Abstract
This article presents a unique approach to Arabic dialect identification using a pre-trained speech classification model. The system categorizes Arabic audio clips into their respective dialects by employing 1D and 2D convolutional neural network technologies built from diverse dialects from the Arab region using deep learning models. Its objective is to enhance traditional linguistic handling and speech technology by accurately classifying Arabic audio clips into their corresponding dialects. The techniques involved include record gathering, preprocessing, feature extraction, prototypical architecture, and assessment metrics. The algorithm distinguishes various Arabic dialects, such as A (Arab nation authorized dialectal), EGY (Egyptian Arabic), GLF (Gulf Arabic), LAV and LF (Levantine Arabic, spoken in Syria, Lebanon, and Jordan), MSA (Modern Standard Arabic), NOR (North African Arabic), and SA (Saudi Arabic). Experimental results demonstrate the efficiency of the proposed approach in accurately determining diverse Arabic dialects, achieving a testing accuracy of 94.28% and a validation accuracy of 95.55%, surpassing traditional machine learning models such as Random Forest and SVM and advanced erudition models such as CNN and CNN2D.
1. Introduction
Dialects are variances in phonology, lexicon, and grammar shaped by cultural influences, educational backgrounds, geographical locations, and socioeconomic levels. Automatic Dialect Identification (ADI) systems seek to identify dialects from spoken utterances by analyzing speech features [1]. More than 420 million people speak Arabic, a Semitic language with an intense cultural heritage and history, particularly in the Arab world and numerous diaspora communities. The linguistic landscape of the Arab world differs significantly, even though Modern Standard Arabic (MSA) is the certified lingua franca of Arab nations and operates as a communication platform in media sources. The Arabic dialects used in colloquial speech diverge considerably compared with MSA based on phonology, morphology, and syntax. Simultaneously, MSA is the solitary structured and standardized variant of Arabic used formally in written communications [2]. A broad range of Arabic dialects has been established over the centuries, each reflecting the area’s distinct history, topography, and cultural influences. These dialects’ pronunciation, vocabulary, grammar, and syntax are greatly diverse; whilst they are generally intelligible, they may pose serious obstacles to cross-regional communication and comprehension. For example, a person who speaks Egyptian Arabic faces a challenge in understanding Gulf Arabic or Levantine Arabic. Dialect identification (DID) is a process that inevitably determines the appropriate dialect within spoken or transcribed Arabic language. Listeners analyze incoming acoustic–phonetic information, including a speaker’s dialect or accent, which may vary from their native dialect across several dimensions of sound structure. The production patterns of non-native speakers frequently vary at all levels of phonological structure, and these discrepancies are prevalent among non-native speakers, irrespective of their native language backgrounds. Comprehending the impact of various linguistic variants on intelligibility, processing, and representation is essential. Listeners exhibit heightened sensitivity to the existence of non-native accents [3].
Dialects are closely related forms of a common language, and language recognition is a remarkably complex task [4]. Applications such as machine translation, speech recognition, and customized user experiences are difficult to develop due to the linguistic diversity across several regions. This situation heralds the discovery of deep learning techniques for automatic Arabic dialect classification to construct more inclusive and efficient language technologies for the Arabic-speaking community. By precisely categorizing Arabic speech according to its dialectal origin, we can construct individualized language-processing systems that gather the unique requirements and preferences of speakers of several dialects. Handcrafted features, namely, prosodic (pitch, intensity, and duration), acoustic (Mel-Frequency Cepstral Coefficients, or MFCCs), and linguistic (phoneme frequencies, n-grams) features, are commonly used in traditional dialect classification methods. However, these techniques involve significant manual effort and might not adequately convey spoken language’s modulation and intricate specifics. Deep learning is a feasible alternative that automatically extracts high-level interpretations from untreated audio data.
Research Gap
Researchers often overlook distinctive region-specific characteristics such as linguistic and acoustic features and vocabulary, focusing instead on broad dialect classifications (such as Egyptian and Levantine), not specific regional variations. Although class imbalances have been mentioned in a few studies, there is no systematic practice associated with dealing with imbalanced datasets from other geographical areas. Moreover, researchers have focused on publicly available datasets, and there is a dearth of research on the variations in Arabic dialects in private datasets.
2. Literature Review
Arabic dialectal languages have received attention due to the mounting demand for social media and internet connectivity, posing opportunities and obstacles in Arabic language processing and machine learning. Applications such as machine translation and sentiment analysis depend on these unofficial data. A dialectal text on social media can be meritoriously processed using deep learning mechanisms. Numerous deep learning representations of the automated classification of Arabic dialectal text were examined using the Arabic Online Commentary dataset. The outcomes are commendable, based on the results obtained for each pair of dialects [2]. Dialect identification is a crucial task required for applications such as e-health and automatic speech recognition. Fundamental frequency, energy, and Mel-frequency cepstrum coefficient parameters were previously extended as methods for automatically identifying Arabic dialects. The effectiveness of these methods was demonstrated by their outperformance of contemporary techniques on five dialect datasets using a convolutional neural network architecture [5]. Two transformer models, BERT (using deep learning) and DistillBERT (employing machine learning), were also implemented to classify texts based on attention mechanisms [6].
A method for recognizing and categorizing Arabic speech dialects based on the speaking nation is presented with an accuracy of 83%, where the system extracts features from 672 audio inputs using convolutional neural network (CNN) techniques. The system is more effective than machine learning models because it uses spectrogram features to translate speech into images, thus improving Arabic speech dialect classification, which is important for machine translation and communication [7]. This systematic literature review identifies research gaps in computational studies of dialectal Arabic, with a focus on popular research topics, dialects, machine learning methodologies, neural grid input features, data types, datasets, system evaluation criteria, publication venues, and trends. It exposes prejudices that prioritize regional dialects over individual vernaculars, text over speech, and Egyptian over all other vernaculars. This review also identifies research gaps, including the dearth of resources for city dialects, the lack of linguistic studies, the neglect of Mauritanian and Bahraini, and the dearth of deep machine learning experiments [8]. SYSTRAN used a variety of neural network models to compete in the Arabic dialect identification subtask of the DSL shared task. A CNN-biLSTM network, a binary CNN-biLSTM system, and a multi-input CNN made up the top-performing systems. Despite a lack of training data, the network generated competitive results [4]. The engraved system of Arabic makes Modern Standard Arabic (MSA) the most commonly used language in Arabic datasets. The Arabic Online Commentary Dataset is a new Arabic resource with dialect annotations. The data were crowdsourced to determine the dialect in more than 100,000 sentences. Automatic classifiers for dialect identification were trained using the data, and the classification accuracy was almost human-like. The classifiers were used to identify dialectical data using a massive web crawl of 3.5 million Arabic newspaper pages [9]. The ADI17 corpus, which comprises 1717 wave files, was used in this study to recommend machine learning models for Arabic dialect identification. Features were extracted using Mel-Frequency Cepstral Coefficients (MFCCs) and Triangular Filter Bank Cepstral Coefficients (TFCCs). KNN, Random Forest, Multi-Layer Perceptron, and Artificial Neural Networks were used to automatically identify extracted features. The accuracy of the results was high [10]. An article, outlined by Kanjirangal et al., mentions the techniques applied in the multi-label country-level dialect identification (MLDID) task, which is the first NADI 2024 Subtask. Using NADI 2023 data, the researchers converted multiclass forecasts to multi-label data using both supervised and unsupervised techniques. To extract samples from the training set, they additionally employed multilingual cross-encoders and Arabic-based sentence encoders. The best validation performance was an F-score of 48.5% using an unsupervised method [11].
