1. Introduction
The integration of fog removal capabilities into fixed surveillance cameras is a critical advancement for enhancing safety, security, and public order [
1]. In environments where visibility is frequently compromised by atmospheric conditions such as fog, the ability to maintain clear and reliable imagery becomes paramount. Surveillance systems, tasked with monitoring critical infrastructure, public spaces, and transportation networks, must operate effectively under adverse weather conditions to ensure continuous protection and situational awareness [
2]. Fog, as a natural phenomenon, obscures visual details, reduces contrast, and hampers the detection of objects or individuals, posing significant risks to security operations. Consequently, equipping surveillance cameras with robust fog removal functionalities is not merely an enhancement but a necessity for modern safety systems [
3,
4].
Extensive research has been conducted on fog removal networks, yielding remarkable progress in restoring visibility from degraded images [
5,
6]. Techniques ranging from traditional approaches like the Dark Channel Prior (DCP) [
7] to advanced deep learning methods such as convolutional neural networks (CNNs) and GridNet architectures [
8] have demonstrated substantial improvements in dehazing performance. These studies have collectively contributed to a deeper understanding of image restoration under foggy conditions, achieving impressive results in various scenarios [
9,
10,
11]. However, a significant challenge persists in the domain of fog removal research: the acquisition of paired datasets—images of the same scene captured both with and without fog. For effective training and evaluation of dehazing algorithms, datasets must include both indoor and outdoor scenes with synthetically or naturally induced fog [
12]. In practice, obtaining such paired images is exceedingly difficult due to the variability of environmental conditions and the impracticality of controlling natural fog in real-world settings. Photographing identical scenes under foggy and clear conditions simultaneously is a logistical challenge, often rendering traditional data collection methods insufficient.
To address this limitation, the generation of synthetic fog becomes a pivotal step in advancing fog removal research [
13]. While numerous studies have focused on dehazing [
14,
15], fewer have explored the equally critical task of fog synthesis [
16]. The ability to artificially create fog in a controlled manner enables researchers to simulate diverse foggy conditions, thereby facilitating the development and validation of dehazing algorithms. Existing fog generation techniques include simplistic approaches, such as uniform fog application [
17], as well as more sophisticated methods like dark channel-based synthesis [
7] and distance-aware (depth-based) fog generation [
18]. Although these methods provide a viable means to simulate fog, they often lack the realism and adaptability required to mirror natural fog distributions accurately. Moreover, synthetic fog generated through rudimentary techniques may not adequately challenge the robustness of modern dehazing networks, potentially leading to overfitting or suboptimal performance when applied to real-world foggy scenes.
Among the various approaches to fog synthesis, the development of a dedicated fog generation network emerges as a promising solution [
16]. Unlike traditional methods that rely on heuristic assumptions or physical models, a neural network-based fog generator can learn complex patterns of fog distribution directly from data, producing more realistic and contextually relevant foggy images. A key insight driving this research is that the efficacy of a fog generation network is closely tied to the architecture of the dehazing network it aims to complement [
8]. Specifically, leveraging a high-performing dehazing network as the backbone of the fog generation process ensures that the synthesized fog aligns with the characteristics that advanced dehazing algorithms are designed to address. This symbiotic relationship between fog generation and removal enhances the overall performance of the system, as the generated fog can effectively test and validate the limits of the dehazing network.
In this study, we propose and validate a novel approach to fog generation and removal tailored for surveillance applications. Our research focuses on training a fog generation network, utilizing a state-of-the-art dehazing neural network as its foundation [
8], to produce synthetic foggy images. These images are then used to evaluate and compare the performance of various fog generation techniques—including simple fog [
17], dark channel-based fog [
7], and depth-aware fog [
18]—against our proposed network-based method [
16]. Unlike existing fog generation methods based on physical models or depth priors, our approach uniquely leverages a high-performance dehazing network (GridNet) in reverse to synthesize fog that is better aligned with modern dehazing pipelines. This network-driven synthesis strategy produces more realistic and structurally consistent fog patterns, enabling more effective evaluation and improvement of dehazing performance. Our experiments demonstrate that the proposed fog generation network, informed by the best-performing dehazing architecture, achieves superior results, as evidenced by quantitative metrics such as Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM). Through this comparative analysis, we confirm that a network-driven fog synthesis approach not only enhances the realism of generated fog but also maximizes the effectiveness of fog removal, offering a robust solution for real-world surveillance systems [
1].
