
Large Language Model-Driven Framework for Automated Constraint Model Generation in Configuration Problems



Abstract
1. Introduction
2. Background
2.1. Constraint Programming
2.2. Constraint Satisfaction Problem
2.3. Configuration
2.4. Large Language Models
2.5. Fine-Tuning and Instruction Tuning
2.6. Prompt Engineering
3. Related Work
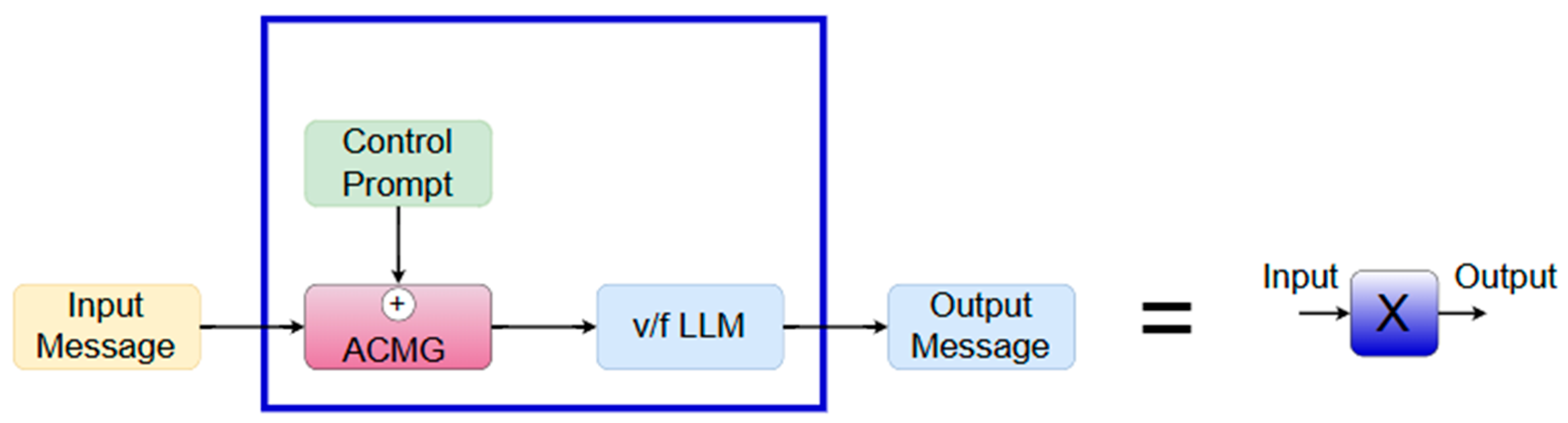
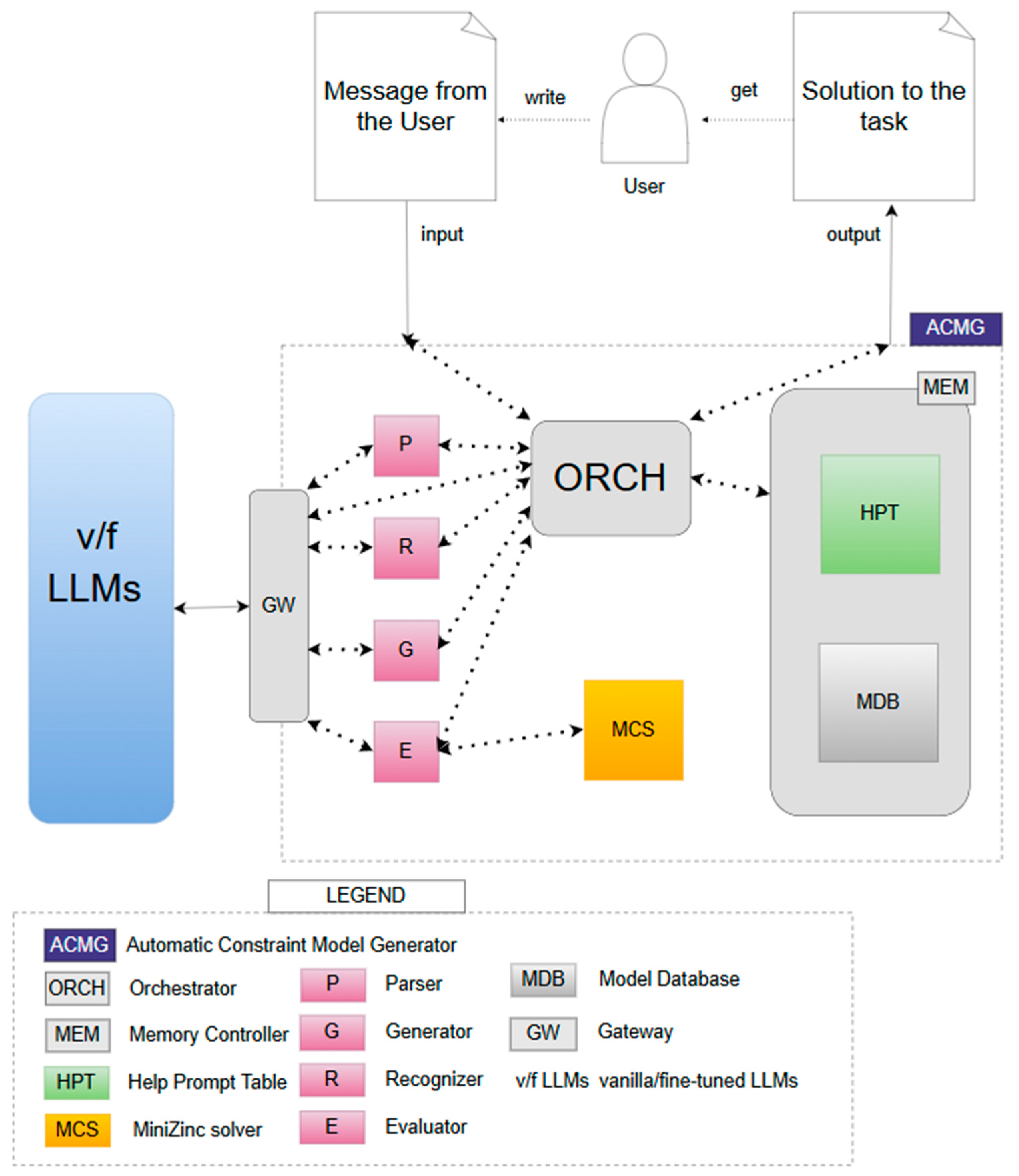
4. Automatic Constraint Model Generator (ACMG)
4.1. Main Components
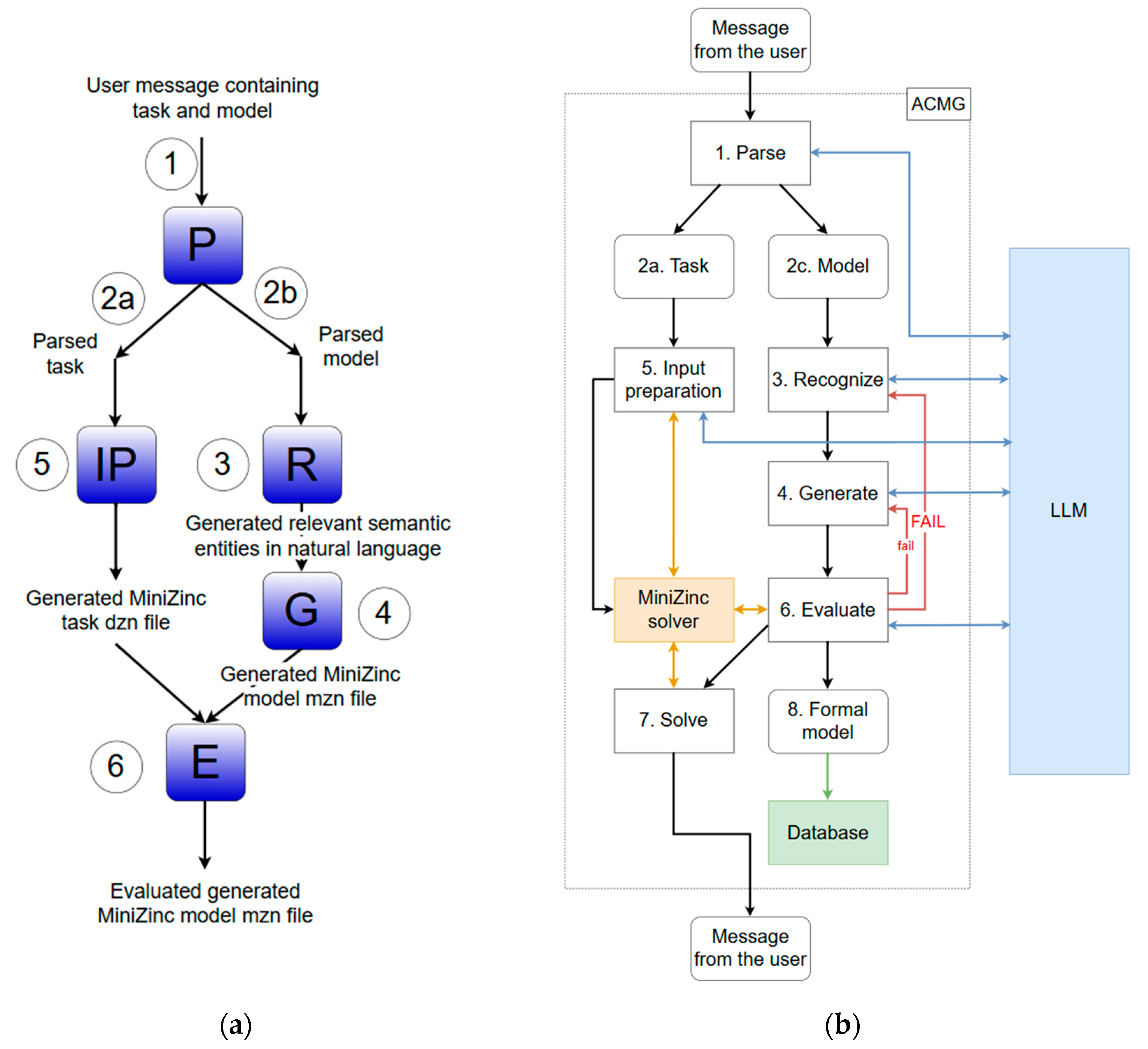
4.2. ACMG Process
- Step 1.
- A natural language prompt (i.e., the user’s message) is forwarded to the LLM to discern the content of the user’s message. With help from the specially designed control prompt [46], an attempt is made to extract the constraint task and model description.
- Step 2.
- The input user message is separated into a constraint task and a model. Each has a separate flow, indicated by 2.a and 2.b. In addition, in this step, with help from the LLM, a name is generated for the new model that is about to be created.
