
Audio Features in Education: A Systematic Review of Computational Applications and Research Gaps




Abstract
1. Introduction
- Low-level acoustic features, such as pitch, intensity, or spectral representations (e.g., MFCCs or spectrograms), are directly extracted from the audio waveform using libraries such as Librosa [4].
- Diarization features, including speaker turn-taking, speaking time, and participant ratios, are obtained by segmenting and labeling who speaks when. For example, PyAnnote [5] is a very common tool to extract diarization information.
- Targeted analysis of audio features. Unlike earlier reviews that broadly categorize audio under “multimodal” or “sensor” headings, our research focuses specifically on audio as a standalone modality. It offers a focused examination of audio features within educational research. It covers a wide range of them, including low-level acoustic properties, linguistic indicators extracted via NLP, and speaker-based metrics obtained through diarization. As far as we are aware, no previous study has provided a systematic identification, categorization, and definition of the audio features employed in educational settings.
- Diagnosis of field-level limitations. While some existing papers describe individual case studies or isolated tools, few have highlighted systemic obstacles that impede pedagogical impact. Our synthesis reveals systemic barriers to pedagogical impact, including the scarcity of actionable feedback, low interpretability of AI models, fragmented and non-replicable datasets, and limited attention to privacy. These gaps highlight a misalignment between technical capability and practical utility.
- Actionable directions for future research. To advance the field, we propose three strategic directions: (1) the release of anonymized, standardized feature-level datasets; (2) the participatory design of feedback systems that actively involve educational practitioners and pedagogical experts; (3) the use of generative AI, particularly fine-tuned LLMs, to translate analytics into tailored, context-aware guidance for teachers and learners.
- RQ1: What are the main technological uses of audio features in educational research?
- RQ2: What are the most common audio features used in educational studies, and how are they extracted?
- RQ3: How do researchers combine audio features with other data sources?
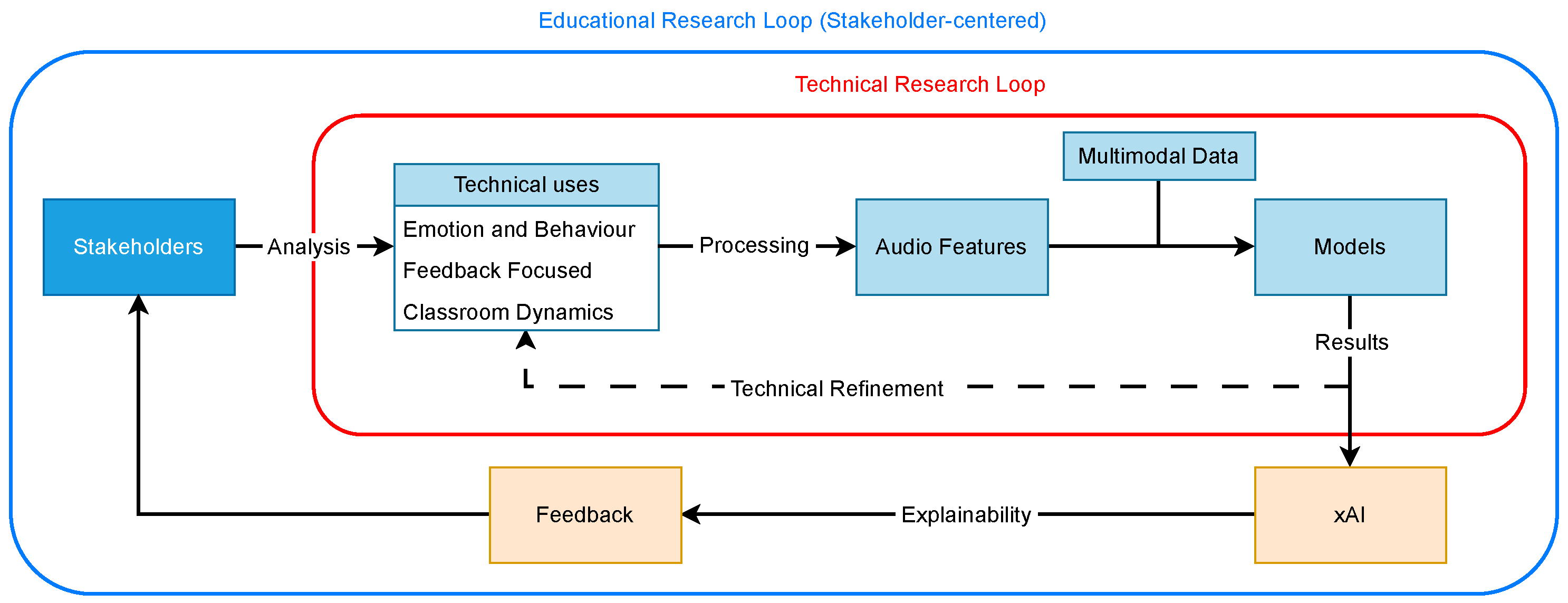
- RQ4: What techniques are employed to process audio features in educational studies, and to what extent are these solutions interpretable?
- RQ5: Which studies provide feedback for participants derived from obtained results?
2. Methodology
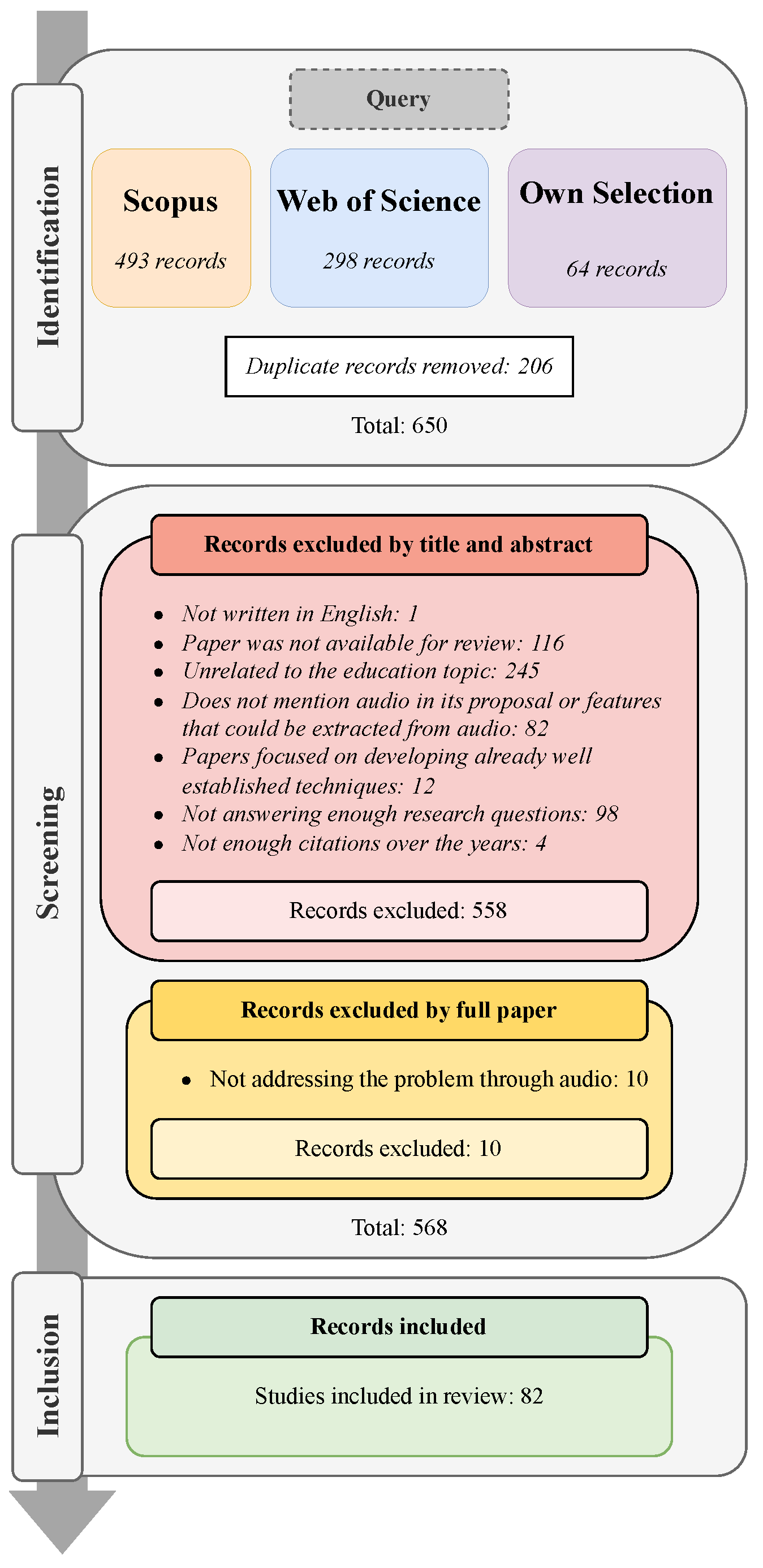
2.1. Identification of Research Works
- Data source: This component targets studies where audio serves as a primary or derived source of data. The query includes terms such as audio and sound to capture explicit references to raw audio. To encompass studies that use features extracted from audio rather than the waveform itself, it also includes terms like speech transcript, dialogue, and discourse features. This increased the likelihood of including work analyzing linguistic or prosodic features even when the term “audio” is not explicitly mentioned.
- Educational context: This block captures the environments in which learning interactions occur. Keywords such as collaborative learning, Group interaction, and teaching practice reflect classroom-based and peer-to-peer learning scenarios. Additionally, terms like meeting transcription are included to capture studies focusing on structured interactions in educational or academic contexts. This broader scope helps cover both formal classroom settings and informal learning environments such as workshops and seminars.
- Techniques: This component targets the computational methods used to process audio and audio-derived data. The query includes terms related to core technologies such as machine learning, deep learning, and artificial intelligence, along with domain-specific methods like speech recognition, voice activity detection, and natural language processing (NLP). These terms ensure the inclusion of studies applying advanced analytical frameworks. The inclusion of learning analytics further ensures alignment with educational objectives, emphasizing the intersection between computational processing and pedagogical insight.
2.2. Screening of Articles
- The paper was not written in English due to language constraints in the review team.
- The full text of the paper was not accessible for review, either due to restricted institutional access, paywall limitations, or the unavailability of a preprint or author-supplied version upon request.
- The paper did not focus on educational settings or learning processes as a primary context or objective.
- The paper did not use audio in its proposal or features that could be extracted from audio (e.g., text transcriptions).
- The paper focused exclusively on technical improvements to well-established audio processing methods (e.g., diarization or speech transcription) without applying them to educational data.
- During title/abstract screening, we required each manuscript to address at least one of our five core research questions. If a paper’s title or abstract showed no substantive discussion of audio-feature methodology or feedback-oriented use of audio, it was excluded under “Not answering enough research questions”. A total of 98 papers fell into this category. For instance, some studies mentioned the presence of audio but did not analyze or extract features from it, nor did they integrate it into the research objectives in a meaningful way.
- The paper was published in 2022 or earlier and had no citations on Google Scholar as of 4 December 2024. Given the volume and the goal of identifying impactful contributions, we applied this criterion as a secondary filtering mechanism to exclude papers that had not generated scholarly attention over time. This step affected only four papers.