The main contributions of this paper are as follows:
We propose a neural network-based fog generation model built upon the GridNet architecture, enabling realistic and context-aware synthetic fog for surveillance imagery.
We design a training strategy that incorporates perceptual and dark channel consistency losses to enhance the visual quality of the generated fog.
We perform comparative evaluations with existing fog generation techniques using standardized dehazing networks and demonstrate superior restoration performance in terms of PSNR and SSIM.
We validate the practical applicability of our approach in real-world surveillance scenarios, highlighting its effectiveness under adverse weather conditions.
2. Related Work
Fog generation and removal have been extensively studied in computer vision to address visibility degradation in adverse weather conditions [
5]. These efforts are pivotal for applications such as surveillance systems [
1], autonomous driving [
13], and outdoor imaging [
17]. This section reviews key methodologies for fog removal and generation, focusing on GridNet [
8], Simple Fog Generation [
17], Depth-Aware Fog Generation [
18], and Dark Channel Prior-based approaches [
7]. Each method offers unique strengths and limitations, which we discuss in the context of their applicability to real-world scenarios.
2.1. GridNet for Fog Removal
GridNet is a sophisticated deep learning architecture designed for image restoration tasks, including fog removal. Introduced by Liu et al. [
8], GridNet leverages a grid-like structure of convolutional layers to process multi-scale features effectively. The network employs Residual Dense Blocks (RDBs) to enhance feature extraction and combines downsampling and upsampling operations to capture both local and global contexts. This hierarchical design allows GridNet to handle varying fog densities and complex scene structures, making it particularly suitable for surveillance applications where image clarity is critical [
4,
19].
2.2. Simple Fog Generation
Simple Fog Generation is a foundational approach to simulating fog in images, often based on uniform fog application techniques [
17]. This method applies a uniform fog layer using a simplified physical model, making it computationally efficient and easy to implement. It has been used to generate synthetic foggy datasets for training dehazing algorithms [
13]. However, its uniform application of fog overlooks scene depth variations and atmospheric heterogeneity, leading to unrealistic results in complex outdoor environments.
2.3. Depth-Aware Fog Generation
Depth-Aware Fog Generation enhances the realism of synthetic fog by incorporating scene depth information into the fog synthesis process. Proposed by Hwang et al. [
18], this method modulates the transmission map based on pixel-wise depth values, better simulating the natural phenomenon of fog where visibility decreases with distance. It has been shown to improve the performance of dehazing networks by providing more challenging and realistic training data [
13].
2.4. Dark Channel Prior for Fog Removal and Generation
The Dark Channel Prior (DCP), introduced by Sun et al. [
7], is a seminal method in fog removal that exploits the observation that, in most non-sky patches of a clear image, at least one color channel has a very low intensity. Beyond fog removal, the DCP has been adapted for fog generation by reversing the process [
7], producing realistic fog effects, particularly in scenes with strong depth cues.
In contrast to these methods, our approach integrates a high-performance dehazing network (GridNet) directly into the fog generation process. This integration enables the generation of synthetic fog that closely reflects the degradation characteristics targeted by modern dehazing networks. Additionally, our method employs perceptual and dark channel consistency losses during training—techniques rarely explored in prior fog synthesis studies—resulting in improved realism and downstream restoration performance.
The reviewed methods—GridNet [
8], Simple Fog Generation [
17], Depth-Aware Fog Generation [
18], and Dark Channel Prior [
7]—represent a spectrum of approaches to fog removal and generation. A notable research gap exists in leveraging high-performance dehazing networks for fog generation [
16], which could unify the strengths of these approaches.
3. Fog Generator Model
In this section, we present the detailed design and implementation of our proposed Fog Generator Model, a neural network-based approach for synthesizing realistic foggy images. Leveraging the architectural strengths of GridNet [
8], our Fog Generator integrates advanced feature extraction and fog synthesis mechanisms.
