
Go Source Code Vulnerability Detection Method Based on Graph Neural Network



Abstract
1. Introduction
- 1.
- 2.
- These methods often represent a function as a single graph, where each node corresponds to a statement, neglecting fine-grained information within the statements [4].
- 3.
- Directly feeding raw source code, which contains a large amount of redundant code, into a graph neural network significantly increases the training time [9].
2. Related Work
2.1. Go Program Vulnerability Detection
2.2. Taint Analysis-Based Vulnerability Detection
3. Preliminaries
3.1. Preprocessing
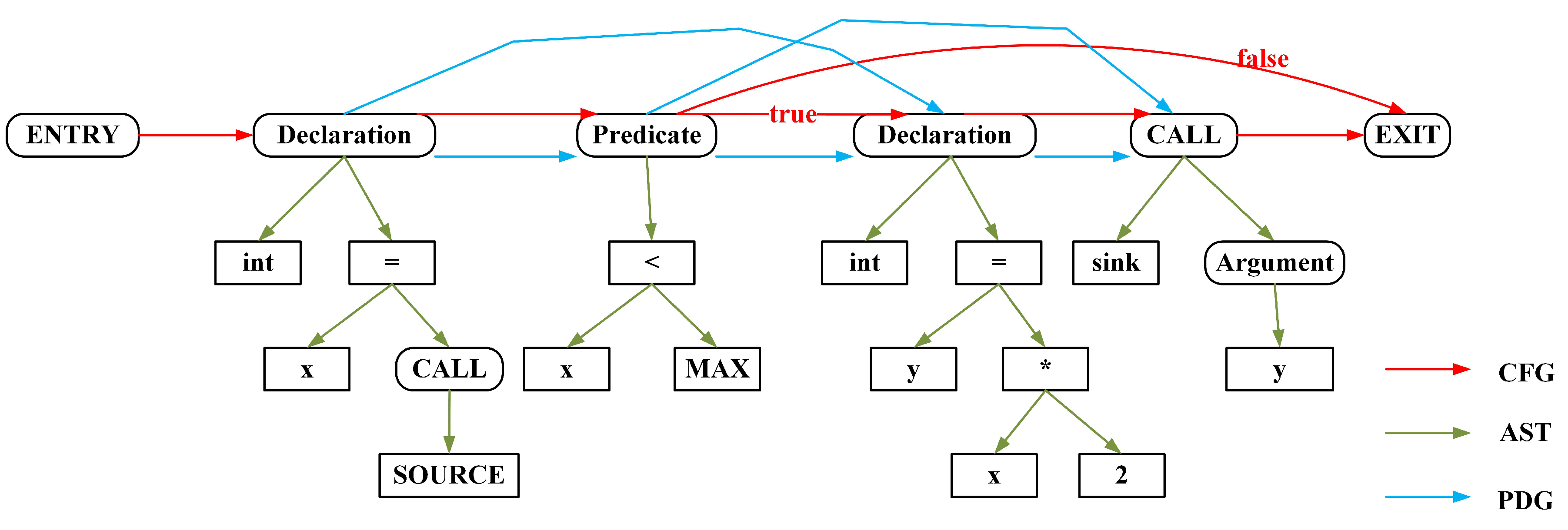
3.2. Graph-Level Features
| Algorithm 1: Go graph-level feature sliced code completion algorithm. |
 |
3.3. Semantic Features
4. Methodology
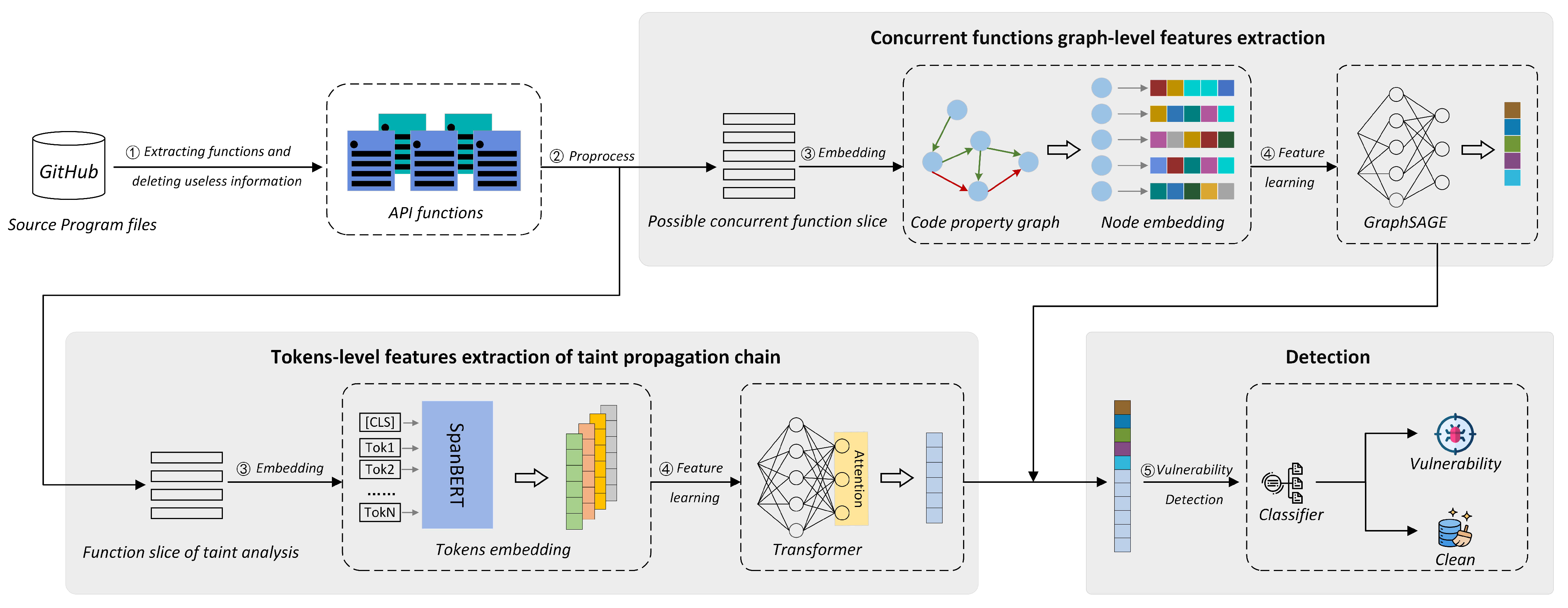
4.1. System Framework
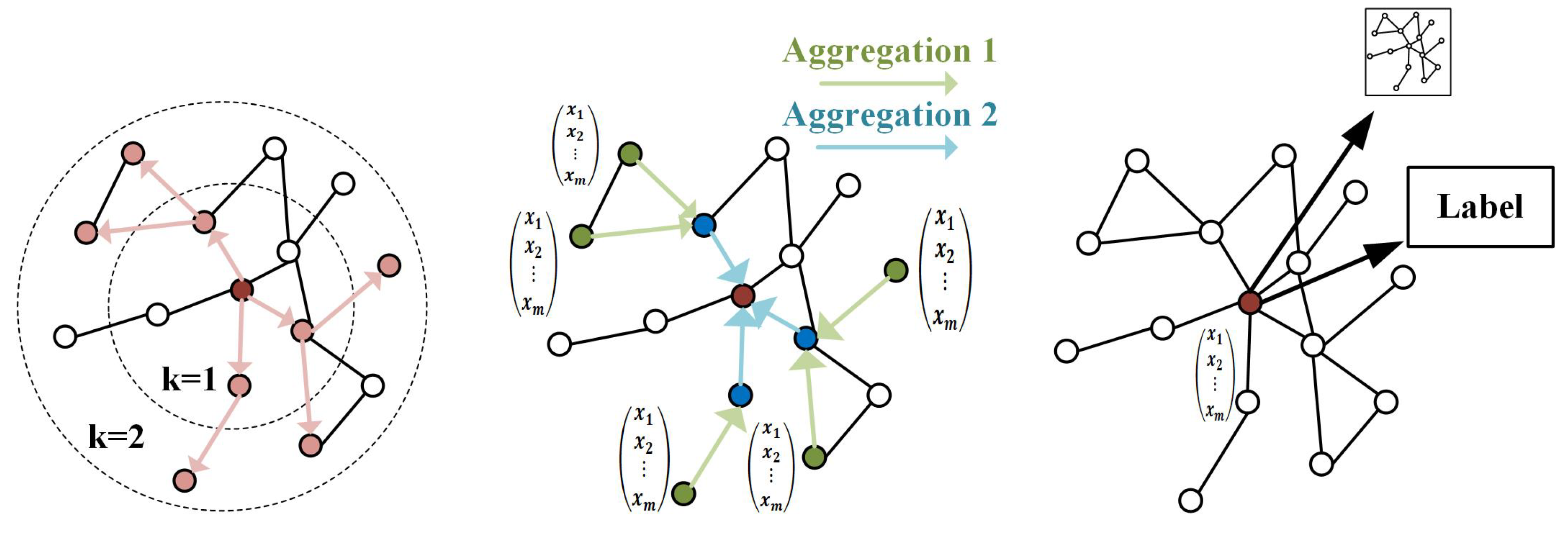
4.2. Graph-Level Feature Extraction
4.3. Semantic Feature Extraction
5. Experiments and Results
5.1. Dataset
5.2. Experimental Setup and Evaluation Metrics
- ,
- ,
- ,
- .