The three Arabic dialects—Gulf, Levantine, and Egyptian—were identified using a new method presented in a study by Abdelazim et al. Several classification techniques, such as Gaussian Naïve Bayes and Support Vector Machines, were used in four experiments. With average gains in precision, recall, and F1-score metrics, the suggested classifier based on convolutional neural networks performed better than other classifiers in all three dialects [12]. The Convolutional Long Short-Term Memory (CLSTM) model, a deep learning and machine learning technique, was used in this study to identify cyberbullying in Arabic YouTube comments. With an accuracy rate of 90%, the model revealed the effectiveness of deep learning in safeguarding users who speak Arabic and offered a framework for dealing with comparable linguistic difficulties in other languages. A study by Birl et al. investigated how to enhance speaker recognition in autonomous speaker identification using synthetic data. By comparing data from synthetic and real speakers, the researchers trained a character-level recurrent neural network on five spoken sentences. To determine whether the synthetic data could offer any useful rules, the network weights were applied to the original dataset. The findings demonstrated that improved classification accuracy, F1-score, precision, and recall were achieved through fine-tuned learning from synthetic speech data. Class imbalance problems were also resolved by this method [13]. A deep learning model was used to create an autonomous dialect detection system. The system uses multi-scale product analysis to extract glottal occurrences, fundamental frequency, and cepstral properties from speech signals. Multi-dimensional characteristics and relationships can be encoded using the Hamilton neural network classifier. The system is reliable in terms of recognizing Arabic dialects, and experimental results demonstrate notable performance improvements over existing HNN-based methods [14]. Researchers are creating automated SLR frameworks to handle the approximately 7000 distinct sign languages. According to an analysis of 988 research papers, transformer-based models and ensemble learning techniques perform better in terms of accuracy and resilience compared with conventional methods [15].
2.1. Audio MFCCS Generation
A technique for generating speech from filter bank Mel-Frequency Cepstral Coefficients (MFCCs), which are normally useless for speech synthesis, is presented in this study. It introduces a generative adversarial network-based noise model, predicts fundamental frequency and voicing information, and transforms spectral wrapping information into all-pole filters [16].
AI-generated or modified deepfake content can look authentic in text, audio, video, and images. The Mel-Frequency Cepstral Coefficient (MFCC) technique is used to examine habits and machine learning-based and deep learning-based tactics to detect deepfake audio. The Fake-or-Real dataset, divided into four sub-datasets, was used as a benchmark. On the for-rece and for-2-sec datasets, the support vector machine (SVM) outperformed other machine learning prototypes in terms of accuracy, whereas the gradient boosting model performed well on the for-norm dataset [17]. Convolutional and recurrent neural networks were used to develop a novel approach to sound classification. To simulate the human auditory system, features were extracted from the audio using the Mel-Frequency Cepstral Coefficient (MFCC) method. Due to its impressive accuracy, the model showed promise as a flexible model for audio classification, with potential applications in healthcare, music production, and speech recognition. More studies may result in advances in the categorization and analysis of audio data [18].
2.2. Feature Selection
Boraj et al. introduced boosted correlation-based feature selection (ECFS), a method that uses feature–feature and feature–class correlations to effectively excerpt relevant feature subsets from multiclass gene manifestation data and machine learning datasets. ECFS has demonstrated high satisfactory classification accuracies across several benchmark datasets, outperforming KNN, Random Forest, and decision tree classifiers [19]. For accurate data models and effective data reduction, feature selection (FS) techniques are applied in data preprocessing. They are habitually engaged in tasks concerning regression, clustering, and classification. Standard filter, wrapper, embedded, hybrid, and advanced topics are covered in this study. To classify gene expression data, a study by Chandra et al. uses ERGS (Effective Range-based Gene Selection), an effective feature selection method. Features that discriminate between classes are given more weight in this method, which uses statistically defined effective ranges of features for each class. Results from experiments demonstrate the efficacy of this method, which can rank genes and pinpoint pertinent genes that cause conditions such as prostate cancer, lung cancer, DLBCL, leukemia, and colon tumors [20].
A study by Van Haluse et al. compares the effectiveness of 6 common filter-based processes with 11 novel threshold-based feature selection strategies for bioinformatics applications. The methods display different behaviors when compared with conventional filter-based techniques. The new methods perform better than conventional filters, which makes them valuable for bioinformatics data analysis, based on experiments conducted on 17 datasets using the Naive Bayes and Support Vector Machine algorithms [21]. Zhu et al. propose a synthetic aperture radar target recognition method based on convolutional neural networks (CNNs). The method uses Spearman’s rank correlation to gauge the resemblance between the unique SAR image and the feature map. High-similarity feature maps are represented and chosen using joint sparse representation (JSR). Inner correlations between feature maps, the test sample, and the training class are also taken into account. For ten ground target classes, experiments demonstrate an average recognition rate of 99.32% under typical operating conditions and exceptional robustness under extended operating conditions [22]. A study by Samb et al. focuses on feature selection in data mining and optimization for classification. Although efficient, the RFE-SVM algorithm is greedy. An alternate strategy uses local search operators in conjunction with the RFE-SVM algorithm to get around this. Promising results from experiments using datasets from the UCI Machine Learning Repository demonstrate the role of local search in classification. The quality of the final classifier is increased by reusing features that were eliminated during the RFE-SVM process [23].
2.3. Augmentation Method
The work proposed by Chen et al. suggests an innovative approach to intrusion detection in computer networks, combining ADASYN sampling with AGM clustering-based sampling. The C3BANet network architecture, which integrates CNN, Bi-directional Long Short-Term Memory, and Channel-Attention mechanisms, is used. The UNSW-NB15 dataset is preprocessed to eliminate noise and inconsistencies, and the model achieves multiclass detection rates of 96.82% after AGM sampling, outperforming mainstream intrusion detection algorithms; thus, the study introduces methodological innovations and offers practical applications [24]. Class imbalance and missing values are the main topics of the study, which looks at augmentation methods for clinical datasets. On some datasets, it was discovered that Gaussian Noise Up-Sampling (GNUS) performs as well as, if not better than, SMOTE and ADASYN. However, in certain situations, augmentation might not enhance classification [25]. A hybrid intrusion detection framework for Internet of Medical Things (IoMT) networks is presented by Salehpour et al. It makes use of ensemble learning, adaptive resampling with ADASYN, and a noise detection model based on Boost. By preprocessing unbalanced data and filtering noise, the stacked model reliably and accurately detects threats. The UNSW-NB15 benchmark is used to experimentally validate the results, which demonstrate successful detection in noisy environments with a reported accuracy of 92.23% [26].
With an emphasis on undersampling, oversampling, and hybrid sampling, this learning assesses 21 sampling techniques on 100 unbalanced record sets. The results demonstrate that the use of sampling techniques has a major influence on classification outcomes. The best results are obtained with Random Under Sampler (RUS), RandomOverSampler (ROS), and Instance Hardness Threshold (IHT), which have well-adjusted accuracy scores (BASs) of 0.8599, 0.8460, and 0.8049, respectively. Additionally, a study by Nhita et al. discovered that dataset complexity cannot be determined solely using the disparity rate and occurrences per trait ratio [27]. A study by Lee et al. used the borderline synthetic minority oversampling technique (SMOTE) to examine the problem of imbalance in event-related potentials in P300-based brain–computer interfaces (BCIs). SMOTE considerably improved the performance of low performers but had no discernible effect on overall BCI performance, indicating that data augmentation can improve the performance of users who are not familiar with P300-based BCIs [28]. The study suggests an approach based on the borderline synthetic minority oversampling technique for identifying emotions in electroencephalogram signals. The technique extracts frequency domain features and augments the data for balance using 32-channel EEG signals from the DEAP dataset. Based on valence and arousal, the one-dimensional convolutional neural network is trained to catalog emotions. With average accuracy rates of 97.47% and 97.76%, respectively, the method performs better than both existing methods and traditional machine learning techniques [29].