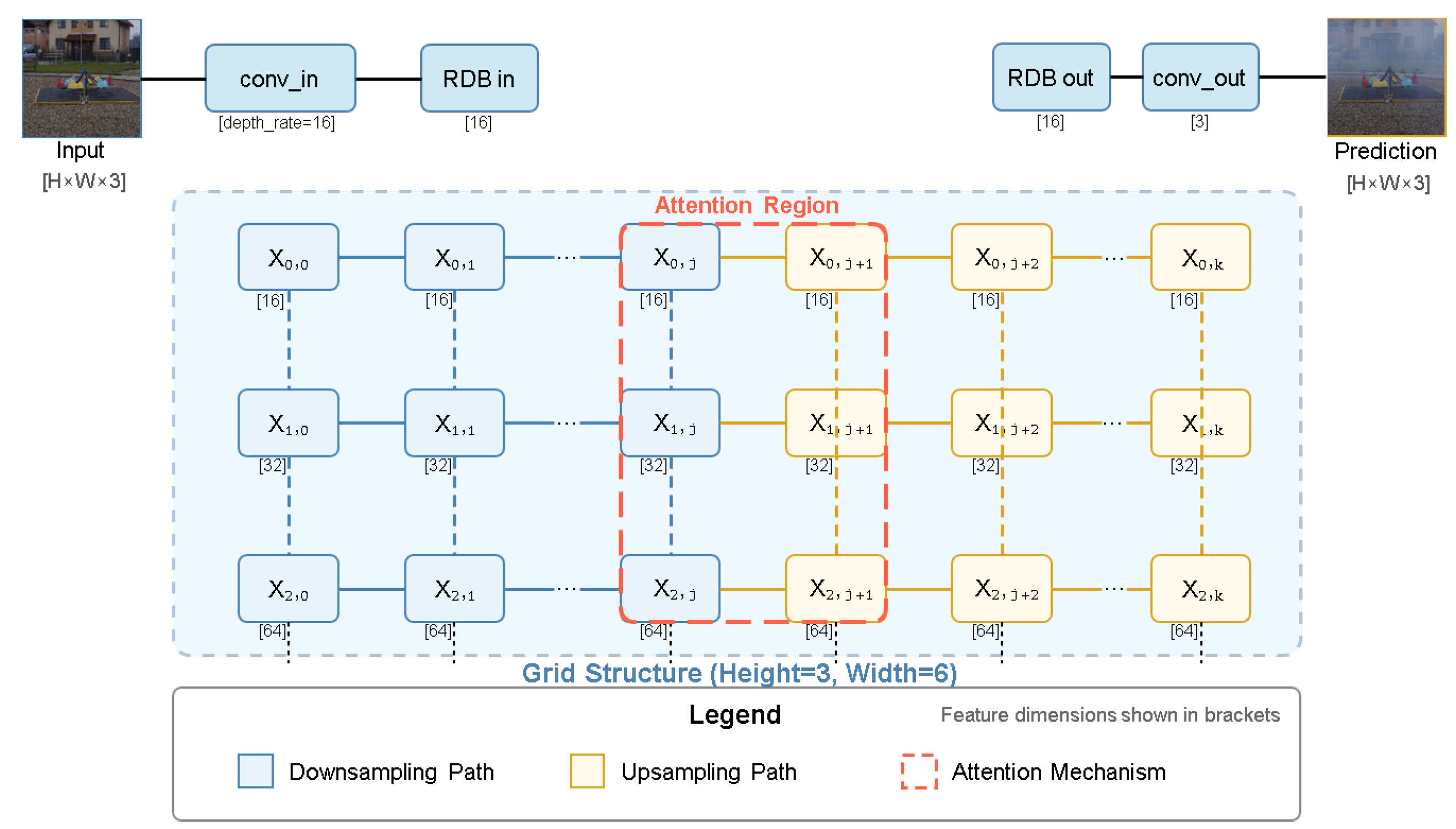
The overall architecture of the proposed Fog Generator Model is illustrated in
Figure 1. This figure provides a high-level overview of how the model synthesizes foggy images from clear inputs, highlighting the use of a GridNet-based backbone, attention modules, and a multi-scale structure. This visual summary helps guide the reader through the subsequent detailed descriptions of each module in this section.
3.1. Training Methodology
The Fog Generator is trained on paired clear and foggy images from the O-HAZE dataset [
12], augmented with synthetic foggy images generated via traditional methods [
7,
17,
18].
3.2. Model Architecture
The proposed Fog Generator Model is built upon the GridNet framework [
8], which was originally designed for image dehazing. In this study, we adapt the GridNet architecture for the inverse task of fog synthesis. The model comprises three primary components: the GridNet backbone, a transmission estimation network, and fog parameter layers.
The network takes a haze-free clear image as input and generates a synthetic foggy image by simulating atmospheric scattering effects. This process is guided by learned fog features and a predicted transmission map.
The fog synthesis process is modeled as follows:
In this formulation, denotes the scene radiance, representing the haze-free ground truth image, while is the synthesized foggy image generated by the model. The transmission map is represented by , and A denotes the global atmospheric light. The learned fog feature map , extracted through the GridNet backbone, captures complex fog structures, and is a blending factor (set to 0.1 in our experiments) that controls the fog density.
