1. Introduction
Dermatological diseases are common in the medical field, and among them, skin pigmentary lesions are primarily caused by an increase or decrease in pigment, leading to changes in skin color. Melanoma is the most severe form of skin cancer within skin pigmentary lesions. In the early stages of the disease, melanoma is easily confused with other benign pigmentary skin lesions [
1], and when the disease progresses to an advanced stage, treatment becomes significantly more difficult. Therefore, early detection of this disease is crucial. Due to factors such as hair, color, and blood vessel [
2,
3] distribution on the skin surface, as well as the low contrast between diseased and healthy skin, even experienced clinicians often struggle to accurately identify the lesion areas, which can hinder the diagnosis of malignant melanoma [
4]. In the medical field, medical image segmentation technology has evolved from manual segmentation to semi-automated and fully automated segmentation, with progressively improved segmentation results [
5]. With the increasing size, complexity, and quantity of medical images, traditional machine learning methods and manual segmentation techniques are no longer sufficient to meet the demands of modern healthcare. The introduction of deep learning methods has, to some extent, addressed this challenge [
6], significantly enhancing the efficiency and accuracy of image segmentation. However, the automatic segmentation of skin lesion images still faces several significant challenges, including hair occlusion [
7], ambiguous lesion boundaries [
8], low contrast between foreground and background [
9], and high intra-class variability of lesion appearances [
10]. These factors place substantial pressure on the discriminative and generalization capabilities of segmentation models. Therefore, the development of more robust segmentation algorithms is of critical importance for enhancing the accuracy and reliability of early melanoma detection [
11].
With the rapid development of deep learning technology, image processing capabilities have significantly improved, and image segmentation has become increasingly widespread in the medical field. Computer-Aided Diagnosis (CAD) [
12] has become an important tool in clinical diagnostics. Computer-aided diagnostic technology enables accurate segmentation of skin lesion areas, significantly improving the efficiency of clinical diagnosis. Traditional segmentation methods, including thresholding [
13], region-based segmentation [
14], edge-based segmentation [
15], and support vector machine (SVM)-based techniques [
16], are limited in their ability to extract high-level semantic features and often struggle to distinguish complex structures. To address common issues in skin lesion image segmentation, such as edge loss and insufficient segmentation accuracy, researchers have proposed various improvement algorithms. Long et al. [
17] pioneered the Fully Convolutional Network (FCN), enabling pixel-level image segmentation in an end-to-end manner, thus laying the foundation for semantic segmentation. Building upon this, a significant breakthrough in medical image segmentation came with the U-Net architecture proposed by Ronneberger et al. [
18], which employs a symmetric encoder-decoder structure and introduces skip connections to mitigate feature loss during up-sampling and down-sampling, effectively merging high-level and low-level semantic features, thereby promoting the widespread application of medical image segmentation. Subsequently, Oktay et al. [
19] introduced the Attention-UNet by embedding an attention mechanism within U-Net, adaptively adjusting the encoder output to extract more effective features. Innani et al. [
20] further proposed an Efficient-GAN framework based on U-Net, employing a composite scaling encoder based on Squeeze-and-Excitation to capture dense features and generate segmentation results, while using adversarial learning to distinguish between real and synthetic labels, ultimately improving the boundary segmentation accuracy in lesion regions.
However, existing deep learning methods still face certain limitations. For instance, when processing skin lesion images, traditional U-Net architectures may experience feature loss during the up-sampling and down-sampling processes of the encoder-decoder, which affects segmentation accuracy. Moreover, existing methods often fail to fully account for the unique characteristics of skin lesion images, such as variations in the size and shape of lesion regions, hair occlusion, bubble interference, and uneven coloration.
To overcome these challenges, we propose a novel skin lesion segmentation framework that synergistically integrates a U-Net architecture incorporating dense convolutional blocks, attention mechanisms, and Long Short-Term Memory (LSTM) module with the discriminative power of a multi-scale Generative Adversarial Network (GAN). The proposed method achieves dual improvements in both segmentation precision and feature discriminability for diverse lesion patterns, demonstrating state-of-the-art performance across multiple benchmark dermatoscopic image datasets. The principal contributions of this work include:
Improvement of U-Net Architecture: We have made significant improvements to the traditional U-Net architecture by enhancing the encoder-decoder up-sampling modules, incorporating attention mechanisms in the skip connections, and integrating generative adversarial training. These modifications strengthen the model’s ability to recognize and segment complex skin lesion features.
Integration of Attention Mechanism: The attention mechanism is introduced into the model, a strategy that significantly improves the model’s ability to segment skin lesions and normal skin areas, as well as distinguish between common and rare types of lesions, by learning the features of the lesion regions in a batch manner.
Addressing Feature Loss Issue: By incorporating the Bidirectional Convolutional Long Short-Term Memory (BDC-LSTM) module, which combines Long Short-Term Memory (LSTM) and Convolutional Neural Networks (CNNs), we effectively address issues such as gradient vanishing or explosion during training. This approach helps retain crucial feature information and focuses on solving the feature loss problem commonly encountered in the traditional U-Net architecture during the up-sampling and down-sampling processes.