2.3. Inclusion of Papers for Review
2.4. Data Analysis
2.5. Synthesis of Results
2.6. Assessment of Bias and Certainty
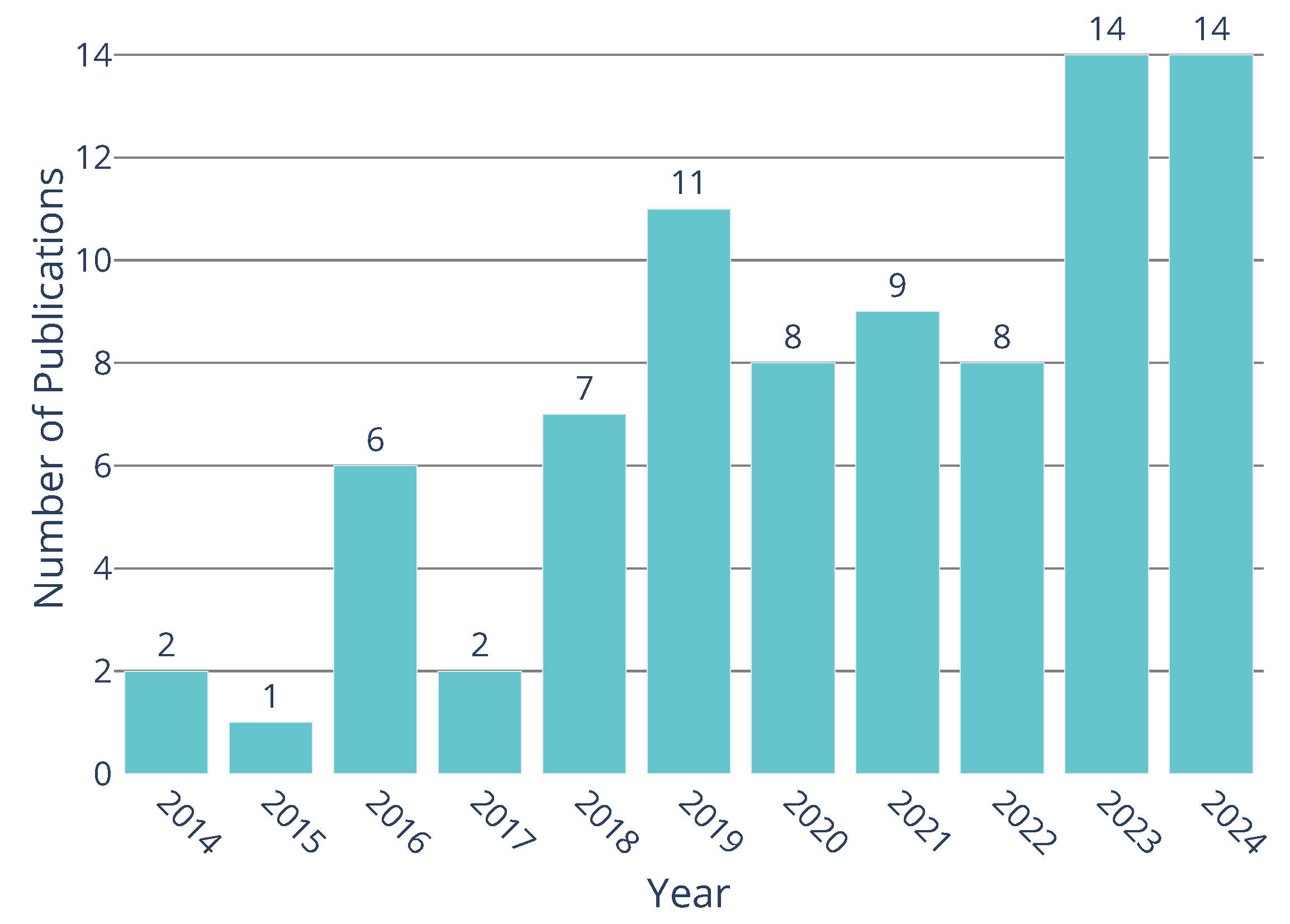
3. Results
3.1. What Are the Main Technological Uses of Audio Features in Educational Research? (RQ1)
3.1.1. Intervention Classification
3.1.2. Emotion and Behavior Analysis
3.1.3. Classroom Dynamics
3.1.4. Feedback Focused
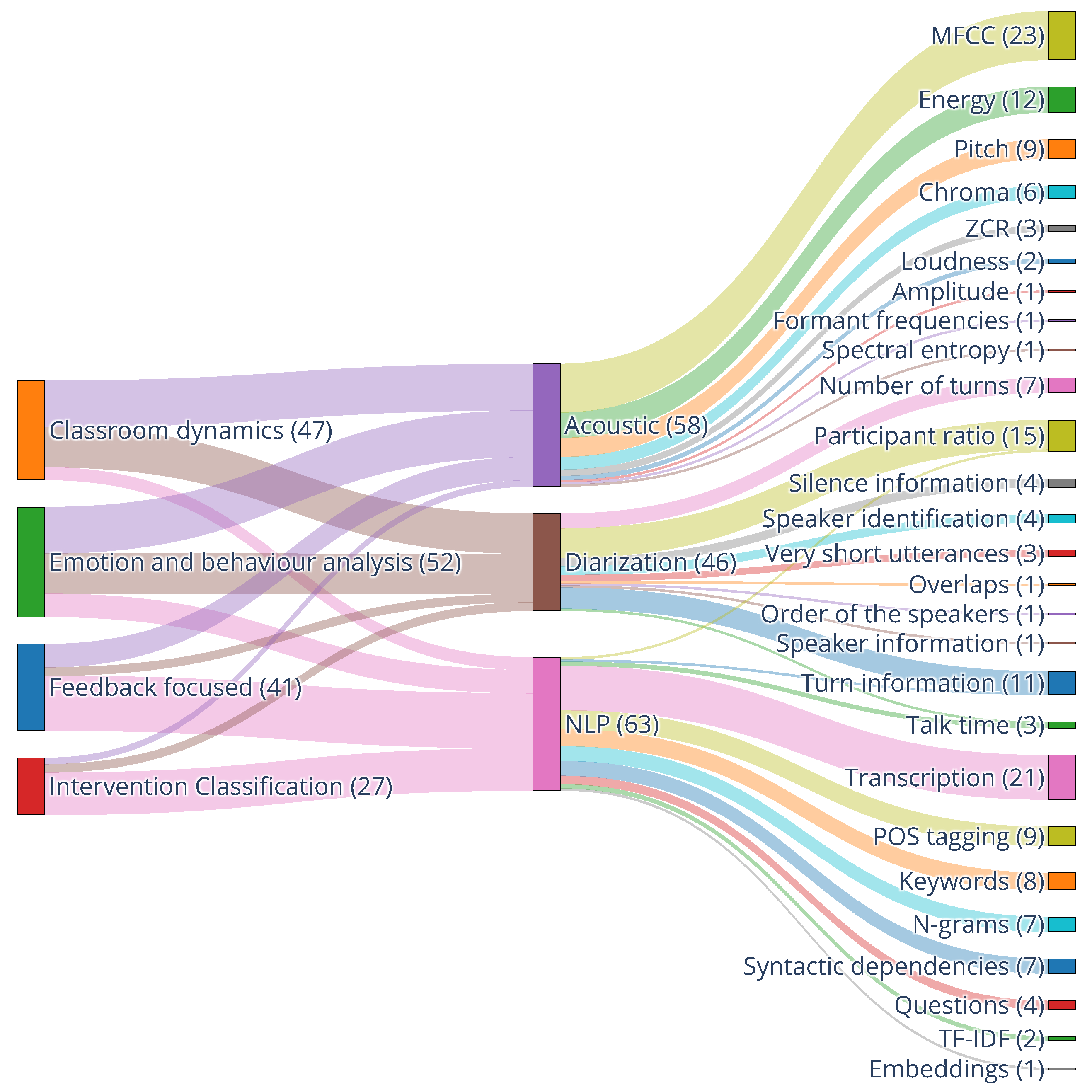
3.2. What Are the Most Common Audio Features Used in Educational Studies, and How Are They Extracted? (RQ2)
3.2.1. Acoustic Features
3.2.2. Diarization-Based Features
3.2.3. NLP-Based Features
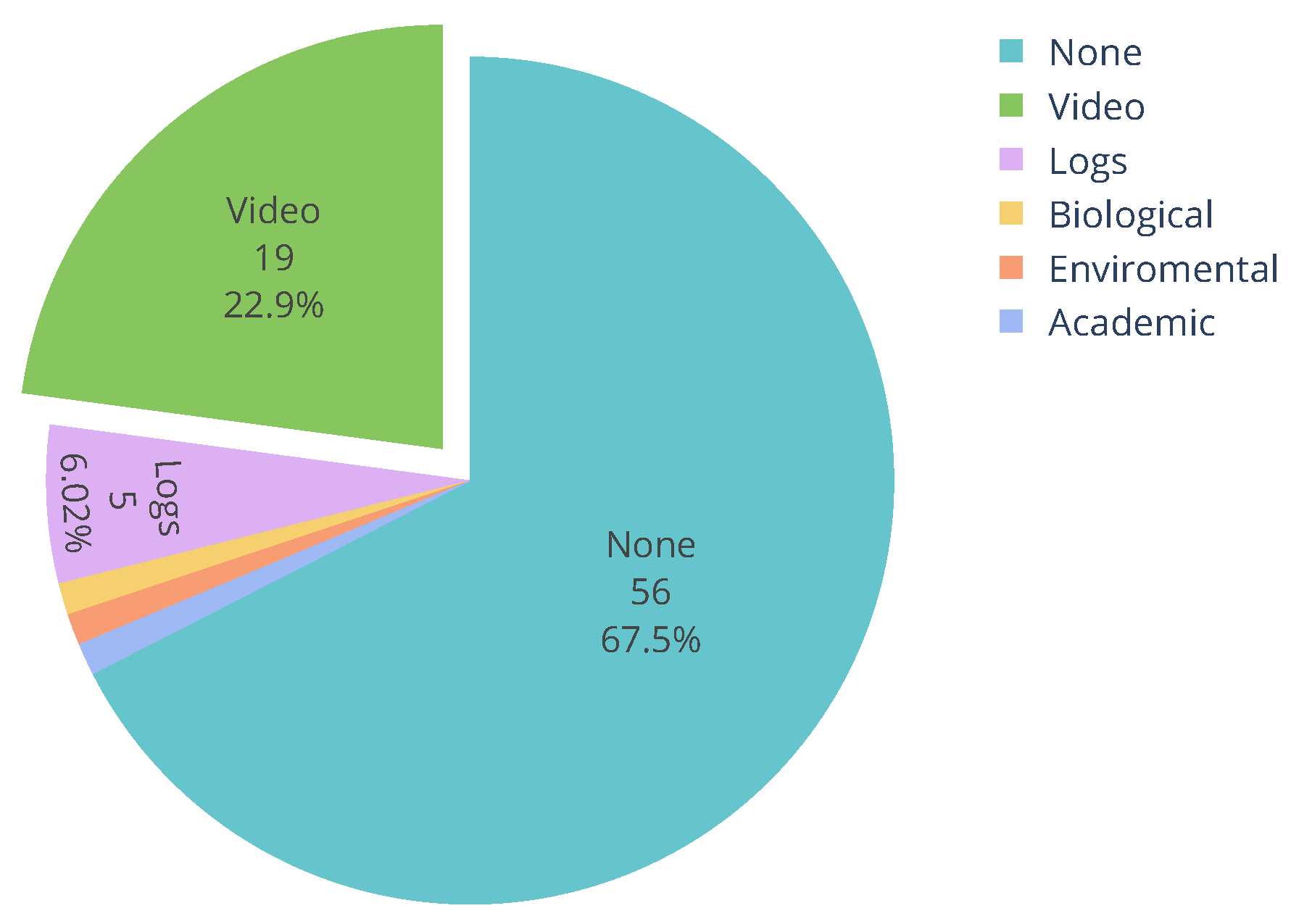
3.3. How Do Researchers Combine Audio Features with Other Data Sources? (RQ3)
3.3.1. Combination of Audio and Video Features
3.3.2. Combination of Audio and Contextual Data
3.4. What Techniques Are Employed to Process Audio Features in Educational Studies, and to What Extent Are These Solutions Interpretable? (RQ4)
3.4.1. Machine Learning Techniques
3.4.2. Deep Learning Techniques
3.4.3. Statistical Analyses
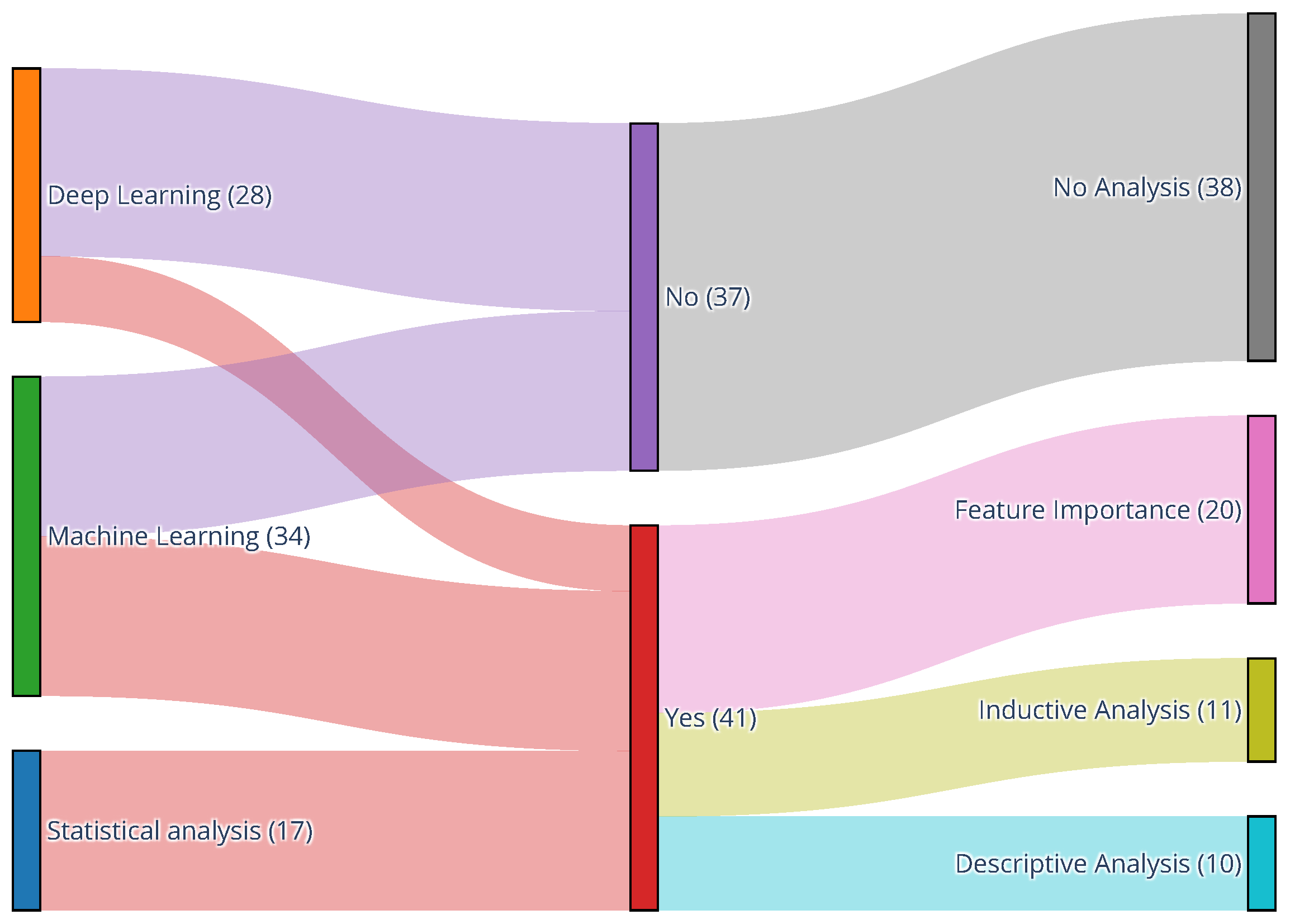
3.4.4. Extent of Interpretability and xAI Practices
- 1.
- Inductive (Correlation-Based) Analysis: Several studies employ correlation and regression analyses to explore associations between audio features and educational outcomes. While not true explainability methods in the xAI sense, these inductive approaches are used as proxies to validate whether model decisions align with expected behavioral patterns. For example, Chejara et al. [82] correlates audio-based collaboration features with model outcomes to check generalizability, while Chejara et al. [98] similarly relies on correlation metrics to validate whether ML models remain robust across different classroom environments. These methods provide initial evidence of construct validity but fall short of revealing how individual predictions are made.
- 2.
- Feature Importance: Tree-based ML algorithms such as random forests or gradient-boosted trees enable direct analysis of feature contributions, often through built-in importance metrics. These have been used to highlight which acoustic or linguistic features drive model predictions. For instance, Donnelly et al. [99] identifies para verbal signals as key markers for detecting teacher questions, and James et al. [32] uses feature importance to analyze contributors to perceived classroom climate. In a more advanced case, Hou et al. [29] applies SHAP values to clarify how emotional features contribute to warm or encouraging feedback. While useful, such practices are applied inconsistently across studies and often without methodological transparency or justification for the selected xAI technique.
- 3.
- Descriptive Analysis: Some studies enhance interpretability by comparing model outputs with human-annotated ground truth or classroom observations. These comparisons, while not algorithmic explanations, provide qualitative insight into how predictions align with real-world phenomena. For instance, Cook et al. [18] illustrates discrepancies between its regression-tree predictions and human-coded discourse segments, while Kelly et al. [19] analyzes how the model compares with the performance of human annotators. These approaches can build trust among end users, particularly educators, by revealing whether the system offers pedagogical value in their reasoning. However, they remain anecdotal and rarely constitute a systematic framework for interpretability.
3.5. Which Studies Provide Feedback for Participants Derived from Obtained Results? (RQ5)
3.5.1. Who Receives the Feedback?
3.5.2. What Kind of Feedback Is Delivered?
3.5.3. When Is Feedback Delivered?
Real-Time Feedback
Post-Session Feedback
Single Exposure or Irregular Delivery
4. Discussion of Findings and Implications
4.1. Challenges in Explainability
4.2. Data Availability and Privacy Constraints
4.3. Lack of Pedagogical Interpretation in Analytical Results
5. Conclusions
Supplementary Materials
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Title | Year | Level | Context |
|---|---|---|---|---|
| Dang, Belle and Nguyen, Andy and Järvelä, Sanna | The Unspoken Aspect of Socially Shared Regulation in Collaborative Learning: AI-Driven Learning Analytics Unveiling ‘Silent Pauses’ | 2024 | K12 | In-person |
| Jacobs, Jennifer and Scornavacco, Karla and Clevenger, Charis and Suresh, Abhijit and Sumner, Tamara | Automated feedback on discourse moves: teachers’ perceived utility of a professional learning tool | 2024 | K12 | In-person |
| Alkhamali, Eman Abdulrahman and Allinjawi, Arwa and Ashari, Rehab Bahaaddin | Combining Transformer, Convolutional Neural Network, and Long Short-Term Memory Architectures: A Novel Ensemble Learning Technique That Leverages Multi-Acoustic Features for Speech Emotion Recognition in Distance Education Classrooms | 2024 | Higher education | Online |
| D’Angelo, Cynthia M. and Rajarathinam, Robin Jephthah | Speech analysis of teaching assistant interventions in small group collaborative problem solving with undergraduate engineering students | 2024 | Higher education | In-person |
| Wang, Deliang and Chen, Gaowei | Are perfect transcripts necessary when we analyze classroom dialogue using AIoT? | 2024 | K12 | In-person |
| Chejara, Pankaj and Kasepalu, Reet and Prieto, Luis P. and Rodríguez-Triana, Mar\ía Jesús and Ruiz Calleja, Adolfo and Schneider, Bertrand | How well do collaboration quality estimation models generalize across authentic school contexts? | 2024 | Higher education | In-person |
| Liu, Xiaoting and Gu, Wen and Ota, Koichi and Hasegawa, Shinobu | Design of Voice Style Detection of Lecture Archives | 2023 | Higher education | In-person |
| Chejara, Pankaj and Prieto, Luis P. and Rodriguez-Triana, Maria Jesus and Kasepalu, Reet and Ruiz-Calleja, Adolfo and Shankar, ShashiKant Kant and Jesús Rodríguez-Triana, María and Calleja, Adolfo-Ruiz and Kasepalu, Reet and Shankar, ShashiKant Kant and Rodriguez-Triana, Maria Jesus and Kasepalu, Reet and Ruiz-Calleja, Adolfo and Shankar, ShashiKant Kant | How to Build More Generalizable Models for Collaboration Quality? Lessons Learned from Exploring Multi-Context Audio-Log Datasets using Multimodal Learning Analytics | 2023 | Higher education | In-person |
| Cosbey, Robin and Wusterbarth, Allison and Hutchinson, Brian | Deep Learning for Classroom Activity Detection from Audio | 2019 | Higher education | In-person |
| Ma, Yingbo and Celepkolu, Mehmet and Boyer, Kristy Elizabeth and Lynch, Collin F. and Wiebe, Eric and Israel, Maya | How Noisy is Too Noisy? The Impact of Data Noise on Multimodal Recognition of Confusion and Conflict During Collaborative Learning | 2023 | K12 | In-person |
| Rajarathinam, Robin Jephthah and D’Angelo, Cynthia M. | Description of Instructor Intervention Using Individual Audio Data in Co-Located Collaboration | 2023 | Higher education | In-person |
| Solopova, Veronika and Rostom, Eiad and Cremer, Fritz and Gruszczynski, Adrian and Witte, Sascha and Zhang, Chengming and López, Fernando Ramos and Plößl, Lea and Hofmann, Florian and Romeike, Ralf and Gläser-Zikuda, Michaela and Benzmüller, Christoph and Landgraf, Tim | PapagAI: Automated Feedback for Reflective Essays | 2023 | Higher education | In-person |
| Canovas, Oscar and Garcia, Felix J. | Analysis of Classroom Interaction Using Speaker Diarization and Discourse Features from Audio Recordings | 2023 | Higher education | In-person |
| Demszky, Dorottya and Wang, Rose and Geraghty, Sean and Yu, Carol | Does Feedback on Talk Time Increase Student Engagement? Evidence from a Randomized Controlled Trial on a Math Tutoring Platform | 2024 | K12 | Online |
| Jensen, Emily and Dale, Meghan and Donnelly, Patrick J. and Stone, Cathlyn and Kelly, Sean and Godley, Amanda and D’Mello, Sidney K. | Toward Automated Feedback on Teacher Discourse to Enhance Teacher Learning | 2020 | Multiple | In-person |
| Demszky, Dorottya and Liu, Jing | M-Powering Teachers: Natural Language Processing Powered Feedback Improves 1:1 Instruction and Student Outcomes | 2023 | K12 | Online |
