1. Introduction
Tomatoes are well-suited for multicyclic cultivation in greenhouse plant factories because of their short growth cycle, which enables multiple harvests annually for a high economic return [
1]. Currently, tomato harvesting is a labor-intensive and time-consuming process [
2] primarily because tomato plants yield a high fruit density in an uneven vertical distribution and their dense foliage often obstructs access to fruit clusters. As these challenges make finding fruits difficult and thereby hinder the effective implementation of mechanical automation, realizing the rapid and accurate identification of ripe tomatoes represents a crucial step toward automating the harvesting process.
Indeed, object recognition plays a crucial role in the vision systems of tomato-harvesting robots. Rapid advances in deep learning have introduced revolutionary computer vision methodologies, with modern object detection algorithms transitioning from traditional handcrafted feature extraction approaches to data-driven paradigms based on neural networks [
3,
4]. Traditional image processing techniques primarily include color feature identification, edge detection, and texture analysis, whereas deep-learning-based detectors widely employ convolutional neural networks (CNNs) to realize feature extraction [
5,
6]. For example, Junhui et al. [
7] achieved an 86.3% recognition accuracy for ripe tomatoes in complex scenarios by analyzing edge contour features and improving the Hough circle transformation algorithm, which significantly enhanced computational efficiency. Furthermore, Zeng [
8] combined image saliency with a CNN model to extract and classify features, achieving an accuracy of 95.6% on a self-assembled dataset containing 26 classes of fruits and vegetables. The recognition accuracy of most CNNs can be improved by increasing the network depth and stacking additional convolutional layers to enhance feature extraction [
9]. However, this approach requires significant computational resources and storage overhead, potentially leading to training inefficiencies, excessive parameters, and challenges in meeting practical deployment requirements for mobile and embedded devices.
Various implementations of object recognition in agricultural produce detection systems have been achieved through representative CNN-based single-stage detectors, particularly the single-shot multibox detector (SSD) [
10] and you only look once (YOLO) [
11] approaches. The operational superiority of these models is derived from their sustained real-time inference speeds and energy-efficient computation, which satisfy the stringent requirements for resource-constrained edge deployment in precision agriculture scenarios. Notably, Xin et al. [
12] replaced the backbone network of an SSD with a lightweight MobileNetV3 network and enhanced its original model framework using depthwise separable convolutions to achieve a recognition accuracy of 92.5%, a 7.9% improvement over that of the baseline model. Zheng et al. [
13] enhanced the original YOLOv8 model by integrating a Large Separable Kernel Attention mechanism, dynamic upsampling layer, and Inner Intersection over Union loss function. The modified model achieved a recognition accuracy of 99.4% on a test dataset, demonstrating a 3.3% higher precision than that provided by a YOLOv5 model. Although CNN-based models typically exhibit satisfactory detection accuracy, two critical steps—threshold filtering and non-maximum suppression (NMS)—dictate their robustness and inference speed [
14]. The Real-Time Detection Transformer (RTDETR) [
15] is a novel detection method that eliminates the need for NMS post-processing, thereby reducing optimization complexity and enhancing robustness. Nevertheless, challenges persist in RTDETR implementation, including redundant backbone architectures and suboptimal data flow between modules.
Researchers have recently focused on developing lightweight network architectures with significantly enhanced model deployment adaptability to edge computing scenarios, including mobile and embedded devices. Zuo et al. [
16] reduced computational costs by replacing standard convolutions with lightweight grouped spatial convolutions and enhanced feature extraction using a triplet attention mechanism in a YOLOv8 backbone network. Furthermore, they optimized multi-scale feature fusion by substituting the original path aggregation network–feature pyramid network with a bidirectional feature pyramid network. The experimental results demonstrated an identification accuracy of 94.4% and reductions in computational cost, parameters, and model size of 32.1%, 47.8%, and 44.4%, respectively, compared with those of the baseline model. Xu et al. [
17] optimized the backbone network using partial convolution and efficient multiscale attention to reduce computational overhead. Furthermore, the original cross-stage partial bottleneck with two convolutions module in the neck structure was replaced with generalized sparse convolution and variety-of-view group shuffle cross stage partial connections modules; an auxiliary head was also incorporated to improve small-target recognition. This model achieved an accuracy of 93.4% and reduced the computational cost, parameters, and model size by 22.9%, 20%, and 50%, respectively, compared to the original model. Furthermore, Zeyang et al. [
18] reduced computational costs by replacing the original backbone network with EfficientNet-B0 and enhanced feature retention using a mobile inverted bottleneck convolution module. They also optimized the loss and activation functions using the Distance Intersection over Union and Hardswish, respectively, to improve convergence and inference speed. Their experimental results indicated an accuracy of 95.9% with a 55.1% reduction in computational cost, 48.9% smaller model, and 59.3% faster inference speed compared to the baseline model. Diye et al. [
19] adopted a lightweight FasterNet backbone to reduce the computational overhead and introduced cascaded group attention and high-level screening–feature fusion pyramid networks to address the feature fusion challenges in complex backgrounds. Furthermore, they implemented the Focaler Intersection over Union loss function to enhance edge detection precision. The resulting model achieved an accuracy of 96.4% with a 16.1% smaller computational cost, 18.2% fewer parameters, and 10.1% faster inference speed compared to the original model.