Extensive Experimental Validation: We conducted extensive experiments on multiple skin lesion image datasets to validate the effectiveness of our proposed method and its applicability in recognizing different types of skin lesions. Additionally, we assessed the generalizability of the model across other datasets.
The following sections of this paper will provide a detailed description of our method, including the design of the model architecture, the implementation of generative adversarial training, and the experimental results and analyses on various datasets.
2. Related Work
Early traditional machine learning segmentation methods are cumbersome and heavily reliant on the physician’s prior knowledge and clinical experience during the feature selection phase, requiring extensive manual intervention. This not only increases operational complexity, but also makes the process susceptible to subjective judgment and external factors, leading to feature extraction bias that ultimately affects segmentation accuracy and the reliability of the final diagnostic results. In contrast, deep learning methods, through end-to-end training, automatically extract high-level features from images, significantly reducing manual intervention and effectively improving the accuracy and stability of medical image segmentation. The U-Net segmentation network enhances the precision and consistency of segmentation results by actively learning image features, incorporating well-designed loss functions, and optimizing through gradient-based algorithms. It has become an essential tool in the field of medical image segmentation, playing a critical role in assisting physicians to make more accurate diagnoses.
The U-Net++ model proposed by Zhou et al. [
21] incorporates a deep network architecture with multi-layer skip connections to improve feature fusion. However, it faces accuracy limitations when handling blurred boundaries and complex lesion shapes. Xiao et al. [
22] introduced a weighted Res-UNet model that builds upon the original Res-UNet by incorporating a weighted attention mechanism. This allows for more precise learning of pixel features in lesion and normal regions, thereby enhancing segmentation accuracy at lesion boundaries. Ruan et al. [
23] proposed the Multi-Attention and Lightweight U-Net (MALUNet) model, which effectively balances parameter efficiency and segmentation performance by integrating multiple attention mechanisms with a lightweight design. However, its effectiveness is constrained when dealing with complex lesion regions. Le et al. [
24] developed a mobile anti-aliasing attention U-Net model, which mitigates high-frequency information loss and enhances segmentation accuracy by using anti-aliasing pooling layers. Nonetheless, this approach results in insufficient capture of fine-grained details, particularly at lesion boundaries. Dai et al. [
25] introduced a multi-scale residual encoder, which enhances feature representation learning by integrating the benefits of adaptive multi-scale features. Gu R et al. [
26] proposed the CA-Net model, which integrates a multi-scale attention mechanism with residual connections, effectively adapting to spatial locations, feature channels, and object scales, thus achieving higher accuracy. However, it still faces performance bottlenecks when dealing with larger-scale contextual relationships. Rahman et al. [
27] presented an integrated attention gating mechanism and multi-scale convolutional model, which effectively addresses segmentation challenges for irregular shapes and multi-scale objects. Nevertheless, it exhibits limited performance when processing lesion boundary regions and suffers from high model complexity. Wu et al. [
28] introduced an image segmentation method that combines an adaptive dual-attention mechanism, effectively improving feature extraction specificity and segmentation accuracy.
Long Short-Term Memory (LSTM) networks have been widely applied in image segmentation tasks due to their outstanding performance in sequence data modeling, particularly in extracting complex spatial dependencies and contextual information from images. Yu H et al. [
29] proposed the MSAU-Net model, which combines bidirectional convolutional LSTMs to extract shared discriminative features from lesion regions, while suppressing features with lower information content. However, this approach results in high complexity, requiring significant computational resources. Shahzaib et al. [
30] introduced the TESL-Net model, which uses Swin-Transformer blocks in the encoder module to effectively extract global contextual information from skin lesion images. Nevertheless, the model’s ability is limited when dealing with complex lesion images. Rao et al. [
31] proposed the U-LSTM model, which integrates the spatial feature extraction capability of CNNs with the temporal sequence modeling ability of LSTMs. This architecture enables simultaneous capture of both static features and dynamic changes of skin lesions; however, the model is structurally complex and demands substantial computational resources. K. P. Arjun et al. [
32] introduced the RCNN-LSTM, combining the strengths of RCNN and LSTM to extract spatial features while handling temporal information, making it suitable for complex image data. Nevertheless, its segmentation performance is limited when processing lesion boundaries in smaller images.
Generative Adversarial Networks (GANs), first proposed by Goodfellow et al. [
33] in 2014, pioneered a new direction in the research of deep generative models. The core concept of GAN involves constructing an adversarial game between a generator and a discriminator, allowing the generator to progressively improve the authenticity of the generated samples. Bi et al. [
34] introduced an adversarial learning-based method for automatic skin lesion segmentation, which enhances segmentation performance by performing data augmentation and deeply fusing features extracted through convolution operations in both the encoder and decoder. Wei Z et al. [
35] proposed the Att-DenseUnet model based on GANs, which effectively integrates multi-scale features within the encoder, thereby strengthening feature representation capabilities. Additionally, by incorporating an attention mechanism, the model suppresses irrelevant regions in the output feature maps, reducing the impact of artifacts. The introduction of adversarial loss further enhances the discriminative power of the generated features, thereby improving the segmentation accuracy of the model. Nidhi Bansal et al. [
36] proposed HEXA-GAN, which significantly enhances the accuracy of hair segmentation and enables natural reconstruction of hair-occluded regions, thereby improving the overall visual consistency of dermoscopic images. Bansal, N. et al. [
37] introduced EA-GAN, which integrates attention mechanisms and vision transformers to effectively remove artifacts and hair interference from lesion areas. This approach substantially improves the quality of skin lesion image preprocessing, thereby enhancing the accuracy and robustness of subsequent diagnostic systems.