| Demszky, Dorottya and Liu, Jing and Hill, Heather C. and Jurafsky, Dan and Piech, Chris | Can Automated Feedback Improve Teachers’ Uptake of Student Ideas? Evidence From a Randomized Controlled Trial in a Large-Scale Online Course | 2024 | Higher education | Online |
| Rajarathinam, Robin Jephthah and Dangelo, Cynthia M. | Turn-taking analysis of small group collaboration in an engineering discussion classroom | 2023 | Higher education | In-person |
| Nazaretsky, Tanya and Mikeska, Jamie N. and Beigman Klebanov, Beata and Mikeska, Jamie N. and Beigman Klebanov, Beata | Empowering Teacher Learning with AI: Automated Evaluation of Teacher Attention to Student Ideas during Argumentation-focused Discussion | 2023 | K12 | Simulation |
| Cv, Siddhartha and Rao, Preeti and Velmurugan, Rajbabu and Siddhartha, C. V. and Rao, Preeti and Velmurugan, Rajbabu | Classroom Activity Detection in Noisy Preschool Environments with Audio Analysis | 2023 | Toddlers | In-person |
| Albaladejo-González, Mariano and Gaspar-Marco, Rubén and Mármol, Félix Gómez and Reich, Justin and Ruipérez-Valiente, José A | Improving Teacher Training Through Emotion Recognition and Data Fusion | 2024 | K12 | In-person |
| Canovas, Oscar and Garcia-Clemente, Felix J. and Pardo, Federico | AI-driven Teacher Analytics: Informative Insights on Classroom Activities | 2023 | Higher education | In-person |
| Li, Zongxi and Xie, Haoran and Wang, Minhong and Wu, Bian and Hu, Yiling | Automatic Coding of Collective Creativity Dialogues in Collaborative Problem Solving Based on Deep Learning Models | 2022 | K12 | In-person |
| Kasepalu, Reet and Chejara, Pankaj and Prieto, Luis P. and Ley, Tobias | Do Teachers Find Dashboards Trustworthy, Actionable and Useful? A Vignette Study Using a Logs and Audio Dashboard | 2022 | ||
| Schlotterbeck, Danner and Jiménez, Abelino and Araya, Roberto and Caballero, Daniela and Uribe, Pablo and Van der Molen Moris, Johan | Teacher, Can You Say It Again? Improving Automatic Speech Recognition Performance over Classroom Environments with Limited Data | 2022 | K12 | In-person |
| Southwell, Rosy and Pugh, Samuel and Perkoff, E. Margaret and Clevenger, Charis and Bush, Jeffrey B. and Lieber, Rachel and Ward, Wayne and Foltz, Peter and DMello, Sidney | Challenges and Feasibility of Automatic Speech Recognition for Modeling Student Collaborative Discourse in Classrooms | 2022 | K12 | In-person |
| Zhang, Shaoyun and Li, Chao | Research on Feature Fusion Speech Emotion Recognition Technology for Smart Teaching | 2022 | Higher education | Online |
| Hunkins, Nicholas and Kelly, Sean and DMello, Sidney | "beautiful work, youre rock stars!": Teacher Analytics to Uncover Discourse that Supports or Undermines Student Motivation, Identity, and Belonging in Classrooms | 2022 | K12 | In-person |
| Alic, Sterling and Demszky, Dorottya and Mancenido, Zid and Liu, Jing and Hill, Heather and Jurafsky, Dan | Computationally Identifying Funneling and Focusing Questions in Classroom Discourse | 2022 | K12 | In-person |
| Dale, Meghan E. and Godley, Amanda J. and Capello, Sarah A. and Donnelly, Patrick J. and DMello, Sidney K. and Kelly, Sean P. | Toward the automated analysis of teacher talk in secondary ELA classrooms | 2022 | K12 | In-person |
| Yuzhong, Hou | Students emotional analysis on ideological and political teaching classes based on artificial intelligence and data mining | 2021 | ||
| Emara, Mona and Hutchins, Nicole M. and Grover, Shuchi and Snyder, Caitlin and Biswas, Gautam | Examining student regulation of collaborative, computational, problem-solving processes in openended learning environments | 2021 | K12 | In-person |
| France, Ann | Teachers Using Dialogue to Support Science Learning in the Primary Classroom | 2021 | K12 | In-person |
| Cánovas Reverte, Óscar and González Férez, Pilar and García Clemente, Félix J. and Pardo García, Federico | Analyzing Wooclap’s Competition Mode with AI Through Classroom Recordings | 2024 | Higher education | In-person |
| Albaladejo-González, Mariano and Gaspar-Marco, Rubén and Mármol, Félix Gómez and Reich, Justin and Ruipérez-Valiente, José A | Improving Teacher Training Through Emotion Recognition and Data Fusion | 2024 | Simulation | |
| Hou, Ruikun and Fütterer, Tim and Bühler, Babette and Bozkir, Efe and Gerjets, Peter and Trautwein, Ulrich and Kasneci, Enkelejda | Automated Assessment of Encouragement and Warmth in Classrooms Leveraging Multimodal Emotional Features and ChatGPT | 2024 | K12 | In-person |
| Sun, Anchen and Londono, Juan J. and Elbaum, Batya and Estrada, Luis and Lazo, Roberto Jose and Vitale, Laura and Villasanti, Hugo Gonzalez and Fusaroli, Riccardo and Perry, Lynn K. and Messinger, Daniel S. | Who Said what? An Automated Approach to Analyzing Speech in Preschool Classrooms | 2024 | Toddlers | In-person |
| Canovas, Oscar and Garcia, Felix J. | Analysis of Classroom Interaction Using Speaker Diarization and Discourse Features from Audio Recordings | 2023 | In-person | |
| García, Federico Pardo and Cánovas, Óscar and García Clemente, Félix J. | Exploring AI Techniques for Generalizable Teaching Practice Identification | 2024 | Higher education | In-person |
| Schlotterbeck, Danner and Uribe, Pablo and Jiménez, Abelino and Araya, Roberto and van der Molen Moris, Johan and Caballero, Daniela | TARTA: Teacher Activity Recognizer from Transcriptions and Audio | 2021 | K12 | In-person |
| Jensen, Emily and Pugh, Samuel L. and Dmello, Sidney K. | A deep transfer learning approach to modeling teacher discourse in the classroom | 2021 | K12 | In-person |
| Li, Zongxi and Xie, Haoran and Wang, Minhong and Wu, Bian and Hu, Yiling | Automatic Coding of Collective Creativity Dialogues in Collaborative Problem Solving Based on Deep Learning Models | 2022 | K12 | In-person |
| Schlotterbeck, Danner and Uribe, Pablo and Araya, Roberto and Jimenez, Abelino and Caballero, Daniela | What classroom audio tells about teaching: A cost-effective approach for detection of teaching practices using spectral audio features | 2021 | K12 | In-person |
| Tsalera, Eleni and Papadakis, Andreas and Samarakou, Maria | Novel principal component analysis-based feature selection mechanism for classroom sound classification | 2021 | Higher education | In-person |
| Demszky, Dorottya and Liu, Jing and Mancenido, Zid and Cohen, Julie and Hill, Heather and Jurafsky, Dan and Hashimoto, Tatsunori | Measuring conversational uptake: A case study on student-teacher interactions | 2021 | K12 | In-person |
| Chejara, Pankaj and Prieto, Luis P. and Ruiz-Calleja, Adolfo and Rodríguez-Triana, María Jesús and Shankar, Shashi Kant and Kasepalu, Reet | Quantifying collaboration quality in face-to-face classroom settings using mmla | 2020 | K12 | In-person |
| Jensen, Emily and Dale, Meghan and Donnelly, Patrick J. and Stone, Cathlyn and Kelly, Sean and Godley, Amanda and DMello, Sidney K. | Toward Automated Feedback on Teacher Discourse to Enhance Teacher Learning | 2020 | K12 | In-person |
| Khan, Muhammed S. and Zualkernan, Imran | Using Convolutional Neural Networks for Smart Classroom Observation | 2020 | K12 | In-person |
| Sharma, Archana and Mansotra, Vibhakar | Multimodal decision-level group sentiment prediction of students in classrooms | 2019 | K12 | Multiple |
| Varatharaj, Ashvini and Botelho, Anthony F. and Lu, Xiwen and Heffernan, Neil T. | Supporting teacher assessment in Chinese language learning using textual and tonal features | 2020 | Higher education | In-person |
| Jie, Liang and Zhao, Xiaoyan and Zhang, Zhaohui | Speech Emotion Recognition of Teachers in Classroom Teaching | 2020 | ||
| Yang, Bohong and Yao, Zeping and Lu, Hong and Zhou, Yaqian and Xu, Jinkai | In-classroom learning analytics based on student behavior, topic and teaching characteristic mining | 2020 | Higher education | In-person |
| Sharma, Archana and Mansotra, Vibhakar | Multimodal decision-level group sentiment prediction of students in classrooms | 2019 | K12 | In-person |
| Suresh, Abhijit and Sumner, Tamara and Jacobs, Jennifer and Foland, Bill and Ward, Wayne | Automating analysis and feedback to improve mathematics teachers classroom discourse | 2019 | K12 | In-person |
| Jensen, Emily and Dale, Meghan and Donnelly, Patrick J. and Stone, Cathlyn and Kelly, Sean and Godley, Amanda and DMello, Sidney K. | Toward Automated Feedback on Teacher Discourse to Enhance Teacher Learning | 2020 | Multiple | In-person |