This extended formulation builds upon the conventional atmospheric scattering model by integrating learned, data-driven fog features alongside the traditional transmission and atmospheric light components. As a result, it enhances both the realism and diversity of synthetic fog patterns beyond what heuristic methods can achieve.
3.2.1. GridNet Backbone
The backbone of our Fog Generator is a modified GridNet, consisting of a grid-like structure with height and width . It employs Residual Dense Blocks (RDBs) with dense layers and a growth rate of 16, enabling rich feature extraction across multiple scales. The network begins with an input convolution layer (conv_in) that maps the three-channel RGB image to a depth rate of 16, followed by a series of RDBs and downsampling/upsampling modules. The output is processed through an output RDB and a final convolution layer (conv_out) to generate fog features . This hierarchical design ensures that both local details and global fog patterns are captured effectively.
3.2.2. Transmission Estimation Network
To model the transmission map , we introduce a shallow convolutional neural network comprising three layers:
A convolution with 32 filters and ReLU activation;
A convolution with 16 filters and ReLU activation;
A convolution with 1 filter followed by a sigmoid activation.
This network takes the clear image
as input and outputs a single-channel transmission map, constrained between 0 and 1. To enhance realism, we apply a depth-dependent modulation:
where
is a vertical gradient ranging from 0 (top) to 1 (bottom), simulating the natural increase in fog density with distance.
3.2.3. Fog Parameter Layers
The atmospheric light A and fog strength are modeled as learnable parameters. The base fog color is initialized as with a variance , adjusted via a tanh function during training. The fog intensity is controlled by a scalar parameter , initialized at 0.5 and fine-tuned to match target fog levels (e.g., 0.2 in our experiments). These parameters allow the model to adaptively synthesize fog with varying characteristics.
3.3. Training Methodology
The Fog Generator is trained on paired clear and foggy images from the O-HAZE dataset [
12], augmented with synthetic foggy images generated via traditional methods. We employ a composite loss function:
where
is the L1 loss between predicted and ground-truth foggy images;
uses VGG-16 features up to layer 16 for perceptual similarity;
enforces dark channel consistency.
Training is conducted over 100 epochs using the Adam optimizer with a learning rate of , on an NVIDIA GPU with CUDA support. The model is saved periodically, with the final weights stored as fog_generator.pth.
3.4. Model Visualization
Figure 2 illustrates the architecture of the Fog Generator Model. The diagram highlights the flow from the input clear image through the GridNet backbone, transmission estimation, and fog parameter integration, culminating in the foggy output.
The Fog Generator Model integrates the strengths of GridNet’s multi-scale processing with a physically inspired synthesis process, offering a versatile tool for generating realistic foggy images. Unlike traditional methods, it adapts to scene content through learned features, addressing the uniformity limitations of Simple Fog Generation and the depth dependency of depth-aware methods. The use of GridNet ensures compatibility with high-performance dehazing networks, aligning with our research goal of optimizing fog removal in surveillance systems.
4. Experiments and Results Analysis
This section outlines the experimental setup and results analysis conducted to evaluate our proposed Fog Generator Model and its impact on fog removal performance using the O-HAZY dataset. We detail the experimental procedure, including dataset description, training of the fog generation network, fog synthesis, fog removal training, and performance evaluation. The results are analyzed through quantitative metrics and visual comparisons, with key findings illustrated using figures and tables.
4.1. Experimental Procedure
4.1.1. O-HAZY Dataset
The O-HAZY dataset [
12], a benchmark for outdoor dehazing, comprises 45 pairs of real hazy and corresponding haze-free images captured in diverse outdoor scenes. Each pair consists of a foggy image and its ground-truth clear counterpart, making it ideal for training and evaluating both fog generation and removal models. The images vary in fog density, scene complexity, and lighting conditions, providing a robust testbed for our experiments. For training, we split the dataset into 36 pairs (80%) for training and 9 pairs (20%) for evaluation, ensuring a balanced representation of foggy conditions. The training set is augmented with synthetic foggy images generated by our proposed method and baseline techniques to enhance model robustness.
4.1.2. Fog Generation Network Training
The Fog Generator Model, described in
Section 3, was trained using the O-HAZY training subset. Clear images were input to the network, which synthesized foggy outputs to match the real hazy images in the dataset. The training utilized a composite loss function combining L1, perceptual, and dark channel losses, as defined in Equation (
3). We employed the Adam optimizer with a learning rate of
and trained for 100 epochs on an NVIDIA RTX 3090 GPU with CUDA support. The batch size was set to 1 due to memory constraints. This process ensured that the network learned to generate realistic fog distributions aligned with real-world conditions observed in O-HAZY.