2.4. Deep Learning Models
An ANN model for speech emotion recognition (SER) using aural datasets and Mel-Frequency Cepstral Coefficient feature extraction is presented by Dolka et al., showing an average accuracy of 99.52% across multiple datasets. The model categorizes audio files based on eight emotional states [30]. The goal of research on speech emotion recognition (SER) is to create human–computer interactions using emotion and speech. A study by Harza et al. uses five deep learning facsimiles, including CNN-LSTM, to classify seven emotions (sadness, happiness, anger, fear, disgust, neutral, and surprise) from audio data from the Toronto Emotional Speech Set (TESS), Surrey Audio-Visual Expressed Emotion (SAVEE), and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS). CNN-LSTM achieved the highest accuracy of 84.35% on the TESS+SAVEE dataset [31]. Preliminary findings from a study of Mel-Frequency Cepstral Coefficient (MFCC) features for human voice speech recognition are presented in this paper. A study by Barua et al. reorganized speech from two Bangla commands using 16 Mel-scale warped cepstral coefficients. The considerable efficacy of MFCC features in speech recognition was demonstrated when a neural network trained with MFCC features was able to identify a single individual using their command [32]. The objective of the research by Singh et al. was to enhance the average accuracy of speech emotion recognition (SER) models while lowering computational costs. To extract features from audio files, researchers suggest a novel method that makes use of Mel-Frequency Cepstral Coefficients (MFCCs) and 1D convolutional neural networks (1D CNNs). Compared with current models, the method achieved an average accuracy of 82.93% when tested on the Ryerson Audio-Visual Database of Emotion (RAVDESS) [33]. By using speech signals to determine gender, age group, and regional dialects, human–machine interaction systems (HMISs) can improve user interaction across sectors. To examine and differentiate feature patterns, a convolutional neural network (CNN)-based classifier and feature extraction technique were employed. The suggested model using Mel-scale frequencies (MSF) successfully recognized gender and region after mining Mel-Frequency Cepstral quantities from dialect-sentence speech signals. The classifier underwent extensive testing, validation, and training [34]. A one-dimensional dilated convolutional neural network (1D-DCNN) is proposed as a novel method for speech emotion recognition. The method enhances speech signals and extracts hidden patterns using a bi-directional gated recurrent unit (BiGRU) and hierarchical features learning blocks (HFLBs). A BiGRU receives the learned emotional features and uses them to recognize temporal cues and modify global weights. Using three benchmarked datasets, the model’s accuracy was 72.75%, 91.14%, and 78.01%, respectively.
A study by Reggiswarashari et al. suggests a speech emotion recognition model that uses segmented audio and convolutional neural networks (CNNs) to predict human emotions. Mel-Frequency Cepstral Coefficients (MFCCs) and other structures are learned by the model from audio waves. Using a combined dataset with audio segmentation and zero padding, it predicts seven emotions with 83.69% accuracy [35]. The process of classifying ambient sounds into genres, emotions, or states is called audio classification. Deep learning has gained popularity as a technique for this. The suggested system employs convolutional neural networks with 1D and 2D convolutions for increased accuracy and Mel-Frequency Cepstral Coefficient techniques for feature extraction from audio signals [36]. For applications involving human–computer interactions, speech emotion recognition is essential. Machine learning methods and hand-crafted features are frequently inadequate and computationally demanding. Robust feature extraction has been accomplished using deep learning algorithms. Vocal utterance feature extraction and classification were accomplished using a specially designed 2D convolutional neural network. The algorithm demonstrated high precision, recall, and F1-scores compared with current techniques. Depending on the language context, customized solutions might be required [37]. Table 1 shows comparisons of the different models used. A study by Im et al. enhances the attention mechanism for Neural Machine Translation tasks by analyzing the Content-Adaptive Recurrent Unit (CARU) and applying it to an attention model and embedding layer, improving performance and convergence [38]. Li et al. presented an innovative design for graph neural networks in audio signal processing using feature similarity and an LSTM aggregator. The unweighted and weighted accuracy of the network was comparable to or superior to existing graph baselines, enhancing interpretability and accurately identifying speech–emotion components [39].

Table 1.
Comparison of recent studies.
3. Methodology
Figure 1 depicts the Arabic region-wise speech recognition and classification model labeled in two phases. In phase 1, the Klaam library processes 4071 Arabic audio clips from five major dialects (MSA, Egyptian, Gulf, Levantine, and North African) to appropriately identify speech. The pre-trained model from the Klaam library was selected because of its notable benefits in recognizing Arabic dialects. It has a solid foundation because it was specially designed and pre-trained on a large quantity of Arabic speech data, enabling it to capture the complex phonetic and prosodic nuances necessary for differentiating Klaam models that have shown state-of-the-art or extremely competitive performance in related Arabic speech tasks. Additionally, by exploiting the model’s prior understanding of Arabic speech, using this pre-trained model made transfer learning easier, allowing for faster convergence, better generalization, and less need for incredibly huge bespoke datasets for each dialect. It also has an open-source community. We sought to improve our dialect detection abilities by using a model designed specifically for Arabic.
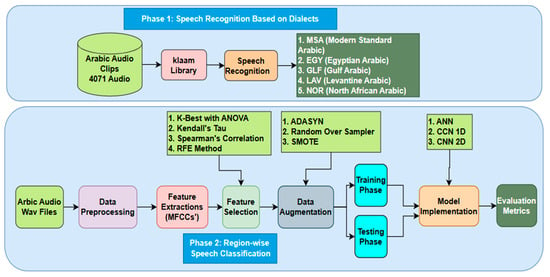
Figure 1.
Basic block diagram for region-wise Arabic speech recognition and classification.
The MFCC feature extraction method is applied for feature extraction, and separated transcriptions are further examined using techniques such as Kendall’s Tau, Spearman’s correlation, and K-Best with ANOVA to choose the superlative features. In phase 2, the focus is on region-wise dialect classification, where feature selection and data augmentation are conducted using techniques such as SMOTE, random oversampling, and ADASYN. CNNs with different architectures (1D and 2D CNNs) and ANNs are deep learning models trained using augmented data. Parameters such as accuracy, precision, recall, and F1-score are simulated to gauge the trained models, and their performances are assessed against raw sample audio data. To correctly identify and categorize Arabic dialects from diverse geographical locations, this study elaborates on an architecture combining linguistic analysis and deep learning techniques, ultimately advancing NLP for the Arabic language. One-dimensional and two-dimensional convolutional neural networks (CNNs) are employed in dialect classification due to their compatibility with the input data format and their proficiency. A 1D CNN is optimal for sequential input, such as raw audio waveforms or text sequences, by employing filters along a single dimension to extract local temporal or sequential patterns, such as distinct phonemes, intonations, or word sequences that are indicative of various languages. A 2D CNN is specifically developed for two-dimensional data, such as spectrograms, which visually depict audio signals and illustrate the variation in frequency content over time. Using filters along both temporal and spectral dimensions, 2D CNNs can acquire intricate time-frequency patterns and prosodic characteristics that differentiate dialects. Both varieties of CNNs autonomously acquire hierarchical features from the data, diminishing the necessity for manual feature engineering. Performance evaluation criteria, including accuracy, precision, recall, F1-score, and the Matthews correlation coefficient, were employed in our study to analyze the performance of various models. Figure 2 represents the research flow diagram.

Figure 2.
Research flow diagram.
3.1. Data Collection
The speech files are recorded from several news broadcasts on TV and radio while keeping the same data. We collaborated with other regional receivers and television locations to acquire pre-recorded dialogue assemblies (such as portions of their annals). With these aligned efforts, the time and expense associated with producing the necessary speech dataset are reduced. Where the speech tapes are longer, the files are divided into shorter segments of 10–30 s. Longer files (more than 30 s) are problematic and can cause the speech recognizer to struggle to match the tapes to their phonetic transcripts. For recordings longer than 10 min, preliminary placement might not work, which would cause problems during the training phase. Shorter recordings can be used to create a more efficient and successful process.