These results of previous research have clearly demonstrated iterative advancements in object recognition and detection technologies by improving critical technical characteristics, including detection accuracy, inference speed, and model size. Although innovative methodological frameworks and engineering solutions have been developed to advance these domains, few studies have evaluated the use of RTDETR-based lightweight models for tomato classification and recognition. To overcome these dual limitations of accuracy degradation and inefficient computation, RTDETR’s NMS-free architecture serves as the foundational framework. Its inherent attention mechanism provides robust occlusion reasoning capabilities, though structural optimization remains essential for agricultural edge deployment. Therefore, this study experimentally investigated the recognition performance of a proposed Lightweight Tomato Real-Time Detection Transformer (LiteTom-RTDETR) on images of tomato samples cultivated in plant factory laboratories in three growth stages (immature, semi-mature, mature) under three supplemental lighting conditions (blue, red, and white). The proposed LiteTom-RTDETR model is based on an RTDETR architecture that was improved to maintain high recognition accuracy while significantly reducing computational complexity. This approach provides a theoretical foundation for the deployment of agricultural vision systems on resource-constrained mobile devices.
The primary focus of this paper encompasses the following aspects:
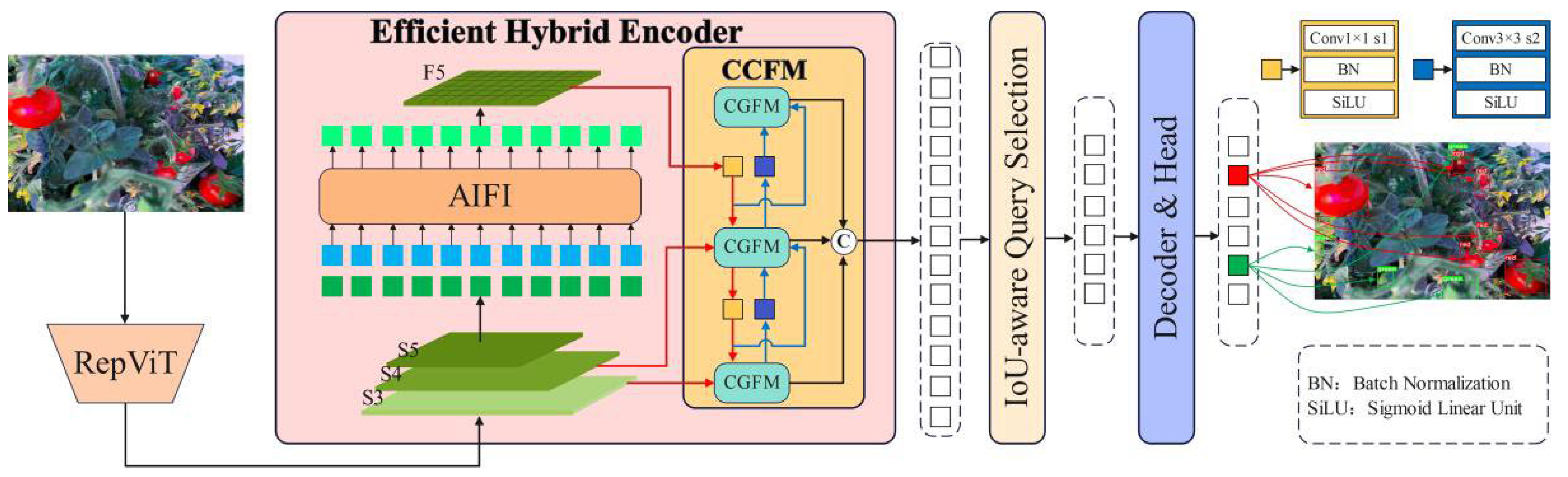
An innovative lightweight tomato-based target detection model named LiteTom-RTDETR is proposed for tomato detection in plant factories. This model not only effectively improves detection performance but also significantly reduces model complexity and parameter counts.
