Based Low-Level and Mid-Level Distance Coding for Smart Home Applications. Sustainability 2017, 9, 856. [Google Scholar] [CrossRef]
- Termritthikun, C.; Kanprachar, S. NU-ResNet: Deep Residual Networks for Thai Food Image Recognition. J. Telecommun. Electron. Comput. Eng. 2018, 10, 29–33. [Google Scholar]
- Horiguchi, S.; Amano, S.; Ogawa, M.; Aizawa, K. Personalized Classifier for Food Image Recognition. IEEE Trans. Multimed. 2018, 20, 2836–2848. [Google Scholar] [CrossRef]
- Ming, Z.-Y.; Chen, J.; Cao, Y.; Forde, C.; Ngo, C.-W.; Chua, T.S. Food Photo Recognition for Dietary Tracking: System and Experiment. In Proceedings of the MultiMedia Modeling: 24th International Conference, MMM 2018, Bangkok, Thailand, 5–7 February 2018; pp. 129–141. [Google Scholar]
- Reddy, V.H.; Kumari, S.; Muralidharan, V.; Gigoo, K.; Thakare, B.S. Food Recognition and Calorie Measurement using Image Processing and Convolutional Neural Network. In Proceedings of the 2019 4th International Conference on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Bangalore, India, 17–18 May 2019; pp. 109–115. [Google Scholar]
- Jiang, S.; Min, W.; Liu, L.; Luo, Z. Multi-Scale Multi-View Deep Feature Aggregation for Food Recognition. IEEE Trans. Image Process. 2020, 29, 265–276. [Google Scholar] [CrossRef] [PubMed]
- Merchant, K.; Pande, Y. ConvFood: A CNN-Based Food Recognition Mobile Application for Obese and Diabetic Patients. In Proceedings of the Emerging Research in Computing, Information, Communication and Applications, Singapore, 3 May 2019; pp. 493–502. [Google Scholar]
- Jeny, A.A.; Junayed, M.S.; Ahmed, I.; Habib, M.T.; Rahman, M.R. FoNet—Local Food Recognition Using Deep Residual Neural Networks. In Proceedings of the 2019 International Conference on Information Technology (ICIT), Bhubaneswar, India, 19–21 December 2019; pp. 184–189. [Google Scholar]
- Tasci, E. Voting combinations-based ensemble of fine-tuned convolutional neural networks for food image recognition. Multimed. Tools Appl. 2020, 79, 30397–30418. [Google Scholar] [CrossRef]
- Metwalli, A.S.; Shen, W.; Wu, C.Q. Food Image Recognition Based on Densely Connected Convolutional Neural Networks. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; pp. 027–032. [Google Scholar]
- He, J.; Shao, Z.; Wright, J.; Kerr, D.; Boushey, C.; Zhu, F. Multi-task Image-Based Dietary Assessment for Food Recognition and Portion Size Estimation. In Proceedings of the 2020 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Shenzhen, China, 6–8 August 2020; pp. 49–54. [Google Scholar]
- Jiang, S.; Min, W.; Lyu, Y.; Liu, L. Few-shot food recognition via multi-view representation learning. ACM Trans. Multimed. Comput. Commun. Appl. 2020, 16, 1–20. [Google Scholar] [CrossRef]
- Zhao, H.; Yap, K.H.; Kot, A.C.; Duan, L. JDNet: A Joint-Learning Distilled Network for Mobile Visual Food Recognition. IEEE J. Sel. Top. Signal Process. 2020, 14, 665–675. [Google Scholar] [CrossRef]
- Minija, S.J.; Emmanuel, W.R.S. Food recognition using neural network classifier and multiple hypotheses image segmentation. Imaging Sci. J. 2020, 68, 100–113. [Google Scholar] [CrossRef]
- He, X.; Wang, F.; Qu, Z. An Improved YOLOv3 Model for Asian Food Image Recognition and Detection. Open J. Appl. Sci. 2021, 11, 1287–1306. [Google Scholar] [CrossRef]
- Liu, C.; Liang, Y.; Xue, Y.; Qian, X.; Fu, J. Food and Ingredient Joint Learning for Fine-Grained Recognition. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 2480–2493. [Google Scholar] [CrossRef]
- Xiao, L.; Lan, T.; Xu, D.; Gao, W.; Li, C. A Simplified CNNs Visual Perception Learning Network Algorithm for Foods Recognition. Comput. Electr. Eng. 2021, 92, 107152. [Google Scholar] [CrossRef]
- Liu, Y.X.; Min, W.Q.; Jiang, S.Q.; Rui, Y. Food Image Recognition via Multi-scale Jigsaw and Reconstruction Network. J. Softw. 2022, 33, 4379–4395. [Google Scholar]
- Zhang, Q.; He, C.; Qin, W.; Liu, D.; Yin, J.; Long, Z.; He, H.; Sun, H.C.; Xu, H. Eliminate the hardware: Mobile terminals-oriented food recognition and weight estimation system. Front. Nutr. 2022, 9, 965801. [Google Scholar] [CrossRef]