| Su, Hang and Dzodzo, Borislav and Wu, Xixin and Liu, Xunying and Meng, Helen | Unsupervised methods for audio classification from lecture discussion recordings | 2019 | Higher education | In-person |
| James, Anusha and Chua, Yi Han Victoria and Maszczyk, Tomasz and Núñez, Ana Moreno and Bull, Rebecca and Lee, Kerry and Dauwels, Justin | Automated classification of classroom climate by audio analysis | 2019 | Toddlers | In-person |
| Ahuja, Karan and Kim, Dohyun and Xhakaj, Franceska and Varga, Virag and Xie, Anne and Zhang, Stanley and Townsend, Jay Eric and Harrison, Chris and Ogan, Amy and Agarwal, Yuvraj | EduSense: Practical Classroom Sensing at Scale | 2019 | Higher education | In-person |
| Barbadekar, Ashwinee and Gaikwad, Vijay and Patil, Sanjay and Chaudhari, Tushar and Deshpande, Shardul and Burad, Saloni and Godbole, Rohini | Engagement Index for Classroom Lecture using Computer Vision | 2019 | In-person | |
| Viswanathan, Sree Aurovindh and VanLehn, Kurt | Collaboration detection that preserves privacy of students speech | 2019 | Higher education | In-person |
| James, Anusha and Chua, Yi Han Victoria and Maszczyk, Tomasz and Núñez, Ana Moreno and Bull, Rebecca and Lee, Kerry and Dauwels, Justin | Automated classification of classroom climate by audio analysis | 2019 | Higher education | In-person |
| Sharma, Archana and Mansotra, Vibhakar | Multimodal decision-level group sentiment prediction of students in classrooms | 2019 | Higher education | In-person |
| Cosbey, Robin and Wusterbarth, Allison and Hutchinson, Brian | Deep Learning for Classroom Activity Detection from Audio | 2019 | Multiple | In-person |
| Gerard, Libby and Kidron, Ady and Linn, Marcia C. | Guiding collaborative revision of science explanations | 2019 | K12 | In-person |
| Kelly, Sean and Olney, Andrew M. and Donnelly, Patrick and Nystrand, Martin and DMello, Sidney K. | Automatically Measuring Question Authenticity in Real-World Classrooms | 2018 | K12 | In-person |
| Shapsough, Salsabeel and Zualkernan, Imran | Using Machine Learning to Automate Classroom Observation for Low-Resource Environments | 2018 | K12 | In-person |
| Howard, Sarah K. and Yang, Jie and Ma, Jun and Ritz, Chrisian and Zhao, Jiahonz and Wynne, Kylie | Using Data Mining and Machine Learning Approaches to Observe Technology-Enhanced Learning | 2018 | K12 | In-person |
| James, Anusha and Kashyap, Mohan and Chua, Yi Han Victoria and Maszczyk, Tomasz and Nunez, Ana Moreno and Bull, Rebecca and Dauwels, Justin | Inferring the Climate in Classrooms from Audio and Video Recordings: A Machine Learning Approach | 2018 | Toddlers | In-person |
| Lugini, Luca and Litman, Diane | Argument Component Classification for Classroom Discussions | 2018 | K12 | In-person |
| Cook, Connor and Olney, Andrew M. and Kelly, Sean and DMello, Sidney K. | An open vocabulary approach for estimating teacher use of authentic questions in classroom discourse | 2018 | K12 | In-person |
| Uzelac, Ana and Gligoric, Nenad and Krco, Srdan and Gligorić, Nenad and Krčo, Srđan | System for recognizing lecture quality based on analysis of physical parameters | 2018 | Higher education | In-person |
| Owens, Melinda T. and Seidel, Shannon B. and Wong, Mike and Bejines, Travis E. and Lietz, Susanne and Perez, Joseph R. and Sit, Shangheng and Subedar, Zahur-Saleh Saleh and Acker, Gigi N. and Akana, Susan F. and Balukjian, Brad and Benton, Hilary P. et al. | Classroom sound can be used to classify teaching practices in college science courses | 2017 | Higher education | In-person |
| Donnelly, Patrick J. and Kelly, Sean and Blanchard, Nathaniel and Nystrand, Martin and Olney, Andrew M. and DMello, Sidney K. | Words matter: Automatic detection of teacher questions in live classroom discourse using linguistics, acoustics, and context | 2017 | K12 | In-person |
| Donnelly, Patrick and Blanchard, Nathan and Samei, Borhan and Olney, Andrew M. and Sun, Xiaoyi and Ward, Brooke and Kelly, Sean and Nystrand, Martin and DMello, Sidney K. | Automatic teacher modeling from live classroom audio | 2016 | K12 | In-person |
| Blanchard, Nathaniel and Donnelly, Patrick J. and Olney, Andrew M. and Samei, Borhan and Ward, Brooke and Sun, Xiaoyi and Kelly, Sean and Nystrand, Martin and DMello, Sidney K. | Identifying Teacher Questions Using Automatic Speech Recognition in Classrooms | 2016 | K12 | In-person |
| Donnelly, Patrick J. and Blanchard, Nathaniel and Samei, Borhan and Olney, Andrew M. and Sun, Xiaoyi and Ward, Brooke and Kelly, Sean and Nystrand, Martin and DMello, Sidney K. | Multi-Sensor modeling of teacher instructional segments in live classrooms | 2016 | K12 | In-person |
| Hardman, Jan | Tutor–student interaction in seminar teaching: Implications for professional development | 2016 | Higher education | In-person |
| Prieto, Luis P. and Sharma, Kshitij and Dillenbourg, Pierre and Jesús, María | Teaching analytics: Towards automatic extraction of orchestration graphs using wearable sensors | 2016 | K12 | In-person |
| Blanchard, Nathaniel and Donnelly, Patrick J. and Olney, Andrew M. and Samei, Borhan and Ward, Brooke and Sun, Xiaoyi and Kelly, Sean and Nystrand, Martin and DMello, Sidney K. | Semi-automatic detection of teacher questions from human-transcripts of audio in live classrooms | 2016 | K12 | In-person |
| Gligoric, Nenad and Uzelac, Ana and Krco, Srdjan and Kovacevic, Ivana and Nikodijevic, Ana | Smart classroom system for detecting level of interest a lecture creates in a classroom | 2015 | Higher education | In-person |
| Li, Zongxi and Xie, Haoran and Wang, Minhong and Wu, Bian and Hu, Yiling | Automatic Coding of Collective Creativity Dialogues in Collaborative Problem Solving Based on Deep Learning Models | 2022 | K12 | In-person |
| Samei, Borhan and Li, Haiying and Keshtkar, Fazel and Rus, Vasile and Graesser, Arthur C. | Context-based speech act classification in intelligent tutoring systems | 2014 | K12 | Online |
References
- Elkins, D.; Hickerson, T. The use of the tape recorder in teacher education. J. Teach. Educ. 1964, 15, 432–438. [Google Scholar] [CrossRef]
- Ochoa, X.; Worsley, M. Augmenting learning analytics with multimodal sensory data. J. Learn. Anal. 2016, 3, 213–219. [Google Scholar] [CrossRef]
- Praharaj, S.; Scheffel, M.; Specht, M.; Drachsler, H. Measuring collaboration quality through audio data and learning analytics. In Unobtrusive Observations of Learning in Digital Environments: Examining Behavior, Cognition, Emotion, Metacognition and Social Processes Using Learning Analytics; Springer: Berlin/Heidelberg, Germany, 2023; pp. 91–110. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. SciPy 2015, 2015, 18–24. [Google Scholar]
- Bredin, H.; Yin, R.; Coria, J.M.; Gelly, G.; Korshunov, P.; Lavechin, M.; Fustes, D.; Titeux, H.; Bouaziz, W.; Gill, M.P. Pyannote.audio: Neural building blocks for speaker diarization. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7124–7128. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 28492–28518. [Google Scholar]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python. 2020. Available online: https://spacy.io/ (accessed on 17 June 2025).
- Lee, L.K.; Cheung, S.K.; Kwok, L.F. Learning analytics: Current trends and innovative practices. J. Comput. Educ. 2020, 7, 1–6. [Google Scholar] [CrossRef]
- Heng, C.H.; Toyoura, M.; Leow, C.S.; Nishizaki, H. Analysis of Classroom Processes Based on Deep Learning With Video and Audio Features. IEEE Access 2024, 12, 110705–110712. [Google Scholar] [CrossRef]
- Schlotterbeck, D.; Uribe, P.; Araya, R.; Jimenez, A.; Caballero, D. What classroom audio tells about teaching: A cost-effective approach for detection of teaching practices using spectral audio features. In Proceedings of the LAK21: LAK21: 11th International Learning Analytics and Knowledge Conference, Stanford, CA, USA, 12–16 April 2021; pp. 132–140. [Google Scholar]
- Worsley, M. Multimodal learning analytics: Enabling the future of learning through multimodal data analysis and interfaces. In Proceedings of the 14th ACM International Conference on Multimodal Interaction, Santa Monica, CA, USA, 22–26 October 2012; pp. 353–356. [Google Scholar]