The following parameters are set when recording to create a corpus: Sampling Rate = 16 kHz (or 8 kHz, depending on the training data), Bits = 16, and Channels = Mono (=single channel). Once the speech recordings are obtained, the spoken words are transcribed and annotated. The statistics used in this study are based on text data taken from 4071 Arabic audio clips. Sports, technology, education, health, economics, security, and justice are among the topics covered in the gathered audio data. There are various data levels within each category of collected data. While some categories have three data levels, others only have two: the data in the sports category include information on boxing, as well as sports in general; the two technology subcategories are electronic device-based technology and mobile phone technology; the education category contains broad information on tutoring, such as literacy rates, public education, higher education, compulsory education, kindergarten, university and college, midway education, main education, and research.
3.2. Automatic Dialect Identification
The Klaam library offers a pre-trained model for speech audio classification and is an open-source framework created especially for Arabic Natural Language Processing (NLP) tasks. A machine learning architecture that has already been trained on a sizable speech information set is known as a pre-trained model. It permits the model to learn generalizable features and patterns, including phonetic information, linguistic subtleties, and acoustic characteristics. By removing the need for in-depth training from the ground up, this pre-training procedure drastically cuts down on the time and resources needed for development. Dialect, speaker, emotion, and language identification are just a few of the speech classification tasks that can be accomplished using the speech classification model in the Klaam library. Using this pre-trained model helps add quick and efficient speech classification capabilities to the Arabic NLP applications. Datasets such as MGB-3, ADI-5, Common Voice, and the Arabic Speech Corpus are used to build a pre-trained Arabic dialect speech classification model: ADI-5 contains a wide variety of regional dialects (Egyptian, Levantine, Gulf, North African, and Modern Standard Arabic) sourced from Al Jazeera TV; MGB-3 is a sizable corpus of Egyptian Arabic speech gathered from YouTube; the Common Voice dataset, which is accessible on Hugging Face, is a multilingual resource with a significant amount of Arabic speech data; the Arabic Speech Corpus offers useful aligned speech and transcriptions for training and assessing speech recognition and classification models. These datasets make it possible to develop a high-quality pre-trained model for Arabic dialect classification with suitable data preprocessing, feature extraction methods, and strong model architectures. The basic architectural block diagram using the speech classification pre-trained method is shown in Figure 3.
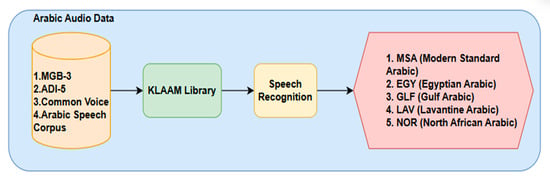
Figure 3.
Region-wise dialect classification.
Of the five classes obtained, we selected two for region-wise classification of Arabic dialects. The problem is binary, since the two classes chosen are Gulf Arabic (GLF) and Modern Arabic (MSA).
3.2.1. Data Preprocessing
The Arabic Wav files undergo preprocessing, including silence removal, time and frequency analysis, sampling, and discrete Fourier transform (DFT) analysis.
3.2.2. Feature Extraction
The structures are mined using Mel-Frequency Cepstral Coefficient (MFCC) extraction. MFCC features capture the spectral and temporal characteristics of the audio wave. The Librosa Python v3.11.13 library is used for feature extraction. Triangular filters are used to extract MFCC features that are necessary for understanding speech content. Human hearing works on a Mel scale, but standard FFTs analyze sound frequencies linearly. Triangle-shaped filters are applied to the FFT’s output. By adding the contributions of each filter, with each concentrating on a specific frequency range, we can capture the parts of the spectrum that are most relevant to human hearing. This model-focused representation yields the MFCC. The distribution of filters is equal, and the filters are spaced logarithmically apart above 1000 Hz. Mel frequency is calculated using the following equation:
mel(f) = 1127In(1 + f/700)
Mel(f): Mel units.
f: actual frequency in Hertz.
In: Natural Logarithm.
The first and second MFCCs can be used to compute the changes in speech from frame to frame. The Arabic audio dataset is used to generate 13 MFCC features. The block diagram for MFCC feature extraction is shown in Figure 4.
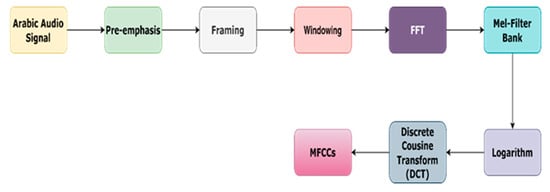
Figure 4.
MFCC feature extraction.
Once the audio is in time domain format, we use the Fast Fourier Transform to convert the audio into a periodogram. We do this to identify the sound by downsampling the audio to obtain a Nyquist frequency.
f_(Nyquist) = 1/2nu
The Fast Fourier Transform (FFT) algorithm can be used to determine a sequence’s discrete Fourier transform (DFT) or its inverse discrete Fourier transform (IDFT). Fourier scrutiny converts a signal from its original domain, usually time or space, to a representation in the frequency domain and vice versa. A spectrogram is created from a periodogram using the Short-time Fourier Transform. This is conducted to facilitate the study of brief, presumably steady audio intervals. The Fast Fourier Transform is then used to translate amplitude to frequency, and the frequency is then converted to the Mel scale. Next, the logarithm of each filter bank energy is calculated. Finally, the log filter bank energies are computed using IDCT, resulting in thirteen features.
3.2.3. Feature Selection
High dimensionality in MFCCs may result in higher training and prediction computation costs. Overfitting occurs when the model picks up on the data’s noise instead of its underlying patterns. Feature choice aims to find the most pertinent geographies that significantly impact the prototype’s action. Reducing the number of features can increase interpretability, decrease training time, and improve model accuracy. The produced MFCCs were subjected to four distinct feature selection techniques. Features were chosen using a statistical approach that combines K-best with ANOVA, based on statistical significance determined using ANOVA. Features with indices 2, 3, 5, 7, and 10 were selected. Two filter-based techniques, Spearman’s correlation and Kendall’s Tau, were used to evaluate the relationship between features and the target variable. Features 6, 9, 2, 4, and 7 were selected using both approaches. Finally, features 2, 4, 6, 7, and 9 were selected using a hybrid feature selection method that uses RFE to iteratively remove features based on how important they are to a model’s performance. We determined that features 2, 4, 6, 7, and 9 were the best MFCC features; these features were used for subsequent analysis.
Based on a correlation matrix of the selected features, features 2, 4, 6, 7, and 9 were a good pick in terms of redundancy. Most of the chosen features showed very low to moderate absolute correlations, ranging from −0.22 to 0.23. The greatest value, 0.54, was observed between features 6 and 7, as shown in Figure 5 and Figure 6.
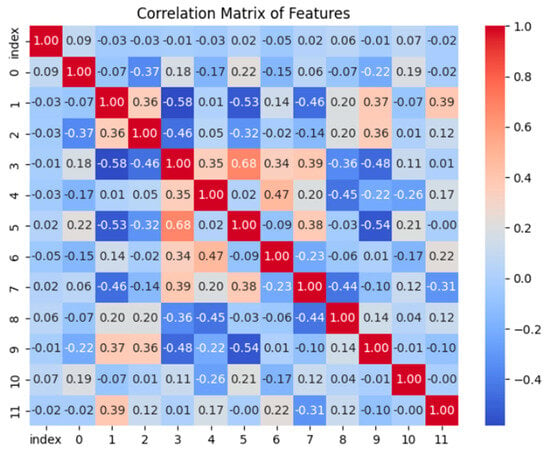
Figure 5.
Correlation matrix for all features.