3. Methods
This paper proposes a novel skin lesion image segmentation model based on the U-Net architecture, incorporating concepts such as dense networks, bidirectional long short-term memory networks, and attention mechanisms. The model consists of two parts: the segmentation module and the discriminator module.
3.1. Segmenter
The proposed segmenter is based on the U-net architecture and primarily consists of the encoder down-sampling path, the decoder up-sampling path, a hybrid multi-scale attention module, and an attention module based on skip connections. These connections correspond to the respective layers between the two paths, as illustrated in
Figure 1. The detailed description of the segmenter is as follows:
3.1.1. Encoder Module
Due to the multi-scale nature and variability of skin lesions, and inspired by the DenseNet architecture that connects all layers densely, we adopt a DenseNet-like [
38] structure in the down-sampling path to enhance the flow of multi-scale information. This path consists of four dense blocks, each containing d dense layers. The output feature map channels of each dense layer are the same, with a growth rate k. Within the same dense block, the resolution of the feature maps remains unchanged, and the input of each dense layer is the concatenation of the outputs from all previous dense layers. As the network depth increases, features in the down-sampling path are reused, leading to a significant increase in memory usage. To address the increased memory consumption caused by dense blocks and to expand the receptive field, a transition layer is introduced after each dense block. This transition layer comprises batch normalization (BN) to stabilize training, a ReLU activation function to introduce non-linearity, a 1 × 1 convolutional layer to reduce the number of channels and computational complexity, and a 2 × 2 average pooling layer for spatial down-sampling of the feature maps, thereby reducing their spatial dimensions and enlarging the receptive field. This design effectively mitigates memory overhead while enhancing the model’s ability to capture multi-scale information. The overall computational process of the dense convolutional module is expressed by the following equation:
In the equation,
represents the non-linear operation consisting of Batch Normalization (BN), ReLU, and convolution operations, and
represents the concatenation of the feature maps from the outputs of layers 1 to
. The architecture of the dense convolutional module is illustrated in
Figure 2.
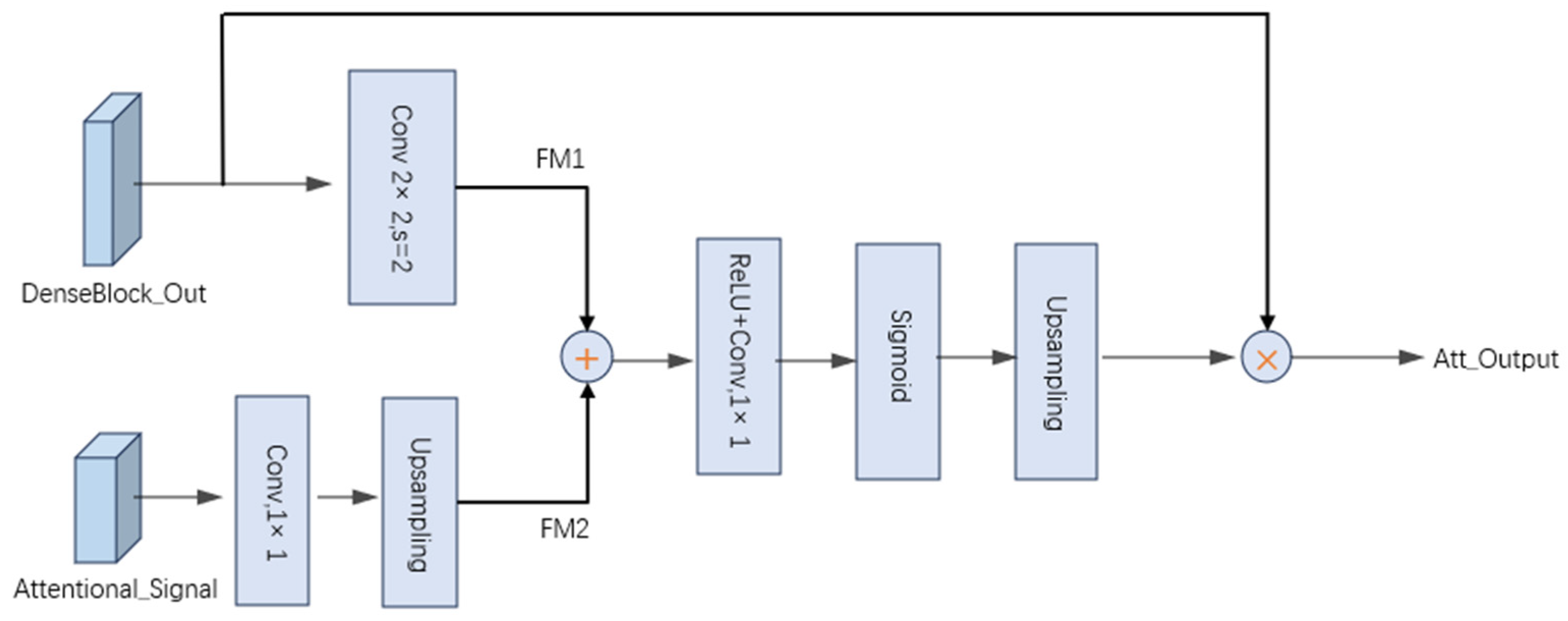
3.1.2. Attention Module
In medical image segmentation tasks, the target regions often exhibit irregular shapes, varying sizes, and blurred boundaries, which cause traditional skip connections to introduce redundant information during feature fusion, thereby affecting segmentation accuracy. To enhance the model’s ability to model critical information, we propose an improved attention mechanism that generates spatial attention maps by jointly leveraging the information from the attention signal Attentional_Signal and the local feature map DenseBlock_Out. The attention module contains two inputs: the attention signal
and the local feature map
. We define the local feature map as
}, where
represents the feature vector at the i-th pixel position in the feature map
, with
channels. The attention signal is defined as
, where
represents the feature vector at the j-th pixel position in the feature map
, with D channels. First, we apply a 1 × 1 convolution, batch normalization, and ReLU activation to the attention signal
to extract global contextual information and reduce dimensionality. Then,
is up-sampled to align its spatial dimensions with
, resulting in channel-matched feature maps
and
. Subsequently,
and
are element-wise added and passed through a ReLU activation to generate the spatial attention map. Finally, the generated attention map is multiplied element-wise with the original input feature map to obtain the attention-modulated output, denoted as Att-Output. The specific computation is shown in Equation (3).