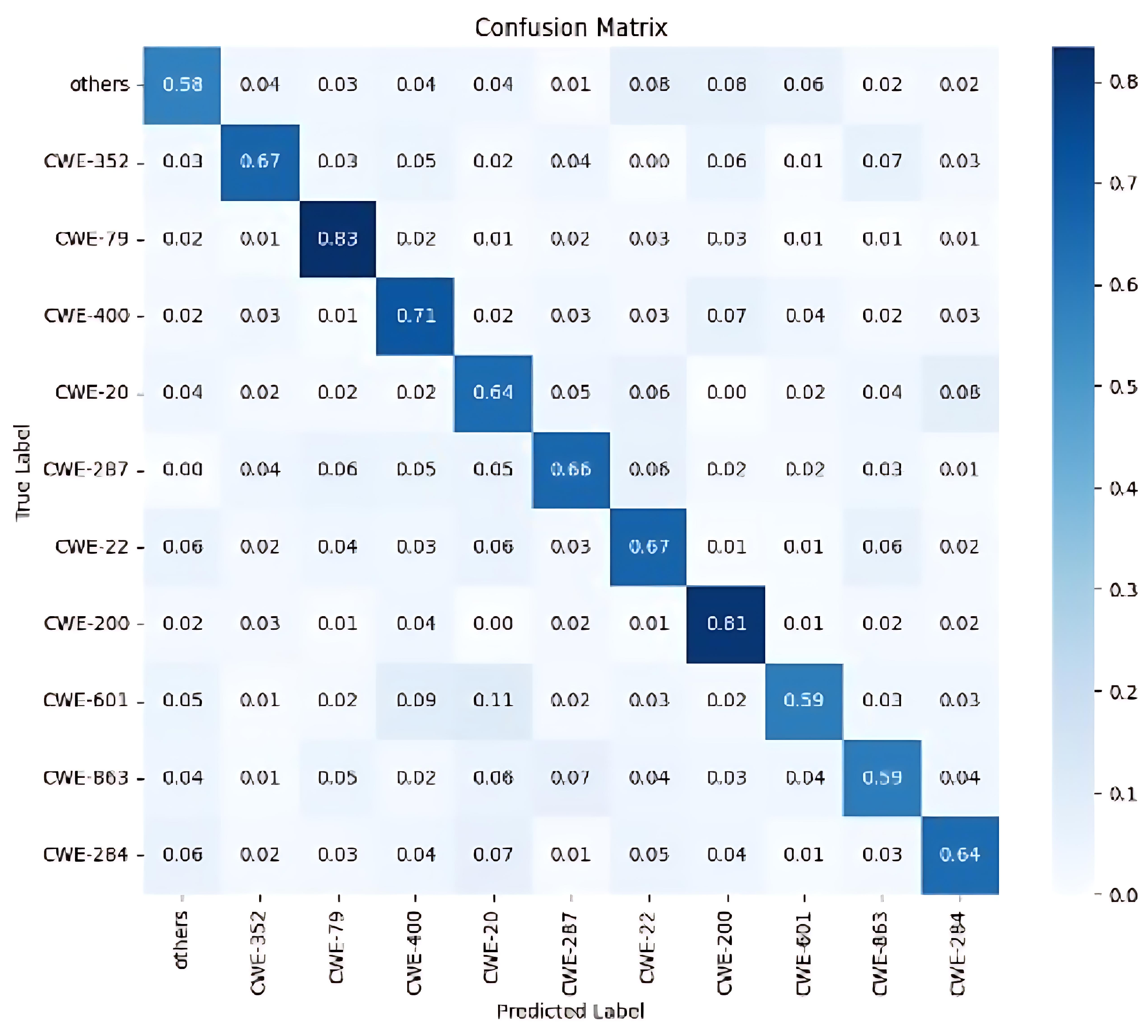
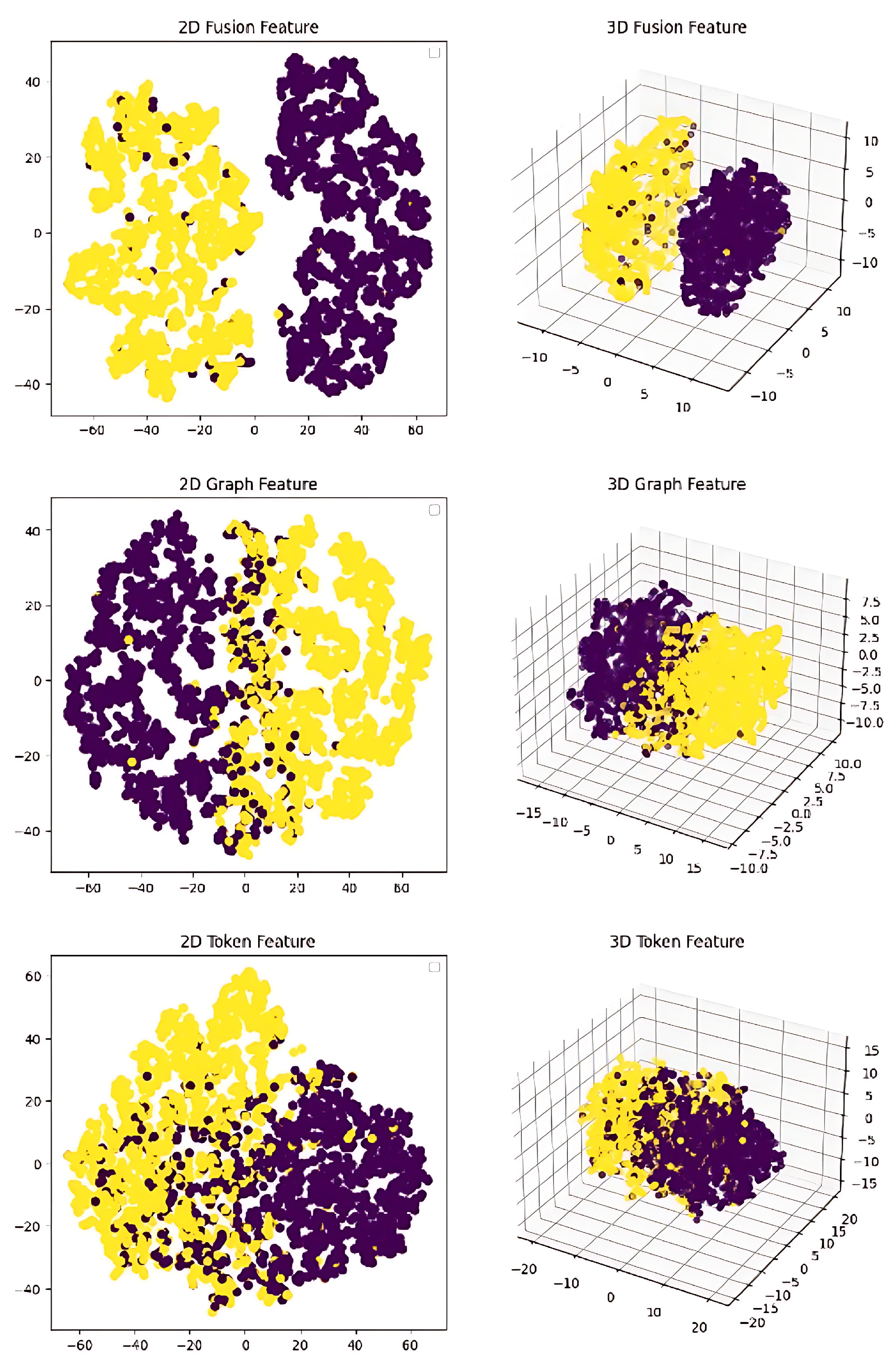
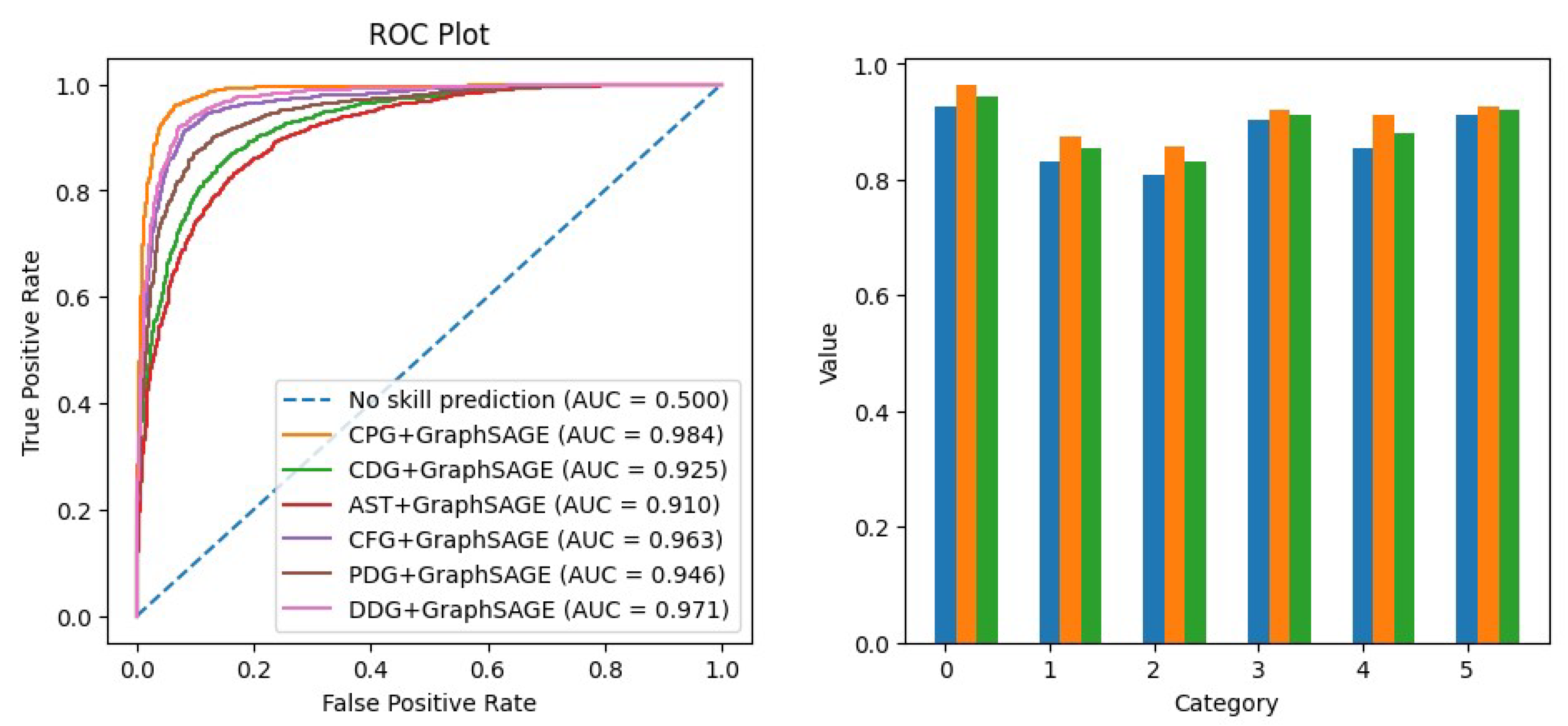
5.3. Results and Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Boucher, N.; Anderson, R. Trojan source: Invisible vulnerabilities. In Proceedings of the 32nd USENIX security symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 6507–6524. [Google Scholar]
- Zhang, C.; Liu, B.; Xin, Y.; Yao, L. Cpvd: Cross project vulnerability detection based on graph attention network and domain adaptation. IEEE Trans. Softw. Eng. 2023, 49, 4152–4168. [Google Scholar] [CrossRef]
- Liu, R.; Wang, Y.; Xu, H.; Sun, J.; Zhang, F.; Li, P.; Guo, Z. Vul-LMGNNs: Fusing language models and online-distilled graph neural networks for code vulnerability detection. Inf. Fusion 2025, 115, 102748. [Google Scholar] [CrossRef]
- Qiu, F.; Liu, Z.; Hu, X.; Xia, X.; Chen, G.; Wang, X. Vulnerability detection via multiple-graph-based code representation. IEEE Trans. Softw. Eng. 2024, 50, 2178–2199. [Google Scholar] [CrossRef]
- Wang, H.; Ye, G.; Tang, Z.; Tan, S.H.; Huang, S.; Fang, D.; Feng, Y.; Bian, L.; Wang, Z. Combining graph-based learning with automated data collection for code vulnerability detection. IEEE Trans. Inf. Forensics Secur. 2020, 16, 1943–1958. [Google Scholar] [CrossRef]
- Xu, Y.; Fang, Y.; Liu, Z.; Zhang, Q. PWAGAT: Potential Web attacker detection based on graph attention network. Neurocomputing 2023, 557, 126725. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, Q.; Deng, H.; Liu, Z.; Yang, C.; Fang, Y. Unknown web attack threat detection based on large language model. Appl. Soft Comput. 2025, 173, 112905. [Google Scholar] [CrossRef]
- Cao, S.; Sun, X.; Bo, L.; Wei, Y.; Li, B. Bgnn4vd: Constructing bidirectional graph neural-network for vulnerability detection. Inf. Softw. Technol. 2021, 136, 106576. [Google Scholar] [CrossRef]