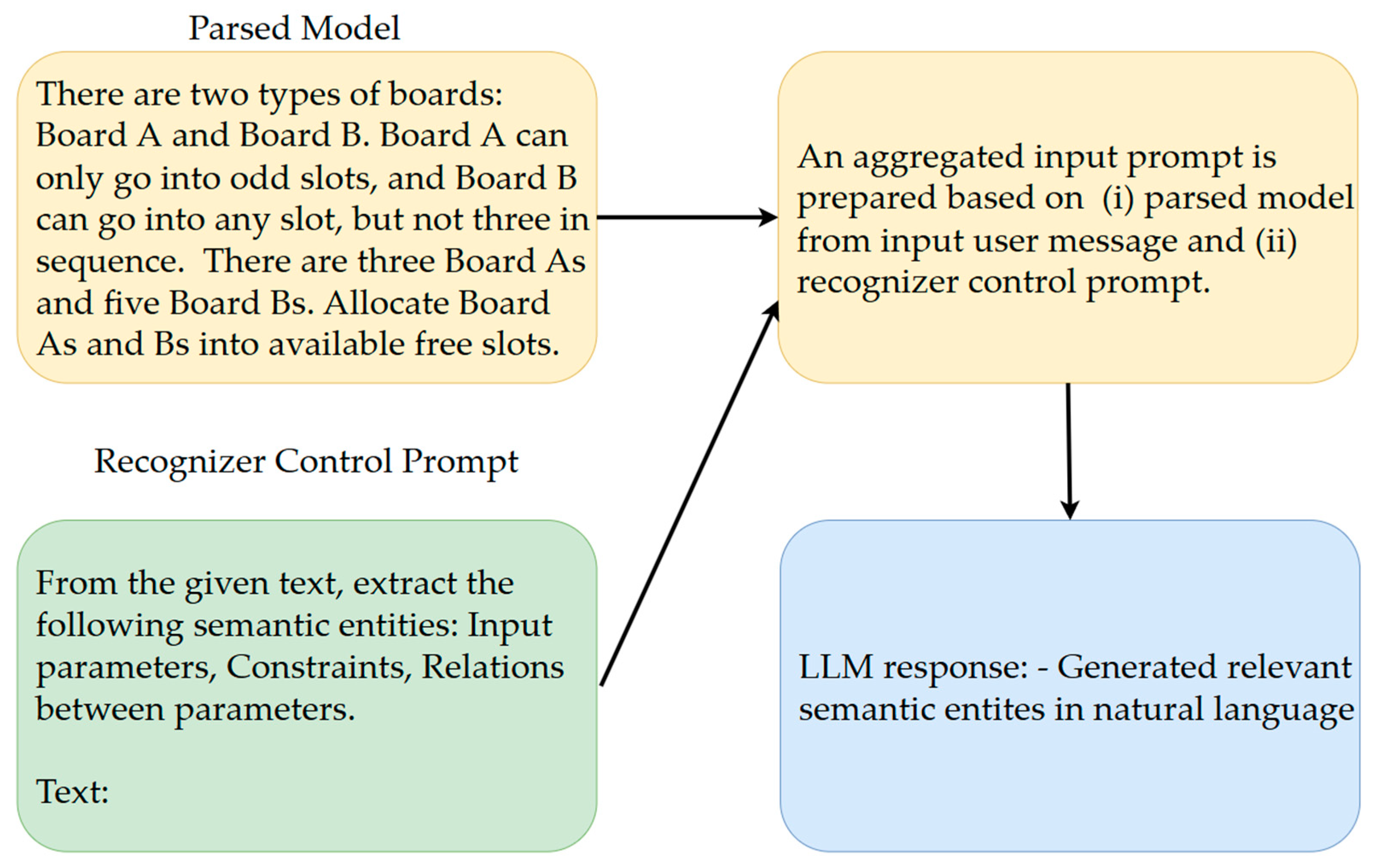
- Step 3.
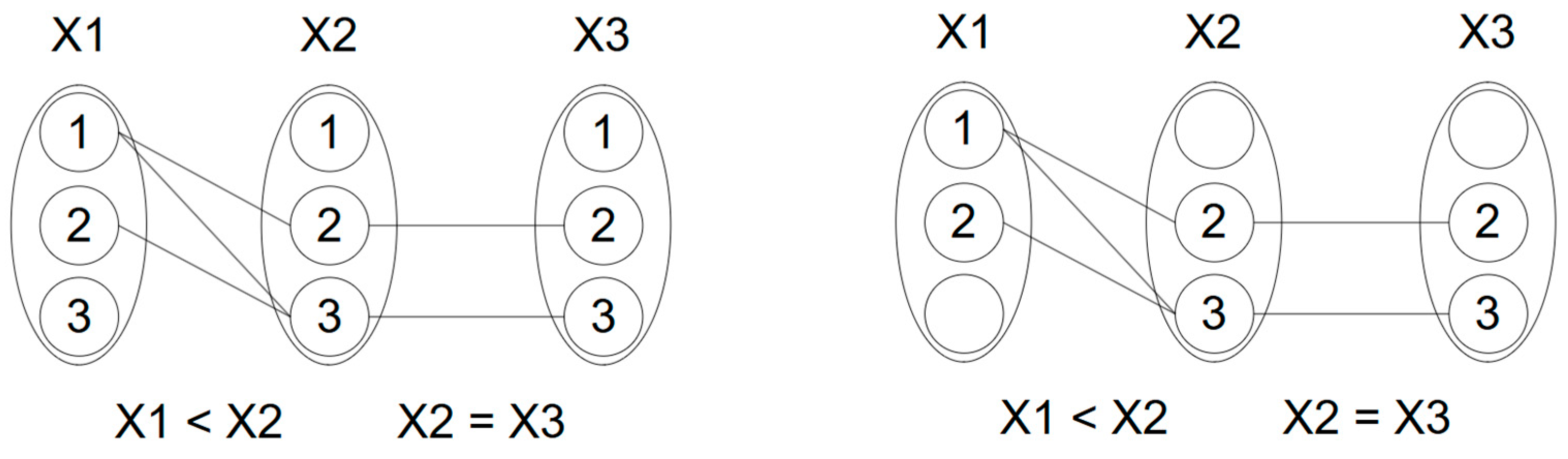
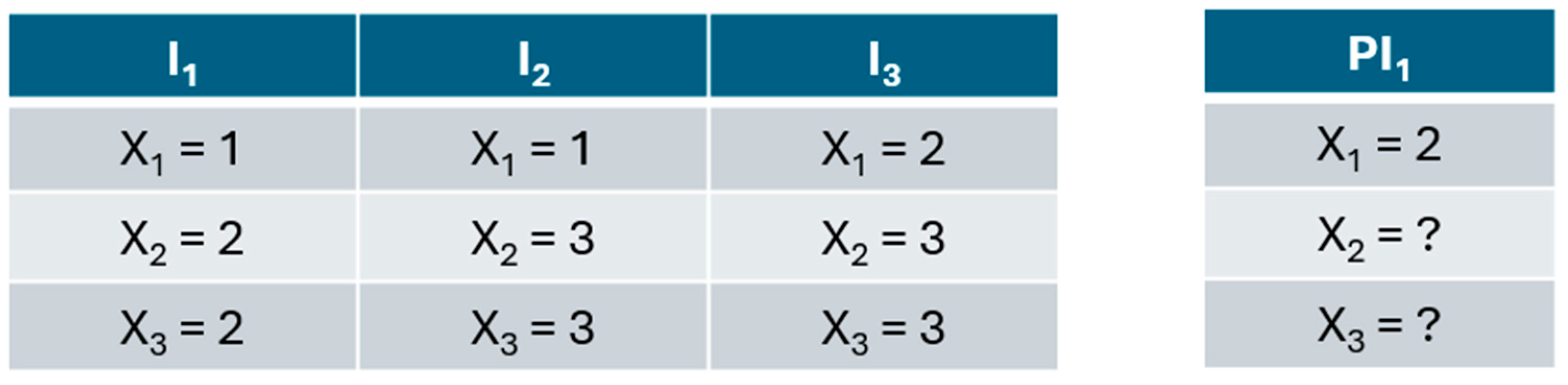
- At this stage, the fine-tuned LLM (the Recognizer) is used to recognize (i.e., extract) the relevant semantic entities from the prompt. Those extracted entities and the original messages that contain the model described in natural language are forwarded to step 4. This step is inspired by studies of the authors of [18,19]. Figure 5 and Figure 6 show steps 3 and 4, respectively. Green is the control prompt fetched from the memory module, yellow are the prompts prepared by the ACMG engine, and blue is the response from the LLM.