In the equation,
denotes a 1 × 1 convolution kernel with ccc filters;
represents a 3 × 3 convolution with a stride of 2; and
refers to a 1 × 1 convolution kernel with a single filter. The up-sampling operation, denoted as Up, utilizes bilinear interpolation to match the spatial dimensions. As a result, the generated attention map shares the same spatial resolution as the output of the dense module
. Subsequently, the attention map is element-wise multiplied with DenseBlock_Out to produce the final output of the attention module.
By performing weighted fusion of features across different hierarchical levels, the attention mechanism effectively captures critical target information at multiple scales while suppressing background noise and irrelevant regions. This enhances the saliency of the target area and improves the network’s ability to focus on and localize the region of interest. The specific attention module is illustrated in
Figure 3.
3.1.3. Channel Spatial Attention Enhancement Module
In our network architecture, the deepest feature map encapsulates global image information, where an attention mechanism is employed to enhance salient spatial and channel-wise features. Specifically, we integrate the Convolutional Block Attention Module (CBAM) [
39] and train it end-to-end alongside the base network to prioritize critical regions and discriminative features while suppressing irrelevant background noise. The core principle of this approach lies in inferring attention weights along two orthogonal dimensions (channel and spatial) and subsequently applying these weights to the original feature maps through multiplicative modulation, thereby enabling adaptive feature refinement. This dual-path attention mechanism allows the model to dynamically emphasize informative features while attenuating redundant or distracting elements, leading to more efficient and discriminative feature representation.
The Convolutional Block Attention Module consists of two sequentially arranged submodules: channel attention and spatial attention. The channel attention mechanism focuses on identifying and emphasizing the most informative channels by adaptively recalibrating channel-wise feature weights, thereby enabling more effective extraction of global contextual information. Distinct from the standard CBAM, which employs global pooling operations, we propose a multi-scale pooling strategy by incorporating average pooling with kernel sizes of 2 × 2 and 4 × 4. This approach captures both local and semi-global statistical information, thereby enhancing the model’s capability to assess the importance of channel features across different spatial scales.
The detailed procedure of the channel attention module is illustrated in
Figure 4. Given an input feature map
, spatial compression is first performed in parallel using average pooling operations with two different kernel sizes (2 × 2 and 4 × 4), global average pooling, and max pooling, respectively generating four feature vectors F
1, F
2, F
3, and F
4, each having spatial dimensions smaller than those of the original feature map. Subsequently, these four feature vectors are separately fed into a shared multi-layer perceptron (MLP) to ensure parameter efficiency. The outputs of the MLP are channel descriptor vectors with spatial dimensions 1 × 1 and channel dimension C. Finally, the four output feature vectors are summed element-wise and passed through a sigmoid activation function, yielding the channel attention weight vector
with size 1 × 1 × C. The detailed computational pipeline is shown in
Figure 4, with the mathematical formulation provided in Equations (4)–(8):
In the equation,
denotes the sigmoid activation function; the multi-layer perceptron is represented by the notation MLP; average pooling is denoted by the symbol
; 2 × 2 pooling is denoted by the symbol
; 4 × 4 pooling is represented by the symbol
; and max pooling is indicated by the symbol
.