4.1.3. Fog Synthesis
Using the trained Fog Generator, we synthesized foggy images from the clear images in both the training and evaluation subsets of O-HAZY. The fog intensity was set to 0.2, reflecting a moderate fog level suitable for surveillance applications. Additionally, we generated foggy images using three baseline methods: Simple Fog Generation (Simple), Depth-Aware Fog Generation (DA), and Dark Channel Prior-based Fog Generation (DC).
Figure 3 illustrates examples of synthetic fog generated by each method, showcasing their visual differences. For instance, the Depth-Aware Fog method highlights a depth-dependent fog distribution, while our GridNet-based approach demonstrates nuanced fog patterns.
4.1.4. Fog Removal Training
Four GridNet-based dehazing models were trained using the synthetic foggy images generated by each method:
ModelS: Trained on images with simple fog;
ModelU: Trained on images with GridNet-based fog;
ModelDA: Trained on images with depth-aware fog;
ModelDC: Trained on images with dark channel fog.
Each model was trained for 30 epochs using the same GridNet architecture, with a loss function combining L1 and perceptual losses (using VGG-16 features). The training process mirrored that of the Fog Generator. The goal was to assess how the quality of synthetic fog influences dehazing performance.
4.1.5. Fog Removal Performance Evaluation
The trained dehazing models were evaluated on the O-HAZY evaluation subset (nine real foggy images). Performance was measured using Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM), standard metrics for image restoration quality. For each model, we computed the average PSNR and SSIM across the evaluation set and visualized the results for qualitative analysis. Example dehazing outputs are shown in
Figure 4, with the GridNet-based model demonstrating superior restoration quality.
4.2. Results Analysis
4.2.1. Training Dynamics
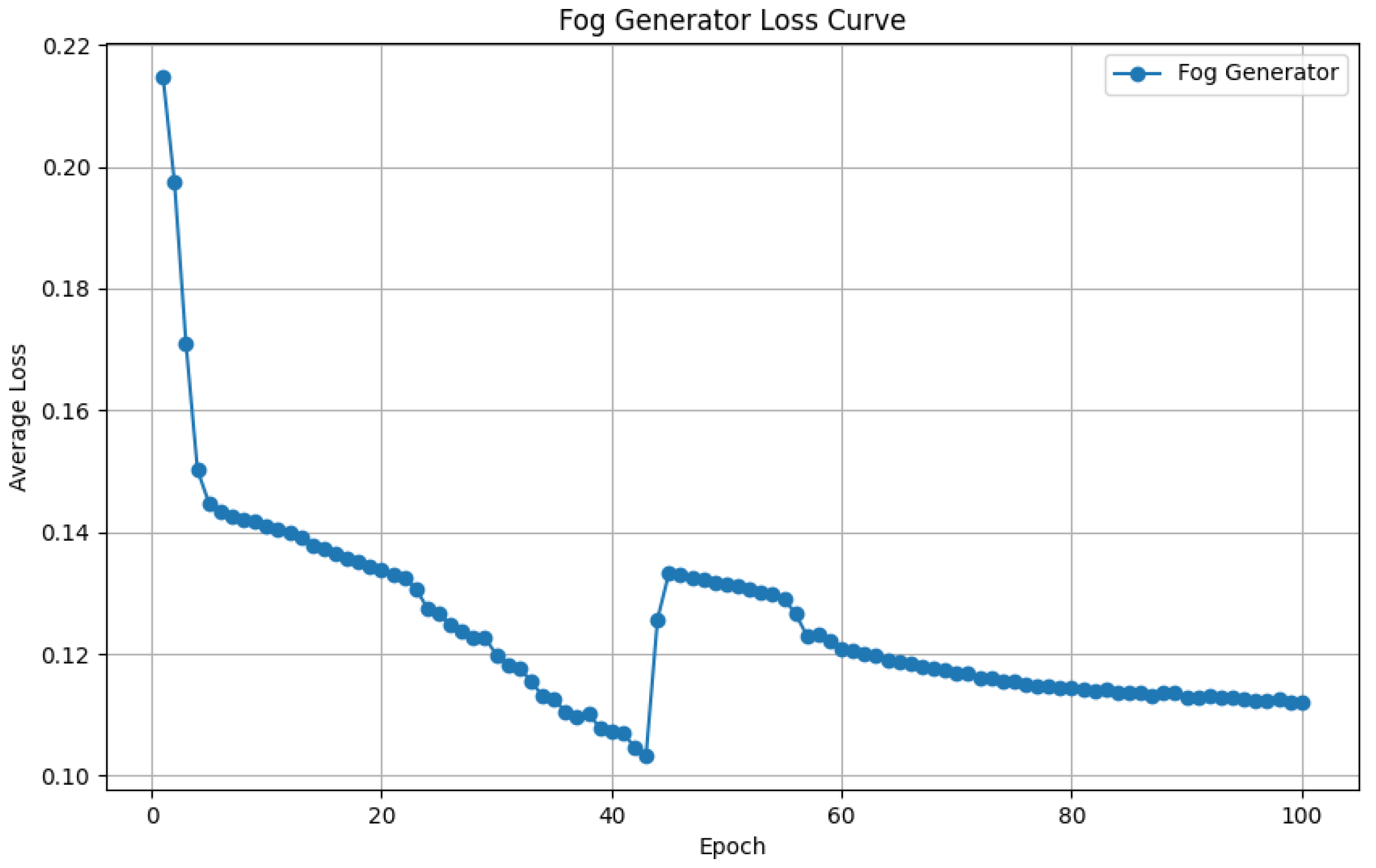
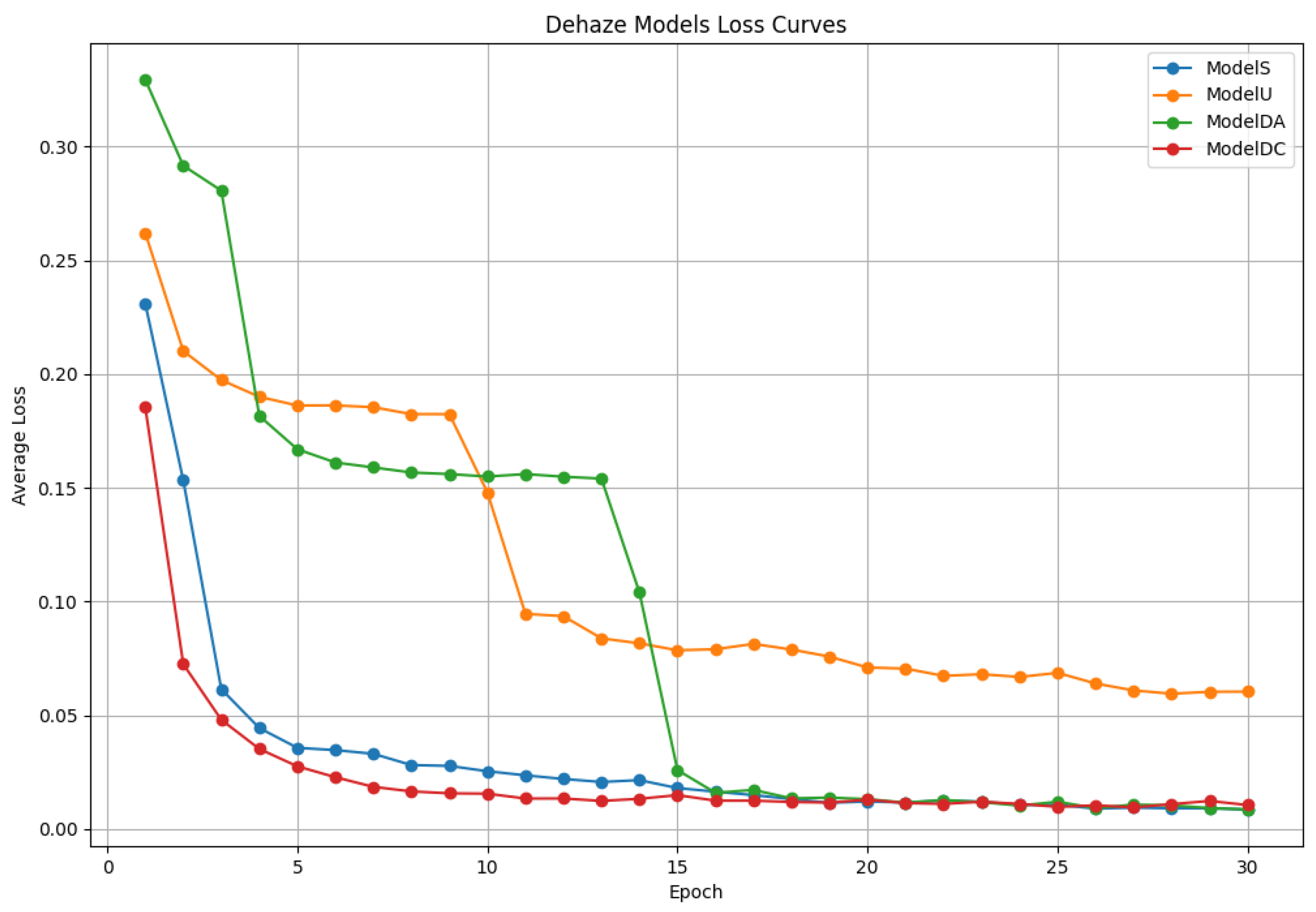
Figure 5 and
Figure 6 depict the training loss curves for the Fog Generator and dehazing models, respectively. The Fog Generator exhibits a steady decline in loss, converging after approximately 80 epochs, indicating effective learning of fog synthesis patterns. Similarly, the dehazing models show consistent loss reduction, with ModelU achieving the lowest final loss, suggesting that training on GridNet-generated fog enhances dehazing optimization.