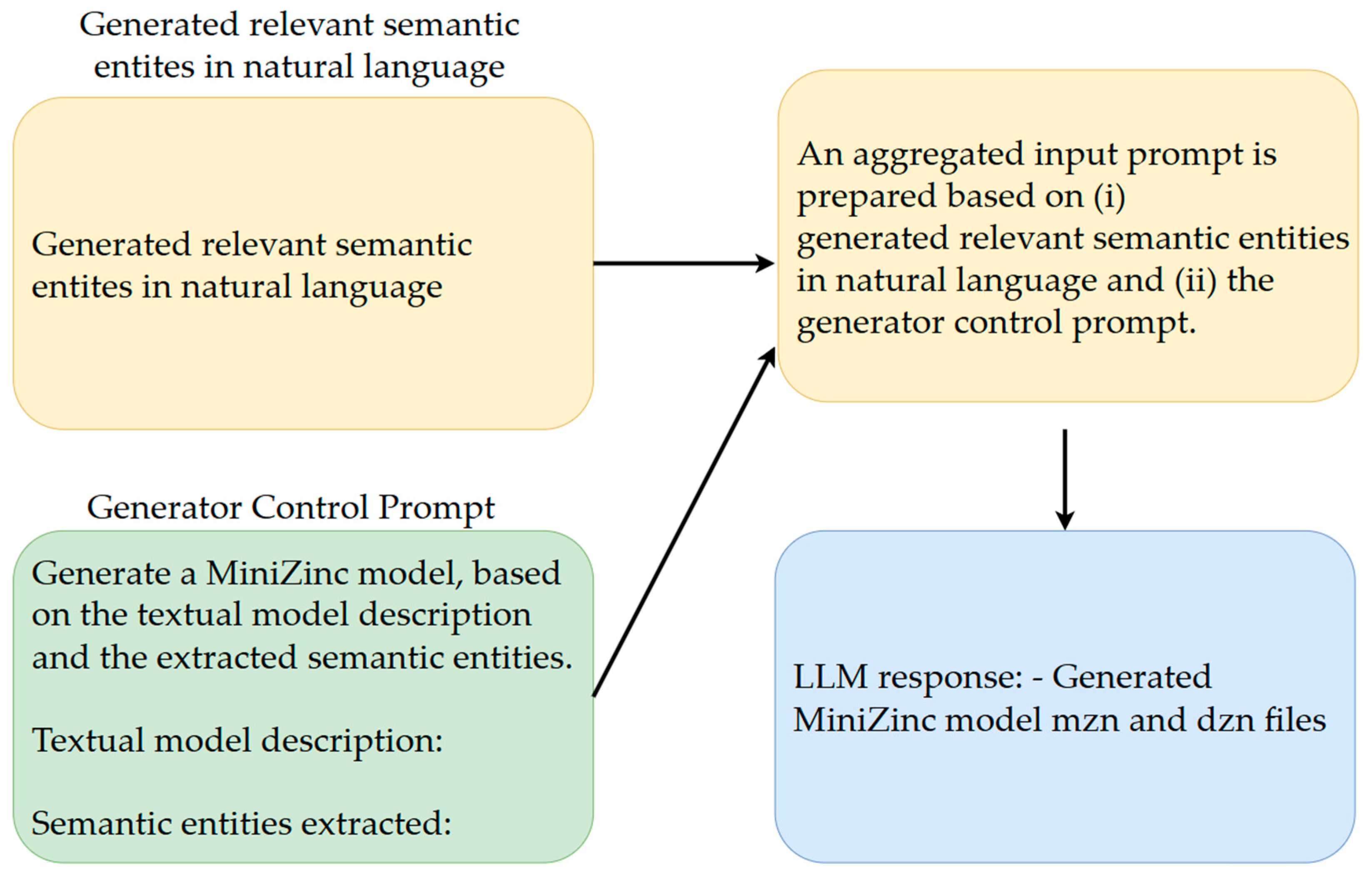
- Step 4.
- Next, another fine-tuned LLM (the Generator) uses the semantic entities and the model description from step 2 to generate a constraint model in the MiniZinc modeling language. The generated MiniZinc model is forwarded to step 6.
- Step 5.