- Wang, J.; Dudy, S.; He, X.; Wang, Z.; Southwell, R.; Whitehill, J. Speaker Diarization in the Classroom: How Much Does Each Student Speak in Group Discussions? In Proceedings of the 17th International Conference on Educational Data Mining, Long Beach, CA, USA, 9–12 July 2024; pp. 360–367. [Google Scholar]
- Wisniewski, B.; Zierer, K.; Hattie, J. The power of feedback revisited: A meta-analysis of educational feedback research. Front. Psychol. 2020, 10, 487662. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. BMJ 2021, 372, n71. [Google Scholar] [CrossRef]
- Chadegani, A.A.; Salehi, H.; Yunus, M.M.; Farhadi, H.; Fooladi, M.; Farhadi, M.; Ebrahim, N.A. A comparison between two main academic literature collections: Web of Science and Scopus databases. arXiv 2013, arXiv:1305.0377. [Google Scholar] [CrossRef]
- Fang, S.; Gao, B.; Wu, Y.; Teoh, T.T. Unibrivl: Robust universal representation and generation of audio driven diffusion models. arXiv 2023, arXiv:2307.15898. [Google Scholar]
- Blanchard, N.; Donnelly, P.J.; Olney, A.M.; Samei, B.; Ward, B.; Sun, X.; Kelly, S.; Nystrand, M.; D’Mello, S.K. Identifying Teacher Questions Using Automatic Speech Recognition in Classrooms. In Proceedings of the SIGDIAL 2016—17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Proceedings of the Conference, Los Angeles, CA, USA, 13–15 September 2016; pp. 191–201. [Google Scholar]
- Cook, C.; Olney, A.M.; Kelly, S.; D’Mello, S.K. An open vocabulary approach for estimating teacher use of authentic questions in classroom discourse. In Proceedings of the 11th International Conference on Educational Data Mining (EDM 2018); International Educational Data Mining Society, Buffalo, NY, USA, 16–20 July 2018; pp. 493–498. [Google Scholar]
- Kelly, S.; Olney, A.M.; Donnelly, P.; Nystrand, M.; D’Mello, S.K. Automatically Measuring Question Authenticity in Real-World Classrooms. Educ. Res. 2018, 47, 451–464. [Google Scholar] [CrossRef]
- Schaffalitzky, C. What Makes Authentic Questions Authentic? Dialogic Pedagog. 2022, 10, A30–A42. [Google Scholar] [CrossRef]
- Liu, X.; Gu, W.; Ota, K.; Hasegawa, S. Design of Voice Style Detection of Lecture Archives. In Proceedings of the IEEE Region 10 Annual International Conference, TENCON 2023, Perth, Australia, 31 October–3 November 2023; pp. 1139–1144. [Google Scholar]
- Lugini, L.; Litman, D. Argument Component Classification for Classroom Discussions. In Proceedings of the EMNLP 2018—5th Workshop on Argument Mining, Brussels, Belgium, 31 October–4 November 2018; pp. 57–67. [Google Scholar]
- Khan, M.S.; Zualkernan, I. Using Convolutional Neural Networks for Smart Classroom Observation. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication, Fukuoka, Japan, 21–24 February 2020; pp. 608–612. [Google Scholar]
- Dang, B.; Nguyen, A.; Järvelä, S. The Unspoken Aspect of Socially Shared Regulation in Collaborative Learning: AI-Driven Learning Analytics Unveiling ‘Silent Pauses’. In Proceedings of the 14th Learning Analytics and Knowledge Conference (LAK ’24), Kyoto, Japan, 18–22 March 2024; ACM Press: New York, NY, USA, 2024; pp. 231–240. [Google Scholar]
- Li, Z.; Xie, H.; Wang, M.; Wu, B.; Hu, Y. Automatic Coding of Collective Creativity Dialogues in Collaborative Problem Solving Based on Deep Learning Models. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), International Conference on Artificial Intelligence in Education (AIED 2022), Durham, UK, 27–31 July 2022; Volume 13357 LNCS, pp. 123–134. [Google Scholar]
- Viswanathan, S.A.; VanLehn, K. Collaboration detection that preserves privacy of students’ speech. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics, International Conference on Artificial Intelligence in Education (AIED 2019), Chicago, IL, USA, 25–29 June 2019; Volume 11625 LNAI, pp. 507–517. [Google Scholar]
- Gligoric, N.; Uzelac, A.; Krco, S.; Kovacevic, I.; Nikodijevic, A. Smart classroom system for detecting level of interest a lecture creates in a classroom. J. Ambient Intell. Smart Environ. 2015, 7, 271–284. [Google Scholar] [CrossRef]
- Yang, B.; Yao, Z.; Lu, H.; Zhou, Y.; Xu, J. In-classroom learning analytics based on student behavior, topic and teaching characteristic mining. Pattern Recognit. Lett. 2020, 129, 224–231. [Google Scholar] [CrossRef]
- Hou, R.; Fütterer, T.; Bühler, B.; Bozkir, E.; Gerjets, P.; Trautwein, U.; Kasneci, E. Automated Assessment of Encouragement and Warmth in Classrooms Leveraging Multimodal Emotional Features and ChatGPT. In Proceedings of the Lecture Notes in Computer Science; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2024; Volume 14829 LNAI, pp. 60–74. [Google Scholar]
- Hou, Y. Students’ emotional analysis on ideological and political teaching classes based on artificial intelligence and data mining. J. Intell. Fuzzy Syst. 2021, 40, 3801–3809. [Google Scholar]
- Jie, L.; Zhao, X.; Zhang, Z. Speech Emotion Recognition of Teachers in Classroom Teaching. In Proceedings of the 32nd Chinese Control and Decision Conference (CCDC 2020), Hefei, China, 22–24 August 2020; pp. 5045–5050. [Google Scholar]
- James, A.; Kashyap, M.; Chua, Y.H.V.; Maszczyk, T.; Nunez, A.M.; Bull, R.; Dauwels, J. Inferring the Climate in Classrooms from Audio and Video Recordings: A Machine Learning Approach. In Proceedings of the 2018 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE 2018), Wollongong, NSW, Australia, 4–7 December 2018; pp. 983–988. [Google Scholar]
- James, A.; Chua, Y.H.V.; Maszczyk, T.; Núñez, A.M.; Bull, R.; Lee, K.; Dauwels, J. Automated classification of classroom climate by audio analysis. In Proceedings of the 9th International Workshop on Spoken Dialogue System Technology, Singapore, 18–20 April 2018; Volume 579, pp. 41–49. [Google Scholar]
- Ramakrishnan, A.; Ottmar, E.; LoCasale-Crouch, J.; Whitehill, J. Toward automated classroom observation: Predicting positive and negative climate. In Proceedings of the 14th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019. [Google Scholar]
- Uzelac, A.; Gligorić, N.; Krčo, S. System for recognizing lecture quality based on analysis of physical parameters. Telemat. Inform. 2018, 35, 579–594. [Google Scholar] [CrossRef]
- Siddhartha, C.V.; Rao, P.; Velmurugan, R. Classroom Activity Detection in Noisy Preschool Environments with Audio Analysis. In Proceedings of the 2023 International Conference on Smart Systems for Applications in Electrical Sciences (ICSSES), Sivakasi, India, 6–7 April 2023; pp. 1–6. [Google Scholar]
- Canovas, O.; Garcia, F.J. Analysis of Classroom Interaction Using Speaker Diarization and Discourse Features from Audio Recordings. In Proceedings of the Learning in the Age of Digital and Green Transition (ICL 2022), Vienna, Austria, 27–30 September 2022; Volume 634 LNNS, pp. 67–74. [Google Scholar]
- Demszky, D.; Liu, J.; Mancenido, Z.; Cohen, J.; Hill, H.; Jurafsky, D.; Hashimoto, T. Measuring Conversational Uptake: A Case Study on Student-Teacher Interactions. arXiv 2021, arXiv:2106.03873. [Google Scholar]
- Demszky, D.; Liu, J.; Hill, H.C.; Jurafsky, D.; Piech, C. Can automated feedback improve teachers’ uptake of student ideas? evidence from a randomized controlled trial in a large-scale online course. Educ. Eval. Policy Anal. 2024, 46, 483–505. [Google Scholar] [CrossRef]
- Cánovas, O.; González, P.; Clemente, F.J.G.; Pardo, F. Analyzing Wooclap’s competition mode with AI through classroom recordings. IEEE Rev. Iberoam. Tecnol. Aprendiz. 2024, 19, 220–229. [Google Scholar]
- Liu, J.; Hill, H.C.; Sanghi, S.; Chung, A.; Demszky, D. Improving Teachers’ Questioning Quality through Automated Feedback: A Mixed-Methods Randomized Controlled Trial in Brick-and-Mortar Classrooms; Annenberg Institute for School Reform at Brown University: Providence, RI, USA, 2023. [Google Scholar]
- Hunkins, N.; Kelly, S.; D’Mello, S. “Beautiful work, you’re rock stars!”: Teacher Analytics to Uncover Discourse that Supports or Undermines Student Motivation, Identity, and Belonging in Classrooms. In Proceedings of the ACM International Conference Proceeding Series, International Conference on Learning Analytics and Knowledge (LAK ’22), Evry, France, 21–25 March 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 230–238. [Google Scholar]