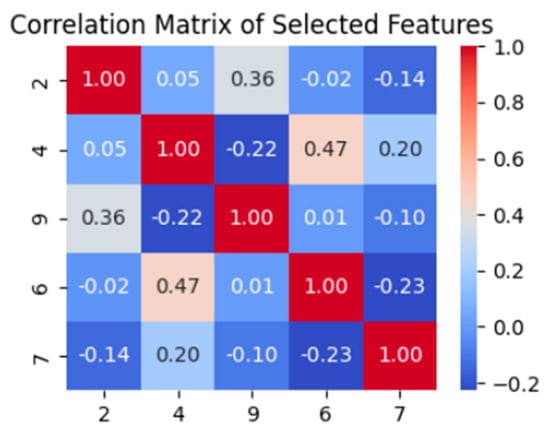
Figure 6.
Correlation matrix for selected features.
SHAP charts (Figure 7 and Figure 8) indicate that our model has strong interpretability. Since the selected features (2, 4, 6, 7, and 9) have a substantially greater magnitude and spread across the unselected features, the charts visually verify that these features are, in fact, the most important in the model’s decision-making process. Thus, our feature selection process is supported by this visualization, which also clarifies the “black box” nature of deep learning models.
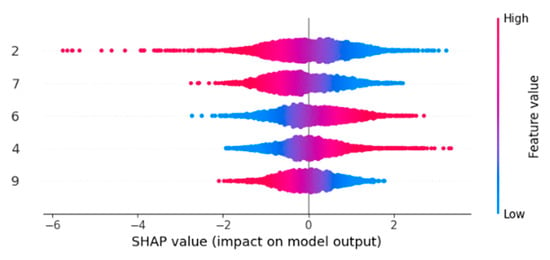
Figure 7.
SHAP diagram for selected features.
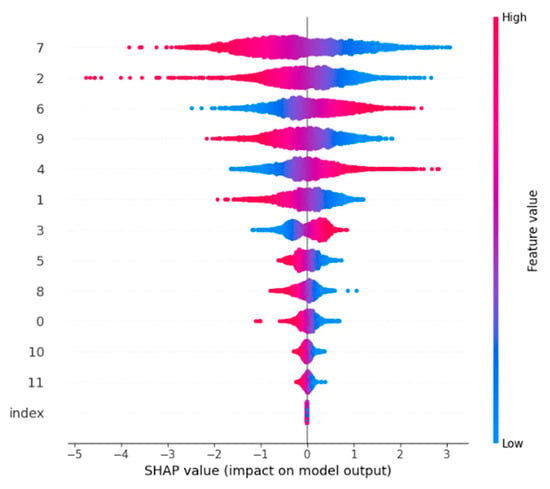
Figure 8.
SHAP diagram for all features.
3.2.4. Data Augmentation
Data augmentation is a practice used in machine learning to significantly increase the size and variety of a training dataset. It enhances model generalization and helps avoid overfitting, which is especially helpful when working with small datasets. Without altering the underlying class labels, augmentation techniques, including rotating, flipping, cropping, or adding noise, add variations to the existing data. Figure 9 shows the class distribution before and after augmentation.
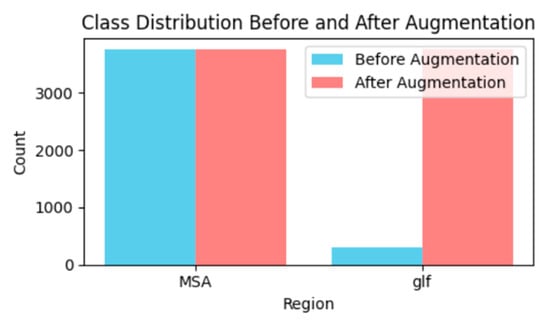
Figure 9.
Class distribution.
- ADASYN: By creating artificial samples close to the decision boundary, this technique aimed to oversample the minority class (GLF). It increased the number of GLF samples from 298 to 3762 while maintaining the initial number of MSA samples at 3762.
- Random oversampling: This technique matches the number of samples in the majority class (MSA) by randomly duplicating samples from the minority class (GLF). The method resulted in a total of 3762 GLF samples.
- Synthetic minority oversampling technique (SMOTE): SMOTE interpolates between pre-existing minority class samples to generate copied trials for the smaller class (GLF), much like ADASYN. This method increased the total number of GLF samples to 3762.
4. Model Architectures
4.1. ANN
The sequential model in Tensor Flow/Keras is used in a feedforward Artificial Neural Network architecture consisting of densely connected layers with distinct numbers of neurons and ReLU activation functions. An input layer of the network initially accepts 13-dimensional feature vectors. It then moves through a sequence of hidden layers with fewer neurons (1000, 750, 500, 250, 100, and 50 per layer). The network can extract more intricate features from the input data because of its hierarchical structure. The network learns complex patterns and represents non-linear relationships in data. It starts with an input layer and progresses through hidden layers with decreasing numbers of neurons. A probability distribution across the classes is created by smearing the softMax stimulation task over the output cover. As a result, each input sample’s class probabilities can be predicted by the network, as shown in Figure 10.
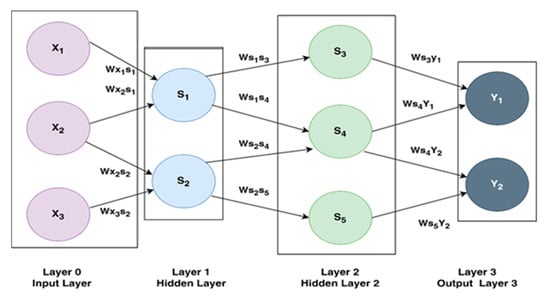
Figure 10.
Artificial Neural Network (ANN) model architecture.
4.2. CNNs
CNNs are deep learning architectures that perform exceptionally well in tasks such as object detection, image recognition, and natural language processing. They can process grid-like facts, such as time sequences and images. Convolutional layers, pooling layers, and completely linked layers are the three foremost ideas that they employ. While 2D CNNs are developed specifically for two-dimensional data, such as images, 1D CNNs are developed for one-dimensional data, such as time series analysis and natural language processing. The archetypal construction is shown in Figure 11.
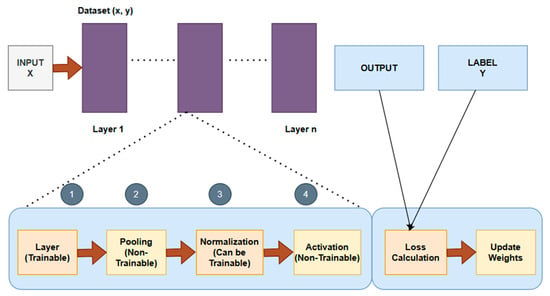
Figure 11.
Archetypal construction of a convolutional neural network (CNN).
5. Model Training
The train_test_split() function in the sci-kit-learn collection is used to divide the data into two sets: a testing set to evaluate the model’s performance on unknown data and a training set to train the model. A minority of the data (20%) are assigned to the testing set based on the test size parameter, which is set to 0.2. By regulating the random number generator used to split the data, the random state constraint, which is set to 42, ensures reproducibility. Lastly, the code provides a fast check on the data splitting process by printing the number of mockups in the teaching and analysis sets. The outcomes of numerous machine learning experiments conducted using various models and data augmentation strategies are compiled in Table 2. The table displays each experiment’s random state, activation function, test size, number of training and testing samples, and model parameters. Artificial Neural Networks (ANNs), 1D convolutional neural networks (1D CNNs), and 2D convolutional neural networks (2D CNNs) are among the models employed. The data augmentation techniques used are ADASYN, RandomOverSampler, and SMOTE.
Table 2.
Details of the model parameters.