- The constraint task is still in natural language form. The constraint task, the valid MiniZinc model generated in step 6, and the relevant control prompt are sent to the LLM, which transforms the constraint task into a data MiniZinc file, i.e., dzn file [46]. Once this is carried out, the generated dzn file is loaded into the MiniZinc solver, and the ACMG can now solve the constraint task in the next step. Figure 9 (bottom left box) contains a generated MiniZinc data file (dzn).
- Step 6.
- The generated MiniZinc model is evaluated by the MiniZinc solver, which checks for syntactic correctness. If the solver reports warnings or errors, the following repair process is initiated:
- 1.
- Inner Repair Loop (Model Regeneration):
- ▪
- The solver’s output (including the model, warnings, errors, and the original natural language description) is sent back to the Generator.
- ▪
- The Generator attempts to regenerate a corrected MiniZinc model, addressing the reported issues.
- ▪
- This inner loop is executed a maximum of three times. If the model remains invalid after three attempts, the process proceeds to the outer loop.
- 2.
- Outer Repair Loop (Semantic Regeneration):
- ▪
- The unresolved warnings/errors, along with the original natural language model description, are returned to Step 3 (Semantic Entity Generation).
- ▪
- The system regenerates the semantic entities that may have caused the persistent issues.
- ▪
- The outer loop also runs at most three times. If the model still fails validation after these attempts, the ACMG engine terminates with an error. Otherwise, the process advances to Step 7.
- Step 7.
- The constraint task is solved with a MiniZinc solver, which already has the model loaded into it. The output from the MiniZinc solver is sent to the user who initiated this process. This step is not shown in Figure 5a, as it does not include communication with the LLM.
- Step 8.
- Finally, if the generated MiniZinc model is invalid, the ACMG engine stops. Otherwise, if there are no warnings or errors, the model is stored in the database for future use, along with its unique identifier (the model name obtained in step 2). The stored model is then loaded into a MiniZinc solver for processing. This step is not shown in Figure 5a, as it does not include communication with the LLM.
4.3. ACMG Architecture
5. Validation
5.1. Datasets
- A.
- The model and constraint task are described in natural language.
- B.
- Model only.
- C.
- Constraint task only.
- D.
- Model-relevant semantic entities.
- E.
- Constraint task-relevant semantic entities.
- F.
- MiniZinc model (mzn file).
- G.
- MiniZinc constraint task (dzn file).
- The model and constraint task are described in natural language.
- Model only.
- Constraint task only.
- The model and constraint task are described in natural language.
- Model only.
- Constraint task only.
- Model-relevant semantic entities.
- Constraint task-relevant semantic entities.
- The model and constraint task are described in natural language.
- Model only.
- Constraint task only.
- MiniZinc model (mzn file).
- MiniZinc constraint task (dzn file).
5.2. Experiments
- Evaluation of Generated Constraint Model’s Syntax Correctness
- 2.
- Evaluation of Generated Constraint Model’s Solution Correctness
- 3.
- Evaluation of Generated Constraint Model’s Validity
5.3. Ablation Study
- Without the fine-tuned model, only the vanilla LLM is used.
- One fine-tuned model was used as the Parser, Recognizer, and Generator. The Evaluator was a vanilla LLM. The one LLM was fine-tuned with one large, combined dataset (fine-tuned with CSPNERMZC-50 [19]).