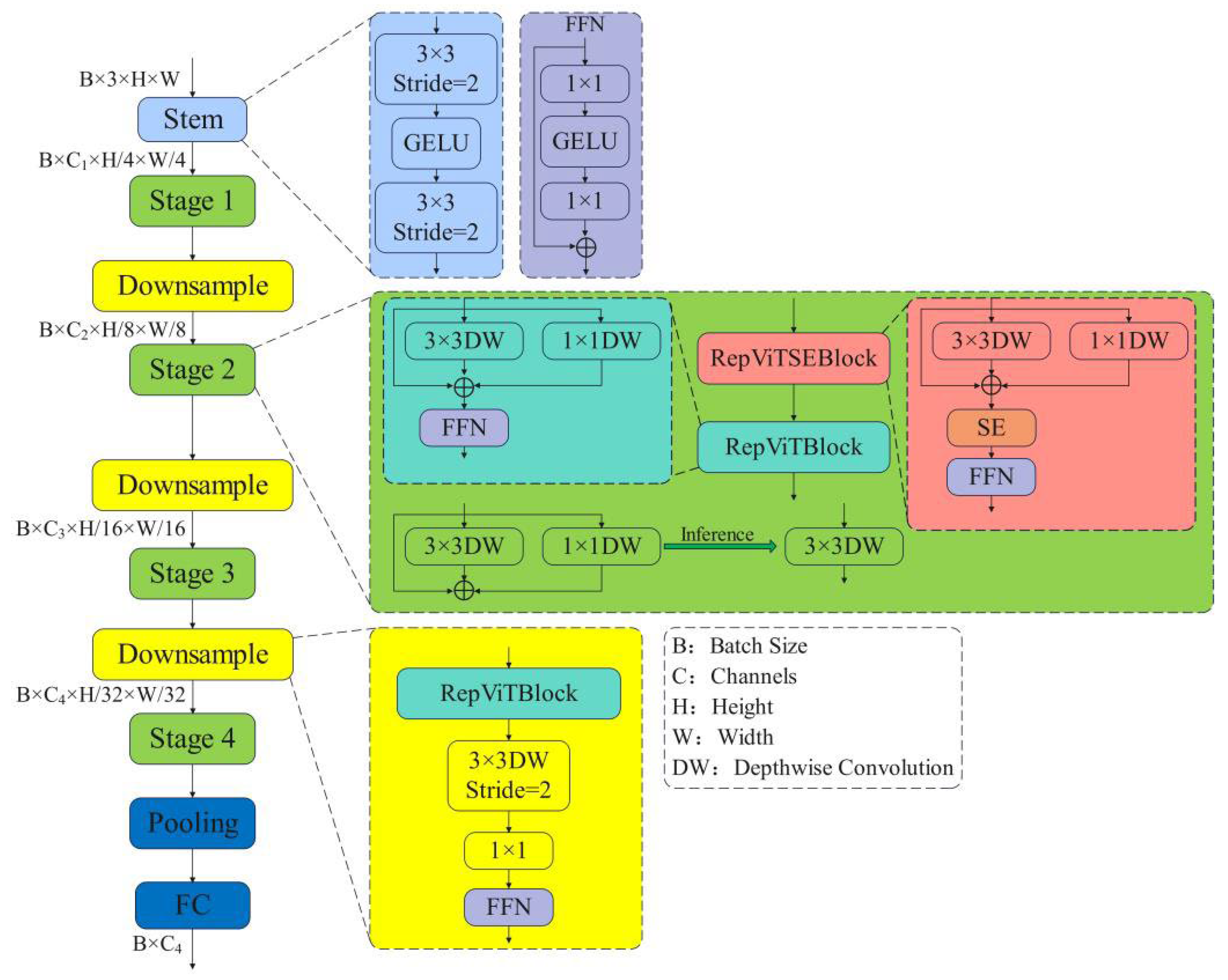
The backbone network of RTDETR-R18 is improved and designed based on the RepViT lightweight network. The backbone network adopts structural re-parameterization with stage-wise SE layer placement mechanisms. The proposed structure significantly reduces the number of parameters and computational requirements, thereby enhancing detection efficiency while preserving its ability to detect, thus leading to improved overall performance.