- Guo, W.; Fang, Y.; Huang, C.; Ou, H.; Lin, C.; Guo, Y. HyVulDect: A hybrid semantic vulnerability mining system based on graph neural network. Comput. Secur. 2022, 121, 102823. [Google Scholar] [CrossRef]
- Liu, Z.; Zhu, S.; Qin, B.; Chen, H.; Song, L. Automatically detecting and fixing concurrency bugs in go software systems. In Proceedings of the 26th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Virtual, 19–23 April 2021; pp. 616–629. [Google Scholar]
- Liu, Z.; Xia, S.; Liang, Y.; Song, L.; Hu, H. Who goes first? Detecting go concurrency bugs via message reordering. In Proceedings of the 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 28 February–4 March 2022; pp. 888–902. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1025–1035. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Tang, W.; Tang, M.; Ban, M.; Zhao, Z.; Feng, M. CSGVD: A deep learning approach combining sequence and graph embedding for source code vulnerability detection. J. Syst. Softw. 2023, 199, 111623. [Google Scholar] [CrossRef]
- Fan, Y.; Wan, C.; Fu, C.; Han, L.; Xu, H. VDoTR: Vulnerability detection based on tensor representation of comprehensive code graphs. Comput. Secur. 2023, 130, 103247. [Google Scholar] [CrossRef]
- Wen, X.C.; Chen, Y.; Gao, C.; Zhang, H.; Zhang, J.M.; Liao, Q. Vulnerability detection with graph simplification and enhanced graph representation learning. In Proceedings of the 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), Melbourne, Australia, 14–20 May 2023; pp. 2275–2286. [Google Scholar]
- Mergendahl, S.; Burow, N.; Okhravi, H. Cross-Language Attacks. In Proceedings of the NDSS, Chengdu, China, 18–20 December 2022; pp. 1–18. [Google Scholar]
- Jackson, J. Microsoft: Rust Is the Industry’s ‘Best Chance’ at Safe Systems Programming, 20 October 2020. Available online: https://thenewstack.io/microsoft-rust-is-the-industrys-best-chance-at-safe-systems-programming/ (accessed on 1 June 2025).