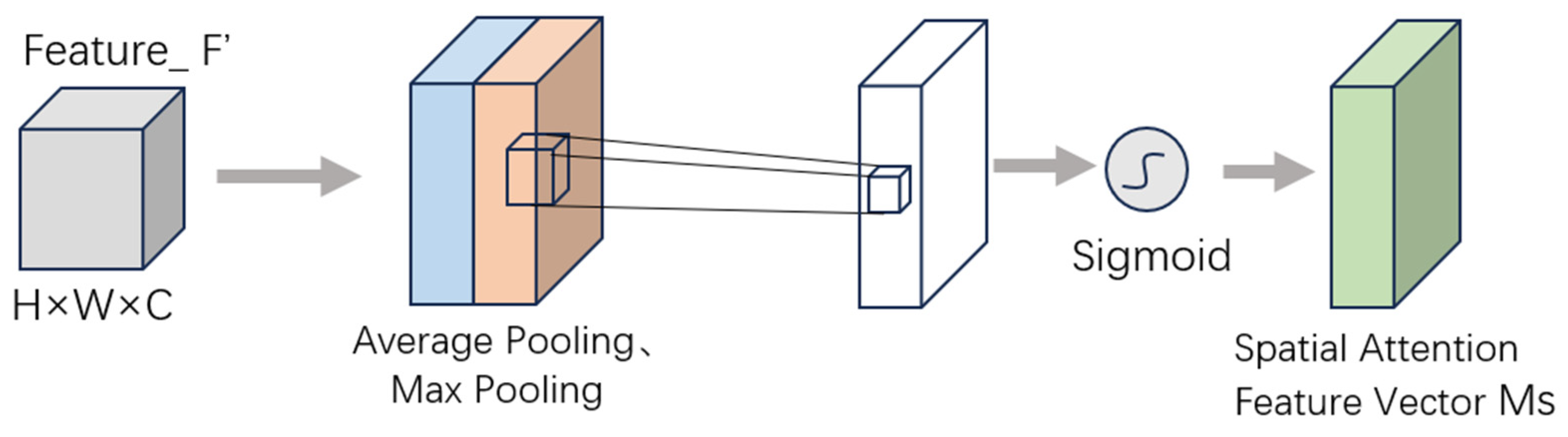
The spatial attention mechanism, in contrast, is designed to focus on salient regions within feature maps by computing pixel-wise importance weights, thereby directing the model’s attention towards critical spatial areas. The computational pipeline operates as follows: Given the channel-refined feature map
, the mechanism first applies both max pooling and average pooling operations along the channel dimension to generate two spatial descriptors (
and
) of size H × W × 1. These descriptors are subsequently concatenated along the channel axis to form a composite feature representation of dimension H × W × 2. This concatenated feature map is then processed through a convolutional layer with a 7 × 7 kernel and stride of 1, which effectively captures broad spatial contextual information. Finally, a sigmoid activation function is applied to generate the spatial attention weights
, where each element represents the relative importance of the corresponding spatial location. The complete mathematical formulation is provided in Equation (9), demonstrating the transformation from channel-refined features to spatially weighted outputs through this carefully designed sequence of operations.
In the equation,
σ denotes the sigmoid activation function,
Conv represents the convolution operation, average pooling is denoted by the symbol
, and max pooling is indicated by
. The complete computational procedure is illustrated in the spatial attention module of
Figure 5.
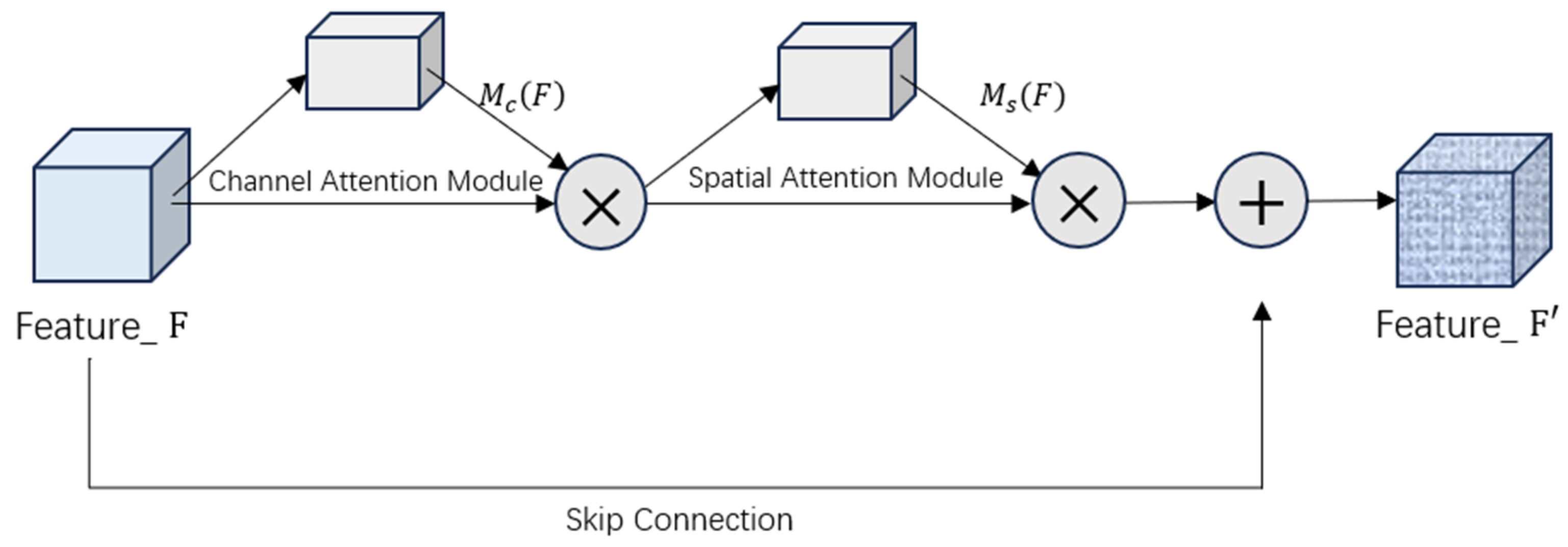
The CBAM module’s operational pipeline follows a carefully designed sequential attention mechanism, as formally characterized below. The input feature map
F first undergoes channel-wise refinement through multiplication with the channel attention vector
, producing the intermediately enhanced feature representation
. This channel-attentive feature map then enters the spatial attention phase, where it is modulated by the spatial attention weights
to yield
F2. The final output
F′ is obtained through a residual summation that combines the original features with the doubly attentive modifications, as mathematically formulated in Equations (10)–(12).