- Dale, M.E.; Godley, A.J.; Capello, S.A.; Donnelly, P.J.; D’Mello, S.K.; Kelly, S.P. Toward the automated analysis of teacher talk in secondary ELA classrooms. Teach. Teach. Educ. 2022, 110, 103584. [Google Scholar] [CrossRef]
- Gerard, L.; Kidron, A.; Linn, M.C. Guiding collaborative revision of science explanations. Int. J. Comput.-Support. Collab. Learn. 2019, 14, 291–324. [Google Scholar] [CrossRef]
- Varatharaj, A.; Botelho, A.F.; Lu, X.; Heffernan, N.T. Supporting teacher assessment in Chinese language learning using textual and tonal features. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), International Conference on Artificial Intelligence in Education (AIED 2020), Ifrane, Morocco, 6–10 July 2020; Volume 12163 LNAI, pp. 562–573. [Google Scholar]
- Alkhamali, E.A.; Allinjawi, A.; Ashari, R.B. Combining Transformer, Convolutional Neural Network, and Long Short-Term Memory Architectures: A Novel Ensemble Learning Technique That Leverages Multi-Acoustic Features for Speech Emotion Recognition in Distance Education Classrooms. Appl. Sci. 2024, 14, 5050. [Google Scholar] [CrossRef]
- Prieto, L.P.; Sharma, K.; Dillenbourg, P.; Jesús, M. Teaching analytics: Towards automatic extraction of orchestration graphs using wearable sensors. In Proceedings of the ACM International Conference Proceeding Series, Niagara Falls, ON, Canada, 6–9 November 2016; Volume 25-29-Apri, pp. 148–157. [Google Scholar]
- Ramakrishnan, A.; Zylich, B.; Ottmar, E.; Locasale-Crouch, J.; Whitehill, J. Toward Automated Classroom Observation: Multimodal Machine Learning to Estimate CLASS Positive Climate and Negative Climate. IEEE Trans. Affect. Comput. 2023, 14, 664–679. [Google Scholar] [CrossRef]
- Sharma, A.; Mansotra, V. Multimodal decision-level group sentiment prediction of students in classrooms. Int. J. Innov. Technol. Explor. Eng. 2019, 8, 4902–4909. [Google Scholar] [CrossRef]
- Zhang, S.; Li, C. Research on Feature Fusion Speech Emotion Recognition Technology for Smart Teaching. Mob. Inf. Syst. 2022, 2022, 82–92. [Google Scholar] [CrossRef]
- Albaladejo-González, M.; Gaspar-Marco, R.; Mármol, F.G.; Reich, J.; Ruipérez-Valiente, J.A. Improving Teacher Training Through Emotion Recognition and Data Fusion. Expert Syst. 2024, 17, 200171. [Google Scholar] [CrossRef]
- Li, H.; Kang, Y.; Ding, W.; Yang, S.; Yang, S.; Huang, G.Y.; Liu, Z. Multimodal Learning for Classroom Activity Detection. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Virtual, 4–8 May 2020; pp. 9234–9238. [Google Scholar]
- Ma, Y.; Celepkolu, M.; Boyer, K.E.; Lynch, C.F.; Wiebe, E.; Israel, M. How Noisy is Too Noisy? The Impact of Data Noise on Multimodal Recognition of Confusion and Conflict During Collaborative Learning. In Proceedings of the 25th International Conference on Multimodal Interaction, Paris, France, 9–13 October 2023. [Google Scholar]
- Su, H.; Dzodzo, B.; Wu, X.; Liu, X.; Meng, H. Unsupervised methods for audio classification from lecture discussion recordings. In Proceedings of the Annual Conference of the International Speech Communication Association, INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 3347–3351. [Google Scholar]
- Cosbey, R.; Wusterbarth, A.; Hutchinson, B. Deep Learning for Classroom Activity Detection from Audio. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing, Brighton, UK, 12–17 May 2019; pp. 3727–3731. [Google Scholar]
- Rajarathinam, R.J.; D’Angelo, C.M. Description of Instructor Intervention Using Individual Audio Data in Co-Located Collaboration. In Proceedings of the Computer-Supported Collaborative Learning Conference, CSCL, Montreal, QC, Canada, 10–14 July 2023; Volume 2023-June, pp. 317–320. [Google Scholar]
- D’Angelo, C.M.; Rajarathinam, R.J. Speech analysis of teaching assistant interventions in small group collaborative problem solving with undergraduate engineering students. Br. J. Educ. Technol. 2024, 55, 1583–1601. [Google Scholar] [CrossRef]
- Demszky, D.; Wang, R.; Geraghty, S.; Yu, C. Does Feedback on Talk Time Increase Student Engagement? Evidence from a Randomized Controlled Trial on a Math Tutoring Platform; EdWorkingPaper No. 23-891; Annenberg Institute for School Reform at Brown University: Providence, RI, USA, 2023. [Google Scholar]
- Chejara, P.; Prieto, L.P.; Ruiz-Calleja, A.; Rodríguez-Triana, M.J.; Shankar, S.K.; Kasepalu, R. Quantifying collaboration quality in face-to-face classroom settings using mmla. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), International Conference on Artificial Intelligence in Education (AIED 2020), Ifrane, Morocco, 6–10 July 2020; Volume 12324 LNCS, pp. 159–166. [Google Scholar]
- Rajarathinam, R.J.; D’Angelo, C.M. Turn-taking analysis of small group collaboration in an engineering discussion classroom. In Proceedings of the ACM International Conference Proceeding Series, Association for Computing Machinery, International Conference on Learning Analytics and Knowledge (LAK ’23), Arlington, TX, USA, 13–17 March 2023; pp. 650–656. [Google Scholar]
- Pardo, F.; Cánovas, O.; Clemente, F.J.G. Exploring AI techniques for generalizable teaching practice identification. IEEE Access 2024, 12, 134702–134713. [Google Scholar]
- Wang, Z.; Pan, X.; Miller, K.F.; Cortina, K.S. Automatic classification of activities in classroom discourse. Comput. Educ. 2014, 78, 115–123. [Google Scholar] [CrossRef]
- Barbadekar, A.; Gaikwad, V.; Patil, S.; Chaudhari, T.; Deshpande, S.; Burad, S.; Godbole, R. Engagement Index for Classroom Lecture using Computer Vision. In Proceedings of the 2019 Global Conference for Advancement in Technology (GCAT 2019), Bengaluru, India, 4–6 October 2019. [Google Scholar]
- Wang, D.; Chen, G. Are perfect transcripts necessary when we analyze classroom dialogue using AIoT? Internet Things 2024, 25, 101105. [Google Scholar] [CrossRef]
- Sun, A.; Londono, J.J.; Elbaum, B.; Estrada, L.; Lazo, R.J.; Vitale, L.; Villasanti, H.G.; Fusaroli, R.; Perry, L.K.; Messinger, D.S. Who Said what? An Automated Approach to Analyzing Speech in Preschool Classrooms. In Proceedings of the 2024 IEEE International Conference on Development and Learning (ICDL 2024), Pittsburgh, PA, USA, 15–18 July 2024. [Google Scholar]
- Southwell, R.; Pugh, S.; Perkoff, E.M.; Clevenger, C.; Bush, J.B.; Lieber, R.; Ward, W.; Foltz, P.; D’Mello, S. Challenges and Feasibility of Automatic Speech Recognition for Modeling Student Collaborative Discourse in Classrooms. In Proceedings of the 15th International Conference on Educational Data Mining (EDM 2022), Durham, UK, 27–31 July 2022. [Google Scholar]
- Blanchard, N.; Donnelly, P.J.; Olney, A.M.; Samei, B.; Ward, B.; Sun, X.; Kelly, S.; Nystrand, M.; D’Mello, S.K. Semi-automatic detection of teacher questions from human-transcripts of audio in live classrooms. In Proceedings of the 9th International Conference on Educational Data Mining (EDM 2016), Raleigh, NC, USA, 4–7 July 2016; pp. 288–291. [Google Scholar]
- Schlotterbeck, D.; Jiménez, A.; Araya, R.; Caballero, D.; Uribe, P.; der Molen Moris, J.V. “Teacher, Can You Say It Again?” Improving Automatic Speech Recognition Performance over Classroom Environments with Limited Data. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), International Conference on Artificial Intelligence in Education (AIED 2022), Durham, UK, 27–31 July 2022; Volume 13355 LNCS, pp. 269–280. [Google Scholar]
- Samei, B.; Li, H.; Keshtkar, F.; Rus, V.; Graesser, A.C. Context-based speech act classification in intelligent tutoring systems. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), International Conference on Artificial Intelligence in Education (AIED 2014), Memphis, TN, USA, 1–5 July 2014; Volume 8474 LNCS, pp. 236–241. [Google Scholar]
- Suresh, A.; Sumner, T.; Jacobs, J.; Foland, B.; Ward, W. Automating analysis and feedback to improve mathematics teachers’ classroom discourse. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, AAAI 2019, 31st Innovative Applications of Artificial Intelligence Conference, IAAI 2019 and the 9th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI 2019), Honolulu, HI, USA, 27 January–1 February 2019; pp. 9721–9728. [Google Scholar]