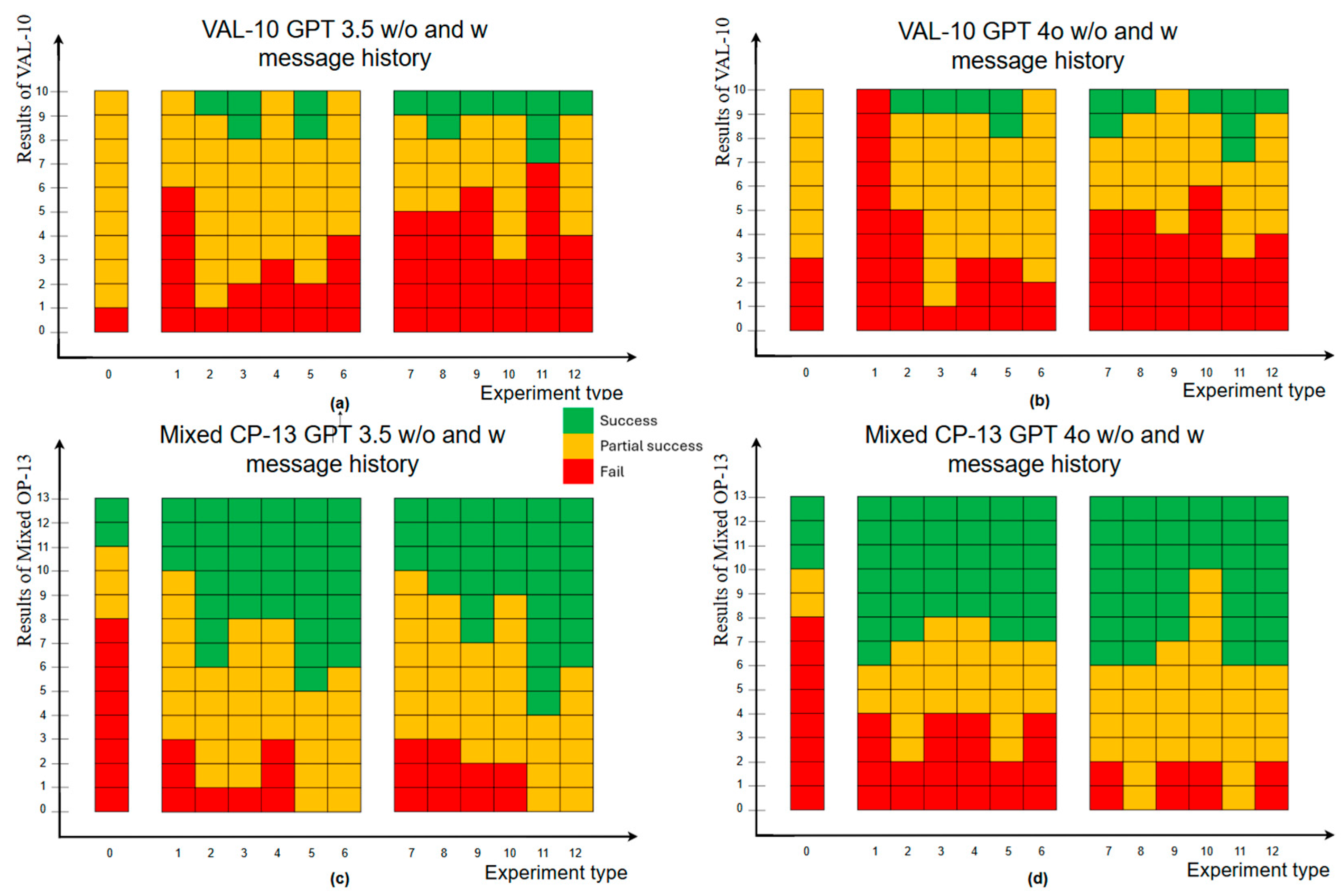
5.4. Results
6. Discussion
6.1. Limitations
6.2. Future Work
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

| Component | Input | Output | Role |
|---|---|---|---|
| Parser | Natural language prompt | {Model, Task} segments | Instruction following |
| Recognizer | Model description | Structured entities | Constraint NER |
| Generator | Entities + model desc. | Structured entities | Constraint-to-code mapping |
| Evaluator | Generated code | Validation diagnostics | Solution verification |
Appendix B
| Algorithm A1. Constraint Model Generation with Iterative Repair Mechanism |
| Input: model (natural language), task, recognizer_model, generator_model Output: status (SATISFIED/UNSATISFIED), result 1: procedure ITERATIVE-REPAIR-REGENERATION 2: model_name ← GENERATE-MODEL-NAME(model) 3: for repair_cycle ← 1 to 3 do 4: recognized ← RECOGNIZER.extract_entities(model) 5: warnings ← null 6: for gen_attempt ← 1 to 3 do 7: constraint_model ← GENERATOR.generate( 8: model, recognized, warnings) 9: task_dzn ← FORMATTER.reformat_task(task, constraint_model) 10: status, result, warnings ← SOLVER.evaluate( 11: constraint_model, task_dzn) 12: if status = SATISFIED then 13: MEMORY.store_model(model_name, constraint_model) 14: return (status, result) 15: return (UNSATISFIED, null) 16: procedure GENERATE 17: if warnings = null then 18: prompt ← PROMPTS.initial(model, recognized) 19: else 20: prompt ← PROMPTS.repair(model, recognized, warnings) 21: return LLM.query(prompt) |
Appendix C
| Component | Base Options | Tuning Status | Ablation Variants |
|---|---|---|---|
| Parser | gpt-3.5/gpt-4o | Both | V1 (vanilla), V2–V6 (tuned) |
| Recognizer | gpt-3.5/gpt-4o | Both | V1 (vanilla), V2–V6 (tuned) |
| Generator | gpt-3.5/gpt-4o | Both | V1 (vanilla), V2–V6 (tuned) |
| Evaluator | gpt-3.5/gpt-4o | Vanilla only | All variants |
Appendix D
| V1 1 | V2 | V3 | V4 | V5 | V6 | |
|---|---|---|---|---|---|---|
| vLLM 5 | P, R, G, E 3 | E | P, E | P, E | E | E |
| fLLM(CSPNER-50) 2 | R | R | R | R | ||
| fLLM(CSPNERMZC-50) | P, R, G | G | G | |||
| fLLM(MZC-50) | G | G | ||||
| fLLM(CSP-50) | P | P | ||||
| fLLM(CSPNER-50) | ||||||
| LLM Qty 4 | 1 | 2 | 3 | 3 | 4 | 4 |
References
- Rossi, F.; van Beek, P.; Walsh, T. (Eds.) Handbook of Constraint Programming; Elsevier: Amsterdam, The Netherlands, 2006. [Google Scholar] [CrossRef]
- Tsouros, D.; Verhaeghe, H.; Kadıoğlu, S.; Guns, T. Holy Grail 2.0: From natural language to constraint models. arXiv 2023, arXiv:2308.01589. [Google Scholar] [CrossRef]
- Freuder, E.C.; O’Sullivan, B. Grand challenges for constraint programming. Constraints 2014, 19, 150–162. [Google Scholar] [CrossRef]
- Yuksekgonul, M.; Chandrasekaran, V.; Jones, E.; Gunasekar, S.; Naik, R.; Palangi, H.; Kamar, E.; Nushi, B. Attention satisfies: A constraint-satisfaction lens on factual errors of language models. arXiv 2023, arXiv:2309.15098. [Google Scholar] [CrossRef]
- Régin, F.; De Maria, E.; Bonlarron, A. Combining constraint programming reasoning with large language model predictions. arXiv 2024, arXiv:2407.13490. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Jiang, J.; Wang, F.; Shen, J.; Kim, S.; Kim, S. A survey on large language models for code generation. arXiv 2024, arXiv:2406.00515. [Google Scholar] [CrossRef]
- OpenAI. ChatGPT: A Large Language Model. 2022. Available online: https://chat.openai.com (accessed on 1 April 2025).