5.1. Hyperparameter Tuning
A detailed explanation of hyperparameter tuning, a method for improving machine learning models, is provided in Table 3. Three data augmentation methods are covered: SMOTE, random oversampling, ADASYN, and no augmentation. The Artificial Neural Network (ANN), one-dimensional convolutional neural network (1D CNN), and two-dimensional convolutional neural network (2D CNN) model architectures’ performances are also contrasted. Important parameters, such as verbosity, patience, batch size, minimum learning rate, epochs, and validation split, are also provided. Additionally, the table methodically examines how various data augmentation strategies affect model performance. We identify the optimal model architecture for the classification task by contrasting the performance of ANNs, 1D CNNs, and 2D CNNs.
Table 3.
Hyperparameters.
5.2. Model Accuracy and Loss
The assessment results for numerous machine learning models trained on datasets with and without the application of different data augmentation techniques are shown in Table 4. A 1D convolutional neural network (1D CNN), a 2D convolutional neural network (2D CNN), and an Artificial Neural Network (ANN) are among the models tested, while ADASYN, random oversampling, and SMOTE are the data augmentation techniques investigated. For every model–augmentation combination, the table presents important performance metrics, such as test accuracy, test loss, validation accuracy, and validation loss. The findings show that, in general, random oversampling enhances the performance of the 2D CNN and ANN models compared with the performance of the no-augmentation model. The 2D CNN model initially exhibited subpar performance, suggesting a significant class imbalance or a complex baseline classification issue; however, ADASYN markedly enhanced the MCC, especially for the 2D CNN.
Table 4.
Model accuracy and loss.
5.3. Effects of Augmentation Methods
Data augmentation methodologies enhance the performance of Arabic dialect classification models by mitigating class imbalances. ADASYN and SMOTE markedly enhance the Matthews correlation coefficient (MCC), a reliable statistic for imbalanced categorization. RandomOverSampler also enhances the Matthews correlation coefficient, albeit to a lesser extent. SMOTE produces efficient synthetic samples, allowing 2D CNN models to acquire discriminative features for dialect classification.
6. Results and Discussion
This section discusses the results of binary and multiclass classification with and without augmentation.
6.1. Binary Classification
The metrics for testing and training accuracy are essential for assessing how well a classification model generalizes. While teaching accuracy gauges the prototype’s performance on the training data, testing accuracy assesses the model’s precision in class label prediction on an independent dataset. A lower training loss denotes better performance, while a higher testing accuracy denotes better generalization ability. A confusion matrix illustrates the model’s effectiveness by showing the number of true positives, true negatives, false positives, and false negatives for every class. The true positive level (sensitivity) and false positive level (specificity) are traded off in the ROC–AUC curve at various classifications onsets: a higher AUC value typically denotes better model performance. Figure 12 shows model accuracy with no augmentation.
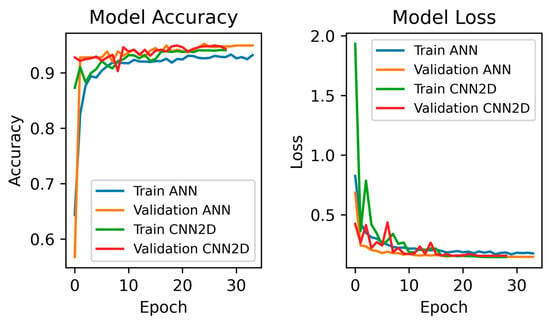
Figure 12.
Model accuracy with no augmentation.
Figure 13, Figure 14, Figure 15 and Figure 16 show the confusion matrix, ROC_AUC curve, and Accuracy_Loss plot with no augmentation, ADAYSN, Random_Oversampler, and SMOTE, and for a binary class. ANN, 1D CNN, and 2D CNN are the three neural network models that are compared using confusion matrices. The models’ performances in terms of identifying two categories, MSA and GLF, are visualized. The counts of false positives, false negatives, and true positives for each model are shown in the matrices. With the most accurate classifications (true positives) and the fewest misclassifications (false positives and false negatives) for both MSA and GLF, the 2D CNN model seems to be the most visually accurate. Although all models show relatively high performances, the 2D CNN surpasses the ANN and 1D CNN in terms of recognizing the occurrences of both categories, indicating that it is the most effective architecture for this specific classification task.
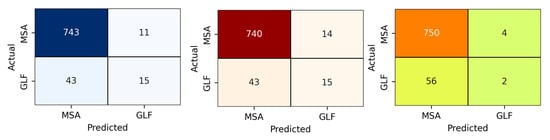

Figure 13.
Confusion matrix, ROC_Curve, and Accuracy_Loss plot with no augmentation and for a binary class.
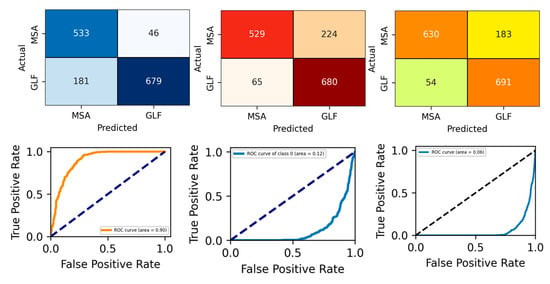
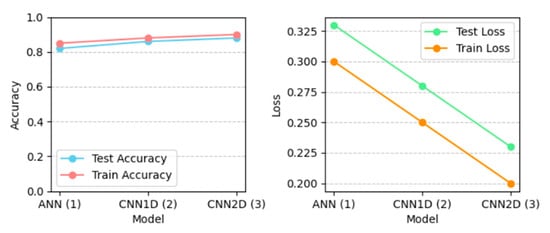
Figure 14.
Confusion matrix, ROC_Curve, and Accuracy_Loss plot with ADASYN and for a binary class.
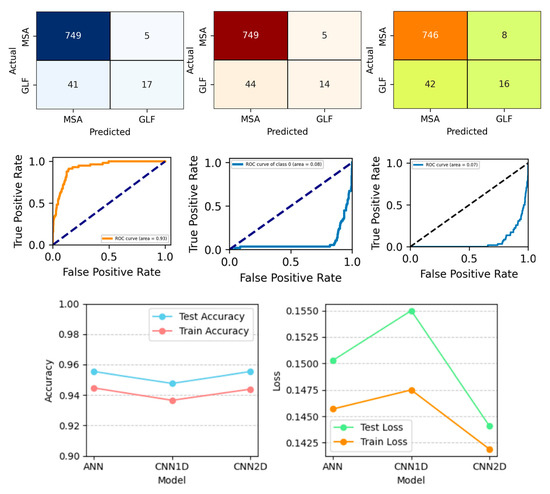
Figure 15.
Confusion matrix, ROC_Curve, and Accuracy_Loss plot with Random_Oversampler and for a binary class.
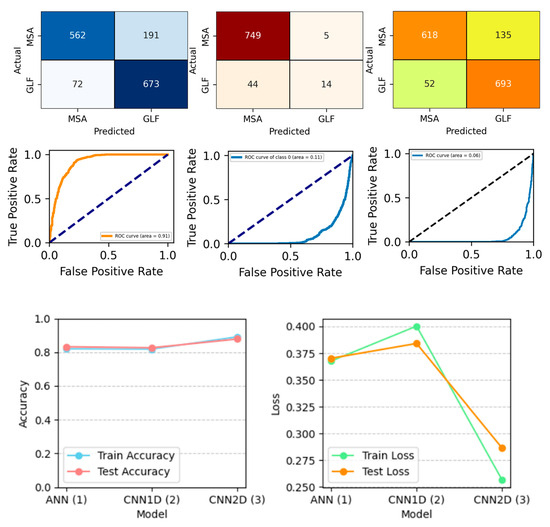
Figure 16.
Confusion matrix, ROC_Curve, and Accuracy_Loss plot with SMOTE and for a binary class.