In the formulation,
denotes the channel attention map,
represents the spatial attention map, and the operator ⊙ indicates element-wise multiplication (Hadamard product). The complete computational procedure is illustrated in
Figure 6.
3.1.4. Bidirectional Convolutional LSTM Temporal Modeling Module
While CBAM enhances critical features through channel and spatial attention mechanisms, it remains limited in capturing long-range spatial dependencies. Moreover, conventional unidirectional LSTM networks can only exploit past information, making them inadequate for modeling bidirectional contextual relationships—particularly when dealing with complex structures or ambiguous boundaries in skin lesion regions. To address these limitations and further improve the model’s capacity for understanding and perceiving lesion areas, we introduce a Bidirectional Convolutional Long Short-Term Memory (BDC-LSTM) module following the attention mechanism. ConvLSTM integrates convolutional operations into the traditional LSTM architecture, enabling it to process spatially structured sequential data more effectively. Unlike fully connected LSTMs, ConvLSTM applies convolutional operations to the input, hidden states, and gating mechanisms, thereby capturing spatial features and local dependencies with greater precision. The core computations of ConvLSTM include the input gate
, forget gate
, output gate
, and the update of the cell state, all of which are adapted to handle spatial information inherent in image data. The corresponding calculation formula is given in Equations (13)–(17).
In the mathematical formulation,
W denotes the learnable weight matrices,
b represents the bias terms,
signifies the input tensor at time step
t,
corresponds to the hidden state tensor, and
indicates the cell state tensor. The operator
σ refers to the sigmoid activation function, while ⊙ designates the element-wise multiplication (Hadamard product) operation.
Building upon this foundation, we integrate the Bidirectional Convolutional Long Short-Term Memory (BDC-LSTM) module after the attention mechanism. On one hand, this strategy leverages the salient features enhanced by the attention mechanism as input, allowing the model to focus more effectively on key regions for spatiotemporal modeling. On the other hand, it compensates for the limitations of attention mechanisms in capturing long-range dependencies, thereby improving the model’s ability to recognize lesion morphology variations and ambiguous boundaries. The BDC-LSTM module consists of two independent ConvLSTM branches: a forward branch that processes the feature sequence
in chronological order, gradually accumulating information from past states; and a backward branch that traverses the sequence in reverse order
, modeling the potential influence of future states on the current state. At each time step, the hidden states from both the forward and backward ConvLSTM branches are non-linearly transformed and fused using a hyperbolic tangent (tanh) activation function, resulting in a more comprehensive spatiotemporal context representation. The detailed process is illustrated in
Figure 7. This bidirectional structure enables BDC-LSTM to aggregate feature information from both temporal directions, effectively establishing long-range contextual dependencies and enhancing the consistency of feature representation as well as segmentation accuracy. The corresponding computation is defined in Equation (18).
In the formulation,
denotes the output at the current time step;
W represents the weight matrix;
indicates the hidden state; and b refers to the bias term. The detailed process is illustrated in
Figure 7.
3.1.5. Decoder Path
The up-sampling pathway adopts a symmetrical architecture utilizing transposed convolutions to facilitate hierarchical feature fusion. Each up-sampling module initially performs bilinear interpolation to double the spatial resolution, followed by a 3 × 3 convolutional layer equipped with batch normalization for effective feature transformation. Subsequently, a ReLU activation function is applied to introduce non-linearity. During the decoding process, the up-sampled feature maps are concatenated along the channel dimension with their corresponding encoder features through skip connections, enabling the seamless integration of high-level semantic information with low-level spatial details. The concatenated features are further refined via dense convolutional blocks, which promote feature reuse and enhance multi-scale representation capability. The decoder progressively reconstructs the spatial resolution through four successive up-sampling stages, each doubling the resolution, culminating in a 1 × 1 convolutional layer that projects the refined features onto the target classes for end-to-end pixel-wise prediction. This architectural design ensures precise segmentation performance while maintaining computational efficiency through systematic feature recombination.