4.2.2. Quantitative Performance
Table 1 summarizes the dehazing performance of each model on the O-HAZY evaluation set. ModelU, trained on GridNet-generated fog, achieves the highest PSNR (17.6018 dB) and SSIM (0.7697), outperforming ModelS (14.8382 dB, 0.7186), ModelDA (14.6777 dB, 0.7125), and ModelDC (14.5749 dB, 0.7007). This result validates our hypothesis that a network-driven fog generation approach improves dehazing efficacy by providing more realistic and challenging training data.
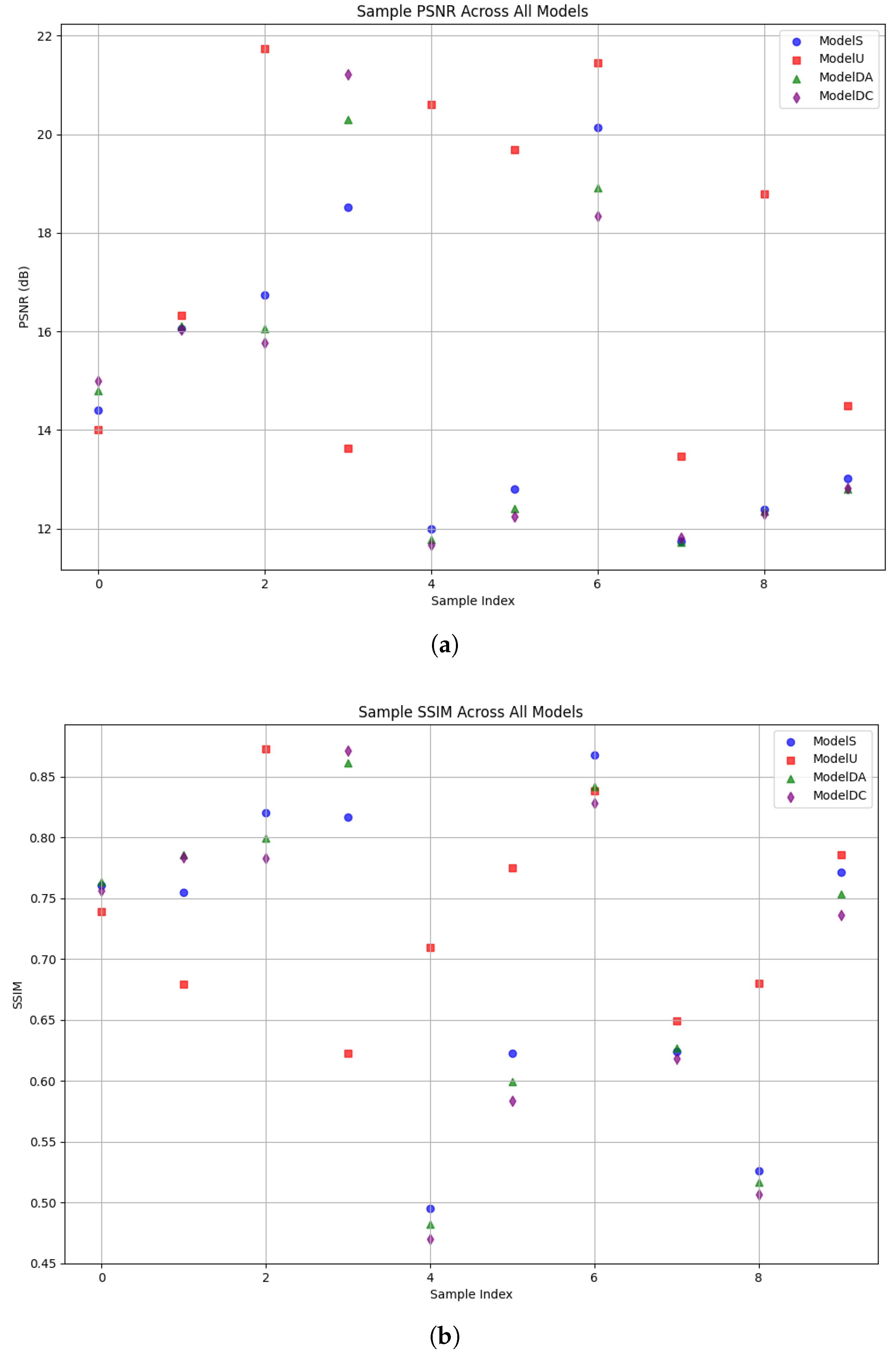
4.2.3. Sample-Level Analysis
Figure 7 presents the sample-level PSNR and SSIM distributions across the evaluation set. The combined PSNR plot shows ModelU consistently achieving higher PSNR values across samples, while the SSIM plot confirms its structural fidelity. These distributions underscore ModelU’s robustness and consistency compared to baseline-trained models.
4.3. Visual Comparison of Real and Synthetic Fog
To evaluate the visual realism of the synthetic fog generated by our method, we compare it with real-world fog and other baseline fog generation methods, as shown in
Figure 8. The figure presents two real images (a clear image and a foggy image captured under natural fog conditions) alongside synthetic fog samples produced using four different approaches: simple fog, depth-aware fog, Dark Channel Prior, and our proposed GridNet-based method.
Among these, the synthetic fog generated by our model exhibits a more natural fog distribution and density that closely resembles the characteristics of real fog. The fog appears more spatially consistent and visually plausible, especially in its interaction with background structures and atmospheric depth. In contrast, the fog produced by the baseline methods tends to be either too sparse or uniformly spread, failing to capture the heterogeneous and complex nature of real fog. These observations visually support the superiority of our method in generating realistic fog, which is critical for training effective dehazing networks in surveillance scenarios.
4.4. Discussion