6.2. Multiclass Classification
Figure 17 shows the accuracy plot for the multiclass with no augmentation technique, which can classify the Arabic dialects of five different regions.
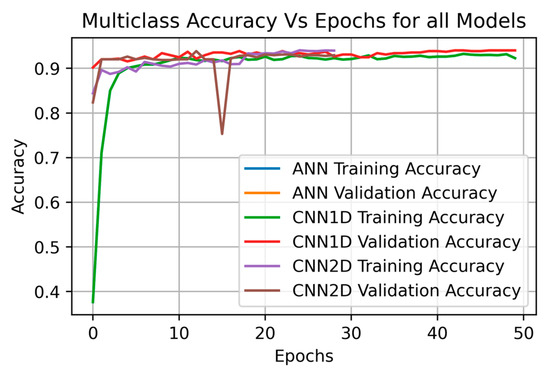
Figure 17.
Training and validation accuracy plots for multiclass techniques with no augmentation.
The classification report for the best model and its evaluation matrices are provided in Table 5.
Table 5.
Classification report for the best model (ANN with RandomOverSampler augmentation).
Table 5 provides an overview of how well a machine learning model performs on a classification test, presenting a classification report of the best model (ANN with a random sampler augmentation method). It displays the metrics for each class, including precision, recall, F1-score, and support, along with overall accuracy, macro average, and weighted average. Based on the report, the model has high precision, recall, and F1-score values when applied to the majority class (index 0); however, it exhibits poorer precision and recall in the minority class (index 1). The greater number of samples in the majority class probably contributed to the high overall accuracy. The high overall accuracy is also reflected in the weighted average, which assigns greater weight to the majority class. Based on the results, a training time of 3.5953 s and an inference latency period per sample of 0.0681 s are concluded.
6.3. Discussion
This study extracts MFCC features from Arabic audio data and identifies the dialects using pre-trained speech classification models. The classification models include ANN, 1D CNN, and 2D CNN. The ANN model with random oversampler augmentation outperforms the 1D CNN and 2D CNN with a test accuracy of 94.33%. These models were also compared with AraBERT, a transformer-based model, which had a testing accuracy of 90.76%, lower than our proposed models. Other research studies on the identification of Arabic dialects using a variety of machine learning models—such as LSTM, KNN, CNN, and RNN-CNN—and datasets are presented in Table 6. The accuracy range varies across the studies, demonstrating how difficult it is to identify Arabic dialects. However, larger datasets and recent developments in deep learning methods have improved accuracy. The approach suggested in this study has the highest reported accuracy (95.5%) and makes use of a model with RandomOverSampler augmentation and a custom dataset.
Table 6.
Comparison of model performance.
7. Conclusions
This study offers a robust approach to the automatic identification of Arabic dialects using a deep learning model. The proposed system demonstrates promising results, accurately classifying Arabic audio clips into their respective dialects. The pre-trained algorithm for speech classification can identify and categorize a variety of Arabic dialects, including EGY, GLF, LAV, MSA, and NOR. This study used MFCC features to categorize Arabic dialects and examined the effects of feature selection techniques such as ANOVA, Kendall’s Tau, Spearman’s correlation, and RFE and data augmentation techniques such as ADASYN, RandomOverSampler, and SMOTE. Based on the results, CNN models consistently outperformed ANN models, with CNNs and random oversampling giving the highest accuracy. Key features that are essential for dialect discrimination were consistently found through feature selection (2, 3, 4, 6, 7, and 9). The 1D CNN model achieved a higher testing accuracy of 94.28% and a validation accuracy of 95.55% using random oversampling. The Matthews correlation coefficient, precision, recall, and F1-score were also used as evaluation metrics to identify the best model. Applications such as speech-to-text transcription and personalized language learning are made possible by these findings, emphasizing the significance of taking data augmentation and feature selection into account when creating reliable and accurate Arabic dialect classification systems.
Future Scope
Future studies may incorporate additional features, refine the model architecture, and expand the dataset to further enhance the system’s performance. Different augmentation techniques can also be used for data with multiclass problems. The dataset can be used for classification, and various techniques can be used to enhance the dialects from all five Arabic regions—MSA, EGY, LAV, NOR, and GLF. Furthermore, this model can be employed to evaluate emotions in Arabic audio data.
Finally, the current model focused on the five main Arabic dialects—MSA, Egyptian, Gulf, Levantine, and North African—based on the available data. Increasing the model’s dialectal coverage to incorporate underrepresented and lower-resource Arabic dialects, such as Mauritanian, Bahraini, Sudanese, and others, is a crucial avenue for future research.
Author Contributions
F.S.A. formulated the study and designed the experimental methodology. F.S.A. was also responsible for collecting all experimental data. B.S.S.T. performed the data analysis under F.S.A. supervision and contributed to the interpretation of the results. The initial draft of the manuscript was written by B.S.S.T. and F.S.A. provided critical revisions and contributed to the final version of the manuscript. F.S.A. secured funding for this research and provided essential resources for its completion. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Kuwait University project number EO 07/23.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author due to privacy reasons.
Acknowledgments
The authors acknowledge the support provided by Kuwait University project number [EO 07/23], which contributed to different aspects of this research.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chittaragi, N.B.; Koolagudi, S.G. Dialect identification using chroma-spectral shape features with ensemble technique. Comput. Speech Lang. 2021, 70, 101230. [Google Scholar] [CrossRef]
- Lulu, L.; Elnagar, A. Automatic Arabic dialect classification using deep learning models. Procedia Comput. Sci. 2018, 142, 262–269. [Google Scholar] [CrossRef]
- Bent, T.; Atagi, E.; Akbik, A.; Bonifield, E. Classification of regional dialects, international dialects, and nonnative accents. J. Phon. 2016, 58, 104–117. [Google Scholar] [CrossRef]
- Michon, E.; Pham, M.Q.; Crego, J.M.; Senellart, J. Neural network architectures for Arabic dialect identification. In Proceedings of the Proceedings of the Fifth Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial 2018), Santa Fe, NM, USA, 20 August 2018; pp. 128–136. [Google Scholar]
- Tibi, N. Automatic arabic dialect identification using deep learning. In Proceedings of the 2022 IEEE Information Technologies & Smart Industrial Systems (ITSIS), Paris, France, 15–17 July 2022; pp. 1–5. [Google Scholar]
- Adel, B.; Meftah, M.C.E.; Laouid, A.; Chait, K.; Kara, M. Using transformers to classify arabic dialects on social networks. In Proceedings of the 2024 6th International Conference on Pattern Analysis and Intelligent Systems (PAIS), El Oued University, Algeria, 24–25 April 2024; pp. 1–7. [Google Scholar]
- Althobaiti, M.J. Automatic Arabic dialect identification systems for written texts: A survey. arXiv 2020, arXiv:2009.12622. [Google Scholar]
- Elnagar, A.; Yagi, S.M.; Nassif, A.B.; Shahin, I.; Salloum, S.A. Systematic literature review of dialectal Arabic: Identification and detection. IEEE Access 2021, 9, 31010–31042. [Google Scholar] [CrossRef]