3.2. Discriminator
The discriminator employs an inverted pyramidal multi-scale feature extraction architecture with progressive spatial down-sampling for robust adversarial discrimination. The network first utilizes three parallel convolutional pathways with varying receptive fields to capture both local and global structural features, where each pathway independently processes the input through
for
. The multi-scale features are then concatenated along the channel dimension to form an enriched representation. Subsequent stages employ strided convolutions for hierarchical feature compression: the second layer maintains dual-path 3 × 3 and 5 × 5 convolutions to preserve multi-scale processing, while the third and fourth layers utilize single 3 × 3 convolutions for efficient spatial reduction. All intermediate layers incorporate batch normalization and LeakyReLU activation to ensure training stability. The final discrimination head employs a 4 × 4 valid convolution coupled with sigmoid activation. The calculation formula for the final discrimination output is shown in Equation (19):
In the formulation,
σ denotes the sigmoid activation function;
W represents the weights of the final convolutional kernel;
Conv represents stride-1 convolution with no padding;
represents the input feature map from the fourth layer; and
b is the bias term.
3.3. Generative Adversarial Network
This paper proposes an adversarial training framework based on Generative Adversarial Network (GAN) [
40], designed to improve the segmentation performance of skin lesions in medical images. By integrating a multi-scale convolutional discriminator with a semantic segmentation network, the framework establishes an end-to-end adversarial optimization mechanism, enabling the generated segmentation maps to closely approximate the ground truth. The entire system is trained through an alternating optimization strategy between the generator and the discriminator, resulting in more stable and accurate segmentation outcomes. During training, the Adam optimizer is employed to optimize both the generator and the discriminator independently over 100 epochs, aiming to accelerate convergence while maintaining model stability. The optimizer parameters are configured as follows: an initial learning rate of 0.0001, a first-order momentum decay rate of 0.9, and a second-order momentum decay rate of 0.999. In addition, mixed-precision training is adopted to reduce memory consumption and enhance computational efficiency, while gradient clipping with a threshold of 1.0 is applied to prevent gradient explosion.
The discriminator is designed with a three-layer multi-scale feature extraction module. Each convolutional layer is followed by batch normalization and a LeakyReLU activation function, which enhances non-linear representation capability and stabilizes the training process. The final discrimination probability is obtained through a 4 × 4 valid convolution followed by a sigmoid activation function, indicating the likelihood that the input segmentation map is real or generated. The generator adopts a four-stage symmetric up-sampling architecture, where each stage consists of bilinear interpolation, a 3 × 3 convolution, batch normalization, and a ReLU activation function. This structure progressively restores the resolution of the feature maps to the original input size. To preserve spatial details and improve localization, skip connections are introduced during the decoding process, linking feature maps from corresponding encoder layers directly to the decoder, thereby enhancing multi-scale feature fusion and spatial precision.
To further improve the model’s generalization capability and adapt to different training phases, a dynamic learning rate adjustment strategy is implemented. When validation metrics (e.g., Dice coefficient or accuracy) show no improvement for five consecutive epochs, the learning rate is automatically reduced by a factor of 0.1, helping the model escape local minima and achieve better overall performance. The final segmentation output is generated via a sigmoid activation function, producing a probability map that aligns closely with the ground truth annotations.
3.4. Loss Function
In the design of the loss function, we combine Dice Loss with Binary Cross-Entropy (BCE) Loss [
41]. The Dice Loss effectively alleviates the class imbalance problem by measuring the overlap between the predicted results and the ground truth masks, thereby promoting the model’s ability to learn more accurate boundary information. On the other hand, BCE Loss, as a pixel-wise loss, provides stable gradient information and enhances the model’s ability to recognize the target regions. The two losses can be expressed as Equations (20)–(22).
3.5. Experimental Details
3.5.1. Experimental Setup
The experiments for the proposed skin lesion image segmentation model were conducted using a deep learning framework based on Python version 3.9 The operating system used is Windows 10, and the GPU utilized is an NVIDIA 3080 with a memory capacity of 16 GB (NVIDIA Corporation, Santa Clara, CA, USA).
3.5.2. Dataset and Preprocessing
In this paper, we utilized the PH
2 dataset alongside the ISIC 2017 and ISIC 2018 datasets from the ISBI challenge for model training and validation. The PH
2 dataset comprises 200 dermoscopic images, which were divided into 140 training samples, 20 validation samples, and 40 test samples. The ISIC 2017 dataset consists of 2000 original images with corresponding annotations, supplemented by 150 validation samples and 600 test samples. The ISIC 2018 dataset contains 2596 images and their annotations, supplemented by 200 validation samples and 596 test samples. The detailed composition of these datasets is summarized in
Table 1. Collectively, these datasets cover three primary types of skin lesions, melanoma, seborrheic keratosis, and nevus, which offer both strong representativeness and significant challenges for segmentation tasks. As illustrated in
Figure 8, images from the ISIC 2017 test set exhibit lesions on raw dermoscopic images. Notably, the presence of noise artifacts such as hair and bubbles is evident, which increases the complexity of lesion segmentation and poses challenges for practical applications.
The dataset utilized in this study exhibits significant challenges for deep learning-based feature extraction, including image noise, blurred boundaries, heterogeneous skin tones, hair occlusion, capillary interference, and diverse lesion morphologies. Given the limited size of publicly available dermatological datasets and the prohibitive cost of manual annotation, we implemented an extensive data augmentation pipeline incorporating both geometric transformations and photometric variations. This approach effectively expanded the training dataset while preserving pathological features, as validated through quantitative performance improvements in subsequent experiments.