While our study demonstrates the effectiveness of the proposed fog generation model in improving dehazing performance, we acknowledge that the evaluation did not include comparisons with recent state-of-the-art dehazing architectures such as FFA-Net, DehazeFormer, or DehazeGS. This was a deliberate decision to isolate the effect of fog generation by maintaining a consistent dehazing network (GridNet) across all experiments. While this helped ensure a controlled comparison among fog synthesis methods, we recognize that incorporating more advanced dehazing networks in future work will provide a broader and more generalizable validation of our synthetic fog generation approach.
Additionally, we acknowledge that a component-wise ablation analysis was not conducted. In particular, we did not individually evaluate the contributions of components such as the perceptual loss, dark channel consistency, and the GridNet-based architectural design. We believe that such analysis would offer important insights into the role of each element in performance improvement. We plan to conduct systematic ablation studies in future work to more rigorously validate our model’s design choices and improve its efficiency.
5. Conclusions
This study successfully validates the efficacy of a network-driven fog generation approach for improving dehazing performance in surveillance systems. By leveraging the GridNet architecture as the backbone for both fog synthesis and removal, the proposed Fog Generator Model produces realistic synthetic fog that enhances the robustness of dehazing networks. Comparative experiments reveal that dehazing models trained on GridNet-generated fog outperform those trained on traditional methods, as evidenced by superior PSNR and SSIM scores on the O-HAZY dataset. These findings confirm that integrating high-performance dehazing networks into fog generation not only bridges the gap in paired dataset availability but also elevates the quality of visibility restoration under adverse weather conditions. The proposed solution offers a practical and effective advancement for real-world surveillance, ensuring reliable operation in foggy environments. Moreover, the proposed fog generation model can be effectively applied in various practical domains such as traffic surveillance, autonomous driving, smart city security cameras, and drone-based environmental monitoring, where robust vision systems are required under adverse weather conditions. Future research could explore real-time implementation, broader dataset applications, and further optimization of the fog generation-dehazing pipeline to enhance its applicability across diverse scenarios.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}