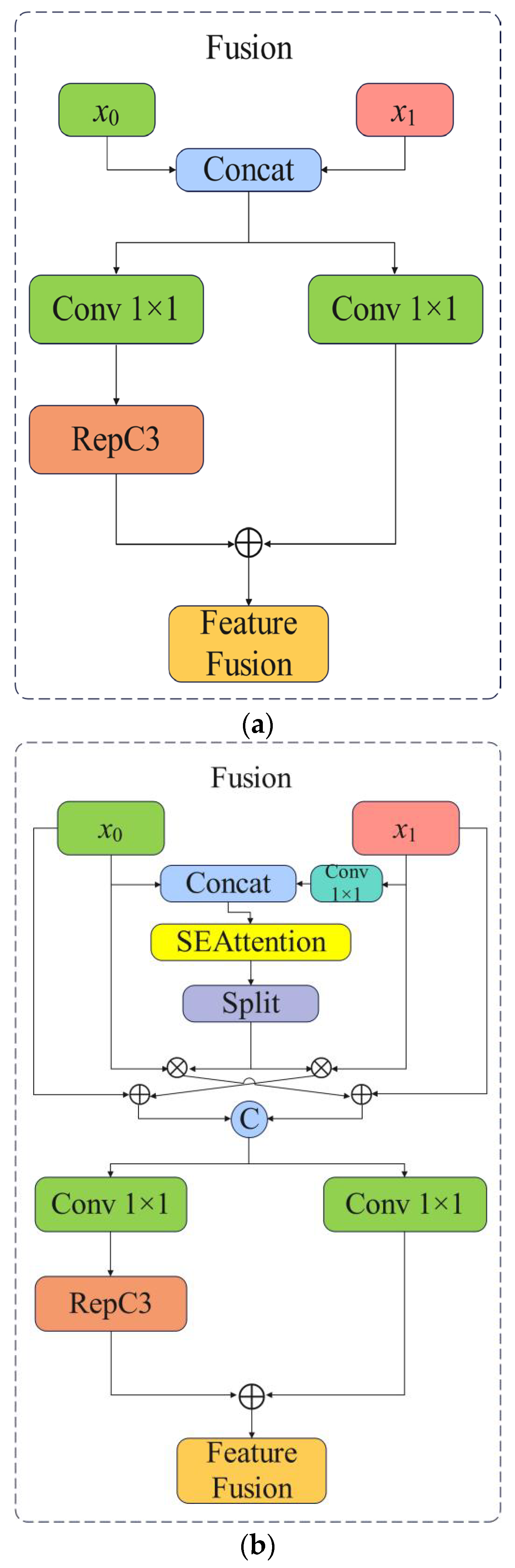
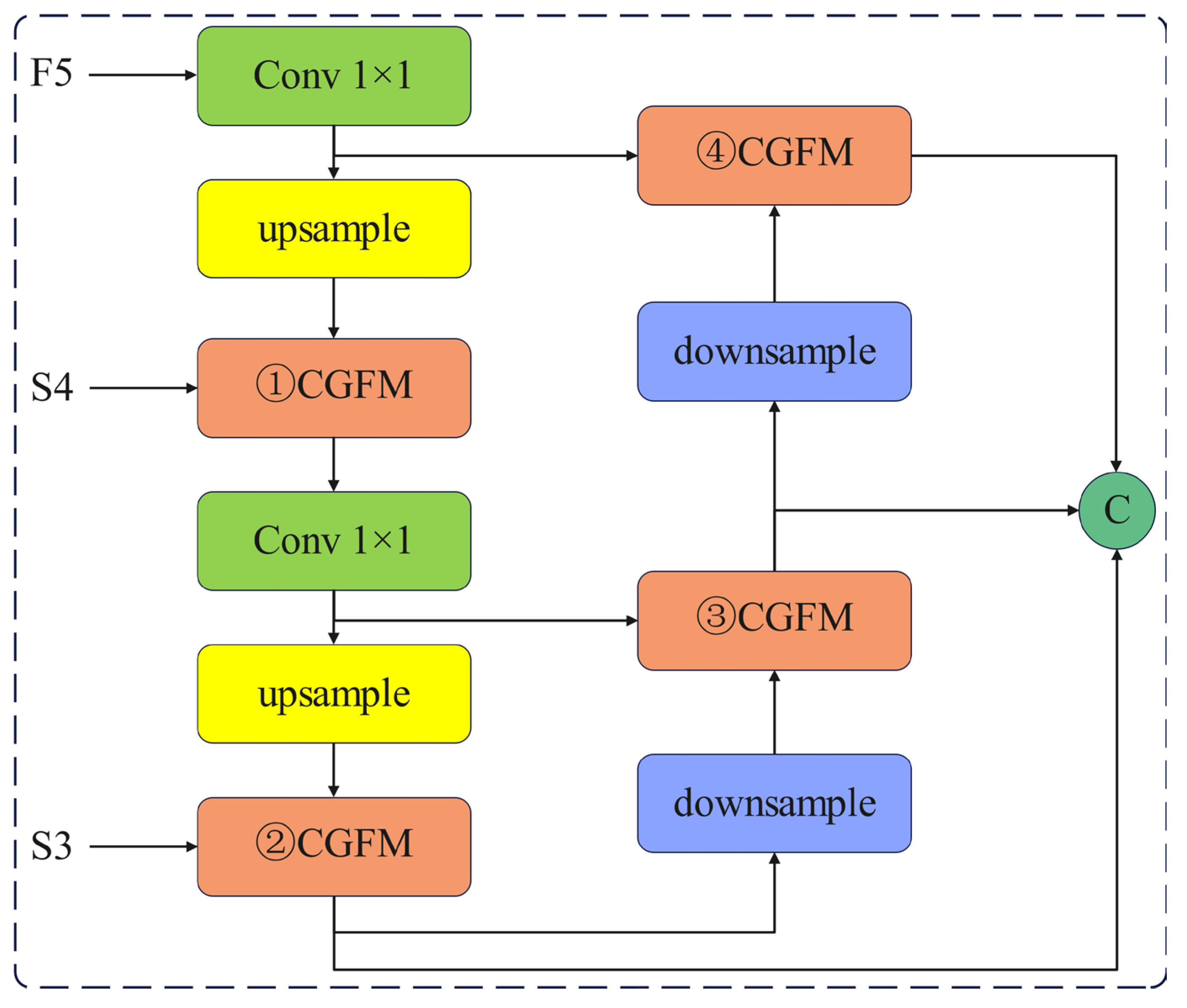
The neck structure is enhanced by the context-guided feature fusion module (CGFM), which achieves multiscale feature fusion through adaptive channel recalibration and dynamic weight allocation. This enhancement increases the model’s interlayer feature interactions during the encoding process through targeted attention weighting, thereby improving its detection capabilities. The SE Attention attention mechanism is employed to dynamically allocate distinct weights to each channel, thereby facilitating the network in prioritizing salient feature information, enhancing the model’s ability to capture crucial information, and improving its detection capability.