To address the challenges posed by varying image sizes and significant resolution discrepancies in skin lesion datasets, this study implements a comprehensive data normalization and augmentation strategy. The specific details of the dataset are shown in
Table 1. Initially, all lesion images are rescaled to a uniform resolution of 256 × 256 pixels to eliminate scale variability. Furthermore, to mitigate the limitation of insufficient sample sizes in publicly available datasets, a multidimensional data augmentation approach is employed. This includes geometric transformations such as rotation, multi-directional translation, scaling, and flipping. These operations enhance data diversity and significantly improve the model’s generalization capability while preserving the integrity of pathological features. The specific training data are presented in
Table 2.
3.5.3. Evaluation Metrics
In this experiment, commonly used segmentation evaluation metrics for medical image segmentation are employed to assess the model’s performance, including
Accuracy, Dice Similarity Coefficient (
Dice), Specificity, Sensitivity (
SE), and mean Intersection over Union (
mIoU), calculated as follows:
In the formulation,
TP denotes the number of positive samples correctly predicted as positive,
FP represents the number of negative samples incorrectly predicted as positive,
FN indicates the number of positive samples incorrectly predicted as negative, and
TN refers to the number of negative samples correctly predicted as negative.
5. Discussion
To tackle the inherent challenges of medical image segmentation, including morphological variability and indistinct lesion boundaries, this study introduces MA-DenseUNet—a novel and task-specific segmentation framework designed to enhance lesion delineation in medical imaging. Specifically, a newly designed dense convolutional module is integrated into the encoder to strengthen feature representation and facilitate the extraction of high-level semantic information. The dense connectivity promotes efficient feature propagation across layers, mitigating issues such as gradient vanishing and feature redundancy.
To further improve the model’s attention to critical lesion regions, a multi-scale Convolutional Block Attention Module (CBAM) is incorporated. By jointly leveraging multi-scale channel and spatial attention, the model effectively concentrates on lesion-relevant features while suppressing background noise. Moreover, to address issues related to blurred lesion boundaries and unclear textures, a Bidirectional Convolutional Long Short-Term Memory (BDC-LSTM) module is embedded within the bottleneck layer. This enables the modeling of forward and backward spatial dependencies, enhancing the integration of local and global contextual information and improving segmentation in complex anatomical structures. Furthermore, a multi-scale Generative Adversarial Network (GAN) is introduced to refine segmentation results through adversarial learning. By employing discriminators at multiple scales, the model enforces fine-grained structural realism in the predicted segmentation maps, particularly at lesion boundaries. This adversarial strategy enhances the generator’s capacity to reconstruct detailed lesion contours, contributing to more stable and robust segmentation outcomes, especially under challenging background conditions.
To evaluate the robustness and generalizability of the proposed method, extensive comparisons are conducted with several state-of-the-art models published in recent years. As shown in
Table 3, on the PH
2 dataset, MA-DenseUNet achieves improvements of 0.6% in Dice coefficient, 0.42% in specificity, and 1.5% in sensitivity over LCAUnet, along with a 2.4% increase in mean Intersection over Union (mIoU). These results confirm the model’s superior capability in accurately localizing skin lesions, particularly by improving recall without compromising precision. Additionally, as illustrated in
Table 4 and
Table 5, MA-DenseUNet consistently outperforms contemporary approaches on the ISIC dataset across all evaluation metrics. The model demonstrates strong adaptability in segmenting various lesion types, especially those characterized by irregular shapes, fuzzy boundaries, and low contrast. These findings substantiate the effectiveness and practical utility of the proposed framework in both controlled experimental settings and real-world clinical scenarios.
6. Conclusions
This study proposes a novel convolutional neural network based on the U-Net architecture, termed MA-DenseUNet, which integrates dense convolutional blocks, a multi-scale attention mechanism, and bidirectional LSTM units to enhance the accuracy and robustness of medical image segmentation tasks. Experimental results demonstrate that each of the proposed components contributes significantly to overall performance improvement. The dense convolutional blocks strengthen the representation of deep semantic features and effectively mitigate gradient vanishing and feature redundancy. To address the considerable variation in lesion sizes—ranging from large regions occupying most of the image to small lesions comprising less than one-tenth of the area—a multi-scale attention mechanism is incorporated to guide the model’s focus toward critical lesion regions while suppressing background noise. Furthermore, the integration of the BDC-LSTM module enhances the modeling of spatial contextual information, showing superior structural awareness and regional consistency, particularly in cases of blurred boundaries and unclear textures. In addition, a multi-scale generative adversarial network (GAN) is employed for joint training, leveraging multi-scale discriminators to refine segmentation details and compensate for the local structure insensitivity of traditional loss functions.
Comprehensive experimental evaluations reveal that MA-DenseUNet achieves outstanding performance across multiple benchmark medical image segmentation datasets, significantly outperforming existing state-of-the-art models, thereby validating its strong segmentation capability and generalizability. Nevertheless, the model remains relatively complex in structure and demands substantial computational resources. Its performance on extremely small lesions or low-contrast images still presents challenges. Future work will focus on incorporating lightweight architectural designs to reduce model complexity, and exploring self-supervised and few-shot learning strategies to further improve the model’s applicability and clinical deployment potential.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}