- Xu, Z.; Chen, B.; Chandramohan, M.; Liu, Y.; Song, F. Spain: Security patch analysis for binaries towards understanding the pain and pills. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 462–472. [Google Scholar]
- Scandariato, R.; Walden, J.; Hovsepyan, A.; Joosen, W. Predicting vulnerable software components via text mining. IEEE Trans. Softw. Eng. 2014, 40, 993–1006. [Google Scholar] [CrossRef]
- Zhou, T.; Sun, X.; Xia, X.; Li, B.; Chen, X. Improving defect prediction with deep forest. Inf. Softw. Technol. 2019, 114, 204–216. [Google Scholar] [CrossRef]
- Li, Y.; Wang, S.; Nguyen, T.N. Vulnerability detection with fine-grained interpretations. In Proceedings of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Athens, Greece, 23–28 August 2021; pp. 292–303. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Jin, H.; Zhu, Y.; Chen, Z. Sysevr: A framework for using deep learning to detect software vulnerabilities. IEEE Trans. Dependable Secur. Comput. 2021, 19, 2244–2258. [Google Scholar] [CrossRef]
- Wu, F.; Wang, J.; Liu, J.; Wang, W. Vulnerability detection with deep learning. In Proceedings of the 2017 3rd IEEE international conference on computer and communications (ICCC), Chengdu, China, 13–16 December 2017; pp. 1298–1302. [Google Scholar]
- Zhou, Y.; Liu, S.; Siow, J.; Du, X.; Liu, Y. Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks. Adv. Neural Inf. Process. Syst. 2019, 32, 10197–10207. [Google Scholar]
- Li, Z.; Zou, D.; Xu, S.; Ou, X.; Jin, H.; Wang, S.; Deng, Z.; Zhong, Y. Vuldeepecker: A deep learning-based system for vulnerability detection. arXiv 2018, arXiv:1801.01681. [Google Scholar]
- Lin, G.; Wen, S.; Han, Q.L.; Zhang, J.; Xiang, Y. Software vulnerability detection using deep neural networks: A survey. Proc. IEEE 2020, 108, 1825–1848. [Google Scholar] [CrossRef]
- Nie, X.; Li, N.; Wang, K.; Wang, S.; Luo, X.; Wang, H. Understanding and tackling label errors in deep learning-based vulnerability detection (experience paper). In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, Seattle, WA, USA, 17–21 July 2023; pp. 52–63. [Google Scholar]