- Liu, Y.-C.; Onthoni, D.; Mohapatra, S.; Irianti, D.; Sahoo, P. Deep-Learning-Assisted Multi-Dish Food Recognition Application for Dietary Intake Reporting. Electronics 2022, 11, 1626. [Google Scholar] [CrossRef]
- Cherpanath, E.D.; Nasreen, P.R.F.; Pradeep, K.; Menon, M.; Jayanthi, V.S. Food Image Recognition and Calorie Prediction Using Faster R-CNN and Mask R-CNN. In Proceedings of the 2023 9th International Conference on Smart Computing and Communications (ICSCC), Kochi, Kerala, 17–19 August 2023; pp. 83–89. [Google Scholar]
- Luo, L. Research on Food Image Recognition of Deep Learning Algorithms. In Proceedings of the 2023 International Conference on Computers, Information Processing and Advanced Education (CIPAE), Ottowa, ON, Canada, 26––28 August 2023; pp. 733–737. [Google Scholar]
- Zuo, W.; Zhang, W.; Ren, Z. Food Recognition and Classification Based on Image Recognition: A Study Utilizing PyTorch and PReNet. In Proceedings of the 2023 IEEE International Conference on Image Processing and Computer Applications (ICIPCA), Changchun, China, 11–13 August 2023; pp. 1325–1330. [Google Scholar]
- Liu, Y. Automatic food recognition based on efficientnet and ResNet. J. Phys. Conf. Ser. 2023, 2646, 012037. [Google Scholar] [CrossRef]
- Ramkumar, G.; Venkatramanan, C.B.; Manonmani, V.; Palanivel, S.; Sakthisaravanan, N.; Kumar, A.K. A Real-time Food Image Recognition System to Predict the Calories by Using Intelligent Deep Learning Strategy. In Proceedings of the 2023 International Conference on Research Methodologies in Knowledge Management, Artificial Intelligence and Telecommunication Engineering (RMKMATE), Chennai, India, 1–2 November 2023; pp. 1–7. [Google Scholar]
- Zhu, S.; Ling, X.; Zhang, K.; Niu, J. Food Image Recognition Method Based on Generative Self-supervised Learning. In Proceedings of the 9th International Conference on Computing and Artificial Intelligence, Tianjin, China, 17–20 March 2023; pp. 203–207. [Google Scholar]
- Rokhva, S.; Teimourpour, B.; Soltani, A.H. Computer vision in the food industry: Accurate, real-time, and automatic food recognition with pretrained MobileNetV2. Food Humanit. 2024, 3, 100378. [Google Scholar] [CrossRef]
- Xiao, Z.; Diao, G.; Deng, Z. Fine grained food image recognition based on swin transformer. J. Food Eng. 2024, 380, 112134. [Google Scholar] [CrossRef]
- Boyd, L.; Nnamoko, N.; Lopes, R. Fine-Grained Food Image Recognition: A Study on Optimising Convolutional Neural Networks for Improved Performance. J. Imaging 2024, 10, 126. [Google Scholar] [CrossRef]
- Wang, H.; Tian, H.; Ju, R.; Ma, L.; Yang, L.; Chen, J.; Liu, F. Nutritional composition analysis in food images: An innovative Swin Transformer approach. Front. Nutr. 2024, 11, 1454466. [Google Scholar] [CrossRef]
- Matsuda, Y.; Yanai, K. Multiple-food recognition considering co-occurrence employing manifold ranking. In Proceedings of the Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), Tsukuba, Japan, 11–15 November 2012; pp. 2017–2020. [Google Scholar]
- Kawano, Y.; Yanai, K. Automatic Expansion of a Food Image Dataset Leveraging Existing Categories with Domain Adaptation. In Proceedings of the ECCV Workshops, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Xin, W.; Kumar, D.; Thome, N.; Cord, M.; Precioso, F. Recipe recognition with large multimodal food dataset. In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Turin, Italy, 29 June–3 July 2015; pp. 1–6. [Google Scholar]
- Xu, R.; Herranz, L.; Jiang, S.; Wang, S.; Song, X.; Jain, R. Geolocalized Modeling for Dish Recognition. IEEE Trans. Multimed. 2015, 17, 1187–1199. [Google Scholar] [CrossRef]
- Ciocca, G.; Napoletano, P.; Schettini, R. Food Recognition and Leftover Estimation for Daily Diet Monitoring. In Proceedings of the New Trends in Image Analysis and Processing—ICIAP 2015 Workshops, Genoa, Italy, 8 September 2015; pp. 334–341. [Google Scholar]
- Farinella, G.M.; Allegra, D.; Stanco, F. A Benchmark Dataset to Study the Representation of Food Images. In Proceedings of the Computer Vision—ECCV 2014 Workshops, Zurich, Switzerland, 6–12 September 2014; pp. 584–599. [Google Scholar]