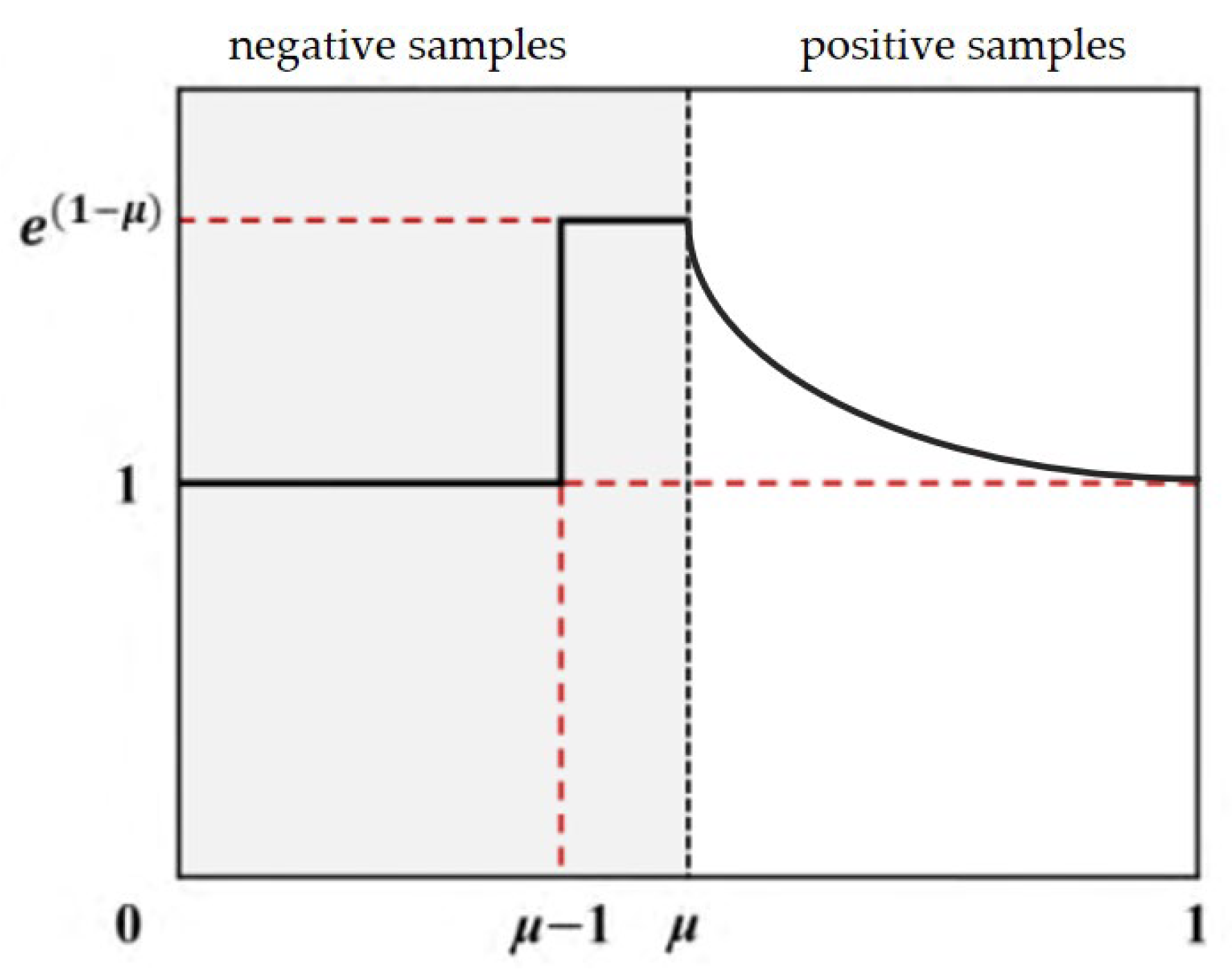
The Sliding Varifocal Loss (SVFL) integrates the dynamic sample weighting of Varifocal Loss (VFL) with the adaptive sliding mechanism. This function dynamically adjusts loss weights based on sample quality, prioritizing high-IoU samples while suppressing ambiguous or low-quality feature regions. This enhances detection accuracy and robustness in dense-object scenarios.
2. Related Work
Compared to established general-purpose object detectors (YOLOv8m and RTDETR), the proposed LiteTom-RTDETR achieves significantly lower parameters, GFLOPs, and model size. When compared to existing RTDETR-based specialized models (PP-DETR [
14], FCHF-DETR [
19], and the model in Reference [
20]), LiteTom-RTDETR also exhibits superior performance with reduced parameters and computational complexity. These results clearly indicate that the proposed LiteTom-RTDETR achieves exceptional computational efficiency, making it particularly suitable for deployment on resource-constrained agricultural mobile devices. The detailed parameter comparison is presented in
Table 1.