- Li, X.; Xin, Y.; Zhu, H.; Yang, Y.; Chen, Y. Cross-domain vulnerability detection using graph embedding and domain adaptation. Comput. Secur. 2023, 125, 103017. [Google Scholar] [CrossRef]
- Wang, C.; Ko, R.; Zhang, Y.; Yang, Y.; Lin, Z. Taintmini: Detecting flow of sensitive data in mini-programs with static taint analysis. In Proceedings of the 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), Melbourne, Australia, 14–20 May 2023; pp. 932–944. [Google Scholar]
- Chen, S.; Lin, Z.; Zhang, Y. {SelectiveTaint}: Efficient data flow tracking with static binary rewriting. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Vancouver, BC, Canada, 11–13 August 2021; pp. 1665–1682. [Google Scholar]
- Zhang, L.; Chen, J.; Diao, W.; Guo, S.; Weng, J.; Zhang, K. {CryptoREX}: Large-scale analysis of cryptographic misuse in {IoT} devices. In Proceedings of the 22nd International Symposium on Research in Attacks, Intrusions and Defenses (RAID 2019), Beijing, China, 23–25 September 2019; pp. 151–164. [Google Scholar]
- Lu, H.; Zhao, Q.; Chen, Y.; Liao, X.; Lin, Z. Detecting and measuring aggressive location harvesting in mobile apps via data-flow path embedding. Proc. ACM Meas. Anal. Comput. Syst. 2023, 7, 18. [Google Scholar] [CrossRef]
- Huang, W.; Dong, Y.; Milanova, A. Type-based taint analysis for Java web applications. In Proceedings of the Fundamental Approaches to Software Engineering: 17th International Conference, FASE 2014, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2014, Grenoble, France, 5–13 April 2014; Proceedings 17. Springer: Berlin/Heidelberg, Germany, 2014; pp. 140–154. [Google Scholar]
- Fu, X.; Cai, H. Scaling application-level dynamic taint analysis to enterprise-scale distributed systems. In Proceedings of the ACM/IEEE 42nd International Conference on Software Engineering: Companion Proceedings, Seoul, Republic of Korea, 5–11 October 2020; pp. 270–271. [Google Scholar]