- Ridnik, T.; Kredo, D.; Friedman, I. Code generation with AlphaCodium: From prompt engineering to flow engineering. arXiv 2024, arXiv:2401.08500. [Google Scholar] [CrossRef]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.D.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating large language models trained on code. arXiv 2021, arXiv:2107.03374. [Google Scholar] [CrossRef]
- Kahneman, D. Thinking, Fast and Slow; Farrar, Straus and Giroux: New York, NY, USA, 2011. [Google Scholar]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.L.; Chen, Y.; Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. arXiv 2023, arXiv:2305.10601. [Google Scholar] [CrossRef]
- Lee, J.; Tay, Y.; Bommasani, R.; Raffel, C.; Zoph, B.; Borgeaud, S.; Yogatama, D.; Bosma, M.; Zhou, D.; Metzler, D.; et al. Emergent abilities of large language models. arXiv 2022, arXiv:2206.07682. [Google Scholar] [CrossRef]
- Chung, H.W.; Hou, L.; Longpre, S.; Zoph, B.; Tay, Y.; Fedus, W.; Li, E.; Wang, X.; Dehghani, M.; Brahma, S.; et al. Scaling instruction-finetuned language models. arXiv 2022, arXiv:2210.11416. [Google Scholar] [CrossRef]
- Almonacid, B. Towards an automatic optimisation model generator assisted with generative pre-trained transformers. arXiv 2023, arXiv:2305.05811. [Google Scholar] [CrossRef]
- Michailidis, K.; Tsouros, D.; Guns, T. Constraint modelling with LLMs using in-context learning. In Proceedings of the 30th International Conference on Principles and Practice of Constraint Programming (CP 2024), Girona, Spain, 2–6 September 2024; Shaw, P., Ed.; Schloss Dagstuhl—Leibniz-Zentrum für Informatik: Wadern, Germany, 2024; Volume 307, pp. 20:1–20:27. [Google Scholar] [CrossRef]
- Dakle, P.P.; Kadıoğlu, S.; Uppuluri, K.; Politi, R.; Raghavan, P.; Rallabandi, S.; Srinivasamurthy, R.S. Ner4Opt: Named entity recognition for optimization modelling from natural language. In Machine Learning, Optimization, and Data Science; Nicosia, G., Pardalos, P., Giuffrida, G., Umeton, R., Sciacca, V., Eds.; Springer: Cham, Switzerland, 2023; pp. 299–319. [Google Scholar] [CrossRef]
- Penco, R. Dataset for Fine-Tuning LLM to Generate Minizinc [Data Set]. Kaggle. 2025. Available online: https://doi.org/10.34740/KAGGLE/DSV/11207997 (accessed on 1 April 2025).
- ACMG Code Repository. Available online: https://github.com/erobpen/ACMG/ (accessed on 1 April 2025).
- Minaee, S.; Mikolov, T.; Nikzad, N.; Chenaghlu, M.; Socher, R.; Amatriain, X.; Gao, J. Large language models: A survey. arXiv 2024, arXiv:2402.06196. [Google Scholar] [CrossRef]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling language modeling with Pathways. arXiv 2022, arXiv:2204.02311. [Google Scholar] [CrossRef]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Enis, M.; Hopkins, M. From LLM to NMT: Advancing low-resource machine translation with Claude. arXiv 2024, arXiv:2404.13813. [Google Scholar] [CrossRef]
- Zhang, S.; Dong, L.; Li, X.; Zhang, S.; Sun, X.; Wang, S.; Li, J.; Hu, R.; Zhang, T.; Wu, F.; et al. Instruction tuning for large language models: A survey. arXiv 2023, arXiv:2308.10792. [Google Scholar] [CrossRef]
- Sahoo, P.; Singh, A.K.; Saha, S.; Jain, V.; Mondal, S.; Chadha, A. A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv 2024, arXiv:2402.07927. [Google Scholar] [CrossRef]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. arXiv 2021, arXiv:2107.13586. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 1 April 2025).
- Khashabi, D.; Min, S.; Khot, T.; Sabharwal, A.; Tafjord, O.; Clark, P.; Hajishirzi, H. UnifiedQA: Crossing format boundaries with a single QA system. arXiv 2020, arXiv:2005.00700. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. arXiv 2020, arXiv:2005.14165. [Google Scholar] [CrossRef]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv 2020, arXiv:2005.11401. [Google Scholar] [CrossRef]
- Gao, L.; Madaan, A.; Zhou, S.; Alon, U.; Liu, P.; Yang, Y.; Callan, J.; Neubig, G. PAL: Program-aided language models. arXiv 2022, arXiv:2211.10435. [Google Scholar] [CrossRef]
- Doan, X.-D. VTCC-NLP at nl4opt competition subtask 1: An ensemble pre-trained language models for named entity recognition. arXiv 2022, arXiv:2212.07219. [Google Scholar] [CrossRef]
- Ning, Y.; Liu, J.; Qin, L.; Xiao, T.; Xue, S.; Huang, Z.; Liu, Q.; Chen, E.; Wu, J. A novel approach for auto-formulation of optimization problems. arXiv 2023, arXiv:2302.04643. [Google Scholar] [CrossRef]
- Wang, K.; Chen, Z.; Zheng, J. Opd@nl4opt: An ensemble approach for the NER task of the optimization problem. arXiv 2023, arXiv:2301.02459. [Google Scholar] [CrossRef]
- Ramamonjison, R.; Yu, T.T.; Li, R.; Li, H.; Carenini, G.; Ghaddar, B.; He, S.; Mostajabdaveh, M.; Banitalebi-Dehkordi, A.; Shi, Y.; et al. NL4Opt competition: Formulating optimization problems based on their natural language descriptions. arXiv 2023, arXiv:2303.08233. [Google Scholar] [CrossRef]
- Gunasekar, S.; Zhang, Y.; Aneja, J.; Mendes, C.C.; Del Giorno, A.; Gopi, S.; Javaheripi, M.; Kauffmann, P.; De Rosa, G.; Saarikivi, O.; et al. Textbooks Are All You Need. arXiv 2023, arXiv:2306.11644. [Google Scholar] [CrossRef]
- Gangwar, N.; Kani, N. Highlighting named entities in input for auto-formulation of optimization problems. In Machine Learning, Optimization, and Data Science; Nicosia, G., Pardalos, P., Umeton, R., Giuffrida, G., Sciacca, V., Eds.; Springer: Cham, Switzerland, 2022; pp. 129–143. [Google Scholar] [CrossRef]
- Nethercote, N.; Stuckey, P.J.; Becket, R.; Brand, S.; Duck, G.J.; Tack, G. MiniZinc: Towards a standard CP modelling language. In Proceedings of the 13th International Conference on Principles and Practice of Constraint Programming, Providence, RI, USA, 25–29 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 529–543. [Google Scholar] [CrossRef]
- Nightingale, P. Savile Row Manual. arXiv 2021, arXiv:2201.03472. [Google Scholar] [CrossRef]
- Akgün, Ö.; Frisch, A.M.; Gent, I.P.; Jefferson, C.; Miguel, I.; Nightingale, P.; Salamon, A.Z. Towards Reformulating Essence Specifications for Robustness. arXiv 2021, arXiv:2111.00821. [Google Scholar] [CrossRef]
- Guns, T. Increasing Modeling Language Convenience with a Universal N-Dimensional Array, CPpy as Python-Embedded Example. In Proceedings of the 18th Workshop on Constraint Modelling and Reformulation at CP (ModRef 2019), Stamford, CT, USA, 30 September 2019. [Google Scholar]
- Stuckey, P.J.; Marriott, K.; Tack, G. MiniZinc Documentation (Version 2.8.3). MiniZinc. 2024. Available online: https://www.minizinc.org/doc-latest/en/index.html (accessed on 1 April 2025).