- Demszky, D.; Liu, J. M-Powering Teachers: Natural Language Processing Powered Feedback Improves 1:1 Instruction and Student Outcomes. In Proceedings of the Tenth ACM Conference on Learning @ Scale, Copenhagen, Denmark, 20–22 July 2023; pp. 23–759. [Google Scholar]
- Song, Y.; Lei, S.; Hao, T.; Lan, Z.; Ding, Y. Automatic Classification of Semantic Content of Classroom Dialogue. J. Educ. Comput. Res. 2021, 59, 496–521. [Google Scholar] [CrossRef]
- Jensen, E.; Pugh, S.L.; D’mello, S.K. A deep transfer learning approach to modeling teacher discourse in the classroom. In Proceedings of the LAK21: 11th International Learning Analytics and Knowledge Conference, Irvine, CA, USA, 12–16 April 2021; pp. 302–312. [Google Scholar]
- Solopova, V.; Rostom, E.; Cremer, F.; Gruszczynski, A.; Witte, S.; Zhang, C.; Lopez, F.R.; Ploessl, L.; Hofmann, F.; Romeike, R.; et al. PapagAI: Automated Feedback for Reflective Essays. In Proceedings of the Advances in Artificial Intelligence (KI 2023), Berlin, Germany, 26–29 September 2023; Volume 14236, pp. 198–206. [Google Scholar]
- Nazaretsky, T.; Mikeska, J.N.; Klebanov, B.B. Empowering Teacher Learning with AI: Automated Evaluation of Teacher Attention to Student Ideas during Argumentation-focused Discussion. In Proceedings of the LAK23: 13th International Learning Analytics and Knowledge Conference, Arlington, TX, USA, 13–17 March 2023; Volume 1, pp. 122–132. [Google Scholar]
- Schlotterbeck, D.; Uribe, P.; Jiménez, A.; Araya, R.; van der Molen Moris, J.; Caballero, D. TARTA: Teacher Activity Recognizer from Transcriptions and Audio. In Proceedings of the Artificial Intelligence in Education: 22nd International Conference, AIED 2021, Utrecht, The Netherlands, 14–18 June 2021; Volume 12748 LNAI, pp. 369–380. [Google Scholar]
- Blikstein, P. Multimodal learning analytics. In Proceedings of the Third International Conference on Learning Analytics and Knowledge, Leuven, Belgium, 8–13 April 2013; pp. 102–106. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the International Conference on Machine Learning (ICML), Bellevue, WA, USA, 28 June–2 July 2011; Volume 11, pp. 689–696. [Google Scholar]
- Ahuja, K.; Kim, D.; Xhakaj, F.; Varga, V.; Xie, A.; Zhang, S.; Townsend, J.E.; Harrison, C.; Ogan, A.; Agarwal, Y. EduSense: Practical Classroom Sensing at Scale. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2019, 3, 1–26. [Google Scholar] [CrossRef]
- Howard, S.K.; Yang, J.; Ma, J.; Ritz, C.; Zhao, J.; Wynne, K. Using Data Mining and Machine Learning Approaches to Observe Technology-Enhanced Learning. In Proceedings of the 2018 IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE 2018), Wollongong, NSW, Australia, 4–7 December 2018; pp. 788–793. [Google Scholar]
- Chan, M.C.E.; Ochoa, X.; Clarke, D. Multimodal learning analytics in a laboratory classroom. In Machine Learning Paradigms: Advances in Learning Analytics; Springer: Cham, Switzerland, 2020; Volume 158, pp. 131–156. [Google Scholar]
- Chejara, P.; Kasepalu, R.; Prieto, L.P.; Rodríguez-Triana, M.J.; Calleja, A.R.; Schneider, B. How well do collaboration quality estimation models generalize across authentic school contexts? Br. J. Educ. Technol. 2023, 55, 1602–1624. [Google Scholar] [CrossRef]
- Kasepalu, R.; Chejara, P.; Prieto, L.P.; Ley, T. Do Teachers Find Dashboards Trustworthy, Actionable and Useful? A Vignette Study Using a Logs and Audio Dashboard. Technol. Knowl. Learn. 2022, 27, 971–989. [Google Scholar] [CrossRef]
- Emara, M.; Hutchins, N.M.; Grover, S.; Snyder, C.; Biswas, G. Examining student regulation of collaborative, computational, problem-solving processes in openended learning environments. J. Learn. Anal. 2021, 8, 49–74. [Google Scholar] [CrossRef]
- Wang, D.; Tao, Y.; Chen, G. Artificial intelligence in classroom discourse: A systematic review of the past decade. Int. J. Educ. Res. 2024, 123, 102275. [Google Scholar] [CrossRef]
- Tsalera, E.; Papadakis, A.; Samarakou, M. Novel principal component analysis-based feature selection mechanism for classroom sound classification. Comput. Intell. 2021, 37, 1827–1843. [Google Scholar] [CrossRef]
- Donnelly, P.; Blanchard, N.; Samei, B.; Olney, A.M.; Sun, X.; Ward, B.; Kelly, S.; Nystrand, M.; D’Mello, S.K. Automatic teacher modeling from live classroom audio. In Proceedings of the UMAP 2016—2016 Conference on User Modeling Adaptation and Personalization, Halifax, NS, Canada, 13–16 July 2016; pp. 45–53. [Google Scholar]
- Donnelly, P.J.; Blanchard, N.; Samei, B.; Olney, A.M.; Sun, X.; Ward, B.; Kelly, S.; Nystrand, M.; D’Mello, S.K. Multi-Sensor modeling of teacher instructional segments in live classrooms. In Proceedings of the ICMI 2016—18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 177–184. [Google Scholar]
- Shapsough, S.; Zualkernan, I. Using Machine Learning to Automate Classroom Observation for Low-Resource Environments. In Proceedings of the GHTC 2018—IEEE Global Humanitarian Technology Conference, San Jose, CA, USA, 18–21 October 2018. [Google Scholar]
- Cánovas, O.; Clemente, F.J.G.; Pardo, F. AI-driven Teacher Analytics: Informative Insights on Classroom Activities. In Proceedings of the 2023 IEEE International Conference on Teaching, Assessment and Learning for Engineering (TALE 2023), Auckland, New Zealand, 28 November–1 December 2023. [Google Scholar]
- Sandanayake, T.C.; Bandara, A.M. Automated classroom lecture note generation using natural language processing and image processing techniques. Int. J. Adv. Trends Comput. Sci. Eng. 2019, 8, 1920–1926. [Google Scholar]
- Lundberg, S. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Mou, A.; Milanova, M.; Baillie, M. Deep Learning Approaches for Classroom Audio Classification Using Mel Spectrograms. In Proceedings of the New Approaches for Multidimensional Signal Processing (NAMSP 2022), Sofia, Bulgaria, 23–25 June 2022. [Google Scholar]
- Alic, S.; Demszky, D.; Mancenido, Z.; Liu, J.; Hill, H.; Jurafsky, D. Computationally Identifying Funneling and Focusing Questions in Classroom Discourse. arXiv 2022, arXiv:2208.04715. [Google Scholar]
- Hardman, J. Tutor–student interaction in seminar teaching: Implications for professional development. Act. Learn. High. Educ. 2016, 17, 63–76. [Google Scholar] [CrossRef]
- France, A. Teachers Using Dialogue to Support Science Learning in the Primary Classroom. Res. Sci. Educ. 2021, 51, 845–859. [Google Scholar] [CrossRef]
- Chejara, P.; Prieto, L.P.; Rodriguez-Triana, M.J.; Kasepalu, R.; Ruiz-Calleja, A.; Shankar, S.K. How to Build More Generalizable Models for Collaboration Quality? Lessons Learned from Exploring Multi-Context Audio-Log Datasets using Multimodal Learning Analytics. In Proceedings of the ACM International Conference Proceeding Series, International Conference on Learning Analytics and Knowledge (LAK ’23), Arlington, TX, USA, 13–17 March 2023; pp. 111–121. [Google Scholar]
- Donnelly, P.J.; Kelly, S.; Blanchard, N.; Nystrand, M.; Olney, A.M.; D’Mello, S.K. Words matter: Automatic detection of teacher questions in live classroom discourse using linguistics, acoustics, and context. In Proceedings of the ACM International Conference Proceeding Series, International Conference on Learning Analytics and Knowledge (LAK ’17), Vancouver, BC, Canada, 13–17 March 2017; pp. 218–227. [Google Scholar]
- Jacobs, J.; Scornavacco, K.; Clevenger, C.; Suresh, A.; Sumner, T. Automated feedback on discourse moves: Teachers’ perceived utility of a professional learning tool. Educ. Technol. Res. Dev. 2024, 72, 1307–1329. [Google Scholar] [CrossRef]
- Owens, M.T.; Seidel, S.B.; Wong, M.; Bejines, T.E.; Lietz, S.; Perez, J.R.; Sit, S.; Subedar, Z.-S.; Acker, G.N.; Akana, S.F.; et al. Classroom sound can be used to classify teaching practices in college science courses. Proc. Natl. Acad. Sci. USA 2017, 114, 3085–3090. [Google Scholar] [CrossRef] [PubMed]
- Jensen, E.; Dale, M.; Donnelly, P.J.; Stone, C.; Kelly, S.; Godley, A.; D’Mello, S.K. Toward Automated Feedback on Teacher Discourse to Enhance Teacher Learning. In Proceedings of the Conference on Human Factors in Computing Systems (CHI 2020), Honolulu, HI, USA, 25–30 April 2020. [Google Scholar]