- Zhang, J.; Tian, C.; Duan, Z. Fastdroid: Efficient taint analysis for android applications. In Proceedings of the 2019 IEEE/ACM 41st International Conference on Software Engineering: Companion Proceedings (ICSE-Companion), Montreal, QC, Canada, 25–31 May 2019; pp. 236–237. [Google Scholar]
- Zhong, Z.; Liu, J.; Wu, D.; Di, P.; Sui, Y.; Liu, A.X. Field-based static taint analysis for industrial microservices. In Proceedings of the 44th International Conference on Software Engineering: Software Engineering in Practice, Pittsburgh, PA, USA, 21–29 May 2022; pp. 149–150. [Google Scholar]
- Liang, J.; Wang, M.; Zhou, C.; Wu, Z.; Jiang, Y.; Liu, J.; Liu, Z.; Sun, J. Pata: Fuzzing with path aware taint analysis. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 23–25 May 2022; pp. 1–17. [Google Scholar]
- Chow, Y.W.; Schäfer, M.; Pradel, M. Beware of the unexpected: Bimodal taint analysis. In Proceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis, Seattle, WA, USA, 17–21 July 2023; pp. 211–222. [Google Scholar]
- Liu, P.; Sun, C.; Zheng, Y.; Feng, X.; Qin, C.; Wang, Y.; Li, Z.; Sun, L. Harnessing the power of llm to support binary taint analysis. arXiv 2023, arXiv:2310.08275. [Google Scholar]
- Qi, Z.; Feng, Q.; Cheng, Y.; Yan, M.; Li, P.; Yin, H.; Wei, T. SpecTaint: Speculative Taint Analysis for Discovering Spectre Gadgets. In Proceedings of the NDSS, Virtual, 21–25 February 2021; pp. 1–14. [Google Scholar]
- Jia, Z.; Yang, C.; Zhao, X.; Li, X.; Ma, J. Design and implementation of an efficient container tag dynamic taint analysis. Comput. Secur. 2023, 135, 103528. [Google Scholar] [CrossRef]
- Sang, Q.; Wang, Y.; Liu, Y.; Jia, X.; Bao, T.; Su, P. Airtaint: Making dynamic taint analysis faster and easier. In Proceedings of the 2024 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–22 May 2024; pp. 3998–4014. [Google Scholar]
- Available online: https://github.com/advisories (accessed on 20 May 2025).