- Ciocca, G.; Napoletano, P.; Schettini, R. Food Recognition: A New Dataset, Experiments, and Results. IEEE J. Biomed. Health Inform. 2017, 21, 588–598. [Google Scholar] [CrossRef]
- Klasson, M.; Zhang, C.; Kjellström, H. A Hierarchical Grocery Store Image Dataset with Visual and Semantic Labels. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 491–500. [Google Scholar]
- Zhou, F.; Lin, Y. Fine-Grained Image Classification by Exploring Bipartite-Graph Labels. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1124–1133. [Google Scholar]
- Merler, M.; Wu, H.; Uceda-Sosa, R.; Nguyen, Q.-B.; Smith, J. Snap, Eat, RepEat: A Food Recognition Engine for Dietary Logging. In Proceedings of the 2nd International Workshop on Multimedia Assisted Dietary Management, Amsterdam, The Netherlands, 16 October 2016; pp. 31–40. [Google Scholar]
- Farinella, G.M.; Allegra, D.; Moltisanti, M.; Stanco, F.; Battiato, S. Retrieval and classification of food images. Comput. Biol. Med. 2016, 77, 23–39. [Google Scholar] [CrossRef]
- Ciocca, G.; Napoletano, P.; Schettini, R. Learning CNN-based Features for Retrieval of Food Images. In Proceedings of the New Trends in Image Analysis and Processing—ICIAP 2017, Catania, Italy, 11–15 September 2017; pp. 426–434. [Google Scholar]
- Chen, X.; Zhu, Y.; Zhou, H.; Diao, L.; Wang, D. ChineseFoodNet: A large-scale Image Dataset for Chinese Food Recognition. arXiv 2017, arXiv:1705.02743. [Google Scholar]
- Hou, S.; Feng, Y.; Wang, Z. VegFru: A Domain-Specific Dataset for Fine-Grained Visual Categorization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 541–549. [Google Scholar]
- Waltner, G.; Schwarz, M.; Ladstätter, S.; Weber, A.; Luley, P.; Lindschinger, M.; Schmid, I.; Scheitz, W.; Bischof, H.; Paletta, L. Personalized Dietary Self-Management Using Mobile Vision-Based Assistance. In Proceedings of the New Trends in Image Analysis and Processing—ICIAP 2017, Catania, Italy, 11–15 September 2017; pp. 385–393. [Google Scholar]
- Kaur, P.; Sikka, K.; Divakaran, A. Combining Weakly and Webly Supervised Learning for Classifying Food Images. arXiv 2017, arXiv:1712.08730. [Google Scholar]
- Lee, K.H.; He, X.; Zhang, L.; Yang, L. CleanNet: Transfer Learning for Scalable Image Classifier Training with Label Noise. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5447–5456. [Google Scholar]
- Min, W.; Jiang, S.; Sang, J.; Wang, H.; Liu, X.; Herranz, L. Being a Supercook: Joint Food Attributes and Multimodal Content Modeling for Recipe Retrieval and Exploration. IEEE Trans. Multimed. 2017, 19, 1100–1113. [Google Scholar] [CrossRef]
- Min, W.; Bao, B.K.; Mei, S.; Zhu, Y.; Rui, Y.; Jiang, S. You Are What You Eat: Exploring Rich Recipe Information for Cross-Region Food Analysis. IEEE Trans. Multimed. 2018, 20, 950–964. [Google Scholar] [CrossRef]
- Min, W.; Liu, L.; Luo, Z.; Jiang, S. Ingredient-Guided Cascaded Multi-Attention Network for Food Recognition. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1331–1339. [Google Scholar]
- Muresan, H.B.; Oltean, M. Fruit recognition from images using deep learning. Acta Univ. Sapientiae Inform. 2017, 10, 26–42. [Google Scholar] [CrossRef]
- Qiu, J.; Lo, F.P.-W.; Sun, Y.; Wang, S.; Lo, B.P.L. Mining Discriminative Food Regions for Accurate Food Recognition. In Proceedings of the British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Zhu, Y.; Zhao, X.; Zhao, C.; Wang, J.; Lu, H. Food det: Detecting foods in refrigerator with supervised transformer network. Neurocomputing 2020, 379, 162–171. [Google Scholar] [CrossRef]
- Tan, Y.; Lu, K.; Rahman, M.M.; Xue, J. Rgbd-Fg: A Large-Scale Rgb-D Dataset for Fine-Grained Categorization. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), Virtual, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Chen, J.; Zhu, B.; Ngo, C.W.; Chua, T.S.; Jiang, Y.G. A Study of Multi-Task and Region-Wise Deep Learning for Food Ingredient Recognition. IEEE Trans. Image Process. 2021, 30, 1514–1526. [Google Scholar] [CrossRef]
- Wu, X.; Fu, X.; Liu, Y.; Lim, E.-P.; Hoi, S.C.H.; Sun, Q. A Large-Scale Benchmark for Food Image Segmentation. In Proceedings of the 29th ACM International Conference on Multimedia 2021, Virtual, 20–24 October 2021. [Google Scholar]