- Topali, P.; Ortega-Arranz, A.; Rodríguez-Triana, M.J.; Er, E.; Khalil, M.; Akçapınar, G. Designing human-centered learning analytics and artificial intelligence in education solutions: A systematic literature review. Behav. Inf. Technol. 2025, 44, 1071–1098. [Google Scholar] [CrossRef]
- Qiu, W.; Thway, M.; Lai, J.W.; Lim, F.S. GenAI for teaching and learning: A Human-in-the-loop Approach. In Proceedings of the Companion Proceedings 15th International Conference on Learning Analytics & Knowledge (LAK25), Dublin, Ireland, 3–7 March 2025; pp. 33–36. [Google Scholar]
- Worsley, M. Framing the future of multimodal learning analytics. In The Multimodal Learning Analytics Handbook; Springer: Berlin/Heidelberg, Germany, 2022; pp. 359–369. [Google Scholar]
- Suresh, A.; Jacobs, J.; Harty, C.; Perkoff, M.; Martin, J.H.; Sumner, T. The TalkMoves Dataset: K-12 Mathematics Lesson Transcripts Annotated for Teacher and Student Discursive Moves. arXiv 2022, arXiv:2204.09652. [Google Scholar]
- Ahn, J.; Campos, F.; Nguyen, H.; Hays, M.; Morrison, J. Co-designing for privacy, transparency, and trust in K-12 learning analytics. In Proceedings of the LAK21: 11th International Learning Analytics and Knowledge Conference, Irvine, CA, USA, 12–16 April 2021; pp. 55–65. [Google Scholar]
- Wiedbusch, M.; Sonnenfeld, N.; Henderson, J. Pedagogical Companions to Support Teachers’ Interpretation of Students’ Engagement from Multimodal Learning Analytics Dashboards. In Proceedings of the International Conference on Computers in Education, Kuching, Malaysia, 28 November–2 December 2022; pp. 432–437. [Google Scholar]
- Li, Q.; Jung, Y.; Wise, A.F. How instructors use learning analytics: The pivotal role of pedagogy. J. Comput. High. Educ. 2025, 1–29. [Google Scholar] [CrossRef]
- Aljohani, N.R.; Fayoumi, A.; Hassan, S.U. Predicting at-risk students using clickstream data in the virtual learning environment. Sustainability 2019, 11, 7238. [Google Scholar] [CrossRef]
- Black, P.; Wiliam, D. Assessment and classroom learning. Assess. Educ. Princ. Policy Pract. 1998, 5, 7–74. [Google Scholar] [CrossRef]
- Tsai, Y.S.; Singh, S.; Rakovic, M.; Lim, L.A.; Roychoudhury, A.; Gasevic, D. Charting design needs and strategic approaches for academic analytics systems through co-design. In Proceedings of the LAK22: 12th International Learning Analytics and Knowledge Conference, Online, 21–25 March 2022; pp. 381–391. [Google Scholar]
- Ouhaichi, H.; Bahtijar, V.; Spikol, D. Exploring design considerations for multimodal learning analytics systems: An interview study. In Proceedings of the Frontiers in Education; Frontiers Media SA: Lausanne, Switzerland, 2024; Volume 9, p. 1356537. [Google Scholar]
- Yan, L.; Zhao, L.; Echeverria, V.; Jin, Y.; Alfredo, R.; Li, X.; Gaševi’c, D.; Martinez-Maldonado, R. VizChat: Enhancing learning analytics dashboards with contextualised explanations using multimodal generative AI chatbots. In Proceedings of the International Conference on Artificial Intelligence in Education, Racife, Brazil, 8–12 July 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 180–193. [Google Scholar]
- Mazzullo, E.; Bulut, O.; Wongvorachan, T.; Tan, B. Learning analytics in the era of large language models. Analytics 2023, 2, 877–898. [Google Scholar] [CrossRef]
- Rüdian, S.; Podelo, J.; Kužílek, J.; Pinkwart, N. Feedback on Feedback: Student’s Perceptions for Feedback from Teachers and Few-Shot LLMs. In Proceedings of the 15th International Learning Analytics and Knowledge Conference, Dublin, Ireland, 3–7 March 2025; pp. 82–92. [Google Scholar]



| Features Combination | Count |
|---|---|
| Acoustic | 21 |
| Acoustic; Diarization | 5 |
| Acoustic; NLP | 10 |
| Diarization | 13 |
| Diarization; NLP | 2 |
| NLP | 30 |
| Tag | Features | Count |
|---|---|---|
| Classroom dynamics | Acoustic | 5 |
| Classroom dynamics | Diarization | 2 |
| Emotion and behavior analysis | Acoustic | 11 |
| Emotion and behavior analysis | Diarization | 10 |
| Emotion and behavior analysis | NLP | 8 |
| Feedback focused | Acoustic | 6 |
| Feedback focused | Diarization | 2 |
| Feedback focused | NLP | 18 |
| Intervention Classification | Acoustic | 9 |
| Intervention Classification | Diarization | 6 |
| Intervention Classification | NLP | 10 |
| Technology Development | Acoustic | 5 |
| Technology Development | NLP | 6 |
| Feature Type | Description |
|---|---|
| Acoustic Features | These capture low-level acoustic properties of audio (e.g., timbre, pitch, intensity, and MFCC). |
| Spectral Features | Includes Mel-frequency cepstral coefficients (MFCC), filter bank energies (Fbank), formant frequencies, spectral entropy, and spectral centroid. These characterize the frequency content of the audio signal. |
| Prosodic Features | Encompasses pitch (fundamental frequency), energy/amplitude (volume), and intensity (decibels), which reveal emphasis, speaking style, or emotional cues. |
| Time-Domain/Statistical Features | Covers zero-crossing rate (ZCR), speech speed/rate (words per minute at the acoustic level), and higher-order statistics (e.g., skewness and kurtosis) of the waveform. |
| Chroma | Represents the intensity of each of the 12 distinct pitch classes in music/speech, useful for tonal or harmonic analysis. |
| Diarization Features | These focus on identifying “who spoke when,” measuring how speech is distributed among individuals, and capturing dynamics of turn-taking. |
| Turn-Taking and Number of Turns | Measures each change of speaker or turn in the conversation (e.g., turn counts, very short utterances, and participant order). |
| Speaking Time/Talk Ratio | Quantifies how long each individual (or group) speaks, useful for comparing teacher vs. student speech. |
| Speaker Identification/Uniqueness | Detects how many distinct voices appear and how often each participant speaks. |
| Silence Detection | Tracks periods of no speech (silent pauses, pause duration, and silence ratio), which can indicate reflection or inactivity. |
| Participation Equality/Participant Ratio | Reflects whether speech is evenly distributed or dominated by a single speaker. |
| Speech Overlap/Interruptions | Monitors when multiple speakers talk simultaneously, showing interaction flow. |
| Direction of Arrival | Locates the position of a speaker in the physical environment, used in multi-microphone setups. |
| NLP Features | These derive from textual representations of speech (i.e., after transcription) and capture linguistic, semantic, or conversational structures. |
| Transcription-Based Lexical Features | Direct use of transcribed text (including raw word tokens, word counts, and words per minute). |
| Keyword/Key-Phrase Detection | Identifies specific terms or question stems (e.g., “why” and “how” domain-related keywords). |
| POS Tagging and Grammatical Analysis | Uses part-of-speech tags, syntactic dependencies, named entities, or discourse relations. |
| N-grams, TF-IDF, and Embeddings | Captures local word sequences (n-grams), term-frequency distributions (TF-IDF), or semantic overlap (embedding-based comparisons and pointwise Jensen–Shannon divergence). |
| Semantic/Pedagogical Indicators | Focuses on features like “teacher uptake of student ideas”, sentiment or emotion in text, and question authenticity. |
| Feature Type | Model | Support |
|---|---|---|
| Academic | 0 | 1 |
| Biological | 1 | 0 |
| Environmental | 1 | 0 |
| Logs | 3 | 2 |
| Video | 13 | 6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pardo, F.; Cánovas, Ó.; Clemente, F.J.G. Audio Features in Education: A Systematic Review of Computational Applications and Research Gaps. Appl. Sci. 2025, 15, 6911. https://doi.org/10.3390/app15126911
Pardo F, Cánovas Ó, Clemente FJG. Audio Features in Education: A Systematic Review of Computational Applications and Research Gaps. Applied Sciences. 2025; 15(12):6911. https://doi.org/10.3390/app15126911
Chicago/Turabian StylePardo, Federico, Óscar Cánovas, and Félix J. García Clemente. 2025. "Audio Features in Education: A Systematic Review of Computational Applications and Research Gaps" Applied Sciences 15, no. 12: 6911. https://doi.org/10.3390/app15126911
APA StylePardo, F., Cánovas, Ó., & Clemente, F. J. G. (2025). Audio Features in Education: A Systematic Review of Computational Applications and Research Gaps. Applied Sciences, 15(12), 6911. https://doi.org/10.3390/app15126911