- Chen, C.S.; Noorizadegan, A.; Young, D.L.; Chen, C. On the selection of a better radial basis function and its shape parameter in interpolation problems. Appl. Math. Comput. 2023, 442, 127713. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CWE-ID | Description | Number |
|---|---|---|
| CWE-79 | Improper neutralization of input during web page generation. (“Cross-Site Scripting”) | 67 |
| CWE-22 | Improper limitation of a pathname to a restricted directory. (“Path Traversal”) | 45 |
| CWE-400 | Uncontrolled resource consumption. | 39 |
| CWE-20 | Improper input validation. | 35 |
| CWE-287 | Improper authentication. | 24 |
| CWE-284 | Improper access control. | 21 |
| CWE-200 | Exposure of sensitive information to an unauthorized user. | 19 |
| CWE-601 | URL redirection to an untrusted site. (“Open Redirect”) | 17 |
| CWE-863 | Incorrect authorization. | 17 |
| CWE-352 | Cross-Site Request Forgery. (CSRF) | 14 |
| Component | Configuration |
|---|---|
| Operating System | Ubuntu 18.04.1 |
| Programming Language | Programming Language |
| Major Python Libraries | Pyg-lib == 0.3.1 + pt21cu121 |
| Torch == 2.0.1 + cu118 | |
| Scikit-learn == 1.3.2 | |
| Transformers == 4.35.2 |
| Parameter | Description | Value |
|---|---|---|
| num_samples | Neighbor sampling size | 25 |
| aggregator_type | Aggregation function | mean |
| embedding_size | Node embedding size | 64 |
| num_layers | Number of graph convolution layers | 2 |
| l2_reg | L2 regularization strength | 0.0001 |
| learning_rate | Learning rate | 0.01 |
| dropout | Dropout rate | 0.3 |
| epochs | Training epochs | 500 |
| Class | Precision | Recall | F1-Score | Sample Size |
|---|---|---|---|---|
| Benign Samples | 0.96 | 0.94 | 0.95 | 1646 |
| Vulnerable Samples | 0.94 | 0.96 | 0.95 | 1604 |
| Accuracy | / | / | 0.95 | 3250 |
| Macro AVG | 0.95 | 0.95 | 0.95 | 3250 |
| Weighted AVG | 0.95 | 0.95 | 0.95 | 3250 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| GoVulDect-Graph | 0.9058 | 0.9039 | 0.9043 |
| GoVulDect-Tokens | 0.8878 | 0.8857 | 0.8859 |
| GoVulDect | 0.9477 | 0.9513 | 0.9489 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| MLP | 0.91 | 0.90 | 0.90 | 0.90 |
| RF | 0.91 | 0.91 | 0.90 | 0.90 |
| KNN | 0.89 | 0.88 | 0.88 | 0.88 |
| SVM | 0.90 | 0.89 | 0.89 | 0.89 |
| BiLSTM | 0.93 | 0.92 | 0.92 | 0.92 |
| XGBoost | 0.94 | 0.95 | 0.94 | 0.95 |
| Model/Tool | Architecture | Target Language | Supported Vulnerabilities |
|---|---|---|---|
| RATS | Rule-based static analysis | C, C++, Perl, PHP, Python | Buffer overflow, TOCTOU, etc. |
| CSGVD | PE-BL + Residual GCN + M-BFA + MLP | C/C++ | / |
| VDoTR | Third-order tensor representation + CircleGGNN + 1-D convolution | C/C++ | CWE-120, CWE-119, CWE-469, CWE-476 |
| AMPLE | Graph simplification + Edge-aware GCN + Kernel-scaled representation | C/C++ | / |
| GoVulDect | SpanBERT + GraphSAGE + Transformer + XGBoost | Go | Concurrency vulnerabilities, SQL injection, XSS, etc. |
| Model/Tool | Dataset Size | Precision * | Recall * | F1-Score * |
|---|---|---|---|---|
| RATS | — | 0.5291 | 0.5400 | 0.5288 |
| CSGVD | 27,318 | 0.7205 | 0.7442 | 0.6733 |
| VDoTR | 93,539 | 0.7947 | 0.7800 | 0.7762 |
| AMPLE | 219,829 | 0.8872 | 0.8860 | 0.8859 |
| GoVulDect | 129,978 | 0.9164 | 0.9137 | 0.9135 |
| Model/Tool | Training Time (s) | Detection Time (s) |
|---|---|---|
| RATS | / | 0.012 |
| CSGVD | 7589.810 | 62.063 |
| VDoTR | 17,822.211 | 79.180 |
| AMPLE | 5125.166 | 17.121 |
| GoVulDect | 4221.945 | 3.116 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, L.; Fang, Y.; Zhang, Q.; Liu, Z.; Xu, Y. Go Source Code Vulnerability Detection Method Based on Graph Neural Network. Appl. Sci. 2025, 15, 6524. https://doi.org/10.3390/app15126524
Yuan L, Fang Y, Zhang Q, Liu Z, Xu Y. Go Source Code Vulnerability Detection Method Based on Graph Neural Network. Applied Sciences. 2025; 15(12):6524. https://doi.org/10.3390/app15126524
Chicago/Turabian StyleYuan, Lisha, Yong Fang, Qiang Zhang, Zhonglin Liu, and Yijia Xu. 2025. "Go Source Code Vulnerability Detection Method Based on Graph Neural Network" Applied Sciences 15, no. 12: 6524. https://doi.org/10.3390/app15126524
APA StyleYuan, L., Fang, Y., Zhang, Q., Liu, Z., & Xu, Y. (2025). Go Source Code Vulnerability Detection Method Based on Graph Neural Network. Applied Sciences, 15(12), 6524. https://doi.org/10.3390/app15126524