- Hou, Q.; Min, W.; Wang, J.; Hou, S.; Zheng, Y.; Jiang, S. FoodLogoDet-1500: A Dataset for Large-Scale Food Logo Detection via Multi-Scale Feature Decoupling Network. arXiv 2021, arXiv:2108.04644. [Google Scholar]
- Fan, B.; Li, W.; Dong, L.; Li, J.; Nie, Z. Automatic Chinese Food recognition based on a stacking fusion model. In Proceedings of the 2023 45th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Sydney Australia, 24–27 July 2023; pp. 1–4. [Google Scholar]
- Chen, C.-S.; Chen, G.-Y.; Zhou, D.; Jiang, D.; Chen, D. Res-VMamba: Fine-Grained Food Category Visual Classification Using Selective State Space Models with Deep Residual Learning. arXiv 2024, arXiv:2402.15761. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Computer Vision—ECCV 2018, 15th European Conference, Munich, Germany, 8–14 September 2018, Proceedings, Part XIV; Springer: Munich, Germany, 2018. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | Our Review | Previous Surveys [1,15] |
|---|---|---|
| Scope | Covers both historical and cutting-edge methods, including CNN-based, ViT, hybrid models, and lightweight architectures | Primarily focused on CNNs or specific paradigms |
| Dataset Analysis | This paper quantitatively analyzes the cultural bias of the dataset (such as the proportion of Asian dishes) and the annotation granularity problem and introduces the relevant methods to deal with the shortcomings of the dataset | Limited discussion of dataset cultural coverage or real-world applicability |
| Method Taxonomy | Four paradigms: CNN-based, ViT, multimodal fusion, lightweight models; includes performance comparisons (Tables S3 and S4) | Often focused on single paradigms (e.g., CNNs) without cross-paradigm comparisons |
| Applications | Expands to nutrient assessment, food safety, and ethical challenges | Focus on traditional scenarios, such as practical applications such as calorie estimation or dish identification |
| Challenges and Future | Highlights cross-cultural generalization, feature mismatch, and ethical risks | Ethical issues and multicultural dataset requirements are rarely addressed, and challenges are mostly technical |
| Methods | Advantages | Disadvantages |
|---|---|---|
| CNN based | Strong ability to extract local features such as texture and shape Simple structure, easier to train and deploy | Limited ability to model global semantic relationships Overfitting can occur on small datasets |
| Vision Transformer | Self-attention mechanisms capture global dependencies Strong robustness to data distribution changes Suitable for large-scale pre-training | Performance declines on small datasets High computational complexity, performance is more obvious on the high resolution image |
| Multimodal fusion | Combine visual and non-visual information Strong generalization ability in cross-cultural scenes Support complex downstream tasks such as nutritional assessment | High labeling cost Multi-source data alignment is complex High complexity of model design |
| Lightweight neural network models | Small computational resource requirements It has good flexibility and real-time performance in actual deployment | Accuracy may drop for larger models Need a targeted optimization design |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, D.; Zuo, E.; Wang, D.; He, L.; Dong, L.; Lu, X. Deep Learning in Food Image Recognition: A Comprehensive Review. Appl. Sci. 2025, 15, 7626. https://doi.org/10.3390/app15147626
Liu D, Zuo E, Wang D, He L, Dong L, Lu X. Deep Learning in Food Image Recognition: A Comprehensive Review. Applied Sciences. 2025; 15(14):7626. https://doi.org/10.3390/app15147626
Chicago/Turabian StyleLiu, Detianjun, Enguang Zuo, Dingding Wang, Liang He, Liujing Dong, and Xinyao Lu. 2025. "Deep Learning in Food Image Recognition: A Comprehensive Review" Applied Sciences 15, no. 14: 7626. https://doi.org/10.3390/app15147626
APA StyleLiu, D., Zuo, E., Wang, D., He, L., Dong, L., & Lu, X. (2025). Deep Learning in Food Image Recognition: A Comprehensive Review. Applied Sciences, 15(14), 7626. https://doi.org/10.3390/app15147626