- Zaidan, O.F.; Callison-Burch, C. Arabic dialect identification. Comput. Linguist. 2014, 40, 171–202. [Google Scholar] [CrossRef]
- Nahar, K.M.; Al-Hazaimeh, O.M.; Abu-Ein, A.; Al-Betar, M.A. Arabic dialect identification using different machine learning methods. arXiv 2022. [Google Scholar] [CrossRef]
- Kanjirangat, V.; Samardzic, T.; Dolamic, L.; Rinaldi, F. NLP_DI at NADI 2024 shared task: Multi-label Arabic Dialect Classifications with an Unsupervised Cross-Encoder. In Proceedings of the Second Arabic Natural Language Processing Conference, Bangkok, Thailand, 16 August 2024; pp. 742–747. [Google Scholar]
- Abdelazim, M.; Hussein, W.; Badr, N. Automatic Dialect identification of Spoken Arabic Speech using Deep Neural Networks. Int. J. Intell. Comput. Inf. Sci. 2022, 22, 25–34. [Google Scholar] [CrossRef]
- Bird, J.J.; Faria, D.R.; Premebida, C.; Ekárt, A.; Ayrosa, P.P. Overcoming data scarcity in speaker identification: Dataset augmentation with synthetic mfccs via character-level rnn. In Proceedings of the 2020 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Ponta Delgada, Portugal, 15–16 April 2020; pp. 146–151. [Google Scholar]
- Tibi, N.; Messaoud, M.A.B. Arabic dialect classification using an adaptive deep learning model. Bull. Electr. Eng. Inform. 2025, 14, 1108–1116. [Google Scholar] [CrossRef]
- Rastogi, U.; Mahapatra, R.P.; Kumar, S. Advancements in Machine Learning Techniques for Hand Gesture-Based Sign Language Recognition: A Comprehensive Review. Arch. Comput. Methods Eng. 2025, 1–38. [Google Scholar] [CrossRef]
- Juvela, L.; Bollepalli, B.; Wang, X.; Kameoka, H.; Airaksinen, M.; Yamagishi, J.; Alku, P. Speech waveform synthesis from MFCC sequences with generative adversarial networks. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, Canada, 15–20 April 2018; pp. 5679–5683. [Google Scholar]
- Hamza, A.; Javed, A.R.R.; Iqbal, F.; Kryvinska, N.; Almadhor, A.S.; Jalil, Z.; Borghol, R. Deepfake audio detection via MFCC features using machine learning. IEEE Access 2022, 10, 134018–134028. [Google Scholar] [CrossRef]
- Rezaul, K.M.; Jewel, M.; Islam, M.S.; Siddiquee, K.; Barua, N.; Rahman, M.; Sulaiman, R.; Shaikh, M.; Hamim, M.; Tanmoy, F. Enhancing Audio Classification Through MFCC Feature Extraction and Data Augmentation with CNN and RNN Models. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 37–53. [Google Scholar] [CrossRef]
- Borah, P.; Ahmed, H.A.; Bhattacharyya, D.K. A statistical feature selection technique. Netw. Model. Anal. Health Inform. Bioinform. 2014, 3, 55. [Google Scholar] [CrossRef]
- Chandra, B.; Gupta, M. An efficient statistical feature selection approach for classification of gene expression data. J. Biomed. Inform. 2011, 44, 529–535. [Google Scholar] [CrossRef]
- Van Hulse, J.; Khoshgoftaar, T.M.; Napolitano, A.; Wald, R. Threshold-based feature selection techniques for high-dimensional bioinformatics data. Netw. Model. Anal. Health Inform. Bioinform. 2012, 1, 47–61. [Google Scholar] [CrossRef]
- Zhu, L. Selection of multi-level deep features via spearman rank correlation for synthetic aperture radar target recognition using decision fusion. IEEE Access 2020, 8, 133914–133927. [Google Scholar] [CrossRef]
- Samb, M.L.; Camara, F.; Ndiaye, S.; Slimani, Y.; Esseghir, M.A. A novel RFE-SVM-based feature selection approach for classification. Int. J. Adv. Sci. Technol. 2012, 43, 27–36. [Google Scholar]
- Chen, X.; Gong, Z.; Huang, D.; Jiang, N.; Zhang, Y. Overcoming Class Imbalance in Network Intrusion Detection: A Gaussian Mixture Model and ADASYN Augmented Deep Learning Framework. In Proceedings of the 2024 4th International Conference on Internet of Things and Machine Learning, Nanchang, China, 9–11 August 2024; pp. 48–53. [Google Scholar]
- Beinecke, J.; Heider, D. Gaussian noise up-sampling is better suited than SMOTE and ADASYN for clinical decision making. BioData Min. 2021, 14, 49. [Google Scholar] [CrossRef]
- Salehpour, A.; Norouzi, M.; Balafar, M.A.; SamadZamini, K. A cloud-based hybrid intrusion detection framework using XGBoost and ADASYN-Augmented random forest for IoMT. IET Commun. 2024, 18, 1371–1390. [Google Scholar] [CrossRef]
- Nhita, F.; Kurniawan, I. Performance and Statistical Evaluation of Three Sampling Approaches in Handling Binary Imbalanced Data Sets. In Proceedings of the 2023 International Conference on Data Science and Its Applications (ICoDSA), Bandung, Indonesia, 9–10 August 2023; pp. 420–425. [Google Scholar]
- Lee, T.; Kim, M.; Kim, S.-P. Data augmentation effects using borderline-SMOTE on classification of a P300-based BCI. In Proceedings of the 2020 8th International Winter Conference on Brain-Computer Interface (BCI), Gangwon, Republic of Korea, 26–28 February 2020; pp. 1–4. [Google Scholar]
- Chen, Y.; Chang, R.; Guo, J. Effects of data augmentation method borderline-SMOTE on emotion recognition of EEG signals based on convolutional neural network. IEEE Access 2021, 9, 47491–47502. [Google Scholar] [CrossRef]
- Dolka, H.; VM, A.X.; Juliet, S. Speech emotion recognition using ANN on MFCC features. In Proceedings of the 2021 3rd International Conference on Signal Processing and Communication (ICPSC), Coimbatore, India, 13–14 May 2021; pp. 431–435. [Google Scholar]
- Hazra, S.K.; Ema, R.R.; Galib, S.M.; Kabir, S.; Adnan, N. Emotion recognition of human speech using deep learning method and MFCC features. Radioelectron. Comput. Syst. 2022, 18, 161–172. [Google Scholar] [CrossRef]
- Barua, P.; Ahmad, K.; Khan, A.A.S.; Sanaullah, M. Neural network based recognition of speech using MFCC features. In Proceedings of the 2014 International Conference on Informatics, Electronics & Vision (ICIEV), Dhaka, Bangladesh, 23–24 May 2014; pp. 1–6. [Google Scholar]
- Singh, Y.B.; Goel, S. 1D CNN based approach for speech emotion recognition using MFCC features. In Artificial Intelligence and Speech Technology; CRC Press: Boca Raton, FL, USA, 2021; pp. 347–354. [Google Scholar]
- Lai, H.-Y.; Hu, C.-C.; Wen, C.-H.; Wu, J.-X.; Pai, N.-S.; Yeh, C.-Y.; Lin, C.-H. Mel-Scale Frequency Extraction and Classification of Dialect-Speech Signals with 1D CNN based Classifier for Gender and Region Recognition. IEEE Access 2024, 12, 102962–102976. [Google Scholar] [CrossRef]
- Reggiswarashari, F.; Sihwi, S.W. Speech emotion recognition using 2D-convolutional neural network. Int. J. Electr. Comput. Eng. 2022, 12, 6594. [Google Scholar] [CrossRef]
- Annabel, L.S.P.; Thulasi, V. Environmental Sound Classification Using 1-D and 2-D Convolutional Neural Networks. In Proceedings of the 2023 7th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 22–24 November 2023; pp. 1242–1247. [Google Scholar]
- Zvarevashe, K.; Olugbara, O.O. Recognition of speech emotion using custom 2D-convolution neural network deep learning algorithm. Intell. Data Anal. 2020, 24, 1065–1086. [Google Scholar] [CrossRef]
- Im, S.-K.; Chan, K.-H. Neural Machine Translation with CARU-Embedding Layer and CARU-Gated Attention Layer. Mathematics 2024, 12, 997. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Y.; Yang, X.; Im, S.-K. Speech emotion recognition based on Graph-LSTM neural network. EURASIP J. Audio Speech Music Process. 2023, 2023, 40. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).