- ACMG Control Prompts Repository. Available online: https://github.com/erobpen/ACMG/tree/main/appendices/Appendix_1 (accessed on 1 April 2025).
- Schulte, C.; Stuckey, P.J. Efficient constraint propagation engines. ACM Trans. Program. Lang. Syst. 2008, 31, 2. Available online: https://www.gecode.org/papers/SchulteStuckey_TOPLAS_2008.pdf (accessed on 1 April 2025). [CrossRef]
- Tack, G. Constraint Propagation: Models, Techniques, Implementation. Ph.D. Dissertation, Saarland University, Saarbrücken, Germany, 2009. Available online: https://www.gecode.org/papers/Tack_PhD_2009.pdf (accessed on 1 April 2025).
- Schulte, C.; Tack, G.; Lagerkvist, M.Z. Modeling and Programming with Gecode. 2010. Available online: https://www.gecode.org/doc-latest/MPG.pdf (accessed on 1 April 2025).
- Google OR-Tools. Google Optimization Tools. 2010. Available online: https://developers.google.com/optimization (accessed on 1 April 2025).
- ACMG Validation Test Suite Repository. Available online: https://github.com/erobpen/ACMG/tree/main/appendices/Appendix_7 (accessed on 1 April 2025).
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2022, arXiv:2201.11903. [Google Scholar] [CrossRef]
- Soudani, H.; Kanoulas, E.; Hasibi, F. Fine Tuning vs. Retrieval Augmented Generation for Less Popular Knowledge. arXiv 2024. [Google Scholar] [CrossRef]
- Wang, Y.; Kordi, Y.; Mishra, S.; Liu, A.; Smith, N.A.; Khashabi, D.; Hajishirzi, H. Self-Instruct: Aligning Language Models with Self-Generated Instructions. arXiv 2022, arXiv:2212.10560. [Google Scholar] [CrossRef]
- Hoffmann, J.; Borgeaud, S.; Mensch, A.; Buchatskaya, E.; Cai, T.; Rutherford, E.; Casas, D.D.; Hendricks, L.A.; Welbl, J.; Clark, A.; et al. Training Compute-Optimal Large Language Models. arXiv 2022, arXiv:2203.15556. [Google Scholar] [CrossRef]
- Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; Bi, X.; et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2025, arXiv:2501.12948. [Google Scholar] [CrossRef]
- Bai, J.; Bai, S.; Chu, Y.; Cui, Z.; Dang, K.; Deng, X.; Fan, Y.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen Technical Report. arXiv 2023, arXiv:2309.16609. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

| ACMG | [17] | [16] | |
|---|---|---|---|
| Multi-step process | Yes | Yes | No |
| NER | Yes | Yes | No |
| RAG | No | Yes | No |
| Encoder LLM in NER | No | Yes | No |
| Decoder LLM in NER | Yes | Yes | No |
| Fine-tuning LLM | Yes | No | No |
| Multiple LLMs | Yes | No | No |
| Prompting technique | Zero-Shot | Few-Shot | Zero-Shot |
| LLM-guided process | Yes | No | Partially |
| Parameter | Value | Notes |
|---|---|---|
| Input format | jsonl | Prompt-completion pairs |
| Tokenization | OpenAI BPE | Subword segmentation (GPT-3.5/4) |
| Batch size | 1 | Sequential processing |
| Epochs | 1 | Default setting |
| Learning rate | Multiplier = 1 | Base rate undisclosed by OpenAI |
| Training loss | 0.057 | Final convergence metric |
| Legend | Valid | Solution |
|---|---|---|
| Fail | Incorrect | Incorrect |
| Partial success | Correct | Incorrect |
| Success | Correct | Correct |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Penco, R.; Pintar, D.; Vranić, M.; Šoštarić, M. Large Language Model-Driven Framework for Automated Constraint Model Generation in Configuration Problems. Appl. Sci. 2025, 15, 6518. https://doi.org/10.3390/app15126518
Penco R, Pintar D, Vranić M, Šoštarić M. Large Language Model-Driven Framework for Automated Constraint Model Generation in Configuration Problems. Applied Sciences. 2025; 15(12):6518. https://doi.org/10.3390/app15126518
Chicago/Turabian StylePenco, Roberto, Damir Pintar, Mihaela Vranić, and Marko Šoštarić. 2025. "Large Language Model-Driven Framework for Automated Constraint Model Generation in Configuration Problems" Applied Sciences 15, no. 12: 6518. https://doi.org/10.3390/app15126518
APA StylePenco, R., Pintar, D., Vranić, M., & Šoštarić, M. (2025). Large Language Model-Driven Framework for Automated Constraint Model Generation in Configuration Problems. Applied Sciences, 15(12), 6518. https://doi.org/10.3390/app15126518