Recent studies, such as References [
14,
19,
20], have explored lightweight RT-DETR variants for edge deployment. Three critical distinctions emerge in LiteTom-RTDETR:
Architectural Innovation: The proposed RepViT+CGFM+SVFL architecture demonstrates significant efficiency improvements across multiple state-of-the-art frameworks: it achieves a simultaneous 44.4% reduction in parameters and 39.5% decrease in GFLOPs relative to Reference [
16]’s SPDRSFE+AFPN+Conv3XCC3 framework; reduces parameters by 18.4% and GFLOPs by 24.1% compared to Reference [
21]’s FasterNet+CGA+HSFPNSFF_Focaler+CloU structure; and attains parameter and GFLOPs reductions of 28.9% and 34.6%, respectively, against Reference [
22]’s SlimNeck+SENetv2+CGBlock design;
Domain-Specific Optimization: The task-specific optimizations for agricultural vision (e.g., enhanced dense-object detection for occluded tomatoes in
Section 3.3.3) contrast with the general-purpose methodology adopted in Reference [
17].
Efficiency–Accuracy Balance: As evidenced in Tables 9 and 10, LiteTom-RTDETR exhibits a 0.6% higher average detection accuracy, 15.5% faster inference speed, and reductions of 36.2% in computational cost and 31.6% in model size relative to the original RTDETR baseline, demonstrating superior efficiency–accuracy trade-offs.
These optimizations establish LiteTom-RTDETR as a deployable solution for resource-limited agricultural edge devices.
5. Conclusions
This study developed an automatic tomato detection model framework that balances complexity and recognition accuracy under challenging illumination conditions. Four phases of work were undertaken: dataset construction, model architecture optimization, detection algorithm deployment, and multistage experimental validation. The key findings of this study are as follows:
The LiteTom-RTDETR model was proposed based on an improved RTDETR architecture. This model achieved performance breakthroughs through three architectural innovations: backbone replacement with RepViT to reduce computational complexity, deployment of a CGFM to enhance multiscale feature representation under variable lighting, and integration of sliding weight mechanisms in the loss function to mitigate class imbalance. These synergistic improvements enabled real-time tomato detection at an inference speed of 52.2 FPS while maintaining a mean average precision of 88.2%.
Ablation experiments were conducted to assess the contributions of the architectural enhancements provided in LiteTom-RTDETR by evaluating five identification models under controlled experimental conditions. The replacement of the original RTDETR backbone with RepViT improved model accuracy while reducing parameter number, computational load, and model size, thereby achieving the preliminary lightweight objectives. Furthermore, the integration of the CGFM and SVFL function improved recognition accuracy without significantly increasing the number of parameters, computations, or model size.
Under identical experimental conditions, the LiteTom-RTDETR model demonstrated significant advantages over the Faster-RCNN, YOLOv8m, and original RTDETR models. The proposed model exhibited a 0.1–13.4% higher mean average precision while accelerating the inference speed by 15.5–84.5%; it also exhibited 33.2–53.0% fewer model parameters, 36.2–79.1% fewer GFLOPs, and a 31.6–75.6% smaller model size. These improvements collectively confirmed the successful lightweight implementation of the model while maintaining superior detection accuracy. Therefore, the proposed LiteTom-RTDETR model shows considerable promise for application in resource-constrained mobile agricultural management equipment.
6. Discussion
Prior successful deployments of lightweight models offer valuable references. Chen et al. [
22] implemented a YOLOv5-based road damage detection system on Android mobile devices, achieving real-time inference at 23 FPS. Similarly, Zhou et al. [
36] deployed an RTDETR-based defect detection model on RK3568 embedded systems, satisfying industrial real-time requirements with <50 ms latency. Building upon these proven approaches, the proposed LiteTom-RTDETR can be effectively deployed on agricultural mobile platforms to facilitate tomato localization and automated harvesting. The robotic harvesting implementation employs a systematic workflow comprising image acquisition, data annotation, model training, inference execution, target recognition, spatial localization, and robotic harvesting execution.
While LiteTom-RTDETR is designed for tomato recognition, its lightweight architecture provides a template for edge-compatible agricultural vision systems. The proposed model can be applied in plant factories, and by modifying training datasets, it can be adapted for crop recognition tasks, such as cucumbers or strawberries. Extending this framework to other crops requires three strategic developments:
Species-specific dataset curation: Collect crop images across diverse environments to ensure sufficient data coverage of different growth stages.
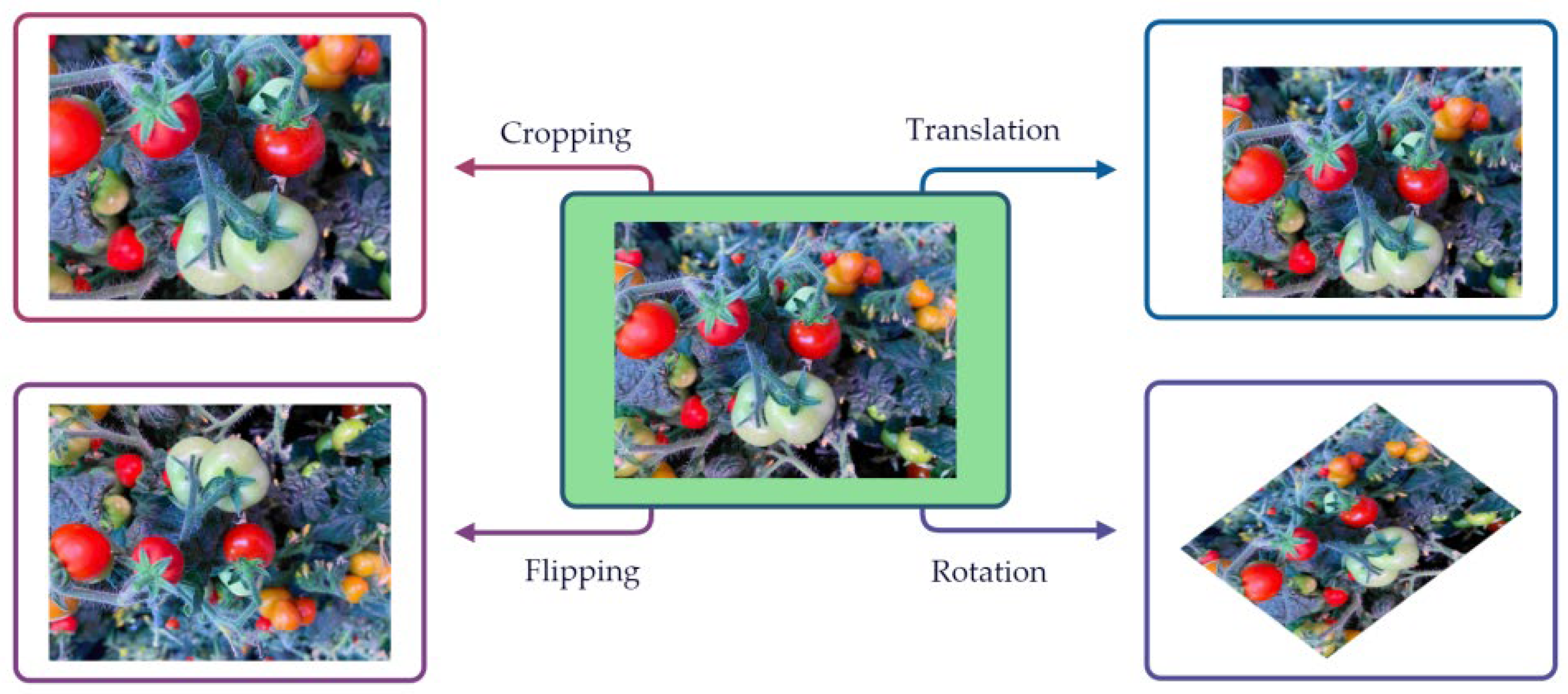
Data annotation and augmentation: Perform data annotation on the collected images to clarify identification targets. Conduct data augmentation when necessary to enhance the model’s generalization capability.
Model training: Perform experimental environment configuration according to
Section 3.4, followed by model training.
The deployment process requires converting the model into a mobile-optimized format and integrating it into the Android Studio project. First, the trained PyTorch model (.pt file) is converted to TensorFlow Lite format (.tflite). Subsequently, the existing model in the Android Studio project is replaced with the newly generated LiteTom-RTDETR model. Finally, a confidence threshold of 0.5 is established, ensuring that only tomato detection results exceeding this confidence level are displayed on the Android interface.
Future work will involve deploying LiteTom-RTDETR on mobile devices, extending its application to tomato localization, and ultimately integrating this solution to guide robotic harvesters for automated picking operations. Additional datasets will be collected, and more recognition networks will be evaluated. Furthermore, this lightweight model will be deployed on automated tomato harvesting equipment for detection trials in real-world vegetable garden environments.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}